Power Generation Optimization of the Combined Cycle Power-Plant System Comprising Turbo Expander Generator and Trigen in Conjunction with the Reinforcement Learning Technique


Abstract
1. Introduction
2. Description of Power Generation System
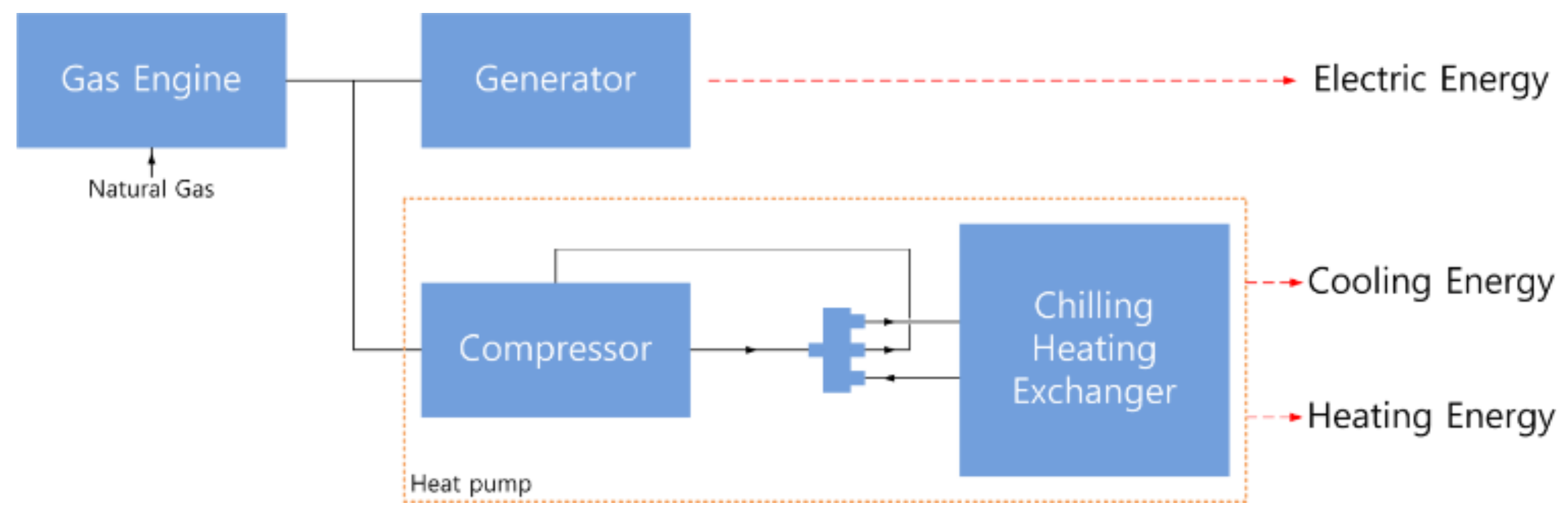
2.1. Trigeneration
2.2. TEG
3. Energy Optimization Method
