1. Introduction
The Non-Technical Losses (NTL) represent a challenge, as electricity theft is identified in both conventional meters and smart metering systems and buildings [
1]. They cause significant financial losses that threaten the security of supply and lead to collective burden as NTL are included in the utility companies’ tariff and paid by all consumers in countries such as India, China, Brazil [
2], Tunisia [
3], Uruguay, etc. Furthermore, analyses of the smart meters data of a grid operator in the Czech Republic are performed to identify suspicious behavior [
4]. Hence, resilient and performant investigations with ML algorithms or energy theft detection systems and on-site inspections are required to discourage and penalize dishonest behaviors [
5].
Various approaches have been studied to identify frauds in electricity consumption. Most of them rely on supervised ML algorithms, namely classification, or combining clustering with classification. In addition, anomaly detection is performed as most of the time, the target or flag is not available. Some famous researchers in ML, namely Andrew Ng, state that anomaly detection is actually a better approach for identifying frauds, as there are fewer similarities among them that make the training impossible [
6]. Furthermore, anomaly detection is indicated when the expected number of positive examples is small, as most of the consumers are normal. The large number of negative examples allows us to fit the Gaussian parameters and estimate the probability. Smart metering systems lead to different types of anomalies that are not usual for conventional meters. Therefore, they generate many types of anomalies that makes it hard for any algorithm to learn, as future anomalies may look less similar.
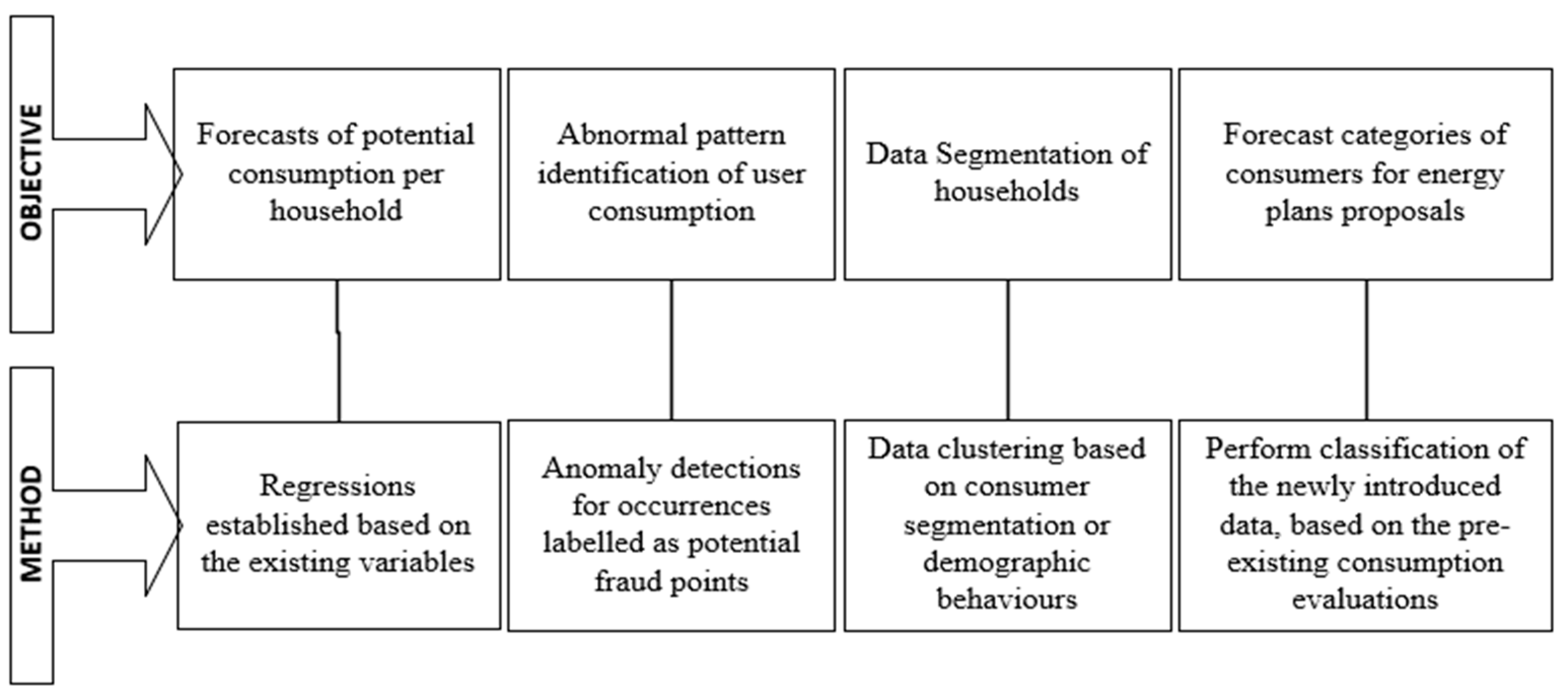
Thus, we identified at least two major challenges regarding fraud detection in electricity consumption. The main challenge in developing performant models for electricity fraud detection is to reduce number of false positives, meaning the consumers falsely identified as suspicious by the algorithm, and the costs associated with on-site investigations while maximizing the true positive or the real suspicious consumers. Another challenge is created by consumers that continuously steal some of the electricity they consume, as it is not an obvious anomaly, especially when the smart meter data are unlabeled.
In the proposed two-stage method that combines unsupervised and supervised ML algorithms, the first stage aims to label the data, whereas the second stage, classification with Two-Class Boosted Decision Tree and Fisher Linear Discriminant for feature selection, brings an additional validation regarding suspicious consumers initially detected by SR-CNN and an anomaly trained model based on martingales for determining variations in time-series data streams. Thus, the hybrid method both label the data and classify the consumers. Compared with the method without classification, the hybrid method increases the accuracy of the model by providing more confidence based on metrics. For example, in case anomaly detection identifies a suspicious consumer (labeled with 1), and the classification methods also classify it as 1, there is clearer evidence that the consumption is fraudulent, and the consumer should be verified onsite. Otherwise, if anomaly detection indicates 1 and classification indicates 0, then the suspicion is not confirmed, and the utility company may choose not to investigate further.
The benefits of classification as a second stage include the following: validation of anomaly detection, bringing more confidence, reducing the costs of onsite investigation, and training the utility company’s employees to conduct such investigations. In our hybrid method, the classification model is quite helpful, providing consistent metrics such as an accuracy of 90%, precision of 0.875, and F1 score of 0.894.
The results of the two unsupervised methods, namely SR-CNN and an anomaly trained model based on martingales for determining variations in time-series data streams, are compared, indicating the best combination of a hybrid approach. Therefore, in comparison with anomaly detection only, the proposed method including a classifier adds more value and increases the confidence of analyses on smart metering consumption data.
This paper is structured in six sections. The second section provides a literature survey of the most recent studies and research; the third section describes the data transformation methodology proposed for electricity anomaly detection in a smart grid environment. It consists of the workflow design and instrumentation stage. The fourth and fifth sections are dedicated to the implementation of the algorithms and simulations with real consumption, using large datasets that are available courtesy of the Commission of Energy Regulation (CER) and Irish Social Science Data Archive (ISSDA). Conclusions are drawn in the final section.
2. Literature Survey
A robust multitask feature extracting fraud detector and a deep learning model (combining a de-noising autoencoder [
7] with a deep Siamese network and a day discriminant network) are proposed to manage high-dimensional data and identify consumption patterns [
2]. The model is trained, using half-hourly smart meter records of over five thousand Irish consumers for 535 days, with significant results weaving the advantages of supervised and unsupervised ML algorithms. It evaluates the false positive rate and recall with a semi-supervised approach.
Another study that handles the Irish consumption dataset uses a pattern-based anomaly detector, combining clustering and classification techniques that improve the predictability of normal and suspicions consumers identifying non-malicious changes in consumers profile by investigating a small sample of data [
8].
