

Research on Energy Management Strategy of a Hybrid Commercial Vehicle Based on Deep Reinforcement Learning

Abstract
:1. Introduction
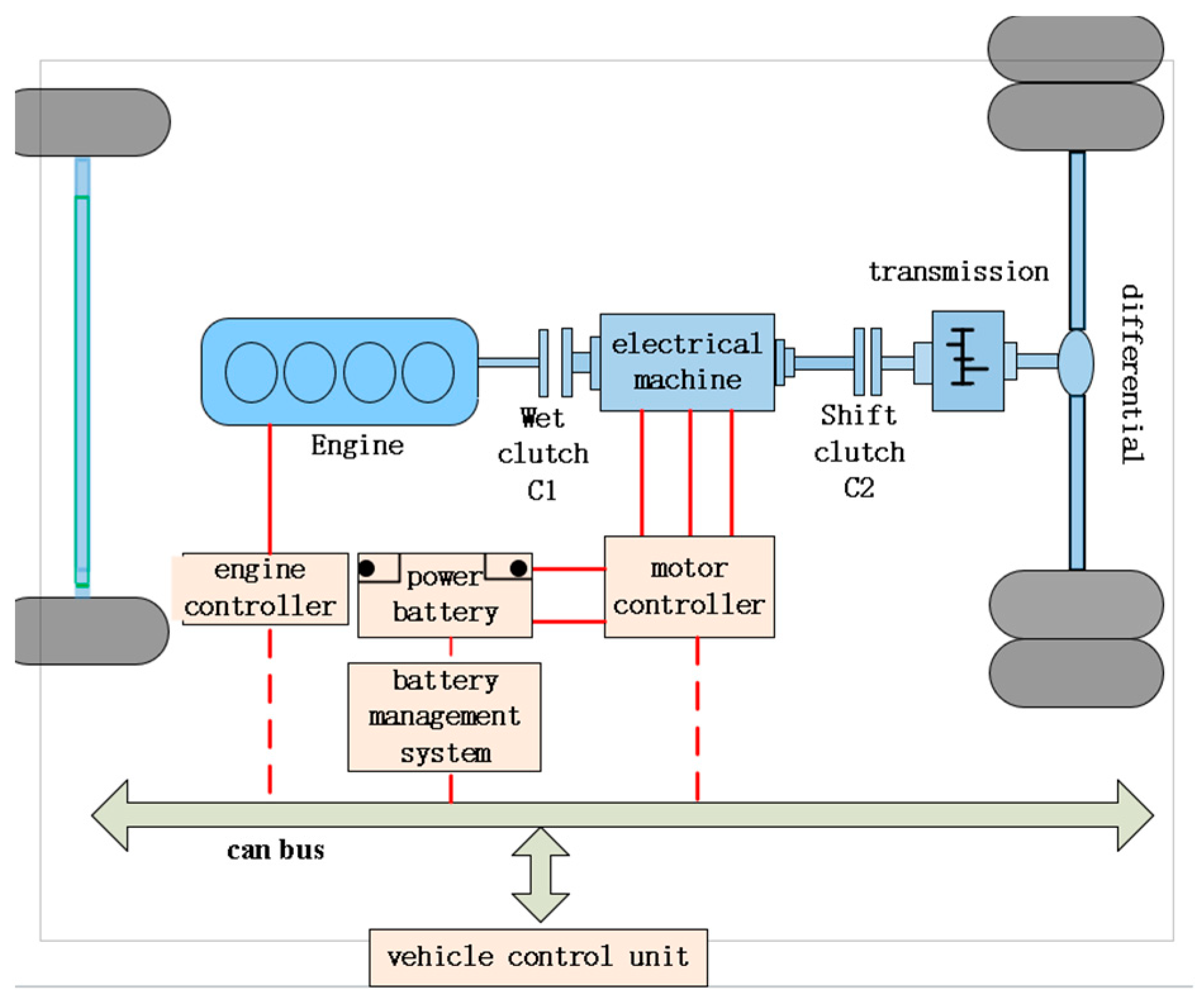
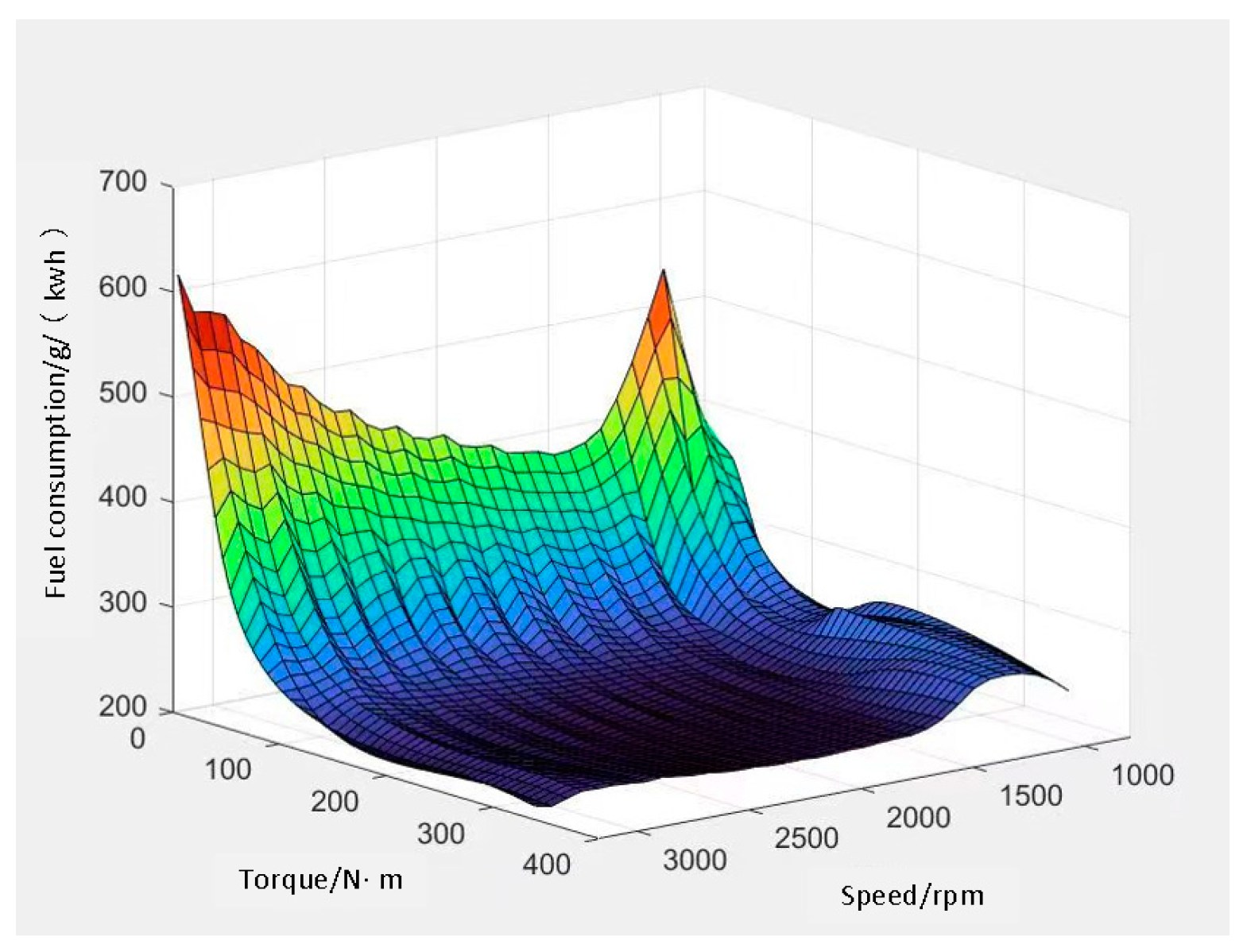
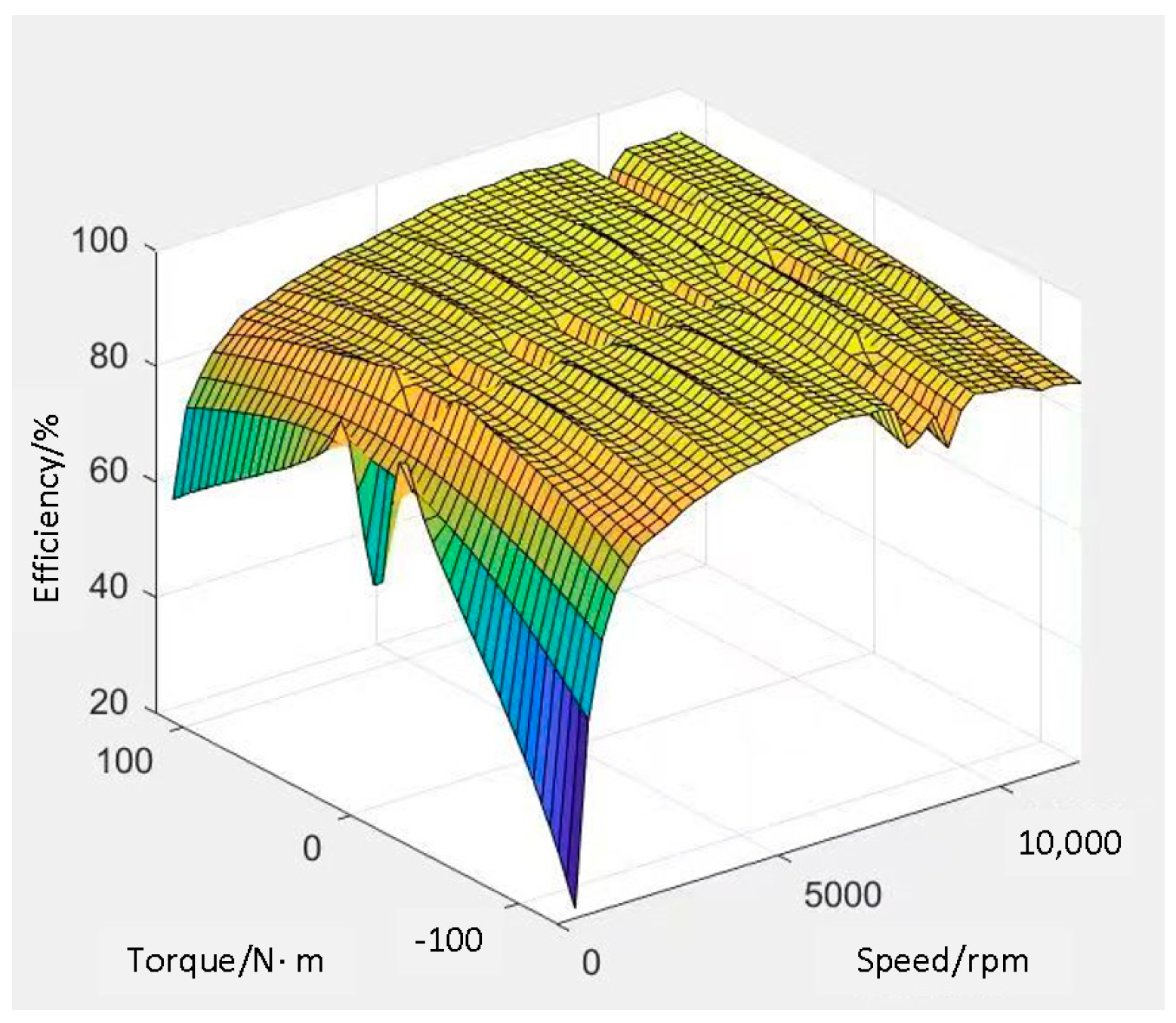
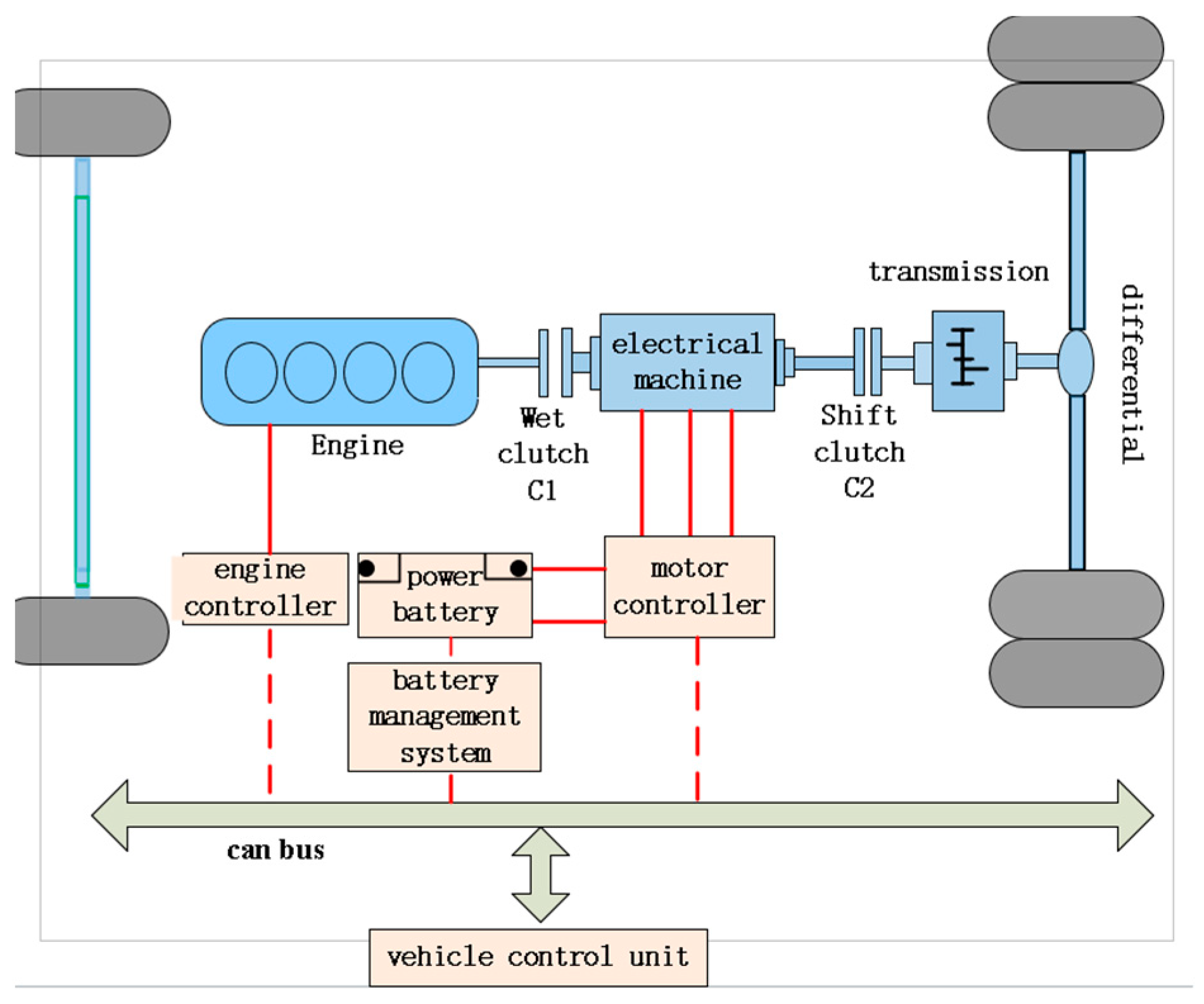
2. Vehicle Power System Construction
3. Introduction to Deep Reinforcement Learning
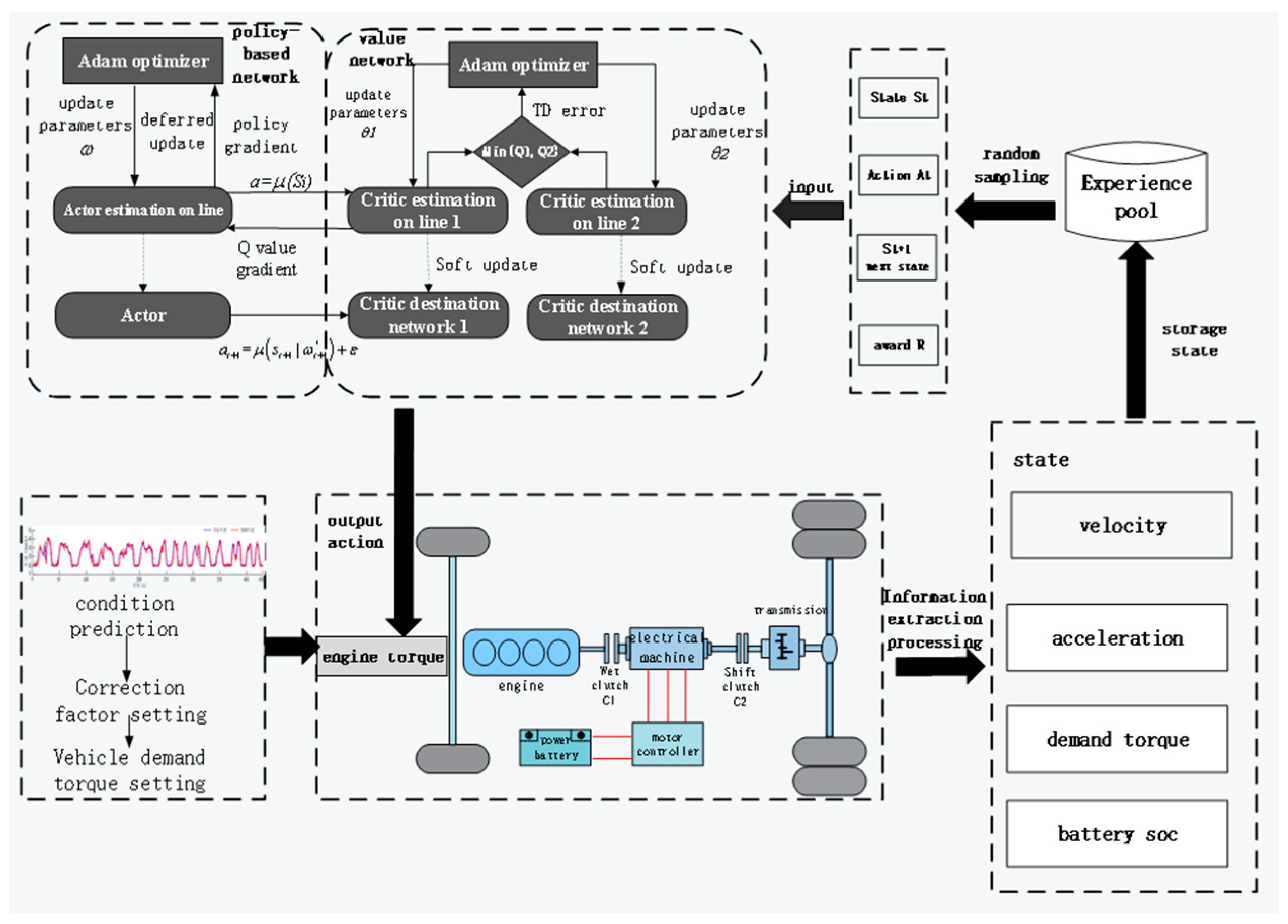
4. Twin Delayed Deep Deterministic Policy Gradient Algorithm
4.1. Twin Delayed Deep Deterministic Policy Gradient Algorithm
4.2. Key Parameter Selection
5. Simulation Verification
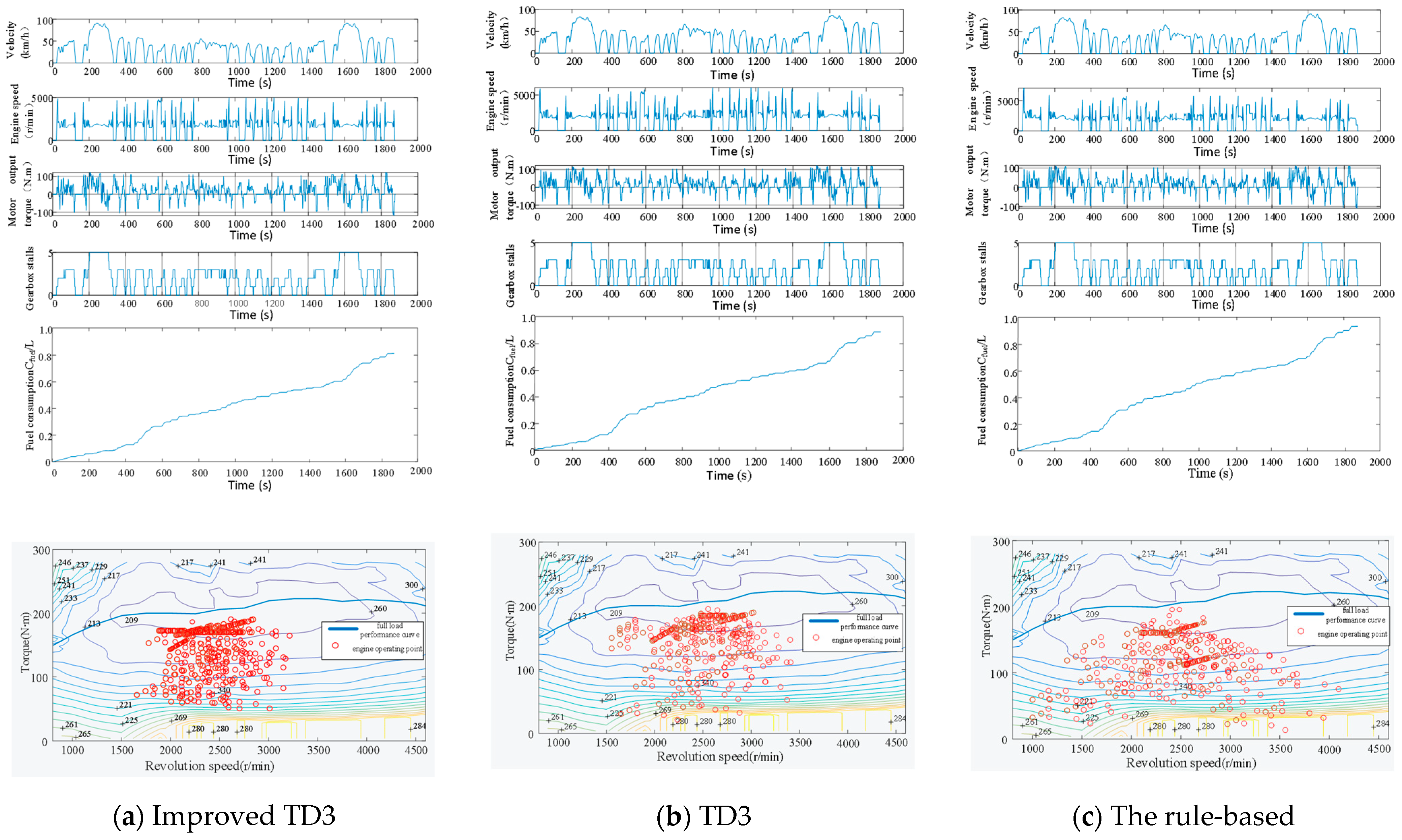
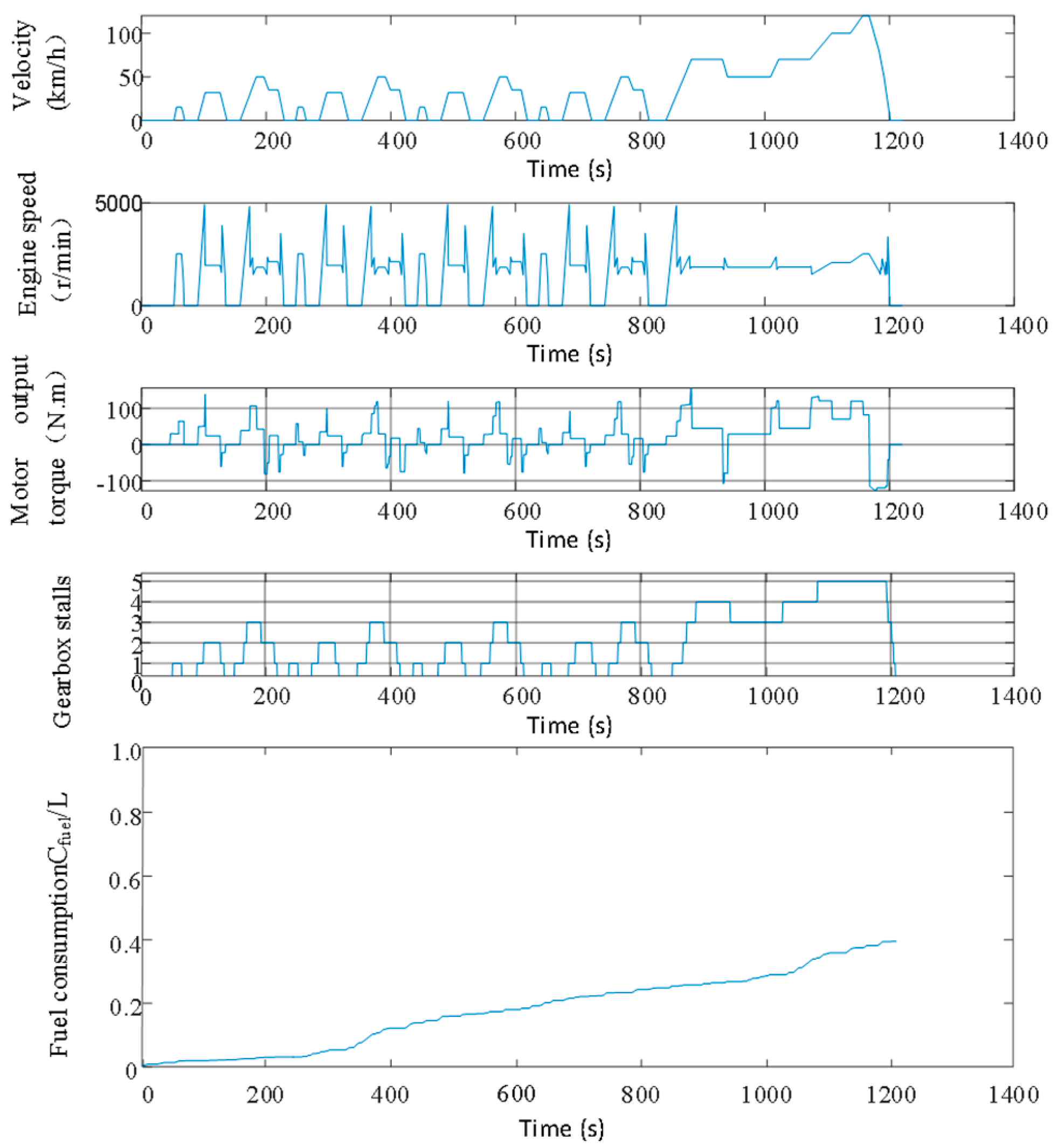
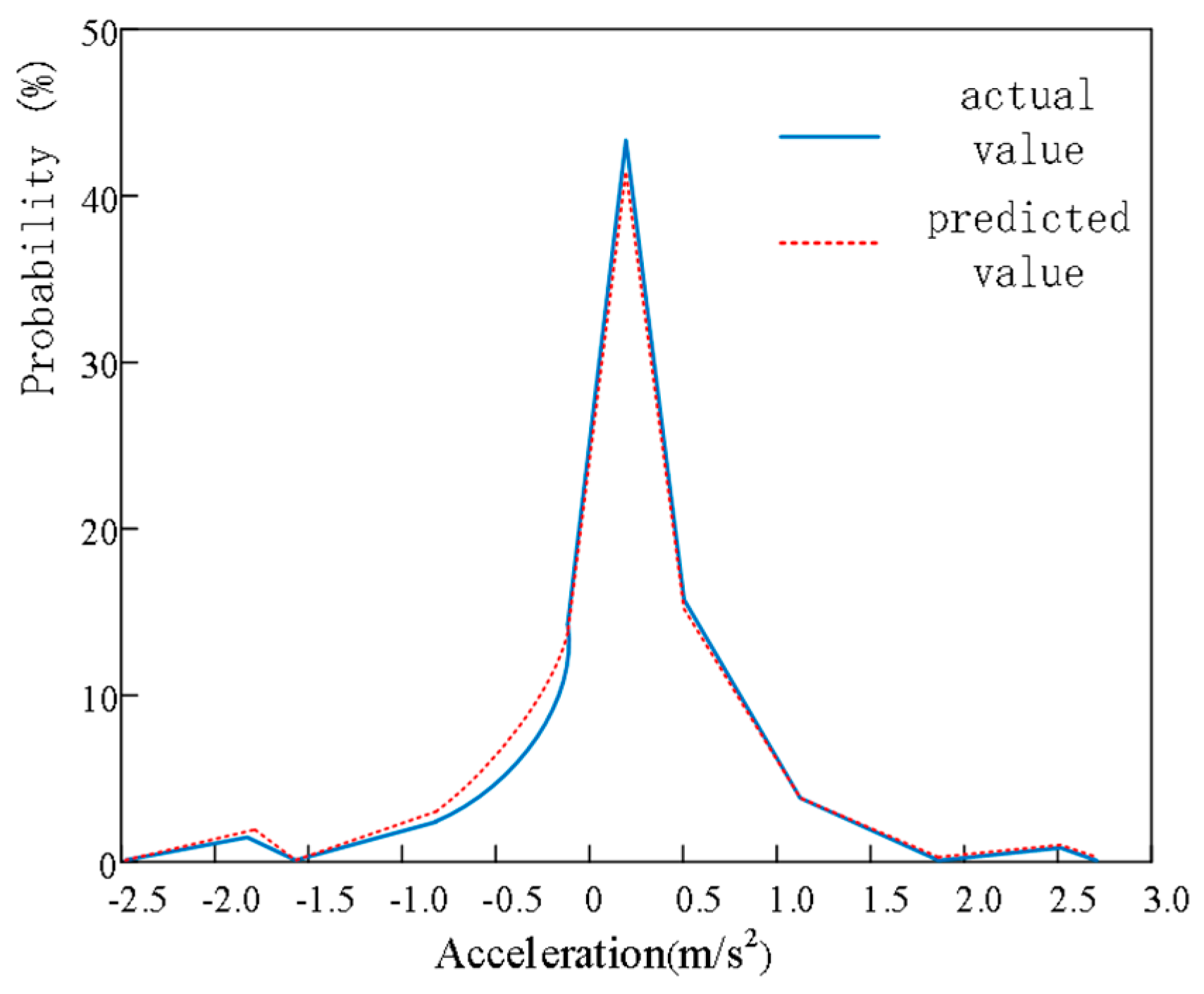
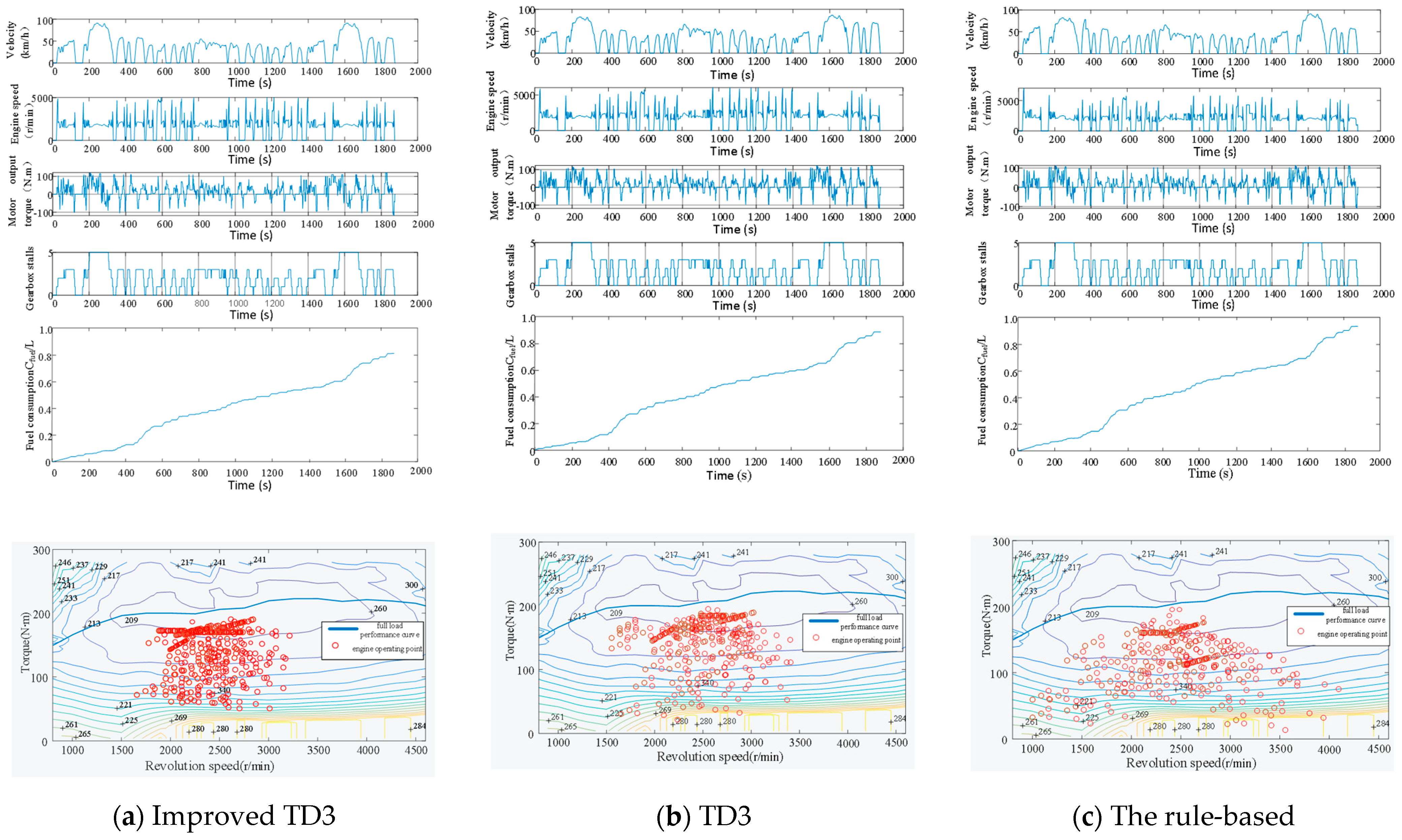
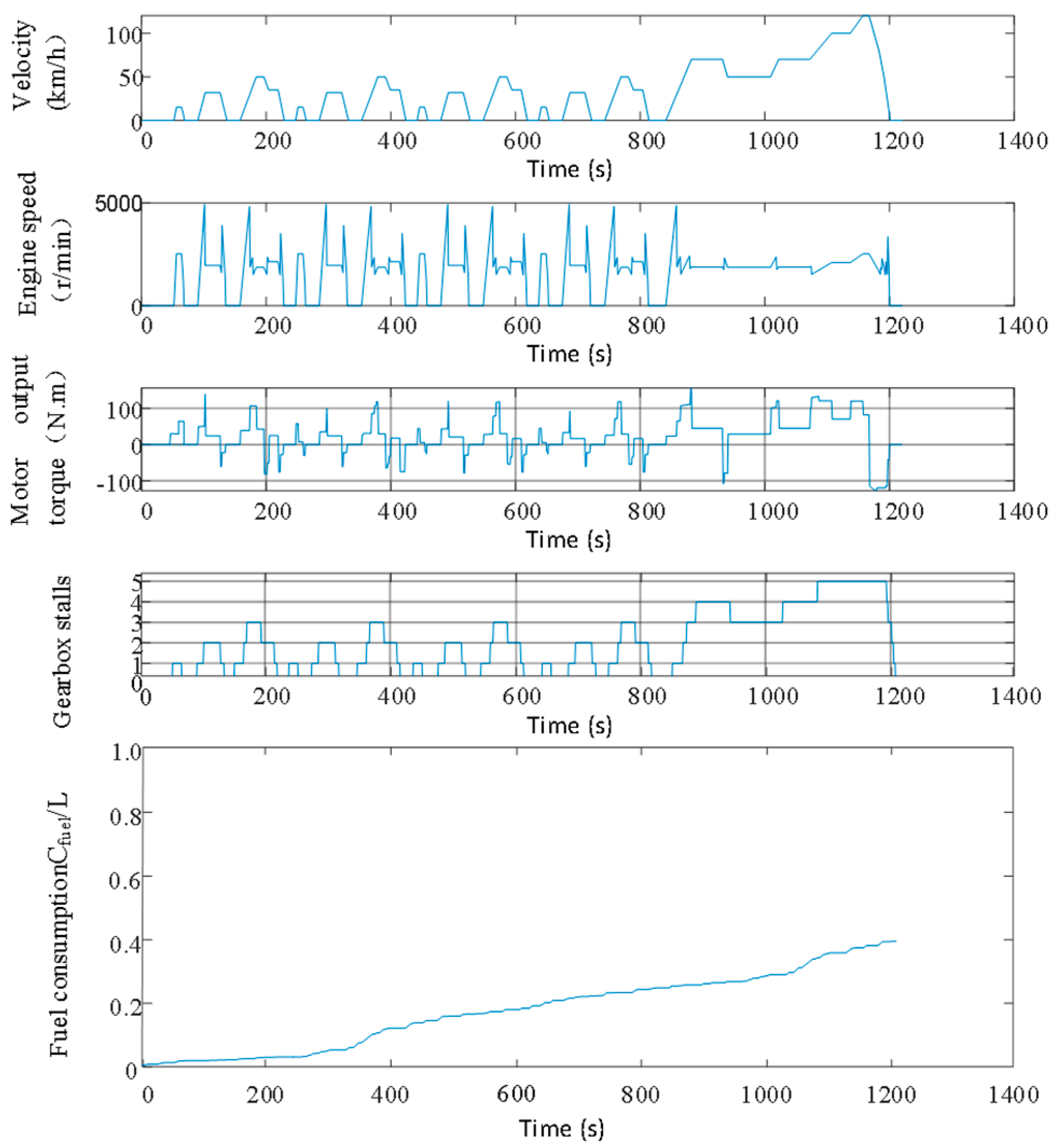
5.1. Subsection Validity Verification
5.2. Adaptability Verification
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, P.; Li, Y.; Wang, Y.; Jiao, X. An intelligent logic rule-based energy management strategy for power-split plug-in hybrid electric vehicle. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7668–7672. [Google Scholar]