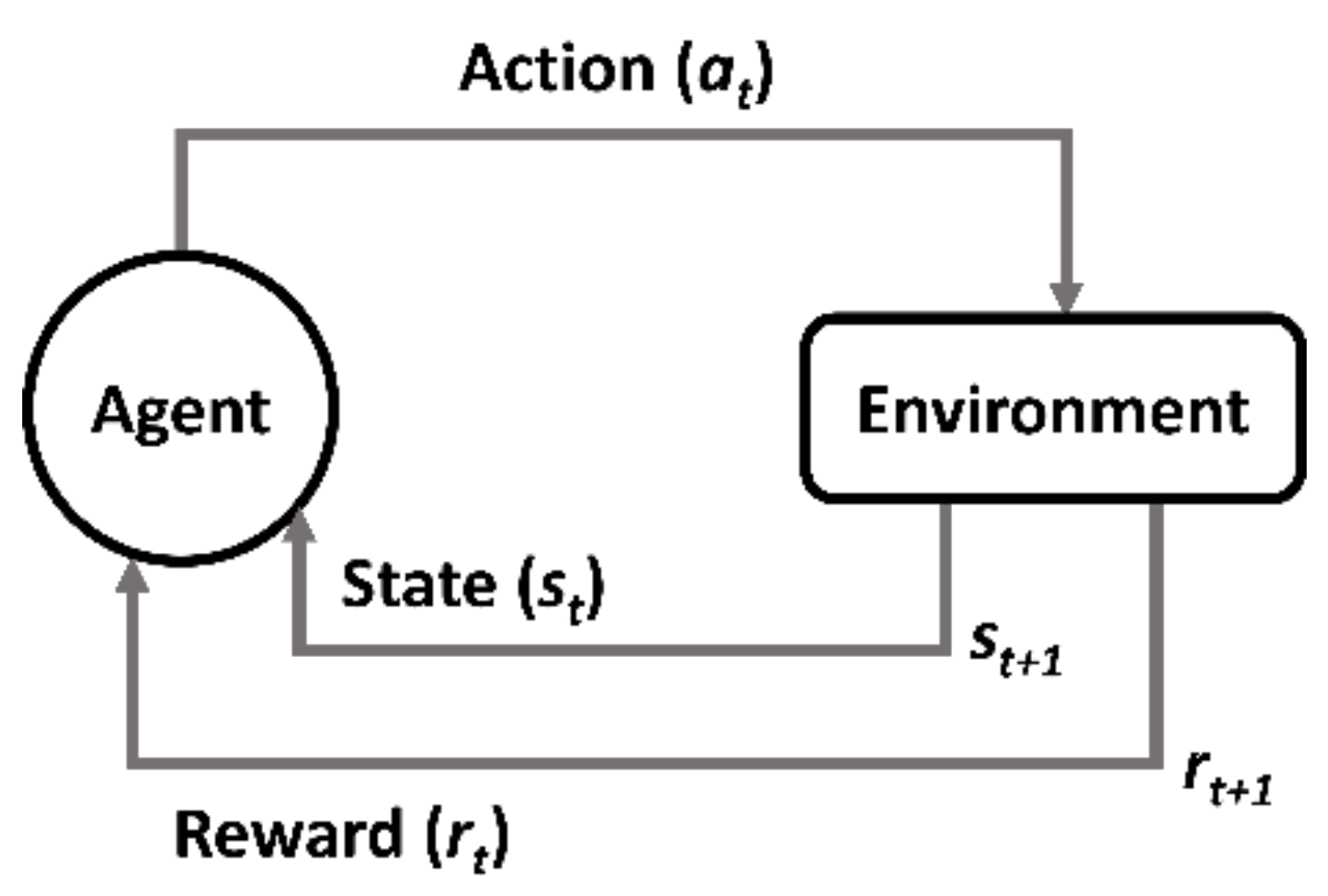
3.1. Reinforced Learning
3.2. Deep Q-Network Algorithm
- Choose an action a in the current state, s.
- Perform action and receive the reward R(s, a).
- Observe the new state S(s, a).
- Update: Q’(s, a) ← R(s, a) + γmax{Q’(S(s, a), a)}
| Algorithm 1: Deep Q-Network Algorithm |
| 1. Initialize replay memory D to capacity N |
