
Evaluating Cultural Impact in Discursive Space through Digital Footprints

 , ,
, , 
Abstract
1. Introduction
1.1. Digital Traces of Discursive Space
1.2. Domplatz Square and SmartSquare Project
1.3. Objectives of This Work
2. Materials and Methods
2.1. Data Collection, Filtering, and Preprocessing
2.1.1. Preprocessing Pipeline
- Filtering domain-specific stopwords: Stopwords were filtered out in order to eliminate the most common terms in a language (e.g., “the”, “a”, “and”), which contain no semantic information thus have no influence on the topic identification and modeling.
- Detection of phrases: the NLP pipeline was designed to work with words as independent entities. However, some case-specific phrases composed of more than one word were considered. To do so, a separate training process took a manually-generated set of the most common phrases expected to appear, in order to identify them as such.
- Identification and classification of emojis and emoticons as (1) emotion or sentiment, (2) action or activity, (3) other. The first two categories were integrated within separate processes of mood extraction and activity detection.
- Detection and grammatical categorization of “clusterable” words: following part-of-speech tagging (POS-tagging) procedures in which each term was attached to a grammatical category determined by its own definition and its contexts within the sentence.
- “Clusterable words”: A list of terms with semantic load and able to be clustered, and their grammatical category, i.e., adjective, verb, and noun.
- Sentiment: Main polarity of the overall opinion—i.e., positive, negative or neutral—present in the text, extracted following standardized sentiment analysis protocol integrated into NLP.
- Mood: Main polarity of the overall emotion—i.e., positive, negative or neutral—present in the text, extracted from a pre-set classification of emojis and emoticons extracted from the open-source library Emojipedia [20].
- Activities: A joint list of verbs generated by POS-tagging procedures, along with the textual translation of the emojis and emoticons portraying activity or action.
- Hashtags used in the post.
- Language in which the text was written, filtering only English and German posts (case-specific process).
- URLs links included in the text.
- Date and time in which the post was generated by the user.
- Numeric ID generated as a random integer for username to ensure anonymization.
- The social network in which the post was generated, Twitter or Instagram.
