
Attention-Based LiDAR–Camera Fusion for 3D Object Detection in Autonomous Driving

Abstract
1. Introduction
- Leveraging downsampled point cloud key points to guide the projection of image features onto corresponding point cloud representations, thereby minimizing geometric information loss during feature mapping and enabling efficient cross-modal alignment.
- Harnessing the adaptive weighting capacity of the Squeeze-and-Excitation Network’s (SENet) channel-wise attention mechanism to generate discriminative multimodal feature maps with enhanced representational power. The fused features are subsequently processed through a center-based detection network to regress precise 3D bounding box parameters.
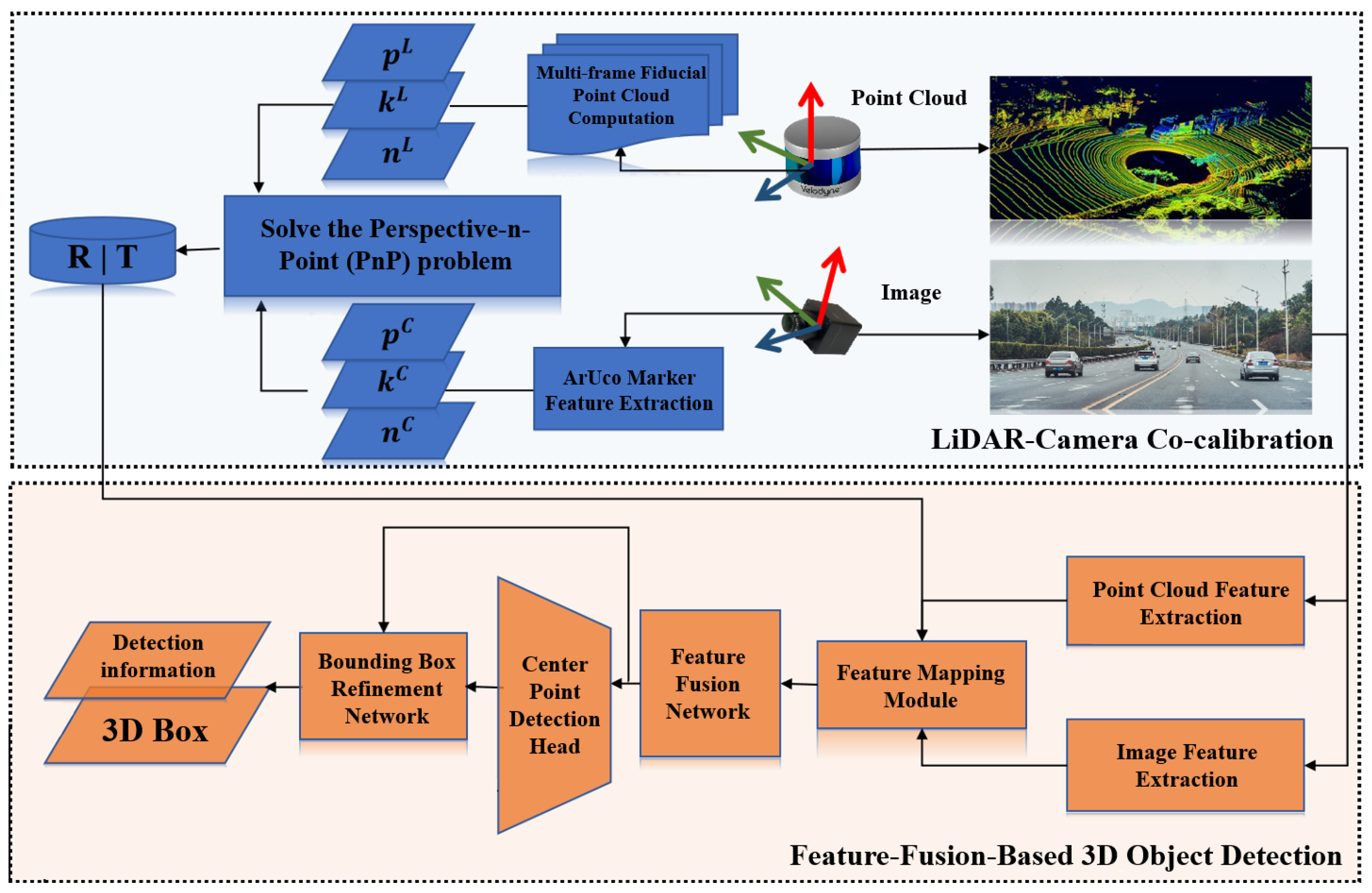
2. Materials and Methods
2.1. Design of Feature Fusion Center Point Detection Network Based on Attention Mechanism
2.2. Multi-Sensor Data Feature Fusion Module
- (1)
- The original data encoding is aligned with the feature
- (2)
- Feature fusion module based on attention mechanism
2.3. Design of Object Detection Network Based on the Central Point
- (1)
- Based on the set size and resolution, the center point of the truth-valued target frame in the three-dimensional space is scaled to correspond to the coordinates of the thermal map, and the low-resolution coordinate corresponding to the truth-valued coordinates of the target center point of K categories is calculated as ;
- (2)
- We calculate the radius of the Gaussian circle for each center point, as shown in Equation (5), where the width and height of the thermal map, and , respectively, are the coordinates of the center point after scaling, and is the standard deviation of the adaptive target size.
