Text Mining National Commitments towards Agrobiodiversity Conservation and Use

 , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Text Mining Methodology
2.1.1. Identifying Meaningful Search Terms to Assess Commitments
2.1.2. Identifying Documents
2.1.3. Scoring the Level of Commitment
2.2. Case Studies
2.2.1. Country Selection
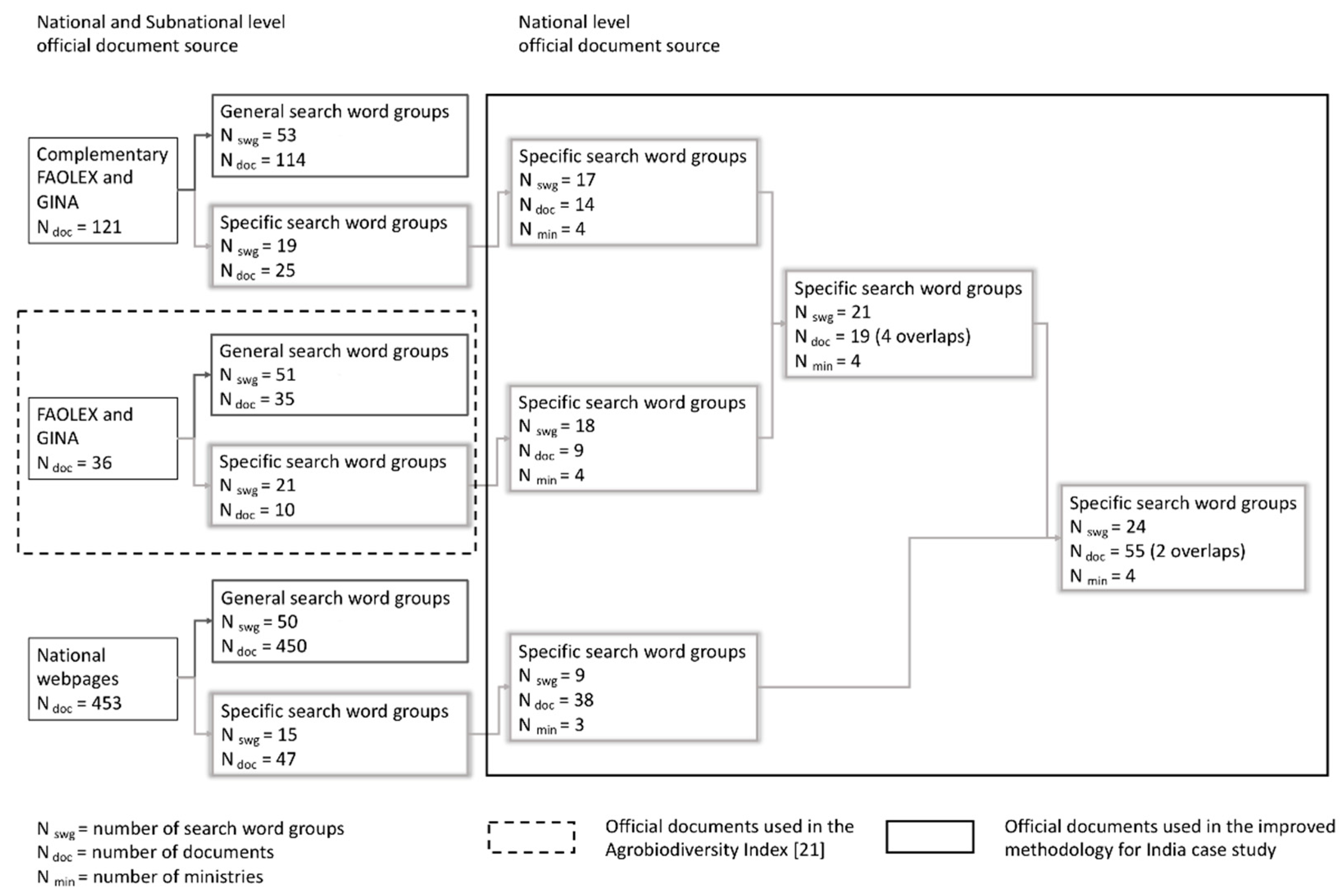
2.2.2. Document Sourcing Strategies: India Case
2.2.3. Country Scoring Differences and Ranking
2.2.4. Factors Predicting National Commitment Scores
Model2b <- glm.nb(source_count ~ country).
