
Design of a Data Management Reference Architecture for Sustainable Agriculture


Abstract
:1. Introduction
- A data management reference architecture design approach is presented, which can be used for different application domains;
- By using this design approach, a novel data management reference architecture for sustainable agriculture was designed for the first time in literature;
- The reference architecture is validated using different case studies obtained from the literature.
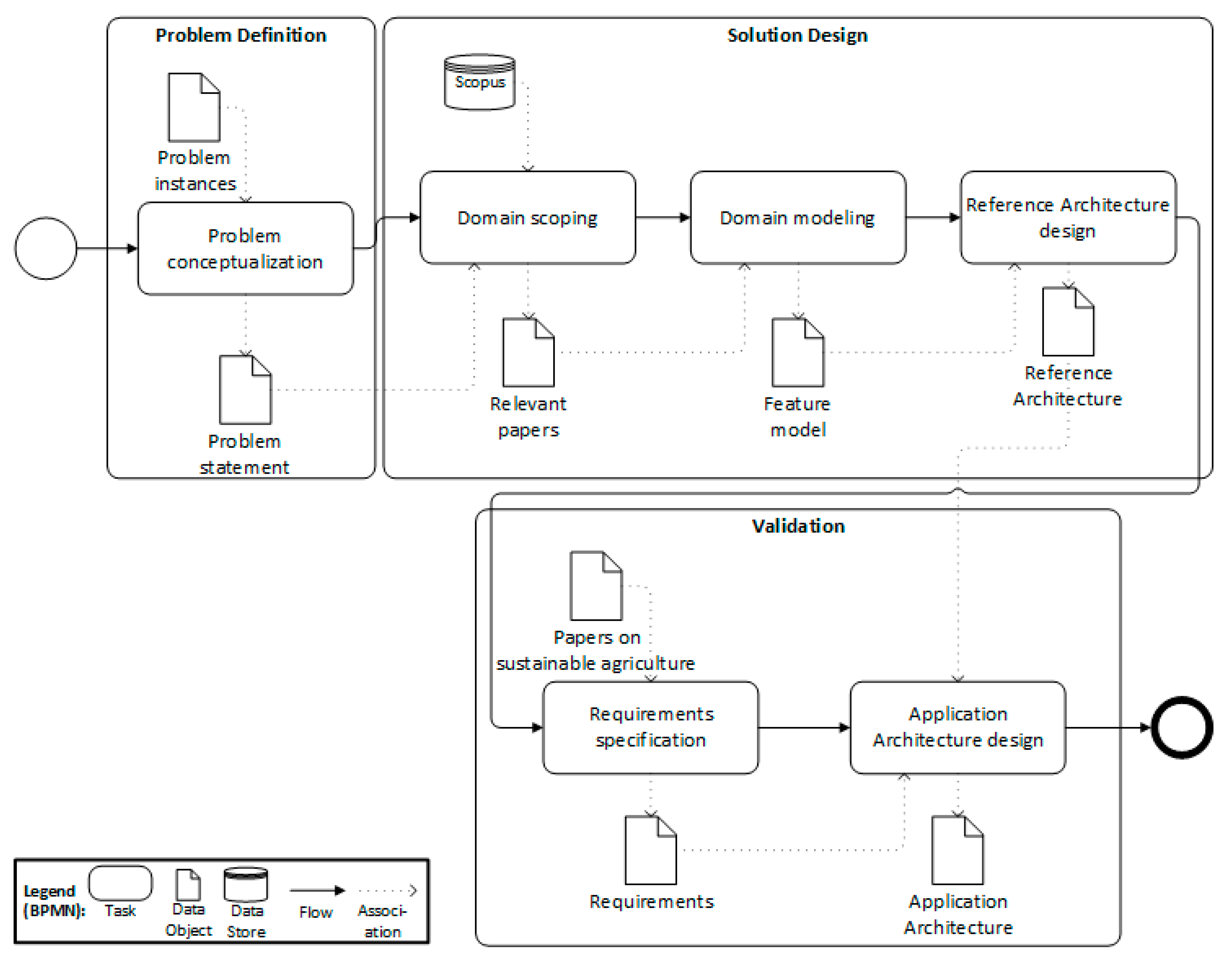
2. Research Method
3. Problem Definition
- Case 1: Satellite images (e.g., Sentinel-2 data) can be obtained from a data provider. These images can be processed to derive plant parameters such as Leaf Area Index (LAI), biomass, and chlorophyll content during the growing season [31]. Afterward, the current growth status and development of cultivated crops at each location in the field can be deduced [32]. This information can be used for site-specific plant protection and fertilization measures [33] and hence, support sustainable agriculture.
- Case 2: Harvested crop volume can be quantified and recorded in real time using numerous sensors [34]. Various parameters such as quantity per hectare and flow can be calculated and crop productivity maps can be built [34]. Farmers can use these maps to optimize inputs such as fertilizers, pesticides, and seeding rates, and increase yields [35].
- Case 3: Machinery process data such as speed, angle, pressure, and flow rate can be obtained through sensors in tractors and equipment [4]. Machine, worker, field, and time slot data can be stored, and basic statistics like minimum, maximum, standard deviation can be computed [4]. As a result, automated documentation of the production process and site-specific work can be attained [4].