- (3)
- We can draw a Gaussian circle with the center point as the center and A as the radius. If the Gaussian circles of the same category overlap, the maximum value of the overlapping part is taken as the value there.
3. Results
3.1. Experiment Preparation
3.2. Evaluation Criteria and Loss Function for 3D Object Detection
3.3. Recognition Algorithm Comparison Experiment
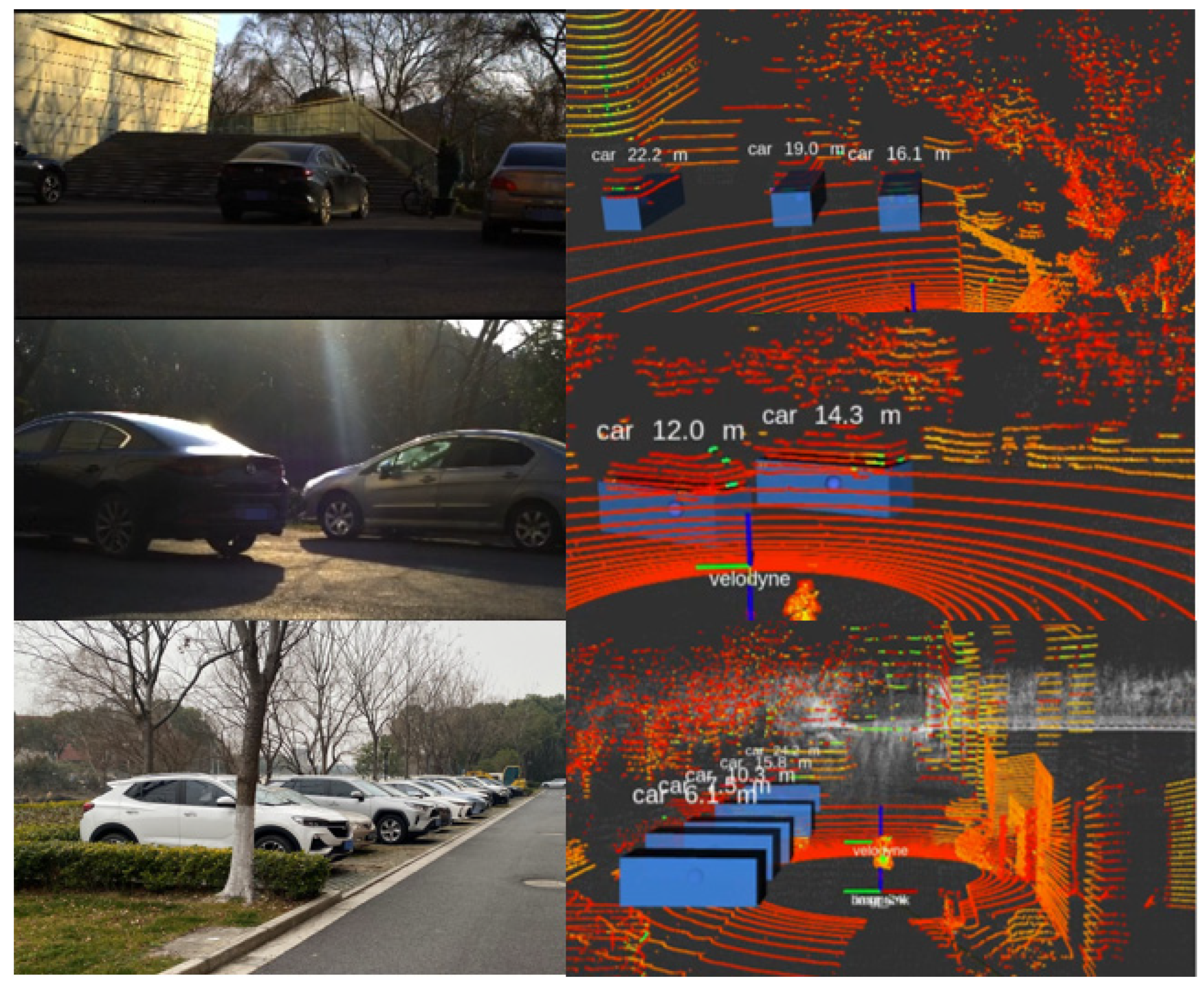
3.4. Analysis of Visual Results of the Recognition Algorithm
4. Discussion and Outlook
- Our architecture achieves the adaptive recalibration of LiDAR geometric and camera semantic features by implementing Squeeze-and-Excitation channel attention mechanisms. Quantitative ablation studies (Figure 8) demonstrate this approach outperforms conventional concatenation fusion by 12.2% mAP. The proposed method effectively resolves the geometric inconsistency between sparse point clouds and high-resolution images, enabling precise alignment of multi-modal representations.
- Through center-based regression in BEV space, our model achieves state-of-the-art performance using the nuScenes benchmark with 64.5% mAP and 63.7 NDS, surpassing LiDAR-only CenterPoint by 3.1% mAP.
- Real-world testing on autonomous platforms (RoboSense RS-Helios LiDAR [RoboSense, Shenzhen, China] and SONY IMX264 cameras [Sony Corporation, Tokyo, Japan]) shows that the system runs at an average inference speed of 147 ms/frame (Figure 11).
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BEV | Bird’s-eye view |
| ROI | Region of interest |
| mAP | Mean Average Precision |
| NDS | nuScenes Detection Score |
| ReLU | Rectified Linear Unit |
| SE | Squeeze-and-Excitation |
References
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2774–2781. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V. Deepfusion: Lidar-camera deep fusion for multi-modal 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Xie, Y.; Xu, C.; Rakotosaona, M.-J.; Rim, P.; Tombari, F.; Keutzer, K.; Tomizuka, M.; Zhan, W. Sparsefusion: Fusing multi-modal sparse representations for multi-sensor 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17591–17602. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. Mvx-net: Multimodal voxelnet for 3D object detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7276–7282. [Google Scholar]
