1. Introduction
Recently, smart city is a prospective research field to solve various urban problems [
1,
2] including city sustainability issues [
3,
4]. Context-awareness for cities is a basis of smart city applications and intelligent urban services [
1,
5,
6]. Most of the smart city applications have been focused on urban ecology issues [
3,
4] and infrastructure management [
1,
7]. However, regarding cities as living spaces of citizens, we should also consider economic, political, and cultural aspects of city sustainability [
8]. To solve the human-centric urban problems, we need contextual information intimately connected to citizens’ lives. To extract the information, various studies have been conducted on discovering social issues mainly from social media [
1,
5,
6,
9]. The social issues vary from citizens’ mutual interest (e.g., iconic movie directors or big sports games) to serious social problems (e.g., housing shortage and real estate bubble). However, those data sources have limitations for reflecting inner minds and feelings of citizens. First, flooding rumors and fake news on social media cause uncertainty for input data [
10]. Also, since social media are public places, users cannot ignore the public eyes during posting [
11,
12].
This study attempts to extract social issues from citizens’ consumption of narrative multimedia (e.g., movies, TV series, and novels) instead of social media. Narrative multimedia reflects social phenomena, and various studies attempted to analyze the reflected social issues computationally [
13,
14,
15]. Although we cannot analyze purchase histories or playlists of each citizen, context of the narrative multimedia industry (e.g., trends of genres or topics) will reveal subjects or issues that the citizens empathize with. Also, according to Jean Baudrillard [
16], consumption is the way modern society speaks for itself. However, these studies focused on a few particular issues and did not present methods for extracting general social issues automatically from large corpora. Also, we cannot merely apply the existing social issue discovery methods [
9]. These methods are mostly based on term frequencies and sentiment analysis. However, most of the proper nouns and named entities in narratives are imaginary things, and diverse literary, figurative, and rhetorical expressions in them hinder accuracy of the sentiment analysis.
We improve these problems by restricting our data sources into subculture narrative multimedia (e.g., web novels, webtoons, etc.). For social issue discovery, subculture narratives have two strong points, (i) frequent interactions between authors and customers and (ii) distinct genres, compared to the conventional ones. Most of the subculture works are published serially through web platforms (e.g., NAVER SERIES (
https://series.naver.com/), Kakao Page (
https://page.kakao.com/), and so on) that provide community spaces for their users (both authors and consumers). The users discuss each episode’s content, and the discussions are a part of subculture authoring [
17,
18,
19]. Some authors ask consumers’ comments for stories, explain characters’ behaviors, give hints for further stories, and open contests for titles of their works or character names. The authors are also enthusiastic consumers of other authors, and some readers try to author and post their drafts. These points make the subculture multimedia reflect social issues more agilely and vividly than the conventional narrative multimedia.
Second, genres of subculture works are more distinct than of the conventional multimedia [
20,
21]. Subculture works describe imaginary worlds, and each genre shares common imaginings (subjects). The authors create their works by adding a few inventive subjects to the shared ones. Sometimes, a good blending becomes a new genre. The authors state genre characteristics included in their works, and their readers also ask the authors to follow practices of the genres.
To attract readers’ attention, authors attempt to put subjects related to popular issues in the real-world. The distribution environment makes this reflection of social issues close to real-time. For example, a Korean movie director, Bong Joon-ho, won Academy awards in January 2020, and his winnings were a massive issue in Korea. In Munpia (
https://www.munpia.com/), one of the most popular web novel platforms in Korea, we found ten web novels that employ movie directors as protagonists. Seven of them started being published in 2020, and only three web novels started before the winnings. These novels are included in a genre, 연예계물 (Entertainment Fiction).
‘재벌 (chaebol)’ and ‘–수저 (– spoon)’ are symbolic terms of inequality issues in Korea. Chaebol indicates affluent families that control large conglomerates. ‘– spoon’ is originated from an English expression, silver spoon, that indicates inherited wealth. Korean citizens use this term to describe their inherited social classes like 금수저 (golden spoon) and 흙수저 (dirt spoon) (
https://www.nytimes.com/2019/10/21/world/asia/south-korea-cho-kuk-gold-spoon-elite.html).
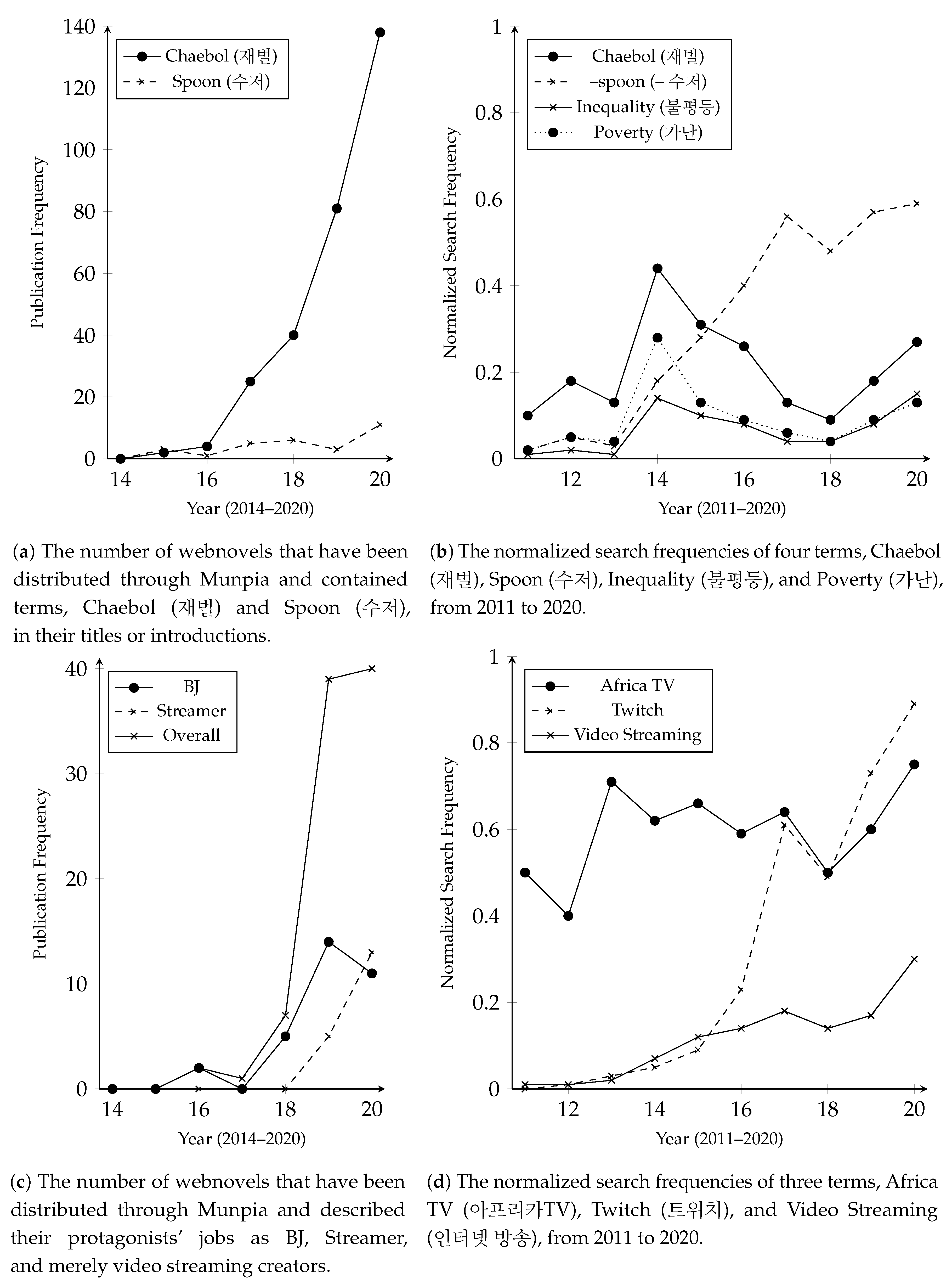
Figure 1a presents the number of web novels that have been distributed through Munpia and contained the two terms in their titles or introductions each year (2014–2020).