- Pam, A.; Bouscayrol, A.; Fiani, P.; Noth, F. Rule-based energy management strategy for a parallel hybrid electric vehicle deduced from dynamic programming. In Proceedings of the 2017 IEEE Vehicle Power and Propulsion Conference (VPPC), Belfort, France, 14–17 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Mansour, C.J. Trip-based optimization methodology for a rule-based energy management strategy using a global optimization routine. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2015, 230, 1529–1545. [Google Scholar] [CrossRef]
- Mansour, C.; Salloum, N.; Francis, S.; Baroud, W. Adaptive energy management strategy for a hybrid vehicle using energetic macroscopic representation. In Proceedings of the 2016 IEEE Vehicle Power and Propulsion Conference (VPPC), Hangzhou, China, 17–20 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–7. [Google Scholar]
- Gao, M.; Du, J. Design method of energy management strategy for range-extended electric buses based on convex optimization. In Proceedings of the 2016 11th International Forum on Strategic Technology (IFOST), Novosibirsk, Russia, 1–3 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 286–290. [Google Scholar]
- Zhao, K.; Bei, J.; Liu, Y.; Liang, Z. Development of global optimization algorithm for series-parallel PHEV energy management strategy based on radar pseudospectral knotting method. Energies 2019, 12, 3268. [Google Scholar] [CrossRef]
- Wu, J.; Cui, N.-X.; Zhang, C.-H.; Pei, W.-H. PSO algorithm-based optimization of plug-in hybrid electric vehicle energy management strategy. In Proceedings of the 2010 8th World Congress on Intelligent Control and Automation, Jinan, China, 6–9 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 3997–4002. [Google Scholar]
- Mason, K.; Grijalva, S. A review of reinforcement learning for autonomous building energy management. Comput. Electr. Eng. 2019, 78, 300–312. [Google Scholar] [CrossRef]
- Lee, H.; Song, C.; Kim, N.; Cha, S.W. Comparative analysis of energy management strategies for HEV: Dynamic programming and reinforcement learning. IEEE Access 2020, 8, 67112–67123. [Google Scholar] [CrossRef]
- Sun, H.; Fu, Z.; Tao, F.; Zhu, L.; Si, P. Data-driven reinforcement-learning-based hierarchical energy management strategy for fuel cell/battery/ultracapacitor hybrid electric vehicles. J. Power Sources 2020, 455, 227964. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Peng, J.; Zhang, H.; He, H. Deep reinforcement learning of energy management with continuous control strategy and traffic information for a series-parallel plug-in hybrid electric bus. Appl. Energy 2019, 247, 454–466. [Google Scholar] [CrossRef]
