Applying Comparable Sales Method to the Automated Estimation of Real Estate Prices



Abstract
1. Introduction
- We propose a novel computational approach designed to estimate the prices of real estates, in particular, those of apartments on the basis of CSM. To the best of our knowledge, this is the first work that applies CSM to machine learning.
- The proposed approach, albeit tested in Korea, is easily applicable to other areas, in particular where high rise residential buildings are closely located, given the popularity of CSM and the general nature of the approach.
- We conduct experiments using real-world datasets with multiple scenarios, empirically showing the superiority of the proposed approach over the existing methods.
- A fully working system based on the proposed approach reported in this paper is currently under development for public service by one of the largest banking companies in South Korea.
2. Literature Review
2.1. Housing Price Estimation
2.2. Price Estimation Models
2.3. Comparables Sales Method Valuation
3. Comparable Sales Method
- Nearby Apartment Transactions: The price of the apartment will follow the transaction (sales) prices of neighboring apartments with similar characteristics.
- Similar Price Transactions: Apartments priced similar in the past will exhibit similar prices in the future.
3.1. Comparable Sales Features Based on Nearby Apartment Transactions
3.1.1. Handling Distance and Intrinsic Features’ Similarity
3.1.2. Extracting Prices of Similar Apartments
3.2. Comparable Sales Features Based on Similar Price Transactions
3.2.1. Building Candidate Transaction Set
3.2.2. Time-Based Filtering
3.2.3. Price-Based Filtering
3.2.4. Price Adjustment Using KB Index
4. Experiment
4.1. Dataset
4.1.1. Target Cities and Periods
4.1.2. Data Sources
Transaction Price
Market Price
4.1.3. Apartment Transaction Features
Apartment Intrinsic Features and Transaction Prices
Time-Variant Features
Distance to Public Facilities
Previous Transactions Features
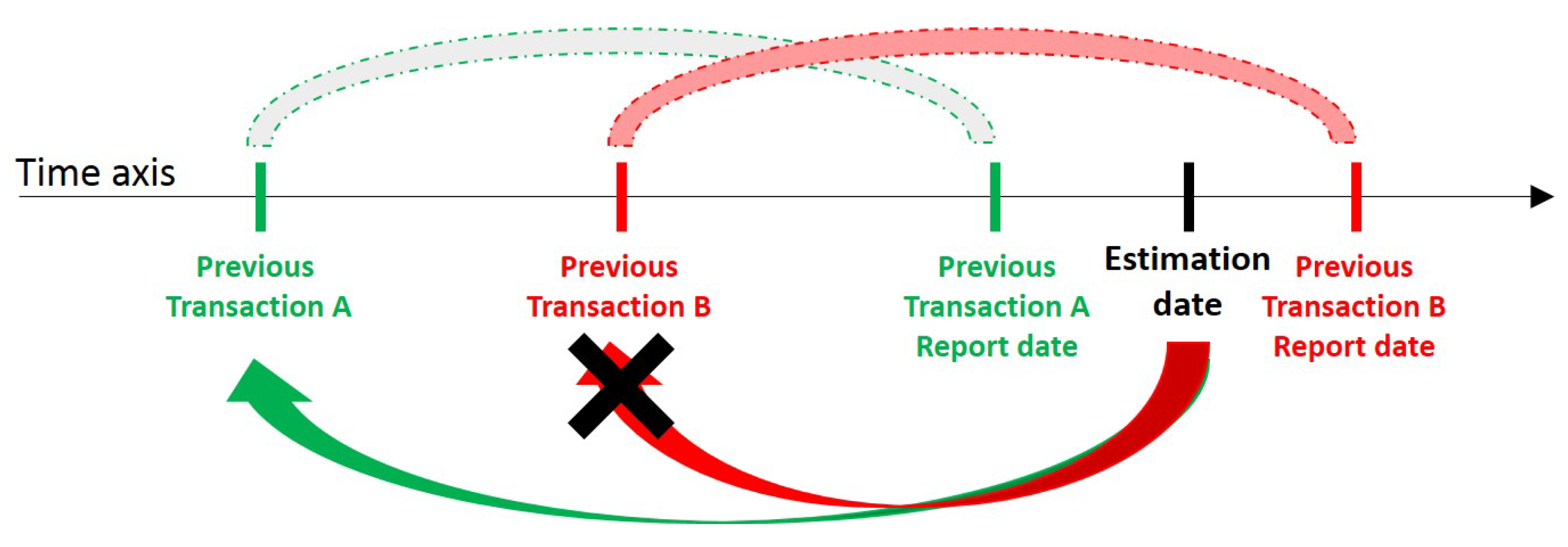
4.1.4. Practical Issues
Anonymity on Transaction Date
Report Days for the Real Estate Transaction
Report Days for Time-Variant Features
Date Difference between Transaction and Market Price
4.2. Methods
4.3. Experiment Settings
4.4. Experiment Metrics
- MAPE measures the average deviation of the predicted values out of the corresponding actual values in percentage. More specifically, it is computed as,where N is the number of apartment transactions, is the predicted kth value and is the corresponding actual value.
