
Forecasting Carbon Price with Secondary Decomposition Algorithm and Optimized Extreme Learning Machine

Abstract
:1. Introduction
- A novel hybrid model for carbon price prediction is constructed, which combines CEEMDAN, VMD, BES, and ELM, providing a new path for accurate forecasting.
- The secondary decomposition algorithm CEEMDAN-VMD was applied to deal with carbon prices and explore its applicability in this field for the first time. The CEEMDAN and VMD are combined to remove the noise component in the carbon price series, reduce the irregularity of the data, and make the prediction easier.
- The excellent global search ability of BES is applied to optimize the weight and bias of ELM, overcomes its inherent instability, and further improve its generalization ability.
- In the empirical study, five sets of actual data from the Hubei, Guangdong, and Shenzhen carbon markets with large market transactions are used as cases. Meanwhile, through the construction of benchmark models and six evaluation indicators, the outstanding predictive performance and universality of CEEMDAN-VMD-BES-ELM are verified.
2. Methodologies
2.1. Complementary Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN)
2.2. Variational Mode Decomposition (VMD)
2.3. Bald Eagle Search (BES) Algorithm
2.4. Extreme Learning Machine (ELM)
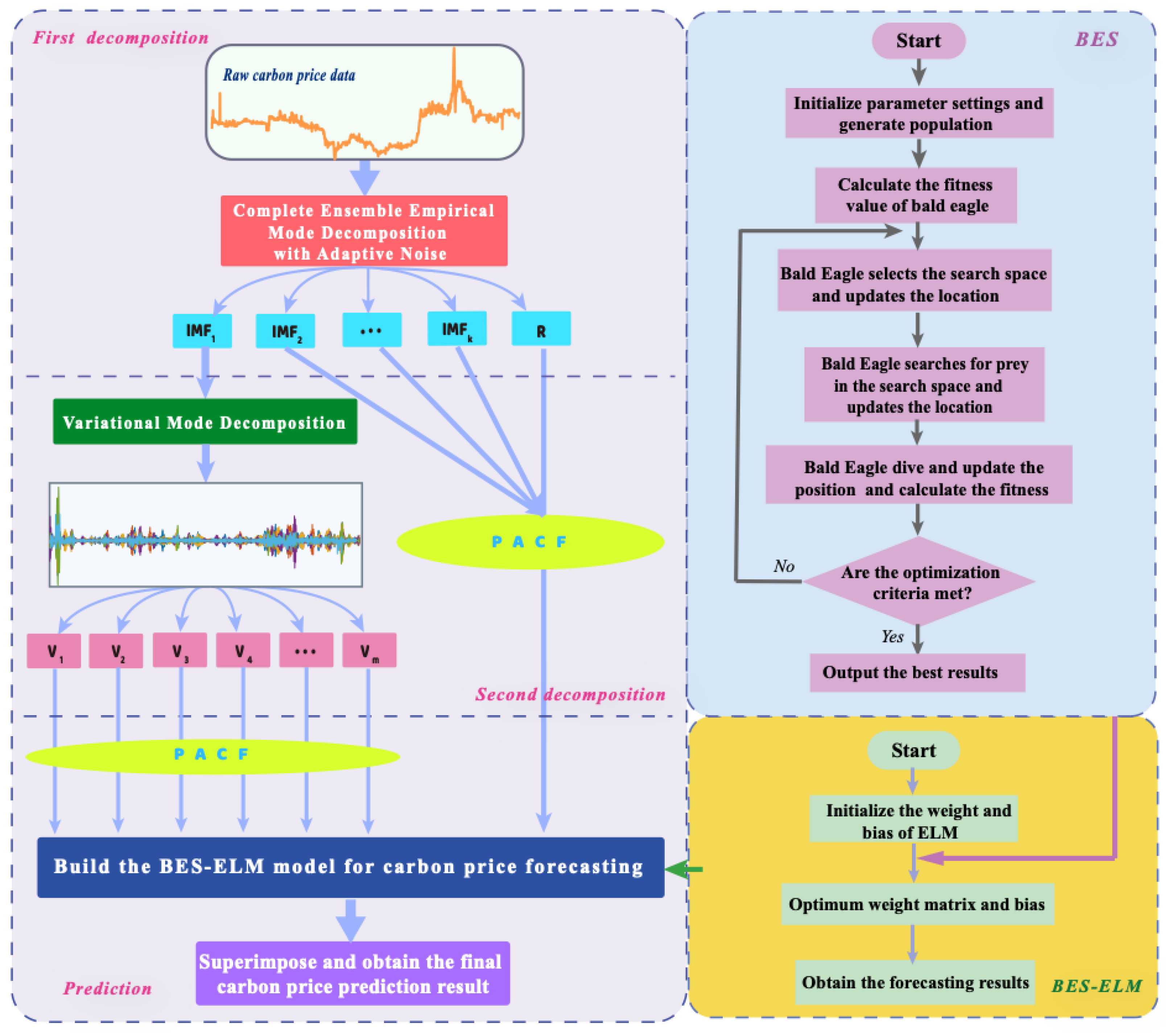
2.5. The Proposed Model
- (1)
- The original carbon price data will be adaptively decomposed by CEEMDAN into k intrinsic mode functions (IMFs) and a residual component R. Among them, the first modal function is called IMF1. Obviously, the non-linear and non-stationary characteristics of the original data are weakened, which reduces the difficulty of prediction.
- (2)
- Among the many component sequences, IMF1 is the most irregular, which will directly affect the accuracy of carbon price prediction. Hence, in the second decomposition, IMF1 is further processed by VMD to obtain a more stable and ordered subsequence cluster ().
- (3)
- The partial autocorrelation function is applied to analyze the inherent correlation of data information and determines the optimal input variables of the prediction model.
- (4)
- The ELM carbon price prediction model improved by the BES algorithm is constructed to predict all components. The outstanding global search capability of BES could determine the optimal weights and thresholds combination of ELM to achieve the goal of improving prediction accuracy.
