“SeoulHouse2Vec”: An Embedding-Based Collaborative Filtering Housing Recommender System for Analyzing Housing Preference

Abstract
1. Introduction
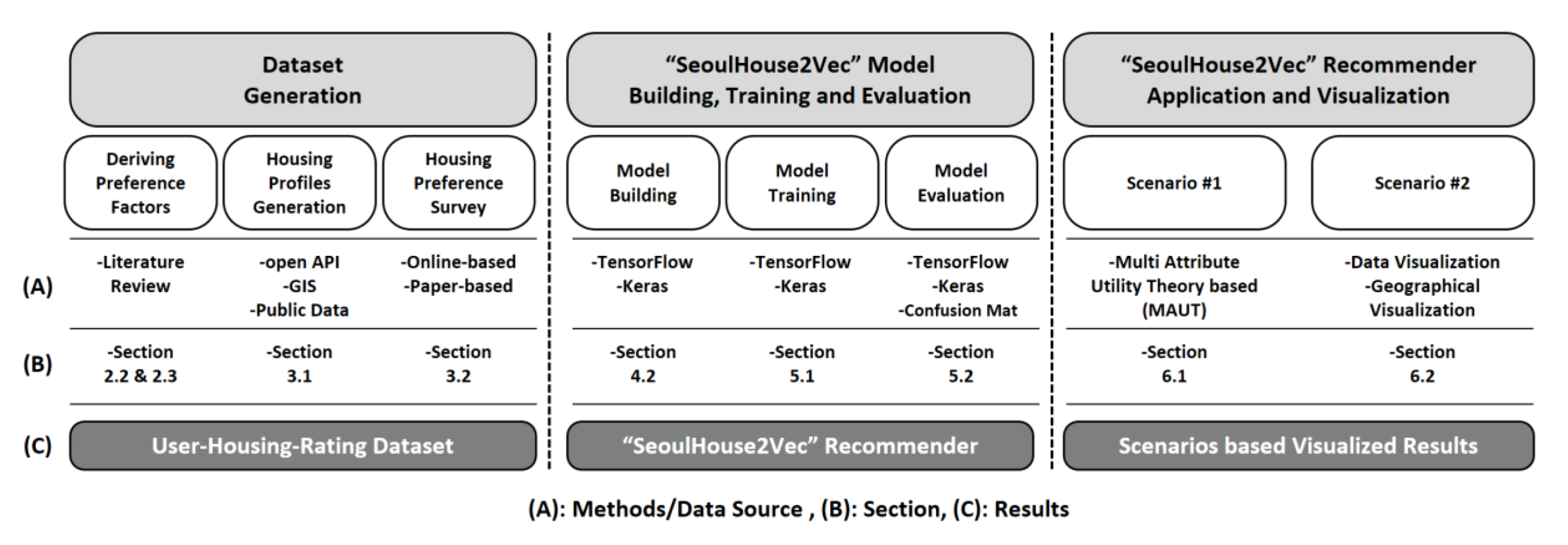
Research Materials, Methods, and Structure of the Paper
2. Literature Review
2.1. Embedding-Based Collaborative Filtering Recommender System
2.2. Housing Preference
2.3. Important Housing Attributes for Housing Preference in South Korea
3. Survey Design
