
Linear Continuous-Time Regression and Dequantizer for Lithium-Ion Battery Cells with Compromised Measurement Quality


Abstract
1. Introduction
- A dequantizing algorithm that recovers information lost due to quantization or large noise magnitudes, hence restoring terminal voltage. It utilizes the inverse normal distribution function to reconstruct time series data from quantized measurements corrupted by Gaussian measurement noise.
- The filtered data are processed by the novel Linear Continuous-Time Regression (LCTR) algorithm, capable of deducing gains, time constants, and bias for first-order or overdamped second-order systems.
- Investigation of the combined algorithms’ sensitivity to quantization noise, measurement noise, steady-state, and time constants. Evaluation statistics include root-mean-square-error (RMSE), time-constant errors, and steady-state errors.
2. Methodology
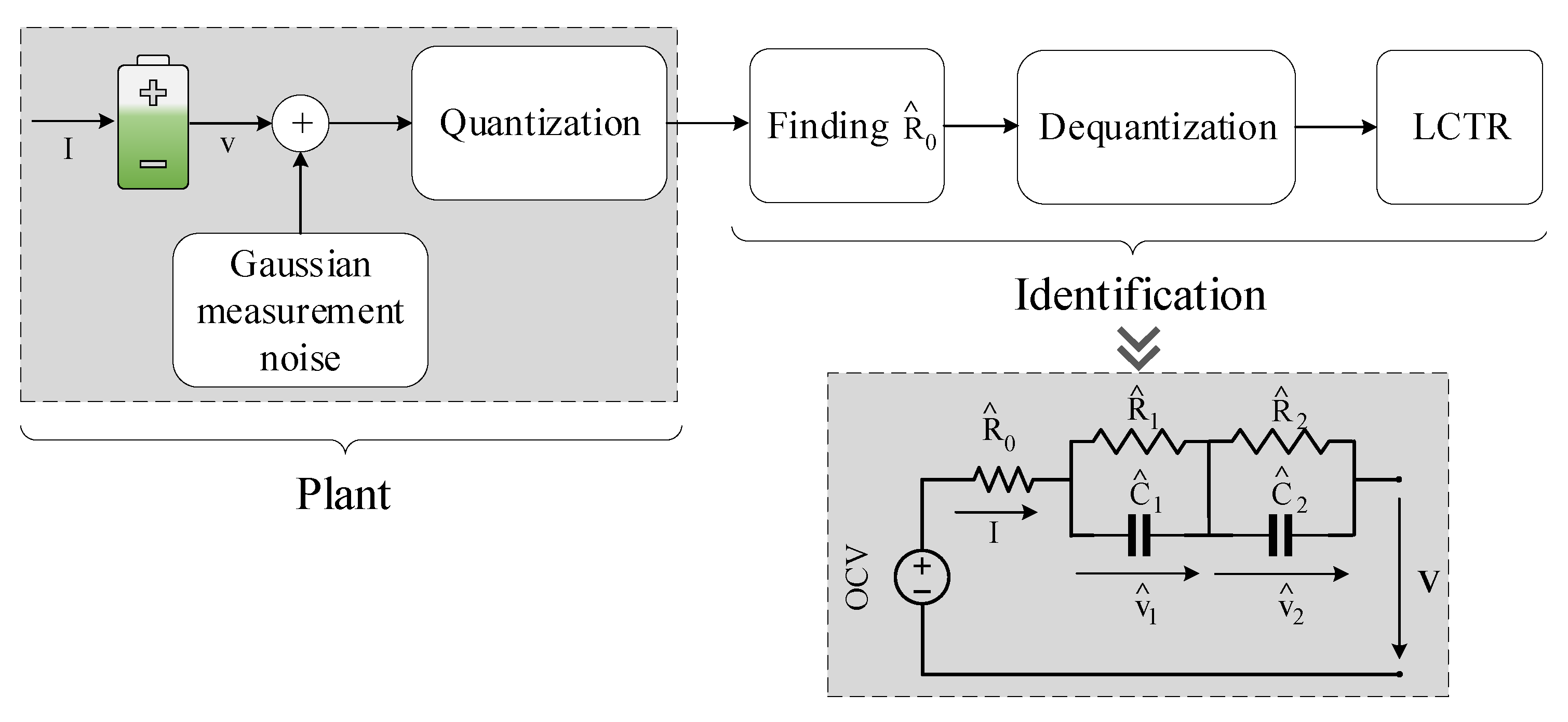
2.1. Overview of the Identification Algorithm
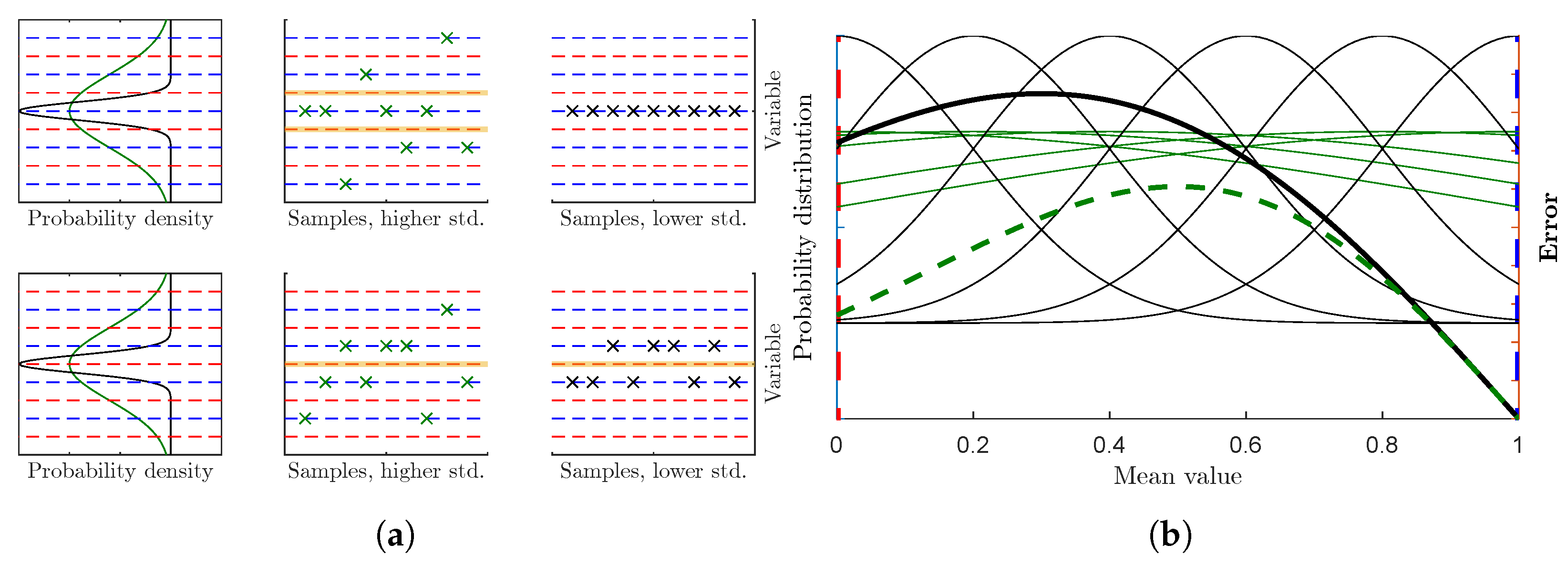
2.2. Dequantizing Algorithm to Alleviate Corrupted Measurements
2.3. Linear Continuous-Time Regression
2.3.1. Single Exponential with and Without Bias
2.3.2. Double Exponential with and Without Bias