Classification algorithms can be useful to detect suspicious consumers [
9]; however, most of the time, labeled data are not always available, and synthetical malicious data are not efficient in detecting issues in consumption data [
10]. Using an Artificial Neural Network (ANN), the current consumption is repeatedly compared with the forecast or typical profile, and if the difference is over a threshold, a suspicion is raised. Furthermore, recent works using deep learning models and dynamic mode decomposition techniques for probabilistic and short-term load forecasting are proposed in [
11,
12]. A forecasting method based on gradient boosting neural networks is proposed for network traffic classification that can be adapted for electricity consumption forecast as input for fraud detection [
13].
The efficiency of the detection methods (Support Vector Machine (SVM), Random Forest (RF), which proved to be the best in this study, and ANN) are assessed considering the fines amount and on-site inspection costs. This approach is formulated as a versatile pipeline method and validated with real data from Uruguayan consumers and increases the profit and assists with planning the budget for the NTL of the utility company [
14].
Six steps are implemented for anomaly detection in smart metering data [
4]. First, data segmentation is performed as creating datasets per day and per smart meter. Then, the association rule mining is applied to identify frequent events instances with an A Priori algorithm. Third, the set of most frequent events is selected from more than one data segment, whereas less frequent events are assimilated with suspicions. Fourth, additional contextual data are augmented to the previous step. Fifth, clustering with clustering silhouette thresholding is performed to detect anomalous behavior. Sixth, the less frequent events are analyzed and clustered to verify if they fit into the existing clusters.
