Development of Output Correction Methodology for Long Short Term Memory-Based Speech Recognition


Abstract
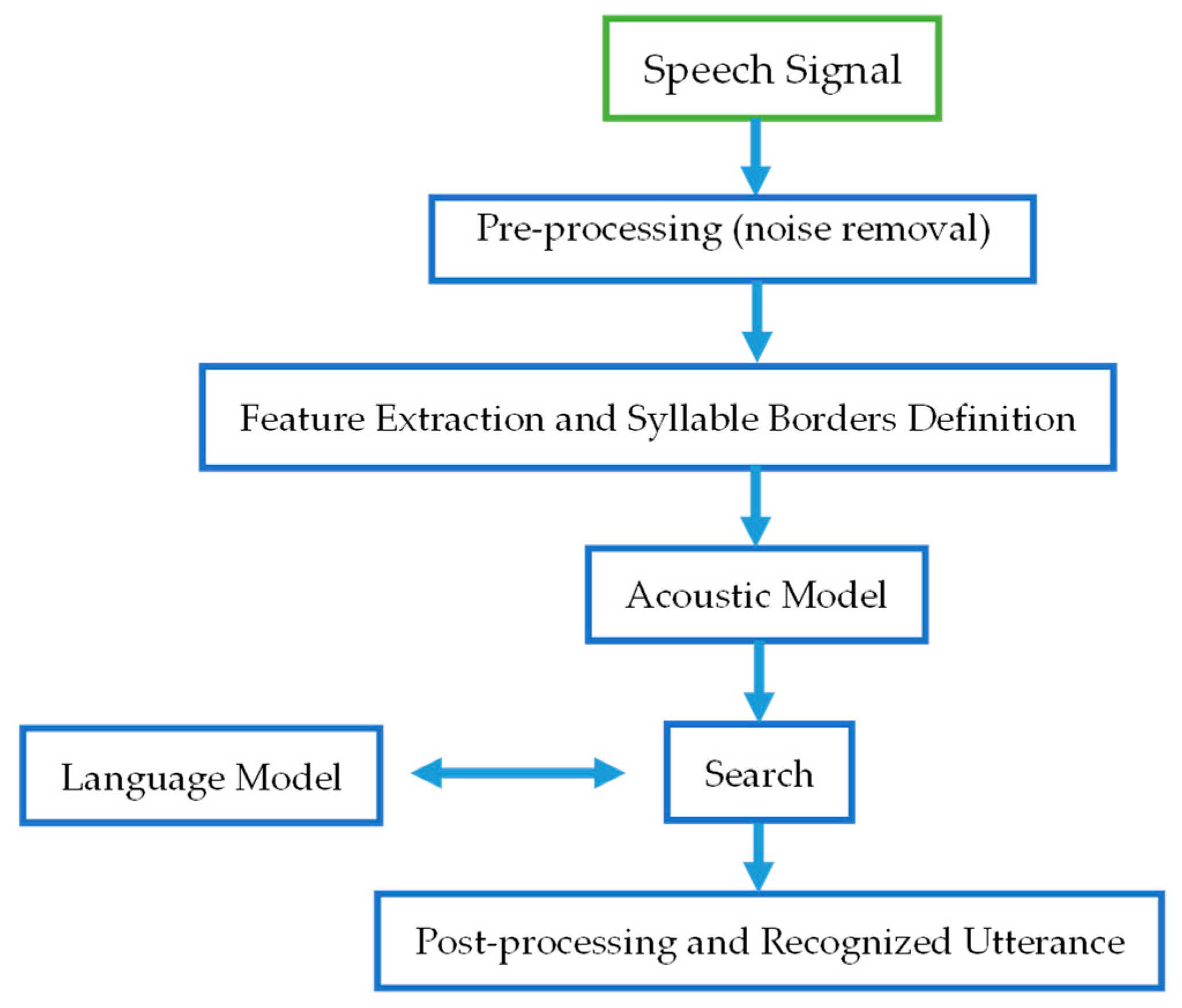
1. Introduction
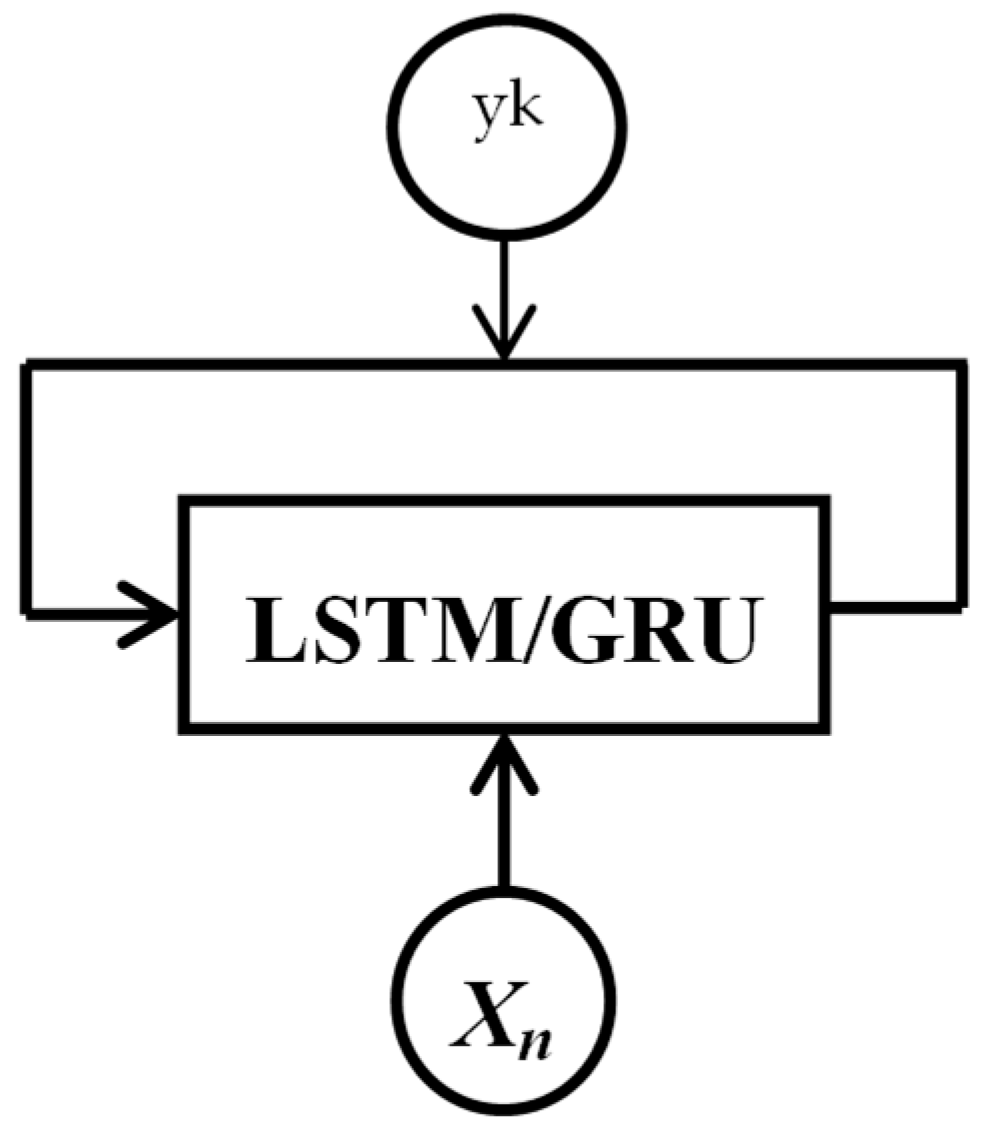
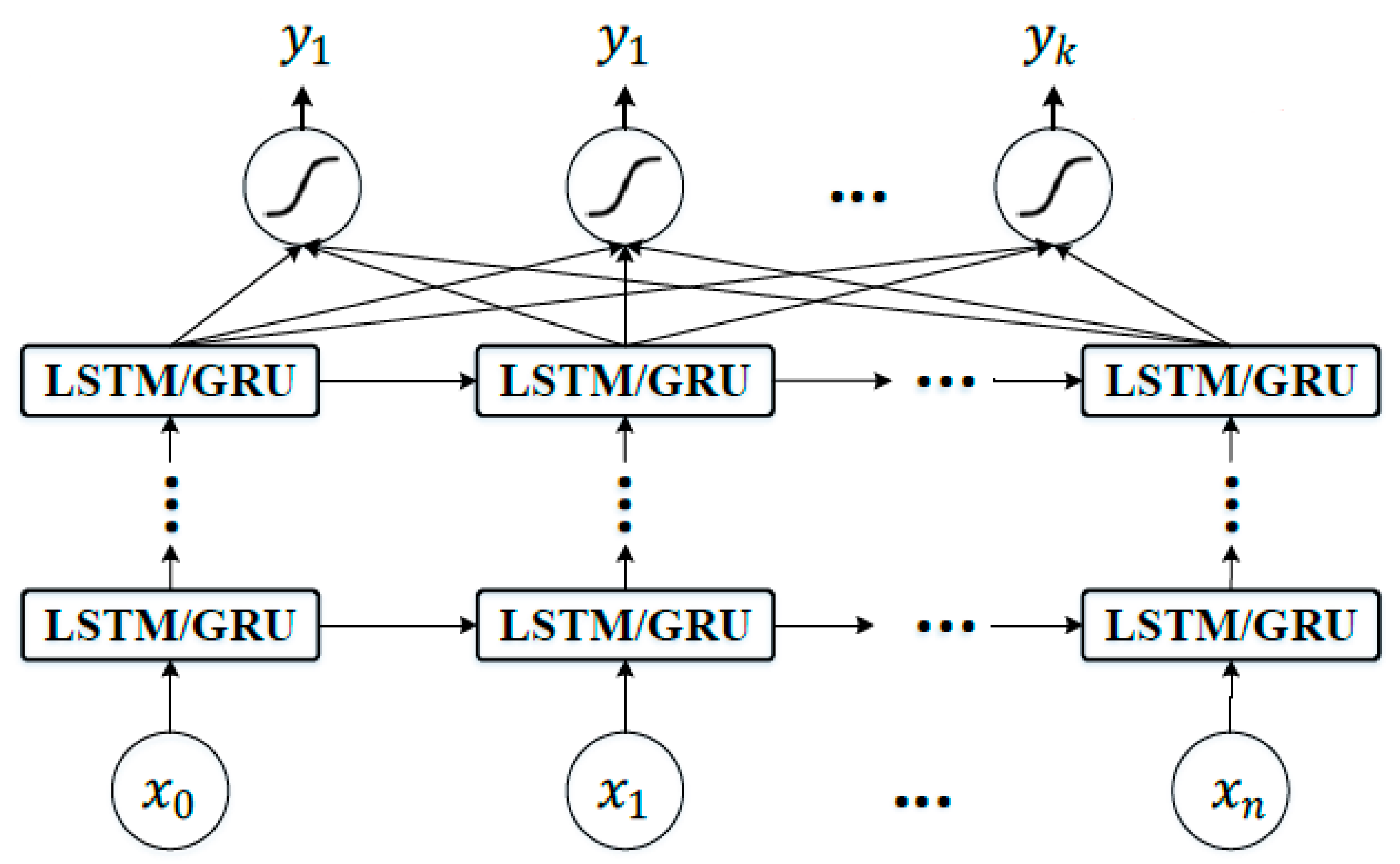
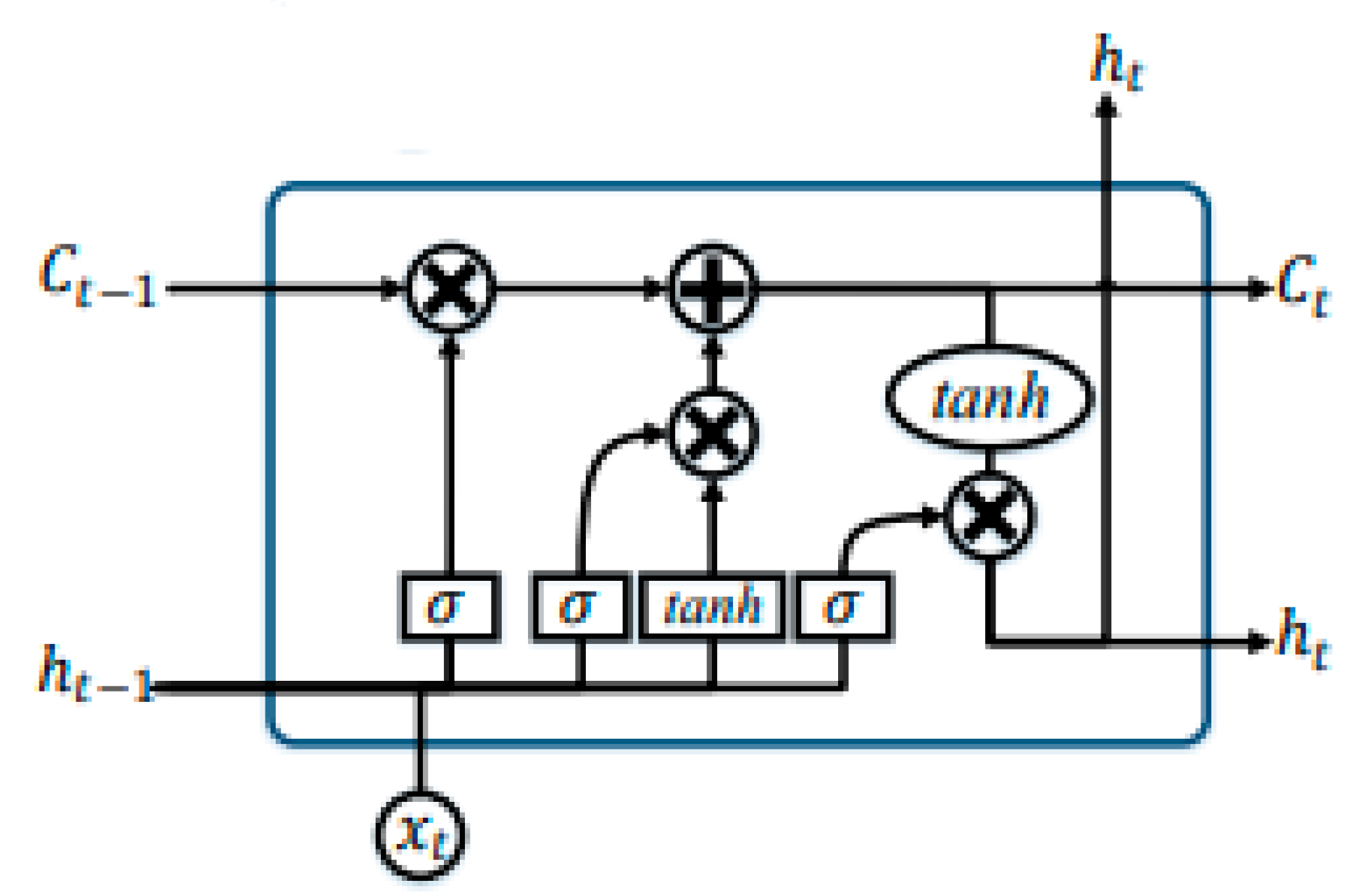
2. Recurrent Neural Networks and Long Short Term Memory
| Forget Gate Activation | (1) | |
| Input Gate: | (2) | |
| Candid Memory Cell Value: | (3) | |
| New Memory Cell Value | (4) | |
| Final Output Gate Values: | (5) | |
| Final Output Gate Values: | (6) |
3. Proposed Correction Approaches for LSTM Speech Recognition
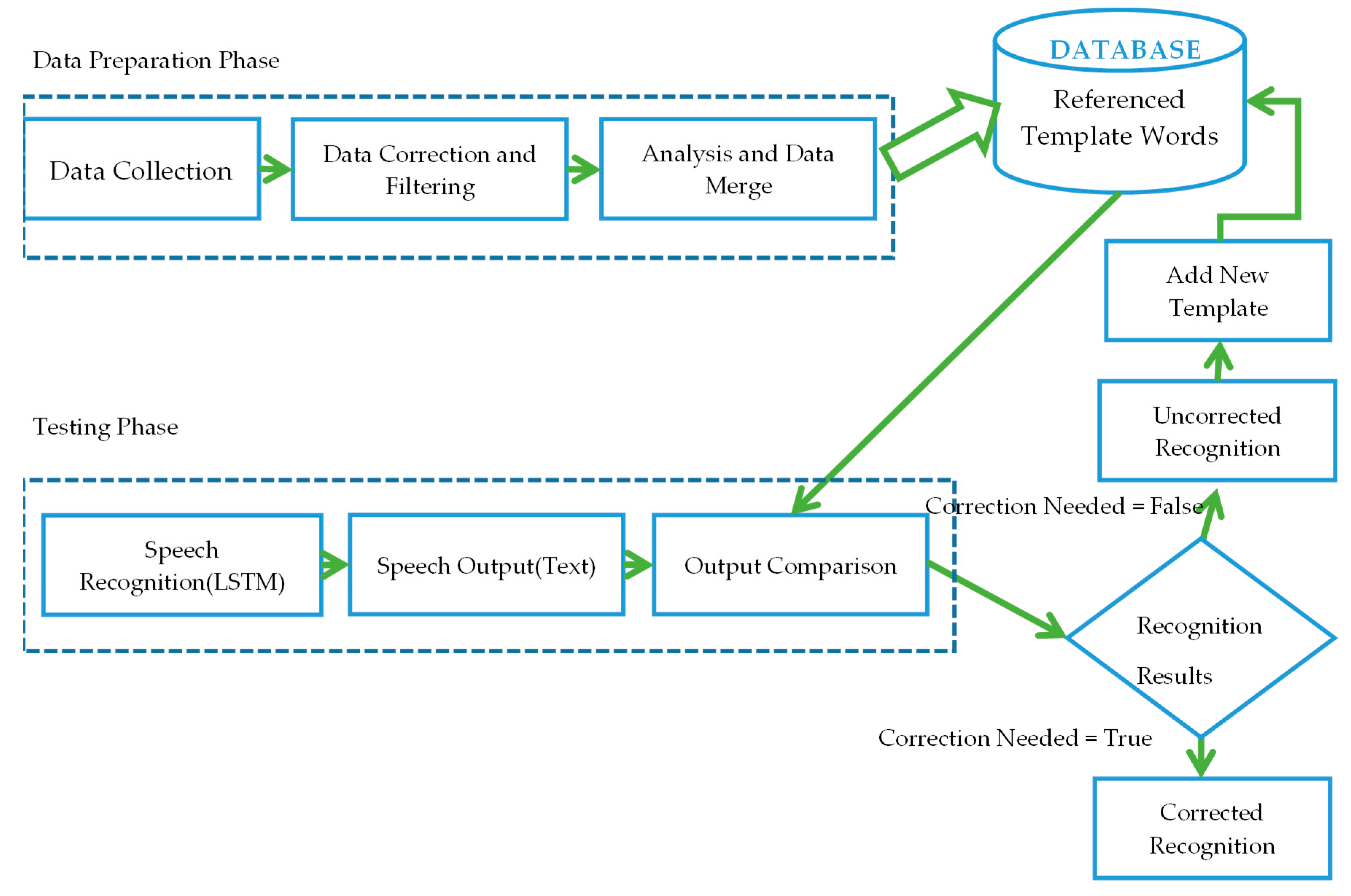
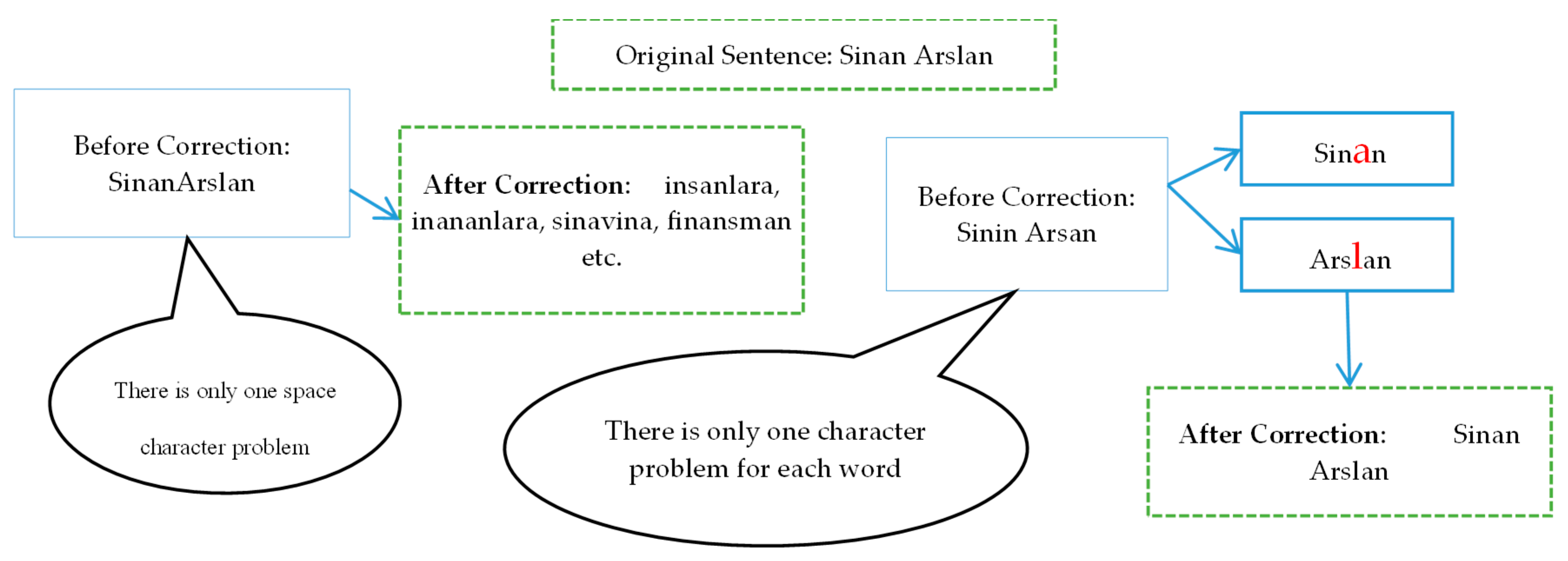
3.1. Data Preparation Phase
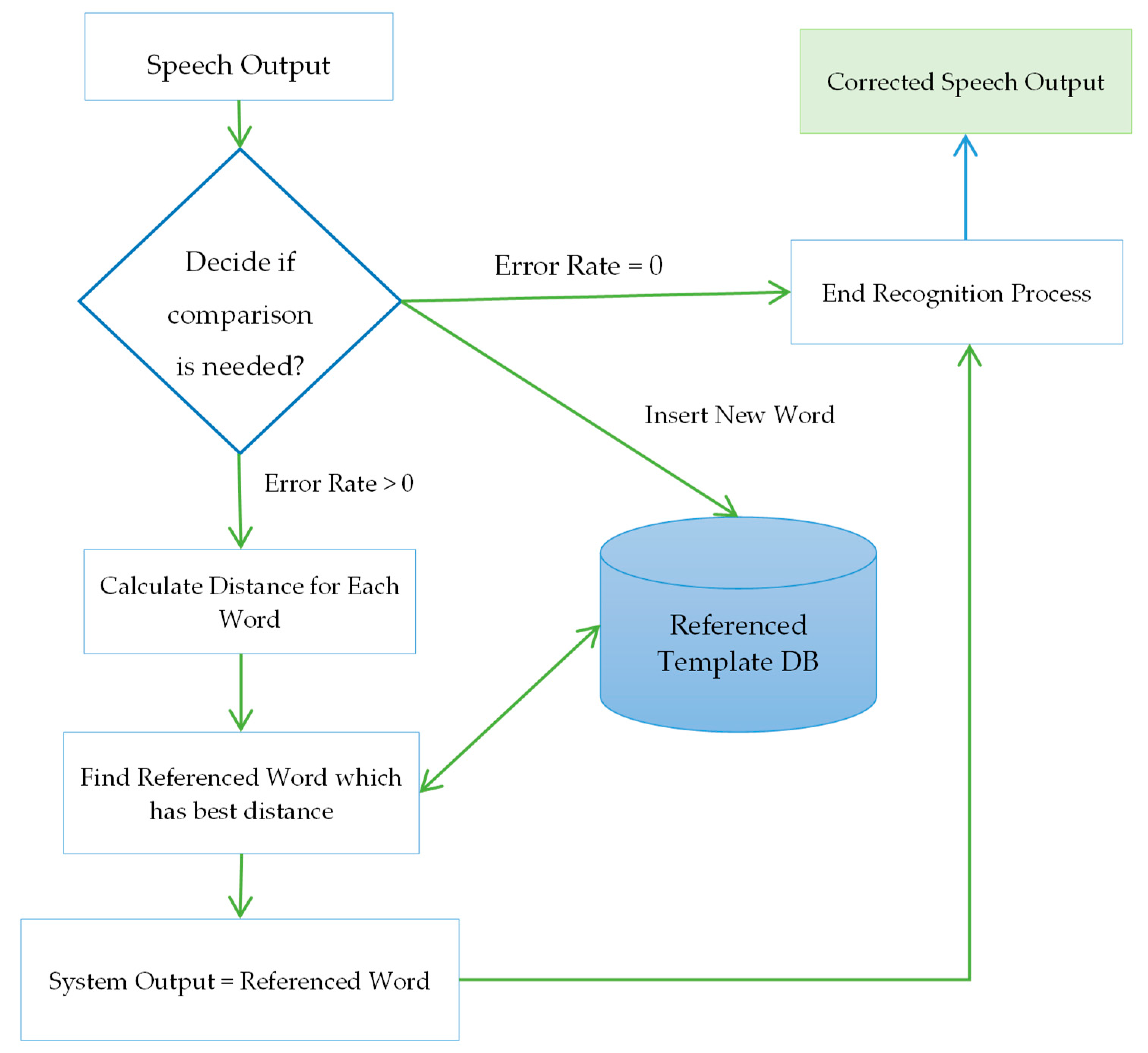
3.2. Testing Phase
3.3. Datasets, Tools and Algorithms Used For Testing Proposed Model
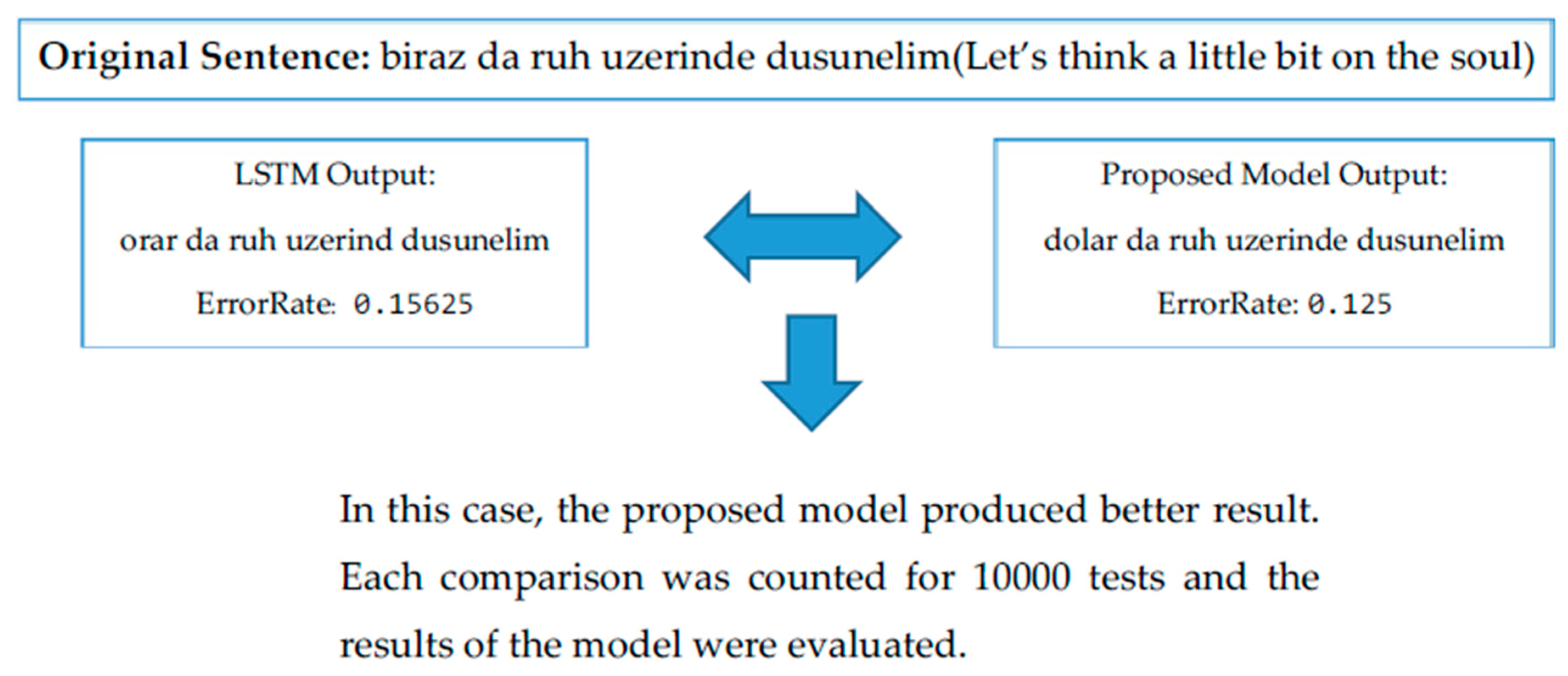
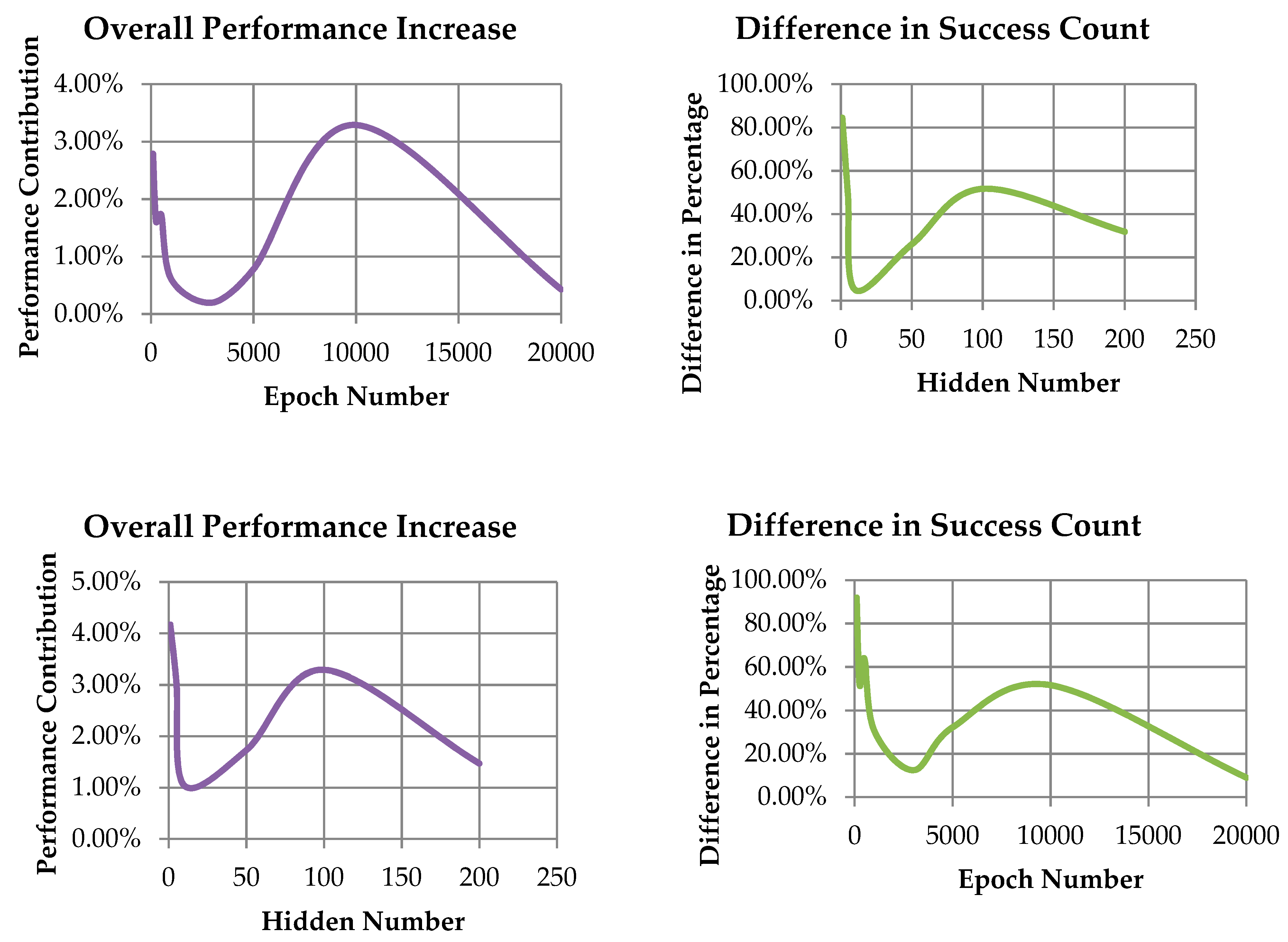
