
The Role of Citizen Science and Deep Learning in Camera Trapping


Abstract
:
1. Introduction
2. Materials and Methods
- automatic generation of much statistical information with an overview,
- map projection,
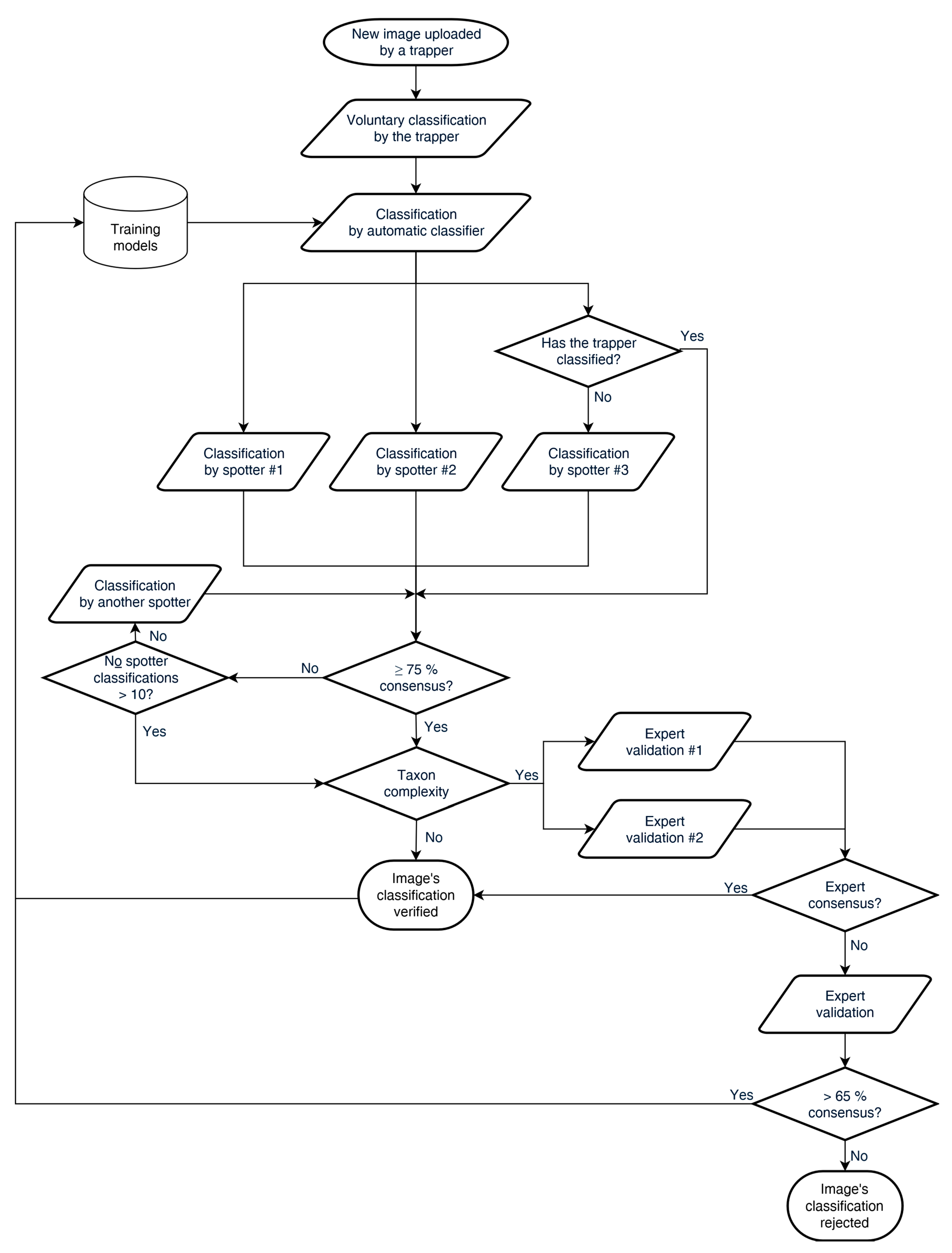
- automatic classification of the uploaded images that helps to engage citizens in data processing and minimises human effort at the same time,
- archiving and compressing of all records,
- export of collected data in various formats, and
- voluntary data embargo while research is active (e.g., to allow threatened species to be protected, their occurrence data should not be revealed to the public).