2.3.3. The LCTR Algorithm
2.4. Matlab Implementations
- The Matlab code of the dequantizer:

- The Matlab code for second-order fit:

3. Results
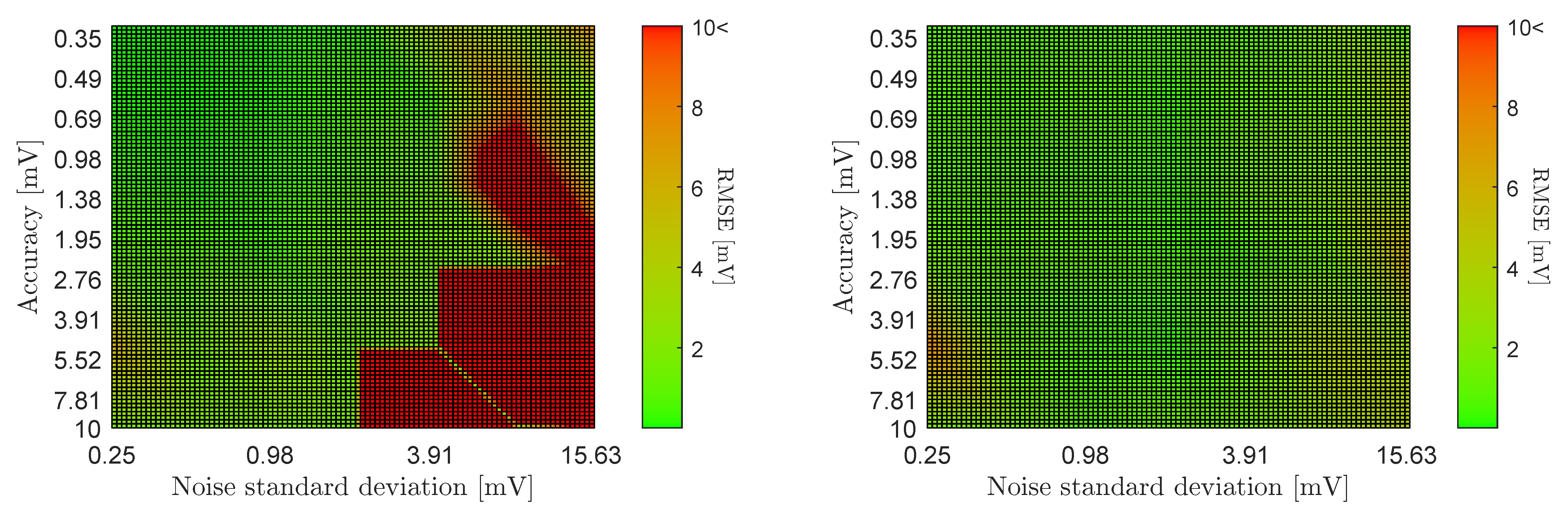
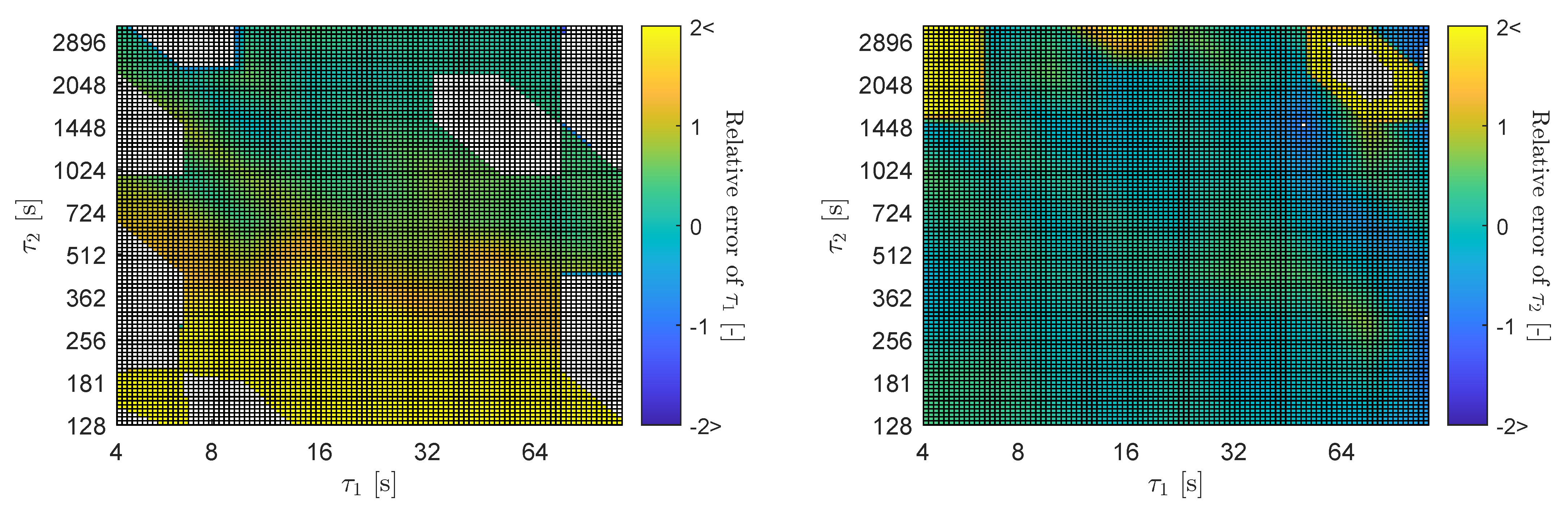
3.1. Sensitivity Analysis Overview
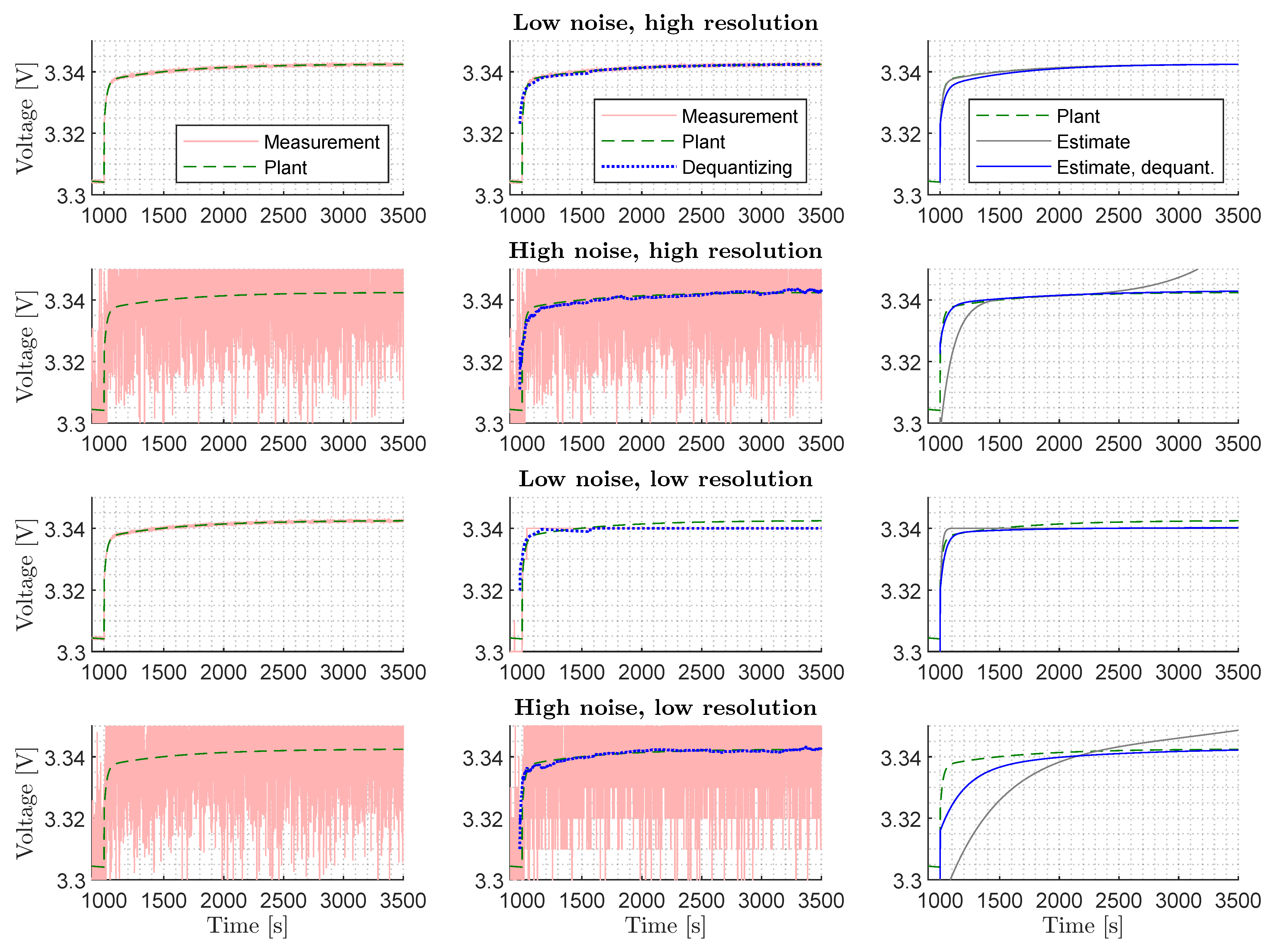
3.2. Visualization of Parameter Identification
3.3. Parameter Sensitivities for the First-Order Model
3.4. Field Test Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pinter, Z.M.; Papageorgiou, D.; Rohde, G.; Marinelli, M.; Træholt, C. Review of control algorithms for reconfigurable battery systems with an industrial example. In Proceedings of the 2021 56th International Universities Power Engineering Conference (UPEC), Middlesbrough, UK, 31 August–3 September 2021; pp. 1–6. [Google Scholar]
- Pinter, Z.M.; Engelhardt, J.; Rohde, G.; Træholt, C.; Marinelli, M. Validation of a Single-Cell Reference Model for the Control of a Reconfigurable Battery System. In Proceedings of the 2022 International Conference on Renewable Energies and Smart Technologies (REST), Tirana, Albania, 28–29 July 2022; Volume 1, pp. 1–5. [Google Scholar]
- Plett, G.L. Battery Management Systems, Volume II: Equivalent-Circuit Methods; Artech House: Norwood, MA, USA, 2015. [Google Scholar]