3. Results
3.1. Methodological Improvements
3.2. Levels of Commitment towards Agrobiodiversity Conservation and Use across Nine Countries
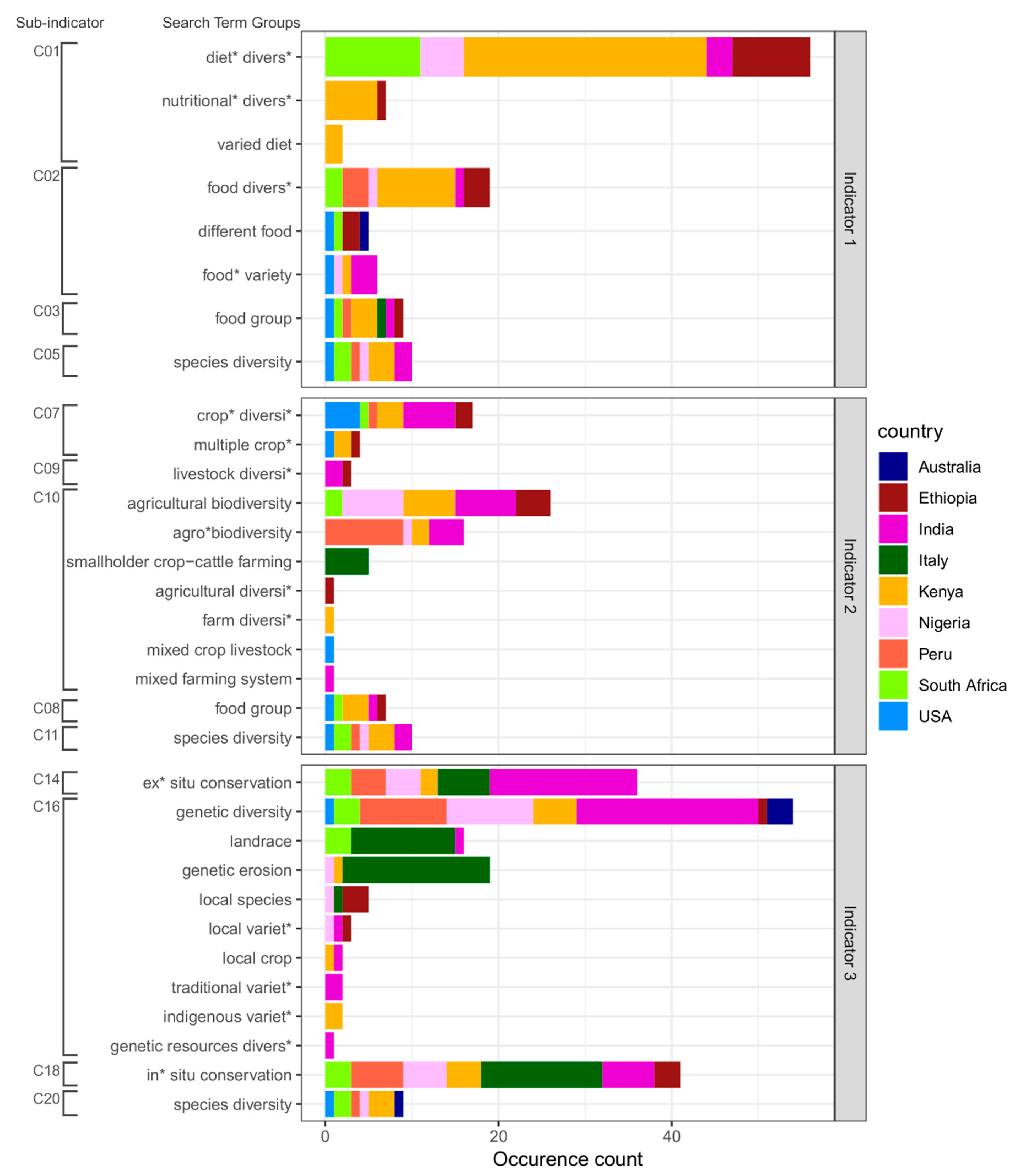
3.2.1. Common and Missing Search Term Groups
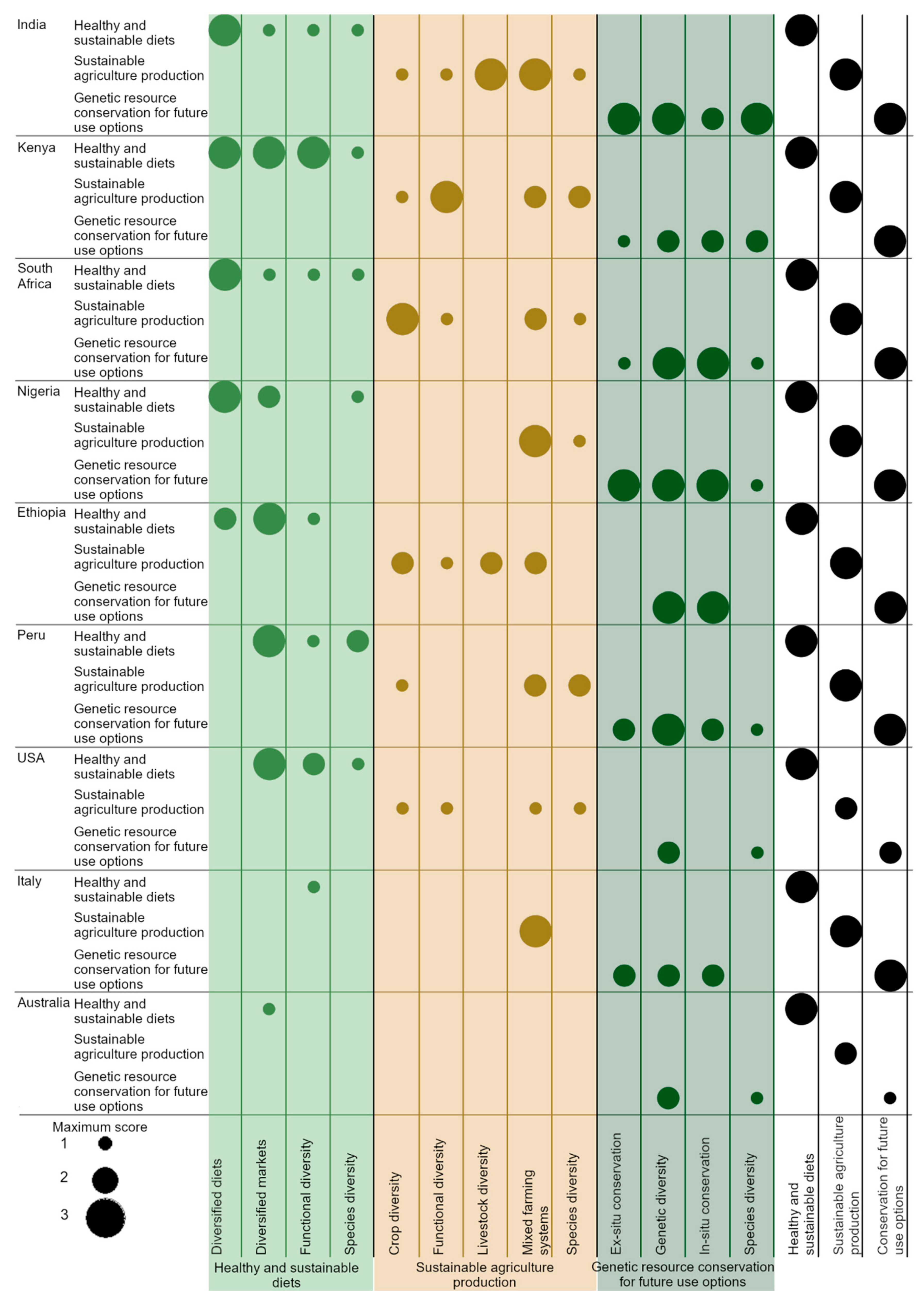
3.2.2. Common Country Strategies towards Agrobiodiversity Conservation and Use
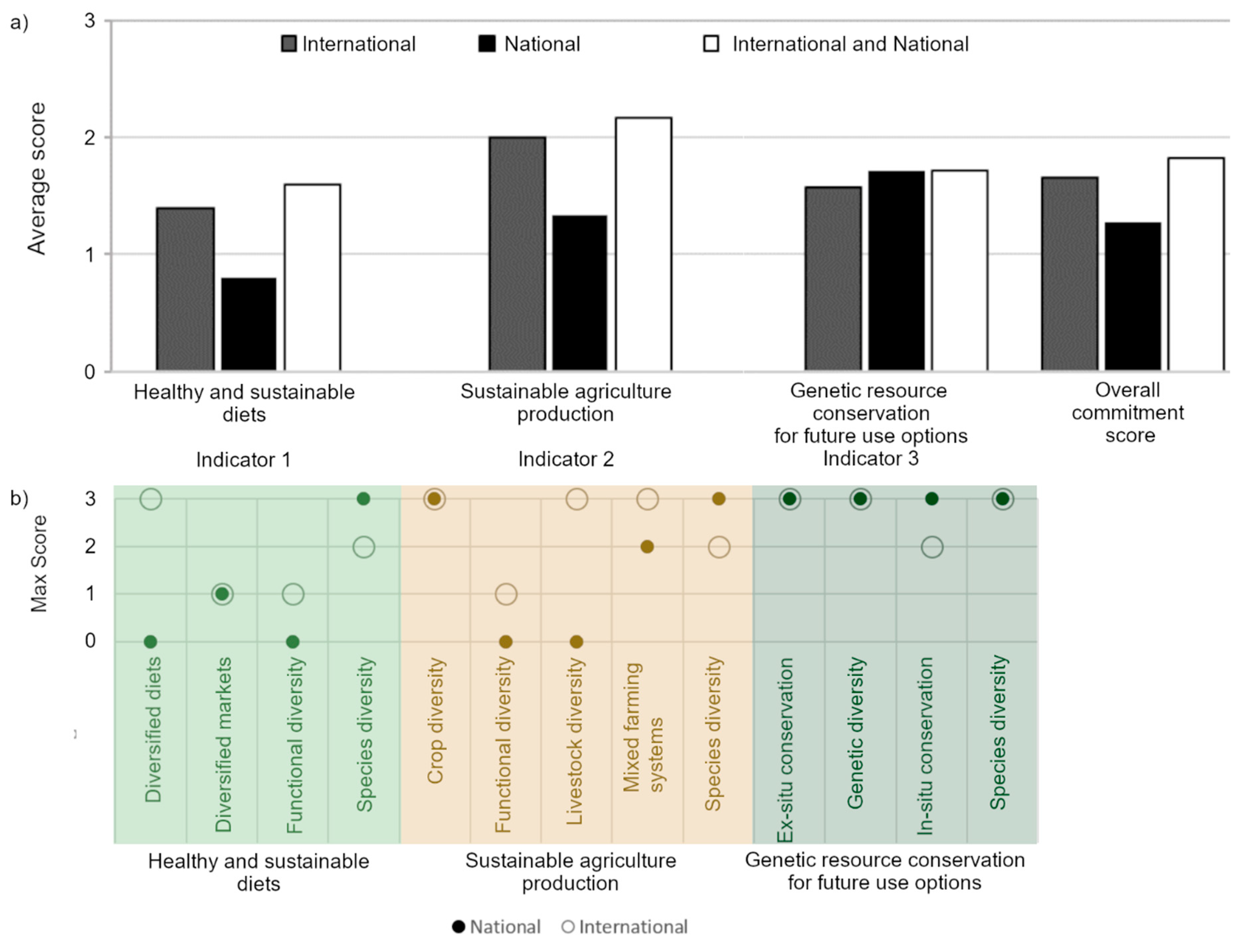
3.3. The Difference between Commitment Scores Based on Documents from International and National Public Policy Repositories (India as In-Depth Case Study)
3.4. Strengths and Weaknesses of the Current Methodology for Scoring a Country’s Commitments and Ranking
4. Discussion
