
Research on Pedestrian Multi-Object Tracking Network Based on Multi-Order Semantic Fusion

Abstract
:1. Introduction
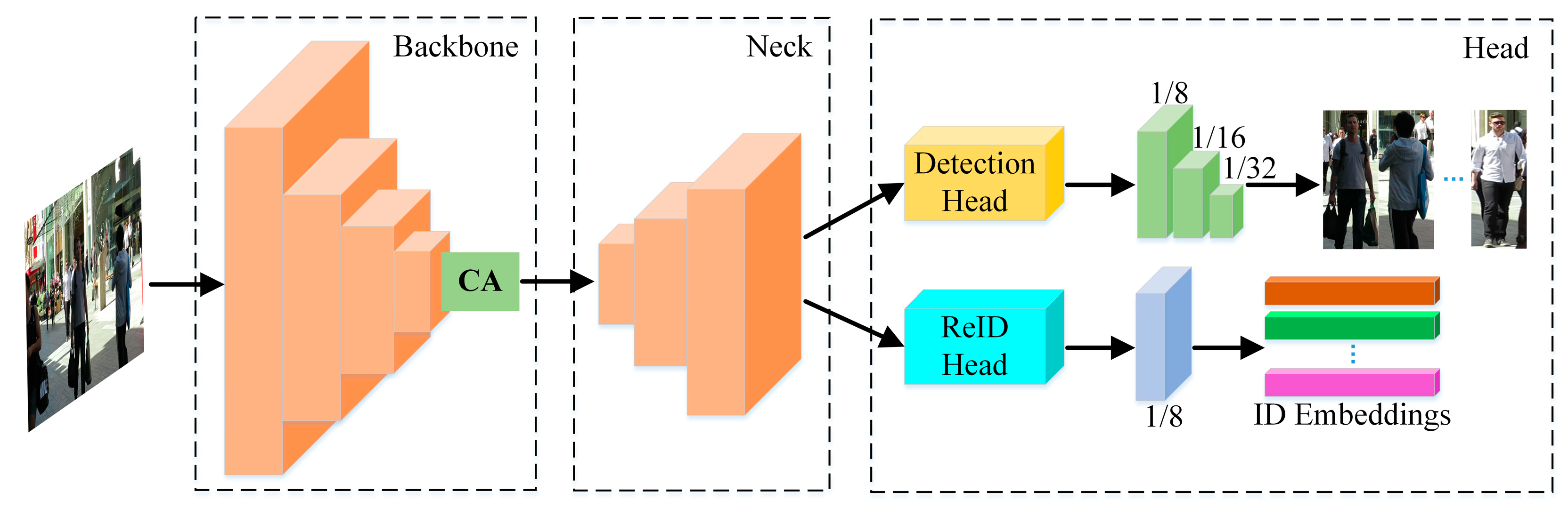
2. Proposed Network
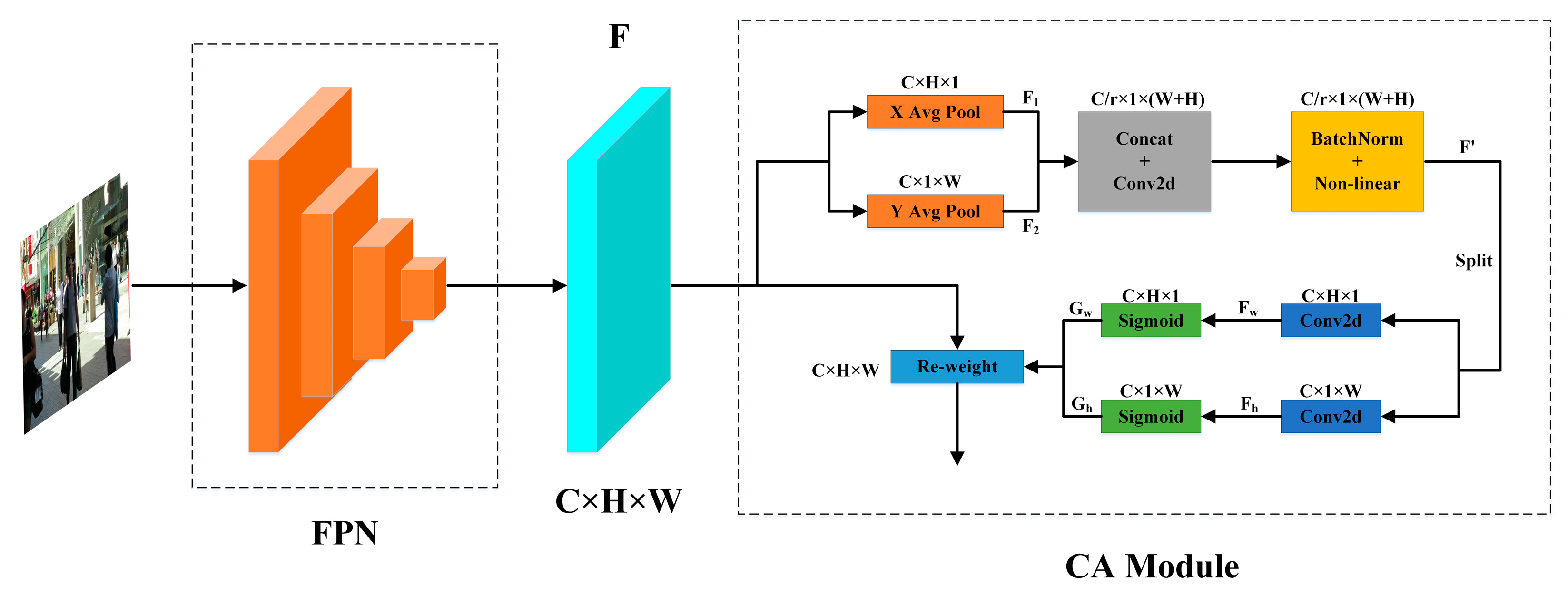
2.1. Improved Backbone Network Part
2.2. Improved ReID Head
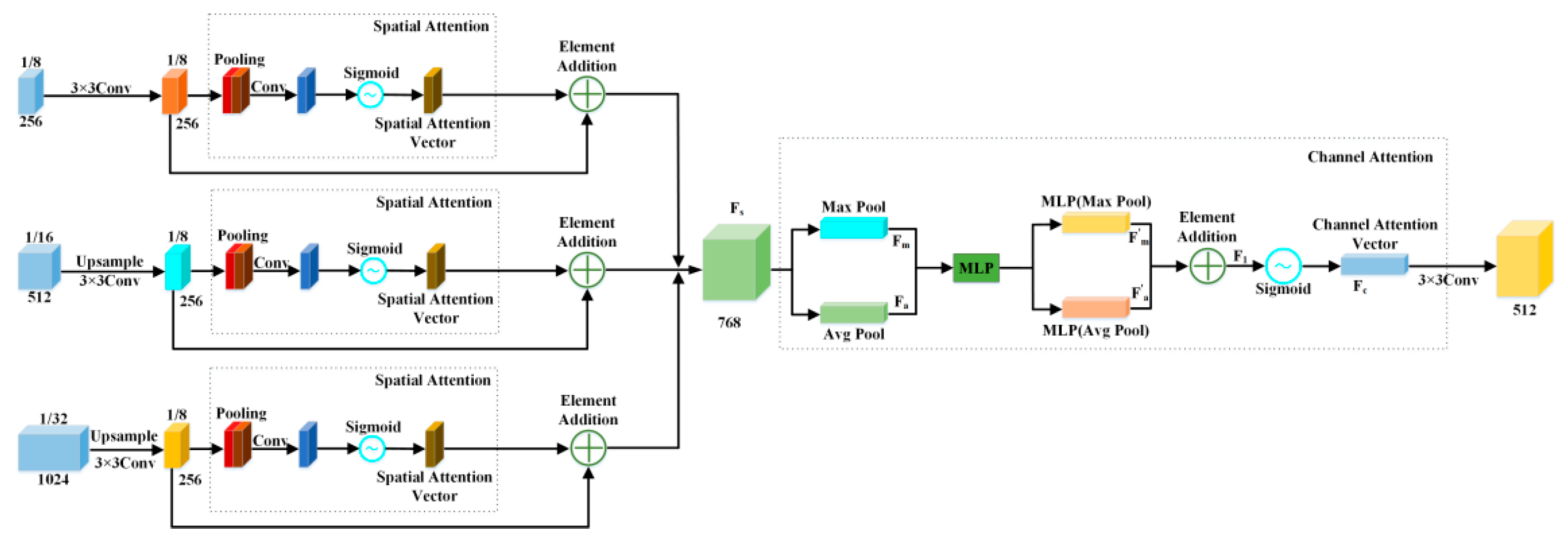
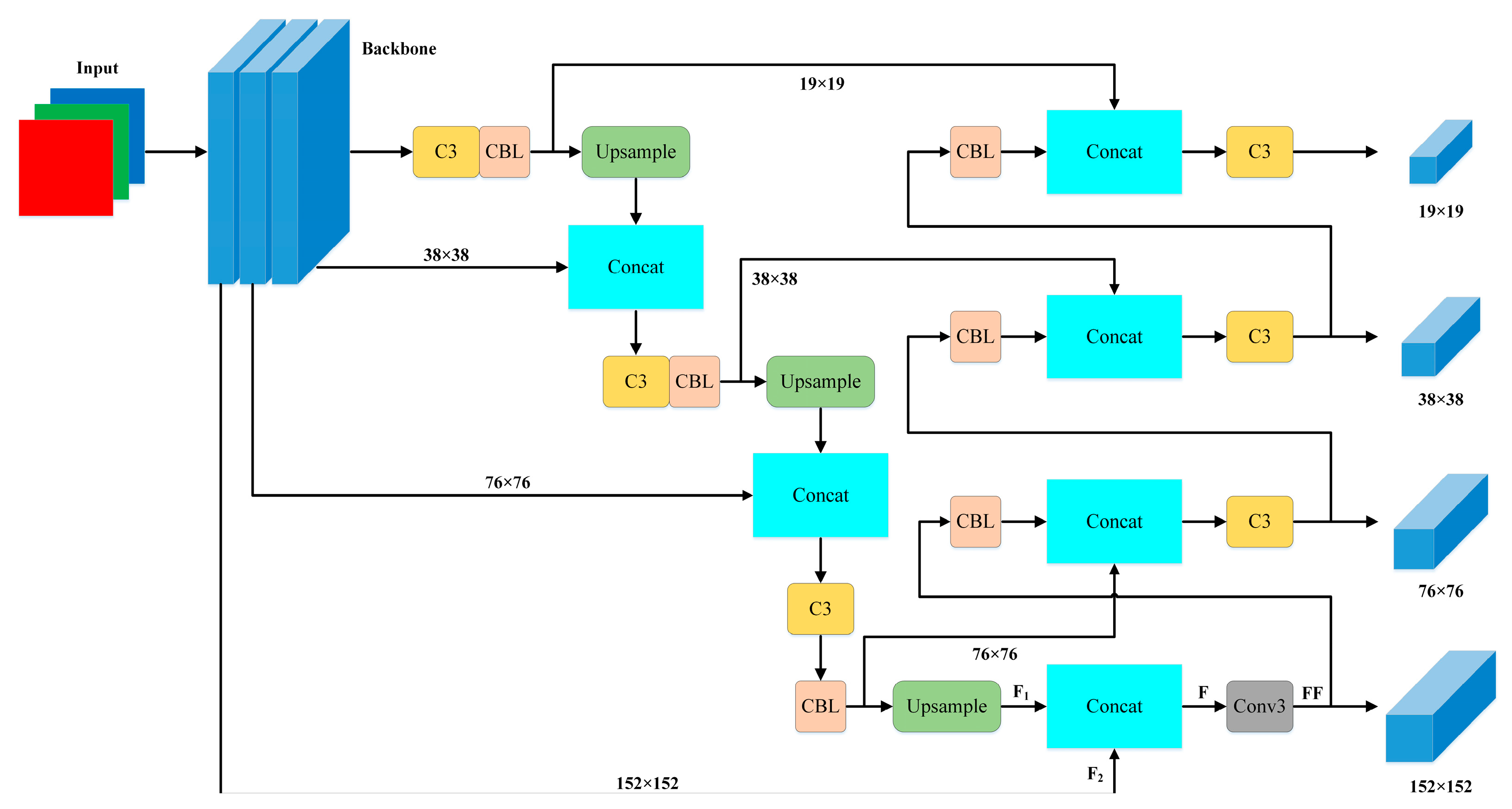
2.3. Improved Detection Head
3. Experimental and Analysis
3.1. Experimental Environment
3.2. Datasets and Evaluation Metrics
3.3. Experimental Results and Analysis
3.3.1. Ablation Experiment
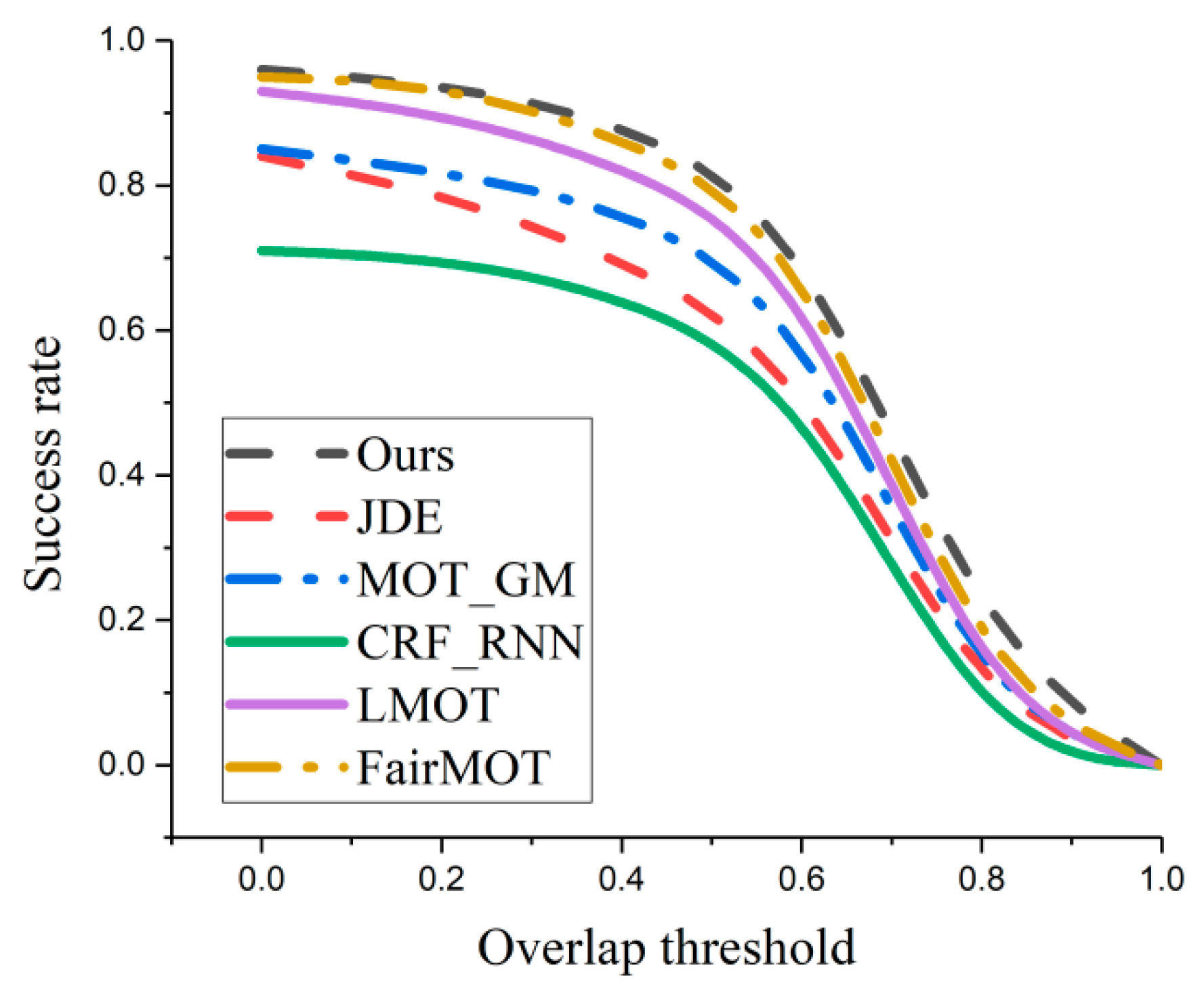
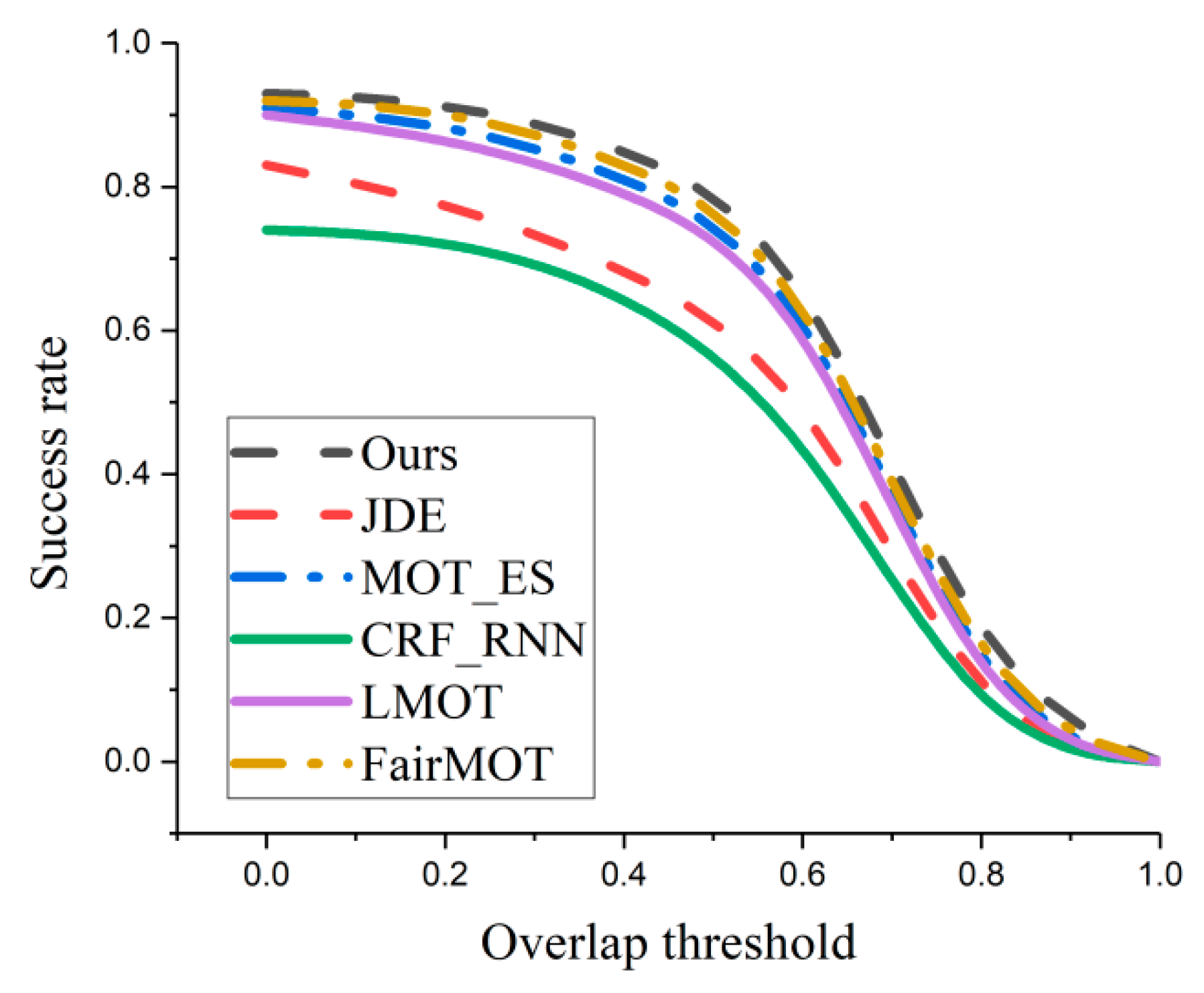
3.3.2. Performance Comparison Experiment with Existing Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luo, W.; Xing, J.; Milan, A. Multiple object tracking: A literature review. J. IEEE Trans. Artif. Intell. 2021, 293, 58–80. [Google Scholar] [CrossRef]
