
Using a YOLO Deep Learning Algorithm to Improve the Accuracy of 3D Object Detection by Autonomous Vehicles


Abstract
1. Introduction
2. Literature Review
- 1.
- Deep Learning and YOLO Framework
- 2.
- Sensor Fusion
- 3.
- Multi-Task Learning
- 4.
- 3D Data Representation
- 5.
- Real-Time Performance
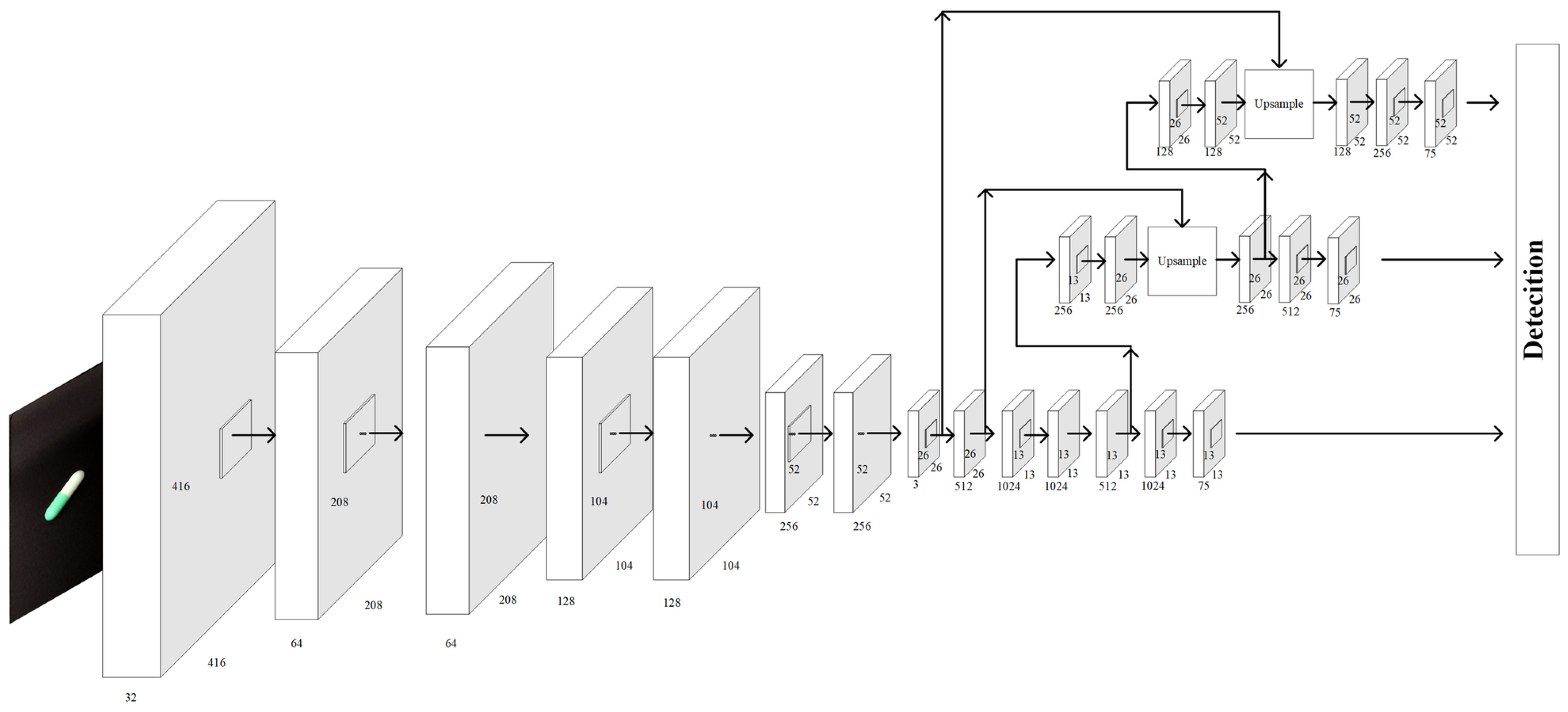
2.1. YOLO Deep Learning Algorithm
2.2. Object Detection in 3D for Autonomous Vehicles
Challenges in 3D Object Detection
2.3. Evaluation of Object Detection Accuracy
2.4. Significance of Accurate 3D Object Detection
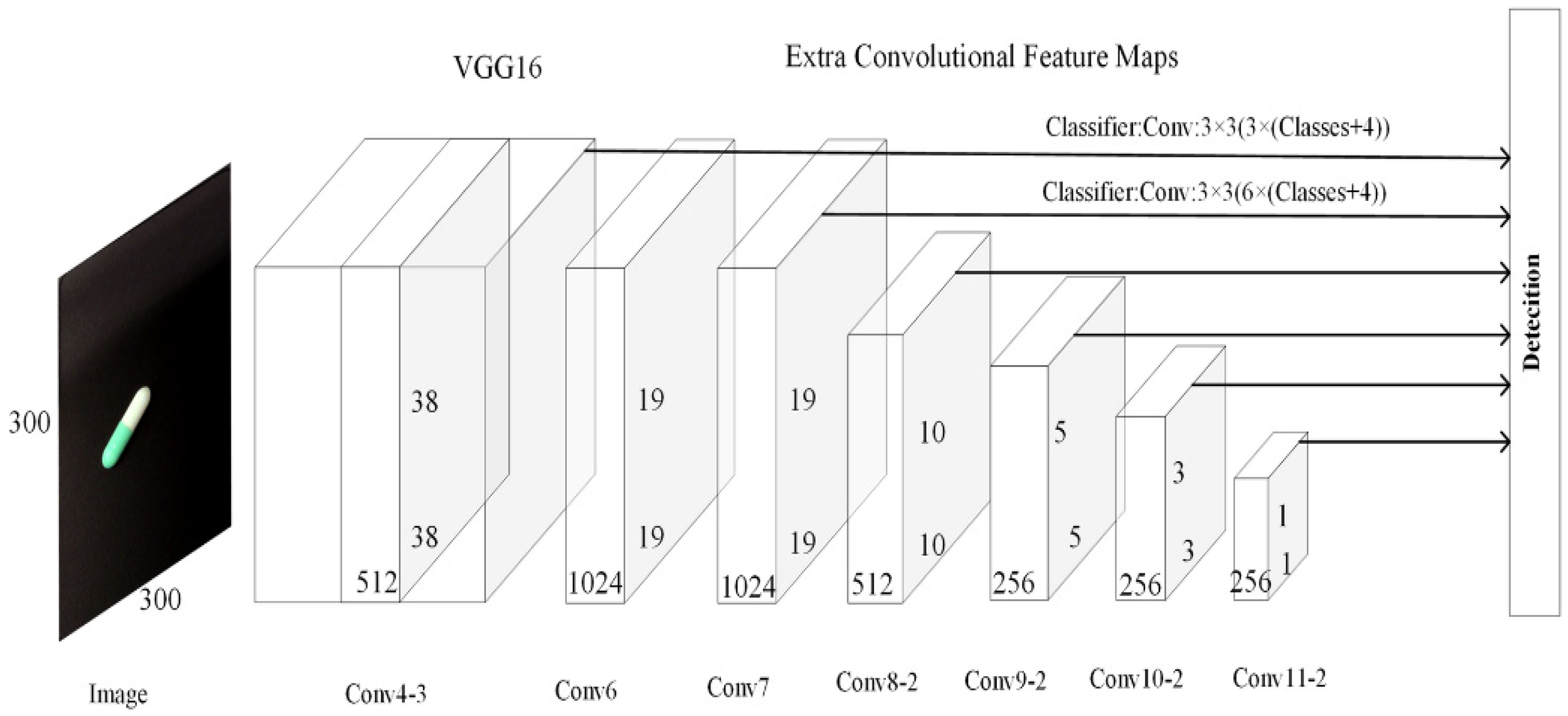
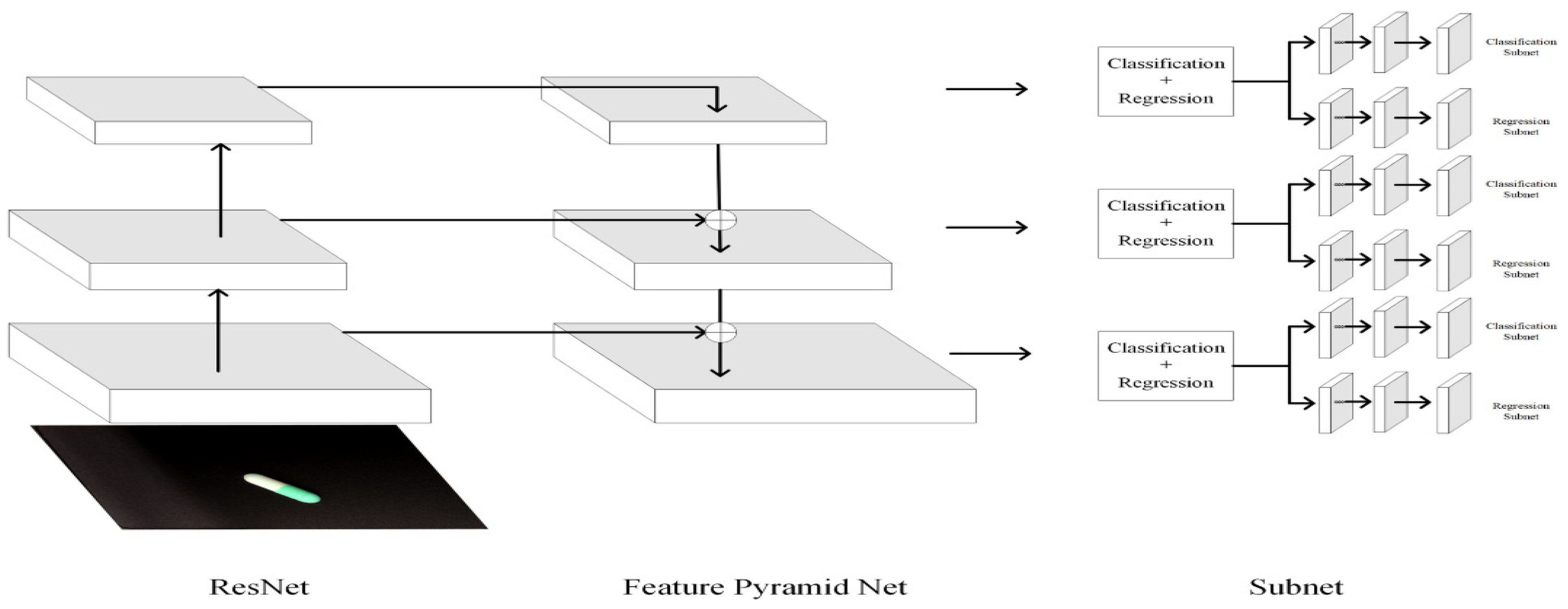
2.5. State-of-the-Art of 3D Detection
3. Methodology
3.1. Modifications to YOLOv4 Architecture for 3D Detection
