Text Mining for Big Data Analysis in Financial Sector: A Literature Review




Abstract
1. Introduction
2. Research Questions
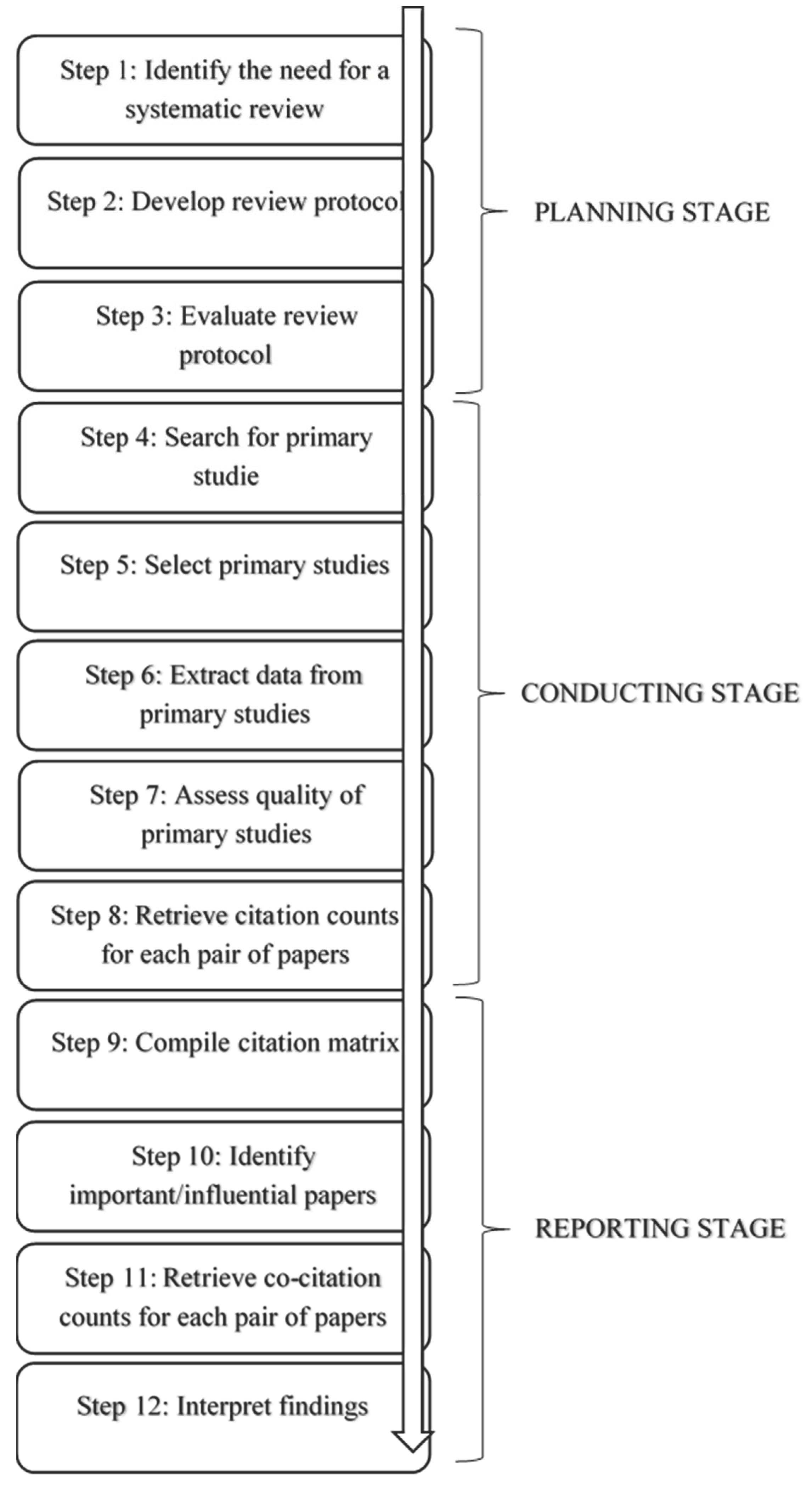
3. Methodology
4. Citation and Co-Citation Analysis
5. Text Mining Techniques in Finance
5.1. Keyword Extraction
5.2. Named Entity Recognition
5.3. Gender Prediction
5.4. Sentiment Analysis
5.5. Topic Extraction
5.6. Social Network Analysis
6. Data Sources Used and Typical Applications of Text Mining in Finance
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. List of Papers Included in the Literature Review
- Al Nasseri, A.; Tucker, A.; de Cesare, S. Quantifying StockTwits semantic terms’ trading behavior in financial markets: An effective application of decision tree algorithms. Expert Systems with Applications, 42(23), 2015, pp. 9192–9210.
- Alostad, H.; Davulcu, H. Directional prediction of stock prices using breaking news on Twitter. In 2015 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), 2015, pp. 523–530.
- AL-Rubaiee, H.; Qiu, R.; Li, D. Visualising Arabic Sentiments and Association Rules in Financial Text. International journal of advanced computer science and applications, 2017, 8(2), pp. 1–7.
- Alvarado, J.C.S.; Verspoor, K.; Baldwing, T. Domain Adaptation of Named Entity Recognition to Support Credit Risk Assessment. In Proceedings of Australasian Language Technology Association Workshop, University of Western Sydney, Australia, 8–9th December, 2015, pp. 84–90.
- Ammann, M.; Frey, R.; Verhofen, M. Do newspaper articles predict aggregate stock returns? Journal of behavioral finance, 2014, 15(3), pp. 195–213.
- Bai, X.; Dong, Y.; Hu, N. Financial report readability and stock return synchronicity. Applied Economics, 2019, 51(4), pp. 346–363.
- Balakrishnan, R.; Qiu, X. Y.; Srinivasan, P. On the predictive ability of narrative disclosures in annual reports. European Journal of Operational Research, 202(3), 2010, pp. 789–801.
- Boskou, G.; Kirkos, E.; Spathis, C. Assessing Internal Audit with Text Mining. Journal of Information Knowledge Management, 17(2), 2018, 1850020.
- Bowers, A. J.; Chen, J. Ask and ye shall receive? Automated text mining of Michigan capital facility finance bond election proposals to identify which topics are associated with bond passage and voter turnout. Journal of Education Finance, 2015, 164–196.
- Cao, M., Chychyla, R., & Stewart, T. Big Data analytics in financial statement audits. Accounting Horizons, 29(2), 2015, pp. 423–429.
- Chen, C. L.; Liu, C. L.; Chang, Y. C.; Tsai, H. P. Opinion mining for relating subjective expressions and annual earnings in US financial statements. Journal of information science and engineering, 29, 2014, 743–764.
