
PnPDA+: A Meta Feature-Guided Domain Adapter for Collaborative Perception †

 ,
, 
Abstract
1. Introduction
- We propose a meta feature-guided domain adapter for collaborative perception, which serves as a plug-and-play architecture that enables the seamless integration of existing vehicles without modifying perception models.
- We introduce a dual-level meta feature representation, categorizing meta features into domain-related meta features and frame-related meta features. The former captures the unique characteristics of different domains, while the latter encodes spatial–temporal information to enhance scene-level semantic understanding.
- We achieve a favorable trade-off between performance and training cost by enabling efficient domain adaptation through lightweight meta feature extraction and minimal fine-tuning steps, thus ensuring the scalability of the collaborative perception network.
- Experiments conducted on OPV2V [7] demonstrates that MFEN significantly improves generalization in diverse domains and enables the rapid integration of heterogeneous vehicles, outperforming state-of-the-art methods by 4.08% without requiring the retraining of existing perception models.
2. Related Work
2.1. Collaborative Perception
2.2. Heterogeneous Domain Adaption
2.3. Meta-Learning
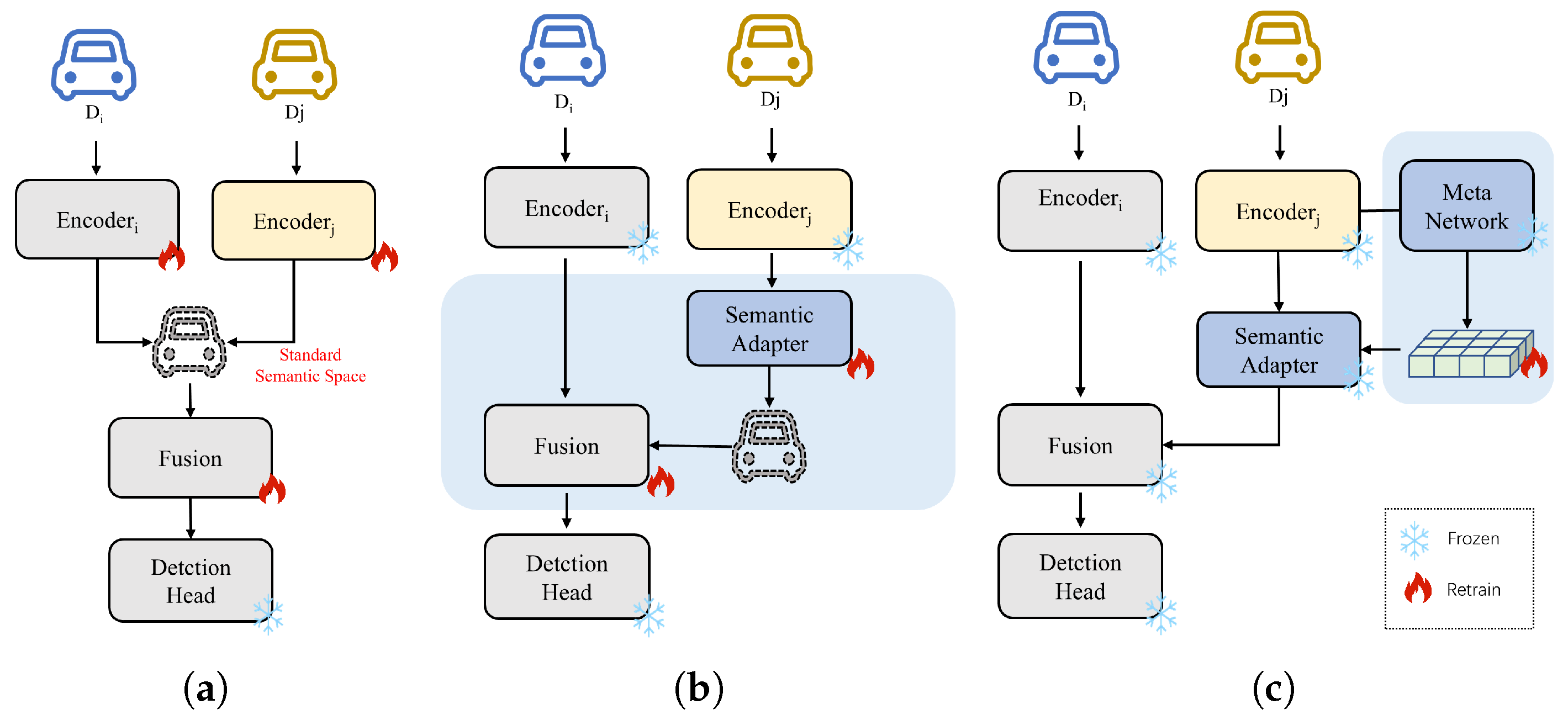
3. System Model
3.1. Preliminary
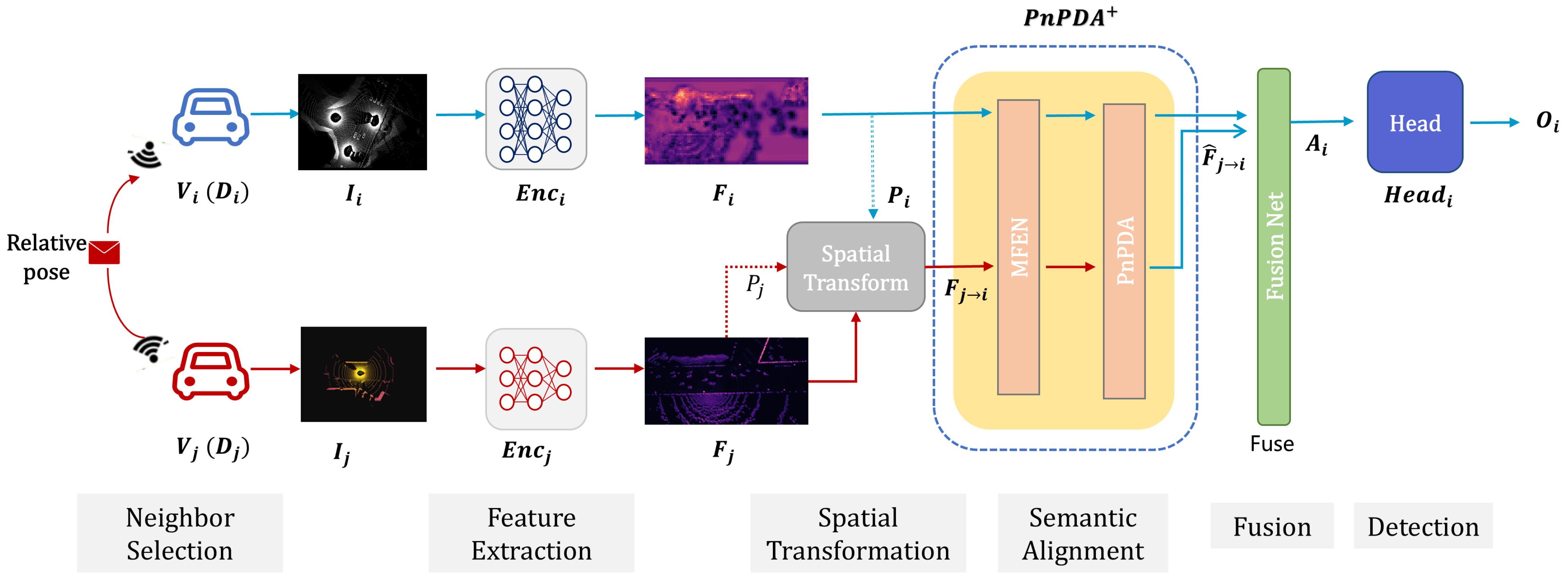
- Feature Extraction: At a given timestamp, each vehicle collects raw sensory data through its onboard sensors and processes it via its local encoder to produce intermediate feature representations as shown in Equation (1).
