
A Q-Learning Rescheduling Approach to the Flexible Job Shop Problem Combining Energy and Productivity Objectives


Abstract
:1. Introduction
2. Related Works
2.1. Energy-Efficient Scheduling
2.1.1. Job Shop Energy-Efficient Scheduling
2.1.2. Flexible Job Shop Energy-Efficient Scheduling
2.2. Job Shop Scheduling Using Artificial Intelligence
2.3. Discussion
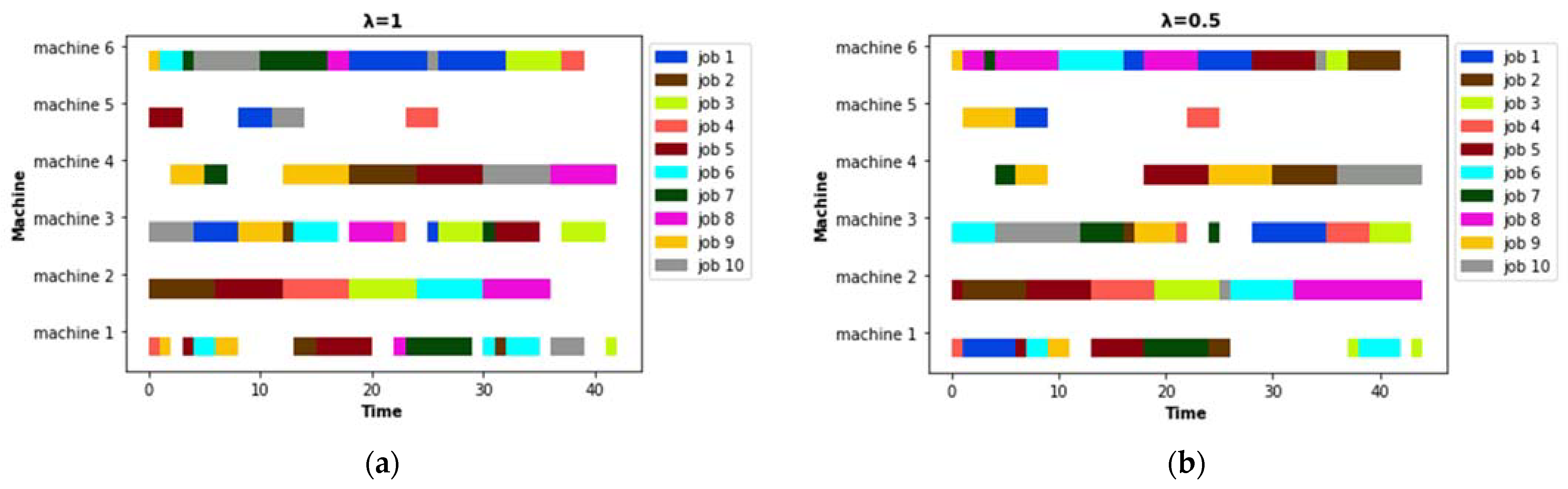
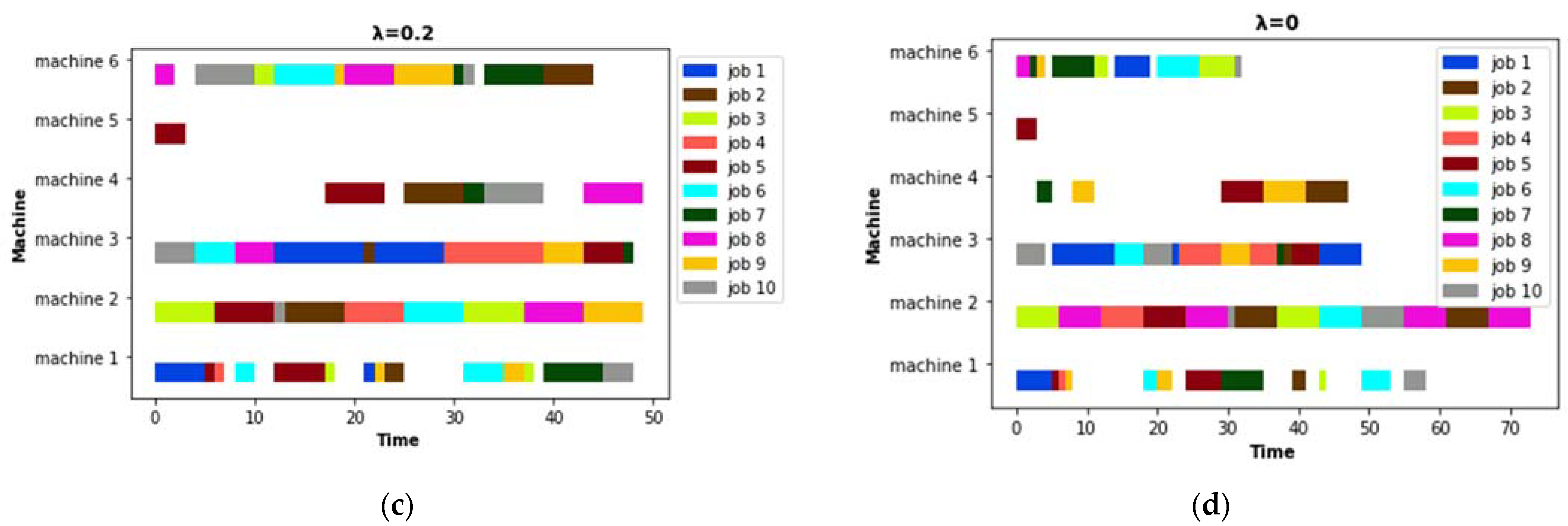
3. A Dynamic Flexible Job Shop Scheduling with Energy Consumption Optimization
3.1. Description of FJSSP
- J = is a set of n independent jobs to be scheduled.
- is the operation i of job j.
- M =… is a set of m machines. We denote the processing time of operation when executed on machine Mk.
- Jobs are independent and no priorities are assigned to any job type.
- Operations of different jobs are independent.
- Each machine can process only one operation at a time.
- Each operation can be processed without interruption during its performance on one of the set of machines.
- There are no precedence constraints among operations of different jobs.
- Two assumptions are considered in this work:
- All machines are available at time 0 and the transportation time is neglected.
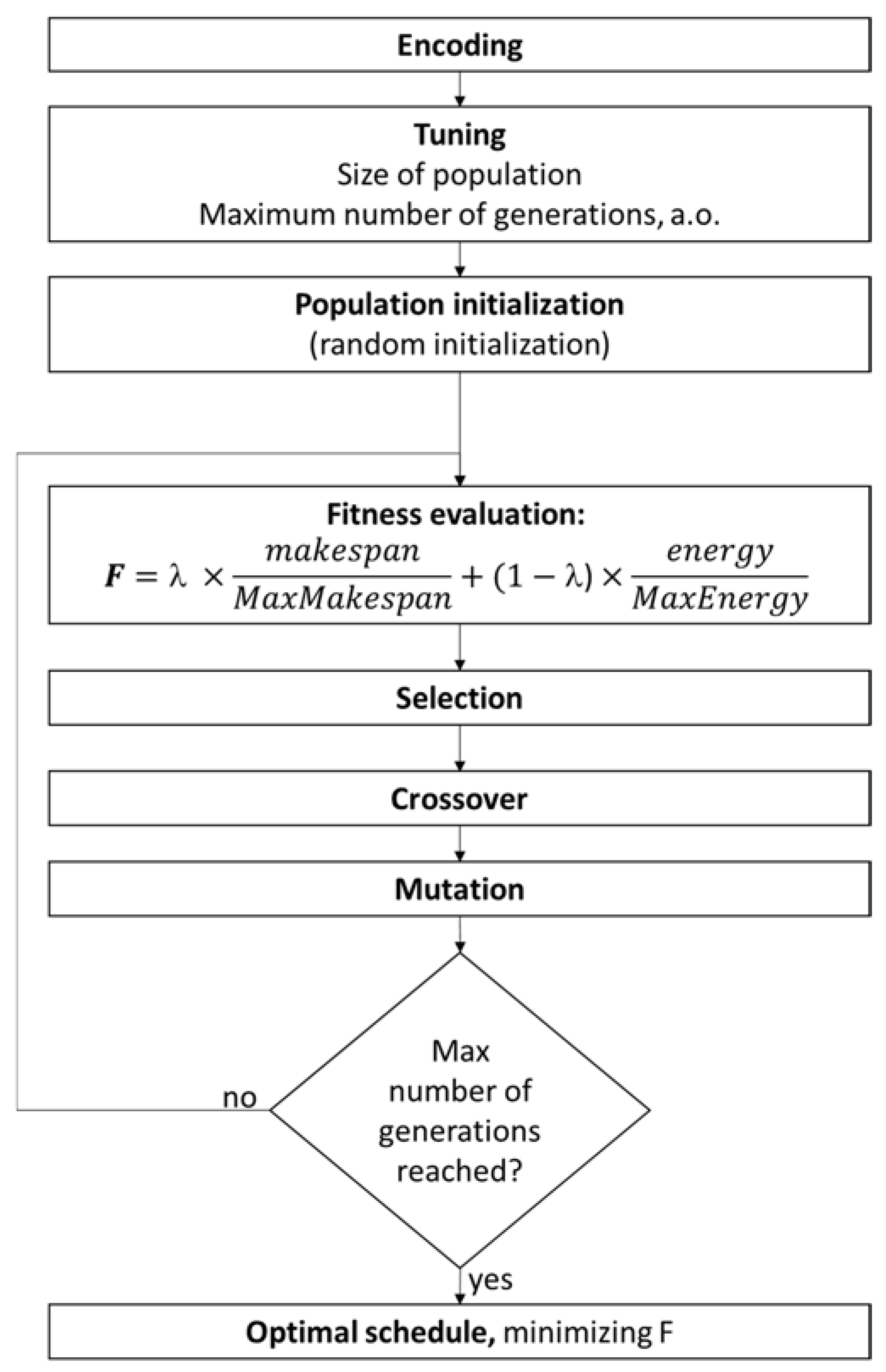
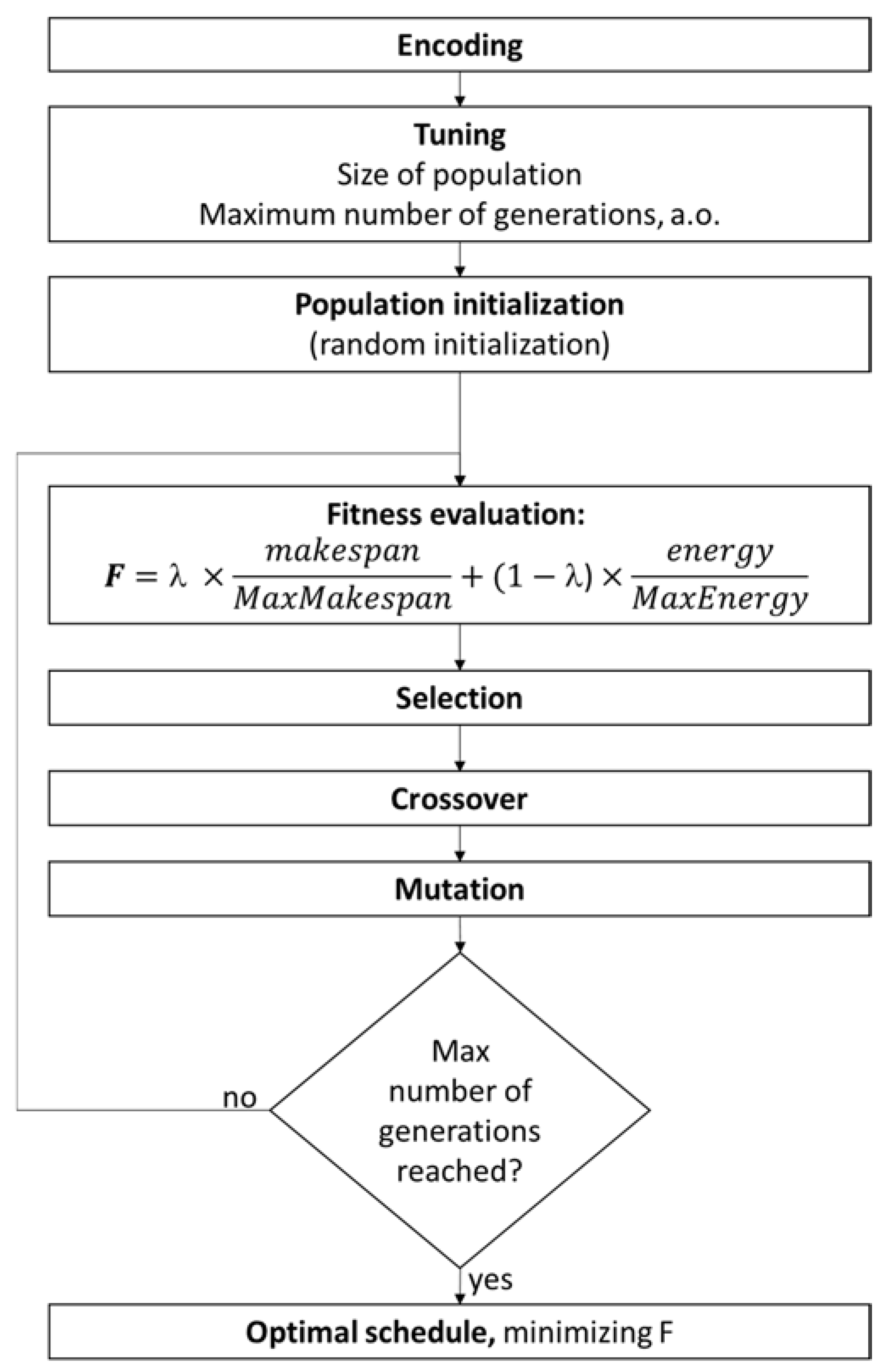
3.2. Genetic Algorithm (GA)
- Encoding: Each chromosome represents a solution for the problem. The genes of the chromosomes describe the assignment of operations to the machines, and the order in which they appear in the chromosome describes the sequence of operations.
- Tuning: The GA includes some tuning parameters that greatly influence the algorithm performance such as the size of population, the number of generations, etc. Despite recent research efforts, the selection of the algorithm parameters remains empirical to a large extent. Several typical choices of the algorithm parameters are reported in [40,41].
- Initial population: a set of initial solution is selected randomly.
- Fitness evaluation: A fitness function is computed for each of the individuals, this parameter indicates the quality of the solution represented by the individuals.
- Selection: At each iteration, the best chromosomes are chosen to produce their progeny.
- Offspring generation: The new generation is obtained by applying genetic operators like crossover and mutation
- Stop criterion: when a fixed number of generations is reached, the algorithm ends and the best chromosome, with their corresponding schedule, is given as output. Otherwise, the algorithm iterates again steps 3–5.
3.3. Disturbances in FJSSP
- The moment when the failure occurs (rescheduling time). These failures are randomly occurring, with a uniform distribution between 0 and the makespan of the original schedule generated with GA algorithm.
- The machine failing.
- The breakdown duration, which obeys to a uniform distribution between 25% and 50% of the makespan.
- There is only one broken-down machine at a time.
- The time taken to transfer a job from the broken-down machine to a properly functioning machine is neglected.
- Machine maintenance is immediate after the failure.
