Robustness Evaluations of Sustainable Machine Learning Models against Data Poisoning Attacks in the Internet of Things



Abstract
1. Introduction
- We determined the efficiency of the ML algorithms, including gradient boosted machines, random forests, naive Bayes statistical classifiers, and feed forward deep learning models, before and after data poisoning attacks to examine their trustworthiness in IoT environments.
- We developed a label modification function that simulates data poisoning attacks by modifying the normal classes of the ToN_IoT and UNSW NB-15 datasets.
- We evaluated each of the ML models’ performances before and after data poisoning attacks, enabling discussion of the potential risks and advantages of these models.
2. Background and Related work
2.1. The Unique Nature of IoT
2.2. Adversarial Machine Learning
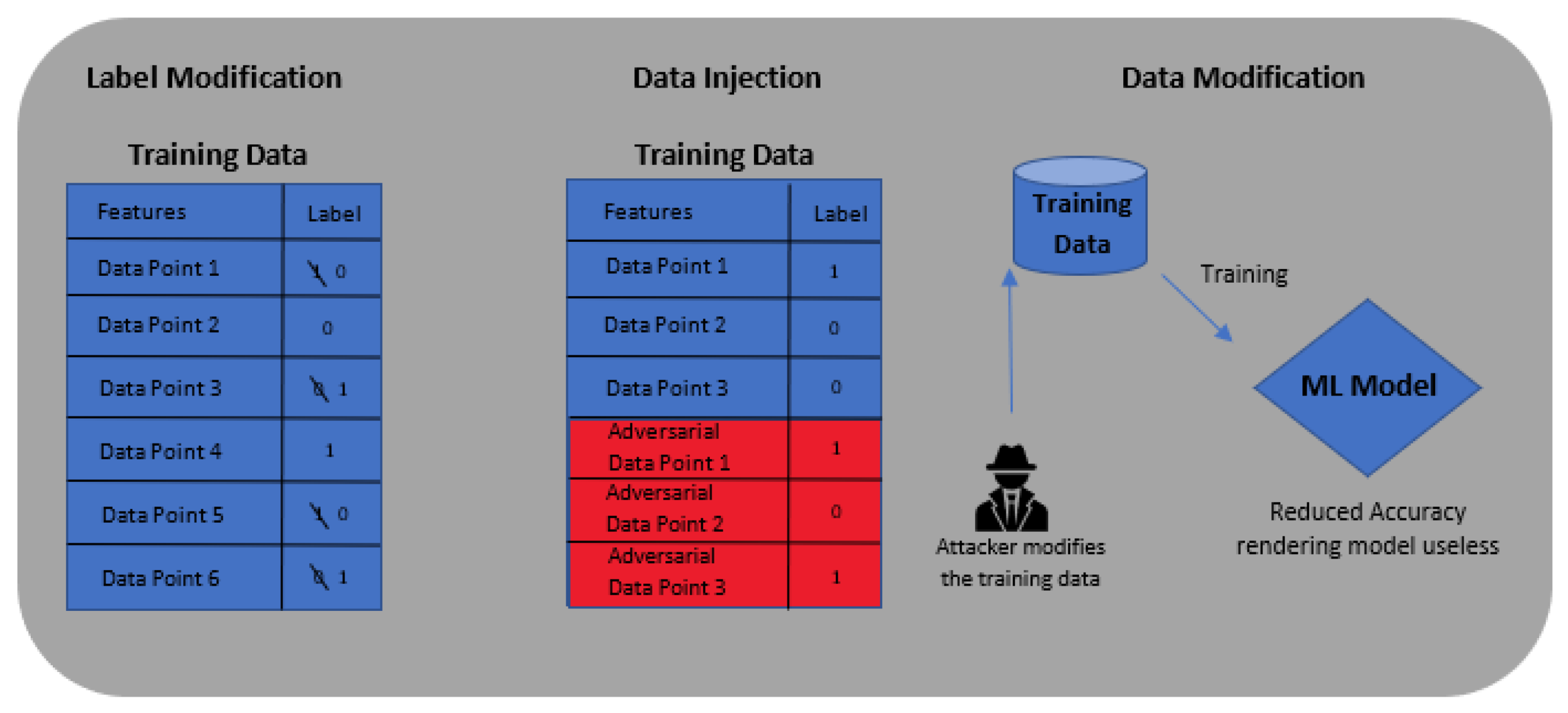
2.3. Data Poisoning Attacks and Defences
2.4. Adversarial Modelling
- Perfect knowledge adversary: This adversary is aware of the model’s parameters and detection techniques used to secure the model. Through the use of an adaptive white-box attack, the attacker can evade the ML model and the detector [26]. Using the assumption that the attacker has full knowledge of the ML algorithm, its parameters, hyperparameters, and the underlying architecture, their aim would be to develop an appropriate loss function to create adversarial examples capable of effectively evading the ML classifier.