4.1. Cross-Country Results and Implications for Global Policy
4.2. Policy Sourcing Strategies
4.3. Importance of Search Term and Data Selection
4.4. Semi and Fully Automated Methodologies
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lu, Y.; Nakicenovic, N.; Visbeck, M.; Stevance, A.-S. Policy: Five priorities for the UN sustainable development goals. Nat. News 2015, 520, 432. [Google Scholar] [CrossRef]
- Moldan, B.; Janoušková, S.; Hák, T. How to understand and measure environmental sustainability: Indicators and targets. Ecol. Indic. 2012, 17, 4–13. [Google Scholar] [CrossRef]
- Nardo, M.; Saisana, M.; Saltelli, A.; Tarantola, S.; Hoffman, A.; Giovannini, E. Handbook on Constructing Composite Indicators: Methodology and User Guide; In OECD Statistics Working Paper, No. 2005/03; OECD Publishing: Paris, France, 2015. [Google Scholar] [CrossRef]
- Wendling, Z.A.; Emerson, J.W.; Esty, D.C.; Levy, M.A.; de Sherbinin, A. 2018 Environmental Performance Index; Yale Center for Environmental Law Policy: New Haven, CT, USA, 2018; Available online: https://epi.yale.edu/ (accessed on 19 October 2019).
- Equal Measures 2030. Harnessing the Power of Data for Gender Equality: Introducing the 2019 EM2030 SDG Gender Index; Plan International USA: Washington, DC, USA, 2019. [Google Scholar]
- Schmidt-Traub, G.; Kroll, C.; Teksoz, K.; Durand-Delacre, D.; Sachs, J.D. National baselines for the Sustainable Development Goals assessed in the SDG Index and Dashboards. Nat. Geosci. 2017, 10, 547. [Google Scholar] [CrossRef]
- Halpern, B.S.; Longo, C.; Hardy, D.; McLeod, K.L.; Samhouri, J.F.; Katona, S.K.; Lester, S.E.; O’Leary, J.; Ranelletti, M.; Rosenberg, A.A.; et al. An index to assess the health and benefits of the global ocean. Nature 2012, 488, 615. [Google Scholar] [CrossRef] [PubMed]
- IAEG-SDGs. Update on the Work to Finalize the Proposals for the Global Indicators. 2016. Available online: https://unstats.un.org/unsd/statcom/47th-session/documents/BG-3-Update-finalize-proposals-for-SDG-global-indicators-E.pdf (accessed on 19 October 2019).
