In this section, we show how the proposed method can be used as an estimator for area changes in the early design stage. We conducted an extensive evaluation of the design and implementation of a commonly used CNN architecture for ImageNet [
42] classification, ResNet-18 [
43]. We also show an evaluation on existing hardware [
20] whle using our roofline model, and show how we can predict performance bottlenecks on a particular VGG-16 implementation.
3.1. Experimental Methodology
We start the evaluation with a review of the use of BOPS as part of the design and implementation process of a CNN accelerator. This section shows the trade-offs that are involved in the process and verifies the accuracy of the proposed model. Because PEs are directly affected by the quantization process, we focus here on the implementation of a single PE. The area of an individual PE depends on the chosen bitwidth, while the change in the amount of input and output features changes both the required number of PEs and size of the accumulator. In order to verify our model, we implemented a weight stationary CNN accelerator, which reads the input feature for each set of read weights and can calculate
n input features and
m output features in parallel, as depicted in
Figure 10. For simplicity, we choose an equal number of input and output features. In this architecture, all of the input features are routed to each of the
m blocks of the PEs, each calculating a single output feature.
The implementation was done for an ASIC while using the TSMC 28 nm technology library, an 800 MHz system clock, and in the nominal corner of
V. We used the value of
for the power analysis, input activity factor, and sequential activity factor.
Table 5 lists the tool versions.
For brevity, we only present the results of experiments at the 800-MHz clock frequency. We performed additional experiments at 600 MHz and 400 MHz. Because the main effect of changing the frequency is reduced power usage and not the area of the cells (the same cells that work for 800 MHz will work at 600 MHz, but not the other way around), we do not show these results. Lowering the frequency of the design can help to avoid the memory bound, but incurs the penalty of longer runtime, as shown in
Section 2.5.
Our results show a high correlation between the design area and BOPS. The choice of an all-to-all topology that is shown in
Figure 10 was made because of an intuitive understanding of how the accelerator calculates the network outputs. However, this choice has a greater impact on the layout’s routing complexity, with various alternatives incuding broadcast or systolic topologies [
16]. For example, a systolic topology, which is a popular choice for high-end NN accelerators [
14], eases the routing complexity by using a mesh architecture. Although it reduces the routing effort and improves the flexibility of the input/output feature count, it requires more complex control for the data movement to the PEs.
In order to verify the applicability of BOPS to different topologies, we also implemented a systolic array that is shown in
Figure 11, where each PE is connected to four neighbors with the ability to bypass any input to any output without calculations. The input feature accumulator is located at the input of the PE. This topology generates natural
PEs, but. with proper control, it is possible to create flexible accelerators.
In the systolic design, we generated three square arrays of
,
, and
PEs, with
. The systolic array area was found to be in linear relation with BOPS, with the goodness of fit
, as shown in
Figure 12.
3.2. System-Level Design Methodology
In this section, we analyze the acceleration of ResNet-18 while using the proposed metrics and show the workflow for the early estimation of the hardware cost when designing an accelerator. We start the discussion by targeting an ASIC that runs at 800 MHz, with
PEs and the same
GHz DDR-4 memory with a 64-bit data bus, as used in
Section 2.5. The impact of changing these constraints is discussed at the end of the section. For the first layer, we replace the
convolution with three
convolutions, as proposed by He et al. [
44]. This allows for us to simplify the analysis by employing universal
kernel PEs for all layers.
We start the design process by comparing different alternatives while using the new proposed OPS-based-roofline analysis, since it helps to explore the design trade-offs between the multiple solutions. We calculate the amount of OPS/s provided by
PEs at 800 MHz and the requirements of each layer. In order to acquire the roofline, we need to calculate the OPS/bit, which depend on the quantization level. For ResNet-18, the current state-of-the-art [
45] achieves 69.56% top-1 accuracy on ImageNet for 4-bit weights and activations, which is only 0.34% less than the 32-bit floating-point baseline (69.9%). Thus, we decided to focus on 2-, 3-, and 4-bit quantization both for weights and activations, which can achieve 65.17%, 68.66%, and 69.56% top-1 accuracy, correspondingly.
