


Bird’s-Eye View Semantic Segmentation for Autonomous Driving through the Large Kernel Attention Encoder and Bilinear-Attention Transform Module

Abstract
:1. Introduction
- We redesign an image encoder combined with the Large Kernel Attention to address the conventional encoder’s lack of remote feature modeling capability.
- To overcome the great difference between image features and BEV features, a view transform module is designed by combining bilinear sampling and attention mechanisms to ensure that BEV features pay more attention to image features that are closely related.
- To address the problem of distortion of BEV features at long distances, a BEV encoder with a large kernel size for BEV features is redesigned to obtain a larger receptive area.
2. Related Work
2.1. Geometry-Based Method
2.2. Network-Based Method
3. Method
3.1. Overall Architecture
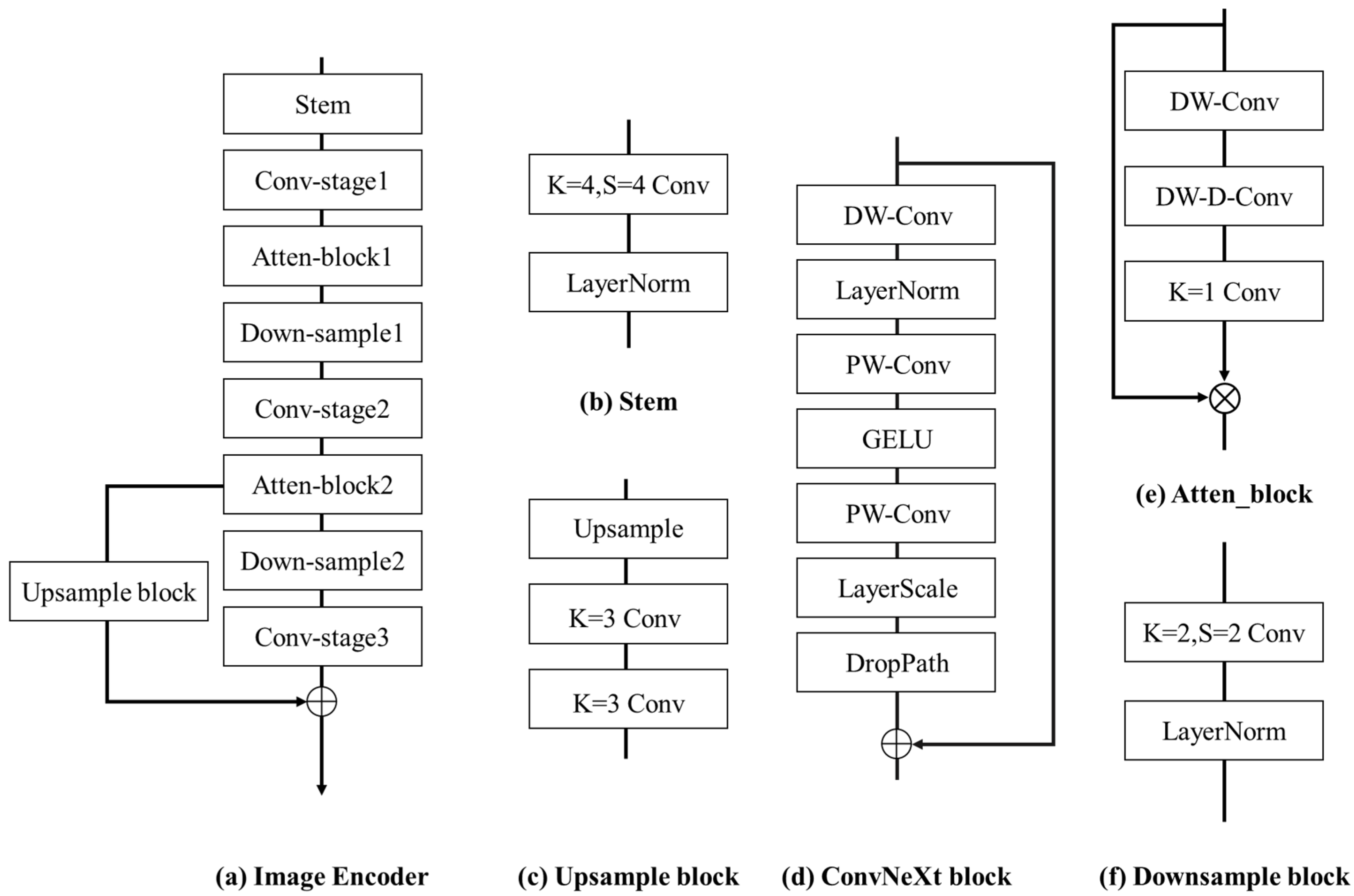
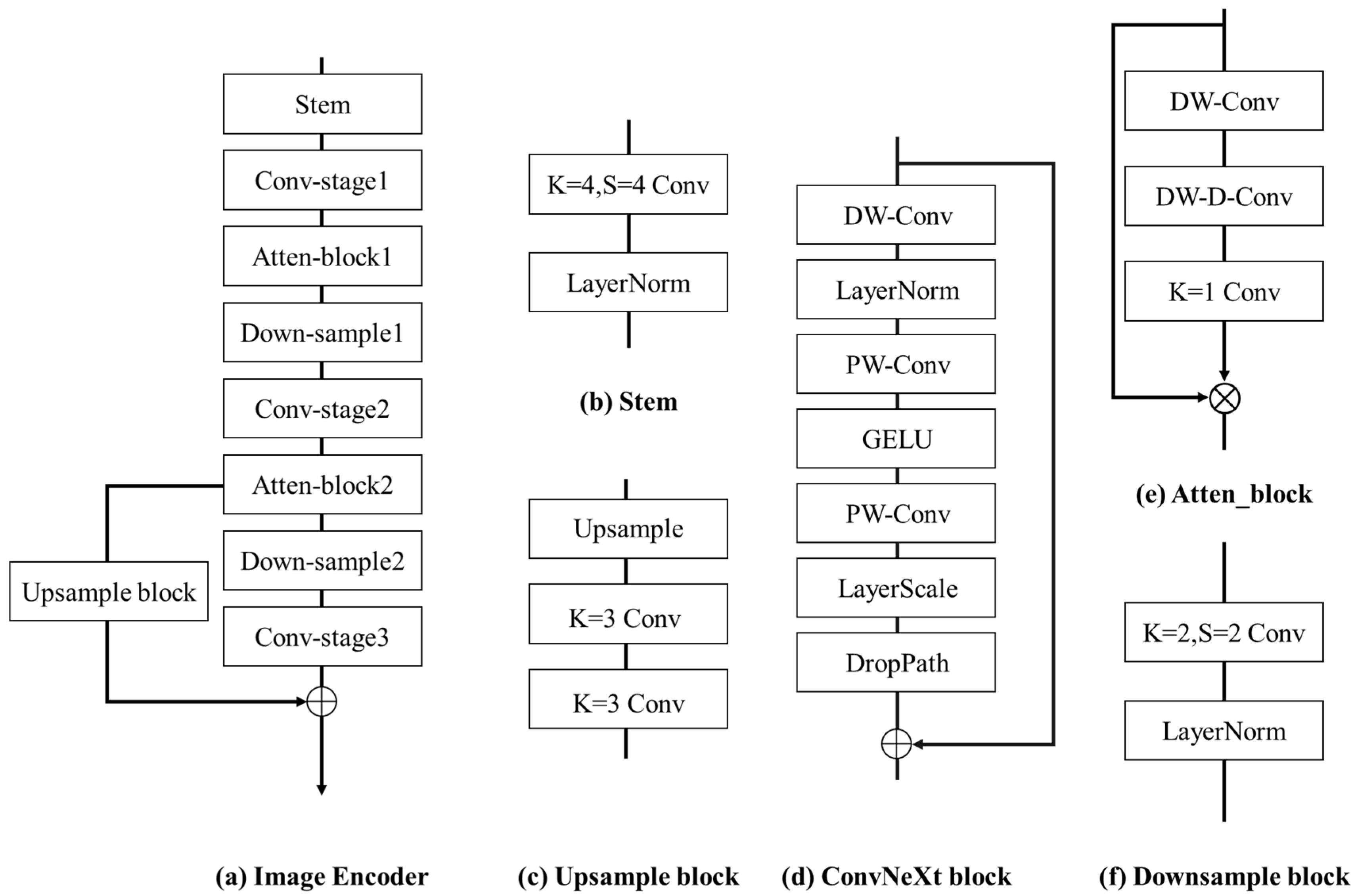
3.2. Image Encoder
3.3. View Transform Module
3.4. BEV Encoder
4. Experiments
4.1. Setup
4.2. Experiment Result
4.3. Detailed Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision And Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Li, Q.; Wang, Y.; Wang, Y.; Zhao, H. Hdmapnet: An online hd map construction and evaluation framework. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 4628–4634. [Google Scholar]
- Mallot, H.A.; Bülthoff, H.H.; Little, J.; Bohrer, S. Inverse perspective mapping simplifies optical flow computation and obstacle detection. Biol. Cybern. 1991, 64, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Reiher, L.; Lampe, B.; Eckstein, L. A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird’s eye view. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Zhu, M.; Zhang, S.; Zhong, Y.; Lu, P.; Peng, H.; Lenneman, J. Monocular 3D vehicle detection using uncalibrated traffic cameras through homography. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3814–3821. [Google Scholar]
- Song, L.; Wu, J.; Yang, M.; Zhang, Q.; Li, Y.; Yuan, J. Stacked homography transformations for multi-view pedestrian detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6049–6057. [Google Scholar]
