
A Short-Term Power Output Forecasting Based on Augmented Naïve Bayes Classifiers for High Wind Power Penetrations



Abstract
:1. Introduction
- The purpose of this study is to reduce the prediction bias and improve the prediction performance of a single prediction model for wind power generation resources. An analogue ensemble was applied to the deterministic wind power output predictions calculated from a single prediction model, and the proposed algorithm was verified using data from the wind farm of Jeju Island.
- Verification using empirical data confirmed that the proposed algorithm has higher prediction accuracy than a single prediction model. Therefore, the proposed algorithm is expected to be utilized in the power system as follows. (1) forecasting of the output of wind power resources and other renewable energy resources, (2) establishment of a real-time power system operation plan considering the characteristics of renewable energy power generation using probabilistic power output modeling, (3) promotion of renewable energy projects, and (4) establishment of a transmission network and substation expansion plan.
2. Methodology
2.1. Multiple Linear Regression Model
| Algorithm 1. MLR |
| Input: Measured data, numerical weather prediction, installed capacity (MW) |
| Output: Wind power outputs (MW) |
| 1: for forecasting data = forecasting start date to forecasting end date |
| 2: Training data ∈ Input data (Date < forecasting date) |
| 3: Evaluate multicollinearity |
| 4: if correlation coefficient < 0.8 then |
| 5: 1. Estimate the regression coefficient |
| 6: 2. Significance test: |
| 7: ifp-value < 0.05 then |
| 8: Return null hypothesis = Reject |
| 9: 3. Goodness of fit test: |
