
TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes


Abstract
:1. Introduction
- A novel transformer–fusion-based YOLO (TF-YOLO) is introduced to effectively fuse the visible and infrared images for multimodal pedestrian detection, enabling precise pedestrian detection in low-light conditions.
- In our TF-YOLO, we first design a two-stream backbone of YOLOv7 [22] to extract multimodal features. Then, we develop a transformer–fusion module to fuse the input visible and infrared data in the two-stream feature extraction backbone in several positions. It can efficiently combine the rich semantic features in high-level and high-resolution detailed features at a low level, which deeply exploits the long-range multi-modal information.
- Our method achieves the best performance with an average precision of 87.85% and a miss rate of 17.27%, which achieves a 5.1% improvement in average precision and a 6.05% improvement in miss rate, respectively, when compared with the state-of-the-art CFT method [23], on the multi-scenario multi-modality dataset (M3FD) [24].
2. Related Works
3. Proposed Methods
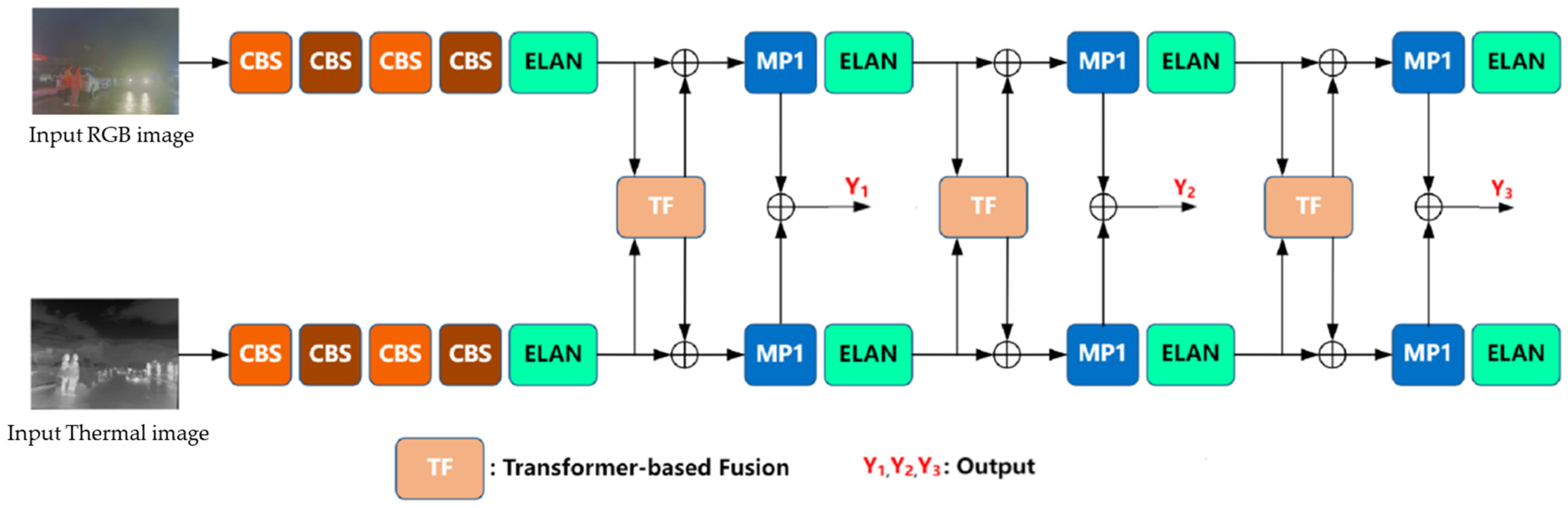
3.1. Overview
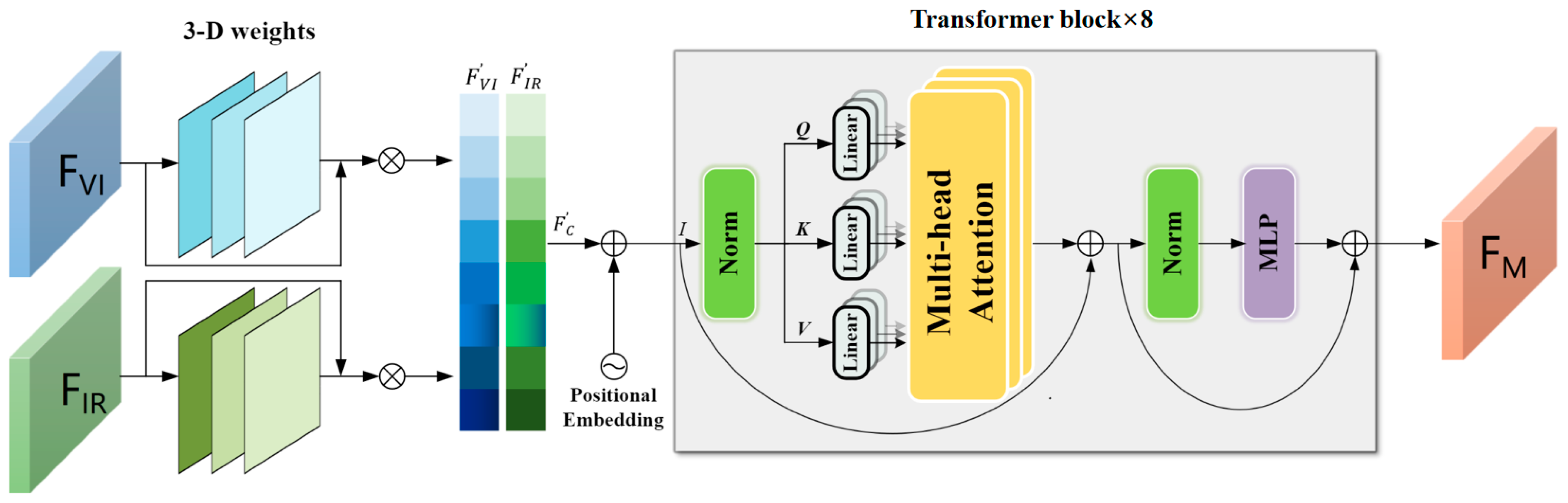
3.2. Transformer–Fusion-Based Two-Stream Backbone
3.3. Training
3.3.1. Loss Function
3.3.2. Training Details
4. Results and Discussions
4.1. Datasets
