
The Organization’s Sustainable Work Stress and Maladjustment Management Plan by Predicting Early Retirement through Big Data Analysis: Focused on the Case of South Korea



Abstract
:1. Introduction
2. Literature Review and Hypothesis Development
2.1. Personnel Information
2.2. Early Retirement
2.3. Prior Studies about Causes of Early Retirement Responses to Work Stress and Mal-Adjustment
2.4. Hypotheses for Early Retirement Analysis
3. Methods and Materials
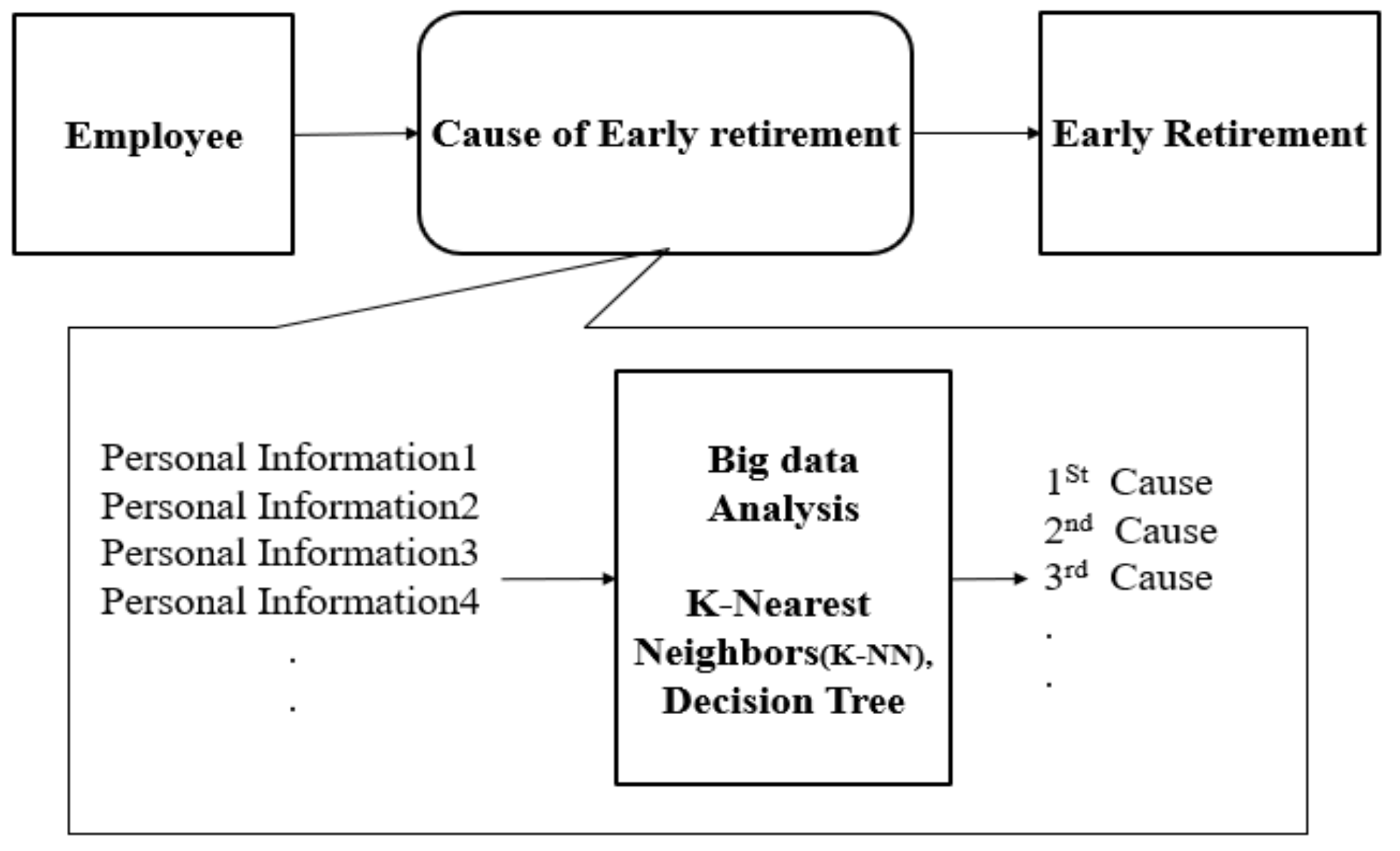
3.1. Research Model
3.2. Maching Learning
3.3. Maching Learning Technique
3.4. Subjects
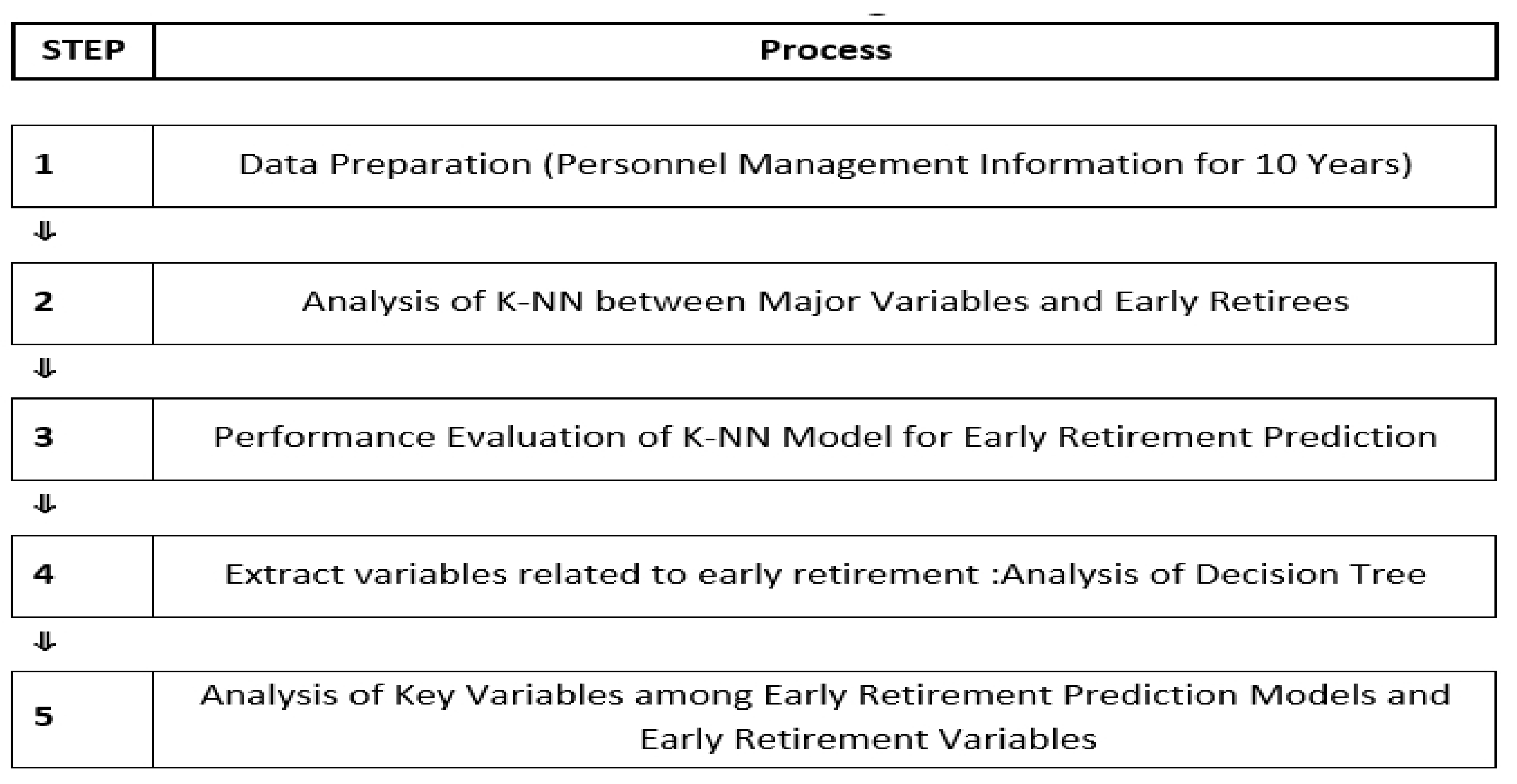
3.5. Analysis Procedure
3.6. Data Processing for Big Data Analysis
4. Results