| 2. Initialize action–value function Q with θ |
| 3. Initialize target action–value function Q with θ− = θ |
| 4. For episode = 1 to num episodes do |
| 5. For t = 1 to T do |
| 6. With probability ε select a random action at, otherwise select at = maxaQ(s, a; θ) |
| 7. Execute action at in emulator and observe reward rt and state st |
| 8. Store transition (st, at, rt, st+1) in D |
| 9. Sample random minibatch of transitions (sj, aj, rj, sj+1) from D |
| 10. Perform a gradient descent step on Lj(θ) with respect to the network parameters θ |
| 11. End For |
| 12. End For |
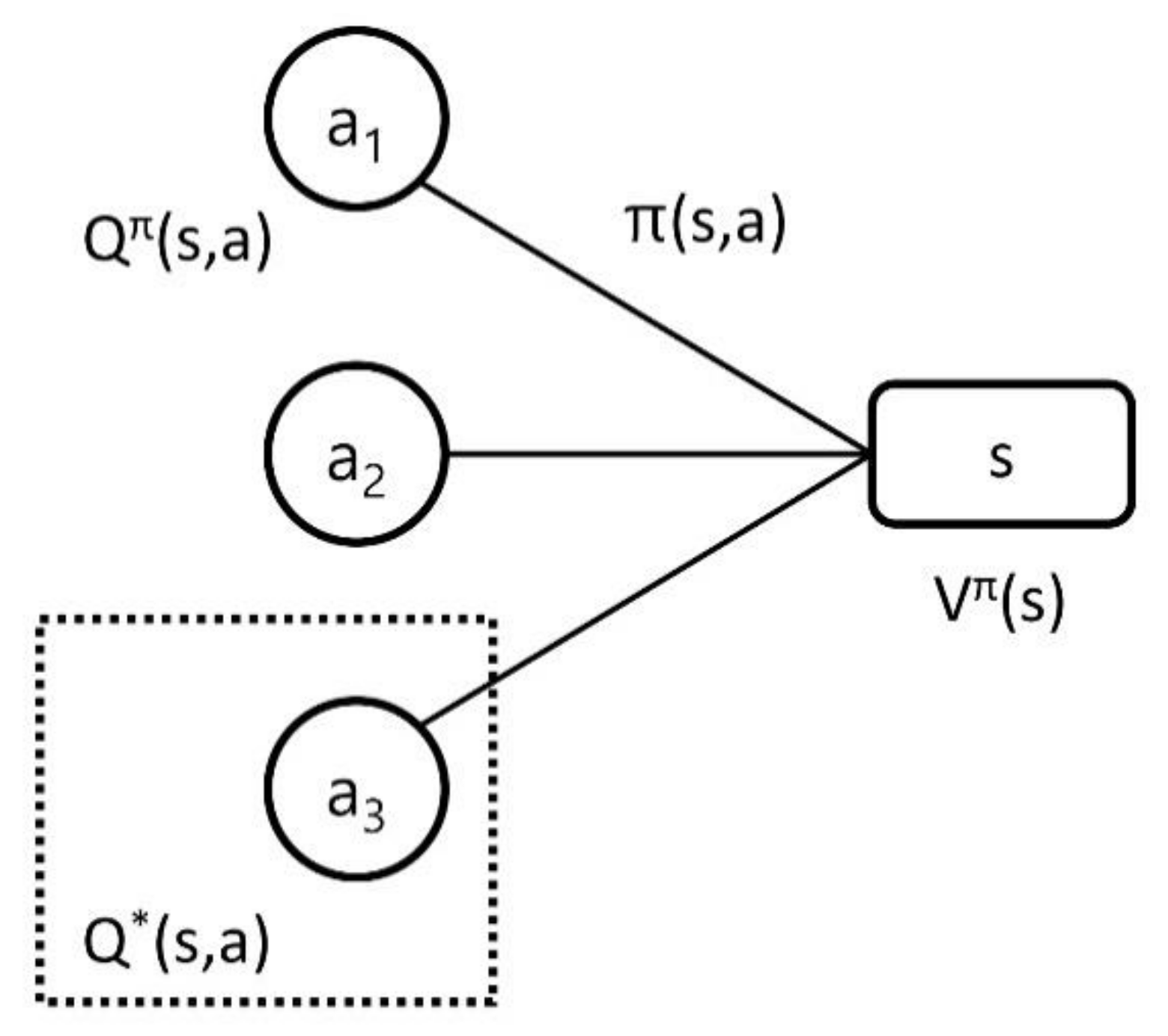
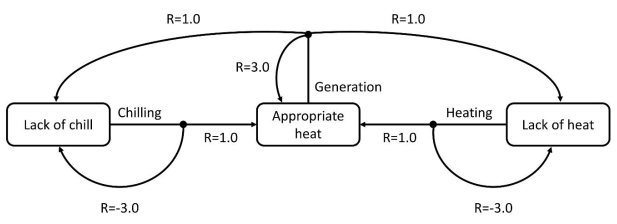
3.3. Action, Reward, and Policy