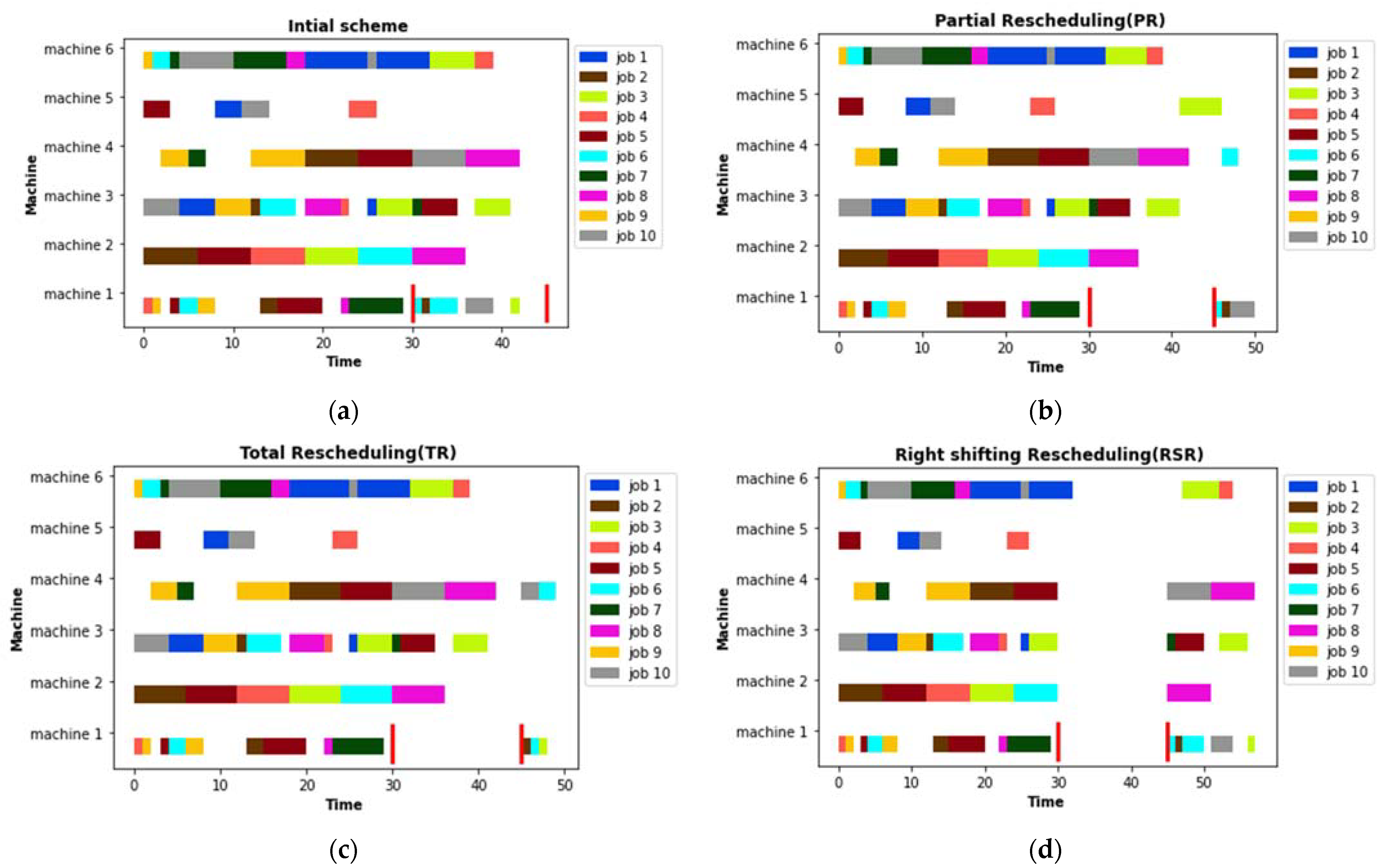
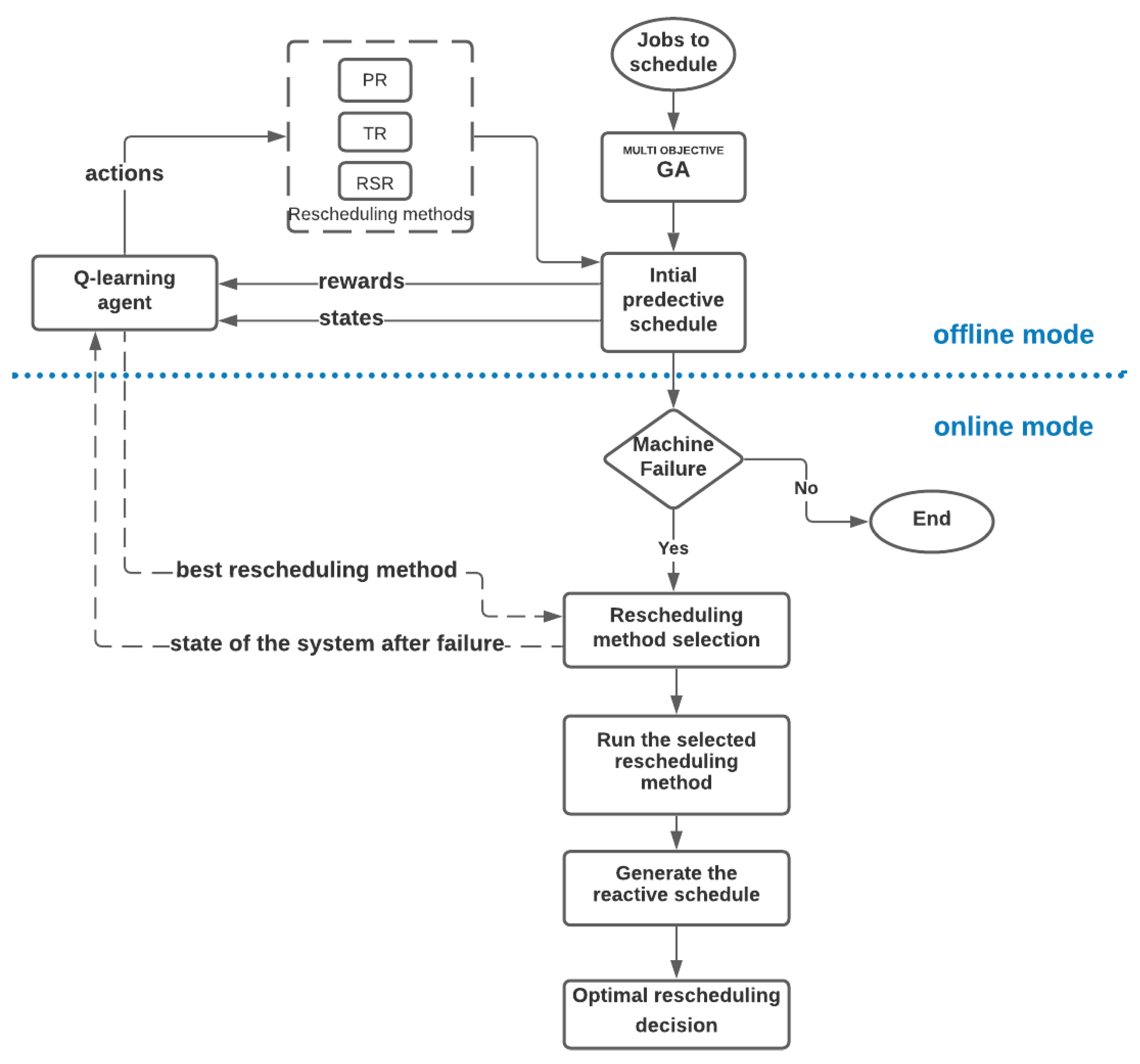
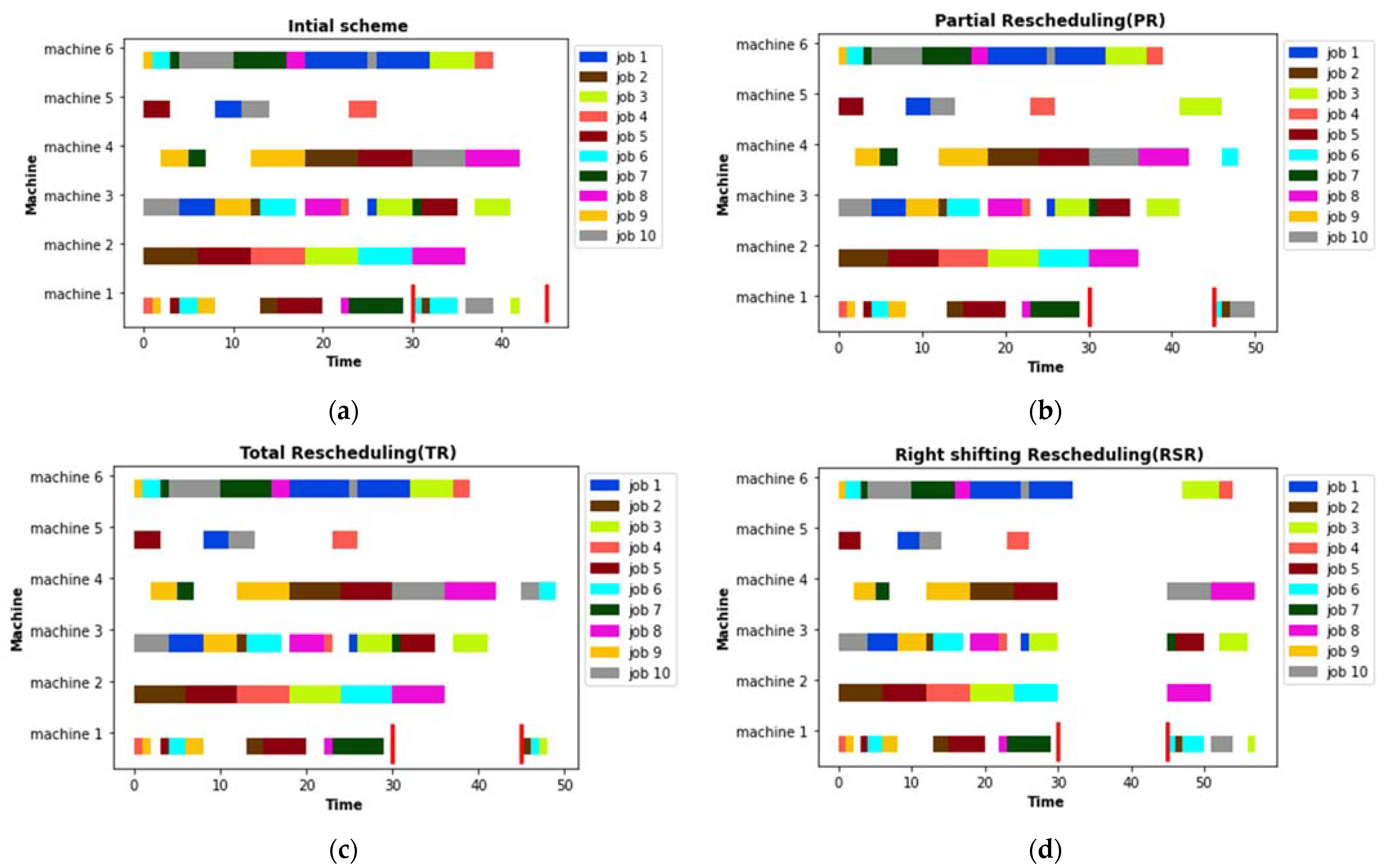
3.4. Rescheduling Strategies
- Right shifting rescheduling (RSR): postpone each remaining operation by the amount of time needed to make the schedule feasible.
- Partial rescheduling (PR): reschedule only the operations affected directly or indirectly by the disturbances and preserve the original schedule as much as possible.
- Total rescheduling (TR): reschedule the entire set of operations that are not processed before the rescheduling point.
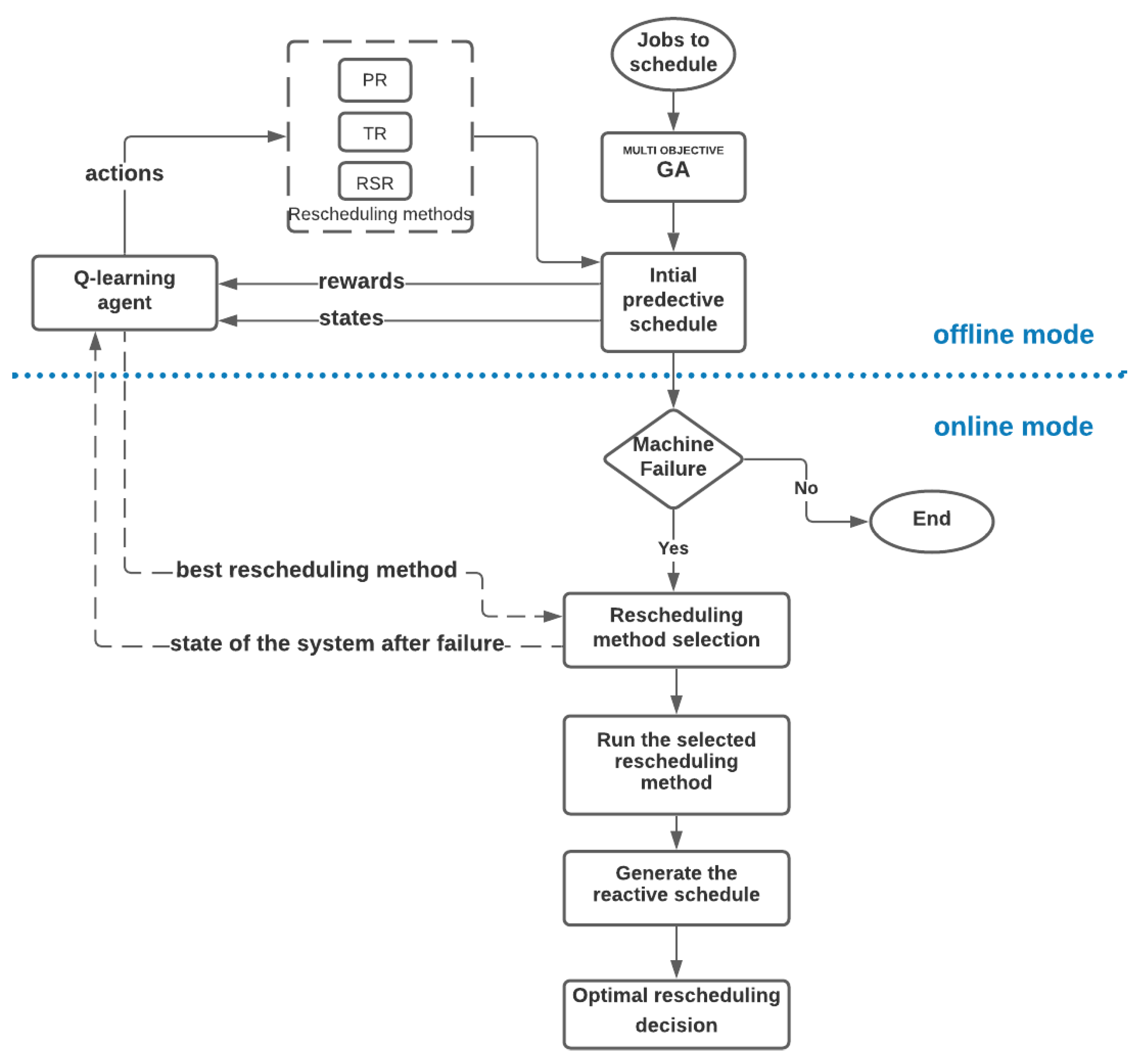
4. Proposed Multi Objective Q-Learning Rescheduling Approach
- An offline mode: in the first place the predictive schedule is obtained using a genetic algorithm, which represents the environment of the Q-learning agent. By interacting with this schedule and simulating experiments of machine failures, this agent learns how to select the optimal rescheduling solution for different states of the system.
- An online mode: when a machine failure occurs, the state of the system at the time of the interruption is delivered to the Q-learning agent. It responds by selecting the optimal rescheduling decision for this particular type of failure.