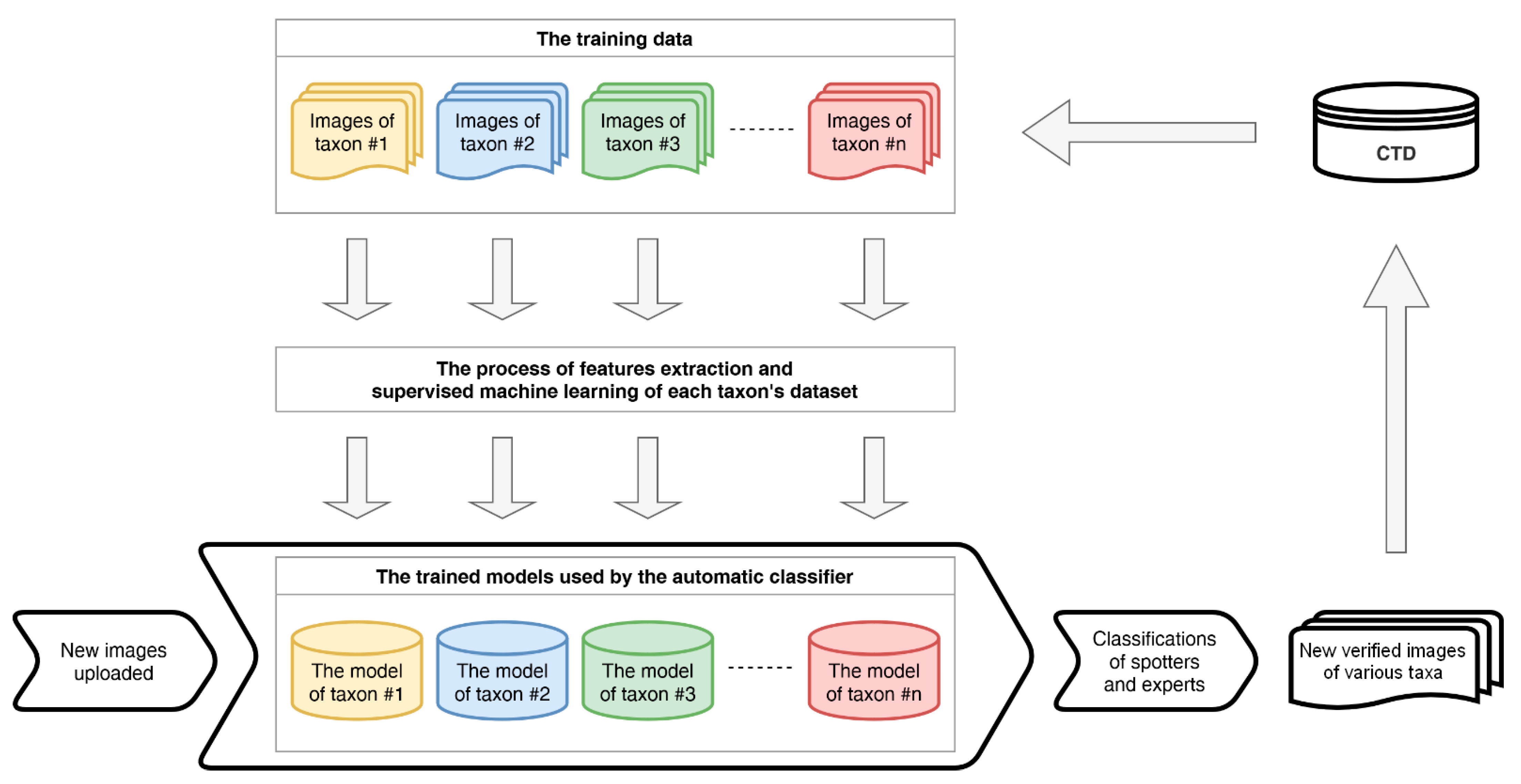
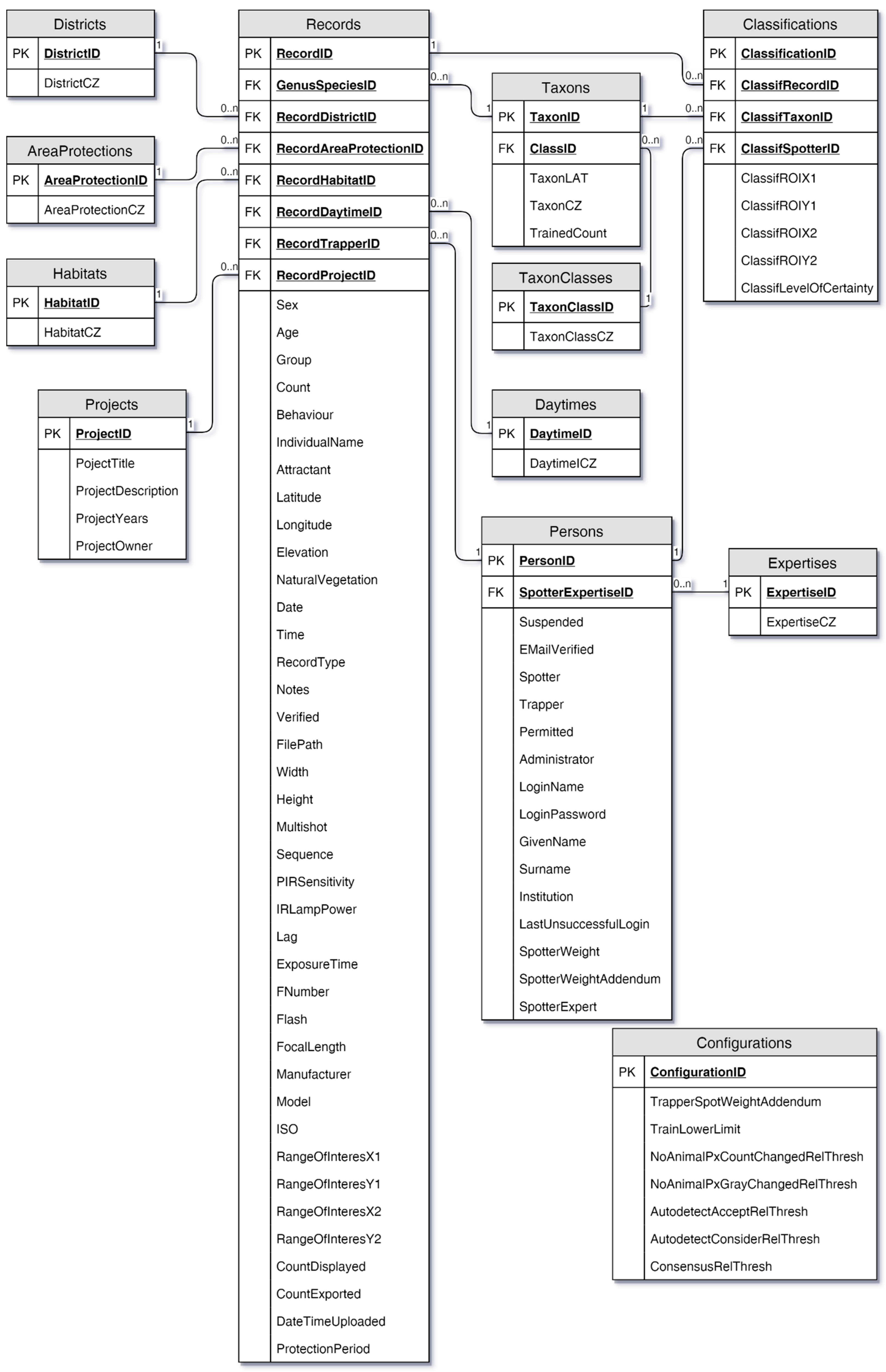
Data (Workflow)
3. Results
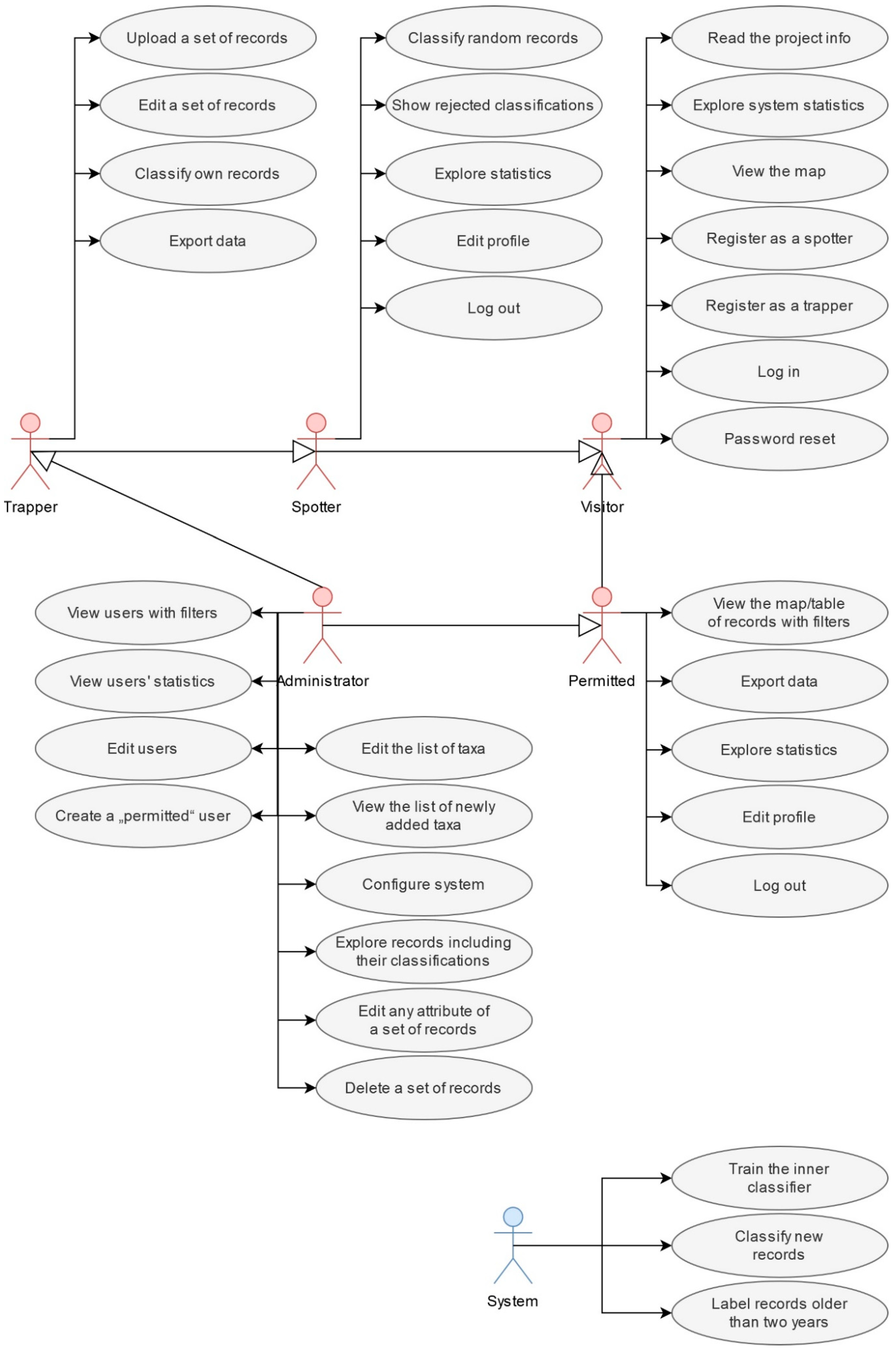
- unknown visitors as normal, nonprivileged web application visitors who are only able to perform a limited number of actions in the system,
- registered spotters, who—in addition to the role of visitors—can classify records; they are mere evaluators, voluntary experts, or laymen; these users do not have access to the records’ attributes,
- permitted users, who—in addition to the role of visitors—can view records with their attributes, export data, and statistics,
- registered trappers, who—in addition to the roles of visitors and spotters together—can view their records with attributes, upload a batch of records to the system for further classification, and export data and statistics,
- administrators, which is a limited group of users with the highest possible position in the hierarchy of roles of this information system, aimed at the maintenance of the system, and
- finally, the system, which is a specific role, performs automatically defined actions.