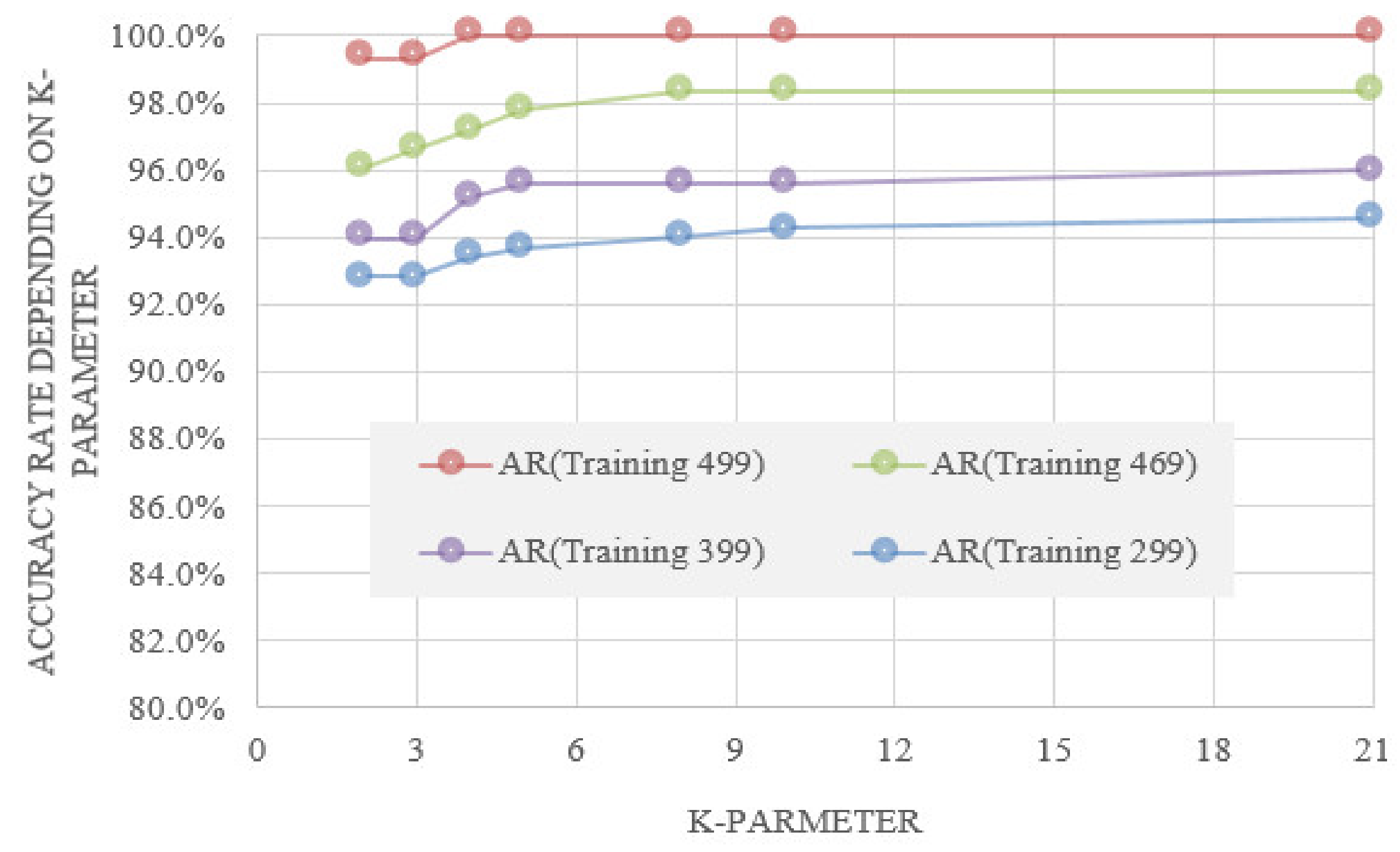
4.1. K-Nearest Neighbor (K-NN) Results
4.2. Decision Tree Results
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- 7 Out of 10 Employees Are Delaying Their Job Change due to Corona 19! 19 May 2020. Available online: https://www.saramin.co.kr/zf_user/help/live/view?idx=106053&listType=news (accessed on 31 October 2021).
