Abstract
Vehicle detection algorithms constitute a fundamental pillar in intelligent driving systems and smart transportation infrastructure. Nevertheless, the inherent complexity and dynamic variability of traffic scenarios present substantial technical barriers to robust vehicle detection. While visual transformer-based detection architectures have demonstrated performance breakthroughs through enhanced perceptual capabilities, establishing themselves as the dominant paradigm in this domain, their practical implementation faces critical challenges due to the quadratic computational complexity inherent in the self-attention mechanism, which imposes prohibitive computational overhead. To address these limitations, this study introduces Mamba RT-DETR (MRD), an optimized architecture featuring three principal innovations: (1) We devise an efficient vehicle detection Mamba (EVDMamba) network that strategically integrates a linear-complexity state space model (SSM) to substantially mitigate computational overhead while preserving feature extraction efficacy. (2) To counteract the constrained receptive fields and suboptimal spatial localization associated with conventional SSM sequence modeling, we implement a multi-branch collaborative learning framework that synergistically optimizes channel dimension processing, thereby augmenting the model’s capacity to capture critical spatial dependencies. (3) Comprehensive evaluations on the BDD100K benchmark demonstrate that MRD architecture achieves a 3.1% enhancement in mean average precision (mAP) relative to state-of-the-art RT-DETR variants, while concurrently reducing parameter count by 55.7%—a dual optimization of accuracy and efficiency.
1. Introduction
In recent years, deep learning has undergone rapid advancements, particularly within the domain of computer vision. A series of groundbreaking architectures—from early convolutional neural networks (CNNs) [1,2,3] to vision transformers (ViTs) [4,5]—have demonstrated remarkable efficacy in addressing complex visual tasks. In object detection, one of the core challenges in downstream applications, two primary methodologies dominate: convolution-based frameworks and transformer structures. While CNNs and their variants excel in balancing accuracy with computational efficiency [6,7], they inherently struggle to capture long-range spatial correlations within images, which limits their contextual understanding capabilities. To mitigate this limitation, researchers have integrated self-attention mechanisms from vision transformers into object detection pipelines, as exemplified by the DETR series of models [8,9]. Despite early concerns over the computational and memory overhead associated with transformer architectures, advancements in hardware infrastructure have alleviated these constraints to some extent. However, recent studies have shifted focus toward re-examining the architectural design of CNNs to further enhance computational efficiency [10,11], driven by growing dissatisfaction with the quadratic complexity inherent to pure transformer structures. This has spurred the development of hybrid architectures that blend convolutional and transformer components—such as MobileViT [12], EdgeViT [13], and EfficientFormer [14]—to optimize performance while reducing computational burden. Notably, hybrid models often face trade-offs between efficiency and accuracy, with many implementations experiencing non-trivial performance degradation. Consequently, achieving an optimal balance between model efficacy and inference speed remains a central challenge in the field. Recent breakthroughs leveraging state space models (SSMs), such as Mamba [15], have introduced promising alternatives by capitalizing on their ability to model long-range dependencies while maintaining linear computational complexity—a critical advantage for large-scale visual tasks.
This paper presents a novel vehicle detection model named Mamba RT-DETR, which applies the visual Mamba model to vehicle detection and designs an efficient vehicle detection feature extraction network called EVDMamba. Unlike classification tasks, object detection often deals with images of higher resolution and pixel density. Existing visual state space models (SSMs), designed mainly for text sequence modeling, are not fully capable of utilizing the channel and spatial information in images. To address this, we introduce a Residual Channel–Spatial Gating (RSCG) module and use a selective 2D scanning module with high-dimensional dot products to enhance channel and spatial feature extraction. Experiments on the BDD100K dataset show that Mamba RT-DETR is highly competitive for vehicle detection. The main contributions of this paper are as follows:
- A Mamba RT-DETR model based on SSM is proposed. By leveraging the linear complexity of SSM, this model improves vehicle detection performance while reducing the number of model parameters.