- RMSPE measures the standard deviation of the predicted values out of the corresponding actual values in percentage. Compared to MAPE, this measure more heavily penalizes outliers. It is computed as,where N is the number of apartment transactions, is the predicted kth value and is the corresponding actual value.
4.5. Performance Results
5. Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CSM | Comparable Sales Method |
| SVM | Support Vector Machines |
| LSTM | Long Short-Term Memory |
| ZHVI | Zillow Home Value Index |
| MOLIT | The Ministry of Land, Infrastructure, and Transport |
| KAB | Korea Appraisal Board |
| KOSIS | Korean Statistical Information Service |
| MAPE | Mean Absolute Percentage Error |
| RMSPE | Root Mean Squared Percentage Error |
| RMSE | Root Mean Square Error |
Appendix A. Algorithms
| Algorithm A1 Extracting neighboring buildings |
| Input: Set of apartment buildings A, buildings coordinate pairs C, number of neighbors to find n |
| Output: Apartment buildings and n neighbors mapping |
| 1: function FindNeighbors() |
| 2: for to do |
| 3: ← |
| 4: ← [] |
| 5: for to do |
| 6: ← EuclideanDistance(,) |
| 7: ← append |
| 8: ← GetTopN_ClosestBuildings() |
| 9: ← append |
| 10 return |
| Algorithm A2 Extracting nearby apartment prices |
| 1: function GetPrice() |
| 2: ← GetNeighborApartment’s_features() |
| 3: ← 0 |
| 4: ← 0 |
| 5: for to do |
| 6: ← CosineSimilarity() |
| 7: if then |
| 8: ← |
| 9: ← |
| 10: return price |
| Algorithm A3 Adding prices of nearby apartments |
| Input: Buildings and neighbors mapping , set of apartments T |
| Output: Set of apartments with comparable sales features |
| 1: function AddApartmentsPriceFeatures() |
| 2: for to do |
| 3: ← ExtractNeighbors() |
| 4: ← [] |
| 5: for to do |
| 6: ← GetPrice() |
| 7: ← append |
| 8: ← append |
| 9: return |
| Algorithm A4 Adding similar price features |
| Input: Transaction A, list of transactions B in the apartments different from apartment, number of price features n to be added, m day interval, day offset to define valid time period for searching similar prices, price offset P to define price boundaries within which price is considered similar, a set of KB Index |
| Output: list of similar price features F for transaction A |
| 1: function AddSimilarPriceFeatures() |
| 2: F← [] |
| 3: ← [] |
| 4: ← GetPreviousTransaction(A) |
| 5: ← |
| 6: ← |
| 7: if then |
| 8: ← |
| 9: ← |
| 10: ← |
| 11: ← |
| 12: for to do |
| 13: ← |
| 14: ← |
| 15: ← |
| 16: ← |
| 17: ← |
| 18: if & then |
| 19: ← |
| 20: if & then |
| 21: ← |
| 22: if & then |
| 23: ← append |
| 24: if isEmpty() then |
| 25: for to do |
| 26: F← append |
| 27: else |
| 28: ← GetTopNtransacions(,,n) |
| 29: for to do |
| 30: F← append |
| 31: return F |
References
- Demyanyk, Y.; Van Hemert, O. Understanding the subprime mortgage crisis. Rev. Financ. Stud. 2009, 24, 1848–1880. [Google Scholar] [CrossRef]
- Cerutti, E.; Dagher, J.; Dell’Ariccia, G. Housing finance and real-estate booms: A cross-country perspective. J. Hous. Econ. 2017, 38, 1–13. [Google Scholar] [CrossRef]
- Northcraft, G.B.; Neale, M.A. Experts, amateurs, and real estate: An anchoring-and-adjustment perspective on property pricing decisions. Organ. Behav. Hum. Decis. Process. 1987, 39, 84–97. [Google Scholar] [CrossRef]
- Pettit, C.; Bakelmun, A.; Lieske, S.N.; Glackin, S.; Thomson, G.; Shearer, H.; Dia, H.; Newman, P. Planning support systems for smart cities. City Cult. Soc. 2018, 12, 13–24. [Google Scholar] [CrossRef]