- Mohanapriya, D.; Mahesh, K. Multi object tracking using gradient-based learning model in video-surveillance. J. China Commun. 2021, 18, 169–180. [Google Scholar] [CrossRef]
- Candamo, J.; Shreve, M.; Kasturi, R. Understanding transit scenes: A survey on human behavior recognition algorithms. J. IEEE Trans. Artif. Intell. 2020, 11, 206–224. [Google Scholar] [CrossRef]
- Ikbal, M.S.; Ramadoss, V. Dynamic Pose Tracking Performance Evaluation of HTC Vive Virtual Reality System. J. IEEE Access 2021, 9, 3798–3815. [Google Scholar] [CrossRef]
- Ravindran, R.; Santora, M.J.; Jamali, M.M. Multi-Object Detection and Tracking, Based on DNN, for Autonomous Vehicles: A Review. J. IEEE Sens. J. 2021, 21, 5668–5677. [Google Scholar] [CrossRef]
- Mostafa, R.; Baraka, H.; Bayoumi, A. LMOT: Efficient Light-Weight Detection and Tracking in Crowds. J. IEEE Access 2022, 10, 83085–83095. [Google Scholar] [CrossRef]
- Li, G.; Chen, X.; Li, M.J. One-shot multi-object tracking using CNN-based networks with spatial-channel attention mechanism. J. Opt. Laser Technol. 2022, 153, 108267. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Wang, X. FairMOT: On the fairness of detection and re-identification in multiple object tracking. J. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, N.; Zhang, L. Multi-Shot Pedestrian Re-Identification via Sequential Decision Making. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6781–6789. [Google Scholar] [CrossRef]
- Yoon, K.; Gwak, J. OneShotDA: Online Multi-Object Tracker With One-Shot-Learning-Based Data Association. J. IEEE Access 2020, 8, 38060–38072. [Google Scholar] [CrossRef]
- Guo, M.; Xu, T.; Liu, J. Attention mechanisms in computer vision: A survey. J. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Aziz, L.; Sheikh, U.U.; Ayub, S. Exploring Deep Learning-Based Architecture, Strategies, Applications and Current Trends in Generic Object Detection: A Comprehensive Review. J. IEEE Access 2020, 8, 170461–170495. [Google Scholar] [CrossRef]
