Minutely Active Power Forecasting Models Using Neural Networks




Abstract
1. Introduction
2. Materials and Methods
2.1. Neural Networks and Performance Metrics
2.1.1. Multi-Layer Perceptron
2.1.2. Convolutional Neural Network
2.1.3. Long Short-Term Memory Network
2.1.4. Performance Metrics
2.2. Tools and Specifications
2.3. Dataset and Configuration
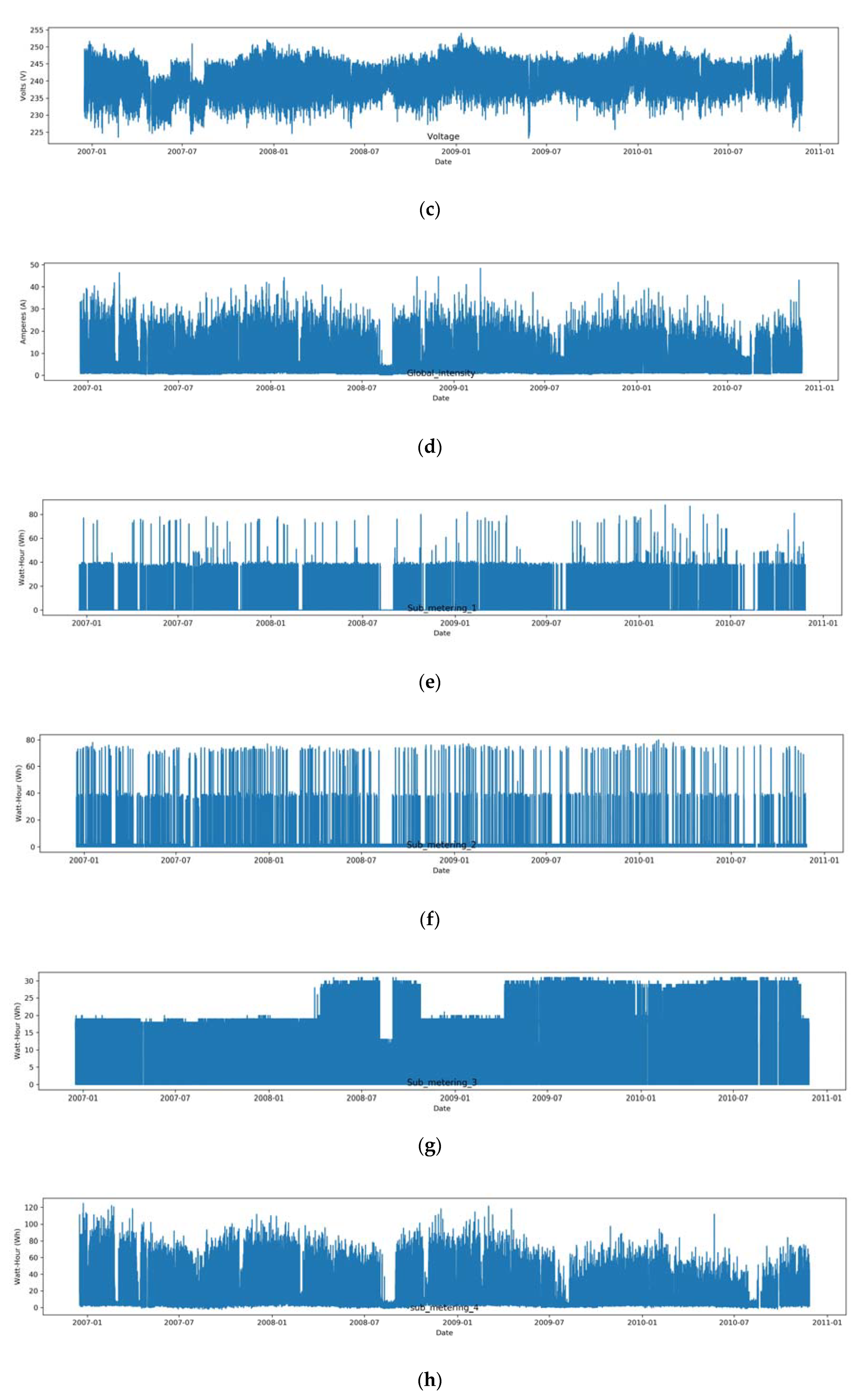
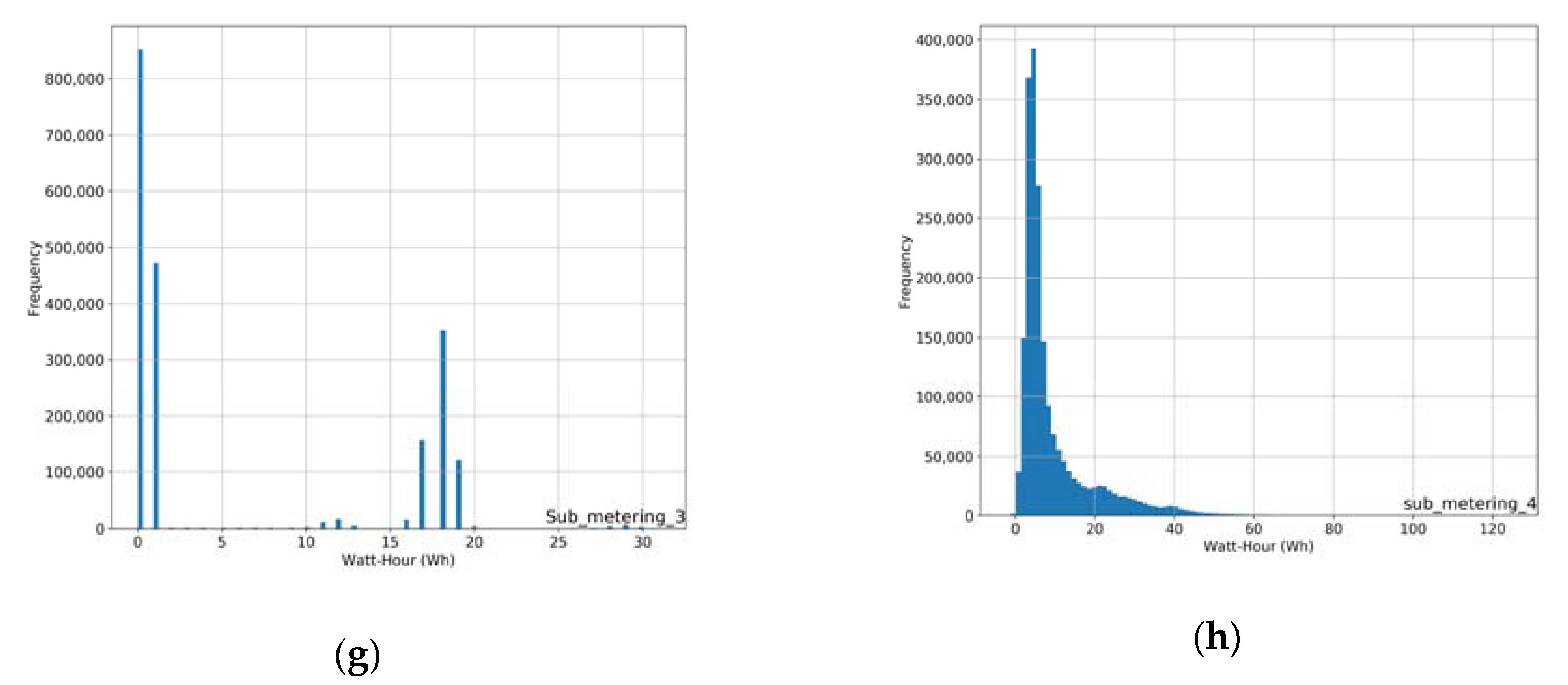
2.4. Data Exploration
2.5. Problem Formulation and Preprocessing
- Values of input features were scaled between [0,1]. Min-max normalization was used in that interval through the MinMaxScaler class of SkLearn since neural networks handle input features well when they are on the same scale and the interval remains small;
- Two input columns were created based on the sliding window method.
- The dataset was split by allocating the first three years of observations to the training set and the last year to the test set. Since the distribution of global active power remains consistently bimodal, we believe that this is a proper holdout validation split;
- The training and test sets were split in input and output columns reshaped as the 3D format (samples, timesteps, features) for CNN and LSTM and (samples, features) for MLP, since it expects a 2D format.
2.6. Neural Network Configurations
3. Results
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Magoutas, B.; Apostolou, D.; Mentzas, G. Situation-aware Demand Response in the smart grid. In Proceedings of the 2011 16th International Conference on Intelligent System Applications to Power Systems, Hersonissos, Greece, 25–28 September 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Rantou, K. Missing Data in Time Series and Imputation Methods. Master’s Thesis, University of the Aegean, Lesbos, Greece, 2017. [Google Scholar]
- Waser, M. Nonliniear Dependencies in and between Time Serie. Master’s Thesis, Vienna University of Technology, Vienna, Austria, 2010. [Google Scholar]
- Verleysen, M.; Francois, D. The Curse of Dimensionality in Data Mining and Time Series Prediction. Comput. Vis. 2005, 3512, 758–770. [Google Scholar] [CrossRef]
- Deep Learning for Time Series and Why DEEP LEARNING? Medium. 2020. Available online: https://towardsdatascience.com/deep-learning-for-time-series-and-why-deep-learning-a6120b147d60 (accessed on 26 March 2020).
