1. Introduction
We cannot deny the revolution that Information and Communication Technologies (ICT) have had in our society in the last twenty years. This revolution has reached all levels of society, and Public Administrations have not been an exception. The progressive implementation of ICT has promoted the development of new rights for citizens and the creation of new communication channels between citizens and Administrations, as well as between the Administrations themselves.
The progressive digitization of work made by civil servants has led to the development of new tools that allow the reception, comprehensive management, and complete traceability of administrative procedures in general, as well as citizen’s requests.
The legal system has been advancing in an attempt to try to define and regulate the way that the application of new technologies is developed in Public Administrations. Although it is not the objective of this work to make an exhaustive analysis of the regulations, it is considered necessary to point out the most important regulations in relation to this work. Given that this work will be based on the case study of a regional administration in Spain, the normative to which we will refer will be that of this country:
Resolution of 19 February 2013, from the Secretariat of State for Public Administrations, which approves the Technical Standard for the Reuse of information resources that establishes the common conditions for the selection, identification, description, format, conditions of use, and availability of documents and information resources prepared or guarded by the public sector [
1].
Law 19/2013, of 9 December, on transparency, access to information, and good governance. This recognizes and guarantees access to information on administrative activity [
2].
Law 39/2015, of 1 October, on the Common Administrative Procedure of Public Administrations [
3].
To comply with the regulations in all matters that relate to public information access by citizens, different initiatives have emerged from the Administrations that have led to open data catalogs development.
Taking into account the datasets published in the Spanish open data catalog [
4], which federates most of the Spanish Public Administrations open data catalogs, it can be concluded that in spite of the existing initiatives, there is a lack of homogeneity which means that two Administrations at the same level do not to publish the same type of information, as well as a lack of standardized vocabularies which causes data to be represented in different ways even if these Administrations publish the same information.
Another aspect that stands out from this analysis is that information is only being published at the data level and that information about administrative processes is not being published at all. It is considered that representing processes, of whatever kind, can be interesting for several reasons:
Modeling processes, whether following linked data principles or not, converts them into actionable objects at the same level as data.
Once these processes can be represented and automatically actionable, it is possible to build intelligent agents that interact with them and perform tasks that go from traceability to auditing.
Administrative procedures are common to all Public Administrations since they derive from the same regulations. This means that all the work done on them can be reused by the entire public sector.
The result of modeling Public Administrations procedures can help sustainability policies in two ways:
Improving decision-making procedures. A better processes knowledge, administrative or not, of those that are carried out in the scope of the organizations leads to improved decision-making procedures as much as they are based on a global and integrating vision.
Administrative management sustainability. Apart from the undoubted improvement in the environmental, social, and economic impact that the implementation of a whole electronic administration implies, it is necessary to highlight the benefits that an adequate knowledge of the internal processes can imply to improve material, economic, and human resources management.
2. Motivation
The goal of the present paper is not only to develop an ontology to represent administrative procedures, but also to facilitate tools which can make these processes actionable objects and facilitate the future development of intelligent agents that analyze and process them favoring organization sustainability through an improvement of policy decision taking.
2.1. Administrative Procedure Visualization
The information of administrative processes represented in a semantic model can be employed to improve the information provided by Public Administrations when a service is applied by a citizen.
Through the information available in administrative procedure catalogues, it is possible to provide high quality information about the tasks that Public Administrations perform when processing citizen applications. Later, through files consultant services, citizens will be able to know the state of a file compared to the tasks established by a procedure.
In this way, citizens can know which part of a procedure has been performed and which part remains to be done, whether they need to get in contact with the administration, and important deadlines, etc.
2.2. Predict Input/Output Registry Activity
The daily registry annotations made through the different channels can be predicted through the information stored in the Public Administrations. In this way, human resources available in the information offices and the capacity of the TI infrastructure can be planned in a more efficient way.
2.3. Administrative Procedures Scheduling
Thanks to historical processing information, the calls for grants and subsidies can be rescheduled to provide a workload of the service that is as linear as possible, avoiding the civil servants work peaks and valleys.
2.4. Analysis and Comparison of Administrative Procedures
From historical administrative processing and given that for the same family of procedures the processing scheme is similar, it will be possible to study the Public Administrations processes and to obtain information about:
The accuracy between the processing of files and what is defined in the standard.
The differences in the definition of the same administrative procedure in two different Public Administrations.
How the processing of records of a specific procedure has evolved over time in the same Service.
Other processing analyses of most frequent actions, which documentation is most commonly remedied, and the detection of bottlenecks, etc.
3. Background and Related Work
In this section, we present work related to our study in different subjects. First of all, we present different approaches to represent workflows that go from BPMN to provenance, and finally we present cases related to the e-Government domain.
Before reviewing related work, it is necessary to define what we understand by administrative procedures. We define administrative procedures and files as:
In this way, we can consider an administrative procedure as an action protocol, a “future” process model, which is the collection of actions that can be carried out in the processing of each individual file. Furthermore, administrative files are the execution traces, instances of each particular procedure that have already happened or are happening, which will require and generate information.
Given the importance for organizations of knowledge about their own processes, it has been necessary to obtain a set of tools that allows the design and modeling of this process management (Business Process Management, BPM). This set of tools is called Business Process Management Software (BPMS) and uses a common notation called Business Management Modeling Notation (BPMN). There have been several attempts to combine BPM with semantic web technology, as we can see in [
5] and [
6]. Although BPMN has been used successfully in the industry, only a few electronic file processing systems implement BPMN as a workflow engine. This is because civil servants prefer tools that are more flexible, compared to the rigid ones that BPMN tends to include. This was the main reason why we decided not to follow BPMN semantic technology to represent administrative process, because we were searching for a model that could fit in almost every system.
The World Wide Web Consortium has been working to represent and model provenance data with the development of the Provenance (PROV-O) ontology [
7], which was designed to represent the actions carried out in the preparation of any information element or software. Provenance describes the way that information entities are created and handled by activities when different agents are involved [
8].
Provenance can only be used as a process representation base once activities have happened, i.e., “in the past”, because it can describe activities that have already happened in some record and it describes who has done those activities. However, provenance does not help to represent administrative procedures “in the future”, which would be the expected processes and all proceedings that will have to be performed in each of the records.
This problem has already been addressed in other domains that have previously applied provenance, like the definition of scientific processes [
9,
10], where they need to establish the relationship between a process execution and its theoretical execution plan. In that way, a Provenance specialization for process modeling called P-PLAN was proposed [
11].
In the Public Administration domain, there has been a lot of work undertaken to achieve the goal of representing e-Government information. At the level of data representation, there are many references like:
Core vocabularies [
12]. The core vocabularies are simplified, re-usable, and extensible data models that capture the fundamental characteristics of an entity in a context-neutral fashion. Nowadays, the current core vocabularies are: Business, location, person, public service, criterion & evidence, and public organization vocabulary.
Common Directory of Organization Units and Offices (DIR3) [
13]. The Common Directory is conceived as an information repository about the organizational structure of a Public Administration and its customer offices. It is a catalogue of administrative units and bodies, administrative registry offices, and public administration citizen services offices.
Contsem project [
14]. The PPROC ontology defines the necessary concepts to describe public procurement processes and the contracts of the public sector (public e-procurement). The ontology has been designed with the main purpose of publishing data about public contracts. This ontology extends the Public Contracts Ontology, an ontology developed by the Czech Open Data initiative.
In order to have a view that is as complete as possible about the administrative domain, it is necessary to join both perspectives: the data and the process level representation. The challenge to support administrative processes in public administrations was described in [
15], where the need to model process patterns, as well as workflow and record management, was identified. The use of ontologies to model public administration processes was also proposed in [
16], where a specific domain ontology was proposed. In this paper, we present a different approach, based on the reuse of existing and more general ontologies like PROV-O and P-PLAN. We propose an extension that reuses these ontologies to increase reusability and to represent not only the processes themselves, but the processes that have been carried out for the generation of some information.
The objective of this paper is to present a representation framework for administrative processes according to the latest standards of the semantic web that have been applied in other areas, such as scientific processes using PROV-O and P-PLAN.
4. Modelling an Extending the Ontologies
In order to use the provenance ontology (PROV-O) and P-PLAN, it is necessary to define several extensions to leverage and reuse their concepts in a new context. We have used the mechanisms provided both in the Provenance Data Model (PROV-DM) and PROV-O to extend and adapt those ontologies to the administrative procedure domain.
Before describing the extensions developed, we will define the most important entities that we want to represent:
Service Catalogue. This is an inventory of the services provided by public administrations and is available to citizens in the scope of their competences.
Procedures Catalogue. This is the internal view of the Service Catalogue which contains the set of administrative acts and phases that are part of the procedure as an answer to a public service.
Administrative phase. This represents an activity that must be done in the context of a procedure.
Administrative act. Each of the administrative actions made in the context of a file and performed inside a phase.
Because of this extension, we have developed a new vocabulary for administrative procedures called A-PROC, which is available at [
17].
In addition to the above, there are several reasons to choose an ontology to model this representation. Ontologies can be considered as a set of representational primitives with which it is possible to model some domain of knowledge. Those representational primitives describe the entities, properties, and relationships that are possible in some specific domain [
16]. As we are describing the entities and relationships that take part in administrative procedures, it is suitable to use an ontology to describe that specific domain. Ontology reuse allows us to improve the ontology development process, saving time and money, and promoting the application of good practices [
18]. The objective of the ontology proposed is not only to describe the entities of administrative procedures, but also to describe information about the entities, activities, and people involved in producing them. In this way, we reuse PROV-O and P-PLAN ontologies that have been successfully applied in other domains.
A key advantage of using ontologies is to enable knowledge sharing. In
Section 5, we show how the ontology proposed can be applied to the information systems of the Principality of Asturias. As most procedures from Public Administrations come from a common legal regulation, having a specific domain ontology for them can improve knowledge sharing between different administrations and improve the transparency of this process for the citizens.