| 10: if adjusted R-square (R2) > 0.65 (general value) then |
| 11: Return goodness of fit = True |
| 12: 4. Predict wind power (ft) |
| 13: if ft < 0 then |
| 14: Return ft = 0 |
| 15: end if |
| 16: if ft > installed capacity then |
| 17: Return ft = installed capacity |
| 18: end if |
| 19: end |
2.2. Naïve Bayes Classification Model
| Algorithm 2. Naïve Bayes classification |
| Input: Measured data, numerical weather prediction, installed capacity (MW) |
| Output: Wind power outputs (MW) |
| 1: for forecasting data = forecasting start date to forecasting end date |
| 2: Training data ∈ Input data (Date < forecasting date) |
| 3: 1. Calculate the prior probability and likelihood |
| 4: 2. Calculate the posterior probability |
| 5: 3. Select the maximum a posteriori estimate |
| 6: 4. Predict wind power (ft) |
| 7: if ft < 0 then |
| 8: Return ft = 0 |
| 9: end if |
| 10: if ft > installed capacity then |
| 11: Return ft = installed capacity |
| 12: end if |
| 13: end |
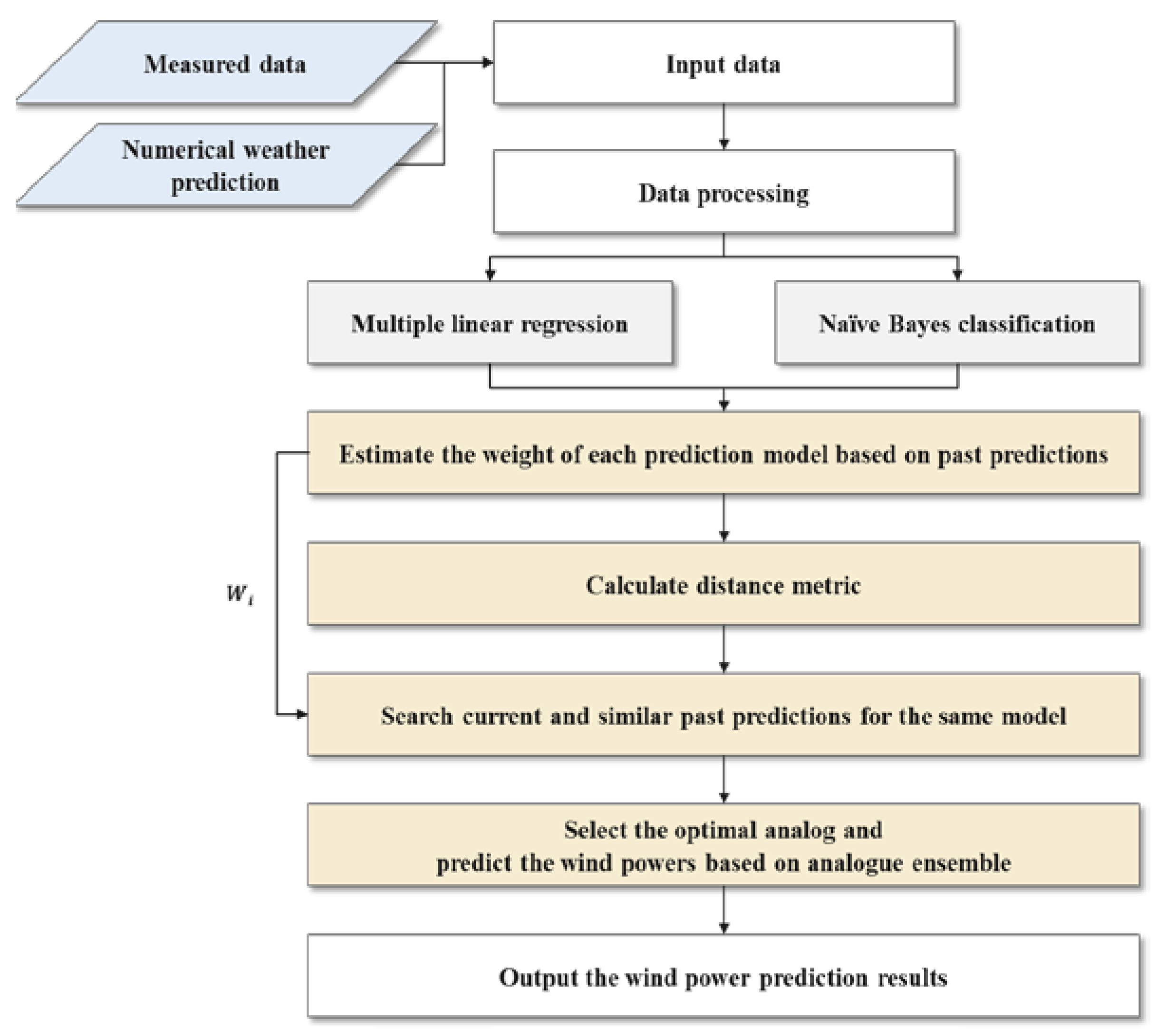
2.3. Hybrid Short-Term Prediction Model: Augmented Naïve Bayes Classifiers
3. Case Study
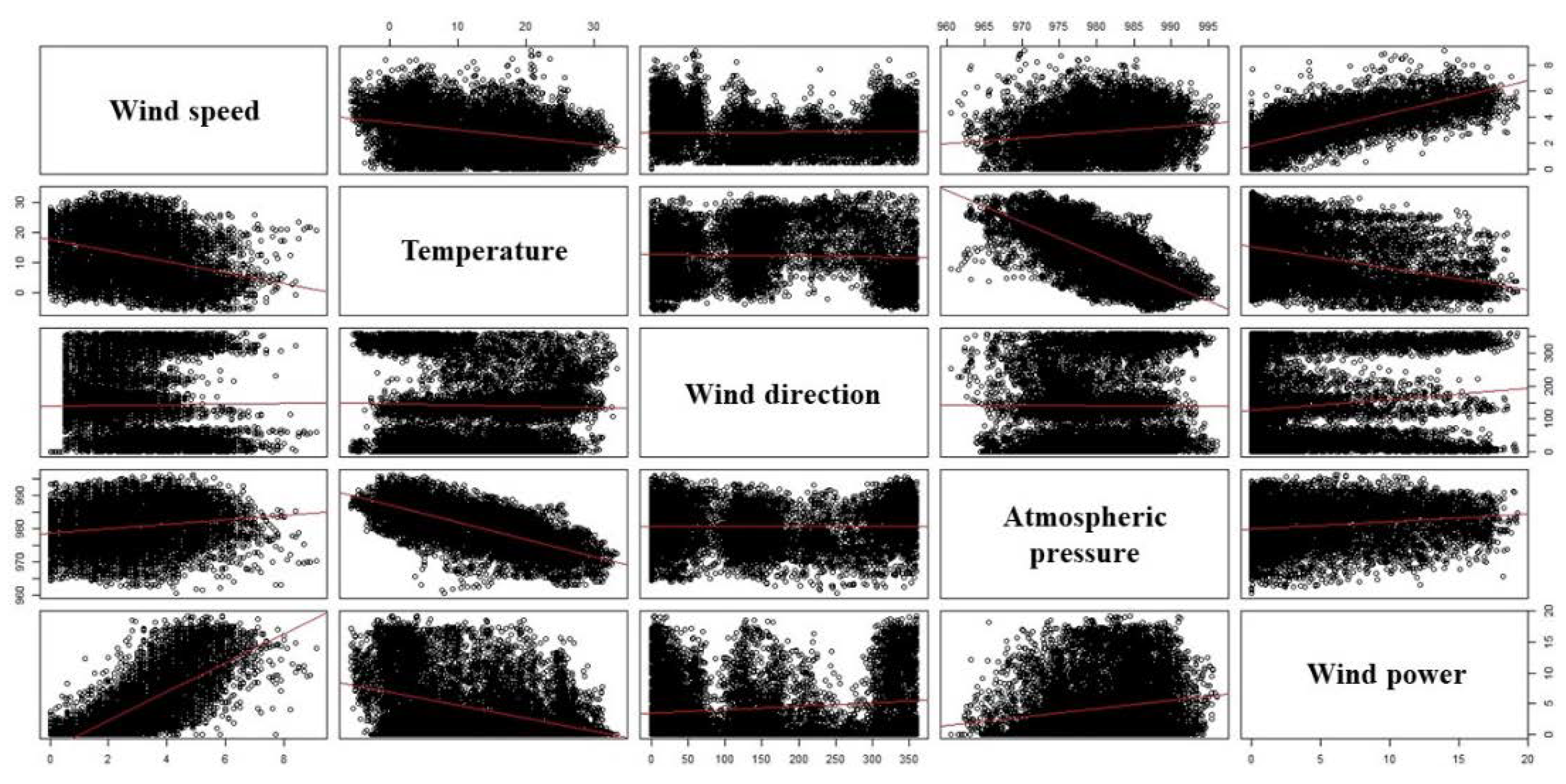
3.1. Data Processing
3.2. Short-Term Wind Power Prediction
3.3. Analysis of Short-Term Wind Power Prediction Results
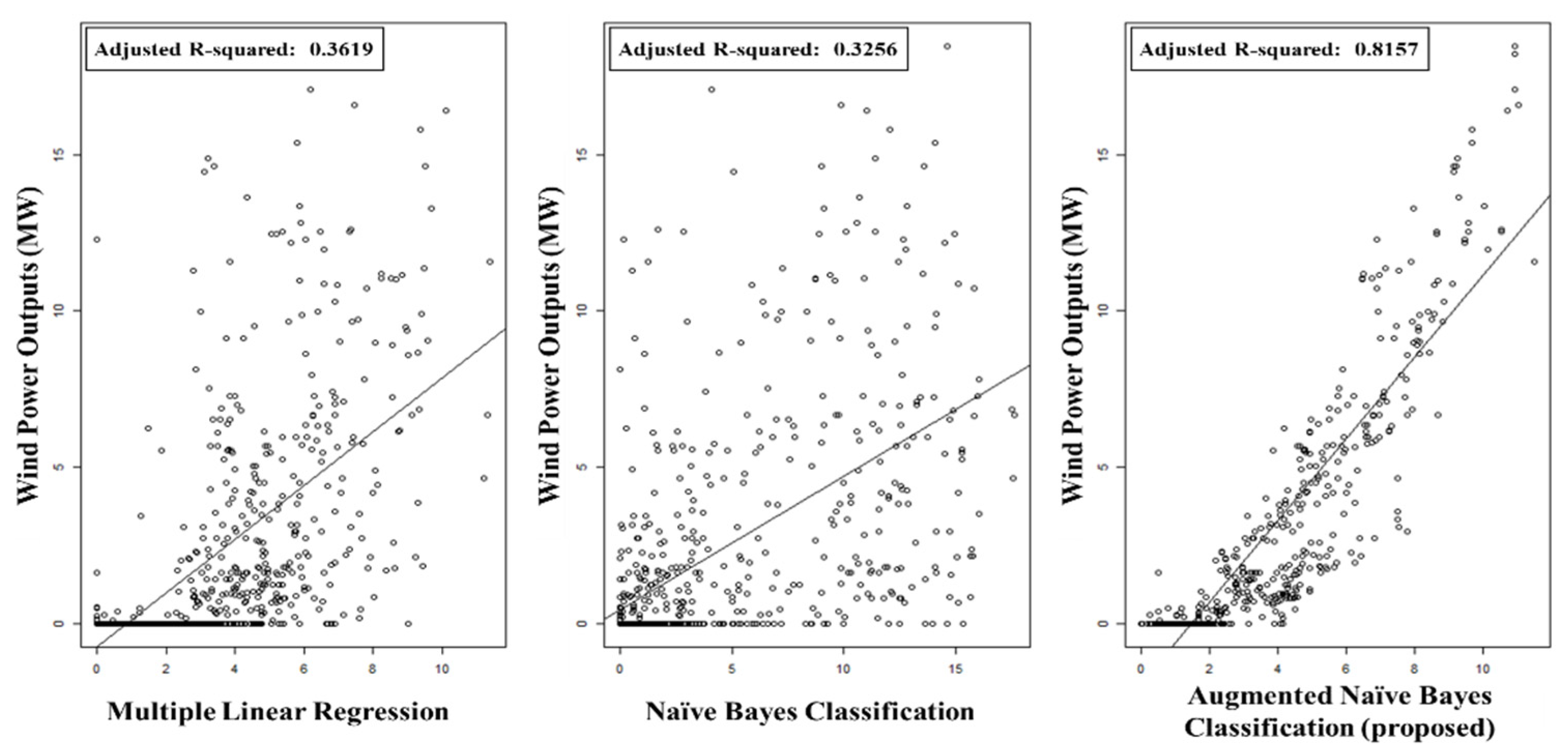
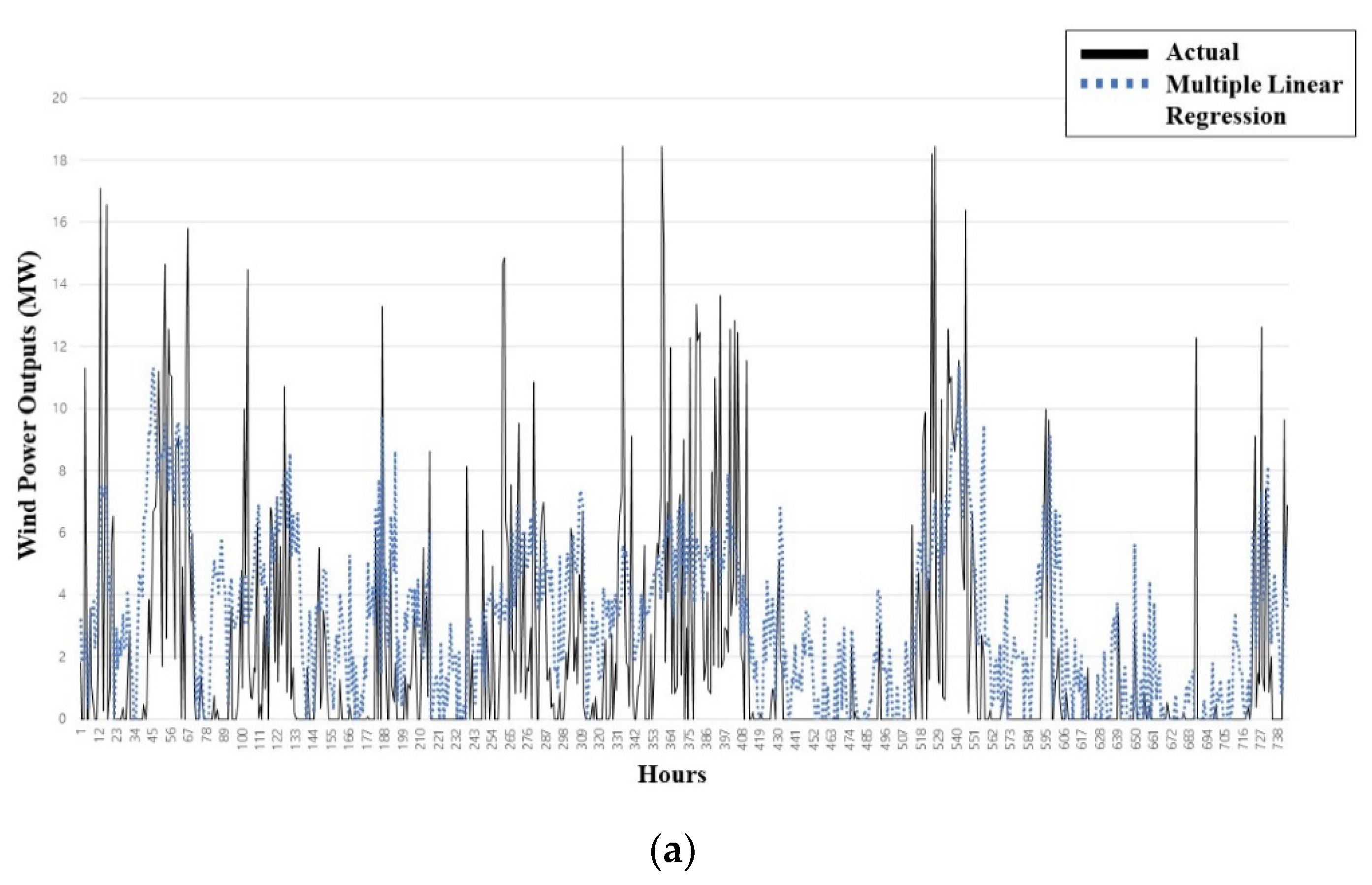
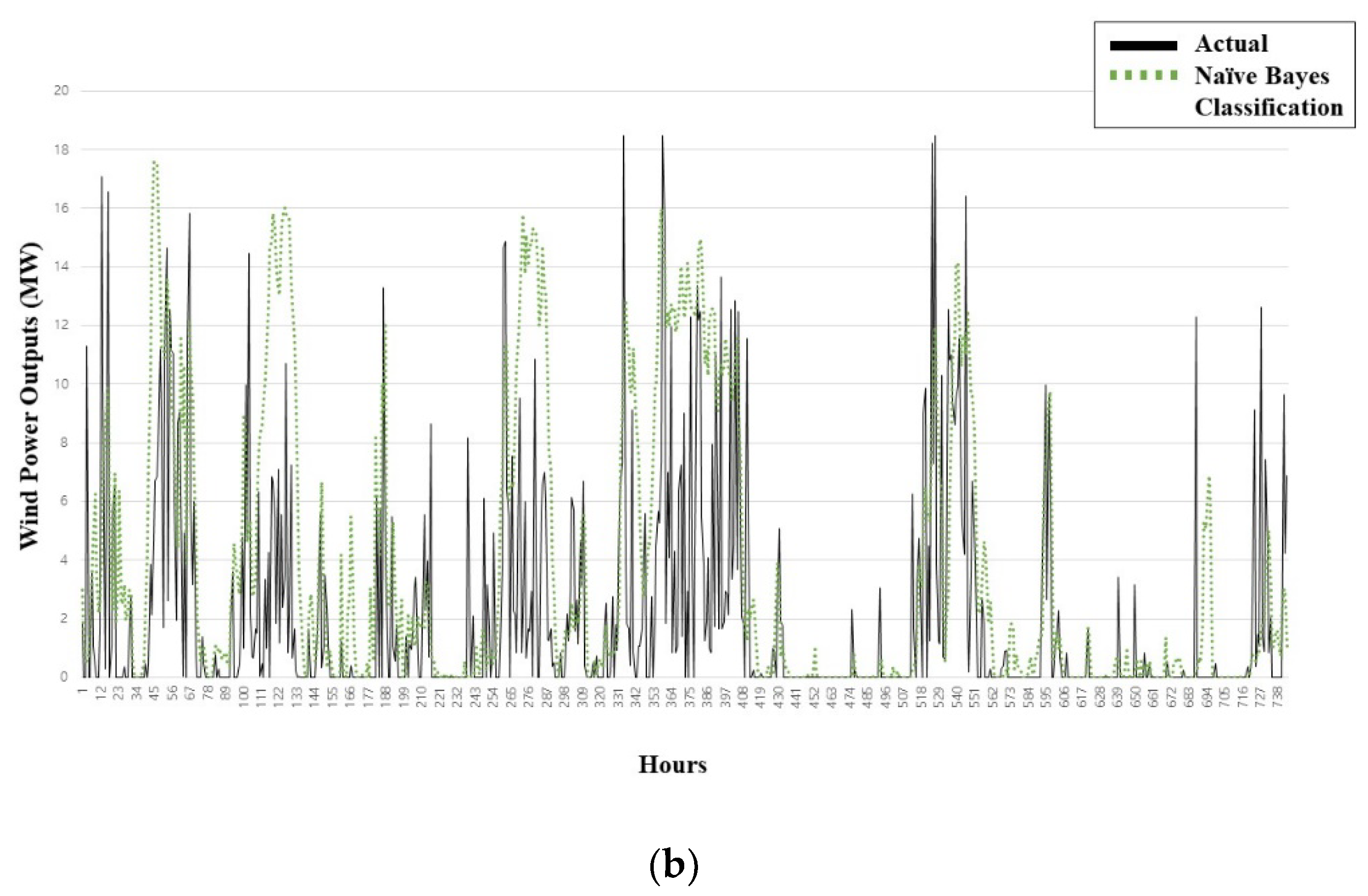
3.3.1. Single Prediction Models: MLR and Naïve Bayes Classification
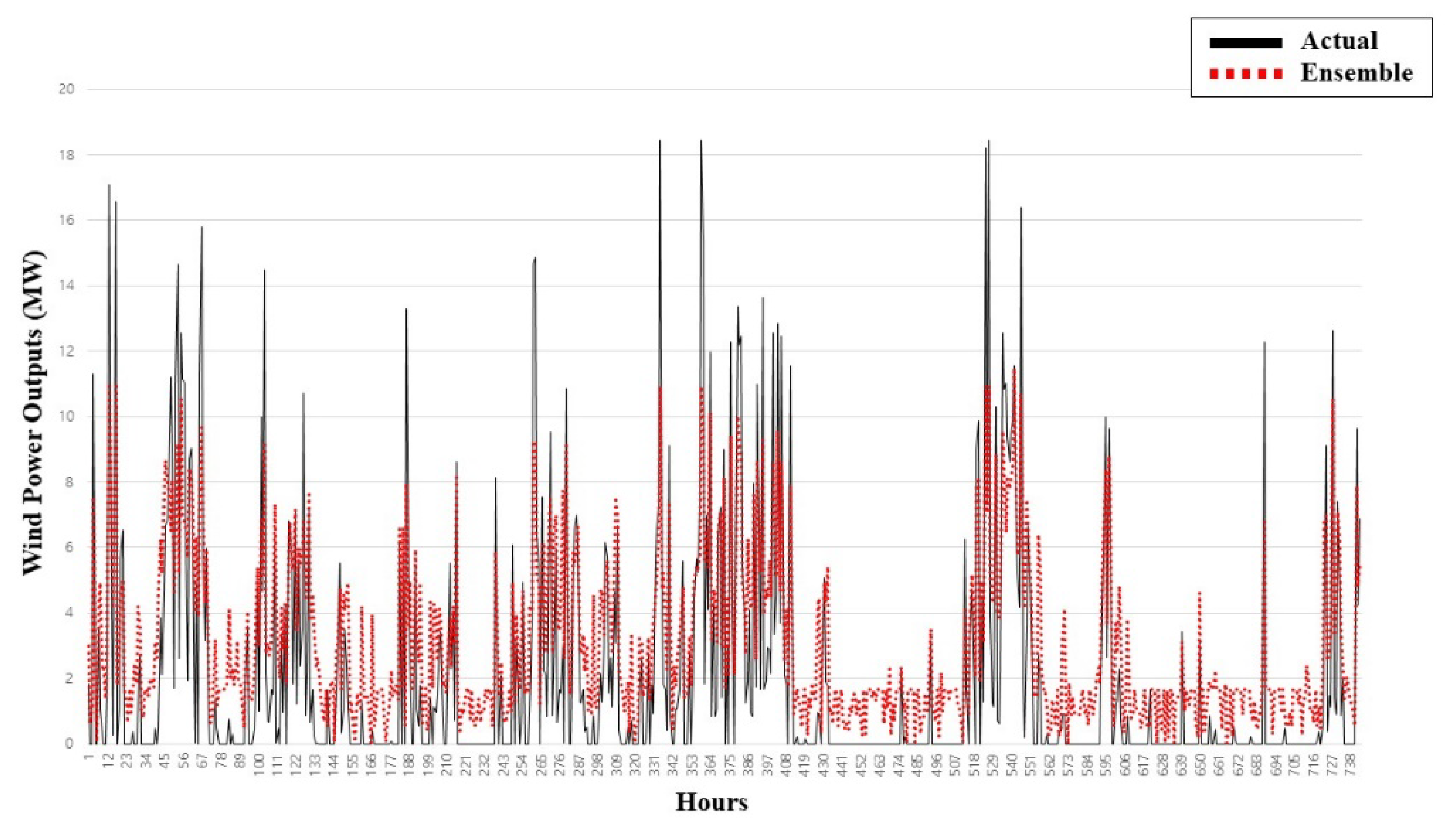
3.3.2. Hybrid Prediction Model: Augmented Naïve Bayes Classifier
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sideratos, G.; Hatziargyriou, N.D. An advanced statistical method for wind power forecasting. IEEE Trans. Power Syst. 2007, 22, 258–265. [Google Scholar] [CrossRef]
