The Dynamical Decision Model of Intersection Congestion Based on Risk Identification


Abstract
1. Introduction
2. Related Work
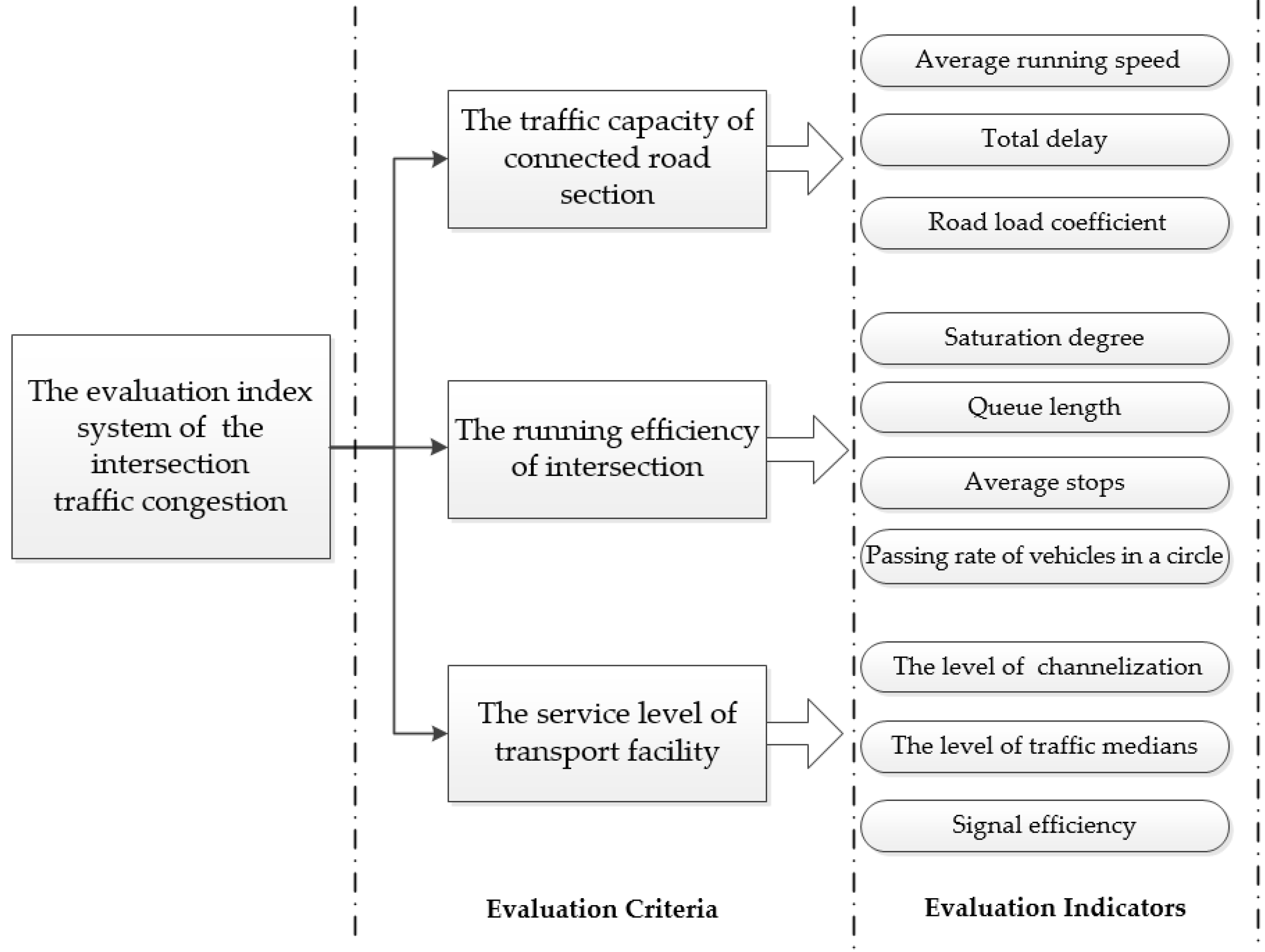
3. The Index System for Evaluating the Intersection Congestion
4. The Dynamic Decision-Making Model for Risk Identification
4.1. General Definitions and Notations
4.2. The Standardization of the Initial Decision Matrix
4.3. The Weighted Decision Matrix
4.4. The Dynamic Decision-Making Model
5. Numerical Example
- ①
- Observer A counts the number of vehicles parked behind the stop line every 15 s.
- ②
- Observer B counts the number of vehicles passing the stop line after parking (number of stopped vehicles) and the number of passing the parking line without stopping (number of non-stopped vehicles) at 1-min intervals.