- Hua, Y.; Zhao, Z.; Li, R.; Chen, X.; Liu, Z.; Zhang, H. Deep Learning with Long Short-Term Memory for Time Series Prediction. IEEE Commun. Mag. 2019, 57, 114–119. [Google Scholar] [CrossRef]
- Koprinska, I.; Wu, D.; Wang, Z. Convolutional Neural Networks for Energy Time Series Forecasting. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Shiblee, M.; Kalra, P.K.; Chandra, B. Time Series Prediction with Multilayer Perceptron (MLP): A New Generalized Error Based Approach. In Computer Vision; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5507, pp. 37–44. [Google Scholar]
- Alamaniotis, M.; Tsoukalas, L.H. Anticipation of minutes-ahead household active power consumption using Gaussian processes. In Proceedings of the 2015 6th International Conference on Information, Intelligence, Systems and Applications (IISA), Corfu, Greece, 6–8 July 2015; pp. 1–6. [Google Scholar]
- Singh, S.; Hussain, S.; Bazaz, M.A. Short term load forecasting using artificial neural network. In Proceedings of the 2017 Fourth International Conference on Image Information Processing (ICIIP), Waknaghat, India, 21–23 December2017; pp. 1–5. [Google Scholar]
- Kuo, P.-H.; Huang, C.-J. A High Precision Artificial Neural Networks Model for Short-Term Energy Load Forecasting. Energies 2018, 11, 213. [Google Scholar] [CrossRef]
- Hossen, T.; Nair, A.S.; Chinnathambi, R.A.; Ranganathan, P. Residential Load Forecasting Using Deep Neural Networks (DNN). In Proceedings of the 2018 North American Power Symposium (NAPS), Fargo, ND, USA, 9–11 September 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, D.; Han, X.; Deng, C.; Taiyuan University of Technology; China Electric Power Research Institute. Review on the research and practice of deep learning and reinforcement learning in smart grids. CSEE J. Power Energy Syst. 2018, 4, 362–370. [Google Scholar] [CrossRef]
- Kampelis, N.; Tsekeri, E.; Kolokotsa, D.; Kalaitzakis, K.; Isidori, D.; Cristalli, C. Development of Demand Response Energy Management Optimization at Building and District Levels Using Genetic Algorithm and Artificial Neural Network Modelling Power Predictions. Energies 2018, 11, 3012. [Google Scholar] [CrossRef]
- Koponen, P.; Hänninen, S.; Mutanen, A.; Koskela, J.; Rautiainen, A.; Järventausta, P.; Niska, H.; Kolehmainen, M.; Koivisto, H. Improved modelling of electric loads for enabling demand response by applying physical and data-driven models: Project Response. In Proceedings of the 2018 IEEE International Energy Conference (ENERGYCON), Limassol, Cyprus, 3–7 June 2018; pp. 1–6. [Google Scholar]
- Ahmad, A.; Javaid, N.; Mateen, A.; Awais, M.; Khan, Z.A. Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach. Energies 2019, 12, 164. [Google Scholar] [CrossRef]
- Walther, J.; Spanier, D.; Panten, N.; Abele, E. Very short-term load forecasting on factory level–A machine learning approach. Procedia CIRP 2019, 80, 705–710. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, Z.; Mourshed, M.; Li, K.; Zhou, Y.; Chang, Y.; Wei, Y.; Feng, S. Electric Vehicle Charging Load Forecasting: A Comparative Study of Deep Learning Approaches. Energies 2019, 12, 2692. [Google Scholar] [CrossRef]
- Deep Learning for Time Series Forecasting: The Electric Load Case, GroundAI. 2020. Available online: https://www.groundai.com/project/deep-learning-for-time-series-forecasting-the-electric-load-case/1 (accessed on 26 March 2020).
- Time Series Analysis, Visualization & Forecasting with LSTM, Medium. 2020. Available online: https://towardsdatascience.com/time-series-analysis-visualization-forecasting-with-lstm-77a905180eba (accessed on 14 February 2020).
- Neural Networks Over Classical Models in Time Series, Medium. 2020. Available online: https://towardsdatascience.com/neural-networks-over-classical-models-in-time-series-5110a714e535 (accessed on 14 February 2020).