4. Discussion
Future Challenges
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Vincent, C.; Meynier, L.; Ridoux, V. Photo-identification in grey seals: Legibility and stability of natural markings. Mammalia 2001, 65, 363–372. [Google Scholar] [CrossRef]
- Pimm, S.L.; Alibhai, S.; Bergl, R.; Dehgan, A.; Giri, C.; Jewell, Z.; Joppa, L.; Kays, R.; Loarie, S. Emerging technologies to conserve biodiversity. Trends Ecol. Evol. 2015, 30, 685–696. [Google Scholar] [CrossRef]
- Terry, A.M.; Peake, T.M.; McGregor, P.K. The role of vocal individuality in conservation. Front. Zool. 2005, 2, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Waits, L.P.; Paetkau, D. Noninvasive genetic sampling tools for wildlife biologists: A review of applications and recommendations for accurate data collection. J. Wildl. Manag. 2005, 69, 1419–1433. [Google Scholar] [CrossRef]
- Linchant, J.; Lisein, J.; Semeki, J.; Lejeune, P.; Vermeulen, C. Are unmanned aircraft systems (UAS s) the future of wildlife monitoring? A review of accomplishments and challenges. Mammal Rev. 2015, 45, 239–252. [Google Scholar] [CrossRef]
- Welbourne, D.J.; Claridge, A.W.; Paull, D.J.; Lambert, A. How do passive infrared triggered camera traps operate and why does it matter? Breaking down common misconceptions. Remote Sens. Ecol. Conserv. 2016, 2, 77–83. [Google Scholar] [CrossRef] [Green Version]
- O’Connell, A.F.; Nichols, J.D.; Karanth, K.U. Camera Traps in Animal Ecology: Methods and Analyses; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Rowcliffe, J.M.; Kays, R.; Kranstauber, B.; Carbone, C.; Jansen, P.A. Quantifying levels of animal activity using camera trap data. Methods Ecol. Evol. 2014, 5, 1170–1179. [Google Scholar] [CrossRef] [Green Version]
- Swann, D.E.; Perkins, N. Camera trapping for animal monitoring and management: A review of applications. In Camera Trapping: Wildlife Management and Research; CSIRO Publishing: Clayton, Australia, 2014; pp. 3–11. [Google Scholar]
- Nichols, J.D.; Williams, B.K. Monitoring for conservation. Trends Ecol. Evol. 2006, 21, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Sutherland, W.J.; Roy, D.B.; Amano, T. An agenda for the future of biological recording for ecological monitoring and citizen science. Biol. J. Linn. Soc. 2015, 115, 779–784. [Google Scholar] [CrossRef] [Green Version]
- Lyons, J.E.; Runge, M.C.; Laskowski, H.P.; Kendall, W.L. Monitoring in the context of structured decision-making and adaptive management. J. Wildl. Manag. 2008, 72, 1683–1692. [Google Scholar] [CrossRef]
- Goldsmith, F.B. Monitoring for Conservation and Ecology; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 3. [Google Scholar]
- Dickman, A.J. Complexities of conflict: The importance of considering social factors for effectively resolving human–wildlife conflict. Anim. Conserv. 2010, 13, 458–466. [Google Scholar] [CrossRef]
- Distefano, E. Human-Wildlife Conflict Worldwide: Collection of Case Studies, Analysis of Management Strategies and Good Practices; FAO: Rome, Italy, 2005. [Google Scholar]
