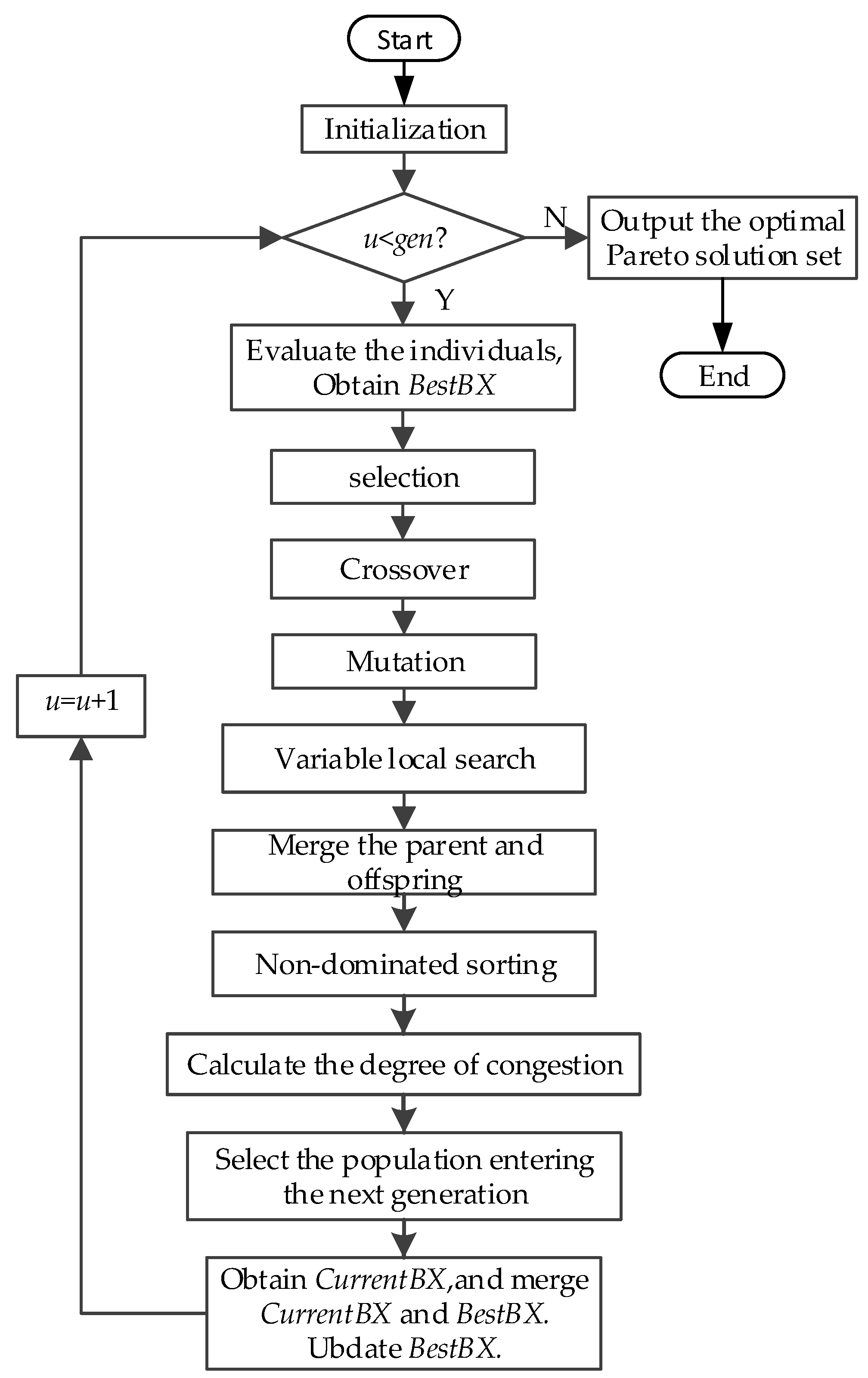
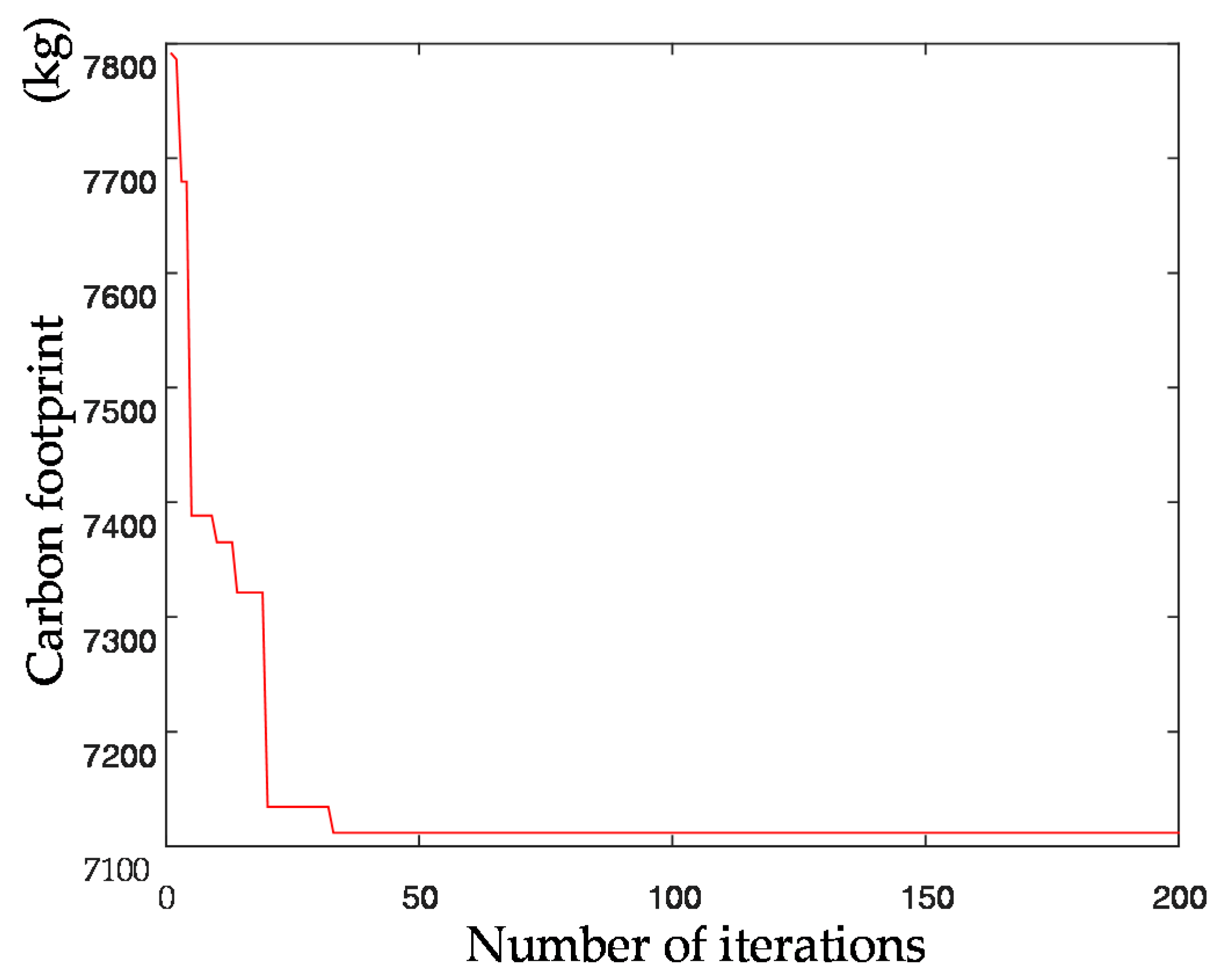
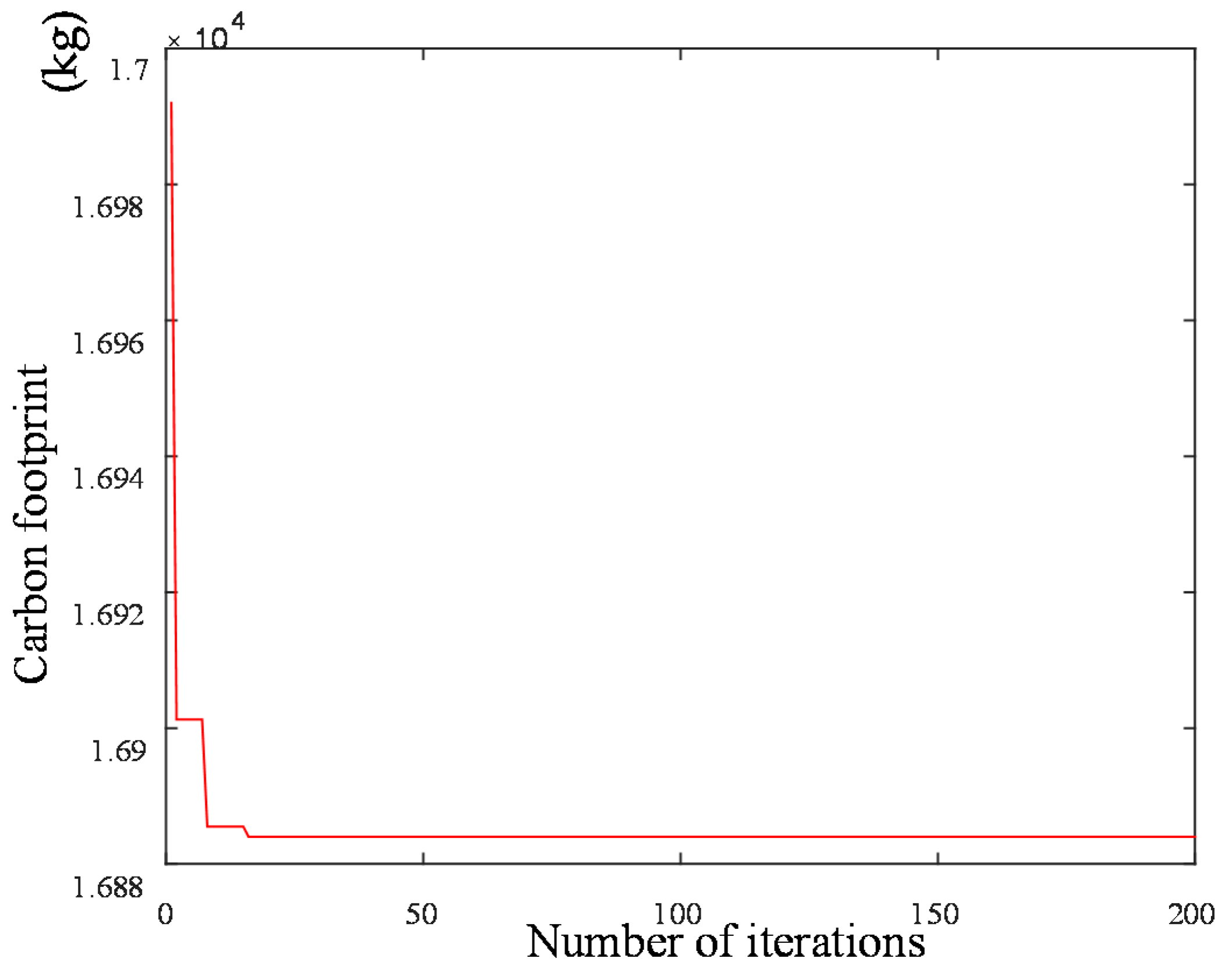
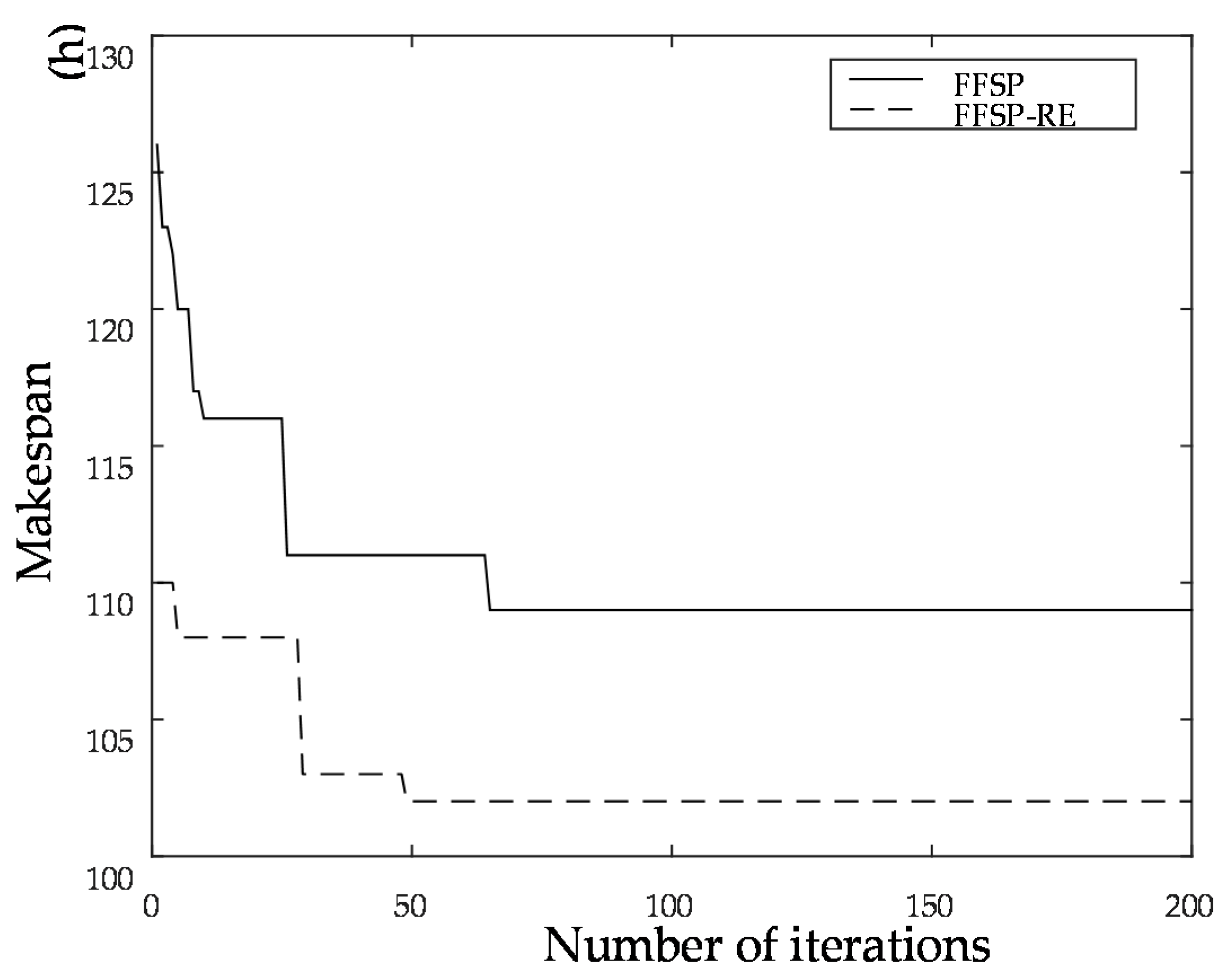
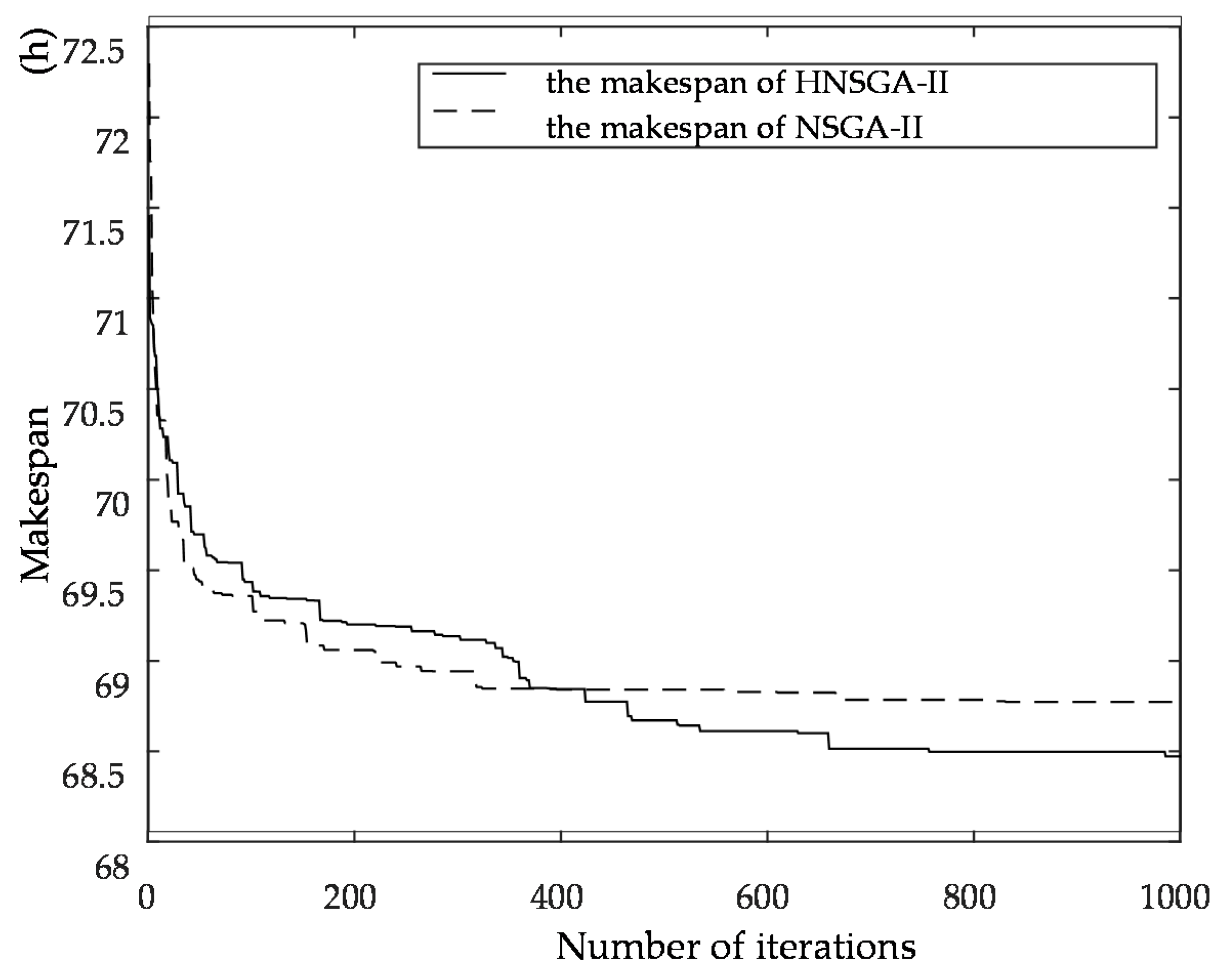
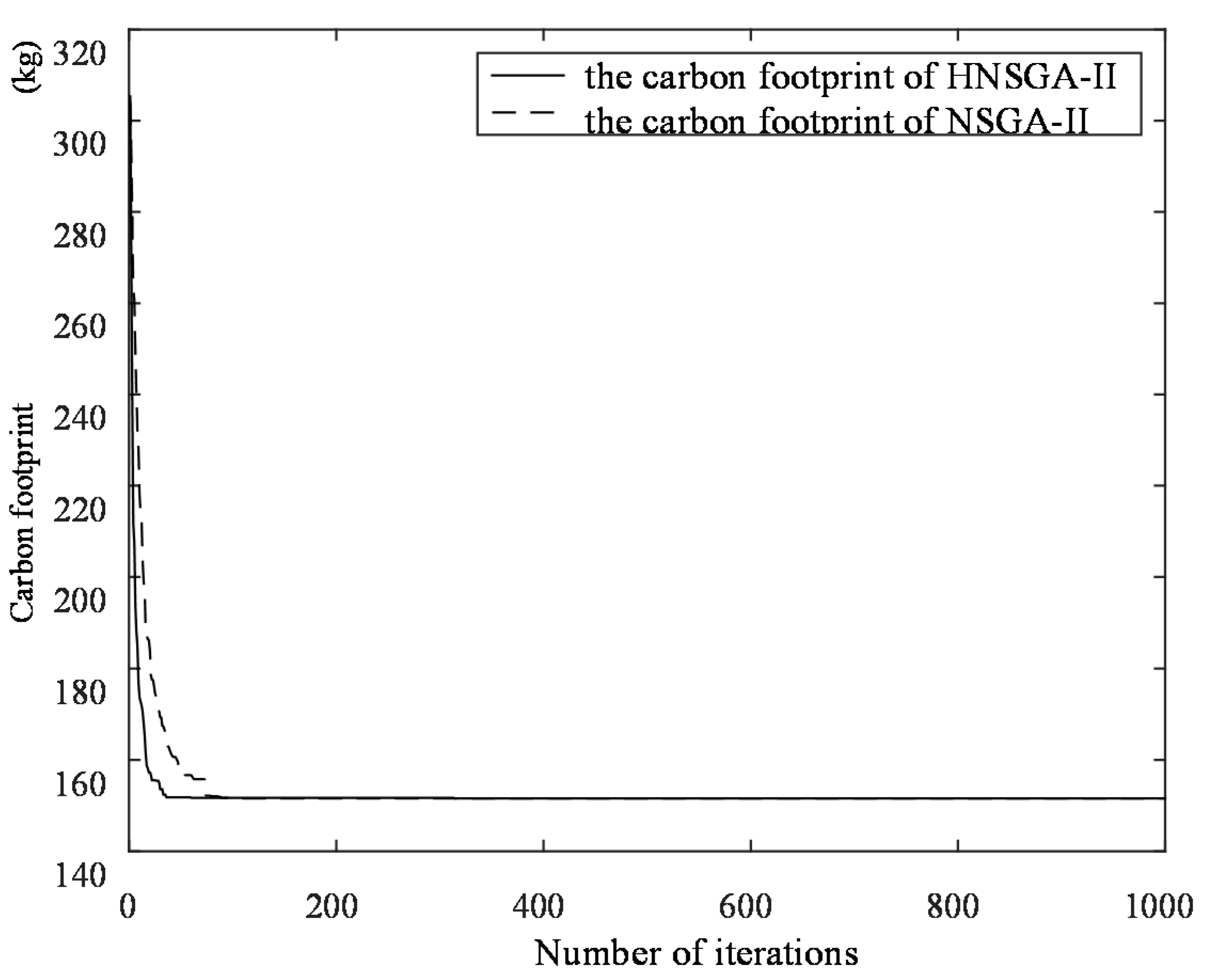
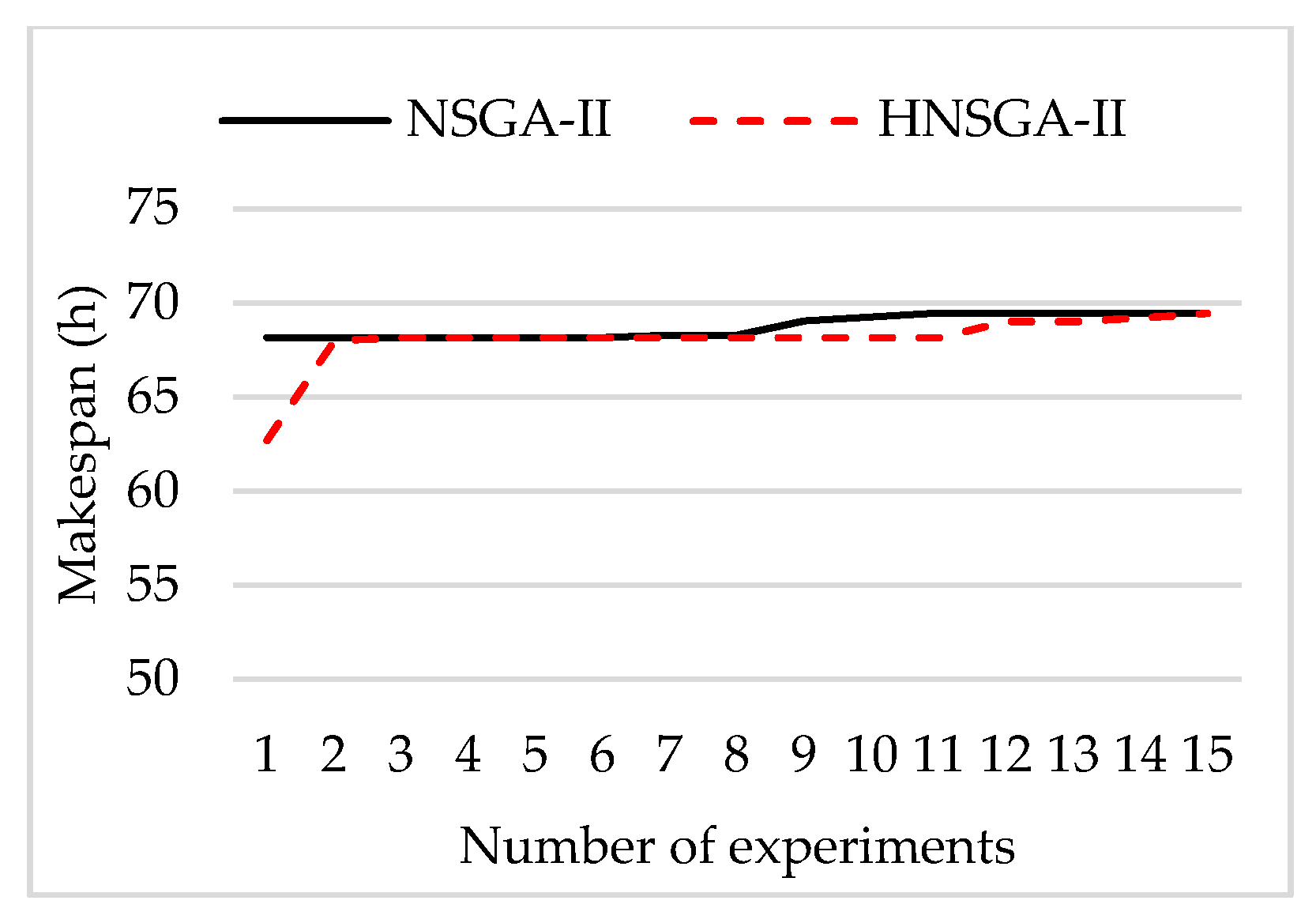
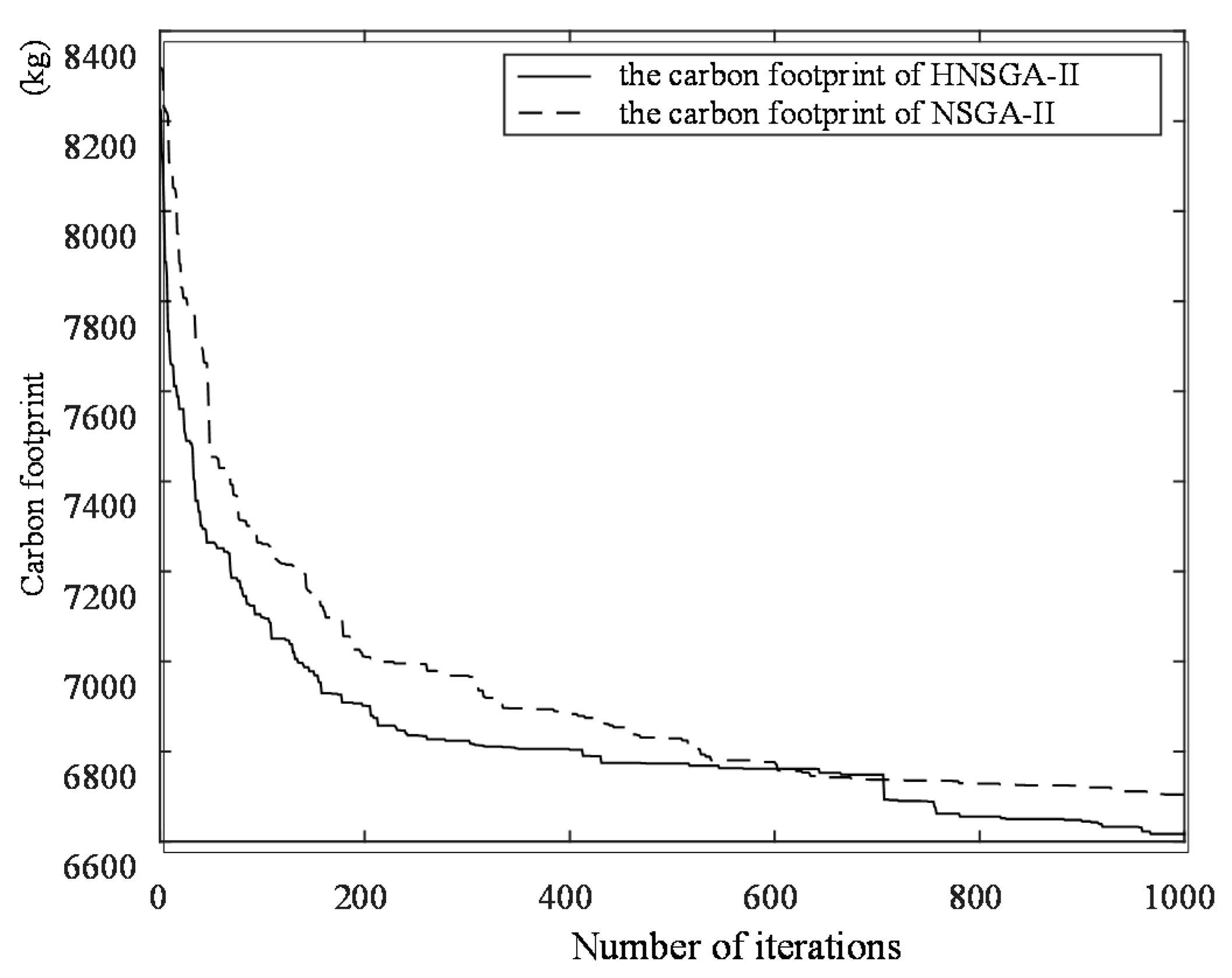
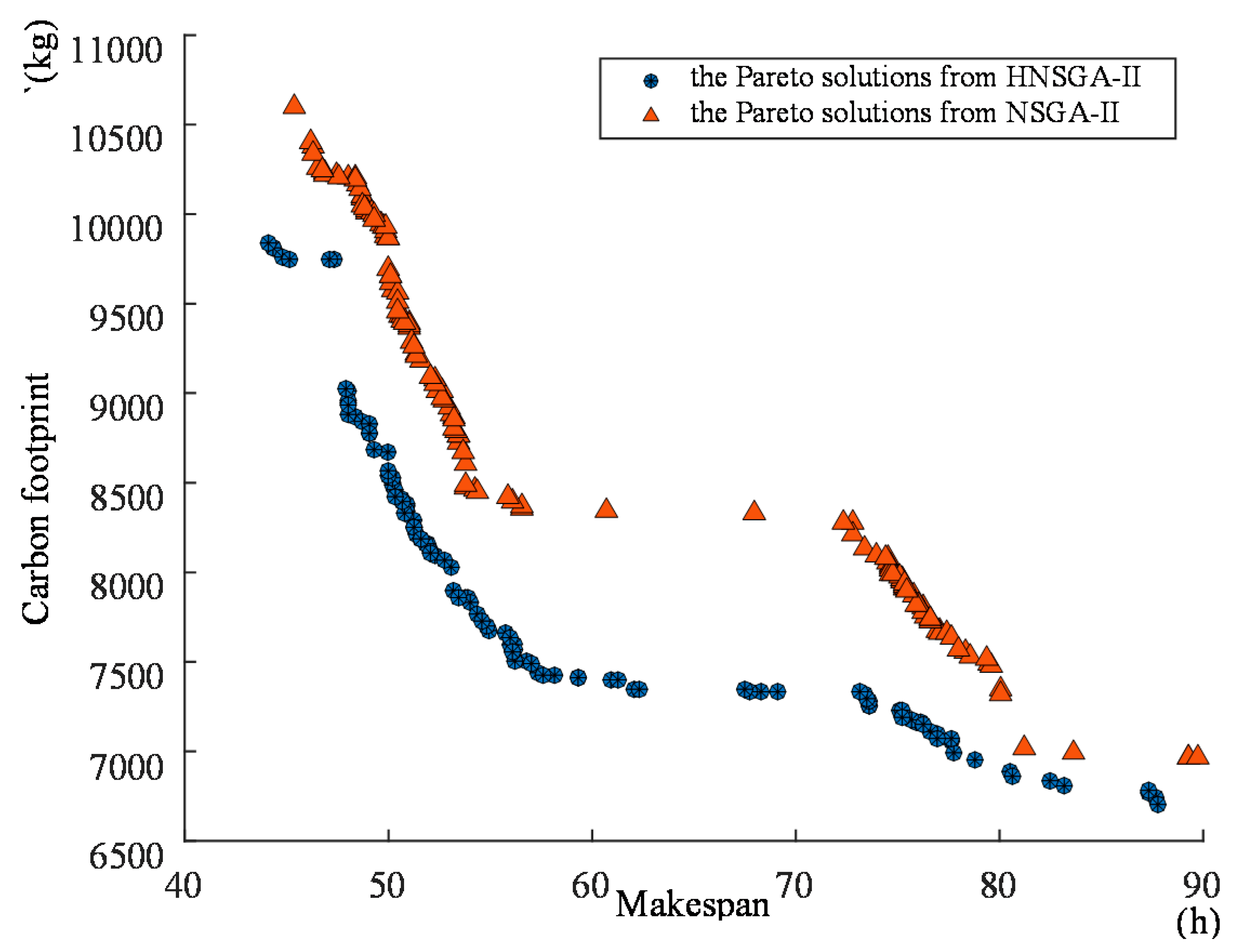
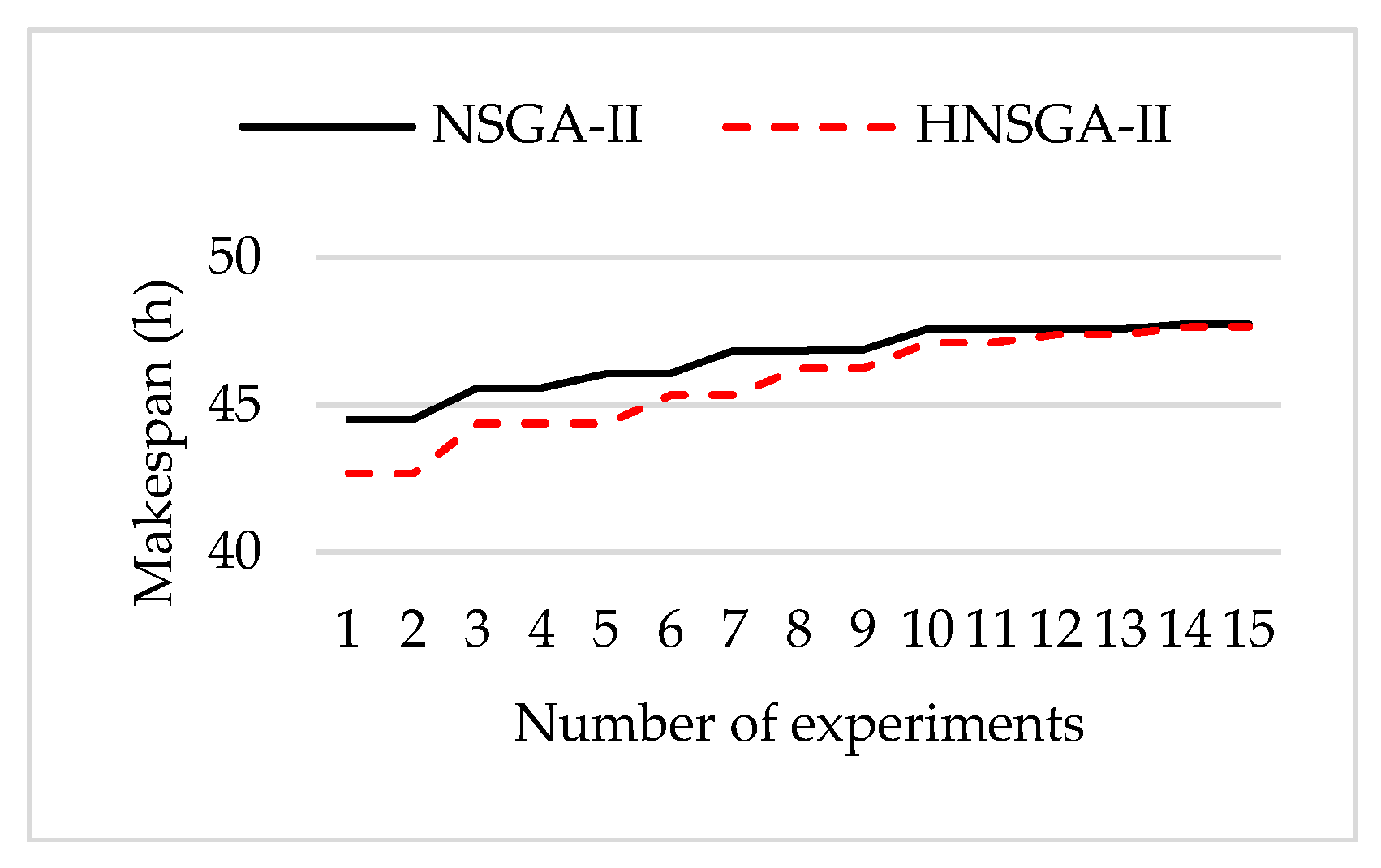