- ③
- Repeat the above process to obtain the data for the survey time period.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vlahogianni, E.I.; Karlaftis, M.G.; Kepaptsoglou, K. Nonlinear autoregressive conditional duration models for traffic congestion estimation. J. Probab. Stat. 2011, 2011, 1–13. [Google Scholar] [CrossRef]
- Min, W.; Wynter, L. Real-time road traffic prediction with spatio-temporal correlations. Transp. Res. Part C Emerg. Technol. 2011, 19, 606–616. [Google Scholar] [CrossRef]
- Alireza, E.; David, L. Spatiotemporal traffic forecasting: Review and proposed directions. Transp. Rev. 2018, 38, 786–814. [Google Scholar] [CrossRef]
- Michalopoulos, P.G.; Pisharody, V.B. Derivation of delays based on improved macroscopic traffic models. Transp. Res. Part B Methodol. 1981, 15, 299–317. [Google Scholar] [CrossRef]
- Morales, J.M. Analytical procedures for estimating freeway traffic congestion. Public Roads 1987, 51, 55–61. [Google Scholar]
- Newell, G.F. A simplified theory of kinematic waves in highway traffic, part I: General theory. Transp. Res. Part B Methodol. 1993, 27, 281–287. [Google Scholar] [CrossRef]
- Zambrano, M.J.L.; Calafate, C.T.; Soler, D.; Cano, J.C.; Manzoni, P. Modeling and characterization of traffic flows in urban environments. Sensors 2018, 18, 2020. [Google Scholar] [CrossRef]
- Sheu, J.B. A fuzzy clustering-based approach to automatic freeway incident detection and characterization. Fuzzy Sets Syst. 2002, 128, 377–388. [Google Scholar] [CrossRef]
- Fu, L.; Hellinga, B.; Zhu, Y. An adaptive model for real-time estimation of overflow queues on congested arterials. IEEE Intell. Transp. Syst. 2001, 219–226. [Google Scholar] [CrossRef]
- Wen, H.M. The Research on the Key Theory and Technology of the Traffic Congestion in Highway. Ph.D. Thesis, University of Jilin, Jilin, China, 2002. (In Chinese). [Google Scholar]
- Zang, H.; Peng, G.X. The prediction model of queue length under the abnormal condition in highway. J. Transp. Inf. Saf. 2003, 21, 10–12. (In Chinese) [Google Scholar]
- Peng, C.L.; Yang, X.G.; Zhang, C.B. Character of traffic flow in queue upstream of bottleneck based on I/O. J. Transp. Inf. Saf. 2004, 12, 1–4. (In Chinese) [Google Scholar]
- Jiang, G.Y.; Dai, L.L.; Bai, Z.; Zhao, J.Q.; Zhen, Z.T. Simulation of recurrent congestion diffusion of urban arterial street. J. Transp. Inf. Saf. 2006, 24, 1–3. (In Chinese) [Google Scholar]
- Juran, I.; Prashker, J.N.; Bekhor, S.; Ishai, I. A dynamic traffic assignment model for the assessment of moving bottlenecks. Transp. Res. Part C Emerg. Technol. 2009, 17, 240–258. [Google Scholar] [CrossRef]
- Lawson, T.W.; Lovell, D.J.; Daganzo, C.F. Using input-output diagram to determine spatial and temporal extents of a queue upstream of a bottleneck. Transp. Res. Rec. 1997, 1572, 140–147. [Google Scholar] [CrossRef]
- Hu, Q.Z.; Liu, Y.S.; Tang, G.Y. Space-Time distribution model on state monitoring of urban traffic congestion. J. Transp. Syst. Eng. Inf. Technol. 2013, 12, 41–45. (In Chinese) [Google Scholar]
- Liu, Y.J.; Tian, C. Analysis of dynamic characteristics of urban traffic congestion based on specificity of network configuration. China J. Highw. Transp. 2013, 26, 163–169. (In Chinese) [Google Scholar]
- Hu, L.W.; Yang, J.Q.; He, Y.R.; Meng, L.; Lou, Z.W.; Hu, C.Y. Urban traffic congestion radiation model and damage caused to service capacity of road network. China J. Highw. Transp. 2019, 32, 145–154. (In Chinese) [Google Scholar]
- Van Zuylen, H.J.; Viti, F. Delay at controlled intersections: The old theory revised. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Toronto, ON, Canada, 17–20 September 2006; pp. 68–73. [Google Scholar] [CrossRef]
- Liu, H.X.; Wu, X.; Ma, W.; Hu, H. Real-time queue length estimation for congested signalized intersections. Transp. Res. Part C Emerg. Technol. 2009, 17, 412–427. [Google Scholar] [CrossRef]