- Bauerfeind, R.; Von Graevenitz, A.; Kimmig, P.; Schiefer, H.G.; Schwarz, T.; Slenczka, W.; Zahner, H. Zoonoses: Infectious Diseases Transmissible from Animals to Humans; John Wiley & Sons: New York, NY, USA, 2020. [Google Scholar]
- Heilbrun, R.D.; Silvy, N.J.; Peterson, M.J.; Tewes, M.E. Estimating bobcat abundance using automatically triggered cameras. Wildl. Soc. Bull. 2006, 34, 69–73. [Google Scholar] [CrossRef]
- Wang, S.W.; Macdonald, D.W. The use of camera traps for estimating tiger and leopard populations in the high altitude mountains of Bhutan. Biol. Conserv. 2009, 142, 606–613. [Google Scholar] [CrossRef]
- Catlin-Groves, C.L. The citizen science landscape: From volunteers to citizen sensors and beyond. Int. J. Zool. 2012, 2012, 349630. [Google Scholar] [CrossRef] [Green Version]
- Welbourne, D.J.; Claridge, A.W.; Paull, D.J.; Ford, F. Camera-traps are a cost-effective method for surveying terrestrial squamates: A comparison with artificial refuges and pitfall traps. PLoS ONE 2020, 15, e0226913. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meek, P.D.; Ballard, G.A.; Sparkes, J.; Robinson, M.; Nesbitt, B.; Fleming, P.J. Camera trap theft and vandalism: Occurrence, cost, prevention and implications for wildlife research and management. Remote Sens. Ecol. Conserv. 2019, 5, 160–168. [Google Scholar] [CrossRef]
- Apps, P.J.; McNutt, J.W. How camera traps work and how to work them. Afr. J. Ecol. 2018, 56, 702–709. [Google Scholar] [CrossRef] [Green Version]
- Hampton, S.E.; Strasser, C.A.; Tewksbury, J.J.; Gram, W.K.; Budden, A.E.; Batcheller, A.L.; Duke, C.S.; Porter, J.H. Big data and the future of ecology. Front. Ecol. Environ. 2013, 11, 156–162. [Google Scholar] [CrossRef] [Green Version]
- Young, S.; Rode-Margono, J.; Amin, R. Software to facilitate and streamline camera trap data management: A review. Ecol. Evol. 2018, 8, 9947–9957. [Google Scholar] [CrossRef] [PubMed]
- Scotson, L.; Johnston, L.R.; Iannarilli, F.; Wearn, O.R.; Mohd-Azlan, J.; Wong, W.M.; Gray, T.N.; Dinata, Y.; Suzuki, A.; Willard, C.E. Best practices and software for the management and sharing of camera trap data for small and large scales studies. Remote Sens. Ecol. Conserv. 2017, 3, 158–172. [Google Scholar] [CrossRef]
- Schipper, J.; Chanson, J.S.; Chiozza, F.; Cox, N.A.; Hoffmann, M.; Katariya, V.; Lamoreux, J.; Rodrigues, A.S.; Stuart, S.N.; Temple, H.J. The status of the world’s land and marine mammals: Diversity, threat, and knowledge. Science 2008, 322, 225–230. [Google Scholar] [CrossRef] [Green Version]
- Glover-Kapfer, P.; Soto-Navarro, C.A.; Wearn, O.R. Camera-trapping version 3.0: Current constraints and future priorities for development. Remote Sens. Ecol. Conserv. 2019, 5, 209–223. [Google Scholar] [CrossRef] [Green Version]
- Forrester, T.; O’Brien, T.; Fegraus, E.; Jansen, P.A.; Palmer, J.; Kays, R.; Ahumada, J.; Stern, B.; McShea, W. An open standard for camera trap data. Biodivers. Data J. 2016, 4, e10197. [Google Scholar] [CrossRef]
