
An Improved Soft Actor–Critic Task Offloading and Edge Computing Resource Allocation Algorithm for Image Segmentation Tasks in the Internet of Vehicles

Abstract
1. Introduction
2. Related Work
3. System Architecture
3.1. Computing Power Network
3.2. Computing Power Allocation System
4. Model Establishment
4.1. Problem Formulation
4.2. Computing Power Model
4.3. Objective Function
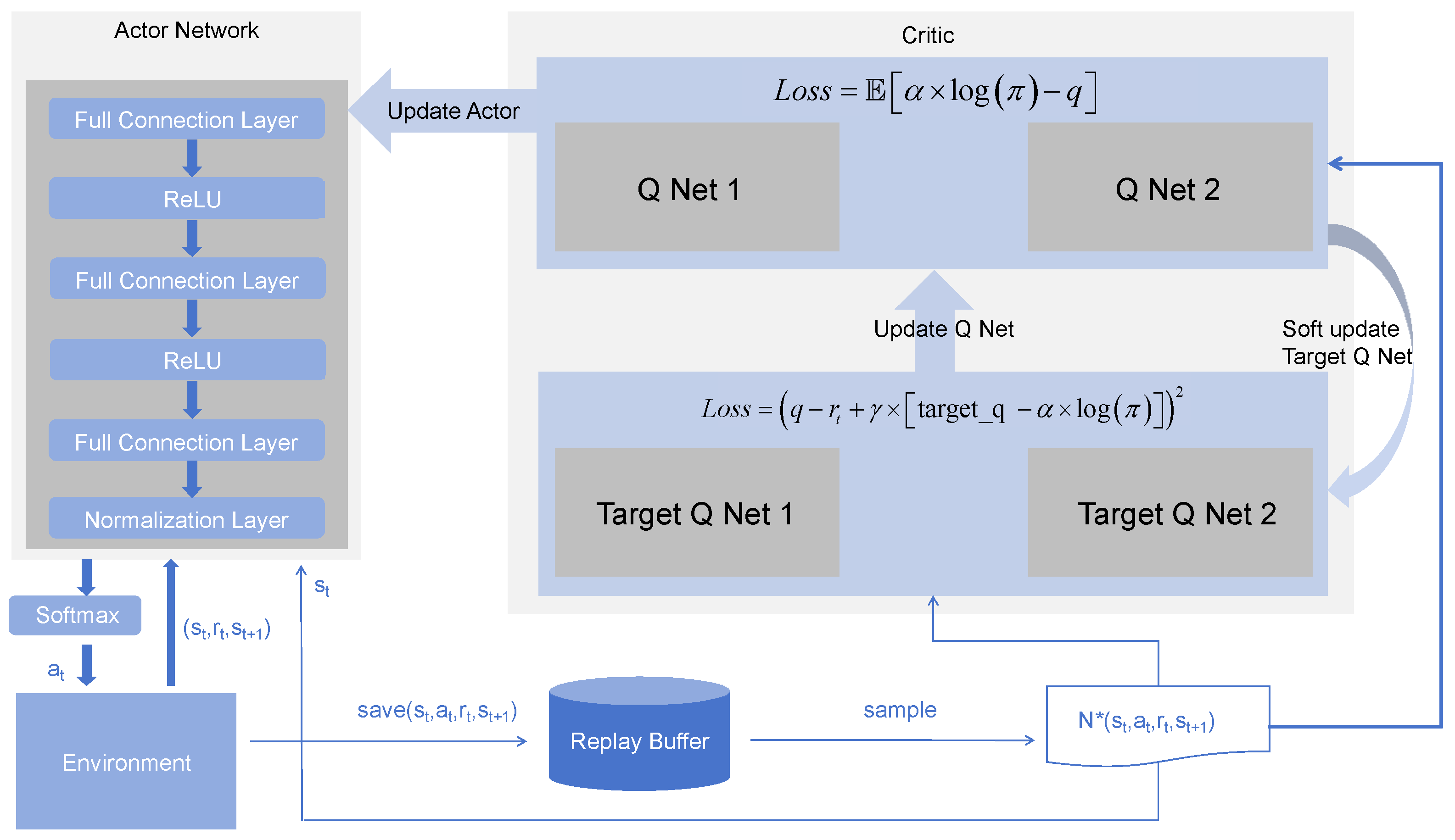
5. Improved SAC (iSAC) Algorithm
5.1. Algorithm Architecture
5.2. MDP Engineering