- Chen, K.; Li, X.; Xu, B.; Yan, J.; Wang, H. Intelligent agents for adaptive security market surveillance. Enterprise Information Systems, 2017, 11(5), pp. 652–671.
- Chen, K.; Yin, J.; Pang, S. A design for a common-sense knowledge-enhanced decision-support system: Integration of high-frequency market data and real-time news. Expert Systems, 2017, 34(3), e12209.
- Chen, W.; Lai, K.; Cai, Y. Topic generation for Chinese stocks: a cognitively motivated topic modeling method using social media data. Quantitative finance and economics, 2018, 2(2), pp. 279–293.
- Chung, W. BizPro: Extracting and categorizing business intelligence factors from textual news articles. International Journal of Information Management, 34(2), 2014, pp. 272–284.
- Chye Koh, H.; Kee Low, C. Going concern prediction using data mining techniques. Managerial Auditing Journal, 2004, 19(3), pp. 462–476.
- Coussement, K.; Van den Poel, D. Integrating the voice of customers through call center emails into a decision support system for churn prediction. Information Management, 45(3), 2008, pp. 164–174.
- Dong, W.; Liao, S.; Liang, L. Financial Statement Fraud Detection using Text Mining: a Systemic Functional Linguistics Theory Perspective. In Proceedings of the Pacific Asia Conference on Information Systems (PACIS), Chiayi, Taiwan, 26th June, 2016, AISeL, p. 188.
- Duan, Z.; He, Y.; Zhong, Y. Corporate social responsibility information disclosure objective or not: An empirical research of Chinese listed companies based on text mining. Nankai Business Review International, 9(4), 2018, pp. 519–539.
- Ediger, D.; Jiang, K.; Riedy, J.; Bader, D.A.; Corley, C. Massive social network analysis: Mining twitter for social good. In Proceedings of 39th International Conference on Parallel Processing, San Diego, CA, USA, 13–16th September, 2010, IEEE, pp. 583–593.
- Eler, D.M.; Grosa, D.; Pola, I.; Garcia, R.; Correia, R.; Teixeira, J. Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information, 2018, 9(4), p. 100.
- Feuerriegel, S.; Gordon, J. Long-term stock index forecasting based on text mining of regulatory disclosures. Decision Support Systems, 112, 2018, 88–97.
- Feuerriegel, S.; Gordon, J. News-based forecasts of macroeconomic indicators: A semantic path model for interpretable predictions. European Journal of Operational Research, 272(1), 2019, pp. 162–175.
- Feuerriegel, S.; Prendinger, H. News-based trading strategies. Decision Support Systems, 90, 2016, 65–74.
- Fisher, I. E.; Garnsey, M. R.; Hughes, M. E. Natural language processing in accounting, auditing and finance: A synthesis of the literature with a roadmap for future research. Intelligent Systems in Accounting, Finance and Management, 2016, 23(3), pp. 157–214.
- Ghailan, O.; Mokhtar, H. M.; Hegazy, O. (2016). Improving Credit Scorecard Modeling Through Applying Text Analysis. institutions, International Journal of Advanced Computer Science and Applications, 7(4), 2016, 512–517.
- Groth, S. S.; Muntermann, J. An intraday market risk management approach based on textual analysis. Decision Support Systems, 50(4), 2011, pp. 680–691.
- Groth, S. S.; Siering, M.; Gomber, P. How to enable automated trading engines to cope with news-related liquidity shocks? Extracting signals from unstructured data. Decision Support Systems, 2014, 62, pp. 32–42.
- Gül, S.; Kabak, Ö.; Topcu, I. A multiple criteria credit rating approach utilizing social media data. Data Knowledge Engineering, 2018, 116, pp. 80–99.
- Gunduz, H.; Cataltepe, Z. Borsa Istanbul (BIST) daily prediction using financial news and balanced feature selection. Expert Systems with Applications, 42(22), 2015, pp. 9001–9011.
- Guo, P.; Shen, Y. The impact of Internet finance on commercial banks’ risk taking: evidence from China. China Finance and Economic Review, 4(1), 2016, p. 16.
- Hagenau, M.; Liebmann, M.; Neumann, D. Automated news reading: Stock price prediction based on financial news using context-capturing features. Decision Support Systems, 2013, 55(3), pp. 685–697.
- Hájek, P. Combining bag-of-words and sentiment features of annual reports to predict abnormal stock returns. Neural Computing and Applications, 29(7), 2018, pp. 343–358.
- Hajek, P.; Henriques, R. Mining corporate annual reports for intelligent detection of financial statement fraud–A comparative study of machine learning methods. Knowledge-Based Systems, 2017, 128, 139–152.
- Han, W.; Fang, Z.; Yang, L. T.; Pan, G.; Wu, Z. Collaborative policy administration. IEEE Transactions on Parallel and Distributed Systems, 25(2), 2014, pp. 498–507.
- Hasan, K.S.; Ng, V. Automatic keyphrase extraction: A survey of the state of the art. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27th June, 2014, 1, pp. 1262–1273.
- Hasan, K.S.; Ng, V. Automatic keyphrase extraction: A survey of the state of the art. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27th June, 2014, 1, pp. 1262–1273.
- Holton, C. Identifying disgruntled employee systems fraud risk through text mining: a simple solution for a multi-billion dollar problem, Decision Support Systems, 2009, 46(4), pp. 853–864.
- Hong, W.; Wang, W.; Weng, Y.; Luo, S.; Hu, P.; Zheng, X.; Qi, J. STOCK PRICE MOVEMENTS PREDICTION WITH TEXTUAL INFORMATION. Mechatronic Systems and Control, 46(3), 2018, pp. 141–149.
- Hsu, M. F.; Yeh, C. C.; Lin, S. J. Integrating dynamic Malmquist DEA and social network computing for advanced management decisions. Journal of Intelligent Fuzzy Systems, 35(1), 2018, pp. 1–11.
- Huang, C. J.; Liao, J. J.; Yang, D. X.; Chang, T. Y.; Luo, Y. C. Realization of a news dissemination agent based on weighted association rules and text mining techniques. Expert Systems with Applications, 37(9), 2010, pp. 6409–6413.
- Huang, H.; Li, Y.; Zhang, Y. Investors’ attention and overpricing of IPO: an empirical study on China’s growth enterprise market. Information Systems and e-Business Management, 16(4), 2018, pp. 761–774.
- Humpherys, S.L.; Moffitt, K.C.; Burns, M.B.; Burgoon, J.K.; Felix, W.F. Identification of fraudulent financial statements using linguistic credibility analysis. Decision Support Systems, 2011, 50(3), pp. 585–594.