3.1.1. 3D Bounding Box Prediction
- Position: In 3D space, the position of an object is represented by its center coordinates (x,y,z)(x, y, z)(x,y,z), where zzz is the depth (distance from the camera or sensor).
- Size: The dimensions of the 3D bounding box are defined by its width www, height hhh, and length lll.
- Orientation: The orientation or rotation of the 3D bounding box must be estimated to account for the object’s pose relative to the AV. A rotation angle θ\thetaθ around the vertical axis usually defines this.
- (x,y,z)(x, y, z)(x,y,z): The 3D center coordinates of the object.
- (w,h,l)(w, h, l)(w,h,l): The dimensions of the 3D bounding box.
- θ\thetaθ: The orientation angle of the object.
3.1.2. Depth Estimation Layer
3.1.3. Multi-Task Learning Framework
- 2D Bounding Boxes: As in traditional YOLOv4, predicting the (x,y)(x, y)(x,y) coordinates, width, height, and confidence score for the 2D bounding box.
- 3D Bounding Boxes: Additional layers predict the center coordinates, dimensions, and orientation of the 3D bounding box.
- Depth Estimation: A depth prediction layer outputs the zzz coordinate (distance from the camera or LIDAR).
- Orientation: A layer predicts the object’s rotation angle θ\thetaθ in 3D space.
3.2. Sensor Fusion for 3D Detection
3.2.1. LIDAR Point Cloud Integration
3.2.2. Multi-Modal Feature Fusion
- Early Fusion: LIDAR and RGB image data are fused at the input level before feature extraction.