Figure 1b shows normalized search frequencies of 재벌 (chaebol), –수저 (– spoon), 불평등 (inequality), and 가난 (poverty) in Korea, which were collected from Google Trends (
https://trends.google.com/trends). The search frequencies of ‘chaebol,’ inequality, and poverty showed peaks in 2014, and the frequency of ‘– spoon’ was steadily increasing since 2013. Web novels containing the two terms also appeared around 2014 and have been consistently increasing. Moreover, the search frequency of ‘– spoon’ and the number of web novels containing ‘– spoon’ commonly showed temporary decrements around 2018. ‘Chaebol’ is related to a genre, 기업물 (Business Fiction).
With the commercial success of video streaming platforms (e.g., YouTube, Twitch, Africa TV, etc.), a new genre, streamer fiction (스트리머물), has been popularized. This genre uses video streamers as protagonists. The streaming platforms have different names for calling video streamers. Africa TV uses BJ (Broadcasting Jockey), Twitch uses Streamer, and so on. Also, web novel writers use these various names for calling video streamers. We have examined whether streaming platforms’ popularity has correlations with usage frequencies of those names in web novels. Africa TV and Twitch were the first and second most popular video streaming platforms in Korea, and Twitch has overtaken Africa TV in terms of their search frequencies in 2019, as shown in
Figure 1d. When video streaming started becoming popular, most of the streamer fiction called their protagonists ‘BJ.’ However, after Africa TV and Twitch got similar search frequencies, the web novel authors started avoiding usages of terms related to particular video streaming platforms, as shown in
Figure 1c. In the same period, the usage frequencies of ‘Streamer’ have been increased dramatically and have overtaken ‘BJ’ in 2020.
These examples underpin that subculture narratives reflect social issues, and we can discover the reflected issues from trends of genres. Although the subculture is resistance against hegemony, according to Dick Hebdige [
22], we do not focus on only critical issues. Since vicarious satisfaction is one of the significant reasons for subculture consumption, subculture works describe stories that their protagonists achieved social desires (e.g., becoming Chaebol, famous video streamer, professional gamers) as much as they suffered by and broke down social irregularities (e.g., inequality, bureaucracy, aristocracy, and so on). Thus, this study aims at discovering social issues that are reflected due to (i) interactions between authors and readers, (ii) pursuits of popularity, and (iii) vicarious satisfaction, not interpreting artistic intentions of authors.
The conflicts and desires can be guidelines for decision makings in various smart city applications. However, social issues discovered from subculture narratives will be extremely varied, as shown in
Section 4. Thus, the issues should be distilled to be used for a particular smart city application. For example, it is not easy to find connections between the popularity of streamer fiction and the smart grid. Although this study does not cover refining the issues for a specific application, we can discuss candidate applications that can employ the discovered social issues.
In data-driven policymaking, occurrence frequencies of discovered social issues and emotional words appearing with the issues can reveal policy demand and urgency for handling the issues. For example, laws for regulating content of video streaming have been absent in Korea, despite its massive influence. Korean national assembly has started discussing the regulation after a national scandal for video streamers’ undisclosed ads (
https://www.koreatimes.co.kr/www/tech/2020/08/133_294254.html). However, as shown in
Figure 1c, genre trends of web novels have said exponentially growing influences of video streaming since 2016. This point is also closely connected with market trend analysis and business intelligence.
Figure 1c presents the rapid chase of Twitch against Africa TV, which is reflected in the webnovel production. Even possession fiction, a recently popular genre, contains criticisms for the subculture industry trends. Furthermore, the proposed methods can be used in other social science studies. There have been studies for analyzing social issues reflected in narrative multimedia [
14,
15,
23]. However, their methods were not designed for the social issue discovery; e.g., the conventional Word2Vec [
24]. This study will provide more sophisticated tools for dealing with narrative multimedia and social issues.
Therefore, this study proposes methods for discovering social issues by analyzing trends of subculture genres automatically. First, we discover key subjects of genres by concentrating on that subculture works in each genre share a unique imaginary world. Since the main subjects are key components of the imaginary world, terms indicating the subjects frequently occur in the subculture works. Also, subculture communities make neologisms or change meanings of existing words to call the subjects that are parts of the imaginings [
20]. Thus, the terms for key subjects (keywords) have different meanings between subculture works and general texts. We use the frequency and semantic difference of words to distinguish keywords from the other words.
The two assumptions for discovering subjects can also be used to measure membership degrees of subculture works for each genre. If a subculture work is in a genre, keywords of the genre will occur in the subculture work frequently and have the same meaning in both the work and the other works in the genre. Using the membership degrees, we can conduct multi-label genre classification for subculture works. Also, subculture genres are continuously evolved and differentiated. Novel genres are born by adding new and attractive subjects to existing genres. Thus, by tracing the inheritance of subjects, we can build a genealogy tree of subculture genres. Correlations between imaginary worlds might be correlations of reflected social phenomena, and the genre genealogy reveals both correlations.
Finally, subjects that correspond to social issues come from the real world rather than imaginings. Although artistic narrative works employ symbols, figurative expressions, and mise-en-scène to criticize the issues (e.g., vertical movements symbolize social classes in ‘Parasite (2019)’), subculture works are more straightforward than the conventional narrative works. Therefore, different from searching imaginary subjects, we discover subjects correlated with the social issues from a genre by searching for words that have the same meanings in both the genre and general texts. Using the discovered issues and the genre genealogy, we can detect social phenomena and understand changes in our society.
To verify the proposed methods, we conducted experiments on Korean web novels. In Korea, various platforms are distributing subculture works (mainly webtoons and web novels) online. Recently, these platforms (e.g., NAVER SERIES and Kakao Page) are extending their customer range to general users, not only subculture mania. Thus, the subculture multimedia reflect Korean society enough to evaluate whether the proposed methods can extract social issues in Korean society. We chose web novels among the two popular subculture multimedia, since extracting terms from textual media is much easier than from graphical one. Based on the case study in Korean web novels, we validate the following research questions:
RQ 1. Word semantic difference between subculture works and general texts is effective to detect imaginary subjects of subculture genres.
RQ 2. Inheritance of the subjects is useful to trace the differentiation of subculture genres.
RQ 3. Contrary to RQ 1, semantic consistency of words can distinguish subjects satirizing social issues from the others.
The remainder of this paper is organized as follows.
Section 2 presents related studies mainly conducted in the computational narrative analysis and the digital humanities.
Section 3 proposes methods for (i) detecting main subjects of subculture genres, (ii) classifying subculture works into the genres, (iii) building the genre genealogy tree, and (iv) discovering social issues criticized by the genres. We evaluate the proposed methods and validate our assumptions in
Section 4. Finally,
Section 5 describes limitations and future directions of this study.
2. Related Work
To the extent of our knowledge, there have not been studies proposing automated methods for discovering social phenomena reflected in narrative multimedia. Content analysis of subculture multimedia has also not been frequently studied. Braincolla (
https://braincolla.com/) is a company that provides a recommendation engine for one of the Korean subculture platforms, Joara (
http://www.joara.com/main.html). Similar to this study, the recommendation engine statistically analyzes occurrences of words to examine subjects and backgrounds of subculture works. Although this engine has been operated on the commercial platform, there has not been any academic publication covering detailed procedures and performance evaluation of the recommendation engine.
A few studies based on Chinese web novels presented features that can be applied to our research. Su [
25] analyzed code-switching (i.e., a word in a language appears among words in other languages) in Chinese web novels. He conducted a statistical analysis for usages of the code-switching according to web novel genres. The analysis shows that the code-switching frequencies are correlated with genres and historical backgrounds of web novels. Although he also presented examples for code-switching purposes, the purposes were closely connected with characteristics of the Chinese language and writing system. However, we could find frequent code-switching in Korean web novels, and it was mainly used for clarifying meanings of imaginary subjects by showing two languages together (e.g., “파이어볼 (Fireball)”). Although this feature’s meanings might depend on languages, it can help improve the accuracy of genre classification and keyword extraction. Lin and Hsieh [
26] attempted to find which factors make a web novel popular. They used mainly three features, keywords extracted based on TF-IDF, usages of function words, and lexical diversity. Although they could not find correlations of these features with popularity features (e.g., the number of hits, favorites, and comments), the proposed features were genres and writing styles of web novels.