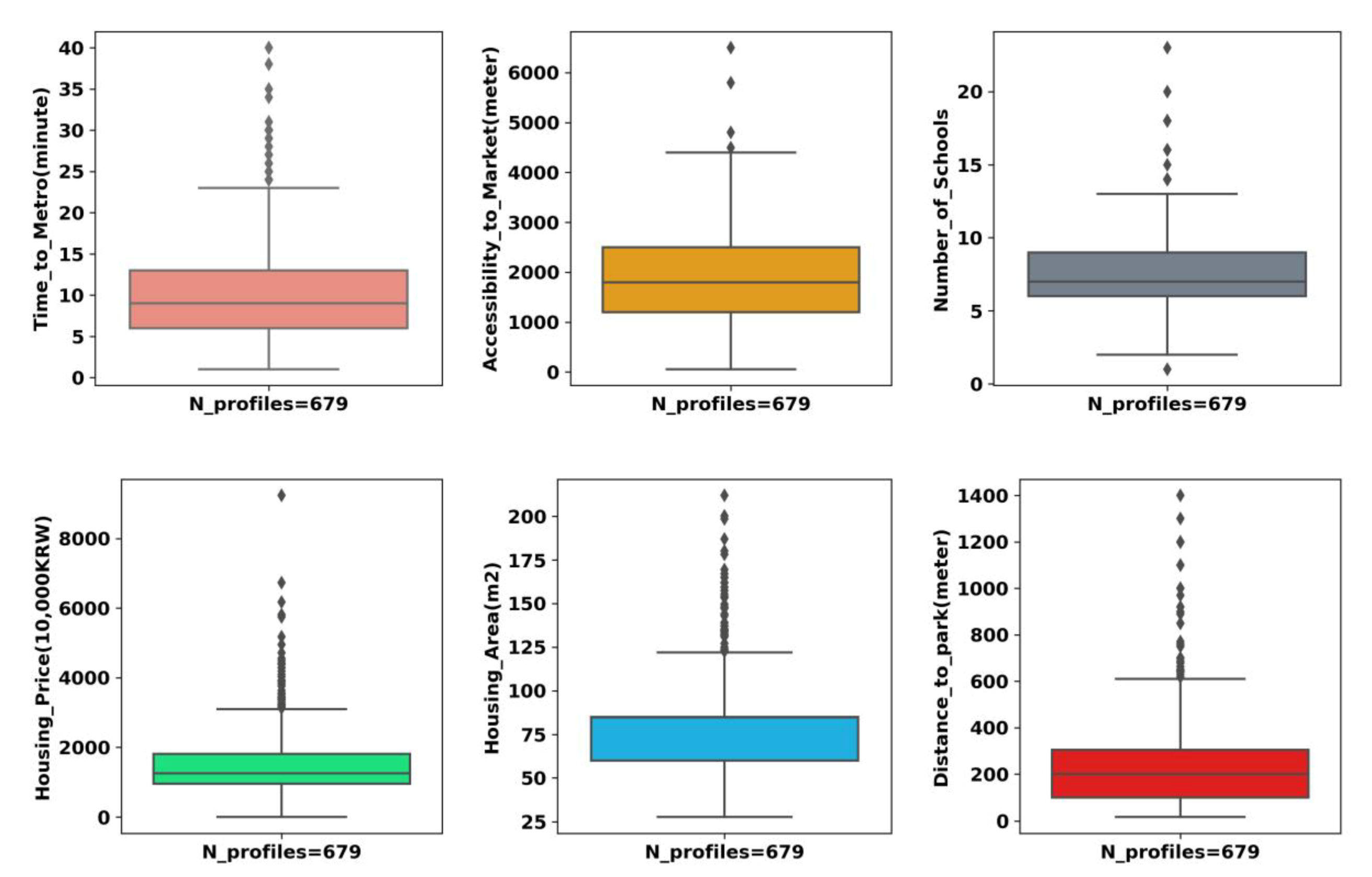
3.1. Housing Attributes and Housing Profiles Composition
3.2. Survey Design
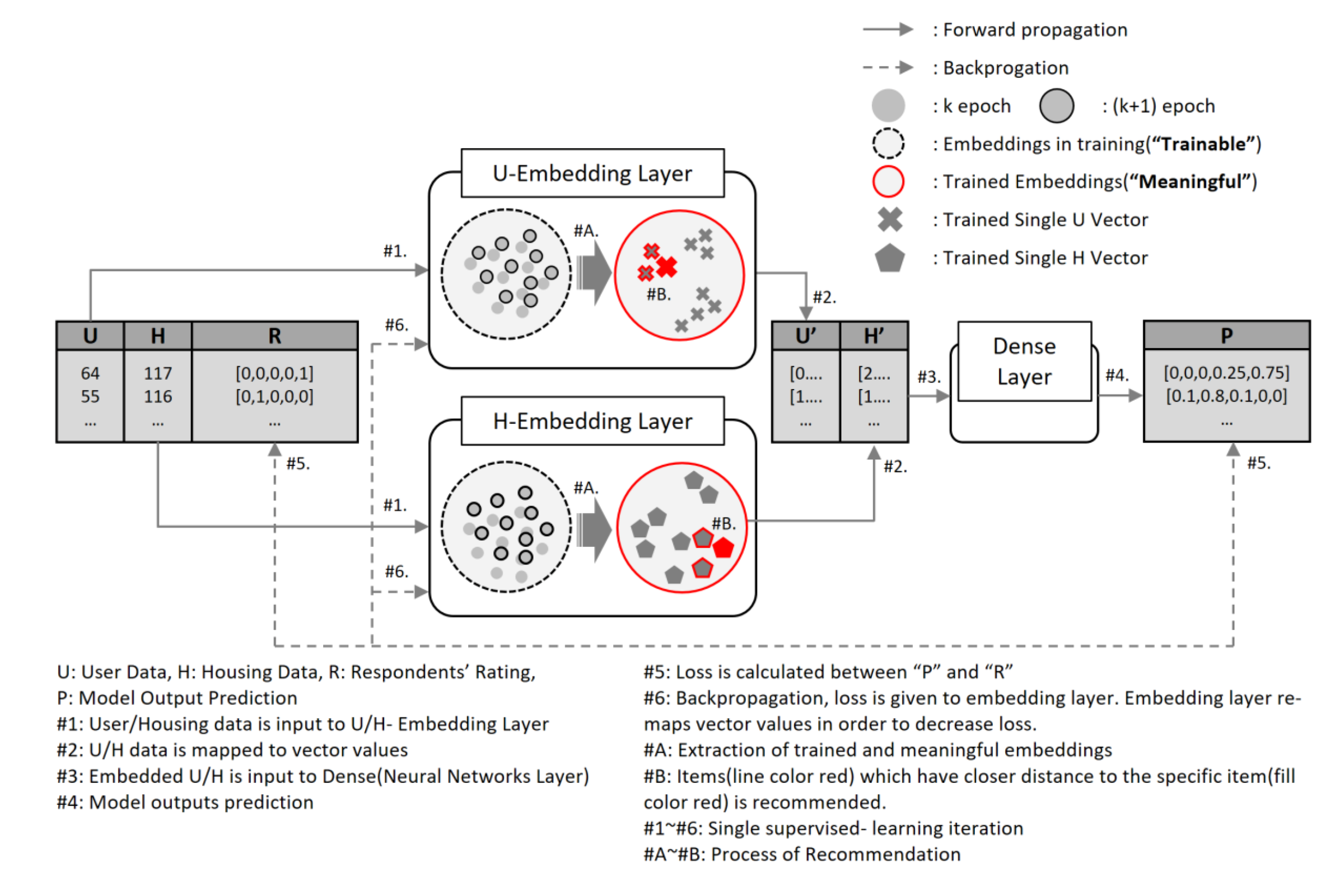
4. “SeoulHouse2Vec” Model Building
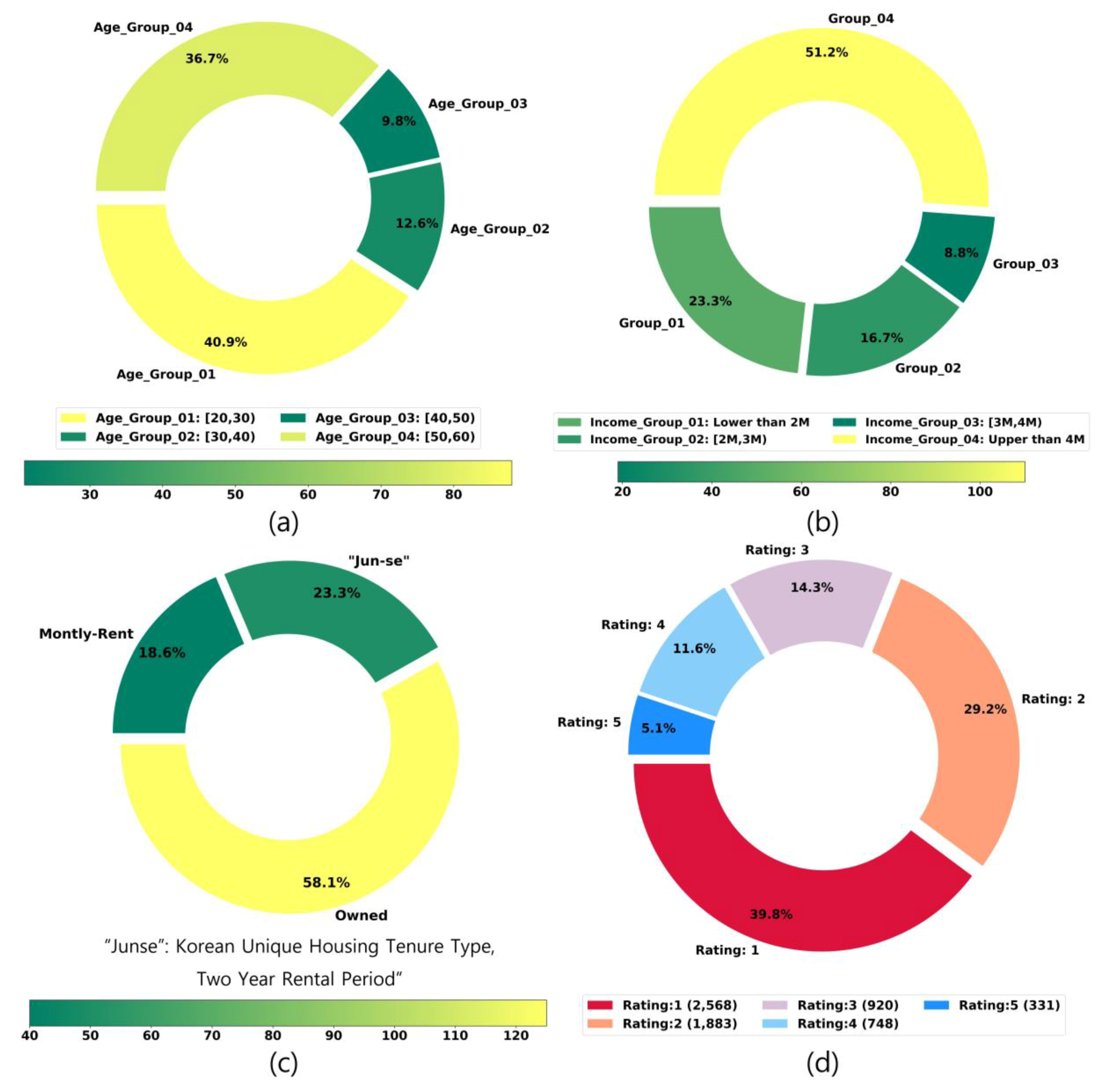
4.1. Dataset of Housing Prefernces Ratings Description
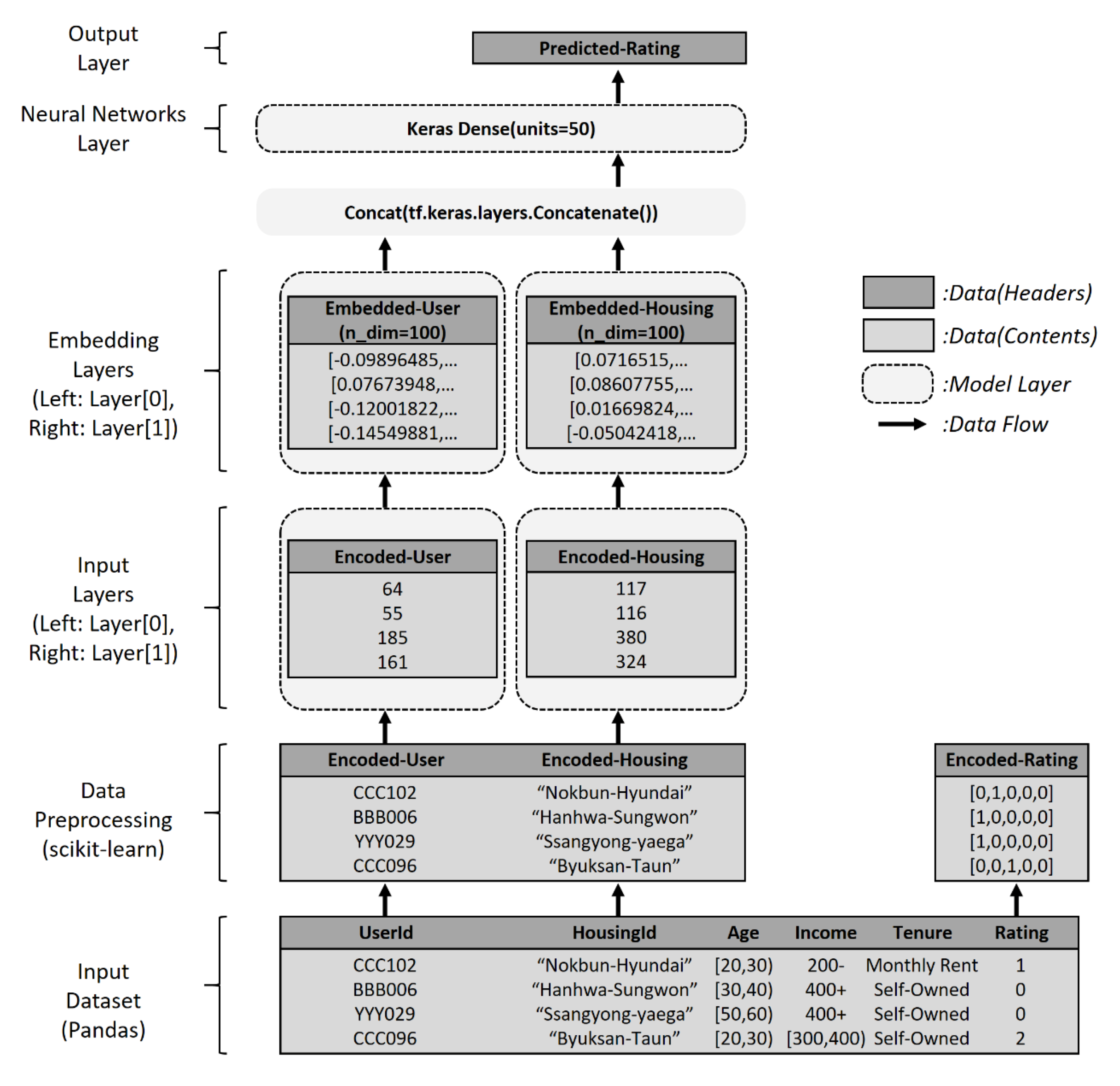
4.2. Model Structure
5. “SeoulHouse2Vec” Model Training, Validating and Evaluation with Confusion Matrix
