
Word Categorization of Vowel Durational Changes in Speech-Modulated Bone-Conducted Ultrasound

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
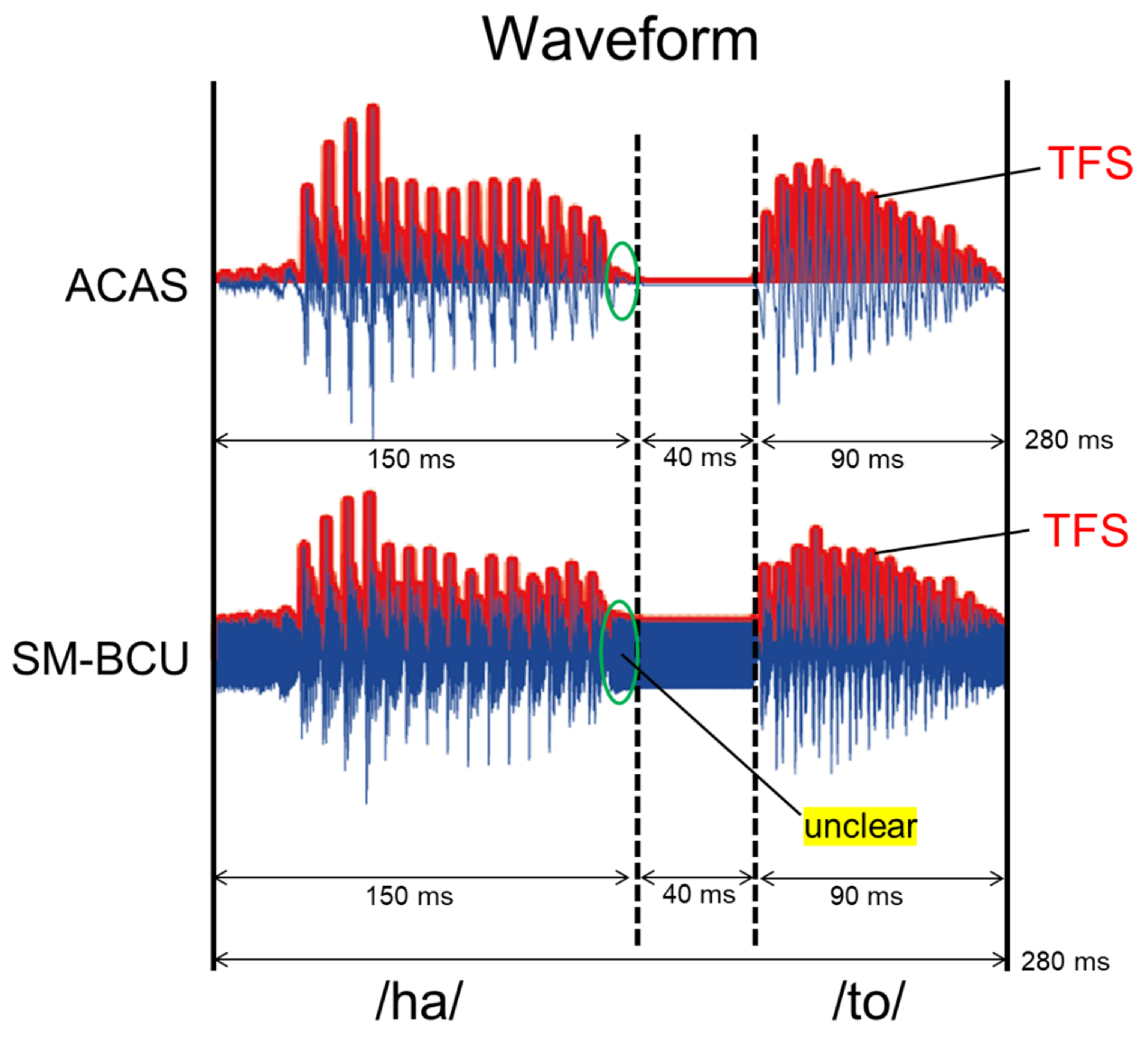
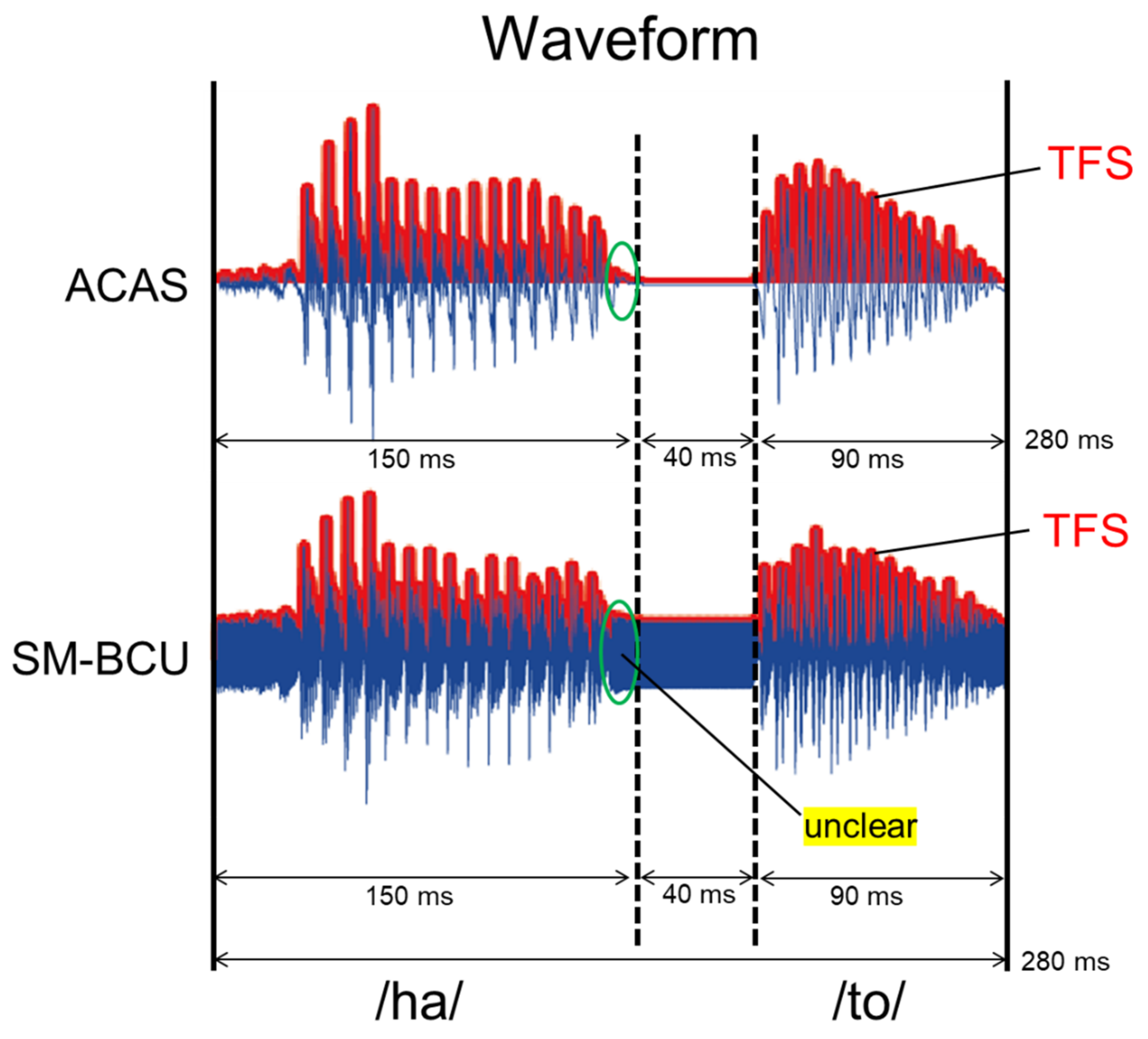
2.2. Stimuli
2.3. Discrimination Task
2.4. Procedure
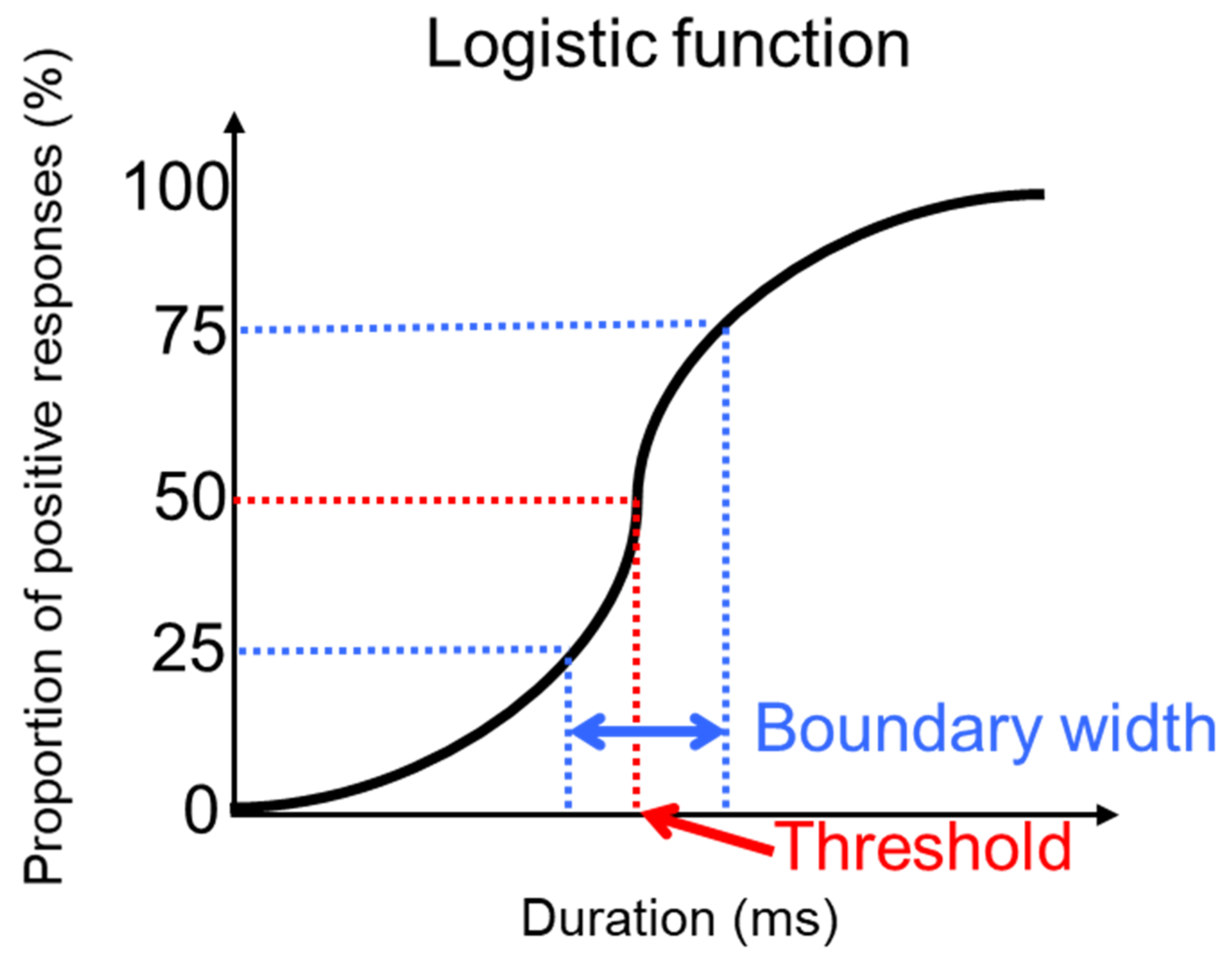
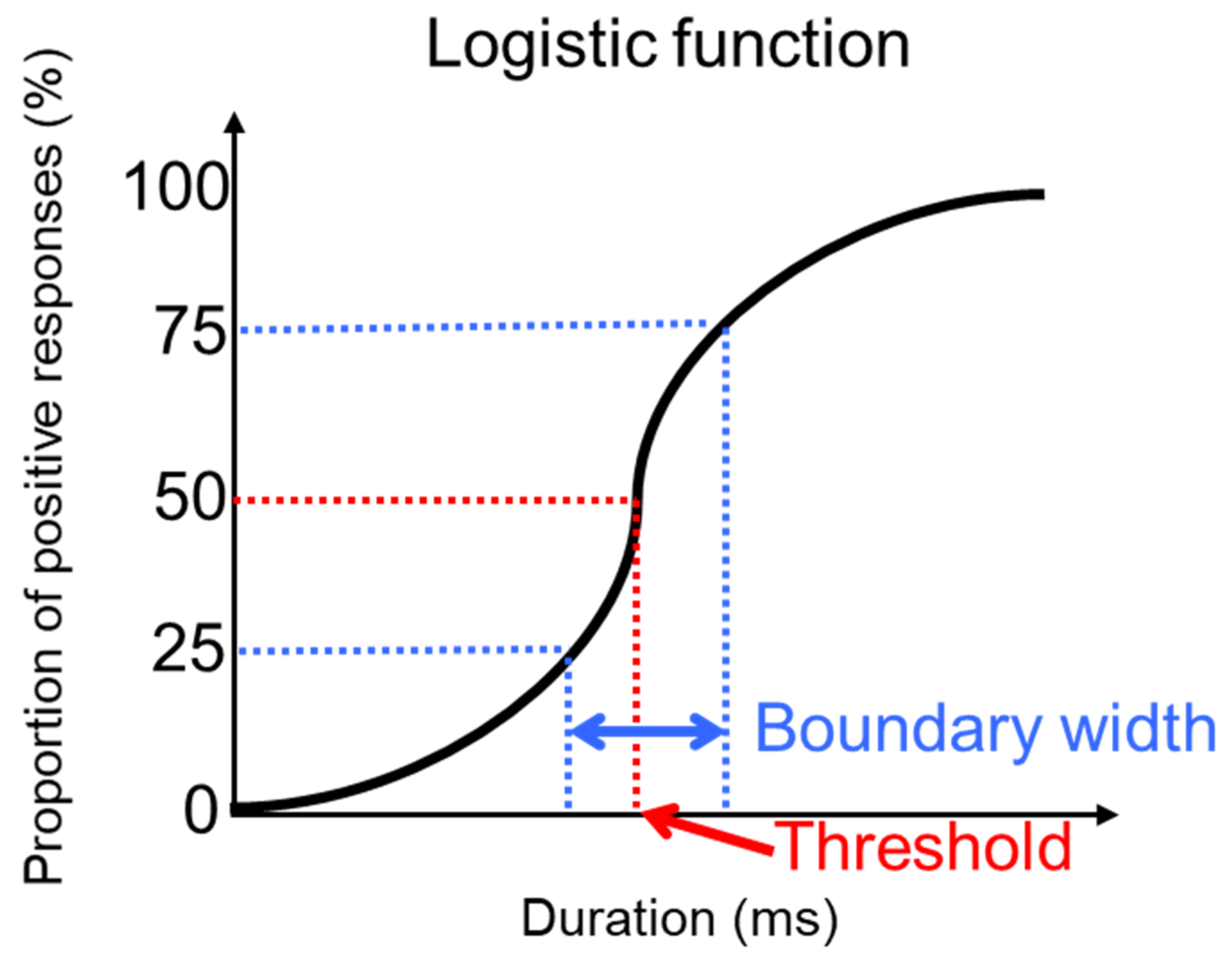
2.5. Analysis
2.6. Statistics
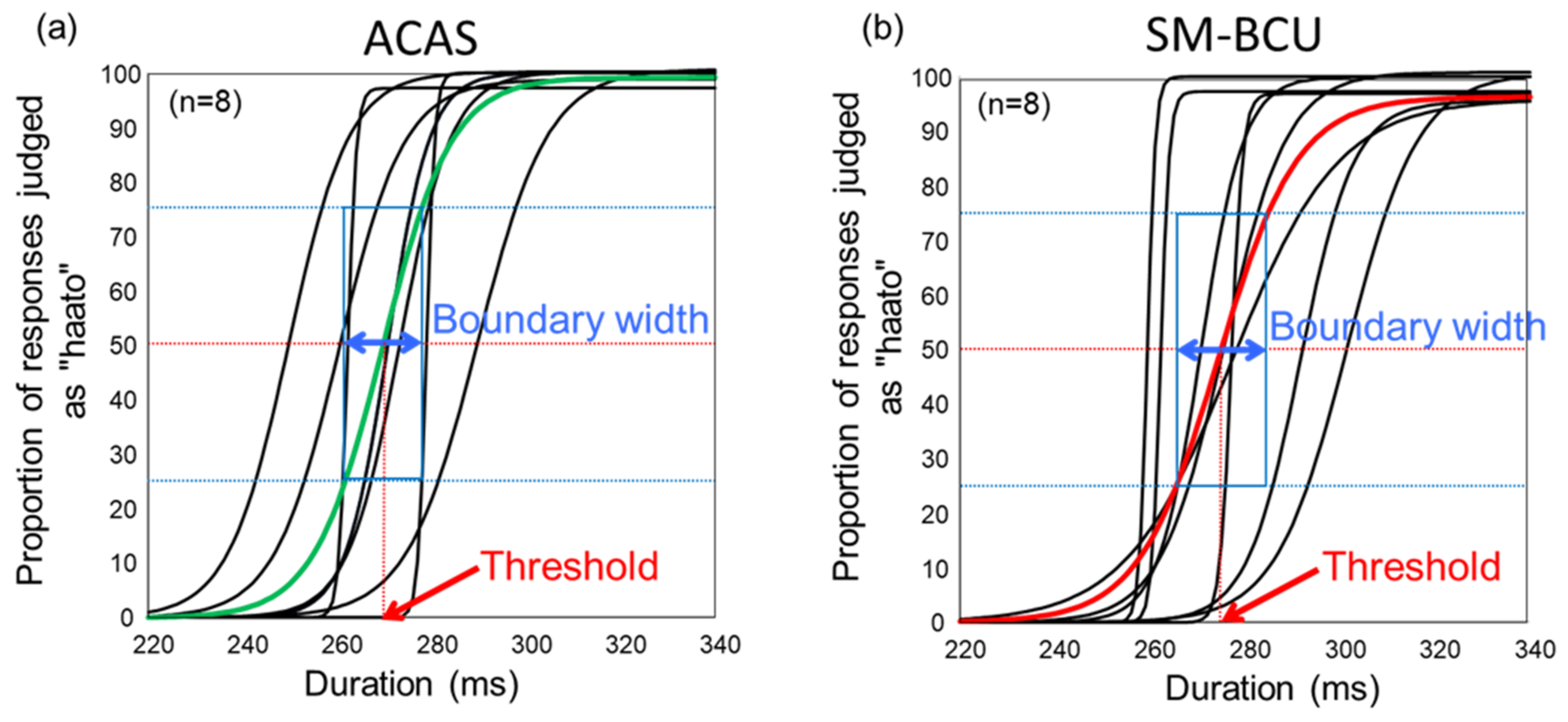
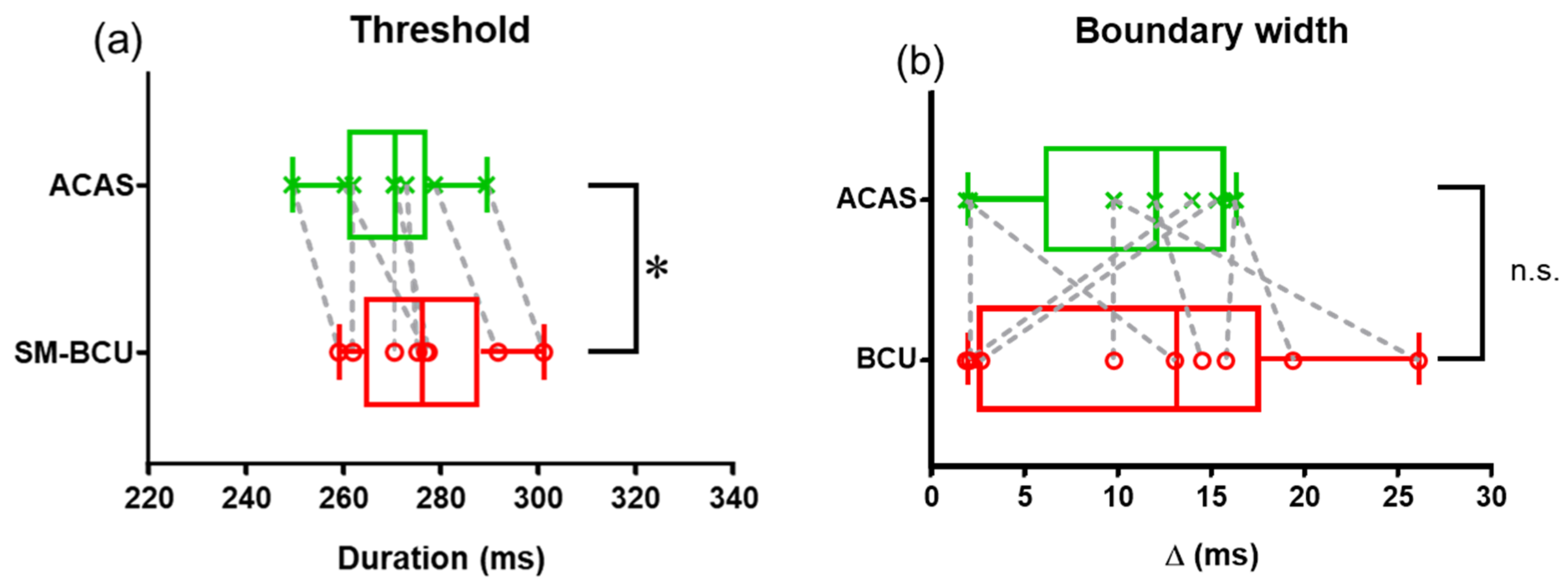
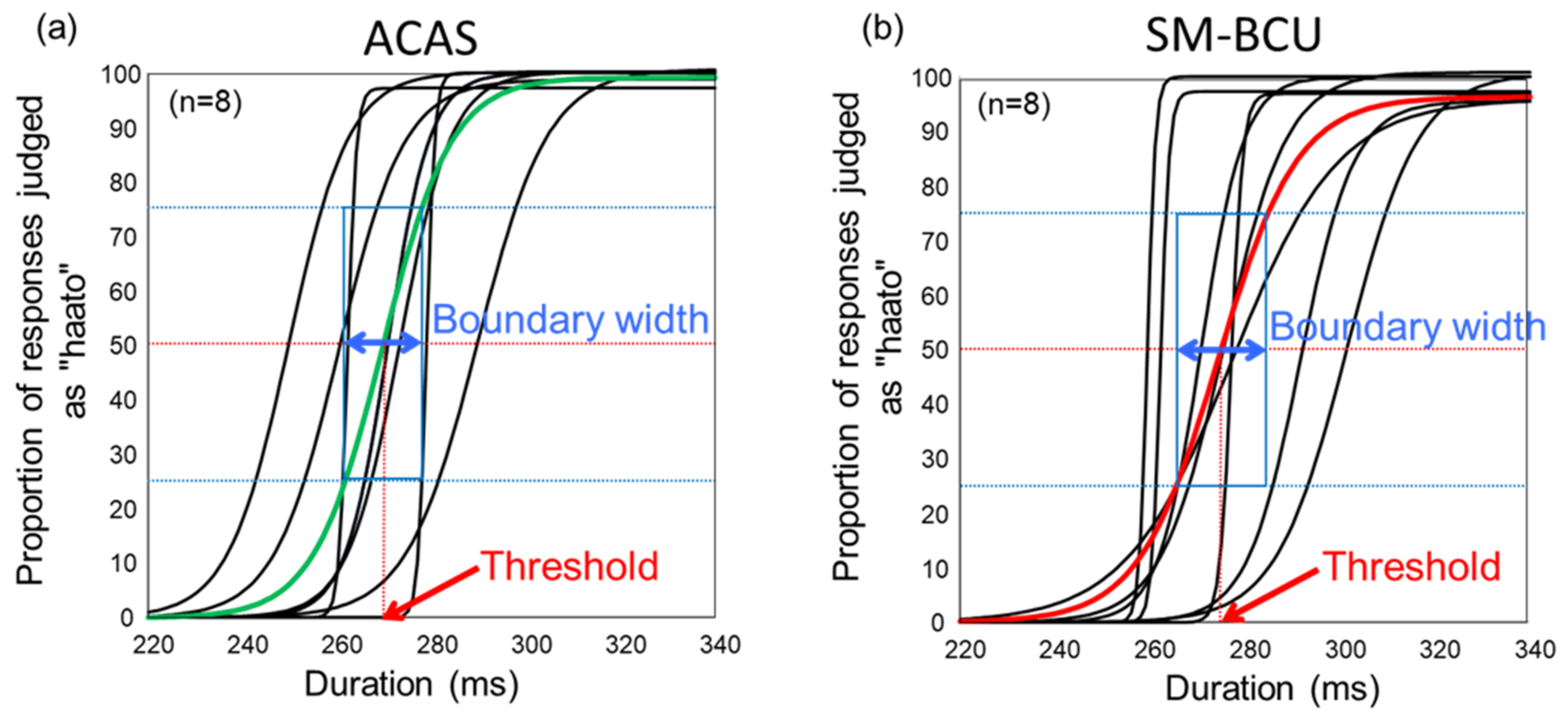
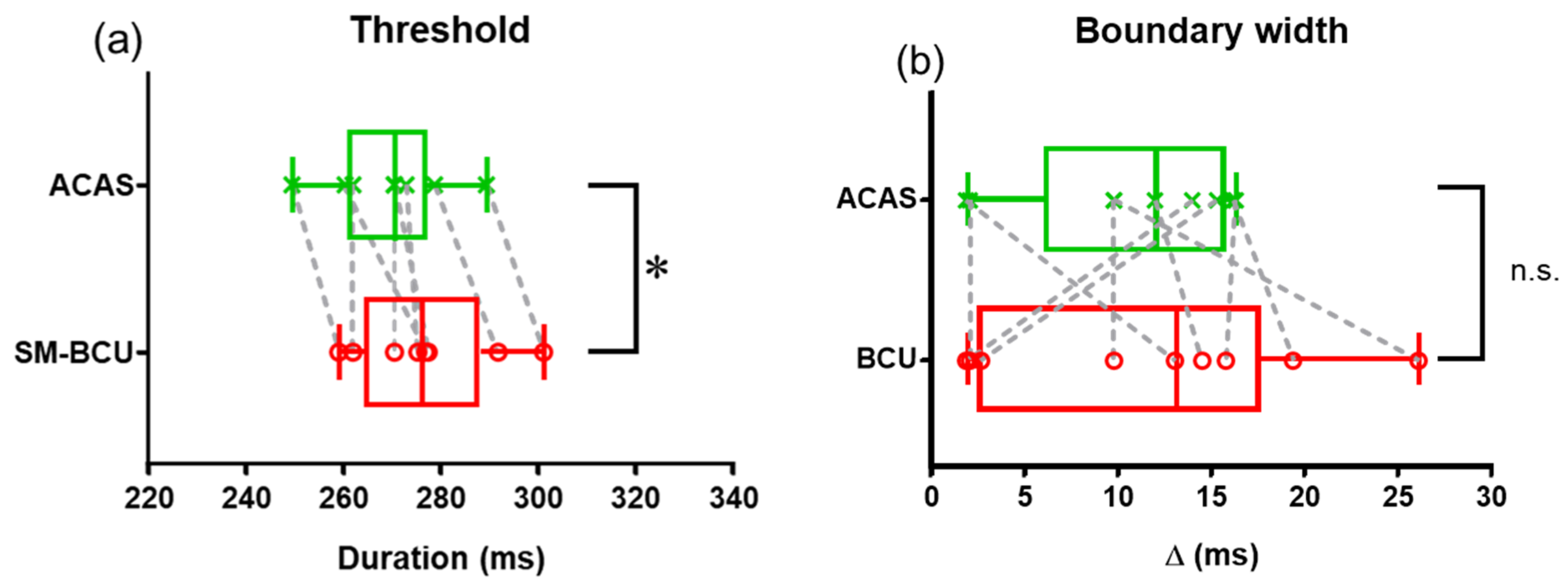
3. Results
4. Discussion
5. Study Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wegel, R.P. Physical data and physiology of excitation of the auditory nerve. Ann. Otol. Rhinol. Laryngol. 1932, 41, 740–799. [Google Scholar] [CrossRef]
- Pumphrey, R. Upper limit of frequency for human hearing. Nature 1950, 166, 571. [Google Scholar] [CrossRef]
- Gavreau, V. Audibillite de sons de frequence elevee. C. R. 1948, 226, 2053–2054. [Google Scholar]
