Network Intrusion Detection through Discriminative Feature Selection by Using Sparse Logistic Regression

Abstract
:1. Introduction
- (1)
- We employ a unique framework, the sparse logistic regression (SPLR) for an intrusion detection system (IDS). The SPLR has not been applied by any other researcher in the domain of IDS, as per our knowledge.
- (2)
- The SPLR reduces the cost function for IDS classification with a sparsity constraint.
- (3)
- Regularization through SPLR, feature selection has been mapped into penalty term of sparsity optimization in order to select more effective and interpretable features for IDS classification.
- (4)
- The SPLR has shown different characteristics that are exceptionally suitable for IDS such as high classification accuracy (detection rate [DR]) and training time to build a model and average training time per sample etc.
2. Related Work
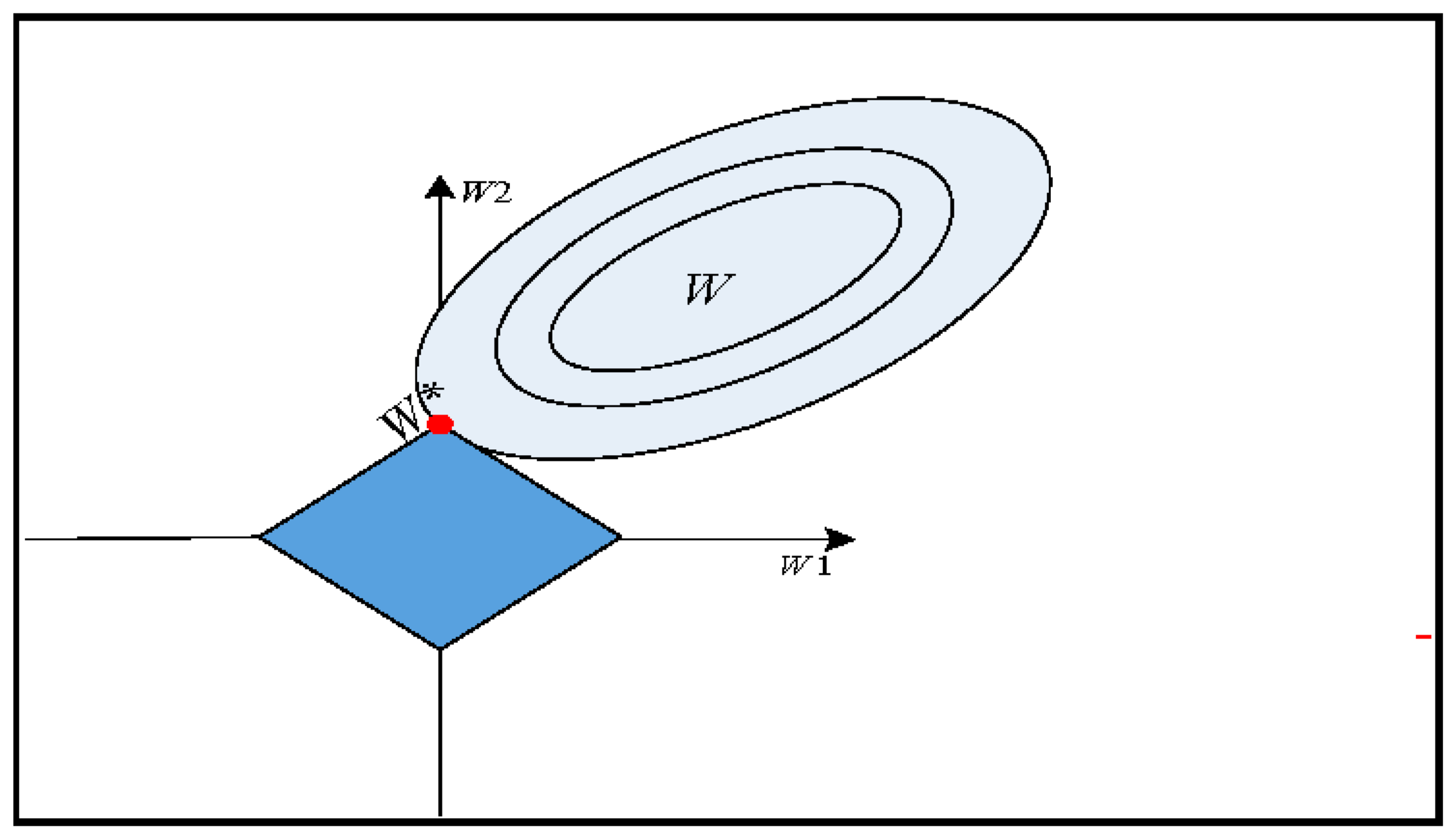
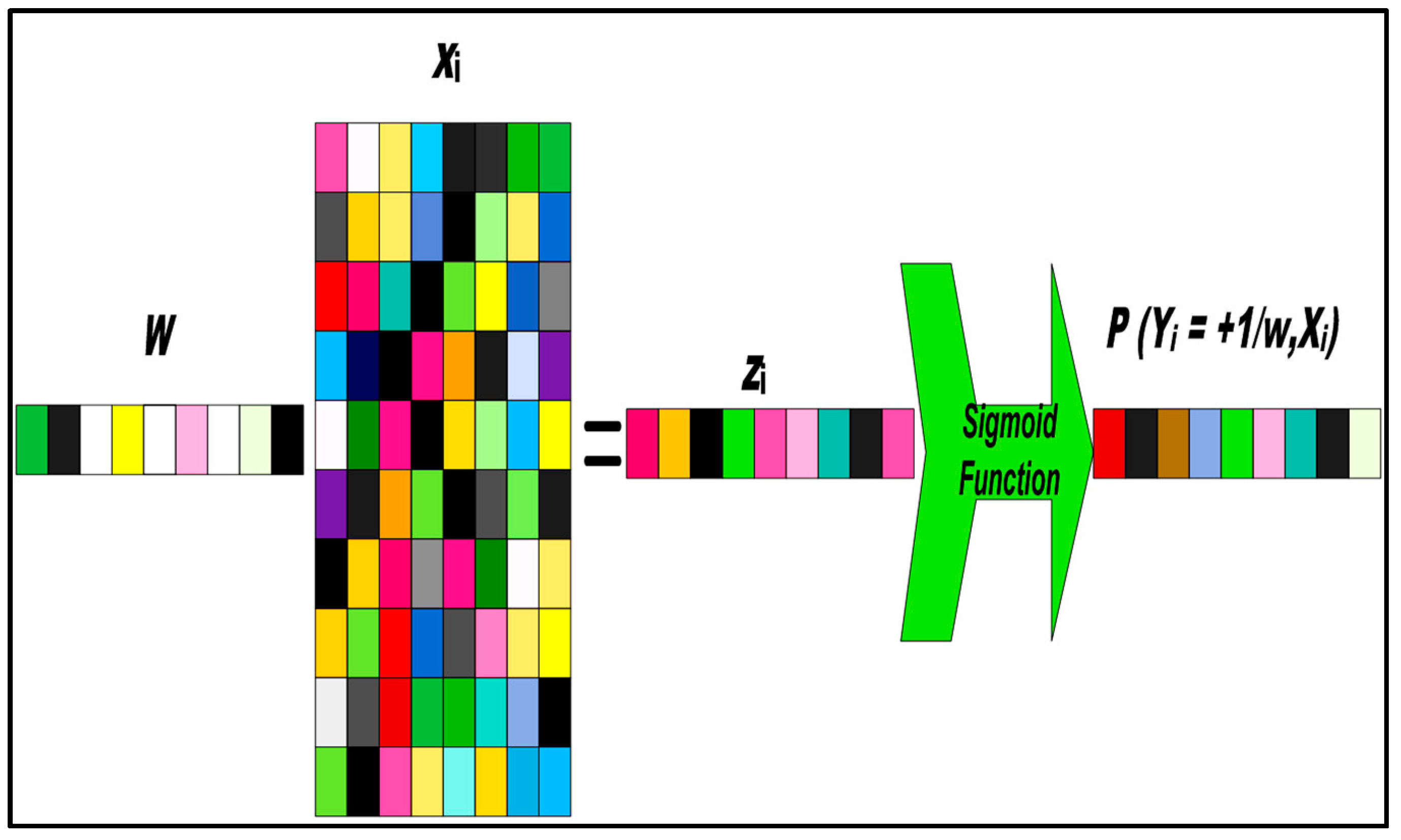
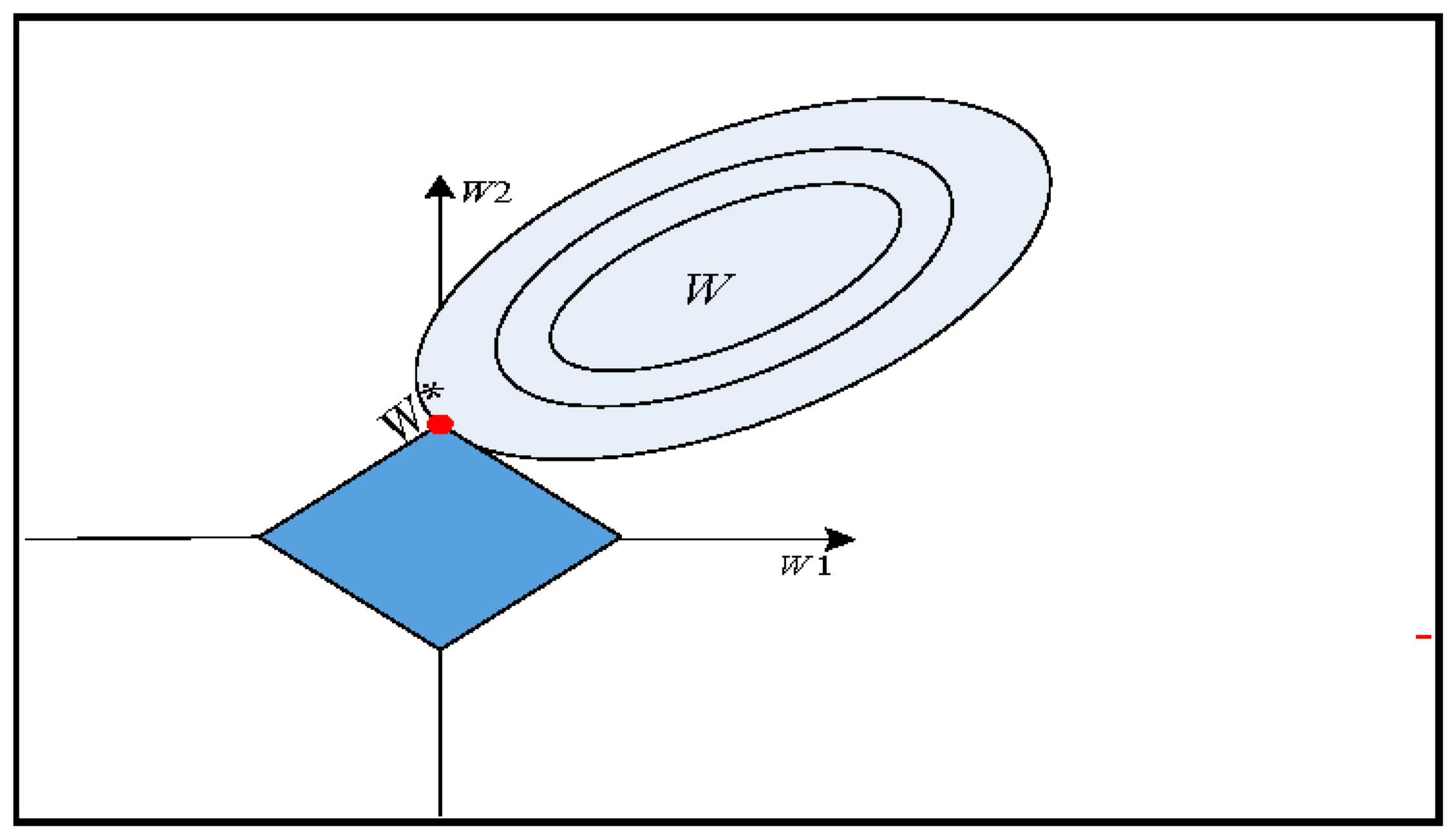
3. Sparse Logistic Regression (SPLR)
Optimization of Algorithm Subsection
| Algorithm 1. Pseudo code for SPLR (Lasso) Algorithm. |
