
U-Net-Based Foreign Object Detection Method Using Effective Image Acquisition System: A Case of Almond and Green Onion Flake Food Process


Abstract
:1. Introduction
2. Material and Methods
2.1. Sample Preparation
2.2. Equipment
2.3. Proposed Method
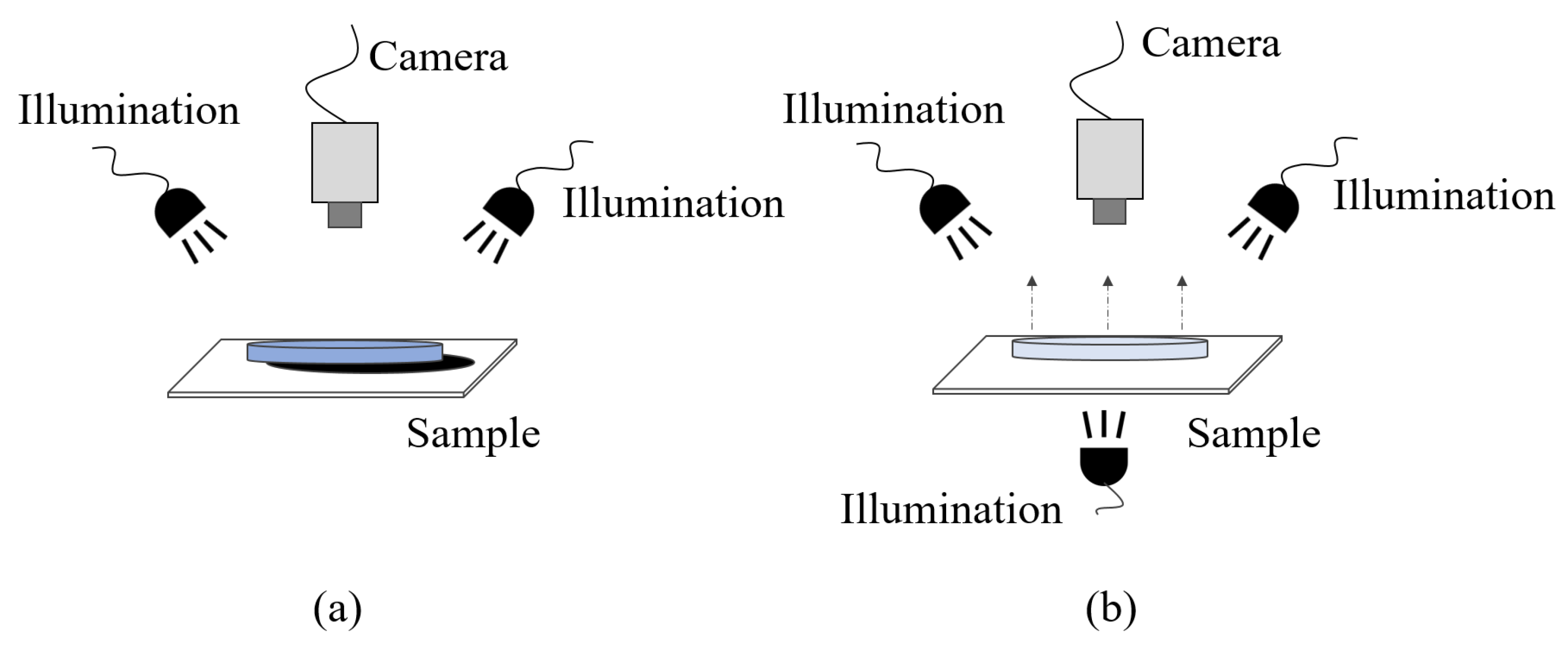
2.3.1. Effective Image Acquisition System
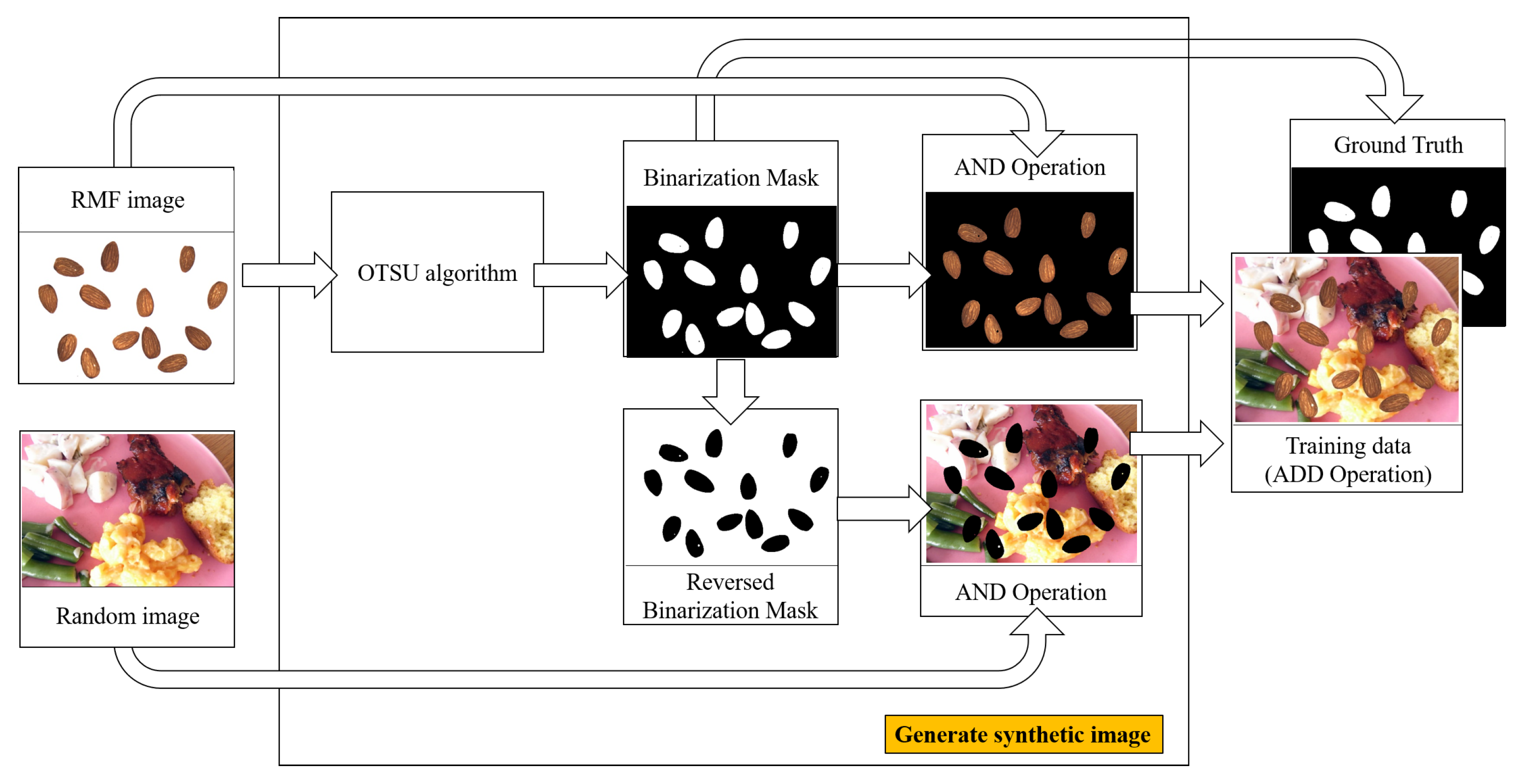
2.3.2. Generating Synthetic Images
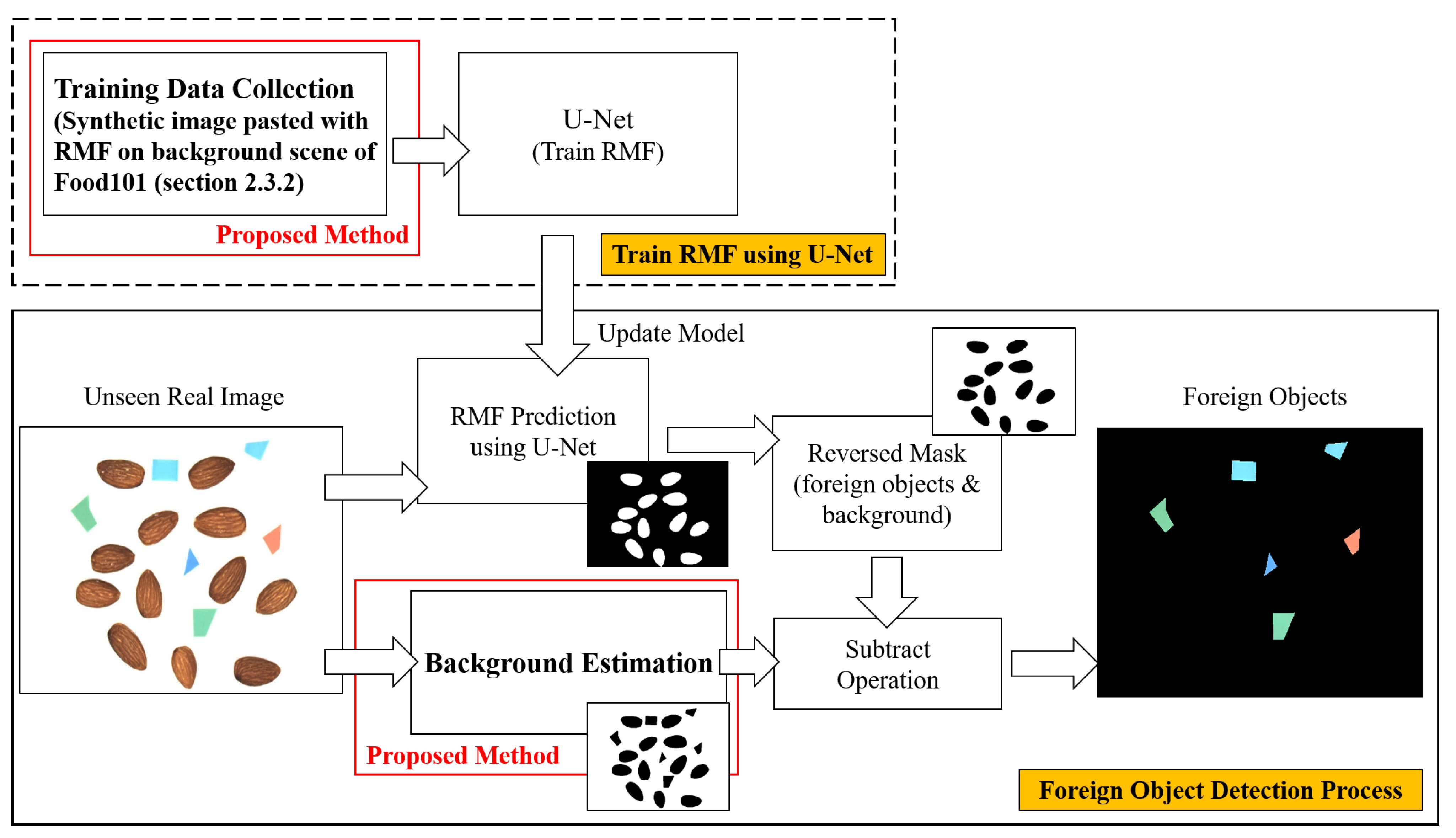
2.3.3. Raw Materials of Food Prediction
2.3.4. Background Estimation
2.4. Histogram Backprojection
2.5. Metrics to Evaluate the DNN Model
3. Results and Discussion
3.1. Training Image and Annotation Acquisition
3.1.1. Effective Image Acquisition System Result
3.1.2. Synthetic Image Result
3.2. Evaluation of the Synthesis Images
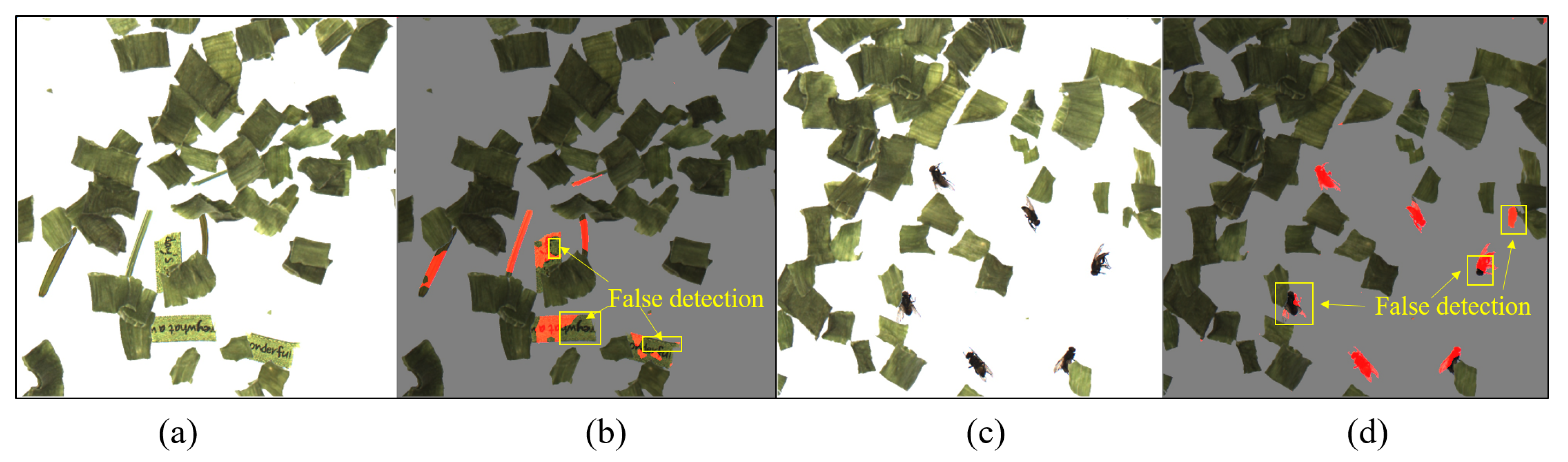
3.3. Foreign Object Detection Performance of Each Method
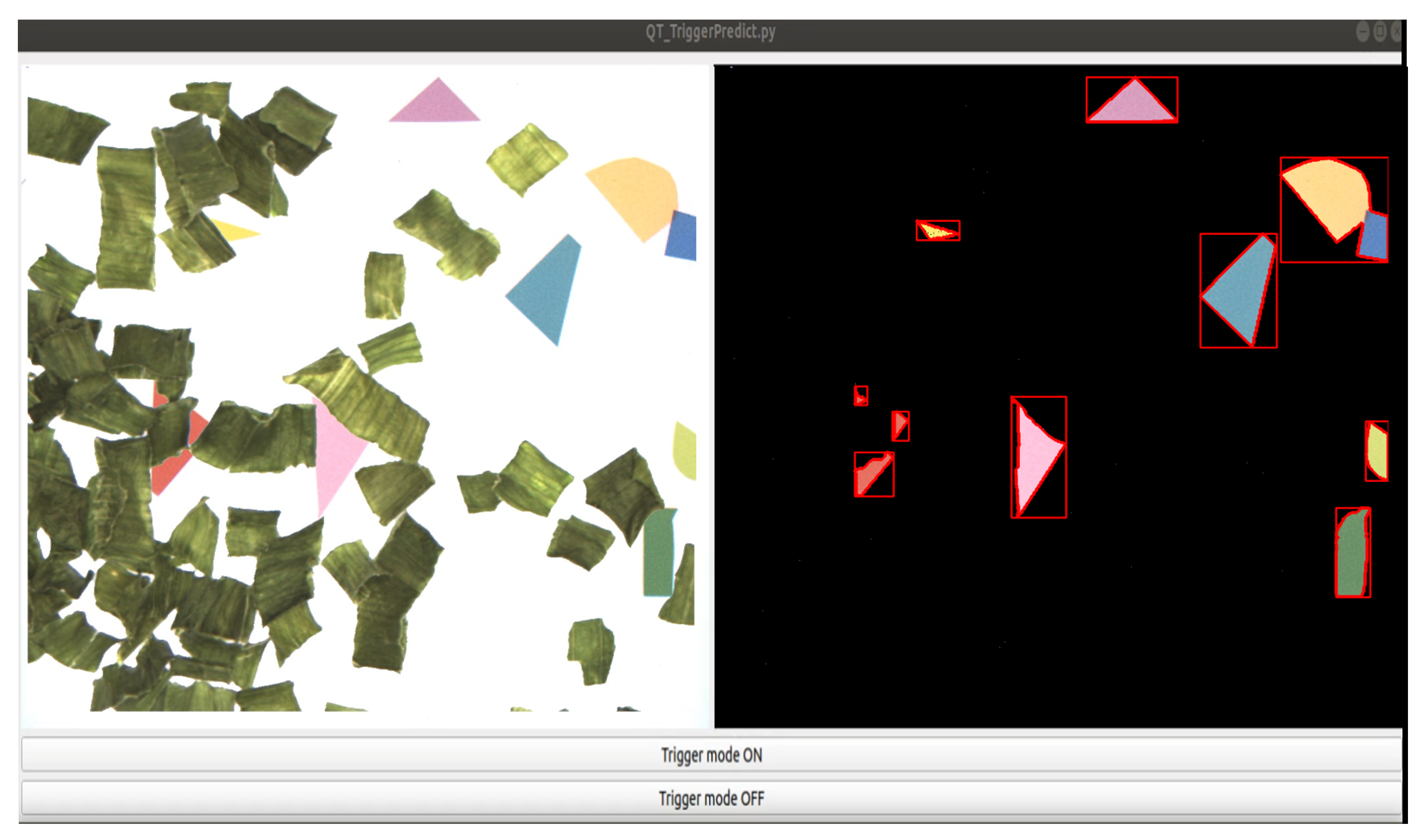
3.4. Foreign Object Detection Platform
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Edwards, M.; Stringer, M. Observations on patterns in foreign material investigations. Food Control 2007, 18, 773–782. [Google Scholar] [CrossRef]
- Trafialek, J.; Kaczmarek, S.; Kolanowski, W. The Risk Analysis of Metallic Foreign Bodies in Food Products. J. Food Qual. 2016, 39, 398–407. [Google Scholar] [CrossRef]
- Djekic, I.; Jankovic, D.; Rajkovic, A. Analysis of foreign bodies present in European food using data from Rapid Alert System for Food and Feed (RASFF). Food Control 2017, 79, 143–149. [Google Scholar] [CrossRef]
- Yang, W.; Li, D.; Zhu, L.; Kang, Y.; Li, F. A new approach for image processing in foreign fiber detection. Comput. Electron. Agric. 2009, 68, 68–77. [Google Scholar] [CrossRef]