Different deep neural networks architectures are proposed in [
15,
16] computing the mean per-class error to assess the performance on multiple datasets and identify the consumption anomalies. Deep multilayer perceptron, fully convolutional networks, multi-convolutional neural networks, and residual networks are evaluated together with other classification specific algorithms for time-series [
17] such as Bag-Of-SFA-Symbols in Vector Space (BOSSVS).
The XMR charts method is applied to time series to detect fraud [
18] in a set with consumption data recorded between 2005 and 2012 of 106 Serbian customers. In 93.4% of the time series with suspicions, the XMR charts successfully indicate an abnormal consumption pattern. It is essential to analyze regular readings; otherwise, this approach affects the Moving Ranges (MR) component of the charts that is the difference of the two consecutive X values.
Linear programming is applied to reduce the NTL and false positives by considering the impact of technical losses in smart grids. In this sense, two novel anomaly detection schemes for smart metering systems and two metrics, loss factor and error term, are suggested to calculate technical losses. Suspicious consumers or malfunctions in smart meters can be identified even if the NTL is intermittent [
19]. This approach considers the equilibrium of quantities at the substation level, meaning that the sum of energies that exits the substation plus technical losses should be equal with the energies that entered. Otherwise, theft and/or malfunction of the smart metering system occur.
An electricity theft detection method using interpolation for missing data, empirical mode decomposition, and K-Nearest Neighbors (K-NN) that is adequate for a time series is proposed in [