Additionally, a study had a similar purpose to this study. Jo and Oh [
23] attempted to discover web novel readers’ inner desires from hashtags annotated on web novels. However, their method also cannot support the automated social issue discovery. They applied TF-IDF (Term Frequency-Inverse Document Frequency) to hashtags annotated by an online book store (Ridibooks) and conducted qualitative discussions based on the TF-IDF values.
The existing studies on the computational narrative analysis mostly focused on conventional narrative multimedia, such as movies, novels, and TV series [
27,
28,
29]. Also, these studies aimed at analyzing storytelling methods rather than subjects and backgrounds; e.g., plot structures [
29,
30,
31], character roles [
32,
33], major events [
34,
35,
36], and so on. Although a few studies [
37,
38] attempted to classify narrative works into genres, they were also based on interactions among characters, which are related to narrative development rather than subjects. Since these studies aimed at analyzing individual narrative works, their approaches are not appropriate to discover macroscopic events from narrative multimedia.
On the other hand, various digital humanities studies attempted to analyze social phenomena reflected in narrative multimedia, despite absence of systematic and automatic methods. Michel et al. [
13] analyzed word usages in millions of books to discover cultural changes. They interpreted temporal distributions of correlated words by comparing the distributions with each other. Peaks of the distributions revealed social events, and their differences between languages (or nationalities) showed cultural differences or information propagation (e.g., Tiananmen in Chinese and English). Their study was meaningful in terms of demonstrating effectiveness of quantitative multimedia analysis as a tool for analyzing social phenomena.
A few studies concentrated on a more specific problem: social equality. Grayson et al. [
14] analyzed gender roles reflected in the 19th-century novels by using word embedding techniques. They examined semantic differences of words in the novels according to genders of authors, and the differences were significant in gendered pronouns. Although their study did not accompany a statistical validation, we referred their approach to compare genres. Chen and Cui [
15] dealt with gender bias in movies by applying social network analysis (SNA) techniques to the movies. They analyzed social relationships and dialogues between characters, considering the characters’ genders. Using the analysis results, they predicted whether movies can pass the Bechdel test and observed changes in gender bias according to time. According to their results, gender bias issues have been improved during the last few decades. Caty Borum Chattoo [
39] analyzed Academy Awards winners to show gender, racial, and ethnic equality issues. Although the analysis did not cover movies’ content, the significant gaps between genders and between races indicated that the media industry is sensitive to social phenomena for better or for worse. As Chen and Cui [
15] said, narrative worlds in artworks are a microcosm of the real world.
There have also been studies attempted to analyze large-scale artwork corpora but not aimed at social issues. Although these studies are not directly correlated with our study, their approaches can be applied to further research on subculture multimedia. Chae et al. [
40] have proposed methods for clustering artworks according to their content by using social tags. They built networks of artworks based on shared social tags between the artworks and applied network analysis techniques. Since subculture genres are also a kind of social tag for subculture works’ content, this approach and our study have a common point: understanding the content of artworks by analyzing a combination of social tags. However, this approach does not cover what kinds of features in artworks are correlated with each social tag, while it is the most primary concern of our study.
Park et al. [
41] measured novelty of artworks by analyzing their citation networks. Their method exhibited effectiveness in detecting paradigm-shifting between genres of classical music. Although it is difficult to detect references between artworks in other kinds of media, we can apply this approach to exploit the propagation of imaginary subjects between subculture works. The propagation will enable us to analyze genre differentiation microscopically and discover landmark pieces that laid cornerstones of each genre.
Jung et al. [
42] attempted to analyze relationships among narrative works that share a common narrative world. They classified connections between narrative works according to how the works extend the narrative world, based on characters and events that commonly appeared in the works. Since subculture genre differentiation is led by adding fresh subjects into shared imaginary worlds of each genre, this approach can be used to observe births of new genres, similar to the above study [
41]. However, it is not easy to distinguish imaginary subjects from named entities. Although our proposed methods dilute the problem by examining whether the subjects appear all over the genre, this solution is too rough to be applied to a single artwork.
In terms of analysis methods, there have been mainly two approaches: (i) information retrieval (IR) and simple natural language processing (NLP) techniques and (ii) SNA techniques. Word embedding and topic modeling techniques were frequently used to analyze the semantics of words in narrative artworks. Grayson et al. [
43] conducted Word2Vec [
24] for all the words in the artworks, including character names. They assumed that characters with similar roles have similar locations in the embedding space. Peng and Jung [
44] applied LDA (Latent Dirichlet Allocation) to discover metaphorical expressions from Chinese poems. Similar to our proposed methods, they assumed that metaphorical expressions have different meanings between the poems and general texts. Also, sentiment analysis was applied to interpret the metaphorical expressions by searching for words with similar sentiments. Reagan et al. [
29] used fluctuations in frequencies of emotional words to compare storytelling methods of narrative works. However, their study did not validate whether the fluctuations have correlations to readers’ perception of the narrative artworks’ content. For the similar purpose, Micha Elsner [
31,
45] employed occurrence frequencies of characters together.
Various studies have been conducted for extracting social networks in narrative artworks and discovering narrative features from the social networks [
46]. These studies extracted the social networks from texts [
47,
48], videos [
33,
49,
50], or both of them [
51,
52]. A few studies applied sentiment analysis to enrich the social networks [
34,
53]. Node centrality on the networks reflected character roles [
33], structures of the social networks were correlated to major events in stories [
34,
35,
36], changes in the structures had relevancy with fluency of stories [
54], and occurrence frequencies of characters showed plot structures [
30,
31]. These extracted narrative features were applied to mainly summarization [
50,
55,
56].
Over the analysis within a single story, a few studies attempted to compare narrative works in terms of their stories. Early studies [
57,
58] used conventional features in SNA, such as cohesion of communities and node centrality. However, the conventional features are not enough to reflect various structural characteristics of the social networks. Also, it is difficult to conjecture what kinds of narrative characteristics are reflected by the conventional features. Therefore, a few recent studies [
27,
30,
59,
60] applied graph embedding techniques to compare stories using simple vector similarity metrics.
Since our study currently does not cover narrative features of subculture works, only subjects, the existing studies in the computational narrative analysis do not have many points that can be applied to this study. However, stories are one of the most significant components composing narrative multimedia as much as subjects and physical expressions. Thus, if subculture works in the same genre share imaginary worlds, which are formulaic and typical, there will also be distinct common points in their storytelling methods. In further studies, the narrative features will be combined with the proposed genre analysis methods.
3. Discovering Social Issues from Subculture Multimedia
Narrative artworks reflect our society. Narrative worlds come from the real world, and events in the imaginary worlds reflect our social issues. A few studies [
14,
15,
39] attempted to analyze social equality issues reflected in the conventional narrative multimedia (e.g., movies). However, there have not been methods for extracting social issues form narrative works automatically. Most of the narrative works do not directly state what they criticize. For example, realism authors (e.g., Stendhal and Honoré de Balzac) stand back and describe a sequence of events realistically. Nevertheless, the state-of-the-art techniques in the computational narrative analysis do not even come close to interpreting the events’ superficial meanings (needless to say comprehension of what the events satirize and criticize). On the other hand, subculture narrative works are far more straightforward than the conventional ones. Their subjects and backgrounds are tightly correlated to what they criticize or desire.