- Singh, K.; Seth, A.; Sandhu, H.S. A Comprehensive Review of Convolutional Neural Network based Image Enhancement Techniques. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Ondrasovic, M.; Tarabek, P. Siamese Visual Object Tracking: A Survey. J. IEEE Access 2021, 9, 110149–110172. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Lin, T.; Dollar, P.; Girshick, R. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Xiao, T.; Wang, B. Joint detection and identification feature learning for person search. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3376–3385. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar] [CrossRef]
- Zheng, L.; Zhang, H.; Sun, S. Person Re-Identification in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3346–3355. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixe, L.; Reid, I. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar] [CrossRef]
- Yoo, Y.S.; Lee, S.H.; Bae, S.H. Effective Multi-Object Tracking via Global Object Models and Object Constraint Learning. J. Sens. 2022, 22, 7943. [Google Scholar] [CrossRef] [PubMed]
- Xiang, J.; Xu, G.; Ma, C.; Hou, J. End-to-End Learning Deep CRF Models for Multi-Object Tracking Deep CRF Models. J. IEEE Trans. Circuits Syst. Video Technol. 2016, 31, 275–288. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, L.; Liu, Y. Towards Real-Time Multi-Object Tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 107–122. [Google Scholar] [CrossRef]
- Xiang, X.; Ren, W.; Qiu, Y. Multi-object Tracking Method Based on Efficient Channel Attention and Switchable Atrous Convolution. J. Neural Process. Lett. 2021, 53, 2747–2763. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MOTA | IDF1 | IDs | MT | ML |
|---|---|---|---|---|---|
| Raw | 64.7 | 56.3 | 1855 | 34.8 | 21.2 |
| CA | 68.5 | 61.9 | 1229 | 38.3 | 19.6 |
| Scale | 71.2 | 67.6 | 1064 | 41.9 | 17.4 |
| Ours | 75.4 | 72.2 | 986 | 45.4 | 15.1 |