2.1.2. Topic Modeling
2.1.3. Expert Terms
2.2. Top Expert-Term Set Selection
2.3. Artificial Topic Construction and Tracking
3. Results
3.1. Activity in Social Media
3.2. Topic Detection and Validation
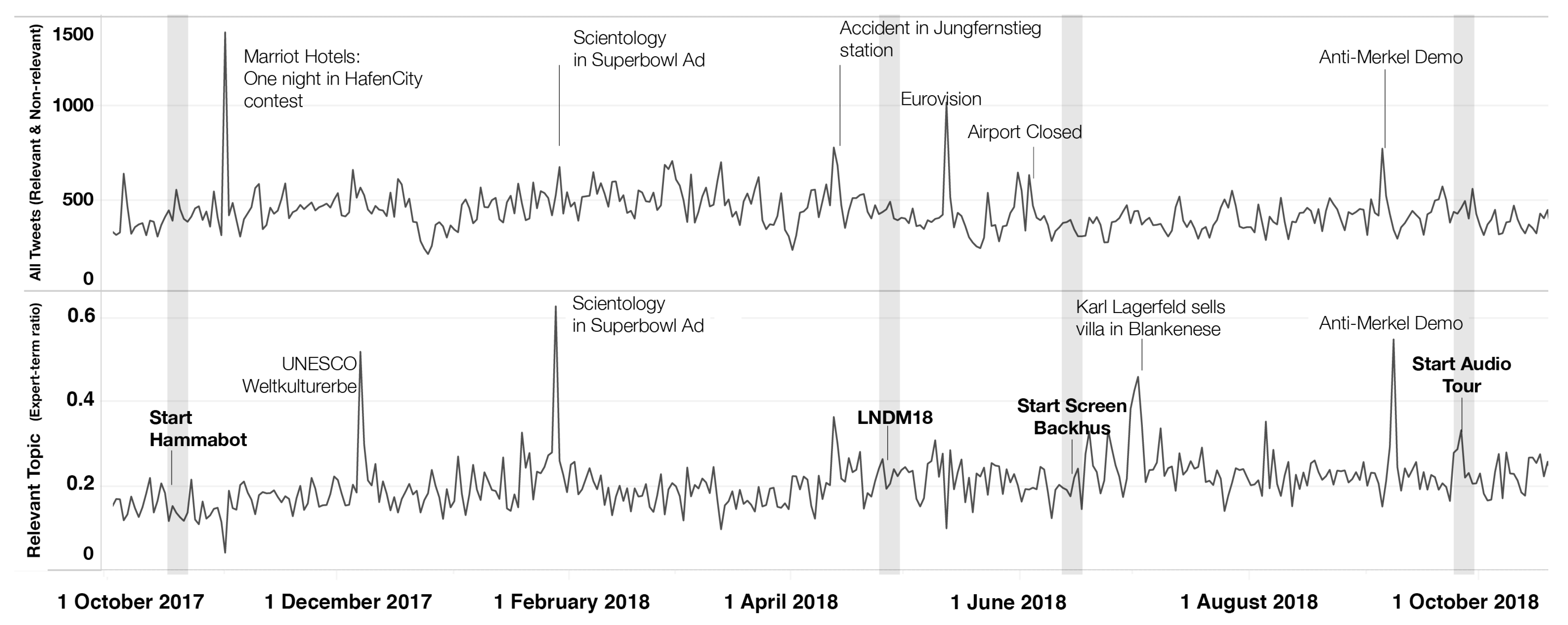
3.3. Long-Term Topic Tracking
4. Discussion
4.1. Theoretical Implications
4.2. Implications for the Urban Practice
5. Conclusions
5.1. Temporal Activity Patterns
5.2. Detecting and Tracking the Cultural Discourse
5.3. Did the Interventions in Domplatz Make an Impact on the Urban Scale?
5.4. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stokols, D.; Shumaker, S. People in places: A transactional view of settings. In Cognition, Social Behavior and the Environment; Harvey, J.H., Ed.; Lawrence Erlbaum: Hillsdale, NJ, USA, 1981; pp. 441–488. [Google Scholar]
- Rapoport, A. Human Aspects of Urban Form; Pergamon: Oxford, UK, 1977; Volume 3. [Google Scholar]
- Lefebvre, H. La producción del espacio. Pap. Rev. Sociol. 1974, 3, 219. [Google Scholar] [CrossRef]
- De Certeau, M. The Practice of Everyday Life; University of California Press: Berkeley/Los Angeles, CA, USA, 1984. [Google Scholar]
- Neal, Z.P. The Connected City: How Networks Are Shaping the Modern Metropolis; Routledge: New York, NY, USA, 2012. [Google Scholar]
- Di Masso, A.; Dixon, J. More than words: Place, discourse and the struggle over public space in Barcelona. Qual. Res. Psychol. 2015, 12, 45–60. [Google Scholar] [CrossRef]
- Saker, M.; Evans, L. Everyday life and locative play: An exploration of Foursquare and playful engagements with space and place. Media Cult. Soc. 2016, 38, 1169–1183. [Google Scholar] [CrossRef]
- Boyd, D.M.; Ellison, N.B. Social network sites: Definition, history, and scholarship. J. Comput. Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef]
- Humphreys, L. Mobile social networks and urban public space. New Media Soc. 2010, 12, 763–778. [Google Scholar] [CrossRef]
- Humphreys, L. Mobile social networks and social practice: A case study of Dodgeball. J. Comput. Mediat. Commun. 2007, 13, 341–360. [Google Scholar] [CrossRef]
- Sutko, D.M.; De Souza e Silva, A. Location-aware mobile media and urban sociability. New Media Soc. 2011, 13, 807–823. [Google Scholar] [CrossRef]
- De Lange, M.; De Waal, M. Owning the city: New media and citizen engagement in urban design. First Monday 2013, 18. [Google Scholar] [CrossRef]
- Campbell, S.W.; Ling, R. Effects of mobile communication. In Media Effects: Advances in Theory and Research, 3rd ed.; Bryant, J., Oliver, M.B., Eds.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2009; pp. 592–606. [Google Scholar]
- Gordon, E.; Baldwin-Philippi, J.; Balestra, M. Why We Engage: How Theories pf Human Behavior Contribute to our Understanding of Civic Engagement in a Digital Era. Berkman Cent. Res. Publ. 2013, 21. Available online: http://ssrn.com/abstract=2343762 (accessed on 20 February 2021). [CrossRef]
- Martin, J.A. Mobile media and political participation: Defining and developing an emerging field. Mob. Media Commun. 2014, 2, 173–195. [Google Scholar] [CrossRef]
- Kozinets, R.V. The field behind the screen: Using netnography for marketing research in online communities. J. Mark. Res. 2002, 39, 61–72. [Google Scholar] [CrossRef]
- Ginzarly, M.; Roders, A.P.; Teller, J. Mapping historic urban landscape values through social media. J. Cult. Herit. 2019, 36, 1–11. [Google Scholar] [CrossRef]
- HafenCity University (HCU). Joint Project of HafenCity University Hamburg Brings Cathedral Square Back to Life. 2017. Available online: https://amh.de/en/digitales-angebot/joint-project-of-hafencity-university-hamburg-brings-cathedral-square-back-to-life (accessed on 9 October 2019).