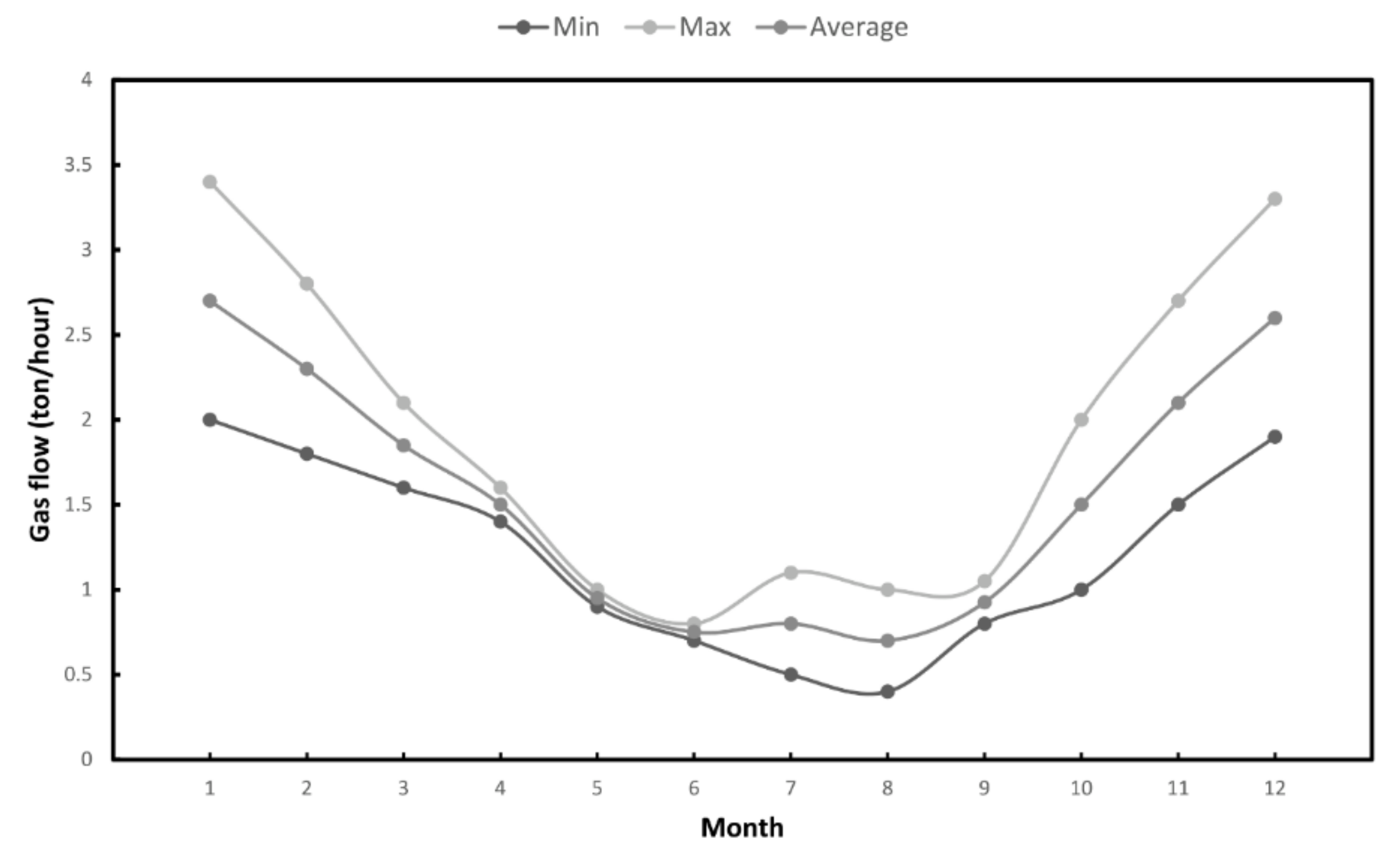
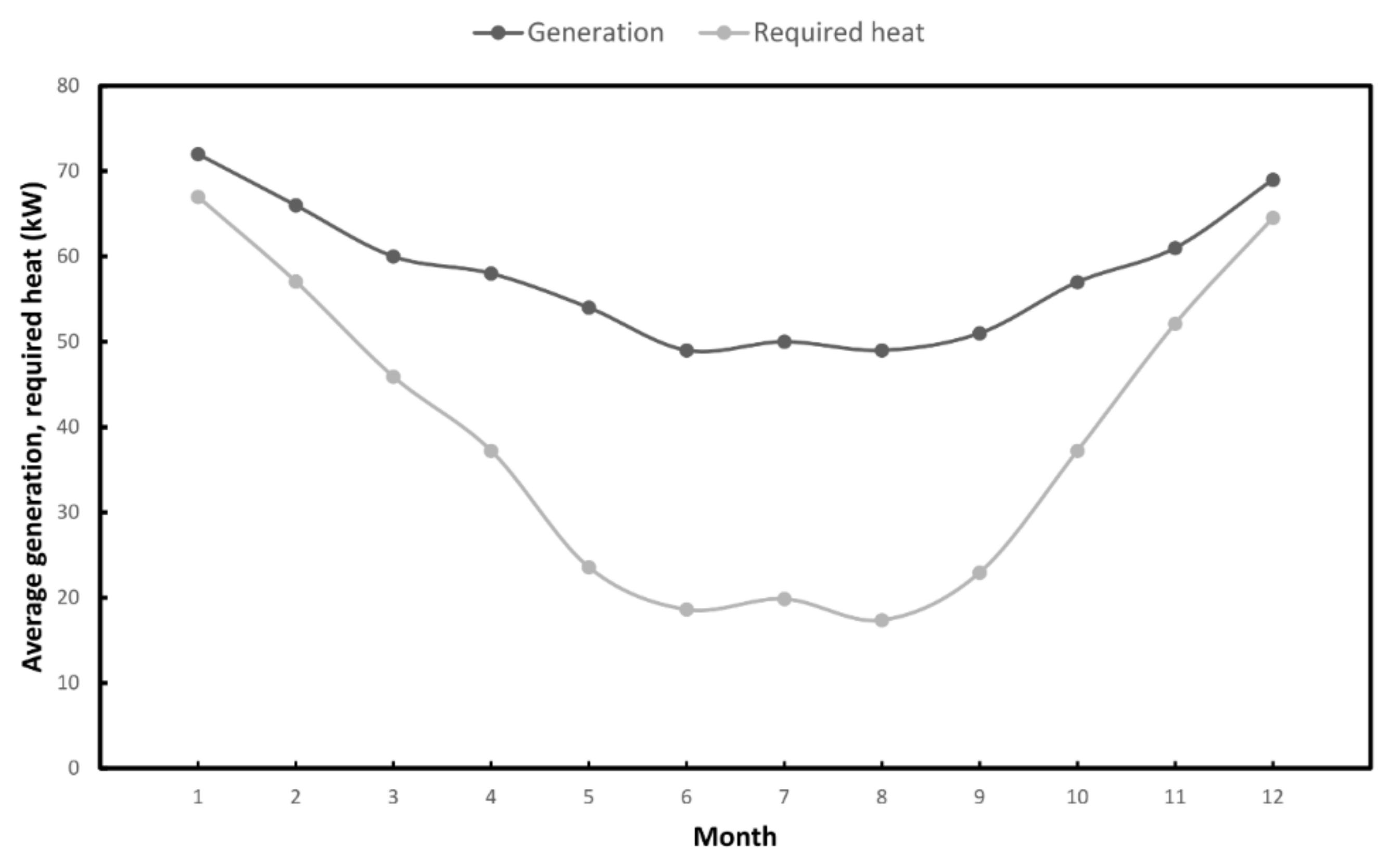
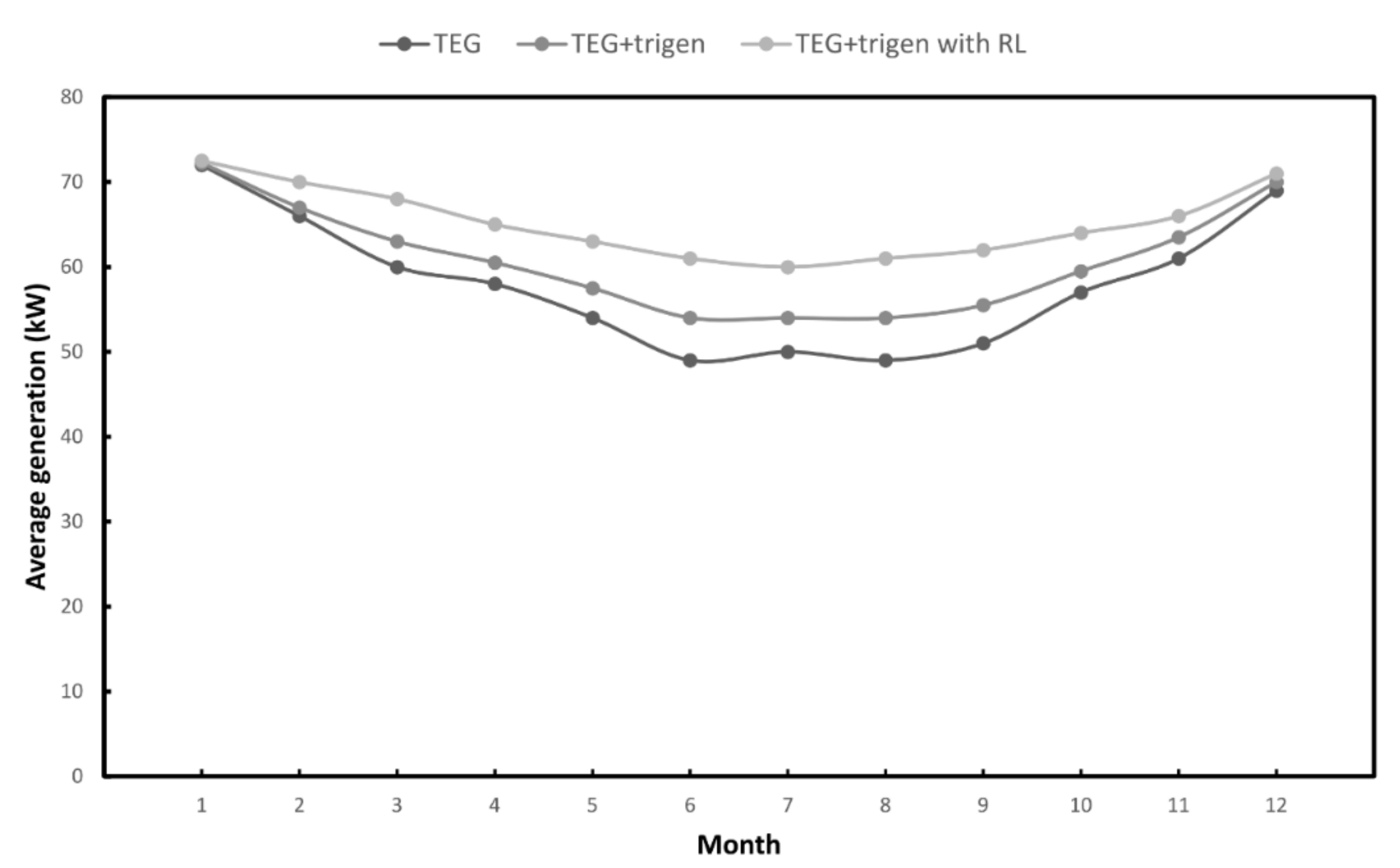
4. Case Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Third Energy Master Plan. 2019. Available online: https://www.etrans.or.kr/ebook/05/files/assets/common/downloads/Third%20Energy%20Master%20Plan.pdf (accessed on 12 October 2020).
