1. Introduction
In recent years, most cities focus on classifying land use/land cover (LULC) based on remote sensing (RS) satellite images, which is costly and lacks timely update. Urban functional zones detection, as an effective way to understand the urban space and the interaction between human activities and the environment, is seldom conducted by the government due to limited budgets and manpower [
1,
2]. Meanwhile, diverse and complex urban functional zones have also been formed and transformed continuously, in order to meet people’s increasing social and economic needs as a result of rapid urbanization [
3,
4]. Thus, the demand for up-to-date urban function information is becoming increasingly crucial, because it is the basis to capture human behavior patterns of a city, and then to effectively inform urban management with respect to traffic control, energy recycling, and emergency management [
5,
6,
7].
In general, urban functional zones are categorized as commercial, recreational, industrial and residential zones. Numerous models have been developed to extract and analyze urban functional zones. Traditionally, urban functional areas are identified based on onsite survey and field observation [
8]. With the improvement of high-resolution satellite images (Landsat, SPOT, QuickBird), many detailed urban land-use maps have also been produced with remote sensing technology, which mainly concentrates on feature representations, semantic cognition classification, and zonal segmentation [
1,
9,
10]. The above-mentioned studies largely take advantage of the spectral features of a city, and satellite images can only describe the natural characteristics of ground elements, and largely ignore and cannot capture the real human activities.
It is the activities of, and interactions between, urban inhabitants that give rise to the characteristic physical environment of the city, and which, in return, also conditions people’s various behaviors in the urban setting. This also empowers social sensing studies in various disciplines. Liu et al. [
11] proposed the concept of social sensing, an important complement to remote sensing that is able to capture social and economic activities in the city and explore the function of a city at a fine and temporal scale. A considerable set of social sensing datasets have been successfully utilized for urban functional zones classification, such as night-time light imagery [
12,
13], cell phone [
14], taxi trajectory [
15,
16,
17], points of interest (POI) [
18], and multi-social media data [
19,
20,
21]. For example, Aubrecht and Torres [
13] effectively identified and distinguished areas of mixed use from the predominant residential areas using night time images. Zhang, Du, and Wang [
1] used hierarchical semantic cognition to classify functional zones in Beijing based on a very-high-resolution (VHR) satellite image and POI data, which produced good experimental results. Pei et al. [
22] utilized the mobile phone dataset and a semi-supervised clustering method to classify different land-use types, and the detection rate of land-use reached 58.03%. Zhan, Ukkusuri, and Zhu [
23] successfully explored the possibility and validity of using social media check-in dataset to classify land-use types.
Meanwhile, many classification methods have also been widely developed to classify land use types and urban functional zones, such as K-Nearest Neighbors [
24], Decision Tree [
25], Support Vector Machine (SVM) [
1,
26], and Random Forest [
19,
27]. For instance, DeFries, Hansen, Townshend, and Sohlberg [
28] used the Decision Tree algorithm to classify global land cover of 8 × 8 km resolution, which achieved an accuracy of over 80%. Mountrakis, Im, and Ogole [
29] reviewed the research on remote sensing implementations using the support vector machine and found this method is especially suitable for multi-class classification problems because of its self-adaptability, quick learning rate, and limited requirements on sample sizes. Huang, Davis, and Townshend [
30] evaluated the performance of SVM compared with the maximum likelihood classifier, neural network classifier, and Decision Tree classifier using Thematic Mapper image of eastern Maryland in the U..S, and their results show that mostly the SVM is more accurate and stable than the other three algorithms because of its optimal separating hyperplane during the training process. Liu et al. [
31] proposed a novel scene classification framework to identify dominant land use type by combining probabilistic topic models and SVM using satellite image, social media data and open street map (OSM) road data, which achieved an overall accuracy of 86.5%. Although SVM is able to deal with high-dimensional and nonlinear problems, the uncertainty caused during the model training process due to its sensitivity to the initial parameters should also be noted. The Random Forest algorithm, a nonparametric classification model, is effective in obtaining accurate and stable predictions and reducing overfitting through building and merging multiple decision trees together [
32], and was quite popular for land use and urban functional zones classification studies in past years [
27,
33,
34,
35]. Yao et al. [
19] used the greedy algorithm, Random Forest algorithm and CBOW-based Word2Vec model to identify urban land use types based on POI data with an accuracy of 87.28%. Jiang et al. [
20] compared several machine learning methods for land use classification with POI data in Boston, U.S. and they concluded that tree-based approaches, e.g., Decision Tree and Random Forest, outperformed Bayesian networks and rule-based learners.