- Limited knowledge adversary: This adversary does not have access to the detector implemented nor the training data; however, it does have knowledge of the detection scheme used to secure the model and the training algorithm. As the attacker is unaware of the underlying architecture and the parameters, a black-box attack must be used [26]. The attacker’s aim would be to create a training set similar in size and quality to the original, to train a substitute model.
- Zero-knowledge adversary: This adversary does not have access to the original detector, nor knowledge of the ML algorithm used. This threat model is very weak, as the attacker is not aware of the defences used to secure the underlying model. The attacker would use a black-box attack such as Carlini and Wagner’s [30] attack to try defeat the ML model. If the attack fails and the adversarial sample is detected, it can be said that the two previous attack models would also fail to defeat the detection mechanism [26].
2.5. Existing Literature
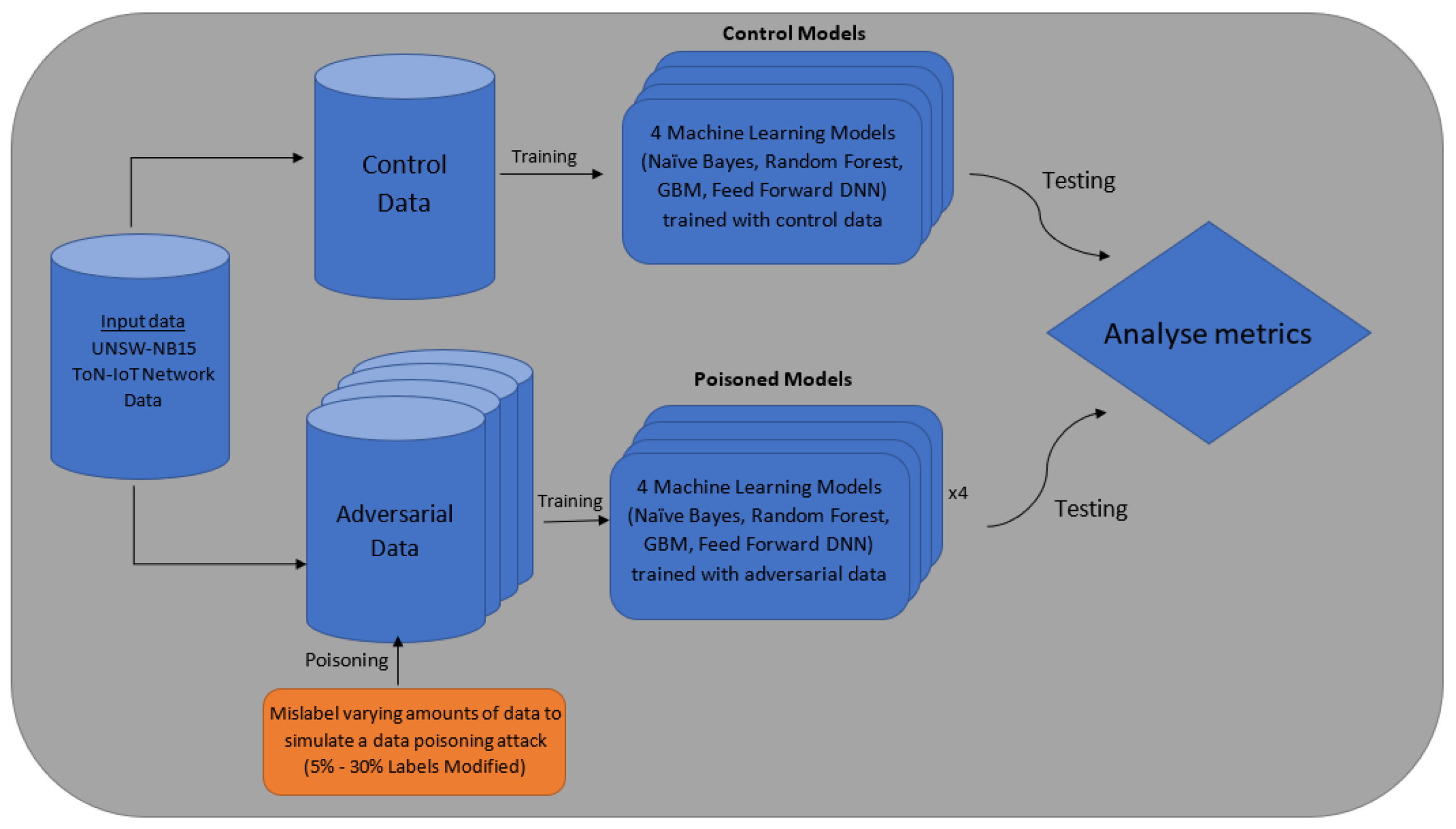
3. Proposed Methodology
3.1. Data Poisoning Process
| Algorithm 1: Data poisoning process using label modification. |
 |
3.2. Machine Learning Models