20] using a labeled dataset provided by State Grid Corporation of China that consists of over 42,000 of daily time series that stretch over 1035 days. Time-series feature extraction is implemented underlying the most significant features for the classification process. Outliers and unbalanced data are adjusted with a simple approach considering the mean and standard deviation, respectively the Synthetic Minority Oversampling Technique (SMOTE), Adaptive Synthetic (ADASYN) sampling approach, etc. Some other approaches are emerging with the progress of IoT and fog technologies [
21,
22], regularly analyzing data steaming. The idea is to catch the irregularities in consumption and perform on-site verifications in a short time interval, compared with the classical way of analyzing larger datasets and performing more analyses that could bring a serious time gap between the problem identification and inspection.
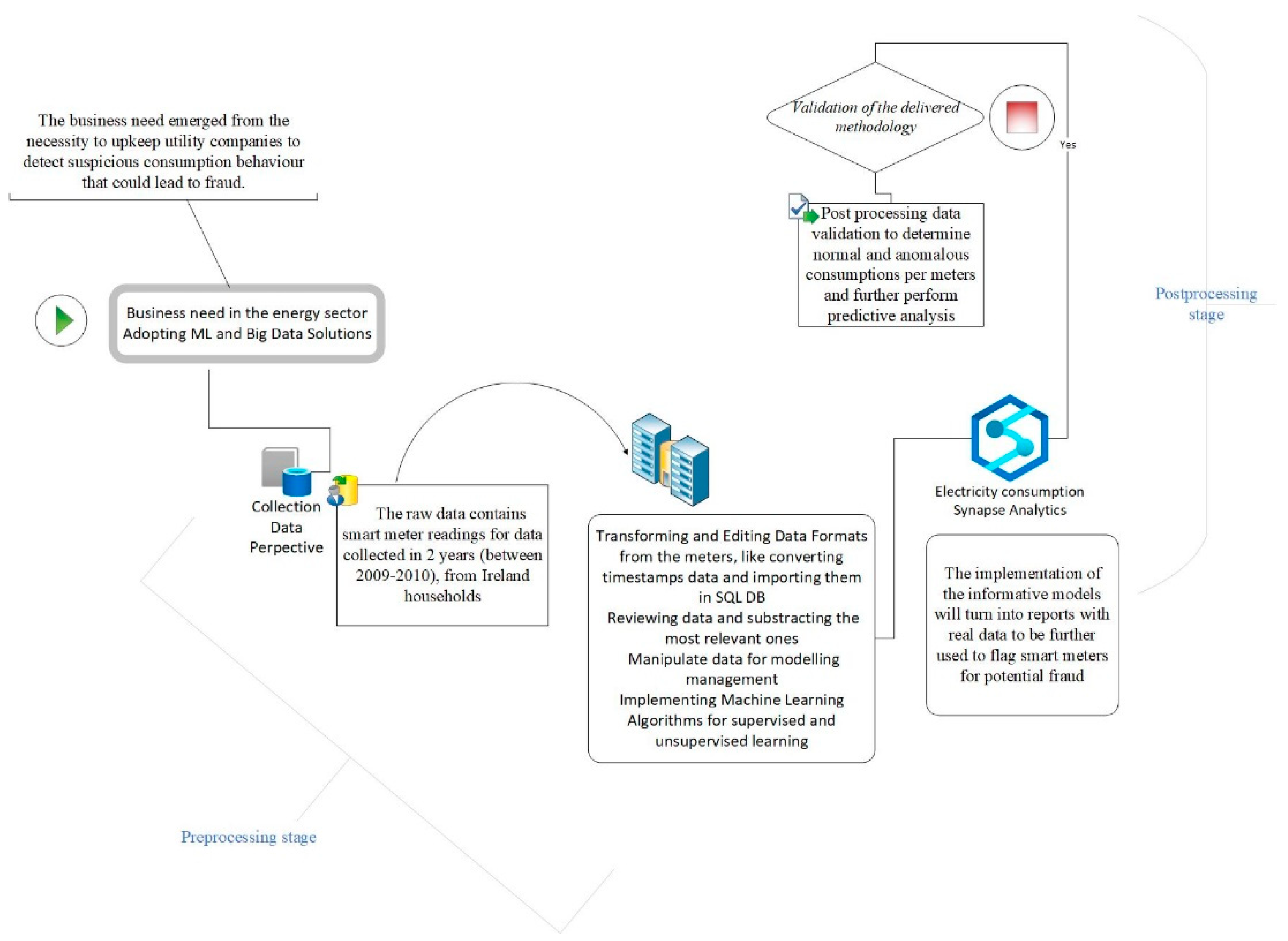
4. Implementation of the Proposed Approach
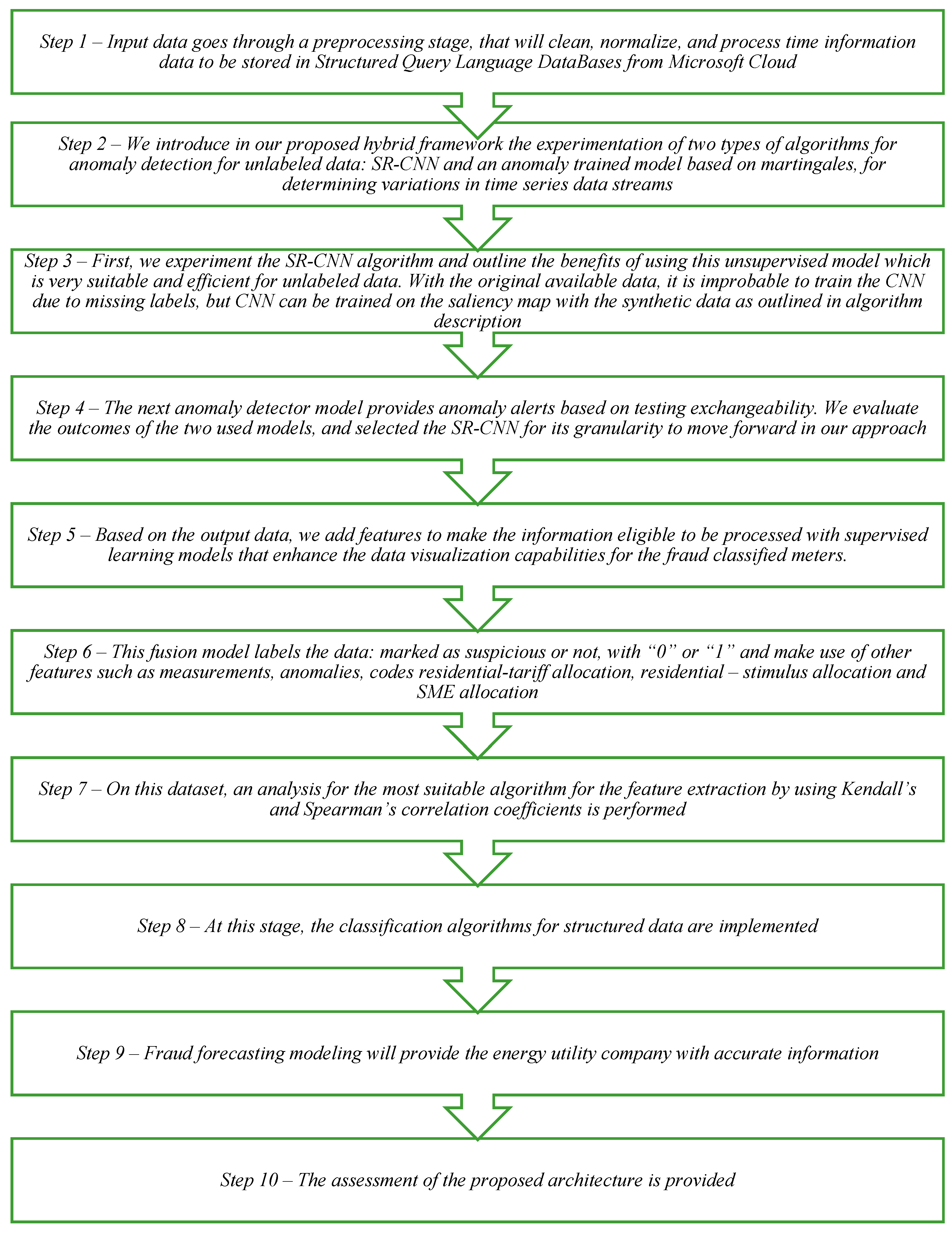
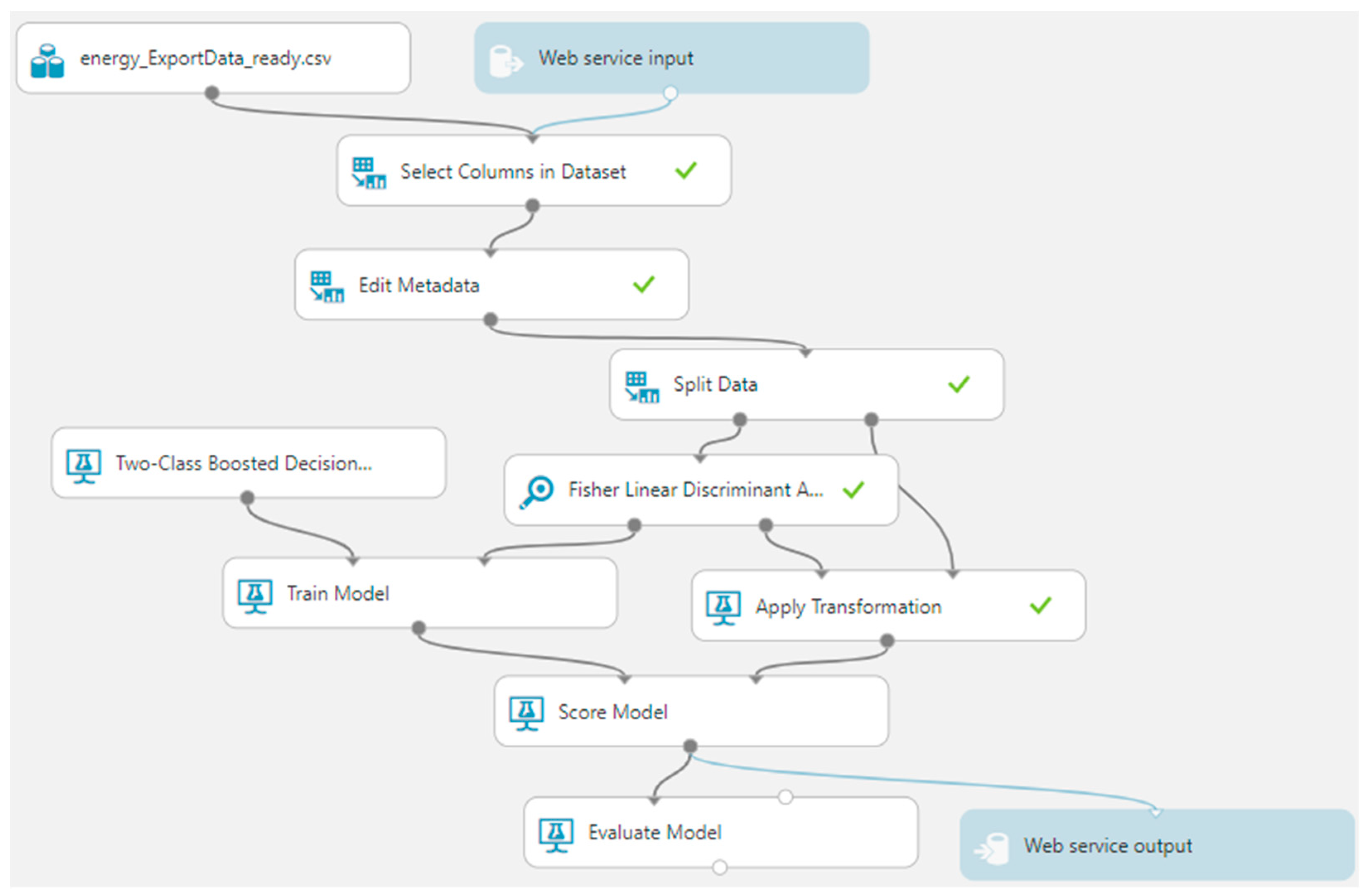
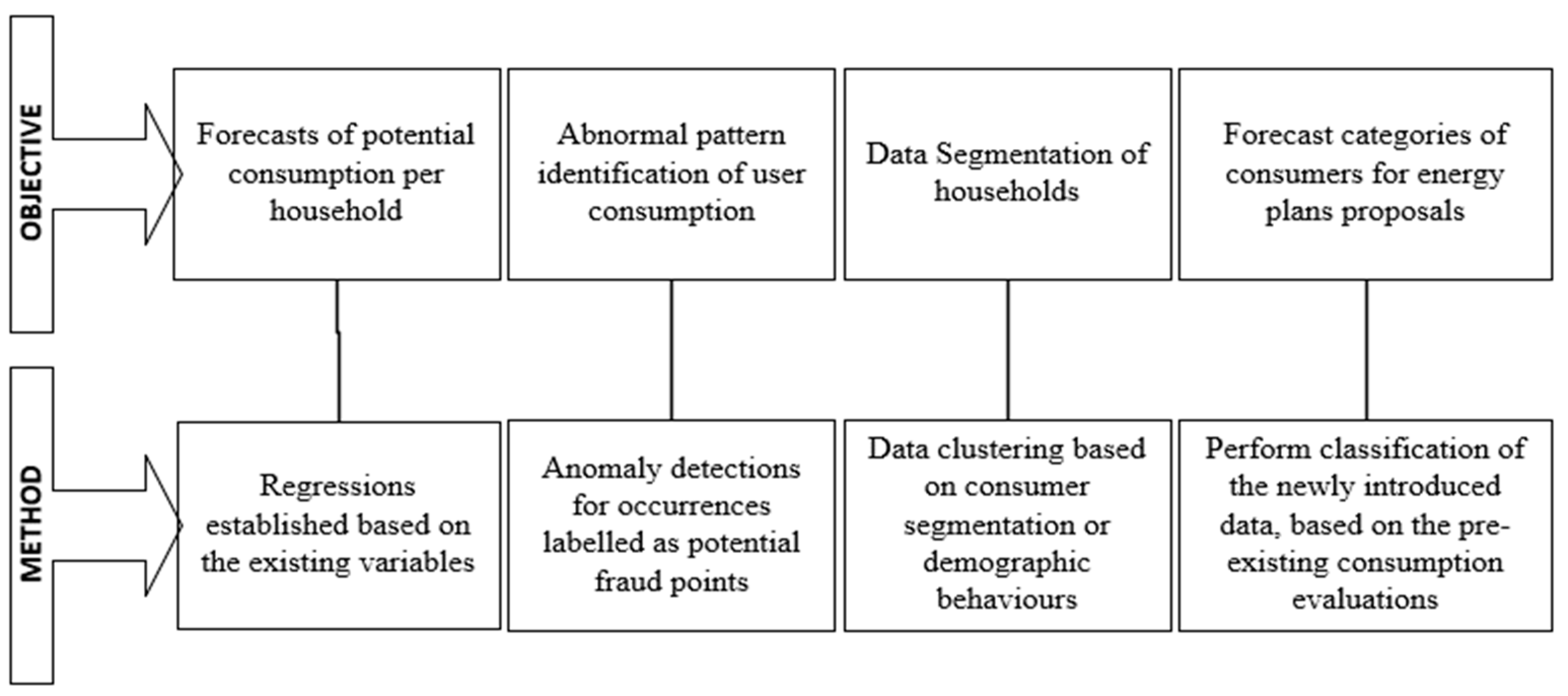
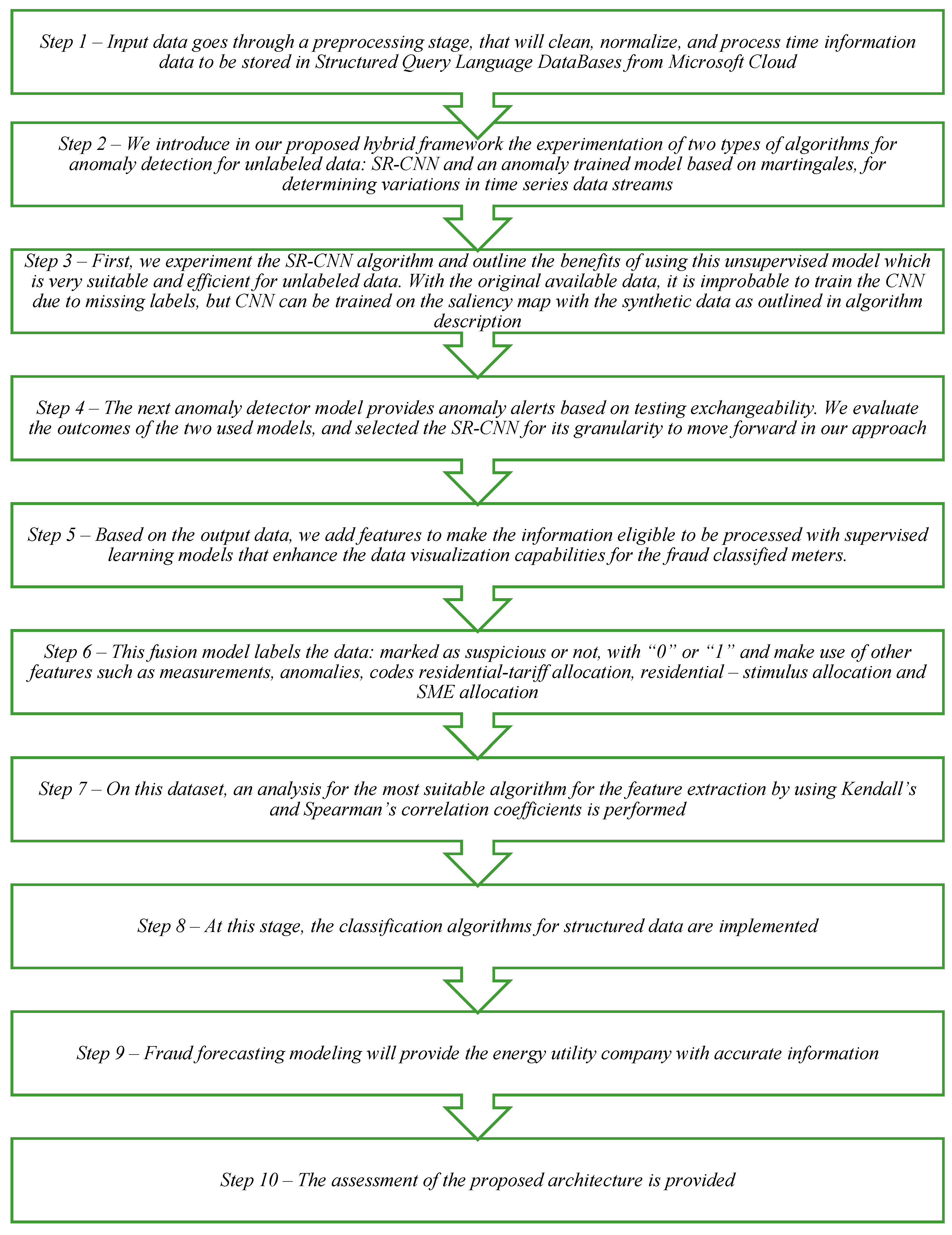
We propose a combined architecture of different ML models that covers the challenge of handling the generalized information from unlabeled raw datasets for anomalous detections for electricity consumption. We propose a hybrid framework that handles the initial unlabeled data with unsupervised ML models and then the application of supervised algorithms for fraud classification with the intention of obtaining predictive analysis. This proposed framework methodology offers easy data ingestion and transformation workflows and implements the most context-suitable ML models, within the following sequential steps (as in
Figure 5).