- Efthimion, P.G.; Payne, S.; Proferes, N. Supervised Machine Learning Bot Detection Techniques to Identify Social Twitter Bots. SMU Data Sci. Rev. 2018, 1, 5. Available online: https://scholar.smu.edu/datasciencereview/vol1/iss2/5 (accessed on 20 February 2021).
- Emojipedia. Available online: http://emojipedia.org (accessed on 14 September 2019).
- Weiss, R.M.; Klammt, A. Mythos Hammaburg. Archäologische Entdeckungen zu den Anfängen Hamburgs; Veröffentlichung des Helms-Museums, Archäologisches Museum Hamburg, Stadtmuseum Harburg: Hamburg, Germany, 2014. [Google Scholar]
- Boßmann, T.; Staffell, I. The shape of future electricity demand: Exploring load curves in 2050s Germany and Britain. Energy 2015, 90, 1317–1333. [Google Scholar] [CrossRef]
- Ghosh, B.; Basu, B.; O’Mahony, M. Analysis of trend in vehicular traffic flow data by wavelets. In Proceedings of the IET Irish Signals and Systems Conference (ISSC), Dublin, Ireland, 28–30 June 2006; pp. 415–419. [Google Scholar] [CrossRef]
- Manovich, L. The practice of everyday (media) life: From mass consumption to mass cultural production? Crit. Inq. 2009, 35, 319–331. [Google Scholar] [CrossRef]
- Carpio-Pinedo, J. La producción de identidad de los nuevos desarrollos urbanos a través del place-based social big data: Los crecimientos del área metropolitana de Madrid durante la burbuja inmobiliaria (1990–2012). EURE 2020, 47, 5–28. (In Spanish) [Google Scholar] [CrossRef]
- Zukin, S. Space and symbols in an age of decline. In Re-Presenting the City; King, A.D., Ed.; Palgrave: London, UK, 1996; pp. 43–59. [Google Scholar]
- Lefebvre, H. The Production of Space; Wiley: Hoboken, NJ, USA, 1974. [Google Scholar]
- Soja, E.W. The spatiality of social life: Towards a transformative retheorisation. In Social Relations and Spatial Structures; Gregory, D., Urry, J., Eds.; Palgrave: London, UK, 1985; pp. 90–127. [Google Scholar]
- Schwartz, R.; Halegoua, G.R. The spatial self: Location-based identity performance on social media. New Media Soc. 2015, 17, 1643–1660. [Google Scholar] [CrossRef]
- Stewart, J. Public Speaking in the City: Debating and Shaping the Urban Experience; Palgrave Macmillan: London, UK, 2009. [Google Scholar]
- Manovich, L. Cultural analytics, social computing and digital humanities. In The Datafied Society: Studying Culture through Data; Schäfer, M.T., van Es, K., Eds.; Amsterdam University Press: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Frias-Martinez, V.; Frias-Martinez, E. Crowdsourcing Land Use Maps via Twitter. Workshop on Data Science for Social Good, 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2014. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.434.1641&rep=rep1&type=pdf (accessed on 20 February 2021).