4. Solution Design and Artifact Description
4.1. Related Reference Architecture Studies
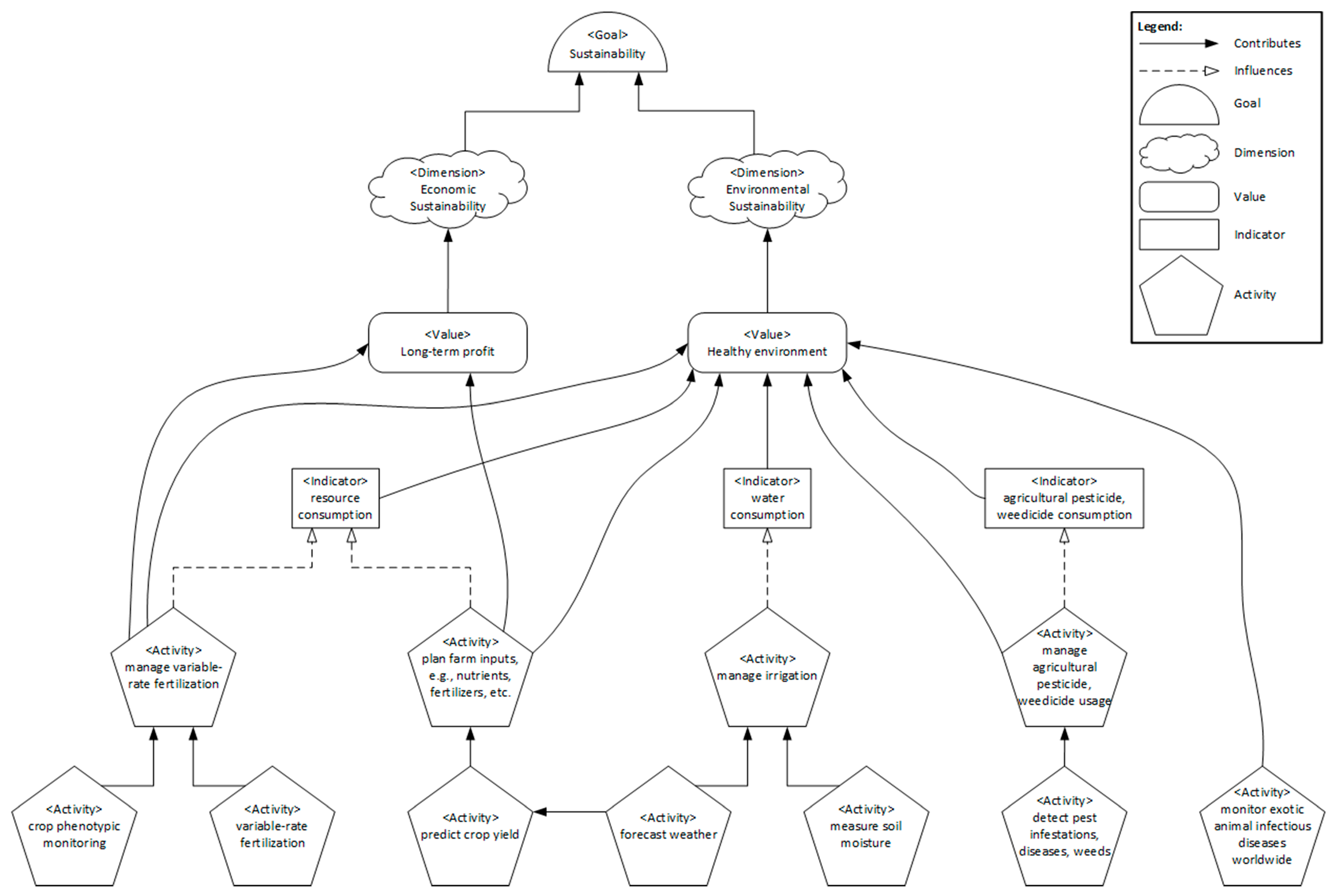
4.2. Domain Scoping
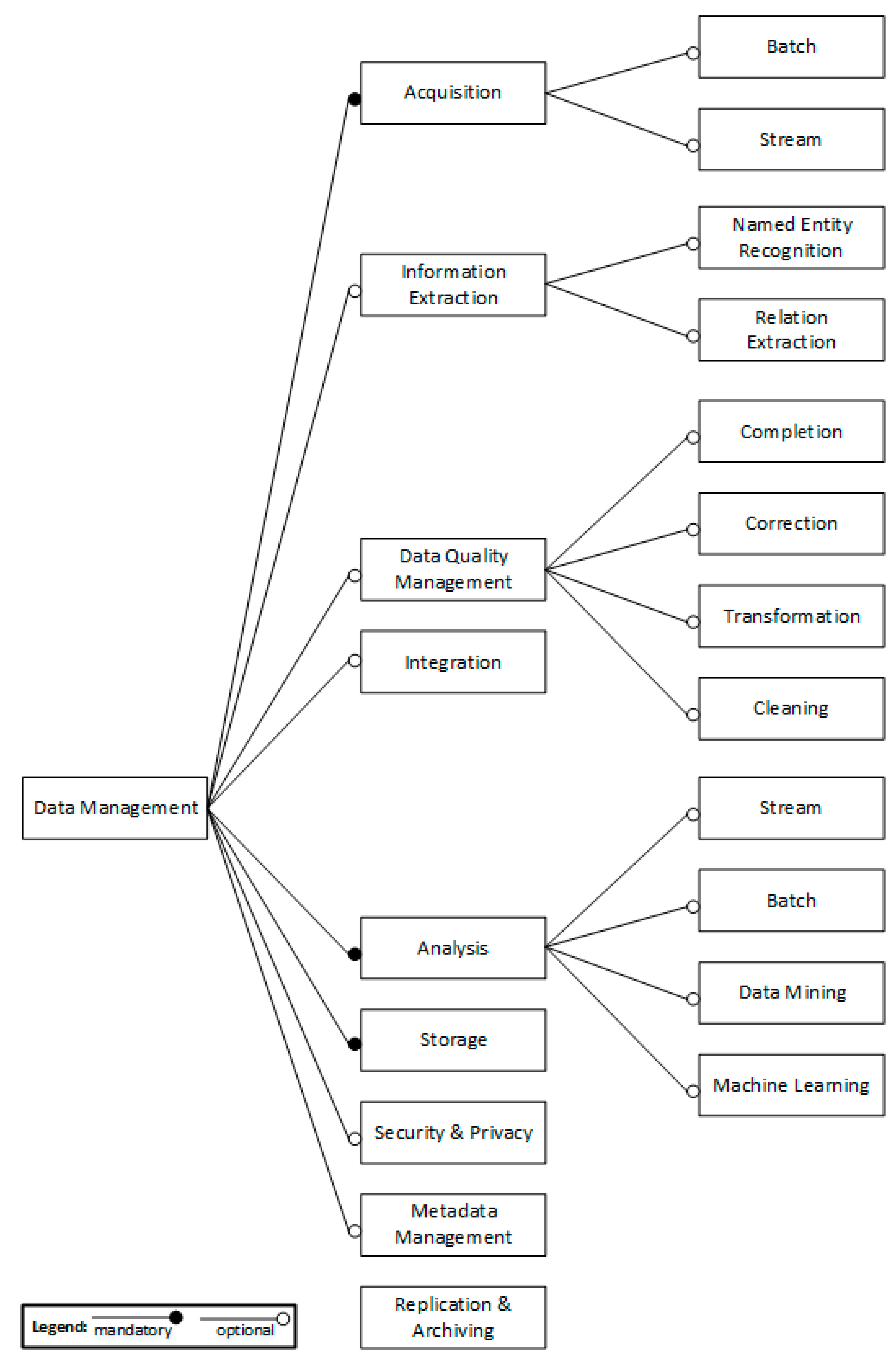
4.3. Domain Modeling
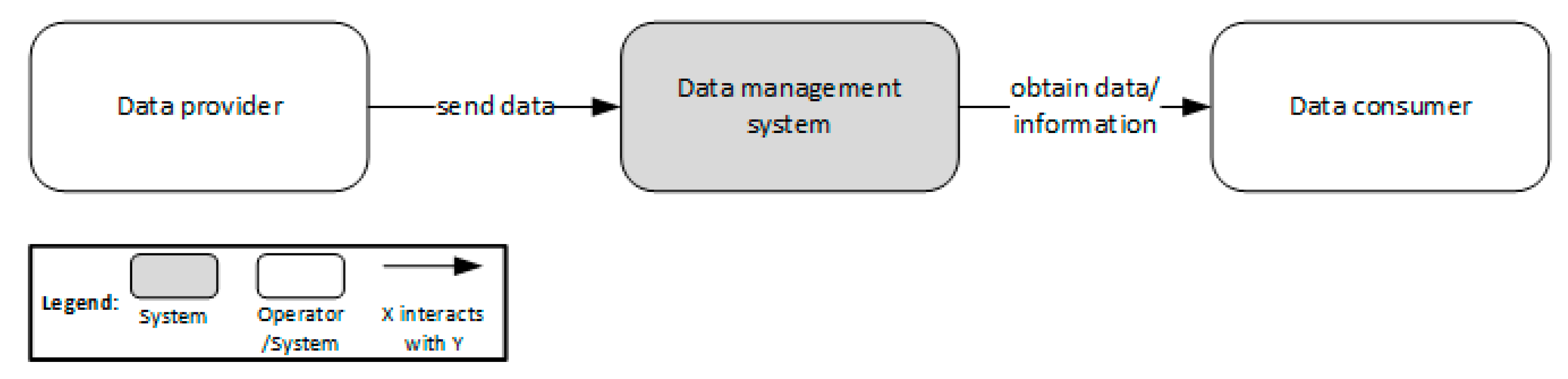
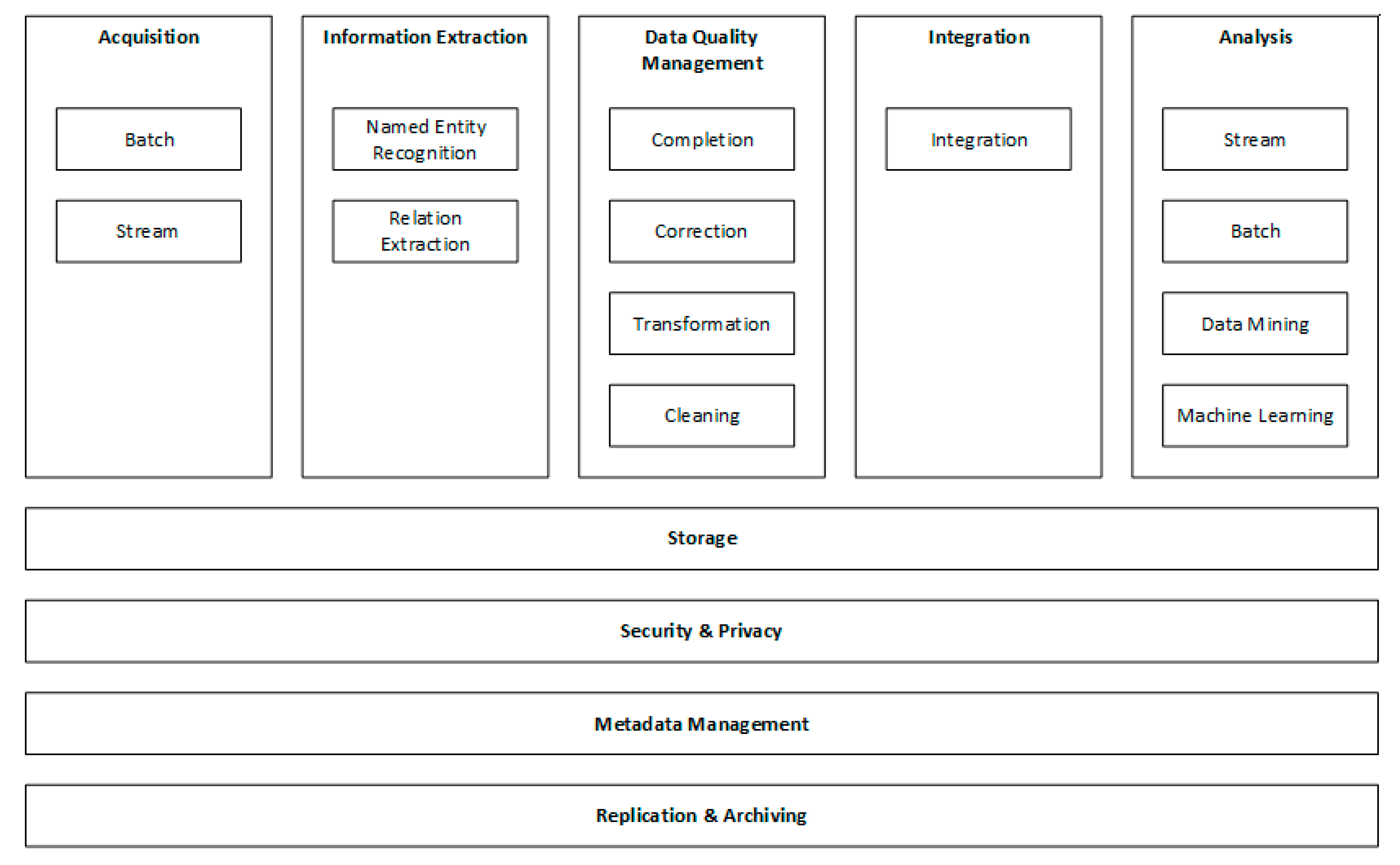
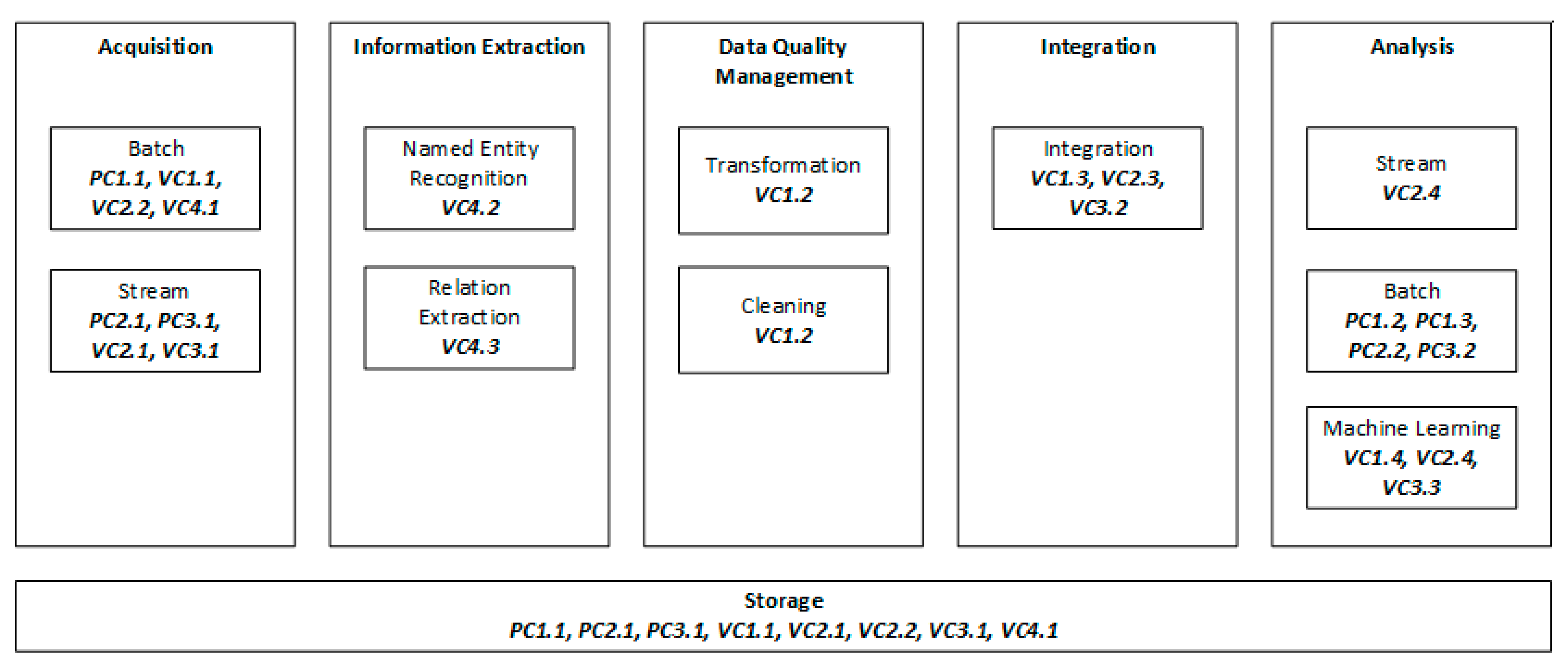
4.4. Reference Architecture Design
5. Validation
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Wolfert, S.; Goense, D.; Sørensen, C.A.G. A future internet collaboration platform for safe and healthy food from farm to fork. In Proceedings of the 2014 Annual SRII Global Conference, San Jose, CA, USA, 23–25 April 2014; pp. 266–273. [Google Scholar]
- Pierce, F.J.; Nowak, P. Aspects of precision agriculture. Adv. Agron. 1999, 67, 1–85. [Google Scholar]
- Murakami, E.; Saraiva, A.M.; Junior, L.C.R.; Cugnasca, C.E.; Hirakawa, A.R.; Correa, P.L. An infrastructure for the development of distributed service-oriented information systems for precision agriculture. Comput. Electron. Agric. 2007, 58, 37–48. [Google Scholar] [CrossRef]
- Steinberger, G.; Rothmund, M.; Auernhammer, H. Mobile farm equipment as a data source in an agricultural service architecture. Comput. Electron. Agric. 2009, 65, 238–246. [Google Scholar] [CrossRef]
- Sørensen, C.; Bildsøe, P.; Fountas, S.; Pesonen Pedersen, S.; Basso, B.; Nash, E. Integration of Farm Management Information Systems to Support Real-Time Management Decisions and Compliance of Management Standards; Center for Research & Technology: Thessaly, Greece, 2009; Available online: http://www.futurefarm.eu (accessed on 14 April 2021).
