
Comparison of Topic Modelling Approaches in the Banking Context

 ,
,
Abstract
1. Introduction
2. Related Work
3. Methodology
3.1. Kernel Principal Component Analysis
3.2. K-Means Clustering
- Declare K initial seed points (initial centroids) defined in P-dimensional vectors (s1, s2 … sp) and the squared Euclidean distance between the ith object and the kth seed vector is obtained:
- Cluster centroids are assigned and all objects are assigned to the closest centroids.
- The centroids changes to move closer to the centre point and the objects are reassigned to the closest centroid.
- Repeat the last 2 steps until no objects can be moved between clusters.
3.3. Dataset
3.4. Experimental Setup
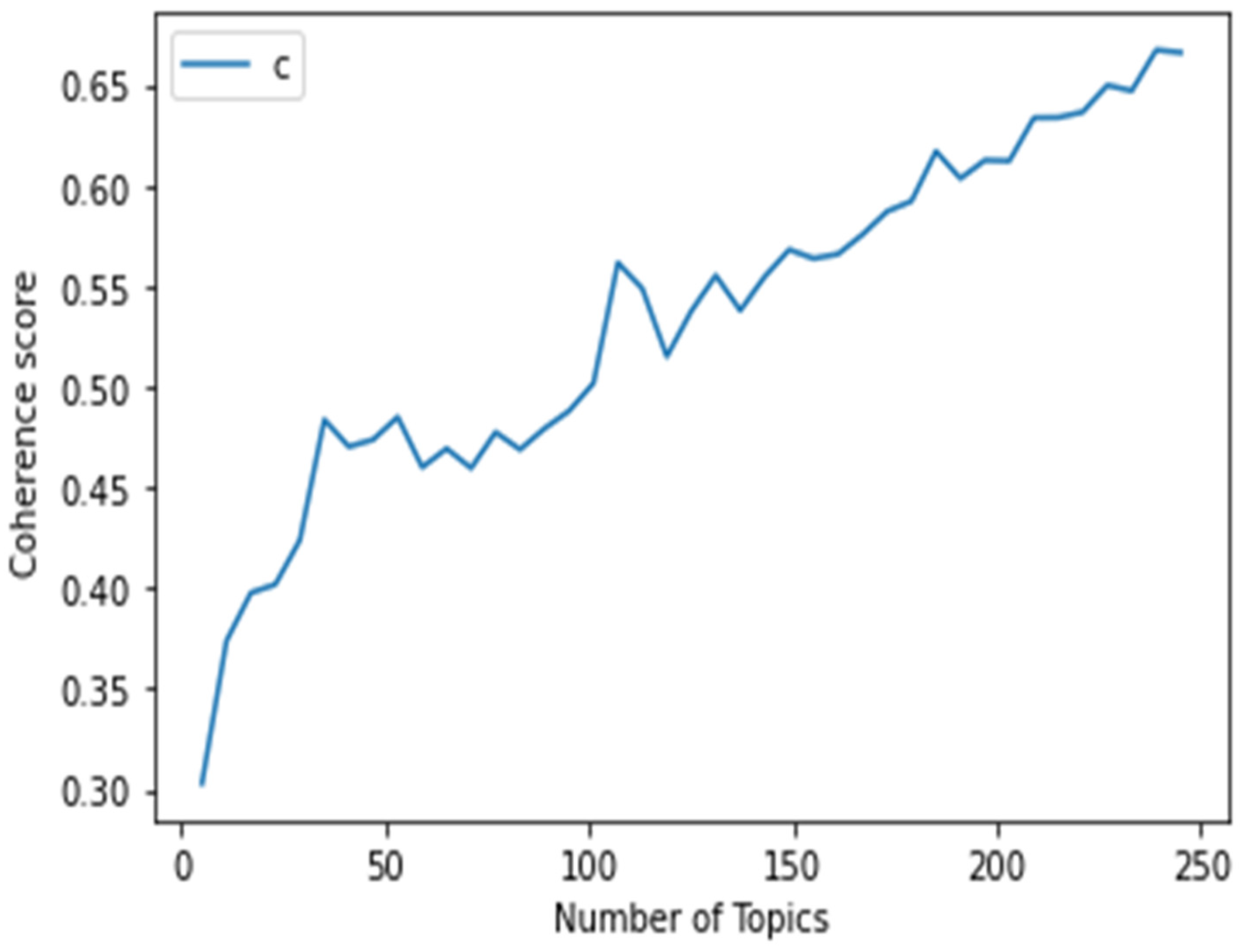
4. Results
5. Conclusions
Contributions, Limitation, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meng, Y.; Zhang, Y.; Huang, J.; Zhang, Y.; Han, J. Topic discovery via latent space clustering of pretrained language model representations. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 3143–3152. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Dandala, B.; Joopudi, V.; Devarakonda, M. Adverse drug events detection in clinical notes by jointly modeling entities and relations using neural networks. Drug Saf. 2019, 42, 135–146. [Google Scholar] [CrossRef] [PubMed]
- Kastrati, Z.; Arifaj, B.; Lubishtani, A.; Gashi, F.; Nishliu, E. Aspect-Based Opinion Mining of Students’ Reviews on Online Courses. In Proceedings of the 2020 6th International Conference on Computing and Artificial Intelligence, Tianjin, China, 23–26 April 2020; pp. 510–514. [Google Scholar]
- Ray, P.; Chakrabarti, A. A mixed approach of deep learning method and rule-based method to improve aspect level sentiment analysis. Appl. Comput. Informatics 2020, 18, 163–178. [Google Scholar] [CrossRef]