5.2.1. State Description
5.2.2. Action Description
5.2.3. Reward Engineering
5.3. Algorithm Implementation
| Algorithm 1 PER-iSAC |
Input: discount factor , temperature coefficient , soft update coefficient , batch size n, learning rate Output: policy
|
6. Experiment Results
6.1. Simulation Settings
6.2. Experimental Results
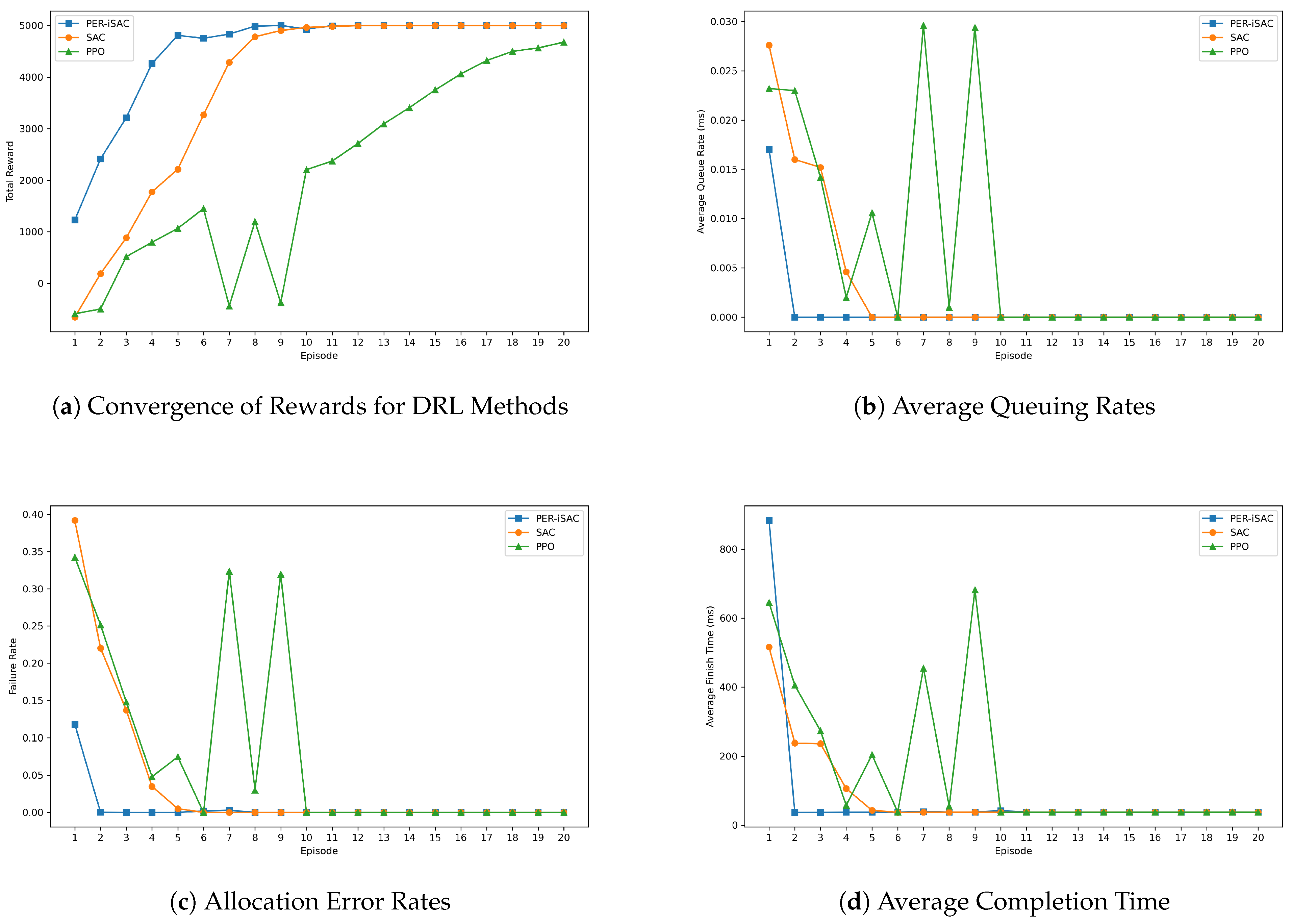
6.2.1. Model Training and Comparative Experiments
- PER-iSAC (Proposed). The scheduling strategy using the PER-iSAC algorithm.