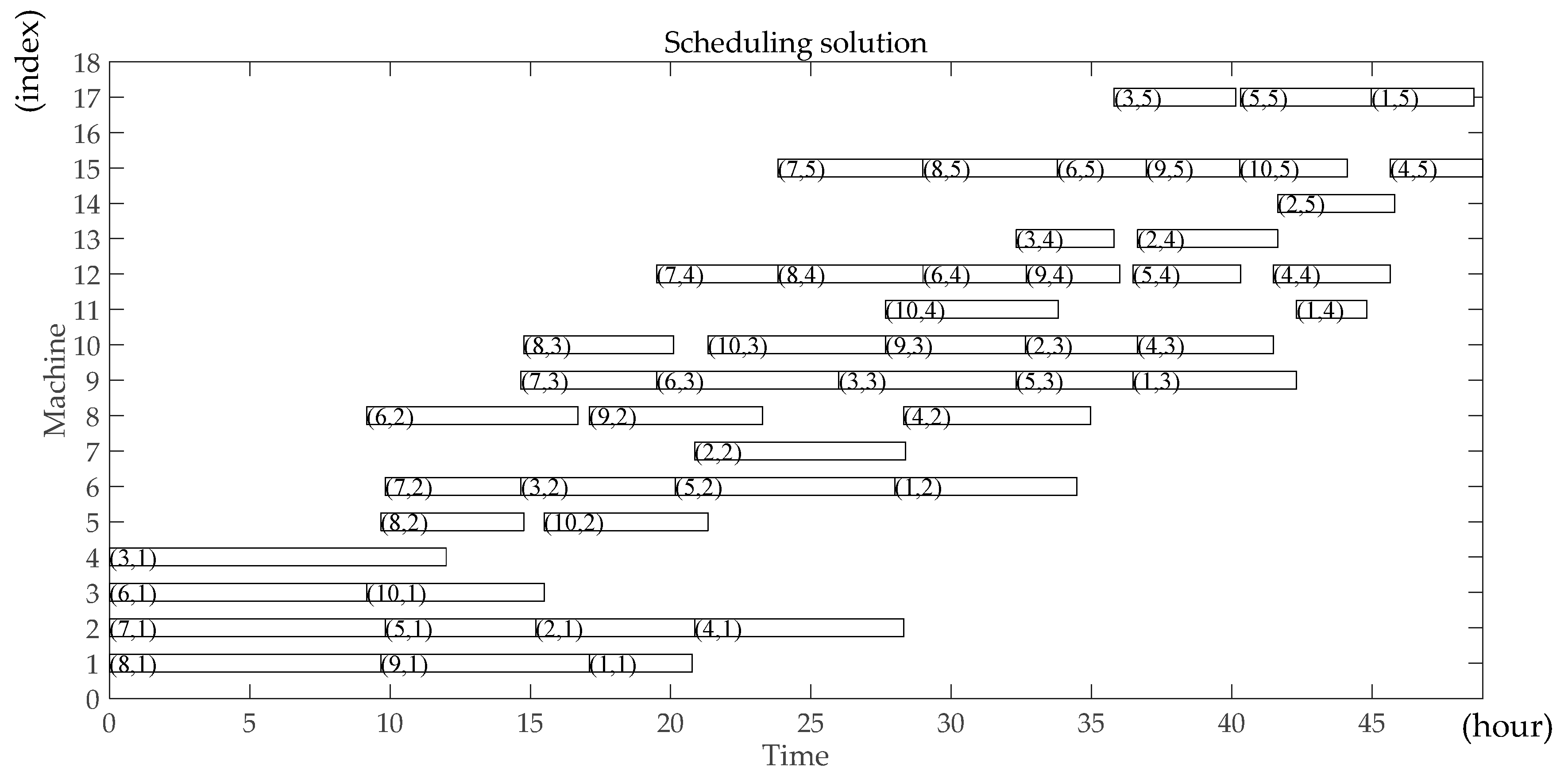
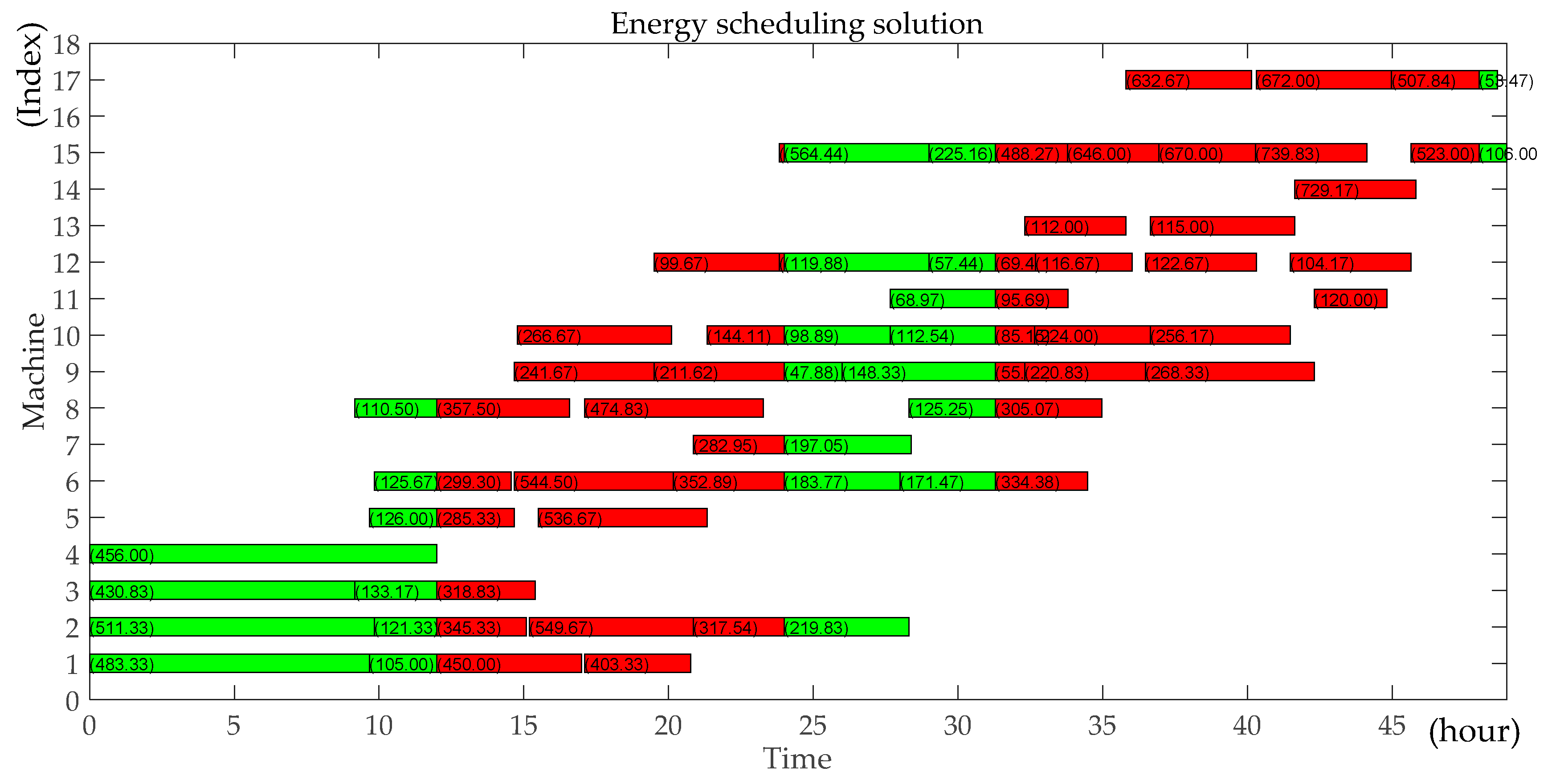
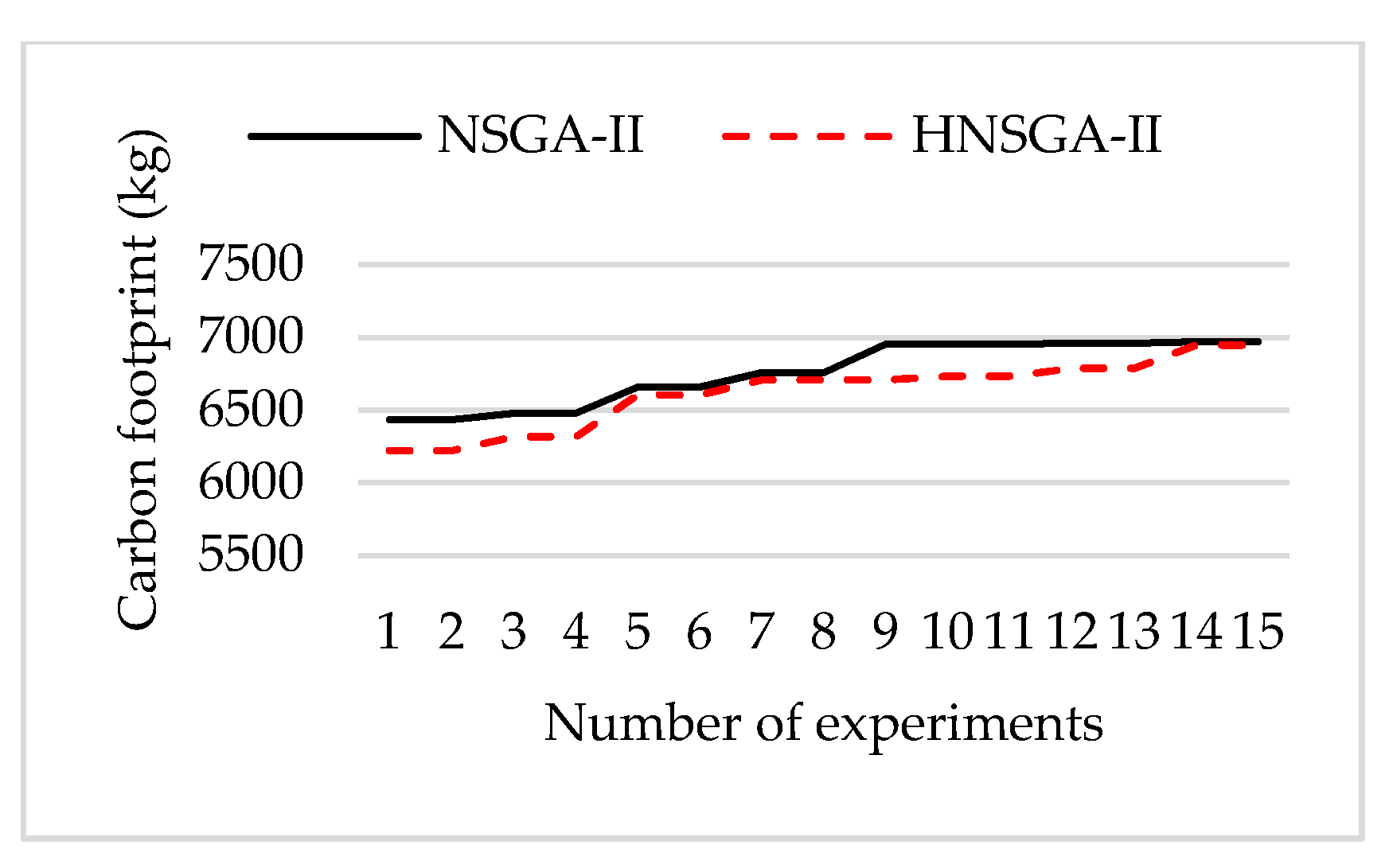The genetic algorithm is an intelligent optimization algorithm based on natural evolution and selection, which has been widely used in many fields such as combinatorial optimization, machine learning, signal processing, adaptive control and artificial life. The genetic algorithm has the advantages of strong global search ability, fast speed and easy implementation, but it is easy to premature convergence. Combining local search with the genetic algorithm can improve the optimization ability of the genetic algorithm. A novel hybrid NSGA-II algorithm with variable local search is proposed, which integrates the advantages of a variable local search and NSGA-II. The variable local search is based on the various neighborhood structures.
