
Nonintrusive Residential Electricity Load Decomposition Based on Transfer Learning


Abstract
1. Introduction
2. Deep Transfer Learning and NILM
3. Transfer Learning Based on an Attention Model
3.1. Attention Model
3.2. Approaches to Transfer Learning
4. Data and Experiment
4.1. Dataset
4.2. Data Preprocessing
4.3. Model Training
4.4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hart, G.W. Nonintrusive Appliance Load Monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Cheng, X.; Li, L.; Wu, H.; Ding, Y.; Song, Y.; Sun, W. A Survey of The Research on Non-intrusive Load Monitoring and Disaggregation. Power Syst. Technol. 2016, 40, 3108–3117. [Google Scholar] [CrossRef]
- Gupta, S.; Reynolds, M.S.; Patel, S.N. ElectriSense:Single-Point Sensing Using EMI for Electrical Event Detection and Classification in the Home. In Proceedings of the 12th ACM International Conference on Ubiquitous Computing; ACM: New York, NY, USA, 2010; pp. 139–148. [Google Scholar] [CrossRef]
- Bouhouras, A.S.; Milioudis, A.N.; Labridis, D.P. Development of Distinct Load Signatures for Higher Efficiency of NILM Algorithms. Electr. Power Syst. Res. 2014, 117, 163–171. [Google Scholar] [CrossRef]
- Leeb, S.B.; Shaw, S.R.; Kirtley, J. Transient Event Detection in Spectral Envelope Estimates for Nonintrusive Load Monitoring. IEEE Trans. Power Deliv. 2014, 10, 1200–1210. [Google Scholar] [CrossRef]
- Medeiros, A.P.; Canha, L.N.; Bertineti, D.P.; de Azevedo, R.M. Event Classification in Non-Intrusive Load Monitoring Using Convolutional Neural Network. In Proceedings of the 2019 IEEE PES Innovative Smart Grid Technologies Conference—Latin America (ISGT Latin America), Gramado, Brazil, 15–18 September 2019; pp. 1–6. [Google Scholar]
- Kim, J.; Le, T.-T.-H.; Kim, H. Nonintrusive Load Monitoring Based on Advanced Deep Learning and Novel Signature. Comput. Intell. Neurosci. 2017, 2017, e4216281. [Google Scholar] [CrossRef]
- Ruano, A.; Hernandez, A.; Ureña, J.; Ruano, M.; Garcia, J. NILM Techniques for Intelligent Home Energy Management and Ambient Assisted Living: A Review. Energies 2019, 12, 2203. [Google Scholar] [CrossRef]
- Pereira, L.; Nunes, N. An Experimental Comparison of Performance Metrics for Event Detection Algorithms in NILM. In Proceedings of the 4th International NILM Workshop, Austin, TX, USA, 7–8 March 2018. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. arXiv 2018, arXiv:1808.01974. [Google Scholar]
