Advanced Camera Image Cropping Approach for CNN-Based End-to-End Controls on Sustainable Computing



Abstract
1. Introduction
2. Related Works
2.1. Research on Awareness of Cars
2.2. Research on Driving Method of Cars
2.3. End-to-End Controls of Cars
3. Image Cropping Approach for Self-Driving Cars
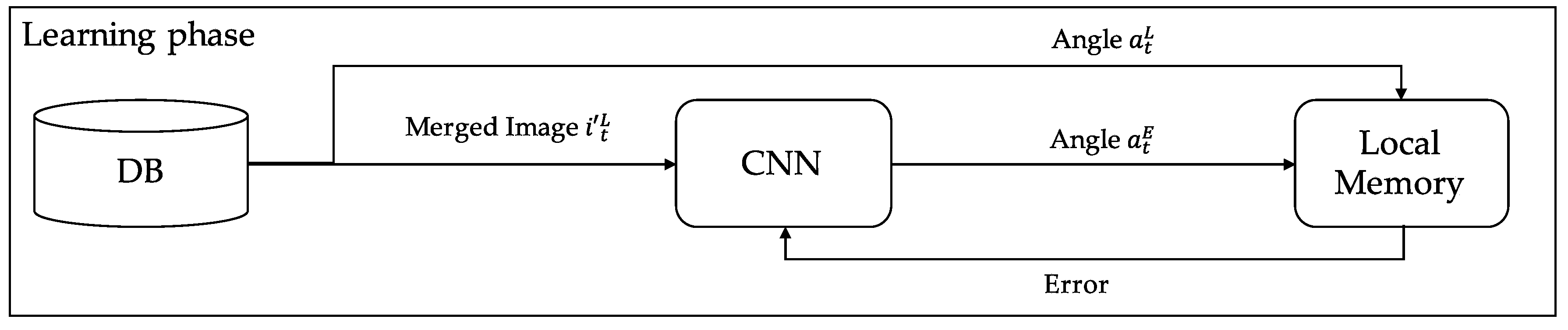
3.1. System Overview
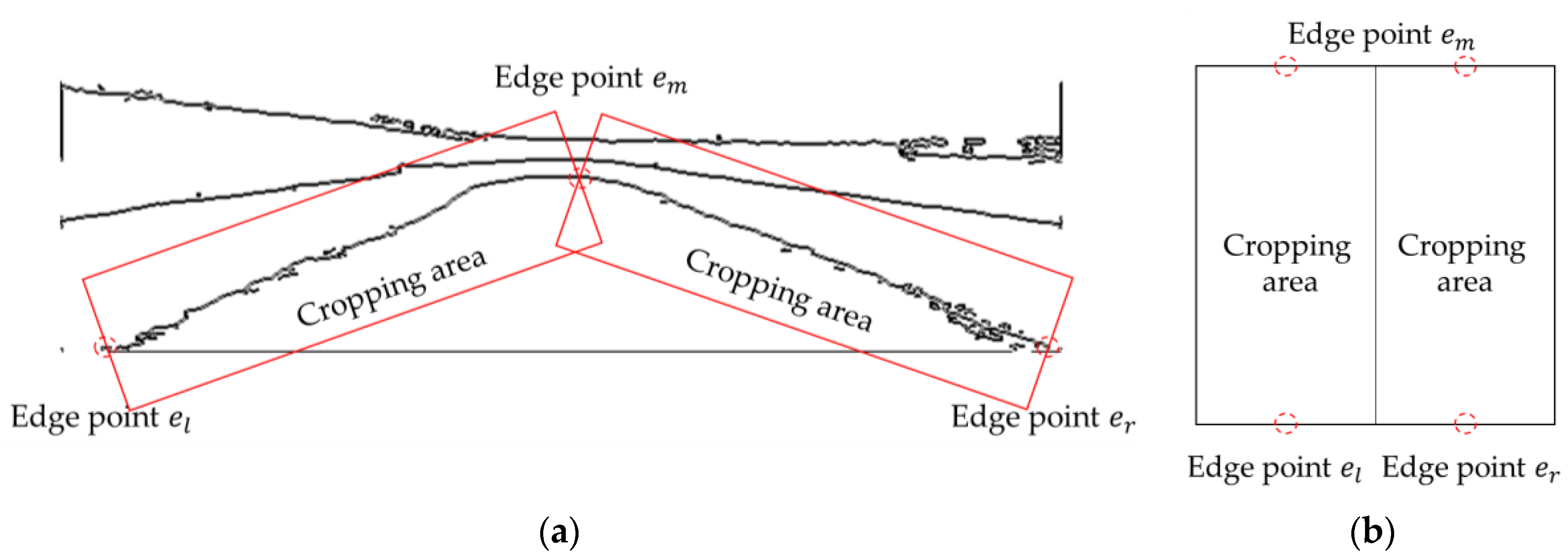
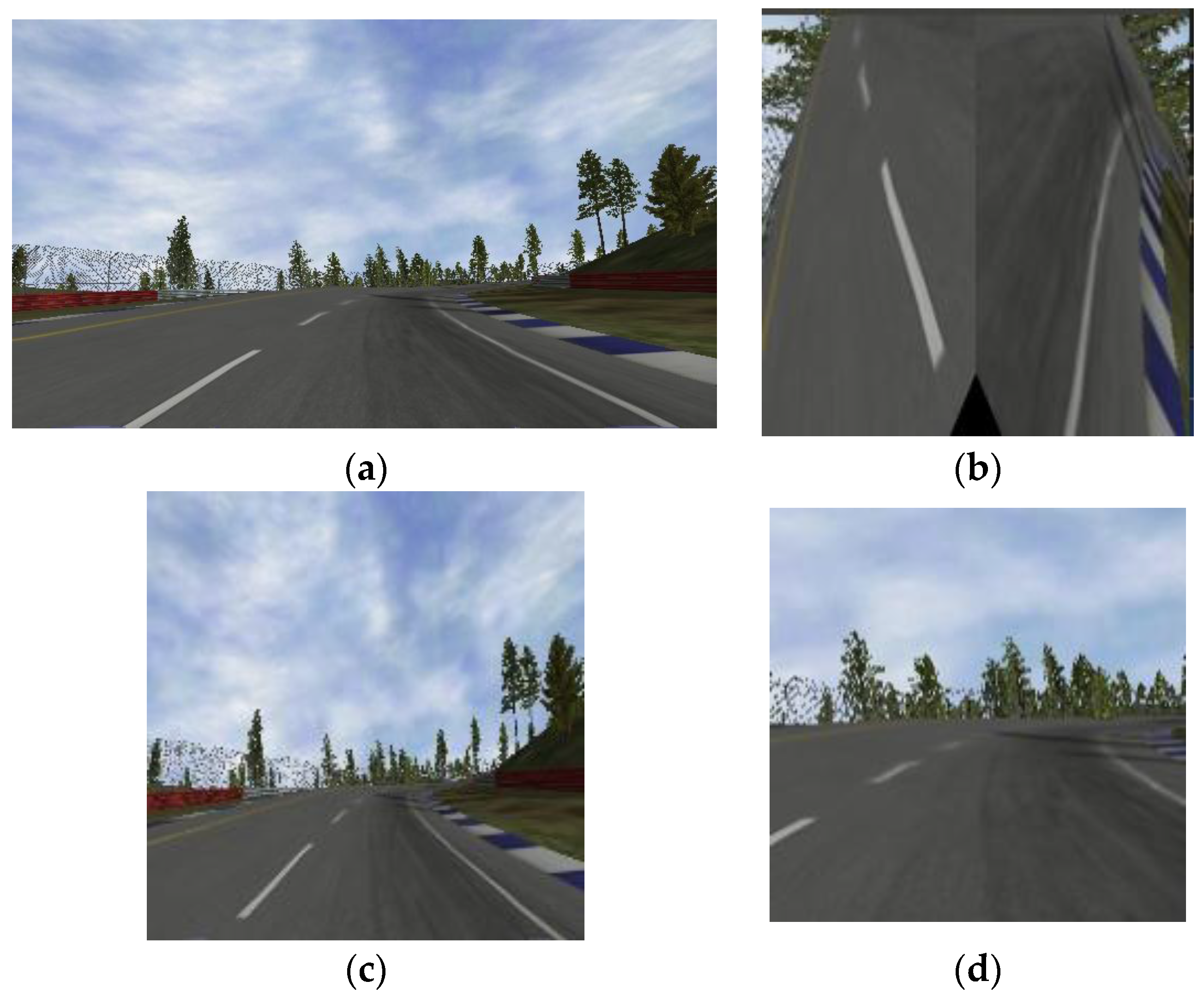
3.2. Extracting and Merging Approaches
3.3. Network Architecture
4. Experiments
4.1. Experimental Environment
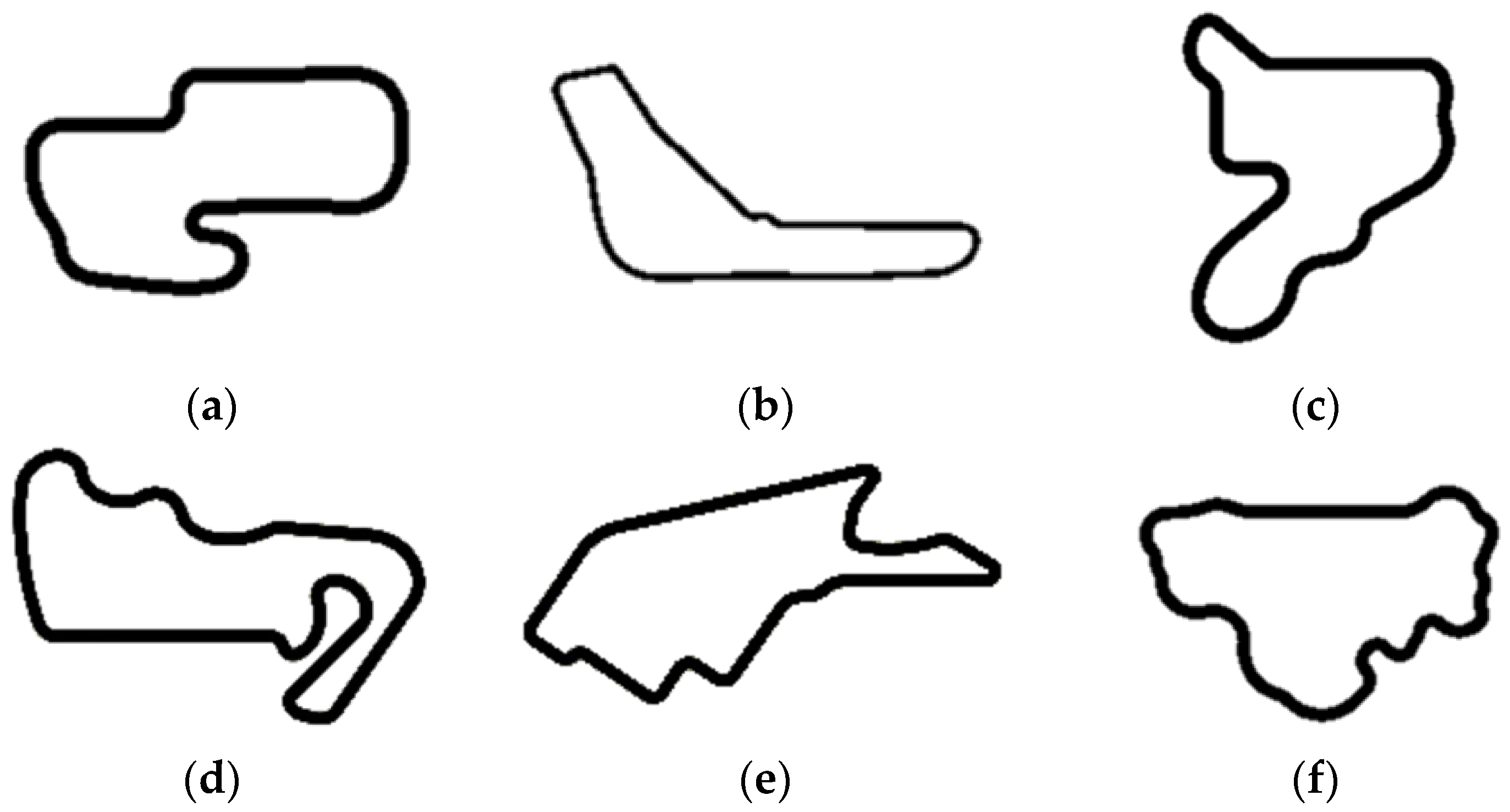
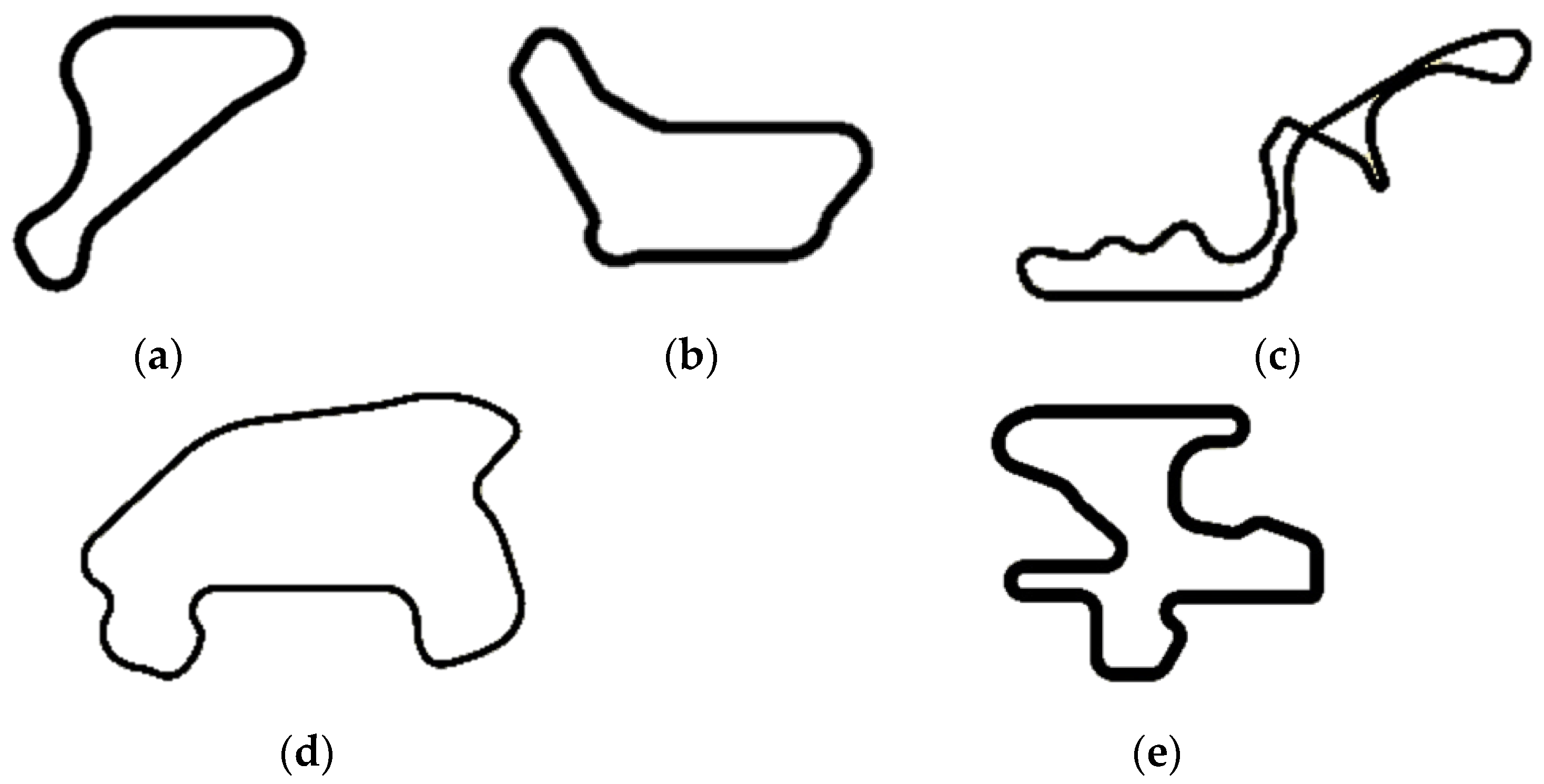
4.2. Learning Routes
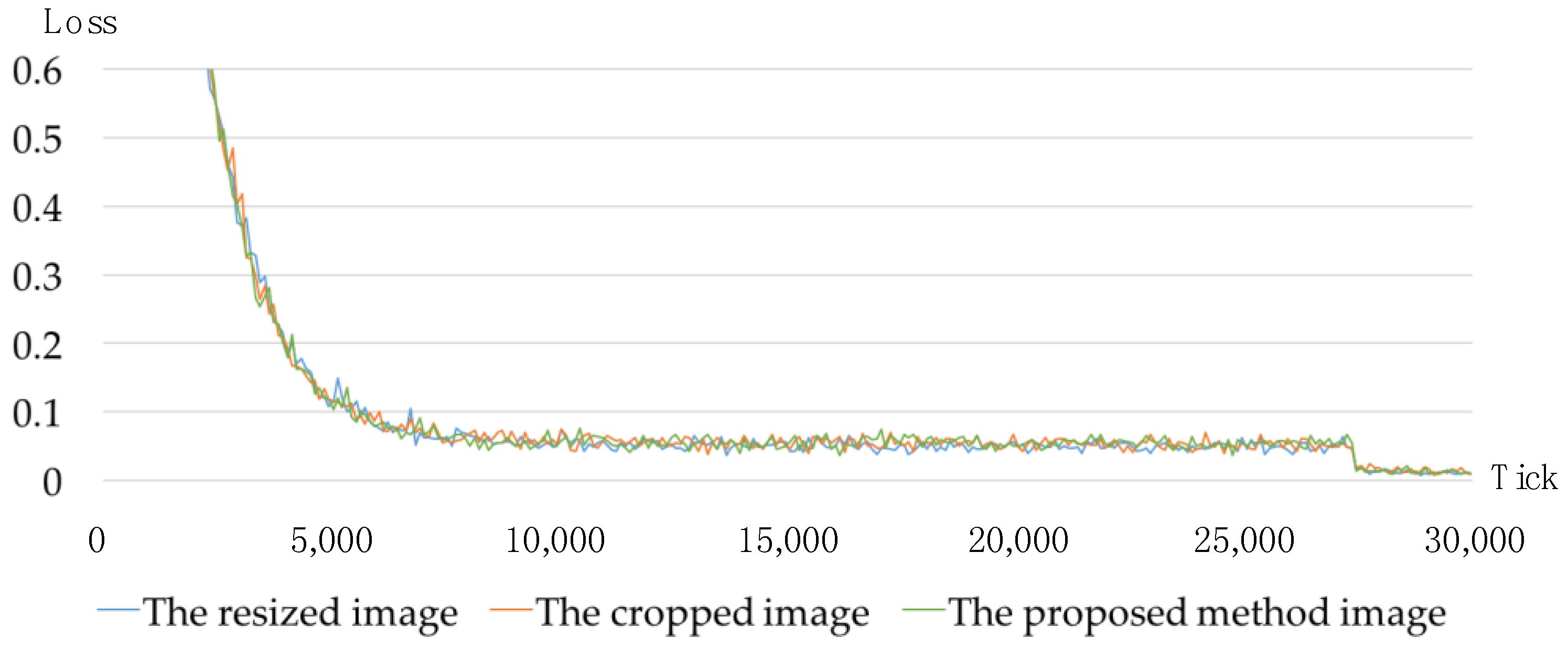
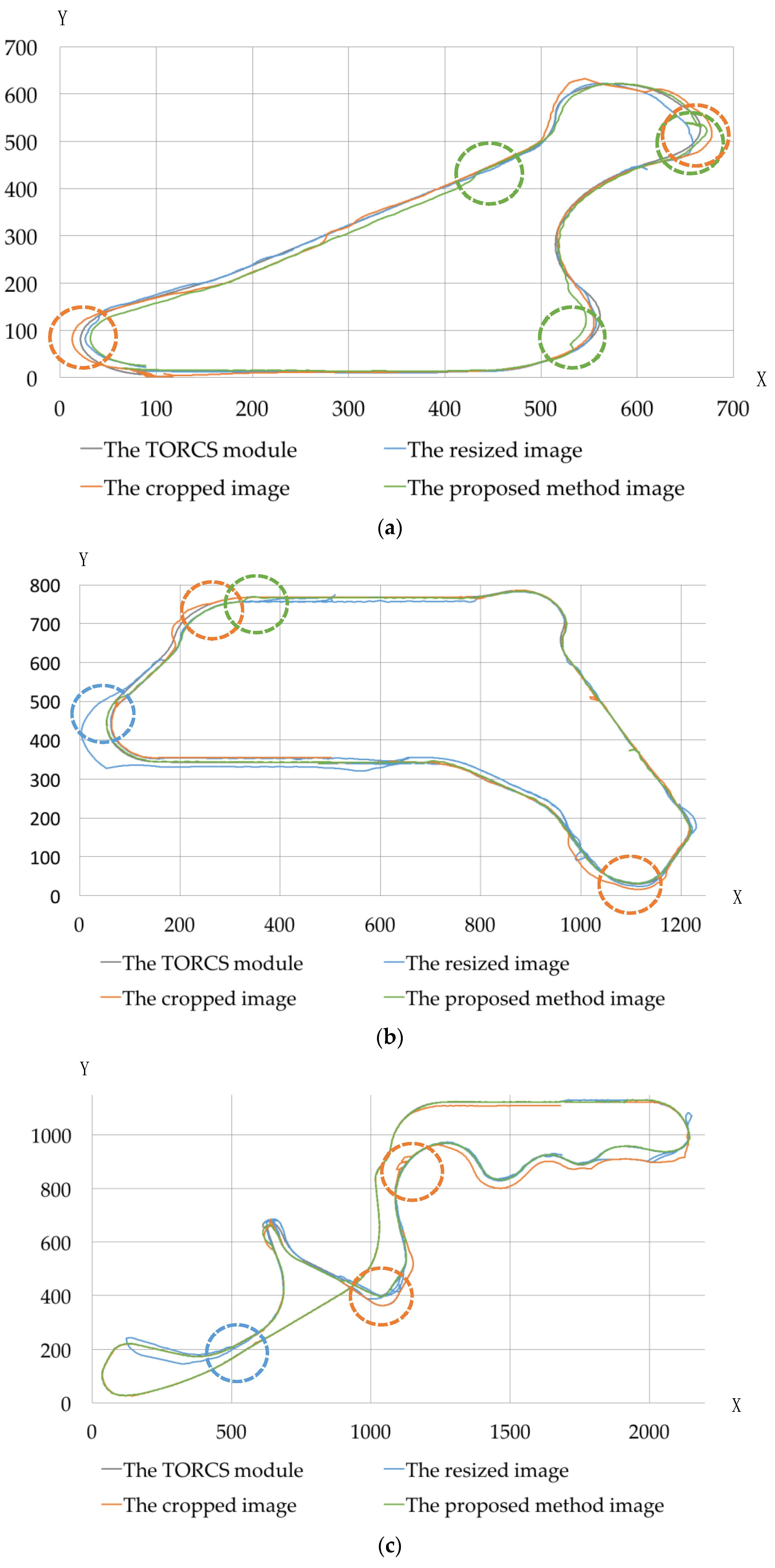
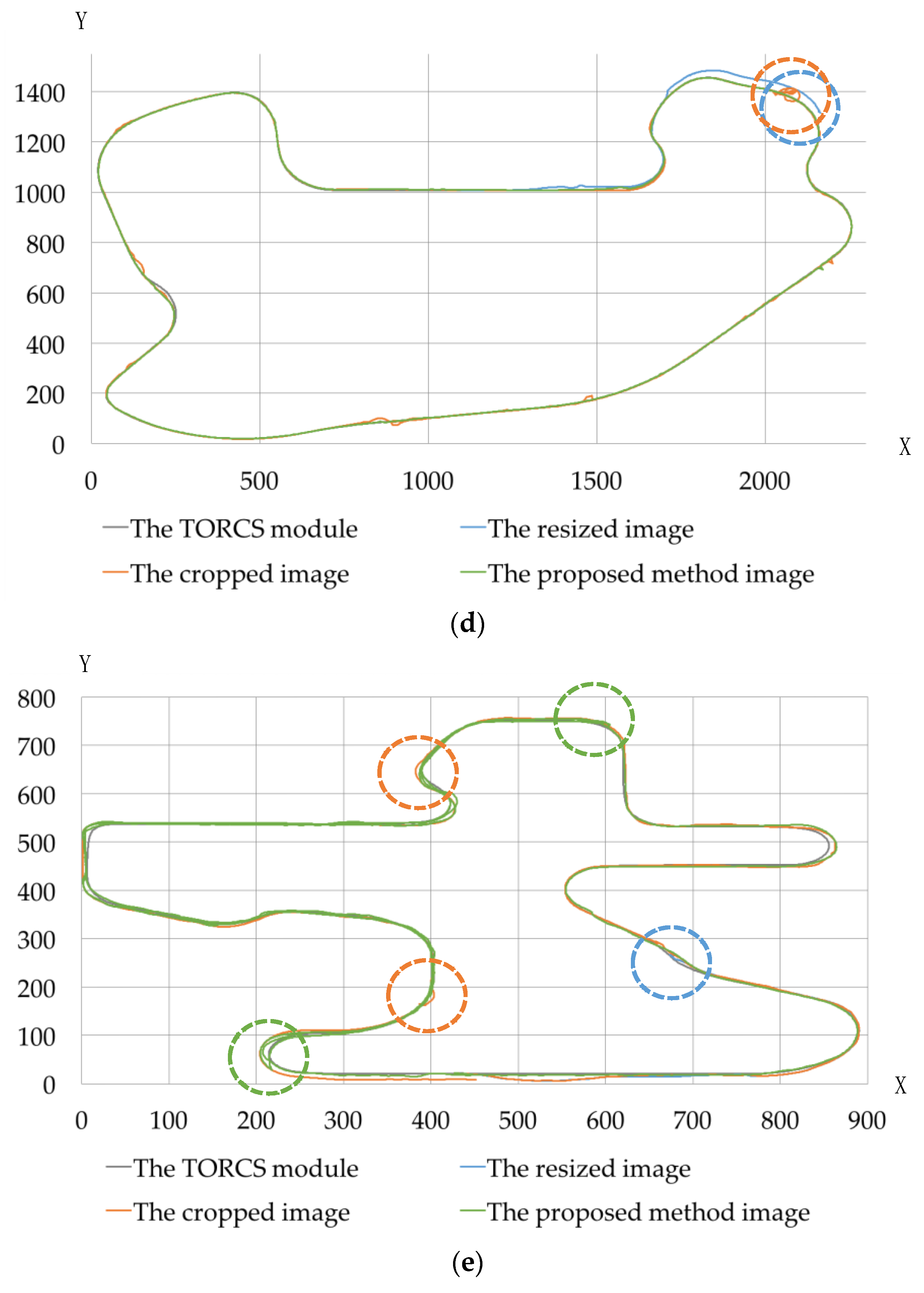