4.2. The Details of the HNSGA-II
4.2.1. Encoding and the Population Initialization
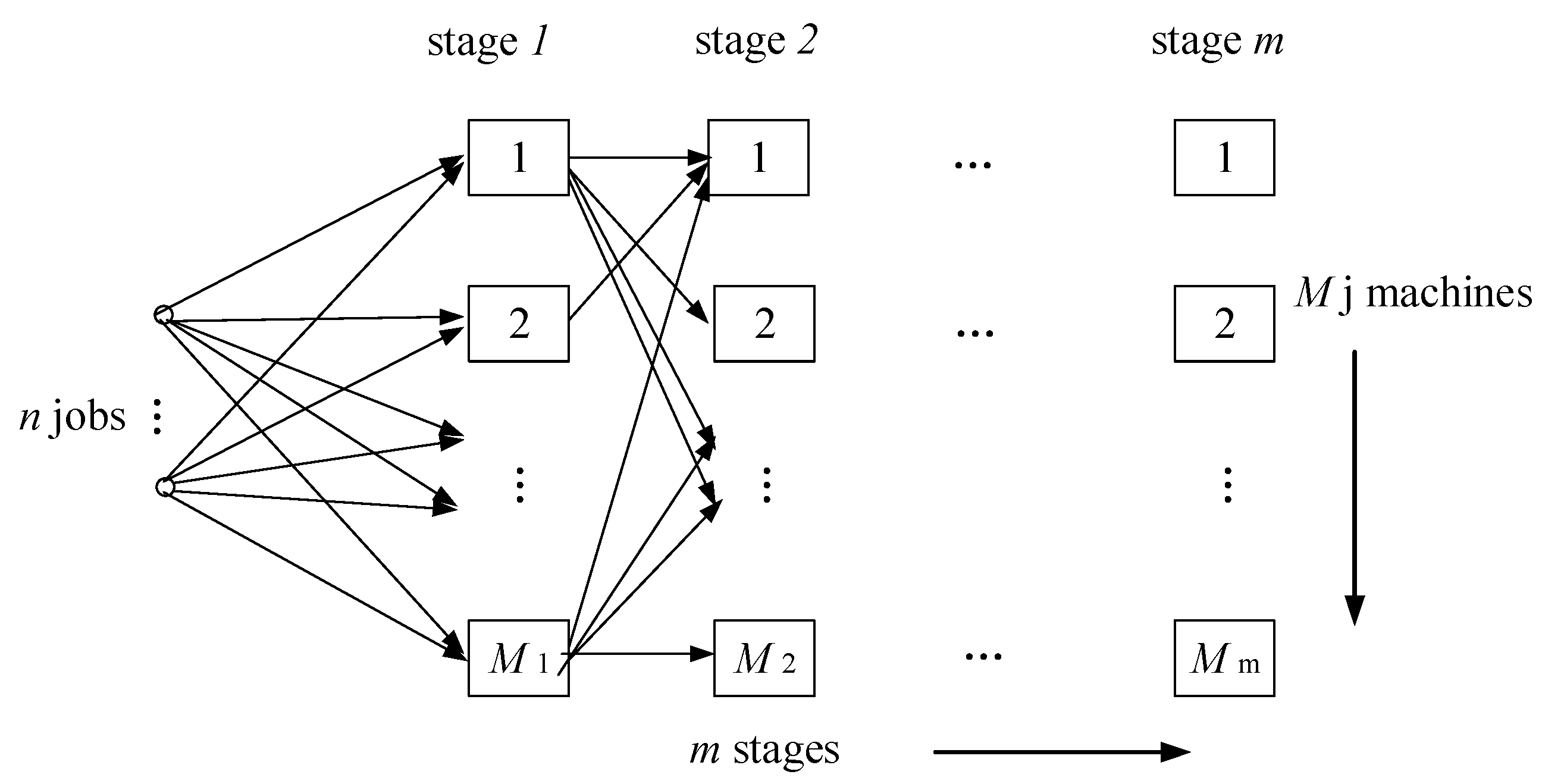
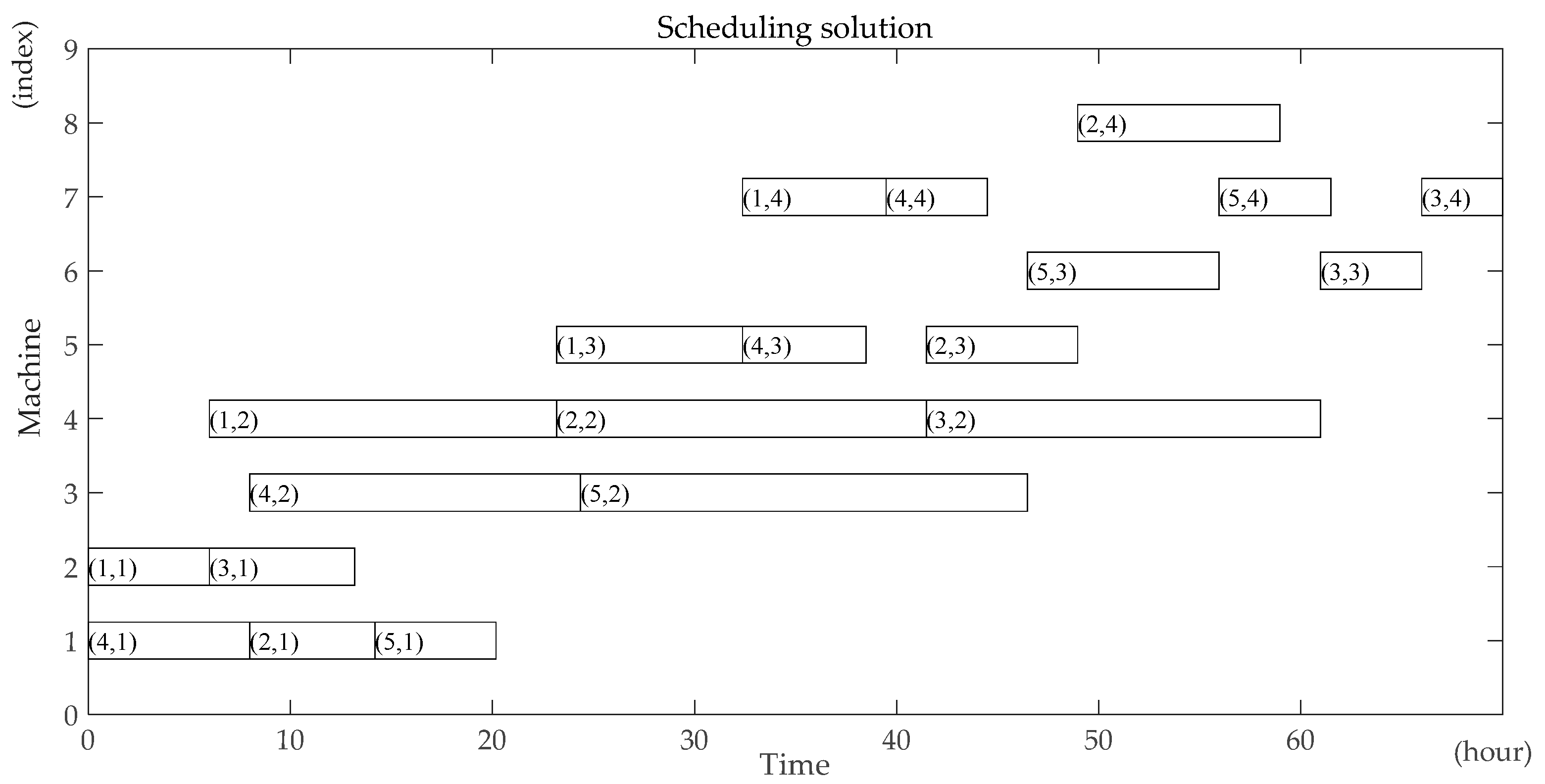
Due to the characters of the FFSP, the operation and machine based encoding method is employed. A chromosome consists of two parts: one is the processing order; the other is the machine assignment. Refer to the above instance of the turbine blades, is a chromosome.
The number in the first row of the chromosome represents the jobs index. The position of the job number at the first row indicates the processing order of the job (2 4 3 5 1). The remainder of the chromosome is a matrix representing the assignment of machines at each stage. For example, represents the job 2 is processed on machine 2 at stage 1, represents the job 2 is processed on machine 3 at stage 2, represents the job 4 is processed on machine 1 at stage 1. For each chromosome, the processing order of jobs is determined according to the position of each job that need to be processed, and the assignment of machines at each stage is determined on the basis of the remaining partial matrix.
If there is a problem with jobs, stages, a population of the HNSGA-II algorithm is initialized by randomly generating a group of matrix as chromosomes. The scale of the population is .
