
A Novel Feature Selection Technique to Better Predict Climate Change Stage of Change




Abstract
:1. Introduction
- Can the prediction accuracy of belonging to a CC-SoC be improved considerably by applying AI techniques such as machine learning (ML) or deep learning?
- Many ML methods exist, but which might be the most accurate for this type of measure (non-linear nominal variable)?
- When dealing with large numbers of variables, can using all variables in the prediction model maximize the prediction accuracy?
2. Literature Review
Research Contributions
3. Methodology
3.1. Data Preparation
- (1)
- I am not concerned;
- (2)
- I would like to reduce my emissions, but I don’t know how;
- (3)
- I would like to reduce my emissions, and will do so in the future;
- (4)
- I have already reduced my emissions significantly.
3.2. Classification Techniques
3.2.1. Multi-Layered Perceptron
3.2.2. Gaussian Naïve Bayes
3.2.3. Logistic Regression
3.2.4. Decision Tree Classifier
3.2.5. K-Nearest Neighbor Classifier
3.2.6. Random Forest Classifier
3.2.7. Support Vector Machine classifier
3.2.8. AdaBoost
3.3. Feature Selection Process
3.3.1. COA-QDA Feature Selection
3.3.2. Lasso
3.3.3. Elastic Net
3.3.4. Random Forest Feature Selection
3.3.5. Extra Trees Feature Selection
3.3.6. New Feature Selection-Based Principal Component Analysis
3.3.7. Finding the Optimal Number of Features for Conventional Feature Selection Techniques
3.4. Sensitivity Analysis
4. Results and Discussion
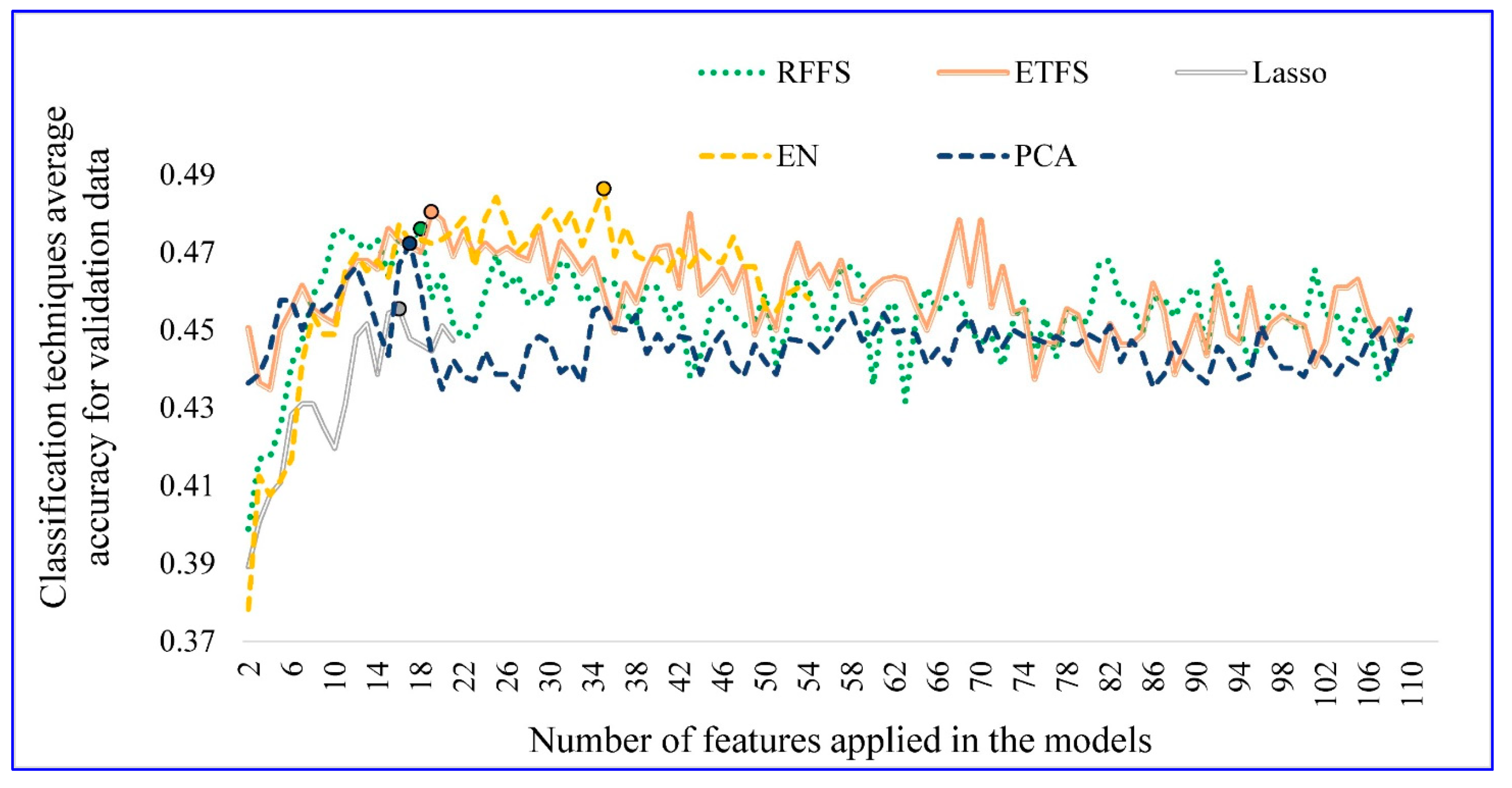
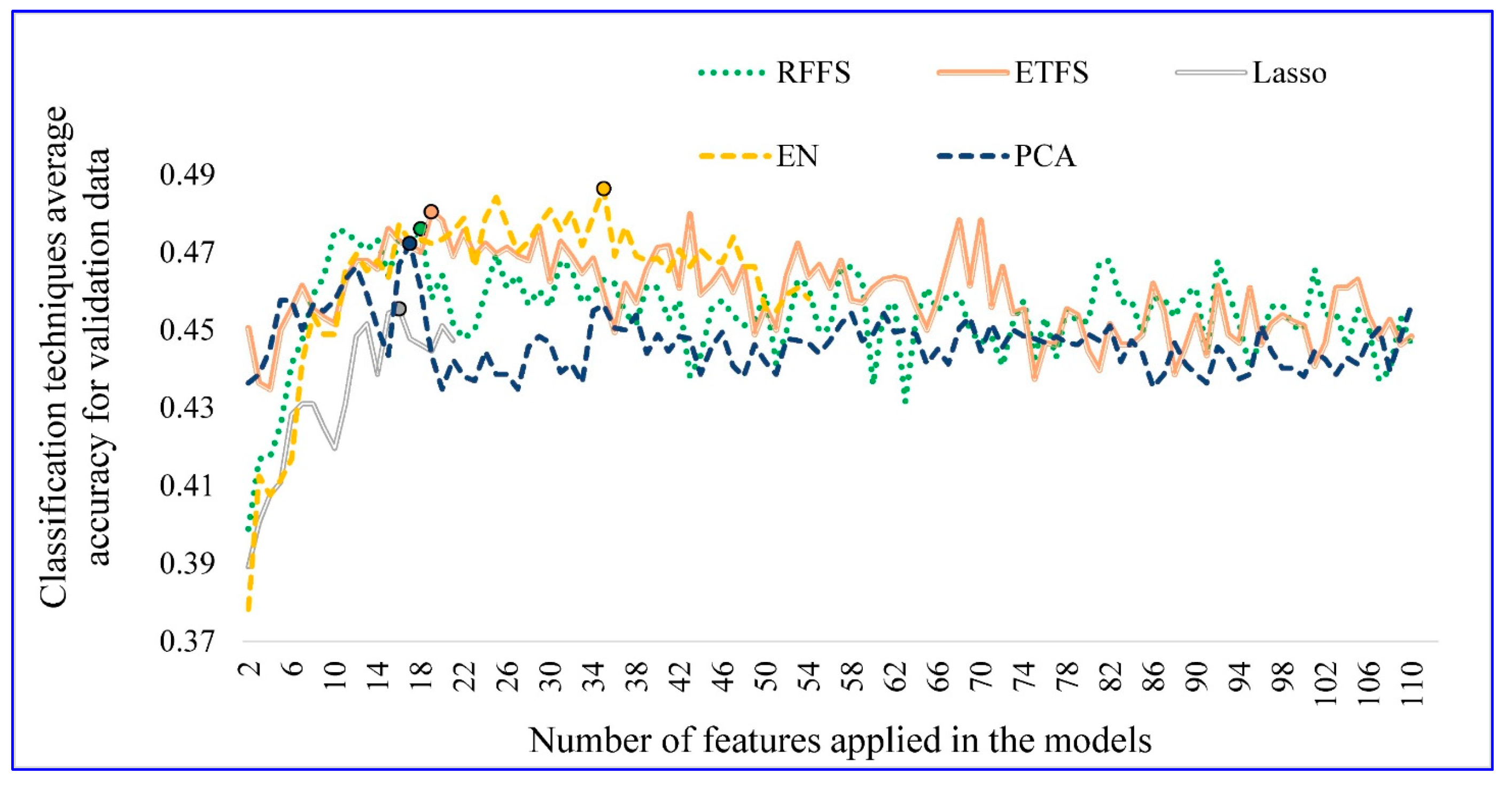
4.1. Optimal Number of Features
4.2. Feature Selection Technique Performance
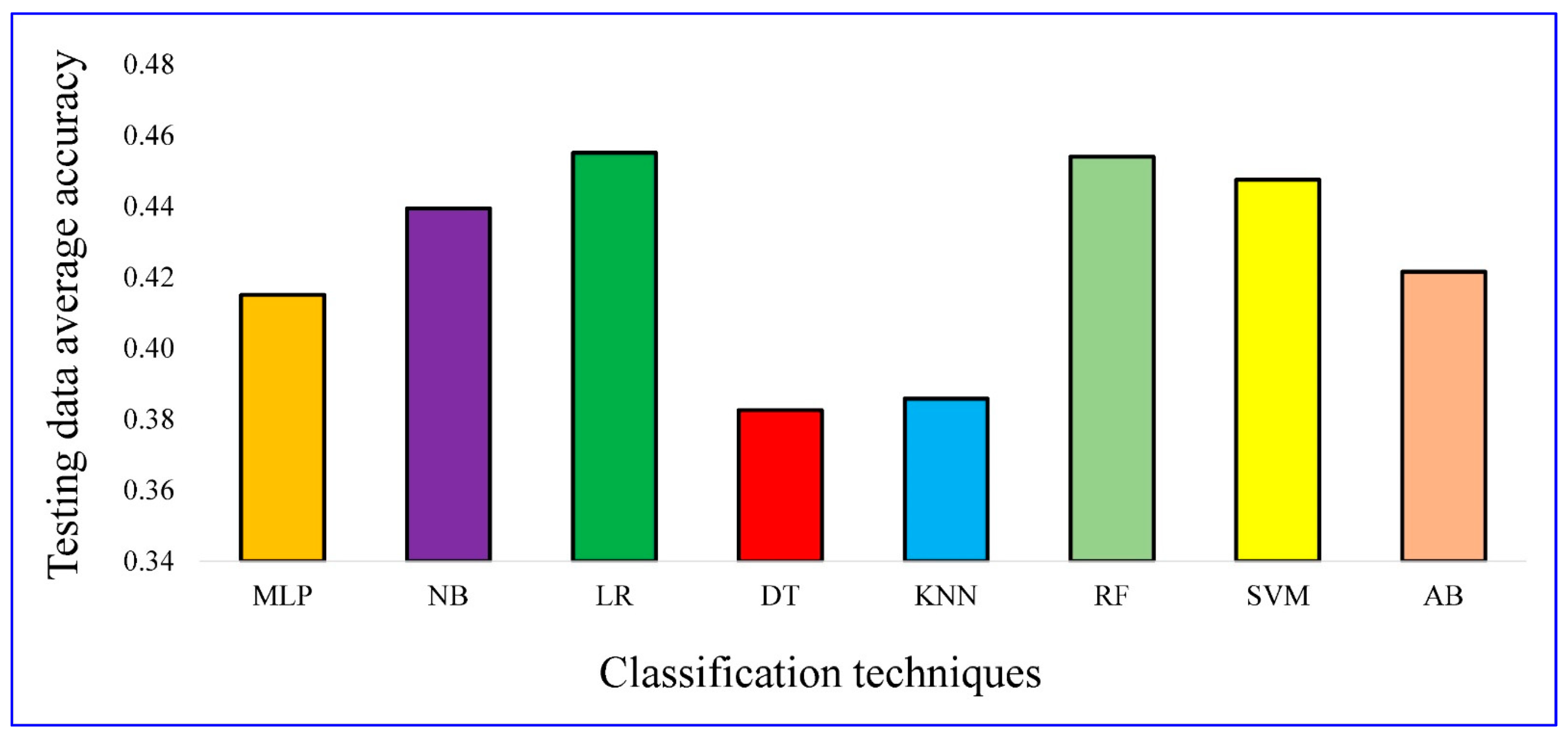
4.3. Classifiers’ Accuracy
4.4. The Most Important Features
4.5. Comparing the Results with Previous Studies
5. Conclusions
- Fifteen optimal features (out of forty-six) are based on transport behavior: nine from transport-related questions and six from GEB transport-based questions. Hence, 32.6% of optimal features are related to transport behavior. This suggests that the application of transport behavior to predict CC-SoC is vital. It should be noted that the original survey focus was on vehicle choice and included only car owners. As such, future research should examine a larger array of transport behaviors with a general population sample.