- Pan, B.; Sun, J.; Leung, H.Y.T.; Andonian, A.; Zhou, B. Cross-view semantic segmentation for sensing surroundings. IEEE Robot. Autom. Lett. 2020, 5, 4867–4873. [Google Scholar] [CrossRef]
- Roddick, T.; Cipolla, R. Predicting semantic map representations from images using pyramid occupancy networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11138–11147. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Qiao, Y.; Dai, J. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 1–18. [Google Scholar]
- Liu, Y.; Wang, T.; Zhang, X.; Sun, J. Petr: Position embedding transformation for multi-view 3d object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 531–548. [Google Scholar]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16, 2020. pp. 194–210. [Google Scholar]
- Reading, C.; Harakeh, A.; Chae, J.; Waslander, S.L. Categorical depth distribution network for monocular 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual. 19–25 June 2021; pp. 8555–8564. [Google Scholar]
- Hu, A.; Murez, Z.; Mohan, N.; Dudas, S.; Hawke, J.; Badrinarayanan, V.; Cipolla, R.; Kendall, A. Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15273–15282. [Google Scholar]
- Xie, E.; Yu, Z.; Zhou, D.; Philion, J.; Anandkumar, A.; Fidler, S.; Luo, P.; Alvarez, J.M. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation. arXiv 2022, arXiv:2204.05088. [Google Scholar]
- Harley, A.W.; Fang, Z.; Li, J.; Ambrus, R.; Fragkiadaki, K. Simple-BEV: What really matters for multi-sensor bev perception? In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2759–2765. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. Visual attention network. arXiv 2022, arXiv:2202.09741. [Google Scholar] [CrossRef]
- Huang, J.; Huang, G.; Zhu, Z.; Ye, Y.; Du, D. Bevdet: High-performance multi-camera 3D object detection in bird-eye-view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. Bevdepth: Acquisition of reliable depth for multi-view 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 1477–1485. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Wang, Y.; Chao, W.-L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8445–8453. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.-L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar++: Accurate depth for 3D object detection in autonomous driving. arXiv 2019, arXiv:1906.06310. [Google Scholar]