For a given bitwidth, the OPS/bit is calculated by dividing the total number of operations by the total number of bits transferred over the memory bus, consisting of reading weights and input activations and writing output activations.
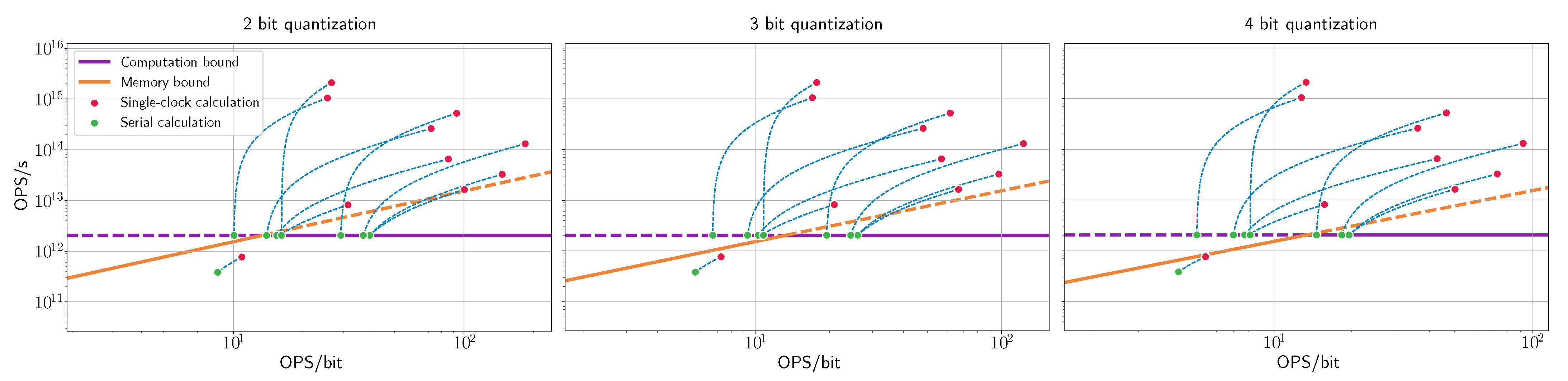
Figure 13 presents the OPS-based roofline for each quantization bitwidth. Note that, for each layer, we provided two points: the red dots are the performance required by the layer, and the green dots are the equivalent performance while using partial-sum computation.
Figure 13 indicates that this accelerator is severely limited by both computational resources and a lack of bandwidth. The system is computationally bounded, which could be inferred from the fact that it does not have enough PEs to calculate all of the features simultaneously. Nevertheless, the system is also memory-bound for any quantization level, which means that adding more PE resources would not fully solve the problem. It is crucial to make this observation at the early stages of the design: it means that micro-architecture changes would not be sufficient to obtain optimal performance.
One possible solution, as mentioned in
Section 2.5, is to divide the channels of the input and output feature maps into smaller groups, and use more than one clock cycle in order to calculate each pixel. In this way, the effective amount of the OPS/s required for the layer is reduced. When the number of feature maps is divisible by the number of available PEs, the layer will fully utilize the computational resources, which is the case for every layer except the first one. However, reducing the number of PEs also reduces the data efficiency and, thus, the OPS/bit also decreases, shifting the points to the left on the roofline plot.
Thus, some layers still require more bandwidth than the memory can supply. In particular, in the case of 4-bit quantization, most of the layers are memory bounded. The only option that properly utilizes the hardware is 2-bit quantization, for which all of the layers except one are within the accelerator’s memory bound. If the accuracy for 2-bit quantized network is insufficient and finer quantization is required, then it is possible to reallocate some of the area used for the PEs to be used for additional local SRAM. By caching the activations and output results for the next layer, we can reduce the required bandwidth from external memory at the expense of performance (i.e., increasing total inference time). Reducing the PE count lowers the compute bound on the roofline, but, at the same time, the use of SRAM increases operation density (i.e., moves the green dots in
Figure 13 to the right), possibly within hardware capabilities. Alternative solutions for the memory-bound problem include changing the CNN architecture (for example, using smaller amount of wide layers [
46]), or adding a data compression scheme on the way to and from the memory [
40,
41,
47].