- Standard SAC. The scheduling strategy using the SAC algorithm.
- PPO Baseline. The scheduling strategy using the PPO algorithm [25].
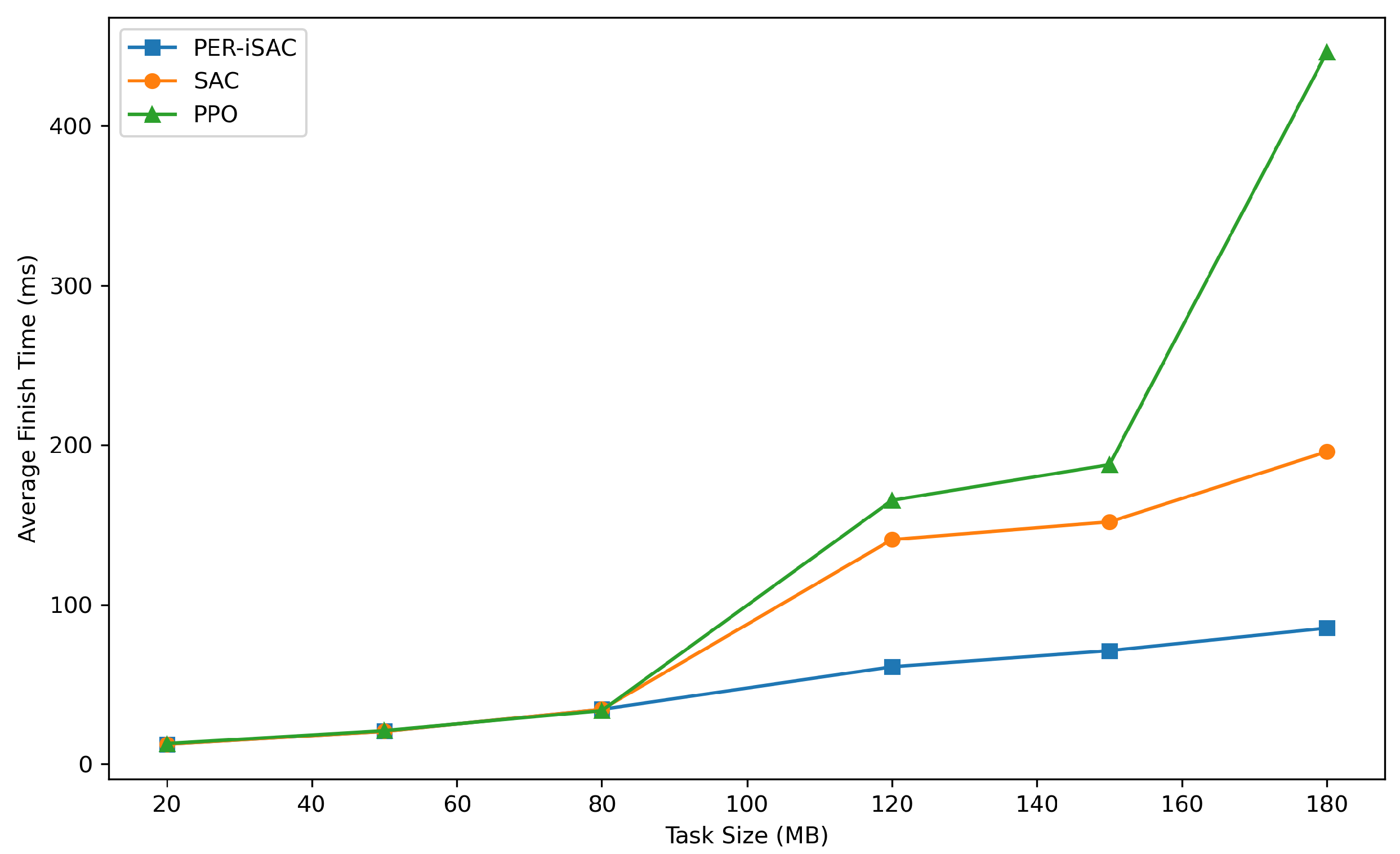
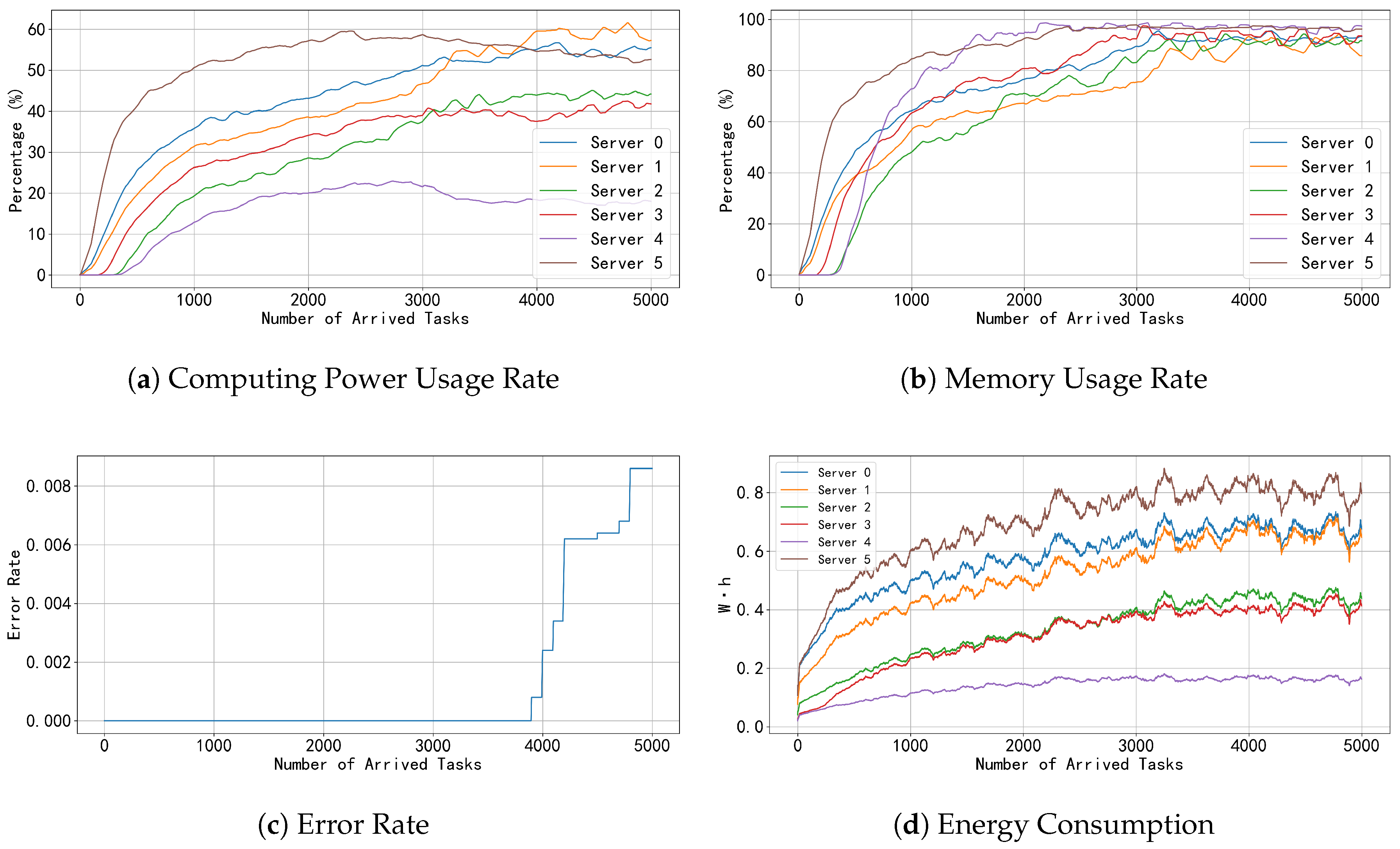
6.2.2. Performance Metrics of the PER-iSAC Model
7. Limitations and Conclusions
7.1. Limitations
7.2. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| SAC | Soft Actor–Critic |
| PER | Prioritized Experience Replay |
| A3C | Asynchronous Advantage Actor–Critic |
| PPO | Proximal Policy Optimization |
| TD | Temporal Difference |
| CPN | Computing Power Network |
| IoV | Internet of Vehicles |
| DRL | Deep Reinforcement Learning |
| FCFS | First-Come-First-Served |
| RSU | Road Side Unit |
References
- Merzougui, S.E.; Limani, X.; Gavrielides, A.; Palazzi, C.E.; Marquez-Barja, J. Leveraging 5G Technology to Investigate Energy Consumption and CPU Load at the Edge in Vehicular Networks. World Electr. Veh. J. 2024, 15, 171. [Google Scholar] [CrossRef]
- Salmane, D.; Mohamed, A.; Khalid, Z.; Driss, B.; Driss, B. Edge Computing Technology Enablers: A Systematic Lecture Study. IEEE Access 2022, 10, 69264–69302. [Google Scholar]
- Zhou, S.; Jadoon, W.; Khan, I.A. Computing Offloading Strategy in Mobile Edge Computing Environment: A Comparison between Adopted Frameworks, Challenges, and Future Directions. Electronics 2023, 12, 2452. [Google Scholar] [CrossRef]
- Guerna, A.; Bitam, S.; Calafate, C.T. Roadside Unit Deployment in Internet of Vehicles Systems: A Survey. Sensors 2022, 22, 3190. [Google Scholar] [CrossRef]
- Mishra, P.; Singh, G. Internet of Vehicles for Sustainable Smart Cities: Opportunities, Issues, and Challenges. Smart Cities 2025, 8, 93. [Google Scholar] [CrossRef]
- Lu, S.; Yao, Y.; Shi, W. CLONE: Collaborative Learning on the Edges. IEEE Internet Things J. 2021, 8, 10222–10236. [Google Scholar] [CrossRef]
- Dai, Z.; Guan, Z.; Chen, Q.; Xu, Y.; Sun, F. Enhanced Object Detection in Autonomous Vehicles through LiDAR—Camera Sensor Fusion. World Electr. Veh. J. 2024, 15, 297. [Google Scholar] [CrossRef]
