
Research on Multi-Target Detection and Tracking of Intelligent Vehicles in Complex Traffic Environments Based on Deep Learning Theory


Abstract
1. Introduction
2. Detection Method of Occluded Targets and Small Targets in Complex Road Traffic Environments Based on YOLOv7
2.1. A Bot-NMS Method for Occlusion Object Detection
2.2. Comparison and Analysis of Different NMS Methods
2.3. Small Target Detection Research
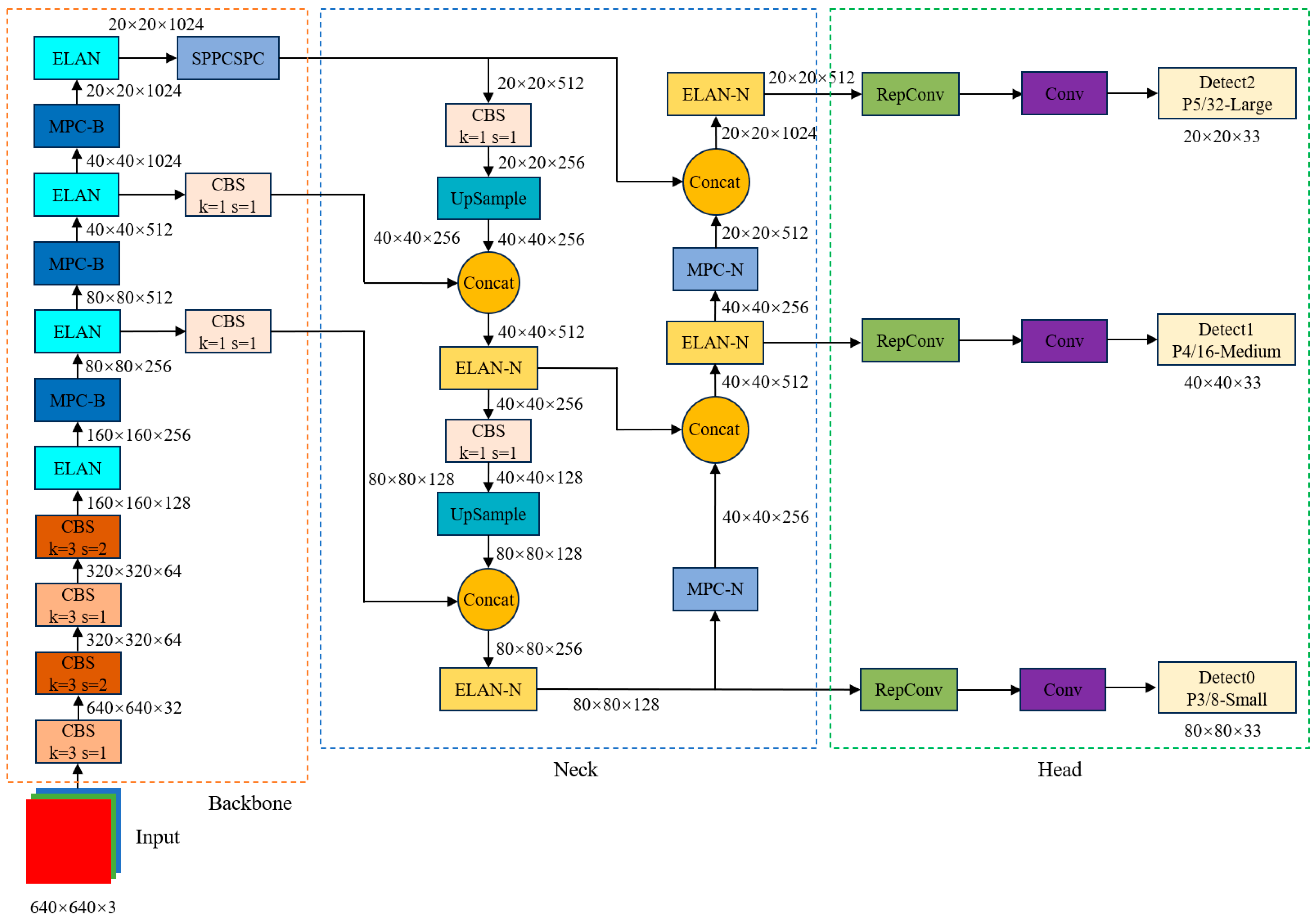
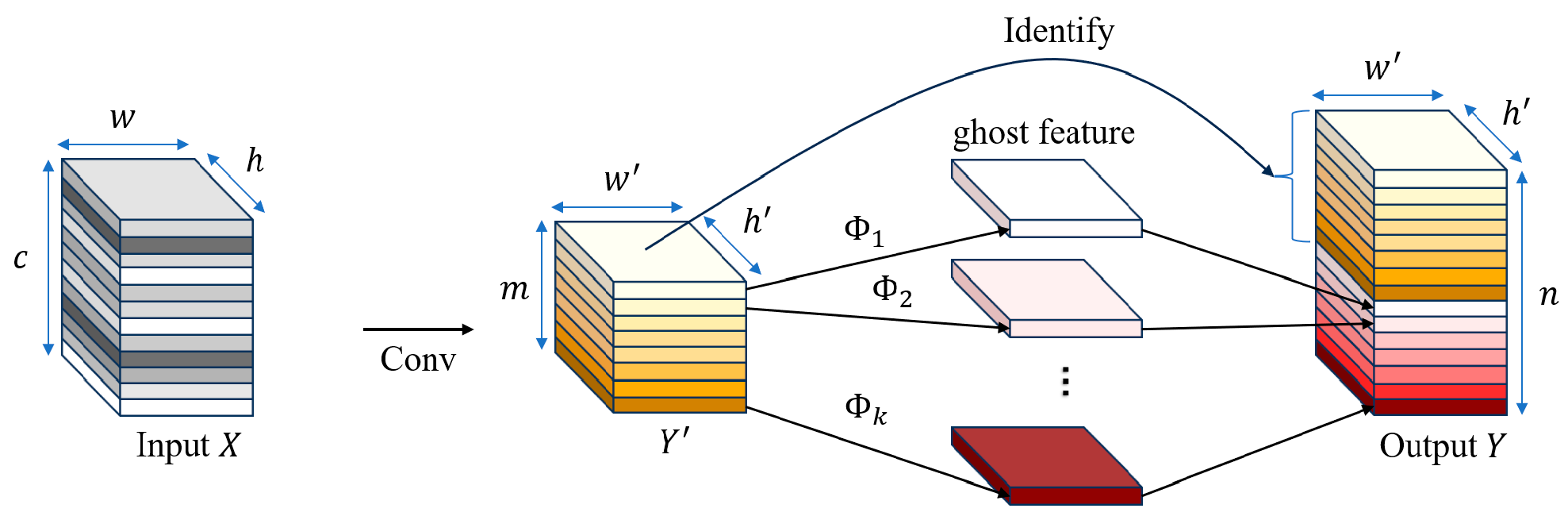
2.3.1. ELAN Module Optimization of the Backbone Network
2.3.2. Multi-Scale Learning and Prior Frame Improvement
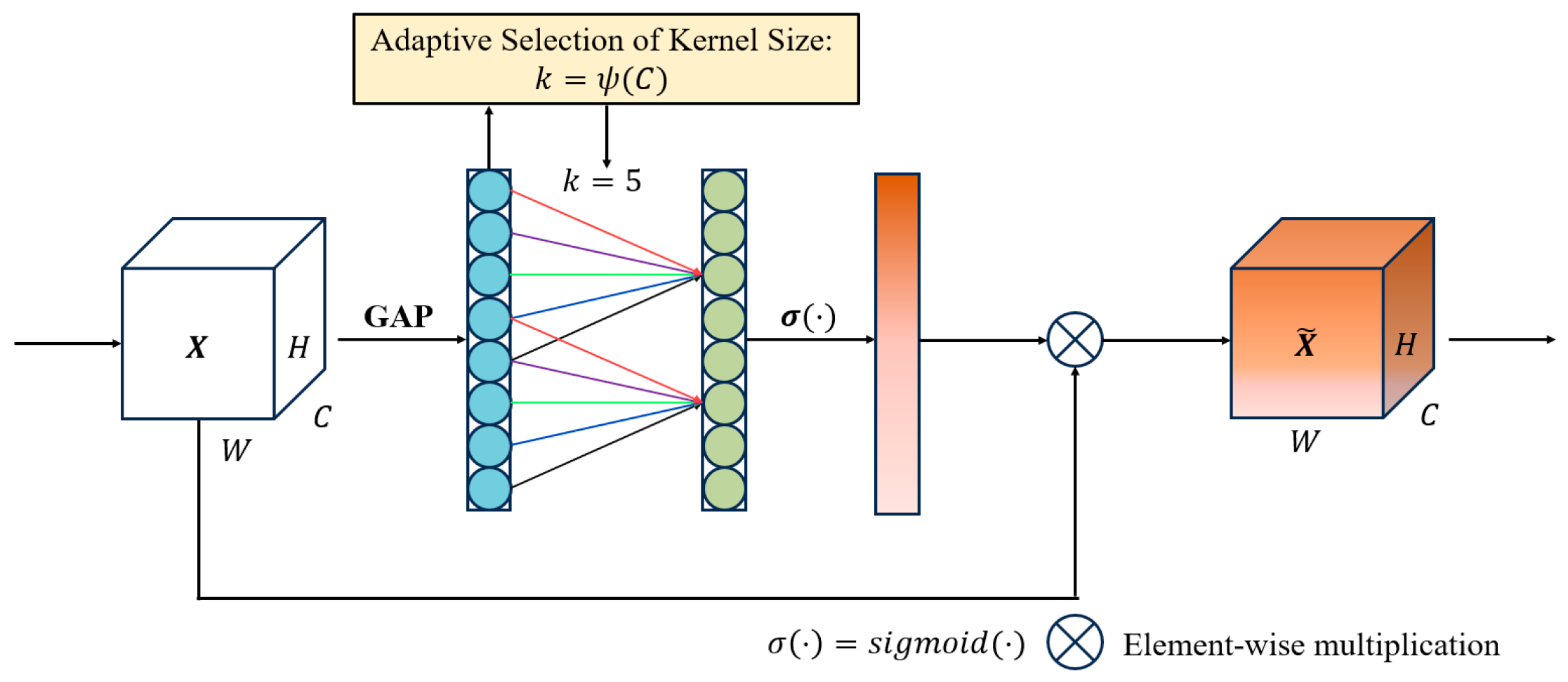
2.3.3. Introduction of ECA Attention Mechanism
2.3.4. Detection Results of Small Targets in Complex Road Traffic Environment
3. ReID Feature Track Tracking Based on Deep Learning
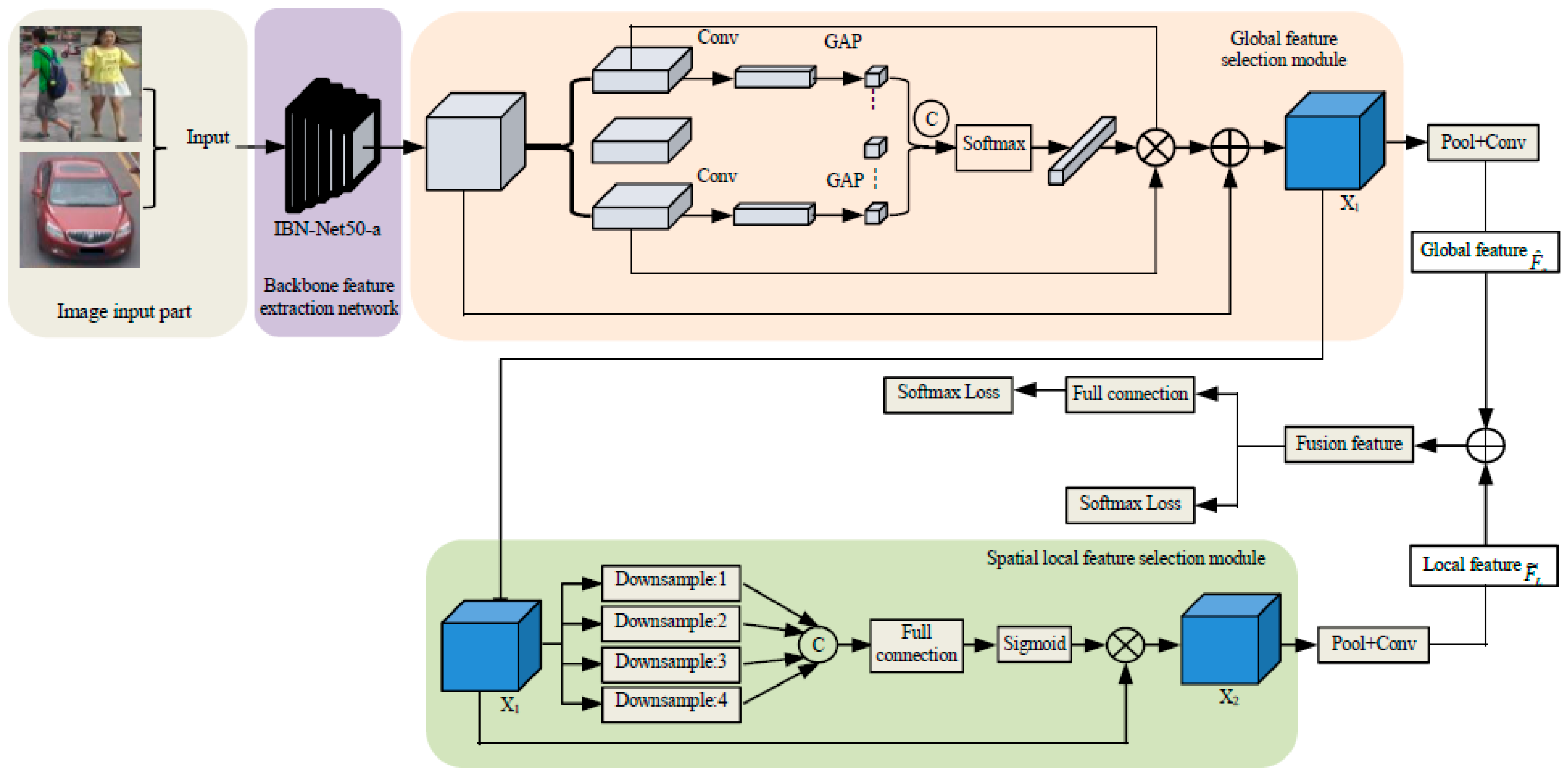
3.1. Design of Object Re-Identification Model Based on Deep Learning
3.1.1. Global Feature Selection Module