- Marinelli, M.; Calearo, L.; Engelhardt, J.; Rohde, G. Electrical Thermal and Degradation Measurements of the LEAF e-plus 62-kWh Battery Pack. In Proceedings of the 2022 International Conference on Renewable Energies and Smart Technologies (REST), Tirana, Albania, 28–29 July 2022; Volume 1, pp. 1–5. [Google Scholar]
- Pinter, Z.M.; Rohde, G.; Marinelli, M. Comparative Analysis of Rule-Based and Model Predictive Control Algorithms in Reconfigurable Battery Systems for EV Fast-Charging Stations. J. Energy Storage. 2023. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4882648 (accessed on 2 July 2024).
- Åström, K.J.; Wittenmark, B. Adaptive Control; Courier Corporation: Chelmsford, MA, USA, 2008. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 2, pp. 531–537. [Google Scholar]
- Wills, A.; Schön, T.B.; Ljung, L.; Ninness, B. Identification of hammerstein—Wiener models. Automatica 2013, 49, 70–81. [Google Scholar] [CrossRef]
- Foss, S.D. A method of exponential curve fitting by numerical integration. Biometrics 1970, 26, 815–821. [Google Scholar] [CrossRef]
- Plett, G.L. A Linear Method to Fit Equivalent Circuit Model Parameter Values to HPPC Relaxation Data From Lithium-Ion Cells. ASME Lett. Dyn. Syst. Control 2025, 5, 011003. [Google Scholar] [CrossRef]