- Ministry of Industry and Information Technology. Vehicle Network (Intelligent Connected Vehicles) Industry Development Action Plan; Ministry of Industry and Information Technology: Beijing, China, 2018. [Google Scholar]
- Lu, S.; Shi, W. Vehicle Computing: Vision and Challenges. J. Inf. Intell. 2022, 1, 23–35. [Google Scholar] [CrossRef]
- Cui, H.; Lei, J. An Algorithmic Study of Transformer-Based Road Scene Segmentation in Autonomous Driving. World Electr. Veh. J. 2024, 15, 516. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Shi, W.; Chen, L.; Zhu, X. Task Offloading Decision-Making Algorithm for Vehicular Edge Computing: A Deep-Reinforcement-Learning-Based Approach. Sensors 2023, 23, 7595. [Google Scholar] [CrossRef]
- Wu, Z.; Jia, Z.; Pang, X.; Zhao, S. Deep Reinforcement Learning-Based Task Offloading and Load Balancing for Vehicular Edge Computing. Electronics 2024, 13, 1511. [Google Scholar] [CrossRef]
- Zhong, A.; Wu, D.; Yang, B.; Wang, R. Heterogeneous resource allocation with latency guarantee for computing power network. Digit. Commun. Netw. 2025, 2352–8648. [Google Scholar] [CrossRef]
- Nie, L.; Wang, H.; Feng, G.; Sun, J.; Lv, H.; Cui, H. A deep reinforcement learning assisted task offloading and resource allocation approach towards self-driving object detection. Cloud Comp. 2023, 12, 131. [Google Scholar] [CrossRef]
- Yuan, X.; Wang, Y.; Li, Y.; Kang, H.; Chen, Y.; Yang, B. Hierarchical flow learning for low-light image enhancement. Digit. Commun. Netw. 2024, 2352–8648. [Google Scholar] [CrossRef]
- Liu, Q.; Tian, Z.; Wang, N.; Lin, Y. DRL-based dependent task offloading with delay-energy tradeoff in medical image edge computing. Complex Intell. Syst. 2024, 10, 3283–3304. [Google Scholar] [CrossRef]
- Xue, J.; Yu, Q.; Wang, L.; Fan, C. Vehicle task offloading strategy based on DRL in communication and sensing scenarios. Ad Hoc Netw. 2024, 159, 103497. [Google Scholar] [CrossRef]
- Yang, B.; Wu, D.; Wang, R.; Yang, Z.; Yang, Y. A fine-grained intrusion protection system for inter-edge trust transfer. Digit. Commun. Netw. 2024, 10, 2352–8648. [Google Scholar] [CrossRef]