- Dieroff, H.G.; Ertel, H. Some thoughts on the perception of ultrasound by man. Arch. Otorhinolaryngol. 1975, 209, 277–290. [Google Scholar] [CrossRef]
- Haeff, A.V.; Knox, C. Perception of ultrasound. Science 1963, 139, 590–592. [Google Scholar] [CrossRef]
- Lenhardt, M.L.; Skellett, R.; Wang, P.; Clarke, A.M. Human ultrasonic speech perception. Science 1991, 253, 82–85. [Google Scholar] [CrossRef] [Green Version]
- Yamashita, A.; Nishimura, T.; Nakagawa, S.; Sakaguchi, T.; Hosoi, H. Assessment of ability to discriminate frequency of bone-conducted ultrasound by mismatch fields. Neurosci. Lett. 2008, 438, 260–262. [Google Scholar]
- Nishimura, T.; Nakagawa, S.; Sakaguchi, T.; Hosoi, H. Ultrasonic masker clarifies ultrasonic perception in man. Hear. Res. 2003, 175, 171–177. [Google Scholar] [CrossRef]
- Nishimura, T.; Nakagawa, S.; Yamashita, A.; Sakaguchi, T.; Hosoi, H. N1m amplitude growth function for bone-conducted ultrasound. Acta Otolaryngol. Suppl. 2009, 562, 28–33. [Google Scholar] [CrossRef]
- Hosoi, H.; Imaizumi, S.; Sakaguchi, T.; Tonoike, M.; Murata, K. Activation of the auditory cortex by ultrasound. Lancet 1998, 351, 496–497. [Google Scholar] [CrossRef]