- UNDP. Human Development Indices and Indicators 2018: Statistical Update; UN: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Pierson, P. When Effect Becomes Cause: Policy Feedback and Political Change. World Politics 1993, 45, 595–628. [Google Scholar] [CrossRef]
- Stoate, C.; Boatman, N.D.; Borralho, R.J.; Carvalho, C.R.; De Snoo, G.R.; Eden, P. Ecological impacts of arable intensification in Europe. J. Environ. Manag. 2001. [Google Scholar] [CrossRef] [PubMed]
- Chaix, E.; Deléger, L.; Bossy, R.; Nédellec, C. Text mining tools for extracting information about microbial biodiversity in food. Food Microbiol. 2019, 81, 63–75. [Google Scholar] [CrossRef]
- Salloum, S.A.; Shaalan, K.; Al-Emran, M.; Monem, A.A. Using text mining techniques for extracting information from research articles. In Intelligent Natural Language Processing: Trends and Applications; Springer: Cham, Switzerland, 2018; Volume 740, pp. 373–397. [Google Scholar] [CrossRef]
- Aureli, S. A comparison of content analysis usage and text mining in CSR corporate disclosure. Int. J. Digit. Account. Res. 2017, 17, 1–32. [Google Scholar] [CrossRef]
- Nunez-Mir, G.C.; Iannone, B.V.; Pijanowski, B.C.; Kong, N.; Fei, S. Automated content analysis: Addressing the big literature challenge in ecology and evolution. Methods Ecol. Evol. 2016, 7, 1262–1272. [Google Scholar] [CrossRef]
- Tamames, J.; de Lorenzo, V. EnvMine: A text-mining system for the automatic extraction of contextual information. Bmc Bioinform. 2010, 11, 294. [Google Scholar] [CrossRef]
- Tobback, E.; Naudts, H.; Daelemans, W.; Junqué de Fortuny, E.; Martens, D. Belgian economic policy uncertainty index: Improvement through text mining. Int. J. Forecast. 2018, 34, 355–365. [Google Scholar] [CrossRef]
- Westergaard, D.; Stærfeldt, H.H.; Tønsberg, C.; Jensen, L.J.; Brunak, S. A comprehensive and quantitative comparison of text-mining in 15 million full-text articles versus their corresponding abstracts. PLoS Comput. Biol. 2018, 14, e1005962. [Google Scholar] [CrossRef] [PubMed]
- Bioversity International. Mainstreaming Agrobiodiversity in Sustainable Food Systems: Scientific Foundations for an Agrobiodiversity Index; Bioversity International: Rome, Italy, 2017. [Google Scholar]
- Bioversity International. The Agrobiodiversity Index: Methodology Report v.1.0. 2018. Available online: https://hdl.handle.net/10568/106478 (accessed on 19 October 2019).
- Bioversity International. Agrobiodiversity Index Report 2019: Risk and Resilience. 2019. Available online: https://hdl.handle.net/10568/100820 (accessed on 19 October 2019).
- Dubash, N.K.; Hagemann, M.; Höhne, N.; Upadhyaya, P. Developments in national climate change mitigation legislation and strategy. Clim. Policy 2013, 13, 649–664. [Google Scholar] [CrossRef]
- GINA. Global Database on the Implementation of Nutrition Action (GINA). 2018. Available online: https://www.who.int/nutrition/gina/en/ (accessed on 19 October 2019).
- FAOLEX. FAOLEX Database. 2018. Available online: https://www.fao.org/faolex/en/ (accessed on 19 October 2019).
- Glyph & Cog, L.L.C. 2019. Available online: https://www.xpdfreader.com/pdftotext-man.html (accessed on 19 October 2019).
- Dean, M. 2014. Available online: https://github.com/deanmalmgren/textract (accessed on 19 October 2019).
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Lewis, J.R. Multipoint scales: Mean and median differences and observed significance levels. Int. J. Hum. Comput. Interact. 1993, 5, 383–392. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 19 October 2019).
- Christensen, R.H.B. Ordinal—Regression Models for Ordinal Data. R Package Version, 28,8-25. 2018. Available online: https://www.cran.r-project.org/package=ordinal/ (accessed on 19 October 2019).
- Lenth, R.V. Least-squares means: The R package lsmeans. J. Stat. Softw. 2016, 69, 1–33. [Google Scholar] [CrossRef]
- O’hara, R.B.; Kotze, D.J. Do not log-transform count data. Methods Ecol. Evol. 2010, 1, 118–122. [Google Scholar] [CrossRef]
- Barbier, E.B.; Burgess, J.C. Sustainable development goal indicators: Analyzing trade-offs and complementarities. World Dev. 2019, 122, 295–305. [Google Scholar] [CrossRef]
- Salton, G.; Yang, C.S. On the Specification of Term Values in Automatic Indexing. J. Doc. 1973, 29, 351–372. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar]
- Höhne, N.E.; Braun, N.; Fekete, H.; Larkin, J.; Elzen, M.; Roelfsema, M.; van’t, H.A.; Böttcher, H. Greenhouse Gas Emission Reduction Proposals and National Climate Policies of Major Economies: Policy Brief; Netherlands Environmental Assessment Agency, Bilthoven and ECOFYS: Utrecht, The Netherlands, 2012. [Google Scholar]
- Globe International. Climate Legislation Study: A Review of Climate Change Legislation in 33 Countries, 3rd ed.; Townshend, T., Fankhauser, S., Aybar, R., Collins, M., Landesman, T., Nachmany, M., Pavese, C., Eds.; Globe International: Melbourne, Australia, 2013; Available online: https://www.businessgreen.com/digital_assets/6235/3rd_GLOBE_Report_--_with_covers.pdf (accessed on 19 October 2019).