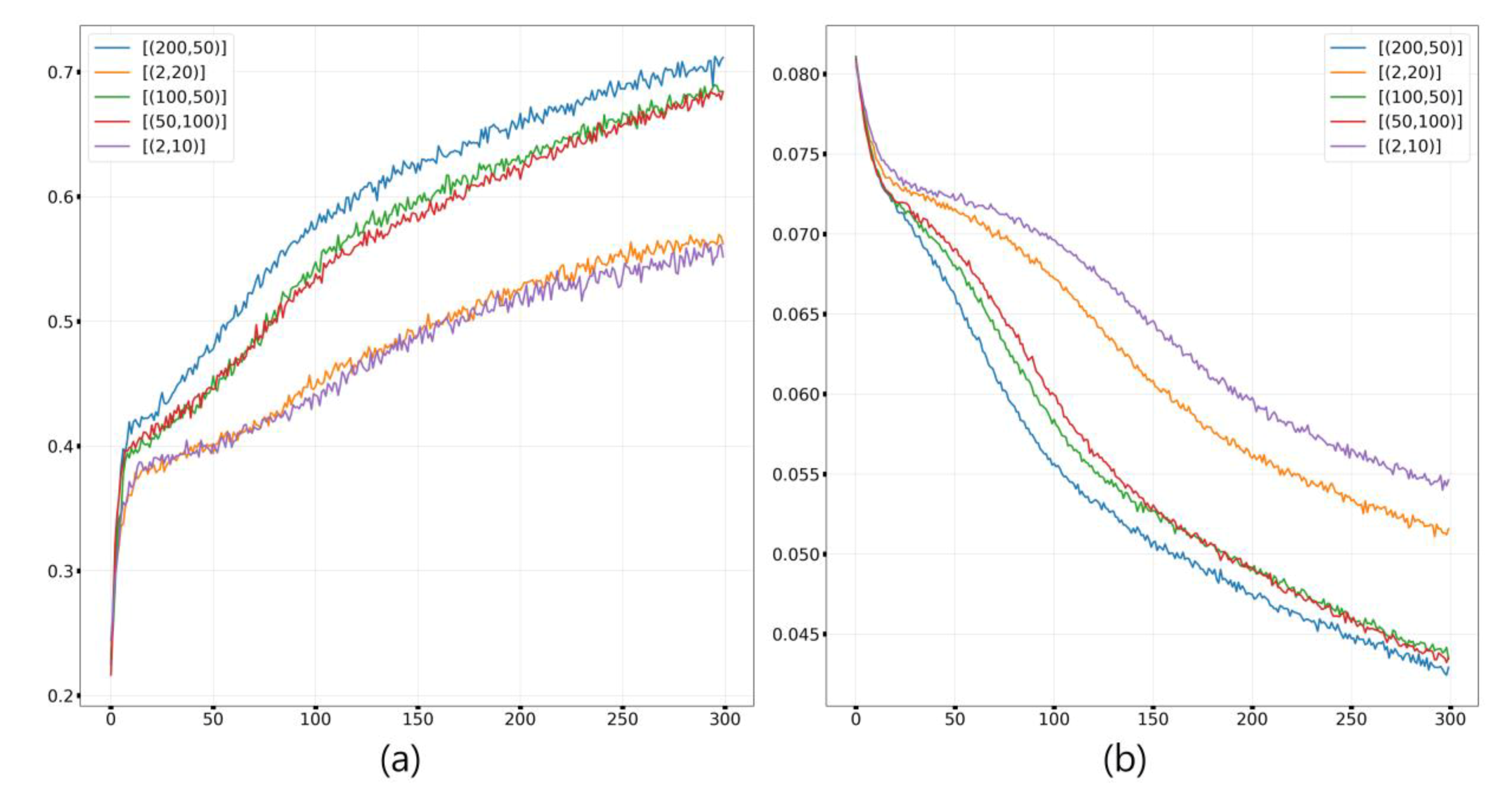
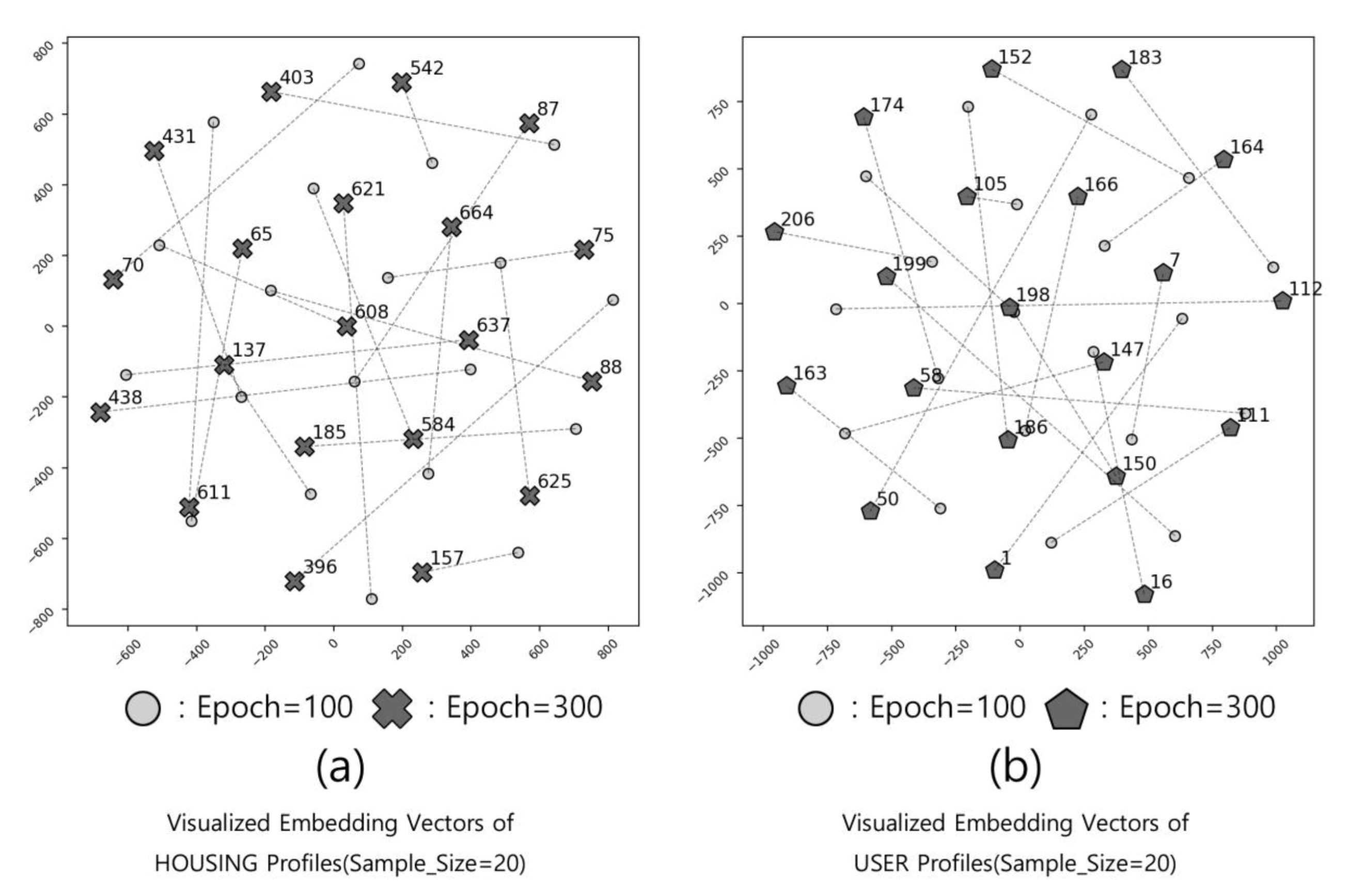
5.1. Model Training and Validating for Tuning Model Hyperparameters
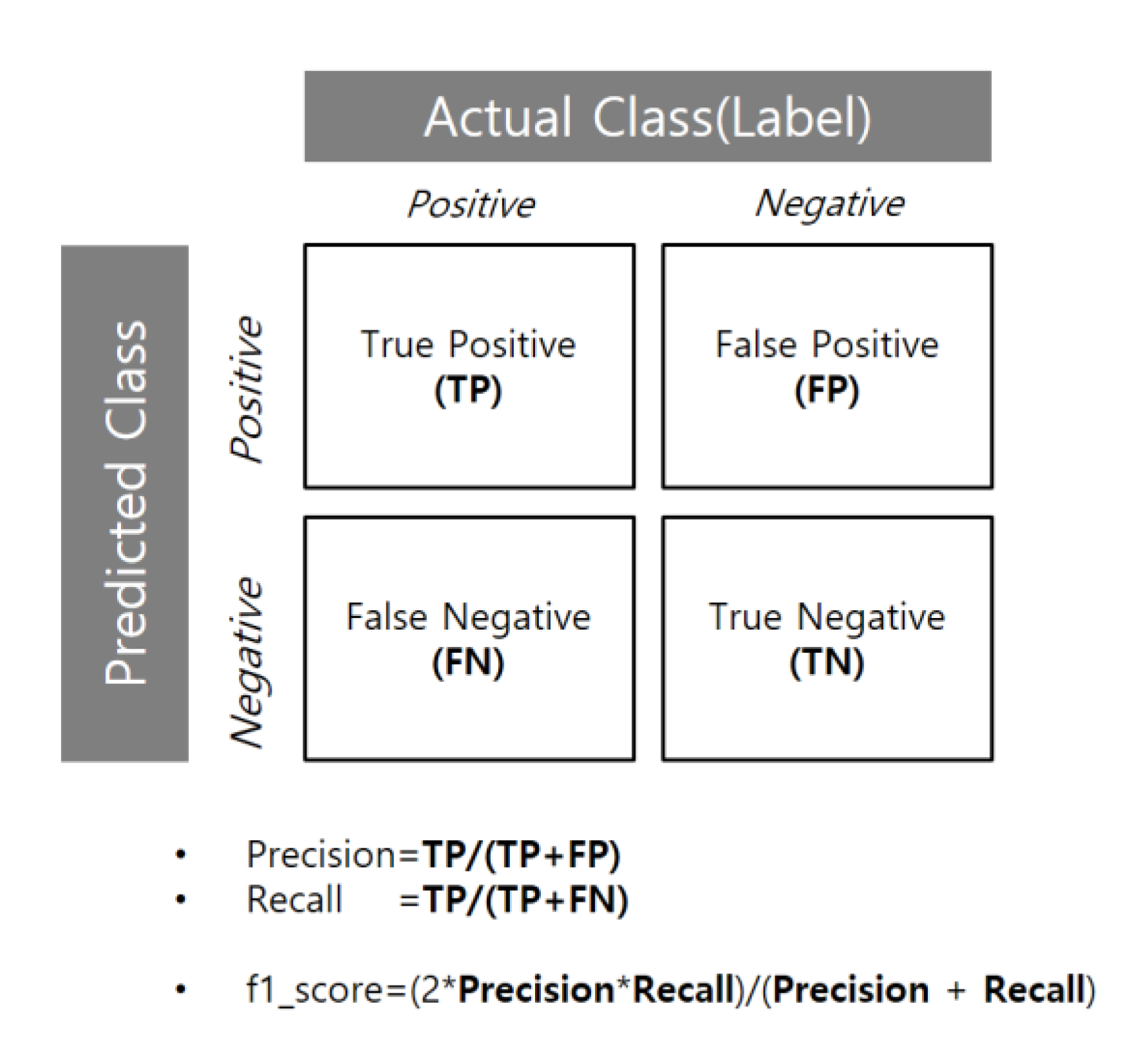
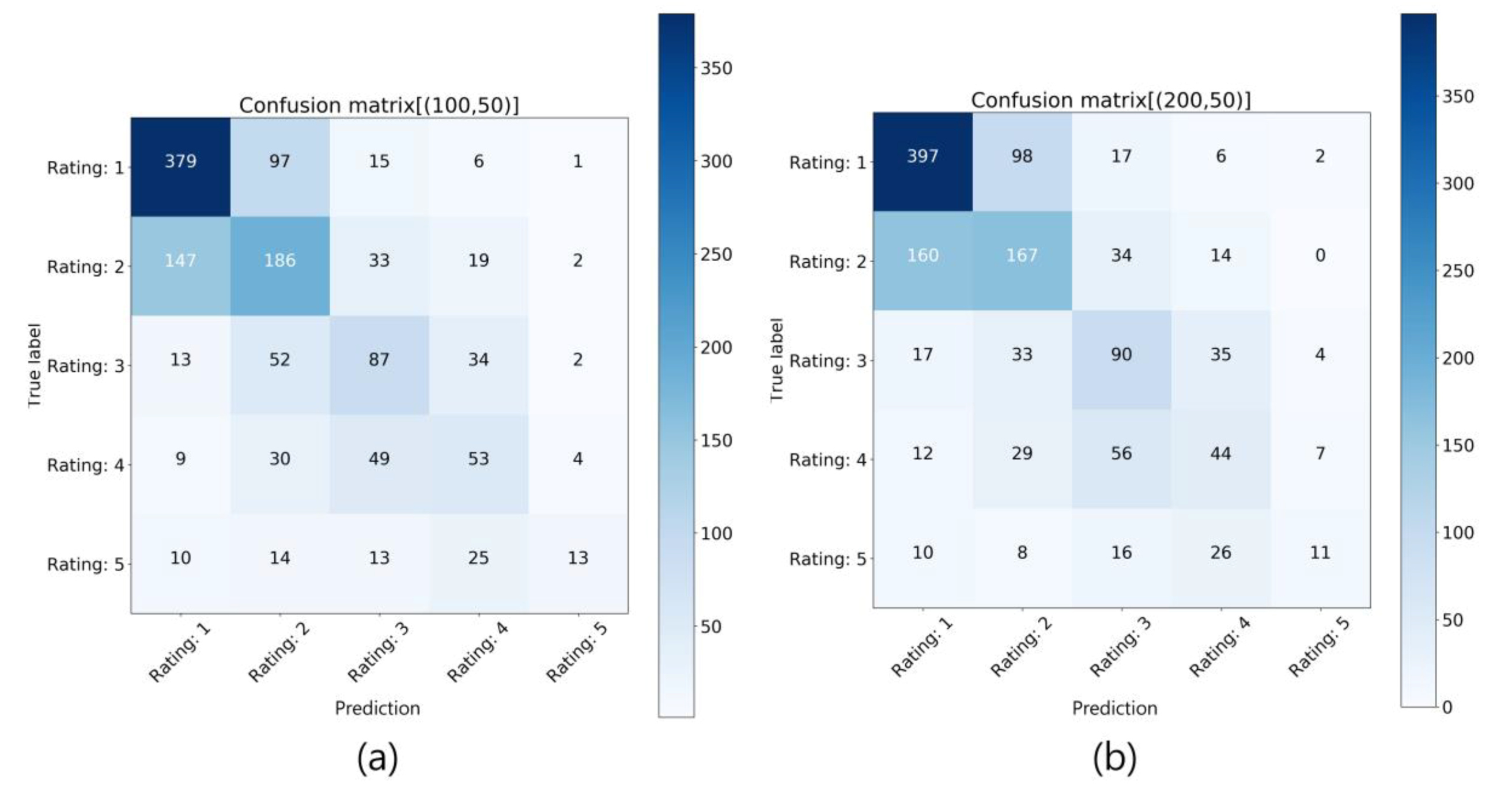
5.2. Evaluation with Confusion Matrix for Estimating Final Performance of the Model.
6. Scenario-Based Demonstration of “SeoulHouse2Vec” Model
6.1. SeoulHouse2Vec Model Demonstration Scenario 1
6.1.1. Scenario: Multi-Attribute Utility Theory
6.1.2. SeoulHouse2Vec Application with MAUT
6.2. SeoulHouse2Vec Model Demonstration Scenario 2
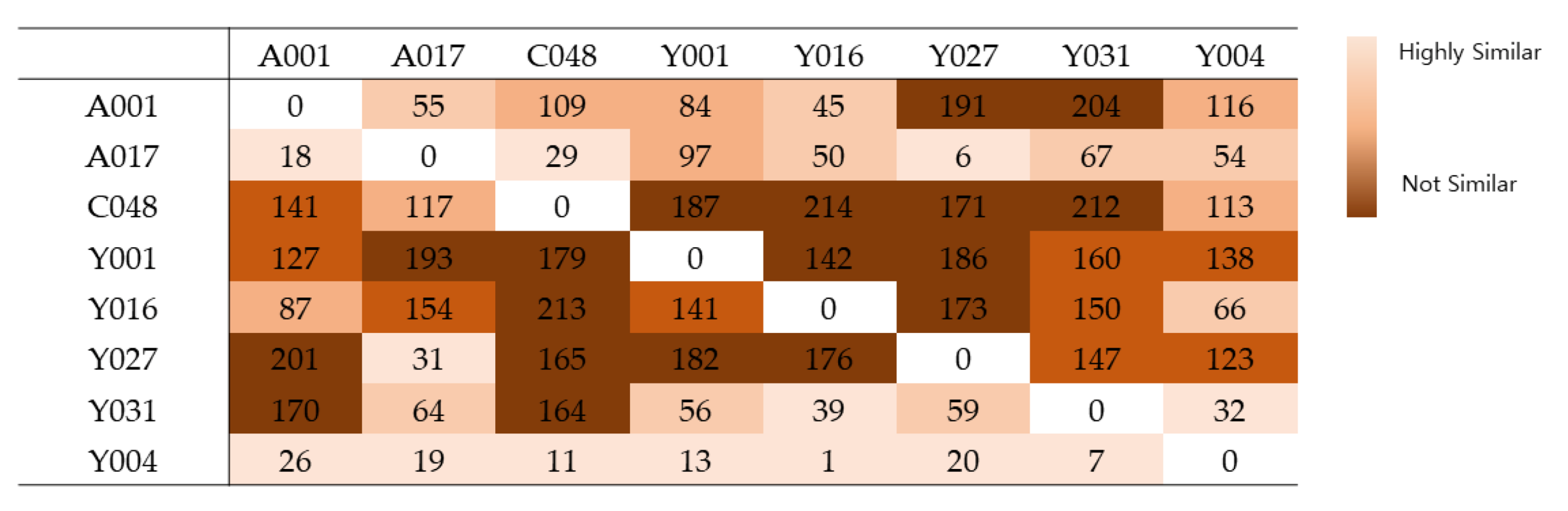
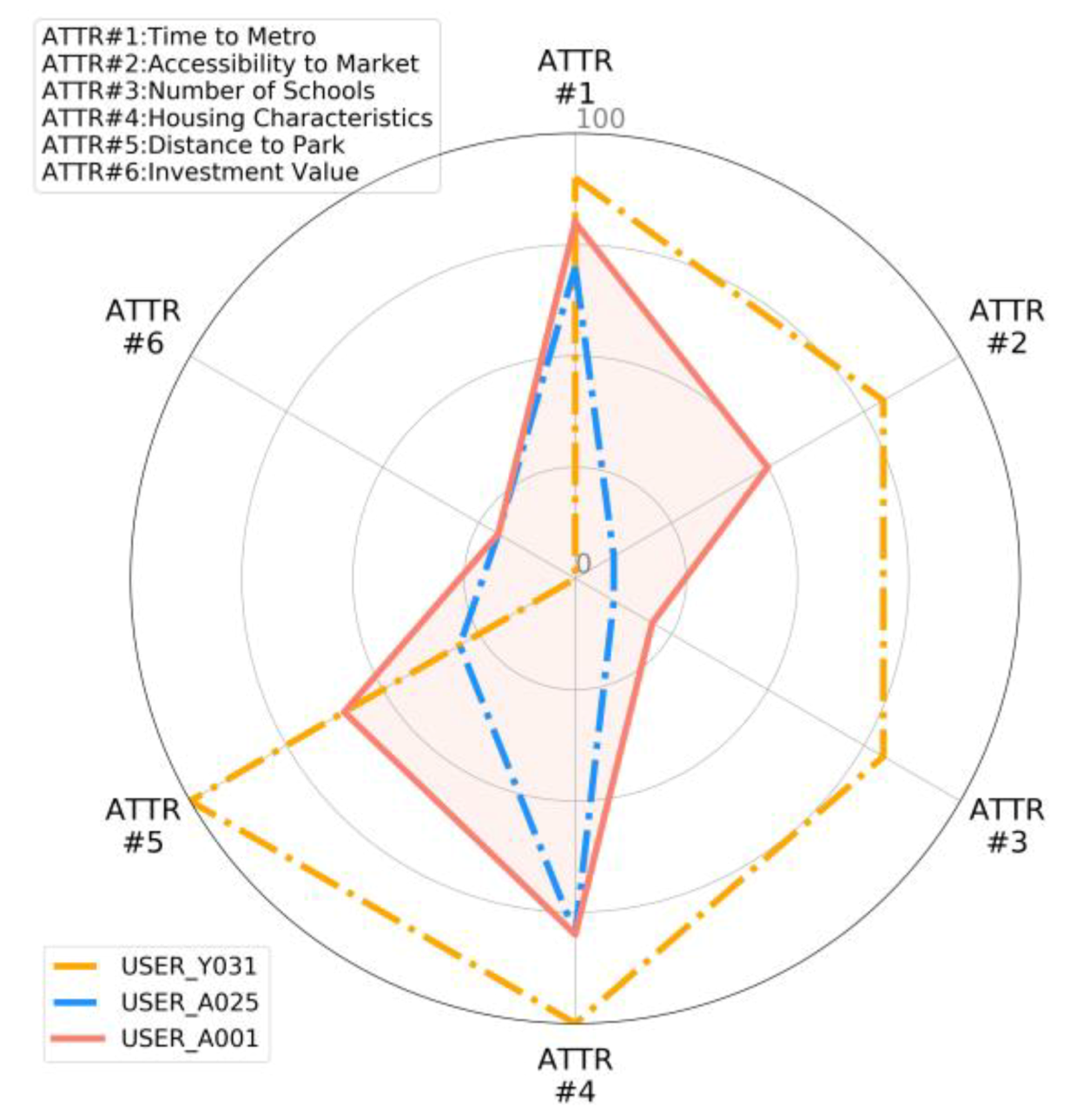
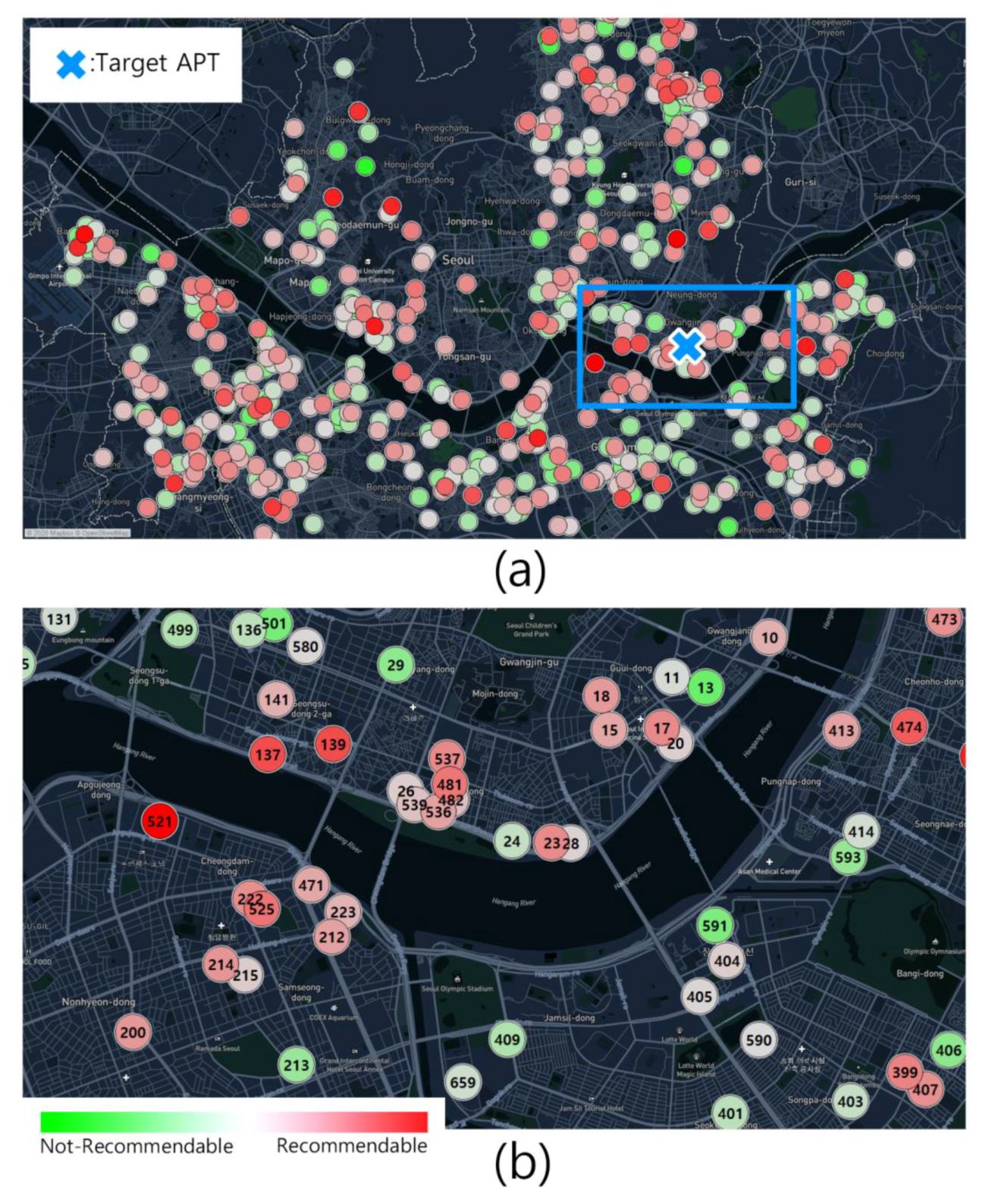
6.2.1. Scenario Presentation
6.2.2. Model Application
6.2.3. Data Analysis
7. Conclusions
- Sustainability in architecture, previous research focused on the use of energy-efficient materials, designing high performance building envelop and optimizing HVAC operation, etc. Unlike previous research, this study is meaningful in that it investigates the rational use of limited housing-related goods. Given that the consumption and supply of housing utilizes limited land and spatial resources, both consumption and supply are closely related to sustainability, which has long-term personal, social, and environmental impacts. Moreover, it may not be possible to revise or reverse the decision. This study suggested the feasibility of using a recommender system to support rational decision making in both housing consumption and supply.