3.2.1. Gradient Boosting Machine
| Algorithm 2: Algorithm of regression tree boosting. |
 |
3.2.2. Random Forest
3.2.3. Naive Bayes
3.2.4. Feed Forward Deep Learning
3.3. Training Phase of ML Algorithms
| Algorithm 3: ML algorithm training process. |
 |
3.4. Validation Process of ML Algorithms
4. Experimental Design
4.1. Data Sets
4.2. Evaluation Metrics
- Accuracy is the proportion of the test data that was correctly classified by the model:
- Precision is the proportion of vectors classified as attacks that are relevant:
- False positive rate (FPR) is the proportion of incorrectly classified attack vectors:
- Detection rate (DR), also known as true positive rate (TPR), is the proportion of correctly classified attack vectors, for which a result of one (1) indicates that the model detected all attack vectors in the test data:
5. Experimental Results
5.1. Original Data (0% Poisoning)
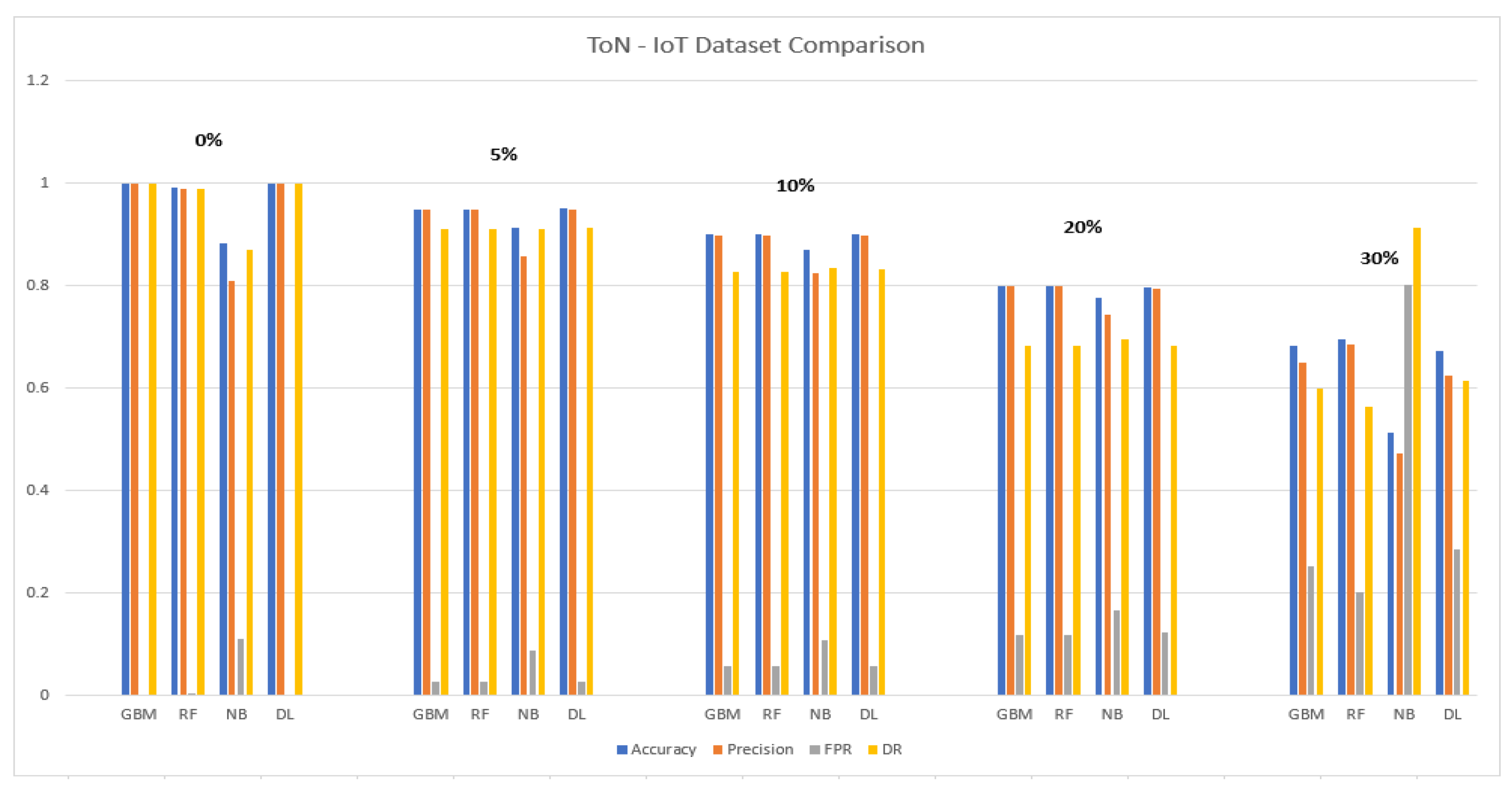
5.1.1. ToN-IoT Dataset
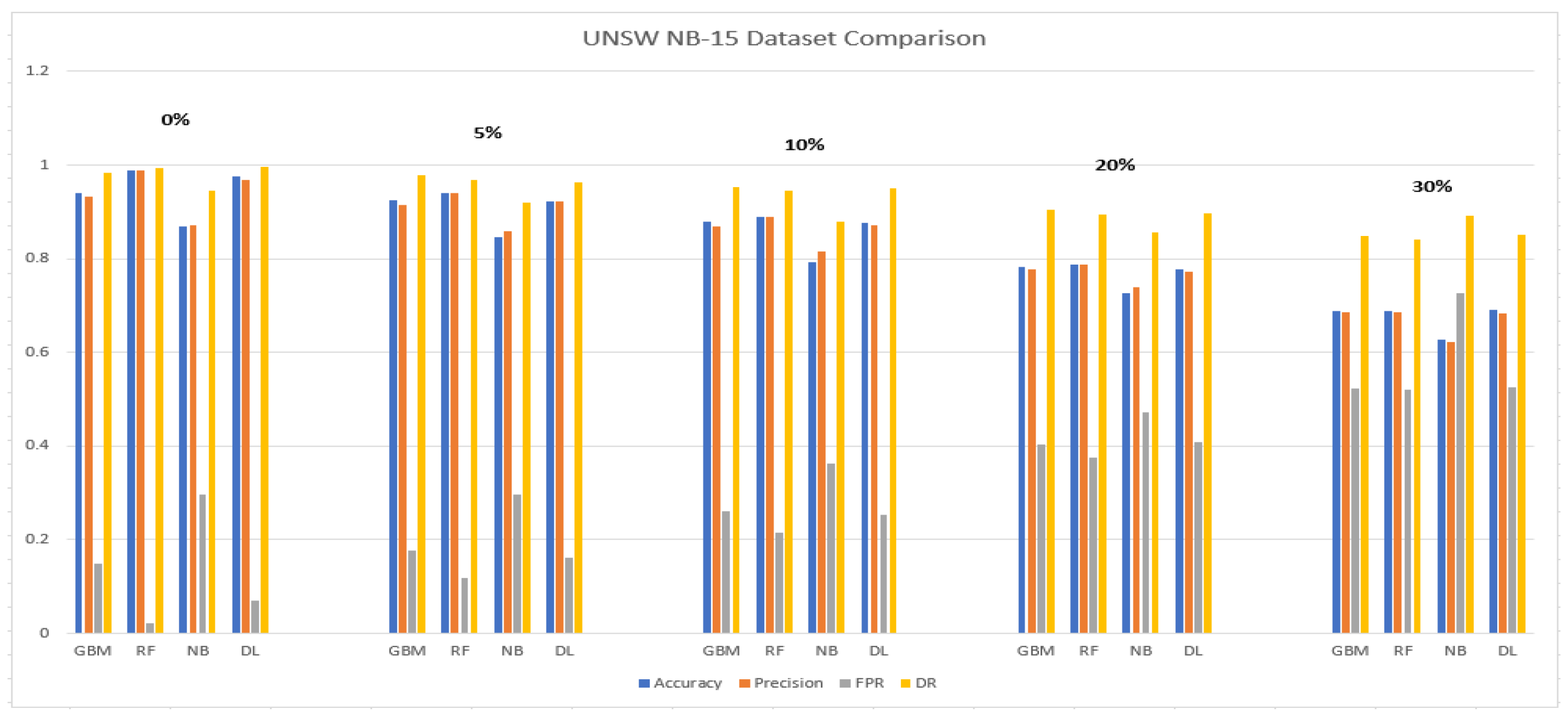
5.1.2. UNSW NB-15 Dataset
5.2. 5% Poisoned Data
5.2.1. ToN-IoT Dataset
5.2.2. UNSW NB-15 Dataset
5.3. 10% Poisoned Data
5.3.1. ToN-IoT Dataset
5.3.2. UNSW NB-15 Dataset