- Jagtap, S.; Bhatt, C.; Thik, J.; Rahimifard, S. Monitoring Potato Waste in Food Manufacturing Using Image Processing and Internet of Things Approach. Sustainability 2019, 11, 3173. [Google Scholar] [CrossRef] [Green Version]
- Lim, J.; Lee, A.; Kang, J.; Seo, Y.; Kim, B.; Kim, G.; Kim, S.M. Non-Destructive Detection of Bone Fragments Embedded in Meat Using Hyperspectral Reflectance Imaging Technique. Sensors 2020, 20, 4038. [Google Scholar] [CrossRef] [PubMed]
- Kwak, D.H.; Son, G.J.; Park, M.K.; Kim, Y.D. Rapid Foreign Object Detection System on Seaweed Using VNIR Hyperspectral Imaging. Sensors 2021, 21, 5279. [Google Scholar] [CrossRef] [PubMed]
- Mohd Khairi, M.T.; Ibrahim, S.; Md Yunus, M.A.; Faramarzi, M. Noninvasive techniques for detection of foreign bodies in food: A review. J. Food Process Eng. 2018, 41, e12808. [Google Scholar] [CrossRef]
- Janowski, A.; Kaźmierczak, R.; Kowalczyk, C.; Szulwic, J. Detecting Apples in the Wild: Potential for Harvest Quantity Estimation. Sustainability 2021, 13, 8054. [Google Scholar] [CrossRef]
- Samiei, S.; Rasti, P.; Richard, P.; Galopin, G.; Rousseau, D. Toward Joint Acquisition-Annotation of Images with Egocentric Devices for a Lower-Cost Machine Learning Application to Apple Detection. Sensors 2020, 20, 4173. [Google Scholar] [CrossRef]
- Zhang, H.; Fritts, J.E.; Goldman, S.A. Image segmentation evaluation: A survey of unsupervised methods. Comput. Vis. Image Underst. 2008, 110, 260–280. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Li, D. Applications of computer vision techniques to cotton foreign matter inspection: A review. Comput. Electron. Agric. 2014, 109, 59–70. [Google Scholar] [CrossRef]