- Kamaruddin, S. S.; Bakar, A. A.; Hamdan, A. R.; Nor, F. M.; Nazri, M. Z. A.; Othman, Z. A.; Hussein, G. S. A text mining system for deviation detection in financial documents. Intelligent Data Analysis, 19(s1), 2015, pp. S19-S44.
- Kamaruddin, S. S.; Hamdan, A. R.; Bakar, A. A.; Mat Nor, F. Deviation detection in text using conceptual graph interchange format and error tolerance dissimilarity function. Intelligent Data Analysis, 2012, 16(3), pp. 487–511.
- Kraus, M.; Feuerriegel, S. Decision support from financial disclosures with deep neural networks and transfer learning. Decision Support Systems, 104, 2017, 38–48.
- Krishnamoorthy, S. Sentiment analysis of financial news articles using performance indicators. Knowledge and Information Systems, 56(2), 2018, pp. 373–394.
- Kucukyilmaz, T.; Cambazoglu, B.B.; Aykanat, C.; Can, F. Chat Mining for Gender Prediction. In Proceedings of the 4th International Conference in Advances in Information Systems (ADVIS), Izmir, Tukrey, 18–20th October, 2006, Springer: Berlin, Heidelberg, pp. 274–283.
- Kumar, B. S.; Ravi, V. A survey of the applications of text mining in financial domain. Knowledge-Based Systems, 114, 2016, 128–147.
- Lee, P.; Owda, M.; Crockett, K. Novel methods for resolving false positives during the detection of fraudulent activities on stock market financial discussion boards. International Journal of Advanced Computer Science and Applications (IJACSA), 2018, 9(1), pp. 1–10.
- Lee, W.S.; So Young, S. Identifying Emerging Trends of Financial Business Method Patents. Sustainability, 2017, 9(9).
- L’Huillier, G.; Alvarez, H.; Ríos, S.A.; Aguilera, F. Topic-based social network analysis for virtual communities of interests in the dark web. ACM SIGKDD Explorations Newsletter, 2011, 12(2), pp. 66–73.
- Li, G.; Dai, J. S.; Park, E. M.; Park, S. T. A study on the service and trend of Fintech security based on text-mining: focused on the data of Korean online news. Journal of Computer Virology and Hacking Techniques, 13(4), 2017, pp. 249–255.
- Li, Q.; Chen, Y.; Wang, J.; Chen, Y.; Chen, H. Web media and stock markets: A survey and future directions from a big data perspective. IEEE Transactions on Knowledge and Data Engineering, 30(2), 2018, pp. 381–399.
- Li, W.; Chen, H.; Nunamaker Jr, J. F. Identifying and profiling key sellers in cyber carding community: AZSecure text mining system. Journal of Management Information Systems, 33(4), 2016, pp. 1059–1086.
- Li, X.; Chen, K.; Sun, S. X.; Fung, T.; Wang, H.; Zeng, D. D. A commonsense knowledge-enabled textual analysis approach for financial market surveillance. INFORMS Journal on Computing, 28(2), 2016, pp. 278–294.
- Li, X.; Sun, S. X.; Chen, K.; Fung, T.; Wang, H. Design theory for market surveillance systems. Journal of Management Information Systems, 32(2), 2015, pp. 278–313.
- Lin, S. J.; Hsu, M. F. Decision making by extracting soft information from CSR news report. Technological and Economic Development of Economy, 24(4), 2018, pp. 1344–1361.
- Linardos, E.; Kermanidis, K. L.; Maragoudakis, M. Using financial news articles with minimal linguistic resources to forecast stock behaviour. International Journal of Data Mining, Modelling and Management, 7(3), 2015, pp. 185–212.
- Lotto, J. Examination of the Status of Financial Inclusion and its Determinants in Tanzania. Sustainability, 2018, 10(8), p. 2873.
- Loughran, T.; McDonald, B. When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. The Journal of Finance, 2010, 66(1), pp. 35–65.
- Lu, H. M.; Chen, H.; Chen, T. J.; Hung, M. W.; Li, S. H. Financial text mining: Supporting decision making using web 2.0 content. IEEE Intelligent Systems, 25(2), 2010, pp. 78–82.
- Lu, Y. C.; Shen, C. H.; Wei, Y. C. Revisiting early warning signals of corporate credit default using linguistic analysis. Pacific-Basin Finance Journal, 24, 2013, 1–21.
- Lugmayr, A.; Grueblbauer, J. Review of information systems research for media industry–recent advances, challenges, and introduction of information systems research in the media industry. Electronic Markets, 27(1), 2017, pp. 33–47.
- Mai, F.; Shan, Z.; Bai, Q.; Wang, X.; Chiang, R. H. How does social media impact bitcoin value? A test of the silent majority hypothesis. Journal of Management Information Systems, 35(1), 2018, pp. 19–52.
- Mao, H.; Jin, X.; Zhu, L. Methods of Measuring Influence of Bank Customer Using Social Network Model. American Journal of Industrial and Business Management, 2015, 5(4), pp. 155–160.
- Maragoudakis, M.; Serpanos, D. Exploiting financial news and social media opinions for stock market analysis using mcmc bayesian inference. Computational Economics, 47(4), 2016, pp. 589–622.
- Masawi, B.; Bhattacharya, S.; Boulter, T. The power of words: A content analytical approach examining whether central bank speeches become financial news. Journal of information science, 40(2), 2014, pp. 198–210.
- Molnar, Z.; Strelka, J. Competitive Intelligence for small and middle enterprises. E M EKONOMIE A MANAGEMENT, 15(3), 2012, pp. 156–170.
- Moro, S.; Cortez, P.; Rita, P. Business intelligence in banking: A literature analysis from 2002 to 2013 using text mining and latent Dirichlet allocation. Expert Systems with Applications, 42(3), 2015, pp. 1314–1324.
- Motokawa, K. Human capital disclosure, accounting numbers, and share price. Journal of Financial Reporting and Accounting, 13(2), 2015, pp. 159–178.
- Nakayama, M.; Wan, Y. Exploratory Study on Anchoring: Fake Vote Counts in Consumer Reviews Affect Judgments of Information Quality. Journal of theoretical and applied electronic commerce research, 2017, 12(1), pp. 1–20.
- Narayanan, V.; Arora, I.; Bhatia, A. Fast and accurate sentiment classification using an enhanced Naive Bayes model. In Proceedings of 14th International Conference on Intelligent Data Engineering and Automated Learning (IDEAL), Hefei, China, 20th-23rd October, 2013, Springer: Berlin, Heidelberg, pp. 194–201.