The novelty of our contribution to the above framework comes from the hybrid approach in two stages. First, we identify the anomalies in an unlabeled time series with the SR-CNN algorithm, and then, we label it as suspicious or not, by establishing a threshold for labeling, when more than 15% of the data points in the time series are detected as anomalies. Two unsupervised ML methods are used for detecting the anomalies in the time series, and their performance is then compared. In the second stage, we use the now labeled time series and associate their tag with the contract offers the consumers have. Since now we have labeled data, supervised ML can be used for training a model that is able to detect the likelihood of someone committing a fraud based on the different parameters of their contract. For this task, we are using a two-class boosted decision tree. The methodology logic and implementation steps are detailed in this section. Considering the targeted multitude of set points
with the distributed features
, the anomaly detection is the process of identifying data points that are deviating from the normal pattern in the dataset. The training models
will classify the points that are normal or anomalies, based on a computed probability and an established limit, such as if
, the anomaly is outlined, else, if
, a normal flag will be provided [
6]. For the anomaly detection methodology, there are several ML models for different classified groups such as nearest-neighbor based algorithms, local correlation integral, K-NN, influenced outliers, connectivity-based outlier factor, and local outlier factor; classification-based techniques include Bayesian Networks, ANN, Decision Tree; statistic-based techniques include parametric and non-parametric models; and clustering-based algorithms include local density cluster-based outlier factor and cluster-based local outlier factor. The approaches for anomaly detection can consist of ANN (Autoencoder), Principal Component Analysis, Multivariate Gaussian Distribution, One-Class SVM, or Neural Nets [
28].
By monitoring the electricity consumption half-hourly, the anomaly detection method will be applied for an univariant time-series model. Therefore, we utilize as a deep learning model the Spectral Residual-SR model from the visual saliency detection field. The Convolutional Neural Network (CNN) model is due to learn a discriminative rule on the saliency map, train through automatically generated anomalies, arbitrarily choose points in the time series, and compute the injection value to substitute the original point. The injection value will be calculated as:
This model has a high predictability for the electricity consumption evaluation [
29].
The principles of the SR-CNN unsupervised algorithm are the following: (1) Fourier Transform (F) to acquire the amplitude spectrum; (2) Computation of SR; and (3) Transposed F that metamorphosizes the grouping to the spatial dimension [
30]. The mathematical model behind a sequence
x, which is an input sequence with the shape n × 1, consists of the following:
—amplitude spectrum of a sequence x;
—corresponding phase spectrum of a sequence x;
—log representation of ;
—average spectrum of , which can be approximated by convoluting the input sequence by -an n × n matrix defined as ;
—spectral residual;
—saliency map.
In parallel, we also experiment with the Machine Learning Studio trained model for anomaly detection and compared the outcomes. This model covers the challenges of obtaining fake anomalies from time-series data with changing data values. The proposed model adds to two mechanisms for evaluating fluctuations from time-series trends: (1) assessing the magnitude of variations (if, for example, the consumption for a meter looks stable for a given timeframe, and after a while, a significant decrease is spotted), and (2) computing the timings and directions of the variations.
The configuration of this model implies connections with the provided time-series data. There is the possibility to transform the data with the Structured Query Language (SQL) Transformation Module or perform a conversion with the Execute R. Afterwards, the anomaly detection model can be adjusted with the selection of the martingale function, which is used to manage the reactivity of the anomaly detector, the strangeness function (which can be RangePercentile, SlowPosTrend, and SlowNegTrend), the strangeness values to establish the history window, and the alert threshold for anomaly scoring, which measures the probability of encountering the time-series anomalies. The mathematical approach for martingales in this model comes from [
31]. Martingales are classes of arbitrary variables
, with weighable functions
, where
is a constant and
for a martingale
. When defining a class of martingales, the above-mentioned power martingale is indexed by
, where
are arbitrary martingales with an initial value 1:
and
can be eliminated with the usage of the following:
The benefit of this approach is the usage of one single algorithm and the ability to be applied on large amounts of data. The challenge that remains open regarding this model rests upon the establishment of a baseline martingale before the distribution transformation. In addition, there is not an evaluation of the errors around the change identification, and there is not a confidence measurement for the occurred changes. For comparing benchmarks, we experiment with the SR-CNN algorithm on the same data sample to be able to assess the anomaly detections sensitivity per meter. Thus, we do the same by using the trained model with a martingales setup. By comparison, we obtain the accuracy statics as shown in
Figure 6.
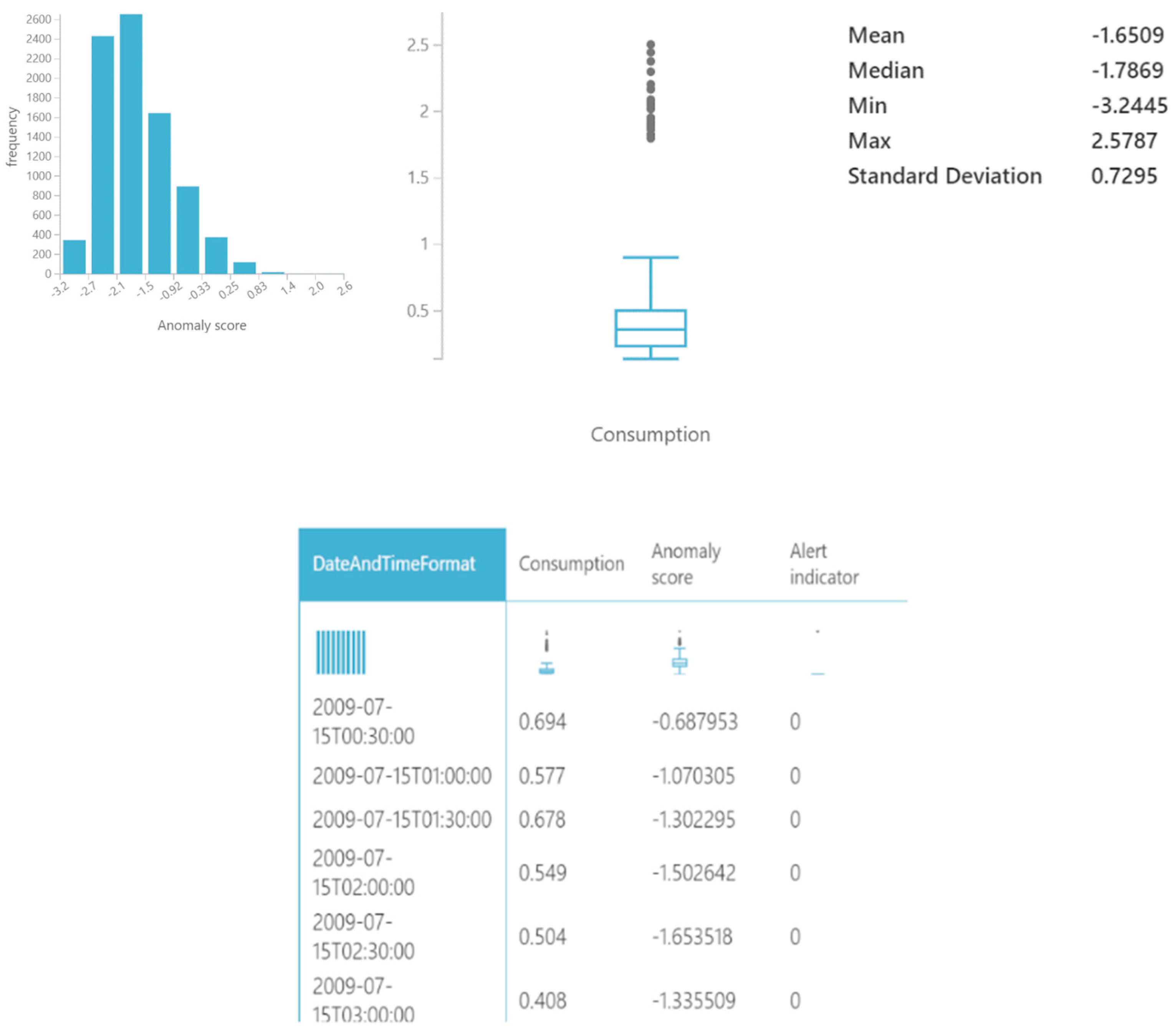
In
Figure 6, we established the alert threshold to a higher value, and the anomaly score was calculated with a deviation of 0.72. By overlooking the time series for the same data batch with the other algorithm, we are able to identify a better precision of anomaly detections per meter ID. The alert threshold uses the highest suitable value, but it did not reach the accuracy of the SR-CNN algorithm anomaly detections.