- Huang, J.-T.; Li, J.; Yu, D.; Deng, L.; Gong, Y. Cross-Language Knowledge Transfer Using Multilingual Deep Neural Network with Shared Hidden Layers. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BA, Canada, 26–31 May 2013; pp. 7304–7308. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kelly, J.; Knottenbelt, W. Neural NILM:Deep Neural Networks Applied to Energy Disaggregation. In Proceedings of the ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Korea, 4–5 November 2015; pp. 55–64. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE Dataset, Domestic Appliance-Level Electricity Demand and Whole-House Demand from Five UK Homes. Sci. Data 2014, 2, 150007. [Google Scholar] [CrossRef]
- Çavdar, İ.H.; Faryad, V. New Design of a Supervised Energy Disaggregation Model Based on the Deep Neural Network for a Smart Grid. Energies 2019, 12, 1217. [Google Scholar] [CrossRef]
- Xia, M.; Liu, W.; Wang, K.; Zhang, X.; Xu, Y. Non-Intrusive Load Disaggregation Based on Deep Dilated Residual Network. Electr. Power Syst. Res. 2019, 170, 277–285. [Google Scholar] [CrossRef]
- Balduzzi, D.; Frean, M.; Leary, L.; Lewis, J.P.; Ma, K.W.-D.; McWilliams, B. The Shattered Gradients Problem: If Resnets Are the Answer, Then What Is the Question? arXiv 2018, arXiv:1702.08591. [Google Scholar]
- Jiang, J.; Kong, Q.; Plumbley, M.; Gilbert, N. Deep Learning Based Energy Disaggregation and On/Off Detection of Household Appliances. arXiv 2019, arXiv:1908.00941. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in neural information processing systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-Point Learning with Neural Networks for Nonintrusive Load Monitoring. arXiv 2017, arXiv:1612.09106. [Google Scholar]
- DIncecco, M.; Squartini, S.; Zhong, M. Transfer Learning for Non-Intrusive Load Monitoring. arXiv 2019, arXiv:1902.08835. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bougares, F.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Kazemi, S.M.; Goel, R.; Eghbali, S.; Ramanan, J.; Sahota, J.; Thakur, S.; Wu, S.; Smyth, C.; Poupart, P.; Brubaker, M. Time2Vec: Learning a Vector Representation of Time. arXiv 2019, arXiv:1907.05321. [Google Scholar]