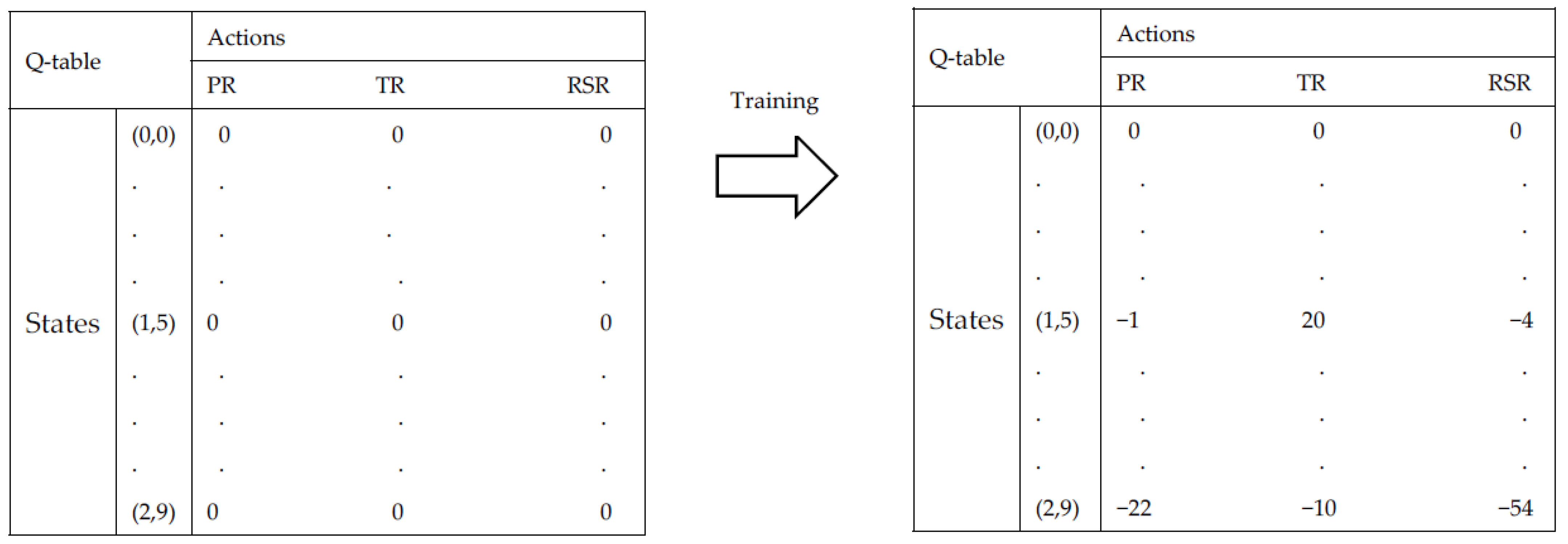
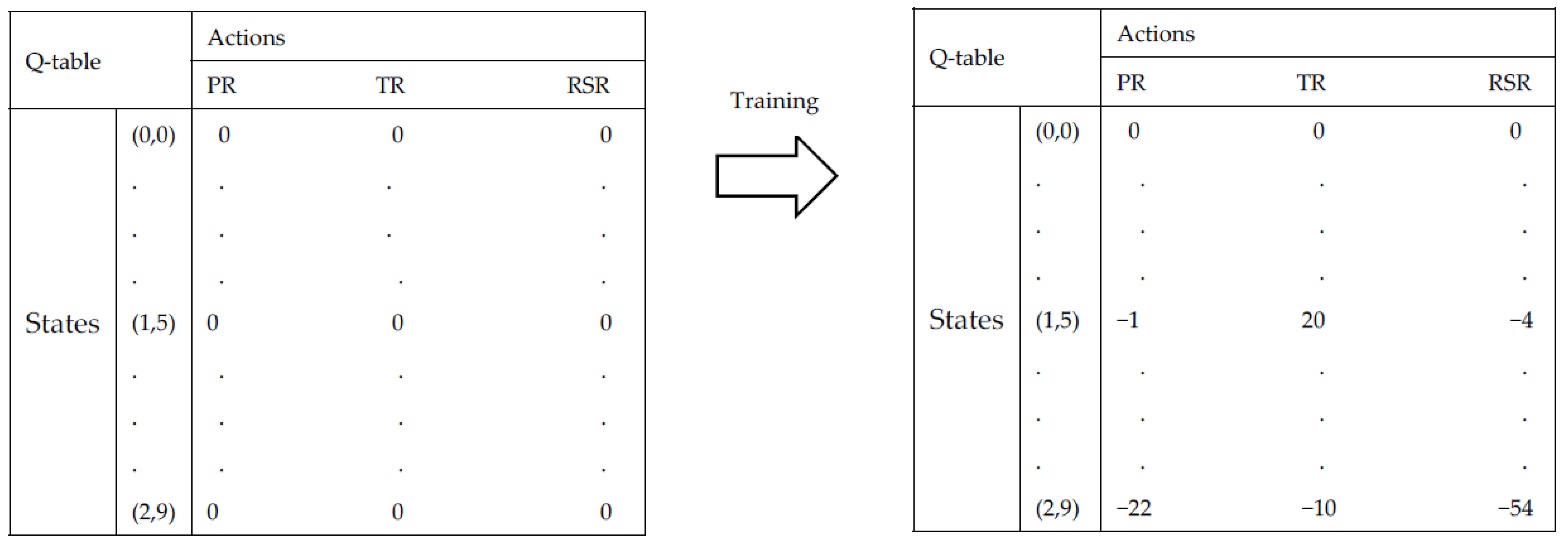
4.1. Q-Learning Terminologies
- Agent: The agent interacts with its environment, selects its own actions, and responds to those actions;
- States: The set of environmental states S is defined as the finite set {,...,}, where the size of the state space is N;
- Actions: The set of actions A is defined as the finite set {,...,}, where the size of the action space is K. Actions can be used to control the system’s state;
- Reward function: The reward function specifies rewards for being in a state or doing some action in a state.
| Algorithm 1 Q-Learning |
| ) randomly |
| Repeat for each episode: |
| Initialize s |
| Repeat for each step of episode |
| Choose an action from a using a policy derived from Q (ε-greedy) |
| Take an action a and observe the reward R and the next state s’ |
| Update |
| Q,,, )) |
| s ← s′ |
| until s is terminal |
4.2. Multi-Objective Q-Learning
| Algorithm 2 Multi-Objective Q-Learning |
| ) randomly |
| Repeat for each episode: |
| Initialize s |
| Repeat for each step of episode |
| Choose an action from a using a policy derived from Q (ε-greedy) |
| and the next state s’ |
| Update |
| , , + γ max , )) |
| (, , + γ max , )) |
| s ← s′ |
| until s is terminal |
4.3. State Space Definition
- s1: indicates the moment when the perturbation happens, e.g., in the beginning, the middle or in the end of the schedule. For this purpose, the initial makespan was divided into 3 intervals, so s1 can take the values 0, 1 or 2.
- s2: defined by the indicator SD which is the ratio of the duration of the directly affected operation by the machine’s breakdown to the total processing time of the remaining operations on failed machine. The formula is described as follows:
4.4. Actions and Reward Space Definition
- Action 0: Partial rescheduling (PR)
- Action 1: Total rescheduling (TR)
- Action 2: Right shifting rescheduling (RSR)
5. Experiments and Results
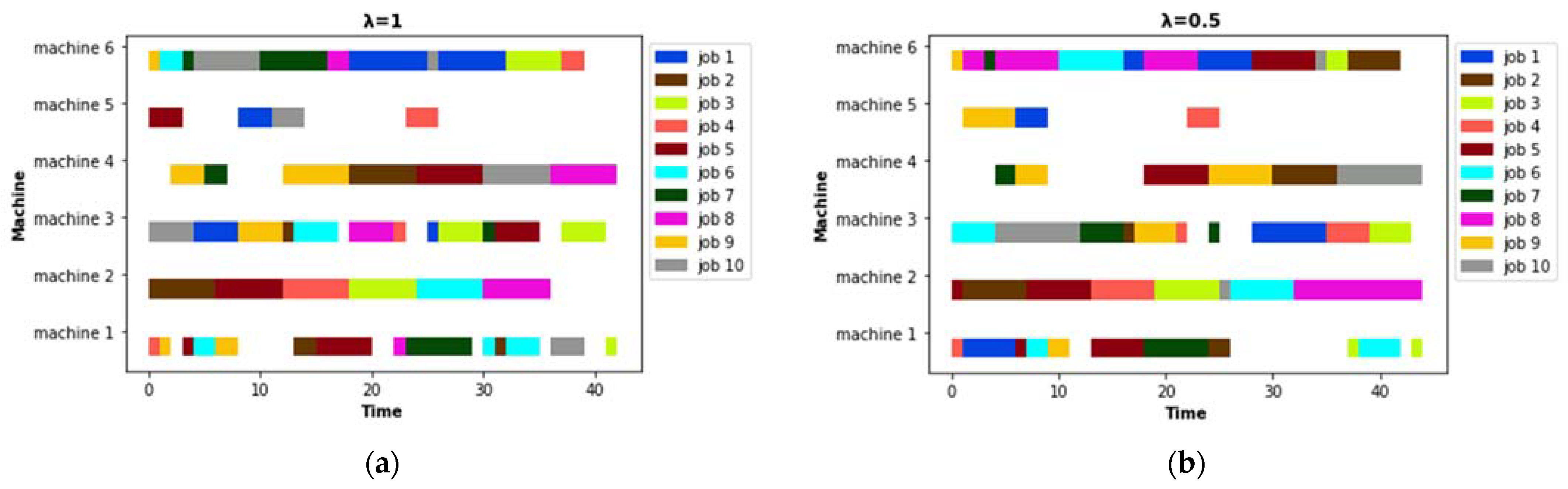
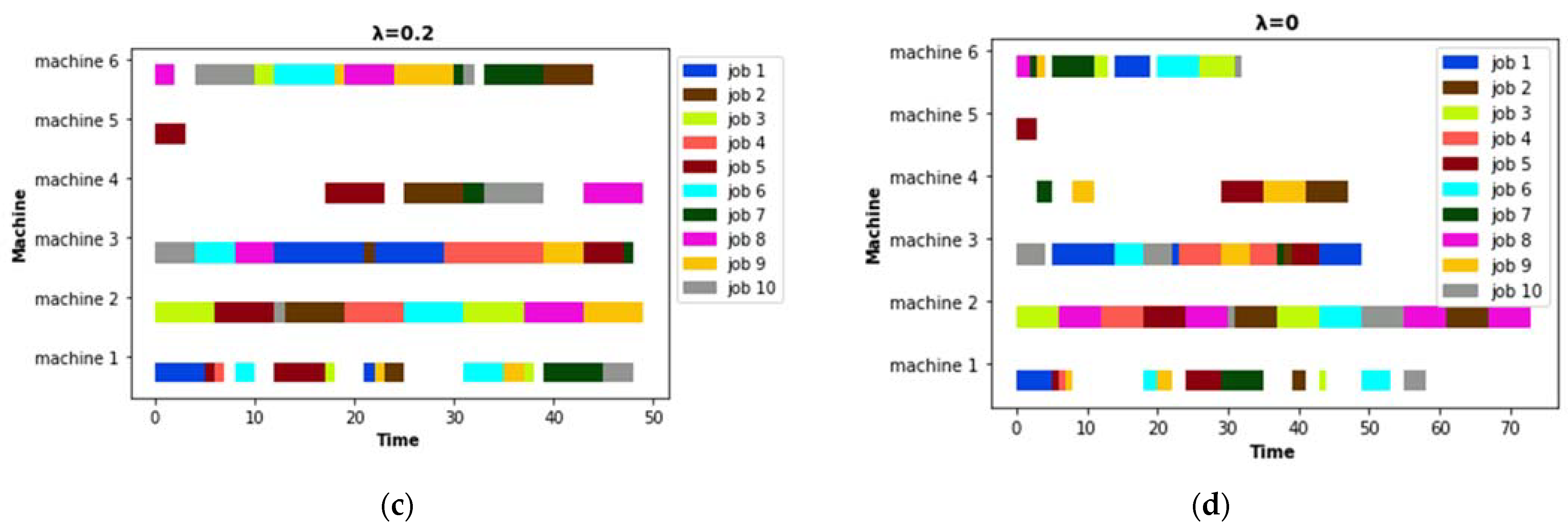
5.1. Predictive Schedule Based on GA
5.2. Rescheduling Strategies
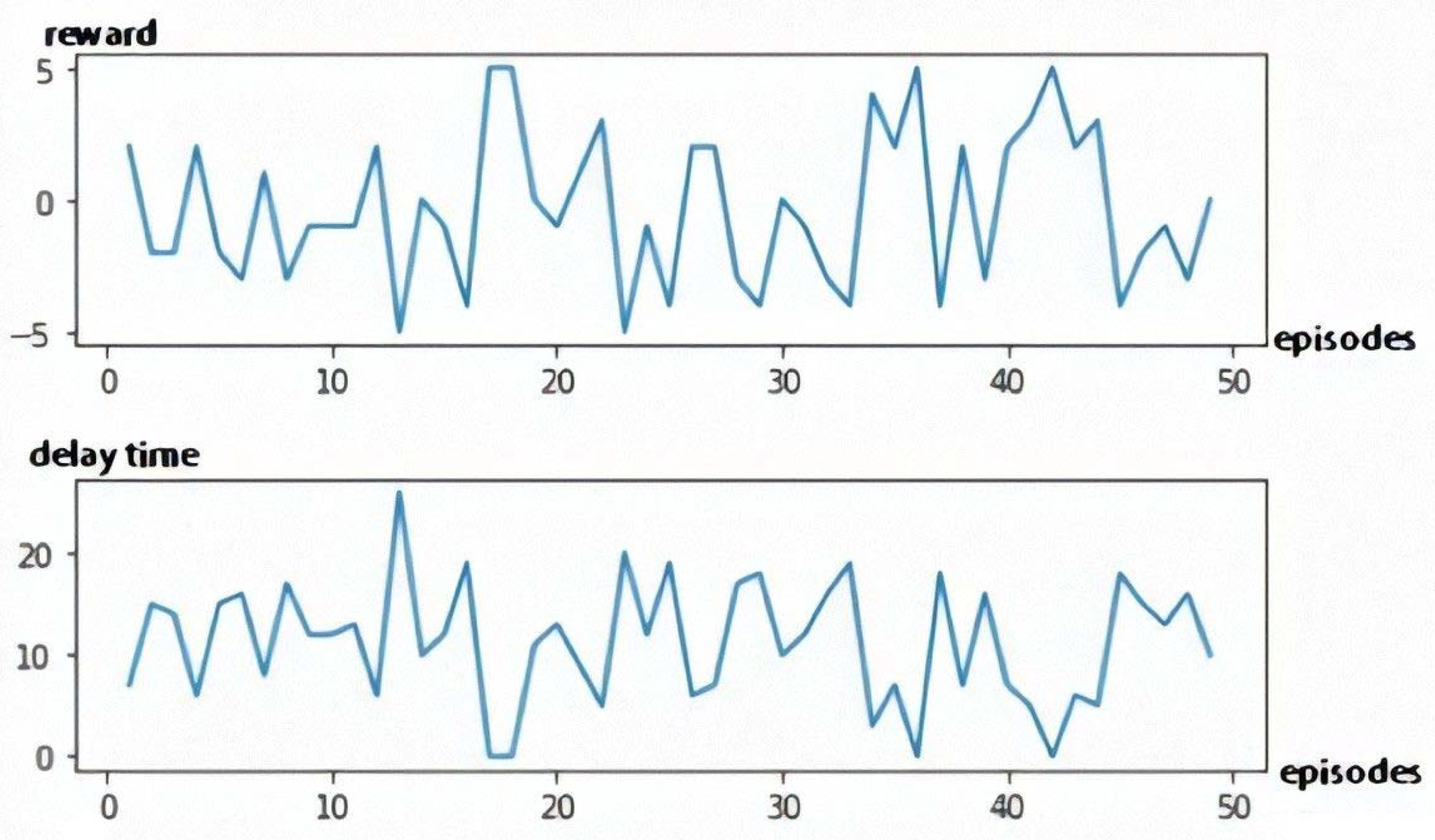
5.3. Rescheduling Based on Q-Learning
- α = 1: A learning rate of 1 means the old value will be completely discarded, the model converges quickly, no large number of episodes are required;
- γ = 0: The agent considers only immediate rewards. In each episode, one state is evaluated (the initial state of the system at a particular time, given the rescheduling time, the failure machine and the breakdown duration)
- ε = 0.8, the balance factor between exploration and exploitation. Exploration refers to searching over the whole sample space while exploitation refers to the exploitation of the promising areas found. In the proposed model, 80% is given to exploitation, so in 80% of cases the agent will choose the action with the biggest reward and in 20% of cases he will randomly choose an action to explore more of its environment.
- The number of episodes is 1000, for the model to converge.