By using the SR-CNN algorithm outputs, we move forward with the proposed hybrid framework steps with ML models for electricity consumption fraud classifications. Following the previous outlined framework, we start by uploading the data files containing the consumption in a storage of the type of
Azure Data Lake Storage Gen2 [
32]. This storage is connected to an Azure Synapse Analytics environment [
33]. In the Azure Synapse Analytics workspace, we create an ingestion pipeline that reads the text files and inserts the data into a SQL table. We perform the data mapping and also import the data regarding each consumer’s tariff and status. The five-digit code specifying the electricity consumption’s date and hour in the
Datetime format was converted and added as a column in the table containing the consumption data.
During the conversion, we note that the format of the code for the date and hour does not always follow the format specified in the manifest file. Normally, the hour should have been registered as a code ranging from 01 to 48, showing 30 min intervals (30 min × 48 = 24 h, so one day). However, we found values of 49 and 50 for this code. Basically, these values overlapped the measurements for the next day. Taking this into account, it is impossible to create a coherent time series, as we have identical timestamps for different values. Thus, we decided to ignore the values for the codes 49 and 50. Furthermore, an Azure Cognitive Service of the type of Anomaly Detector was created [
34] that can analyze a time series and identify the indexes containing anomalies [
35]. The method used by the Anomaly Detector is based on unsupervised learning using the SR-CNN algorithm. Further on, we use code written in Python to build a chronologically ordered time series for each electricity consumption meter. Then, each time series using the Anomaly Detector service was analyzed.
Therefore, for anomaly detection identification, we recognize unusual patterns in the data per day, which can be flagged for further analysis. For the smart meter time-series data, alerts can be sent out when drifting, since this can imply potential anomalies. By using the trained SR-CNN model, the algorithms can provide accurate deviations for cycles, spikes, and downs and possible pattern detections.
In this section, we detailed our main contribution, which is represented by the innovative methodology proposal, which combines supervised and unsupervised ML algorithms. The final goal is to obtain fast and accurate predictions regarding the fraudulent household consumers. Of course, this seems unrealistic when we have available only unlabeled raw data inputs. For this, to reach the end goal, we brought our contribution to build the state-of-the-art framework methodology, after performing input raw data refinement, data digestion, applying statistical methods for features extraction, evaluating, comparing, refining, training, and selecting the most suitable models and algorithms to be applied. We obtained scoring regarding fraudulent households with data that were not suitable for any singular or pre-existing ML model. We contributed to the achievement of predictions by applying combined ML models: unsupervised ones at the beginning and by establishing thresholds transforming data to be eligible for supervised ones. Another important contribution to be considered is the reduction of a complex process to a feasible, detailed, and performant one, which can be integrated to be used by the field consumption electricity evaluators. In the next section, we will demonstrate the simulation results.
5. Results
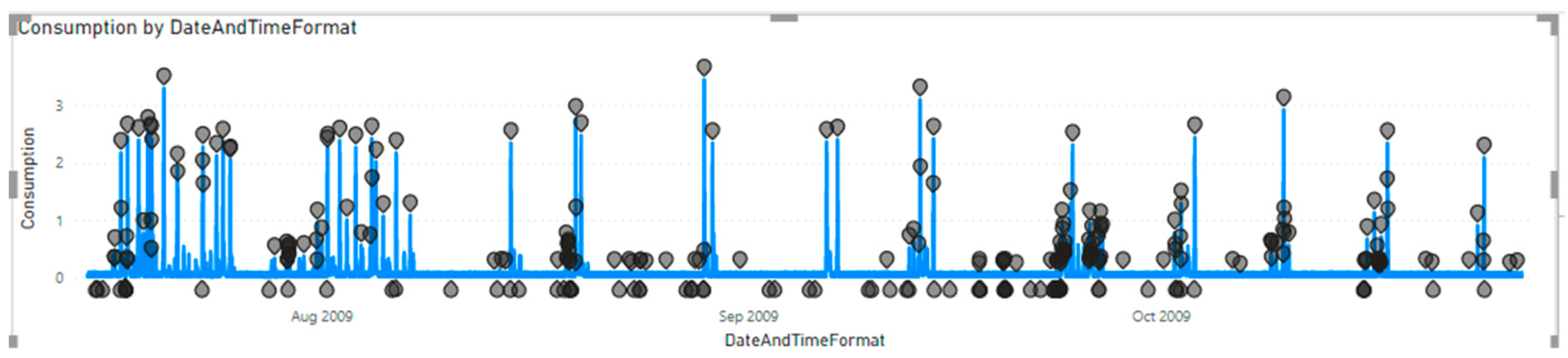
A closer look per meter ID, after applying the anomaly detector algorithm, will provide summarized information regarding the number of measurements and number of detected anomalies in the time series for different indexes. We can zoom in, taking for sample purposes the assessment results from a random meter, for which we obtained a total number of measurements of 466, with detected anomalies in the entire time series at different indexes as shown in
Figure 7.
We can access the anomaly detection trends information. Consumption increased for the last 1.10 days on record. For instance, consumption jumped from 0.07 to 0.12 during its steepest incline between Sunday 27 September 2009 and Sunday 27 September 2009. Consumption was unexpectedly high on Sunday 27 September 2009. It had a value of 0.12, which is outside the expected range of 0.08–0.12. Consumption experienced the longest period of growth (+0.07) between Saturday 26 September 2009 and Sunday 27 September 2009.
From using the SR-CNN algorithm through the Azure Anomaly Detector, we proceed to analyze the time-series data for the electricity consumption meters for labeled data.
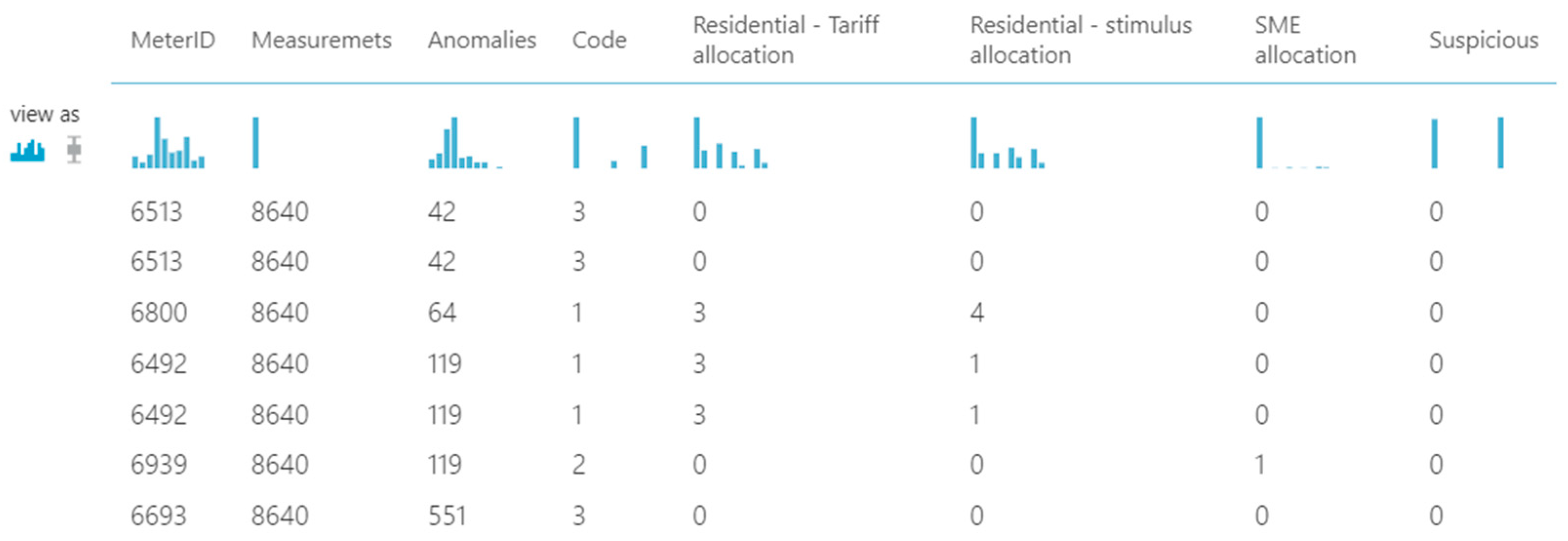
Therefore, we established a threshold, considering that if more than 15% of the data points in the time series are detected as anomalies, we mark the respective electricity consumption meter as suspicious and we label it for analysis. We perform a join using the IDs of the electricity consumption meters between the table containing the meter ID with a flag for whether it is marked as suspicious or not and the characteristics of the contract for that meter ID such as code, residential stimulus, residential tariff, and SME, obtaining a set of labeled data. Then, this dataset was imported in our model for discovering, given a certain set of parameters for the contract, if the consumer is rather likely to commit a fraud or not. We converted the letters symbolizing contract characteristics into numerical values (
Table 3).