- (5)
- The final carbon price prediction result will be obtained by summing the forecasting results of all subsequences.
3. Data Preprocessing
3.1. Data Description
3.2. First Decomposition
3.3. Secondary Decomposition
3.4. Input Selection
4. Empirical Analysis
4.1. Accuracy Evaluation
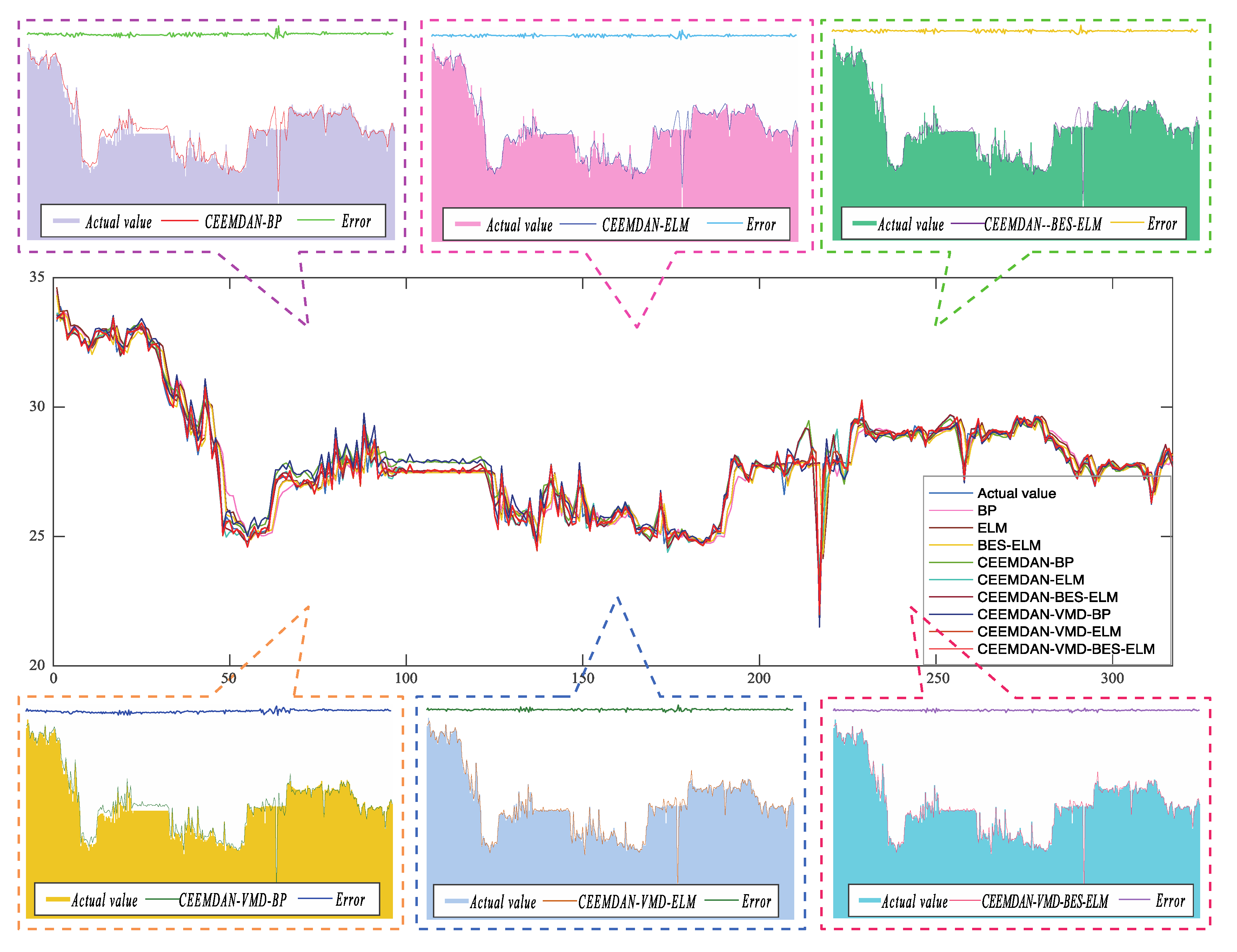
4.2. Forecasting Experiments
4.2.1. Hubei Carbon Market
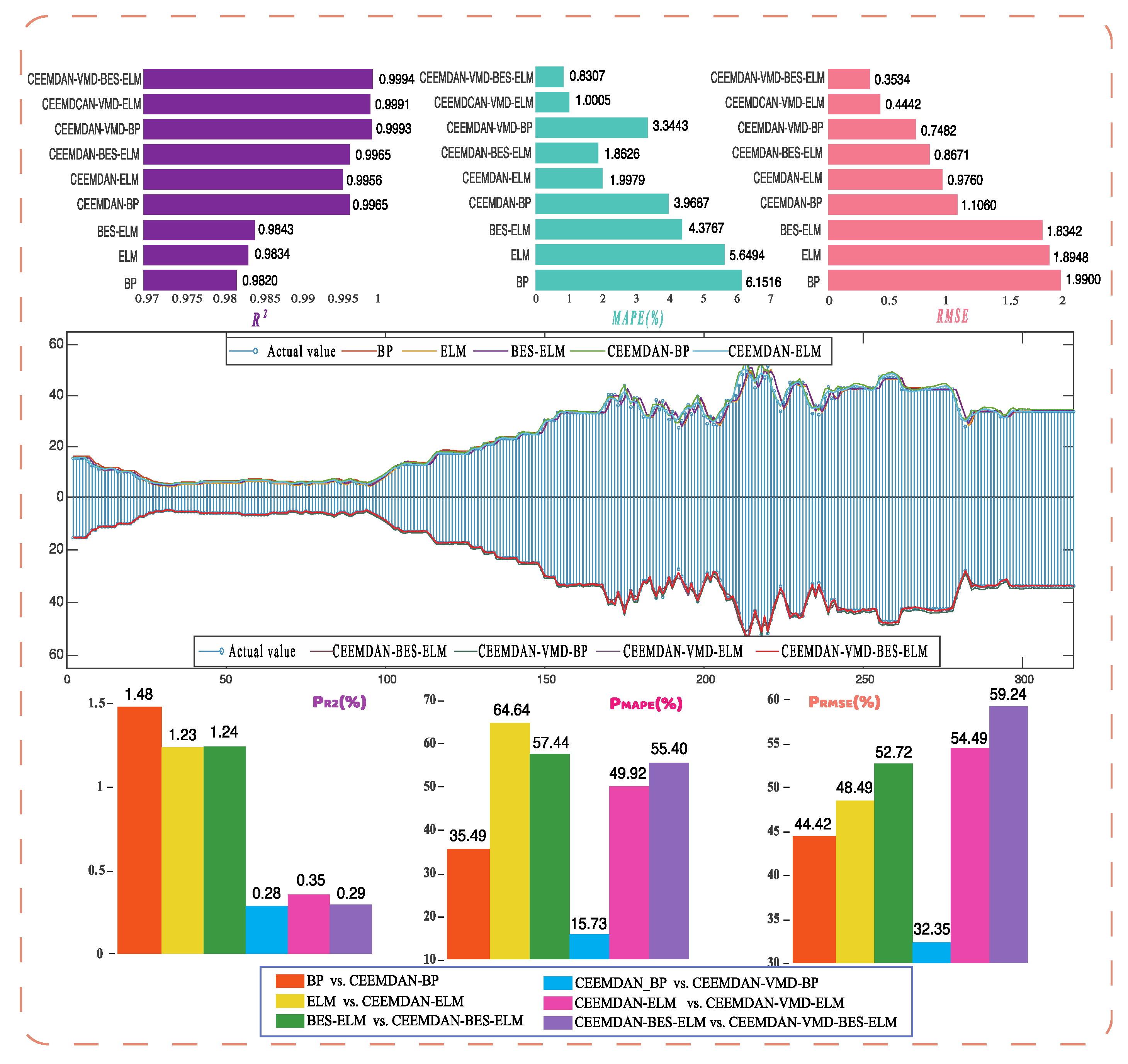
- (A)
- Comparing all evaluation indicators, CEEMDAN-VMD-BES-ELM has excellent predictive performance. The proposed model has the highest value, the lowest and values, which are 0.9938, 0.3987, and 0.1667 respectively.
- (B)
- When the individual models are combined with CEEMDAN, the prediction accuracy of the former has been greatly improved. For example, for the BP model, the , , and are 0.8925, 1.5164, and 0.7075, respectively. However, the three indicators of CEEMDAN-BP are 0.9566, 1.1724, and 0.4564, and the corresponding improvement percentage indicators are 7.19%, 22.69%, and 35.50% respectively. Comparing ELM and CEEMDAN-ELM, , , and are 7.57%, 32.25%, and 41.08%, respectively. For BES-ELM and CEEMDAN-BES-ELM, the former’s increased by 8.09%, decreased by 36.74%, and decreased by 45.55%.
- (C)
- Comparing the model combined CEEMDAN-EMD with the model combined CEEMDAN, the former has better prediction performance. For CEEMDAN-ELM, the , , and are 0.9619, 0.9799, and 0.4146, respectively. However, the three values to CEEMDAN-VMD-ELM are 0.9919, 0.4373, and 0.1914 respectively. The corresponding three improvement percentage index values are 3.12%, 55.37%, and 53.84%.
- (D)
- Comparing the BES-ELM model with the ELM model, the former has a stronger ability to capture sequence features. For ELM, , , and , the values are 0.8942, 1.4463, and 0.7038 respectively. However, the three values of BES-ELM are 0.8968, 1.4190, and 0.6835 respectively. Similarly, comparing CEEMDAN-ELM with CEEMDAN-BES-ELM, CEEMDAN-VMD-ELM, and CEEMDAN-VMD-BES-ELM, the model fused with ELM optimized by BES has better prediction accuracy.
4.2.2. Guangdong Carbon Market
4.2.3. Shenzhen Carbon Market
- (A)
- In the empirical analysis of all datasets, the CEEMDAN-VMD-BES-ELM constructed in this paper is the best in any evaluation indicators, which fully demonstrates that the proposed model proposed is robust and suitable for carbon price prediction.