- Xie, D.; Chen, A.; Gu, C.; Tai, J. Time-domain modeling of grid-connected CHP for its interaction with the power grid. IEEE Tran. Power Syst. 2018, 33, 6430–6440. [Google Scholar] [CrossRef]
- KOGAS Research Institute, Localization of TEG technical plan (plan) service, Technical Report, October. 2015. Available online: http://www.kogas.or.kr/portal/downloadBbsFile.do?atchmnflNo=26421 (accessed on 17 August 2016).
- Kim, H.; You, H.; Choi, K.; Han, S. A study on interconnecting to the power grid of new energy using the natural gas pressure. J. Electr. Eng. Technol. 2020, 15, 307–314. [Google Scholar] [CrossRef]
- Hong, S.; Kim, K.; You, H.; Ha, J. Research articles: Turbo expander power generation using pressure drop at valve station in natural gas transportation pipeline. J. Korean Inst. Gas 2012, 16, 1–7. [Google Scholar]
- Lin, C.; Wu, W.; Wang, B.; Shahidehpour, M.; Zhang, B. Joint commitment of generation units and heat exchange stations for combined heat and power systems. IEEE Trans. Sustain. Energy 2020, 11, 1118–1127. [Google Scholar] [CrossRef]
- Li, Z.; Wu, W.; Wang, J.; Zhang, B.; Zheng, T. Transmission-constrained unit commitment considering combined electricity and district heating networks. IEEE Trans. Sustain. Energy 2016, 7, 480–492. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, H.; Tan, C.; Chen, X.; Rajagopal, R.; Xia, Q.; Kang, C. Economic benefits of integrating solar-powered heat pumps into a CHP system. IEEE Trans. Sustain. Energy 2018, 9, 1702–1712. [Google Scholar] [CrossRef]
- Zhou, Y.; Hu, W.; Min, Y.; Dai, Y. Integrated power and heat dispatch considering available reserve of combined heat and power units. IEEE Trans. Sustain. Energy 2019, 10, 1300–1310. [Google Scholar] [CrossRef]
- Yao, S.; Gu, W.; Zhou, S.; Lu, S.; Wu, C.; Pan, G. Hybrid timescale dispatch hierarchy for combined heat and power system considering the thermal inertia of heat sector. IEEE Access 2018, 6, 63033–63044. [Google Scholar] [CrossRef]
- Liu, B.; Li, J.; Zhang, S.; Gao, M.; Ma, H.; Li, G.; Gu, C. Economic dispatch of combined heat and power energy systems using electric boiler to accommodate wind power. IEEE Access 2020, 8, 41288–41297. [Google Scholar] [CrossRef]
- Dai, Y.; Chen, L.; Min, Y.; Chen, Q.; Hu, K.; Hao, J.; Xu, F. Dispatch model of combined heat and power plant considering heat transfer process. IEEE Trans. Sustain. Energy 2017, 8, 1225–1236. [Google Scholar] [CrossRef]
- Cao, Y.; Wei, W.; Wu, L.; Mei, S.; Shahidehpour, M.; Li, Z. Decentralized operation of interdependent power distribution network and district heating network: A market-driven approach. IEEE Trans. Smart Grid. 2019, 10, 5374–5385. [Google Scholar] [CrossRef]
- Dai, Y.; Chen, L.; Min, Y.; Mancarella, P.; Chen, Q.; Hao, J.; Xu, F. A general model for thermal energy storage in combined heat and power dispatch considering heat transfer constraints. IEEE Trans. Sustain. Energy 2018, 9, 1518–1528. [Google Scholar] [CrossRef]
- Lin, C.; Wu, W.; Zhang, B.; Sun, Y. Decentralized solution for combined heat and power dispatch through benders decomposition. IEEE Trans. Sustain. Energy 2017, 8, 1361–1372. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, N.; Botterud, A.; Kang, C. On an equivalent representation of the dynamics in district heating networks for combined electricity-heat operation. IEEE Trans. Power Syst. 2020, 35, 560–570. [Google Scholar] [CrossRef]
- Gao, Y.; Zeng, D.; Zhang, L.; Hu, Y.; Xie, Z. Research on modeling and deep peak regulation control of a combined heat and power unit. IEEE Access 2020, 8, 91546–91557. [Google Scholar] [CrossRef]
- Li, J.; Lin, J.; Song, Y.; Xing, X.; Fu, C. Operation optimization of power to hydrogen and heat (P2HH) in ADN coordinated with the district heating network. IEEE Trans. Sustain. Energy 2019, 10, 1672–1683. [Google Scholar] [CrossRef]
- Deng, B.; Teng, Y.; Hui, Q.; Zhang, T.; Qian, X. Real-coded quantum optimization-based bi-level dispatching strategy of integrated power and heat systems. IEEE Access 2020, 8, 47888–47899. [Google Scholar] [CrossRef]