In all cases, null values were replaced with 0 (zero). Furthermore, we selected the columns for training: Code, Residential-tariff allocation, Residential-stimulus allocation, SME allocation, Suspicious. Thus, these are all categorical columns with integer data types now. Then, the data were split 70% for training the model and 30% for evaluating the model, by using the Two-Class Boosted Decision Tree from the two-class classification algorithms and the Fisher Linear Discriminant analysis as outlined in the supervised proposed ML model for fraud classification and predictive analytics on electricity consumption. The steps of the methodology at this stage are the following: data selection, feature selection using two types of algorithms, applying data transformations, evaluating the model, and output retrieval based on the added webservices, which will provide the fraud probability for the household contract details (as in
Figure 8).
By applying the above model, the following results format can be obtained for the trained model also deployed as a web service:
‘Energy analysis [Predictive Exp.]’ test returned [“3”,”3”,”3”,”0”,”0”,”1”,”0.789865434169769”]...
Result: {“Results”:{“output1”:{“type”:”table”,”value”:{“ColumnNames”:[“Code”,”Residential-Tariff allocation”,”Residential-stimulus allocation”,”SME allocation”,”Suspicious”,”Scored Labels”,”Scored Probabilities”],”ColumnTypes”:[“Int32”,”Int32”,”Int32”,”Int32”,”Int32”,”Int32”,”Double”],”Values”:[[“3”,”3”,”3”,”0”,”0”,”1”,”0.789865434169769”]]}}}}.
In this example, we send to the prediction model for analysis a consumer contract with the following details: Code: 3, Residential-tariff allocation: 3, Residential-stimulus allocation: 3, SME allocation: 0. The return result has 1 for the value of the Scored Label, meaning that this consumer is more likely to be fraudulent with a probability of 0.79 (on a scale from 0 to 1), as indicated by the returned Scored Probabilities field.
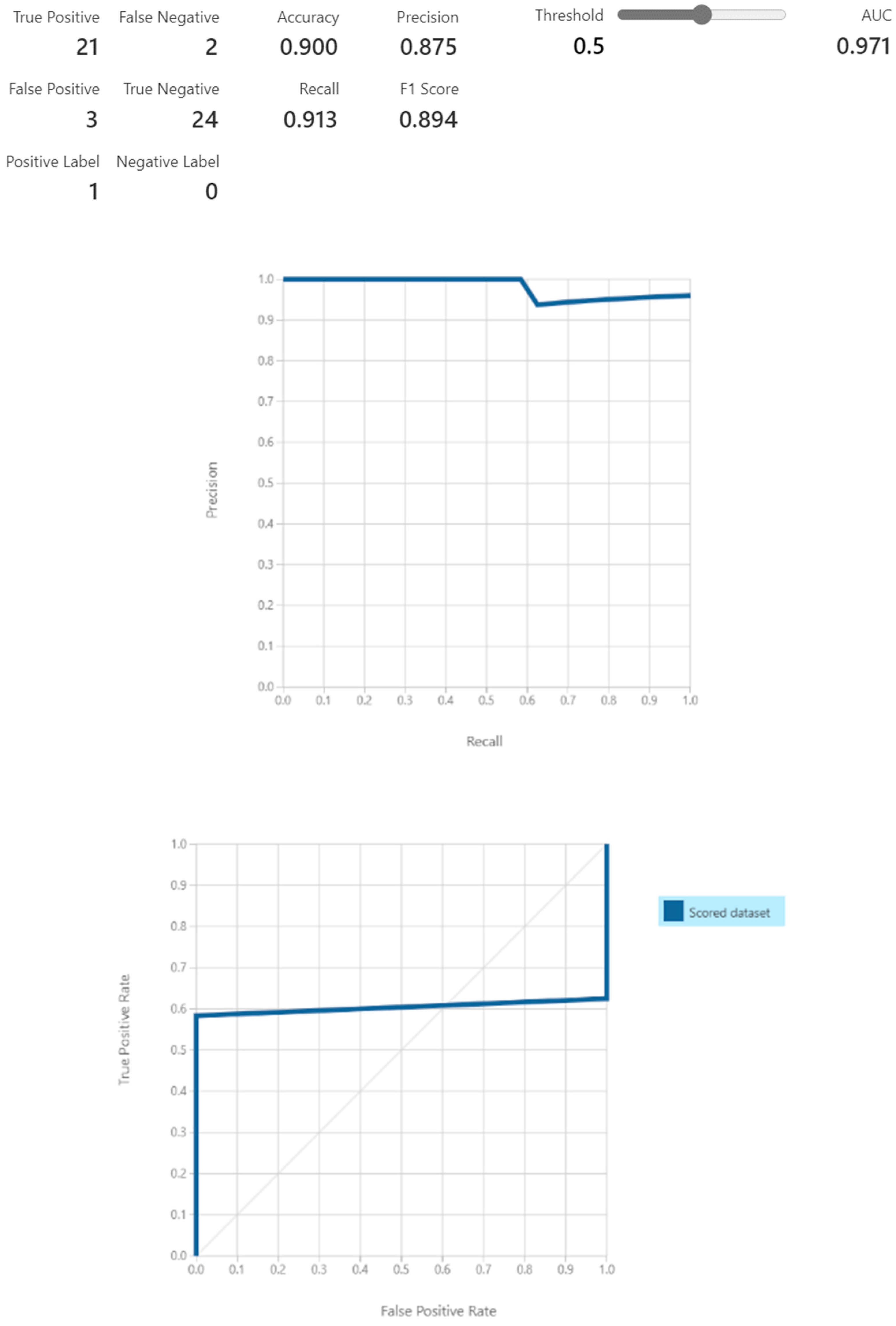
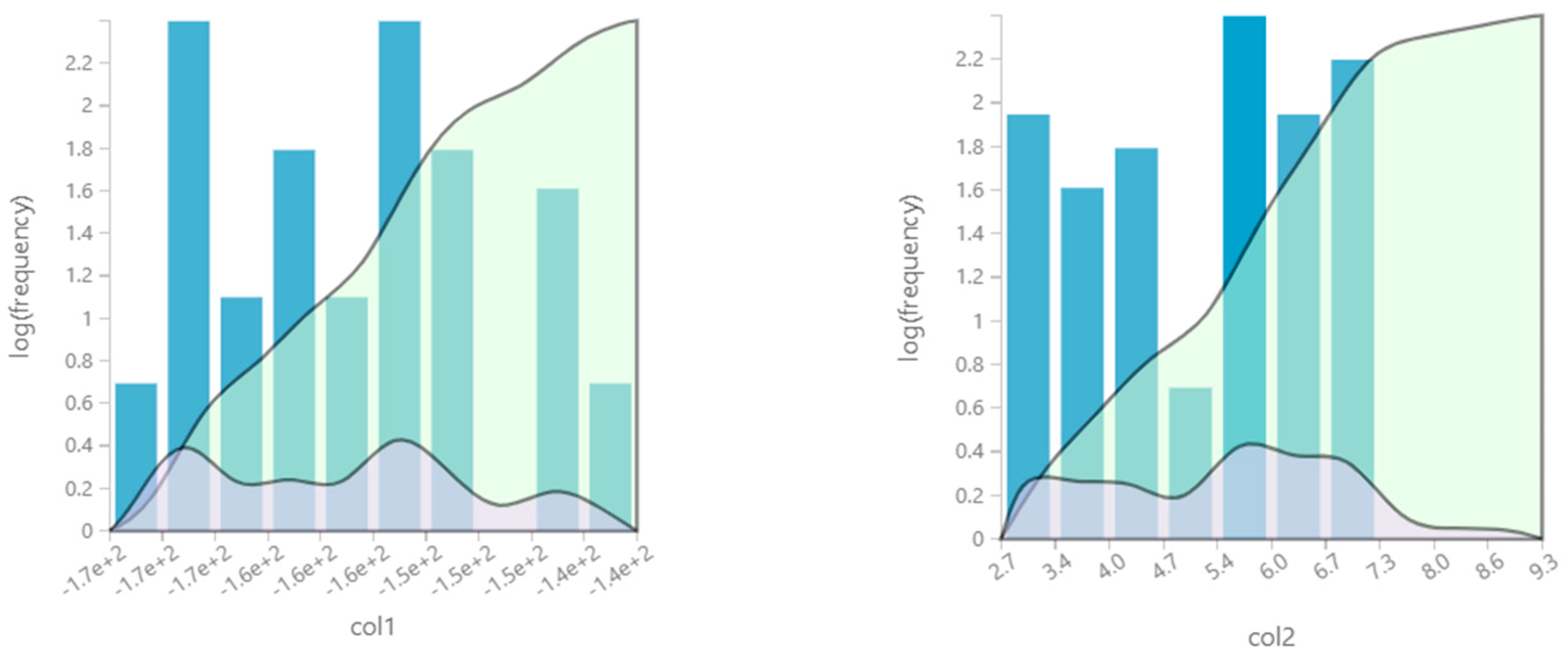
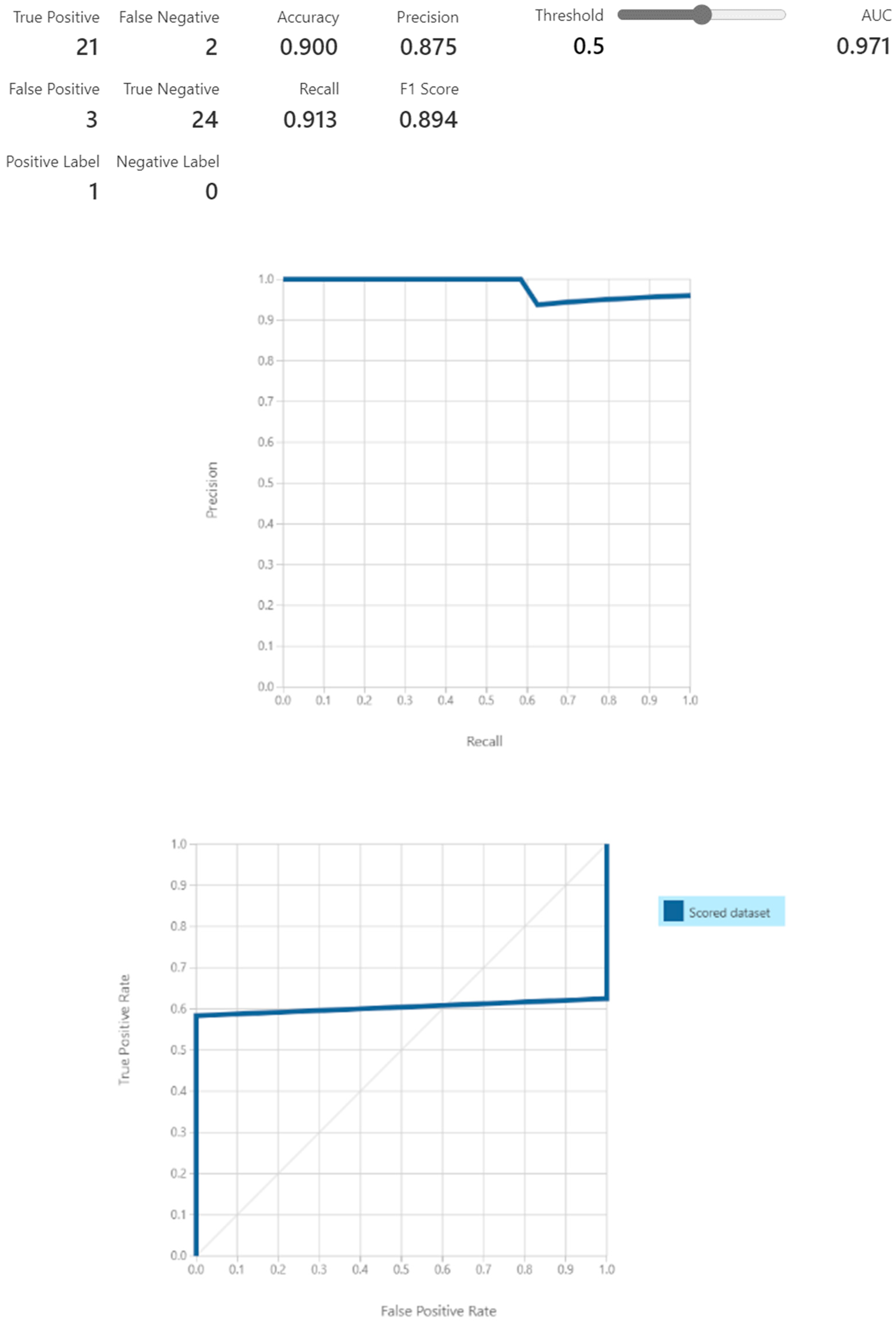
We submit the evaluation of the above ML model for fraud detections for the sampled data and obtain the scores as shown in
Figure 9.
The evaluation of the above proposed framework has an accuracy of 90%, a precision score of 0.875, and an F1 score of 0.894.
6. Conclusions