- (B)
- When the single model is compared with the corresponding model combined with CEEMDAN, the latter is more competitive in prediction results and evaluation criteria. It may be because the inherent complexity of the carbon price time series has been weakened after being processed by CEEMDAN, reducing the difficulty of forecasting, which illustrates the suitability of the introduction of data preprocessing methods to process carbon price data.
- (C)
- After the introduction of the secondary decomposition algorithm, through the comparison of the prediction accuracy of the corresponding models, it is obvious that the model combined with CEEMAN-VMD has a more satisfactory forecasting accuracy than the model combined with CEEMDAN. It demonstrates that the reprocessing of IMF1 obtained by decomposing CEEMDAN could break through the limitation of accuracy and predict the carbon price more effectively.
- (D)
- It is necessary to optimize ELM output weights and hidden layer thresholds through BES. According to the experimental results, whether it is ELM, CEEMDAN-ELM, or CEEMDAN-VMD-ELM, the models optimized by BES predict superior performance, that is, BES-ELM is better than ELM, CEEMDAN-BES-ELM is better than CEEMDAN-ELM, and CEEMDAN-VMD-BES-ELM is better than CEEMDAN-VMD-ELM. Hence, BES could improve the stability of ELM and better capture the non-linear characteristics of the carbon price.
5. Conclusions and Discussion
- (1)
- The prediction accuracy of CEEMDAN-VMD-BES-ELM in the empirical analysis is the most prominent of all models, which fully reflects the excellent robustness and prediction performance of the proposed model, which is suitable for carbon price forecasting.
- (2)
- The experimental results show that CEEMDAN could effectively decompose the carbon price and improve the prediction accuracy of the model. Taking the Hubei carbon market as an example, after combining with CEEMDAN, the of BES-ELM increased by 8.09%, the decreased by 36.74%, and the decreased by 45.55%. Obviously, CEEMDAN decomposes the original carbon price into more stable subsequences, making the prediction more accurate. This conclusion is also confirmed by Lu et al. [38].
- (3)
- The novel secondary decomposition algorithm CEEMDAN-VMD is introduced into the field of carbon price prediction, which significantly improves the forecasting performance of the model. The highly volatile IMF1 was decomposed by VMD into more regular component sequences, which reduces the difficulty of prediction and improves the prediction accuracy [27,39]. The experimental results prove that CEEMDAN-VMD could effectively extract the complex characteristics of carbon price and further break through the limitation of accuracy.
- (4)
- Faced with the instability caused by the randomness of output weights and hidden layer thresholds to ELM, it is necessary to apply optimization algorithms to determine the best values of its parameters [40,41]. Therefore, in this paper, the BES algorithm is applied to select the optimal combination of ELM parameters. The experimental results indicate that the model combined with BES-ELM could better capture the volatility of the carbon price and has better forecasting performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Series | Lag | |||
|---|---|---|---|---|
| SZA-2013 | SZA-2014 | SZA-2015 | ||
| First Decomposition | Raw data | |||
| IMF1 | ||||
| IMF2 | ||||
| IMF3 | ||||
| IMF4 | ||||
| IMF5 | ||||
| IMF6 | ||||
| IMF7 | ||||
| IMF8 | ||||
| IMF9 | ||||
| IMF10 | ||||
| Residual | ||||
| Second Decomposition | ||||