- Neighbor Selection: To enable cooperative perception, each vehicle communicates with its neighboring vehicles located within a predefined communication range R. The neighbor set of is denoted as , where if the Euclidean distance between their pose and satisfies .
- Spatial Transformation: Each neighboring vehicle transmits its feature along with its pose to the ego vehicle . And, applies a spatial transformation to map from ’s coordinate frame to its own, based on the relative pose between and , yielding the spatially aligned feature . This ensures that all received features are spatially consistent in the ego vehicle’s coordinate frame.
- Semantic Alignment: Note that, due to variations in encoder architectures, features from different vehicles may differ semantically, even when observing the same scene. Therefore, a domain adapter should be introduced to map the spatially aligned feature into the semantic space of the ego vehicle , producing the semantically aligned feature for consistent downstream fusion.
- Fusion: Finally, vehicle aggregates its own feature with the semantically aligned features from all neighbors to form the fused representation .
- Detection: This is then passed through a task-specific (such as object detection or trajectory prediction) head to generate the final output .
3.2. Meta Feature-Guided Domain Adapter
4. Methodology
4.1. Adaptive Feature Alignment
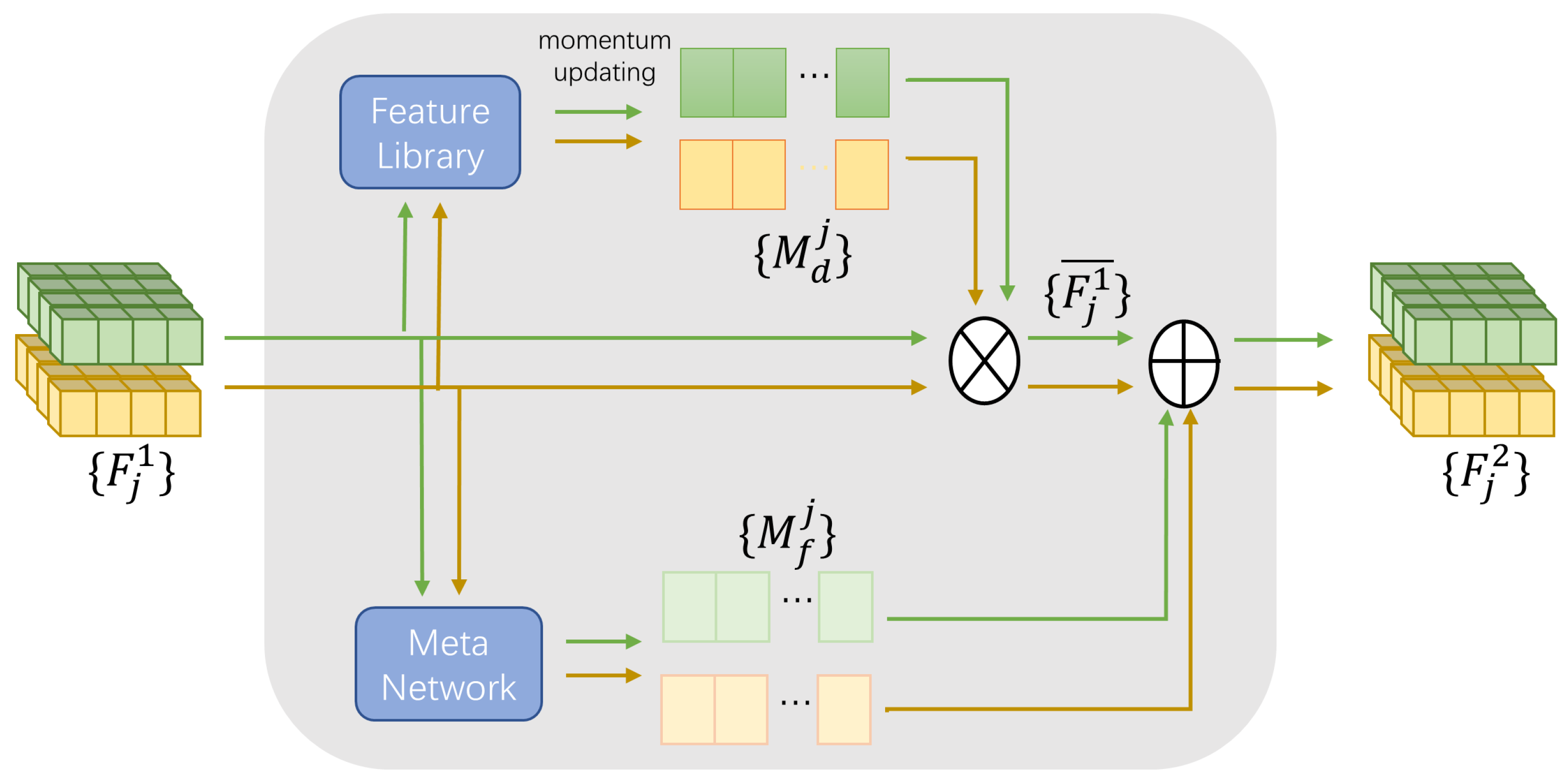
4.2. MFEN
4.2.1. Domain-Related Meta Feature
4.2.2. Frame-Related Meta Feature
4.2.3. Enhanced Domain-Specific Feature
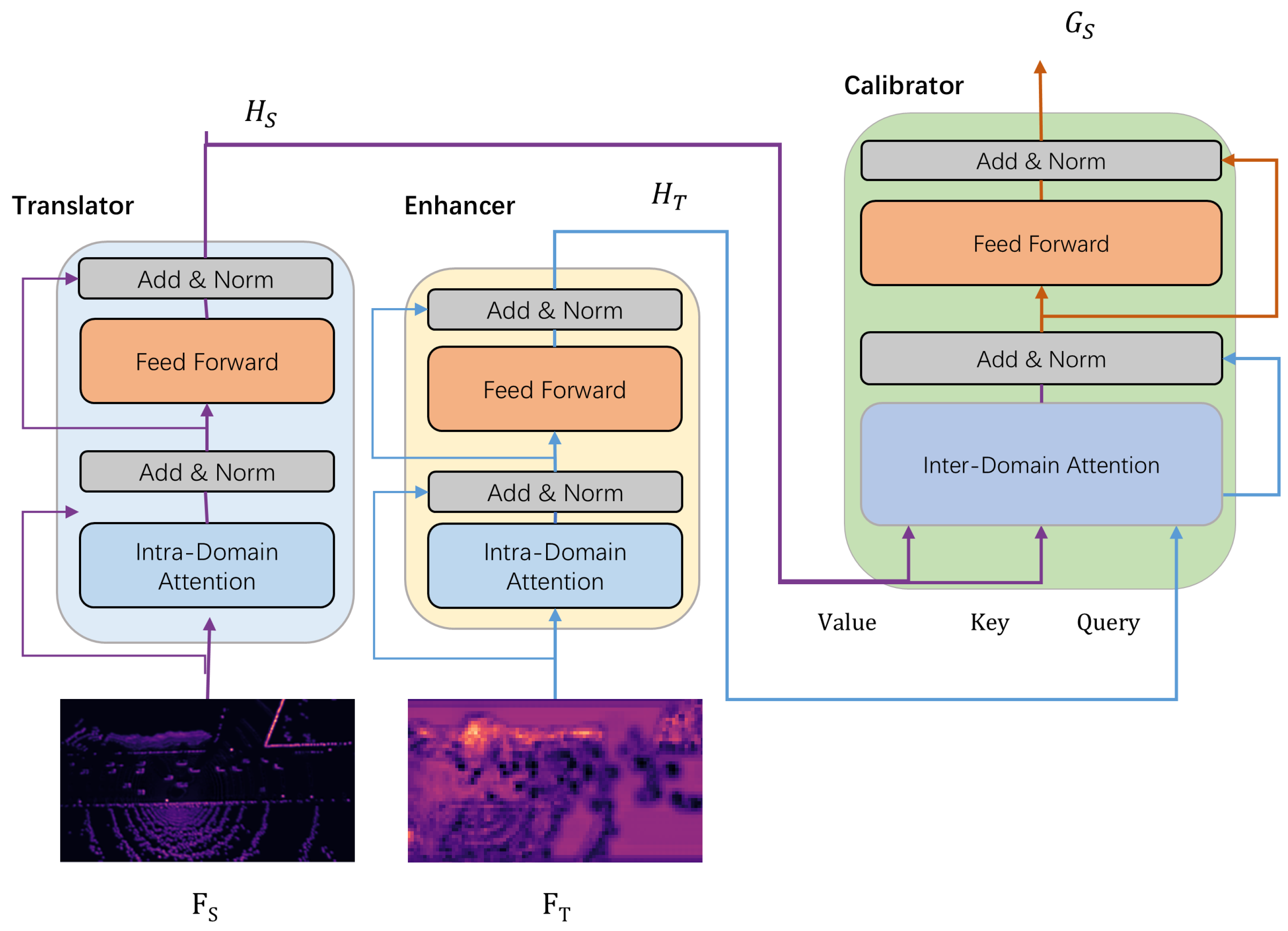
4.3. PnPDA
4.3.1. Semantic Translator and Enhancer
4.3.2. Semantic Calibrator
4.4. Loss
4.4.1. PnPDA Loss
4.4.2. MFEN Loss
5. Experiments and Discussions
5.1. Experimental Settings
- Dataset. We conducted experiments on OPV2V [7], a large-scale benchmark for cooperative perception in autonomous driving. The dataset consists of 73 diverse driving scenarios, covering six different road types and nine distinct cities, including eight built-in CARLA environments and one highly realistic digital city reconstructed from Los Angeles. Each scenario features multiple autonomous vehicles collecting 3D point cloud data and RGB camera images with synchronized timestamps. In total, the dataset contains approximately 12,000 LiDAR frames, 48,000 RGB images, and 230,000 annotated 3D bounding boxes. OPV2V [7] provides a realistic and diverse cooperative perception setting, making it well suited for evaluating feature alignment methods in heterogeneous multi-agent settings.
- Evaluation Metrics. We evaluate 3D object detection performance using average precision (AP) at intersection over union (IoU) thresholds of 0.5 and 0.7, where the IoU is a unitless metric ranging from 0 to 1. Following standard practice [9,11,13] in the field, evaluation is conducted within a predefined spatial region of and .
- Experimental Designs. To simulate realistic heterogeneity, we utilize three commonly used LiDAR encoders: PointPillar [25], VoxelNet [26], and SECOND [27], each available in multiple configurations. Table 1 summarizes the detailed parameters of the heterogeneous encoders and their performance under homogeneous settings.
- Comparison Methods. We compare PnPDA+ against two methods that address feature heterogeneity. Specifically, MPDA [5] serves as a strong baseline that addresses domain discrepancies via attention-based semantic adaptation. We also implement a lightweight domain adaptation baseline, called HETE, which applies a simple max-pooling layer followed by a convolution for spatial and channel alignment. It should be noted that although HEAL [4] is another method capable of handling sensor heterogeneity, it requires retraining the feature encoders of all agents, which contradicts the plug-and-play principle of our method and thus is excluded from direct comparison.