- Nardo, M.; Petracco-Giudici, M.; Naltsidis, M. Walking down wall street with a tablet: A survey of stock market predictions using the web. Journal of Economic Surveys, 30(2), 2016, pp. 356–369.
- Nassirtoussi, A. K.; Aghabozorgi, S.; Wah, T. Y.; Ngo, D. C. L. Text mining for market prediction: A systematic review. Expert Systems with Applications, 41(16), 2014, pp. 7653–7670.
- Nassirtoussi, A. K.; Aghabozorgi, S.; Wah, T. Y.; Ngo, D. C. L. Text mining of news-headlines for FOREX market prediction: A Multi-layer Dimension Reduction Algorithm with semantics and sentiment. Expert Systems with Applications, 42(1), 2015, pp. 306–324.
- Neumann, M.; Sartor, N. A semantic network analysis of laundering drug money. Journal of Tax Administration, 2(1), 2016, pp. 73–94.
- Nishanth, K. J.; Ravi, V.; Ankaiah, N.; Bose, I. Soft computing based imputation and hybrid data and text mining: The case of predicting the severity of phishing alerts. Expert Systems with Applications, 39(12), 2012, pp. 10583–10589.
- Nizer, P. S. M.; Nievola, J. C. Predicting published news effect in the Brazilian stock market. Expert Systems with Applications, 39(12), 2012, pp. 10674–10680.
- Nopp, C.; Hanbury, A. Detecting Risks in the Banking System by Sentiment Analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17th-21st September, 2015, pp. 591–600.
- Novalija, I.; Mladenić, D.; Bradeško, L. OntoPlus: Text-driven ontology extension using ontology content, structure and co-occurrence information. Knowledge-Based Systems, 24(8), 2011, pp. 1261–1276.
- Oliveira, N.; Cortez, P.; Areal, N. The impact of microblogging data for stock market prediction: using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Systems with Applications, 73, 2017, 125–144.
- Ong, T. H.; Chen, H.; Sung, W. K.; Zhu, B. Newsmap: a knowledge map for online news. Decision Support Systems, 39(4), 2005, pp. 583–597.
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Foundations and Trends® in Information Retrieval, 2008, 2(1–2), pp. 1–135.
- Park, S.; Lee, W.; Moon, I. C. Associative topic models with numerical time series. Information Processing Management, 51(5), 2015, pp. 737–755.
- Patrick J. The Scamseek Project – Text Mining for Financial Scams on the Internet. In: Williams G.J.; Simoff S.J. (eds) Data Mining. Lecture Notes in Computer Science, 3755, 2006, Springer, Berlin, Heidelberg.
- Phuong, D.V.; Phuong, T.M. Gender Prediction Using Browsing History. In Knowledge and Systems Engineering; Huynh, V.; Denoeux, T.; Tran, D.; Le, A.; Pham, S.; Eds.; Advances in Intelligent Systems and Computing, Springer: Cham, 244, 2014, pp. 271–283.
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: an experimental study. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP), Edinburgh, Scotland, UK, 27th–31st July, 2011, Association for Computational Linguistics, pp. 1524–1534.
- Roh, T.; Jeong, Y.; Yoon, B. Developing a Methodology of Structuring and Layering Technological Information in Patent Documents through Natural Language Processing. Sustainability, 2017, 9(11).
- Rönnqvist, S.; Sarlin, P. Bank distress in the news: Describing events through deep learning. Neurocomputing, 264, 2017, 57–70.
- Sakai, H.; Masuyama, S. Assigning polarity to causal information in financial articles on business performance of companies. IEICE transactions on information and systems, 92(12), 2009, pp. 2341–2350.
- Saleiro, P.; Rodrigues, E. M.; Soares, C.; Oliveira, E. Texrep: a text mining framework for online reputation monitoring. New Generation Computing, 35(4), 2017, pp. 365–389.
- Santos, C. L.; Rita, P.; Guerreiro, J. Improving international attractiveness of higher education institutions based on text mining and sentiment analysis. International Journal of Educational Management, 32(3), 2018, pp. 431–447.
- Schniederjans, D.; Cao, E. S.; Schniederjans, M. Enhancing financial performance with social media: An impression management perspective. Decision Support Systems, 55(4), 2013, pp. 911–918.
- Schumaker, R.P.; Chen, H. Textual analysis of stock market prediction using breaking financial news. ACM Transactions on Information Systems, 2009, 27(2), pp. 1–19.
- Schumaker, R.P.; Zhang, Y.; Huang, C.N.; Chen, H. Evaluating sentiment in financial news articles. Decision Support Systems, 2012, 53(3), pp. 458–464.
- See-To, E. W.; Yang, Y. Market sentiment dispersion and its effects on stock return and volatility. Electronic Markets, 27(3), 2017, pp. 283–296.
- Seki, K.; Shibamoto, M. Construction and application of sentiment lexicons in Finance. International Journal of Multimedia Data Engineering and Management (IJMDEM), 9(1), 2018, pp. 22–35.
- Seo, J. H.; Park, E. M. A study on financing security for smartphones using text mining. Wireless Personal Communications, 98(4), 2018, pp. 3109–3127.
- Shynkevich, Y.; McGinnity, T. M.; Coleman, S. A.; Belatreche, A. Forecasting movements of health-care stock prices based on different categories of news articles using multiple kernel learning. 2016, Decision Support Systems, 85, 74–83.
- Staines, J.; Barber, D. Topic factor models: Uncovering thematic structure in equity market data. Intelligent Data Analysis, 19(s1), 2015, pp. S69-S85.
- Takahashi, S.; Takahashi, M.; Takahashi, H.; Tsuda, K. Analysis of stock price return using textual data and numerical data through text mining. In International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, 2006, pp. 310–316.
- Tetlock, P.C. Giving content to investor sentiment: The role of media in the stock market. Journal of Finance, 2007, 62(3), pp. 1139–1168.
- Tobback, E.; Naudts, H.; Daelemans, W.; de Fortuny, E. J.; Martens, D. Belgian economic policy uncertainty index: Improvement through text mining. International journal of forecasting, 2018, 34(2), pp. 355–365.
- Tsai, M. F.; Wang, C. J. On the risk prediction and analysis of soft information in finance reports. European Journal of Operational Research, 257(1), 2017, pp. 243–250.
- Tsai, M. F.; Wang, C. J.; Chien, P. C. Discovering finance keywords via continuous-space language models. ACM Transactions on Management Information Systems (TMIS), 2016, 7(3), p. 7.
- Tsukioka, Y.; Yanagi, J.; Takada, T. Investor sentiment extracted from internet stock message boards and IPO puzzles. International Review of Economics Finance, 56, 2018, 205–217.