- Jeon, H.S.; Wang, E.J. A study on an exit interview process, influencing the withdrawal of a turnover decision: Semiconductor manufacturing plant case. Korean J. Ind. Organ. Psychol. 2014, 27, 805–830. [Google Scholar] [CrossRef]
- Kim, Y.P.; Kim, H.J. Predicting Early Retirees Using Personality Data. J. Digit. Contents Soc. 2019, 19, 141–147. [Google Scholar] [CrossRef]
- Eom, D.W. The status and causes of Early separation of separation of college graduate newcomers: Focusing on the HRM perspectives. J. Vocat. Educ. Train. 2008, 11, 237–260. [Google Scholar] [CrossRef]
- Song, Y.S. A Study on Defining Strategic Human Resource Development (SHRD) Domains and Tasks in large Korean enterprises. J. Corp. Educ. Talent. Res. 2009, 11, 75–98. Available online: https://www-riss-kr.oca.korea.ac.kr/link?id=A103798228 (accessed on 31 October 2021).
- Kwon, D.B.; Cho, D.Y. HRD Expert Armed with a System Approach. In HRD Essence, 1st ed.; Woo, S., Bae, K., Ian, J., Eds.; Parkyoungsa: Korea, Seoul, 2013; pp. 4–5. [Google Scholar]
- Chung, D.B. Major factors affecting turnover intention of college graduates: Comparison and analysis according to regular workers quarterly. J. Labor Policy 2019, 19, 93–127. Available online: http://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE09229114 (accessed on 31 October 2021).
- Jang, Y.H.; Kim, T.S. Study on the Determinants of Early Retirement: Focusing on Early Retirees at the Seongseo Industrial Complex in Daegu. J. Daegu Gyeongbuk Dev. Inst. 2019, 18, 1–22. [Google Scholar] [CrossRef]
- Park, E.S.; Oh, K.T.; Lee, M.J. The Effect of Job Satisfaction and Wage Level on Turnover Intention: Focusing on Moderating Effect of Trust. Korea Corp. Manag. Rev. 2017, 24, 1–19. [Google Scholar] [CrossRef]
- Park, J.S.; Hwang, H.S. The Application of Regionalization Learning through Big Data Analysis of Space and place. Sungshin Women’s Univ. Educ. Res. Inst. 2018, 73, 129–149. [Google Scholar] [CrossRef]
- Jones, W. Personal Information Management; Information Science and Technology, Chapter 10; Willy: California, CA, USA, 2009; pp. 453–504. [Google Scholar] [CrossRef]
- Rhee, J.H. An Exploratory Study about Justice Perceptions in Early Retirement Plans and its Effects on the Consequence. J. Hum. Resour. Manag. 2002, 26, 67–88. Available online: https://scholar-dkyobobook-co-kr.oca.korea.ac.kr/searchDetail.laf?barcode=4030008012994 (accessed on 31 October 2021).