- The introduced improvement method for conventional feature selection models can increase the average prediction accuracy of EN and Lasso by 2.8% and 0.8%, respectively. RFFS, ETFS, and PCA can also determine the optimal number of features using the proposed improvement method.
- The average testing data accuracy of COA-QDA is 0.7%, 0.9%, 2.2%, 4.8%, and 5.6% higher than that of ETFS, EN, RFFS, Lasso, and PCA. Accordingly, COA-QDA outperforms other feature selection techniques in terms of accuracy. Using an appropriate feature selection technique, such as COA-QDA, can increase the average accuracy by 3.8% as compared to not using all features in the model.
- COA-QDA provides the highest testing accuracy, with a value of 53.7%. The highest COA-QDA testing data accuracy is 1.3%, 2.6%, 3.9%, 5.6%, and 6.1% higher than that of EN, RFFS, ETFS, Lasso, and PCA, respectively. Furthermore, using all features in the prediction models results in a model with 3% lower testing data accuracy than COA-QDA.
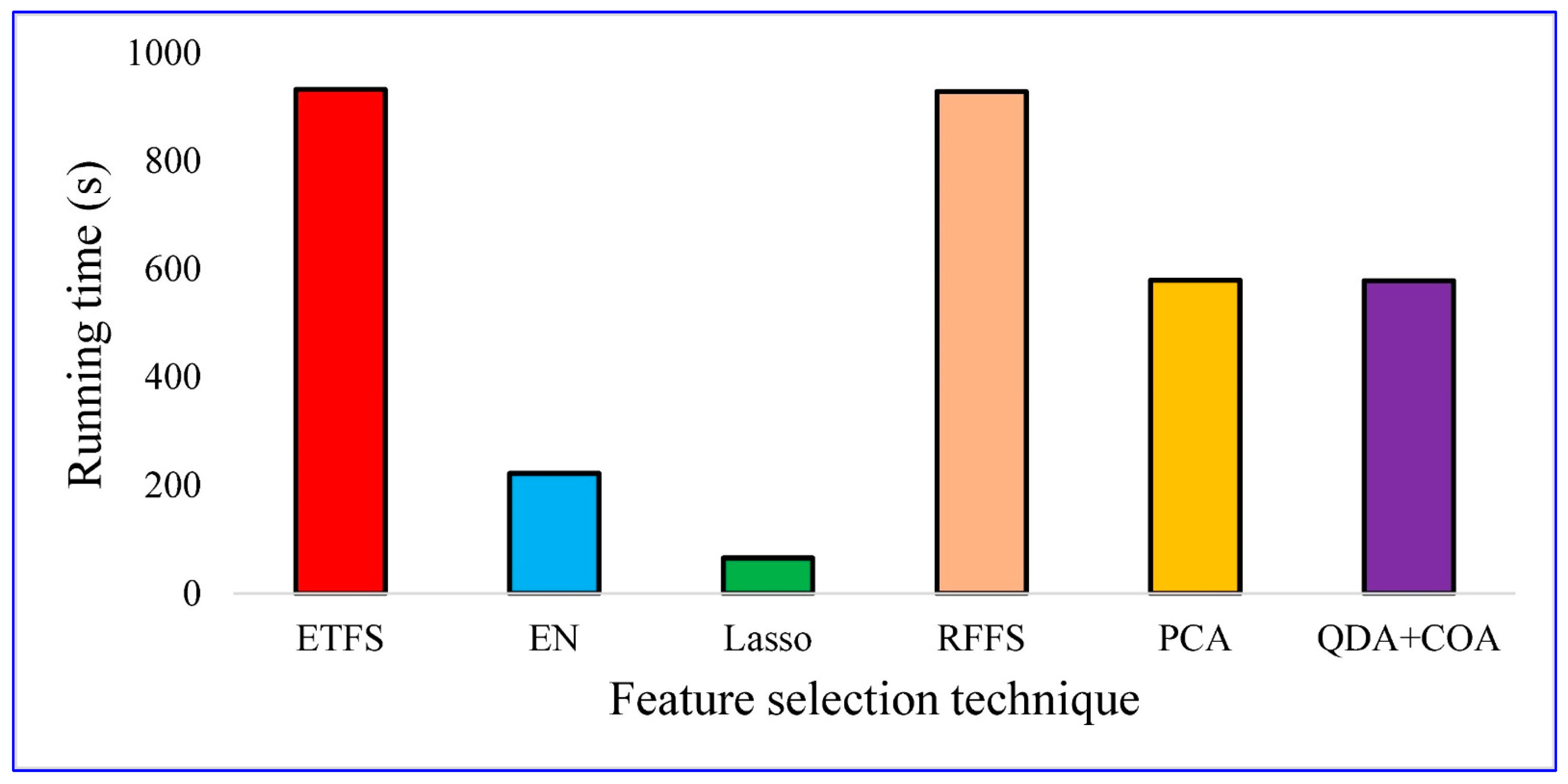
- Lasso is the fastest feature selection method regarding the average running time, followed by EN, COA-QDA, PCA, RFFS, and ETFS.