5.4. 20% Poisoned Data
5.4.1. ToN-IoT Dataset
5.4.2. UNSW NB-15 Dataset
5.5. 30% Poisoned Data
5.5.1. ToN-IoT Dataset
5.5.2. UNSW NB-15 Dataset
5.6. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.; Du, X.; Ali, I.; Guizani, M. A survey of machine and deep learning methods for internet of things (IoT) security. IEEE Commun. Surv. Tutor. 2020. [Google Scholar] [CrossRef]
- Rebala, G. An Introduction to Machine Learning; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Moustafa, N.; Choo, K.K.R.; Radwan, I.; Camtepe, S. Outlier Dirichlet mixture mechanism: Adversarial statistical learning for anomaly detection in the fog. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1975–1987. [Google Scholar] [CrossRef]
- Stellios, I.; Kotzanikolaou, P.; Psarakis, M.; Alcaraz, C.; Lopez, J. A Survey of IoT-Enabled Cyberattacks: Assessing Attack Paths to Critical Infrastructures and Services. IEEE Commun. Surv. Tutor. 2018, 20, 3453–3495. [Google Scholar] [CrossRef]
- Vorobeychik, Y. Adversarial Machine Learning; Morgan & Claypool: San Rafael, CA, USA, 2018. [Google Scholar]
- Duddu, V. A Survey of Adversarial Machine Learning in Cyber Warfare. Def. Sci. J. 2018, 68, 356–366. [Google Scholar] [CrossRef]
- Moustafa, N.; Creech, G.; Slay, J. Anomaly detection system using beta mixture models and outlier detection. In Progress in Computing, Analytics and Networking; Springer: Berlin/Heidelberg, Germany, 2018; pp. 125–135. [Google Scholar]
- Keshk, M.; Moustafa, N.; Sitnikova, E.; Creech, G. Privacy preservation intrusion detection technique for SCADA systems. In Proceedings of the 2017 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 14–16 November 2017; pp. 1–6. [Google Scholar]
- Steinhardt, J.; Koh, P.W.W.; Liang, P.S. Certified defenses for data poisoning attacks. In Advances in Neural Information Processing Systems; NIPS Proceedings: Long Beach, CA, USA, 2017; pp. 3517–3529. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. arXiv 2012, arXiv:1206.6389. [Google Scholar]
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating machine learning: Poisoning attacks and countermeasures for regression learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 19–35. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Moustafa, N. ToN_IoT Datasets. 2019. Available online: https://search.datacite.org/works/10.21227/fesz-dm97# (accessed on 7 August 2020).