- Pennacchiotti, M.; Gurumurthy, S. Investigating topic models for social media user recommendation. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 101–102. [Google Scholar]
- Wang, D.; Zhu, S.; Li, T.; Gong, Y. Multi-document summarization using sentence-based topic models. In Proceedings of the ACL-IJCNLP 2009 Conference Short Papers, Proceedings of the Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; World Scientific: Singapore, 2009; pp. 297–300. [Google Scholar]
- Tepper, N.; Hashavit, A.; Barnea, M.; Ronen, I.; Leiba, L. Collabot: Personalized group chat summarization. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 771–774. [Google Scholar]
- Sabeeh, V.; Zohdy, M.; Bashaireh, R.A. Fake News Detection Through Topic Modeling and Optimized Deep Learning with Multi-Domain Knowledge Sources. In Advances in Data Science and Information Engineering; Springer: Cham, Switzerland, 2021; pp. 895–907. [Google Scholar]
- Wang, T.; Huang, Z.; Gan, C. On mining latent topics from healthcare chat logs. J. Biomed. Inform. 2016, 61, 247–259. [Google Scholar] [CrossRef]
- Adanir, G.A. Detecting topics of chat discussions in a computer supported collaborative learning (CSCL) environment. Turk. Online J. Distance Educ. 2019, 20, 96–114. [Google Scholar] [CrossRef]
- Agrawal, A.; Fu, W.; Menzies, T. What is wrong with topic modeling? And how to fix it using search-based software engineering. Inf. Softw. Technol. 2018, 98, 74–88. [Google Scholar] [CrossRef]
- Silveira, R.; Fernandes, C.G.; Neto, J.A.M.; Furtado, V.; Pimentel Filho, J.E. Topic modelling of legal documents via legal-bert. In Proceedings of the CEUR Workshop, Virtual Event, College Station, TX, USA, 19–20 August 2021; ISSN 1613-0073. Available online: http://ceur-ws.org (accessed on 12 October 2022).