4.1.1. Multi-Scenario Multi-Modality Dataset (M3FD)
4.1.2. UTokyo Multispectral Object Detection Dataset
4.2. Evaluation Metrics
4.2.1. Precision and Recall
4.2.2. Log-Average Miss Rate (MR)
4.3. Detection Evaluation on the M3FD
4.4. Detection Evaluation on the UTokyo Dataset
4.5. Comprehensive Comparison
4.6. Ablation Experiments
4.7. Discussion
4.7.1. Explanation of Results
4.7.2. Limitations of the Proposed Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balsa-Barreiro, J.; Valero-Mora, P.M.; Berné-Valero, J.L.; Varela-García, F.-A. GIS mapping of driving behavior based on naturalistic driving data. ISPRS Int. J. Geo-Inf. 2019, 8, 226. [Google Scholar] [CrossRef]
- Balsa-Barreiro, J.; Valero-Mora, P.M.; Menéndez, M.; Mehmood, R. Extraction of naturalistic driving patterns with geographic information systems. Mob. Netw. Appl. 2020, 28, 619–635. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D. Deep neural network based vehicle and pedestrian detection for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Zhang, C.; Berger, C. Pedestrian Behavior Prediction Using Deep Learning Methods for Urban Scenarios: A Review. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10279–10301. [Google Scholar] [CrossRef]
- Pedestrian Safety: Prevent Pedestrian Crashes. Available online: https://www.nhtsa.gov/road-safety/pedestrian-safety (accessed on 4 October 2021).
