
SLAM Meets NeRF: A Survey of Implicit SLAM Methods





Abstract
1. Introduction
2. Evolution of SLAM and NeRF
2.1. Evolution of SLAM Algorithms
2.2. Evolution of NeRF Algorithms
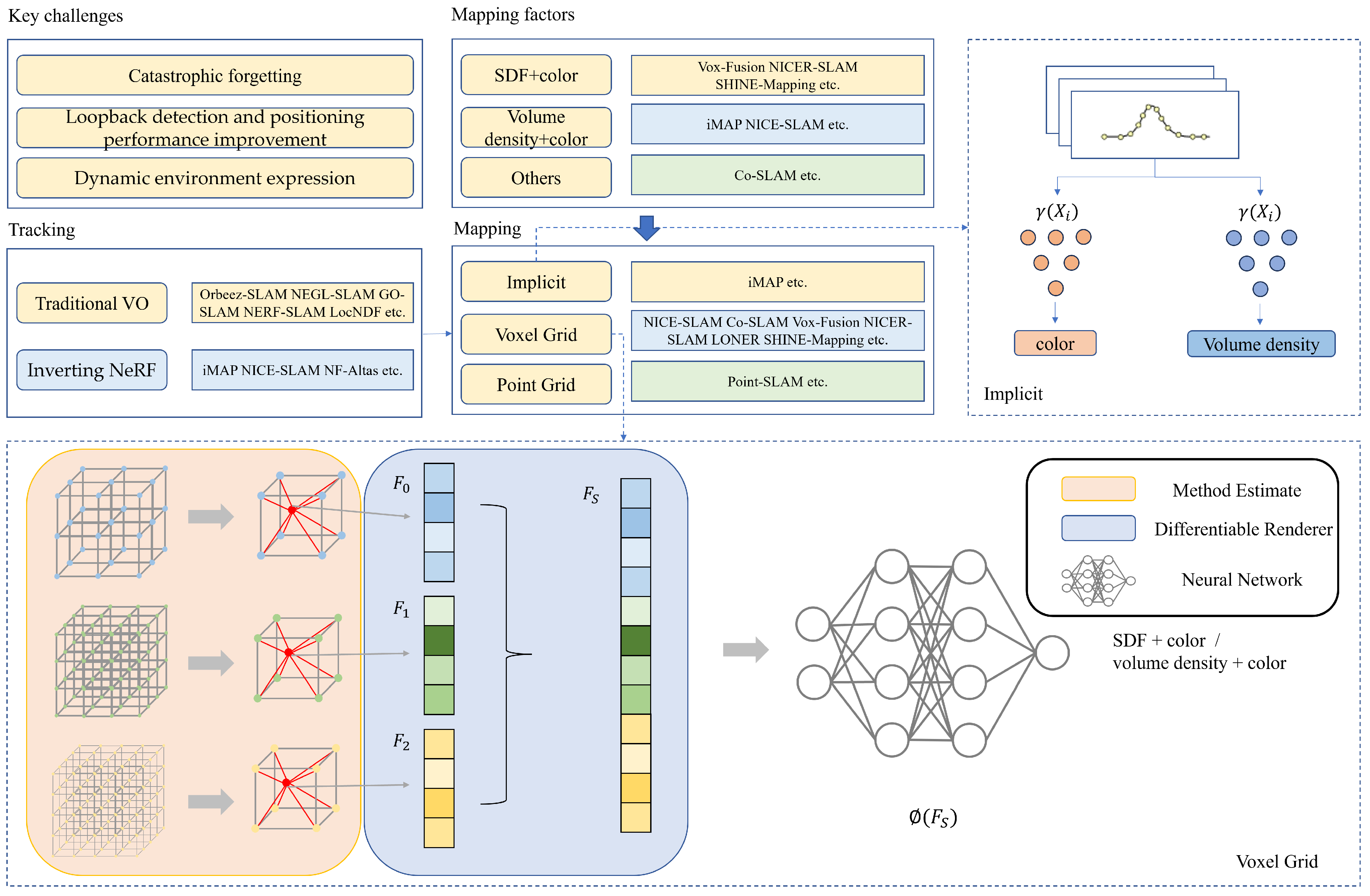
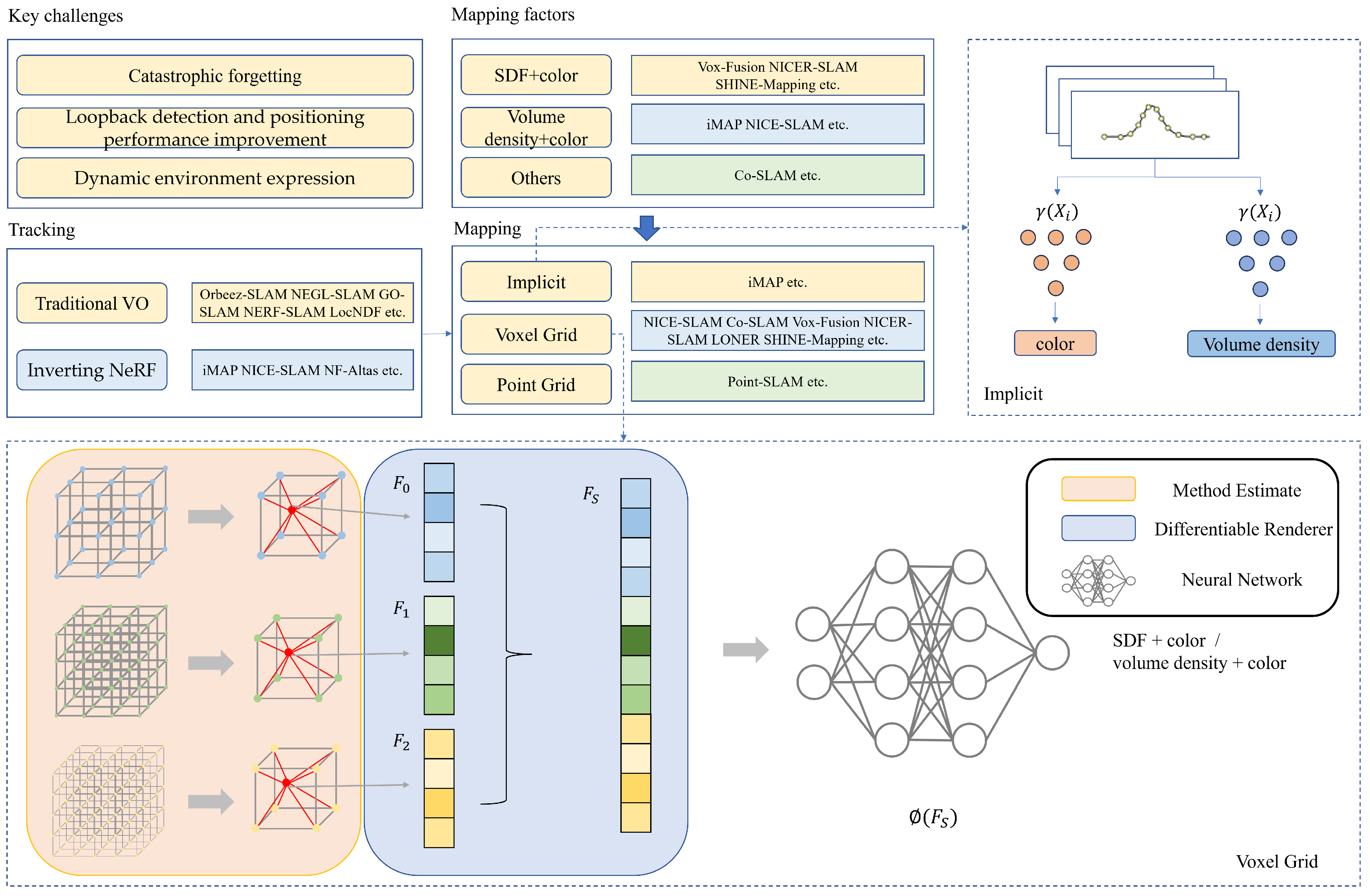
3. NeRF-Based SLAM State-of-the-Art
3.1. NeRF-Based SLAM in Mapping
3.1.1. Map Representations
- A.
- Implicit Representations
- B.
- Implicit Joint Representations using Voxels
- C.
- Implicit Joint Representations Using Points
3.1.2. Map Encoding
- A.
- Parametric Encoding
- B.
- Frequency Encoding
- C.
- Mixture Encoding
3.2. NeRF-Based-SLAM in Tracking
3.2.1. The Method of Inverting NeRF
3.2.2. The Method of VO
3.3. Loss Function
4. Dataset and System Evaluation
4.1. Datasets
4.2. System Evaluation
4.2.1. Scene Reconstruction Evaluation
4.2.2. TUM Evaluation
5. Current Issues and Future Work
5.1. Dynamic Environment Expression
5.2. SDF and Volume Density Considerations
- SDF values and volume densities decoded by MLP networks cannot be mutated without losing texture features. However, since zero iso-surface decision boundaries are abrupt, the use of SDF values can enable the extraction of surfaces containing texture features.