- Ivanova, P.; Sauhats, A.; Linkevics, O. District heating technologies: Is it chance for CHP plants in variable and competitive operation conditions? IEEE Trans. Ind. Appl. 2019, 55, 35–42. [Google Scholar] [CrossRef]
- Rong, A.; Luh, P.B. A dynamic regrouping based dynamic programming approach for unit commitment of the transmission-constrained multi-site combined heat and power system. IEEE Trans. Power Syst. 2018, 33, 714–722. [Google Scholar] [CrossRef]
- Xue, Y.; Li, Z.; Lin, C.; Guo, Q.; Sun, H. Coordinated dispatch of integrated electric and district heating systems using heterogeneous decomposition. IEEE Trans. Sustain. Energy 2020, 11, 1495–1507. [Google Scholar] [CrossRef]
- Dai, Y.; Chen, L.; Min, Y.; Mancarella, P.; Chen, Q.; Hao, J.; Xu, F. Integrated dispatch model for combined heat and power plant with phase-change thermal energy storage considering heat transfer process. IEEE Trans. Sustain. Energy 2018, 9, 1234–1243. [Google Scholar] [CrossRef]
- Zhou, Y.; Shahidehpour, M.; Wei, Z.; Li, Z.; Sun, G.; Chen, S. Distributionally robust co-optimization of energy and reserve for combined distribution networks of power and district heating. IEEE Trans. Power Syst. 2020, 35, 2388–2398. [Google Scholar] [CrossRef]
- Virasjoki, V.; Siddiqui, A.S.; Zakeri, B.; Salo, A. Market power with combined heat and power production in the Nordic energy system. IEEE Trans. Power Syst. 2018, 33, 5263–5275. [Google Scholar] [CrossRef]
- Zhou, H.; Li, Z.; Zheng, J.H.; Wu, Q.H.; Zhang, H. Robust scheduling of integrated electricity and heating system hedging heating network uncertainties. IEEE Trans. Smart Grid. 2020, 11, 1543–1555. [Google Scholar] [CrossRef]
- Teng, Y.; Sun, P.; Leng, O.; Chen, Z.; Zhou, G. Optimal operation strategy for combined heat and power system based on solid electric thermal storage boiler and thermal inertia. IEEE Access 2019, 7, 180761–180770. [Google Scholar] [CrossRef]
- Rigo-Mariani, R.; Zhang, C.; Romagnoli, A.; Kraft, M.; Ling, K.V.; Maciejowski, J. A combined cycle gas turbine model for heat and power dispatch subject to grid constraints. IEEE Trans. Sustain. Energy 2020, 11, 448–456. [Google Scholar] [CrossRef]
- Tan, B.; Chen, H. Stochastic multi-objective optimized dispatch of combined chilling, heating, and power microgrids based on hybrid evolutionary optimization algorithm. IEEE Access 2019, 7, 176218–176232. [Google Scholar] [CrossRef]
- Nazari-Heris, M.; Mohammadi-Ivatloo, B.; Gharehpetian, G.B.; Shahidehpour, M. Robust short-term scheduling of integrated heat and power microgrids. IEEE Syst. J. 2019, 13, 3295–3303. [Google Scholar] [CrossRef]
- Liu, N.; Wang, J.; Wang, L. Hybrid energy sharing for multiple microgrids in an integrated heat–electricity energy system. IEEE Trans. Sustain. Energy 2019, 10, 1139–1151. [Google Scholar] [CrossRef]
- Koch, K.; Alt, B.; Gaderer, M. Dynamic modeling of a decarbonized district heating system with CHP plants in electricity-based mode of operation. Energies 2020, 13, 4134. [Google Scholar] [CrossRef]
- Olabi, A.; Wilberforce, T.; Sayed, E.T.; Elsaid, K.; Abdelkareem, M.A. Prospects of fuel cell combined heat and power systems. Energies 2020, 13, 4104. [Google Scholar] [CrossRef]
- Calise, F.; Cappiello, F.L.; Dentice d’Accadia, M.; Libertini, L.; Vicidomini, M. Dynamic simulation and thermoeconomic analysis of a trigeneration system in a hospital application. Energies 2020, 13, 3558. [Google Scholar] [CrossRef]
- Li, W.; Li, T.; Wang, H.; Dong, J.; Li, Y.; Cui, D.; Ge, W.; Yang, J.; Onyeka Okoye, M. Optimal dispatch model considering environmental cost based on combined heat and power with thermal energy storage and demand response. Energies 2019, 12, 817. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intel. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Zhang, Z.; Yao, R.; Huang, S.; Chen, Y.; Mei, S.; Sun, K. An online search method for representative risky fault chains based on reinforcement learning and knowledge transfer. IEEE Trans. Power Syst. 2020, 35, 1856–1867. [Google Scholar] [CrossRef]
- Nguyen, K.K.; Duong, T.Q.; Vien, N.A.; Le-Khac, N.; Nguyen, M. Non-cooperative energy efficient power allocation game in D2D communication: A multi-agent deep reinforcement learning approach. IEEE Access 2019, 7, 100480–100490. [Google Scholar] [CrossRef]