Therefore, we first classify subculture works into their genres, which are groups of works sharing key subjects. Since most subculture works deal with imaginary worlds, the subjects can be discovered by searching for words used in different meanings from general texts. The subculture genres have short life-cycles and are differentiated according to time. Thus, we represent the differentiation of genres as a genealogy tree. Finally, social issues that correspond to each genre can be detected by examining words used in similar meanings to the general texts, since targets of desires and criticism should co-exist in both real and imaginary worlds. Moreover, we can trace diachronic changes in social issues and analyze correlations between the issues by combining the social issues and the genealogy tree.
3.1. Genealogy Tree of Genres
Subculture genres mostly start from a monumental work, thrive by numerous imitators, and lose popularity by other genres’ advents. The new genres are differentiated from existing ones, and boundaries between the genres are not always distinct. However, we still have a clue. The subculture communities give names to the genres, and the authors and readers tag those genre names on each work. In Korean subculture communities, the names are in a format of ‘–물 (a suffix used to indicate an object, an entity, or a material)’ [
20]. For example, in return fiction (회귀물), protagonists go back to the past and try to live a perfect life by avoiding all mistakes made at their previous trials. Game fiction (게임물) uses famous video games (e.g., League Of Legends) as its background. This genre connects successes in the games to success in real life. These genres are commonly based on dissatisfaction for real life.
Similar to the examples, subculture works in the same genre share key subjects and backgrounds. The game fiction and its branches include game-originated subjects, such as ‘quests,’ ‘levels,’ ‘dungeons,’ and so on. As key components of their imaginary worlds, these terms have similar meanings in the genres and different meanings between the genres and the others. Based on the semantic difference, we define the subculture genre as follows;
Definition 1 (Subculture Genre).
The genre indicates a group of artworks that share subjects, ambiances, backgrounds, types of narrative development, physical expressions, and so on. Although the genre covers various narrative characteristics, the subculture communities use this concept to distinguish subculture works according to their key subjects and backgrounds. Thus, subculture genres have a group of words, which are correlated with their shared subjects and have unique meanings in the genres. The relationship between subculture works and genres can be formulated as:where indicates a membership degree of the a-th subculture work for the i-th genre , θ denotes a minimum threshold for the membership degree, refers to a set of words that are related to essential subjects of , is a function for measuring semantic difference between the n-th word in and in , and indicates an occurrence frequency of in .
Vicarious satisfaction is one of the significant reasons for subculture consumption. Thus, subculture works reflect desires or conflicts in the real world, and their subjects will be what authors (and readers) want to achieve or break down. Thus, the rise and fall of genres can show diachronic changes in social issues. To analyze the changes, we build the genealogy tree of genres to trace roots and branches of the genres and related social issues.
When a genre is differentiated from existing ones, the novel one inherits subjects of the existing ones. The inheritance reveals whether two genres are relatives, and their publication frequencies show which genre is an ancestor of the other. For example, possession fiction (빙의물) describes protagonists that suddenly became a fictional character of video games or web novels. Both possession fiction and game fiction commonly include lots of game-originated subjects. Their protagonists commonly get ‘achievements,’ raise their ‘levels,’ and clear ‘quests.’ The shared subjects let us know the two genres are relatives. However, recently, possession fiction has a higher publication frequency than game fiction. Also, game fiction was popularized much sooner than possession fiction (the 2000s and 2010s, respectively). Thus, we can assume that game fiction is one of the ancestors of possession fiction. Using the inherited subjects and publication frequencies, we define the genre genealogy tree as follows;
Definition 2 (Genealogy tree).
The genre genealogy tree indicates a hierarchical, directed, and acyclic graph for presenting differentiation of genres. A genre is established by mixing and extending its parent genres. Thus, we can understand new genres using an assumption that the children inherit characteristics (e.g., subjects and backgrounds) of their parents. If two genres have a parent-child relationship, we can detect it from shared subjects between the two genres. Then, we designate a popularized genre sooner than the other one as a parent and vice versa. When is a genealogy tree of a genre set , can be defined as a matrix representing relationships between genres and a vector describing layers of the genres . This can be formulated as:where refers to the set size, indicates a relationship of for , and means that is on the -th layer. When is a parent of , and ; otherwise . Also, if , , and is a natural number .
Based on these definitions, the following sections introduce methods for (i) discovering key subjects of genres, (ii) classifying subculture works into the genres, and (iii) revealing roots and branches of the genres.
3.1.1. Extracting Genre Keywords
A considerable number of subculture works have genre annotations labeled by their authors (or editors). The annotations are significant to readers’ first impressions of the works. Although the readers can evaluate writing styles or narrative development after reading the works, the genres let the readers know whether the subculture works deal with their preferable subjects. Also, we can label subculture works by using readers’ comments in subculture communities or platforms. In this study, we have collected 200 web novels, and 117 of the 200 novels have genre annotations.
From the annotated novels, we can discover each genre’s keywords, which are related to common subjects, backgrounds, or character types of the genre. The keywords correspond to components of shared imaginary worlds in the genre. Therefore, most of the keywords (i) are neologisms or (ii) have semantic differences between usages in general texts and in subculture works. Since a few genres (e.g., the apocalypse fiction or picaresque fiction) have unique ambiances, (iii) emotional words can also be the keywords.
Peng and Jung [
44] estimated the semantic difference of words between poems and general texts using LDA. If we compare narrative works with general texts, occurrence frequencies of words, which are the basis of LDA, will clearly show their difference. However, the subculture genres are differentiated and evolved according to time. Keywords of the genres will be inherited to their children with little changes in their meanings. Therefore, we should observe semantic relationships between words more finely than document-level co-occurrences.
Therefore, we use the representation learning instead of topic modeling. If a word has different meanings between a general text corpus and a subculture multimedia corpus, relative distances of to other words in the embedding space will differ between the two corpora. Also, if the word has consistent meanings only among artworks in a genre , we can assume that is a keyword of . Finally, keywords of have high occurrence frequencies in a subculture work , when is a member of .
The Skip-Gram method of Word2Vec [
24] is used for embedding words in both general texts and subculture works. Since Skip-Gram is well-known and widely-used, we do not explain its procedures in detail. We first embed words in a general text corpus (e.g., Wikipedia dump (
https://dumps.wikimedia.org/backup-index.html) or news articles) and use word vectors as pre-trained vectors for embedding the words in subculture works. Thus, a word
gets multiple vector representations from embedding for the general texts (
) to embedding for a subculture work
(
). Additionally, we use introductions and comments for the subculture works collected from subculture platforms and written by their authors and readers, together for embedding words in each subculture work. The interactions in subculture platforms could contain more concise explanations for the imaginary worlds than literary expressions in the subculture works.
Semantic similarity between words within a corpus is estimated by using the cosine similarity of word vectors. Then, a semantic difference for a word between two corpora is measured based on the similarity. When
indicates a universal set of words, the semantic similarity between words can be represented as:
where
and
indicate semantic similarity between
and
in the general text corpus
G and in
, respectively. When
refers to the
n-th row of
, we can compare the meaning of
in
G with in
by comparing
with
. A semantic distance between
in
G and
in
can be formulated as:
To discover keywords of
, we search words that have low semantic distances among subculture works included in
and high semantic distances between members of
and the other subculture works. This approach is similar to the feature selection for clustering. When
is a feature set, we have to find words that maximize inner-compactness of
and minimize outer-adjacency of
. To reduce search spaces, we focus on (i) words that have not appeared in
G (neologisms), (ii) nouns/noun phrases excluding pronouns, and (iii) emotional words/phrases (discovered by using a dictionary (
https://github.com/park1200656/KnuSentiLex)). Also, the keywords of
should frequently occur in most members of
, not in the other genres. An objective function for searching keywords consists of two parts. First, outer-adjacency of
for
can be measured as:
The first and second terms assess semantic differences of
between general texts and
and between the other genres and
, respectively. The last term examines whether
is a usual term regardless of genres. Also, the frequency can filter insignificant named entities (e.g., names of characters and places). Then, inner-compactness of
for
can be measured as:
The first term has a low value when indicates the same concept in all subculture works of . The other term examines whether has high occurrence frequencies on allover . Among words appeared in , we find that minimizes .