- Chang, Y.L.; Cui, Y.B.; Zhang, P. Multi-phase signal setting and capacity of signalized intersection. J. Southeast Univ. 2009, 25, 123–127. (In Chinese) [Google Scholar]
- Zheng, F.F.; Van Zuylen, H. Uncertainty and predictability of urban link travel time: Delay distribution–based analysis. Transp. Res. Rec. 2010, 2192, 136–146. [Google Scholar] [CrossRef]
- Lin, P.Q.; Zhuo, F.Q.; Yao, K.B.; Rang, B.; Xu, J.M. Solving and simulation of microcosmic control model of intersection traffic flow in connected-vehicle network environment. China J. Highw. Transp. 2015, 28, 82–92. (In Chinese) [Google Scholar]
- Xu, J.M.; Yan, X.W.; Jing, B.B.; Wang, Y.J. Dynamic network partitioning method based on intersections with different degree of saturation. J. Transp. Syst. Eng. Inf. Technol. 2017, 17, 145–152. (In Chinese) [Google Scholar]
- Zhao, J.; Zhen, Z.; Han, Y. Delay and optimal cycle length model for tandem intersections. China J. Highw. Transp. 2019, 32, 135–144. (In Chinese) [Google Scholar]
- Yu, Z.; Huang, L.H.; Li, X.Y.; Li, B.; Zou, B. Queueing process sensing and prediction at intersection based on video. J. Transp. Syst. Eng. Inf. Technol. 2020, 20, 33–39. (In Chinese) [Google Scholar]
- Yang, D.; Chen, Y.; Xin, L.; Zhang, Y. Real-time detecting and tracking of traffic shockwaves based on weighted consensus information fusion in distributed video network. IEEE Intell. Transp. Syst. 2013, 8, 377–387. [Google Scholar] [CrossRef]
- He, Z.; Qi, G.; Lu, L.; Chen, Y. Network-wide identification of turn-level intersection congestion using only low-frequency probe vehicle data. Transp. Res. Part C Emerg. Technol. 2019, 108, 320–339. [Google Scholar] [CrossRef]
- Li, S.; Li, G.; Cheng, Y.; Ran, B. Intersection congestion analysis based on cellular activity data. IEEE Access 2020, 8, 43476–43481. [Google Scholar] [CrossRef]
- Xia, X.; Deng, W.; Hu, Q.Z. Research on interval-number evaluation method and solutions for traffic congestion in urban road sections. J. Transp. Syst. Eng. Inf. Technol. 2007, 17, 121–125. (In Chinese) [Google Scholar]
- Su, F.; Dong, H.; Jia, L.; Sun, X. On urban road traffic state evaluation index system and method. Mod. Phys. Lett. B 2017, 31, 1650428. [Google Scholar] [CrossRef]
- Zhang, P.; Zhao, J.; Wang, Z.Y.; An, H.S.; Peng, S. Overall evaluation of signal controlled intersection based on Monte Carlo simulation. J. Heilongjiang Inst. Technol. 2013, 327, 1–5. (In Chinese) [Google Scholar]
- Chen, K.M.; Yan, B.J. Analysis of Road Traffic Capacity; People Communications Publishing House: Beijing, China, 2003; pp. 188–190. [Google Scholar]
- Hao, N.; Feng, Y.; Zhang, K.; Tian, G.; Zhang, L.; Jia, H. Evaluation of traffic congestion degree: An integrated approach. Int. J. Distrib. Sens. Netw. 2017, 13, 1–14. [Google Scholar] [CrossRef]
- Zhu, Q.; Hui, L.; Xia, G.; Yu, M. Dynamic multi-attribute decision making of carrier-based aircraft landing risk. J. Harbin Eng. Univ. 2013, 34, 616–622. (In Chinese) [Google Scholar]
- Qing, L.Z.; Ye, Q.G. A new grey incidence model of interval numbers and its application. In Proceedings of the 2011 IEEE International Conference on Systems Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; pp. 1881–1885. [Google Scholar] [CrossRef]
- Wang, X.; Xie, K.; Abdel-Aty, M.; Chen, X.; Tremont, P.J. Systematic approach to hazardous-intersection identification and countermeasure development. J. Transp. Eng. 2014, 140, 04014022. [Google Scholar] [CrossRef]
- Zhao, N.; Wei, C.P.; Bi, Y.Z. Determining expert weights and its sensitivity analysis based on the correlation coefficient and the standard deviations. J. Qufu Norm. Univ. 2013, 39, 25–32. (In Chinese) [Google Scholar]
- Xu, Y.J.; Da, Q.L. Standard and mean deviation methods for linguistic group decision making and their applications. Expert Syst. Appl. 2010, 37, 5905–5912. [Google Scholar] [CrossRef]