- Blei, D.M.; Lafferty, J.D. A correlated topic model of science. Ann. Appl. Stat. 2007, 1, 17–35. [Google Scholar] [CrossRef]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical dirichlet processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Zhen, L.; Yabin, S.; Ning, Y. A Short Text Topic Model Based on Semantics and Word Expansion. In Proceedings of the 2022 IEEE 2nd International Conference on Computer Communication and Artificial Intelligence (CCAI), Beijing, China, 6–8 May 2022; pp. 60–64. [Google Scholar]
- Chen, W.; Wang, J.; Zhang, Y.; Yan, H.; Li, X. User based aggregation for biterm topic model. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 2, pp. 489–494. [Google Scholar]
- Zhu, Q.; Feng, Z.; Li, X. GraphBTM: Graph enhanced autoencoded variational inference for biterm topic model. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Alsmadi, A.A.; Sha’Ban, M.; Al-Ibbini, O.A. The Relationship between E-Banking Services and Bank Profit in Jordan for the Period of 2010–2015. In Proceedings of the 2019 5th International Conference on E-Business and Applications, Bangkok, Thailand, 25–28 February 2019; pp. 70–74. [Google Scholar]
- Ailemen, I.O.; Enobong, A.; Osuma, G.O.; Evbuomwan, G.; Ndigwe, C. Electronic banking and cashless policy in Nigeria. Int. J. Civ. Eng. Technol. 2018, 9, 718–731. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Dewangan, J.K.; Sharaff, A.; Pandey, S. Improving topic coherence using parsimonious language model and latent semantic indexing. In ICDSMLA 2019; Springer: Singapore, 2020; pp. 823–830. [Google Scholar]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 50–57. [Google Scholar]
- Alfieri, L.; Gabrielyan, D. The Communication Reaction Function of the European Central Bank. An Analysis Using Topic Modelling; Eesti Pank: Tallinn, Estonia, 2021. [Google Scholar]
- Bertalan, V.G.; Ruiz, E.E.S. Using topic modeling to find main discussion topics in Brazilian political websites. In Proceedings of the 25th Brazilian Symposium on Multimedia and the Web, Rio de Janeiro, Brazil, 29 October–1 November 2019; pp. 245–248. [Google Scholar]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Kastrati, Z.; Kurti, A.; Imran, A.S. WET: Word embedding-topic distribution vectors for MOOC video lectures dataset. Data Brief 2020, 28, 105090. [Google Scholar] [CrossRef] [PubMed]
- Qi, B.; Costin, A.; Jia, M. A framework with efficient extraction and analysis of Twitter data for evaluating public opinions on transportation services. Travel Behav. Soc. 2020, 21, 10–23. [Google Scholar] [CrossRef]
- Çallı, L.; Çallı, F. Understanding Airline Passengers during COVID-19 Outbreak to Improve Service Quality: Topic Modeling Approach to Complaints with Latent Dirichlet Allocation Algorithm. Res. Rec. J. Transp. Res. Board 2022. [Google Scholar] [CrossRef]
- Doh, T.; Kim, S.; Yang, S.-K.X. How You Say It Matters: Text Analysis of FOMC Statements Using Natural Language Processing. Fed. Reserv. Bank Kans. City Econ. Rev. 2021, 106, 25–40. [Google Scholar] [CrossRef]
- Edison, H.; Carcel, H. Text data analysis using Latent Dirichlet Allocation: An application to FOMC transcripts. Appl. Econ. Lett. 2020, 28, 38–42. [Google Scholar] [CrossRef]
- Lee, H.; Seo, H.; Geum, Y. Uncovering the topic landscape of product-service system research: From sustainability to value creation. Sustainability 2018, 10, 911. [Google Scholar] [CrossRef]