- Inamdar, A.; Suresh, D.S. Application of color sorter in wheat milling. Int. Food Res. J. 2014, 21, 2083. [Google Scholar]
- Lorente, D.; Aleixos, N.; Gómez-Sanchis, J.; Cubero, S.; García-Navarrete, O.L.; Blasco, J. Recent advances and applications of hyperspectral imaging for fruit and vegetable quality assessment. Food Bioprocess Technol. 2012, 5, 1121–1142. [Google Scholar] [CrossRef]
- Lo, Y.C.; Chang, C.C.; Chiu, H.C.; Huang, Y.H.; Chen, C.P.; Chang, Y.L.; Jou, K. CLCC: Contrastive Learning for Color Constancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8053–8063. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Rong, D.; Xie, L.; Ying, Y. Computer vision detection of foreign objects in walnuts using deep learning. Comput. Electron. Agric. 2019, 162, 1001–1010. [Google Scholar] [CrossRef]
- Shen, Y.; Zhou, H.; Li, J.; Jian, F.; Jayas, D.S. Detection of stored-grain insects using deep learning. Comput. Electron. Agric. 2018, 145, 319–325. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. arXiv 2021, arXiv:2106.04803. [Google Scholar]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. arXiv 2021, arXiv:2106.04560. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. arXiv 2021, arXiv:2111.09883. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7369–7378. [Google Scholar]
- Yuan, Y.; Chen, X.; Chen, X.; Wang, J. Segmentation transformer: Object-contextual representations for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Montreal, QC, Canada, 11–17 October 2021; Volume 1. [Google Scholar]
- Mohan, R.; Valada, A. Efficientps: Efficient panoptic segmentation. Int. J. Comput. Vis. 2021, 129, 1551–1579. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
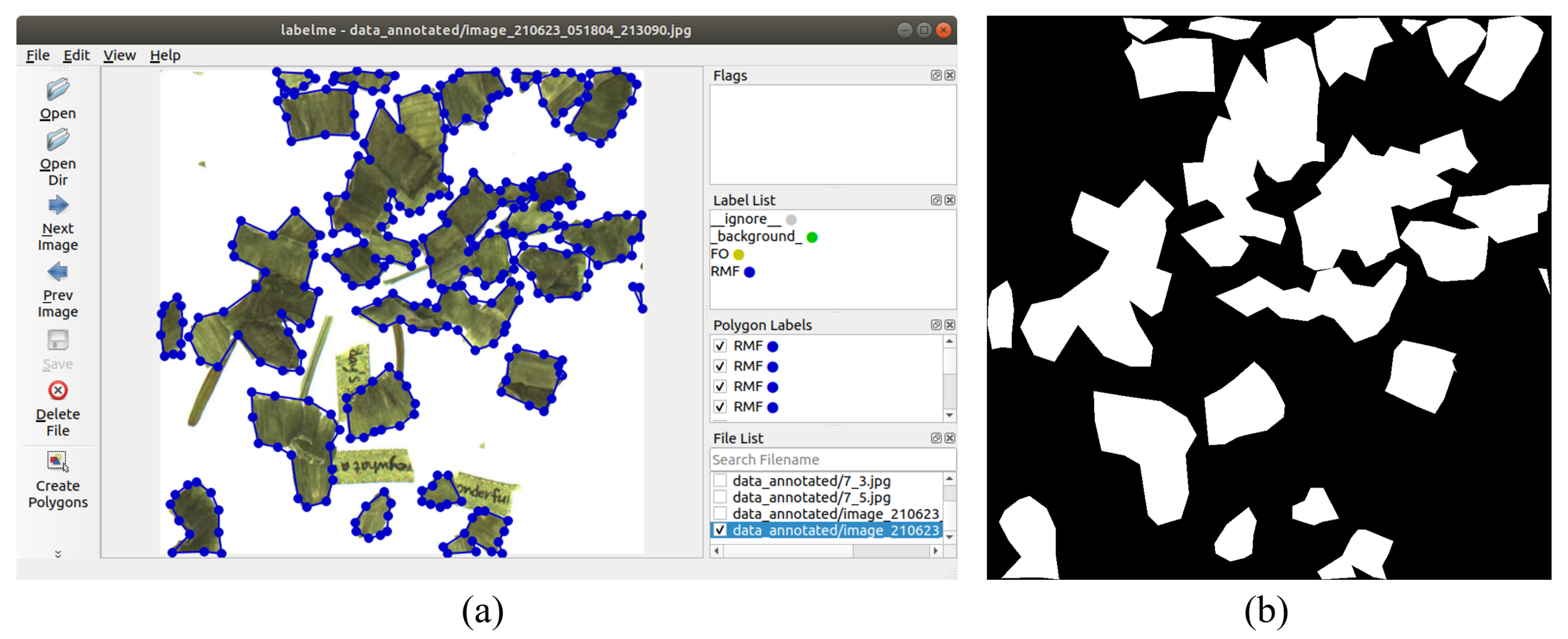