- Krystalakos, O.; Nalmpantis, C.; Vrakas, D. Sliding Window Approach for Online Energy Disaggregation Using Artificial Neural Networks. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence—SETN ’18; ACM Press: Patras, Greece, 2018; pp. 1–6. [Google Scholar]
- Ebrahim, A.F.; Mohammed, O. Household Load Forecasting Based on a Pre-Processing Non-Intrusive Load Monitoring Techniques. In Proceedings of the 2018 IEEE Green Technologies Conference (GreenTech), Austin, TX, USA, 4–6 April 2018; pp. 107–114. [Google Scholar]
- Kolter, J.Z.; Johnson, M.J. REDD: A Public Data Set for Energy Disaggregation Research. In Proceedings of the Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA, USA, 21–24 August 2011; Volume 25, pp. 59–62. [Google Scholar]
- Murray, D.; Stankovic, L.; Stankovic, V. An Electrical Load Measurements Dataset of United Kingdom Households from a Two-Year Longitudinal Study. Sci. Data 2017, 4, 160122. [Google Scholar] [CrossRef] [PubMed]
- Zeidi, O.A. Deep Neural Networks for Non-Intrusive Load Monitoring. Master’s Thesis, MONASH University, Melbourne, Australia, 2018. [Google Scholar]
- Zhou, Z.; Xiang, Y.; Xu, H.; Yi, Z.; Shi, D.; Wang, Z. A Novel Transfer Learning-Based Intelligent Nonintrusive Load-Monitoring With Limited Measurements. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Mean | Std |
|---|---|---|
| Aggregate | 522 | 814 |
| Microwave | 500 | 800 |
| Refrigerator | 200 | 400 |
| Dishwasher | 700 | 1000 |
| Washing machine | 400 | 700 |
| Input window size | 599 |
| Maximum epochs | 100 |
| Batch size | 1000 |
| Patience of early-stopping | 5 |
| Learning rate | 0.001 |
| Appliance | Training Set | Test Set | ||
|---|---|---|---|---|
| House | Samples (M) | House | Samples (M) | |
| Microwave | 10, 12, 19 | 18.22 | 4 | 6.76 |
| Refrigerator | 2, 5, 9 | 19.33 | 15 | 6.23 |
| Dishwasher | 5, 7, 9, 13, 16 | 30.82 | 20 | 5.17 |
| Washing machine | 2, 5, 7, 9, 15, 16, 17 | 43.47 | 8 | 6.12 |
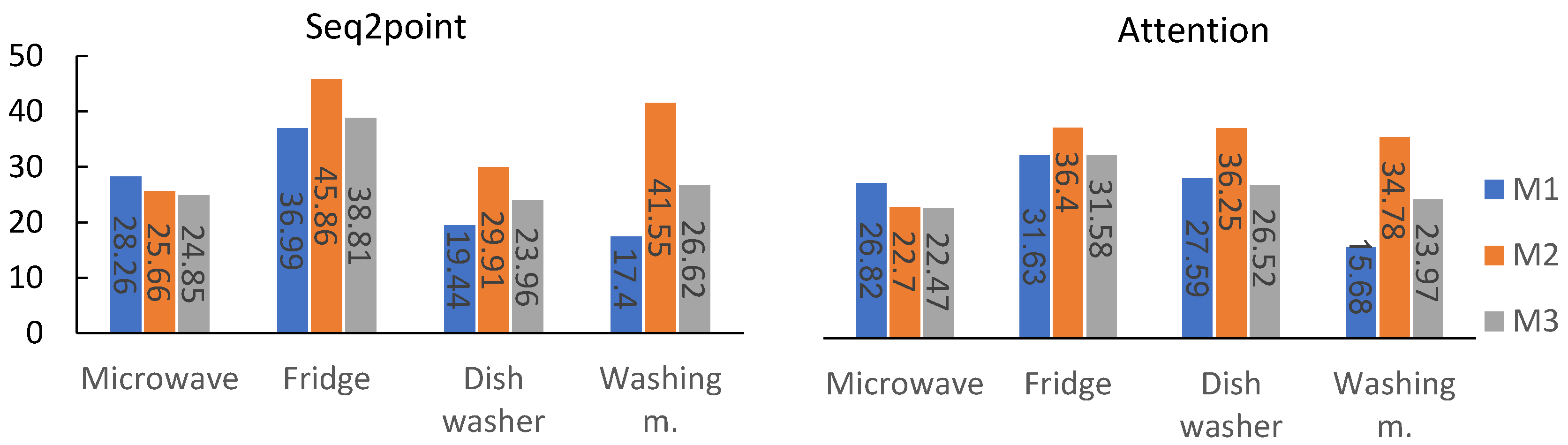
| Appliance | Trained on REDD Test on REDD | Pretrained on REFIT Test on REDD | ||||||
|---|---|---|---|---|---|---|---|---|
| Seq2point | Attention | Seq2point | Attention | |||||
| MAE | SAE | MAE | SAE | MAE | SAE | MAE | SAE | |
| Microwave | 28.26 | 0.1575 | 26.82 | 0.0889 | 25.66 | 0.2954 | 22.70 | 0.2331 |