When is a keyword set of , defining a threshold is the simplest way for composing , such as . However, genres evolve and branch according to time, and keywords of old genres will not show enough cohesion because of being inherited to their descendants. Therefore, we set individual thresholds for each genre by using distributions of ; , when , , and are a threshold, arithmetic mean, and standard deviation of for all the words, and is a weighting factor. We have empirically searched according to the accuracy of the genre classification in a range with a step size . And, has been set as .
3.1.2. Classifying Subculture Works into Genres
Based on the keywords of genres, we can classify unlabeled subculture works. Even if a subculture work has genre characteristics not annotated by its author (or editor), we can detect the omitted annotations. The same approaches to the keyword search are applied to the classification. Equations (
5) and (
6) assess whether the keywords have the unique and shared meanings in a genre. In the classification, if keywords of a genre have the same meanings in a subculture work, the subculture work will be a member of the genre. Also, the keywords should have enough frequencies in the subculture work.
Subculture works contain characteristics of multiple genres, and their membership degrees are not uniform for the contained genres. Thus, Equation (
6) is modified to measure the appropriateness of subculture works for each genre, not of keywords. We compare the target subculture work with other works, based on explicit genre annotations given by their authors (or editors). The membership function can be formulated as:
If is bigger than a threshold , we determine that has a characteristic of . We assign independent thresholds for each genre by searching cut points that maximize the classification accuracy with a step size . The accuracy is assessed by score for emphasizing recall than precision. Subculture works contain characteristics of various genres. Authors might intend most of the genre characteristics, but some could be flowed in unintentionally while imitating other popular pieces. Thus, we focus on what we should find rather than what we have already known.
3.1.3. Building Genealogy Trees of Genres
Shared keywords between genres indicate that the genres share subjects. These genres might be ancestors and descendants, but we do not know exact relationships between them. We find the relationships of genres using the following heuristics;
Semantic distance: Let suppose that , , and share keywords. If the keywords have more similar meanings in and than in and , the shortest path between and should have fewer hops than the shortest path between and .
Differentiation of genres: If is an ancestor of , will have more other keywords excluding inherited ones from .
Life cycles of genres: The creation of subculture works is focused on trendy and popular genres. The temporal distribution of published works in each genre reveals when the genres are spotlighted and faded away. If was popular sooner than the other ones, would be their ancestors.
To measure the semantic distance between genres, we recompose vector representations of words. In
Section 3.1.1, the word embedding was conducted for each subculture work. We compose word vectors for each genre by considering membership degrees of subculture works for genres (Equation (
7)), since subculture works are mixtures of multiple genres. We aggregate word vectors for subculture works using a weighted average, where weighting factors are the membership degrees. This can be formulated as:
By comparing
with
, we can examine semantic distance between
in
and
in
. The semantic distance is measured by the same method with the keyword extraction (Equations (
3) and (
4)).
To compare
with
, common keywords between them (
) will be the most significant, and the other keywords (
) and the remaining words (
) might be the second and last, respectively. Therefore, we apply individual weighing factors to the three groups. Semantic distance between genres can be measured as:
where
and
are the weighting factors for the shared and remaining keywords, respectively. We have empirically searched
and
according to the accuracy of building the genre genealogy tree in a range
with a step size
. The weighting factors have been set as
and
.
To draw the genealogy tree, we first compose a network, which has genres as nodes and their semantic distance as edges. The tree is revealed by deleting unnecessary edges and assigning levels on the nodes. The temporal distributions of genres determine directions of the edges. We compose the Gaussian distribution of monthly publication frequencies of each genre:
. Then, if
, head of an edge between
and
is
. Also, when
is in a range
, and
satisfies the same condition for
, we suppose that
and
are in the same generation (
in Equation (
2)). Genres in the oldest generation are assigned on level 1, and the others are labeled according to the descending order of their generation.
The genre genealogy tree allows multiple parents and children. Thus, merely deleting edges except the smallest semantic distance is not an adequate approach. We focus on that genealogy trees cannot have cyclic paths. We first reduce edge density in the network by deleting edges with bigger semantic distances than median distance (). Subsequently, we search cyclic paths and delete edges with the largest semantic distance in the paths.
The subculture genres come from a few origins (e.g., myths, J. R. R. Tolkien, Jules Gabriel Verne, Lewis Carroll, Jin Yong, and so on) and are born under influences of multiple fore-parents. Therefore, the genealogy tree should allow multiples paths between two nodes. However, at the same time, complicated connections between neighboring nodes are not desirable. We solve this problem by using intersections between keyword sets and reserving longer paths as possible. First, we delete one-hop connections among genres on the same level. If two similar genres were popular in the same period, they might be branches of the same parents, rather than one gives birth to another. Then, we examine parents of each genre and common ancestors of the parents. When has two parents and , procedures for deleting meaningless connections are as follows;
- 1.
Check whether and have common ancestors.
- 2.
If and share common ancestors, search the closest common ancestor.
- 3.
When is the closest common ancestor, examine inheritance of keywords by comparing , , and with each other.
- (a)
If and , delete the connection between and , and vice versa.
- (b)
If and , accept both of them as parents of .
- (c)
Otherwise, if , delete from the path between and (same for ).
These procedures check whether parent genres have remained a distinctive legacy to their children. We iteratively conduct the procedures, until there are no more edges to delete.
3.2. Correlations of Genres with Social Issues
To discover subculture genres and their genealogy, we have concentrated on words used in different meanings from the general texts, since subjects and backgrounds of subculture works are imaginary. However, targets of social desires or grievances will be the ones that exist in the real world. Authors, readers, and characters in the subculture works will show intense emotions for those targets, whether the emotions are positive or negative. For example, the game and professional gamer also exist in the real world, and they mostly have similar meanings in both game fiction (게임물) and the general text corpus. The game fiction supposes an imaginary world that video games become significant parts of the real world. Thus, their readers and characters desire successes in the games and based on the games. We extract the keywords of social issues by using the following heuristics;
Semantic distance: Reflection of the social issues is more straightforward in subculture multimedia than in conventional narrative multimedia. Most of the subculture works describe social issues without complicated symbols, figurative expressions, or mise-en-scène. Therefore, keywords related to social issues have similar meanings in both of the subculture works and general texts.
Emotional intensity: Vicarious satisfaction for social desires and conflicts is one of the primary purposes of subculture multimedia consumption, and it will accompany intense emotions. Thus, we search words that frequently co-occurred with emotional words.
Word2Vec [
24] is based on the assumption that frequently co-occurred words are semantically correlated. In other words, the co-occurred words have close locations in the embedding space. Thus, if readers and characters frequently show emotional reactions for a word
, the emotional words will be located around
. Also, words related to the same social issue will have similar vector representations.
To find words that satisfy the above requirements, we first cluster words according to their vector representations (Equation (
8)). We do not know the meanings or significance of components in word vectors, and narrative works contain various types of terms (e.g., proper nouns, neologisms, emotional words, and so on). Therefore, this task requires a clustering algorithm that is robust to noises and can find arbitrarily shaped clusters. Thus, the DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm is used. Before clustering the words, we add a component to the word vectors to consider the semantic distance between the words in the general texts and the words in the subculture genre. Addition of
as the new component gathers semantically consistent words into the same cluster.
The clusters correspond to key subjects of the genre. Most of the subjects are imaginary or figurative, but some of them straightforwardly imitate the real world. Also, if the imitation is correlated to social desires or conflicts, readers and authors will show longing or anger. Therefore, each cluster is assessed by the average semantic distance of words in the cluster. Also, we conduct the sentiment analysis for sentences that include the words. Keywords of social issues will occur frequently and accompany intense sentiment. An objective function for ranking clusters can be formulated as:
where
is a set of sentences that are in
and include
,
indicates the
l-th sentence,
refers to the degree of sentiment in
, and
denotes the frequency of
in
.
assesses a word in a cluster, and the cluster is evaluated by the average of
for all the words in the cluster. Using the objective function, we first obtain clusters that correspond to social issues and choose words in the clusters that can be labels of the social issues. For the sentiment analysis, we use a dictionary of emotional words and phrases (also used in
Section 3.1.1). In the dictionary, sentiment degrees were annotated with five steps: −2, −1, 0, 1, and 2. We normalized them into
.