- Wada, K. Labelme: Image Polygonal Annotation with Python. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 2 November 2021).
- Kushwaha, A.; Gupta, S.; Bhanushali, A.; Dastidar, T.R. Rapid Training Data Creation by Synthesizing Medical Images for Classification and Localization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 4272–4279. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhou, T.; Ruan, S.; Canu, S. A review: Deep learning for medical image segmentation using multi-modality fusion. Array 2019, 3, 100004. [Google Scholar] [CrossRef]
- Roy, K.; Chaudhuri, S.S.; Pramanik, S. Deep learning based real-time Industrial framework for rotten and fresh fruit detection using semantic segmentation. Microsyst. Technol. 2021, 27, 3365–3375. [Google Scholar] [CrossRef]
- Chang, S.; Lee, U.; Hong, M.J.; Jo, Y.D.; Kim, J.B. Lettuce Growth Pattern Analysis Using U-Net Pre-Trained with Arabidopsis. Agriculture 2021, 11, 890. [Google Scholar] [CrossRef]
- Trebing, K.; Staǹczyk, T.; Mehrkanoon, S. SmaAt-UNet: Precipitation nowcasting using a small attention-UNet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Zhao, X.; Yuan, Y.; Song, M.; Ding, Y.; Lin, F.; Liang, D.; Zhang, D. Use of Unmanned Aerial Vehicle Imagery and Deep Learning UNet to Extract Rice Lodging. Sensors 2019, 19, 3859. [Google Scholar] [CrossRef] [Green Version]
- Karsch, K.; Hedau, V.; Forsyth, D.; Hoiem, D. Rendering Synthetic Objects into Legacy Photographs. ACM Trans. Graph. 2011, 30, 1–12. [Google Scholar] [CrossRef]