| Method | MOTA | IDF1 | IDs | MT | ML |
|---|---|---|---|---|---|
| Raw | 62.8 | 54.5 | 5226 | 33.1 | 23.9 |
| CA | 67.1 | 60.2 | 4643 | 37.6 | 20.1 |
| Scale | 70.3 | 65.7 | 3976 | 40.4 | 18.5 |
| Ours | 74.3 | 70.3 | 3575 | 44.1 | 16.6 |
| Method | MOTA | MOTP | IDF1 | IDs | MT | ML | FPS |
|---|---|---|---|---|---|---|---|
| JDE | 64.4 | - | 55.8 | 1544 | 35.4 | 20.0 | 18.8 |
| FairMOT | 74.9 | - | 72.8 | 1074 | 44.7 | 15.9 | 25.9 |
| MOT_GM | 64.5 | 76.7 | 70.9 | 816 | 36.4 | 20.7 | 6.5 |
| CRF_RNN | 50.3 | 74.8 | 54.4 | 702 | 18.3 | 35.7 | 1.5 |
| LMOT | 73.2 | - | 72.3 | 669 | 44.0 | 17.0 | 29.6 |
| Ours | 75.4 | 81.6 | 72.2 | 986 | 45.4 | 15.1 | 25.8 |
| Method | MOTA | MOTP | IDF1 | IDs | MT | ML | FPS |
|---|---|---|---|---|---|---|---|
| JDE | 63.0 | - | 59.5 | 6171 | 35.7 | 17.3 | 18.8 |
| FairMOT | 73.7 | 81.3 | 72.3 | 3303 | 43.2 | 17.3 | 25.9 |
| MOT_ES | 73.3 | - | 71.8 | 3372 | 41.1 | 17.2 | 19.0 |
| CRF_RNN | 53.1 | 76.1 | 53.7 | 2518 | 24.2 | 30.7 | 1.4 |
| LMOT | 72.0 | - | 70.3 | 3071 | 45.4 | 17.3 | 29.6 |
| Ours | 74.3 | 81.7 | 70.3 | 3575 | 44.1 | 16.6 | 25.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Han, C. Research on Pedestrian Multi-Object Tracking Network Based on Multi-Order Semantic Fusion. World Electr. Veh. J. 2023, 14, 272. https://doi.org/10.3390/wevj14100272
Liu C, Han C. Research on Pedestrian Multi-Object Tracking Network Based on Multi-Order Semantic Fusion. World Electric Vehicle Journal. 2023; 14(10):272. https://doi.org/10.3390/wevj14100272
Chicago/Turabian StyleLiu, Cong, and Chao Han. 2023. "Research on Pedestrian Multi-Object Tracking Network Based on Multi-Order Semantic Fusion" World Electric Vehicle Journal 14, no. 10: 272. https://doi.org/10.3390/wevj14100272
APA StyleLiu, C., & Han, C. (2023). Research on Pedestrian Multi-Object Tracking Network Based on Multi-Order Semantic Fusion. World Electric Vehicle Journal, 14(10), 272. https://doi.org/10.3390/wevj14100272