4.2.2. Low-Carbon Scheduling Decoding Algorithm
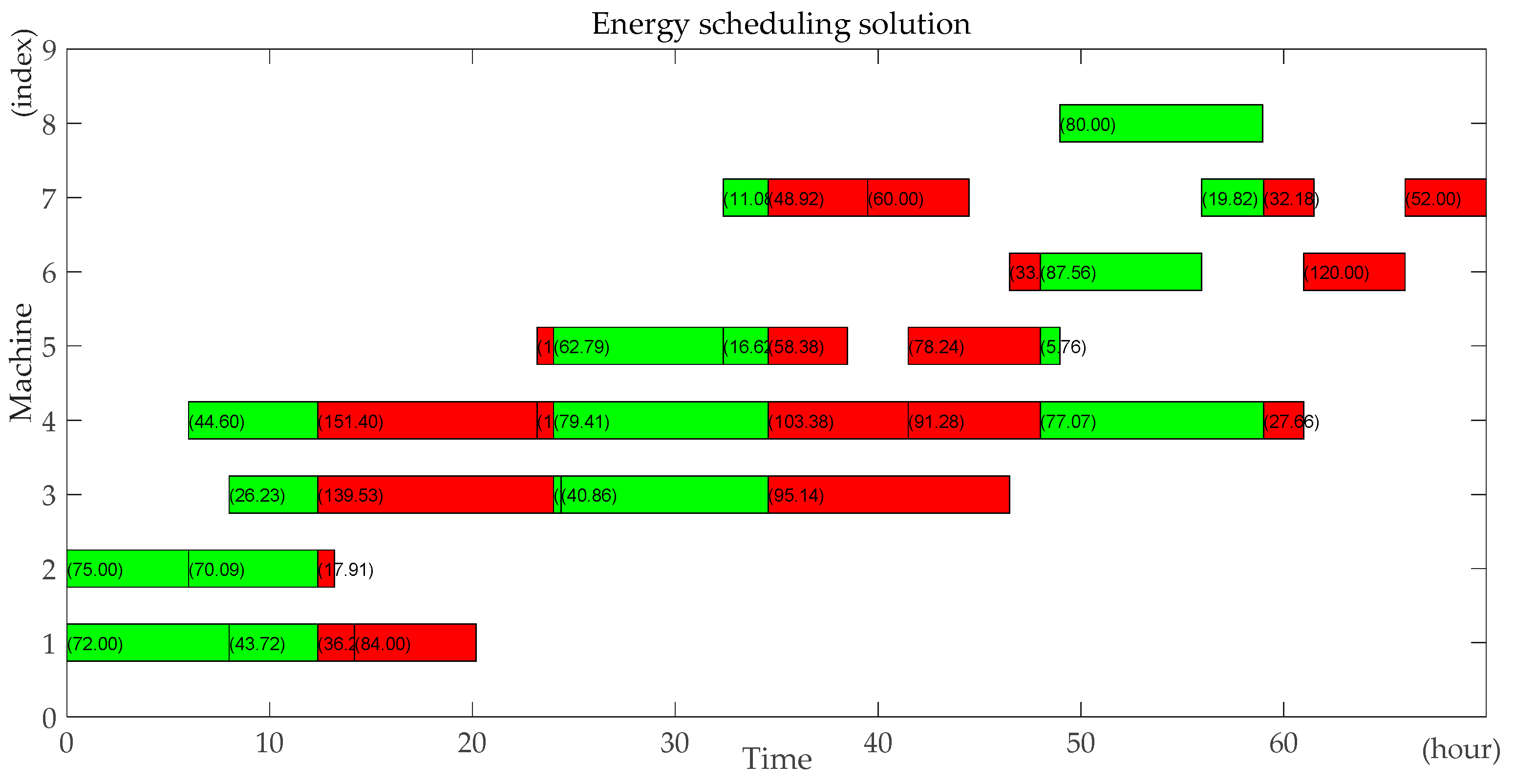
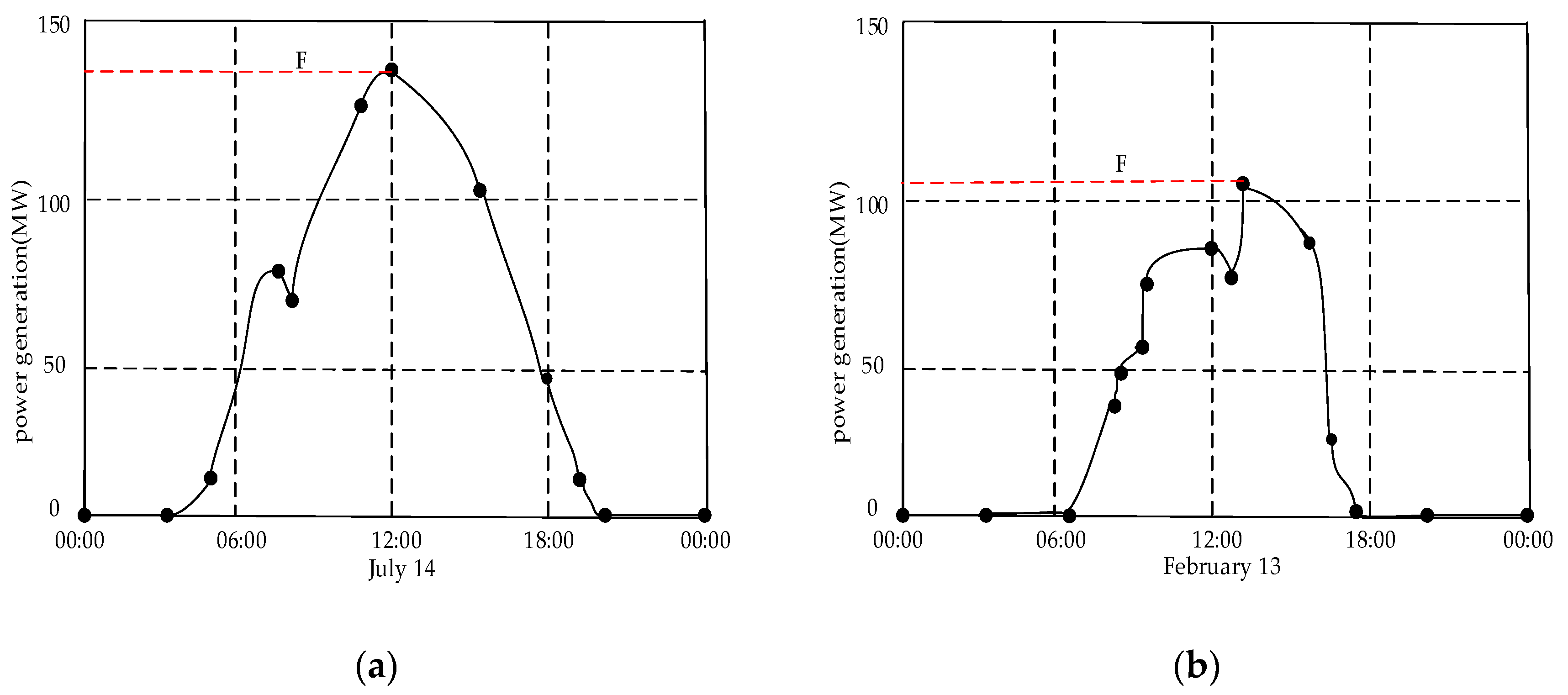
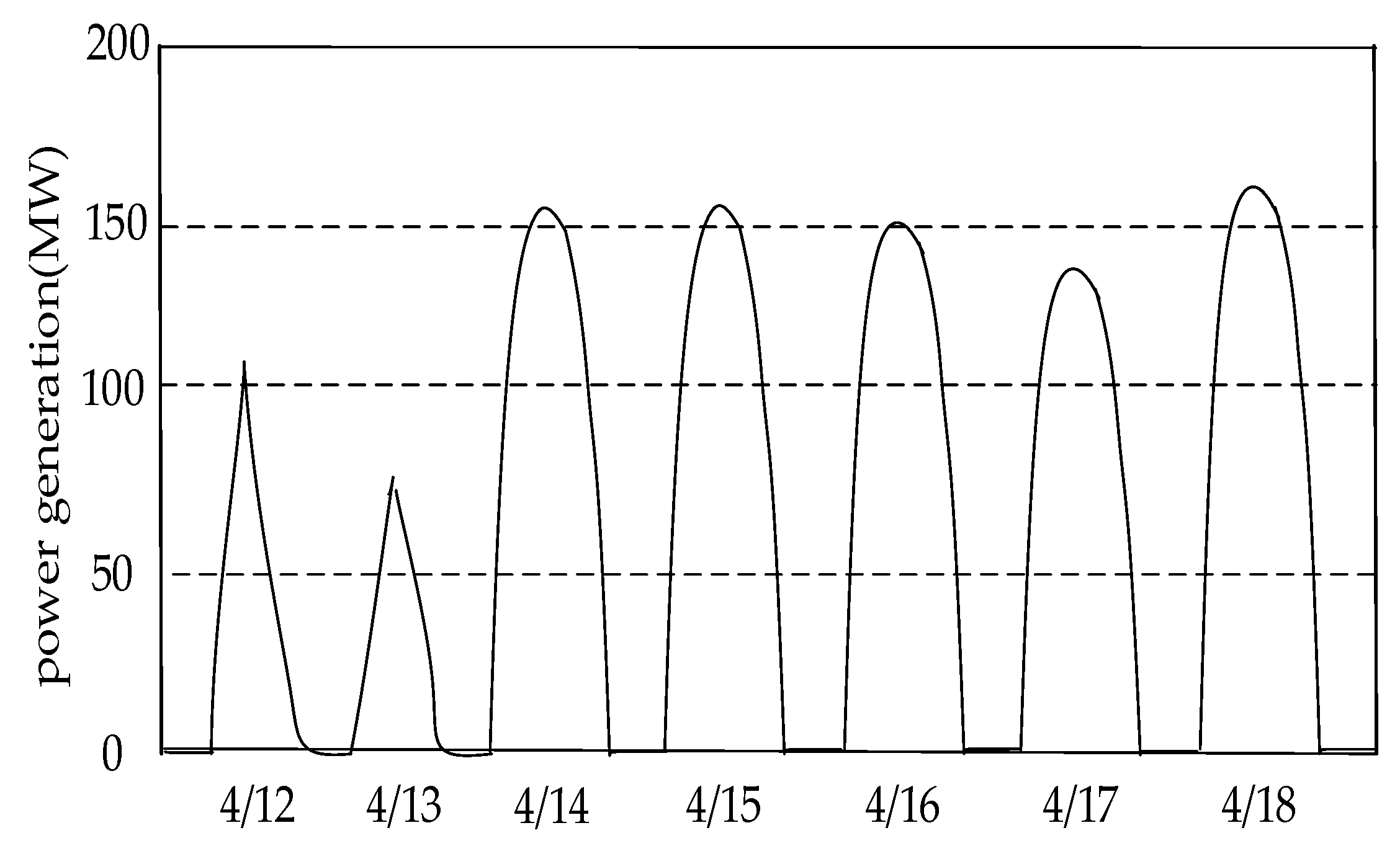
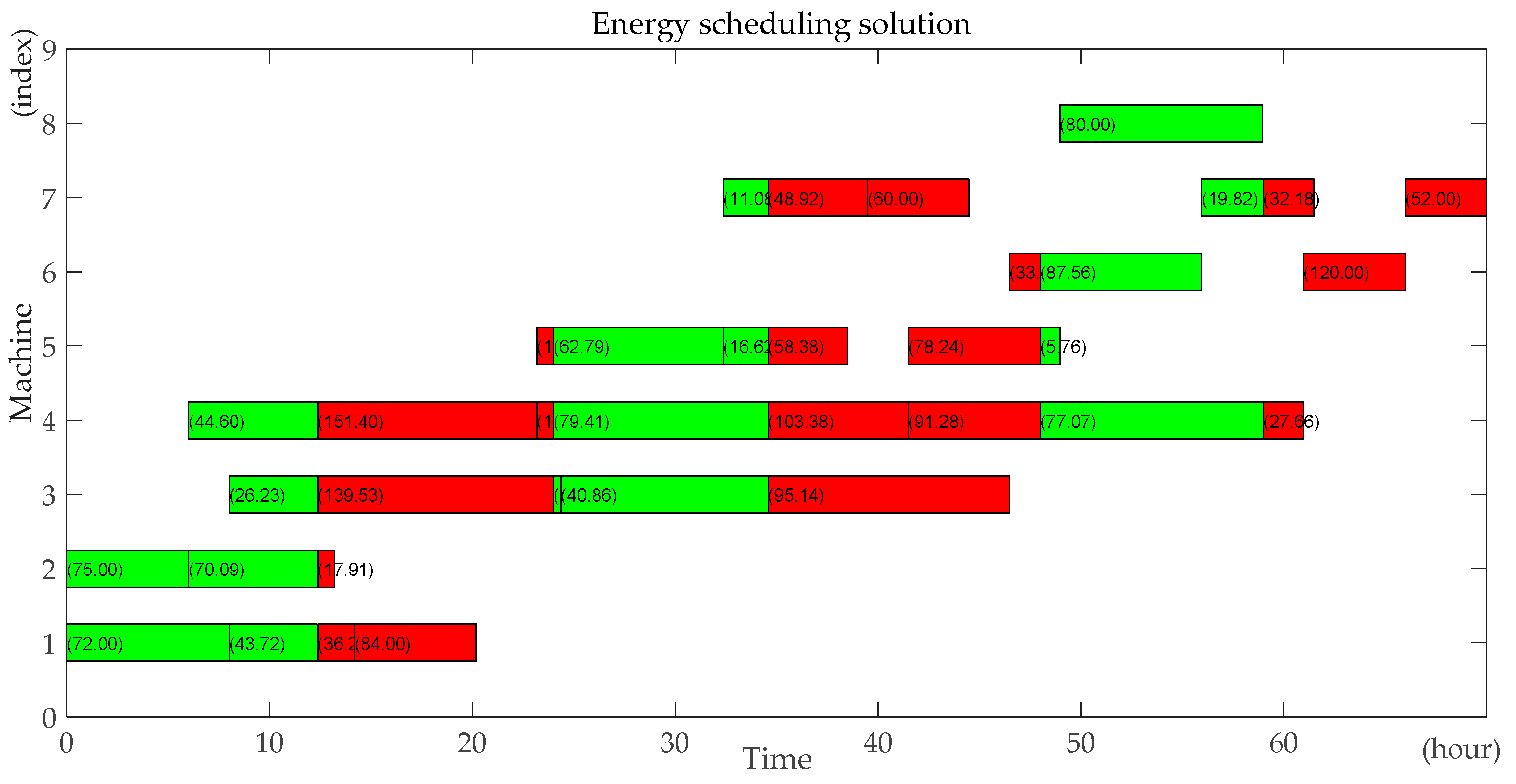
Taking into account the periodicity and randomness of power generated by solar energy, as well as the limited capacity of energy storage devices, solar energy cannot supply power to the workshop for a long time. Therefore, the production process is powered by solar energy and fossil fuel periodically. The power generation fluctuates randomly according to weather conditions and the available renewable power does not exceed the capacity of the energy storage device. Due to the features of solar energy, carbon dioxide will not be generated during the process of consuming the solar energy, whether in the process of production or in the idle time. Therefore, in order to ensure that enterprises can minimize their carbon footprint, they give priority to running the photovoltaic power station micro-grid for energy in isolation. When the energy in the energy storage device is exhausted, the micro-grid is switched to run in parallel, power is generated from the traditional power grid using the non-renewable energy, which generates carbon footprint.