- Even with the fact that housing supply ratio in Seoul is about 95%, housing prices are rapidly increasing as of late. To address this in terms of massive housing supply, policymakers are discussing the lifting of the greenbelt zones where development has been restricted over the years. While there are various causes of steep rises in the prices, the model proposed in this study has one potential technique to solve problems known to prevent the housing market from functioning rationally, including imbalanced information between housing consumers and suppliers, rather hasty housing decision based on consumers’ biased information, and the limited exploration of the alternatives.
- From the user’s viewpoint, the scope of existing housing alternative searches was limited to the local scope of dong or gu (district). However, the SeoulHouse2Vec model proposed in this study is significant in that it extends the search scope for housing alternatives from the previous dong to the entire Seoul area by utilizing public big data and GIS data.
- If Seoul’s regional scope is expanded through data mining and web crawler technology to collect alternatives throughout Gyeonggi-do and South Korea, it will be possible to apply a further expanded model.
- The SeoulHouse2Vec model provides one possibility of assessing the outcome of past housing decision-making. If the level of housing satisfaction is higher than the current one, certain alternative with the attributes similar to the current one can be presented. Conversely, if the current housing satisfaction level is low, an alternative with the opposite attributes, one whose embedding distance is far, may be prioritized. This will help support the current housing decision-making process by quantitatively analyzing and reflecting the past decision-making process. This may be particularly useful for users who have little experience and knowledge in searching for housing alternatives.
- SeoulHouse2Vec has the potential to track the user’s decision-making process, analyze preferences, and support the architect’s planning and initial design stage. It is now becoming increasingly important to reflect users’ perspective in architectural planning and design. This is an important factor not only in design quality, but also in determining the market price of buildings. Currently, the architectural planning phase involves analyzing the requirements of prospective users and contractors, and relying on the architect’s knowledge, experience, and intuition to generate the information necessary to proceed with the design process. The model proposed here includes user information on age, income, and housing tenure type; housing profile information related to housing attributes; and preference information, which is the relationship between the user and the alternatives. The dataset may provide a quantitative basis in the architectural decision-making process.
- The SeoulHouse2Vec model not only measures users’ housing preferences based on demographic attributes, but users with divergent demographic characteristics may also have highly similar housing preferences depending on the importance of each preference variable. Even in groups with matching demographic characteristics, housing choice may vary depending on how significant respondents consider each variable. This preference tendency can be reflected through the embedding method.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Korean Statistical Information Service. Population. Available online: https://kosis.kr/visual/populationKorea/PopulationByNumber/PopulationByNumberMain.do?mb=N (accessed on 3 July 2020).
- Seoul Metropolitan Government. Seoul Statistics Publication, Statistics Annual Report, 2018 Major Administrative Statics. Available online: https://data.seoul.go.kr/together/statbook/statbookList.do#submenu47 (accessed on 3 June 2020).