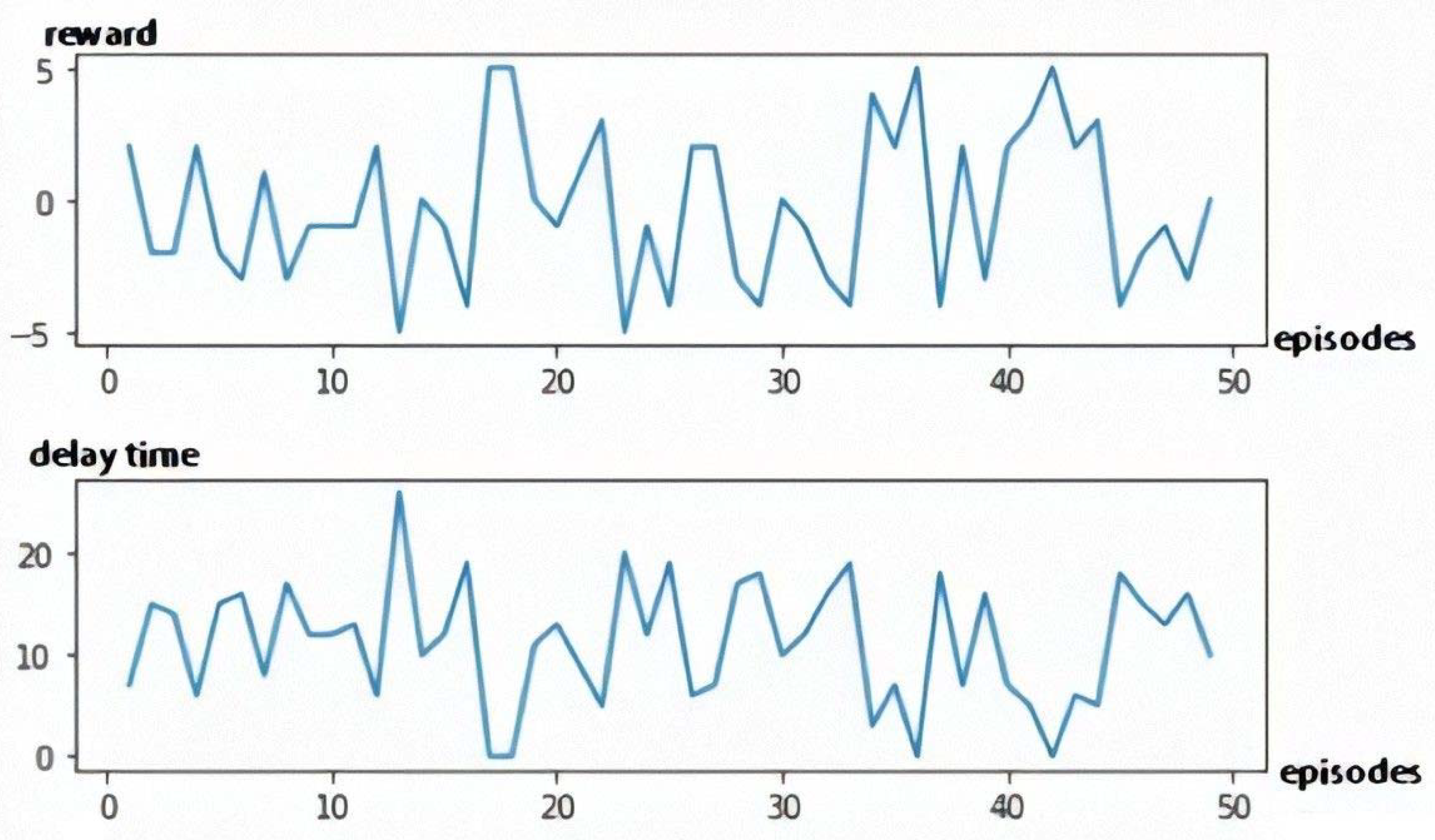
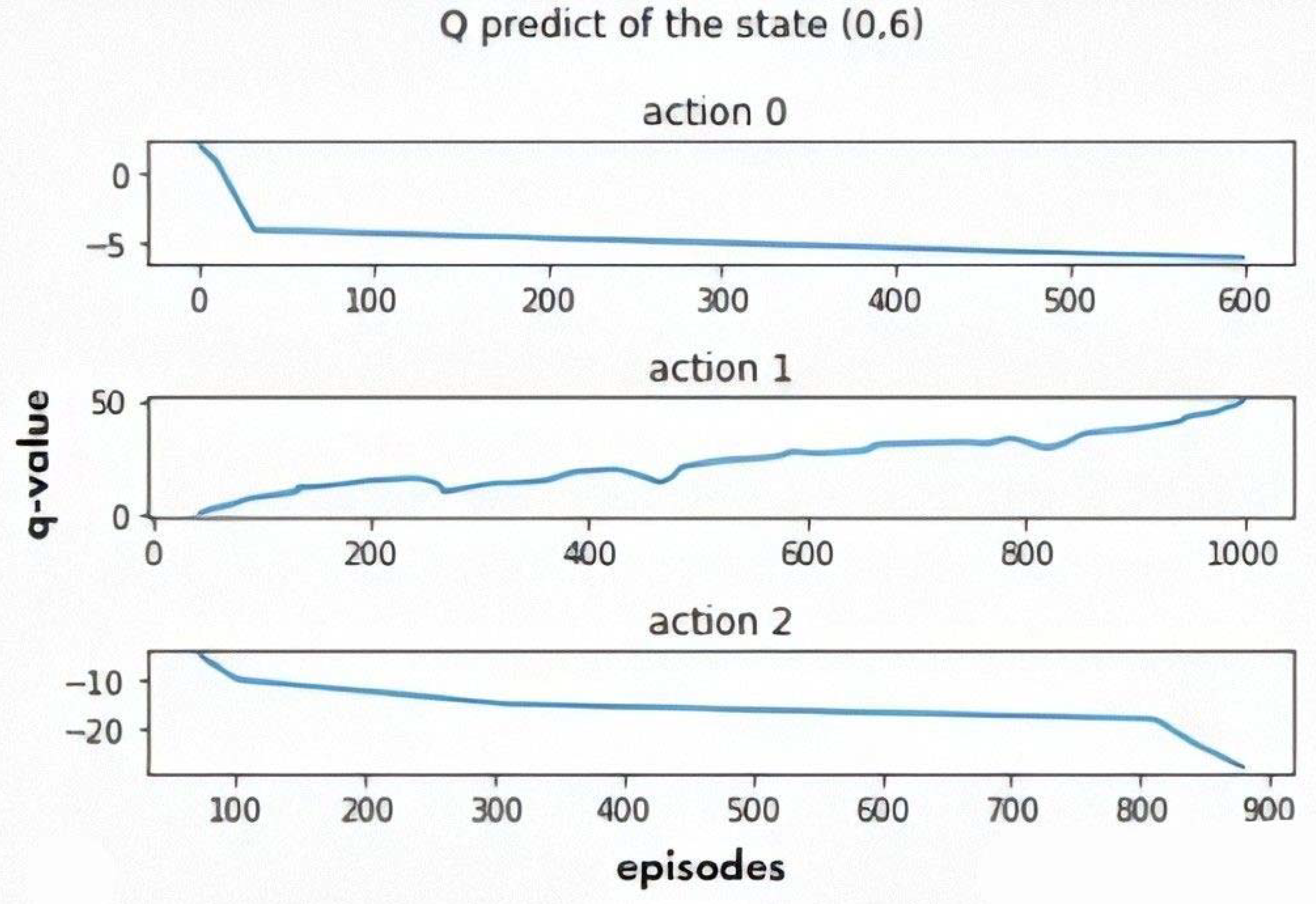
5.3.1. The Single Objective Q-Learning
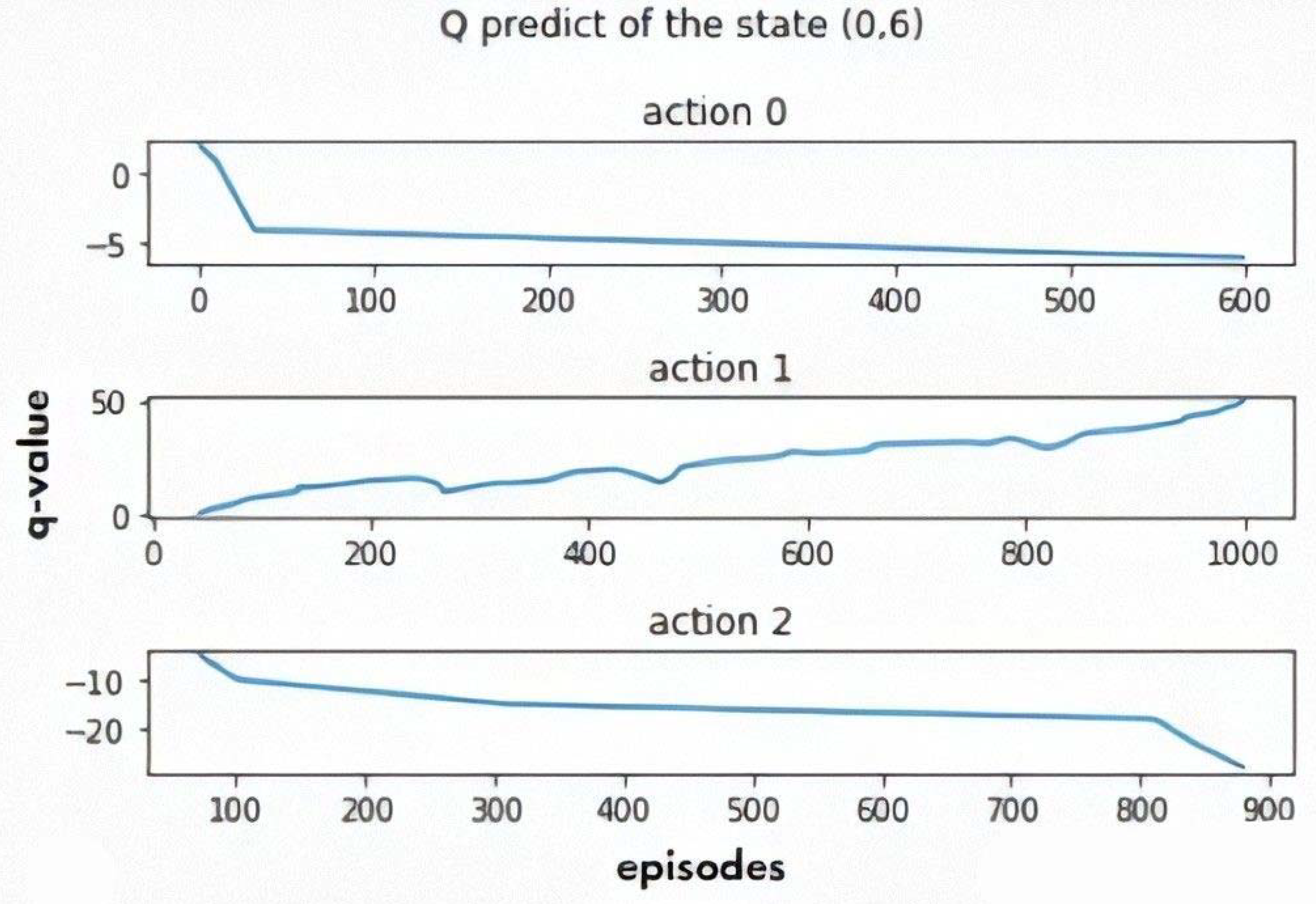
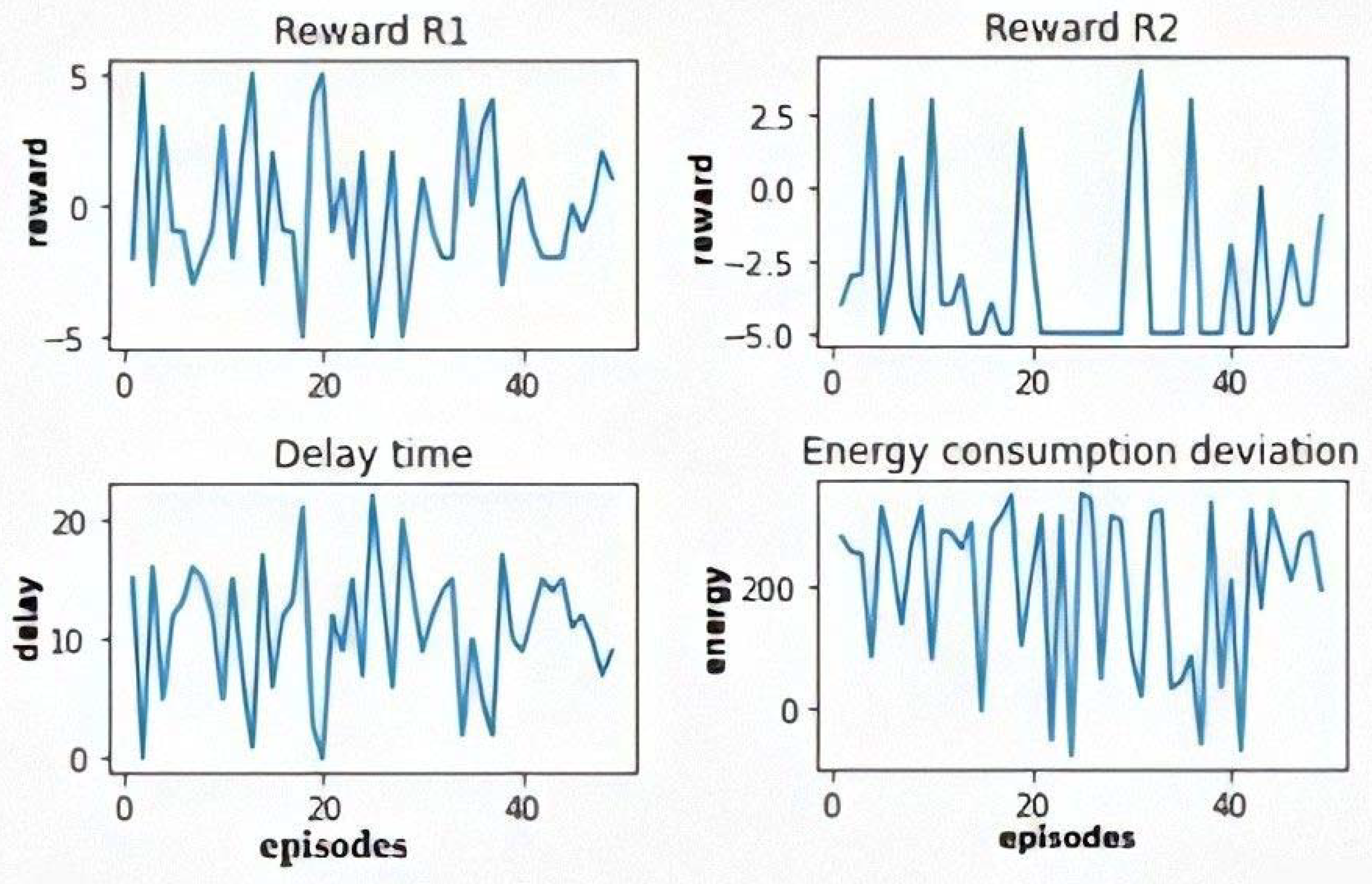
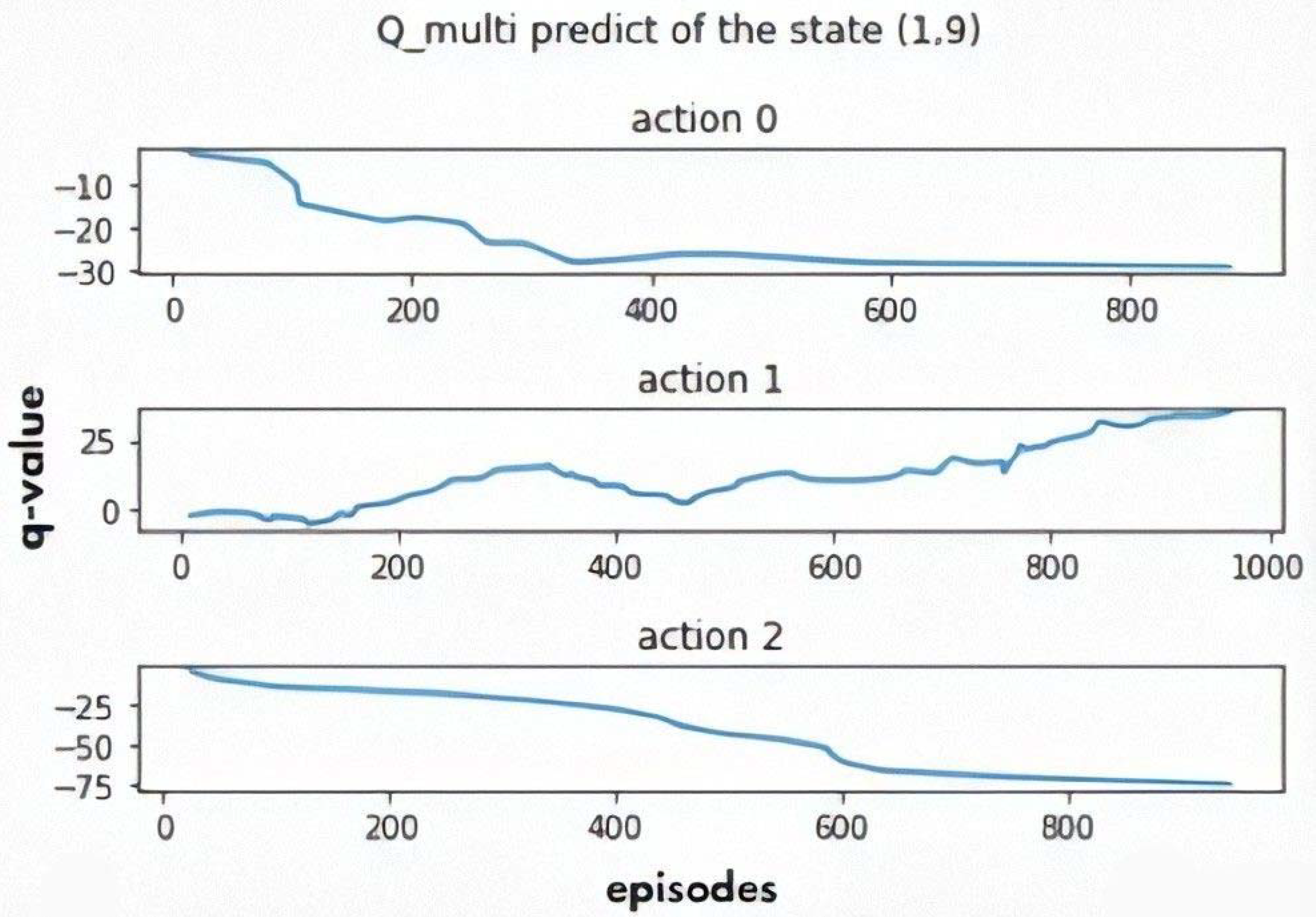
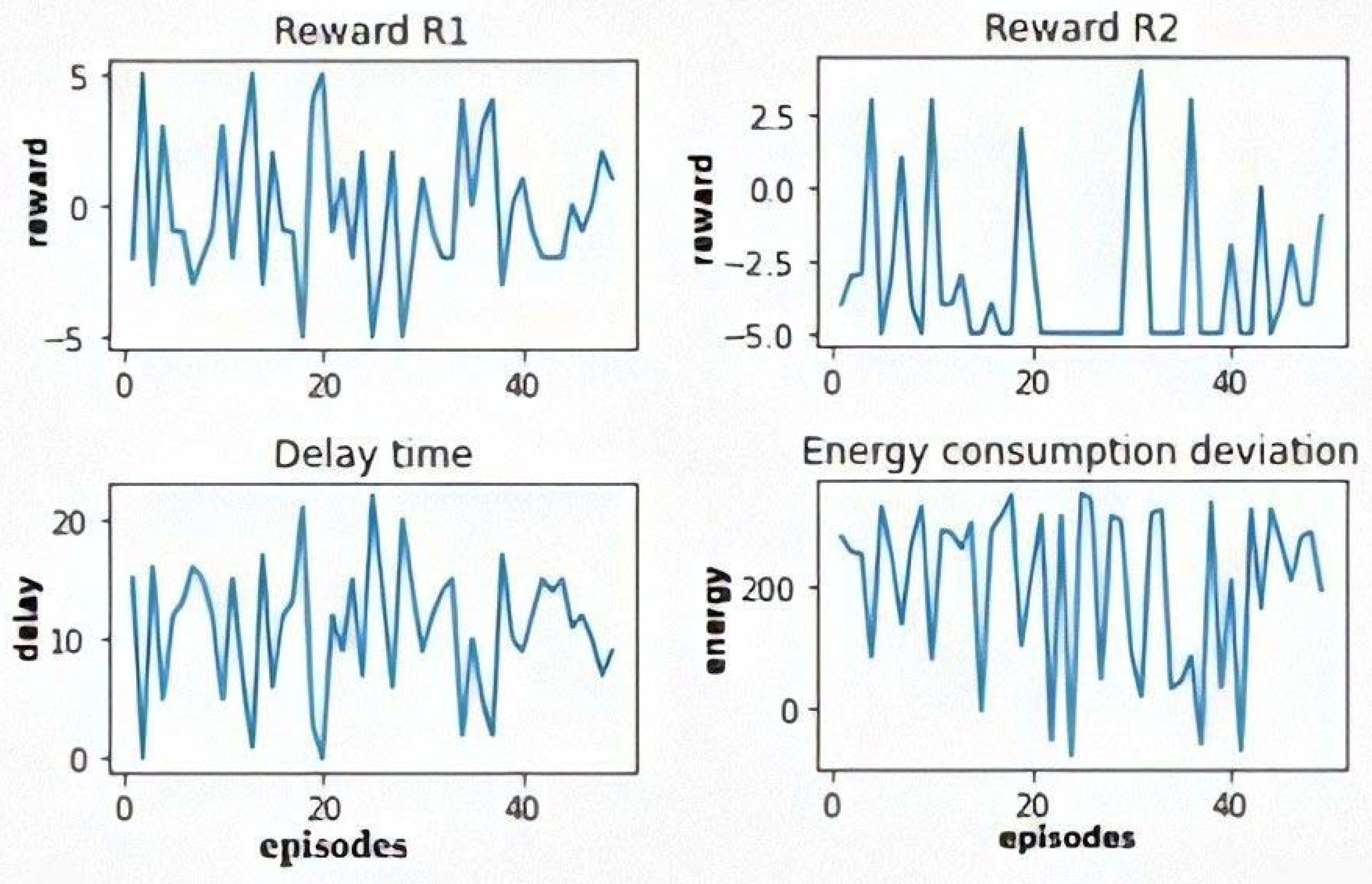
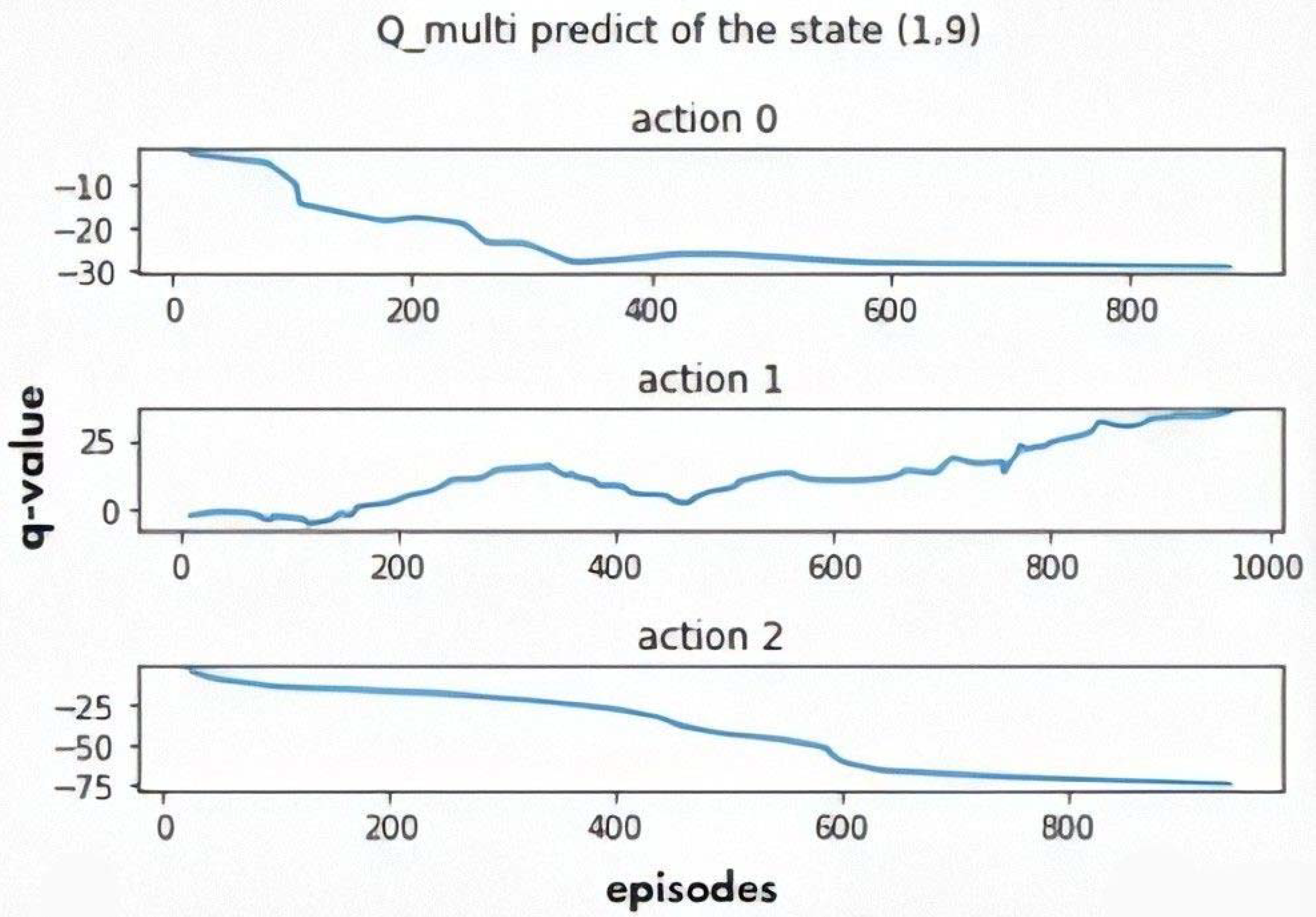
5.3.2. The Multi-Objective Q-Learning
5.4. Models Validation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | Size | p | Weight of BF | Predictive Schedule | Machine Failure | State of the System | Reactive Schedule | Q-Learning | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PR | TR | RSR | Single Objective | Multi-Objective | |||||||||||||
| MK (Time Units) | EC (kWh) | Failure Time | Broken-Down Machine | Failure Duration | MK (Time Units) | EC (kWh) | MK (Time Units) | EC (kWh) | MK (Time Units) | EC (kWh) | |||||||
| MK01 | 10 × 6 | 2 | 1 | 42 | 3046 | 3 | 5 | 20 | (0.5) | 46 | 3064 | 45 | 3115 | 61 | 3160 | TR | TR |
| 16 | 4 | 19 | (1.9) | 60 | 3128 | 55 | 3243 | 66 | 3180 | TR | TR | ||||||
| 8 | 1 | 17 | (0.6) | 57 | 3099 | 50 | 3190 | 58 | 3142 | TR | TR | ||||||
| 23 | 3 | 14 | (1.7) | 57 | 3101 | 56 | 3218 | 58 | 3142 | TR | TR | ||||||
| 13 | 5 | 10 | (0.4) | 46 | 3058 | 45 | 3028 | 52 | 3106 | TR | TR | ||||||
| 13 | 6 | 20 | (0.9) | 56 | 3098 | 54 | 3204 | 59 | 3148 | TR | TR | ||||||
| 0.5 | 49 | 2837 | 11 | 1 | 12 | (0.5) | 54 | 2872 | 58 | 2826 | 61 | 2909 | TR | TR | |||
| 7 | 5 | 23 | (0.9) | 56 | 2890 | 57 | 2724 | 76 | 2999 | PR | TR | ||||||
| 22 | 2 | 22 | (1.9) | 62 | 2950 | 56 | 2968 | 65 | 2993 | TR | TR | ||||||
| 5 | 2 | 12 | (0.3) | 54 | 2935 | 54 | 2853 | 55 | 2939 | TR | TR | ||||||
| 11 | 1 | 12 | (0.6) | 54 | 2872 | 58 | 2826 | 61 | 2909 | PR | PR | ||||||
| 13 | 4 | 13 | (0.2) | 50 | 2839 | 54 | 2816 | 54 | 2867 | PR | PR | ||||||
| 0.2 | 52 | 2672 | 31 | 2 | 15 | (1.9) | 64 | 2702 | 67 | 2711 | 67 | 2672 | PR | PR | |||
| 4 | 2 | 20 | (0.4) | 75 | 2797 | 78 | 2757 | 75 | 2800 | TR | PR | ||||||
| 10 | 4 | 14 | (0.0) | 52 | 2673 | 58 | 2670 | 59 | 2714 | PR | PR | ||||||
| 10 | 1 | 21 | (0.6) | 64 | 2728 | 68 | 2632 | 73 | 2798 | TR | PR | ||||||
| 20 | 2 | 22 | (1.7) | 72 | 2769 | 76 | 2773 | 75 | 2820 | PR | PR | ||||||
| 6 | 5 | 26 | (0.9) | 65 | 2727 | 68 | 2704 | 74 | 2804 | PR | TR | ||||||
| 0 | 79 | 2554 | 23 | 6 | 20 | (0.9) | 91 | 2649 | 99 | 2612 | 102 | 2692 | PR | TR | |||
| 1 | 5 | 26 | (0.3) | 79 | 2560 | 79 | 2574 | 102 | 2686 | PR | PR | ||||||
| 31 | 2 | 37 | (1.8) | 92 | 2668 | 110 | 2706 | 116 | 2776 | PR | PR | ||||||
| 3 | 2 | 24 | (1.6) | 88 | 2639 | 100 | 2666 | 106 | 2689 | PR | PR | ||||||
| 16 | 2 | 34 | (0.6) | 98 | 2700 | 110 | 2744 | 116 | 2776 | PR | PR | ||||||
| 30 | 6 | 20 | (1.9) | 79 | 2564 | 79 | 2605 | 98 | 2668 | PR | PR | ||||||
| MK02 | 10 × 6 | 3.5 | 1 | 32 | 3173 | 15 | 1 | 12 | (1.7) | 46 | 3234 | 45 | 3223 | 45 | 3263 | TR | TR |
| 4 | 2 | 16 | (0.7) | 45 | 3216 | 47 | 3330 | 49 | 3263 | PR | PR | ||||||
| 18 | 6 | 9 | (1.8) | 40 | 3205 | 37 | 3296 | 43 | 3239 | TR | TR | ||||||
| 1 | 6 | 12 | (0.3) | 44 | 3223 | 46 | 3071 | 44 | 3245 | PR | PR | ||||||
| 10 | 2 | 4 | (0.9) | 49 | 3232 | 52 | 3386 | 51 | 3287 | PR | PR | ||||||
| 2 | 4 | 9 | (0.4) | 38 | 3191 | 37 | 3282 | 43 | 3239 | TR | TR | ||||||
| 0.5 | 37 | 2479 | 5 | 6 | 17 | (0.6) | 49 | 2525 | 48 | 2334 | 56 | 2593 | TR | TR | |||
| 17 | 6 | 11 | (1.9) | 42 | 2494 | 45 | 2334 | 50 | 2557 | PR | TR | ||||||
| 25 | 6 | 13 | (2.9) | 45 | 2497 | 46 | 2384 | 50 | 2557 | PR | TR | ||||||
| 10 | 1 | 9 | (0.7) | 44 | 2503 | 47 | 2187 | 46 | 2533 | PR | TR | ||||||
| 18 | 6 | 9 | (1.6) | 42 | 2490 | 40 | 2342 | 46 | 2490 | TR | TR | ||||||
| 5 | 4 | 11 | (0.3) | 38 | 2487 | 42 | 2288 | 50 | 2557 | PR | TR | ||||||
| 0.2 | 49 | 1992 | 23 | 2 | 14 | (1.7) | 59 | 2035 | 62 | 2014 | 65 | 2088 | PR | TR | |||
| 16 | 1 | 23 | (0.9) | 53 | 2018 | 54 | 1996 | 64 | 2082 | PR | TR | ||||||
| 1 | 6 | 16 | (0.4) | 55 | 2017 | 50 | 1935 | 60 | 2058 | TR | TR | ||||||
| 11 | 1 | 18 | (0.7) | 63 | 2014 | 52 | 1983 | 67 | 2100 | TR | TR | ||||||
| 24 | 2 | 20 | (1.9) | 64 | 2062 | 57 | 2071 | 72 | 2130 | PR | TR | ||||||
| 5 | 6 | 18 | (0.6) | 60 | 2040 | 58 | 1940 | 66 | 2040 | TR | TR | ||||||
| 0 | 49 | 1964 | 21 | 4 | 16 | (1.9) | 56 | 1990 | 52 | 1996 | 66 | 2066 | TR | PR | |||
| 35 | 3 | 20 | (2.9) | 66 | 2010 | 68 | 2045 | 71 | 2030 | PR | PR | ||||||
| 2 | 4 | 15 | (0.5) | 55 | 2000 | 64 | 1990 | 65 | 2060 | PR | TR | ||||||
| 10 | 4 | 19 | (0.6) | 61 | 2035 | 55 | 1992 | 69 | 2084 | TR | TR | ||||||
| 10 | 5 | 20 | (0.9) | 60 | 2038 | 60 | 1985 | 68 | 2087 | TR | TR | ||||||
| 22 | 1 | 14 | (1.6) | 52 | 1995 | 54 | 1981 | 64 | 2054 | PR | PR | ||||||
| MK03 | 15 × 8 | 3 | 1 | 206 | 8846 | 113 | 4 | 70 | (1.8) | 255 | 9120 | 239 | 9135 | 279 | 9430 | TR | TR |
| 45 | 6 | 66 | (0.4) | 254 | 9262 | 246 | 9042 | 272 | 9374 | TR | TR | ||||||
| 55 | 2 | 59 | (0.6) | 250 | 9063 | 221 | 9263 | 268 | 9342 | TR | TR | ||||||
| 75 | 2 | 53 | (1.7) | 250 | 9078 | 219 | 8824 | 272 | 9374 | TR | TR | ||||||
| 1 | 2 | 65 | (0.3) | 221 | 9839 | 238 | 9001 | 246 | 9166 | PR | PR | ||||||
| 57 | 8 | 82 | (0.8) | 269 | 9276 | 237 | 9160 | 301 | 9606 | TR | TR | ||||||
| 0.5 | 227 | 7515 | 83 | 8 | 67 | (1.8) | 278 | 7787 | 254 | 7201 | 309 | 8171 | TR | TR | |||
| 182 | 4 | 88 | (2.9) | 310 | 7905 | 296 | 7874 | 317 | 8235 | PR | PR | ||||||
| 66 | 2 | 77 | (0.6) | 244 | 7618 | 249 | 7209 | 302 | 8115 | PR | TR | ||||||
| 44 | 1 | 80 | (0.4) | 304 | 8014 | 307 | 7516 | 317 | 8235 | PR | TR | ||||||
| 94 | 4 | 66 | (1.4) | 266 | 7791 | 242 | 7387 | 297 | 8075 | PR | PR | ||||||
| 97 | 3 | 67 | (1.4) | 264 | 7969 | 243 | 7426 | 276 | 7907 | PR | PR | ||||||
| 0.2 | 231 | 7200 | 94 | 2 | 98 | (1.9) | 273 | 7408 | 263 | 7275 | 335 | 8032 | TR | TR | |||
| 29 | 4 | 76 | (0.5) | 284 | 7598 | 291 | 7222 | 300 | 7832 | PR | TR | ||||||
| 13 | 1 | 111 | (0.6) | 355 | 8042 | 368 | 8118 | 355 | 8192 | PR | PR | ||||||
| 98 | 3 | 116 | (1.8) | 337 | 7907 | 278 | 7327 | 349 | 8136 | TR | TR | ||||||
| 170 | 4 | 88 | (2.9) | 304 | 7544 | 282 | 7497 | 313 | 7856 | TR | TR | ||||||
| 40 | 1 | 116 | (0.7) | 334 | 7958 | 350 | 7742 | 353 | 8176 | PR | TR | ||||||
| 0 | 253 | 6574 | 152 | 6 | 97 | (1.9) | 328 | 7040 | 336 | 6952 | 348 | 7239 | PR | TR | |||
| 64 | 4 | 67 | (0.4) | 282 | 6790 | 325 | 6900 | 325 | 7150 | PR | PR | ||||||
| 105 | 1 | 103 | (1.8) | 341 | 7081 | 338 | 7080 | 369 | 7502 | TR | TR | ||||||
| 43 | 8 | 121 | (0.7) | 296 | 7010 | 276 | 6816 | 358 | 7414 | TR | TR | ||||||
| 30 | 8 | 104 | (0.6) | 278 | 6983 | 299 | 6916 | 361 | 7438 | PR | TR | ||||||
| 86 | 3 | 73 | (1.5) | 297 | 6846 | 288 | 6805 | 334 | 7222 | PR | TR | ||||||
| MK04 | 15 × 8 | 2 | 1 | 67 | 5206 | 6 | 4 | 31 | (0.6) | 102 | 5427 | 84 | 5214 | 102 | 5486 | TR | TR |
| 1 | 3 | 17 | (0.1) | 74 | 5249 | 77 | 5398 | 84 | 5334 | PR | PR | ||||||
| 49 | 3 | 27 | (2.9) | 110 | 5398 | 94 | 5347 | 109 | 5470 | TR | TR | ||||||
| 30 | 2 | 17 | (1.3) | 67 | 5206 | 72 | 5315 | 84 | 5342 | PR | PR | ||||||
| 11 | 2 | 19 | (0.3) | 67 | 5206 | 75 | 5342 | 87 | 5366 | PR | PR | ||||||
| 1 | 7 | 26 | (0.4) | 83 | 5324 | 87 | 5495 | 93 | 5422 | PR | PR | ||||||
| 0.5 | 73 | 4872 | 43 | 3 | 26 | (1.9) | 96 | 4976 | 87 | 4891 | 99 | 5080 | TR | TR | |||
| 34 | 4 | 25 | (1.7) | 71 | 4999 | 68 | 5054 | 98 | 5072 | TR | TR | ||||||
| 3 | 1 | 23 | (0.4) | 95 | 5015 | 93 | 5023 | 99 | 5080 | TR | TR | ||||||
| 28 | 6 | 18 | (1.8) | 98 | 5007 | 84 | 4976 | 95 | 5048 | TR | TR | ||||||
| 3 | 6 | 20 | (0.3) | 84 | 4974 | 85 | 4723 | 94 | 5040 | PR | TR | ||||||
| 36 | 2 | 28 | (1.4) | 73 | 4886 | 78 | 4930 | 80 | 4886 | PR | PR | ||||||
| 0.2 | 76 | 4562 | 40 | 4 | 35 | (1.9) | 106 | 4738 | 92 | 4724 | 112 | 4850 | TR | TR | |||