On the other hand, apparently the higher accuracy of classification is always desirable for classifications. To find a more accurate method for inferring hybrid transportation modes based on trajectory data, Xiao, Wang, Fu, and Wu [
36] compared different tree-based ensemble models and traditional method, and it was noted that eXtreme Gradient Boosting (XGBoost) was able to achieve the highest classification accuracy. Moreover, although many machine learning classification methods have been used for urban functional zones, XGBoost, as a newly developed machine learning method, has not been applied in the field of urban functional zones classification from existing literature. To bridge the research gap, this research aims to compare XGBoost with other commonly used classification methods, including Logistic Regression, K-Nearest Neighbours, Decision Tree, Support Vector Machines and Random Forest, in the field of urban functional zones classification through the case study in Yuzhong, Chongqing, China based on the multi-source geospatial datasets, including nightlight imagery, social media records, POI and Baidu Heat Map. We believe that this research can significantly help other urban functional zones classification applications while enough datasets are available and the target research context is similar as the case study in this research. The remainder of this paper is divided into four sections.
Section 2 briefly describes the research area and how the geospatial datasets are selected.
Section 3 and
Section 4 introduce the methodology and the results, and lastly the discussion and conclusion are included in
Section 5.
5. Discussion and Conclusion
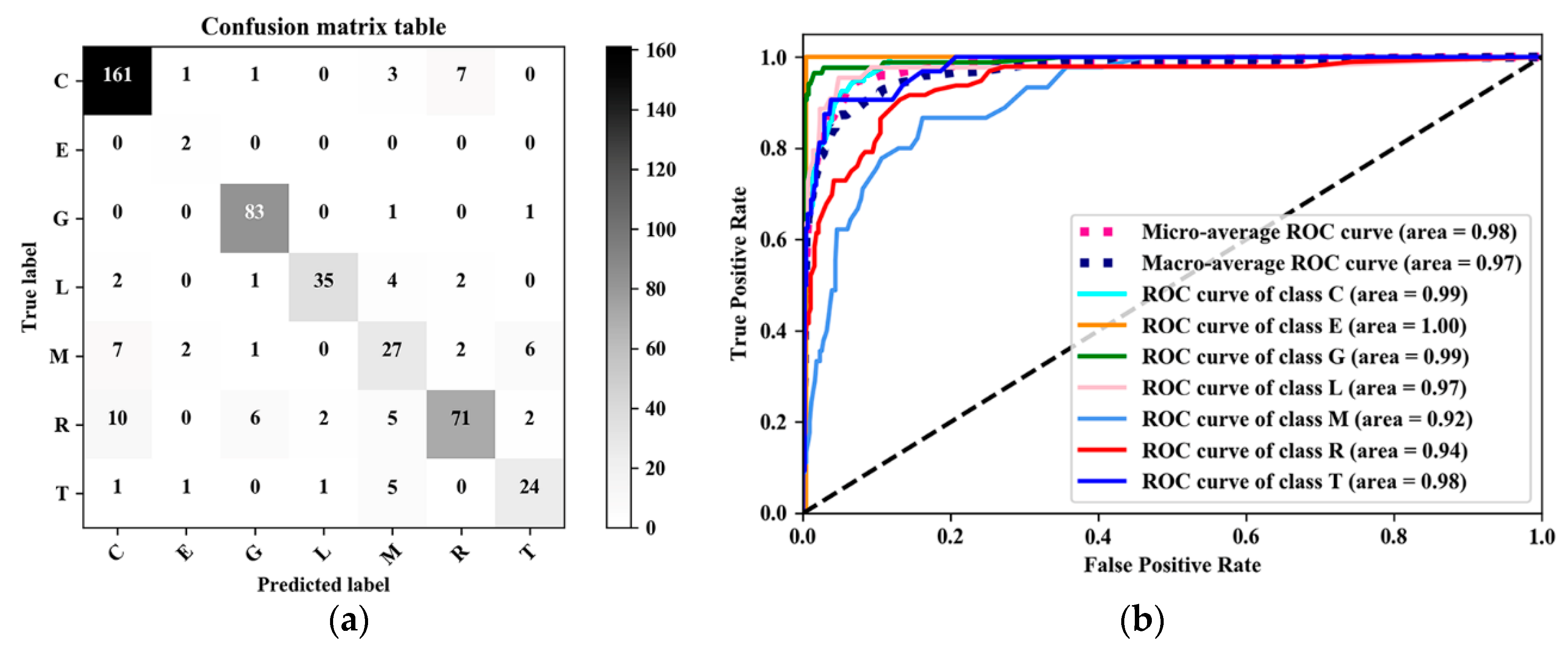
It has been an increasingly important issue recently to conduct the urban functional zones classification because it could provide a good reference for urban planners and decision makers to monitor the changes of urban functional zones over space and time for making better plans and decisions. However, urban functional zones classification remains a challenge due to the complexity of urban systems and the limitation of datasets. Although many classification approaches have been used to distinguish between different urban functional zones based on various kinds of datasets, there is still room for improvement in terms of designing and employing more effective models for better accuracy in the field. Newly