- Shirota, Y.; Yano, Y.; Hashimoto, T.; Sakura, T. Monetary policy topic extraction by using LDA: Japanese monetary policy of the second ABE cabinet term. In Proceedings of the 2015 IIAI 4th International Congress on Advanced Applied Informatics, Okayama, Japan, 12–16 July 2015; pp. 8–13. [Google Scholar]
- Moro, S.; Cortez, P.; Rita, P. Business intelligence in banking: A literature analysis from 2002 to 2013 using text mining and latent Dirichlet allocation. Expert Syst. Appl. 2015, 42, 1314–1324. [Google Scholar] [CrossRef]
- Westerlund, M.; Olaneye, O.; Rajahonka, M.; Leminen, S. Topic modelling on e-petition data to understand service innovation resistance. In Proceedings of the International Society for Professional Innovation Management (ISPIM) Conference, Palazzo dei Congressi, Florence, Italy, 4–7 June 2019; pp. 1–13. [Google Scholar]
- Tabiaa, M.; Madani, A. Analyzing the Voice of Customer through online user reviews using LDA: Case of Moroccan mobile banking applications. Int. J. Adv. Trends Comput. Sci. Eng. 2021, 10, 32–40. [Google Scholar] [CrossRef]
- Damane, M. Topic Classification of Central Bank Monetary Policy Statements: Evidence from Latent Dirichlet Allocation in Lesotho. Acta Univ. Sapientiae Econ. Bus. 2022, 10, 199–227. [Google Scholar] [CrossRef]
- Bastani, K.; Namavari, H.; Shaffer, J. Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints. Expert Syst. Appl. 2019, 127, 256–271. [Google Scholar] [CrossRef]
- Gan, J.; Qi, Y. Selection of the Optimal Number of Topics for LDA Topic Model—Taking Patent Policy Analysis as an Example. Entropy 2021, 23, 1301. [Google Scholar] [CrossRef] [PubMed]
- Hristova, G. Topic modelling of chat data: A case study in the banking domain. AIP Conf. Proc. 2021, 2333, 150014. [Google Scholar]
- Ali, F.; Kwak, D.; Khan, P.; El-Sappagh, S.; Ali, A.; Ullah, S.; Kwak, K.S. Transportation sentiment analysis using word embedding and ontology-based topic modeling. Knowl.-Based Syst. 2019, 174, 27–42. [Google Scholar] [CrossRef]
- Teh, Y.; Jordan, M.; Beal, M.; Blei, D. Sharing clusters among related groups: Hierarchical dirichlet processes. In Advances in Neural Information Processing Systems 17, Proceedings of the Neural Information Processing Systems, NIPS 2004, Vancouver, BC, Canada, 13–18 December 2004; ACM: New York, NY, USA, 2004. [Google Scholar]
- Zhai, Z.; Liu, B.; Xu, H.; Jia, P. Constrained LDA for grouping product features in opinion mining. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2011; pp. 448–459. [Google Scholar]
- Zhao, X.; Jiang, J.; Yan, H.; Li, X. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid. In Proceedings of the Conference on Empirical Methods in Natural Language, Cambridge, MA, USA, 9–11 October 2010. [Google Scholar]
- Chen, Z.; Mukherjee, A.; Liu, B. Aspect extraction with automated prior knowledge learning. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 347–358. [Google Scholar]
- Yan, X.; Guo, J.; Lan, Y.; Cheng, X. A biterm topic model for short texts. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1445–1456. [Google Scholar]
- Xia, Y.; Tang, N.; Hussain, A.; Cambria, E. Discriminative bi-term topic model for headline-based social news clustering. In Proceedings of the Twenty-Eighth International Flairs Conference, Hollywood, FL, USA, 18–25 May 2015. [Google Scholar]
- Yanuar, M.R.; Shiramatsu, S. Aspect extraction for tourist spot review in Indonesian language using BERT. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 298–302. [Google Scholar]