- Hossain, M.B.; Pokhrel, S.R.; Choi, J. Orchestrating Smart Grid Demand Response Operations with URLLC and MuZero Learning. IEEE Internet Things J. 2024, 11, 6692–6704. [Google Scholar] [CrossRef]
- Nam, D.H. A Comparative Study of Mobile Cloud Computing, Mobile Edge Computing, and Mobile Edge Cloud Computing. In Proceedings of the 2023 Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE), Las Vegas, NV, USA, 24–27 July 2023. [Google Scholar] [CrossRef]
- Tang, X.; Cao, C.; Wang, Y.; Zhang, S.; Liu, Y.; Li, M.; He, T. Computing power network: The architecture of convergence of computing and networking towards 6G requirement. China Commun. 2021, 18, 175–185. [Google Scholar] [CrossRef]
- Andriulo, F.C.; Fiore, M.; Mongiello, M.; Traversa, E.; Zizzo, V. Edge Computing and Cloud Computing for Internet of Things: A Review. Informatics 2024, 11, 71. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:abs/1707.06347. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | System Model | Solution Approach | Performance Metrics | Limitations |
|---|---|---|---|---|
| Shi et al. [13] | Cloud-edge-vehicle VEC, partial offloading | TODM_DDPG with actor–critic framework | System cost reduction | Not considering task dependencies |
| Wu et al. [14] | Multi-vehicle, multi-server VEC, MDP | TOLB with TD3 and TOPSIS | System cost reduction | Not considering vehicular mobility |
| Zhong et al. [15] | CPN with non-independent subtasks | Optimized cycle, dynamic bandwidth | Latency violation probability reduction | Not adequately addressing task correlations, resource preferences, or modeling diverse tasks and heterogeneous resources |
| Nie et al. [16] | MEC for self-driving, end-edge collaboration | DRPL with DNN, permutation grouping | Time utility improvement | Not considering task dependencies and the priority of image tasks |
| Liu et al. [18] | RIDM tasks as DAG, edge computing | DCDO-DRL with S2S and SAC | Execution utility improvement | Without considering vehicular mobility and the priority of image tasks |