- Cadman, M.; González-Talaván, A. Publishing Camera Trap Data, a Best Practice Guide; Global Biodiversity Information Facility: Copenhagen, Denmark, 2014. [Google Scholar]
- Nguyen, H.; Maclagan, S.J.; Nguyen, T.D.; Nguyen, T.; Flemons, P.; Andrews, K.; Ritchie, E.G.; Phung, D. Animal recognition and identification with deep convolutional neural networks for automated wildlife monitoring. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 40–49. [Google Scholar]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef] [Green Version]
- Norouzzadeh, M.S.; Morris, D.; Beery, S.; Joshi, N.; Jojic, N.; Clune, J. A deep active learning system for species identification and counting in camera trap images. Methods Ecol. Evol. 2021, 12, 150–161. [Google Scholar] [CrossRef]
- Schneider, S.; Taylor, G.W.; Linquist, S.; Kremer, S.C. Past, present and future approaches using computer vision for animal re-identification from camera trap data. Methods Ecol. Evol. 2019, 10, 461–470. [Google Scholar] [CrossRef] [Green Version]
- Swanson, A.; Kosmala, M.; Lintott, C.; Packer, C. A generalized approach for producing, quantifying, and validating citizen science data from wildlife images. Conserv. Biol. 2016, 30, 520–531. [Google Scholar] [CrossRef] [PubMed]
- Hsing, P.-Y.; Bradley, S.; Kent, V.T.; Hill, R.A.; Smith, G.C.; Whittingham, M.J.; Cokill, J.; Crawley, D.; Stephens, P.A. Economical crowdsourcing for camera trap image classification. Remote Sens. Ecol. Conserv. 2018, 4, 361–374. [Google Scholar] [CrossRef]
- Parsons, A.W.; Goforth, C.; Costello, R.; Kays, R. The value of citizen science for ecological monitoring of mammals. PeerJ 2018, 6, e4536. [Google Scholar] [CrossRef] [Green Version]
- Willi, M.; Pitman, R.T.; Cardoso, A.W.; Locke, C.; Swanson, A.; Boyer, A.; Veldthuis, M.; Fortson, L. Identifying animal species in camera trap images using deep learning and citizen science. Methods Ecol. Evol. 2019, 10, 80–91. [Google Scholar] [CrossRef] [Green Version]
- Ceccaroni, L.; Bibby, J.; Roger, E.; Flemons, P.; Michael, K.; Fagan, L.; Oliver, J.L. Opportunities and risks for citizen science in the age of artificial intelligence. Citiz. Sci. Theory Pract. 2019, 4, 29. [Google Scholar] [CrossRef] [Green Version]
- Green, S.E.; Rees, J.P.; Stephens, P.A.; Hill, R.A.; Giordano, A.J. Innovations in camera trapping technology and approaches: The integration of citizen science and artificial intelligence. Animals 2020, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Berger-Wolf, T.Y.; Rubenstein, D.I.; Stewart, C.V.; Holmberg, J.A.; Parham, J.; Menon, S.; Crall, J.; Van Oast, J.; Kiciman, E.; Joppa, L. Wildbook: Crowdsourcing, computer vision, and data science for conservation. arXiv 2017, arXiv:1710.08880. [Google Scholar]
- Access to Biological Collections Data Task Group Access to Biological Collection Data (ABCD), Version 2.06; Biodiversity Information Standards (TDWG): Geneva, Switzerland, 2007.