developed machine learning classifier XGBoost has shown its high efficiency and effectiveness in many applications. However, it has not been tested and utilized in urban functional zones classification. Hence, in this study, the XGBoost model was employed, tested, and compared with other commonly used classification models to classify a variety of urban functional zones in the case study of Yuzhong District, Chongqing, China. In these successful experiments, the XGBoost model was found to be the best among all these commonly used models tested in this research, with the highest accuracy of 88.05%. The results could explicitly demonstrate that the XGBoost model could effectively be applied in urban functional zones classification through the combination of physical and socioeconomic features extracted from high-resolution satellite images and multi-source geospatial data, respectively. In this study, ensemble classifiers, such as XGBoost and Random Forest, have also shown a promising classification performance compared to other kinds of state-of-the-art classifiers. In addition, although XGBoost is a highly sophisticated algorithm, the model is still quite straightforward to use and is able to perform better than Random Forest and the other tested models based on accuracy, confusion matrix, ROC curves, and AUC values in this case study. This might be due to the following aspects: First, XGBoost is a regularized boosting technique and allows users to define custom optimization objectives and evaluation criteria, which is of high flexibility as well as able to reduce overfitting. Second, XGBoost is also able to handle missing values, which could decrease the uncertainty. Furthermore, Random Forest model ranks the second of all these tested models in the case study. As a tree-based model, the Decision Tree has also performed well, but less accurate than XGBoost and Random Forest models, respectively. Surprisingly, Multinomial Logistic Regression, as the most commonly used and simplest model, shows an accuracy of 70.86%, which is even better than SVM and K-Nearest Neighbors models in this study. SVM, although proved to be efficient in previous studies [
26,
44], only achieved an accuracy of 67.71% in this case study, which is less than most of the classification model tested in this study. The K-Nearest Neighbors model performed worst in both accuracy and classification separability in this study.