3.1.2. Spatial Local Feature Selection Module
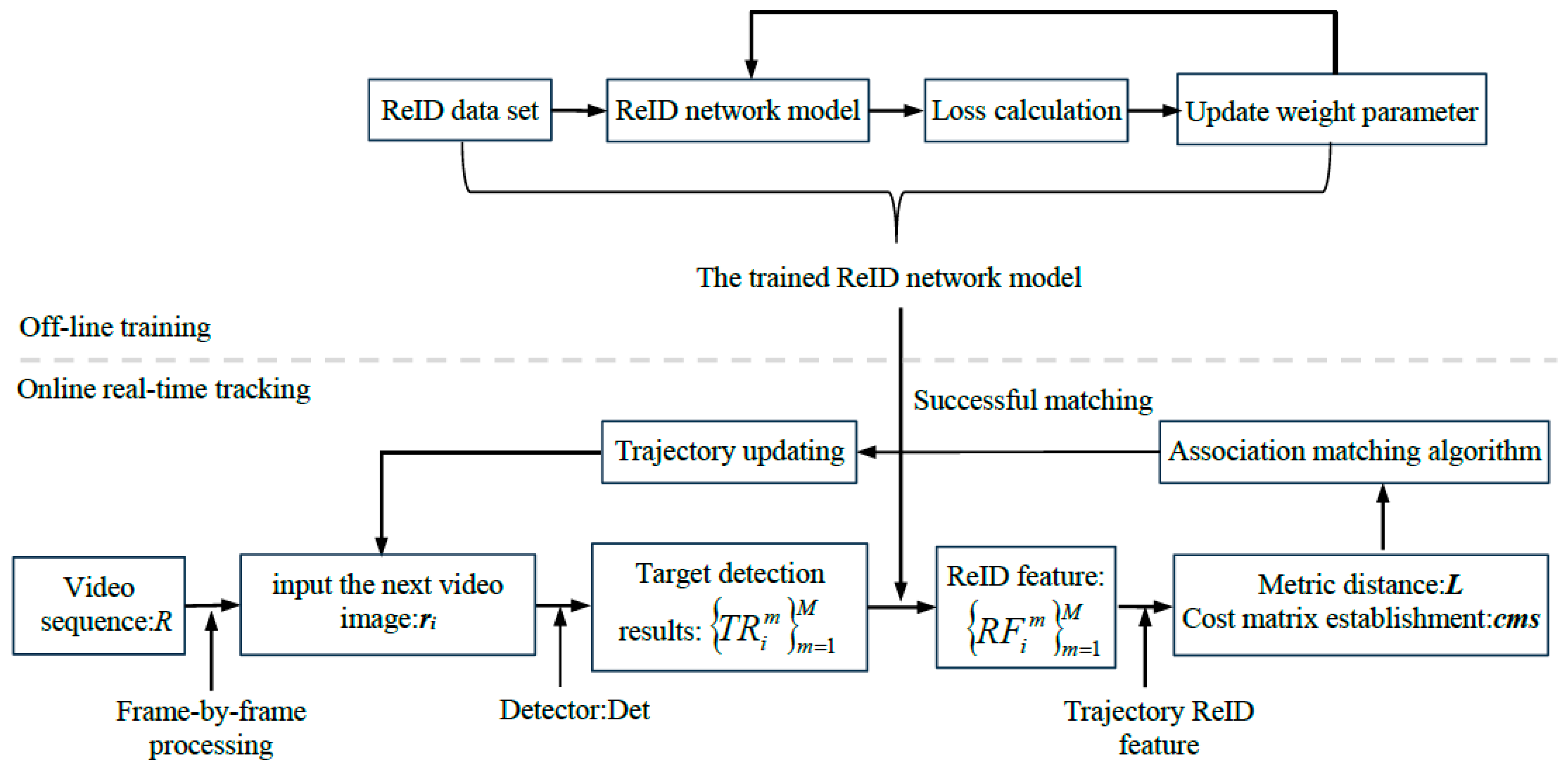
3.2. Trajectory Tracking Method Based on ReID Feature
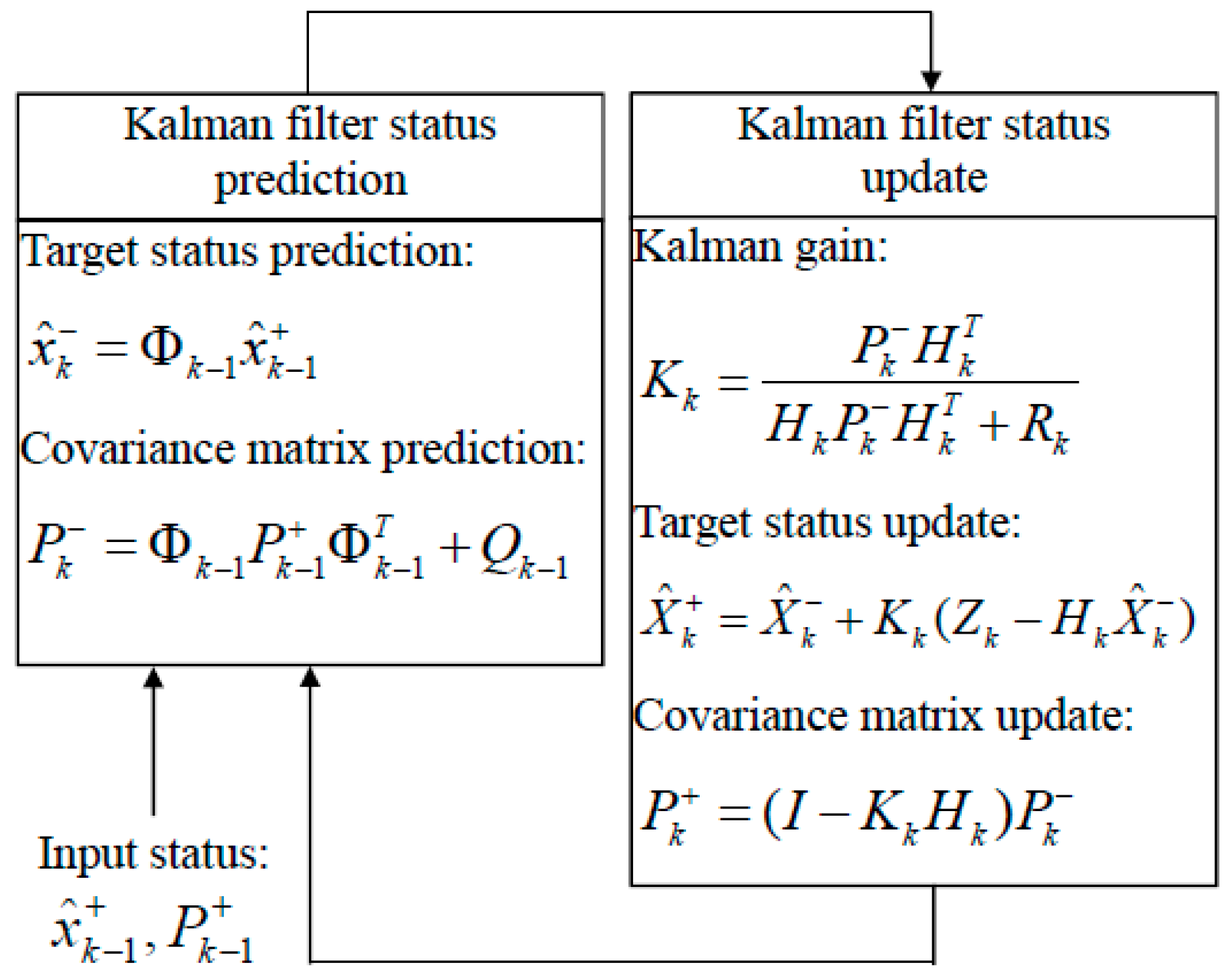
3.2.1. Trajectory Update Based on ReID Feature
3.2.2. Similarity Measure in Target Association
3.2.3. Trajectory Updating
3.3. Target Rerecognition and Tracking Experiment
3.3.1. Vehicle Re-Identification Verification Based on ReID Model
3.3.2. Pedestrian Re-Identification Verification Based on ReID Model
3.3.3. Comparison Experiment and Result Analysis of Multi-Target Tracking
4. Conclusions
- (1)
- In order to solve the problem of the missing and false detection of small targets due to dense occlusion in complex traffic environments, a non-maximum suppression method, Bot-NMS, is proposed to improve the deep learning ability of network models for dense occlusion targets and solve the problem of missing targets. The comparison results of the SCTSD dataset show that the performance of recall and accuracy are improved;