4. A Case Study on Korean Web Novels
To validate the effectiveness of the proposed methods, we have examined the performance of the proposed methods for analyzing Korean web novels. For the research questions on
Section 1, we first evaluate whether words with the semantic difference correspond to subjects of subculture works (RQ 1) using the accuracy of the genre keyword extraction. Also, the accuracy of the genre classification shows whether the subjects are criteria of genre boundaries. Subsequently, the genre genealogy tree’s accuracy supports that we can trace genre differentiation using subject inheritance (RQ 2). Finally, correlations of words without the semantic difference with social issues (RQ 3) are validated by the accuracy of the social issue detection.
4.1. Data Collection and Pre-Processing
We collected 200 Korean web novels published from 2016 to 2020 and distributed through a subculture platform, Munpia (
https://www.munpia.com/). There are four major web novel platforms in Korea, NAVER SERIES, Kakao Page, Munpia, and Joara. However, we could not crawl web novels from NAVER SERIES and Kakao Page. Also, a significant number of web novels distributed through Joara were adult content. Therefore, we chose Munpia as our data source. Moreover, as shown in Sosul Network (
https://sosul.network/), a website for crowd-sourcing reviews for web novels, popular web novels on Munpia are also distributed through NAVER SERIES and Kakao Page. Thus, we assume that web novels collected from Munpia can represent Korean web novels.
We used only the first 20 episodes in each web novel since the main subjects of web novels have already appeared while describing their protagonists’ motivations. Also, despite an enormous number of web novels distributed through Munpia (39,005 on October 22nd, 2020), we conducted experiments with only 200 web novels due to the following four reasons. First, the proposed methods build the genre genealogy tree by analyzing life cycles of subculture genres. Therefore, our web novel corpus should have genre diversity and be evenly distributed over the years. Second, as we discussed in
Section 1, not all web novels are authored by full-time writers. Many web novels in Munpia are published by enthusiastic consumers, and some of these web novels contain only a few episodes. The proposed methods use introductions written by authors (or editors) and comments for the episodes with web novels’ main texts. Thus, web novels in our corpus should have a meaningful number of comments (5.31 comments per episode). Finally, ground-truth data for our experiment was composed by human evaluators due to the absence of benchmark datasets, and we could not conduct the experiment with an excessive number of web novels. Therefore, among the available web novels, we chose web novels with three criteria, the number of episodes, genres, publication years, and the number of comments. As a general text corpus, we used a Korean Wikipedia corpus.
The web novel texts were segmented into sentences, and we conducted POS (Part-Of-Speech) tagging, stemming, and removing stop words. We restricted the search space into neologisms, nouns/noun phrases, and emotional words/phrases for all the proposed methods. However, we conducted representation learning of all the words, since adjacency between postpositional particles and other words affects the nouns’ meanings in Korean. Word2Vec has various hyper-parameters, and we empirically tuned the parameters to distinguish words with the semantic difference from words without the difference well. We made as close to 1 or 0 as possible. Thus, we found parameters that minimize using a grid search on: the number of epochs (40 to 200 with a step size ), the learning rate (0.00025 to 0.25 with a step size ), the number of dimensions (32 to 256 with a step size ), the number of negative samples k (5 to 15 with a step size ), and the weighting factor for the noise distribution (0.00 to 1.00 with a step size ). We determined the hyper-parameters as: , , , , and .
To evaluate the proposed methods, we collected ground truth datasets by conducting a questionnaire survey. First, we composed a group of human evaluators that consists of 37 Korean web novel consumers. User communities give names to subculture genres, and there have not been official taxonomies and names of the genres. Therefore, the evaluators first annotated genre labels on web novels in our corpus that they have read. We used genre labels only that are annotated by the majority of the evaluators. We obtained 635 annotations for 147 web novels (on average 4.32 labels on each novel) with 36 genres; 53 novels had not read by any evaluator.
Table 1 presents a list of the genres. Other survey questions related to experimental procedures will be described in each section.
4.2. Accuracy of Extracting Genre Keywords
We assess the accuracy of the proposed method for extracting genre keywords to evaluate the proposed method’s usefulness and validate the effectiveness of word semantic difference for discovering imaginary subjects from literary texts (RQ 1). The accuracy was assessed by comparing the results of the proposed method with user survey results. The evaluators corrected the keyword sets by adding missing keywords and deleting incorrect ones. We took changes only agreed by the majority of the evaluators. To measure the accuracy, we employed the precision, recall, and
score. When
is the edited keyword set of
, the accuracy metrics are calculated as:
where
,
, and
indicate the precision, recall, and
score for
, respectively.
Word2Vec [
24] and a three-layered fully-connected neural network were used as a baseline method. Word vectors for each genre have already composed in
Section 3.1.3. We classified words into keywords or non-keywords using the neural network; input layer: 128 nodes, first hidden layer: 128 nodes, second hidden layer: 64 nodes, third hidden layer: 64 nodes, and output layer: 1 node. Activation functions of all the layers were the sigmoid. 80% and 20% of the words were used as training and testing data with 5-fold cross-validation. The accuracy was assessed for each genre and aggregated using the arithmetic mean.
The second column of
Table 2 shows the experimental results of the keyword extraction. Due to the lack of spaces, we present results for ten genres that are ancestors of the possession fiction, which is the most popular recently. Although both precision and recall of the proposed method were reasonable (
Table 3), a few genres had mostly the same keyword sets (e.g., raid fiction and hunter fiction). Also, we obtained too small keyword sets from several genres (e.g., apocalypse fiction). These results show that some subjects are difficult to be stated as a few terms. Main subjects of a few genres were close to relationships among characters (e.g., 로맨틱판타지물 (romantic fantasy fiction) and 육아물 (rearing fiction)). Significance of the subjects was also not considered by the proposed method. The raid fiction and hunter fiction had similar keywords, but a few terms (e.g., 보스 (boss monster) and 패턴 (pattern)) had distinctively higher frequencies in the raid fiction. In further research, we have to extend the concept of subjects over mere terms and find other genre characteristics more than imaginary subjects. The second column of
Table 3 presents the accuracy of the proposed method.
The fore-mentioned problem did not affect the accuracy of keyword extraction. Nevertheless, we found another problem: Wikipedia cannot cover colloquial languages. For example, a Korean word, 사이다 (cider), is also used in the meaning of ‘inexorable’ or ‘feisty,’ not only in a kind of beverage. This word frequently occurred in several genres and was used in the same meaning. However, 사이다 (cider) was selected as keywords, since our general text corpus (Wikipedia) is written in literary style. According to Robert McKee [
61], among movie scripts, play scripts, and novels, play scripts are the closest to the literary languages, movie scripts are the most similar to the colloquial languages, and novels are in the middle. As a kind of snack culture, web novels look closer to everyday languages than ordinary novels. In further research, the general text corpus should cover the colloquial languages, and we have to add methods for handling polysemy and homonymy issues to the proposed methods.
The proposed method outperformed the baseline method in terms of both accuracy and variance. Performance improvement was more distinctive in precision than in recall. Word vectors used by both methods contain information for co-occurrences of words. Imaginary subjects occur more frequently than other words. Thus, terms for the subjects (keywords) could have distinctively different locations between embedding spaces for subculture works and general texts. By comparing the two embedding spaces, the proposed method can get the difference. Since the subjects also co-occur with each other frequently, the baseline could find locations where the subjects were densely located. However, it is difficult to distinguish ordinary words from the dense area without comparing the two embedding spaces, as shown in the low precision of the baseline method.
4.3. Accuracy of Classifying Subculture Works into Genres
This section evaluates the proposed multi-label classification method for subculture genres. Since the classification is based on the genre keywords, classification performance also supports RQ 1. We used only genre annotations collected from the web novel platform to compose the keyword sets and membership functions of genres. Then, we compared the automated labeling results with the annotations acquired form the evaluators. The accuracy was also measured by the precision, recall, and score. Methods for calculating the metrics are the same as the previous experiment.