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral Pedestrian Detection using Deep Fusion Convolutional Neural Networks. In Proceedings of the 24th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 27–29 April 2016; Volume 587, pp. 509–514. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Chen, Y.; Xie, H.; Shin, H. Multi-layer fusion techniques using a CNN for multispectral pedestrian detection. IET Comput. Vis. 2018, 12, 1179–1187. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Zhou, K.; Chen, L.; Cao, X. Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems. In Computer Vision–ECCV 2020, Proceedings of the16th European Conference, Glasgow, UK, 23–28 August 2020; Part XVIII 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 787–803. [Google Scholar]
- Chen, Y.; Shin, H. Multispectral image fusion based pedestrian detection using a multilayer fused deconvolutional single-shot detector. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2020, 37, 768–779. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Guided Attentive Feature Fusion for Multispectral Pedestrian Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 72–80. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Multispectral pedestrian detection via simultaneous detection and segmentation. arXiv 2018, arXiv:1808.04818. [Google Scholar]
- Cao, Y.; Guan, D.; Wu, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Box-level segmentation supervised deep neural networks for accurate and real-time multispectral pedestrian detection. ISPRS J. Photogramm. Remote Sens. 2019, 150, 70–79. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Low-Cost Multispectral Scene Analysis with Modality Distillation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 803–812. [Google Scholar]
- Zuo, X.; Wang, Z.; Liu, Y.; Shen, J.; Wang, H. LGADet: Light-weight anchor-free multispectral pedestrian detection with mixed local and global attention. Neural Process. Lett. 2023, 55, 2935–2952. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, X.; Chen, X.; Yang, X.; Lei, Z.; Liu, Z. Weakly Aligned Cross-Modal Learning for Multispectral Pedestrian Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5127–5137. [Google Scholar]
- Wanchaitanawong, N.; Tanaka, M.; Shibata, T.; Okutomi, M. Multi-Modal Pedestrian Detection with Large Misalignment Based on Modal-Wise Regression and Multi-Modal IoU. In Proceedings of the 2021 17th International Conference on Machine Vision and Applications (MVA), Aichi, Japan, 25–27 July 2021; pp. 1–6. [Google Scholar]
- Hu, W.; Fu, C.; Cao, R.; Zang, Y.; Wu, X.-J.; Shen, S.; Gao, X.-Z. Joint dual-stream interaction and multi-scale feature extraction network for multi-spectral pedestrian detection. Appl. Soft Comput. 2023, 147, 110768. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Qingyun, F.; Dapeng, H.; Zhaokui, W. Cross-modality fusion transformer for multispectral object detection. arXiv 2021, arXiv:2111.00273. [Google Scholar]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-Aware Dual Adversarial Learning and a Multi-Scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Zhang, Y.; Chen, J.; Huang, D. Cat-det: Contrastively Augmented Transformer for Multi-Modal 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 908–917. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common Objects in Context. In Computer Vision–ECCV 2014, Proceedings of the13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V 13; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Takumi, K.; Watanabe, K.; Ha, Q.; Tejero-De-Pablos, A.; Ushiku, Y.; Harada, T. Multispectral Object Detection for Autonomous Vehicles. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, New York, NY, USA, 23 October 2017; pp. 35–43. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP (%) | MR (%) | Average Computation Time (s/f) |
|---|---|---|---|
| ACF + T + THOG | 42.95 | 67.91 | 0.13 |
| MFDSSD | 75.71 | 32.28 | 0.06 |
| CFT | 84.55 | 23.32 | 0.05 |
| TF-YOLO (ours) | 87.85 | 17.27 | 0.05 |
| Method | AP (%) |
|---|---|
| YOLOv7-VI | 75.10 |
| YOLOv7-IR | 79.21 |
| Two-stream YOLOv7 | 82.46 |
| TF-YOLO (Transformer–fusion + Two-stream YOLOv7) | 87.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Ye, J.; Wan, X. TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes. World Electr. Veh. J. 2023, 14, 352. https://doi.org/10.3390/wevj14120352
Chen Y, Ye J, Wan X. TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes. World Electric Vehicle Journal. 2023; 14(12):352. https://doi.org/10.3390/wevj14120352
Chicago/Turabian StyleChen, Yunfan, Jinxing Ye, and Xiangkui Wan. 2023. "TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes" World Electric Vehicle Journal 14, no. 12: 352. https://doi.org/10.3390/wevj14120352
APA StyleChen, Y., Ye, J., & Wan, X. (2023). TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes. World Electric Vehicle Journal, 14(12), 352. https://doi.org/10.3390/wevj14120352