| 7 | 1 | 27 | (0.4) | 103 | 4779 | 107 | 4723 | 104 | 4786 | PR | TR | ||||||
| 42 | 7 | 21 | (1.7) | 95 | 4635 | 88 | 5479 | 101 | 4579 | PR | TR | ||||||
| 21 | 3 | 30 | (0.7) | 109 | 4750 | 90 | 4615 | 109 | 4826 | PR | TR | ||||||
| 30 | 1 | 37 | (1.8) | 110 | 4742 | 105 | 4810 | 113 | 4858 | TR | PR | ||||||
| 11 | 6 | 25 | (0.5) | 87 | 4621 | 85 | 4600 | 103 | 4778 | PR | TR | ||||||
| 0 | 90 | 4406 | 37 | 4 | 32 | (1.7) | 107 | 4510 | 102 | 4572 | 126 | 4658 | TR | PR | |||
| 23 | 2 | 41 | (0.7) | 94 | 4459 | 96 | 4462 | 131 | 4734 | PR | PR | ||||||
| 33 | 3 | 39 | (1.9) | 113 | 4528 | 107 | 4559 | 129 | 4679 | TR | PR | ||||||
| 8 | 7 | 36 | (0.5) | 135 | 4611 | 121 | 4580 | 130 | 4726 | TR | TR | ||||||
| 3 | 5 | 28 | (0.8) | 96 | 4492 | 105 | 4488 | 121 | 4654 | PR | TR | ||||||
| 20 | 7 | 24 | (0.4) | 108 | 4490 | 103 | 4518 | 114 | 4598 | TR | PR | ||||||
| MK05 | 15 × 4 | 1.5 | 1 | 179 | 5577 | 30 | 2 | 81 | (0.5) | 260 | 5866 | 227 | 6121 | 286 | 5925 | TR | TR |
| 116 | 3 | 50 | (1.9) | 224 | 5702 | 225 | 5676 | 230 | 5781 | PR | PR | ||||||
| 84 | 2 | 48 | (1.5) | 229 | 5741 | 206 | 5777 | 229 | 5777 | TR | TR | ||||||
| 124 | 4 | 48 | (2.8) | 229 | 5749 | 216 | 5639 | 230 | 5781 | TR | TR | ||||||
| 28 | 3 | 48 | (0.3) | 234 | 5766 | 210 | 5496 | 234 | 5797 | TR | TR | ||||||
| 5 | 3 | 78 | (0.4) | 257 | 5855 | 234 | 5911 | 257 | 5889 | TR | TR | ||||||
| 0.5 | 186 | 4977 | 134 | 1 | 79 | (2.9) | 257 | 5243 | 231 | 5248 | 262 | 5309 | TR | TR | |||
| 57 | 3 | 67 | (0.5) | 256 | 5197 | 247 | 5177 | 256 | 5257 | PR | PR | ||||||
| 77 | 2 | 86 | (1.8) | 262 | 5227 | 234 | 5162 | 273 | 5325 | TR | TR | ||||||
| 49 | 3 | 87 | (0.6) | 276 | 5277 | 252 | 5384 | 276 | 5337 | TR | TR | ||||||
| 122 | 4 | 65 | (1.9) | 246 | 5202 | 240 | 5216 | 255 | 5253 | TR | TR | ||||||
| 13 | 4 | 64 | (0.4) | 257 | 5247 | 223 | 5120 | 257 | 5261 | TR | TR | ||||||
| 0.2 | 197 | 4834 | 89 | 2 | 51 | (1.5) | 241 | 4990 | 216 | 4882 | 252 | 5054 | TR | TR | |||
| 2 | 3 | 55 | (0.3) | 256 | 5030 | 232 | 4956 | 254 | 5062 | TR | TR | ||||||
| 43 | 2 | 71 | (0.5) | 261 | 5058 | 212 | 4925 | 274 | 5142 | TR | TR | ||||||
| 159 | 4 | 80 | (2.9) | 280 | 5156 | 274 | 5112 | 280 | 5166 | TR | TR | ||||||
| 15 | 2 | 62 | (1.8) | 243 | 4982 | 218 | 4888 | 260 | 5086 | TR | TR | ||||||
| 105 | 4 | 57 | (1.6) | 247 | 5027 | 243 | 4958 | 255 | 5066 | TR | TR | ||||||
| 0 | 223 | 4751 | 171 | 4 | 92 | (2.9) | 311 | 5015 | 294 | 5050 | 311 | 5103 | TR | TR | |||
| 15 | 3 | 58 | (0.3) | 284 | 4980 | 286 | 5049 | 289 | 5007 | PR | RR | ||||||
| 19 | 1 | 77 | (0.5) | 257 | 4901 | 247 | 4911 | 299 | 5055 | TR | PR | ||||||
| 93 | 3 | 66 | (1.5) | 287 | 4998 | 270 | 4950 | 295 | 5039 | TR | TR | ||||||
| 111 | 4 | 68 | (1.7) | 287 | 5002 | 268 | 4922 | 291 | 5023 | TR | TR | ||||||
| 140 | 2 | 104 | (1.9) | 281 | 5002 | 284 | 4990 | 284 | 5139 | PR | TR | ||||||
| MK06 | 10 × 15 | 3 | 1 | 86 | 8108 | 6 | 7 | 30 | (0.5) | 116 | 8359 | 114 | 8646 | 121 | 8458 | TR | TR |
| 57 | 7 | 33 | (1.9) | 116 | 8317 | 107 | 8317 | 119 | 8438 | TR | TR | ||||||
| 25 | 8 | 25 | (0.3) | 106 | 8235 | 107 | 8317 | 114 | 8388 | PR | PR | ||||||
| 37 | 8 | 26 | (1.7) | 104 | 8202 | 95 | 8563 | 107 | 8318 | TR | TR | ||||||
| 18 | 8 | 43 | (0.7) | 143 | 8471 | 115 | 8597 | 130 | 8548 | TR | TR | ||||||
| 35 | 6 | 43 | (1.6) | 106 | 8242 | 99 | 8421 | 118 | 8428 | TR | TR | ||||||
| 0.5 | 99 | 8004 | 57 | 5 | 33 | (1.8) | 127 | 8156 | 117 | 8039 | 135 | 8364 | TR | TR | |||
| 25 | 7 | 47 | (0.7) | 143 | 8359 | 141 | 7669 | 147 | 8484 | TR | TR | ||||||
| 3 | 6 | 41 | (0.3) | 131 | 8193 | 121 | 7749 | 141 | 8424 | TR | TR | ||||||
| 54 | 2 | 49 | (1.9) | 135 | 8885 | 120 | 7800 | 140 | 8414 | TR | TR | ||||||
| 83 | 1 | 46 | (2.9) | 142 | 8212 | 139 | 8164 | 145 | 8346 | TR | TR | ||||||
| 29 | 4 | 50 | (0.8) | 130 | 8265 | 133 | 7728 | 153 | 8534 | PR | TR | ||||||
| 0.2 | 114 | 7435 | 1 | 8 | 51 | (1.8) | 143 | 7630 | 138 | 7254 | 162 | 7915 | TR | TR | |||
| 6 | 7 | 31 | (0.3) | 147 | 7748 | 149 | 7140 | 150 | 7795 | PR | TR | ||||||
| 91 | 5 | 32 | (1.9) | 161 | 7843 | 153 | 7438 | 171 | 8005 | TR | TR | ||||||
| 78 | 8 | 34 | (2.9) | 131 | 7547 | 128 | 7370 | 150 | 7795 | TR | TR | ||||||
| 34 | 9 | 35 | (0.5) | 121 | 7528 | 134 | 7071 | 145 | 7725 | PR | TR | ||||||
| 26 | 9 | 51 | (0.7) | 239 | 7658 | 239 | 7459 | 164 | 7935 | PR | TR | ||||||
| 0 | 141 | 6564 | 26 | 9 | 64 | (0.6) | 148 | 6807 | 163 | 6885 | 206 | 7214 | PR | PR | |||
| 66 | 5 | 51 | (1.8) | 150 | 6716 | 159 | 6746 | 186 | 7014 | PR | PR | ||||||
| 36 | 1 | 60 | (0.7) | 172 | 6930 | 181 | 6875 | 202 | 7147 | PR | TR | ||||||
| 94 | 7 | 39 | (2.9) | 167 | 6702 | 162 | 6753 | 185 | 6916 | TR | PR | ||||||
| 30 | 2 | 61 | (0.9) | 159 | 6881 | 160 | 6700 | 196 | 7114 | PR | TR | ||||||
| 49 | 9 | 44 | (1.7) | 155 | 6822 | 158 | 6643 | 184 | 6994 | PR | TR | ||||||
| MK07 | 20 × 5 | 3 | 1 | 164 | 5599 | 43 | 1 | 59 | (0.5) | 220 | 5803 | 200 | 5702 | 226 | 5909 | PR | TR |
| 112 | 5 | 77 | (2.9) | 242 | 5891 | 221 | 5841 | 244 | 5999 | TR | TR | ||||||
| 8 | 5 | 73 | (0.4) | 228 | 5861 | 208 | 5834 | 237 | 5964 | TR | TR | ||||||
| 65 | 2 | 75 | (1.8) | 217 | 5872 | 196 | 5656 | 240 | 5979 | TR | TR | ||||||
| 52 | 4 | 75 | (0.7) | 244 | 5942 | 245 | 5875 | 244 | 5999 | PR | PR | ||||||
| 1 | 5 | 58 | (0.3) | 214 | 5495 | 222 | 5633 | 223 | 5894 | PR | PR | ||||||
| 0.5 | 189 | 4699 | 5 | 1 | 86 | (0.5) | 270 | 4920 | 228 | 4695 | 280 | 5154 | TR | TR | |||
| 86 | 4 | 84 | (1.9) | 274 | 4950 | 248 | 4932 | 274 | 5124 | TR | TR | ||||||
| 77 | 2 | 54 | (1.5) | 243 | 4982 | 206 | 4624 | 258 | 5044 | TR | TR | ||||||
| 59 | 1 | 84 | (0.7) | 243 | 4899 | 234 | 4569 | 273 | 5119 | TR | TR | ||||||
| 145 | 1 | 89 | (2.9) | 272 | 4859 | 254 | 4964 | 285 | 5179 | TR | TR | ||||||
| 94 | 1 | 48 | (1.7) | 233 | 4799 | 208 | 4564 | 248 | 4994 | TR | TR | ||||||
| 0.2 | 220 | 4345 | 81 | 5 | 62 | (1.5) | 285 | 4577 | 248 | 4277 | 290 | 4695 | TR | TR | |||
| 157 | 1 | 94 | (2.9) | 288 | 4493 | 275 | 4553 | 317 | 4830 | TR | TR | ||||||
| 39 | 3 | 92 | (0.5) | 307 | 4750 | 273 | 4267 | 312 | 4805 | TR | TR | ||||||
| 87 | 2 | 78 | (1.7) | 253 | 4518 | 257 | 4366 | 299 | 4740 | PR | TR | ||||||
| 35 | 2 | 102 | (0.8) | 276 | 4658 | 294 | 4498 | 339 | 4890 | PR | TR | ||||||
| 110 | 4 | 80 | (1.8) | 299 | 4696 | 288 | 4563 | 300 | 4745 | TR | TR | ||||||
| 0 | 236 | 4097 | 44 | 2 | 61 | (0.7) | 253 | 4216 | 272 | 4092 | 297 | 4407 | PR | TR | |||
| 79 | 3 | 111 | (1.9) | 285 | 4381 | 290 | 4290 | 350 | 4667 | PR | TR | ||||||
| 51 | 3 | 99 | (0.9) | 267 | 4319 | 271 | 4198 | 332 | 4577 | PR | TR | ||||||
| 55 | 4 | 77 | (0.5) | 297 | 4355 | 310 | 4228 | 326 | 4547 | PR | TR | ||||||
| 172 | 4 | 104 | (2.9) | 316 | 4298 | 325 | 4452 | 341 | 4517 | PR | PR | ||||||
| 99 | 1 | 72 | (1.5) | 302 | 4331 | 269 | 4178 | 308 | 4457 | TR | TR | ||||||
| MK08 | 20 × 10 | 1.5 | 1 | 523 | 13,255 | 292 | 7 | 250 | (1.9) | 613 | 13,956 | 604 | 14,405 | 775 | 15,523 | PR | PR |
| 125 | 7 | 192 | (0.7) | 579 | 13,683 | 582 | 13,250 | 715 | 14,983 | PR | PR | ||||||
| 94 | 1 | 153 | (0.3) | 681 | 14,735 | 693 | 14,974 | 681 | 14,677 | PR | PR | ||||||
| 242 | 3 | 185 | (1.8) | 584 | 13,809 | 577 | 13,755 | 701 | 14,938 | TR | TR | ||||||
| 86 | 9 | 207 | (0.5) | 559 | 13,579 | 567 | 13,712 | 727 | 15,091 | PR | PR | ||||||
| 238 | 3 | 151 | (1.7) | 568 | 13,684 | 555 | 13,458 | 672 | 14,596 | TR | TR | ||||||
| 0.5 | 524 | 12,499 | 81 | 5 | 258 | (0.8) | 495 | 13,852 | 401 | 13,451 | 487 | 14,596 | TR | TR | |||
| 216 | 2 | 189 | (1.9) | 292 | 12,902 | 293 | 12,979 | 372 | 13,642 | PR | PR | ||||||
| 106 | 9 | 139 | (0.5) | 280 | 12,699 | 273 | 12,587 | 371 | 13,552 | TR | TR | ||||||