- Kwon, S.I. The Empitical Study on Influencing Factor of Employee’s Preretirement Decision: Emphasis on The Employees of The Banking Industries in Pusan. Silla Univ. J. 1996, 41, 39–72. Available online: https://www-riss-kr.oca.korea.ac.kr/link?id=A2051109 (accessed on 31 October 2021).
- Kim, J.W.; Soo, S.K. A Study on Antecedents of Early Retirement, A Comparison with Turnover. J. Korea Adult Hum. Resour. Manag. 2015, 22, 207–223. [Google Scholar] [CrossRef]
- MZ Generation Has Many Early Retirements within a Year. Determined within an Average of 5 Months after Joining the Company. Available online: https://www.fnnews.com/news/202106020840283018 (accessed on 2 June 2021).
- Cho, B.S. A Study on the Factors Influencing Voluntary Turnovers of the Employees in Physical Education and Athletic Organizations. Master’s Thesis, Seoul University, Seoul, Korea, 1997. Available online: https://www-riss-kr.oca.korea.ac.kr/link?id=T707043 (accessed on 31 October 2021).
- Lee, S.H. The Present Status of EIS in Regards to Domestic and International Companies in Korea. Master’s Thesis, Korea University, Seoul, Korea, 2004. Available online: https://www-riss-kr.oca.korea.ac.kr/link?id=T9553950 (accessed on 31 October 2021).
- Kim, S.Y.; Chang, W.S.; Kim, M.Y. Canonical correlations analysis between organizational adaptation variables and individual characteristics, structural, learning experiences at work variables for college graduate early careers. J. Koreans Educ. 2007, 26, 141–164. [Google Scholar]
- Lee, Y.M.; Lim, J.Y. A Research on Influential Factors Impacting the Turnover of Newcomers and the Outcomes of Successful Turnover. Korea Corp. Manag. Rev. 2010, 12, 129–153. Available online: https://www-riss-kr.oca.korea.ac.kr/link?id=A103798568 (accessed on 31 October 2021).
- Park, J.H.; Ru, S.J. Turnover intention and turnover behavior of early college graduates: Analysis of the influence of individual characteristics, job satisfaction, and organizational structural factors. Korean Sociol. Assoc. 2008, 2008, 853–871. Available online: https://www.dbpia.co.kr/Journal/articleDetail?nodeId=NODE01689913 (accessed on 31 October 2021).
- Kim, E.S.; Jung, C.Y. The Role of General Characteristics and Job Satisfaction in voluntary Turnover Process. J. Eng. Educ. Res. 2010, 23, 107–122. [Google Scholar]
- Lee, M.K. A Study on the Influential Factors Affecting Turnover Intention of Early Career of Graduates. J. Korean Soc. Study Career Educ. 2013, 26, 61–81. [Google Scholar]
- Beecroft, P.C.; Dorey, F.; Wenten, M. Turnover intention in new graduate nurses: A multivariate analysis. J. Adv. Nurs. 2008, 62, 41–52. [Google Scholar] [CrossRef] [Green Version]
- Park, S.Y.; Song, Y.S. Different perceptions on college-graduated employee’s competency: HRD practitioners vs. college student. J. Corp. Educ. Talent. Res. 2008, 10, 27–45. [Google Scholar]
- Hong, S.J.; Jyung, C.Y. The relationship among Work Adjustment, Individual Characteristics and Organizational Characteristics of Newcomers. J. Agric. Educ. Hum. Resour. Dev. 2015, 47, 125–151. [Google Scholar] [CrossRef]
- Lee, S.Y.; Park, C.W.; Lee, M.R. Exploration on the Young Employee’s Labor Mobility. J. Eng. Educ. Res. 2014, 17, 30–45. [Google Scholar] [CrossRef]
- Lee, C.S. Survey on the Status of Employee Turnover: Employee Turnover and Corporate Countermeasures. Hyundai Economic Research Institute. 2007. Available online: http://www.fki.or.kr/Common/Download.aspx?id=5bd0811c-1930-4ec3-b7d6-5f8c2cfab63c (accessed on 31 August 2021).