- Rodrigo Navarro, J.; Kakkar, A.; Schatz, R.; Pang, X.; Ozolins, O.; Udalcovs, A.; Popov, S.; Jacobsen, G. Blind phase search with angular quantization noise mitigation for efficient carrier phase recovery. Photonics 2017, 4, 37. [Google Scholar] [CrossRef]
- Saab, R.; Wang, R.; Yılmaz, Ö. Quantization of compressive samples with stable and robust recovery. Appl. Comput. Harmon. Anal. 2018, 44, 123–143. [Google Scholar] [CrossRef]
- Qiu, K.; Dogandzic, A. Sparse signal reconstruction from quantized noisy measurements via GEM hard thresholding. IEEE Trans. Signal Process. 2012, 60, 2628–2634. [Google Scholar] [CrossRef]
- Márquez-Ramírez, V.; Nava, F.; Zúñiga, F. Correcting the Gutenberg–Richter b-value for effects of rounding and noise. Earthq. Sci. 2015, 28, 129–134. [Google Scholar] [CrossRef]
- Stanković, I.; Brajović, M.; Daković, M.; Ioana, C.; Stanković, L. Quantization in compressive sensing: A signal processing approach. IEEE Access 2020, 8, 50611–50625. [Google Scholar] [CrossRef]
- Zymnis, A.; Boyd, S.; Candes, E. Compressed sensing with quantized measurements. IEEE Signal Process. Lett. 2009, 17, 149–152. [Google Scholar] [CrossRef]