4. Experiment and Results
5. Conclusions
6. Future Works and Restriction
Author Contributions
Funding
Conflicts of Interest
References
- Tran, D.T. Fuzzy Approaches to Speech and Speaker Recognition. Ph.D. Thesis, Canberra University, Canberra, Australia, 2000. [Google Scholar]
- Uddin, M.T.; Uddiny, M.A. Human activity recognition from wearable sensors using extremely randomized trees. In Proceedings of the International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Dhaka, Bangladesh, 13–15 September 2015; pp. 1–6. [Google Scholar]
- Jalal, A. Human activity recognition using the labelled depth body parts information of depth silhouettes. In Proceedings of the 6th International Symposium on Sustainable Healthy Buildings, Seoul, Korea, 27 February 2012; pp. 1–8. [Google Scholar]
- Jalal, A.; Uddin, M.Z.; Kim, J.T.; Kim, T.-S. Daily Human Activity Recognition Using Depth Silhouettes and R Transformation for Smart Home. In International Conference on Smart Homes and Health Telematics; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6719, pp. 25–32. [Google Scholar]
- Ahad, M.A.R.; Kobashi, S.; Tavares, J.M.R. Advancements of image processing and vision in healthcare. J. Healthcare Eng. 2018, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Jalal, A.; Quaid, M.A.K.; Hasan, A.S. Wearable Sensor-Based Human Behaviour Understanding and Recognition in Daily Life for Smart Environments. In Proceedings of the International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 18–20 December 2017; pp. 1–7. [Google Scholar]
- Arora, S.J.; Singh, R.P. Automatic Speech Recognition: A Review. Int. J. Comput. Appl. 2012, 60, 34–44. [Google Scholar]
- Chen, I.K.; Chi, C.Y.; Hsu, S.L.; Chen, L.G. A real-time system for object detection and location reminding with RGB-D camera. In Proceedings of the Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–13 January 2014; pp. 1–2. [Google Scholar]