- Bensoltane, R.; Zaki, T. Towards Arabic aspect-based sentiment analysis: A transfer learning-based approach. Soc. Netw. Anal. Min. 2022, 12, 7. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Zhu, L.; Pergola, G.; Gui, L.; Zhou, D.; He, Y. Topic-Driven and Knowledge-Aware Transformer for Dialogue Emotion Detection. arXiv 2021, arXiv:2106.01071. [Google Scholar]
- Grootendorst, M. BERTopic: Neural topic modelling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Abuzayed, A.; Al-Khalifa, H. BERT for Arabic topic modeling: An experimental study on BERTopic technique. Procedia Comput. Sci. 2021, 189, 191–194. [Google Scholar] [CrossRef]
- Raju, S.V.; Bolla, B.K.; Nayak, D.K.; Kh, J. Topic Modelling on Consumer Financial Protection Bureau Data: An Approach Using BERT Based Embeddings. In Proceedings of the 2022 IEEE 7th International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2022; pp. 1–6. [Google Scholar]
- Ogunleye, B.O. Statistical Learning Approaches to Sentiment Analysis in the Nigerian Banking Context. Ph.D. Thesis, Sheffield Hallam University, Sheffield, UK, 2021. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analysing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. ArXiv 2019, arXiv:1908.10084. [Google Scholar]
- Araci, D. FinBERT: Financial Sentiment Analysis with Pre-Trained Language Models. arXiv 2019, arXiv:1908.10063. [Google Scholar]
- Albalawi, R.; Yeap, T.H.; Benyoucef, M. Using Topic Modeling Methods for Short-Text Data: A Comparative Analysis. Front. Artif. Intell. 2020, 3, 42. [Google Scholar] [CrossRef] [PubMed]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 399–408. [Google Scholar]
- Asghari, M.; Sierra-Sosa, D.; Elmaghraby, A.S. A topic modeling framework for spatio-temporal information management. Inf. Process. Manag. 2020, 57, 102340. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 1997; pp. 583–588. [Google Scholar]
- Lyu, C.; Basumallik, S.; Eftekharnejad, S.; Xu, C. A data-driven solar irradiance forecasting model with minimum data. In Proceedings of the 2021 IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 2–5 February 2021; pp. 1–6. [Google Scholar]



{kind=link}
{kind=link}
| Algorithm | Experimental Set Up |
|---|---|
| ISOMAP | number of neighbours = 15, n_components = 5, eigen_solver = ‘auto’ |
| PCA | n_components = 5 |
| KPCA | n_components = 5, kernel = ‘radial basis function’, gamma = 15, random_state = 42 |
| SVD | n_components = 5, algorithm = ‘randomized’, random_state = 0 |
| UMAP | number of neighbours = 15, n_components = 10, min_dist = 0.0, metric = ‘cosine’ |
| Algorithm | Experimental Set Up |
|---|---|
| K-means Clustering | n_cluster = 8, n_init = 10, max_iter = 300, init = ‘k-means++’ |
| Agglomerative Clustering | n_cluster = 2, linkage = ‘ward’, metric = ‘Euclidean’ |
| HDBSCAN | min_cluster_size = 10, metric = ‘Euclidean’, cluster_selection_method = ‘eom’, alpha = 1.0 |
| DBSCAN | Eps = 0.30, min_samples = 9, metric = ‘Euclidean’ |
| BIRCH | Threshold = 0.01, n_cluster = 3 |
| OPTICS | min_samples = 10, Eps = 0.8, metric = ‘minkowski’ |
| Meanshift | max_iter = 300, min_bin_freq = 1 |
| Spectral Clustering | n_cluster = 8, eigen_solver = ‘arpack’, assign_labels = ‘kmeans’, n_init = 10 |
| Model | Coherence Score (Cv) | Coherence Score (Umass) |
|---|---|---|
| LDA | 0.3919 | −9.1174 |
| LSI | 0.3912 | −2.6630 |
| HDP | 0.6347 | −16.5378 |
| LDA | Terms |
|---|---|
| Topic 1 | customer, cenbank_central, branch, time, month, people, guy, atm, even, week, still, day, service, call, complaint, nothing, customer_care, money, customer_service, thing |
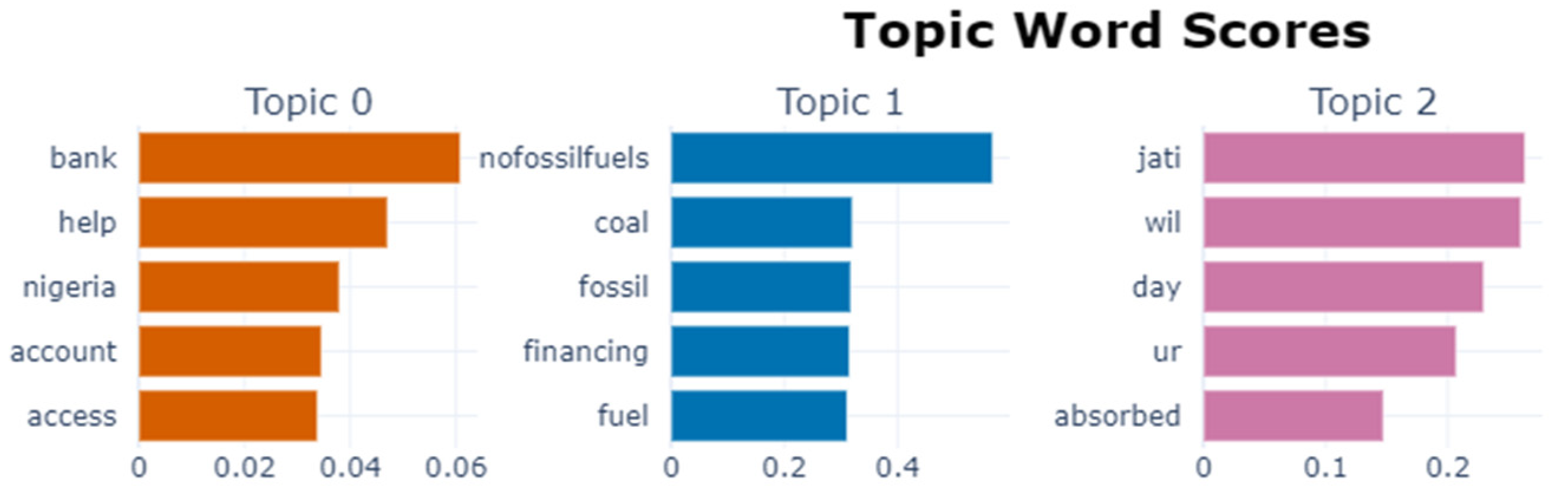