- Research on the Status of New College Graduates Leaving Early and Corporate Response. 7 June 2011. Available online: http://www.korcham.net/nCham/Service/Economy/appl/KcciReportDetail.asp?SEQ_NO_C010=20110607001&CHAM_CD=B001 (accessed on 31 October 2021).
- Bae, P.S. Exploring the Components of the Employment Support Program at the University Related to the Early Separation of College Graduate Newcomers. Master’s Thesis, Haiyang University, Seoul, Korea, 2017. Available online: hdl.handle.net/20.500.11754/33201 (accessed on 31 October 2021).
- The Korea Employer’s Federation. Investigation of the Status of Recruitment of New Employees. 2016. Available online: https://www.kefplaza.com/web/pages/gc79582b.do?bbsFlag=View&bbsId=0001&nttId=5023 (accessed on 31 October 2021).
- Yun, B.R. HR Analytics Applying Machine Learning for Retention Classification. Master’s Thesis, Seoul University, Seoul, Korea, 2020. Available online: https://s-space.snu.ac.kr/handle/10371/166997?mode=full (accessed on 31 October 2021).
- Kim, E.B. An Educational Study on the Failure Process of Re-employment of University Graduates with Resignation Experience. Korean Hum. Resour. Dev. Strategy 2018, 13, 77–107. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Researchers | Research Results |
|---|---|
| 1. Um Dong-wook [7] | Working conditions, including promotion, remuneration, working hours, and prospects caused them to leave the first company. |
| 2. Lee Seok-yeol, Park Cheol-woo, Lee Mi-ra [26] | Men were 10 percent more likely to maintain their first job than women, and the cause of their first year’s separation was shown as a result of salary, major mismatch, and wage welfare factors. |
| 3. Lee Young-min, Lim Jeong-yeon [19] | The reason for preparing for the separation was not feeling rewarded for work and dissatisfaction with wages and working conditions. Additionally, job satisfaction, salary, major, etc. were the factors that affected the job. |
| 4. Lee Cheol-sun [27] | Psychological factors such as low assessment of oneself and possibility of self-improvement appear to be the main reasons for the separation of jobs. |
| 5. Korea Chamber of Commerce and Industry [28] | Problems such as discordance of major and aptitude, dissatisfaction with rewards, dissatisfaction with working conditions, failure in adjusting to organizational culture, problems of promotion and career development, and conflicts in human relations at work appear as reasons for early separations. |
| 6. The Korea Employer’s Federation [30] | Failure to adapt to the organization and duties, dissatisfaction with salary and benefits, dissatisfaction with working area and working environment, and preparation for employment at public officials and public corporations were the reasons for early separations. |
| Total | Current Employee | Retired Person * | Early Retirement Person ** |
|---|---|---|---|
| 648 | 290 | 358 | 128 |
| No | Personnel Information Item | No | Personnel Information Item |
|---|---|---|---|
| 1 | Gender | 10 | Career at other companies |
| 2 | Age | 11 | Single or married |
| 3 | Age when he or she resigns | 12 | With or without children |