- Casini, M.; Garulli, A.; Vicino, A. Bounding nonconvex feasible sets in set membership identification: OE and ARX models with quantized information. IFAC Proc. Vol. 2012, 45, 1191–1196. [Google Scholar] [CrossRef]
- Yu, C.; You, K.; Xie, L. Quantized identification of ARMA systems with colored measurement noise. Automatica 2016, 66, 101–108. [Google Scholar] [CrossRef]
- Xu, J.; Li, J.; Xu, S. Analysis of quantization noise and state estimation with quantized measurements. J. Control Theory Appl. 2011, 9, 66–75. [Google Scholar] [CrossRef]
- Steinstraeter, M.; Gandlgruber, J.; Everken, J.; Lienkamp, M. Influence of pulse width modulated auxiliary consumers on battery aging in electric vehicles. J. Energy Storage 2022, 48, 104009. [Google Scholar] [CrossRef]
- GWL/Power CALB CA100FI—Lithium Cell LiFePO4 (3.2 V/100 Ah), Datasheet. Available online: https://files.gwl.eu/ (accessed on 1 January 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R | ||||||||
|---|---|---|---|---|---|---|---|---|
| Nominal value | 2 mV | 0.31 mV | 22 s | 647 s | 0.63 m | 0.47 m | 0.24 m | 80% |
| Minimum value | 0.25 mV | 0.63 mV | 4.3 s | 128 s | - | - | - | 10% |
| Maximum value | 16 mV | 10 mV | 111 s | 3275 s | - | - | - | 100% |