- Köksal, Ö.; Tekinerdogan, B. Architecture design approach for IoT-based farm management information systems. Precis. Agric. 2019, 20, 926–958. [Google Scholar] [CrossRef] [Green Version]
- Groeneveld, D.; Tekinerdogan, B.; Garousi, V.; Catal, C. A domain-specific language framework for farm management information systems in precision agriculture. Precis. Agric. 2020, 22, 1067–1106. [Google Scholar] [CrossRef]
- Jin, X.B.; Yu, X.H.; Wang, X.Y.; Bai, Y.T.; Su, T.L.; Kong, J.L. Deep learning predictor for sustainable precision agriculture based on internet of things system. Sustainability 2020, 12, 1433. [Google Scholar] [CrossRef] [Green Version]
- Kaya, A.; Keceli, A.S.; Catal, C.; Yalic, H.Y.; Temucin, H.; Tekinerdogan, B. Analysis of transfer learning for deep neural network based plant classification models. Comput. Electron. Agric. 2019, 158, 20–29. [Google Scholar] [CrossRef]
- Loures, L.; Chamizo, A.; Ferreira, P.; Loures, A.; Castanho, R.; Panagopoulos, T. Assessing the Effectiveness of Precision Agriculture Management Systems in Mediterranean Small Farms. Sustainability 2020, 12, 3765. [Google Scholar] [CrossRef]
- Podlasek, A.; Koda, E.; Vaverková, M.D. The Variability of Nitrogen Forms in Soils Due to Traditional and Precision Agriculture: Case Studies in Poland. Int. J. Environ. Res. Public Health 2021, 18, 465. [Google Scholar] [CrossRef] [PubMed]
- Verdouw, C.; Tekinerdogan, B.; Beulens, A.; Wolfert, S. Digital twins in smart farming. Agric. Syst. 2021, 189, 103046. [Google Scholar] [CrossRef]
- Keceli, A.S.; Catal, C.; Kaya, A.; Tekinerdogan, B. Development of a recurrent neural networks-based calving prediction model using activity and behavioral data. Comput. Electron. Agric. 2021, 170, 105285. [Google Scholar] [CrossRef]
- Catal, C.; Tekinerdogan, B. Aligning education for the life sciences domain to support digitalization and industry 4.0. Procedia Comput. Sci. 2019, 158, 99–106. [Google Scholar] [CrossRef]
- Nadal, S.; Herrero, V.; Romero, O.; Abelló, A.; Franch, X.; Vansummeren, S.; Valerio, D. A software reference architecture for semantic-aware Big Data systems. Inf. Softw. Technol. 2017, 90, 75–92. [Google Scholar] [CrossRef] [Green Version]
- Salma, C.A.; Tekinerdogan, B.; Athanasiadis, I.N. Domain-driven design of big data systems based on a reference architecture. In Software Architecture for Big Data and the Cloud; Morgan Kaufmann: Burlington, MA, USA, 2017; pp. 49–68. [Google Scholar]
- Tummers, J.; Kassahun, A.; Tekinerdogan, B. Reference architecture design for farm management information systems: A multi-case study approach. Precis. Agric. 2020, 22, 1–29. [Google Scholar] [CrossRef]
- DeLonge, M.S.; Miles, A.; Carlisle, L. Investing in the transition to sustainable agriculture. Environ. Sci. Policy 2016, 55, 266–273. [Google Scholar] [CrossRef] [Green Version]
- Gregor, S.; Hevner, A.R. Positioning and presenting design science research for maximum impact. MIS Q. 2013, 37, 337–355. [Google Scholar] [CrossRef]
- Hevner, A.R.; March, S.T.; Park, J.; Ram, S. Design science in information systems research. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef] [Green Version]
- Wieringa, R.J. Design Science Methodology for Information Systems and Software Engineering; Springer: Berlin, Germany, 2014. [Google Scholar]
- Runeson, P.; Engström, E.; Storey, M.A. The design science paradigm as a frame for empirical software engineering. In Contemporary Empirical Methods in Software Engineering; Springer: Cham, Germany, 2020; pp. 127–147. [Google Scholar]
- Köksal, Ö.; Tekinerdogan, B. Feature-driven domain analysis of session layer protocols of internet of things. In Proceedings of the 2017 IEEE International Congress on Internet of Things (ICIOT), Honolulu, HI, USA, 25–30 June 2017; pp. 105–112. [Google Scholar]
- van Geest, M.; Tekinerdogan, B.; Catal, C. Design of a reference architecture for developing smart warehouses in industry 4.0. Comput. Ind. 2021, 124, 103343. [Google Scholar] [CrossRef]
- Tekinerdogan, B.; Öztürk, K. Feature-driven design of SaaS architectures. In Software Engineering Frameworks for the Cloud Computing Paradigm; Springer: London, UK, 2013; pp. 189–212. [Google Scholar]