| 4 | Reason for Resignation * | 13 | Distance between residence and company |
| 5 | Position | 14 | Work period after promoted |
| 6 | Final salary | 15 | Union membership status |
| 7 | Highest level of education attained | 16 | Length of service |
| 8 | Whether having professional engineer license or not | 17 | Series of class |
| 9 | Whether having foreign language certificate or not | 18 | Whether having engineer license or not |
| No | Personnel Data | Normalization | Remark |
|---|---|---|---|
| 1 | Gender | Male = 0, Female = 1 | Convert the number data of the item into a relative number between 0.0~1.0 |
| 2 | Age | Age number between 0~100 | |
| 3 | Retirement age | Retirement age number between 0~100 | |
| 4 | Reason for retirement | Reason for retirement is used as a tagging data to distinguish early retirees, setting early retirees to 0, and others to 1 | |
| 5 | Position | Set by rank (Set as value between 0~3 for Contractor, Specialist, General employee, Executive) | |
| 6 | Final salary class | Salary class number between 0~100 | |
| 7 | Final educational degree | Set by rank (Set as value for middle school graduate ~ Ph. D graduate. Middle school graduate as 0.4, high school graduate as 1, undergraduate as 2, graduate as 3, Ph. D as 3) | |
| 8 | Technical licenses | Set status of licensing as 0, 1 | |
| 9 | Foreign language ability | Set foreign language ability as 0, 1 | |
| 10 | Experience in other companies | Set as the number of companies worked for prior to current employment | |
| 11 | Marriage | Set marriage status as 0, 1 | |
| 12 | Children | Set as number of children as 0, 1 | |
| 13 | Residence and distance to company | Set as the linear distance from the residence indicated in the personnel data to current employment | |
| 14 | Workdays after promotion | Set as number of days after promotion | |
| 15 | Registry in labor union | Set status of registration as 0 or 1 | |
| 16 | Total years worked | Set as total number of years worked | |
| 17 | Job group | Set technical job groups as 0, administrative job groups as 1 | |
| 18 | Engineering licenses | Set status of licensing as 0, 1 |
| Remark | T (Predicting as Non-Early Retirement) | F (Predicting as Early Retirement) |
|---|---|---|
| T (Real Non-early retirement) | T-T → Accurate (Predicting non-resigner as non-early- retirement) | T-F → Error (Predicting early-resigner as non-early- retirement) |
| F (Real early retirement) | T-F → Error (Predicting non-resigner as early- retirement) | F-F → Accurate (Predicting early-resigner as early- retirement) |
| Classification | Number of Content |
|---|---|
| Full Data | 648 |
| Personnel Information | 18 |
| Employees | 520 |
| Early Retirees | 128 |
| Training Data | 299, 399, 469, 499 |
| Test Data | 349, 249, 179, 149 |
| K-Value | 2, 3, 4, 5, 8, 10, 21 |
| Training Data | Test Data | K | T-T | T-F | F-T | F-F | Error Rate | Accurate Rate |
|---|---|---|---|---|---|---|---|---|
| 499 | 149 | 2 | 145 | 0 | 1 | 3 | 0.7% | 99.3% |
| 3 | 145 | 1 | 0 | 3 | 0.7% | 99.3% | ||
| 4 | 145 | 0 | 0 | 4 | 0.0% | 100.0% | ||
| 5 | 145 | 0 | 0 | 4 | 0.0% | 100.0% | ||
| 8 | 145 | 0 | 0 | 4 | 0.0% | 100.0% | ||
| 10 | 145 | 0 | 0 | 4 | 0.0% | 100.0% | ||