- A loss function based on SDF values constrains the on-surface points and off-surface points, so SDF values can provide more geometric information.
- The loss function of an SDF sets the SDF value away from the surface of the object as a cut-off value. Combined with the voxel skipping strategy, unnecessary calculations can be avoided, while the volume density is affected by floating objects in the air, which requires more sampling points and more calculations. Combined with the voxel skipping strategy, unnecessary calculations can be avoided. And because the volume density is affected by floating objects in the air, the calculation cost is large.
- An SDF value can visually describe the distance between a sampling point and an object’s surface, which is conducive to the realization of AR and VR.
5.3. Loop Detection and Positioning Performance Improvements
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khairuddin, A.R.; Talib, M.S.; Haron, H. Review on simultaneous localization and mapping (SLAM). In Proceedings of the 2015 IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 27–29 November 2015; pp. 85–90. [Google Scholar]
- Vallivaara, I.; Haverinen, J.; Kemppainen, A.; Röning, J. Magnetic field-based SLAM method for solving the localization problem in mobile robot floor-cleaning task. In Proceedings of the 2011 15th International Conference on Advanced Robotics (ICAR), Tallinn, Estonia, 20–23 June 2011; pp. 198–203. [Google Scholar]
- Yang, T.; Li, P.; Zhang, H.; Li, J.; Li, Z. Monocular vision SLAM-based UAV autonomous landing in emergencies and unknown environments. Electronics 2018, 7, 73. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, H.; Di, H.; Tao, Y.; Gong, J.; Xiong, G.; Qi, J. Real-time 6d lidar slam in large scale natural terrains for ugv. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 662–667. [Google Scholar]
- Yeh, Y.J.; Lin, H.Y. 3D reconstruction and visual SLAM of indoor scenes for augmented reality application. In Proceedings of the 2018 IEEE 14th International Conference on Control and Automation (ICCA), Anchorage, AL, USA, 12–15 June 2018; pp. 94–99. [Google Scholar]
- Strasdat, H.; Montiel, J.M.; Davison, A.J. Visual SLAM: Why filter? Image Vis. Comput. 2012, 30, 65–77. [Google Scholar] [CrossRef]
- Taheri, H.; Xia, Z.C. SLAM; definition and evolution. Eng. Appl. Artif. Intell. 2021, 97, 104032. [Google Scholar] [CrossRef]
- Macario Barros, A.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A comprehensive survey of visual slam algorithms. Robotics 2022, 11, 24. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Kazerouni, I.A.; Fitzgerald, L.; Dooly, G.; Toal, D. A survey of state-of-the-art on visual SLAM. Expert Syst. Appl. 2022, 205, 117734. [Google Scholar] [CrossRef]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. Nice-slam: Neural implicit scalable encoding for slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12786–12796. [Google Scholar]
- Wang, H.; Wang, J.; Agapito, L. Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, AL, Canada, 18–22 June 2023; pp. 13293–13302. [Google Scholar]
- Sandström, E.; Li, Y.; Van Gool, L.; Oswald, M.R. Point-slam: Dense neural point cloud-based slam. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 18–22 June 2023; pp. 18433–18444. [Google Scholar]
- Sunderhauf, N.; Lange, S.; Protzel, P. Using the unscented kalman filter in mono-SLAM with inverse depth parametrization for autonomous airship control. In Proceedings of the 2007 IEEE International Workshop on Safety, Security and Rescue Robotics, Rome, Italy, 27–29 September 2007; pp. 1–6. [Google Scholar]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Mendes, E.; Koch, P.; Lacroix, S. ICP-based pose-graph SLAM. In Proceedings of the 2016 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Lausanne, Switzerland, 23–27 October 2016; pp. 195–200. [Google Scholar]