To improve government open data initiatives, Public Administrations will preferably use formats that offer semantic representation of the information, enabling a better understanding of the information represented and its automated treatment [
1].
4.1. Extending PROV-O to Represent Administrative Procedures
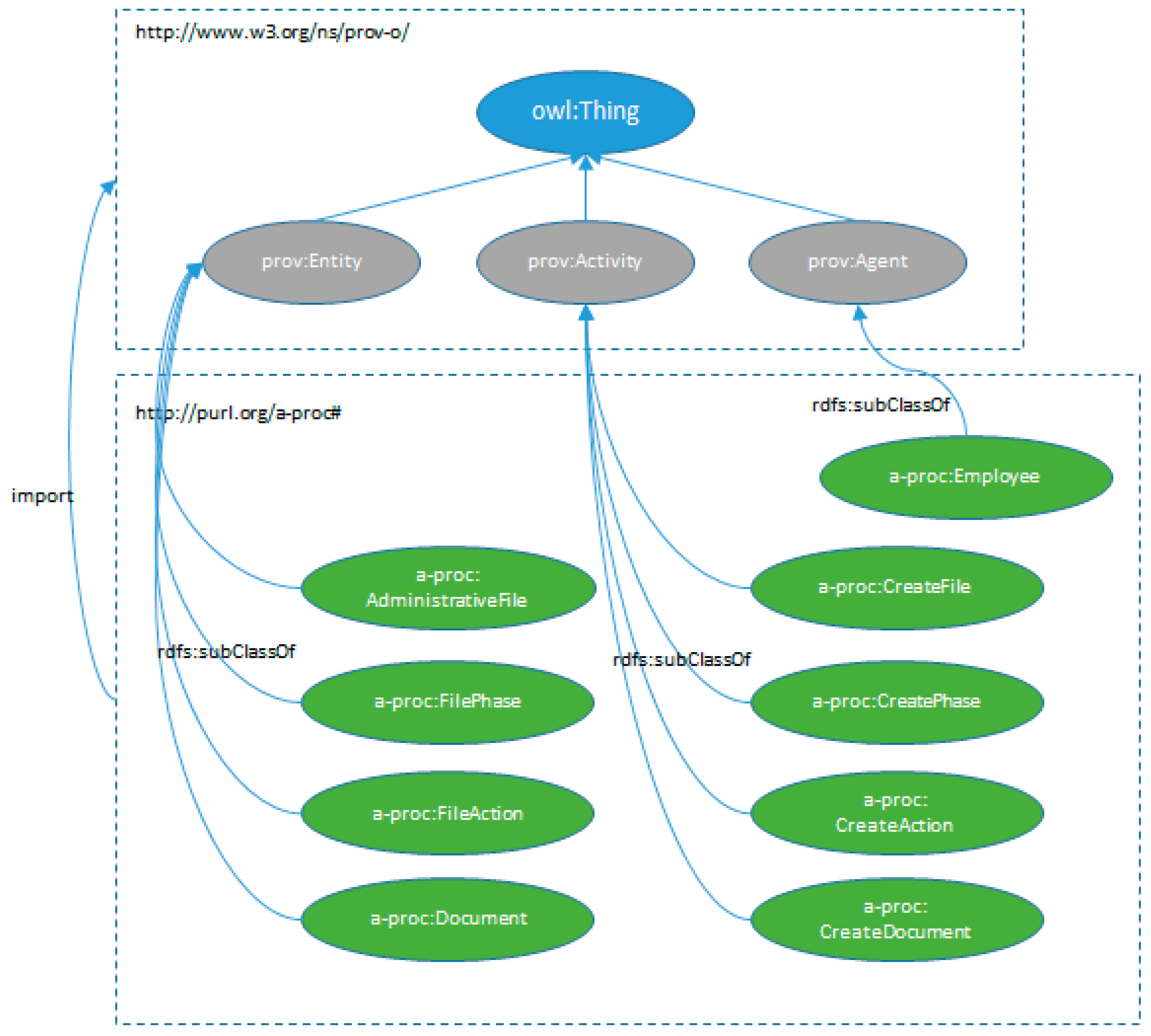
In the same way that Provenance is employed to declare the origin of a given information resource, it is very useful to know the steps that have been followed in the context of a Public Administration to manage and generate the information resources that are employed. In the context of Public Administrations, one possibility is to declare the tasks that have been carried out, who has undertaken them, and what new information has been generated from them, with the goal of being able to analyze, track, and share that information or even to warrant the quality and integrity of the process that has been used.
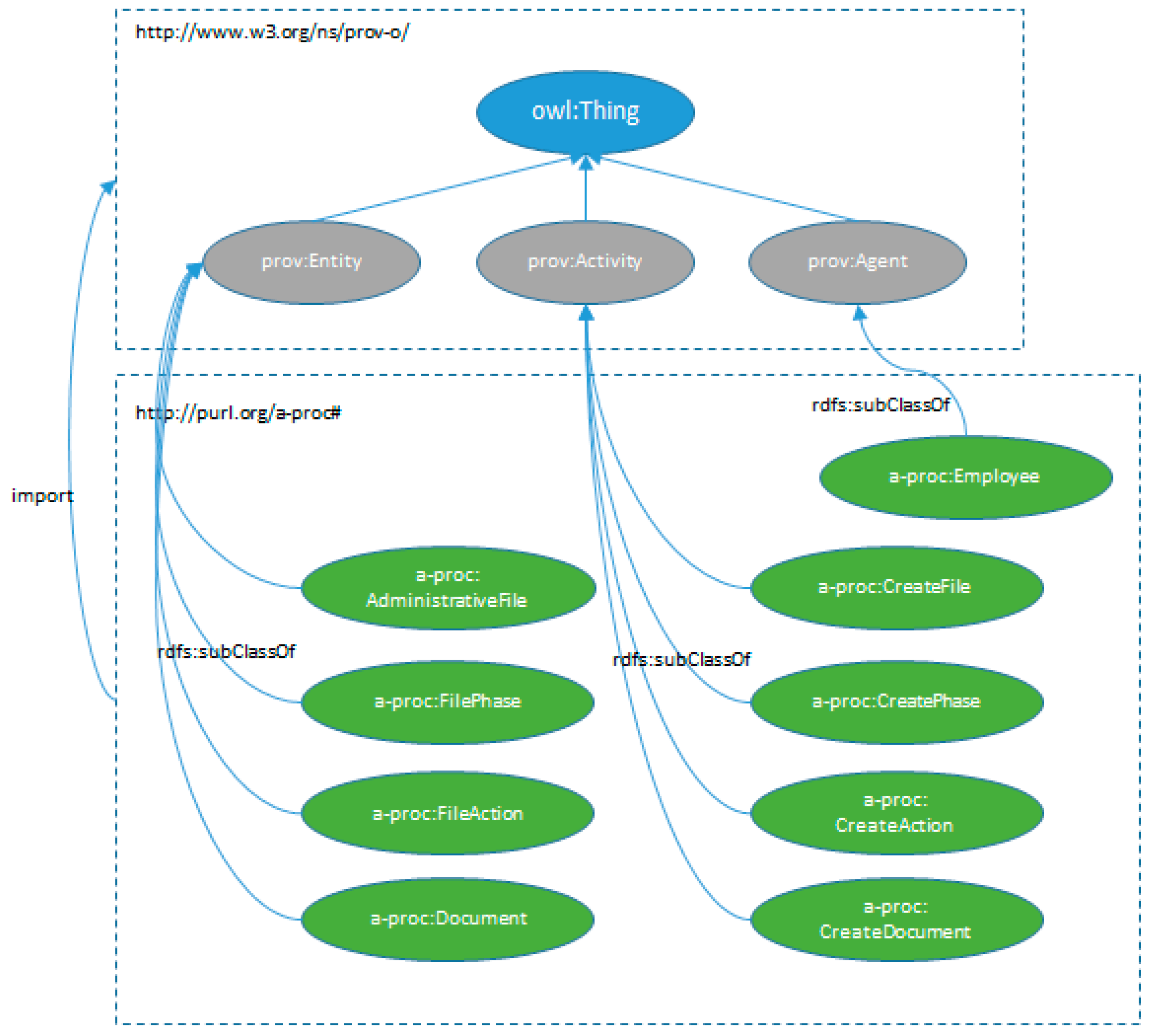
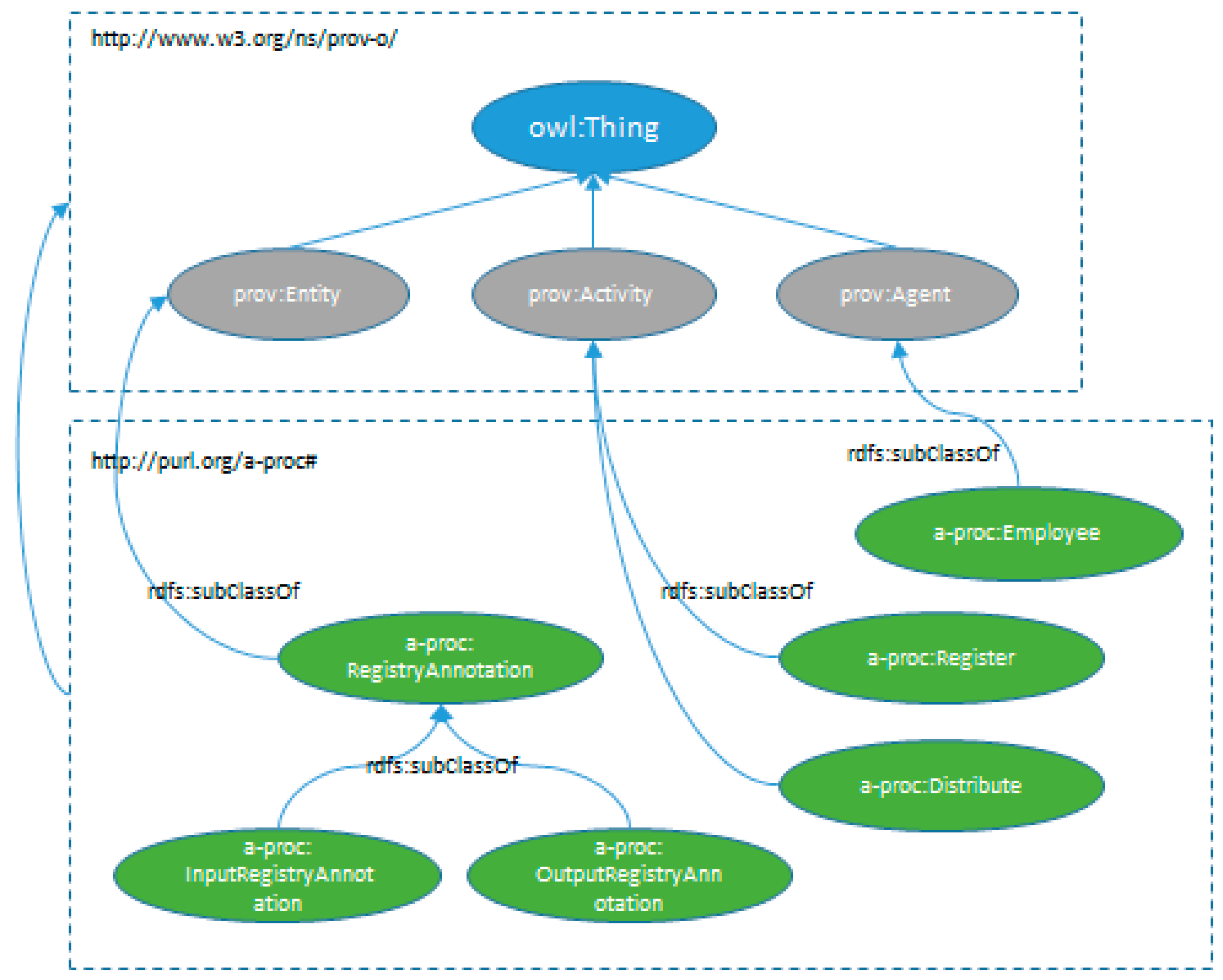
Figure 1 depicts the way in which an administrative process is created. It shows the PROV-O extension to represent administrative files. We have created subclasses of prov:Entity for the entities: AdministrativeFile, FilePhase, FileAction, and Document. In the same way, we have defined activities which are subclasses of prov:Activity to describe the actions that manipulate previous entities. Finally, we defined the class Employee as a subclass of prov:Agent to represent public administration employees.