- An EVDMamba module is designed. It introduces a dilated scanning mechanism and optimizes the module structure to enhance the performance of SSM in image feature extraction.
- The idea of gated aggregation is combined with effective convolutions and residual connections, and an RSCG module is introduced to capture local dependencies and enhance model robustness.
2. Related Work
2.1. Object Detection
Object detection, a key computer vision technology, focuses on identifying and locating objects in images. Current detection architectures mainly fall into two categories: those based on convolutional neural networks [7,16,17] and those using transformer architectures [18,19,20]. In recent years, detection methods have evolved from two-stage detectors (e.g., RCNN series [7,21]) to one-stage detectors (e.g., SSD and YOLO series [22,23,24]). Detection frameworks also split into anchor-based and anchor-free approaches [25]. These advances have driven the field forward, improving both algorithm speed and detection accuracy.
However, conventional object detection algorithms face a common bottleneck: they often require numerous hand-designed components, such as non-maximum suppression (NMS). The introduction of transformer-based detectors [9] changed this paradigm by directly outputting detection results through a sequential prediction mechanism, eliminating traditional prior designs and achieving an end-to-end detection framework. This innovation simplified algorithms and unified the mathematical formulation of detection tasks. Since the debut of DETR, researchers have made systematic improvements to address its slow convergence, low computational efficiency, and poor small object detection performance. Deformable DETR [8] replaced the standard multi-head attention module with a deformable attention mechanism, using dynamic sparse sampling to reduce attention computation complexity from quadratic to linear. This improved training convergence speed by over 10 times without sacrificing detection accuracy. Anchor DETR [26] incorporated anchor priors into the transformer query vector generation process, using spatial position encoding and scale-aware anchor initialization to boost small object detection AP on the COCO dataset by 4.2 percentage points. Efficient DETR [27] focused on computational efficiency, reconstructing the encoder module with a cross-scale feature fusion architecture and using knowledge distillation and hierarchical pruning. This achieved a 2.3× inference speed increase with a 45% reduction in parameters. RT-DETR [28], designed for real-time detection, used lightweight depthwise separable self-attention modules and a dynamic convolution-enhanced detection head, combined with progressive distillation training. It maintained 68.9% mAP, surpassing YOLOv7 in both speed and accuracy by 32% and 2.4 percentage points, respectively. These advancements reflect the growing application of transformers in object detection and push algorithms toward greater efficiency, intelligence, and practicality.
2.2. Visual State Space Models
Research on state space models shows Mamba models have linear computational complexity in long-sequence modeling, solving the efficiency bottleneck of transformers. In vision backbones, Vision Mamba [29], the first pure vision backbone based on a selective state space mechanism, marked Mamba’s entry into vision computing. VMamba [30] enhanced 2D image scanning with a cross-scan module, achieving 87.6% top-1 accuracy on ImageNet. LocalMamba [31] focused on window scanning for vision spatial modeling, improving local dependency capture via dynamic scanning and boosting mIoU on ADE20K over ViT-B by 4.3 points. Inspired by breakthroughs of Mamba models in visual tasks [29,30,31], this paper presents Mamba RT-DETR, a new state space-driven object detection algorithm. It features an innovative global-local state space collaboration mechanism for global receptive field modeling.
3. Materials and Methods
3.1. Overall Architecture
The design architecture of MRD is illustrated in Figure 1. The model consists of a backbone, a neck, and a decoder part. The backbone is composed of a Stem module, an EVDMamba module, and a Visual Feature Fusion module. It starts with the Stem module for downsampling, producing a 2D feature map with a resolution of H⁄4 and W⁄4. Subsequently, all models consist of EVDMamba and Vision Clue Merge modules for further downsampling. In the neck design, the PAFPN method is adopted, using the EVDMamba module instead of cf2 to capture a richer flow of gradient information.