- Kamal, S.; Jalal, A.; Kim, D. Depth Images-based Human Detection, Tracking and Activity Recognition Using Spatiotemporal Features and Modified HMM. J. Electr. Eng. Technol. 2016, 11, 1857–1862. [Google Scholar] [CrossRef]
- Fonseca, L.M.G. Digital image processing in remote sensing. In Proceedings of the International Proceedings Conference on Computer Graphics and Image Processing, Rio de Janerio, Brazil, 11–14 October 2009; pp. 59–71. [Google Scholar]
- Jalal, A.; Kim, Y. Ridge body parts features for human pose estimation and recognition from RGB-D video data. In Proceedings of the 5th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014; pp. 1–6. [Google Scholar]
- Anusuya, M.A.; Katti, S.K. Speech Recognition by Machine: A Review. Int. J. Comput. Sci. Inf. Secur. 2009, 4, 181–205. [Google Scholar]
- Rathore, M.M.U.; Ahmad, A.; Paul, A.; Wu, J. Real-time continuous feature extraction in large size satellite images. J. Syst. Arch. 2016, 64, 122–132. [Google Scholar] [CrossRef]
- Farooq, A.; Jalal, A.; Kamal, S. Dense RGB-D Map-Based Human Tracking and Activity Recognition using Skin Joints Features and Self Organizing Map. KSII Trans. Int. Inf. Syst. 2015, 9, 1859–1869. [Google Scholar]
- Jalal, A.; Kim, S. Global security using human face understanding under vision ubiquitous architecture system. World Acad. Sci. Eng. Technol. 2006, 13, 7–11. [Google Scholar]
- Yoshimoto, H.; Date, N.; Yonemoto, S. Vision-based real-time motion capture system using multiple cameras. In Proceedings of the IEEE Conference on Multisensor Fusion and Integration for Intelligent Systems, Las Vegas, NV, USA, 7 October 2003; pp. 247–251. [Google Scholar]
- Kamal, S.; Jalal, A. A hybrid feature extraction approach for human detection, tracking and activity recognition using depth sensors. Arab. J. Sci. Eng. 2016, 41, 1043–1051. [Google Scholar] [CrossRef]
- Lam, M.W.; Chen, X.; Hu, S.; Yu, J.; Liu, X.; Meng, H. Gaussian process LSTM recurrent neural network language models for speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 7235–7239. [Google Scholar]
- Afouras, T. Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 12, 1–13. [Google Scholar] [CrossRef]
- Kowsari, K.; Heidarysafa, M.; Brown, D.E.; Meimandi, K.J.; Barnes, L.E. Rmdl: Random multi model deep learning for classification. In Proceedings of the 2nd International Conference on Information System and Data Mining, Lakeland, FL, USA, 9–11 April 2018; pp. 19–28. [Google Scholar]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications(ICMLA), Cancun, Mexico, 18–21 December 2017; Available online: https://arxiv.org/abs/1709.08267 (accessed on 1 February 2019).