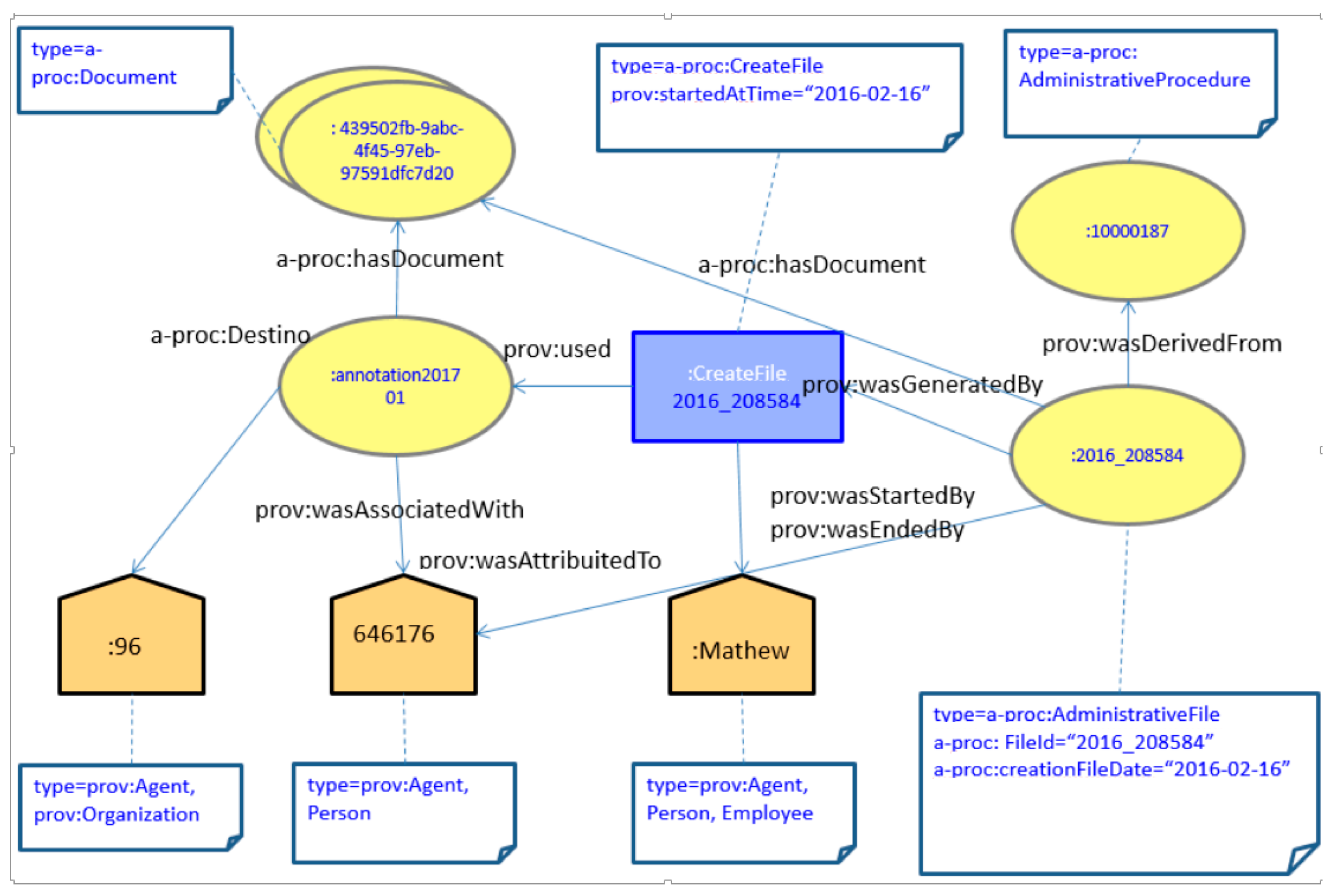
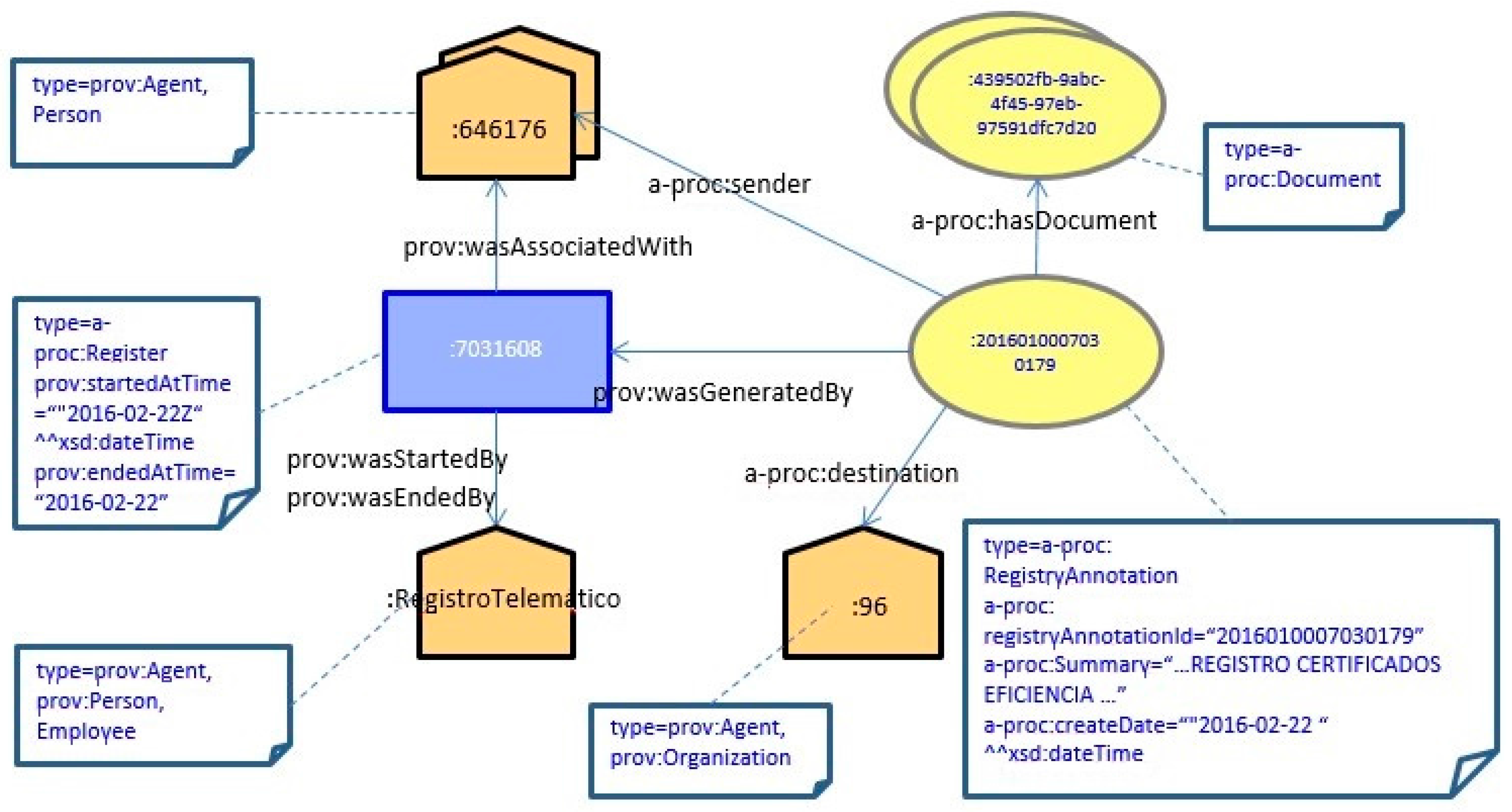
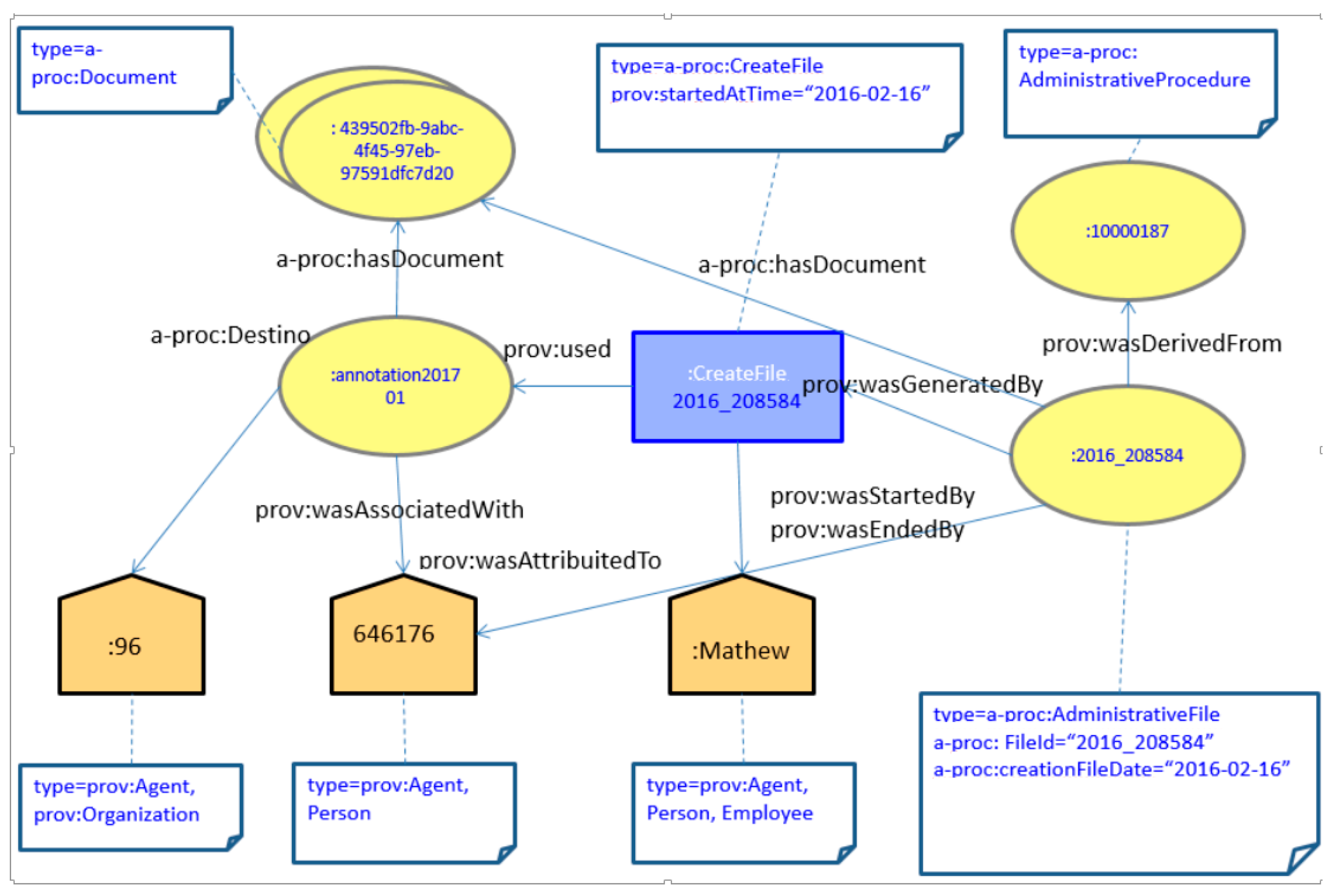
As an example,
Figure 2 shows an example of an administrative file identified as :2016_208584. From a citizen request by citizen: 646176 and its corresponding input registry annotation (:annotation201701) generated by employee: Mathew, an administrative file is created which relates the citizen request and the provided documentation.
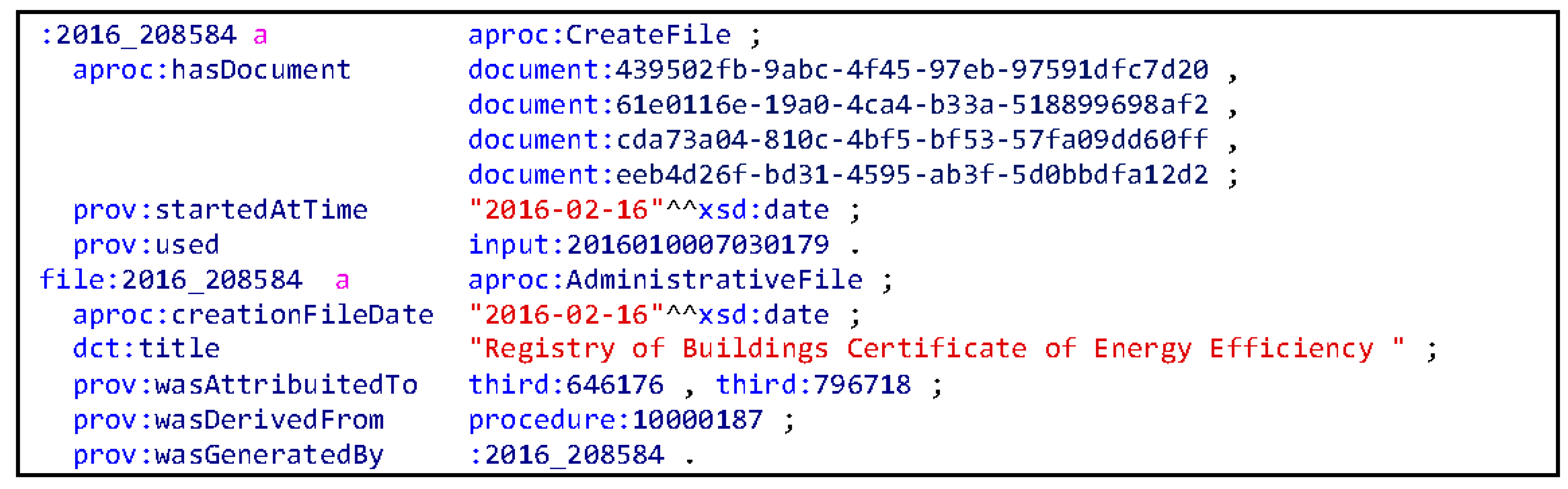
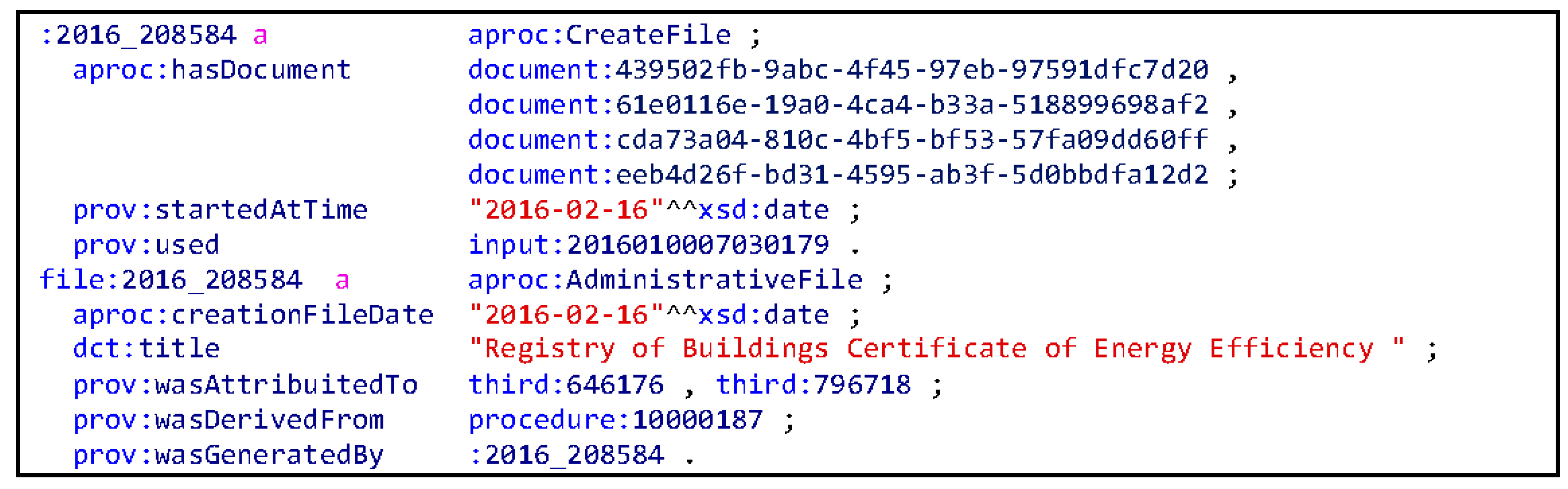
Figure 3 shows the same information depicted in
Figure 2 but in Turtle format.
4.2. Extending PROV-O to Represent Registry Annotations
All documentation entering into or exiting from a Public Administration must have its corresponding annotation in a registry. In the case of input information, the documentation that is managed includes requests or writings, made by citizens, companies, institutions, or other administrations, which are presented to some organization department. The path which these requests undergoes, from the point in which they are presented until they arrive to their destination, varies depending on which channel they have been presented to, and above all, depending on the nature of that documentation, but it is always mandatory to keep a record about the point at which a request is at. In the case of the output record, it is usually different, as the only mandatory information that is usually represented is the instant at which the documentation has exited the organization, its origin, and its destination.