- (2)
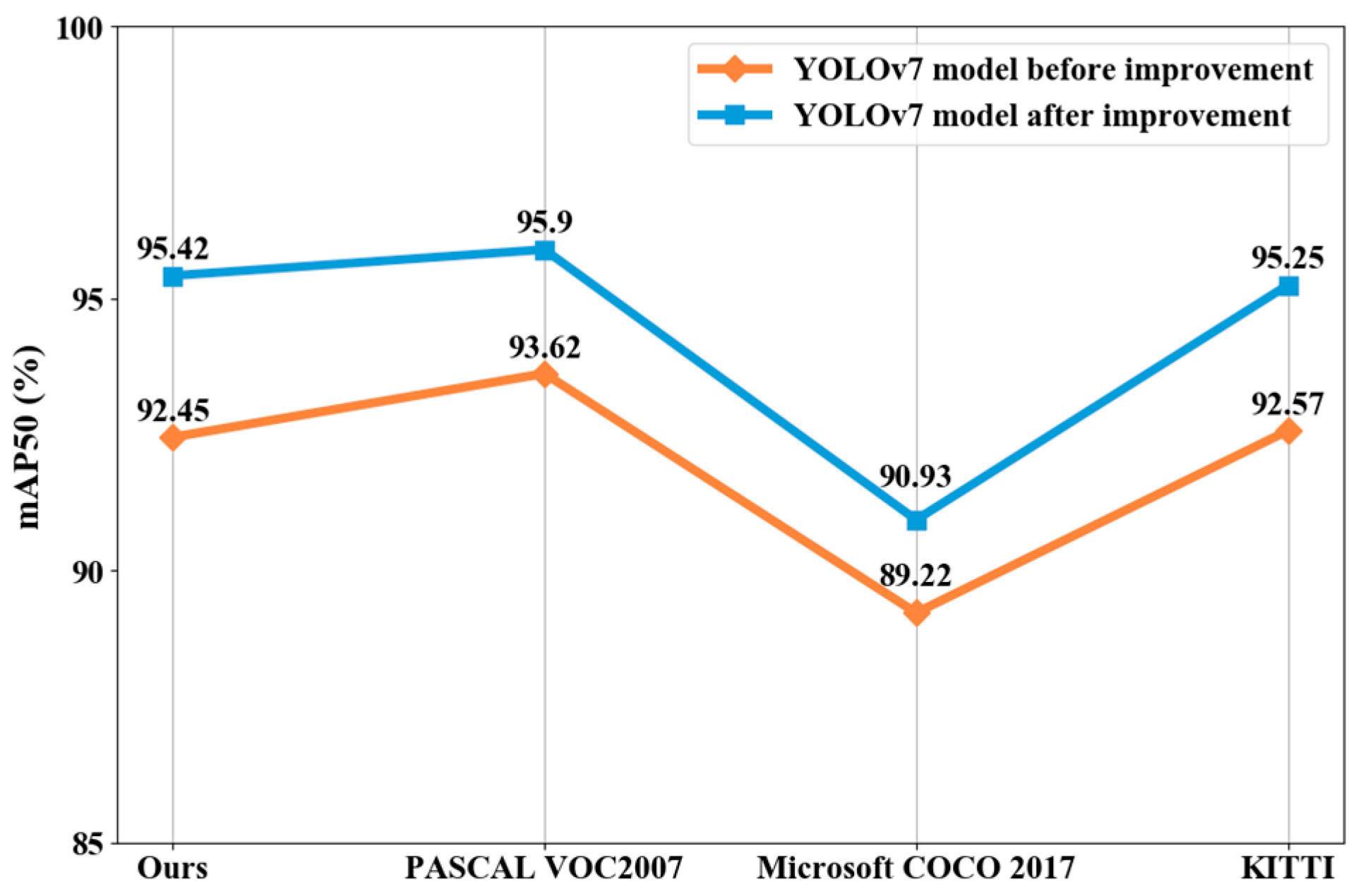
- In the backbone network of YOLOv7, the overall structure of the network is improved by introducing multi-scale learning, prior frames, and attention mechanisms, and the detection ability of the network of small targets is improved. The model performance was evaluated through a variety of datasets such as PASCAL VOC2007, Microsoft COCO2017, and KITTI; the improved model had a significant improvement in the mAP50 and the average Time was less than 17 ms, which met the requirements for the real-time detection of intelligent vehicles;
- (3)
- In order to solve the problem of target ID association failure and low tracking accuracy caused by target occlusion in complex road environments based on deep learning theory, a ReID model for target re-identification was constructed to obtain target global features and foreground features. Based on the trained ReID network model, the