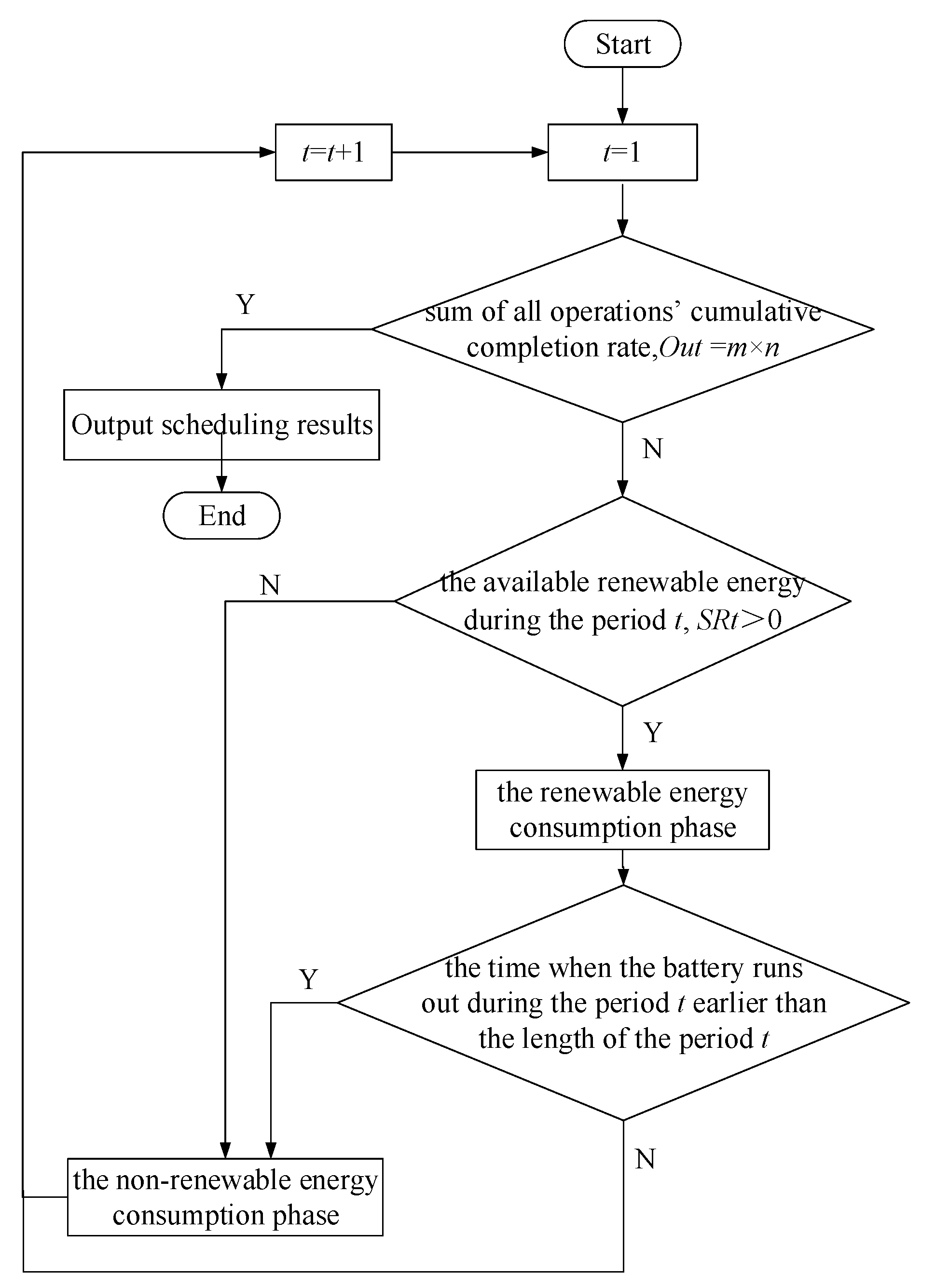
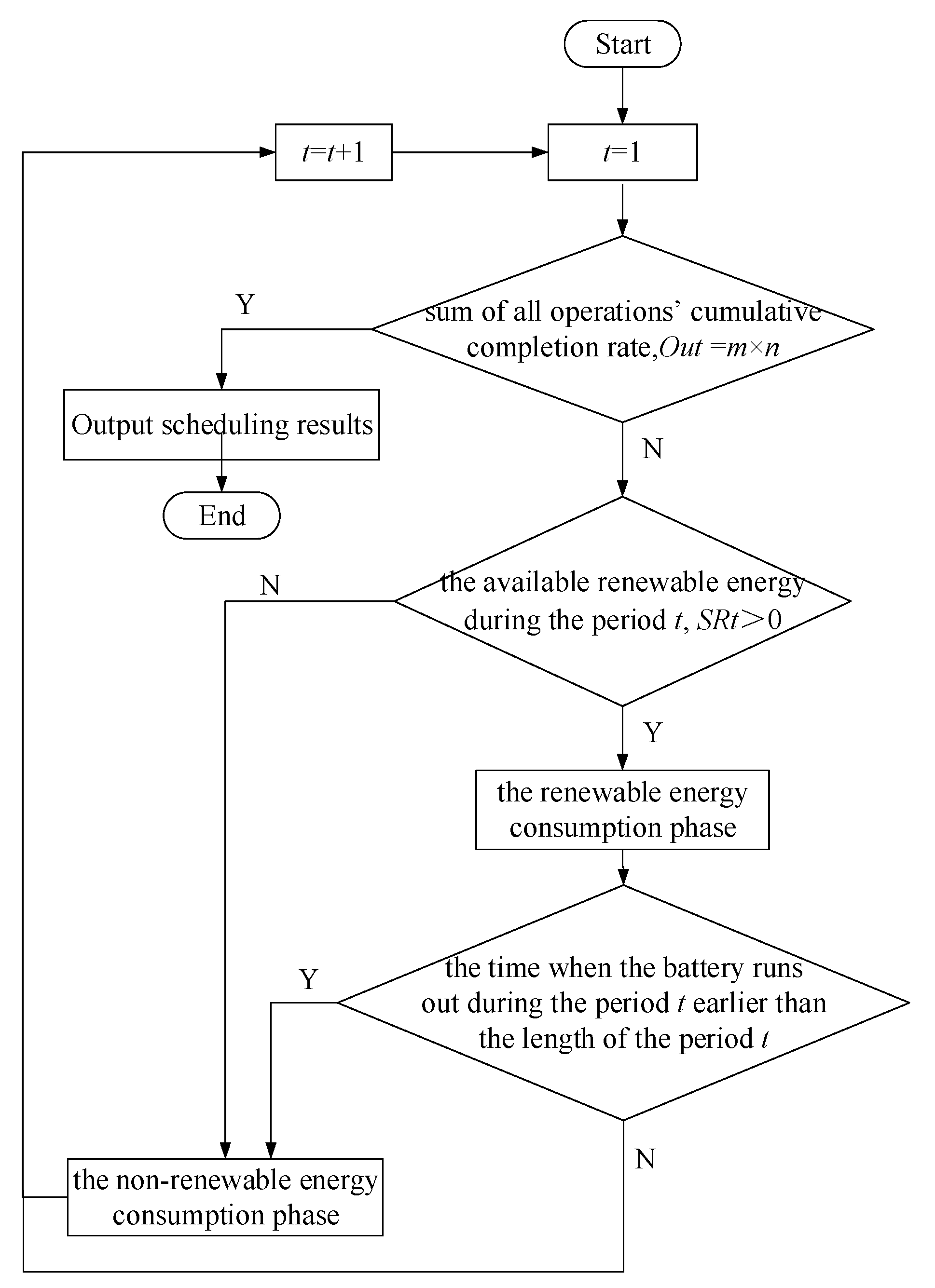
Each period is divided into two parts: the renewable energy consumption phase and the non-renewable energy consumption phase. According to the processing order of jobs and the assignment of machines at each stage, the processing operations and the idle machines in each period can be determined. Based on the rule that prioritizes renewable energy, the following low-carbon scheduling algorithm can construct a low carbon scheduling solution. The flowchart of the low-carbon scheduling algorithm is shown in
Figure 7. The detailed steps are as follows:
Step1: Set the number of period, ; the available renewable energy during period , . Obtain the operation which is processed at the beginning of the initial period based on the chromosome. Calculate the sum of the renewable energy consumption per unit time of the processing operations, .
Step2: Calculate the sum of all operations’ cumulative completion rate, . If , go to Step12; otherwise, go to Step3.
Step3: Calculate the time when the battery runs out during period , that is, . Record the current renewable energy consumption of operations and the current completion rate of operations at the renewable energy consumption phase during period .
Step4: Calculate the cumulative completion rate of the processing operations. If each cumulative completion rate of the processing operations is less than 1, let and go to Step 8; otherwise, go to Step5.
Step5: Calculate the time when the first completed operation is finished processing at the renewable energy consumption phase, . Recalculate the current renewable energy consumption and the current completion rate of operations at the renewable energy consumption phase from the beginning of period to .
Step6: Determine whether all the completed operations have follow-up stage at . If yes, then if the machine where the follow-up stage is processed does not start processing or is idle, the follow-up stage enters the processing state; otherwise, it will not be processed at . Otherwise, go to Step7.
Step7: Determine whether all the machines on which the completed operations are processed have subsequent unprocessed operations that need to be processed at according to the chromosome. If all the subsequent unprocessed operations are not at the first stage and all the previous stages have not yet finished processing, processing will not be started and the machine keeps idle; If all the subsequent unprocessed operations are at the first stage or all the subsequent unprocessed operations are not at the first stage and any the previous stage is completed, the subsequent unprocessed operations are arranged to enter the processing state according to the following rules:
The shortest renewable processing time of the subsequent unprocessed operations have first priority.
If the renewable processing time is the same, the lowest renewable energy processing energy consumption per unit time of the subsequent unprocessed operations has second priority.
If the energy consumption is the same, select one randomly.
The priority order of the subsequent unprocessed operations selected for the processing state is: the processing time processing energy consumption per unit time.
Step8: Update . Calculate , if , go to Step12. Otherwise, if , proceed to Step3; otherwise, go to Step9.
Step9: If the time when the battery runs out during period earlier than the period length of period , that is, , then calculate the remaining time of period , that is, , go to Step10; otherwise, let , go to Step3.
Step10: Refer to Step3-Step7, calculate the non-renewable energy consumption of operations and the completion rate of operations at the non-renewable energy consumption phase of period . If any operation is completed during this time, select unprocessed operations into the processing state according to the priority order: the processing time processing energy consumption per unit time.
Step11: Update . Calculate , if , go to Step12. Otherwise, if , let , go to Step3; otherwise, go to Step10.
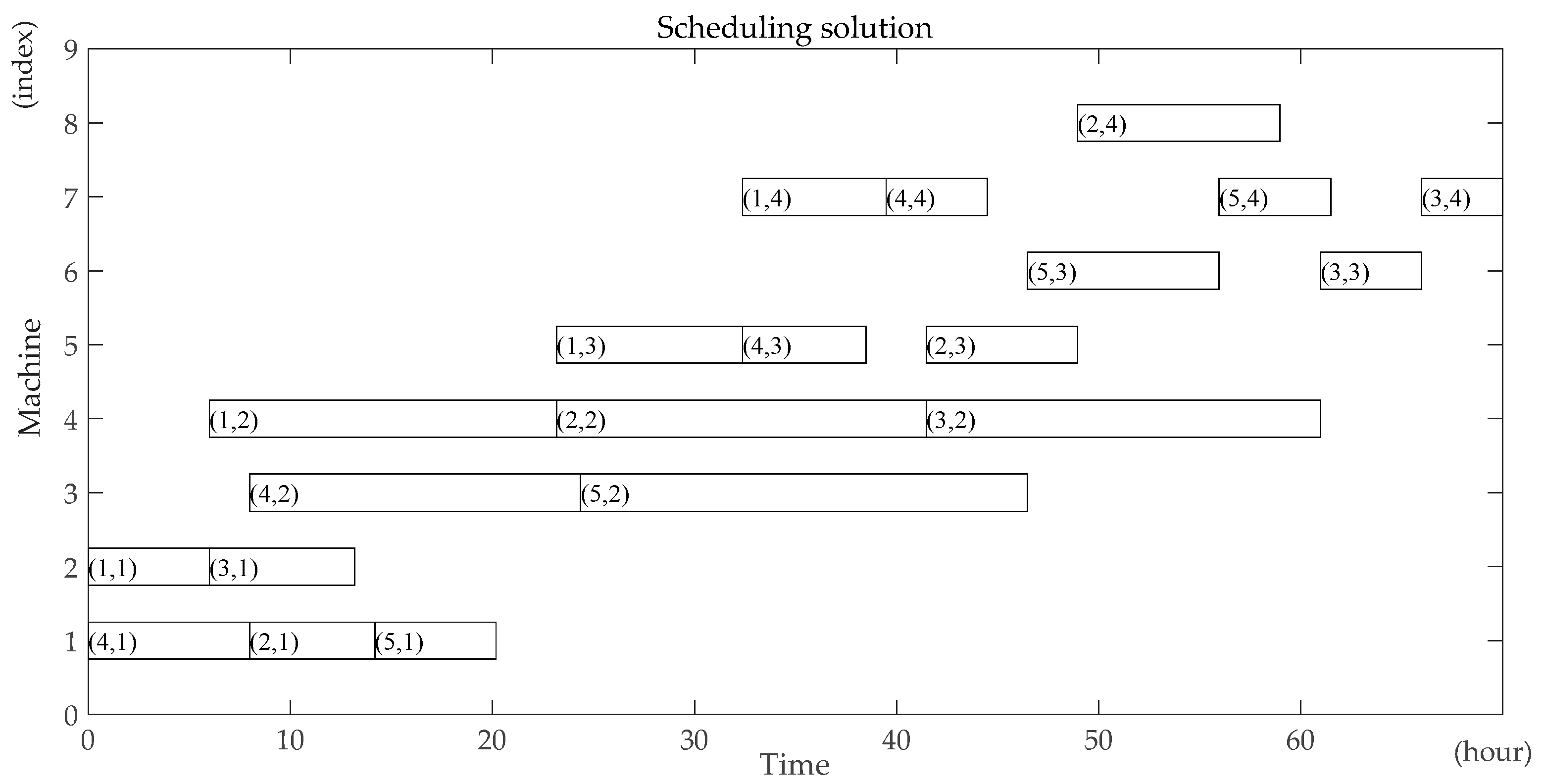
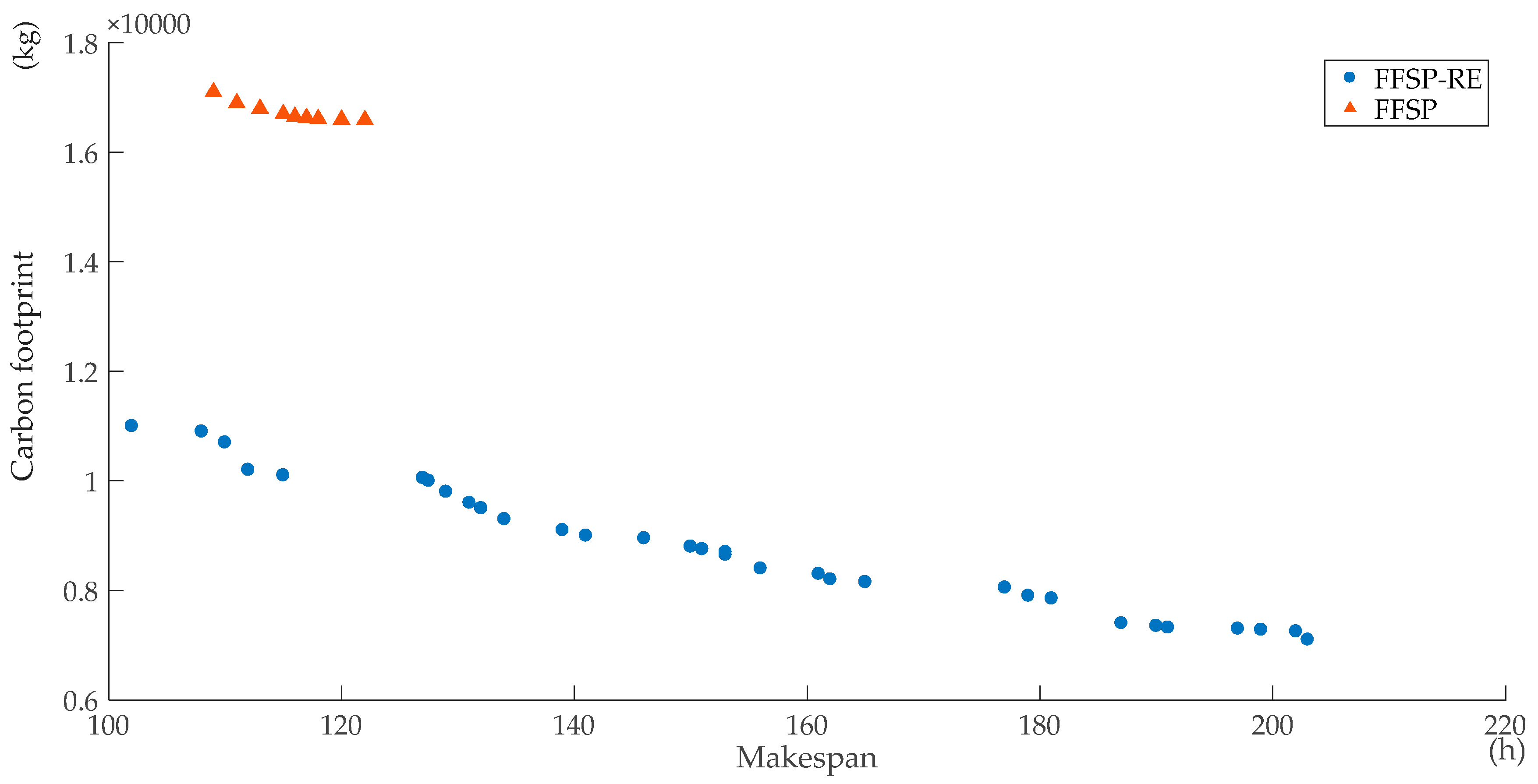
Step12: Calculate all operations’ starting time and completing time using the renewable energy and the non-renewable energy during each period respectively based on all operations’ renewable energy consumption and non-renewable energy consumption during each period. Output the scheduling solution and the energy scheduling assignment. Calculate the makespan according to the scheduling solution. Calculate the total carbon footprint.