- Soomro, K.; Bhutta, M.N.M.; Khan, Z.; Tahir, M.A. Smart city big data analytics: An advanced review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1319. [Google Scholar] [CrossRef]
- Borst, R.; McCluskey, W. Comparative evaluation of the comparable sales method with geostatistical valuation models. Pac. Rim Prop. Res. J. 2007, 13, 106–129. [Google Scholar] [CrossRef]
- Cupal, M. The Comparative Approach theory for real estate valuation. Procedia-Soc. Behav. Sci. 2014, 109, 19–23. [Google Scholar] [CrossRef]
- Park, B.; Bae, J.K. Using machine learning algorithms for housing price prediction: The case of Fairfax County, Virginia housing data. Expert Syst. Appl. 2015, 42, 2928–2934. [Google Scholar] [CrossRef]
- Ren, Y.; Fox, E.B.; Bruce, A. Clustering correlated, sparse data streams to estimate a localized housing price index. Ann. Appl. Stat. 2017, 11, 808–839. [Google Scholar] [CrossRef]
- Korea Appraisal Board. Korea Real Estate Market Report Vol.9. 2019. Available online: http://www.kab.co.kr/kab/home/eng/trend/trend02.jsp (accessed on 21 June 2020).
- Ministry of Land, Infrastructure and Transport (MOLIT). Transaction Price Open System. 2019. Available online: http://rt.molit.go.kr/ (accessed on 21 June 2020).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Neural Information Processing Systems 2018, Montreal, QC, Canada, 3–8 December 2018; pp. 6638–6648. [Google Scholar]
- Xiao, Y. Hedonic housing price theory review. In Urban Morphology And Housing Market; Springer: Singapore, 2017; pp. 11–40. [Google Scholar]
- Mirkatouli, J.; Samadi, R.; Hosseini, A. Evaluating and analysis of socio-economic variables on land and housing prices in Mashhad, Iran. Sustain. Cities Soc. 2018, 41, 695–705. [Google Scholar] [CrossRef]
- Hussain, T.; Abbas, J.; Wei, Z.; Nurunnabi, M. The Effect of Sustainable Urban Planning and Slum Disamenity on The Value of Neighboring Residential Property: Application of The Hedonic Pricing Model in Rent Price Appraisal. Sustainability 2019, 11, 1144. [Google Scholar] [CrossRef]
- Čeh, M.; Kilibarda, M.; Lisec, A.; Bajat, B. Estimating the performance of random forest versus multiple regression for predicting prices of the apartments. ISPRS Int. J. Geo-Inf. 2018, 7, 168. [Google Scholar] [CrossRef]
- Gu, J.; Zhu, M.; Jiang, L. Housing price forecasting based on genetic algorithm and support vector machine. Expert Syst. Appl. 2011, 38, 3383–3386. [Google Scholar] [CrossRef]
- Bin, J.; Tang, S.; Liu, Y.; Wang, G.; Gardiner, B.; Liu, Z.; Li, E. Regression model for appraisal of real estate using recurrent neural network and boosting tree. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 8–11 September 2017; pp. 209–213. [Google Scholar]
- Poursaeed, O.; Matera, T.; Belongie, S. Vision-based real estate price estimation. Mach. Vis. Appl. 2018, 29, 667–676. [Google Scholar] [CrossRef]
- Bency, A.J.; Rallapalli, S.; Ganti, R.K.; Srivatsa, M.; Manjunath, B. Beyond Spatial Auto-Regressive Models: Predicting Housing Prices with Satellite Imagery. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 320–329. [Google Scholar]
- Law, S.; Paige, B.; Russell, C. Take a look around: Using street view and satellite images to estimate house prices. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Bradley, J.; Amde, M. Random Forests and Boosting in MLlib. 2015. Available online: https://databricks.com/blog/2015/01/21/random-forests-and-boosting-in-mllib.html (accessed on 21 June 2020).