- Huang, J.; Huang, G. Bevdet4d: Exploit temporal cues in multi-camera 3D object detection. arXiv 2022, arXiv:2203.17054. [Google Scholar]
- Lu, C.; van de Molengraft, M.J.G.; Dubbelman, G. Monocular semantic occupancy grid mapping with convolutional variational encoder-decoder networks. IEEE Robot. Autom. Lett. 2019, 4, 445–452. [Google Scholar] [CrossRef]
- Hendy, N.; Sloan, C.; Tian, F.; Duan, P.; Charchut, N.; Xie, Y.; Wang, C.; Philbin, J. Fishing net: Future inference of semantic heatmaps in grids. arXiv 2020, arXiv:2006.09917. [Google Scholar]
- Zou, J.; Zhu, Z.; Huang, J.; Yang, T.; Huang, G.; Wang, X. HFT: Lifting Perspective Representations via Hybrid Feature Transformation for BEV Perception. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 7046–7053. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Can, Y.B.; Liniger, A.; Paudel, D.P.; Van Gool, L. Structured bird’s-eye-view traffic scene understanding from onboard images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15661–15670. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3D object detection from multi-view images via 3D-to-2D queries. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 180–191. [Google Scholar]
- Liu, Y.; Yan, J.; Jia, F.; Li, S.; Gao, Q.; Wang, T.; Zhang, X.; Sun, J. Petrv2: A unified framework for 3D perception from multi-camera images. arXiv 2022, arXiv:2206.01256. [Google Scholar]
- Zhou, B.; Krähenbühl, P. Cross-view transformers for real-time map-view semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13760–13769. [Google Scholar]
- Chen, S.; Cheng, T.; Wang, X.; Meng, W.; Zhang, Q.; Liu, W. Efficient and robust 2D-to-bev representation learning via geometry-guided kernel transformer. arXiv 2022, arXiv:2206.04584. [Google Scholar]
- Saha, A.; Mendez, O.; Russell, C.; Bowden, R. Translating images into maps. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 9200–9206. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Lifting | Batch Size | mIoU |
|---|---|---|---|