- Tumarkin, R.; Whitelaw, R.F. News or noise? Internet Postings Stock Prices. Financial Analysts Journal, 2001, 57(3), pp. 41–51.
- Wagh, R.S. Knowledge discovery from legal documents dataset using text mining techniques. International Journal of Computer Applications, 2013, 66(23), pp. 32–34.
- Wang, B.; Huang, H.; Wang, X. A novel text mining approach to financial time series forecasting. Neurocomputing, 2012, 83, 136–145.
- Wang, H.; Wu, J.; Yuan, S.; Chen, J. On characterizing scale effect of Chinese mutual funds via text mining. Signal Processing, 124, 2016, 266–278.
- Wang, T.; Kannan, K. N.; Ulmer, J. R. The association between the disclosure and the realization of information security risk factors. Information Systems Research, 24(2), 2013, pp. 201–218.
- Xia, Y.; Su, W.; Lau, R. Y.; Liu, Y. Discovering latent commercial networks from online financial news articles. Enterprise Information Systems, 7(3), 2013, pp. 303–331.
- Xie, Y.; Jiang, H. Stock Market Forecasting Based on Text Mining Technology: A Support Vector Machine Method. JCP, 12(6), 2017, pp. 500–510.
- Xing, F. Z.; Cambria, E.; Welsch, R. E. Intelligent asset allocation via market sentiment views. ieee ComputatioNal iNtelligeNCe magaziNe, 13(4), 2018, pp. 25–34.
- Xing, F. Z.; Cambria, E.; Welsch, R. E. Natural language based financial forecasting: a survey. Artificial Intelligence Review, 50(1), 2018, pp. 49–73.
- Yan, J.; Wang, K.; Liu, Y.; Xu, K.; Kang, L.; Chen, X.; Zhu, H. Mining social lending motivations for loan project recommendations. Expert Systems with Applications, 111, 2018, 100–106.
- Yang, R.; Yu, Y.; Liu, M.; Wu, K. Corporate risk disclosure and audit fee: a text mining approach. European Accounting Review, 27(3), 2018, pp. 583–594.
- Yao, C. Z.; Sun, B. Y.; Lin, J. N. A study of correlation between investor sentiment and stock market based on Copula model. Kybernetes, 46(3), 2017, pp. 550–571.
- Yong, S. H. I.; Tang, Y. R.; Cui, L. X.; Wen, L. O. N. G. A text mining based study of investor sentiment and its influence on stock returns. Economic Computation Economic Cybernetics Studies Research, 52(1), 2017, pp. 183–199.
- Yu, M.; Guo, C. Using news to predict Chinese medicinal material price index movements. Industrial Management Data Systems, 118(5), 2018, pp. 998–1017.
- Yuan, X.; Chang, W.; Zhou, S.; Cheng, Y. Sequential Pattern Mining Algorithm Based on Text Data: Taking the Fault Text Records as an Example. Sustainability, 10(11), 2018, p. 4330.
- Zhao, D. Frontiers of big data business analytics: patterns and cases in online marketing. In Big data and business analytics; Leibowitz, J.; Eds.; CRC Press: Boca Raton, 2013, pp. 46–68.
References
- Abrahamson, E.; Rosenkopf, L. Social Network Effects on the Extent of Innovation Diffusion: A Computer Simulation. Organ. Sci. 1997, 8, 289–309. [Google Scholar] [CrossRef]
- Adams, R.J.; Smart, P.; Huff, A.S. Shades of grey: Guidelines for working with the grey literature in systematic reviews for management and organizational studies. Int. J. Manag. Rev. 2017, 19, 432–454. [Google Scholar] [CrossRef]
- Alvarado, J.C.S.; Verspoor, K.; Baldwing, T. Domain Adaptation of Named Entity Recognition to Support Credit Risk Assessment. In Proceedings of the Australasian Language Technology Association Workshop, Parramatta, Australia, 8–9 December 2015; pp. 84–90. [Google Scholar]
- Arner, D.W.; Barberis, J.; Buckley, R.P. The evolution of Fintech: A new post-crisis paradigm. Georget. J. Int. Law. 2015, 47, 1271. [Google Scholar] [CrossRef]
- Bannan-Ritland, B. The role of design in research: The integrative learning design framework. Educ. Res. 2003, 32, 21–24. [Google Scholar] [CrossRef]
- Batistič, S.; Černe, M.; Vogel, B. Just how multi-level is leadership research? A document co-citation analysis 1980–2013 on leadership constructs and outcomes. Leadersh. Q. 2017, 28, 86–103. [Google Scholar] [CrossRef]
- Best, A.; Terpstra, J.L.; Moor, G.; Riley, B.; Norman, C.D.; Glasgow, R.E. Building knowledge integration systems for evidence-informed decisions. J. Health Organ. Manag. 2009, 23, 627–641. [Google Scholar] [CrossRef] [PubMed]
- Bharti, S.K.; Babu, K.S. Automatic Keyword Extraction for Text Summarization: A Survey. 2017. Available online: https://arxiv.org/ftp/arxiv/papers/1704/1704.03242.pdf (accessed on 12 August 2018).
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Charness, G.; Gneezy, U. Strong evidence for gender differences in risk taking. J. Econ. Behav. Organ. 2012, 83, 50–58. [Google Scholar] [CrossRef]
- Chye Koh, H.; Kee Low, C. Going concern prediction using data mining techniques. Manag. Audit. J. 2004, 19, 462–476. [Google Scholar] [CrossRef]
- Coussement, K.; Van den Poel, D. Integrating the voice of customers through call center emails into a decision support system for churn prediction. Inf. Manag. 2008, 45, 164–174. [Google Scholar] [CrossRef]
- Dong, W.; Liao, S.; Liang, L. Financial Statement Fraud Detection using Text Mining: A Systemic Functional Linguistics Theory Perspective. In Proceedings of the Pacific Asia Conference on Information Systems (PACIS), Chiayi, Taiwan, 26 June 2016; p. 188. [Google Scholar]
- Ediger, D.; Jiang, K.; Riedy, J.; Bader, D.A.; Corley, C. Massive social network analysis: Mining twitter for social good. In Proceedings of the 39th International Conference on Parallel Processing, San Diego, CA, USA, 13–16 September 2010; pp. 583–593. [Google Scholar]
- Eler, D.M.; Grosa, D.; Pola, I.; Garcia, R.; Correia, R.; Teixeira, J. Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information 2018, 9, 100. [Google Scholar] [CrossRef]
- Elshendy, M.; Fronzetti Colladon, A. Big data analysis of economic news: Hints to forecast macroeconomic indicators. Int. J. Eng. Bus. Manag. 2017, 9, 1847979017720040. [Google Scholar] [CrossRef]
- Fan, W.; Wallace, L.; Rich, S.; Zhang, Z. Tapping the power of text mining. Commun. ACM 2006, 49, 77–82. [Google Scholar] [CrossRef]
- Farzindar, A.; Lapalme, G. Letsum, an automatic legal text summarizing system. In Legal Knowledge and Information Systems: JURIX 2004: The Seventeenth Annual Conference; Gordon, T., Ed.; IOS Press: Berlin, Germany, 2004; pp. 11–18. [Google Scholar]
- Finacle Connect. Connecting the Banking World. Artificial Intelligence Powered Banking. 2018. Available online: https://active.ai/wp-content/uploads/2018/05/Finacle-Connect-2018-leading-ai-online.pdf (accessed on 12 August 2018).