- Bayrak, T. A content analysis of top-ranked universities’ mission statements from five global regions. Int. J. Educ. Dev. 2020, 72, 102–130. [Google Scholar] [CrossRef]
- Barchard, K.A.; Pace, L.A. Preventing human error: The impact of data entry methods on data accuracy and statistical results. Comput. Hum. Behav. 2011, 27, 1834–1839. [Google Scholar] [CrossRef]
- Neri, F.; Raffaelli, R. Text Mining Applied to Multilingual Corpora. In Knowledge Mining; Springer: Berlin/Heidelberg, Germany, 2005; pp. 123–131. Available online: https://link.springer.com/chapter/10.1007/3-540-32394-5_9#citeas (accessed on 19 October 2019).
- Deng, K.; Bol, P.; Li, K.J.; Lui, J. On the unsupervised analysis of domain-specific Chinese texts. Proc. Natl. Sci. Acad. USA 2016, 113, 6154–6159. [Google Scholar] [CrossRef] [PubMed]
- Muff, K.; Kapalka, A.; Dyllick, T. The Gap Frame—Translating the SDGs into relevant national grand challenges for strategic business opportunities. Int. J. Manag. Educ. 2017, 15, 363–383. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators and Subindicators (Subindicator Code) | Search Term Groups | Search Terms |
|---|---|---|
| Pillar 1-Indicator 1: Level of commitment to enhancing Agrobiodiversity in consumption and markets for healthy diets | 52 | 71 |
| General subindicator Healthy and sustainable diets (C04) | 35 | 38 |
| Specific subindicators Diversified diets (C01) | 3 | 11 |
| Diversified markets (C02) | 10 | 18 |
| Functional diversity (C03) | 2 | 2 |
| Species diversity (C05) | 1 | 1 |
| Varietal diversity (C06) | 1 | 1 |
| Pillar 2-Indicator 2: Level of commitment to enhancing production and maintenance of Agrobiodiversity for sustainable agriculture | 78 | 105 |
| General subindicator Sustainable agricultural production (C12) | 58 | 70 |
| Specific subindicators Crop diversity (C07) | 5 | 12 |
| Functional diversity (C08) | 2 | 2 |
| Livestock diversity (C09) | 1 | 4 |
| Mixed farming systems (C10) | 10 | 15 |
| Species diversity (C11) | 1 | 1 |
| Varietal diversity (C13) | 1 | 1 |
| Pillar 3-Indicator 3: Level of commitment to enhancing Agrobiodiversity genetic resource management for conservation and use options | 93 | 126 |
| General subindicator Genetic resource conservation for current and future use options (C17) | 59 | 75 |
| Specific subindicators Ex-situ conservation (C14) | 3 | 4 |
| Functional diversity (C15) | 1 | 1 |
| Genetic diversity (C16) | 19 | 27 |
| In-situ conservation (C18) | 1 | 2 |
| Seed diversity (C19) | 8 | 15 |
| Species diversity (C20) | 1 | 1 |
| Varietal diversity (C21) | 1 | 1 |
| Total | 215 | 302 |
| Classification | Definition | Examples of Where This Occurs | Score |
|---|---|---|---|
| Not applicable | The search term occurs while referring to an external body or document. | References, external company profiles, staff profiles. | 0 |
| Mention | The search term is included as part of a description of country or company commitments, but there is no information about strategies or targets related to the search term. | Background information, facts, introduction text, recommendations, support information, studies, procedures, responsibilities of stakeholders, table of contents, headings. | 1 |