- Imaizumi, S.; Mori, K.; Kiritani, S.; Hosoi, H.; Tonoike, M. Task-dependent laterality for cue decoding during spoken language processing. Neuroreport 1998, 30, 899–903. [Google Scholar] [CrossRef]
- Ohyama, K.; Kusakari, J.; Kawamoto, K. Ultrasonic electrocochleography in guinea pig. Hear. Res. 1985, 17, 143–151. [Google Scholar] [CrossRef]
- Nishimura, T.; Sakaguchi, T.; Nakagawa, S.; Hosoi, H.; Watanabe, Y.; Tonoike, M.; Imaizumi, S. Dynamic range for bone conduction ultrasound. In Proceedings of the 12th International Conference on Biomagnetism, Espoo, Finland, 13–17 August 2000; pp. 125–128. [Google Scholar]
- Sakaguchi, T.; Hirano, T.; Nishimura, T.; Nakagawa, S.; Watanabe, Y.; Hosoi, H.; Imaizumi, S.; Tonoike, M. Cerebral neuromagnetic responses evoked by two-channel bone-conducted ultrasound stimuli. In Proceedings of the 12th International Conference on Biomagnetism, Espoo, Finland, 13–17 August 2000; pp. 121–124. [Google Scholar]
- Nishimura, T.; Nakagawa, S.; Sakaguchi, T.; Hosoi, H.; Tonoike, M. Effect of stimulus duration for bone-conducted ultrasound on N1m in man. Neurosci. Lett. 2002, 327, 119–122. [Google Scholar] [CrossRef]
- Sakaguchi, T.; Hirano, T.; Watanabe, Y.; Nishimura, T.; Hosoi, H.; Imaizumi, S.; Nakagawa, S.; Tonoike, M. Inner head acoustic field for bone-conducted sound calculated by finite-difference time-domain method. Jpn. J. Appl. Phys. 2002, 41, 3604–3608. [Google Scholar] [CrossRef]
- Okayasu, T.; Nishimura, T.; Yamashita, A.; Nakagawa, S.; Nagatani, Y.; Yanai, S.; Uratani, Y.; Hosoi, H. Duration-dependent growth of N1m for speech-modulated bone-conducted ultrasound. Neurosci. Lett. 2011, 495, 72–76. [Google Scholar] [CrossRef]
- Okayasu, T.; Nishimura, T.; Uratani, Y.; Yamashita, A.; Nakagawa, S.; Yamanaka, T.; Hosoi, H.; Kitahara, T. Temporal window of integration estimated by omission in bone-conducted ultrasound. Neurosci. Lett. 2019, 696, 1–6. [Google Scholar] [CrossRef]
- Nishimura, T.; Okayasu, T.; Uratani, Y.; Fukuda, F.; Saito, O.; Hosoi, H. Peripheral perception mechanism of ultrasonic hearing. Hear. Res. 2011, 277, 176–183. [Google Scholar] [CrossRef]