- Kowsari, K. Text classification algorithms: A survey. Information 2019, 10, 1–68. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 98, 1735–1780. [Google Scholar] [CrossRef]
- Kaisheng, Y. ; Deep-Gated Recurrent Neural Networks. arXiv 2015, arXiv:1508.03790. [Google Scholar]
- Koutnik, J.; Greff, K.; Gomez, F.; Schmidhuber, J. A Clockwork RNN. arXiv 2014, arXiv:1402.3511. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An Empirical Exploration of Recurrent Network Architectures. Int. Conf. Mach. Learn. 2015, 37, 2342–2350. [Google Scholar]
- Gers, F.A.; Schmidhuber, J. Recurrent Nets that Time and Count. In Proceedings of the IEEE-INNS-ENNS International Joint Conference, Como, Italy, 24–27 July 2000; pp. 1–6. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Irie, K.; Tüske, Z.; Alkhouli, T.; Schlüter, R.; Ney, H. LSTM, GRU, Highway and a Bit of Attention: An Empirical Overview for Language Modelling in Speech Recognition. Interspeech 2016, 9, 3519–3523. [Google Scholar]
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the International Conference on Industrial Electronics and Applications, Melborne, Australia, 19–21 June 2013; pp. 1–6. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D. A Depth Video Sensor-Based Life-Logging Human Activity Recognition System for Elderly Care in Smart Indoor Environments. Sensors 2014, 14, 11735–11759. [Google Scholar] [CrossRef] [PubMed]
- Jalal, A.; Kim, Y.-H.; Kim, Y.-J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. Individual detection-tracking-recognition using depth activity images. In Proceedings of the 12th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Goyang City, Korea, 28–30 October 2015; pp. 450–455. [Google Scholar]
- Wu, H.; Pan, W.; Xiong, X.; Xu, S. Human activity recognition based on the combined SVM&HMM. In Proceedings of the IEEE International Conference on Information and Automation (ICIA), Hailar, China, 28–30 July 2014; pp. 219–224. [Google Scholar]
- Salor, Ö.; Pellom, B.; Çiloğlu, T.; Hacıoğlu, K.; Demirekler, M. On Developing New Text and Audio Corpora and Speech Recognition Tools for the Turkish Language. In Proceedings of the International Conference on Spoken Language Processing (ICSLP), Denver, CO, USA, 16–20 September 2002; pp. 1–5. [Google Scholar]
- Salor, Ö.; Pellom, B.L.; Ciloglu, T.; Demirekler, M. Turkish speech corpora and recognition tools developed by porting SONIC: Towards multilingual speech recognition. Comput. Speech Lang. 2007, 21, 580–593. [Google Scholar] [CrossRef]
- Garofolo, J.S.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L. DARPA TIMIT: Acoustic-Phonetic Continuous Speech Corpus CD-ROM; NIST: Gaithersburg, Maryland, USA, speech disc 1-1.1; 1993. [Google Scholar]
- Liberman, M.; Cieri, C. The creation, distribution and use of linguistic data. In Proceedings of the First International Conference on Language Resources and Evaluation. European Language Resources Association, Granada, Spain, 28–30 May 1998; Available online: https://catalog.ldc.upenn.edu/ (accessed on 1 January 2017).
- Akın, A.A.; Akın, M.D. Zemberek, an open source nlp framework for Turkic languages. Structure 2007, 10, 1–5. [Google Scholar]
- Sak, H.; Güngör, T.; Saraçlar, M. Turkish language resources: Morphological parser, morphological disambiguator and web corpus. In Advances in Natural Language Processing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 417–427. [Google Scholar]
- Koopmann, J. Database Journal–The Knowledge Center for Database Professionals; 2003. Available online: https://www.postgresql.org/ (accessed on 1 January 2015).
- Van Rossum, G. Python; Corporation for National Research Initiatives(CNRI): Reston, VA, USA, 1995; Available online: https://www.python.org/ (accessed on 5 January 2015).
- McKerns, M.M.; Strand, L.; Sullivan, T.; Fang, A.; Aivazis, M.A. Building a framework for predictive science. In Proceedings of the 10th Python in Science Conference, Austin, TX, USA, 11–16 July 2011; Available online: https://pypi.org/project/dill (accessed on 10 January 2015).
- McKerns, M.M.; Aivazis, M. Pathos: A Framework for Heterogeneous Computing. 2010. Available online: https://librosa.github.io/librosa/ (accessed on 15 January 2015).
- Hettinger, R. Namedtuple Factory Function for Tuples with Named Fields. Available online: https://docs.python.org/2/library/collections.html (accessed on 17 January 2015).
- Olpihant, T.E. Guide to Numpy. Ph.D. Thesis, MIT University, Cambridge, MA, USA, 2006. Available online: https://www.numpy.org/ (accessed on 15 February 2017).
- Lyons, J. Python Speech Features. 2013. Available online: https://python-speech-features.readthedocs.io/en/latest/ (accessed on 15 February 2017).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; Available online: https://www.tensorflow.org/install/pip (accessed on 20 February 2017).
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1996, 10, 707–710. [Google Scholar]
- Damerau, F.J. A technique for computer detection and correction of spelling errors. Commun. ACM 1964, 7, 171–176. [Google Scholar] [CrossRef]
- Jaro, M.A. Advances in record linkage methodology as applied to the 1985 census of Tampa Florida. J. Stat. Assoc. 1989, 84, 414–420. [Google Scholar] [CrossRef]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. In Proceedings of the Section on Survey Research Methods. American Statistical Association, Washington, DC, USA, 1990, 10 January 1990; pp. 354–359. [Google Scholar]
- Aldous, D.; Diaconis, P. Longest increasing subsequences: from patience sorting to the Baik–Deift–Johansson theorem. Bull. Am. Math. Soc. 1999, 36, 413–432. [Google Scholar] [CrossRef]
- Singhal, A. Modern Information Retrieval: A Brief Overview. Bull. IEEE Comput. Soc. Tech. Comm. Data Eng. 2001, 24, 35–43. [Google Scholar]
- Lu, J.; Lin, C.; Wang, W.; Li, C.; Wang, H. String similarity measures and joins with synonyms. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 373–384. [Google Scholar]
- Siderite Zackwehdex. Super Fast and Accurate String Distance Algorithm: Sift4. Available online: https://siderite.blogspot.com/2014/11/super-fast-and-accurate-string-distance.html (accessed on 11 November 2017).