| Topic 2 | job, morgan, free, min, company, una, fossil_fuel, ready, hey_investment, gas_coal, financing_oil, earth_stop, company_nofossil, nofossilfuel, fargo_jpmorgan, change, actually, head, woman, country |
| Topic 3 | help, access, account, money, transaction, please, transfer, pls, yet, day, number, kindly, yesterday, back, today, issue, alert, need, airtime, fund |
| Topic 4 | loan, help, veilleur, bbnaija, cenbank_central, kindly_follow, day, send_direct, officialefcc, message_details, monthly, thank, house, enable_assist, salary, ph, advise_appropriately, heritagebank, eyin_ole, force |
| Topic 5 | card, charge, never, new, use, open, year, debit, later, small, fee, pay, dey, top, see, right, also, month, nyou, far |
| Topic 6 | business, lagos, great, school, news, monetizable_activity, world, additional_information, soon, let, part, good, best, opportunity, today, deposit, wish, thanks, trump, event |
| Topic 7 | dm, help, detail, thank, number, twitter, kindly, please, complaint, sorry, send, tweet, transaction, handle, account, information, send_dm, channel, phone_number, message |
| Topic 8 | line, phone, support, ng, mobile, mtnng_mtn, hope, food, consumer, government, international, buhari, sort, whatsapp, explanation, enable, lagos, foundation, industry, ubaat |
| Topic 9 | always, poor, stop, financial, ng_union, cool, youfirst, sport, business, service, finance, internet_banking, premiercool, mind, tell, thing, daily, single, fast, vista_intl |
| Topic 10 | credit_card, citi, bill, state, debt, payment, chase, omo_iya, mastercard, nthank, ng, future, true, alat, abuja, pay, india, atm_machine, child, product |
| HDP | Terms |
|---|---|
| Topic 1 | help, access, account, money, transaction, please, dm, number, day, guy, still, app, la, time, kindly, director, blame, transfer, banking, yet |
| Topic 2 | oct, promise, still, baba, dont, thread, access, longer, v, gift, swift, start, fccpnigeria, delay, sent, reminder, partnership, mind, list, help |
| Topic 3 | facebook, association, knowledge, deduction, nhere, aware, help, complete, travel, away, assistance, delivery, goalcomnigeria, review, nation, fire, aw, fintech, right, peace |
| Topic 4 | product, notice, wonder, unclemohamz, operation, banker, exchange, cenbank_central, plz, otherwise, see, respectively, better, blue, internet, help, tired, customer_service, pain, deal |
| Topic 5 | black, blame, joke, help, branch, personally, negative, notice, merger, tuesday, okay, today, aw, everyday, market, rectify, private, executive, receiver, appropriately |
| Topic 6 | help, duty, angry, samuel, die, fintech, sorry_experience, worst, wizkidayo_wizkidayo, opay, nysc, gov, weekly, brilafm, glad, star, closing, ubafc, question, omo_iya |
| Topic 7 | true, space, fast, head, explorer, star, v, help, pastor, meant, etc, place, capital, still, sept, mbuhari_muhammad, aisha, war, sincerely, morning |
| Topic 8 | account, apology, olu, fact, tomorrow, news, power, noodle, advance, help, completely, document, pick, lately, mistake, mastercard, okay, life, lie, several |
| Topic 9 | hey_investment, experience, help, delete, peter, allowance, told, poor, access, reflect, unilorin, brilafm, complaint_enquiry, wallet, deduct, chidi, directly, imagine, enable_assist, capitalone |
| Topic 10 | form, resolution, report, concerned, cantstopwont, nplease, anyone, sister, offer, worth, awareness, october, keep, day, till_date, last, problem, ibrahim, shit, reno |
| LSI | Terms |
|---|---|