4.2.3. Crossover
Crossover operator is the intersection of two parent chromosomes. It could obtain more excellent chromosomes through crossover. Among the various genetic algorithms for solving FFSP, most of the crossover operators use the position-based crossover (PBX) and the liner order crossover (LOX) [
35]. Therefore, considering the coding characteristics of the chromosomes, the crossover operator integrating the LOX with PBX is proposed.
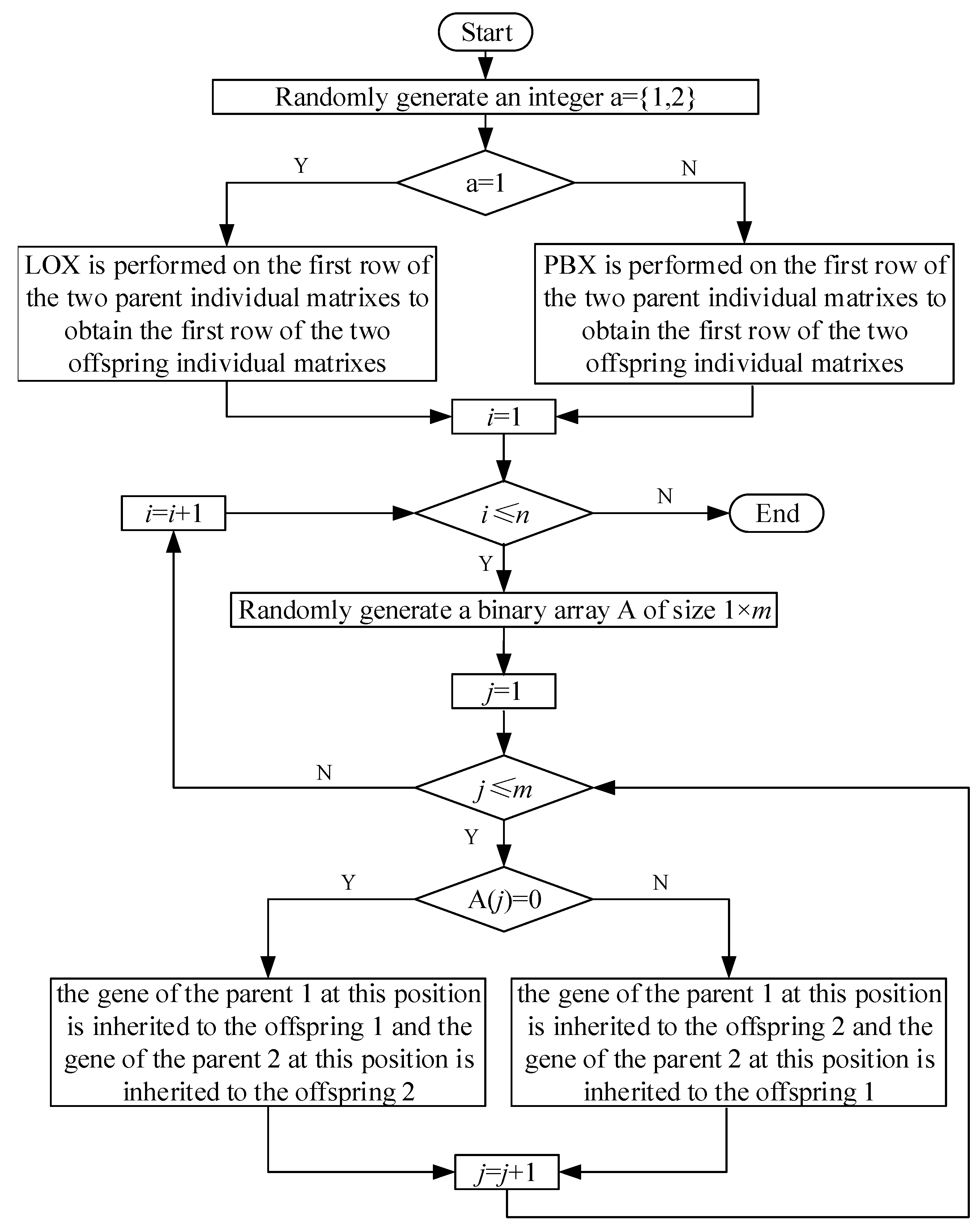
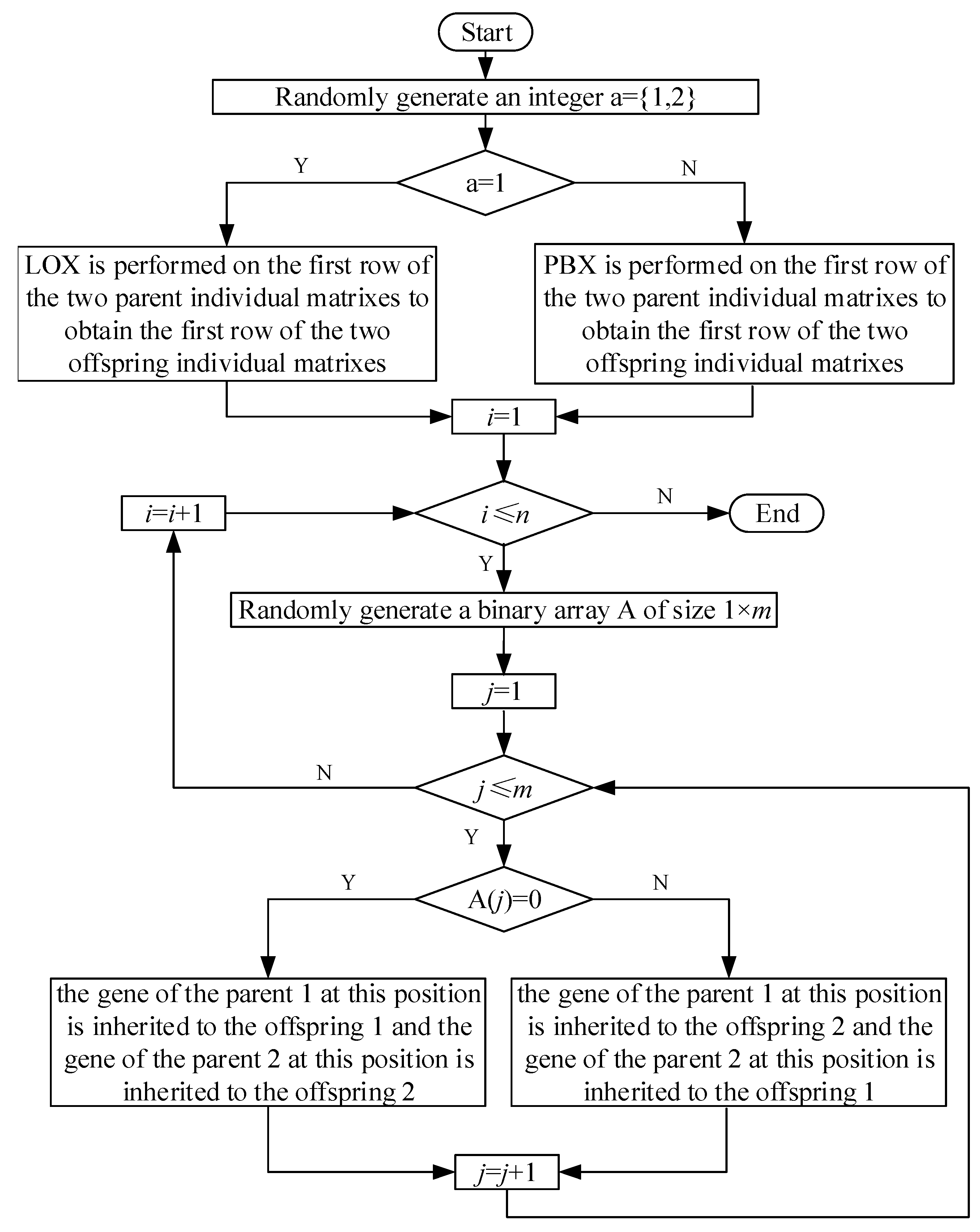
The flowchart of the algorithm for crossover is shown in
Figure 8. The detailed steps are as follows:
Step1: Randomly generate an integer between 1 and 2. If it is 1, go to Step2; if it is 2, go to Step3.
Step2: LOX is performed on the first row of the two parent individual matrixes to obtain the first row of the two offspring individual matrixes, and go to Step4.
Step3: PBX is performed on the first row of the two parent individual matrixes to obtain the first row of the two offspring individual matrixes, and go to Step4.
Step4: Randomly generate a binary array of size .
Step5: For row 2 to row of the parent individual matrix, starting from the first column, from left to right, each column is sequentially evaluated from top to bottom according to the binary array, if it’s 0, the gene of the parent 1 at this position is inherited to the offspring 1 and the gene of the parent 2 at this position is inherited to the offspring 2; If it is 1, the gene of the parent 1 at this position is inherited to the offspring 2 and the gene of the parent 2 at this position is inherited to the offspring 1.
4.2.4. Non-Dominated Sorting Crossover
For the sorting of the non-dominated levels in the algorithm, the definition of Pareto non-dominated solution should first be defined. A non-dominated solution is the solution that is not dominated by any other feasible solution. The dominated relationship for a minimization is for any two feasible solutions
and
, if the following conditions are satisfied,
Then we call
dominates
, shown as
,
is the non-dominated solution,
is the dominated solution [
36],
is the total number of the objectives.
If is not dominated by other individuals in the population, then is recorded as the Pareto non-dominated solution, that is, the Pareto optimal solution. The set of all the non-dominated solutions is the Pareto optimal solution set.
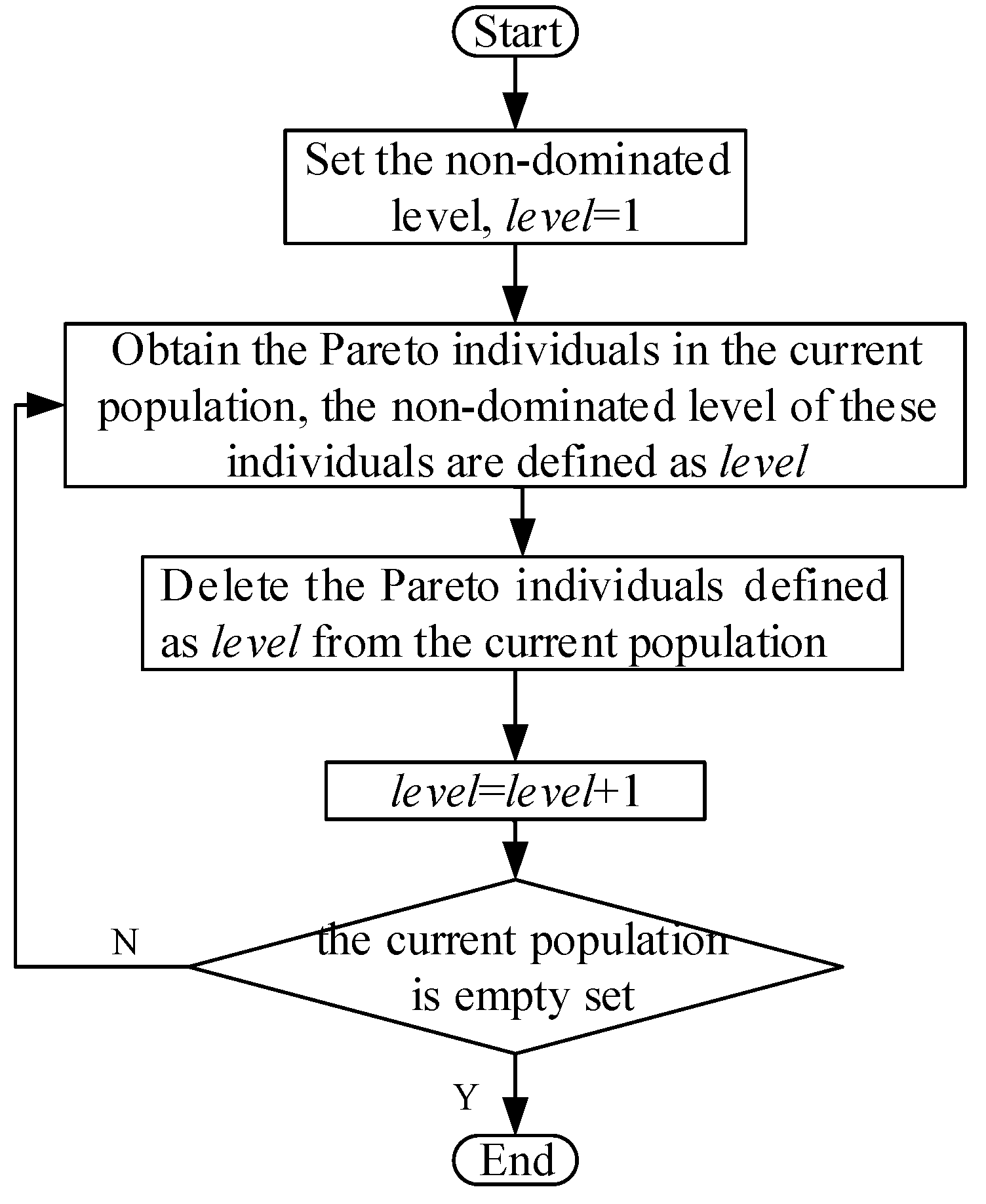
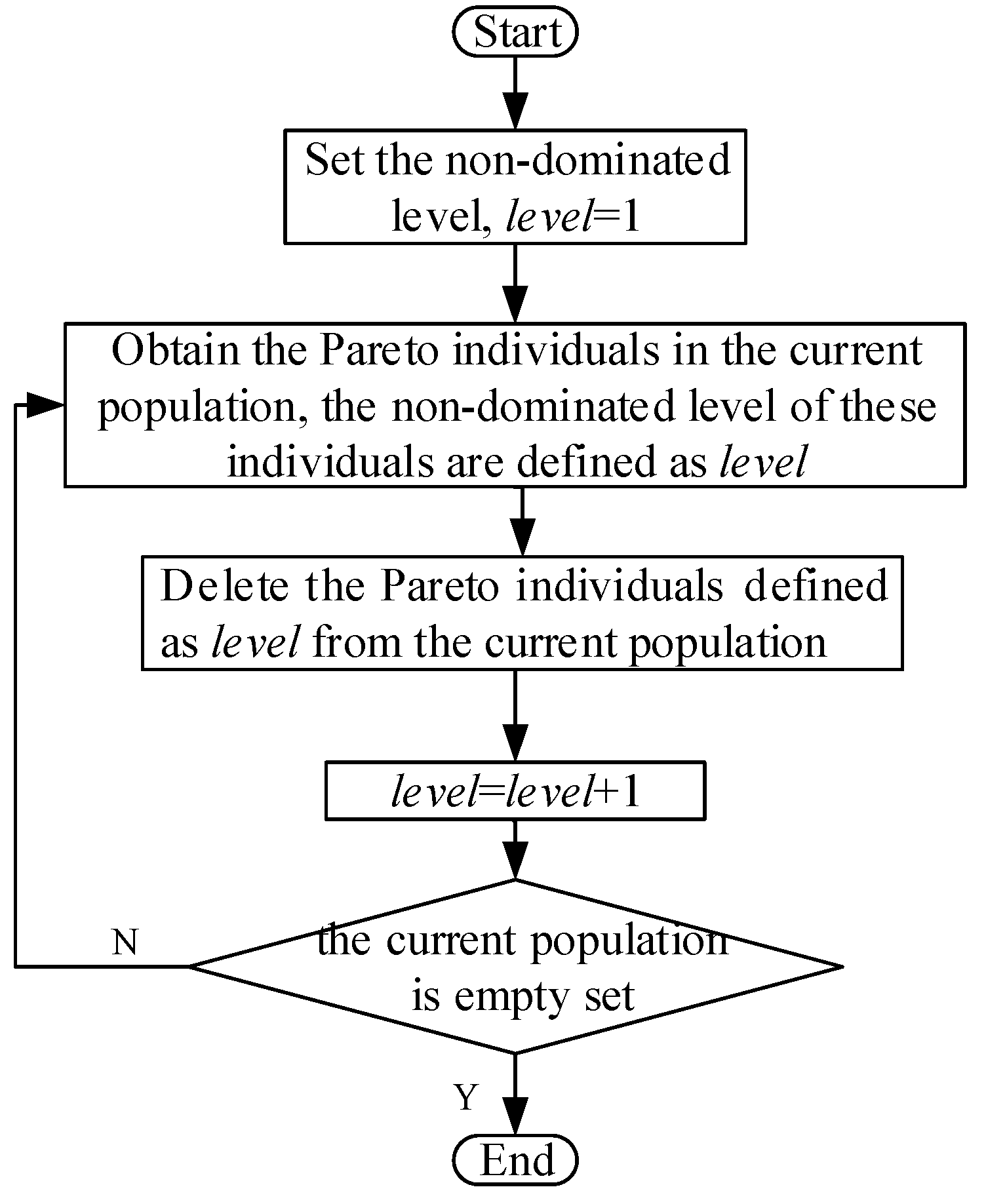
In order to select the best individual to enter the next generation, all the individuals in the population are divided into different non-dominated levels. The individuals in a lower level are selected preferentially to the next generation. The non-dominated ranking algorithm is proposed. The flowchart of the non-dominated ranking algorithm is shown in
Figure 9.