- Wang, Z.X.; Shao, C.L.; Tang, Z.L. Method for ranking interval numbers based on relative superiority and its application to multiple attribute decision making. Fuzzy Syst. Math. 2013, 27, 142–148. (In Chinese) [Google Scholar]
- Sengupta, A.; Pal, T.K. On comparing interval numbers: A study on existing ideas. Fuzzy Prefer. Ord. Interval Numbers Decis. Probl. 2009, 2, 25–37. [Google Scholar] [CrossRef]
- Sun, C. Research on Urban Traffic Network State Evaluation and Analysis. Master’s Thesis, South China University of Technology, Guangzhou, China, 2010. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| = index of decision scheme, | |
| = index of time-point, | |
| = index of decision indicator, | |
| = weight coefficient of time-point | |
| = weight coefficient of indicator | |
| = set of decision scheme | |
| = set of time-point | |
| = set of indicator | |
| = weight vector of time-points | |
| = weight vector of decision indicators | |
| = matrix of attribute value of decision corresponding to time-point and indicator , | |
| = matrix of weighted value of decision corresponding to time-point and indicator , | |
| = matrix of ideal value of decision corresponding to time-point and indicator , | |
| = risk-free decision matrix sequence | |
| = positive ideal matrix of intersection congestion | |
| = negative ideal matrix of intersection congestion | |
| = synthetic decision matrix sequence | |
| = decision matrix sequence for comparison | |
| = decision matrix sequence for standardization | |
| = matrix sequence with corresponding to the decision | |
| = relevancy of intersection congestion | |
| = subordinate degree of intersection congestion | |
| = number of vehicles parked behind the stop line | |
| = number of vehicles passing the stop line after parking | |
| = number of passing the parking line without stopping | |
| = import delay | |
| = average delay of passing vehicles after stopping | |
| = average vehicle delay at intersection, | |
| = data collection interval | |
| = the risk-free decision matrix of intersection | |
| = the values of the attributes of decision scheme corresponding to time-point , indicator | |
| = frequency of occurrence at time-point , indicator | |
| = the average covering length of vehicle type | |
| = the number of signal cycles during the observation | |
| = the number of different types of vehicles in the queue of each signal cycle |
| Intersection A | ||||
|---|---|---|---|---|
| No. | Time Period | Average Queue Length (m) | Average Delay (s) | Average Saturation Degree (%) |
| 16:30–17:30 | 16.69 | 26.37 | 81.65 | |
| 17:30–18:30 | 21.46 | 29.43 | 93.24 | |
| 18:30–19:30 | 27.62 | 32.2 | 107.02 | |
| Intersection B | ||||
| No. | Time Period | Average Queue Length (m) | Average Delay (s) | Average Saturation Degree (%) |
| 16:30–17:30 | 11.29 | 21.42 | 69.03 | |
| 17:30–18:30 | 16.57 | 26.68 | 81.46 | |
| 18:30–19:30 | 23.89 | 30.31 | 90.79 | |
| Intersection C | ||||
| No. | Time Period | Average Queue Length (m) | Average Delay (s) | Average Saturation Degree (%) |
| 16:30–17:30 | 17.23 | 25.51 | 90.76 | |
| 17:30–18:30 | 24.39 | 34.47 | 103.69 | |
| 18:30–19:30 | 32.08 | 40.12 | 118.37 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Lin, K.; Jiao, P.; Lu, H. The Dynamical Decision Model of Intersection Congestion Based on Risk Identification. Sustainability 2020, 12, 5923. https://doi.org/10.3390/su12155923
Sun X, Lin K, Jiao P, Lu H. The Dynamical Decision Model of Intersection Congestion Based on Risk Identification. Sustainability. 2020; 12(15):5923. https://doi.org/10.3390/su12155923
Chicago/Turabian StyleSun, Xu, Kun Lin, Pengpeng Jiao, and Huapu Lu. 2020. "The Dynamical Decision Model of Intersection Congestion Based on Risk Identification" Sustainability 12, no. 15: 5923. https://doi.org/10.3390/su12155923
APA StyleSun, X., Lin, K., Jiao, P., & Lu, H. (2020). The Dynamical Decision Model of Intersection Congestion Based on Risk Identification. Sustainability, 12(15), 5923. https://doi.org/10.3390/su12155923