References
- Hashim, H.; Ramlan, M.R.; Shiun, L.J.; Siong, H.C.; Kamyab, H.; Majid, M.Z.A.; Lee, C.T. An Integrated Carbon Accounting and Mitigation Framework for Greening the Industry. Energy Procedia 2015, 75, 2993–2998. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; He, Z. Carbon price forecasting with optimization prediction method based on unstructured combination. Sci. Total Environ. 2020, 725, 138350. [Google Scholar] [CrossRef]
- Lotze, H.K.; Tittensor, D.P.; Bryndum-Buchholz, A.; Eddy, T.D.; Cheung, W.W.L.; Galbraith, E.D.; Barange, M.; Barrier, N.; Bianchi, D.; Blanchard, J.; et al. Global ensemble projections reveal trophic amplification of ocean biomass declines with climate change. Proc. Natl. Acad. Sci. USA 2019, 116, 12907–12912. [Google Scholar] [CrossRef] [Green Version]
- Zhao, C.; Liu, B.; Piao, S.; Wang, X.; Lobell, D.B.; Huang, Y.; Huang, M.; Yao, Y.; Bassu, S.; Ciais, P.; et al. Temperature increase reduces global yields of major crops in four independent estimates. Proc. Natl. Acad. Sci. USA 2017, 114, 9326–9331. [Google Scholar] [CrossRef] [Green Version]
- Carrão, H.; Naumann, G.; Barbosa, P. Global projections of drought hazard in a warming climate: A prime for disaster risk management. Clim. Dyn. 2018, 50, 2137–2155. [Google Scholar] [CrossRef] [Green Version]
- Park, S.-Y.; Sur, C.; Lee, J.-H.; Kim, J.-S. Ecological drought monitoring through fish habitat-based flow assessment in the Gam river basin of Korea. Ecol. Indic. 2020, 109, 105830. [Google Scholar] [CrossRef]
- Sun, W.; Wang, Y. Factor analysis and carbon price prediction based on empirical mode decomposition and least squares support vector machine optimized by improved particle swarm optimization. Carbon Manag. 2020, 11, 315–329. [Google Scholar] [CrossRef]
- Song, Y.; Liu, T.; Liang, D.; Li, Y.; Song, X. A Fuzzy Stochastic Model for Carbon Price Prediction Under the Effect of Demand-related Policy in China’s Carbon Market. Ecol. Econ. 2019, 157, 253–265. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J. Estimating the impacts of emissions trading scheme on low-carbon development. J. Clean. Prod. 2019, 238, 117913. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, C. Analysis and forecasting of the carbon price using multi—Resolution singular value decomposition and extreme learning machine optimized by adaptive whale optimization algorithm. Appl. Energy 2018, 231, 1354–1371. [Google Scholar] [CrossRef]
- Tian, C.; Hao, Y. Point and interval forecasting for carbon price based on an improved analysis-forecast system. Appl. Math. Model. 2020, 79, 126–144. [Google Scholar] [CrossRef]
- Hao, Y.; Tian, C.; Wu, C. Modelling of carbon price in two real carbon trading markets. J. Clean. Prod. 2020, 244, 118556. [Google Scholar] [CrossRef]
- Wang, J.; Sun, X.; Cheng, Q.; Cui, Q. An innovative random forest-based nonlinear ensemble paradigm of improved feature extraction and deep learning for carbon price forecasting. Sci. Total Environ. 2021, 762, 143099. [Google Scholar] [CrossRef]
- Benz, E.; Trück, S. Modeling the price dynamics of CO2 emission allowances. Energy Econ. 2009, 31, 4–15. [Google Scholar] [CrossRef]
- Koop, G.; Tole, L. Forecasting the European carbon market. J. R. Stat. Soc. Ser. A 2013, 176, 723–741. [Google Scholar] [CrossRef] [Green Version]
- Fan, X.; Li, S.; Tian, L. Chaotic characteristic identification for carbon price and an multi-layer perceptron network prediction model. Expert Syst. Appl. 2015, 42, 3945–3952. [Google Scholar] [CrossRef]