- Clapham, D. Housing theory, housing research and housing policy. Hous. Theory Soc. 2018, 35. [Google Scholar] [CrossRef]
- Sixsmith, A.; Sixsmith, J. Ageing in place in the United Kingdom. Ageing Int. 2008, 32, 219–235. [Google Scholar] [CrossRef]
- Mattews, T.; Stephens, C. Constructing housing decisions in later life: A discursive analysis of older adults’ discussions about their housing decisions in New Zealand. Hous. Theory Soc. 2017, 34. [Google Scholar] [CrossRef]
- Jeong, S.; Choi, M. A study on the characteristics of eco-generation housing choice. Resid. Environ. 2017, 15, 113–133. [Google Scholar]
- Kim, J.H.; Lee, J.S. The effect of apartment environment properties on consumer preference: Conjoint analysis of view quality and park accessibility. Mark. Manag. Res. 2014, 19, 91–109. [Google Scholar]
- Van Ham, M. Housing Behaviour, Handbook of Housing Studies; SAGE: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Steglich, W.G. Housing, Family, and Society; Wiley: New York, NY, USA, 1978. [Google Scholar]
- Jansen, S.; Coolen, H.; Goetgeluk, R. The Measurement and Analysis of Housing Preference and Choice; Springer: Berlin, Germany, 2011. [Google Scholar]
- Earnhard, D. Combining revealed and stated data to examine housing decisions using discrete choice analysis. J. Urban Econ. 2002, 51, 143–169. [Google Scholar] [CrossRef]
- Wang, D.; Li, S. Housing preferences in a transitional housing system: The case of Beijing, China. Environ. Plan. A Econ. Space 2004, 36, 69–87. [Google Scholar] [CrossRef]
- Seo, D.; Kwon, Y. In-migration and housing choice in Ho Chi Minh City: Toward sustainable housing development in Vietnam. Sustainability 2017, 1738. [Google Scholar] [CrossRef]
- Ge, J.; Hokao, K. Research on residential lifestyles in Japanese cities from the viewpoints of residential preference, residential choice and residential satisfaction. J. Landsc. Urban Plan. 2006, 78, 165–178. [Google Scholar] [CrossRef]
- Marsh, A.; Gibb, K. Uncertainty, expectations and behavioural aspects of housing market choices. Hous. Theory Soc. 2011, 28. [Google Scholar] [CrossRef]
- Molin, E.; Oppewal, H.; Timmermans, H. Predicting consumer response to new housing: A stated choice experiment. J. Hous. Built Environ. 1996, 11, 297–311. [Google Scholar] [CrossRef]
- Liao, F.; Farber, S.; Ewing, R. Compact development and preference heterogeneity in residential location choice behaviour: A latent class analysis. Urban Stud. 2015, 52, 314–337. [Google Scholar] [CrossRef]
- Park, M.; Hagishima, A.; Tanimoto, J.; Chun, C. Willingness to pay for improvements in environmental performance of residential buildings. Build. Environ. 2013, 60, 225–233. [Google Scholar] [CrossRef]
- Cheung, H.; Chung, T. A study on subjective preference to daylit residential indoor environment using conjoint analysis. Build. Environ. 2008, 43, 2101–2111. [Google Scholar] [CrossRef]
- Hille, S.; Curtius, H.; Wüstenhagen, R. Red is the new blue—The role of color, building integration and country-of-origin in homeowners’ preferences for residential photovoltaics. Energy Build. 2018, 162, 21–31. [Google Scholar] [CrossRef]
- Mansour, O.; Radford, S. Rethinking the environmental and experiential categories of sustainable building design: A conjoint analysis. Build. Environ. 2016, 98, 47–54. [Google Scholar] [CrossRef]
- Hoshino, T. Estimation and analysis of preference heterogeneity in residential choice behaviour. Urban Stud. 2010, 48, 362–382. [Google Scholar] [CrossRef]
- Mulliner, E.; Algrnas, M. Preferences for housing attributes in Saudi Arabia: A comparison between consumers’ and property practitioners’ views. Cities 2018, 83, 152–164. [Google Scholar] [CrossRef]
- Jancz, A.; Trojanek, R. Housing preferences of seniors and pre-senior citizens in Poland—A case study. Sustainability 2020, 12, 4599. [Google Scholar] [CrossRef]
- Wang, C.; Lincoln, C.; Liang, H. Housing preference for modern urban designers using fuzzy-AHP. Open House Int. 2018, 43, 33–42. [Google Scholar]
- Opoku, R.; Abdul-Muhmin, A. Housing preferences and attribute importance among low-income consumers in Saudi Arabia. Habitat Int. 2010, 34. [Google Scholar] [CrossRef]
- Jiang, H.; Chen, S. Dwelling unit choice in a condominium complex: Analysis of willingness to pay and preference heterogeneity. Urban Stud. 2016, 53, 2273–2292. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM Spec. Issue Inf. Filter. 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 12. [Google Scholar] [CrossRef]
- Herlocker, J.; Konstan, J.; Reidl, J. Explaining collaborative filtering recommendations. In Proceedings of the ACM Conference on Computer Supported Cooperative Work, Philadelphia, PA, USA, 2–6 December 2000. [Google Scholar]
- Barkan, O.; Koenigstein, N. ITEM2VEC: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Salerno, Italy, 13–16 September 2016. [Google Scholar]
- Zarzour, H.; Al-Sharif, Z.; Jararweh, Y. RecDNNing: A recommender system using deep neural network with user and item embeddings. In Proceedings of the 10th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 11–13 June 2019; pp. 99–103. [Google Scholar]
- Ozsoy, M. From word embeddings to item recommendation. arXiv 2016, arXiv:1601.01356. [Google Scholar]
- Yang, Z.; He, J.; He, S.A. Collaborative filtering method based on forgetting theory and neural item embedding. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 1606–1610. [Google Scholar]
- Seoul Metropolitan Government. Seoul Metropolitan Government Housing Status (Housing Type, Occupancy Type, etc.). Available online: https://opengov.seoul.go.kr/data/10565468 (accessed on 3 August 2020).
- Seoul Metropolitan Government. Seoul Metropolitan Apartment Information. Available online: https://data.seoul.go.kr/dataList/OA-15818/S/1/datasetView.do (accessed on 3 August 2020).
- Resnick, P.; Varian, H. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Schafer, B.; Konstan, J.; Riedl, J. E-commerce recommendation applications. Data Min. Knowl. Discov. 2000, 5, 115–153. [Google Scholar] [CrossRef]
- Smith, B.; Linden, G. Two decades of recommender systems at Amazon.com. IEEE Internet Comput. 2017, 21, 12–18. [Google Scholar] [CrossRef]
- Schafer, J.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative filtering recommender systems. Adapt. Web 2007, 4321, 291–324. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web 2011, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; pp. 175–186. [Google Scholar]
- Valcarce, D.; Landin, A.; Parapar, J.; Barreiro, A. Collaborative filtering embeddings for memory-based recommender systems. Eng. Appl. Artif. Intell. 2019, 85, 347–356. [Google Scholar] [CrossRef]
- Guo, C.; Berkhahn, F. Entity embeddings of categorical variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- Keras Embedding Layer. Available online: https://keras.io/api/layers/core_layers/embedding/:03 (accessed on 3 August 2020).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. Available online: https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf (accessed on 3 August 2020).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 3 August 2020).
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. arXiv. 2019. Available online: https://arxiv.org/pdf/1707.07435.pdf (accessed on 3 August 2020).
- Grbovic, M.; Radosavljevic, V.; Djuric, N.; Bhamidipati, N.; Savla, J.; Bhagwan, V.; Sharp, D. E-commerce in your inbox: Product recommendations at scale. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2015, Sydney, NSW, Australia, 10–13 August 2015; pp. 1809–1818. [Google Scholar]
- Kim, Y.; Seo, J. Analysis of residential preference characteristics according to the aging of the baby boomers. Resid. Environ. 2013, 11, 37–49. [Google Scholar] [CrossRef]
- Lee, H.; Park, H.; Go, S. A study on the preference of residential environment when purchasing apartments through conjoint analysis. J. Korean Hous. Assoc. 2009, 20, 27–35. [Google Scholar]
- Son, J.; Lee, B. A study on the characteristics of apartment housing preference according to lifestyle. Resid. Environ. 2017, 15, 151–161. [Google Scholar]
- Kim, T.; Kwon, K.; Choi, E.; Hong, S. A study on changes in housing demand by region through analysis of Gyeonggi-do’s housing satisfaction and preference. Gyeonggi Inst. Basic Res. 2013, 1–113. [Google Scholar]
- Ministry of Land, Infrastructure and Transport. Apartment Price. Available online: http://www.realtyprice.kr/notice/main/mainBody.htm (accessed on 3 August 2020).