- Mid-Level Fusion: Features extracted by separate LIDAR and RGB branches are fused in the middle layers of the network.
- Late Fusion: Features are fused at the detection head level, combining high-level information from both LIDAR and camera modalities.
3.3. Network Training Strategy
3.3.1. Loss Functions
- 2D Bounding Box Loss: Traditional YOLOv4 includes objectness loss (confidence score) and 2D bounding box regression loss (typically using smooth L1 or IoU-based loss).
- 3D Bounding Box Loss: This includes losses for the predicted 3D bounding box center (x,y,z)(x, y, z)(x,y,z), dimensions (w,h,l)(w, h, l)(w,h,l), and orientation θ\thetaθ. A commonly used loss for 3D bounding box regression is Huber loss (smooth L1 loss).
- Depth Estimation Loss: A depth loss (mean squared error or smooth L1 loss) penalizes incorrect depth predictions.
- Orientation Loss: Orientation error is minimized using angular regression, typically measured by cosine similarity or direct angular error.
- The multi-task loss function is given as:
3.3.2. Training Dataset
3.3.3. Transfer Learning
3.4. Incorporation of Post-Processing
3.4.1. Non-Maximum Suppression (NMS)
3.4.2. Bounding Box Refinement
3.5. Computational Considerations
3.6. Tools
3.6.1. TensorFlow
3.6.2. Keras
4. Results and Discussion
4.1. Training
4.2. Results
4.2.1. Implementation of a YOLO Deep Learning to Enhance the 3D Object Detection System in Autonomous Driving
4.2.2. Evaluation of the Accuracy of the Model for the Object Detection System
4.3. Discussion
4.4. Comparison of This Study with Existing Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chehri, A.; Mouftah, H.T. Autonomous vehicles in sustainable cities, the beginning of a green adventure. Sustain. Cities Soc. 2019, 51, 101751. [Google Scholar] [CrossRef]
- Zadobrischi, E.; Damian, M. Vehicular Communications Utility in Road Safety Applications: A Step toward Self-Aware Intelligent Traffic Systems. Symmetry 2021, 13, 438. [Google Scholar] [CrossRef]
- Bhatti, G.; Mohan, H.; Singh, R.R. Towards the future of smart electric vehicles: Digital twin technology. Renew. Sustain. Energy Rev. 2021, 141, 110801. [Google Scholar] [CrossRef]
- Sheela, J.J.J. Solar Powered Autonomous Vehicle with Smart Headlights Aswini. Eur. J. Mol. Clin. Med. 2020, 7, 262. [Google Scholar]
- Victoire, T.A.; Karunamurthy, A.; Sathish, S.; Sriram, R. AI-based Self-Driving Car. Int. J. Innov. Sci. Res. Technol. 2023, 8, 29–37. [Google Scholar]
- Thakur, A.; Mishra, S.K. An in-depth evaluation of deep learning-enabled adaptive approaches for detecting obstacles using sensor-fused data in autonomous vehicles. Eng. Appl. Artif. Intell. 2024, 133, 108550. [Google Scholar] [CrossRef]
- Willers, O.; Sudholt, S.; Raafatnia, S.; Abrecht, S. Safety concerns and mitigation approaches regarding the use of deep learning in safety-critical perception tasks. In International Conference on Computer Safety, Reliability, and Security; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Kelleher, J.; Wong, Y.; Wohns, A.W.; Fadil, C.; Albers, P.K.; McVean, G. Inferring whole-genome histories in large population datasets. Nat. Genet. 2019, 51, 1330–1338. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Ogliari, E.; Leva, S.; Lughi, V. Advanced Methods for Photovoltaic Output Power Forecasting: A Review. Appl. Sci. 2020, 10, 487. [Google Scholar] [CrossRef]
- Moawad, G.N.; Elkhalil, J.; Klebanoff, J.S.; Rahman, S.; Habib, N.; Alkatout, I. Augmented Realities, Artificial Intelligence, and Machine Learning: Clinical Implications and How Technology Is Shaping the Future of Medicine. J. Clin. Med. 2020, 9, 3811. [Google Scholar] [CrossRef] [PubMed]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2019, 37, 362–386. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016. [Google Scholar]
- Tsang, S.H. Review: YOLOv2 & YOLO9000—You Only Look Once (Object Detection). 2018. Available online: https://towardsdatascience.com/review-yolov2-yolo9000-you-only-look-once-object-detection-7883d2b02a65 (accessed on 24 February 2019).