- Foley, A.M.; Leahy, P.G.; Marvuglia, A.; McKeogh, E.J. Current methods and advances in forecasting of wind power generation. Renew. Energ. 2012, 37, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Li, L.L.; Zhao, X.; Tseng, M.L.; Tan, R.R. Short-term wind power forecasting based on support vector machine with improved dragonfly algorithm. J. Clean. Prod. 2020, 242, 118447. [Google Scholar] [CrossRef]
- Han, C.; Vinel, A. Reducing forecasting error by optimally pooling wind energy generation sources through portfolio optimization. Energy 2022, 239, 122099. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Tao, R. Wind speed forecasting based on variational mode decomposition and improved echo state network. Renew. Energ. 2020, 164, 729–751. [Google Scholar] [CrossRef]
- Tian, Z.; Li, H.; Li, F. A combination forecasting model of wind speed based on decomposition. Energy Rep. 2021, 7, 1217–1233. [Google Scholar] [CrossRef]
- Colak, I.; Sagiroglu, S.; Yesilbudak, M. Data mining and wind power prediction: A literature review. Renew. Energ. 2012, 46, 241–247. [Google Scholar] [CrossRef]
- Peng, H.; Liu, F.; Yang, X. A hybrid strategy of short term wind power prediction. Renew. Energ. 2013, 50, 590–595. [Google Scholar] [CrossRef]
- Li, C.; Lin, S.; Xu, F.; Liu, D.; Liu, J. Short-term wind power prediction based on data mining technology and improved support vector machine method: A case study in Northwest China. J. Clean. Prod. 2018, 205, 909–922. [Google Scholar] [CrossRef]
- Naik, J.; Satapathy, P.; Dash, P.K. Short-term wind speed and wind power prediction using hybrid empirical mode decomposition and kernel ridge regression. Appl. Soft Comput. 2018, 70, 1167–1188. [Google Scholar] [CrossRef]
- Abba, S.I.; Hadi, S.J.; Abdullahi, J. River water modelling prediction using multi-linear regression, artificial neural network, and adaptive neuro-fuzzy inference system techniques. Procedia Comput. Sci. 2017, 120, 75–82. [Google Scholar] [CrossRef]
- Taejin, L. R-Probability Statistics; Saengneung Publisher, 2016; ISBN 9788970508832. Available online: https://booksr.co.kr/html/book/book.asp?seq=696967 (accessed on 20 May 2021).
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; Volume 15, pp. 713–714. [Google Scholar]
- Matsuura, M. Bayesian Statistical Modeling Using Stand and R; Gilbut, 2019; ISBN 9791160507324. Available online: https://www.enlib.or.kr/service/search_detail.asp?kid=ALL&id=2507803 (accessed on 20 May 2021).