- Implementation Details. All encoders, fusion networks, and detection heads follow their original configurations. During the pre-training stage, we adopt Adam optimizer with an initial learning rate of 0.001 and apply a learning rate decay of 0.1 at the 10th and 50th epochs. A similar training strategy is used during the fine-tuning stage.
5.2. Detection Performance
5.3. Ablation Study
5.4. Visualizations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Akopov, A.S.; Beklaryan, L.A.; Thakur, M. Improvement of maneuverability within a multiagent fuzzy transportation system with the use of parallel biobjective real-coded genetic algorithm. IEEE Trans. Intell. Transp. Syst. 2021, 23, 12648–12664. [Google Scholar] [CrossRef]
- Kamel, M.A.; Yu, X.; Zhang, Y. Formation control and coordination of multiple unmanned ground vehicles in normal and faulty situations: A review. Annu. Rev. Control 2020, 49, 128–144. [Google Scholar] [CrossRef]
- Hu, S.; Fang, Z.; Deng, Y.; Chen, X.; Fang, Y. Collaborative perception for connected and autonomous driving: Challenges, possible solutions and opportunities. arXiv 2024, arXiv:2401.01544. [Google Scholar] [CrossRef]
- Lu, Y.; Hu, Y.; Zhong, Y.; Wang, D.; Wang, Y.; Chen, S. An extensible framework for open heterogeneous collaborative perception. arXiv 2024, arXiv:2401.13964. [Google Scholar]
- Xu, R.; Li, J.; Dong, X.; Yu, H.; Ma, J. Bridging the domain gap for multi-agent perception. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 6035–6042. [Google Scholar]
- Luo, T.; Yuan, Q.; Luo, G.; Xia, Y.; Yang, Y.; Li, J. Plug and Play: A Representation Enhanced Domain Adapter for Collaborative Perception. In Proceedings of the European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 287–303. [Google Scholar]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2583–2589. [Google Scholar]
- Chen, Q.; Tang, S.; Yang, Q.; Fu, S. Cooper: Cooperative perception for connected autonomous vehicles based on 3d point clouds. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 514–524. [Google Scholar]
- Chen, Q.; Ma, X.; Tang, S.; Guo, J.; Yang, Q.; Fu, S. F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Washington, DC, USA, 7–9 November 2019; pp. 88–100. [Google Scholar]
- Wang, T.H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2vnet: Vehicle-to-vehicle communication for joint perception and prediction. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 605–621. [Google Scholar]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer. In Proceedings of the 17th European Conference on Computer Vision, ECCV 2022; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2022; pp. 107–124. [Google Scholar]
- Xu, R.; Tu, Z.; Xiang, H.; Shao, W.; Zhou, B.; Ma, J. CoBEVT: Cooperative Bird’s Eye View Semantic Segmentation with Sparse Transformers. In Proceedings of the Conference on Robot Learning, PMLR, Atlanta, GA, USA, 6–9 November 2023; pp. 989–1000. [Google Scholar]
- Hu, Y.; Fang, S.; Lei, Z.; Zhong, Y.; Chen, S. Where2comm: Communication-efficient collaborative perception via spatial confidence maps. Adv. Neural Inf. Process. Syst. 2022, 35, 4874–4886. [Google Scholar]