- Frias-Martinez, V.; Soto, V.; Hohwald, H.; Frias-Martinez, E. Characterizing urban landscapes using geolocated tweets. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Conference on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 239–248. [Google Scholar]
- Lieven, C.; Lüders, B.; Kulus, D.; Thoneick, R. Enabling digital co-creation in urban planning and development. In Human Centred Intelligent Systems; Zimmermann, A., Howlett, R.J., Jain, L.C., Eds.; Springer: Singapore, 2021; pp. 415–430. [Google Scholar]
- Thoneick, R. Integrating online and onsite participation in urban planning. Int. J. E-Plan. Res. 2021, 10, 1–20. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Week | Event | Total Social Media Posts | Human-Generated % |
|---|---|---|---|
| Week 41—2017 | Hammabot 1 | 22,218 | 72.06% |
| Week 42—2017 | Hammabot | 45,626 | 80.99% |
| Week 23—2018 | Scr.2 Backhus | 82,404 | 65.24% |
| Week 24—2018 | Scr. Backhus | 83,469 | 63.19% |
| Week 38—2018 | Audio Tour | 90,787 | 60.63% |
| Week 39—2018 | Audio Tour | 58,161 | 88.73% |
| Week 13—2019 | Scr. Bürgerstiftung | 70,618 | 85.25% |
| Week 14—2019 | Scr. Bürgerstiftung | 68,344 | 85.13% |
| Week 20—2019 | LNDM 3 | 61,369 | 84.84% |
| Week 11—2018 | (control week) | 126,647 | 66.65% |
| Week 43—2018 | (control week) | 8536 | 61.55% |
| Week 45—2018 | (control week) | 8111 | 64.73% |
| Week 21—2019 | LNDM | 29,314 | 83.05% |
| Week 44—2018 | (control week) | 7985 | 60.59% |
| Week 16—2018 | LNDM | 82,508 | 69.12% |
| Week 17—2018 | LNDM | 82,616 | 66.73% |
| Topic | Number of Posts | Number of Expert Terms | Ratio of Expert Terms/Post | Relevance Cluster |
|---|---|---|---|---|
| 1 | 7070 | 490 | 6.93% | 2 (relevant) |
| 2 | 3616 | 30 | 0.83% | 3 |
| 3 | 2915 | 230 | 7.89% | 1 (relevant) |
| 4 | 2666 | 16 | 0.60% | 3 |
| 5 | 6018 | 14 | 0.23% | 3 |
| 6 | 3286 | 1 | 0.03% | 3 |
| 7 | 2613 | 0 | 0.00% | 3 |
| 8 | 3190 | 18 | 0.56% | 3 |
| 9 | 1787 | 2 | 0.11% | 3 |
| 10 | 1838 | 5 | 0.27% | 3 |
| No Topic | 10,298 | 1 | 0.01% | 3 |
| Topic 1—Relevant | Topic 2—Non-Relevant | No Topic | |||
|---|---|---|---|---|---|
| Social Media | Artificially Generated | Social Media | Artificially Generated | Social Media | |
| Week 11—2018 | 56 | 207 | 251 | 261 | 86 |
| Week 43—2018 | 221 | 455 | 196 | 14 | 28 |
| Week 45—2018 | 232 | 439 | 180 | 30 | 57 |
| Source | Reference Week to Model Against | Topic | Number of Posts | Number Expert Terms | Ratio of Expert Terms/Post | Relevant is Highest |
|---|---|---|---|---|---|---|
| week2018-11 | artificial-week2018-43 | Relevant | 28,321 | 554 | 1.96% | TRUE |
| week2018-11 | artificial-week2018-43 | Non-relevant | 23,808 | 142 | 0.60% | |
| week2018-11 | artificial-week2018-43 | No Topic | 20,756 | 18 | 0.09% | |
| week2018-16 | artificial-week2018-43 | Relevant | 23,405 | 1748 | 7.47% | TRUE |
| week2018-16 | artificial-week2018-43 | Non-relevant | 14,100 | 1 | 0.01% | |
| week2018-16 | artificial-week2018-43 | No Topic | 12,276 | 4 | 0.03% | |
| week2018-17 | artificial-week2018-43 | Relevant | 19,847 | 686 | 3.46% | TRUE |
| week2018-17 | artificial-week2018-43 | Non-relevant | 16,941 | 397 | 2.34% | |
| week2018-17 | artificial-week2018-43 | No Topic | 11,398 | 13 | 0.11% | |
| week2018-23 | artificial-week2018-43 | Relevant | 19,173 | 326 | 1.70% | FALSE |
| week2018-23 | artificial-week2018-43 | Non-relevant | 16,550 | 399 | 2.41% | |
| week2018-23 | artificial-week2018-43 | No Topic | 10,963 | 2 | 0.02% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
López Baeza, J.; Bley, J.; Hartkopf, K.; Niggemann, M.; Arias, J.; Wiedenhöfer, A. Evaluating Cultural Impact in Discursive Space through Digital Footprints. Sustainability 2021, 13, 4043. https://doi.org/10.3390/su13074043
López Baeza J, Bley J, Hartkopf K, Niggemann M, Arias J, Wiedenhöfer A. Evaluating Cultural Impact in Discursive Space through Digital Footprints. Sustainability. 2021; 13(7):4043. https://doi.org/10.3390/su13074043
Chicago/Turabian StyleLópez Baeza, Jesús, Jens Bley, Kay Hartkopf, Martin Niggemann, James Arias, and Anais Wiedenhöfer. 2021. "Evaluating Cultural Impact in Discursive Space through Digital Footprints" Sustainability 13, no. 7: 4043. https://doi.org/10.3390/su13074043
APA StyleLópez Baeza, J., Bley, J., Hartkopf, K., Niggemann, M., Arias, J., & Wiedenhöfer, A. (2021). Evaluating Cultural Impact in Discursive Space through Digital Footprints. Sustainability, 13(7), 4043. https://doi.org/10.3390/su13074043