- Keser, S.; Edizkan, R. Phonem-Based Isolated Turkish Word Recognition with Subspace Classifier. In Proceedings of the IEEE Signal Processing and Communications Applications Conference (SIU), Antalya, Turkey, 9–11 April 2009; pp. 93–96. [Google Scholar]
- Aksoylar, C.; Mutluergil, S.O.; Erdogan, H. The Anatomy of a Turkish Speech Recognition System. In Proceedings of the IEEE Signal Processing and Communications Applications Conference (SIU), Antalya, Turkey, 9–11 April 2009; pp. 512–515. [Google Scholar]
- Çiloğlu, T.; Çömez, M.; Şahin, S. Language Modelling for Turkish as a Agglutinative Languages. In Proceedings of the IEEE Signal Processing and Communications Applications Conference (SIU), Kuşadası, Turkey, 28–30 April 2004; pp. 1–2. [Google Scholar]
- Büyük, O.; Erdoğan, H.; Oflazer, K. Using Hybrid Lexicon Units and Incorporating Language Constraints in Speech Recognition. In Proceedings of the IEEE Signal Processing and Communications Applications Conference, Kayseri, Turkey, 16–18 May 2005; pp. 111–114. [Google Scholar]
- Jalal, A.; Quaid, M.A.; Sidduqi, M.A. A Triaxial Acceleration-based Human Motion Detection for Ambient Smart Home System. Int. Conf. Appl. Sci. Technol. 2019, 7, 1–6. [Google Scholar]
- Ahmad, J. Robust spatio-temporal features for human interaction recognition via artificial neural network. In Proceedings of the IEEE Conference on International Conference on Frontiers of Information Technology, Islamabad, Pakistan, 18–20 December 2018. [Google Scholar]
- Jalal, A.; Uddin, M.Z.; Kim, J.T.; Kim, T.S. Recognition of Human Home Activities via Depth Silhouettes and R Transformation for Smart Homes. Indoor Built Environ. 2012, 21, 184–190. [Google Scholar] [CrossRef]
- Jalal, A.; Rasheed, Y.A. Collaboration achievement along with performance maintenance in video streaming. In Proceedings of the IEEE Conference on Interactive Computer Aided Learning, Villach, Austria, 26–28 September 2007; pp. 1–8. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distance Algorithm | Error Rate Before Correction | Error Rate After Correction | Count of Better Performance(Not Corrected- Corrected) | Difference in Success Count (%) | Overall Performance Increase (%) |
|---|---|---|---|---|---|
| NormalizedLevenstain | 0.3062 | 0.2730 | 2390-7610 | 52.20% | 3.32% |
| DamerauLevenstein | 14.8955 | 14.8143 | 3831-6169 | 23.38% | 0.54% |
| JaroWinkler | 0.2315 | 0.2093 | 3499-6501 | 30.02% | 2.22% |
| LongestCommonSubsequence | 17.7432 | 17.1749 | 3476-6524 | 30.48% | 3.20% |
| MetricLCS | 0.2835 | 0.2558 | 2289-7711 | 54.22% | 2.76% |
| OptimalStringAlignment | 14.9061 | 14.8344 | 3831-6169 | 23.38% | 0.46% |
| PrecomputedCosine | 0.2860 | 0.2798 | 4397-5703 | 13.06% | 0.6% |
| Qgram | 27.5372 | 26.4720 | 3879-6121 | 22.42% | 3.84% |
| Levensthein | 14.9278 | 14.8536 | 3851-6149 | 22.98% | 0.49% |
| Sift4 | 19.8155 | 19.8039 | 4402-5598 | 11.96% | 0.58% |
| WeightedLevensthein | 14.9278 | 14.8536 | 3851-6149 | 22.98% | 0.43% |
| Test Set | Optimization Algorithm | Learning Rate | Standard Deviation | Epoch Number | Batch Size | NOE | Mean |
|---|---|---|---|---|---|---|---|
| Set 1-10 | GradientDescent | 0.01 | 0.1 | 10000 | 1 | 1 | 0 |
| Test Set | Error Rate Before Correction | Error Rate After Correction | Count of Better Performance(Not Corrected-Corrected) | Difference in Success Count (%) | Overall Performance Increase (%) |
|---|---|---|---|---|---|
| NL-Test Set1 | 0.3062 | 0.2734 | 2417-7583 | 51.66% | 3.28% |
| NL-Test Set2 | 0.2717 | 0.2572 | 3504-6496 | 29.92% | 1.45% |
| NL-Test Set3 | 0.1934 | 0.1677 | 1810-8190 | 63.80% | 2.57% |
| NL-Test Set4 | 0.2516 | 0.2321 | 2713-7287 | 45.74% | 2.04% |
| NL-Test Set5 | 0.3758 | 0.3602 | 3166-6834 | 36.68% | 1.56% |
| NL-Test Set6 | 0.3074 | 0.2719 | 3040-6960 | 39.20% | 3.55% |
| NL-Test Set7 | 0.0934 | 0.0789 | 2557-7443 | 48.86% | 1.45% |
| NL-Test Set8 | 0.3149 | 0.3007 | 4138-5862 | 17.24% | 1.42% |
| NL-Test Set9 | 0.4265 | 0.4097 | 3883-6117 | 22.34% | 1.68% |
| NL-Test Set10 | 0.1461 | 0.1307 | 2463-7537 | 50.96% | 1.54% |
| Name of Authors | Recognition Approach | Vocabulary | Error Rate |
|---|---|---|---|
| Keser and Edizkan [58] | Common Vector Approach(CVA) | METU 1.0 Dataset | 70 % |
| Aksoylar et al. [59] | HMM | METU 1.0 Dataset, SUVoice | Sports News: 37 % |
| Salor et al. [37] | HMM | METU 1.0 Dataset | 29.2% |
| Çiloğlu et al. [60] | HMM, N-gram | METU 1.0 Dataset | 35.91% |
| Büyük et al. [61] | HMM | METU 1.0 Dataset-2151 Test Data | 3% increase performance |
| Proposed Model | LSTM | METU 1.0 Dataset | 24.82% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arslan, R.S.; Barışçı, N. Development of Output Correction Methodology for Long Short Term Memory-Based Speech Recognition. Sustainability 2019, 11, 4250. https://doi.org/10.3390/su11154250
Arslan RS, Barışçı N. Development of Output Correction Methodology for Long Short Term Memory-Based Speech Recognition. Sustainability. 2019; 11(15):4250. https://doi.org/10.3390/su11154250
Chicago/Turabian StyleArslan, Recep Sinan, and Necaattin Barışçı. 2019. "Development of Output Correction Methodology for Long Short Term Memory-Based Speech Recognition" Sustainability 11, no. 15: 4250. https://doi.org/10.3390/su11154250
APA StyleArslan, R. S., & Barışçı, N. (2019). Development of Output Correction Methodology for Long Short Term Memory-Based Speech Recognition. Sustainability, 11(15), 4250. https://doi.org/10.3390/su11154250