- Lee, H.; Cha, S.W. Reinforcement learning based on equivalent consumption minimization strategy for optimal control of hybrid electric vehicles. IEEE Access 2020, 9, 860–871. [Google Scholar] [CrossRef]
- Aljohani, T.M.; Mohammed, O. A Real-Time Energy Consumption Minimization Framework for Electric Vehicles Routing Optimization Based on SARSA Reinforcement Learning. Vehicles 2022, 4, 1176–1194. [Google Scholar] [CrossRef]
- Li, W.; Cui, H.; Nemeth, T.; Jansen, J.; Ünlübayir, C.; Wei, Z.; Feng, X.; Han, X.; Ouyang, M.; Dai, H.; et al. Cloud-based health-conscious energy management of hybrid battery systems in electric vehicles with deep reinforcement learning. Appl. Energy 2021, 293, 116977. [Google Scholar] [CrossRef]
- Li, W.; Cui, H.; Nemeth, T.; Jansen, J.; Ünlübayir, C.; Wei, Z.; Zhang, L.; Wang, Z.; Ruan, J.; Dai, H.; et al. Deep reinforcement learning-based energy management of hybrid battery systems in electric vehicles. J. Energy Storage 2021, 36, 102355. [Google Scholar] [CrossRef]
- Yue, S.; Wang, Y.; Xie, Q.; Zhu, D.; Pedram, M.; Chang, N. Model-free learning-based online management of hybrid electrical energy storage systems in electric vehicles. In Proceedings of the IECON 2014-40th Annual Conference of the IEEE Industrial Electronics Society, Dallas, TX, USA, 29 October–1 November 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Li, W.; Zheng, C.; Xu, D. Research on Energy Management Strategy of Fuel Cell Hybrid Electric Vehicle Based on Deep Reinforcement Learning. J. Integr. Technol. 2021, 10, 47–60. [Google Scholar]
- Tang, X.; Chen, J.; Liu, T.; Li, J.; Hu, X. Research on Intelligent Following Control and Energy Management Strategy of Hybrid Electric Vehicle Based on Deep Reinforcement Learning. Chin. J. Mech. Eng. 2021, 57, 237–246. [Google Scholar]
- Zhao, C. Study on Integrated Optimization Control Strategy of Fuel Consumption and Emission of PHEVs. Master’s Thesis, Chongqing Jiaotong University, Chongqing, China, 2022. [Google Scholar]
- Zhang, S.; Wang, K.; Yang, R.; Huang, W. Research on the Energy management strategy of Deep Reinforcement Learning for hybrid electric Bus. Chin. Intern. Combust. Engine Eng. 2021, 42, 10–16+22. [Google Scholar]
- Xu, L.; Wang, J.; Chen, Q. Kalman filtering state of charge estimation for battery management system/based on a stochastic fuzzy neural network battery model. Energy Convers. Manag. 2012, 53, 33–39. [Google Scholar] [CrossRef]