At this point, BOPS can be used in order to estimate the power and area of each alternative for implementing the the accelerator while using the PE micro-design. In addition, other trade-offs can be considered, such as the influence of modifying some parameters that were fixed at the beginning: lowering the ASIC frequency will decrease the computational bound, which reduces the cost and only hurts the performance if the network is not memory bounded. An equivalent alternative is to decrease the number of PEs. Both of the procedures will reduce the power consumption of the accelerator, as well the computational performance. The system architect may also consider changing the parameters of the algorithm, e.g., change the feature sizes, use different quantization for the weights and for the activations, include pruning, etc.
It is also possible to reverse the design order: start with a BOPS estimate of the number of PEs that can fit into a given area, and then calculate the ASIC frequency and memory bandwidth that would allow for full utilization of the accelerator. This can be especially useful if the designer has a specific area or power goal.
To summarize, it is extremely important, from an architectural point of view, to be able to predict in the early stages of the design whether the proposed (micro)architecture is going to meet the project targets. At the project exploration stage, the system architect can choose from multiple alternatives in order to make the right trade-offs (or even negotiate to change the product definition and requirements). Introducing such alternatives later may be very hard or even impossible.
3.3. Evaluation of Eyeriss Architecture
In this section, we demonstrate the evaluation of existing CNN hardware architecture—the Eyeris [
20] implementation of VGG-16—while using our modified roofline analysis. We visualized the required performance (compute and memory bandwidth) of each layer in
Figure 14. As earlier, red dots denote the required performance, the purple horizontal line shows the available compute resource, and the diagonal orange line is the memory bandwidth bound. The required performance is obviously compute bounded since PEs are not enough to calculate all of the layers; the calculation is performed in cycles. The required performance when calculating in cycles is plotted in green dots. If we compare the Eyeriss roofline analysis to our architecture from
Section 3, we can see a difference in the movement of the required performance. This phenomenon is the result of the different hardware architectural structures. Our example utilized weight stationary architecture, which has an overhead when calculating in cycles: the input features are read multiple times for each set of weights. Eyeriss architecture uses a row stationary approach and it has enough local memory to re-use all of the weights and the activations before reading additional data. It allows for the overhead of re-reading the activations for each set of weights to be avoided. Because the roofline analysis shows asymptotical performance, data compression and data-drop techniques [
20] that may help reduce memory bandwidth and compute requirements are excluded from the roofline analysis. While these approaches can change the hardware requirements, it is infeasible to accurately estimate their impact on the performance, due to their dependency on the data distribution.
Our analysis shows that VGG-16 on Eyeriss hardware has some memory bounded layers. While two of these layers are close to the memory bound and can possibly get inside the memory bound of the compression scheme [
20], the first and the three last layers suffer from poor performance compared to other layers. To evaluate the slowdown, in
Table 6 we show the real performance that is based on the roofline model as well as the amount of time that is required for calculations (in the absence of a memory bound). Our prediction of the performance is similar to the performance results that are shown by Chen et al. [
20].
In the case of Eyeriss, adding more local SRAM cannot resolve the memory bound issue. Eyeriss already re-uses the weights and activations (i.e., no data are read multiple times), so the only option is to increase the memory speed. To conclude, the roofline analysis results should be a tool for the architect to use during the planning process. Performance degradation in some layers may be tolerable, as long as we have an appropriate metric to accurately evaluate the impact on the entire network. The main benefit of using the roofline analysis is that we can predict the areas where the network architecture is not optimal and where we may need to focus on the design. It is up to the architect of the hardware to make these decisions.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}