- Movshovitz-Attias, Y.; Kanade, T.; Sheikh, Y. How Useful Is Photo-Realistic Rendering for Visual Learning? In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 202–217. [Google Scholar]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1310–1319. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man. Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Bortnowski, P.; Gładysiewicz, L.; Król, R.; Ozdoba, M. Models of Transverse Vibration in Conveyor Belt—Investigation and Analysis. Energies 2021, 14, 4153. [Google Scholar] [CrossRef]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–165. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101—Mining Discriminative Components with Random Forests. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 446–461. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. LSUN: Construction of a Large-Scale Image Dataset using Deep Learning with Humans in the Loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In Artificial Neural Networks—ICANN 2010; Diamantaras, K., Duch, W., Iliadis, L.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 92–101. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Kwon, J.S.; Lee, J.M.; Kim, W.Y. Real-time detection of foreign objects using X-ray imaging for dry food manufacturing line. In Proceedings of the 2008 IEEE International Symposium on Consumer Electronics, Vilamoura, Portugal, 14–16 April 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Nan, W.Q.H.M.S. Color Sorting Algorithm Based on Color Linear CCD. Trans. Chin. Soc. Agric. Mach. 2008, 10, 105–108. [Google Scholar]
- Chen, P.; Gao, M.; Huang, J.; Yang, Y.; Zeng, Y. High-Speed Color Sorting Algorithm Based on FPGA Implementation. In Proceedings of the 2018 IEEE 27th International Symposium on Industrial Electronics (ISIE), Cairns, Australia, 13–15 June 2018; pp. 235–239. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Indexing via color histograms. In Active Perception and Robot Vision; Springer: Berlin/Heidelberg, Germany, 1992; pp. 261–273. [Google Scholar]