| 10 | 7 | 227 | (0.6) | 434 | 14,046 | 340 | 13,581 | 491 | 14,632 | TR | TR | ||||||
| 418 | 10 | 152 | (2.9) | 404 | 13,048 | 393 | 13,226 | 420 | 13,495 | TR | TR | ||||||
| 42 | 3 | 196 | (0.4) | 359 | 13,481 | 330 | 13,013 | 458 | 14,335 | TR | TR | ||||||
| 0.2 | 543 | 12,365 | 337 | 7 | 159 | (1.9) | 619 | 12,848 | 595 | 12,872 | 682 | 13,616 | TR | TR | |||
| 132 | 5 | 226 | (0.8) | 646 | 13,377 | 632 | 13,348 | 773 | 14,435 | TR | TR | ||||||
| 201 | 8 | 174 | (1.6) | 631 | 13,198 | 589 | 12,976 | 720 | 13,958 | TR | TR | ||||||
| 131 | 1 | 184 | (0.4) | 717 | 14,009 | 734 | 13,683 | 728 | 14,030 | PR | TR | ||||||
| 320 | 1 | 158 | (1.8) | 689 | 13,467 | 699 | 13,173 | 709 | 13,859 | PR | TR | ||||||
| 15 | 3 | 147 | (0.3) | 592 | 12,889 | 581 | 12,550 | 690 | 13,688 | TR | TR | ||||||
| 0 | 561 | 12,320 | 194 | 9 | 260 | (1.9) | 590 | 12,810 | 584 | 12,949 | 785 | 14,336 | TR | PR | |||
| 29 | 10 | 146 | (0.3) | 750 | 13,720 | 714 | 13,661 | 722 | 13,769 | TR | TR | ||||||
| 126 | 4 | 260 | (0.9) | 607 | 13,062 | 612 | 12,789 | 821 | 14,660 | PR | TR | ||||||
| 214 | 10 | 140 | (1.4) | 694 | 13,464 | 667 | 13,404 | 703 | 13,598 | TR | TR | ||||||
| 430 | 10 | 204 | (2.9) | 782 | 13,396 | 744 | 13,420 | 782 | 13,876 | TR | PR | ||||||
| 86 | 3 | 263 | (0.8) | 689 | 13,809 | 640 | 13,244 | 826 | 14,687 | TR | TR | ||||||
| MK09 | 20 × 10 | 3 | 1 | 342 | 13,900 | 189 | 2 | 132 | (1.8) | 464 | 14,965 | 413 | 14,429 | 567 | 15,250 | TR | TR |
| 244 | 7 | 97 | (2.9) | 518 | 14,433 | 488 | 14,404 | 531 | 14,890 | TR | TR | ||||||
| 68 | 10 | 107 | (0.2) | 372 | 14,124 | 382 | 14,259 | 441 | 14,890 | PR | PR | ||||||
| 50 | 9 | 94 | (0.4) | 377 | 14,259 | 379 | 14,044 | 424 | 14,720 | PR | PR | ||||||
| 115 | 1 | 97 | (1.5) | 413 | 14,533 | 478 | 14,341 | 423 | 14,810 | PR | PR | ||||||
| 112 | 9 | 91 | (0.5) | 467 | 14,212 | 451 | 14,176 | 442 | 14,900 | TR | TR | ||||||
| 0.5 | 362 | 12,788 | 215 | 4 | 144 | (1.9) | 504 | 13,813 | 438 | 13,166 | 507 | 14,238 | TR | TR | |||
| 115 | 6 | 90 | (0.4) | 369 | 12,841 | 382 | 12,566 | 445 | 13,518 | PR | TR | ||||||
| 141 | 6 | 91 | (1.6) | 369 | 12,884 | 373 | 12,642 | 462 | 13,788 | PR | TR | ||||||
| 261 | 2 | 102 | (2.9) | 443 | 13,637 | 442 | 13,389 | 442 | 13,798 | TR | TR | ||||||
| 122 | 5 | 175 | (1.7) | 458 | 13,583 | 452 | 13,434 | 529 | 14,458 | TR | TR | ||||||
| 29 | 10 | 181 | (0.6) | 726 | 13,635 | 693 | 12,213 | 815 | 14,618 | TR | TR | ||||||
| 0.2 | 367 | 12,437 | 228 | 8 | 134 | (1.9) | 501 | 13,260 | 483 | 13,236 | 506 | 13,827 | TR | TR | |||
| 34 | 10 | 97 | (0.2) | 378 | 12,529 | 393 | 12,566 | 448 | 13,247 | PR | PR | ||||||
| 43 | 9 | 169 | (0.7) | 455 | 13,258 | 486 | 13,009 | 538 | 14,147 | PR | TR | ||||||
| 184 | 6 | 93 | (1.5) | 405 | 12,760 | 412 | 12,314 | 452 | 13,287 | PR | TR | ||||||
| 245 | 8 | 177 | (2.9) | 537 | 13,469 | 514 | 13,413 | 549 | 14,257 | TR | TR | ||||||
| 92 | 9 | 142 | (0.6) | 441 | 13,012 | 435 | 12,495 | 510 | 13,867 | TR | TR | ||||||
| 0 | 434 | 12,322 | 118 | 8 | 126 | (0.4) | 548 | 13,358 | 528 | 13,451 | 562 | 13,062 | TR | TR | |||
| 187 | 10 | 192 | (1.7) | 520 | 13,031 | 457 | 12,622 | 628 | 14,262 | TR | TR | ||||||
| 46 | 2 | 185 | (0.6) | 514 | 13,154 | 491 | 13,579 | 612 | 14,102 | TR | TR | ||||||
| 186 | 1 | 193 | (1.8) | 555 | 13,585 | 541 | 13,309 | 627 | 14,252 | TR | TR | ||||||
| 13 | 1 | 215 | (0.5) | 569 | 13,729 | 563 | 14,034 | 651 | 14,492 | TR | TR | ||||||
| 244 | 1 | 158 | (1.9) | 532 | 13,330 | 527 | 13,199 | 588 | 13,862 | TR | TR | ||||||
| MK10 | 20 × 15 | 1.5 | 1 | 292 | 13,707 | 1 | 8 | 148 | (1.8) | 365 | 14,400 | 356 | 14,376 | 421 | 15,126 | TR | TR |
| 57 | 9 | 79 | (0.4) | 342 | 14,155 | 330 | 13,920 | 367 | 14,631 | TR | TR | ||||||
| 88 | 9 | 132 | (0.7) | 396 | 14,630 | 367 | 14,336 | 531 | 15,236 | TR | TR | ||||||
| 203 | 1 | 130 | (2.9) | 415 | 14,436 | 366 | 14,331 | 429 | 15,214 | TR | TR | ||||||
| 41 | 1 | 86 | (0.3) | 345 | 14,050 | 326 | 14,246 | 379 | 14,664 | TR | TR | ||||||
| 119 | 4 | 139 | (1.7) | 363 | 14,400 | 345 | 14,095 | 419 | 15,104 | TR | TR | ||||||
| 0.5 | 297 | 12,710 | 10 | 7 | 146 | (0.5) | 420 | 13,946 | 409 | 13,082 | 453 | 14,426 | TR | TR | |||
| 212 | 2 | 135 | (2.9) | 319 | 13,494 | 393 | 13,629 | 436 | 14,239 | TR | TR | ||||||
| 122 | 6 | 86 | (1.7) | 370 | 13,235 | 322 | 12,722 | 390 | 13,733 | TR | TR | ||||||
| 17 | 13 | 128 | (0.4) | 307 | 12,787 | 311 | 12,340 | 359 | 13,392 | PR | TR | ||||||
| 157 | 4 | 138 | (1.9) | 391 | 13,667 | 368 | 12,983 | 444 | 14,327 | TR | TR | ||||||
| 91 | 3 | 125 | (0.7) | 372 | 13,327 | 359 | 12,538 | 414 | 13,997 | TR | TR | ||||||
| 0.2 | 316 | 11,826 | 8 | 3 | 150 | (0.4) | 352 | 12,223 | 385 | 12,334 | 474 | 13,564 | PR | PR | |||
| 125 | 8 | 83 | (1.6) | 354 | 12,252 | 350 | 11,921 | 406 | 12,816 | TR | TR | ||||||
| 123 | 7 | 156 | (1.9) | 410 | 12,802 | 401 | 12,610 | 484 | 13,674 | TR | TR | ||||||
| 50 | 6 | 150 | (0.6) | 403 | 12,705 | 400 | 12,049 | 469 | 13,509 | TR | TR | ||||||
| 151 | 5 | 123 | (1.8) | 427 | 12,852 | 388 | 12,249 | 450 | 13,300 | PR | PR | ||||||
| 254 | 3 | 156 | (2.9) | 457 | 12,516 | 438 | 12,582 | 463 | 13,296 | TR | PR | ||||||
| 0 | 344 | 11,483 | 54 | 10 | 91 | (0.7) | 375 | 11,848 | 370 | 11,747 | 438 | 12,517 | TR | TR | |||
| 72 | 8 | 126 | (0.5) | 405 | 12,117 | 440 | 11,758 | 473 | 12,902 | PR | TR | ||||||
| 162 | 1 | 102 | (1.6) | 410 | 11,999 | 378 | 11,732 | 451 | 12,553 | PR | TR | ||||||
| 272 | 7 | 136 | (2.9) | 451 | 11,838 | 435 | 12,241 | 485 | 12,750 | TR | PR | ||||||
| 112 | 8 | 143 | (0.8) | 436 | 12,441 | 422 | 12,176 | 494 | 13,133 | TR | TR | ||||||
| 178 | 4 | 169 | (1.9) | 438 | 12,381 | 429 | 12,135 | 514 | 13,183 | TR | TR | ||||||
References
- Giret, A.; Trentesaux, D.; Prabhu, V. Sustainability in Manufacturing Operations Scheduling: A State of the Art Review. J. Manuf. Syst. 2015, 37, 126–140. [Google Scholar] [CrossRef]
- Zhang, L.; Li, X.; Gao, L.; Zhang, G. Dynamic Rescheduling in FMS That Is Simultaneously Considering Energy Consumption and Schedule Efficiency. Int. J. Adv. Manuf. Technol. 2016, 87, 1387–1399. [Google Scholar] [CrossRef]
- Nouiri, M.; Bekrar, A.; Trentesaux, D. Towards Energy Efficient Scheduling and Rescheduling for Dynamic Flexible Job Shop Problem. IFAC-Pap. 2018, 51, 1275–1280. [Google Scholar] [CrossRef]
- Masmoudi, O.; Delorme, X.; Gianessi, P. Job-Shop Scheduling Problem with Energy Consideration. Int. J. Prod. Econ. 2019, 216, 12–22. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, H.; Lohse, N.; Petrovic, S. A Multi-Objective Genetic Algorithm for Optimisation of Energy Consumption and Shop Floor Production Performance. Int. J. Prod. Econ. 2016, 179, 259–272. [Google Scholar] [CrossRef] [Green Version]
- Kemmoe, S.; Lamy, D.; Tchernev, N. Job-Shop like Manufacturing System with Variable Power Threshold and Operations with Power Requirements. Int. J. Prod. Res. 2017, 55, 6011–6032. [Google Scholar] [CrossRef]
- Raileanu, S.; Anton, F.; Iatan, A.; Borangiu, T.; Anton, S.; Morariu, O. Resource Scheduling Based on Energy Consumption for Sustainable Manufacturing. J. Intell. Manuf. 2017, 28, 1519–1530. [Google Scholar] [CrossRef]
- Mokhtari, H.; Hasani, A. An Energy-Efficient Multi-Objective Optimization for Flexible Job-Shop Scheduling Problem. Comput. Chem. Eng. 2017, 104, 339–352. [Google Scholar] [CrossRef]
- Gong, X.; De Pessemier, T.; Martens, L.; Joseph, W. Energy-and Labor-Aware Flexible Job Shop Scheduling under Dynamic Electricity Pricing: A Many-Objective Optimization Investigation. J. Clean. Prod. 2019, 209, 1078–1094. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Li, J.; Han, Y.; Sang, H. Improved Artificial Immune Algorithm for the Flexible Job Shop Problem with Transportation Time. Meas. Control 2020, 53, 2111–2128. [Google Scholar] [CrossRef]