- LSTM for Time Series Prediction, Medium. 2020. Available online: https://towardsdatascience.com/lstm-for-time-series-prediction-de8aeb26f2ca (accessed on 14 February 2020).
- UCI Machine Learning Repository: Individual Household Electric Power Consumption Data Set, Archive.ics.uci.edu. 2020. Available online: https://archive.ics.uci.edu/ml/datasets/individual+household+electric+power+consumption (accessed on 14 February 2020).
- Perceptron Learning Algorithm: A Graphical Explanation of Why It Works, Medium. 2020. Available online: https://towardsdatascience.com/perceptron-learning-algorithm-d5db0deab975 (accessed on 26 March 2020).
- Multilayer Perceptron—DeepLearning 0.1 Documentation, Deeplearning.net. 2020. Available online: http://deeplearning.net/tutorial/mlp.html (accessed on 26 March 2020).
- CS231n Convolutional Neural Networks for Visual Recognition, Cs231n.github.io. 2020. Available online: http://cs231n.github.io/convolutional-networks/ (accessed on 26 March 2020).
- LeNail, A. NN-SVG: Publication-Ready Neural Network Architecture Schematics. J. Open Source Softw. 2019, 4, 747. [Google Scholar] [CrossRef]
- Recurrent Neural Network—An Overview|ScienceDirect Topics, Sciencedirect.com. 2020. Available online: https://www.sciencedirect.com/topics/engineering/recurrent-neural-network (accessed on 26 March 2020).
- Understanding LSTM Networks—Colah’s Blog, Colah.github.io. 2020. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 26 March 2020).
- How to Select the Right Evaluation Metric for Machine Learning Models: Part 1 Regression Metrics, Medium. 2020. Available online: https://medium.com/@george.drakos62/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-1-regrression-metrics-3606e25beae0 (accessed on 26 March 2020).
- Dimkonto/Minutely-Power-Forecasting, GitHub. 2020. Available online: https://github.com/dimkonto/Minutely-Power-Forecasting (accessed on 15 February 2020).
- Ebeid, E.; Heick, R.; Jacobsen, R. Deducing Energy Consumer Behavior from Smart Meter Data. Futur. Internet 2017, 9, 29. [Google Scholar] [CrossRef]
- Brownlee, J. How to Develop Multi-Step LSTM Time Series Forecasting Models for Power Usage, Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/ (accessed on 16 February 2020).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; Available online: https://arxiv.org/abs/1412.6980v8 (accessed on 9 April 2020).
- An Intro to Hyper-Parameter Optimization Using Grid Search and Random Search, Medium. 2020. Available online: https://medium.com/@cjl2fv/an-intro-to-hyper-parameter-optimization-using-grid-search-and-random-search-d73b9834ca0a (accessed on 24 February 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scores | MLP | 1D CNN | Baseline LSTM | Baseline LSTM (Synchrony) | Stacked LSTM (No Dropout) | Stacked LSTM (Dropout 0.2) | Bidirectional LSTM |
|---|---|---|---|---|---|---|---|
| Train Score (Loss) | 0.00797 | 0.00846 | 0.00798 | 0.00826 | 0.00824 | 0.00839 | 0.00808 |
| Test Score (Loss) | 0.00670 | 0.00716 | 0.00672 | 0.00701 | 0.00689 | 0.00711 | 0.00677 |
| Neural Network Type | Average Training Time per Epoch (Seconds) |
|---|---|
| MLP | 20 |
| 1D CNN | 42 |
| Baseline LSTM (Synchrony) | 98 |
| Baseline LSTM | 120.25 |
| Stacked LSTM | 165.25 |
| Bidirectional LSTM | 269.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kontogiannis, D.; Bargiotas, D.; Daskalopulu, A. Minutely Active Power Forecasting Models Using Neural Networks. Sustainability 2020, 12, 3177. https://doi.org/10.3390/su12083177
Kontogiannis D, Bargiotas D, Daskalopulu A. Minutely Active Power Forecasting Models Using Neural Networks. Sustainability. 2020; 12(8):3177. https://doi.org/10.3390/su12083177
Chicago/Turabian StyleKontogiannis, Dimitrios, Dimitrios Bargiotas, and Aspassia Daskalopulu. 2020. "Minutely Active Power Forecasting Models Using Neural Networks" Sustainability 12, no. 8: 3177. https://doi.org/10.3390/su12083177
APA StyleKontogiannis, D., Bargiotas, D., & Daskalopulu, A. (2020). Minutely Active Power Forecasting Models Using Neural Networks. Sustainability, 12(8), 3177. https://doi.org/10.3390/su12083177