- Nam, S.B.; Hur, J. A hybrid spatio-temporal forecasting of solar generating resources for grid integration. Energy 2019, 177, 503–510. [Google Scholar] [CrossRef]
- Delle Monache, L.; Nipen, T.; Liu, Y.; Roux, G.; Stull, R. Kalman filter and analog schemes to postprocess numerical weather predictions. Mon. Weather Rev. 2011, 139, 3554–3570. [Google Scholar] [CrossRef] [Green Version]
- Sperati, S.; Alessandrini, S.; Delle Monache, L. Gridded probabilistic weather forecasts with an analog ensemble. Q. J. R. Meteorol. Soc. 2017, 143, 2874–2885. [Google Scholar] [CrossRef]
- Delle Monache, L.; Eckel, F.A.; Rife, D.L.; Nagarajan, B.; Searight, K. Probabilistic weather prediction with an analog ensemble. Mon. Weather Rev. 2013, 141, 3498–3516. [Google Scholar] [CrossRef] [Green Version]
- Zhao, P.; Wang, J.; Xia, J.; Dai, Y.; Sheng, Y.; Yue, J. Performance evaluation and accuracy enhancement of a day-ahead wind power forecasting system in China. Renew. Energ. 2012, 43, 234–241. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, X. Wind power forecasting of an offshore wind turbine based on high-frequency SCADA data and deep learning neural network. Energy 2020, 201, 117693. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Data |
|---|---|
| Measured data |
|
| Numerical weather prediction |
|
| Installed capacity |
|
| Date | Hour | Wind Speed (m/s) | Temperature (℃) | Wind Direction (°) | Atmospheric Pressure (atm) | Wind Power (MW) |
|---|---|---|---|---|---|---|
| 1 January 2017 | 0 | 2.4 | 3.5 | 64 | 991.8 | 0.51063 |
| 1 January 2017 | 1 | 2.2 | 2.3 | 80.5 | 991.7 | 0.48632 |
| 1 January 2017 | 2 | 1.9 | 1.3 | 76.1 | 991.7 | 0.55926 |
| 1 January 2017 | 3 | 1.8 | 3 | 54.6 | 991.6 | 0.55926 |
| 1 January 2017 | 4 | 0.8 | 3.8 | 82 | 991.4 | 0.04863 |
| ⁞ | ⁞ | ⁞ | ⁞ | ⁞ | ⁞ | ⁞ |
| 31 May 2018 | 20 | 1.6 | 15.8 | 4.5 | 976.7 | 0.72947 |
| 31 May 2018 | 21 | 1.5 | 15.1 | 30.3 | 976.9 | 2.11547 |
| 31 May 2018 | 22 | 3.7 | 14.6 | 35.8 | 977.1 | 2.99084 |
| 31 May 2018 | 23 | 3.2 | 15 | 48.8 | 977.7 | 3.01516 |
| 31 May 2018 | 24 | 2.8 | 14.7 | 43.5 | 978 | 1.04558 |
| Method | NMAE | RMSE | |
|---|---|---|---|
| MLR | 0.1092 | 3.1334 | 0.3619 |
| Naïve Bayes classification | 0.1241 | 4.3798 | 0.3256 |
| Augmented naïve Bayes classifiers | 0.0764 | 1.9804 | 0.8157 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, G.; Hur, J. A Short-Term Power Output Forecasting Based on Augmented Naïve Bayes Classifiers for High Wind Power Penetrations. Sustainability 2021, 13, 12723. https://doi.org/10.3390/su132212723
Kim G, Hur J. A Short-Term Power Output Forecasting Based on Augmented Naïve Bayes Classifiers for High Wind Power Penetrations. Sustainability. 2021; 13(22):12723. https://doi.org/10.3390/su132212723
Chicago/Turabian StyleKim, Gyeongmin, and Jin Hur. 2021. "A Short-Term Power Output Forecasting Based on Augmented Naïve Bayes Classifiers for High Wind Power Penetrations" Sustainability 13, no. 22: 12723. https://doi.org/10.3390/su132212723
APA StyleKim, G., & Hur, J. (2021). A Short-Term Power Output Forecasting Based on Augmented Naïve Bayes Classifiers for High Wind Power Penetrations. Sustainability, 13(22), 12723. https://doi.org/10.3390/su132212723