- Mazhelis, O.; Luoma, E.; Warma, H. Defining an internet-of-things ecosystem. In Internet of Things, Smart Spaces, and Next Generation Networking; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–14. [Google Scholar]
- Firouzi, F.; Farahani, B.; Weinberger, M.; DePace, G.; Aliee, F.S. IoT Fundamentals: Definitions, Architectures, Challenges, and Promises. In Intelligent Internet of Things; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–50. [Google Scholar]
- Firouzi, F.; Farahani, B. Architecting IoT Cloud. In Intelligent Internet of Things; Springer: Berlin/Heidelberg, Germany, 2020; pp. 173–241. [Google Scholar]
- Bröring, A.; Schmid, S.; Schindhelm, C.K.; Khelil, A.; Käbisch, S.; Kramer, D.; Le Phuoc, D.; Mitic, J.; Anicic, D.; Teniente, E. Enabling IoT ecosystems through platform interoperability. IEEE Softw. 2017, 34, 54–61. [Google Scholar] [CrossRef]
- Salman, T.; Jain, R. A survey of protocols and standards for internet of things. arXiv 2019, arXiv:1903.11549. [Google Scholar]
- Ahlers, D.; Wienhofen, L.W.; Petersen, S.A.; Anvaari, M. A Smart City ecosystem enabling open innovation. In Proceedings of the International Conference on Innovations for Community Services, Wolfsburg, Germany, 24–26 June 2019; pp. 109–122. [Google Scholar]
- Tange, K.; De Donno, M.; Fafoutis, X.; Dragoni, N. Towards a systematic survey of industrial IoT security requirements: Research method and quantitative analysis. In Proceedings of the Workshop on Fog Computing and the IoT, Montreal, QC, Canada, 15–18 April 2019; pp. 56–63. [Google Scholar]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Saxena, V.; Jain, D.; Goyal, P.; Sikdar, B. A survey on IoT security: Application areas, security threats, and solution architectures. IEEE Access 2019, 7, 82721–82743. [Google Scholar] [CrossRef]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.; Tygar, J.D. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on SECURITY and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006; pp. 16–25. [Google Scholar]
- McDaniel, P.; Papernot, N.; Celik, Z.B. Machine learning in adversarial settings. IEEE Secur. Priv. 2016, 14, 68–72. [Google Scholar] [CrossRef]
- Thomas, T.; Vijayaraghavan, A.P.; Emmanuel, S. Adversarial Machine Learning in Cybersecurity. In Machine Learning Approaches in Cyber Security Analytics; Thomas, T., Vijayaraghavan, A.P., Emmanuel, S., Eds.; Springer: Singapore, 2020; pp. 185–200. [Google Scholar] [CrossRef]
- Biggio, B.; Rieck, K.; Ariu, D.; Wressnegger, C.; Corona, I.; Giacinto, G.; Roli, F. Poisoning behavioral malware clustering. In Proceedings of the 2014 Workshop on Artificial Intelligent and Security Workshop, Salamanca, Spain, 4–6 June 2014; pp. 27–36. [Google Scholar]
- Nelson, B.; Barreno, M.; Chi, F.J.; Joseph, A.D.; Rubinstein, B.I.; Saini, U.; Sutton, C.; Tygar, J.; Xia, K. Misleading learners: Co-opting your spam filter. In Machine Learning in Cyber Trust; Springer: Berlin/Heidelberg, Germany, 2009; pp. 17–51. [Google Scholar]