- The highest testing data accuracy is obtained by combining COA-QDA and LR (COA-QDA/LR), followed by EN/LR, RFFS/SVM, COA-QDA/NB, COA-QDA/RF, and all features/SVM. The testing data accuracy these methods is equal to 53.7%, 52.4%, 51.1%, 50.6%, 50.6%, and 50.6%, respectively. This may be a result of the type of dependent variable (ordinal).
- The average testing data accuracy of LR, RF, SVM, NB, AB, MLP, KNN, DT is 45.5%, 45.4%, 44.8%, 43.9%, 42.2%, 41.5% 38.6%, and 38.3%, in the order given. Therefore, in this study LR and RF outperformed other classifiers based on the average prediction accuracy.
6. Limitations and Recommendations for Future Studies
- The measure, Climate Change Stage of Change, captures individuals’ self-assessment of their climate concern and behavioral intentions. It does measure what their actual climate impacts are. It is possible for a person not to be concerned about climate change and lead a low-carbon lifestyle. It should only be considered with respect to how strongly they would likely support or react to climate-related information.
- In this study, the performance of COA-QDA is only examined on the CC-SoC prediction study. Accordingly, it is recommended that assessing the performance of COA-QDA on different prediction problems with different complexities will be considered in future studies.
- This study applies Coyote Optimization Algorithm to propose a feature selection method (i.e., COA-QDA). Hence, it is suggested to employ various robust metaheuristic algorithms to generate new feature selection methods using the proposed approach.
- One of the limitations of this study is to consider testing data accuracy as the performance indicator. It is recommended that the effects of COA-QDA on testing data F1-score will be examined in future studies.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McCright, A.M.; Marquart-Pyatt, S.T.; Shwom, R.L.; Brechin, S.R.; Allen, S. Ideology, capitalism, and climate: Explaining public views about climate change in the United States. Energy Res. Soc. Sci. 2016, 21, 180–189. [Google Scholar] [CrossRef]
- Yang, M.X.; Tang, X.; Cheung, M.L.; Zhang, Y. An institutional perspective on consumers’ environmental awareness and pro-environmental behavioral intention: Evidence from 39 countries. Bus. Strat. Environ. 2020, 30, 566–575. [Google Scholar] [CrossRef]
- Anable, J. ‘Complacent Car Addicts’ or ‘Aspiring Environmentalists’? Identifying travel behaviour segments using attitude theory. Transp. Policy 2005, 12, 65–78. [Google Scholar] [CrossRef] [Green Version]
- Susilo, Y.O.; Williams, K.; Lindsay, M.; Dair, C. The influence of individuals’ environmental attitudes and urban design features on their travel patterns in sustainable neighborhoods in the UK. Transp. Res. Part D Transp. Environ. 2012, 17, 190–200. [Google Scholar] [CrossRef] [Green Version]
- Gaker, D.; Walker, J.L. Revealing the Value of “Green” and the Small Group with a Big Heart in Transportation Mode Choice. Sustainability 2013, 5, 2913–2927. [Google Scholar] [CrossRef] [Green Version]
- Wynes, S.; Nicholas, K.A. The climate mitigation gap: Education and government recommendations miss the most effective individual actions. Environ. Res. Lett. 2017, 12, 074024. [Google Scholar] [CrossRef] [Green Version]
- Waygood, E.O.D.; Wang, B.; Daziano, R.A.; Patterson, Z.; Kohlová, M.B. The climate change stage of change measure: Vehicle choice experiment. J. Environ. Plan. Manag. 2021, 1–30. [Google Scholar] [CrossRef]
- Prochaska, J.; Colleen, O.; Redding, A.; Evers, K.E. The transtheoretical model and stages of change. In Health Behavior: Theory, Research, and Practice; John Wiley & Sons: San Francisco, CA, USA, 2015. [Google Scholar]