- Arsevska, E.; Valentin, S.; Rabatel, J.; De Goër de Hervé, J.; Falala, S.; Lancelot, R.; Roche, M. Web monitoring of emerging animal infectious diseases integrated in the French Animal Health Epidemic Intelligence System. PLoS ONE 2019, 13, e0199960. [Google Scholar] [CrossRef] [Green Version]
- Mohsen, S.; Guiping, H.; Huber, I.; Archontoulis, S.V. Coupling machine learning and crop modeling improves crop yield prediction in the US Corn Belt. Scientific Reports (Nature Publisher Group). arXiv 2021, arXiv:2008.04060. [Google Scholar]
- Sanjeevi, P.; Prasanna, S.; Siva Kumar, B.; Gunasekaran, G.; Alagiri, I.; Vijay Anand, R. Precision agriculture and farming using Internet of Things based on wireless sensor network. Trans. Emerg. Telecommun. Technol. 2020, 31, e3978. [Google Scholar] [CrossRef]
- Sharma, R.; Kamble, S.S.; Gunasekaran, A.; Kumar, V.; Kumar, A. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput. Oper. Res. 2020, 119, 104926. [Google Scholar] [CrossRef]
- Shi, Y.; Zhu, Y.; Wang, X.; Sun, X.; Ding, Y.; Cao, W.; Hu, Z. Progress and development on biological information of crop phenotype research applied to real-time variable-rate fertilization. Plant Methods 2020, 16, 11. [Google Scholar] [CrossRef]
- Clevers, J.G.; Kooistra, L.; Van den Brande, M.M. Using Sentinel-2 data for retrieving LAI and leaf and canopy chlorophyll content of a potato crop. Remote Sens. 2017, 9, 405. [Google Scholar] [CrossRef] [Green Version]
- Bach, H.; Migdall, S.; Mauser, W.; Angermair, W.; Sephton, A.J.; Martin-de-Mercado, G. An integrative approach of using satellite-based information for Precision farming: TalkingFields. In Proceedings of the 61st International Astronautical Congress, Prague, Czech Republic, 27 September–1 October 2010. [Google Scholar]
- Bach, H.; Mauser, W. Sustainable agriculture and smart farming. In Earth Observation Open Science and Innovation; Springer: Cham, Germany, 2018; pp. 261–269. [Google Scholar]
- Burlacu, G.; Costa, R.; Sarraipa, J.; Jardim-Golcalves, R.; Popescu, D. A conceptual model of farm management information system for decision support. In Doctoral Conference on Computing, Electrical and Industrial Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 47–54. [Google Scholar]
- Srivastava, S. Space Inputs for Precision Agriculture: Scope for Prototype Experiments in the Diverse Indian Agro-Ecosystems. In Proceedings of the Map Asia 2002, Bangkok, Thailand, 7–9 August 2002; pp. 1–4. [Google Scholar]
- Nikkilä, R.; Seilonen, I.; Koskinen, K. Software architecture for farm management information systems in precision agriculture. Comput. Electron. Agric. 2010, 70, 328–336. [Google Scholar] [CrossRef]
- Kaloxylos, A.; Groumas, A.; Sarris, V.; Katsikas, L.; Magdalinos, P.; Antoniou, E.; Politopoulou, Z.; Wolfert, S.; Brewster, C.; Eigenmann, R.; et al. A cloud-based Farm Management System: Architecture and implementation. Comput. Electron. Agric. 2014, 100, 168–179. [Google Scholar] [CrossRef]
- Kruize, J.W.; Wolfert, J.; Scholten, H.; Verdouw, C.N.; Kassahun, A.; Beulens, A.J. A reference architecture for Farm Software Ecosystems. Comput. Electron. Agric. 2016, 125, 12–28. [Google Scholar] [CrossRef] [Green Version]
- McAfee, A. & Brynjolfsson, E. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Ashmore, R.; Calinescu, R.; Paterson, C. Assuring the Machine Learning Lifecycle: Desiderata, Methods, and Challenges. arXiv 2019, arXiv:1905.04223. [Google Scholar]
- Dayal, U.; Akatsu, M.; Gupta, C.; Vennelakanti, R.; Lenardi, M. Expanding global big data solutions with innovative analytics. Hitachi Rev. 2014, 63, 333–339. [Google Scholar]
- Suriarachchi, I.; Plale, B. Crossing analytics systems: A case for integrated provenance in data lakes. In Proceedings of the 2016 IEEE 12th International Conference on e-Science (e-Science), Baltimore, MD, USA, 23–27 October 2016; pp. 349–354. [Google Scholar]
- Rao, W.; Jiang, J.; Yang, M.; Peng, W.; Zhou, A. Research on Energy Interconnection Oriented Big Data Sharing Platform Reference Architecture. In Advanced Computational Methods in Energy, Power, Electric Vehicles, and Their Integration; Springer: Singapore; pp. 217–225.