| FISHING [26] | MLP | - | 30.0 |
| LSS [11] | Depth Estimation | 8 (4) | 33.0 (32.1) |
| FIERY [13] | Depth Estimation | 12 | 35.8 |
| CVT [32] | Deformable Attn. | 16 | 36.0 |
| GKT [33] | Geometry Attn. | 16 | 37.2 |
| TIIM [34] | Ray Attn. | 8 | 38.9 |
| BEVFormer [9] | Deformable Attn. | 1 | 44.4 |
| Simple-BEV [15] | Bilinear | 2 (40) | 42.5 (47.4) |
| Ours | Bilinear-Attn. | 2 | 45.6 |
| ResNet-101 | Conv-LKA | ResNet-18 | Res-RepLK | Parameters | FLOPs | mIoU |
|---|---|---|---|---|---|---|
| √ | - | √ | - | 42.1 M | 428.3 G | 43.0 |
| √ | - | - | √ | 40.6 M | 512.7 G | 44.3 |
| - | √ | √ | - | 38.1 M | 552.1 G | 44.8 |
| - | √ | - | √ | 36.6 M | 653.5 G | 45.6 |
| Kernel Size | Parameters | mIoU |
|---|---|---|
| 7 × 7 | 36.5 M | 43.9 |
| 9 × 9 | 36.5 M | 44.5 |
| 13 × 13 | 36.6 M | 45.6 |
| 31 × 31 | 36.7 M | 45.4 |
| Encoder | MLP | Depth | Bilinear | Attention | mIoU |
|---|---|---|---|---|---|
| LKA-RepLK | √ | - | - | - | 37.2 |
| LKA-RepLK | - | √ | - | - | 44.8 |
| LKA-RepLK | - | - | √ | - | 44.7 |
| LKA-RepLK | - | - | √ | √ | 45.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Wu, X.; Zhang, W.; Yu, W. Bird’s-Eye View Semantic Segmentation for Autonomous Driving through the Large Kernel Attention Encoder and Bilinear-Attention Transform Module. World Electr. Veh. J. 2023, 14, 239. https://doi.org/10.3390/wevj14090239
Li K, Wu X, Zhang W, Yu W. Bird’s-Eye View Semantic Segmentation for Autonomous Driving through the Large Kernel Attention Encoder and Bilinear-Attention Transform Module. World Electric Vehicle Journal. 2023; 14(9):239. https://doi.org/10.3390/wevj14090239
Chicago/Turabian StyleLi, Ke, Xuncheng Wu, Weiwei Zhang, and Wangpengfei Yu. 2023. "Bird’s-Eye View Semantic Segmentation for Autonomous Driving through the Large Kernel Attention Encoder and Bilinear-Attention Transform Module" World Electric Vehicle Journal 14, no. 9: 239. https://doi.org/10.3390/wevj14090239
APA StyleLi, K., Wu, X., Zhang, W., & Yu, W. (2023). Bird’s-Eye View Semantic Segmentation for Autonomous Driving through the Large Kernel Attention Encoder and Bilinear-Attention Transform Module. World Electric Vehicle Journal, 14(9), 239. https://doi.org/10.3390/wevj14090239