- Waygood, E.; Avineri, E. Does “500g of CO2 for a mile trip” mean anything? Towards more effective presentation of CO2 Information. In Proceedings of the Transportation Research Board 90th Annual Meeting, Washington, DC, USA, 23–27 January 2011. [Google Scholar]
- Daziano, R.A.; Waygood, E.O.D.; Patterson, Z.; Kohlová, M.B. Increasing the influence of CO2 emissions information on car purchase. J. Clean. Prod. 2017, 164, 861–871. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Waygood, E.; Daziano, R.A.; Patterson, Z.; Feinberg, M. Does hedonic framing improve people’s willingness-to-pay for vehicle greenhouse gas emissions? Transp. Res. Part D Transp. Environ. 2021, 98, 102973. [Google Scholar] [CrossRef]
- Waygood, E.O.; Wang, B.; Daziano, R.A.; Patterson, Z.; Kohlová, M.B. Vehicle choice and CO2 emissions information: Framing effects and individual climate change stage of change. In Proceedings of the Annual Meeting Transportation Research Board, Washington, DC, USA, 12–16 January 2020. [Google Scholar]
- Zha, D.; Yang, G.; Wang, W.; Wang, Q.; Zhou, D. Appliance energy labels and consumer heterogeneity: A latent class approach based on a discrete choice experiment in China. Energy Econ. 2020, 90, 104839. [Google Scholar] [CrossRef]
- Bedard, S.A.N.; Tolmie, C.R. Millennials’ green consumption behaviour: Exploring the role of social media. Corp. Soc. Responsib. Environ. Manag. 2018, 25, 1388–1396. [Google Scholar] [CrossRef]
- Cheung, M.L.; Pires, G.D.; Rosenberger, P.J.; Leung, W.K.; Sharipudin, M.-N.S. The role of consumer-consumer interaction and consumer-brand interaction in driving consumer-brand engagement and behavioral intentions. J. Retail. Consum. Serv. 2021, 61, 102574. [Google Scholar] [CrossRef]
- Liu, Y.; Cirillo, C. A generalized dynamic discrete choice model for green vehicle adoption. Transp. Res. Part A Policy Pract. 2018, 114, 288–302. [Google Scholar] [CrossRef]
- Wang, S.; Mo, B.; Hess, S.; Zhao, J. Comparing hundreds of machine learning classifiers and discrete choice models in predicting travel behavior: An empirical benchmark. arXiv 2021, arXiv:2102.01130. [Google Scholar]
- Lee, D.; Kang, S.; Shin, J. Using Deep Learning Techniques to Forecast Environmental Consumption Level. Sustainability 2017, 9, 1894. [Google Scholar] [CrossRef] [Green Version]
- Amasyali, K.; El-Gohary, N. Machine learning for occupant-behavior-sensitive cooling energy consumption prediction in office buildings. Renew. Sustain. Energy Rev. 2021, 142, 110714. [Google Scholar] [CrossRef]
- Lee, D.; Kim, M.; Lee, J. Adoption of green electricity policies: Investigating the role of environmental attitudes via big data-driven search-queries. Energy Policy 2016, 90, 187–201. [Google Scholar] [CrossRef]
- Ping, P.; Qin, W.; Xu, Y.; Miyajima, C.; Takeda, K. Impact of Driver Behavior on Fuel Consumption: Classification, Evaluation and Prediction Using Machine Learning. IEEE Access 2019, 7, 78515–78532. [Google Scholar] [CrossRef]
- Chang, X.; Wu, J.; Liu, H.; Yan, X.; Sun, H.; Qu, Y. Travel mode choice: A data fusion model using machine learning methods and evidence from travel diary survey data. Transp. A Transp. Sci. 2019, 15, 1587–1612. [Google Scholar] [CrossRef]
- Wade, B.S.; Joshi, S.H.; Gutman, B.A.; Thompson, P.M. Machine learning on high dimensional shape data from subcortical brain surfaces: A comparison of feature selection and classification methods. Pattern Recognit. 2017, 63, 731–739. [Google Scholar] [CrossRef]
- Sanchez-Pinto, L.N.; Venable, L.R.; Fahrenbach, J.; Churpek, M.M. Comparison of variable selection methods for clinical predictive modeling. Int. J. Med. Inform. 2018, 116, 10–17. [Google Scholar] [CrossRef]
- Climate Watch. Global GHG Emissions. Available online: https://www.climatewatchdata.org (accessed on 20 May 2018).