track update process of the tracking target was designed, and the correlation cost matrix of cosine distance and IoU overlap was established to realize the correlation between the target detection object, tracking trajectory, and ReID feature similarity. The VERI-776 vehicle re-identification dataset and MARKET1501 pedestrian re-identification dataset were used to complete ReID model training and comparative analysis with mainstream methods. The multi-target tracking performance was compared and verified on the MOT16 dataset. The accuracy of ID matching and the tracking of occlusion targets were verified by combining the road target video collected using the dashcam in the realistic complex traffic environment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, P.; Geng, K.K.; Wang, Z.W.; Liu, Z.C.; Yin, G.D. Review on Environmental Perception Methods of Autonomous Vehicles. J. Mech. Eng. 2023, 59, 281–303. [Google Scholar]
- Jiang, W.H.; Xin, X.; Chen, W.W.; Cui, W.W. Multi-condition Parking Space Recognition Based on Information Fusion and Decision Planning of Automatic Parking System. J. Mech. Eng. 2021, 57, 131–141. [Google Scholar]
- Xu, X.; Zhao, J.; Li, Y.; Gao, H.; Wang, X. BANet: A Balanced Atrous Net Improved From SSD for Autonomous Driving in Smart Transportation. IEEE Sens. J. 2021, 21, 25018–25026. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wang, F. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Li, G.; Ji, Z.; Qu, X.; Zhou, R.; Cao, D. Cross-Domain Object Detection for Autonomous Driving: A Stepwise Domain Adaptative YOLO Approach. IEEE Trans. Intell. Veh. 2022, 7, 603–615. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 7464–7475. [Google Scholar]
- Wang, H.; Xu, Y.; Wang, Z.; Cai, Y.; Chen, L.; Li, Y. CenterNet-Auto: A Multi-object Visual Detection Algorithm for Autonomous Driving Scenes Based on Improved CenterNet. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 742–752. [Google Scholar] [CrossRef]