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D mapping with an RGB-D camera. IEEE Trans. Robot. 2013, 30, 177–187. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE international conference on robotics and automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 834–849. [Google Scholar]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. Cnn-slam: Real-time dense monocular slam with learned depth prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6243–6252. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- A detailed map of Higgs boson interactions by the ATLAS experiment ten years after the discovery. Nature 2022, 607, 52–59. [CrossRef]
- Yen-Chen, L.; Florence, P.; Barron, J.T.; Rodriguez, A.; Isola, P.; Lin, T.Y. inerf: Inverting neural radiance fields for pose estimation. In Proceedings of the 2021 IEEE RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1323–1330. [Google Scholar]
- Lin, C.H.; Ma, W.C.; Torralba, A.; Lucey, S. Barf: Bundle-adjusting neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5741–5751. [Google Scholar]
- Yu, A.; Li, R.; Tancik, M.; Li, H.; Ng, R.; Kanazawa, A. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5752–5761. [Google Scholar]
- Hedman, P.; Srinivasan, P.P.; Mildenhall, B.; Barron, J.T.; Debevec, P. Baking neural radiance fields for real-time view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 5855–5864. [Google Scholar]
- Sun, C.; Sun, M.; Chen, H.T. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5459–5469. [Google Scholar]
- Fridovich-Keil, S.; Yu, A.; Tancik, M.; Chen, Q.; Recht, B.; Kanazawa, A. Plenoxels: Radiance fields without neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5501–5510. [Google Scholar]
- Sucar, E.; Liu, S.; Ortiz, J.; Davison, A.J. iMAP: Implicit mapping and positioning in real-time. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6229–6238. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5470–5479. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Cui, Z.; Oswald, M.R.; Geiger, A.; Pollefeys, M. Nicer-slam: Neural implicit scene encoding for rgb slam. arXiv 2023, arXiv:2302.03594. [Google Scholar]
- Yang, X.; Li, H.; Zhai, H.; Ming, Y.; Liu, Y.; Zhang, G. Vox-Fusion: Dense tracking and mapping with voxel-based neural implicit representation. In Proceedings of the 2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Singapore, 17–21 October 2022; pp. 499–507. [Google Scholar]
- Yan, D.; Lyu, X.; Shi, J.; Lin, Y. Efficient Implicit Neural Reconstruction Using LiDAR. arXiv 2023, arXiv:2302.14363. [Google Scholar]
- Shi, Y.; Yang, R.; Wu, Z.; Li, P.; Liu, C.; Zhao, H.; Zhou, G. City-scale continual neural semantic mapping with three-layer sampling and panoptic representation. Knowl.-Based Syst. 2024, 284, 111145. [Google Scholar] [CrossRef]
- Isaacson, S.; Kung, P.C.; Ramanagopal, M.; Vasudevan, R.; Skinner, K.A. LONER: LiDAR Only Neural Representations for Real-Time SLAM. IEEE Robot. Autom. Lett. 2023, 8, 8042–8049. [Google Scholar] [CrossRef]
- Zhong, X.; Pan, Y.; Behley, J.; Stachniss, C. Shine-mapping: Large-scale 3d mapping using sparse hierarchical implicit neural representations. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 8371–8377. [Google Scholar]
- Liu, J.; Chen, H. Towards Real-time Scalable Dense Mapping using Robot-centric Implicit Representation. arXiv 2023, arXiv:2306.10472. [Google Scholar]
- Yu, X.; Liu, Y.; Mao, S.; Zhou, S.; Xiong, R.; Liao, Y.; Wang, Y. NF-Atlas: Multi-Volume Neural Feature Fields for Large Scale LiDAR Mapping. arXiv 2023, arXiv:2304.04624. [Google Scholar] [CrossRef]
- Li, P.; Zhao, R.; Shi, Y.; Zhao, H.; Yuan, J.; Zhou, G.; Zhang, Y.Q. Lode: Locally conditioned eikonal implicit scene completion from sparse lidar. arXiv 2023, arXiv:2302.14052. [Google Scholar]
- Wiesmann, L.; Guadagnino, T.; Vizzo, I.; Zimmerman, N.; Pan, Y.; Kuang, H.; Behley, J.; Stachniss, C. Locndf: Neural distance field mapping for robot localization. IEEE Robot. Autom. Lett. 2023, 8, 4999–5006. [Google Scholar] [CrossRef]
- Rosinol, A.; Leonard, J.J.; Carlone, L. Nerf-slam: Real-time dense monocular slam with neural radiance fields. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 3437–3444. [Google Scholar]