- Ogutu, J.O.; Piepho, H.P.; Schulz-Streeck, T. A comparison of random forests, boosting and support vector machines for genomic selection. BMC Proc. 2011, 5, 11. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the KDD ’16, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Barone, A. Comparative Market Analysis. 2019. Available online: https://www.investopedia.com/terms/c/comparative-market-analysis.asp (accessed on 21 June 2020).
- Borst, R.A.; McCluskey, W. The modified comparable sales method as the basis for a property tax valuations system and its relationship and comparison to spatially autoregressive valuation models. In Mass Appraisal Methods: An International Perspective for Property Valuers; Wiley: Hoboken, NJ, USA, 2008; pp. 49–69. [Google Scholar]
- Collins, G. Groundwater Valuation in Texas: The Comparable Transactions Method. In Rice University’s Baker Institute FOR Public Policy Report; James, A., Ed.; Baker III Institute for Public Policy of Rice University: Houston, TX, USA, 2018. [Google Scholar]
- Healy, M.; Bergquist, K. The sales comparison approach and timberland valuation. Apprais. J. 1994, 62, 587. [Google Scholar]
- KB Kookmin Bank. Market Price Open System. 2019. Available online: https://onland.kbstar.com/ (accessed on 21 June 2020).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 21 June 2020).
- Davis, M.A.; Palumbo, M.G. The Price of Residential Land in Large US Cities. J. Urban Econ. 2008, 63, 352–384. [Google Scholar] [CrossRef]
- Young Yoon, J. Gov’t Renews War on Real Estate Speculation. 2018. Available online: https://www.koreatimes.co.kr/www/biz/2018/12/367_254423.html (accessed on 21 June 2020).
- Charles, L.; Garion, L.; Youngman, L. Testing alternative theories of the property price-trading volume correlation. J. Real Estate Res. 2002, 23, 253–264. [Google Scholar]
- De Wit, E.R.; Englund, P.; Francke, M.K. Price and transaction volume in the Dutch housing market. Reg. Sci. Urban Econ. 2013, 43, 220–241. [Google Scholar] [CrossRef]
- Wang, X.R.; Hui, E.C.M.; Sun, J.X. Population migration, urbanization and housing prices: Evidence from the cities in China. Habitat Int. 2017, 66, 49–56. [Google Scholar] [CrossRef]
- Xue, C.; Ju, Y.; Li, S.; Zhou, Q. Research on the Sustainable Development of Urban Housing Price Based on Transport Accessibility: A Case Study of Xi’an, China. Sustainability 2020, 12, 1497. [Google Scholar] [CrossRef]
- Machin, S. Houses and schools: Valuation of school quality through the housing market. Labour Econ. 2011, 18, 723–729. [Google Scholar] [CrossRef]
- Lan, F.; Wu, Q.; Zhou, T.; Da, H. Spatial Effects of Public Service Facilities Accessibility on Housing Prices: A Case Study of Xi’an, China. Sustainability 2018, 10, 4503. [Google Scholar] [CrossRef]
- Park, J.H.; Lee, D.K.; Park, C.; Kim, H.G.; Jung, T.Y.; Kim, S. Park accessibility impacts housing prices in Seoul. Sustainability 2017, 9, 185. [Google Scholar] [CrossRef]
- Cinar, U.K. Combining Domain Knowledge & Machine Learning: Making Predictions using Boosting Techniques. In Proceedings of the 2019 3rd International Conference on Advances in Artificial Intelligence, Istanbul, Turkey, 22–24 October 2019; pp. 9–13. [Google Scholar]
- Chen, L.; Yao, X.; Liu, Y.; Zhu, Y.; Chen, W.; Zhao, X.; Chi, T. Measuring Impacts of Urban Environmental Elements on Housing Prices Based on Multisource Data—A Case Study of Shanghai, China. ISPRS Int. J. Geo-Inf. 2020, 9, 106. [Google Scholar] [CrossRef]