- Wang, Y.; Hsieh, J.; Chen, P.; Chang, M.; So, H.; Li, X. SSMILEtrack: SiMIlarity LEarning for Occlusion-Aware Multiple Object Tracking. arXiv 2024, arXiv:2211.08824v4. Available online: https://arxiv.org/pdf/2211.08824.pdf (accessed on 20 October 2023).
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi-Object Tracking by Associating Every Detection Box. arXiv 2022, arXiv:2110.06864v3. Available online: https://arxiv.org/pdf/2110.06864.pdf (accessed on 20 October 2023).
- Aharon, N.; Orfaig, R.; Bobrovsky, B. BoT-SORT: Robust Associations Multi-Pedestrian Tracking. arXiv 2022, arXiv:2206.14651v2. Available online: https://arxiv.org/pdf/2206.14651.pdf (accessed on 20 October 2023).
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. StrongSORT: Make deepsort great again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 9686–9696. [Google Scholar]
- Maggiolino, G.; Ahmad, A.; Cao, J.; Kitani, K. Deep OC-SORT: Multi-Pedestrian Tracking by Adaptive Re-Identification. arXiv 2023, arXiv:2302.11813v1. Available online: https://arxiv.org/pdf/2302.11813.pdf (accessed on 16 June 2024).
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object Tracking. arXiv 2020, arXiv:1909.12605v2. Available online: https://arxiv.org/pdf/1909.12605.pdf (accessed on 20 October 2023).
- Chaabane, M.; Zhang, P.; Beveridge, J.; O’Hara, S. DEFT: Detection Embeddings for Tracking. arXiv 2021, arXiv:2102.02267v2. Available online: https://arxiv.org/pdf/2102.02267.pdf (accessed on 20 October 2022).
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850v2. Available online: https://arxiv.org/pdf/1904.07850.pdf (accessed on 20 October 2022).
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Pang, Z.; Li, Z.; Wang, N. SimpleTrack: Understanding and Rethinking 3D Multi-object Tracking. arXiv 2021, arXiv:2111.09621v1. Available online: https://arxiv.org/pdf/2111.09621.pdf (accessed on 20 October 2023).