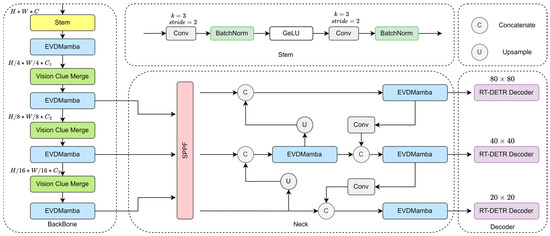
Figure 1.
Framework of MRD. MRD incorporates EVDMamba with selective SSM as its core backbone structure, leveraging a simple Stem module to partition the input image into distinct patches and implementing Vision Clue Merge to perform downsampling operations.
3.2. Mamba
The state space sequence models S4 [32] and Mamba [15] are both built upon the framework of state space models, originating from a continuous dynamical system. This system establishes a mapping between an input sequence and output sequence through an implicit latent representation . By leveraging this hidden state mechanism, the architecture simultaneously captures temporal dependencies while maintaining explicit input–output relationships in sequence modeling tasks. The system can be mathematically defined as follows:
In Equation (1), the state transition matrix defines the temporal evolution mechanism of the latent state vector h(t), while the input mapping matrix establishes the coupling between external inputs and the hidden state dynamics. Complementing these components, the observation matrix serves as the projection operator that translates the internal state representation into observable outputs. To adapt this continuous-time formulation for discrete sequence processing in Mamba, the model employs a fixed discretization strategy that converts the continuous parameters A and B into their discrete-time equivalents and through established numerical methods. Among various discretization techniques, the Zero-Order Hold (ZOH) approach is frequently adopted due to its computational efficiency and stability properties. The discretized version can be defined as follows:
In Equation (4), ∆ functions as a temporal scaling factor that modulates the model’s temporal resolution, while the discrete-time parameters ∆A and ∆B represent the transformed counterparts of their continuous-domain equivalents within a specified time interval. Here, denotes the identity matrix of appropriate dimensionality. Following this discretization process, the system dynamics are implemented through linear recurrence relations, which can be formally expressed as follows:
The complete sequence transformation can be equivalently expressed through a convolutional representation, mathematically characterized by the following formulation:
The structured convolutional kernel serves as the fundamental operation for sequence transformation, where specifies the dimensionality of the input sequence. In the proposed architectural design, the model leverages a convolutional formulation to enable parallelizable training processes while simultaneously adopting a linear recurrence relation to optimize the efficiency of autoregressive inference.
3.3. EVDMamba
In the field of computer vision, both convolutional neural networks and visual transformers typically use convolutional operations for downsampling. However, this traditional convolutional downsampling method can interfere with the selective operations of SS2D [30] at different stages of information flow. Based on previous studies [30,33], this paper introduces a more concise and efficient approach. Firstly, the computation pipeline is simplified by removing normalization layers. Then, the feature map is segmented to make the processing more precise and effective. For redundant feature maps, they are appended to the channel dimension, allowing the full utilization of this feature information. Finally, a 4× compressed pointwise convolution is used for downsampling instead of the conventional stride-2 3 × 3 convolution. This design effectively preserves the feature maps selected by the previous SS2D layer, thus better serving the training of the model.
This paper introduces the ES2D [34] module in the design of EVDMamba, as shown in Figure 2, serving as the core module for MRD and thereby initiating its data processing with a convolutional module. It performs deep feature extraction on the input feature and utilizes the SiLU non-linear activation function σ(∙) to achieve non-linear mapping in the feature space. This module refers to the layer normalization mechanism and residual connection design of the transformer module, effectively supporting deep stacked training through cross-layer gradient propagation. In EVDMamba, ES2D employs a selective state space model (S6) to achieve long-range spatial dependency modeling via a hidden state evolution equation, outputting intermediate states . On the other hand, RSCG enhances the feature output from ES2D through parallel pathways that facilitate cross-channel interaction and local spatial focusing by utilizing dynamic channel gating and spatial attention mechanisms.