- Zhu, B.; Han, D.; Wang, P.; Wu, Z.; Zhang, T.; Wei, Y.-M. Forecasting carbon price using empirical mode decomposition and evolutionary least squares support vector regression. Appl. Energy 2017, 191, 521–530. [Google Scholar] [CrossRef] [Green Version]
- Han, M.; Ding, L.; Zhao, X.; Kang, W. Forecasting carbon prices in the Shenzhen market, China: The role of mixed-frequency factors. Energy 2019, 171, 69–76. [Google Scholar] [CrossRef]
- Zhu, B.; Wei, Y. Carbon price forecasting with a novel hybrid ARIMA and least squares support vector machines methodology. Omega 2013, 41, 517–524. [Google Scholar] [CrossRef]
- Sun, G.; Chen, T.; Wei, Z.; Sun, Y.; Zang, H.; Chen, S. A Carbon Price Forecasting Model Based on Variational Mode Decomposition and Spiking Neural Networks. Energies 2016, 9, 54. [Google Scholar] [CrossRef] [Green Version]
- Chevallier, J. Wavelet packet transforms analysis applied to carbon prices. Econ. Bull. 2011, 31, 1731–1747. [Google Scholar]
- Zhu, B. A Novel Multiscale Ensemble Carbon Price Prediction Model Integrating Empirical Mode Decomposition, Genetic Algorithm and Artificial Neural Network. Energies 2012, 5, 355–370. [Google Scholar] [CrossRef]
- Zhou, J.; Yu, X.; Yuan, X. Predicting the Carbon Price Sequence in the Shenzhen Emissions Exchange Using a Multiscale Ensemble Forecasting Model Based on Ensemble Empirical Mode Decomposition. Energies 2018, 11, 1907. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Wu, P.; Chen, H.; Liu, J.; Zhou, L. Carbon price forecasting with variational mode decomposition and optimal combined model. Phys. A Stat. Mech. Appl. 2019, 519, 140–158. [Google Scholar] [CrossRef]
- Sun, W.; Huang, C. A carbon price prediction model based on secondary decomposition algorithm and optimized back propagation neural network. J. Clean. Prod. 2020, 243, 118671. [Google Scholar] [CrossRef]
- Sun, S.; Wei, L.; Xu, J.; Jin, Z. A New Wind Speed Forecasting Modeling Strategy Using Two-Stage Decomposition, Feature Selection and DAWNN. Energies 2019, 12, 334. [Google Scholar] [CrossRef]
- Peng, T.; Zhou, J.; Zhang, C.; Zheng, Y. Multi-step ahead wind speed forecasting using a hybrid model based on two-stage decomposition technique and AdaBoost-extreme learning machine. Energy Convers. Manag. 2017, 153, 589–602. [Google Scholar] [CrossRef]
- Sun, W.; Huang, C. A novel carbon price prediction model combines the secondary decomposition algorithm and the long short-term memory network. Energy 2020, 207, 118294. [Google Scholar] [CrossRef]
- Huang, N.E. The empirical mode decomposition and the hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.H.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assistant data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Alsattar, H.A.; Zaidan, A.A.; Zaidan, B.B. Novel meta-heuristic bald eagle search optimisation algorithm. Artif. Intell. Rev. 2019, 53, 2237–2264. [Google Scholar] [CrossRef]
- Zhou, J.; Huo, X.; Xu, X.; Li, Y. Forecasting the Carbon Price Using Extreme-Point Symmetric Mode Decomposition and Extreme Learning Machine Optimized by the Grey Wolf Optimizer Algorithm. Energies 2019, 12, 950. [Google Scholar] [CrossRef] [Green Version]
- Dégerine, S.; Lambert-Lacroix, S. Characterization of the partial autocorrelation function of nonstationary time series. J. Multivar. Anal. 2003, 87, 46–59. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Zhou, X.; Zhu, B.; He, K.; Wang, P. Measuring the maturity of carbon market in China: An entropy-based TOPSIS approach. J. Clean. Prod. 2019, 229, 94–103. [Google Scholar] [CrossRef]