- Sangani, D.; Erickson, K.; Al Hasan, M. Predicting zillow estimation error using linear regression and gradient boosting. In Proceedings of the 2017 IEEE 14th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Orlando, FL, USA, 22–25 October 2017; pp. 530–534. [Google Scholar]


{kind=link}
| Region | Size 1 | Population 2 | Density 2 |
|---|---|---|---|
| Seoul | 605.24 | 9.7 million | 16,034 |
| Gyeonggi | 10,187.79 | 13 million | 1279 |
| Unit | km2 | people | people/km2 |
| Each Scenario | Train | Test |
|---|---|---|
| Scenario 1 | 1/1/2010 ∼ 12/31/2017 | 1/1/2018 ∼ 6/30/2018 |
| Scenario 2 | 1/1/2010 ∼ 6/30/2018 | 7/1/2018 ∼ 12/31/2018 |
| Region | Scenario | Train | Test |
|---|---|---|---|
| Seoul | 1 | 479,892 | 20,318 |
| 2 | 508,433 | 12,689 | |
| Geyonggi | 1 | 996,475 | 36,876 |
| 2 | 1,050,579 | 31,175 |
| Feature | Description | Measurement Unit |
|---|---|---|
| District | District the apartment belongs to | Category |
| Neighborhood | Town the apartment belongs to | Category |
| Specific floor | Specific floor the apartment is located on | Floor Number |
| PY | Size of the apartment in the unit of Pyeong meters | Pyeong |
| Exclusive area | Private area used exclusively by the apartment | m |
| Households | Number of households of the same size in the complex | Count |
| Rooms | Number of bedrooms in the apartment | Count |
| Bathrooms | Number of bathrooms in the apartment | Count |
| Parking lot | Number of parking lots in the apartment complex | Count |
| Front door status | The type of the building’s main entrance door | Category |
| Direction status | The direction the apartment’s living room faces | Category |
| Total households | Number of households in the apartment complex | Count |
| Total buildings | Number of buildings in the apartment complex | Count |
| Highest floor | Highest top floor of the apartment complex | Floor Number |
| Lowest floor | Lowest top floor of the apartment complex | Floor Number |
| Heating method | The type of heating method | Category |
| Heating fuel | The type of heating fuel | Category |
| Center longitude | Central longitude of the apartment complex | GPS |
| Center latitude | Central latitude of the apartment complex | GPS |
| Transaction Price | Apartment’s price sold | 10,000 KRW |
| m: meter | ||
| Category Features | Seoul | Gyeonggi |
|---|---|---|
| District | 25 | 32 |
| Neighborhood | 258 | 488 |
| Feature | Description | Measurement Unit |
|---|---|---|
| Transaction_volume | Transaction volume in the district | Count |
| Move_in | Number of moved-in people in the region | Count |
| Move_out | Number of moved-out people in the region | Count |
| Age | Number of months passed from the construction date | Count |
| Feature | Description | Measurement Unit |
|---|---|---|
| Dist_Subway | Distance to the nearest subway | m |
| Dist_School | Distance to the nearest school | m |
| Dist_University | Distance to the nearest university | m |
| Dist_Kindergarten | Distance to the nearest kindergarten | m |
| Dist_Daycare | Distance to the nearest daycare | m |
| Dist_Hospital | Distance to the nearest hospital | m |
| Dist_Mart | Distance to the nearest mart | m |
| Dist_Office | Distance to the nearest government office | m |
| Dist_Culture | Distance to the nearest culture center | m |
| Dist_Park | Distance to the nearest park | m |
| m: meter | ||
| Feature | Description | Measurement Unit |
|---|---|---|
| Time interval 1 | Time interval since T | Number of Days |
| Specific floor 1 | Specific floor at T | Floor Number |
| Selling price 1 | Transaction price at T | 10,000 KRW |
| Time interval 2 | Time interval since T | Number of Days |