- Machmudah, A.; Shanmugavel, M.; Parman, S.; Manan, T.S.A.; Dutykh, D.; Beddu, S.; Rajabi, A. Flight Trajectories Optimization of Fixed-Wing UAV by Bank-Turn Mechanism. Drones 2022, 6, 69. [Google Scholar] [CrossRef]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. TrackFormer: Multi-Object Tracking with Transformers. arXiv 2021, arXiv:2101.02702v1. [Google Scholar]
- Brillantes, A.K.; Sybingco, E.; Billones, R.K.; Bandala, A.; Fillone, A.; Dadios, E. Observation-Centric with Appearance Metric for Computer Vision-Based Vehicle Counting. J. Adv. Inf. Technol. 2023, 14, 1261–1272. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-Maximum Suppression Method | Various Detection Classes | Evaluation Index | ||||||
|---|---|---|---|---|---|---|---|---|
| Car | Bus | Truck | Motor Bike | Bicycle | Person | mAP50 | Time | |
| NMS | 87.9 | 91.1 | 91.2 | 88.5 | 82.2 | 86.3 | 89.4 | 15.4 |
| DIoU-NMS | 91.1 | 95.3 | 95.4 | 92.2 | 86.1 | 90.1 | 91.1 | 15.6 |
| Soft-NMS | 90.1 | 94.3 | 94.3 | 91.2 | 84.7 | 88.9 | 90.7 | 15.5 |
| Bot-NMS | 92.3 | 96.1 | 96.5 | 93.8 | 87.4 | 91.5 | 91.5 | 15.7 |
| Feature Map Size | Receptive Field | Prior Frame Size |
|---|---|---|
| 20 × 20 | big | (116,253), (168,111), (376,300) |
| 40 × 40 | middle | (37,29), (58,143), (78,58) |
| 80 × 80 | lesser | (8,12), (16,35), (30,74) |
| 160 × 160 | small | (2, 6), (4, 13), (6, 7) |
| Detection Model | Parameters (M) | GLOPs | mAP50 | Time |
|---|---|---|---|---|
| Improved YOLOv7 | 0.00 | 0.00 | 91.46 | 15.69 |
| +ECA | +0.04 | +0.095 | 92.56 | 16.09 |
| +CA | +1.16 | +0.90 | 91.96 | 18.29 |
| +SA | +1.18 | +0.88 | 93.26 | 17.69 |
| Evaluation Index of Recall Rate | Various Detection Classes | |||||
|---|---|---|---|---|---|---|
| Car | Bus | Truck | Motor Bike | Bicycle | Person | |
| YOLOv7 model | 93.1 | 96.3 | 96.1 | 92.1 | 89.0 | 92.3 |
| Improved YOLOv7 model | 95.3 | 97.2 | 97.6 | 96.9 | 93.7 | 95.6 |
| Evaluation Index of Detection Accuracy | Various Detection Classes | |||||
|---|---|---|---|---|---|---|
| Car | Bus | Truck | Motor Bike | Bicycle | Person | |
| YOLOv7 model | 95.8 | 96.9 | 97.3 | 96.2 | 93.3 | 95.6 |
| Improved YOLOv7 model | 96.0 | 97.1 | 97.5 | 97.5 | 94.4 | 96.9 |
| Parameter Name | Parameter Setting |
|---|---|
| Input image size | 640 × 640 × 3 |
| Epochs | 300 |
| Batch size | 32 |
| Optimizer | SGD |
| weight_decay | 5 × 10−4 |
| Init_lr | 1 × 10−2 |
| Momentum | 0.937 |
| Lr_scheduler | CosineAnnealingLR |
| Save_period | 10 |
| Vehicle Re-Identification Method | Rank-1 (%) | Rank-5 (%) | mAP (%) |
|---|---|---|---|
| RAM | 88.9 | 93.8 | 61.7 |
| SAN | 92.0 | 97.1 | 72.3 |
| PNVR | 94.1 | 98.0 | 74.5 |
| Ours | 94.3 | 98.1 | 77.6 |
| Pedestrian Rerecognition Method | Rank-1 (%) | mAP (%) |
|---|---|---|
| PSE | 87.9 | 69.0 |
| MaskReID | 90.0 | 72.9 |
| DuATM | 91.4 | 76.6 |
| Ours | 91.7 | 77.9 |
| MOT Method | MOTA↑ (%) | IDF1↑ (%) | ID Sw.↓ | FPS↓ |
|---|---|---|---|---|
| Baseline | 69.4 | 74.6 | 607 | 43.1 |
| Ours | 72.1 | 77.8 | 524 | 34.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Yan, S.; Xia, C. Research on Multi-Target Detection and Tracking of Intelligent Vehicles in Complex Traffic Environments Based on Deep Learning Theory. World Electr. Veh. J. 2025, 16, 325. https://doi.org/10.3390/wevj16060325
Chen X, Yan S, Xia C. Research on Multi-Target Detection and Tracking of Intelligent Vehicles in Complex Traffic Environments Based on Deep Learning Theory. World Electric Vehicle Journal. 2025; 16(6):325. https://doi.org/10.3390/wevj16060325
Chicago/Turabian StyleChen, Xuewen, Shilong Yan, and Chenxi Xia. 2025. "Research on Multi-Target Detection and Tracking of Intelligent Vehicles in Complex Traffic Environments Based on Deep Learning Theory" World Electric Vehicle Journal 16, no. 6: 325. https://doi.org/10.3390/wevj16060325
APA StyleChen, X., Yan, S., & Xia, C. (2025). Research on Multi-Target Detection and Tracking of Intelligent Vehicles in Complex Traffic Environments Based on Deep Learning Theory. World Electric Vehicle Journal, 16(6), 325. https://doi.org/10.3390/wevj16060325