4.3. Experimental Results and Performance Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cho, H.; Seo, Y.W.; Kumar, B.V.; Rajkumar, R.R. A Multi-Sensor Fusion System for Moving Object Detection and Tracking in Urban Driving Environments. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Khoobjou, E.; Mazinan, A.H. On Hybrid Intelligence-based Control Approach with its Application to Flexible Robot System. Hum.-Cent. Comput. Inf. Sci. 2017, 7, 1–18. [Google Scholar] [CrossRef]
- Sung, Y.; Kwak, J.; Park, J.H. Graph-Based Motor Primitive Generation Framework: UAV Motor Primitives by Demonstration-based Learning. Hum.-Cent. Comput. Inf. Sci. 2015, 5, 1–9. [Google Scholar] [CrossRef]
- Abedin, M.Z.; Dhar, P.; Deb, K. Traffic Sign Recognition Using Hybrid Features Descriptor and Artificial Neural Network Classifier. In Proceedings of the 19th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2016. [Google Scholar]
- Jin, J.; Fu, K.; Zhang, C. Traffic Sign Recognition with Hinge Loss Trained Convolutional Neural Networks. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1991–2000. [Google Scholar] [CrossRef]
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. DeepLanes: End-To-End Lane Position Estimation using Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Jiman, K.; Chanjong, P. End-to-End Ego Lane Estimation based on Sequential Transfer Learning for Self-Driving Cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ramos, S.; Gehrig, S.; Pinggera, P.; Franke, U.; Rother, C. Detecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Redondo Beach, CA, USA, 11–14 June 2017. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient Deep Learning for Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Schneemann, F.; Heinemann, P. Context-based