- Li, Y.; Ren, S.; Wu, P.; Chen, S.; Feng, C.; Zhang, W. Learning distilled collaboration graph for multi-agent perception. Adv. Neural Inf. Process. Syst. 2021, 34, 29541–29552. [Google Scholar]
- Xiang, H.; Xu, R.; Ma, J. HM-ViT: Hetero-modal vehicle-to-vehicle cooperative perception with vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer vision, Paris, France, 2–3 October 2023; pp. 284–295. [Google Scholar]
- Chen, Z.; Shi, Y.; Jia, J. Transiff: An instance-level feature fusion framework for vehicle-infrastructure cooperative 3d detection with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 18205–18214. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Javed, K.; White, M. Meta-learning representations for continual learning. arXiv 2019, arXiv:1905.12588. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Rao, Y.; Zhao, W.; Chen, G.; Tang, Y.; Zhu, Z.; Huang, G.; Zhou, J.; Lu, J. Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18082–18091. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder | Type | Voxel Resolution (m) | 2D/3D Layers | Half Lidar Cropping Range [x, y] (m) | AP@0.5/ AP@0.7 |
|---|---|---|---|---|---|
| PointPillar [25] | pp8 | 0.8, 0.8, 0.8 | 4/0 | [140.8, 64.8] | 85.9/62.9 |
| pp6 | 0.6, 0.6, 0.4 | 19/0 | [153.6, 38.4] | 86.7/68.7 | |
| pp4 | 0.4, 0.4, 0.4 | 19/0 | [140.8, 64.8] | 87.2/77.7 | |
| VoxelNet [26] | vn6 | 0.6, 0.6, 0.4 | 0/3 | [153.6, 38.4] | 85.7/71.2 |
| vn4 | 0.4, 0.4, 0.4 | 0/3 | [140.8, 64.8] | 85.5/77.8 | |
| SECOND [27] | sd2 | 0.2, 0.2, 0.4 | 12/12 | [140.8, 64.8] | 84.0/64.8 |
| sd1 | 0.1, 0.1, 0.4 | 13/13 | [140.8, 64.8] | 65.1/52.9 |
| Scenario | PnPDA+ | HETE | MPDA |
|---|---|---|---|
| PP8–PP4 * | 54.6/40.5 | 44.0/23.0 | 54.5/40.2 |
| PP8–PP4 + | 60.7/42.5 | 53.2/38.8 | |
| PP8–SD2 * | 56.2/41.7 | 54.1/39.0 | 53.4/38.2 |
| PP8–SD2 + | 55.4/39.2 | 27.1/6.1 | |
| PP8–VN6 * | 52.5/38.1 | 10.5/1.2 | 52.9/38.0 |
| PP8–VN6 + | 53.7/39.3 | 20.1/3.3 |
| PnPDA | Domain-Related Meta Feature | Frame-Related Meta Feature | pp8–pp4 | pp8–vn4 | pp8–sd2 |
|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 54.6/40.5 | 63.7/44.0 | 55.4/39.2 |
| ✓ | ✓ | – | 28.8/19.3 | 50.0/36.0 | 53.6/37.3 |
| ✓ | – | ✓ | 5.7/1.7 | 58.2/44.6 | 3.5/2.0 |
| ✓ | – | – | 4.3/1.1 | 49.7/21.5 | 1.2/0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xin, L.; Zhou, G.; Yu, Z.; Wang, D.; Luo, T.; Fu, X.; Li, J. PnPDA+: A Meta Feature-Guided Domain Adapter for Collaborative Perception. World Electr. Veh. J. 2025, 16, 343. https://doi.org/10.3390/wevj16070343
Xin L, Zhou G, Yu Z, Wang D, Luo T, Fu X, Li J. PnPDA+: A Meta Feature-Guided Domain Adapter for Collaborative Perception. World Electric Vehicle Journal. 2025; 16(7):343. https://doi.org/10.3390/wevj16070343
Chicago/Turabian StyleXin, Liang, Guangtao Zhou, Zhaoyang Yu, Danni Wang, Tianyou Luo, Xiaoyuan Fu, and Jinglin Li. 2025. "PnPDA+: A Meta Feature-Guided Domain Adapter for Collaborative Perception" World Electric Vehicle Journal 16, no. 7: 343. https://doi.org/10.3390/wevj16070343
APA StyleXin, L., Zhou, G., Yu, Z., Wang, D., Luo, T., Fu, X., & Li, J. (2025). PnPDA+: A Meta Feature-Guided Domain Adapter for Collaborative Perception. World Electric Vehicle Journal, 16(7), 343. https://doi.org/10.3390/wevj16070343