- Tran, D.A.; Fischer, P.; Smajic, A.; So, Y. Real-Time Object Detection for Autonomous Driving Using Deep Learning; Goethe University Frankfurt: Frankfurt, Germany, 2021. [Google Scholar]
- Francies, M.L.; Ata, M.M.; Mohamed, M.A. A robust multiclass 3D object recognition based on modern YOLO deep learning algorithms. Concurr. Comput. Pract. Exp. 2021, 34, e6517. [Google Scholar] [CrossRef]
- Padmanabula, S.S.; Puvvada, R.C.; Sistla, V.; Kolli, V.K.K. Object Detection Using Stacked YOLOv3. Ing. Syst. Inf. 2020, 25, 691–697. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2024, arXiv:2004.10934. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar]
- Xu, Y.; Zhou, Y.; Wang, J.; Choy, C.; Fang, T. Fusion3D: A comprehensive multi-modality fusion framework for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 21–27 June 2021; pp. 1108–1117. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar] [CrossRef]
- Zhao, X.; Yang, J.; Tan, H. The effects of subjective knowledge on the acceptance of fully autonomous vehicles depend on individual levels of trust. In Proceedings of the International Conference on Human-Computer Interaction, Staffordshire, UK, 11 July 2022; Springer: Cham, Switzerland, 2022; pp. 297–308. [Google Scholar]
- Lashkov, I.; Yuan, R.; Zhang, G. Edge-Computing-Empowered Vehicle Tracking and Speed Estimation Against Strong Image Vibrations Using Surveillance Monocular Camera. IEEE Trans. Intell. Transp. Syst. 2023, 24, 13486–13502. [Google Scholar] [CrossRef]
- Mustafa, Z.; Nsour, H. Using Computer Vision Techniques to Automatically Detect Abnormalities in Chest X-rays. Diagnostics 2023, 13, 2979. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M.; Zhang, G. Machine Learning Applications in Internet-of-Drones: Systematic Review, Recent Deployments, and Open Issues. ACM Comput. Surv. 2023, 55, 1–45. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Ball, J.E. A Survey on Deep-Learning-Based LiDAR 3D Object Detection for Autonomous Driving. Sensors 2022, 22, 9577. [Google Scholar] [CrossRef] [PubMed]
- Nowakowski, M.; Kurylo, J. Usability of Perception Sensors to Determine the Obstacles of Unmanned Ground Vehicles Operating in Off-Road Environments. Appl. Sci. 2023, 13, 4892. [Google Scholar] [CrossRef]
- Fursa, I.; Fandi, E.; Musat, V.; Culley, J.; Gil, E.; Teeti, I.; Bilous, L.; Sluis, I.V.; Rast, A.; Bradley, A.; et al. Worsening Perception: Real-Time Degradation of Autonomous Vehicle Perception Performance for Simulation of Adverse Weather Conditions. SAE Int. J. Connect. Autom. Veh. 2022, 5, 87–100. [Google Scholar] [CrossRef]
- Mao, H.; Yang, X.; Dally, B. A Delay Metric for Video Object Detection: What Average Precision Fails to Tell. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 573–582. [Google Scholar]
- Alibeigi, M.; Ljungbergh, W.; Tonderski, A.; Hess, G.; Lilja, A.; Lindström, C.; Motorniuk, D.; Fu, J.; Widahl, J.; Petersson, C. Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 20178–20188. [Google Scholar]
- Faris, O.; Muthusamy, R.; Renda, F.; Hussain, I.; Gan, D.; Seneviratne, L.; Zweiri, Y. Proprioception and Exteroception of a Soft Robotic Finger Using Neuromorphic Vision-Based Sensing. Soft Robot. 2023, 10, 467–481. [Google Scholar] [CrossRef] [PubMed]
- Mahrez, Z.; Sabir, E.; Badidi, E.; Saad, W.; Sadik, M. Smart Urban Mobility: When Mobility Systems Meet Smart Data. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6222–6239. [Google Scholar] [CrossRef]