Detection of Pedestrian Crossing Intention for Autonomous Driving in Urban Environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016. [Google Scholar]
- Han, H.; Park, S. Traffic Information Service Model Considering Personal Driving Trajectories. J. Inf. Process. Syst. 2017, 13, 951–969. [Google Scholar] [CrossRef][Green Version]
- Kaiser, J.; Tieck, J.C.V.; Hubschneider, C.; Wolf, P.; Weber, M.; Hoff, M.; Friedrich, A.; Wojtasik, K.; Roennau, A.; Kohlhaas, R.; et al. Towards a Framework for End-to-end Control of a Simulated Vehicle with Spiking Neural Networks. In Proceedings of the IEEE International Conference on Simulation, Modeling, and Programming for Autonomous Robots (SIMPAR), San Francisco, CA, USA, 13–16 December 2016. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv, 2016; arXiv:1604.07316. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Pen, Y.; Cheng, C.A.; Saigol, K.; Lee, K.; Yan, X.; Theodoru, E.; Boost, B. Agile Off-Road Autonomous Driving Using End-to-End Deep Imitation Learning. arXiv, 2017; arXiv:1709.07174. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. Deepvo: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Yang, S.; Wang, W.; Liu, C.; Deng, W.; Hedrick, J.K. Feature Analysis and Selection for Training an End-to-End Autonomous Vehicle Controller using Deep Learning Approach. In Proceedings of the IEEE International Conference on Intelligent Vehicles Symposium (IV), Redondo Beach, CA, USA, 11–14 June 2017. [Google Scholar]
- Lee, G.H.; Faundorfer, F.; Pollefeys, M. Motion Estimation for Self-Driving Cars with a Generalized Camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Wolf, P.; Hubschneider, C.; Weber, M.; Bauer, A.; Härtl, J.; Dürr, F.; Zöllner, J.M. Learning How to Drive in a Real World Simulation with Deep Q-Networks. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017. [Google Scholar]
- Lee, U.; Yoon, S.; Shim, H.; Vasseur, P.; Demonceaux, C. Local Path Planning in a Complex Environment for Self-Driving Car. In Proceedings of the IEEE 4th Annual International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Hong Kong, China, 4–7 June 2014. [Google Scholar]
- Canny, J.A. Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- TORCS—The Open Racing Car Simulator. Available online: http://torcs.sourceforge.net/index.php (accessed on 4 January 2018).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 4 January 2018).
- OpenCV. Available online: https://opencv.org/ (accessed on 4 January 2018).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Content |
|---|---|
| Development Platform | Ubuntu 16.04 (Canonical, London, UK) |
| Tool | Pycharm 2017.1.4 (JetBrains, Prague, Czech Repubilc) |
| CPU | i7-6850 K CPU@3.60 GHz (Intel Corporation, Santa Clara, USA) |
| GPU | NVIDIA TITAN XP 12 GB × 4 (Nvidia Corporation, Santa Clara, USA) |
| Memory | 16 GB DDR4 |
| Library | OpenCV 3.1.0, Tensorflow, Share memory |
| Method | CG Speedway Number 1 | CG Track 2 | Wheel 2 | E-Track 4 | Alpine 2 |
|---|---|---|---|---|---|
| The proposed method | 791.5418 | 320.236 | 593.2503 | 301.958 | 492.6927 |
| The resized image [14] | 833.7867 | 448.4071 | 744.6954 | 426.2724 | 525.1988 |
| The cropped image [13] | 912.9649 | 406.769 | 650.2188 | 278.4263 | 690.5489 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sung, Y.; Jin, Y.; Kwak, J.; Lee, S.-G.; Cho, K. Advanced Camera Image Cropping Approach for CNN-Based End-to-End Controls on Sustainable Computing. Sustainability 2018, 10, 816. https://doi.org/10.3390/su10030816
Sung Y, Jin Y, Kwak J, Lee S-G, Cho K. Advanced Camera Image Cropping Approach for CNN-Based End-to-End Controls on Sustainable Computing. Sustainability. 2018; 10(3):816. https://doi.org/10.3390/su10030816
Chicago/Turabian StyleSung, Yunsick, Yong Jin, Jeonghoon Kwak, Sang-Geol Lee, and Kyungeun Cho. 2018. "Advanced Camera Image Cropping Approach for CNN-Based End-to-End Controls on Sustainable Computing" Sustainability 10, no. 3: 816. https://doi.org/10.3390/su10030816
APA StyleSung, Y., Jin, Y., Kwak, J., Lee, S.-G., & Cho, K. (2018). Advanced Camera Image Cropping Approach for CNN-Based End-to-End Controls on Sustainable Computing. Sustainability, 10(3), 816. https://doi.org/10.3390/su10030816