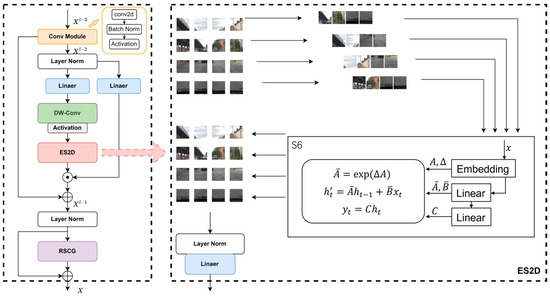
Figure 2.
Illustration of the EVDMamba architecture.
Recently, some works [33,35,36] have found that gating mechanisms demonstrate strong performance in both natural language processing and visual processing. Therefore, this paper proposes a Residual-based Spatial–Channel Attention Gating module (RSCG), aimed at improving the model’s performance without significantly increasing the computational cost.
As show in Figure 3, the RSCG module employs a dual-branch structure to extract channel and spatial information from the inputs and , and it utilizes gating mechanisms to control the flow of information, enabling the model to more effectively transmit important features.
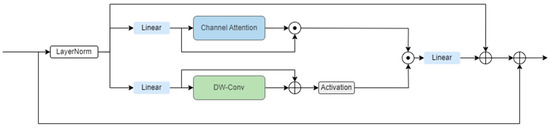
Figure 3.
The details of RSCG.
On the branch, depthwise separable convolutions are used as the position embedding model. By cascading residuals, gradients are more effectively backpropagated during training, thereby preserving and utilizing the spatial structural information of the image while maintaining a low computational cost, significantly enhancing performance. The RSCG module uses the non-linear GeLU activation function to control the flow of information across layers. After processing through the spatial branch, local information is fused with the globally refined information that has passed through a linear layer.
The feature information obtained from the dual branches is added to the original input information through residual connections, allowing the RSCG module to capture more global and local features without a significant increase in computational cost.
4. Results
4.1. Datasets
This study primarily focuses on vehicle detection in complex road conditions under various weather scenarios, hence the selection of the BDD100K dataset. BDD100K is a large-scale and diverse public driving dataset that includes images from different times of day (e.g., day and night), various scenes (highways, urban streets, and residential areas), and different weather conditions (sunny, rainy, and snowy). The BDD100K dataset comprises 69,434 training images, 9919 validation images, and 20,000 test images, with an image resolution of 1280 × 720.
4.2. Training Details and Evaluation Metrics
During the training process in this paper, the model optimizer chosen was AdamW with a momentum parameter of 0.9, a weight decay parameter of 0.001, an initial learning rate of 0.0001, a training epoch setting of 300, and a batch size of 16. The configuration of the experimental host is as shown in Table 1.

Table 1.
The details of the training platform.
To test the performance of the proposed algorithm, mean average precision (mAP@50) and the number of parameters are used as the main evaluation metrics. The mean average precision is calculated as follows:
In the above equation, P and R represent precision and recall, respectively.
The number of parameters refers to the total number of trainable parameters in the model, which is an important metric for measuring the complexity of deep learning models and evaluating computational requirements.
Floating-point operations (Flops) represent a fundamental measure of the computational complexity of a machine learning (ML) model, particularly in deep learning. It quantifies the total number of floating-point calculations (like additions, subtractions, multiplications, and divisions) required for a single forward pass of the model, typically during inference.
4.3. Performance Comparison on the BDD100K Dataset
Currently, there are many deep learning-based object detection algorithms. To demonstrate the advantages of our proposed algorithm, we compared it with existing classic object detection models on the BDD100K dataset. The compared algorithms include convolutional neural network-based object detection algorithms (YOLOv5m, YOLOv6s, and YOLO8m) and transformer-based object detection algorithms (RT-DETR-r18, RT-DETR-r34, and RT-DETR-r50). The specific results are shown in Table 2. It can be seen that on the challenging BDD100K dataset, compared to both convolutional neural network-based algorithms and transformer algorithms, our studied algorithm achieves the highest mAP@50, and the number of parameters is significantly lower than other object detection algorithms. The proposed MRD achieves a 1.9% increase in mAP@50 with only 9.1M parameters, realizing a lightweight algorithm without sacrificing high recognition accuracy in complex traffic scenes.