- Friedmann, E.; Lowengart, O. The Effect of Gender Differences on the Choice of Banking Services. J. Serv. Sci. Manag. 2016, 9, 361–377. [Google Scholar] [CrossRef]
- Furner, C.P.; Zinko, R.; Zhu, Z. Examining the Role of Mobile Self-Efficacy in the Word-of-Mouth/Mobile Product Reviews Relationship. Int. J. E-Serv. Mob. Appl. (IJESMA) 2017, 10, 40–60. [Google Scholar] [CrossRef]
- Galli, E.; Rossi, S.P.S. Bank Credit Access and Gender Discrimination: An Empirical Analysis. In Contributions to Economics; Springer: Berlin, Germany, 2014; pp. 111–123. [Google Scholar]
- Glancy, F.H.; Yadav, S.B. A computational model for financial reporting fraud detection. Decis. Support Syst. 2011, 50, 595–601. [Google Scholar] [CrossRef]
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification Using Distant Supervision. CS224N Project Report, Stanford. 2009, Volume 1. Available online: https://cs.stanford.edu/people/alecmgo/papers/TwitterDistantSupervision09.pdf (accessed on 12 August 2018).
- Gray, G.L.; Debreceny, R.S. A taxonomy to guide research on the application of data mining to fraud detection in financial statement audits. Int. J. Account. Inf. Syst. 2014, 15, 357–380. [Google Scholar] [CrossRef]
- Grishman, R.; Sundheim, B. Message understanding conference-6: A brief history. In Proceedings of the COLING 1996: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996; Volume 1, pp. 466–471. [Google Scholar]
- Hagenau, M.; Liebmann, M.; Neumann, D. Automated news reading: Stock price prediction based on financial news using context-capturing features. Decis. Support Syst. 2013, 55, 685–697. [Google Scholar] [CrossRef]
- Hajizadeh, E.; Ardakani, H.D.; Shahrabi, J. Application of data mining techniques in stock markets: A survey. J. Econ. Int. Financ. 2010, 2, 109–118. [Google Scholar]
- Hasan, K.S.; Ng, V. Automatic keyphrase extraction: A survey of the state of the art. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 1262–1273. [Google Scholar]
- Herráez, B.; Bustamante, D.; Saura, J.R. Information classification on social networks. Content analysis of e-commerce companies on Twitter. Revista Espacios 2017, 38, 16. [Google Scholar]
- Holton, C. Identifying disgruntled employee systems fraud risk through text mining: A simple solution for a multi-billion dollar problem. Decis. Support Syst. 2009, 46, 853–864. [Google Scholar] [CrossRef]
- Humpherys, S.L.; Moffitt, K.C.; Burns, M.B.; Burgoon, J.K.; Felix, W.F. Identification of fraudulent financial statements using linguistic credibility analysis. Decis. Support Syst. 2011, 50, 585–594. [Google Scholar] [CrossRef]
- Hussin, M.F.; Kamel, M.S.; Nagi, M.H. An efficient two-level SOMART document clustering through dimensionality reduction. In Proceedings of the International Conference on Neural Information Processing, Calcutta, India, 22–25 November 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 158–165. [Google Scholar]
- Jin, M.; Wang, Y.; Zeng, Y. Application of Data Mining Technology in Financial Risk Analysis. Wirel. Pers. Commun. 2018, 102, 3699–3713. [Google Scholar] [CrossRef]
- Klopotan, I.; Zoroja, J.; Meško, M. Early warning system in business, finance, and economics: Bibliometric and topic analysis. Int. J. Eng. Bus. Manag. 2018, 10, 1847979018797013. [Google Scholar] [CrossRef]
- Kucukyilmaz, T.; Cambazoglu, B.B.; Aykanat, C.; Can, F. Chat Mining for Gender Prediction. In Proceedings of the 4th International Conference in Advances in Information Systems (ADVIS), Izmir, Tukrey, 18–20 October 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 274–283. [Google Scholar]
- Kumar, B.S.; Ravi, V. A survey of the applications of text mining in financial domain. Knowl.-Based Syst. 2016, 114, 128–147. [Google Scholar] [CrossRef]
- Lee, W.S.; So Young, S. Identifying Emerging Trends of Financial Business Method Patents. Sustainability 2017, 9, 1670. [Google Scholar]
- L’Huillier, G.; Alvarez, H.; Ríos, S.A.; Aguilera, F. Topic-based social network analysis for virtual communities of interests in the dark web. ACM SIGKDD Explor. Newslett. 2011, 12, 66–73. [Google Scholar] [CrossRef]
- Lotto, J. Examination of the Status of Financial Inclusion and its Determinants in Tanzania. Sustainability 2018, 10, 2873. [Google Scholar] [CrossRef]
- Loughran, T.; McDonald, B. When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. J. Financ. 2010, 66, 35–65. [Google Scholar] [CrossRef]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Mao, H.; Jin, X.; Zhu, L. Methods of Measuring Influence of Bank Customer Using Social Network Model. Am. J. Ind. Bus. Manag. 2015, 5, 155–160. [Google Scholar] [CrossRef]
- Mathew, S. Financial Services Data Management: Big Data Technologies in Financial Services. Oracle White Paper. 2012. Available online: http://www.oracle.com/us/industries/financial-services/bigdata-in-fs-final-wp-1664665.pdf (accessed on 12 August 2018).
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- Moody, C.E. Mixing Dirichlet Topic Models and Word Embeddings to Make lda2vec. 2016. Available online: https://arxiv.org/abs/1605.02019 (accessed on 12 August 2018).