| Number of test points | 7 | 6 | 9 | 9 | 1 | 1 | 1 | 91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pinter, Z.M.; Marinelli, M.; Trimboli, M.S.; Plett, G.L. Linear Continuous-Time Regression and Dequantizer for Lithium-Ion Battery Cells with Compromised Measurement Quality. World Electr. Veh. J. 2025, 16, 116. https://doi.org/10.3390/wevj16030116
Pinter ZM, Marinelli M, Trimboli MS, Plett GL. Linear Continuous-Time Regression and Dequantizer for Lithium-Ion Battery Cells with Compromised Measurement Quality. World Electric Vehicle Journal. 2025; 16(3):116. https://doi.org/10.3390/wevj16030116
Chicago/Turabian StylePinter, Zoltan Mark, Mattia Marinelli, M. Scott Trimboli, and Gregory L. Plett. 2025. "Linear Continuous-Time Regression and Dequantizer for Lithium-Ion Battery Cells with Compromised Measurement Quality" World Electric Vehicle Journal 16, no. 3: 116. https://doi.org/10.3390/wevj16030116
APA StylePinter, Z. M., Marinelli, M., Trimboli, M. S., & Plett, G. L. (2025). Linear Continuous-Time Regression and Dequantizer for Lithium-Ion Battery Cells with Compromised Measurement Quality. World Electric Vehicle Journal, 16(3), 116. https://doi.org/10.3390/wevj16030116