Table 2.
Performance comparison on the BDD100K dataset.
4.4. Performance Comparison on the KITTI Dataset
To further validate the effectiveness of our algorithm, we compare it with a range of detection algorithms on the KITTI dataset, as shown in Table 3. It can be seen that our algorithm’s mAP@50 outperforms other detection algorithms on the KITTI dataset. For example, compared to RT-DETR-r18, YOLOv5m, YOLOv6s, and YOLOv8m, our algorithm achieves an increase in mAP@50 by 1.2%, 8.2%, 9.1%, and 2.8%, respectively. Therefore, the overall performance of the proposed algorithm is further validated on the KITTI dataset.
Table 3.
Performance comparison on the KITTI dataset.
4.5. Ablation Study
Ablation experiments (Table 4) quantitatively verify the impact of the EVDMamba module and the enhanced FPAFN module on detection accuracy and model lightweighting by comparing the performance of different backbone and neck combinations: The baseline model (ResNet34 + HybridEncoder) has 30.0M parameters and a mAP@50 of 0.511. When only modifying the neck to the enhanced FPAFN, the parameters decrease to 22.8M (a reduction of 24%), but the mAP@50 drops by 0.6% to 0.508, indicating that optimizing the neck alone may lead to accuracy loss due to the lack of global modeling capability in ResNet34. When only replacing the backbone with EVDMamba, the parameters are significantly reduced to 9.8M (a reduction of 67.3%), and the mAP@50 increases by 3.0% to 0.526, demonstrating the effectiveness of EVDMamba’s linear-complexity SSM and RSCG modules in lightweighting and global feature modeling. With full module optimization (EVDMamba + enhanced FPAFN), the parameters are further reduced to 9.1M (a 70% reduction compared to the baseline), the mAP@50 increases to 0.535 (an improvement of 4.7%), and the mAP@50:95 increases to 0.302 (an improvement of 7.9%). This highlights the synergistic benefits of the backbone and neck modules—EVDMamba compensates for the lack of global features, while the enhanced FPAFN optimizes cross-layer feature fusion, ultimately achieving dual optimization of parameters and accuracy.
Table 4.
Ablation experiment.
4.6. Visualization
To clearly demonstrate the performance of the improved algorithm in object detection across diverse traffic scenarios, this study extracts a subset of scene views from the BDD100K dataset based on attribute labels. The selected scenes encompass four typical driving scenario types (urban streets, highways, residential areas, and tunnels), three time periods (daytime, nighttime, and dawn/dusk), and four weather conditions (overcast, clear, rainy, and snowy). Detection results for these extracted scenes are visualized to provide intuitive comparisons. Additionally, output features from the model’s encoding phase are extracted and visualized as heatmaps to analyze spatial attention patterns.
The above visualization results systematically validate the vehicle detection capability of the MRD model across multiple scenarios, complex weather conditions, and varying lighting environments. In typical scenarios such as urban streets, highways, residential areas, and tunnels (Figure 4), the MRD model demonstrates excellent detection performance even under challenging conditions such as heavily occluded vehicles and distant targets. For low-light environments (Figure 5), the model exhibits outstanding nighttime detection ability, successfully identifying black vehicles that are highly blended with the surroundings. As shown in Figure 6, during rainy conditions with interferences such as raindrop occlusion and strong light glare, the model still maintains stable detection outputs, fully demonstrating its strong robustness and anti-interference capabilities.


Figure 4.
Detection results in natural traffic scenes.

Figure 5.
Detection results in different weather.