- Okayasu, T.; Nishimura, T.; Yamashita, A.; Saito, O.; Fukuda, F.; Yanai, S.; Hosoi, H. Human ultrasonic hearing is induced by a direct ultrasonic stimulation of the cochlea. Neurosci. Lett. 2013, 539, 71–76. [Google Scholar]
- Nishimura, T.; Okayasu, T.; Yamashita, A.; Hosoi, H.; Kitahara, T. Perception mechanism of bone conducted ultrasound and its clinical use. Audiol. Res. 2021, 11, 244–253. [Google Scholar] [CrossRef]
- Nakagawa, S.; Okamoto, Y.; Fujisaka, Y. Development of a bone-conducted ultrasonic hearing aid for the profoundly deaf. Trans. Jpn. Soc. Med. Biol. Eng. 2006, 44, 184–189. [Google Scholar]
- Koizumi, T.; Nishimura, T.; Yamashita, A.; Yamanaka, T.; Imamura, T.; Hosoi, H. Residual inhibition of tinnitus induced by 30-kHz bone-conducted ultrasound. Hear. Res. 2014, 310, 48–53. [Google Scholar] [CrossRef]
- Okamoto, Y.; Nakagawa, S.; Fujimoto, K.; Tonoike, M. Intelligibility of boneconducted ultrasonic speech. Hear. Res. 2005, 208, 107–113. [Google Scholar] [CrossRef]