All this information is referred to as an annotation registry, and can be used to keep evidence about documentation traceability, which can be especially important for organizations in order to improve their internal processes and the response and delay time for the citizens.
Registry annotations do not have legal regulation as administrative procedures, and it is not so easy to establish a relationship between the registry annotation and its theoretical execution plan. This is the reason why we do not use P-PLAN to represent registry annotations.
Figure 4 depicts the representation of annotation records and their relationship with PROV-O concepts. Annotation records are defined as subclasses of prov:Entity to represent each annotation. Given that the information recorded differs depending on an input or output annotation, we created two classes :InputRegistryAnnotation and :OutputRegistryAnnotation. In the same way as we did for administrative records, we created the corresponding activities to manage these activities. The Employee class is also defined as a subclass of prov:Agent to represent public administration employees.
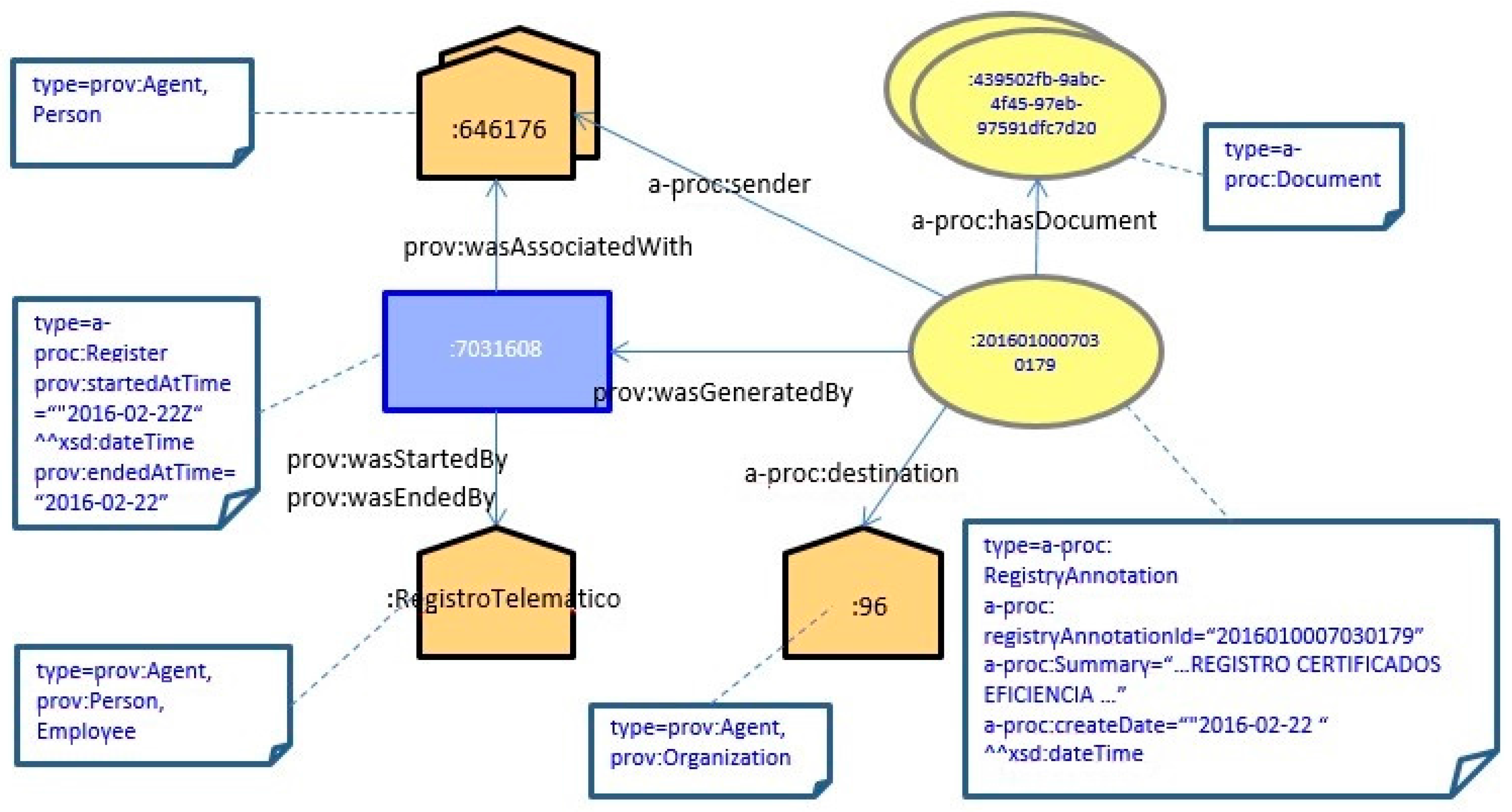
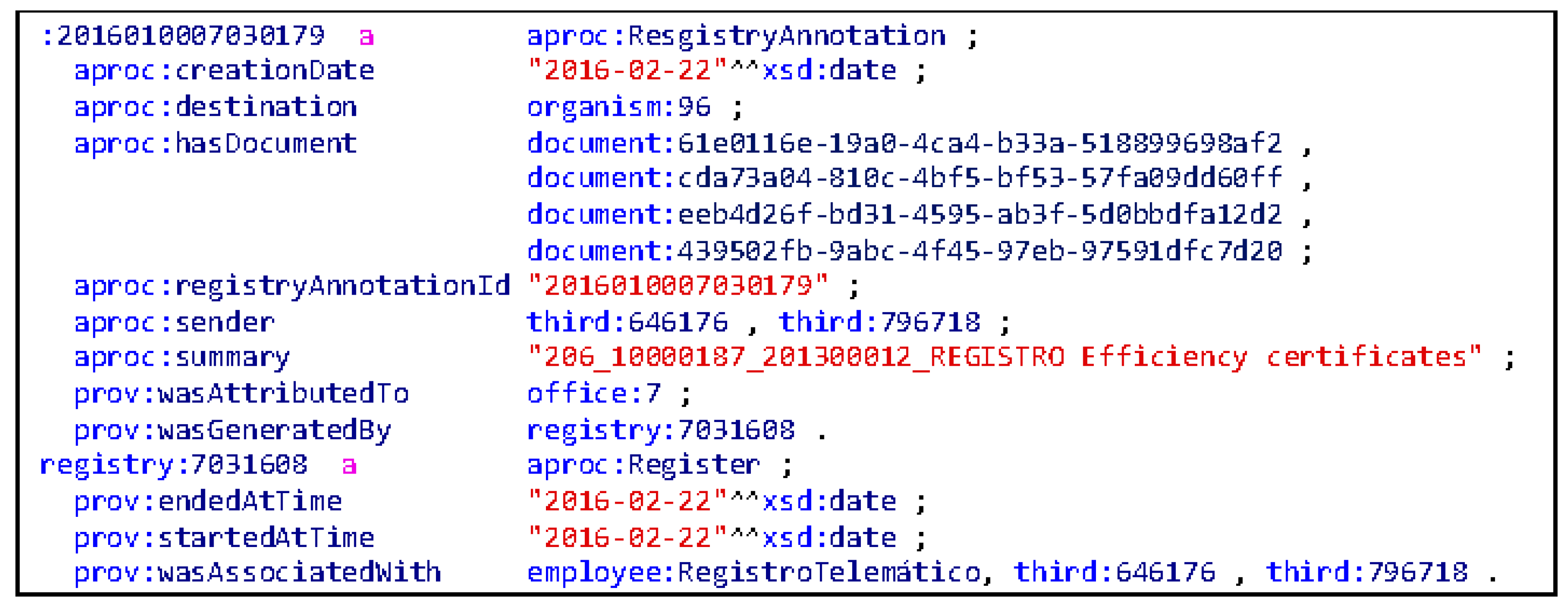
Figure 5 shows an example of how an annotation record is defined from the documentation presented by a citizen in some registry office. The annotation record has been created and has a given department from the organization as the destination.
Figure 6 shows the same information in Turtle.