| Refrigerator | 36.99 | 0.3168 | 31.63 | 0.2292 | 45.86 | 0.1897 | 36.40 | 0.0183 |
| Dishwasher | 19.44 | 0.3139 | 27.59 | 0.2565 | 29.91 | 0.7898 | 36.25 | 0.5370 |
| Washing m. | 17.40 | 0.1073 | 15.68 | 0.1204 | 41.55 | 0.5924 | 34.78 | 0.8437 |
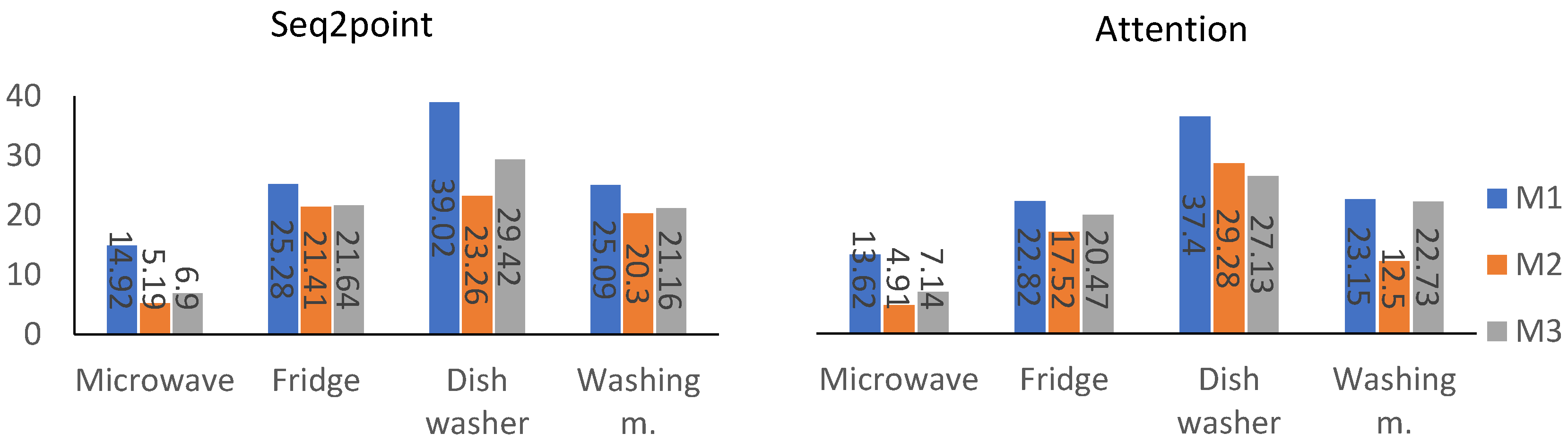
| Appliance | Trained on UK-DALE Test on UK-DALE | Pretrained on REFIT Test on UK-DALE | ||||||
|---|---|---|---|---|---|---|---|---|
| Seq2point | Attention | Seq2point | Attention | |||||
| MAE | SAE | MAE | SAE | MAE | SAE | MAE | SAE | |
| Microwave | 14.92 | 0.5146 | 13.62 | 0.4270 | 5.19 | 0.0601 | 4.91 | 0.0024 |
| Refrigerator | 25.28 | 0.3355 | 22.82 | 0.3123 | 21.41 | 0.1901 | 17.52 | 0.0172 |
| Dishwasher | 39.02 | 0.6837 | 37.40 | 0.5075 | 23.26 | 0.3515 | 29.28 | 0.2647 |
| Washing m. | 25.09 | 0.4881 | 23.15 | 0.7655 | 20.30 | 0.8073 | 12.50 | 0.5829 |
| Appliance | Pretrained on REFIT Fine-Tuning on REDD | Pretrained on REFIT Fine-Tuning on UK-DALE | ||||||
|---|---|---|---|---|---|---|---|---|
| Seq2point | Attention | Seq2point | Attention | |||||
| MAE | SAE | MAE | SAE | MAE | SAE | MAE | SAE | |
| Microwave | 24.85 | 0.1685 | 22.47 | 0.0499 | 6.90 | 0.4921 | 7.14 | 0.4042 |
| Refrigerator | 38.81 | 0.0138 | 31.58 | 0.1823 | 21.64 | 0.2127 | 20.47 | 0.2613 |
| Dishwasher | 23.96 | 0.4319 | 26.52 | 0.5062 | 29.42 | 0.4147 | 27.13 | 0.4552 |
| Washing m. | 26.62 | 0.2386 | 23.97 | 0.1236 | 21.16 | 0.4503 | 22.73 | 0.5540 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, M.; Liu, Y.; Liu, Q. Nonintrusive Residential Electricity Load Decomposition Based on Transfer Learning. Sustainability 2021, 13, 6546. https://doi.org/10.3390/su13126546
Yang M, Liu Y, Liu Q. Nonintrusive Residential Electricity Load Decomposition Based on Transfer Learning. Sustainability. 2021; 13(12):6546. https://doi.org/10.3390/su13126546
Chicago/Turabian StyleYang, Mingzhi, Yue Liu, and Quanlong Liu. 2021. "Nonintrusive Residential Electricity Load Decomposition Based on Transfer Learning" Sustainability 13, no. 12: 6546. https://doi.org/10.3390/su13126546
APA StyleYang, M., Liu, Y., & Liu, Q. (2021). Nonintrusive Residential Electricity Load Decomposition Based on Transfer Learning. Sustainability, 13(12), 6546. https://doi.org/10.3390/su13126546