- Kaiser, F.; Wilson, M.R. Goal-directed conservation behavior: The specific composition of a general performance. Pers. Individ. Differ. 2004, 36, 1531–1544. [Google Scholar] [CrossRef]
- Dunlap, R.E.; Van Liere, K.D.; Mertig, A.G.; Jones, R.E. New Trends in Measuring Environmental Attitudes: Measuring Endorsement of the New Ecological Paradigm: A Revised NEP Scale. J. Soc. Issues 2000, 56, 425–442. [Google Scholar] [CrossRef]
- Majidifard, H.; Jahangiri, B.; Rath, P.; Contreras, L.U.; Buttlar, W.G.; Alavi, A.H. Developing a prediction model for rutting depth of asphalt mixtures using gene expression programming. Constr. Build. Mater. 2020, 267, 120543. [Google Scholar] [CrossRef]
- Naseri, H.; Jahanbakhsh, H.; Khezri, K.; Shirzadi Javid, A.A. Toward sustainability in optimizing the fly ash concrete mixture ingredients by introducing a new prediction algorithm. Environ. Dev. Sustain. 2021. [Google Scholar] [CrossRef]
- Hasan, K.; Alam, A.; Das, D.; Hossain, E.; Hasan, M. Diabetes Prediction Using Ensembling of Different Machine Learning Classifiers. IEEE Access 2020, 8, 76516–76531. [Google Scholar] [CrossRef]
- Ontivero-Ortega, M.; Lage-Castellanos, A.; Valente, G.; Goebel, R.; Valdes-Sosa, M. Fast Gaussian Naïve Bayes for searchlight classification analysis. NeuroImage 2017, 163, 471–479. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.; Wesseloo, J.; Potvin, Y.; Li, X. Discrimination of Mine Seismic Events and Blasts Using the Fisher Classifier, Naive Bayesian Classifier and Logistic Regression. Rock Mech. Rock Eng. 2015, 49, 183–211. [Google Scholar] [CrossRef]
- Hajmeer, M.; Basheer, I. Comparison of logistic regression and neural network-based classifiers for bacterial growth. Food Microbiol. 2003, 20, 43–55. [Google Scholar] [CrossRef]
- Suresh, A.; Udendhran, R.; Balamurgan, M. Hybridized neural network and decision tree based classifier for prognostic decision making in breast cancers. Soft Comput. 2019, 24, 7947–7953. [Google Scholar] [CrossRef]
- Rau, C.-S.; Wu, S.-C.; Chien, P.-C.; Kuo, P.-J.; Cheng-Shyuan, R.; Hsieh, H.-Y.; Hsieh, C.-H. Prediction of Mortality in Patients with Isolated Traumatic Subarachnoid Hemorrhage Using a Decision Tree Classifier: A Retrospective Analysis Based on a Trauma Registry System. Int. J. Environ. Res. Public Health 2017, 14, 1420. [Google Scholar] [CrossRef] [Green Version]
- Duca, A.L.; Bacciu, C.; Marchetti, A. A K-nearest neighbor classifier for ship route prediction. In Proceedings of the OCEANS 2017—Aberdeen, Aberdeen, UK, 19–22 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Noi, P.T.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Dogru, N.; Subasi, A. Traffic accident detection using random forest classifier. In Proceedings of the 2018 15th Learning and Technology Conference (L&T), Jeddah, Saudi Arabia, 25–26 February 2018. [Google Scholar]
- Chapleau, R.; Gaudette, P.; Spurr, T. Application of Machine Learning to Two Large-Sample Household Travel Surveys: A Characterization of Travel Modes. Transp. Res. Rec. J. Transp. Res. Board 2019, 2673, 173–183. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Zhang, F.; Ma, X.; Wu, L. Predicting daily diffuse horizontal solar radiation in various climatic regions of China using support vector machine and tree-based soft computing models with local and extrinsic climatic data. J. Clean. Prod. 2020, 248, 119264. [Google Scholar] [CrossRef]
- Li, L.-L.; Zhao, X.; Tseng, M.-L.; Tan, R.R. Short-term wind power forecasting based on support vector machine with improved dragonfly algorithm. J. Clean. Prod. 2020, 242, 118447. [Google Scholar] [CrossRef]
- Hu, G.; Yin, C.; Wan, M.; Zhang, Y.; Fang, Y. Recognition of diseased Pinus trees in UAV images using deep learning and AdaBoost classifier. Biosyst. Eng. 2020, 194, 138–151. [Google Scholar] [CrossRef]
- Pierezan, J.; Coelho, L.D.S. Coyote optimization algorithm: A new metaheuristic for global optimization problems. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Pierezan, J.; Maidl, G.; Yamao, E.M.; Coelho, L.D.S.; Mariani, V.C. Cultural coyote optimization algorithm applied to a heavy duty gas turbine operation. Energy Convers. Manag. 2019, 199, 111932. [Google Scholar] [CrossRef]
- Pierezan, J.; Coelho, S.; Mariani, V.C.; Lebensztajn, L. Multiobjective Coyote Algorithm Applied to Electromagnetic Optimization. In Proceedings of the 2019 22nd International Conference Computation of Electromagnetic Fields, Paris, France, 15–19 July 2019; pp. 1–4. [Google Scholar]
- Naseri, H.; Ehsani, M.; Golroo, A.; Nejad, F.M. Sustainable pavement maintenance and rehabilitation planning using differential evolutionary programming and coyote optimisation algorithm. Int. J. Pavement Eng. 2021, 1–18. [Google Scholar] [CrossRef]
- Srivastava, S.; Gupta, M.R.; Frigyik, B.A. Bayesian quadratic discriminant analysis. J. Mach. Learn. Res. 2007, 8, 1277–1305. [Google Scholar]
- Kim, K.S.; Choi, H.H.; Moon, C.S.; Mun, C.W. Comparison of k-nearest neighbor, quadratic discriminant and linear discriminant analysis in classification of electromyogram signals based on the wrist-motion directions. Curr. Appl. Phys. 2011, 11, 740–745. [Google Scholar] [CrossRef]
- Naseri, H.; Shokoohi, M.; Jahanbakhsh, H.; Golroo, A.; Gandomi, A.H. Evolutionary and swarm intelligence algorithms on pavement maintenance and rehabilitation planning. Int. J. Pavement Eng. 2021, 1–16. [Google Scholar] [CrossRef]