| 21 | 145 | 0 | 0 | 4 | 0.0% | 100.0% | ||
| 469 | 179 | 2 | 155 | 5 | 2 | 17 | 3.9% | 96.1% |
| 3 | 156 | 4 | 2 | 17 | 3.4% | 96.6% | ||
| 4 | 156 | 4 | 1 | 18 | 2.8% | 97.2% | ||
| 5 | 157 | 3 | 1 | 18 | 2.2% | 97.8% | ||
| 8 | 158 | 2 | 1 | 18 | 1.7% | 98.3% | ||
| 10 | 158 | 2 | 1 | 18 | 1.7% | 98.3% | ||
| 21 | 158 | 2 | 1 | 18 | 1.7% | 98.3% | ||
| 399 | 249 | 2 | 197 | 11 | 4 | 37 | 6.0% | 94.0% |
| 3 | 199 | 9 | 6 | 35 | 6.0% | 94.0% | ||
| 4 | 202 | 6 | 6 | 35 | 4.8% | 95.2% | ||
| 5 | 202 | 6 | 5 | 36 | 4.4% | 95.6% | ||
| 8 | 202 | 6 | 5 | 36 | 4.4% | 95.6% | ||
| 10 | 202 | 6 | 5 | 36 | 4.4% | 95.6% | ||
| 21 | 203 | 5 | 5 | 36 | 4.0% | 96.0% | ||
| 299 | 349 | 2 | 269 | 16 | 9 | 55 | 7.2% | 92.8% |
| 3 | 270 | 15 | 10 | 54 | 7.2% | 92.8% | ||
| 4 | 274 | 11 | 12 | 52 | 6.6% | 93.4% | ||
| 5 | 272 | 13 | 9 | 55 | 6.3% | 93.7% | ||
| 8 | 273 | 12 | 9 | 55 | 6.0% | 94.0% | ||
| 10 | 276 | 9 | 11 | 53 | 5.7% | 94.3% | ||
| 21 | 275 | 10 | 9 | 55 | 5.4% | 94.6% |
| Remark | Training Data 400, Test Data 248 AR = 95.1% | Training Data 555, Test Data 93 AR = 95.7% | Training Data 647, Test Data 1 AR = 100.0% |
|---|---|---|---|
| Relevance Factor (Relevance index) | 1. Working years (100.0%) | 1. Working years (100.0%) | 1. Working years (100.0%) |
| 2. Period after Promotion (54.75%) | 2. Certificate of Tech Master (53.51%) | 2. Certificate of Tech Master (53.63%) | |
| 3. Certificate of Tech Master (51.50%) | 3. Period after promotion (53.51%) | 3. Period after promotion (53.63%) | |
| 4. Position (45.50%) | 4. Distance (42.34%) | 4. Distance (42.81%) | |
| 5. Working day (44.25%) | 5. Position (38.38%) | 5. Union (40.96%) | |
| 6. Distance (15.75%) | 6. Sex (15.14%) | 6. Position (40.03%) | |
| 7. Salary Class (14.25%) | 7. Salary class (14.05%) | 7. Salary class (28.13%) | |
| 8. Sex (13.25%) | 8. Career experience (6.49%) | 8. Education degree (14.84%) | |
| 9. Education degree (4.50%) | 9. Certificate of Tech (5.95%) | 9. Age (12.36) | |
| 10. Certificate of Tech (3.25) | 10. Age (3.96%) | 10. Sex (10.82%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ham, H.; Kim, E.; Cho, D. The Organization’s Sustainable Work Stress and Maladjustment Management Plan by Predicting Early Retirement through Big Data Analysis: Focused on the Case of South Korea. Sustainability 2022, 14, 434. https://doi.org/10.3390/su14010434
Ham H, Kim E, Cho D. The Organization’s Sustainable Work Stress and Maladjustment Management Plan by Predicting Early Retirement through Big Data Analysis: Focused on the Case of South Korea. Sustainability. 2022; 14(1):434. https://doi.org/10.3390/su14010434
Chicago/Turabian StyleHam, Hyunjung, Eunbee Kim, and Daeyeon Cho. 2022. "The Organization’s Sustainable Work Stress and Maladjustment Management Plan by Predicting Early Retirement through Big Data Analysis: Focused on the Case of South Korea" Sustainability 14, no. 1: 434. https://doi.org/10.3390/su14010434
APA StyleHam, H., Kim, E., & Cho, D. (2022). The Organization’s Sustainable Work Stress and Maladjustment Management Plan by Predicting Early Retirement through Big Data Analysis: Focused on the Case of South Korea. Sustainability, 14(1), 434. https://doi.org/10.3390/su14010434