4.2.5. The Crowding Degree Comparison Operator
After combining the parents and the offspring, calculate the crowding degree, which ensures the diversity of population and the population evolve toward a better direction. The definition of crowding degree is in Equation (20). The objective values of all individuals at the same non-dominated level are sorted in ascending order, and then calculate the average side length of the rectangle composed of and , that is the crowding degree of . The calculation procedure of the crowding degree is as follows:
Step1: Let , the crowding degree of , for the total number of individuals at the same non-dominated level.
Step2: Calculate the crowding degree of
:
The crowding degree of the two boundary points: , . , and are adjacent Pareto individuals at the same non-dominated level. denotes the maximum value of the k-th objective, denotes the minimum value of the k-th objective function. Two objectives are studied in this paper, so the value of is 1 and 2.
The crowding degree of
is shown in
Figure 10. It can be seen from
Figure 10 that the smaller
is, the more crowded around
is.
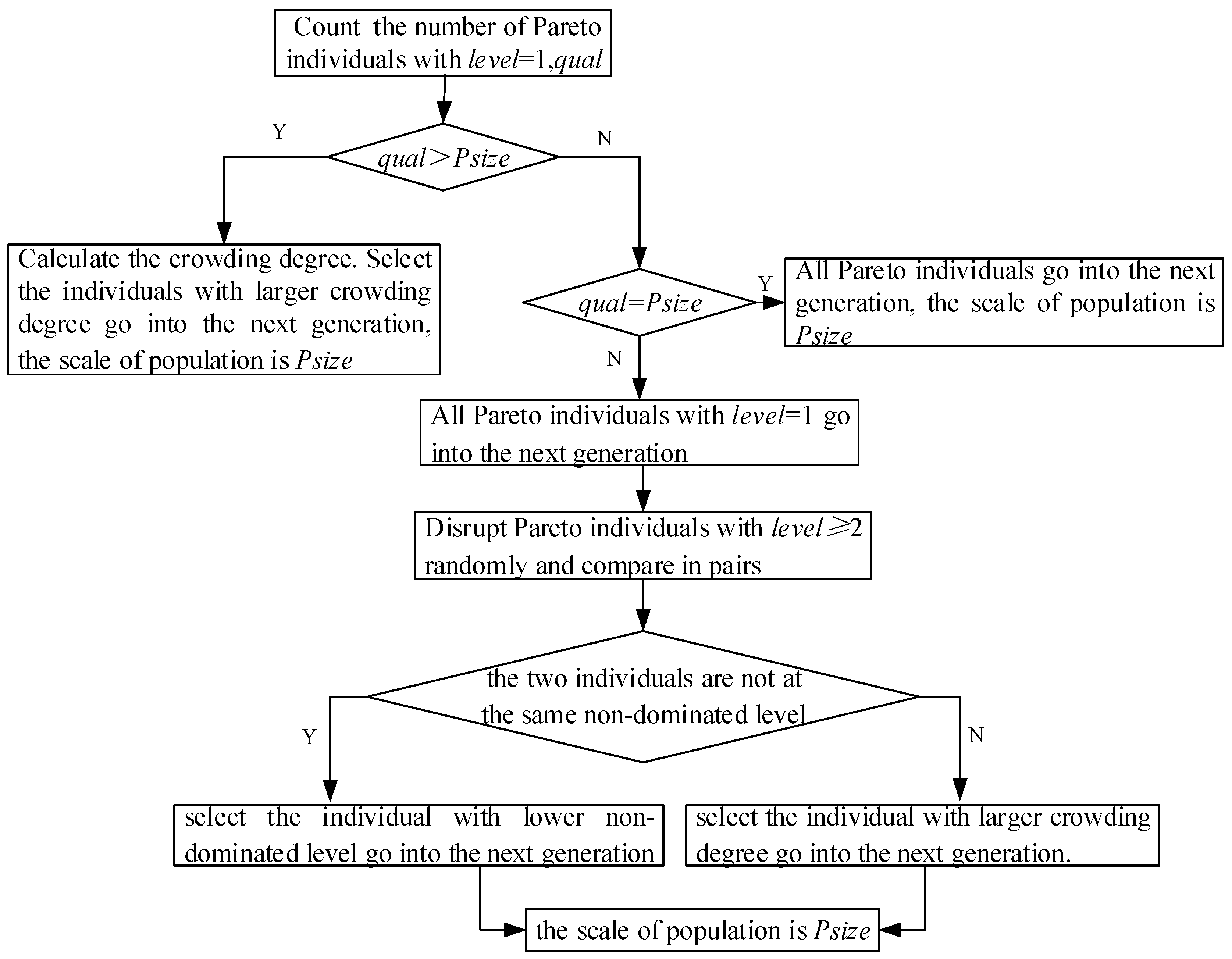
Individuals entering the next generation are selected based on the non-dominated level and the crowding degree. The flowchart of selecting individuals is shown in
Figure 11. The detailed steps are as follows:
Step 1: Count , the number of Pareto individuals with . If , go to Step2; if , go to Step3; if , go to Step4.
Step2: Calculate the crowding degree. Select the individuals with larger crowding degree go into the next generation, the scale of population is .
Step3: All Pareto individuals go into the next generation, the scale of population is .
Step4: All Pareto individuals with go into the next generation. Then, disrupt Pareto individuals with randomly. Compare in pairs, if the two individuals are not at the same non-dominated level, select the individual with lower non-dominated level go into the next generation, otherwise, select the individual with larger crowding degree go into the next generation. The scale of population is .
Chromosomes with a lower non-dominated level are selected into the next generation, which can keep the elite individuals in the population to a great extent. The diversity of the population can be ensured by selecting individuals with a larger crowding degree at the same non-dominated level.
4.2.6. Variable Local Search Strategy
It is easy for the genetic algorithm to fall into a local optimum, so it is necessary to integrate a local search with the genetic algorithm. The primary problem in designing a variable local search strategy is to design the neighborhood structures. Considering the structure of FFSP, 5 kinds of local search methods are developed according to the operation and machine based encoding method. The traditional local search mainly includes swap and insert, which are relatively simple and easy to implement. Therefore, for the production scheduling problem, many algorithms use these two local search methods [
37]. Besides, we develop another three local search methods: (1) reassign the machine of an operation, which is the mutation operation in this paper; (2) reassign the machines of all stages of a job, which is more complicated and has stronger local search ability than reassigning the machine of a operation; (3) Reverse the elements between two positions, which can produce a greater disturbance to the original chromosome, so that the algorithm cannot fall into the local optimum and expand the search space. Therefore, the 5 kinds of local search methods are as follows.
Swap. Randomly select two positions in the first row of the chromosome, and then swap the whole column genes at the two selected positions.
Insert. Randomly select two positions, and , in the first row of the chromosome, where . Then insert the whole column genes at before those at .
Reassign the machine of an operation. Randomly select one position in the machine assignment part of the chromosome, and then reassign the machine of the operation at the selected position.
Reassign the machines of a job’s all stages. Randomly select one position in the first row of the chromosome, and then reassign all stages machines of a job at the selected position.
Reverse the genes between two positions. Randomly select two positions in the first row of the chromosome, and then reverse the whole column genes between the two selected positions.
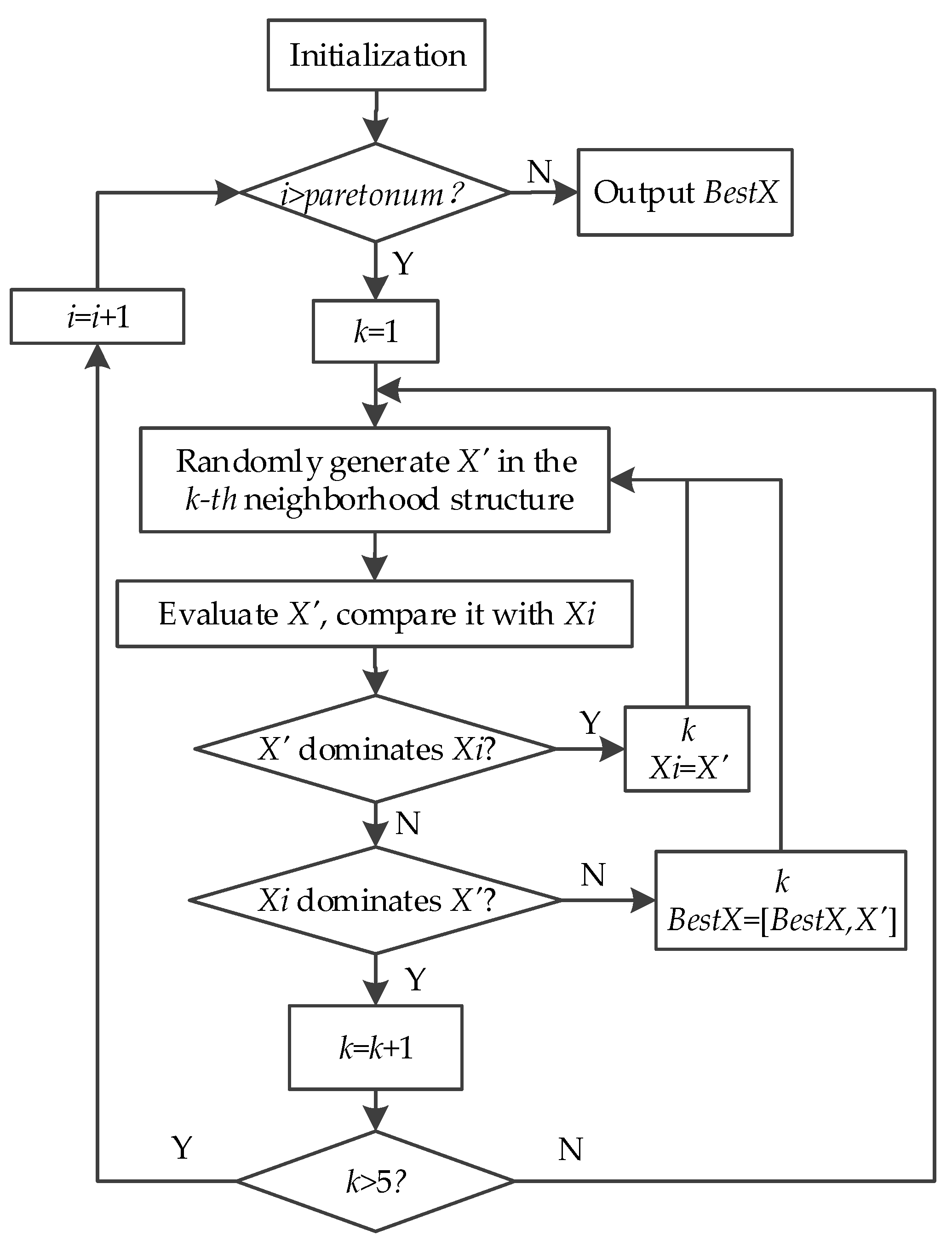
Based on the above 5 kinds of local search methods, the local search process is shown in
Figure 12, specific steps are as follows:
Step1: Set . Input initialization parameters: the Pareto optimal solution set of the offspring, ; the i-th individual of , Calculate the number of , . Let .
Step2: If , go to Step6; otherwise, let .
Step3: Randomly generate a new solution according to the local search method , is compared with by the crowding degree comparison operator.
Step4: If then and continue searching within the local search method , go to Step3. If and are non-dominated by each other, then append to and continue searching within local search method , go to Step3. If , let , go to Step5.
Step5: If , then let , go to Step2; otherwise, go to Step3, transfer to the next local search method.
Step6: Output , calculate the number of the current , . If , then combine the parent and offspring directly; otherwise, from to , let replace the dominated solution in the offspring population in turn.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}