- Naseri, H.; Fani, A.; Golroo, A. Toward equity in large-scale network-level pavement maintenance and rehabilitation scheduling using water cycle and genetic algorithms. Int. J. Pavement Eng. 2020, 1–13. [Google Scholar] [CrossRef]
- Naseri, H.; Jahanbakhsh, H.; Hosseini, P.; Nejad, F.M. Designing sustainable concrete mixture by developing a new machine learning technique. J. Clean. Prod. 2020, 258, 120578. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Muthukrishnan, R.; Rohini, R. LASSO: A feature selection technique in predictive modeling for machine learning. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016. [Google Scholar]
- Fonti, V. Feature Selection Using LASSO; VU Amsterdam: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Cui, L.; Bai, L.; Wang, Y.; Jin, X.; Hancock, E.R. Internet financing credit risk evaluation using multiple structural interacting elastic net feature selection. Pattern Recognit. 2021, 114, 107835. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Jaiswal, J.K.; Samikannu, R. Application of Random Forest Algorithm on Feature Subset Selection and Classification and Regression. In Proceedings of the 2017 World Congress on Computing and Communication Technologies (WCCCT), Tiruchirappalli, India, 2–4 February 2017; pp. 65–68. [Google Scholar] [CrossRef]
- Yamauchi, T. Mouse trajectories and state anxiety: Feature selection with random forest. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013. [Google Scholar]
- Sharma, J.; Giri, C.; Granmo, O.-C.; Goodwin, M.; Sharma, J.; Giri, C.; Granmo, O.-C.; Goodwin, M. Multi-layer intrusion detection system with ExtraTrees feature selection, extreme learning machine ensemble, and softmax aggregation. EURASIP J. Inf. Secur. 2019, 2019, 15. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Wu, W.; Massart, D.; Boucon, C.; de Jong, S. Feature selection in principal component analysis of analytical data. Chemom. Intell. Lab. Syst. 2002, 61, 123–132. [Google Scholar] [CrossRef]
- Song, F.; Guo, Z.; Mei, D. Feature selection using principal component analysis. In Proceedings of the 2010 International Conference on System Science, Engineering Design and Manufacturing Informatization, Yichang, China, 12–14 November 2010. [Google Scholar]
- Ramachandran, A.; Anupama, K.R.; Adarsh, R.; Pahwa, P. Machine learning-based techniques for fall detection in geriatric healthcare systems. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 232–237. [Google Scholar]
- Meti, N.; Saednia, K.; Lagree, A.; Tabbarah, S.; Mohebpour, M.; Kiss, A.; Lu, F.-I.; Slodkowska, E.; Gandhi, S.; Jerzak, K.J.; et al. Machine Learning Frameworks to Predict Neoadjuvant Chemotherapy Response in Breast Cancer Using Clinical and Pathological Features. JCO Clin. Cancer Inform. 2021, 5, 66–80. [Google Scholar] [CrossRef]
- Vanhoenshoven, F.; Napoles, G.; Falcon, R.; Vanhoof, K.; Koppen, M. Detecting malicious URLs using machine learning techniques. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016. [Google Scholar]
- Ahmad, J.; Fiaz, M.; Kwon, S.; Sodanil, M.; Vo, B.; Baik, S.W. Gender Identification using MFCC for Telephone Applications—A Comparative Study. arXiv 2016, arXiv:1601.01577. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Socio-Demographic Variables | Frequency | Percent | Mode | |
|---|---|---|---|---|
| Gender | Male | 794 | 50.2 | ☑ |
| Female | 787 | 49.8 | ||
| Household cars | 1 | 616 | 39.0 | |
| 2 | 739 | 46.7 | ☑ | |
| 3 | 155 | 9.8 | ||
| 4 or more | 71 | 4.5 | ||
| Residence location | Greater Philadelphia | 926 | 58.6 | ☑ |
| Greater Boston | 655 | 41.4 | ||
| Education | Professional or Doctorate degree | 80 | 5.1 | |
| Master’s degree | 229 | 14.5 | ||
| Bachelor’s degree | 610 | 38.6 | ☑ | |
| Associate degree | 145 | 9.2 | ||
| Some college, no degree | 314 | 19.9 | ||
| High School Graduate (Diploma or equivalent GED) | 192 | 12.1 | ||
| 1–12th grade | 11 | 0.7 | ||
| Household income | Less than $30,000 | 105 | 6.7 | |
| $30,000–$39,999 | 105 | 6.6 | ||
| $40,000–$49,999 | 134 | 8.5 | ||
| $50,000–$59,999 | 163 | 10.3 | ||
| $60,000–$74,999 | 247 | 15.6 | ☑ | |
| $75,000–$84,999 | 133 | 8.4 | ||
| $85,000–$99,999 | 165 | 10.4 | ||
| $100,000–$124,999 | 174 | 11.0 | ||
| $125,000–$149,999 | 109 | 6.9 | ||
| $150,000–$174,999 | 66 | 4.2 | ||
| More than $175,000 | 103 | 6.5 | ||
| I prefer not to answer | 77 | 4.9 | ||
| Hispanic | Yes | 104 | 6.6 | |
| No | 1477 | 93.4 | ☑ | |
| Political | Strongly conservative | 110 | 7.0 | |
| Moderately conservative | 364 | 23.0 | ||
| Independent | 633 | 40.0 | ☑ | |
| Moderately liberal | 320 | 20.2 | ||
| Strongly liberal | 154 | 9.7 | ||
| Feature Selection Techniques | Data Type | MLP | NB | LR | DT | KNN | RF | SVM | AB | Average Accuracy | Maximum Accuracy | Accuracy Standard Deviation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| All features | Training | 0.461 | 0.528 | 0.623 | 0.570 | 0.438 | 0.979 | 0.838 | 0.519 | 0.620 | 0.979 | 0.179 |
| Testing | 0.338 | 0.481 | 0.502 | 0.351 | 0.390 | 0.502 | 0.506 | 0.459 | 0.441 | 0.506 | 0.066 | |
| ETFS | Training | 0.571 | 0.521 | 0.554 | 0.557 | 0.514 | 0.900 | 0.687 | 0.503 | 0.601 | 0.900 | 0.125 |
| Testing | 0.498 | 0.476 | 0.494 | 0.446 | 0.407 | 0.494 | 0.468 | 0.494 | 0.472 | 0.498 | 0.030 | |