- Wirth, M.; Zaremba, R. Flame Region Detection Based on Histogram Backprojection. In Proceedings of the 2010 Canadian Conference on Computer and Robot Vision, 31 May–2 June 2010; pp. 167–174. [Google Scholar] [CrossRef]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Singh, A.; Sha, J.; Narayan, K.S.; Achim, T.; Abbeel, P. Bigbird: A large-scale 3d database of object instances. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 509–516. [Google Scholar]
- The Food-101 Data Set. Available online: https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/ (accessed on 2 November 2021).
- Le, Q.V. Building high-level features using large scale unsupervised learning. In Proceedings of the 2013 IEEE international Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8595–8598. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Food | Types | Samples for Training Dataset | Samples for Test Dataset |
|---|---|---|---|
| Almond | RMF | 1470 | 883 |
| Insects | 178 | 107 | |
| Wood debris | 184 | 106 | |
| Plants | 179 | 98 | |
| Paper scraps | 181 | 101 | |
| Metal part | 177 | 100 | |
| Plastic scraps | 188 | 108 | |
| GOF | RMF | 2174 | 1204 |
| Insects | 178 | 103 | |
| Wood debris | 184 | 105 | |
| Plants | 179 | 103 | |
| Paper scraps | 181 | 102 | |
| Metal part | 177 | 100 | |
| Plastic scraps | 188 | 107 |
| Food | Test Dataset | Training Dataset | Insects | Wood Debris | Plants | Paper Scraps | Metal Parts | Plastic Scraps | Mean |
|---|---|---|---|---|---|---|---|---|---|
| Almond | 1 | Real Images | 0.84 | 0.85 | 0.84 | 0.87 | 0.81 | 0.83 | 0.84 |