- Tan, F.; Yan, P.; Guan, X. Deep reinforcement learning: From Q-learning to deep Q-learning. In Neural Information Processing, Proceedings of the 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Proceedings, Part IV 24; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 475–483. [Google Scholar]
- Agostinelli, F.; Hocquet, G.; Singh, S.; Baldi, P. From reinforcement learning to deep reinforcement learning: An overview. In Braverman Readings in Machine Learning. Key Ideas from Inception to Current State, Proceedings of the International Conference Commemorating the 40th Anniversary of Emmanuil Braverman’s Decease, Boston, MA, USA, 28–30 April 2017; Invited Talks; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 298–328. [Google Scholar]
- Lyu, L.; Shen, Y.; Zhang, S. The Advance of reinforcement learning and deep reinforcement learning. In Proceedings of the 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 25–27 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 644–648. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Basic Parameter | Numerical Value |
|---|---|---|
| Vehicle parameters | Quality of preparation/(kg) | 2670 |
| Rolling damping coefficient | 0.0132 | |
| Wind resistance coefficient | 0.55 | |
| Wheelbase (mm) | 3360 | |
| Rolling radius (mm) | 369 | |
| Engine | Rated power/(kW) | 120 |
| Calibrated speed/(r/min) | 4200 | |
| Maximum torque/(N·m) | 320 | |
| Motor | Rated power/(kW) | 25 |
| Peak power/(kW) | 50 | |
| Maximum torque/(N·m) | 120 | |
| Power cell | Rated capacity/(Ah) | 15 |
| Rated voltage/(V) | 330 | |
| Main reducer | Transmission ratio | 4.33 |
| Parameter Name | Value (m) |
|---|---|
| Minimum sample set n | 64 |
| Discount factor | 0.9 |
| Renewal coefficient | 0.001 |
| Sample number of experience pool | 118,000 |
| The actor estimates the network learning rate | 0.001 |
| Delayed updated | 3 |
| Estimate the network learning rate of Critic | 0.001 |
| Control Strategy | Equivalent Fuel Consumption (L/100 km) | Final SOC |
|---|---|---|
| Consider the TD3 of the condition prediction | 6.411 | 0.33 |
| TD3 | 6.622 | 0.32 |
| Rule-based control | 6.941 | 0.31 |
| Control Strategy | Equivalent Fuel Consumption (L/100 km) | Final SOC |
|---|---|---|
| Consider the TD3 of the condition prediction | 6.327 | 0.35 |
| TD3 | 6.512 | 0.34 |
| Rule-based control | 6.884 | 0.34 |