| Xue et al. [19] | VEC with ISAC, joint sensing-computation | VAFPO with SNDAO, priority factor | System overhead minimization | It is not yet clear |
| Servers | GPU Computing Power (TFLOPS) | GPU Storage (GB) | Idle Load Power (W) | Full Load Power (W) |
|---|---|---|---|---|
| S0 | 200~250 | 32 | 300~500 | 500~1000 |
| S1 | 140~160 | 24 | 150~350 | 350~500 |
| S2 | 130~150 | 24 | 150~300 | 300~500 |
| S3 | 100~120 | 16 | 50~150 | 200~450 |
| S4 | 110~130 | 16 | 50~150 | 200~500 |
| S5 | 100~120 | 8 | 50~100 | 150~300 |
| Parameters | Values |
|---|---|
| Computing Power Requirement | 200~4000 GFLOPs |
| Image Data Size | 4.8~180 MB |
| Model Data Size | 10~500 MB |
| Task Result Coefficient 1 | 0.1~0.3 |
| Completion Time Coefficient 2 | 1.2~1.5 |
| Link Speed | 5G: 100 Mbps~10 GbpsOptical Fiber Network: 200~400 Gbps |
| Communication Range | 10~500 m |
| Communication Delay | 1~2 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, W.; Yu, H.; Yang, B.; Ren, A.; Liu, W. An Improved Soft Actor–Critic Task Offloading and Edge Computing Resource Allocation Algorithm for Image Segmentation Tasks in the Internet of Vehicles. World Electr. Veh. J. 2025, 16, 353. https://doi.org/10.3390/wevj16070353
Zou W, Yu H, Yang B, Ren A, Liu W. An Improved Soft Actor–Critic Task Offloading and Edge Computing Resource Allocation Algorithm for Image Segmentation Tasks in the Internet of Vehicles. World Electric Vehicle Journal. 2025; 16(7):353. https://doi.org/10.3390/wevj16070353
Chicago/Turabian StyleZou, Wei, Haitao Yu, Boran Yang, Aohui Ren, and Wei Liu. 2025. "An Improved Soft Actor–Critic Task Offloading and Edge Computing Resource Allocation Algorithm for Image Segmentation Tasks in the Internet of Vehicles" World Electric Vehicle Journal 16, no. 7: 353. https://doi.org/10.3390/wevj16070353
APA StyleZou, W., Yu, H., Yang, B., Ren, A., & Liu, W. (2025). An Improved Soft Actor–Critic Task Offloading and Edge Computing Resource Allocation Algorithm for Image Segmentation Tasks in the Internet of Vehicles. World Electric Vehicle Journal, 16(7), 353. https://doi.org/10.3390/wevj16070353