- Yamashita, A.; Nishimura, T.; Nagatani, Y.; Okayasu, T.; Koizumi, T.; Sakaguchi, T.; Hosoi, H. Comparison between bone-conducted ultrasound and audible sound in speech recognition. Acta Otolaryngol. Suppl. 2009, 562, 34–39. [Google Scholar] [CrossRef]
- Yamashita, A.; Nishimura, T.; Nagatani, Y.; Sakaguchi, T.; Okayasu, T.; Yanai, S.; Hosoi, H. The effect of visual information in speech signals by bone-conducted ultrasound. Neuroreport 2009, 21, 119–122. [Google Scholar] [CrossRef]
- Shimokura, R.; Fukuda, F.; Hosoi, H. A case study of auditory rehabilitation in a deaf participant using a bone-conducted ultrasonic hearing aid. Behav. Sci. Res. 2012, 50, 187–198. [Google Scholar]
- Okayasu, T.; Nishimura, T.; Nakagawa, S.; Yamashita, A.; Nagatani, Y.; Uratani, Y.; Yamanaka, T.; Hosoi, H. Evaluation of prosodic and segmental change in speechmodulated bone-conducted ultrasound by mismatch fields. Neurosci. Lett. 2014, 559, 117–121. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer. Version 5.1.04. Available online: http://www.praat.org/ (accessed on 4 April 2009).
- Levitt, H. Transformed up-down methods in psychoacoustics. J. Acoust. Soc. Am. 1971, 49 (Suppl. S2), 467–477. [Google Scholar] [CrossRef]