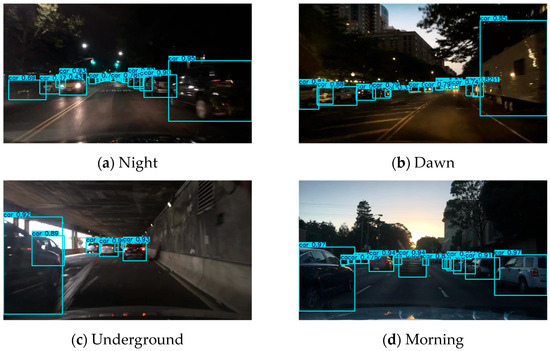
Figure 6.
Test results under the influence of light.
As show in Figure 7, in the sunny scenario, the model shows strong heat responses to vehicle locations on the road, indicating its ability to effectively capture and accurately locate vehicles under favorable lighting conditions, thus demonstrating excellent detection performance under ideal illumination. In the morning scenario, where lighting conditions are more challenging—such as backlighting and low-angle sunlight—the heatmap indicates a more scattered focus on vehicles. While the model can still recognize general vehicle locations, showing a certain level of robustness, feature extraction and localization accuracy are somewhat compromised. In the underground parking scenario with dim lighting, the model focuses on key vehicle parts such as the body outline, suggesting it possesses some degree of adaptability to low-light environments by relying on critical features for target localization. However, the heatmap quality is noticeably inferior compared to that in the sunny scenario.
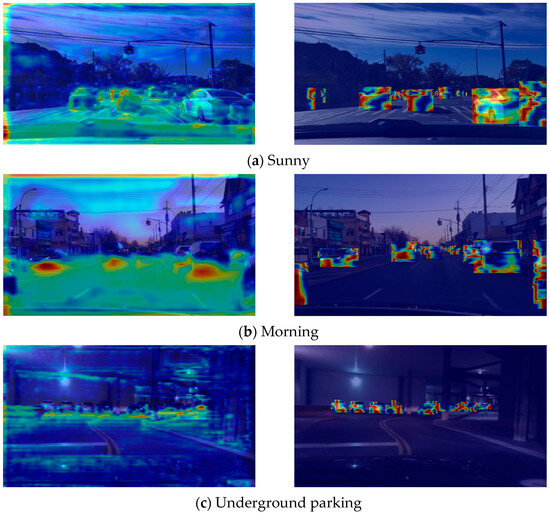
Figure 7.
Heatmap visualization.
In summary, the model maintains detection capability across varying lighting conditions. Nonetheless, there remains room for improvement in scenarios involving complex or low-light illumination. Future work could focus on optimizing illumination normalization or enhancing feature extraction modules for scenes with challenging morning lighting. Additionally, for low-light environments such as underground parking, integrating infrared imaging or employing advanced image enhancement algorithms in preprocessing could further improve detection performance and heatmap quality.
5. Discussion
The MRD model achieves a dual breakthrough in detection accuracy and computational efficiency by introducing a linear-complexity state space model (SSM) and a multi-branch collaborative framework for vehicle detection tasks. On the BDD100K and KITTI datasets, MRD achieves 0.535 (BDD100K) and 0.752 (KITTI) mAP@50 with only 9.1M parameters, representing 3.1% and 1.2% improvements, respectively, compared to mainstream RT-DETR variants, while reducing parameter count by 55.7%. CNNs like YOLOv8m struggle with long-range dependencies, evident in their 1.6% lower mAP@50 than MRD on BDD100K. The multi-branch framework fuses global context (via SSM) and local details (via convolutions), resolving this limitation.
Although MRD demonstrates strong performance, it still faces technical limitations: Firstly, as an emerging architecture, the lightweight deployment strategies for SSM remain immature, particularly lacking hardware-adapted optimization for edge computing devices, which hinders inference efficiency. Secondly, in scenarios involving small objects (pixel occupancy < 1%) and heavy occlusions, detection confidence drops below 0.7, highlighting limitations in modeling low-resolution features and complex occlusion relationships.