| Specific floor 2 | Specific floor at T | Floor Number |
| Selling price 2 | Transaction price at T | 10,000 KRW |
| Region | Scenario | Day Difference | ||||
|---|---|---|---|---|---|---|
| MAX | MIN | Median | Mean | STD | ||
| Seoul | 1 | 4 | 0 | 3 | 2.14 | 1.37 |
| 2 | 4 | 0 | 1 | 1.53 | 0.89 | |
| Geyonggi | 1 | 4 | 0 | 3 | 2.1 | 1.38 |
| 2 | 4 | 0 | 1 | 1.6 | 1.12 | |
| MAPE | Market Price | Boosting | Baseline | Ours | ||||
|---|---|---|---|---|---|---|---|---|
| District | Scenarios | Common | MinMax | Basic (B) | B + Nearby (N) | B + Similar (S) | B + N + S | |
| Seoul | Scenario 1 | 6.28 | 6.35 | LightGBM | 6.42 | 6.19 *** | 5.84 *** | 5.68 *** |
| CatBoost | 6.03 | 5.99 *** | 5.49 *** | 5.41 *** | ||||
| Scenario 2 | 7.99 | 8.07 | LightGBM | 8.89 | 8.57 *** | 7.97 *** | 7.75 *** | |
| CatBoost | 8.34 | 8.15 *** | 7.2 *** | 7.14 *** | ||||
| Gyoenggi | Scenario 1 | 5.44 | 5.47 | LightGBM | 4.86 | 4.83 *** | 4.82 *** | 4.79 *** |
| CatBoost | 4.96 | 4.93 *** | 4.98 *** | 4.94 *** | ||||
| Scenario 2 | 5.78 | 5.83 | LightGBM | 5.37 | 5.32 ** | 5.28 *** | 5.22 *** | |
| CatBoost | 5.41 | 5.37 *** | 5.38 *** | 5.33 *** | ||||
| RMSPE | Market Price | Boosting | Baseline | Ours | ||||
|---|---|---|---|---|---|---|---|---|
| District | Scenarios | Common | MinMax | Basic (B) | B + Nearby (N) | B + Similar (S) | B + N + S | |
| Seoul | Scenario 1 | 7.89 | 7.95 | LightGBM | 8.39 | 8.13 *** | 7.71 *** | 7.54 *** |
| CatBoost | 8.13 | 8.07 *** | 7.53 *** | 7.42 *** | ||||
| Scenario 2 | 10.3 | 10.36 | LightGBM | 11.1 | 10.78 *** | 10.04 *** | 9.82 *** | |
| CatBoost | 10.69 | 10.49 *** | 9.38 *** | 9.31 *** | ||||
| Gyoenggi | Scenario 1 | 7.81 | 7.84 | LightGBM | 6.9 | 6.87 *** | 6.84 *** | 6.8 *** |
| CatBoost | 7.15 | 7.1 *** | 7.14 | 7.08 *** | ||||
| Scenario 2 | 11.4 | 11.29 | LightGBM | 11.31 | 11.3 | 11.26 | 11.23 *** | |
| CatBoost | 11.44 | 11.4 *** | 11.42 * | 11.37 *** | ||||
| Cumulative Percentage | Market Price | Boosting | Baseline | Ours | ||||
|---|---|---|---|---|---|---|---|---|
| District | Scenarios | Common | MinMax | Basic (B) | B + Nearby (N) | B + Similar (S) | B + N + S | |
| Seoul | Scenario 1 | 81.45 | 81.21 | LightGBM | 79.18 | 80.73 *** | 82.76 *** | 83.78 *** |
| CatBoost | 81.46 | 81.72 *** | 84.83 *** | 85.54 *** | ||||
| Scenario 2 | 69.31 | 68.93 | LightGBM | 62.94 | 65.05 *** | 68.44 *** | 69.91 *** | |
| CatBoost | 67.14 | 67.69 * | 73.49 *** | 73.95 *** | ||||
| Gyoenggi | Scenario 1 | 86.58 | 86.52 | LightGBM | 89.0 | 89.21 *** | 89.24 *** | 89.41 *** |
| CatBoost | 88.31 | 88.47 *** | 88.09 *** | 88.35 | ||||
| Scenario 2 | 84.5 | 84.35 | LightGBM | 86.27 | 86.55 ** | 86.74 *** | 87.05 *** | |
| CatBoost | 85.98 | 86.16 ** | 86.18 *** | 86.44 *** | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Choi, S.; Yi, M.Y. Applying Comparable Sales Method to the Automated Estimation of Real Estate Prices. Sustainability 2020, 12, 5679. https://doi.org/10.3390/su12145679
Kim Y, Choi S, Yi MY. Applying Comparable Sales Method to the Automated Estimation of Real Estate Prices. Sustainability. 2020; 12(14):5679. https://doi.org/10.3390/su12145679
Chicago/Turabian StyleKim, Yunjong, Seungwoo Choi, and Mun Yong Yi. 2020. "Applying Comparable Sales Method to the Automated Estimation of Real Estate Prices" Sustainability 12, no. 14: 5679. https://doi.org/10.3390/su12145679
APA StyleKim, Y., Choi, S., & Yi, M. Y. (2020). Applying Comparable Sales Method to the Automated Estimation of Real Estate Prices. Sustainability, 12(14), 5679. https://doi.org/10.3390/su12145679