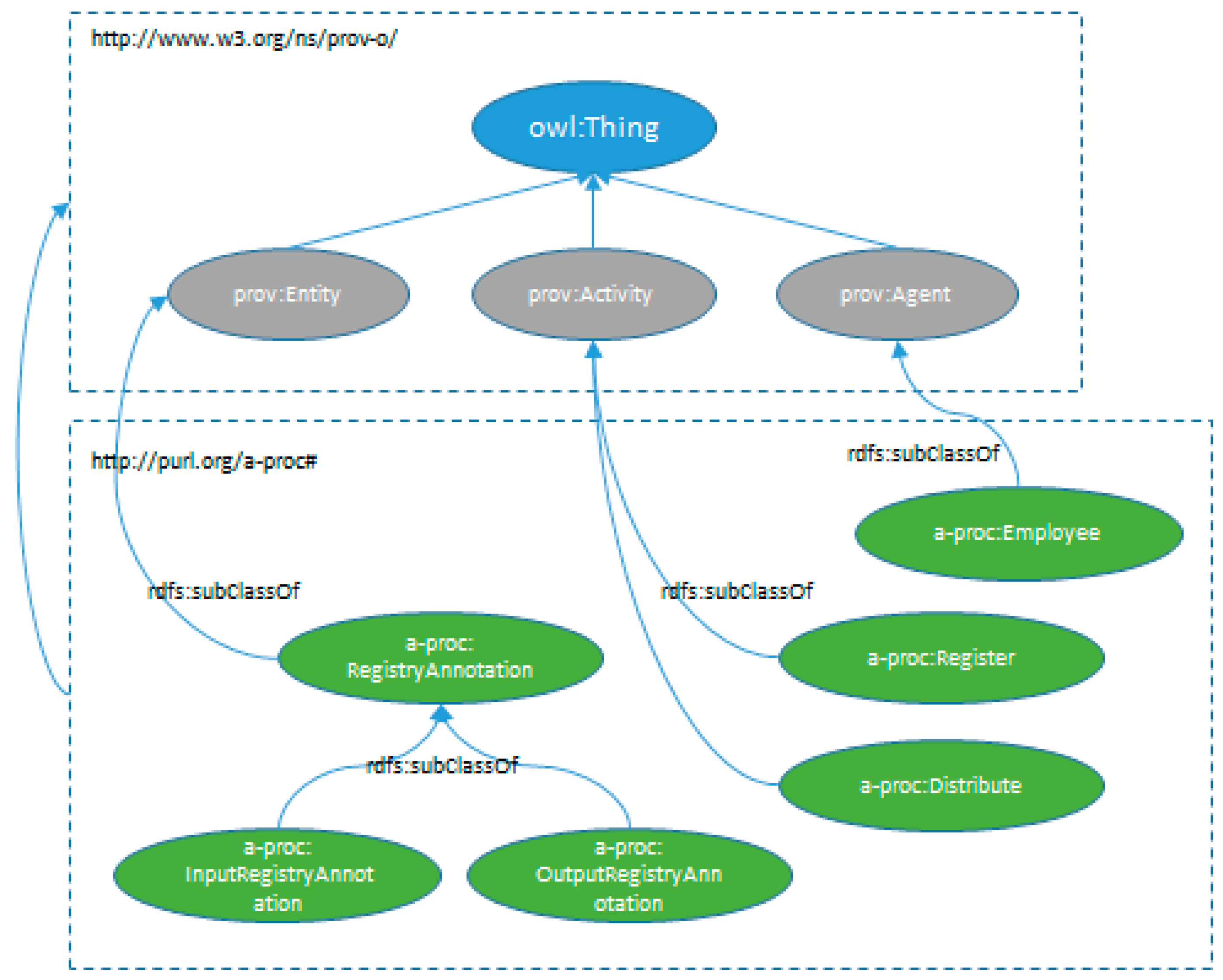
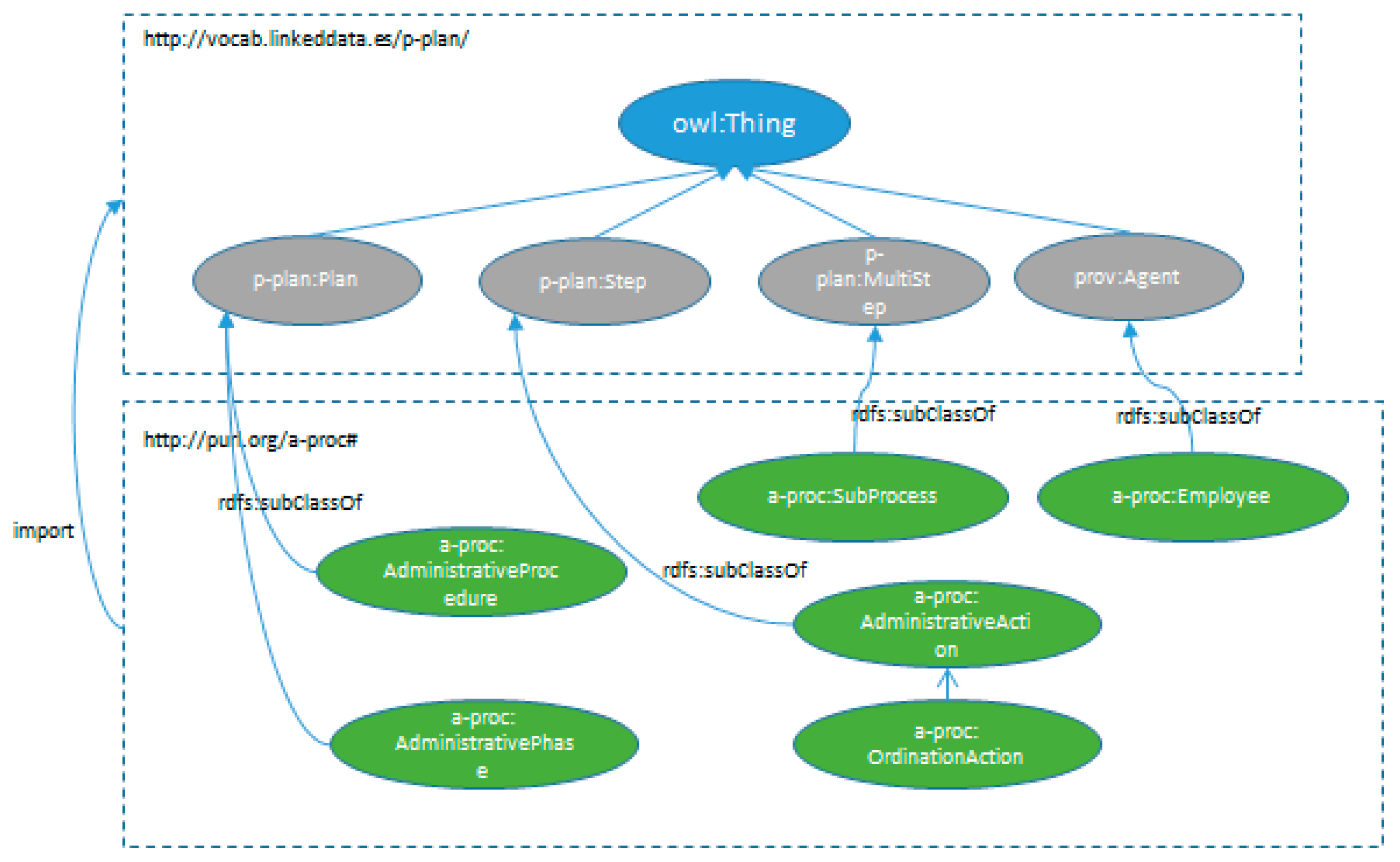
4.3. Extending P-PLAN to Represent Administrative Procedures
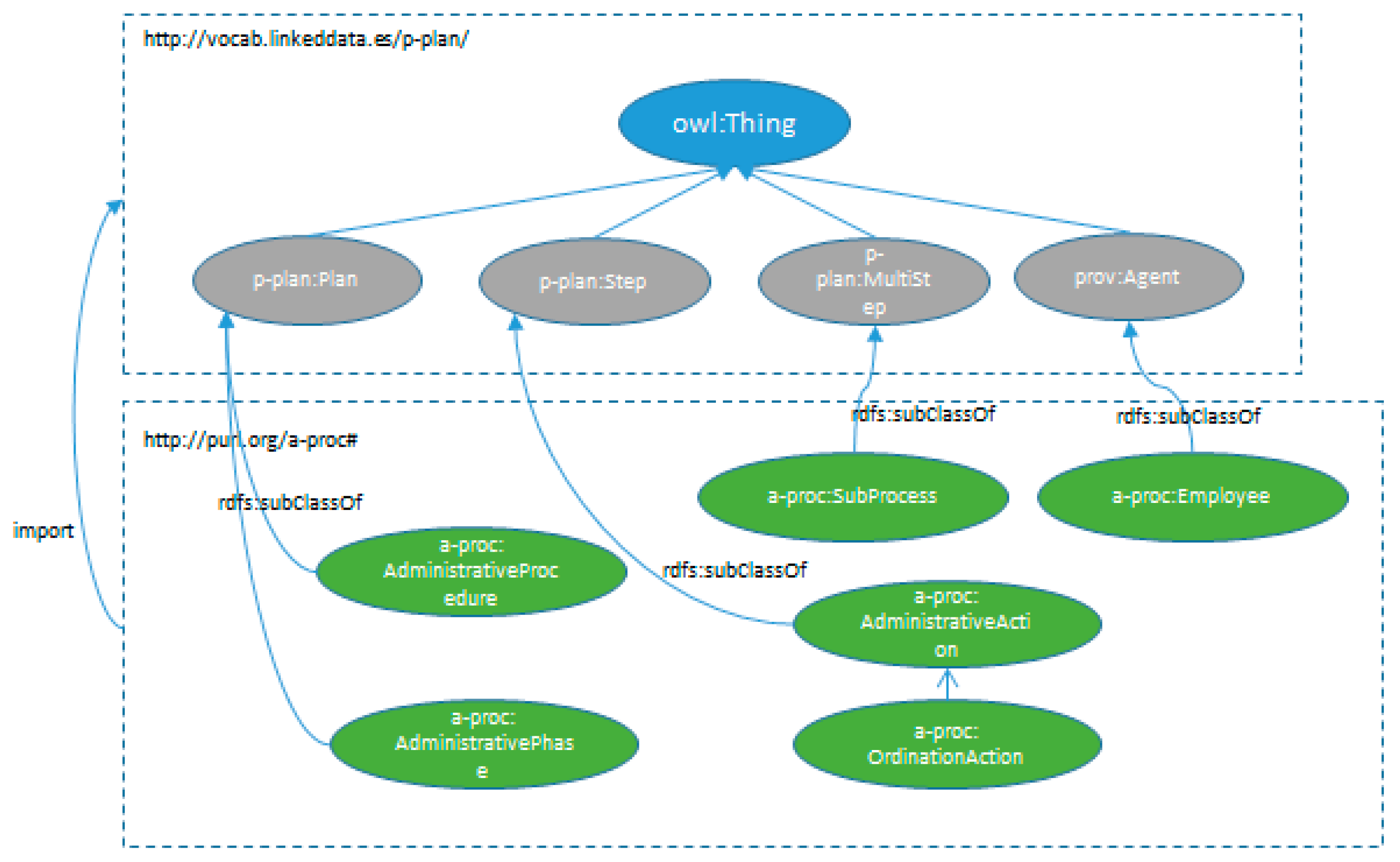
We have seen how we can define administrative procedures as process execution models that will later be carried out in the context of a public administration: the administrative records. We have also seen that it is possible to represent them as an extension of P-PLAN using the ontology mechanisms.
In
Figure 7 depicts the representation of administrative procedures and their relationship with P-PLAN concepts.
Figure 8 shows the representation of an individual administrative procedure in turtle format.
5. Evaluation
With the goal of evaluating the expressiveness of the ontology developed and to foster future research, we have created a knowledge base from data of the Principality of Asturias Public Administration. The data has been collected from the administrative procedures recorded from 2012 to 2016.