- Sang, G.M.; Xu, L.; De Vrieze, P. Simplifying big data analytics systems with a reference architecture. In Working Conference on Virtual Enterprises; Springer: Cham, Germany, 2017; pp. 242–249. [Google Scholar]
- Arass, M.E.; Ouazzani-Touhami, K.; Souissi, N. Data Life Cycle: Towards a Reference Architecture. Int. J. 2020, 9. [Google Scholar] [CrossRef]
- Pääkkönen, P.; Pakkala, D. Extending reference architecture of big data systems towards machine learning in edge computing environments. J. Big Data 2020, 7, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Maier, M. Towards a Big Data Reference Architecture. Master’s Thesis, University of Eindhoven, Eindhoven, The Netherlands, 2013. [Google Scholar]
- Meehan, J.; Aslantas, C.; Zdonik, S.; Tatbul, N.; Du, J. Data Ingestion for the Connected World. In Proceedings of the 8th Biennial Conference on Innovative Data Systems Research (CIDR’17), Chaminade, CA, USA, 8–11 January 2017. [Google Scholar]
- Stonebraker, M.; Madden, S.; Dubey, P. Intel “big data” science and technology center vision and execution plan. ACM SIGMOD Rec. 2013, 42, 44–49. [Google Scholar] [CrossRef] [Green Version]
- Adnan, K.; Akbar, R. An analytical study of information extraction from unstructured and multidimensional big data. J. Big Data 2019, 6, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Singh, S. Natural language processing for information extraction. arXiv 2018, arXiv:1807.02383. [Google Scholar]
- Gangadharan, V.; Gupta, D. Recognizing Named Entities in Agriculture Documents using LDA based Topic Modelling Techniques. Procedia Comput. Sci. 2020, 171, 1337–1345. [Google Scholar] [CrossRef]
- Oliveira, P.; Rodrigues, F.; Henriques, P.R. A formal Definition of Data Quality Problems; ICIQ: Tarragona, Spain, 2005. [Google Scholar]
- Ziegler, P.; Dittrich, K.R. Data integration—problems, approaches, and perspectives. In Conceptual Modelling in Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2005; pp. 39–58. [Google Scholar]
- Lenzerini, M. Data integration: A theoretical perspective. In Proceedings of the twenty-first ACM SIGMOD-SIGACT-SIGART symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002; pp. 233–246. [Google Scholar]
- Batini, C.; Lenzerini, M.; Navathe, S.B. A comparative analysis of methodologies for database schema integration. ACM Comput. Surv. (CSUR) 1986, 18, 323–364. [Google Scholar] [CrossRef]
- Cugola, G.; Margara, A. Processing flows of information: From data stream to complex event processing. ACM Comput. Surv. (CSUR) 2012, 44, 1–62. [Google Scholar] [CrossRef]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache flink: Stream and batch processing in a single engine. Bull. IEEE Comput. Soc. Tech. Comm. Data Eng. 2015, 36, 28–38. [Google Scholar]
- Begoli, E. A short survey on the state of the art in architectures and platforms for large scale data analysis and knowledge discovery from data. In Proceedings of the WICSA/ECSA 2012 Companion Volume, Helsinki, Finland, 20–24 August 2012; pp. 177–183. [Google Scholar]
- Chen, J.; Chen, Y.; Du, X.; Li, C.; Lu, J.; Zhao, S.; Zhou, X. Big data challenge: A data management perspective. Front. Comput. Sci. 2013, 7, 157–164. [Google Scholar] [CrossRef]
- DAMA International. DAMA-DMBOK: Data Management Body of Knowledge, 2nd ed.; Technics Publications, LLC: Basking Ridge, NJ, USA, 2017. [Google Scholar]
- Kim, C.H.; Weston, R.H.; Hodgson, A.; Lee, K.H. The complementary use of IDEF and UML modelling approaches. Comput. Ind. 2003, 50, 35–56. [Google Scholar] [CrossRef]
- Penzenstadler, B.; Femmer, H. A Generic Model for Sustainability; Technical Report; TUM: Munich, Germany, 2012. [Google Scholar]
- Penzenstadler, B.; Femmer, H. A generic model for sustainability with process-and product-specific instances. In Proceedings of the 2013 Workshop on Green in/by Software Engineering, Fukuoka, Japan, 26 March 2013; pp. 3–8. [Google Scholar]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop yield prediction using deep neural networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Natural Resources Conservation Service, United States Department of Agriculture, Web Soil Survey. 2019. Available online: https://data.nal.usda.gov/dataset/natural-resources-conservation-service-web-soil-survey (accessed on 23 April 2021).
- USDA NASS. Surveys; National Agricultural Statistics Service, U.S. Department of Agriculture: District of Columbia, WA, USA, 2019.
- Wan, Z.; Xia, X.; Lo, D.; Murphy, G.C. How does Machine Learning Change Software Development Practices? IEEE Trans. Softw. Eng. 2019. [Google Scholar] [CrossRef]
- Yokoyama, H. Machine learning system architectural pattern for improving operational stability. In Proceedings of the 2019 IEEE International Conference on Software Architecture Companion (ICSA-C), Hamburg, Germany, 25–26 March 2019; pp. 267–274. [Google Scholar]
- Glória, A.; Dionisio, C.; Simões, G.; Cardoso, J.; Sebastião, P. Water management for sustainable irrigation systems using internet-of-things. Sensors 2020, 20, 1402. [Google Scholar] [CrossRef] [Green Version]
- Campos, N.G.S.; Rocha, A.R.; Gondim, R.; Coelho da Silva, T.L.; Gomes, D.G. Smart & green: An internet-of-things framework for smart irrigation. Sensors 2020, 20, 190. [Google Scholar]
- Wang, X.C.; Chen, M.; Sun, G.X.; Zhang, Y.; Zhang, Y.N. Design and test of control system on variable fertilizer applicator for winter wheat. Trans. CSAE 2015, 31, 88–92. [Google Scholar]
- Yinyan, S.; Man, C.; Xiaochan, W.; Odhiambo, M.O.; Weimin, D. Numerical simulation of spreading performance and distribution pattern of centrifugal variable-rate fertilizer applicator based on DEM software. Comput. Electron. Agric. 2018, 144, 249–259. [Google Scholar] [CrossRef]
- Boegh, E.; Soegaard, H.; Broge, N.; Hasager, C.B.; Jensen, N.O.; Schelde, K.; Thomsen, A. Airborne multispectral data for quantifying leaf area index, nitrogen concentration, and photosynthetic efficiency in agriculture. Remote Sens. Environ. 2002, 81, 179–193. [Google Scholar] [CrossRef]