| Strategy | The search term is included as part of a description of country or company commitments, and there is a specific strategy related to the search term. | Strategic goals, objectives, strategy statements. When the structure of the sentence includes the following, to promote, to support, to improve, to accelerate, e.g., “Improve household dietary diversity knowledge and practice of farmers”. | 2 |
| Target | The search term is included as part of a description of country or company commitments, and there is a specific target related to the search term, usually with a time-bound threshold that needs to be met. | Percentages (%), specific indicator and/or output to be attained. E.g., “10% more households have increased household dietary diversity by 2030”. | 3 |
| Countries | Criteria | Agrobiodiversity Index [20,21] | This paper |
|---|---|---|---|
| All nine | Scored subindicators | General and Specific | Specific |
| All nine | Unit of analysis | 302 Search terms | 302 Search terms and 215 search term groups |
| All nine | Policies included | National and Subnational Official and non-official | National Official |
| All nine | Overall scores, country rank | Average | Average, Model 1 and Model 2 |
| India | Policy type | Policy, Legislation | Policy, Legislation, Regulation |
| India | Policy search themes | Agricultural and rural development Cultivated plants Environment Food and nutrition | Agricultural and rural development Cultivated plants Environment Food and nutrition Fisheries and aquaculture Forestry Land and soil Livestock Mineral resources and energy Sea Water Wild species and ecosystems |
| India | Public policy repositories | International | International vs. national |
| Agrobiodiversity Index [21] | Scores and Ranking Estimated in This Paper | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| County | Model 1 | Model 2a | Model 2b | |||||||
| Overall Scores | Rank | Overall Scores | Rank | Rank | Group | Rank | Group | Rank | Group | |
| India | 1.67 | 1 | 1.44 | 1 | 1 | a | 2 | ab | 4 | ab |
| Kenya | 1.62 | 2 | 1.39 | 2 | 2 | a | 1 | a | 1 | a |
| South Africa | 1.43 | 3 | 1.17 | 3 | 3 | ab | 5 | abc | 3 | ab |
| Nigeria | 1.38 | 4 | 1.11 | 4 | 5 | ab | 4 | abc | 6 | ab |
| Ethiopia | 1.33 | 5 | 1.06 | 5 | 6 | ab | 7 | abc | 7 | ab |
| Peru | 1.33 | 6 | 1.06 | 6 | 4 | ab | 6 | abc | 2 | ab |
| Italy | 1.00 | 7 | 0.56 | 8 | 8 | ab | 3 | ab | 5 | ab |
| USA | 0.95 | 8 | 0.72 | 7 | 7 | ab | 8 | bc | 8 | ab |
| Australia | 0.48 | 9 | 0.22 | 9 | 9 | c | 9 | c | 9 | b |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juventia, S.D.; Jones, S.K.; Laporte, M.-A.; Remans, R.; Villani, C.; Estrada-Carmona, N. Text Mining National Commitments towards Agrobiodiversity Conservation and Use. Sustainability 2020, 12, 715. https://doi.org/10.3390/su12020715
Juventia SD, Jones SK, Laporte M-A, Remans R, Villani C, Estrada-Carmona N. Text Mining National Commitments towards Agrobiodiversity Conservation and Use. Sustainability. 2020; 12(2):715. https://doi.org/10.3390/su12020715
Chicago/Turabian StyleJuventia, Stella D., Sarah K. Jones, Marie-Angélique Laporte, Roseline Remans, Chiara Villani, and Natalia Estrada-Carmona. 2020. "Text Mining National Commitments towards Agrobiodiversity Conservation and Use" Sustainability 12, no. 2: 715. https://doi.org/10.3390/su12020715
APA StyleJuventia, S. D., Jones, S. K., Laporte, M.-A., Remans, R., Villani, C., & Estrada-Carmona, N. (2020). Text Mining National Commitments towards Agrobiodiversity Conservation and Use. Sustainability, 12(2), 715. https://doi.org/10.3390/su12020715