- Qi, S.; Wang, B.; Zhang, J. Policy design of the Hubei ETS pilot in China. Energy Policy 2014, 75, 31–38. [Google Scholar] [CrossRef]
- Lu, H.; Ma, X.; Huang, K.; Azimi, M. Carbon trading volume and price forecasting in China using multiple machine learning models. J. Clean. Prod. 2020, 249, 119386. [Google Scholar] [CrossRef]
- Rahimpour, A.; Amanollahi, J.; Tzanis, C.G. Air quality data series estimation based on machine learning approaches for urban environments. Air Qual. Atmos. Health 2021, 14, 191–201. [Google Scholar] [CrossRef]
- Ding, J.; Chen, G.; Yuan, K. Short-Term Wind Power Prediction Based on Improved Grey Wolf Optimization Algorithm for Extreme Learning Machine. Processes 2020, 8, 109. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.-F.; Li, L.-L.; Tseng, M.-L.; Lim, M.K. Prediction short-term photovoltaic power using improved chicken swarm optimizer-Extreme learning machine model. J. Clean. Prod. 2020, 248, 119272. [Google Scholar] [CrossRef]






| Datasets | Type | Date (Day/Month/Year) | Size | Train | Test |
|---|---|---|---|---|---|
| Hubei | HBEA | 2 April 2014–31 December 2020 | 1804 | 1487 | 317 |
| Guangdong | GDEA | 19 December 2013–31 December 2020 | 1918 | 1587 | 331 |
| Shenzhen | SZA-2013 | 19 June 2013–31 December 2020 | 2102 | 1707 | 395 |
| SZA-2014 | 6 August 2014–31 December 2020 | 1682 | 1367 | 315 | |
| SZA-2015 | 14 July 2015–31 December 2020 | 1345 | 1087 | 258 |
| Series | Lag | ||
|---|---|---|---|
| HBEA | GDEA | ||
| First Decomposition | Raw data | ||
| IMF1 | |||
| IMF2 | |||
| IMF3 | |||
| IMF4 | |||
| IMF5 | |||
| IMF6 | |||
| IMF7 | |||
| IMF8 | |||
| IMF9 | |||
| IMF10 | |||
| Residual | |||
| Second Decomposition | |||
| Model | Parameters |
|---|---|
| BPNN | Iteration times = 100; Learning rate = 0.1; Goal = 0.00004 |
| ELM | ; g(x) = ‘sig’ |
| Evaluation Criteria | Calculation Formula |
|---|---|
| Models | MAPE (%) | RMSE | |
|---|---|---|---|
| BP | 0.8925 | 1.5164 | 0.7075 |
| ELM | 0.8942 | 1.4463 | 0.7038 |
| BES-ELM | 0.8968 | 1.4190 | 0.6835 |
| CEEMDAN-BP | 0.9566 | 1.1724 | 0.4564 |
| CEEMDAN-ELM | 0.9619 | 0.9799 | 0.4146 |
| CEEMDAN-BES-ELM | 0.9693 | 0.8976 | 0.3721 |
| CEEMDAN-VMD-BP | 0.9844 | 0.8533 | 0.3059 |
| CEEMDAN-VMD-ELM | 0.9919 | 0.4373 | 0.1914 |
| CEEMDAN-VMD-BES-ELM | 0.9938 | 0.3987 | 0.1667 |
| Benchmark Model | Comparative Model | ||||
|---|---|---|---|---|---|
| BP | vs. | CEEMDAN-BP | 7.19 | 22.69 | 35.50 |
| ELM | vs. | CEEMDAN-ELM | 7.57 | 32.25 | 41.08 |
| BES-ELM | vs. | CEEMDAN-EBES-ELM | 8.09 | 36.74 | 45.55 |
| CEEMDAN-BP | vs. | CEEMDAN-VMD-BP | 2.90 | 27.22 | 32.97 |
| CEEMDAN-ELM | vs. | CEEMDAN-VMD-ELM | 3.12 | 55.37 | 53.84 |
| CEEMDAN-BES-ELM | vs. | CEEMDAN-VMD-BES-ELM | 2.53 | 55.58 | 55.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Wang, Q. Forecasting Carbon Price with Secondary Decomposition Algorithm and Optimized Extreme Learning Machine. Sustainability 2021, 13, 8413. https://doi.org/10.3390/su13158413
Zhou J, Wang Q. Forecasting Carbon Price with Secondary Decomposition Algorithm and Optimized Extreme Learning Machine. Sustainability. 2021; 13(15):8413. https://doi.org/10.3390/su13158413
Chicago/Turabian StyleZhou, Jianguo, and Qiqi Wang. 2021. "Forecasting Carbon Price with Secondary Decomposition Algorithm and Optimized Extreme Learning Machine" Sustainability 13, no. 15: 8413. https://doi.org/10.3390/su13158413
APA StyleZhou, J., & Wang, Q. (2021). Forecasting Carbon Price with Secondary Decomposition Algorithm and Optimized Extreme Learning Machine. Sustainability, 13(15), 8413. https://doi.org/10.3390/su13158413