As a comparison group, we used Doc2Vec [
62] that is widely applied to classify documents. After conducting Doc2Vec for each web novel, we classified the web novels into genres according to their document vectors using a three-layered fully-connected neural network. This network had a similar structure to the one in the previous experiment; we extended its output layer to 36 nodes (as with the number of genres). Training and validation methods were also the same. The third column of
Table 3 shows accuracy of the genre classification.
The proposed method outperformed the baseline method, whereas precision was not significantly improved, especially in terms of variance. As discussed in the previous section, keywords of some genres were not distinctive enough. The indistinctiveness did not hinder the keyword extraction much but affected the accuracy of the genre classification. This problem had two aspects. First, the proposed method showed reasonable recall but low precision for genres with a few keywords. There might be other features determining memberships for the genres. For example, apocalypse fiction has a few keywords, such as 종말 (apocalypse), 부수다 (destroy), 마지막 (last), and so on. The core keywords enabled us to discover novels included in the genre. However, for some web novels, including these keywords, the evaluators did not label them as apocalypse fiction. To find its reasons, we examined frequencies of emotional words and phrases in both groups (true positives and false positives). We found that the false positives had much less negative emotions than the true positives.
Second, when plural genres had duplicated keywords, and the keywords occurred in a novel frequently, the proposed method assigned the novel on all the genres. Thus, the duplicated keywords made these genres exhibit low precision and high recall. Although most of the keywords are duplicated, occurrence frequencies of keywords can be a clue for classifying these kinds of genres. For example, the raid fiction and hunter fiction shared most of their keyword sets. However, the frequency of some keywords, such as 공략 (tactics), 레이드 (raid), and 패턴 (pattern), was much higher in the raid fiction.
Our classification method was affected by this problem because we used independent classifiers, which consist of a membership function and a threshold for each genre. Also, the membership functions (Equation (
7)) did not consider correlations between keywords. Although the baseline method did not consider keywords, its lower variance indicate that machine learning (ML)-based classifiers can be an efficient solution for considering the correlations among genres and between keywords. Our further research will be focused on integrating the proposed heuristics with ML techniques.
4.4. Accuracy of Building Genealogy Trees of Genres
This section evaluates the proposed method’s performance for building genre genealogy trees and validates correlations of subject inheritance between genres with differentiation of the genres (RQ 2). To assess the generated genre genealogy tree, we asked the evaluators to edit the tree by adding or deleting nodes/edges. Among the editions, we accepted only editions made by the majority of the evaluators. Then, the tree’s accuracy was measured by the minimum number of editions required to transform the original into the edited version. As a baseline method, Doc2Vec and the hierarchical agglomerative clustering were employed. We composed document vectors for each genre (not for each web novel) and clustered them according to the cosine similarity between the document vectors. First, we discuss the results of the proposed method regarding the content of web novel genres. Since we could not find credible publications for Korean web novel genres, we referred one of the biggest Korean wiki websites (
https://namu.wiki/w/%EC%9E%A5%EB%A5%B4%EB%AC%B8%ED%95%99). Then, we evaluate the accuracy of the proposed method by comparing it with the baseline method.
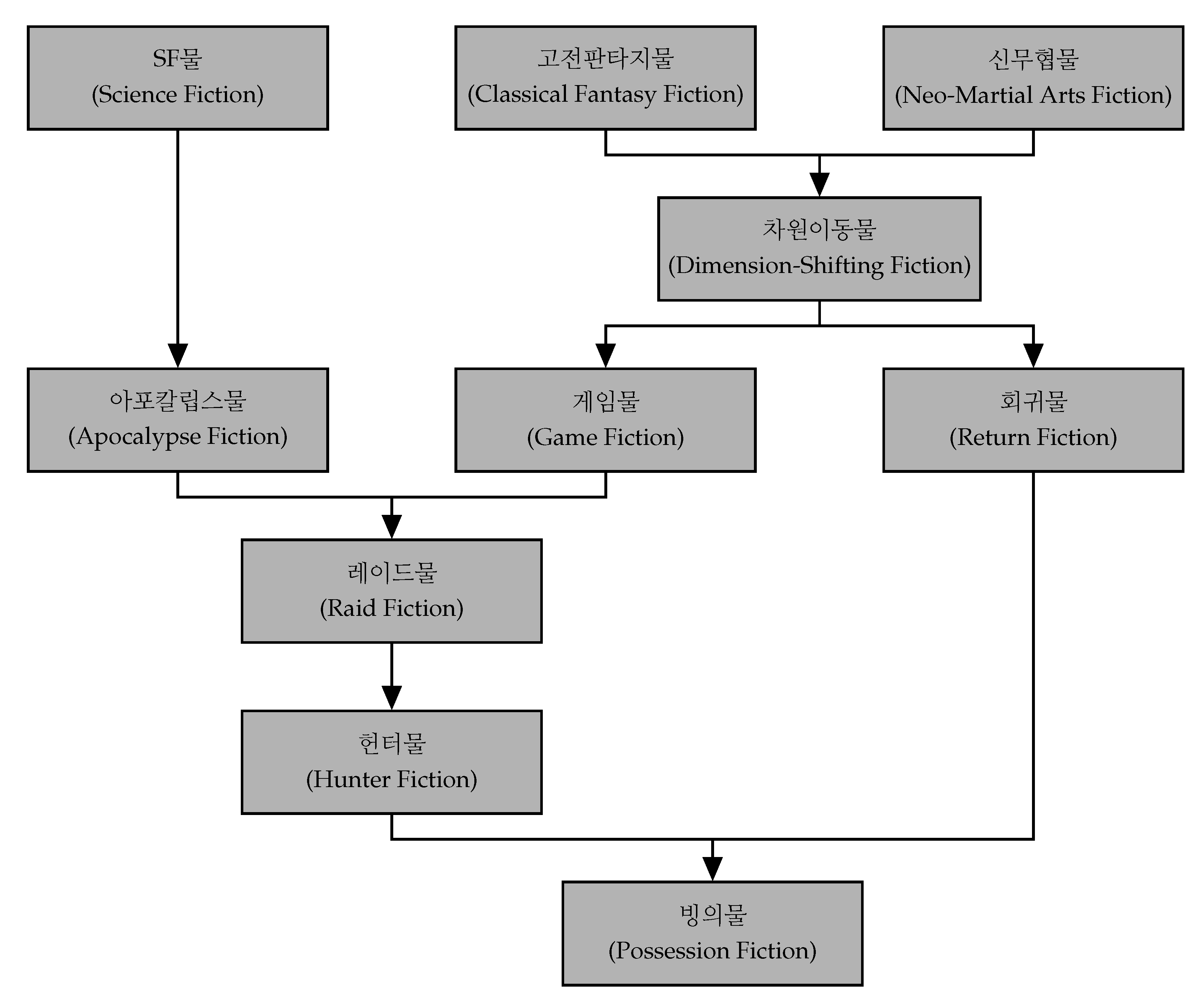
Figure 2 presents a part of the genre genealogy tree built by the proposed methods. The tree is focused on the possession fiction (빙의물), which is the most popular recently, and its ancestors. The possession fiction indicates works that fictional characters of novels or video games are suddenly possessed by protagonists (who lived in the real world). Common points of these works are (i) omniscient protagonists, (ii) shifting into imaginary worlds, (iii) fighting for survival, and (iv) mechanical equality. We traced where these points come from by using the genealogy tree.
The first characteristic is a heritage of the return fiction (회귀물). The return fiction describes protagonists going back to the past and fixing all the trials and errors. Experienced protagonists of this genre know future events and have been in the events. Although the protagonists have archenemies that made them return, they also have conflicts with characters who cannot recognize and acknowledge their ability and capability (mainly privileged groups, such as 귀족 (noble), 공무원 (public servant), and 재벌 (chaebol)). Major keywords of this genre were ‘회귀 (return),’ ‘후회 (regret),’ ‘복수 (revenge),’ ‘과거 (past),’ ‘실수 (mistake),’ and so on.