| Control Strategy | Equivalent Fuel Consumption (L/100 km) | Final SOC |
|---|---|---|
| Consider the TD3 of the condition prediction | 6.388 | 0.32 |
| TD3 | 6.575 | 0.32 |
| Rule-based control | 6.924 | 0.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xi, J.; Ma, J.; Wang, T.; Gao, J. Research on Energy Management Strategy of a Hybrid Commercial Vehicle Based on Deep Reinforcement Learning. World Electr. Veh. J. 2023, 14, 294. https://doi.org/10.3390/wevj14100294
Xi J, Ma J, Wang T, Gao J. Research on Energy Management Strategy of a Hybrid Commercial Vehicle Based on Deep Reinforcement Learning. World Electric Vehicle Journal. 2023; 14(10):294. https://doi.org/10.3390/wevj14100294
Chicago/Turabian StyleXi, Jianguo, Jingwei Ma, Tianyou Wang, and Jianping Gao. 2023. "Research on Energy Management Strategy of a Hybrid Commercial Vehicle Based on Deep Reinforcement Learning" World Electric Vehicle Journal 14, no. 10: 294. https://doi.org/10.3390/wevj14100294
APA StyleXi, J., Ma, J., Wang, T., & Gao, J. (2023). Research on Energy Management Strategy of a Hybrid Commercial Vehicle Based on Deep Reinforcement Learning. World Electric Vehicle Journal, 14(10), 294. https://doi.org/10.3390/wevj14100294