- Barreno, M.; Nelson, B.; Joseph, A.D.; Tygar, J.D. The security of machine learning. Mach. Learn. 2010, 81, 121–148. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Rubinstein, B.I.; Nelson, B.; Huang, L.; Joseph, A.D.; Lau, S.h.; Rao, S.; Taft, N.; Tygar, J.D. Antidote: Understanding and defending against poisoning of anomaly detectors. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, Chicago, IL, USA, 4–6 November 2009; pp. 1–14. [Google Scholar]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! targeted clean-label poisoning attacks on neural networks. In Advances in Neural Information Processing Systems; NIPS Proceedings: Long Beach, CA, USA, 2018; pp. 6103–6113. [Google Scholar]
- Yang, C.; Wu, Q.; Li, H.; Chen, Y. Generative poisoning attack method against neural networks. arXiv 2017, arXiv:1703.01340. [Google Scholar]
- Schapire, R.E. Boosting: Foundations and Algorithms; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- James, G. An Introduction to Statistical Learning: With Applications in R; Springer: New York, NY, USA, 2013. [Google Scholar]
- Ma, Y.; Zhang, C. Ensemble Machine Learning: Methods and Applications; Springer: Boston, MA, USA, 2012. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Chapter 4—Algorithms: The Basic Methods. In Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Witten, I.H., Frank, E., Hall, M.A., Eds.; Morgan Kaufmann: Boston, MA, USA, 2011; pp. 85–145. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Nielsen, M.A. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015; Volume 2018. [Google Scholar]
- The H20 API. Available online: https://docs.h2o.ai/h2o/latest-stable/h2o-docs/faq/r.html (accessed on 7 August 2020).
- The ML Code. Available online: https://github.com/Nour-Moustafa/TON_IoT-Network-dataset (accessed on 7 August 2020).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Parameters | |||||||
|---|---|---|---|---|---|---|---|
| Gradient Boosted Machine | Random Forest | Naive Bayes | Feed-Forward Deep Neural Network | ||||
| Trees | 100 | Trees | 150 | Laplace Smoothing Parameter | 3 | Hidden Layer Size | [15,15] |
| Max Depth | 5 | Stopping Rounds | 2 | Max after balance size | 5 | Epochs | 10 |
| Min Rows | 2 | Seed | 10000 | Minimum sdev | 0.01 | ||
| Learning Rate | 0.01 | Distribution | Multinomial | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dunn, C.; Moustafa, N.; Turnbull, B. Robustness Evaluations of Sustainable Machine Learning Models against Data Poisoning Attacks in the Internet of Things. Sustainability 2020, 12, 6434. https://doi.org/10.3390/su12166434
Dunn C, Moustafa N, Turnbull B. Robustness Evaluations of Sustainable Machine Learning Models against Data Poisoning Attacks in the Internet of Things. Sustainability. 2020; 12(16):6434. https://doi.org/10.3390/su12166434
Chicago/Turabian StyleDunn, Corey, Nour Moustafa, and Benjamin Turnbull. 2020. "Robustness Evaluations of Sustainable Machine Learning Models against Data Poisoning Attacks in the Internet of Things" Sustainability 12, no. 16: 6434. https://doi.org/10.3390/su12166434
APA StyleDunn, C., Moustafa, N., & Turnbull, B. (2020). Robustness Evaluations of Sustainable Machine Learning Models against Data Poisoning Attacks in the Internet of Things. Sustainability, 12(16), 6434. https://doi.org/10.3390/su12166434