- Tan, L.; Huangfu, T.; Wu, L.; Chen, W. Comparison of RetinaNet, SSD, and YOLO v3 for real-time pill identification. BMC Med. Inform. Decis. Mak. 2021, 21, 324. [Google Scholar] [CrossRef] [PubMed]
- Aliper, A.; Plis, S.; Artemov, A.; Ulloa, A.; Mamoshina, P.; Zhavoronkov, A. Deep Learning Applications for Predicting Pharmacological Properties of Drugs and Drug Repurposing Using Transcriptomic Data. Mol. Pharm. 2016, 13, 2524–2530. [Google Scholar] [CrossRef]
- Swastika, W.; Pradana, B.J.; Widodo, R.B.; Sitepu, R.; Putra, G.G. Web-Based Application for Malaria Parasite Detection Using Thin-Blood Smear Images. J. Image Graph. 2023, 11, 288–293. [Google Scholar] [CrossRef]
- Rodriguez-Gonzalez, C.G.; Herranz-Alonso, A.; Escudero-Vilaplana, V.; Ais-Larisgoitia, M.A.; Iglesias-Peinado, I.; Sanjurjo-Saez, M. Robotic dispensing improves patient safety, inventory management, and staff satisfaction in an outpatient hospital pharmacy. J. Eval. Clin. Pract. 2018, 25, 28–35. [Google Scholar] [CrossRef]
- Ahmad, H.M.; Rahimi, A. Deep learning methods for object detection in smart manufacturing: A survey. J. Manuf. Syst. 2022, 64, 181–196. [Google Scholar] [CrossRef]
- Shui, Y.; Yuan, K.; Wu, M.; Zhao, Z. Improved Multi-Size, Multi-Target and 3D Position Detection Network for Flowering Chinese Cabbage Based on YOLOv8. Plants 2024, 13, 2808. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Zhang, H.; Li, J.; Ye, R.; Zhou, X.; Dong, B.; Li, L. High-Accuracy Maize Disease Detection Based on Attention-GAN and Few-Shot Learning. Plants 2023, 12, 3105. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Zhou, Y.; He, Y.; Zhu, H.; Wang, C.; Li, H.; Jiang, Q. Monocular 3d object detection: An extrinsic parameter free approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7556–7566. Available online: https://www.researchgate.net/publication/382604989_Recent_Advances_in_3D_Object_Detection_for_Self-Driving_Vehicles_A_Survey (accessed on 17 December 2024).
- Pérez-García, F.; Sparks, R.; Ourselin, S. TorchIO: A Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. Comput. Methods Programs Biomed. 2021, 208, 106236. [Google Scholar] [CrossRef]
- Wang, R.; Wang, Z.; Xu, Z.; Wang, C.; Li, Q.; Zhang, Y.; Li, H. A Real-Time Object Detector for Autonomous Vehicles Based on YOLOv4. Comput. Intell. Neurosci. 2021, 2021, 9218137. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cepni, S.; Atik, M.E.; Duran, Z. Vehicle Detection Using Different Deep Learning Algorithms from Image Sequence. Balt. J. Mod. Comput. 2020, 8, 347–358. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murendeni, R.; Mwanza, A.; Obagbuwa, I.C. Using a YOLO Deep Learning Algorithm to Improve the Accuracy of 3D Object Detection by Autonomous Vehicles. World Electr. Veh. J. 2025, 16, 9. https://doi.org/10.3390/wevj16010009
Murendeni R, Mwanza A, Obagbuwa IC. Using a YOLO Deep Learning Algorithm to Improve the Accuracy of 3D Object Detection by Autonomous Vehicles. World Electric Vehicle Journal. 2025; 16(1):9. https://doi.org/10.3390/wevj16010009
Chicago/Turabian StyleMurendeni, Ramavhale, Alfred Mwanza, and Ibidun Christiana Obagbuwa. 2025. "Using a YOLO Deep Learning Algorithm to Improve the Accuracy of 3D Object Detection by Autonomous Vehicles" World Electric Vehicle Journal 16, no. 1: 9. https://doi.org/10.3390/wevj16010009
APA StyleMurendeni, R., Mwanza, A., & Obagbuwa, I. C. (2025). Using a YOLO Deep Learning Algorithm to Improve the Accuracy of 3D Object Detection by Autonomous Vehicles. World Electric Vehicle Journal, 16(1), 9. https://doi.org/10.3390/wevj16010009