The return fiction also comes from the dimension-shifting fiction (차원이동물). In the classical genre fiction, all the fictional characters are residents of the imaginary world. Thus, authors do not have restrictions for designing characters and events. At the same time, readers feel difficulties in sympathizing with the characters. This genre uses protagonists who lived in the real world and suddenly moved into the imaginary world. The protagonists solve problems in the imaginary world to go back home. Primary keywords of this genre were ‘차원이동 (dimension-shifting),’ ‘집 (home),’ ‘가족 (family),’ and other keywords inherited from the classical fantasy/neo-martial arts fictions.
Game fiction (게임물) commonly uses video games as their backgrounds. In their narrative world, everything is operated according to game systems. Every player gets fair rewards for their achievements and efforts. The main rhetoric in this genre is that protagonists are treated unfairly because of social pressures, despite their ability or talent. Under the game systems, which guarantee mechanical equality, the protagonists achieve everything that they deserve. Therefore, keywords of this genre included ‘시스템 (system),’ ‘실력 (ability),’ ‘재능 (talent),’ ‘운 (luck),’ and other keywords related to the game systems (e.g., monsters, levels, and skills).
Raid fiction (레이드물) and hunter fiction (헌터물) focus on ‘raids’ and ‘dungeons’ in Video games. At the beginning of these genres, the raid fiction imitated the famous online game, ‘World Of Warcraft.’ A difference from the game fiction is that their backgrounds are based on ‘gamified real world.’ In these genres, gigantic monsters or dungeons suddenly appeared in the real world, and heroes with superpowers hunt the monsters to save the world. These superpowers and ways to grow the superpowers follow the game systems. The backgrounds, which are a reflection of the real world, make conflicts between the protagonists and the ancien regime. The protagonists overthrow social problems radically and aggressively. As culprits causing the problems, these genres mainly use 공무원 (public servant), 재벌 (chaebol), 국회의원 (a member of national assembly) and so on. Excluding keywords inherited from the game fiction, main keywords of these genres were ‘게이트 (gate),’ ‘헌터 (hunter),’ ‘초능력 (superpower),’ and so on.
Apocalypse fiction describes struggles for survival after or during the apocalypse. Although causes of the apocalypse are different in each novel (e.g., zombies, aliens, and gods), irresistible violence destroys human society and enforces the jungle’s law. Therefore, keywords of this genre included ‘종말 (apocalypse),’ ‘부수다 (destroy),’ ‘배신 (betrayal),’ ‘생존 (survival),’ and so on.
The genre genealogy tree and explanations for the genres on the tree show inheritance of genre characteristics and how they are inherited. We can also see what kinds of desires are reflected by each genre (e.g., desires for recognition and fair opportunities). Excluding the running examples, there are various genres; e.g., 스트리머물 (streamer fiction), 연예계물 (entertainment fiction), and 대체역사물 (alternative history fiction). These genres are closely connected not only with the serious social problems (e.g., inequality, authoritarianism, and imperialism) but also with cultural shifts or trends (e.g., popular video games and the advent of video streaming services).
The fourth column of
Table 3 shows the accuracy of the genre genealogy tree. Since the hierarchical clustering does not allow multiple parents, it showed significantly lower performance than the proposed method. This result is enough to show that genres are affected by multiple existing genres, and we need a method designed to trace the differentiation of subculture genres. We measured variances by measuring the edit distance for each evaluator’s answer, and both methods exhibited high variances. Understandings for web novel content would be subjective. In further research, we should look for better representation than the genealogy tree or a more accurate method for building the tree, to find a genre differentiation model that can convince the majority. However, the results of the proposed method and the evaluators also had lots of differences. Since the genealogy tree of all the collected genres is too vast, we explain based on the possession fiction and its ancestors (
Figure 2).
First, on the evaluators’ answer, the apocalypse fiction had no connection. Since the proposed method does not consider a standalone genre, a few shared keywords made connections between the apocalypse fiction and science fiction (e.g., 외계인 (alien) and 괴수 (monster)) and between the apocalypse fiction and raid fiction (e.g., 뒷통수 (backstabbing)). The unnecessary connections also appeared between the game fiction and the streamer fiction and between the tower climbing fiction (탑등반물) and the hunter fiction. The proposed heuristics concentrate on only tracing the inheritance of genre keywords. We made connections between all genres that have shared keywords to increase the edge density of the tree. However, the experimental result showed that we have to consider degrees of influence between genres. Although Equation (
9) measures semantic differences between genres, we used it only to filter edges roughly before applying the heuristics.
The evaluators also annotated the raid fiction and hunter fiction as siblings, and they had only one parent, the game fiction. Also, they answered that the two genres are on the same generation. The proposed method assigned generations of genres by using temporal distributions of the number of published subculture works in the genres with a range . We should extend the length of the range. Moreover, the proposed method attempts to increase the genealogy tree’s depth. We found other genres met this problem (e.g., 탑등반물 (tower climbing fiction) and 이세계물 (Different world fiction)), and it indicates that the genealogy tree is not as deep as our expectation. In further research, we should find a way how we can recognize siblings that share most of the keywords.
4.5. Accuracy of Detecting Correlations of Genres to Social Issues
We evaluated the usefulness of the proposed social issue discovery method and validated the semantic consistency’s effectiveness for recognizing real world-oriented subjects in subculture multimedia (RQ 3). We set top-10 word clusters according to Equation (
10) as social issues detected by the proposed method. The evaluators corrected the results for each genre by adding or deleting clusters. The correction was conducted in a range of word clusters discovered in
Section 3.2. Similar to the previous experiments, we aggregated corrections agreed by the majority of the evaluators and made ground truth. By comparing the original results with the corrected ones, we calculated precision, recall, and
score for each genre and merge them using the arithmetic mean.
This experiment also employed a combination of word embedding models and simple neural networks as a baseline method. We composed vector representations of each word cluster by averaging vectors of words included in the cluster. A three-layered fully-connected neural network, which had the same structure with the network in
Section 4.2, was trained to predict whether a word cluster corresponds to social issues. Training and validation methods were the same as the methods in
Section 4.2. The fifth column of
Table 3 presents the accuracy of the social issue detection.
Due to the limited space,
Table 2 presents 10 of the 36 genres, which are the ancestors of the possession fiction.
Table 1 and
Table 2 showed that the proposed methods had more difficulties in discovering social issues from old genres than from recent ones. For example, issues discovered from 고전판타지물 (classical fantasy fiction) and 신무협물 (neo-martial arts fiction) were far from problems in modern society. The evaluators also annotated much less social issues on the old genres than on the others. Considering the genre generations in
Table 1, the first generation had 3.71 social issues on average, and the fourth generation got 12.50 annotations on average. However, even in the same generation, genres had a high variance in the number of annotations. Although 도시판타지물 (urban fantasy fiction) and 대체역사물 (alternative history fiction) were long-lived genres, they included various social issues as many as the latest genres. We could find 육아물 (rearing fiction) as an opposite case.
This problem made the proposed methods perform low average precision and high variance in the precision, as shown in
Table 3. Also, since the proposed method fixed the number of social issues (top-10) in each genre, the baseline method performed much less variance than the proposed method, and the gap was more significant in the precision. Although the proposed method outperformed the baseline, there was a problem in our assumption that all the genres are correlated to particular social issues. The problem will be solved by using the proposed features as inputs of ML techniques.
The experimental result indicates that subculture genres have different sensitivity in reflecting social issues. Although they come from our deficiency, not all of them will be thinly veiled, and some of them will focus on telling comforts and hopes. Also, despite the high variance, subculture genres have become more connected to social issues over time. Subculture platforms have also moved from printed books via websites to mobile applications. This move might affect the changes in the social reflection of the genres. Thus, the trials for observing our society through subculture multimedia will become more significant.





{kind=link}
{kind=link}