- Wang, J.; Li, F.; An, Y.; Zhang, X.; Sun, H. Towards Robust LiDAR-Camera Fusion in BEV Space via Mutual Deformable Attention and Temporal Aggregation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5753–5764. [Google Scholar] [CrossRef]
- Liu, M.; Jia, Y.; Lyu, Y.; Dong, Q.; Yang, Y. BAFusion: Bidirectional Attention Fusion for 3D Object Detection Based on LiDAR and Camera. Sensors 2024, 24, 4718. [Google Scholar] [CrossRef]
- Huang, K.; Shi, B.; Li, X.; Li, X.; Huang, S.; Li, Y. Multi-modal sensor fusion for auto driving perception: A survey. arXiv 2022, arXiv:2202.02703. [Google Scholar]
- Pandey, G.; McBride, J.R.; Savarese, S.; Eustice, R.M. Automatic Extrinsic Calibration of Vision and Lidar by Maximizing Mutual Information. J. Field Robot. 2014, 32, 696–722. [Google Scholar] [CrossRef]
- Guan, T.; Wang, J.; Lan, S.; Chandra, R.; Wu, Z.; Davis, L.; Manocha, D. M3detr: Multi-representation, multi-scale, mutual-relation 3D object detection with transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 772–782. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Shi, P.; Liu, Z.; Dong, X.; Yang, A. CL-fusionBEV: 3D object detection method with camera-LiDAR fusion in Bird’s Eye View. Complex Intell. Syst. 2024, 10, 7681–7696. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, J.; Xiao, J.; Zhao, Y.; Chen, W.; Ren, Y.; Yu, H. MLF3D: Multi-Level Fusion for Multi-Modal 3D Object Detection. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; pp. 1588–1593. [Google Scholar]
- Zhu, M.; Ma, C.; Ji, P.; Yang, X. Cross-modality 3D object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3772–3781. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10386–10393. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Bae, W.; Yoo, J.; Chul Ye, J. Beyond deep residual learning for image restoration: Persistent homology-guided manifold simplification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 145–153. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3D object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7345–7353. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3D object detection. In Proceedings of the Computer vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 720–736. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Ahmad, J.; Del Bue, A. mmfusion: Multimodal fusion for 3D objects detection. arXiv 2023, arXiv:2311.04058. [Google Scholar]