- Moro, S.; Cortez, P.; Rita, P. Business intelligence in banking: A literature analysis from 2002 to 2013 using text mining and latent Dirichlet allocation. Expert Syst. Appl. 2015, 42, 1314–1324. [Google Scholar] [CrossRef]
- Nakayama, M.; Wan, Y. Exploratory Study on Anchoring: Fake Vote Counts in Consumer Reviews Affect Judgments of Information Quality. J. Theor. Appl. Electron. Commer. Res. 2017, 12, 1–20. [Google Scholar] [CrossRef]
- Narayanan, V.; Arora, I.; Bhatia, A. Fast and accurate sentiment classification using an enhanced Naive Bayes model. In Proceedings of the 14th International Conference on Intelligent Data Engineering and Automated Learning (IDEAL), Hefei, China, 20–23 October 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 194–201. [Google Scholar]
- Nassirtoussi, A.K.; Aghabozorgi, S.; Wah, T.Y.; Ngo, D.C.L. Text mining for market prediction: A systematic review. Expert Syst. Appl. 2014, 41, 7653–7670. [Google Scholar] [CrossRef]
- Ngai, E.W.; Hu, Y.; Wong, Y.H.; Chen, Y.; Sun, X. The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decis. Support Syst. 2011, 50, 559–569. [Google Scholar] [CrossRef]
- Niazi, M. Do systematic literature reviews outperform informal literature reviews in the software engineering domain? An initial case study. Arab. J. Sci. Eng. 2015, 40, 845–855. [Google Scholar] [CrossRef]
- Nopp, C.; Hanbury, A. Detecting Risks in the Banking System by Sentiment Analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 591–600. [Google Scholar]
- Ong, T.H.; Chen, H.; Sung, W.K.; Zhu, B. Newsmap: A knowledge map for online news. Decis. Support Syst. 2005, 39, 583–597. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends® Inf. Retr. 2008, 2, 1–135. Available online: https://www.nowpublishers.com/article/Details/INR-011 (accessed on 24 February 2019). [CrossRef]
- Pejic-Bach, M.; Pivar, J.; Krstić, Ž. Big Data for Prediction: Patent Analysis–Patenting Big Data for Prediction Analysis. In Big Data Governance and Perspectives in Knowledge Management; IGI Global: London, UK, 2019; pp. 218–240. [Google Scholar]
- Phuong, D.V.; Phuong, T.M. Gender Prediction Using Browsing History. In Knowledge and Systems Engineering; Huynh, V., Denoeux, T., Tran, D., Le, A., Pham, S., Eds.; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2014; Volume 244, pp. 271–283. [Google Scholar]
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.E.; Dimitriou, A.; Papavassiliou, S. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 2015 13th International Conference on Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- Reyes-Menendez, A.; Saura, J.; Alvarez-Alonso, C. Understanding# WorldEnvironmentDay user opinions in Twitter: A topic-based sentiment analysis approach. Int. J. Environ. Res. Public Health 2018, 15, 2537. [Google Scholar]
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP), Edinburgh, Scotland, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 1524–1534. [Google Scholar]
- Roh, T.; Jeong, Y.; Yoon, B. Developing a Methodology of Structuring and Layering Technological Information in Patent Documents through Natural Language Processing. Sustainability 2017, 9, 2117. [Google Scholar] [CrossRef]
- Saju, J.C.; Shaja, A.S. A Survey on Efficient Extraction of Named Entities from New Domains Using Big Data Analytics. In Proceedings of the 2nd International Conference on Recent Trends and Challenges in Computational Models (ICRTCCM), Tindivanam, India, 3–4 February 2017; pp. 170–175. [Google Scholar]
- Saura, J.R.; Palos-Sánchez, P.; Cerdá Suárez, L.M. Understanding the digital marketing environment with KPIs and web analytics. Future Internet 2017, 9, 76. [Google Scholar] [CrossRef]
- Schumaker, R.P.; Chen, H. Textual analysis of stock market prediction using breaking financial news. ACM Trans. Inf. Syst. 2009, 27, 1–19. [Google Scholar] [CrossRef]
- Schumaker, R.P.; Zhang, Y.; Huang, C.N.; Chen, H. Evaluating sentiment in financial news articles. Decis. Support Syst. 2012, 53, 458–464. [Google Scholar] [CrossRef]
- Srivastava, U.; Gopalkrishnan, S. Impact of Big Data Analytics on Banking Sector: Learning for Indian Banks. Procedia Comput. Sci. 2015, 50, 643–652. [Google Scholar] [CrossRef]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.E.; Papavassiliou, S. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimedia Tools Appl. 2018, 77, 283–326. [Google Scholar]
- Sun, S.; Luo, C.; Chen, J. A review of natural language processing techniques for opinion mining systems. Inf. Fusion 2017, 36, 10–25. [Google Scholar] [CrossRef]
- Tetlock, P.C. Giving content to investor sentiment: The role of media in the stock market. J. Financ. 2007, 62, 1139–1168. [Google Scholar] [CrossRef]
- Tumarkin, R.; Whitelaw, R.F. News or noise? Internet Postings Stock Prices. Financ. Anal. J. 2001, 57, 41–51. [Google Scholar] [CrossRef]
- Turner, D.; Schroeck, M.; Shockley, R. Analytics: The Real-World Use of Big Data in Financial Services. J. Shanghai Jiaotong Univ. (Sci.) 2012, 21, 210–214. [Google Scholar]
- Vemuri, V.K. Mastering digital business: How powerful combinations of disruptive technologies are enabling the next wave of digital transformation, by Nicholas D. Evans. J. Inf. Technol. Case Appl. Res. 2017, 19, 128–130. [Google Scholar] [CrossRef]
- Wagh, R.S. Knowledge discovery from legal documents dataset using text mining techniques. Int. J. Comput. Appl. 2013, 66, 32–34. [Google Scholar]
- Wahono, R.S. A Systematic Literature Review of Software Defect Prediction: Research Trends, Datasets, Methods and Frameworks. J. Softw. Eng. 2015, 1, 1–16. [Google Scholar]
- Wang, N.; Liang, H.; Jia, Y.; Ge, S.; Xue, Y.; Wang, Z. Cloud computing research in the IS discipline: A citation/co-citation analysis. Decis. Support Syst. 2016, 86, 35–47. [Google Scholar] [CrossRef]
- Wuthrich, B.; Cho, V.; Leung, S.; Permunetilleke, D.; Sankaran, K.; Zhang, J. Daily stock market forecast from textual web data. In Proceedings of the 1998 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 14 October 1998; pp. 2720–2725. [Google Scholar]
- Yehia, A.M.; Ibrahim, L.F.; Abulkhair, M.F. Text Mining and Knowledge Discovery from Big Data: Challenges and Promise. Int. J. Comput. Sci. Issues (IJCSI) 2016, 13, 54–61. [Google Scholar]
- Zekić-Sušac, M.; Has, A. Data Mining as Support to Knowledge Management in Marketing. Bus. Syst. Res. 2015, 6, 18–30. [Google Scholar] [CrossRef]
- Zhai, C.; Velivelli, A.; Yu, B. A cross-collection mixture model for comparative text mining. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 743–748. [Google Scholar]
- Zhai, Y.; Hsu, A.; Halgamuge, S.K. Combining news and technical indicators in daily stock price trends prediction. In Proceedings of the 4th International Symposium on Neural Networks (ISNN), Nanjing, China, 3–7 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1087–1096. [Google Scholar]
- Zhang, C.; Zhang, P. Predicting Gender from Blog Posts; University of Massachussetts: Amherst, MA, USA, 2010. [Google Scholar]
- Zhang, D.; Zhou, L. Discovering golden nuggets: Data mining in financial application. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2004, 34, 513–522. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. 2018. Available online: https://arxiv.org/abs/1801.07883/ (accessed on 12 August 2018).