| EN | Training | 0.735 | 0.505 | 0.561 | 0.554 | 0.497 | 0.935 | 0.754 | 0.515 | 0.632 | 0.935 | 0.149 |
| Testing | 0.476 | 0.485 | 0.524 | 0.398 | 0.420 | 0.489 | 0.498 | 0.472 | 0.470 | 0.524 | 0.039 | |
| Lasso | Training | 0.620 | 0.473 | 0.507 | 0.532 | 0.477 | 0.887 | 0.647 | 0.474 | 0.577 | 0.887 | 0.133 |
| Testing | 0.437 | 0.433 | 0.455 | 0.416 | 0.394 | 0.481 | 0.437 | 0.398 | 0.431 | 0.481 | 0.027 | |
| RFFS | Training | 0.556 | 0.491 | 0.517 | 0.559 | 0.473 | 0.914 | 0.659 | 0.479 | 0.581 | 0.914 | 0.138 |
| Testing | 0.459 | 0.481 | 0.494 | 0.394 | 0.381 | 0.494 | 0.511 | 0.446 | 0.457 | 0.511 | 0.045 | |
| PCA | Training | 0.620 | 0.408 | 0.470 | 0.548 | 0.473 | 0.927 | 0.627 | 0.477 | 0.569 | 0.927 | 0.153 |
| Testing | 0.398 | 0.381 | 0.459 | 0.420 | 0.407 | 0.476 | 0.455 | 0.394 | 0.424 | 0.476 | 0.033 | |
| COA-QDA | Training | 0.529 | 0.500 | 0.553 | 0.569 | 0.428 | 0.946 | 0.768 | 0.493 | 0.598 | 0.946 | 0.161 |
| Testing | 0.494 | 0.506 | 0.537 | 0.433 | 0.385 | 0.506 | 0.502 | 0.472 | 0.479 | 0.537 | 0.046 |
| Ranking | Questions (Features) | Group |
|---|---|---|
| 1 | What was your total household income before taxes during the past 12 months? | Socio-demographic |
| 2 | I buy milk in returnable bottles | GEB |
| 3 | How much would you be willing to pay per ton of additional GHG emissions? | Extra features |
| 4 | The production year of the current vehicle | Transport-related |
| 5 | I talk with friends about problems related to the environment | GEB |
| 6 | In summer, I turn the AC off when I leave my home for more than 4 h. | GEB |
| 7 | I own a fuel-efficient automobile | GEB |
| 8 | Government rules allow mini-vans, vans, pick-ups, and SUVs to pollute more than passenger cars, for every gallon of gas used | Extra features |
| 9 | For long trips (more than 6 h), I take an airplane. | GEB |
| 10 | Do you have the base model or do you have a model with optional upgrades? | Transport-related |
| 11 | Age | Socio-demographic |
| 12 | When do you expect to purchase (or lease) your next car? | Transport-related |
| 13 | I buy convenience foods | GEB |
| 14 | Please select the make of your car | Transport-related |
| 15 | What is your relationship status? | Socio-demographic |
| 16 | I reuse my shopping bags. | GEB |
| 17 | I have pointed out unecological behavior to someone. | GEB |
| 18 | How many people have driver licenses in your household (including you)? | Socio-demographic |
| 19 | What is your gender? | Socio-demographic |
| 20 | Human destruction of the natural environment has been greatly exaggerated. | NEP |
| 21 | We are approaching the limit of the number of people the earth can support. | NEP |
| 22 | How many people are in your household including you? | Socio-demographic |
| 23 | I buy beverages in cans | GEB |
| 24 | Plants and animals have as much right as humans to exist | NEP |
| 25 | I wait until I have a full load before doing my laundry | GEB |
| 26 | I put dead batteries in the garbage. | GEB |
| 27 | If I am offered a plastic bag in a store, I take it. | GEB |
| 28 | How long would you plan on keeping your next car? | Transport-related |
| 29 | Current car annual mileage | Transport-related |
| 30 | Will you purchase or lease your next car? | Transport-related |
| 31 | After meals, I throw leftovers in the garbage disposal. | GEB |
| 32 | How often do you commute by car? | Transport-related |
| 33 | Describe your housing type | Socio-demographic |
| 34 | I drive my car into the city | GEB |
| 35 | All cars, mini-vans, vans, pickups, and SUVs pollute about the same amount for each mile driven. | Extra features |
| 36 | In hotels, I have the towels changed daily. | GEB |
| 37 | Please select the model of your car | Transport-related |
| 38 | When humans interfere with nature it often produces disastrous consequences | NEP |
| 39 | I am a member of a carpool. | GEB |
| 40 | I bought solar panels to produce energy | GEB |
| 41 | I drive in such a way as to keep my fuel consumption as low as possible | GEB |
| 42 | I requested an estimate on having solar power installed | GEB |
| 43 | The earth has plenty of natural resources if we just learn how to develop them | NEP |
| 44 | If things continue on their present course, we will soon experience a major ecological disaster | NEP |
| 45 | For distances up to 20 miles, I use public transport | GEB |
| 46 | I bring empty bottles to a recycling bin | GEB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naseri, H.; Waygood, E.O.D.; Wang, B.; Patterson, Z.; Daziano, R.A. A Novel Feature Selection Technique to Better Predict Climate Change Stage of Change. Sustainability 2022, 14, 40. https://doi.org/10.3390/su14010040
Naseri H, Waygood EOD, Wang B, Patterson Z, Daziano RA. A Novel Feature Selection Technique to Better Predict Climate Change Stage of Change. Sustainability. 2022; 14(1):40. https://doi.org/10.3390/su14010040
Chicago/Turabian StyleNaseri, Hamed, E. Owen D. Waygood, Bobin Wang, Zachary Patterson, and Ricardo A. Daziano. 2022. "A Novel Feature Selection Technique to Better Predict Climate Change Stage of Change" Sustainability 14, no. 1: 40. https://doi.org/10.3390/su14010040
APA StyleNaseri, H., Waygood, E. O. D., Wang, B., Patterson, Z., & Daziano, R. A. (2022). A Novel Feature Selection Technique to Better Predict Climate Change Stage of Change. Sustainability, 14(1), 40. https://doi.org/10.3390/su14010040