| Synthetic Images | 0.83 | 0.84 | 0.83 | 0.85 | 0.79 | 0.82 | 0.82 | ||
| Synthetic Images + Real Images | 0.85 | 0.85 | 0.85 | 0.89 | 0.80 | 0.85 | 0.84 | ||
| 2 | Real Images | 0.78 | 0.79 | 0.81 | 0.82 | 0.72 | 0.81 | 0.78 | |
| Synthetic Images | 0.82 | 0.81 | 0.82 | 0.83 | 0.74 | 0.82 | 0.80 | ||
| Synthetic Images + Real Images | 0.83 | 0.82 | 0.81 | 0.84 | 0.74 | 0.82 | 0.81 | ||
| 3 | Real Images | 0.77 | 0.73 | 0.73 | 0.81 | 0.72 | 0.72 | 0.74 | |
| Synthetic Images | 0.78 | 0.81 | 0.83 | 0.84 | 0.79 | 0.81 | 0.81 | ||
| Synthetic Images + Real Images | 0.79 | 0.79 | 0.81 | 0.85 | 0.81 | 0.82 | 0.81 | ||
| GOF | 1 | Real Images | 0.81 | 0.86 | 0.75 | 0.82 | 0.78 | 0.81 | 0.80 |
| Synthetic Images | 0.73 | 0.78 | 0.54 | 0.70 | 0.73 | 0.77 | 0.70 | ||
| Synthetic Images + Real Images | 0.83 | 0.85 | 0.76 | 0.83 | 0.80 | 0.82 | 0.81 | ||
| 2 | Real Images | 0.77 | 0.81 | 0.62 | 0.75 | 0.70 | 0.77 | 0.73 | |
| Synthetic Images | 0.72 | 0.77 | 0.52 | 0.68 | 0.71 | 0.74 | 0.69 | ||
| Synthetic Images + Real Images | 0.78 | 0.82 | 0.59 | 0.76 | 0.71 | 0.76 | 0.73 | ||
| 3 | Real Images | 0.75 | 0.81 | 0.63 | 0.71 | 0.71 | 0.74 | 0.72 | |
| Synthetic Images | 0.73 | 0.78 | 0.51 | 0.69 | 0.74 | 0.73 | 0.69 | ||
| Synthetic Images + Real Images | 0.76 | 0.81 | 0.58 | 0.70 | 0.74 | 0.76 | 0.72 |
| Food | Test Dataset | Method | Insects | Wood Debris | Plants | Paper Scraps | Metal Parts | Plastic Scraps | Mean |
|---|---|---|---|---|---|---|---|---|---|
| Almond | 1 | DLFOD | 0.83 | 0.84 | 0.83 | 0.85 | 0.79 | 0.82 | 0.82 |
| HBFOD | 0.27 | 0.71 | 0.79 | 0.76 | 0.73 | 0.78 | 0.67 | ||
| 2 | DLFOD | 0.82 | 0.81 | 0.82 | 0.83 | 0.74 | 0.82 | 0.80 | |