| Topic 1 | help, access, account, money, transaction, please, number, day, dm, transfer, yet, guy, cenbank_central, kindly, pls, time, card, issue, still, back |
| Topic 2 | account, access, money, help, please, number, transaction, transfer, yet, kindly, back, pls, yesterday, guy, cenbank_central, naira, credit, detail, card, debit |
| Topic 3 | money, account, help, number, access, back, day, guy, cenbank_central, dm, refund, detail, people, still, yet, time, please, month, atm, reverse |
| Topic 4 | access, help, account, transaction, please, money, dm, kindly, number, thank, detail, complaint, diamond, pls, day, transfer, cenbank_central, twitter, central, response |
| Topic 5 | transaction, help, money, please, account, card, day, cenbank_central, yet, kindly, time, dm, detail, still, successful, debit, access, today, online, number |
| Topic 6 | please, transaction, pls, card, number, day, dm, help, account, transfer, money, time, access, thank, guy, kindly, even, detail, cenbank_central, people |
| Topic 7 | day, transaction, card, time, guy, money, cenbank_central, branch, people, still, customer, issue, month, even, debit, today, complaint, service, please, year |
| Topic 8 | card, day, debit, cenbank_central, please, guy, dm, people, branch, pls, month, time, transfer, use, charge, number, atm, yet, eyin_ole, ur_ur |
| Topic 9 | dm, number, day, card, guy, people, issue, time, nplease, please, detail, debit, kindly, transfer, help, check, customer, pls, even, account |
| Topic 10 | today, refund, people, news, day, business, transaction, number, citizen, transfer, global, pls, need, customer, citi, kindly, guy, month, america, please |
| Model | Component 1 (Embedding) | Component 2 (Dimension Reduction) | Component 3 (Clustering) | Coherence Score |
|---|---|---|---|---|
| BERTopic | BERT | Kernel PCA | BIRCH | 0.7071 |
| BERTopic | BERT | Kernel PCA | DBSCAN | 0.7528 |
| BERTopic | BERT | Kernel PCA | HDBSCAN | 0.4294 |
| BERTopic | BERT | Kernel PCA | Agglomerative Clustering | 0.4165 |
| BERTopic | BERT | Kernel PCA | OPTICS | 0.4902 |
| BERTopic | BERT | Kernel PCA | Spectral Clustering | 0.8451 |
| BERTopic | BERT | Kernel PCA | K-means | 0.8463 |
| BERTopic | BERT | ISOMAP | K-means | 0.4951 |
| BERTopic | BERT | PCA | K-means | 0.5251 |
| BERTopic | BERT | SVD | K-means | 0.5283 |
| BERTopic | BERT | UMAP | K-means | 0.5340 |
| BERTopic | BERT | UMAP | Spectral Clustering | 0.6267 |
| BERTopic | BERT | UMAP | MeanShift | 0.7522 |
| BERTopic | BERT | UMAP | HDBSCAN | 0.6705 |
| BERTopic | FinBERT | UMAP | HDBSCAN | 0.6667 |
| BERTopic | SBERT | UMAP | HDBSCAN | 0.6678 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ogunleye, B.; Maswera, T.; Hirsch, L.; Gaudoin, J.; Brunsdon, T. Comparison of Topic Modelling Approaches in the Banking Context. Appl. Sci. 2023, 13, 797. https://doi.org/10.3390/app13020797
Ogunleye B, Maswera T, Hirsch L, Gaudoin J, Brunsdon T. Comparison of Topic Modelling Approaches in the Banking Context. Applied Sciences. 2023; 13(2):797. https://doi.org/10.3390/app13020797
Chicago/Turabian StyleOgunleye, Bayode, Tonderai Maswera, Laurence Hirsch, Jotham Gaudoin, and Teresa Brunsdon. 2023. "Comparison of Topic Modelling Approaches in the Banking Context" Applied Sciences 13, no. 2: 797. https://doi.org/10.3390/app13020797
APA StyleOgunleye, B., Maswera, T., Hirsch, L., Gaudoin, J., & Brunsdon, T. (2023). Comparison of Topic Modelling Approaches in the Banking Context. Applied Sciences, 13(2), 797. https://doi.org/10.3390/app13020797