- Salido, M.A.; Escamilla, J.; Barber, F.; Giret, A. Rescheduling in Job-Shop Problems for Sustainable Manufacturing Systems. J. Clean. Prod. 2017, 162, S121–S132. [Google Scholar] [CrossRef] [Green Version]
- Caldeira, R.H.; Gnanavelbabu, A.; Vaidyanathan, T. An Effective Backtracking Search Algorithm for Multi-Objective Flexible Job Shop Scheduling Considering New Job Arrivals and Energy Consumption. Comput. Ind. Eng. 2020, 149, 106863. [Google Scholar] [CrossRef]
- Xu, B.; Mei, Y.; Wang, Y.; Ji, Z.; Zhang, M. Genetic Programming with Delayed Routing for Multiobjective Dynamic Flexible Job Shop Scheduling. Evol. Comput. 2021, 29, 75–105. [Google Scholar] [CrossRef]
- Luo, J.; El Baz, D.; Xue, R.; Hu, J. Solving the Dynamic Energy Aware Job Shop Scheduling Problem with the Heterogeneous Parallel Genetic Algorithm. Future Gener. Comput. Syst. 2020, 108, 119–134. [Google Scholar] [CrossRef]
- Tian, S.; Wang, T.; Zhang, L.; Wu, X. An Energy-Efficient Scheduling Approach for Flexible Job Shop Problem in an Internet of Manufacturing Things Environment. IEEE Access 2019, 7, 62695–62704. [Google Scholar] [CrossRef]
- Nouiri, M.; Trentesaux, D.; Bekrar, A. EasySched: Une Architecture Multi-Agent Pour l’ordonnancement Prédictif et Réactif de Systèmes de Production de Biens En Fonction de l’énergie Renouvelable Disponible Dans Un Contexte Industrie 4.0. arXiv 2019, arXiv:1905.12083. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin, Germany, 2007. [Google Scholar]
- Shahzad, A.; Mebarki, N. Learning Dispatching Rules for Scheduling: A Synergistic View Comprising Decision Trees, Tabu Search and Simulation. Computers 2016, 5, 3. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.L.; Rong, G.; Weng, W.; Feng, Y.P. Mining Scheduling Knowledge for Job Shop Scheduling Problem. IFAC-Pap. 2015, 48, 800–805. [Google Scholar] [CrossRef]
- Zhao, M.; Gao, L.; Li, X. A Random Forest-Based Job Shop Rescheduling Decision Model with Machine Failures. J. Ambient. Intell. Humaniz. Comput. 2019, 1–11. [Google Scholar] [CrossRef]
- Li, Y.; Carabelli, S.; Fadda, E.; Manerba, D.; Tadei, R.; Terzo, O. Machine Learning and Optimization for Production Rescheduling in Industry 4.0. Int. J. Adv. Manuf. Technol. 2020, 110, 2445–2463. [Google Scholar] [CrossRef]
- Pereira, M.S.; Lima, F. A Machine Learning Approach Applied to Energy Prediction in Job Shop Environments. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 2665–2670. [Google Scholar]
- Li, Y.; Chen, Y. Neural Network and Genetic Algorithm-Based Hybrid Approach to Dynamic Job Shop Scheduling Problem. In Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 4836–4841. [Google Scholar]
- Wang, C.; Jiang, P. Manifold Learning Based Rescheduling Decision Mechanism for Recessive Disturbances in RFID-Driven Job Shops. J. Intell. Manuf. 2018, 29, 1485–1500. [Google Scholar] [CrossRef]
- Mihoubi, B.; Bouzouia, B.; Gaham, M. Reactive Scheduling Approach for Solving a Realistic Flexible Job Shop Scheduling Problem. Int. J. Prod. Res. 2021, 59, 5790–5808. [Google Scholar] [CrossRef]
- Adibi, M.A.; Shahrabi, J. A Clustering-Based Modified Variable Neighborhood Search Algorithm for a Dynamic Job Shop Scheduling Problem. Int. J. Adv. Manuf. Technol. 2014, 70, 1955–1961. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Riedmiller, S.; Riedmiller, M. A Neural Reinforcement Learning Approach to Learn Local Dispatching Policies in Production Scheduling. In Proceedings of the IJCAI, Stockholm, Sweden, 31 July–6 August 1999; Volume 2, pp. 764–771. [Google Scholar]
- Chen, X.; Hao, X.; Lin, H.W.; Murata, T. Rule Driven Multi Objective Dynamic Scheduling by Data Envelopment Analysis and Reinforcement Learning. In Proceedings of the 2010 IEEE International Conference on Automation and Logistics, Hong Kong and Macau, China, 16–20 August 2010; pp. 396–401. [Google Scholar]
- Gabel, T.; Riedmiller, M. Distributed Policy Search Reinforcement Learning for Job-Shop Scheduling Tasks. Int. J. Prod. Res. 2012, 50, 41–61. [Google Scholar] [CrossRef]
- Zhao, M.; Li, X.; Gao, L.; Wang, L.; Xiao, M. An Improved Q-Learning Based Rescheduling Method for Flexible Job-Shops with Machine Failures. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 331–337. [Google Scholar]
- Shahrabi, J.; Adibi, M.A.; Mahootchi, M. A Reinforcement Learning Approach to Parameter Estimation in Dynamic Job Shop Scheduling. Comput. Ind. Eng. 2017, 110, 75–82. [Google Scholar] [CrossRef]
- Luo, S. Dynamic Scheduling for Flexible Job Shop with New Job Insertions by Deep Reinforcement Learning. Appl. Soft Comput. 2020, 91, 106208. [Google Scholar] [CrossRef]
- Bouazza, W.; Sallez, Y.; Beldjilali, B. A Distributed Approach Solving Partially Flexible Job-Shop Scheduling Problem with a Q-Learning Effect. IFAC 2017, 50, 15890–15895. [Google Scholar] [CrossRef]
- Wang, Y.-F. Adaptive Job Shop Scheduling Strategy Based on Weighted Q-Learning Algorithm. J. Intell. Manuf. 2020, 31, 417–432. [Google Scholar] [CrossRef]
- Trentesaux, D.; Pach, C.; Bekrar, A.; Sallez, Y.; Berger, T.; Bonte, T.; Leitão, P.; Barbosa, J. Benchmarking Flexible Job-Shop Scheduling and Control Systems. Control. Eng. Pract. 2013, 21, 1204–1225. [Google Scholar] [CrossRef] [Green Version]
- Nouiri, M.; Bekrar, A.; Trentesaux, D. An Energy-Efficient Scheduling and Rescheduling Method for Production and Logistics Systems. Int. J. Prod. Res. 2020, 58, 3263–3283. [Google Scholar] [CrossRef]
- Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 43–55. [Google Scholar]
- Nouiri, M.; Bekrar, A.; Jemai, A.; Trentesaux, D.; Ammari, A.C.; Niar, S. Two Stage Particle Swarm Optimization to Solve the Flexible Job Shop Predictive Scheduling Problem Considering Possible Machine Breakdowns. Comput. Ind. Eng. 2017, 112, 595–606. [Google Scholar] [CrossRef]
- Yuan, B.; Gallagher, M. A hybrid approach to parameter tuning in genetic algorithms. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–4 September 2005; Volume 2. [Google Scholar]
- Angelova, M.; Pencheva, T. Tuning genetic algorithm parameters to improve convergence time. Int. J. Chem. Eng. 2011, 2011, 646917. [Google Scholar] [CrossRef] [Green Version]
- Vieira, G.E.; Herrmann, J.W.; Lin, E. Rescheduling Manufacturing Systems: A Framework of Strategies, Policies, and Methods. J. Sched. 2003, 6, 39–62. [Google Scholar] [CrossRef]
- Qiao, F.; Wu, Q.; Li, L.; Wang, Z.; Shi, B. A Fuzzy Petri Net-Based Reasoning Method for Rescheduling. Trans. Inst. Meas. Control. 2011, 33, 435–455. [Google Scholar] [CrossRef]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An Introduction to Deep Reinforcement Learning. In Foundations and Trends in Machine Learning; University of California: Berkeley, CA, USA, 2018; Volume 11, pp. 219–354. [Google Scholar]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv Preprint 2017, arXiv:1701.07274. [Google Scholar]
- Brandimarte, P. Routing and Scheduling in a Flexible Job Shop by Tabu Search. Ann. Oper. Res. 1993, 41, 157–183. [Google Scholar] [CrossRef]
- Nouiri, M. Implémentation d’une Méta-Heuristique Embarquée Pour Résoudre Le Problème d’ordonnancement Dans Un Atelier Flexible de Production. Ph.D. Thesis, Ecole Polytechnique de Tunisie, Carthage, Tunisia, 2017. [Google Scholar]
- Bożejko, W.; Uchroński, M.; Wodecki, M. Parallel Hybrid Metaheuristics for the Flexible Job Shop Problem. Comput. Ind. Eng. 2010, 59, 323–333. [Google Scholar] [CrossRef]
| Reference | Type of Problem | Type of Disturbance | Scheduling/ Rescheduling Techniques | Architecture | Objective Function | AI Techniques | ||
|---|---|---|---|---|---|---|---|---|
| Centralized | Distributed | Mono-Objective | Multi-Objective | |||||