- Ministry of Land, Infrastructure and Transport. Available online: http://www.molit.go.kr/USR/NEWS/m_71/dtl.jsp?id=95082611 (accessed on 3 August 2020).
- Ministry of Land, Infrastructure and Transport. Article 3 (1) 1 of the Enforcement Decree of the Korean Housing Act; Ministry of Land, Infrastructure and Transport: Seoul, Korea, 2019.
- Ministry of Land, Infrastructure and Transport. Article 3–5 of the Enforcement Decree of the Building Act; Ministry of Land, Infrastructure and Transport: Seoul, Korea, 2000.
- Paul, E.; Green, A.; Krieger, M. Conjoint analysis with product-positioning applications. In Handbooks in Operations Research and Management Science: Marketing; Eliashberg, J., Lilien, G.L., Eds.; Elsevier: Amsterdam, The Netherlands, 1993; Volume 5, pp. 467–515. [Google Scholar]
- Dyer, J.S.; Fishburn, P.C.; Steuer, R.E.; Wallenius, J.; Zionts, S. Multiple criteria decision making, multiattribute utility theory: The next ten years. Manag. Sci. 1992, 38, 645–654. [Google Scholar] [CrossRef]
- Churchman, C.W.; Ackoff, R.L. An approximate measure of value. Oper. Res. 1954, 2, 172–187. [Google Scholar] [CrossRef]
- Debreu, G. Topological methods in cardinal utility theory. In Mathematical Methods in the Social Sciences; Arrow, K.J., Karlin, S., Suppes, P., Eds.; Stanford University Press: Stanford, CA, USA, 1960. [Google Scholar]
- Dyer, J.S.; Sarin, R.K. Measurable multiattribute value functions. Oper. Res. 1979, 27, 810–822. [Google Scholar] [CrossRef]
- Keeney, R.L.; Raiffa, H. Decisions with multiple objectives: Preferences and value tradeoffs; Wiley: New York, NY, USA, 1976. [Google Scholar]
- Keeney, R.L. Quasi-separable utility functions. Nav. Res. Logist. Q. 1968, 15, 551–565. [Google Scholar] [CrossRef]
- Ahn, J.; Bang, Y.; Pil, S. Consumer preference survey using multi-attribute utility theory. Manag. Inform. Res. 2008, 18, 1–20. [Google Scholar]
- Statistics Korea, Population and Household. Available online: https://kostat.go.kr/portal/korea/kor_nw/1/2/4/index.board?bmode=read&bSeq=&aSeq=380351&pageNo=1&rowNum=10&navCount=10&currPg=&searchInfo=srch&sTarget=title&sTxt=2019 (accessed on 3 August 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Research Purpose | Research Method | Housing Preference Variables |
|---|---|---|---|
| [6] | Explores important factors of newly married eco boomers’ house selection | Multiple linear regression analysis | Housing location, housing facilities, eco-friendliness, educational environment, living convenience, residential safety, residential status, economic power, family |
| [53] | Investigates lifestyle demographic characteristics and analyzes the effects on characteristic factors of apartment housing preference | Pearson correlation, regression | Location of educational facilities, location of commercial districts, apartment exterior, apartment functions, community within the complex, interior design, interior, indoor function, privacy, storage space |
| [51] | Studies the influence of view quality and park accessibility on consumers’ apartment preference to determine implications for revitalizing apartment marketing | Conjoint analysis | View, size, park accessibility, apartment prices, brand awareness |
| [42] | Identifies factors to consider in future housing policies and explains differences in housing demand by region | Binary/multiple logistics regression | Housing size, housing facility level, noise, odor, management status, green area facility, convenient facility within complex, air and water quality, surrounding facilities, cultural performance facilities, public transportation convenience, security, access to major facilities, neighborhood parks, children’s educational conditions, management costs, relationship with local residents, housing investment value |
| [50] | Establishing future housing policies and marketing strategies based on the housing preferences of baby boomers | Technical statistics and cluster analysis | Social factors (leisure activities, relationships with friends and neighbors, composition and community level of neighbors), location factors (ease of use of elderly services, safety, cleanliness of surrounding area), personal factors (physical function, distance from children), physical factors (housing style, housing size), economic factors (housing price/rent, housing costs) |
| [51] | Providing predictive data to meet the diverse needs of consumers and improve their residential value | Conjoint analysis | Price per 3.3 square meters, housing characteristics, complex characteristics, location, investment value |
| No. | Item | Criterion (unit) |
|---|---|---|
| ATTR#1 | Time to Metro | Walking distance to the nearest subway station (minute) |
| ATTR#2 | Accessibility to Market | Distance to the nearest supermarket (meter) |
| ATTR#3 | Number of Schools | Number of educational facilities within 1 km |
| ATTR#4 | Housing Price | Prices of the created profiles (10,000 KRW) |
| ATTR#5 | Housing Area | Housing area (m2) |
| ATTR#6 | Number of Rooms | Number of rooms excluding living rooms and kitchens |
| ATTR#7 | Number of Bathrooms | Number of bathrooms |
| ATTR#8 | Distance to Park | Distance to the nearest park (meter) |
| ATTR#9 | Investment value | Ranked in top 10 construction capacity (yes/no) |
| ATTR#1 | ATTR#2 | ATTR#3 | ATTR#5 | ATTR#6 | ATTR#7 | ATTR#8 | ATTR#9 | |
|---|---|---|---|---|---|---|---|---|
| Total | 11.23 | 1870.40 | 7.79 | 83.87 | 3.09 | 1.71 | 233.28 | 0.42 |
| Reference | 7 | 1600 | 6 | 138.85 | 4 | 2 | 100 | 0 |
| Top 50 | 12.72 | 1876.06 | 7.6 | 87.78 | 3.18 | 1.8 | 262.78 | 0.48 |
| Top 25 | 12.12 | 1949.32 | 6.68 | 84.87 | 3.08 | 1.84 | 256.28 | 0.44 |
| Top 10 | 11.50 | 2137.8 | 7.1 | 85.24 | 3 | 1.8 | 254.9 | 0.7 |
| Top 5 | 5.4 | 2680 | 8.6 | 96.96 | 3.2 | 1.8 | 258.2 | 0.6 |
| Distance(Closest) | Profile (Gu, Dong, and Apartment Name) |
|---|---|
| 1st | Dongdaemun-gu, Jangan-dong, Raemian Jangan 2-Cha |
| 2nd | Gangnam-gu, Apgujeong-dong, Hanyang 3 |
| 3rd | Gangseo-gu, Banghwa-dong, Banghwa 3-Danji |
| 4th | Mapo-gu, Yonggang-dong, Mapo Yongang Samsung Raemian |
| 5th | Gangdong-gu, Cheonho-dong, Raemian Gangdong Palace |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jun, H.J.; Kim, J.H.; Rhee, D.Y.; Chang, S.W. “SeoulHouse2Vec”: An Embedding-Based Collaborative Filtering Housing Recommender System for Analyzing Housing Preference. Sustainability 2020, 12, 6964. https://doi.org/10.3390/su12176964
Jun HJ, Kim JH, Rhee DY, Chang SW. “SeoulHouse2Vec”: An Embedding-Based Collaborative Filtering Housing Recommender System for Analyzing Housing Preference. Sustainability. 2020; 12(17):6964. https://doi.org/10.3390/su12176964
Chicago/Turabian StyleJun, Han Jong, Jae Hee Kim, Deuk Young Rhee, and Sun Woo Chang. 2020. "“SeoulHouse2Vec”: An Embedding-Based Collaborative Filtering Housing Recommender System for Analyzing Housing Preference" Sustainability 12, no. 17: 6964. https://doi.org/10.3390/su12176964
APA StyleJun, H. J., Kim, J. H., Rhee, D. Y., & Chang, S. W. (2020). “SeoulHouse2Vec”: An Embedding-Based Collaborative Filtering Housing Recommender System for Analyzing Housing Preference. Sustainability, 12(17), 6964. https://doi.org/10.3390/su12176964