- Deery, D.M.; Rebetzke, G.J.; Jimenez-Berni, J.A.; James, R.A.; Condon, A.G.; Bovill, W.D.; Hutchinson, P.; Scarrow, J.; Davy, R.; Furbank, R.T. Methodology for high-throughput field phenotyping of canopy temperature using airborne thermography. Front. Plant Sci. 2016, 7, 1808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Q.; Yang, W.; Wu, F.; Pang, S.; Jin, S.; Chen, F.; Wang, X. High-throughput crop phenotyping: Accelerators for development of breeding and precision agriculture. Bull. Chin. Acad. Sci. 2018, 33, 940–946. [Google Scholar]
- Tian, M.; Ban, S.; Chang, Q.; You, M.; Luo, D.; Wang, L.; Wang, S. Use of hyperspectral images from UAV-based imaging spectroradiometer to estimate cotton leaf area index. Trans. Chin. Soc. Agric. Eng. 2016, 32, 102–108. [Google Scholar]
- Busemeyer, L.; Mentrup, D.; Möller, K.; Wunder, E.; Alheit, K.; Hahn, V.; Maurer, H.P.; Reif, J.C.; Würschum, T.; Müller, J.; et al. BreedVision—A multi-sensor platform for non-destructive field-based phenotyping in plant breeding. Sensors 2013, 13, 2830–2847. [Google Scholar] [CrossRef] [PubMed]
- Sharma, L.K.; Bu, H.; Franzen, D.W.; Denton, A. Use of corn height measured with an acoustic sensor improves yield estimation with ground based active optical sensors. Comput. Electron. Agric. 2016, 124, 254–262. [Google Scholar] [CrossRef] [Green Version]
- Arsevska, E.; Roche, M.; Hendrikx, P.; Chavernac, D.; Falala, S.; Lancelot, R.; Dufour, B. Identification of terms for detecting early signals of emerging infectious disease outbreaks on the web. Comput. Electron. Agric. 2016, 123, 104–115. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Input | Data Processing | Data Output | Outcome |
|---|---|---|---|
| satellite images | derive plant parameters via computer vision algorithms | plant parameters such as Leaf Area Index (LAI), biomass, and chlorophyll content | track current growth status and development of cultivated crop at each location |
| harvested crops volume via sensors | build crop productivity maps | various parameters such as quantity per hectare and flow on the map | use such maps to optimize inputs such as fertilizers, pesticides, and seeding rates, and increase yields |
| machinery process data via sensors | compute statistics | machine, worker, field, and time slot data along with basic statistics such as minimum, maximum, and standard deviation | attain automated documentation of production process and site-specific work |
| [15] | [42] | [43] | [44] | [45] | [46] | [47] | |
|---|---|---|---|---|---|---|---|
| Ingestion | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Information Extraction | ✓ | ||||||
| Data Quality Management | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Integration | ✓ | ✓ | ✓ | ✓ | |||
| Analysis | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Storage | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Security/Privacy | ✓ | ✓ | |||||
| Metadata Management | ✓ | ||||||
| Replication/Archiving | ✓ | ✓ | ✓ |
| Case | # | Functionality |
|---|---|---|
| PC1 | PC1.1. | obtain and store satellite images |
| PC1.2. | process images to derive plant parameters, such as leaf area index (LAI), biomass, and chlorophyll content | |
| PC1.3. | deduce the current growth status and development of cultivated crops at each location in the field | |
| PC2 | PC2.1. | obtain and store harvested crop volume in real time using sensors |
| PC2.2. | calculate parameters such as quantity per hectare and flow and build crop productivity maps | |
| PC3 | PC3.1. | obtain and store machinery process data; such as speed, angle, pressure, and flow rate through sensors in tractors |
| PC3.2. | compute basic figures; such as minimum, maximum, standard deviation and produce documentation of the production process | |
| VC1 | VC1.1. | acquire and store historical data on weather, soil, plant population, and planting process |
| VC1.2. | remove unusable data and normalize the remaining data | |
| VC1.3. | combine data on weather, soil, plant population, and planting process | |
| VC1.4. | build ML models and deploy the one that best satisfies requirements | |
| VC2 | VC2.1. | measure and store real time environmental data |
| VC2.2. | obtain and store weather forecast | |
| VC2.3. | combine measurement and forecast data | |
| VC2.4. | decide on irrigation based on predefined rules or a prediction model | |
| VC3 | VC3.1. | obtain and store data, such as crop three-dimensional size, biomass, and vegetation index |
| VC3.2. | combine multisource sensor data, such as color, depth, and spectral data, with environmental and crop physiology data | |
| VC3.3. | build ML models and deploy the one that best satisfies requirements for real time variable-rate fertilization | |
| VC4 | VC4.1. | obtain and store news from online news platforms |
| VC4.2. | extract named entities, such as location, date, disease, hosts, and number of cases | |
| VC4.3. | detect predefined types of relationships among recognized entities |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giray, G.; Catal, C. Design of a Data Management Reference Architecture for Sustainable Agriculture. Sustainability 2021, 13, 7309. https://doi.org/10.3390/su13137309
Giray G, Catal C. Design of a Data Management Reference Architecture for Sustainable Agriculture. Sustainability. 2021; 13(13):7309. https://doi.org/10.3390/su13137309
Chicago/Turabian StyleGiray, Görkem, and Cagatay Catal. 2021. "Design of a Data Management Reference Architecture for Sustainable Agriculture" Sustainability 13, no. 13: 7309. https://doi.org/10.3390/su13137309
APA StyleGiray, G., & Catal, C. (2021). Design of a Data Management Reference Architecture for Sustainable Agriculture. Sustainability, 13(13), 7309. https://doi.org/10.3390/su13137309