- Yang, D.-Q.; Tan, K.; Huang, Z.-P.; Li, X.-W.; Chen, B.-H.; Ren, G.-P.; Xiao, W. An automatic method for removing empty camera trap images using ensemble learning. Ecol. Evol. 2021, 11, 7591–7601. [Google Scholar] [CrossRef]
- Bubnicki, J.W.; Churski, M.; Kuijper, D.P. Trapper: An open source web-based application to manage camera trapping projects. Methods Ecol. Evol. 2016, 7, 1209–1216. [Google Scholar] [CrossRef] [Green Version]
- McShea, W.J.; Forrester, T.; Costello, R.; He, Z.; Kays, R. Volunteer-run cameras as distributed sensors for macrosystem mammal research. Landsc. Ecol. 2016, 31, 55–66. [Google Scholar] [CrossRef]
- Colbert-Lewis, D. Scientific Style and Format: The CSE Manual for Authors, Editors and Publishers. Ref. Rev. 2016, 30, 29–30. [Google Scholar]
- Schneider, S.; Greenberg, S.; Taylor, G.W.; Kremer, S.C. Three critical factors affecting automated image species recognition performance for camera traps. Ecol. Evol. 2020, 10, 3503–3517. [Google Scholar] [CrossRef]
- Franzen, M.; Kloetzer, L.; Ponti, M.; Trojan, J.; Vicens, J. Machine Learning in Citizen Science: Promises and Implications. In The Science of Citizen Science; Springer: Cham, Switzerland, 2021; p. 183. [Google Scholar]
- Deb, D.; Wiper, S.; Gong, S.; Shi, Y.; Tymoszek, C.; Fletcher, A.; Jain, A.K. Face recognition: Primates in the wild. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–10. [Google Scholar]
- Körschens, M.; Barz, B.; Denzler, J. Towards automatic identification of elephants in the wild. arXiv 2018, arXiv:1812.04418. [Google Scholar]
- Nipko, R.B.; Holcombe, B.E.; Kelly, M.J. Identifying Individual Jaguars and Ocelots via Pattern-Recognition Software: Comparing HotSpotter and Wild-ID. Wildl. Soc. Bull. 2020, 44, 424–433. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Format | Example |
|---|---|---|
| Date | YYYY-MM-DD | 24.02.2019 |
| Time | HH:MM:SS | 4:12:49 |
| Width | Integer | 2592 |
| Height | Integer | 2000 |
| Multi-shot | Integer | 0 |
| Exposure time | String | 1/5 |
| F-number | Decimal number | 2.7 |
| ISO | Integer | 250 |
| Focal length | Decimal number | 4.1 |
| Flash | Boolean: true or false | true |
| Lamp power | Enumeration: ‘N/A’, ‘low’, ‘normal’, ‘high’ or ‘boost’ | N/A |
| PIR sensitivity | Enumeration: ‘N/A’, ‘low’, ‘normal’ or ‘high’ | normal |
| Manufacturer | String | Cuddeback |
| Model | String | Attack |
| Latitude | Decimal number | 50.2997617 |
| Longitude | Decimal number | 12.8975392 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adam, M.; Tomášek, P.; Lehejček, J.; Trojan, J.; Jůnek, T. The Role of Citizen Science and Deep Learning in Camera Trapping. Sustainability 2021, 13, 10287. https://doi.org/10.3390/su131810287
Adam M, Tomášek P, Lehejček J, Trojan J, Jůnek T. The Role of Citizen Science and Deep Learning in Camera Trapping. Sustainability. 2021; 13(18):10287. https://doi.org/10.3390/su131810287
Chicago/Turabian StyleAdam, Matyáš, Pavel Tomášek, Jiří Lehejček, Jakub Trojan, and Tomáš Jůnek. 2021. "The Role of Citizen Science and Deep Learning in Camera Trapping" Sustainability 13, no. 18: 10287. https://doi.org/10.3390/su131810287
APA StyleAdam, M., Tomášek, P., Lehejček, J., Trojan, J., & Jůnek, T. (2021). The Role of Citizen Science and Deep Learning in Camera Trapping. Sustainability, 13(18), 10287. https://doi.org/10.3390/su131810287