| [4] | JSP | Integer linear programming | × | Energy cost | ||||
| [5] | JSP | NSGA-II | × | Energy consumption And total weighted tardiness | ||||
| [6] | JSP | GRASP × ELS | × | Makespan | ||||
| [7] | JSP | IBM ILOG OPL: ILOG CP Optimizer | × | Makespan and energy consumption | ||||
| [8] | FJSP | Evolutionary algorithm | × | Total completion time; total availability of system; energy consumption | ||||
| [9] | FSJP | NSGA-III | × | Makespan; total energy cost; total labor cost; maximal workload; and total workload | ||||
| [10] | FJSP | hybrid meta-heuristic: AIA and SA | × | Maximal completion Time and total energy consumption | ||||
| [11] | JSP | Disruptions | match-up technique and memetic algorithm | × | Makespan and energy consumption | |||
| [2] | FJSP | New jobs arrival and machine breakdown | GA | × | Energy consumption and schedule efficiency | |||
| [12] | FJSP | New job arrivals | BSA with slack-based insertion strategy | × | Makespan, total energy consumption, and instability | |||
| [13] | FJSP | New job arrivals | GPHH-DR | × | Mean tardiness and energy efficiency | |||
| [14] | DJSP | New job arrivals | parallel GA | × | Total tardiness; total energy cost; disruption to the original schedule | |||
| [15] | FJSP | Machine breakdown and urgent order arrival | PN-ACO + IOT | × | Energy consumption | |||
| [3] | FJSP | Machine breakdowns | PSO | × | Makespan and Less global energy consumption | |||
| [16] | FJSP | Machine breakdowns | PSO with editable ponderation factor | × | Makespan and energy consumption | |||
| [28] | JSP | × | Summed tardiness | neural network + Q-learning | ||||
| [22] | JSP | GA | × | Makespan | ANN | |||
| [29] | JSP | Fluctuation of WIP | × | Mean flow time and Mean tardiness | Q-learning | |||
| [30] | JSP | × | Makespan | Policy gradient | ||||
| [18] | JSP | TS | × | Lateness | DT | |||
| [19] | JSP | Petri net-based branch-and-bound algorithm | × | Makespan | DT | |||
| [23] | DJSP | Machine breakdown and new job arrivals | GA | × | Makespan | BPNN | ||
| [24] | JSP | Recessive disturbances | RSR/PR/TR | × | Time accumulation error | SLLE + GRNN + LS-SVM | ||
| [20] | DJSP | Machine failure | RSR/TR | × | Delay and deviation | RF | ||
| [26] | DJSP | Random job arrivals and Machine breakdowns | MVNS | × | Mean flow time | k-means | ||
| [32] | DJSP | Random job arrivals and Machine breakdowns | VNS | × | Mean flow time | Q-learning | ||
| [31] | FJSP | Machine failure | GA | × | Makespan | Q-learning | ||
| [21] | FJSP | Availability of machines and setup workers | GA + TS | × | Makespan | ML classification | ||
| [25] | FJSP | New job insertions | GA-Opt | × | Makespan | BPNN | ||
| [33] | FSJP | New job insertions | × | Total tardiness | DQN | |||
| [34] | FSJP | New job insertions | × | Makespan; total weighted completion time; | Q-learning | |||
| [35] | JSP | New job insertions | × | Earliness and tardiness punishment | Q-learning | |||
| Our method | FJSP | Breakdown of machines | GA | × | Makespan, robustness and energy consumption | Multi-objective Q-learning | ||
| Jobs | Operations | Processing Machine and Time (Time Units) | |||
|---|---|---|---|---|---|
| M1 | M2 | M3 | M4 | ||
| J1 | O11 O21 O31 | 3 5 9 | 5 - 12 | - 4 8 | 7 5 10 |
| J2 | O12 O22 O32 | 2 - 5 | 2 - 2 | 1 - 4 | 4 9 2 |
| J3 | O13 O23 O33 | - 4 5 | 5 - 6 | 6 4 8 | 5 4 - |
| Instances | The Proposed GA | PSO by [47] | TS by [48] |
|---|---|---|---|
| Mk01 | 42 | 41 | 42 |
| Mk02 | 32 | 26 | 32 |
| Mk03 | 206 | 207 | 211 |
| Mk04 | 67 | 65 | 81 |
| Mk05 | 179 | 171 | 186 |
| Mk06 | 86 | 61 | 86 |
| Mk07 | 164 | 173 | 157 |
| Mk08 | 523 | 523 | 523 |
| Mk09 | 342 | 307 | 369 |
| Mk10 | 292 | 312 | 296 |
| Instance | Size | Weight | KPIs | |
|---|---|---|---|---|
| MK | EC | |||
| MK01 | 10 × 6 | 1 | 42 | 2812 |
| 0.5 | 44 | 2457 | ||
| 0.2 | 49 | 2411 | ||
| 0 | 73 | 2229 | ||
| Schedule | Makespan (MK) | Energy Consumption(EC) | |
|---|---|---|---|
| Predictive schedule | 42 | 2812 | |
| Reactive schedule | PR schedule | 50 | 3046 |
| TR schedule | 49 | 2895 | |
| RSR schedule | 57 | 2887 | |
| Instance | Size | p | Weight of BF | Predictive Schedule | Machine Failure | State of the System | Reactive Schedule | Q-Learning | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PR | TR | RSR | Single Objective | Multi-Objective | |||||||||||||
| MK (Time Units) | EC (kWh) | Failure Time | Broken-Down Machine | Failure Duration | MK (Time Units) | EC (kWh) | MK (Time Units) | EC (kWh) | MK (Time Units) | EC (kWh) | |||||||
| MK01 | 10 × 6 | 2 | 1 | 42 | 3046 | 3 | 5 | 20 | (0.5) | 46 | 3064 | 45 | 3115 | 61 | 3160 | TR | TR |
| 16 | 4 | 19 | (1.9) | 60 | 3128 | 55 | 3243 | 66 | 3180 | TR | TR | ||||||
| 8 | 1 | 17 | (0.6) | 57 | 3099 | 50 | 3190 | 58 | 3142 | TR | TR | ||||||
| 23 | 3 | 14 | (1.7) | 57 | 3101 | 56 | 3218 | 58 | 3142 | TR | TR | ||||||
| 13 | 5 | 10 | (0.4) | 46 | 3058 | 45 | 3028 | 52 | 3106 | TR | TR | ||||||
| 13 | 6 | 20 | (0.9) | 56 | 3098 | 54 | 3204 | 59 | 3148 | TR | TR | ||||||
| 0.5 | 49 | 2837 | 11 | 1 | 12 | (0.5) | 54 | 2872 | 58 | 2826 | 61 | 2909 | TR | TR | |||
| 7 | 5 | 23 | (0.9) | 56 | 2890 | 57 | 2724 | 76 | 2999 | PR | TR | ||||||
| 22 | 2 | 22 | (1.9) | 62 | 2950 | 56 | 2968 | 65 | 2993 | TR | TR | ||||||
| 5 | 2 | 12 | (0.3) | 54 | 2935 | 54 | 2853 | 55 | 2939 | TR | TR | ||||||
| 11 | 1 | 12 | (0.6) | 54 | 2872 | 58 | 2826 | 61 | 2909 | PR | PR | ||||||
| 13 | 4 | 13 | (0.2) | 50 | 2839 | 54 | 2816 | 54 | 2867 | PR | PR | ||||||
| 0.2 | 52 | 2672 | 31 | 2 | 15 | (1.9) | 64 | 2702 | 67 | 2711 | 67 | 2672 | PR | PR | |||
| 4 | 2 | 20 | (0.4) | 75 | 2797 | 78 | 2757 | 75 | 2800 | TR | PR | ||||||
| 10 | 4 | 14 | (0.0) | 52 | 2673 | 58 | 2670 | 59 | 2714 | PR | PR | ||||||
| 10 | 1 | 21 | (0.6) | 64 | 2728 | 68 | 2632 | 73 | 2798 | TR | PR | ||||||
| 20 | 2 | 22 | (1.7) | 72 | 2769 | 76 | 2773 | 75 | 2820 | PR | PR | ||||||
| 6 | 5 | 26 | (0.9) | 65 | 2727 | 68 | 2704 | 74 | 2804 | PR | TR | ||||||
| 0 | 79 | 2554 | 23 | 6 | 20 | (0.9) | 91 | 2649 | 99 | 2612 | 102 | 2692 | PR | TR | |||
| 1 | 5 | 26 | (0.3) | 79 | 2560 | 79 | 2574 | 102 | 2686 | PR | PR | ||||||
| 31 | 2 | 37 | (1.8) | 92 | 2668 | 110 | 2706 | 116 | 2776 | PR | PR | ||||||
| 3 | 2 | 24 | (1.6) | 88 | 2639 | 100 | 2666 | 106 | 2689 | PR | PR | ||||||
| 16 | 2 | 34 | (0.6) | 98 | 2700 | 110 | 2744 | 116 | 2776 | PR | PR | ||||||
| 30 | 6 | 20 | (1.9) | 79 | 2564 | 79 | 2605 | 98 | 2668 | PR | PR | ||||||
| Instances | CPU Time (s) | |
|---|---|---|
| Traditional Rescheduling | Q-Learning | |
| MK01 | 6.173 | 0.001 |
| MK02 | 7.261 | |
| MK03 | 45.068 | |
| MK04 | 13.680 | |
| MK05 | 24.488 | |
| MK06 | 48.855 | |
| MK07 | 30.716 | |
| MK08 | 61.261 | |
| MK09 | 85.610 | |
| MK10 | 84.545 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naimi, R.; Nouiri, M.; Cardin, O. A Q-Learning Rescheduling Approach to the Flexible Job Shop Problem Combining Energy and Productivity Objectives. Sustainability 2021, 13, 13016. https://doi.org/10.3390/su132313016
Naimi R, Nouiri M, Cardin O. A Q-Learning Rescheduling Approach to the Flexible Job Shop Problem Combining Energy and Productivity Objectives. Sustainability. 2021; 13(23):13016. https://doi.org/10.3390/su132313016
Chicago/Turabian StyleNaimi, Rami, Maroua Nouiri, and Olivier Cardin. 2021. "A Q-Learning Rescheduling Approach to the Flexible Job Shop Problem Combining Energy and Productivity Objectives" Sustainability 13, no. 23: 13016. https://doi.org/10.3390/su132313016
APA StyleNaimi, R., Nouiri, M., & Cardin, O. (2021). A Q-Learning Rescheduling Approach to the Flexible Job Shop Problem Combining Energy and Productivity Objectives. Sustainability, 13(23), 13016. https://doi.org/10.3390/su132313016