The systems selected as information sources have been:
Administrative Procedures Management Systems. We employed custom information systems which are being used by the Principality of Asturias public administration: EUG (Unified Management Desktop or
Escritorio Unificado del Gestor, in Spanish
) and SPIGA (Administrative Management and Production Support Integration or
Soporte Producción Integración y Gestión Administrativa, in Spanish). SPIGA is a clinet-server application used since 2002 with file processing functionalities and a document management system. EUG was a project developed following the principles of openFWPA [
19] and a Service Oriented Architecture to provide file processing functionalities, digital signature, interoperability, and a mechanism to allow integration with other applications through web services.
Input/Output registry (Registro E/S, in Spanish). The input/output document registry system is the system where registry annotations are completed and oversees the distribution of records from their creation until they arrive at their destination. It is also the system where output annotations are recorded for output records.
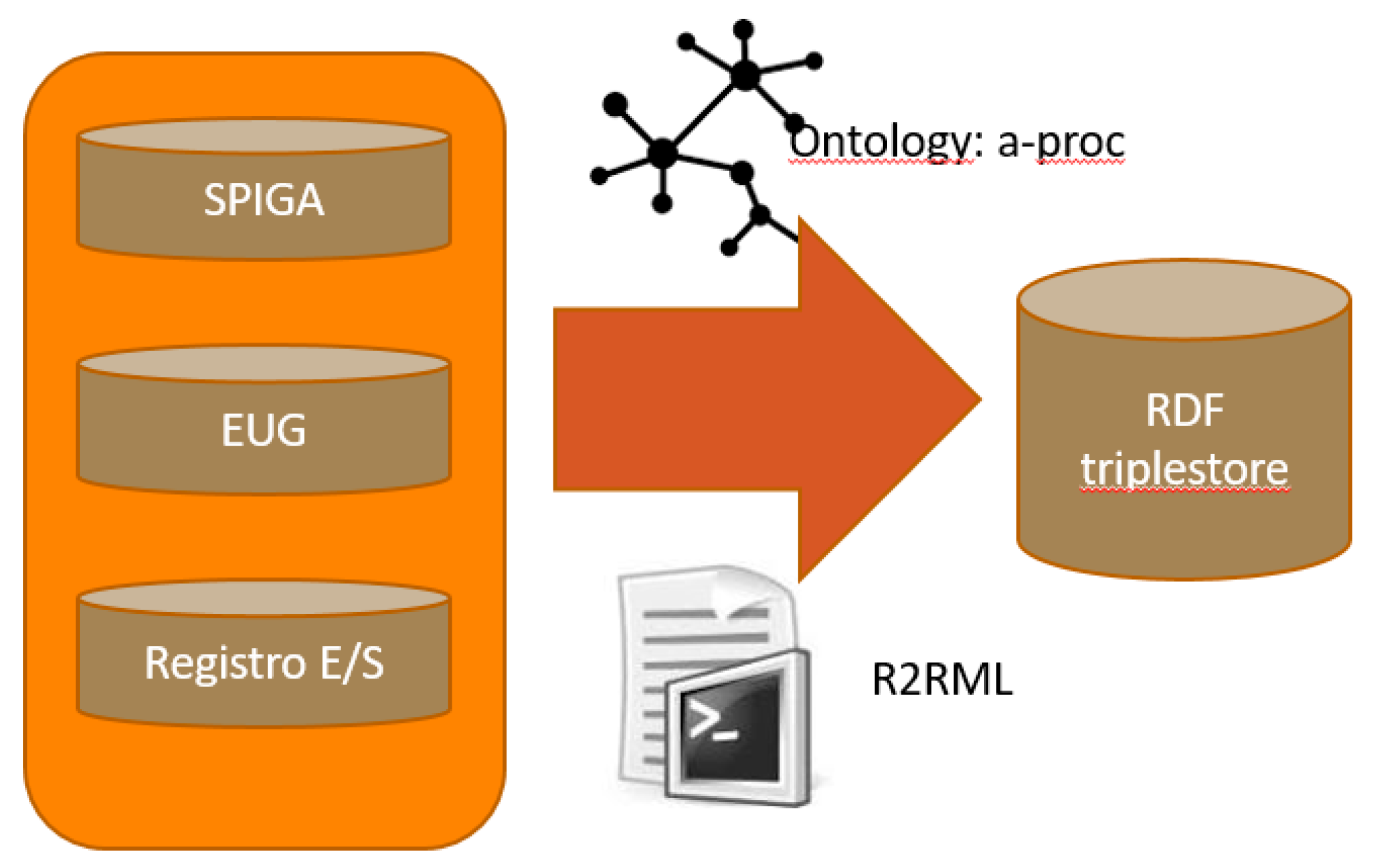
The period of 2012–2016 was chosen in order to have closed files which will no longer be modified by civil servants. The three systems identified as the origin of the information use relational databases to store the information, so we used R2RML [
20] scripts to transform the data of the administrative procedures and store them in an RDF triple-store, as is shown in
Figure 9.
The current system metrics are:
6.8 million annotation records.
428 administrative procedures.
310.000 administrative files.
According to the legal regulation, the administrative procedures are classified as follows:
Grants and subsidies: 225.
Authorizations, licenses and registrations: 127.
Complaints and sanctions: 39.
Human resources: 6.
Others: 31.
There is a disproportion between the number of annotation records and the number of administrative files and procedures. This is because the annotation registry system covers the whole public administration, and the Administrative Procedures Management System only covers certain sectors in the Principality of Asturias administration. These systems cover sectors like tourism, retail, or industry, but do not cover other main sectors like healthcare, education, or agriculture, which have their own specific systems.
We defined several SPARQL queries that can be applied to the knowledge base to obtain some information that could help decision taking, as an example.
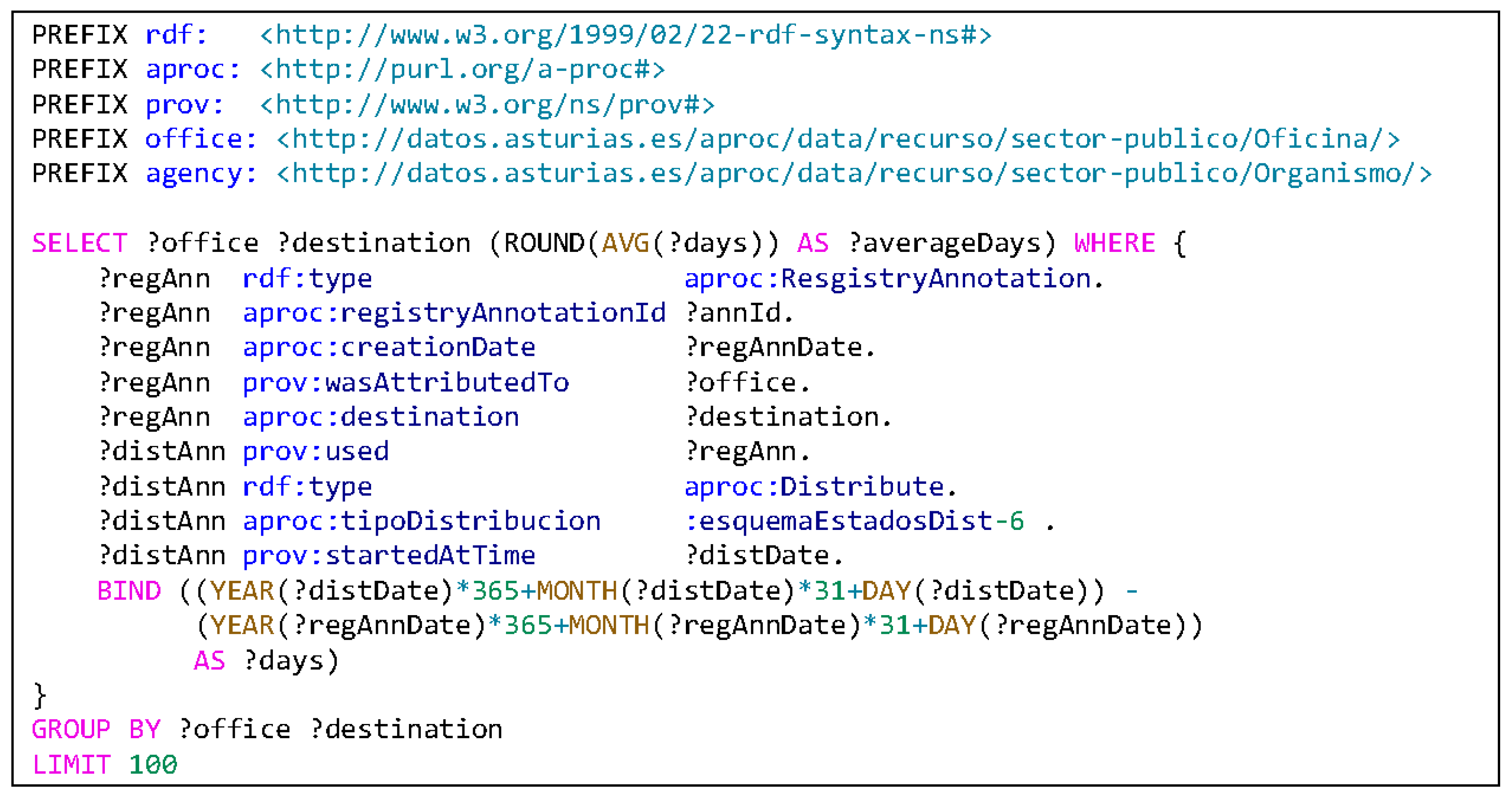
5.1. Compute Average Time of Annotation Record Distribution
A good way to know how well the mechanisms of document distribution work for information provided by a citizen is to calculate the average time it takes between a citizen presenting some documentation in a public administration office and the point at which that information arrives at its destination.