Future research will focus on the following three directions: (1) Model Compression and Edge Adaptation: By implementing dynamic sparsification of the SSM state matrix, mixed-precision quantization, and edge-device-specific compilation strategies, we aim to reduce FLOPs to below 10G and achieve end-to-end real-time detection on edge devices. (2) Multimodal Fusion and Scene Generalization: Integrating LiDAR and infrared imagery, we will design cross-modal feature alignment modules and employ generative data augmentation to simulate extreme scenarios. This will enhance robustness for small objects and adverse weather conditions. (3) Architecture Optimization and Mechanism Exploration: Developing hierarchical state space models to reduce neck parameters, combined with neural radiance fields (NeRF) to improve 3D scene understanding, will further refine target localization accuracy. These efforts will advance MRD toward high robustness and low energy consumption, enabling its practical deployment in intelligent driving and smart transportation systems.
Author Contributions
Conceptualization, K.L. and X.H.; supervision, X.H.; methodology, K.L. and X.H.; software, K.L.; validation, K.L.; formal analysis, K.L.; data curation, K.L.; visualization, K.L.; supervision, X.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 24 May 2019; pp. 6105–6114. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17773–17783. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. RepViT: Revisiting Mobile CNN From ViT Perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 6–22 June 2024; pp. 15909–15920. [Google Scholar]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking Mobile Block for Efficient Attention-Based Models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 1 October 2023; IEEE Computer Society: Washington, DC, USA, 2023; pp. 1389–1400. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer. arXiv 2022, arXiv:2110.02178. [Google Scholar]
- Chen, Z.; Zhong, F.; Luo, Q.; Zhang, X.; Zheng, Y. EdgeViT: Efficient Visual Modeling for Edge Computing. In Proceedings of the Wireless Algorithms, Systems, and Applications, Dalian, China, 24–26 November 2022; Wang, L., Segal, M., Chen, J., Qiu, T., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 393–405. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. EfficientFormer: Vision Transformers at MobileNet Speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2024, arXiv:2312.00752. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; XU, C.; Wang, Y. Transformer in Transformer. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 15908–15919. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.S.; Koltun, V. Point Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A Cascaded R-CNN with Multiscale Attention and Imbalanced Samples for Traffic Sign Detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A Simple and Strong Anchor-Free Object Detector. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1922–1933. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor DETR: Query Design for Transformer-Based Detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 1 March–28 February 2022; Volume 36, pp. 2567–2575. [Google Scholar] [CrossRef]
- Yao, Z.; Ai, J.; Li, B.; Zhang, C. Efficient DETR: Improving End-to-End Object Detector with Dense Prior. arXiv 2021, arXiv:2104.01318. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. arXiv 2024, arXiv:2501.14679. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. VMamba: Visual State Space Model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Huang, T.; Pei, X.; You, S.; Wang, F.; Qian, C.; Xu, C. LocalMamba: Visual State Space Model with Windowed Selective Scan. arXiv 2024, arXiv:2403.09338. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently Modeling Long Sequences with Structured State Spaces. arXiv 2022, arXiv:2111.00396. [Google Scholar]
- Wang, Z.; Li, C.; Xu, H.; Zhu, X.; Li, H. Mamba YOLO: A Simple Baseline for Object Detection with State Space Model. arXiv 2024, arXiv:2406.05835. [Google Scholar] [CrossRef]
- Pei, X.; Huang, T.; Xu, C. EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba. arXiv 2024, arXiv:2403.09977. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 17 July 2017; pp. 933–941. [Google Scholar]
- Rajagopal, A.; Nirmala, V. Convolutional Gated MLP: Combining Convolutions and gMLP. In Proceedings of the Big Data, Machine Learning, and Applications, Shanghai, China, 15–18 July 2024; Borah, M.D., Laiphrakpam, D.S., Auluck, N., Balas, V.E., Eds.; Springer Nature: Singapore, 2024; pp. 721–735. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).