- Deng, J.; Wu, Q.; Chen, X.; Xia, S.; Sun, Z.; Liu, G.; Yu, W.; Pei, L. Nerf-loam: Neural implicit representation for large-scale incremental lidar odometry and mapping. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 8218–8227. [Google Scholar]
- Zhang, Y.; Tosi, F.; Mattoccia, S.; Poggi, M. Go-slam: Global optimization for consistent 3D instant reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 3727–3737. [Google Scholar]
- Chung, C.M.; Tseng, Y.C.; Hsu, Y.C.; Shi, X.Q.; Hua, Y.H.; Yeh, J.F.; Chen, W.C.; Chen, Y.T.; Hsu, W.H. Orbeez-slam: A real-time monocular visual slam with orb features and nerf-realized mapping. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 9400–9406. [Google Scholar]
- Mao, Y.; Yu, X.; Wang, K.; Wang, Y.; Xiong, R.; Liao, Y. NGEL-SLAM: Neural Implicit Representation-based Global Consistent Low-Latency SLAM System. arXiv 2023, arXiv:2311.09525. [Google Scholar]
- Moad, G.; Rizzardo, E.; Thang, S.H. Living radical polymerization by the RAFT process. Aust. J. Chem. 2005, 58, 379–410. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. Adv. Neural Inf. Process. Syst. 2021, 34, 16558–16569. [Google Scholar]
- Straub, J.; Whelan, T.; Ma, L.; Chen, Y.; Wijmans, E.; Green, S.; Engel, J.J.; Mur-Artal, R.; Ren, C.; Verma, S. The Replica dataset: A digital replica of indoor spaces. arXiv 2019, arXiv:1906.05797. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Abou-Chakra, J.; Dayoub, F.; Sünderhauf, N. Implicit object mapping with noisy data. arXiv 2022, arXiv:2204.10516. [Google Scholar]
- Vizzo, I.; Chen, X.; Chebrolu, N.; Behley, J.; Stachniss, C. Poisson surface reconstruction for LiDAR odometry and mapping. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 5624–5630. [Google Scholar]
- Liao, Y.; Xie, J.; Geiger, A. KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2D and 3D. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3292–3310. [Google Scholar] [CrossRef]
- Fang, J.; Yi, T.; Wang, X.; Xie, L.; Zhang, X.; Liu, W.; Nießner, M.; Tian, Q. Fast dynamic radiance fields with time-aware neural voxels. In Proceedings of the SIGGRAPH Asia 2022, Daegu, Republic of Korea, 6–9 December 2022; pp. 1–9. [Google Scholar]
- Fridovich-Keil, S.; Meanti, G.; Warburg, F.R.; Recht, B.; Kanazawa, A. K-planes: Explicit radiance fields in space, time, and appearance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancuver, BC, Canada, 18–22 June 2023; pp. 12479–12488. [Google Scholar]
- Cao, A.; Johnson, J. Hexplane: A fast representation for dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancuver, BC, Canada, 18–22 June 2023; pp. 130–141. [Google Scholar]

{kind=link}
| Method Name | Year | Utilized Sensors | Decoded Parameters | ||||
|---|---|---|---|---|---|---|---|
| RGB-D | RGB | LiDAR | SDF | Density | Color | ||
| NICE-SLAM [11] | 2022 | ✓ | ✓ | ✓ | |||
| Vox-Fusion [35] | 2022 | ✓ | ✓ | ✓ | |||
| NICER-SLAM [34] | 2023 | ✓ | ✓ | ✓ | |||
| Co-SLAM [12] | 2023 | ✓ | ✓ | ✓ | |||
| LONER [38] | 2023 | ✓ | ✓ | ✓ | |||
| Shine-mapping [39] | 2023 | ✓ | ✓ | ✓ | |||
| NF-Atlas [41] | 2023 | ✓ | ✓ | ✓ | |||
| LODE [42] | 2023 | ✓ | ✓ | ✓ | |||
| NeRF-LOAM [45] | 2023 | ✓ | ✓ | ✓ | |||
| LocNDF [11] | 2023 | ✓ | ✓ | ✓ | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, K.; Cheng, Y.; Chen, Z.; Wang, J. SLAM Meets NeRF: A Survey of Implicit SLAM Methods. World Electr. Veh. J. 2024, 15, 85. https://doi.org/10.3390/wevj15030085
Yang K, Cheng Y, Chen Z, Wang J. SLAM Meets NeRF: A Survey of Implicit SLAM Methods. World Electric Vehicle Journal. 2024; 15(3):85. https://doi.org/10.3390/wevj15030085
Chicago/Turabian StyleYang, Kaiyun, Yunqi Cheng, Zonghai Chen, and Jikai Wang. 2024. "SLAM Meets NeRF: A Survey of Implicit SLAM Methods" World Electric Vehicle Journal 15, no. 3: 85. https://doi.org/10.3390/wevj15030085
APA StyleYang, K., Cheng, Y., Chen, Z., & Wang, J. (2024). SLAM Meets NeRF: A Survey of Implicit SLAM Methods. World Electric Vehicle Journal, 15(3), 85. https://doi.org/10.3390/wevj15030085