| HBFOD | 0.22 | 0.57 | 0.64 | 0.69 | 0.68 | 0.62 | 0.57 | ||
| 3 | DLFOD | 0.78 | 0.81 | 0.83 | 0.84 | 0.79 | 0.81 | 0.81 | |
| HBFOD | 0.21 | 0.49 | 0.48 | 0.43 | 0.51 | 0.51 | 0.43 | ||
| GOF | 1 | DLFOD | 0.73 | 0.78 | 0.54 | 0.70 | 0.73 | 0.77 | 0.70 |
| HBFOD | 0.71 | 0.72 | 0.19 | 0.64 | 0.72 | 0.78 | 0.62 | ||
| 2 | DLFOD | 0.72 | 0.77 | 0.52 | 0.68 | 0.71 | 0.74 | 0.69 | |
| HBFOD | 0.66 | 0.62 | 0.17 | 0.55 | 0.56 | 0.64 | 0.53 | ||
| 3 | DLFOD | 0.73 | 0.78 | 0.51 | 0.69 | 0.74 | 0.73 | 0.69 | |
| HBFOD | 0.51 | 0.45 | 0.16 | 0.34 | 0.48 | 0.52 | 0.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, G.-J.; Kwak, D.-H.; Park, M.-K.; Kim, Y.-D.; Jung, H.-C. U-Net-Based Foreign Object Detection Method Using Effective Image Acquisition System: A Case of Almond and Green Onion Flake Food Process. Sustainability 2021, 13, 13834. https://doi.org/10.3390/su132413834
Son G-J, Kwak D-H, Park M-K, Kim Y-D, Jung H-C. U-Net-Based Foreign Object Detection Method Using Effective Image Acquisition System: A Case of Almond and Green Onion Flake Food Process. Sustainability. 2021; 13(24):13834. https://doi.org/10.3390/su132413834
Chicago/Turabian StyleSon, Guk-Jin, Dong-Hoon Kwak, Mi-Kyung Park, Young-Duk Kim, and Hee-Chul Jung. 2021. "U-Net-Based Foreign Object Detection Method Using Effective Image Acquisition System: A Case of Almond and Green Onion Flake Food Process" Sustainability 13, no. 24: 13834. https://doi.org/10.3390/su132413834
APA StyleSon, G.-J., Kwak, D.-H., Park, M.-K., Kim, Y.-D., & Jung, H.-C. (2021). U-Net-Based Foreign Object Detection Method Using Effective Image Acquisition System: A Case of Almond and Green Onion Flake Food Process. Sustainability, 13(24), 13834. https://doi.org/10.3390/su132413834