- Li, Z.; Yu, Z.; Wang, W.; Anandkumar, A.; Lu, T.; Alvarez, J.M. Fb-bev: Bev representation from forward-backward view transformations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6919–6928. [Google Scholar]
- Yang, C.; Chen, Y.; Tian, H.; Tao, C.; Zhu, X.; Zhang, Z.; Huang, G.; Li, H.; Qiao, Y.; Lu, L. Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspective supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17830–17839. [Google Scholar]
- Yu, Z.; Liu, Q.; Wang, W.; Zhang, L.; Zhao, X. PolarBEVDet: Exploring Polar Representation for Multi-View 3D Object Detection in Bird’s-Eye-View. arXiv 2024, arXiv:2408.16200. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modality | Car/% | Truck/% | Bus/% | mAP/% | NDS |
|---|---|---|---|---|---|---|
| PointPillars [27] | LiDAR | 67.5 | 43.6 | 62.2 | 59.7 | 57.3 |
| CenterPoint [18] | LiDAR | 82.5 | 52.7 | 63.6 | 61.4 | 62.6 |
| MV3D [12] | LiDAR and Camera | 78.6 | 36.7 | 54.5 | 54.6 | 52.1 |
| 3D-CVF [26] | LiDAR and Camera | 81.5 | 49.3 | 53.9 | 59.6 | 59.2 |
| mmFUSION [28] | LiDAR and Camera | 86.3 | 52.9 | 65.1 | 64.2 | 69.4 |
| FB-BEV [29] | Camera | 71.7 | 43.3 | 39.6 | 53.7 | 62.4 |
| BEVFormerv2 [30] | Camera | 74.8 | 48.4 | 43.0 | 55.6 | 63.4 |
| PolarBEVDet [31] | Camera | 73.9 | 45.2 | 37.8 | 55.8 | 63.5 |
| Ours | LiDAR and Camera | 83.4 | 52.3 | 65.4 | 64.5 | 63.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Huang, X.; Hu, Z. Attention-Based LiDAR–Camera Fusion for 3D Object Detection in Autonomous Driving. World Electr. Veh. J. 2025, 16, 306. https://doi.org/10.3390/wevj16060306
Wang Z, Huang X, Hu Z. Attention-Based LiDAR–Camera Fusion for 3D Object Detection in Autonomous Driving. World Electric Vehicle Journal. 2025; 16(6):306. https://doi.org/10.3390/wevj16060306
Chicago/Turabian StyleWang, Zhibo, Xiaoci Huang, and Zhihao Hu. 2025. "Attention-Based LiDAR–Camera Fusion for 3D Object Detection in Autonomous Driving" World Electric Vehicle Journal 16, no. 6: 306. https://doi.org/10.3390/wevj16060306
APA StyleWang, Z., Huang, X., & Hu, Z. (2025). Attention-Based LiDAR–Camera Fusion for 3D Object Detection in Autonomous Driving. World Electric Vehicle Journal, 16(6), 306. https://doi.org/10.3390/wevj16060306