The classification of the fraud consumption for the electricity users is a challenging process due to the amount of data that needs to be processed and the factors that must be considered when analyzing the data, such as type of consumers, locations, timeframes of the evaluations, time of the day when the measurements are performed, determination of factors that influence the trends in in electricity consumption, weather conditions, etc. This research started from the hypothesis that there is a need to implement an extensive methodology that overcomes the impediments of obtaining rapidly accurate predictive data for consumption anomaly detections and, at the same time, also forecasts capabilities for potential fraud electricity consumers. Therefore, we proposed a hybrid model approach based on rigorous assessments and testing of the available existing technologies, ML models, and algorithms for the integration of those most suitable for such an approach. This research can be further extended with the evaluation of the proposed methodology on real-time data, as until now, it was assessed only by using recorded consumptions. In addition, the inclusion of the supervised learning model incorporates feature extractions algorithms that can be set up to include even more features than those currently used in the current work. Using all the aforementioned, our model can be tested out with extended featured data and can be refined and evaluated with actual onsite inspections.
In this paper, we point out the motivation for detecting frauds in the reporting of electricity consumption. Then, we perform an analysis of the existing approaches that use big data and ML for fraud detection and proceed to propose our own analysis framework. The methodology consists of using unsupervised ML for detecting anomalies in time-series data, establishing a threshold for the percentage of anomaly points from the total measures, and labeling the meters situated over the threshold as suspicious. Then, using a supervised ML approach, we train a classification model to predict the likelihood of consumers to commit a fraud based upon their consumption pattern and contract parameters. In the end, we apply the proposed methodology on the dataset and evaluate the results for anomaly consumption detections and fraud classification for electricity consumers. The research can be extended for real-time data evaluations.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}