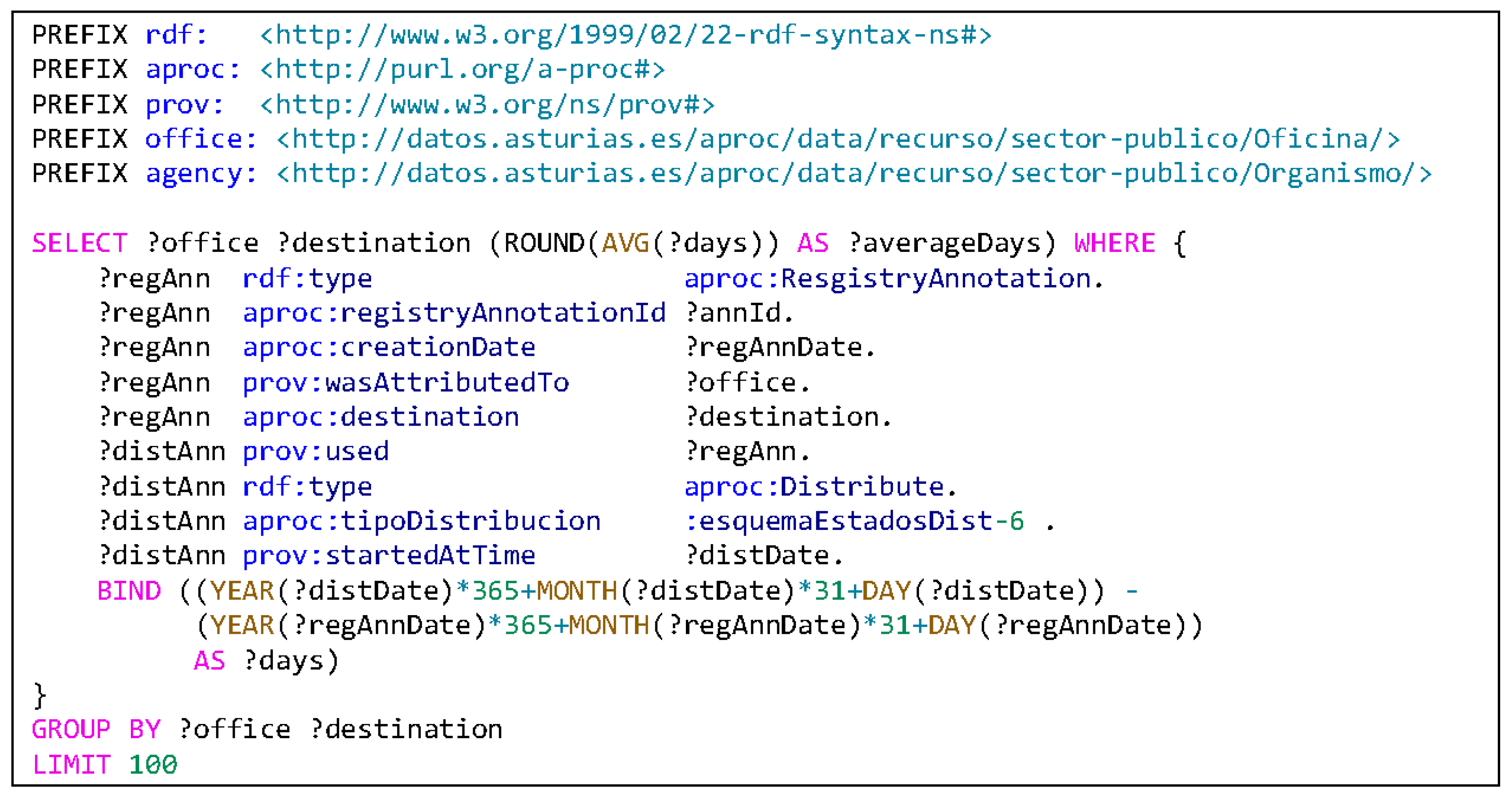
Figure 10 shows a SPARQL query that computes, from annotation records, those distribution actions with a state value of 6 (which means “accepted”), and from those two elements, it computes the number of days as the difference between the creation and acceptance date and returns the average of all those values for the same office and the same destination code.
Table 1 shows the results of that SPARQL query. As can be seen, the results vary between 0 to more than 85 days. From this information, an administration policy manager can decide that there are some cases where the document distribution process must be reviewed.
5.2. Compute Average Record Creation Time
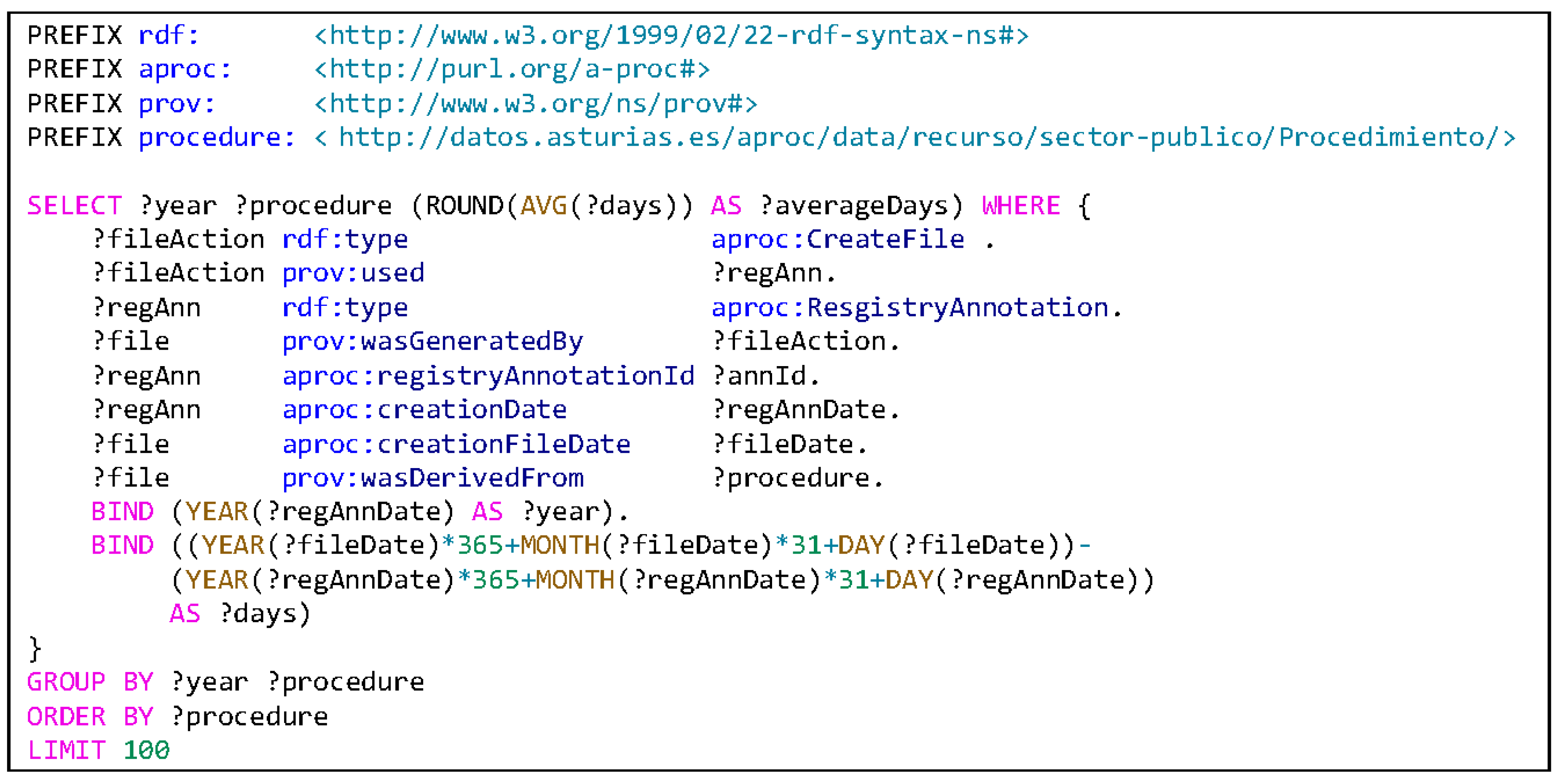
Another possible query is to measure the impact that some policy decisions can have on the organization performance in order to speed up the citizen response time. For example, it is possible to measure the time between requests are presented by a citizen and the point at which a record has been created by a management body. In this example, we have taken the creation date as a reference, but it could be extended to other indicators like the record resolution date or the payment date.
Figure 11 shows how to obtain the records which are related to some annotation registry and computes the number of days as the difference between the record creation and the record annotation date. The results are represented in
Table 2, where it is possible to see that some values are abnormally high, like 22 or 12 days, which should be reviewed by a policy maker.
6. Conclusions
The work presented in this paper can be used to open a new research line about how to represent knowledge in the Public Administration Procedures domain, leveraging general propose vocabularies that have already been applied in other domains.
We did not try to develop a new ontology vocabulary from scratch, but we tried to reuse and extend existing ontology concepts from PROV-O and P-PLAN in order to obtain the necessary expressiveness. Nevertheless, these extensions are not intended to be a final work, but a basis on which to develop future research or standardization works.
We have detected several circumstances in records and administrative procedures that are not completely covered with our proposed extensions. Defining an administrative procedure with P-PLAN represents an ideal situation where records are always forwardly processed; however, this is not always the case. In practice, administrative files processing can become more complex, affected by several decisions, some of which are derived from some concrete data from the file, which can affect the procedure linearity producing forward leaps or even backward leaps. One of the intervening factors in this distortion is the human factor, i.e., the people who control the record processing. It is possible that, depending on the information or situation of some file, some person decides to take an action which is different from those actions that were originally planned or to omit some of them. We consider that being able to detect these situations can also help policy makers to take some decisions to detect or avoid these exceptions, or even to mitigate possible corrupt behavior.
The extensions proposed in this paper have been implemented in accordance with the Spanish rules for Public Administration as a case study; it is possible that during some future standardization process, it will be necessary to adapt and generalize some concepts so that they can be applied in other domains.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}