- Kagomiya, T.; Nakagawa, S. An evaluation of bone-conducted ultrasonic hearing-aid regarding transmission of Japanese prosodic phonemes. In Proceedings of the 20th International Congress on Acoustics, ICA, Sydney, Australia, 23–27 August 2010; pp. 23–27. [Google Scholar]
- Lorenzi, C.; Gilbert, G.; Carn, H.; Garnier, S.; Moore, B.C. Speech perception problems of the hearing impaired reflect inability to use temporal fine structure. Proc. Natl. Acad. Sci. USA 2006, 103, 18866–18869. [Google Scholar] [CrossRef] [Green Version]
- Nishimura, T.; Okayasu, T.; Saito, O.; Shimokura, R.; Yamashita, A.; Yamanaka, T.; Hosoi, H.; Kitahara, T. An examination of the effects of broadband air-conduction masker on the speech intelligibility of speech-modulated bone-conduction ultrasound. Hear. Res. 2014, 317, 41–49. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Okayasu, T.; Nishimura, T.; Yamashita, A.; Nagatani, Y.; Inoue, T.; Uratani, Y.; Yamanaka, T.; Hosoi, H.; Kitahara, T. Word Categorization of Vowel Durational Changes in Speech-Modulated Bone-Conducted Ultrasound. Audiol. Res. 2021, 11, 357-364. https://doi.org/10.3390/audiolres11030033
Okayasu T, Nishimura T, Yamashita A, Nagatani Y, Inoue T, Uratani Y, Yamanaka T, Hosoi H, Kitahara T. Word Categorization of Vowel Durational Changes in Speech-Modulated Bone-Conducted Ultrasound. Audiology Research. 2021; 11(3):357-364. https://doi.org/10.3390/audiolres11030033
Chicago/Turabian StyleOkayasu, Tadao, Tadashi Nishimura, Akinori Yamashita, Yoshiki Nagatani, Takashi Inoue, Yuka Uratani, Toshiaki Yamanaka, Hiroshi Hosoi, and Tadashi Kitahara. 2021. "Word Categorization of Vowel Durational Changes in Speech-Modulated Bone-Conducted Ultrasound" Audiology Research 11, no. 3: 357-364. https://doi.org/10.3390/audiolres11030033
APA StyleOkayasu, T., Nishimura, T., Yamashita, A., Nagatani, Y., Inoue, T., Uratani, Y., Yamanaka, T., Hosoi, H., & Kitahara, T. (2021). Word Categorization of Vowel Durational Changes in Speech-Modulated Bone-Conducted Ultrasound. Audiology Research, 11(3), 357-364. https://doi.org/10.3390/audiolres11030033