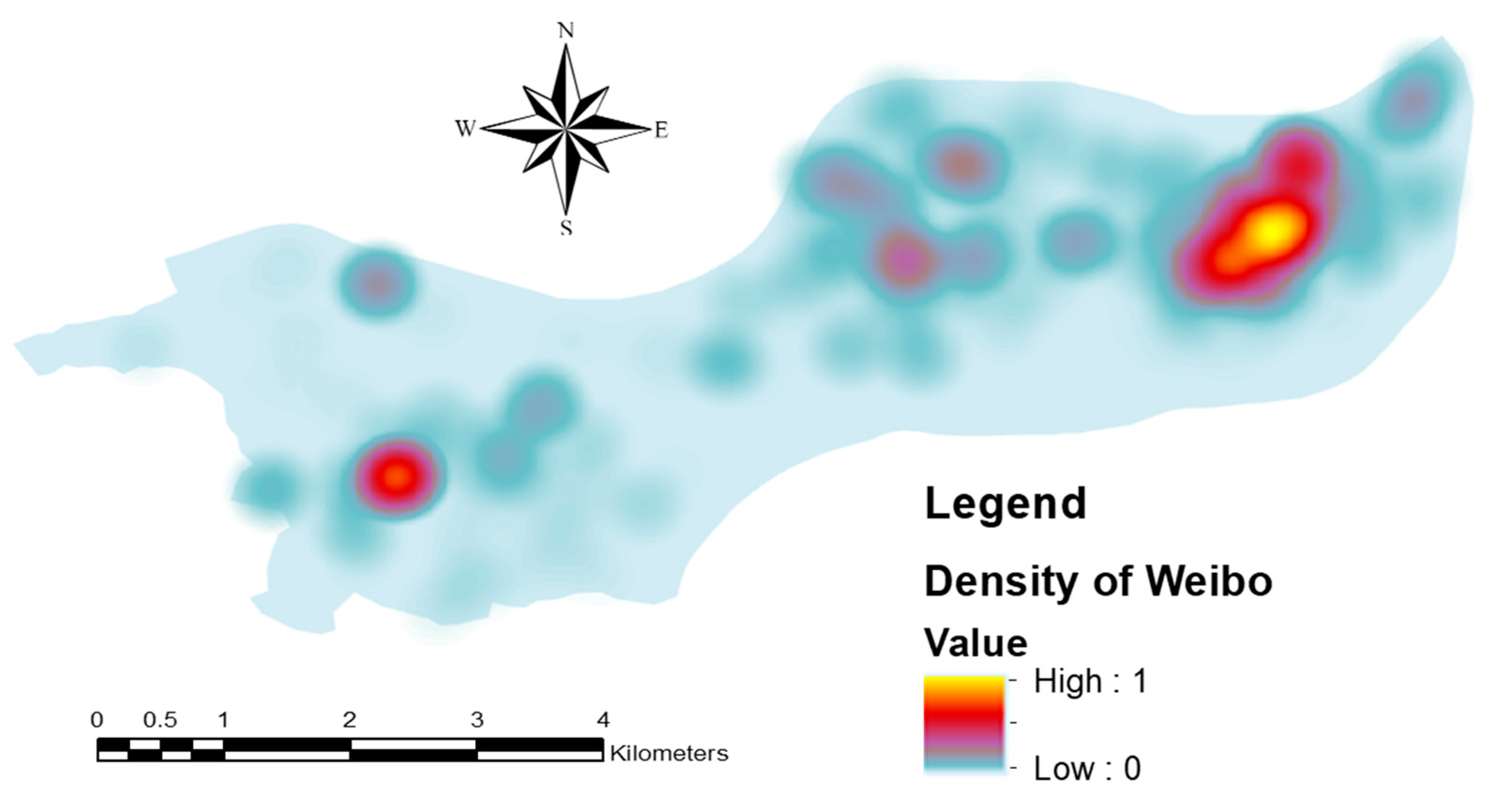
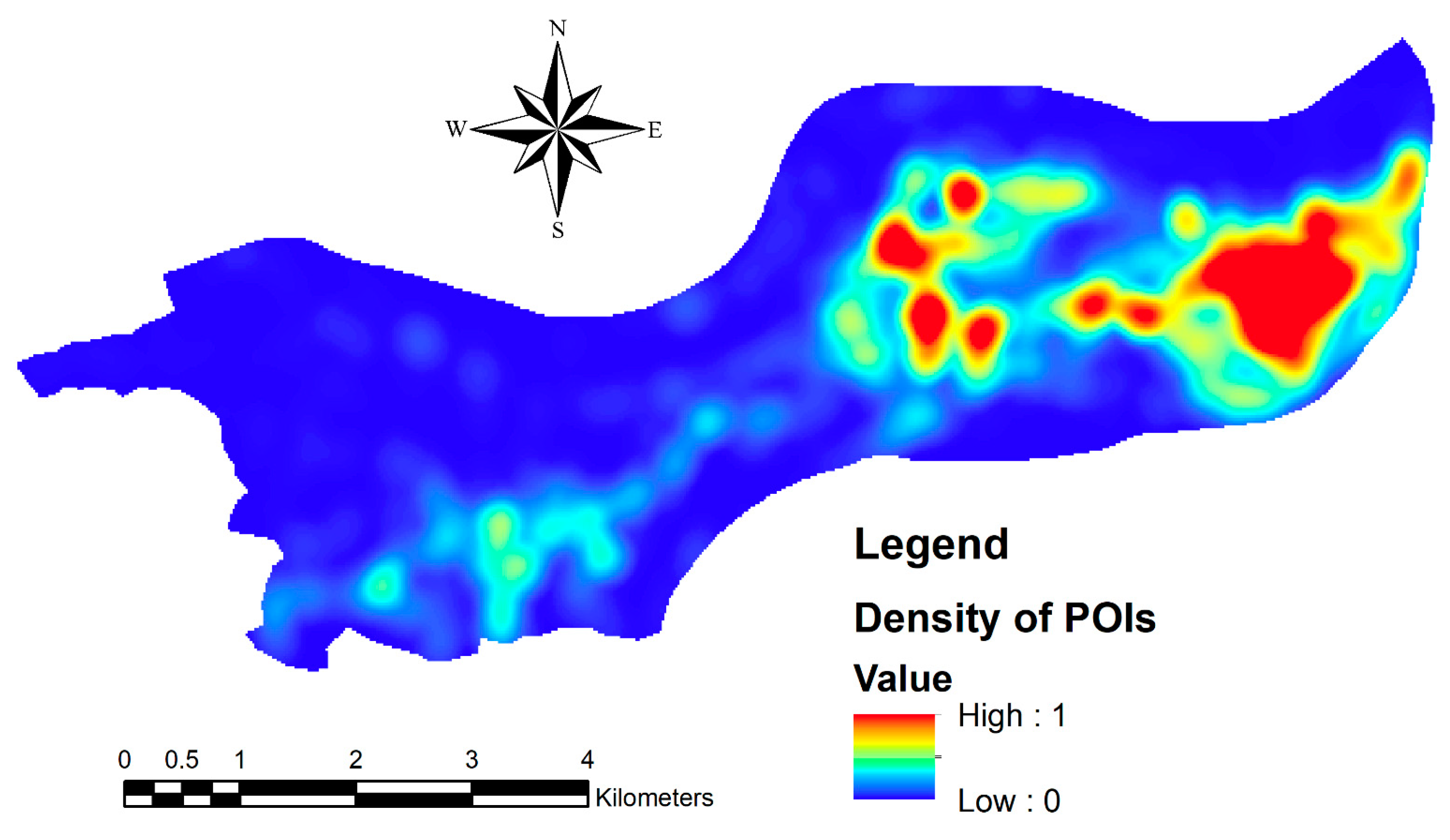
The success of our comparison between these models could be a good reference to other case studies in urban functional zones classification or even other applications of classifications. Furthermore, as the extension of our current research, more efforts will be put into the temporal dimension of urban functional zones classification, which requires even more efficient classification models or even integration of high-performance computation. In addition, in this research, the sample size was set to be 100 m by 100 m given the data availability and the size of the research area. However, the scale may also matter in the performance of these models, we would like to continue our research on this direction in the future. On the other hand, our case study based on multi-source geospatial datasets has also revealed the value of nighttime light imagery, social media datasets, POI datasets, and Baidu Heat Map to the recognition of urban functional zones. Of course, more geospatial datasets, especially social sensing datasets, are also worth exploring, which will also be one direction of our future research.
Last but not least, there are also a few limitations in this research. First, there exist some uncertainties on these multi-source geospatial data collected. Given that it applies to all these models, the influence on the results of our study could be ignored. Second, considering the computation intensity, the parameters calibration in this research could also be improved for possibly more precise results. These aspects will be addressed in our future research.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}