- Zhao, D. Frontiers of big data business analytics: Patterns and cases in online marketing. In Big Data and Business Analytics; Leibowitz, J., Ed.; CRC Press: Boca Raton, FL, USA, 2013; pp. 46–68. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Authors, Publication Year | Total Citations | Objectives |
|---|---|---|---|
| Text mining for market prediction: A systematic review | Nassirtoussi, Wah, Aghabozorgi, and Ngo (2014) [20] | 97 | The study presents an overview of studies related to the market forecast based on online text mining and creates an outlook to the main elements. In addition, the paper presented a scomparison of all systems with the identification of the main differentiating factors. |
| Identification of fraudulent financial statements using linguistic credibility analysis | Humpherys, Moffitt, Burns, Burgoon, and Felix (2011) [28] | 73 | The study analyses corporate fraud detection “through a unique application of existing text-mining methods on the Management’s Discussion and Analysis and tests for linguistic differences between fraudulent and non-fraudulent MD & As” (Humpherys, Moffitt, Burns, Burgoon, and Felix, 2011, p.585). |
| Evaluating sentiment in financial news articles | Schumaker et al. (2012) [6] | 71 | The study deals with the choice of words and tones used in newspaper articles and their relation to the movements in stock prices. |
| Newsmap: a knowledge map for online news | Ong et al. (2005) [8] | 62 | This study focuses on the automatic generation of a NewsMap knowledge hierarchy map, based on online news, especially in finance and healthcare. |
| Integrating the voice of customers through call center emails into a decision support system for chum prediction | (Coussement and Van den Poel, 2008) [30] | 51 | The study analyzes the effect of adding text information to the churn prediction system that uses only traditional marketing information. |
| Authors | Research |
|---|---|
| Hasan and Ng (2014) [44] | Automatic keyword extraction |
| Roh, Jeong, and Yoon (2017) [45] | Multilayered keyword extraction methodology for structuring technological information through natural language processing (NLP), h purpose: discovering trends in patent analysis, technology classification or knowledge flow among technologies |
| Eler et al. (2018) [46] | Pre-processing steps with impact on text mining techniques: lowercasing, deletions, stemming/ lemmatization, PoS (Part-of-Speech) tagging, parsing |
| Authors | Research |
|---|---|
| Alvarado, Verspoor, and Baldwin (2015) [49] | Named entity recognition analysis on financial documentation and publicly available non-financial data set to extract information of risk assessment |
| Ritter et al. (2011) [50] | Supervised approach for named entity recognition |
| Authors | Research |
|---|---|
| Phuong and Phuong (2014) [52] | Users’ gender based on browsing history, important for marketing and personalization |
| Kucukyilmaz et al. (2006) [53] | Gender prediction in computer-mediated-communication/ chatbots |
| Lotto (2018) [54] | Gender prediction to predict financial inclusion, compared with traditional banking services |
| Authors | Research |
|---|---|
| Pang and Lee (2008) [36] | Sentiment analysis for determination of writer’s attitude towards the specific topic |
| Nopp and Hanbury (2015) [58] | Sentiment analysis to detect risks in the banking system |
| Narayanan et al. (2013) [59] | Algorithms with correct feature selection and noise removal process |
| Authors | Research |
|---|---|
| Moro et al. (2015) [64] | Topic detection of a large number of manuscripts using text mining techniques when detecting terms belonging to business intelligence and banking domains (dirlecht allocation model), topics: credit banking, risk, fraud detection, credit approval and bankruptcy |
| Zhao et al. (2011) [65] | Social media as a source of entity-oriented topics, unsupervised machine learning approach |
| Lee and So Young (2017) [66] | Framework to identify the rise and fall of emerging topics in the financial industry |
| Authors | Research |
|---|---|
| Ediger et al. (2010) [68] | Metrics for social network analysis: centrality measures, node degrees (used to find users who are highly connected), closeness (goal is to find users who can spread information to others), clustering coefficient, PageRank |
| L’Huillier et al. (2011) [69] | Integration of social network analysis and topic detection |
| Mao, Jin, and Zhu (2015) [70] | Social network analysis to explore the way that bank customers impact each other |
| Text-Mining Technique | Internal Data | Example of Internal Data | External Data | Example of External Data | Example Application |
|---|---|---|---|---|---|
| Keyword extraction | ✓ | News, social media feeds, patents | Fraud detection and Stock market prediction | ||
| Named entity recognition | ✓ | Publicly available non-financial data, e.g., social media | Customer relationship management | ||
| Gender prediction | ✓ | Publicly available non-financial data, e.g., social media | Customer relationship management | ||
| Sentiment analysis | ✓ | News; social media feeds; Financial statements | Fraud detection and Stock price prediction | ||
| Topic extraction | ✓ | Legal documents | ✓ | News, social media feeds | Summarization |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pejić Bach, M.; Krstić, Ž.; Seljan, S.; Turulja, L. Text Mining for Big Data Analysis in Financial Sector: A Literature Review. Sustainability 2019, 11, 1277. https://doi.org/10.3390/su11051277
Pejić Bach M, Krstić Ž, Seljan S, Turulja L. Text Mining for Big Data Analysis in Financial Sector: A Literature Review. Sustainability. 2019; 11(5):1277. https://doi.org/10.3390/su11051277
Chicago/Turabian StylePejić Bach, Mirjana, Živko Krstić, Sanja Seljan, and Lejla Turulja. 2019. "Text Mining for Big Data Analysis in Financial Sector: A Literature Review" Sustainability 11, no. 5: 1277. https://doi.org/10.3390/su11051277
APA StylePejić Bach, M., Krstić, Ž., Seljan, S., & Turulja, L. (2019). Text Mining for Big Data Analysis in Financial Sector: A Literature Review. Sustainability, 11(5), 1277. https://doi.org/10.3390/su11051277