- Jang, B.; Kim, M.; Harerimana, G.; Kim, J.W. Q-Learning algorithms: A comprehensive classification and applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar] [CrossRef]
- Ferreira, L.R.; Aoki, A.R.; Lambert-Torres, G. A reinforcement learning approach to solve service restoration and load management simultaneously for distribution networks. IEEE Access 2019, 7, 145978–145987. [Google Scholar] [CrossRef]
- Gan, X.; Guo, H.; Li, Z. A new multi-agent reinforcement learning method based on evolving dynamic correlation matrix. IEEE Access 2019, 7, 162127–162138. [Google Scholar] [CrossRef]
- Park, Y.J.; Lee, Y.J.; Kim, S.B. Cooperative multi-agent reinforcement learning with approximate model learning. IEEE Access 2020, 8, 125389–125400. [Google Scholar] [CrossRef]
- Silva, F.L.D.; Nishida, C.E.H.; Roijers, D.M.; Costa, A.H.R. Coordination of electric vehicle charging through multiagent reinforcement learning. IEEE Trans. Smart Grid. 2020, 11, 2347–2356. [Google Scholar] [CrossRef]
- Wang, W.; Yu, N.; Gao, Y.; Shi, J. Safe off-policy deep reinforcement learning algorithm for Volt-VAR control in power distribution systems. IEEE Trans. Smart Grid. 2020, 11, 3008–3018. [Google Scholar] [CrossRef]
- Xu, H.; Domínguez-García, A.D.; Sauer, P.W. Optimal tap setting of voltage regulation transformers using batch reinforcement learning. IEEE Trans. Power Syst. 2020, 35, 1990–2001. [Google Scholar] [CrossRef]
- Xu, X.; Jia, Y.; Xu, Y.; Xu, Z.; Chai, S.; Lai, C.S. A multi-agent reinforcement learning-based data-driven method for home energy management. IEEE Trans. Smart Grid. 2020, 11, 3201–3211. [Google Scholar] [CrossRef]
- Yan, Z.; Xu, Y. Data-driven load frequency control for stochastic power systems: A deep reinforcement learning method with continuous action search. IEEE Trans. Power Syst. 2019, 34, 1653–1656. [Google Scholar] [CrossRef]
- Yan, Z.; Xu, Y. Real-time optimal power flow: A Lagrangian based deep reinforcement learning approach. IEEE Trans. Power Syst. 2020, 35, 3270–3273. [Google Scholar] [CrossRef]
- Bregar, K.; Mohorčič, M. Improving indoor localization using convolutional neural networks on computationally restricted devices. IEEE Access 2018, 6, 17429–17441. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Type | Unit | Spec |
|---|---|---|---|
| Performance | Chilling Capacity | kcal/h | 48,160 |
| kW | 56 | ||
| Heating Capacity | kcal/h | 57,620 | |
| kW | 67 | ||
| Power Output | kW | 30 | |
| Power Consumption | Chilling | kW | 1.1 |
| Heating | kW | 1.02 | |
| Operating Current | Chilling | A | 6.1 |
| Heating | A | 5.8 | |
| Fuel Consumption | Gas Type | N-13 | |
| Chilling | kW | 69 | |
| Heating | kW | 69 | |
| Operating Temperature | Chilling | −10–50 °C | |
| Heating | −20–20 °C |
| Label | TEG | TEG + Trigen | TEG + Trigen with RL |
|---|---|---|---|
| ηout (%) | 79% | 85% | 88% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.T.; Song, G.S.; Han, S. Power Generation Optimization of the Combined Cycle Power-Plant System Comprising Turbo Expander Generator and Trigen in Conjunction with the Reinforcement Learning Technique. Sustainability 2020, 12, 8379. https://doi.org/10.3390/su12208379
Kim HT, Song GS, Han S. Power Generation Optimization of the Combined Cycle Power-Plant System Comprising Turbo Expander Generator and Trigen in Conjunction with the Reinforcement Learning Technique. Sustainability. 2020; 12(20):8379. https://doi.org/10.3390/su12208379
Chicago/Turabian StyleKim, Hyoung Tae, Gen Soo Song, and Sangwook Han. 2020. "Power Generation Optimization of the Combined Cycle Power-Plant System Comprising Turbo Expander Generator and Trigen in Conjunction with the Reinforcement Learning Technique" Sustainability 12, no. 20: 8379. https://doi.org/10.3390/su12208379
APA StyleKim, H. T., Song, G. S., & Han, S. (2020). Power Generation Optimization of the Combined Cycle Power-Plant System Comprising Turbo Expander Generator and Trigen in Conjunction with the Reinforcement Learning Technique. Sustainability, 12(20), 8379. https://doi.org/10.3390/su12208379