| Input: Sparse function (.) and sparse regularization function with regularization parameter λ. Initialize: Step size and affine combination parameter Output: Optimum Result
|
4. Experimental Results and Discussion
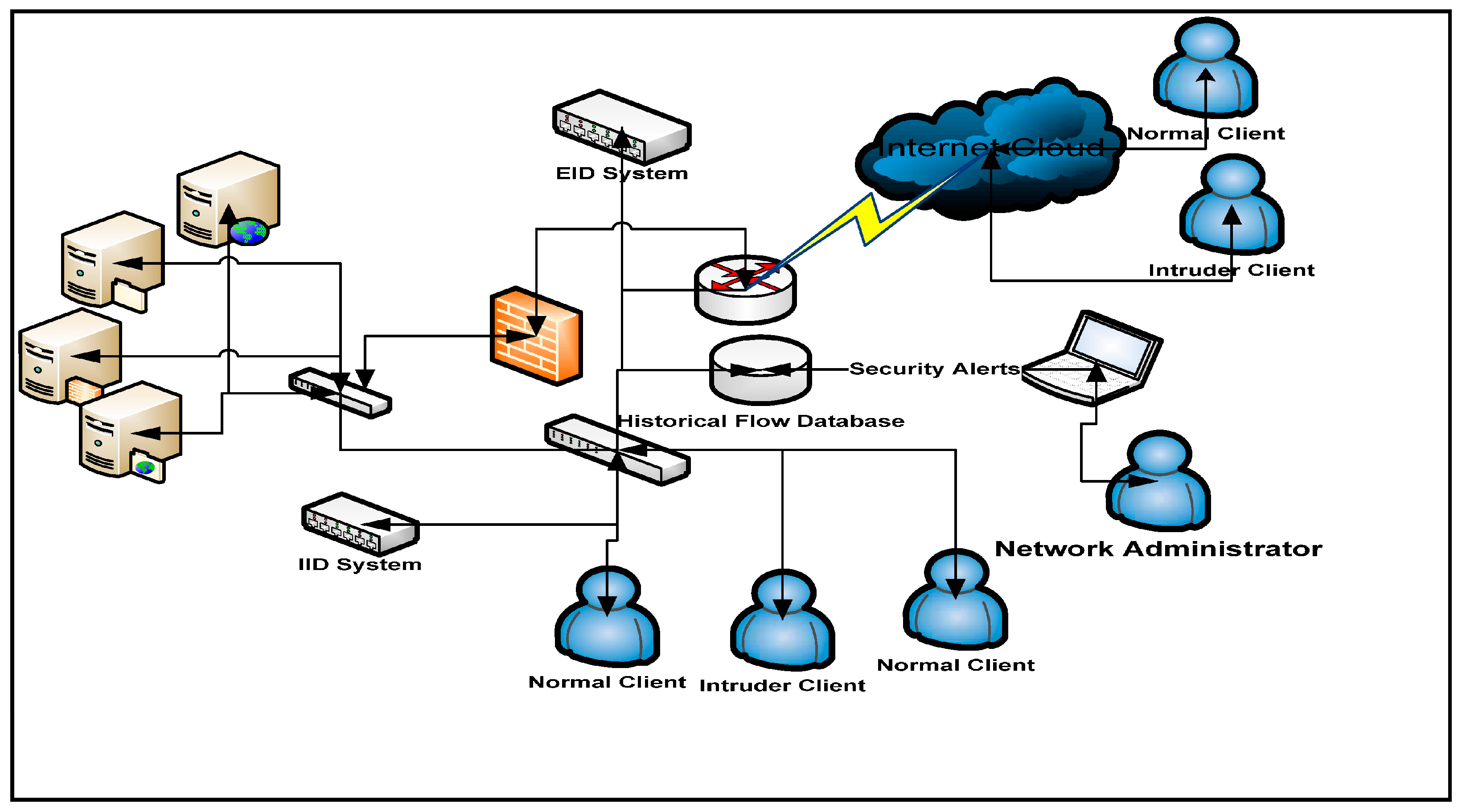
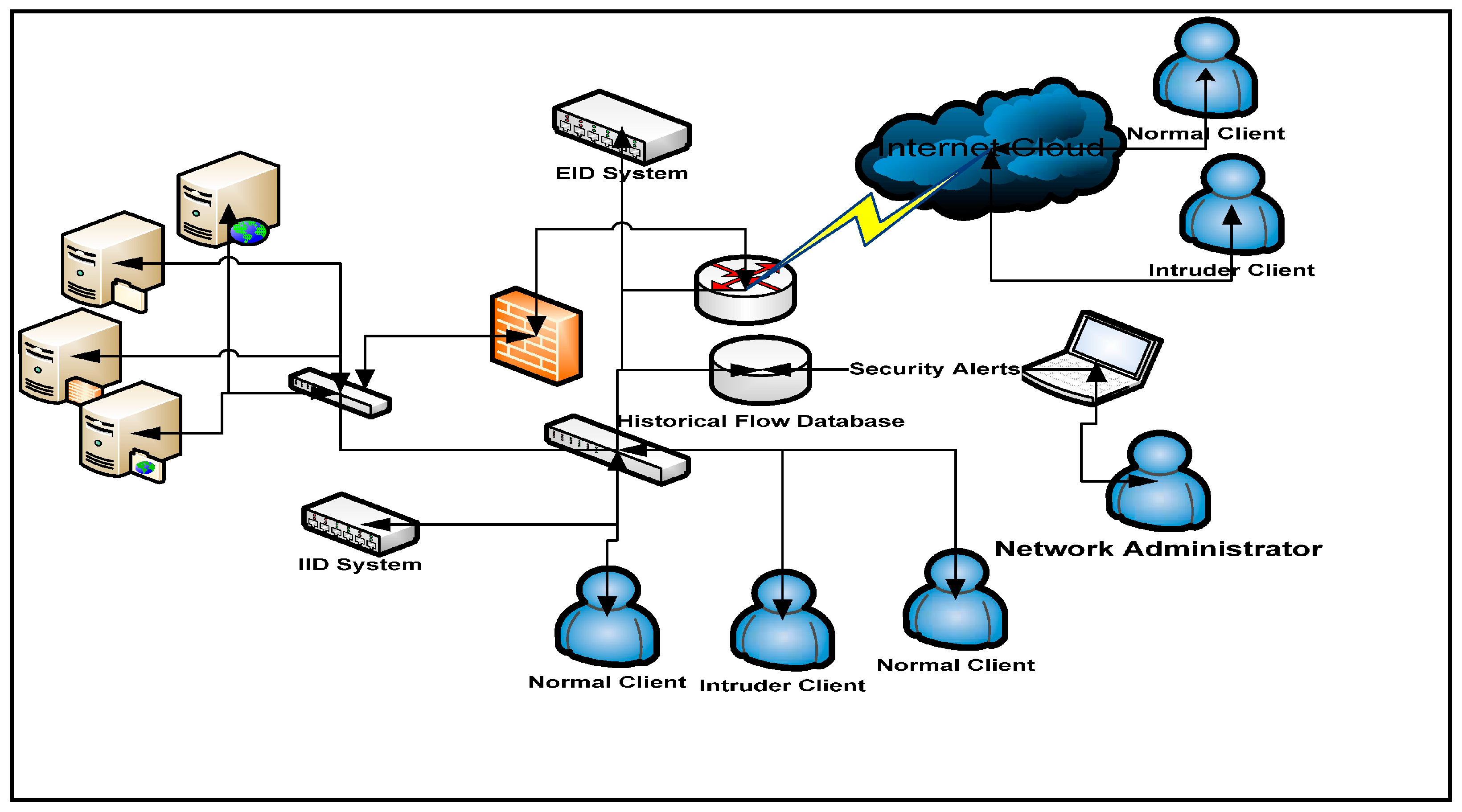
4.1. KDD Cup 1999 Dataset
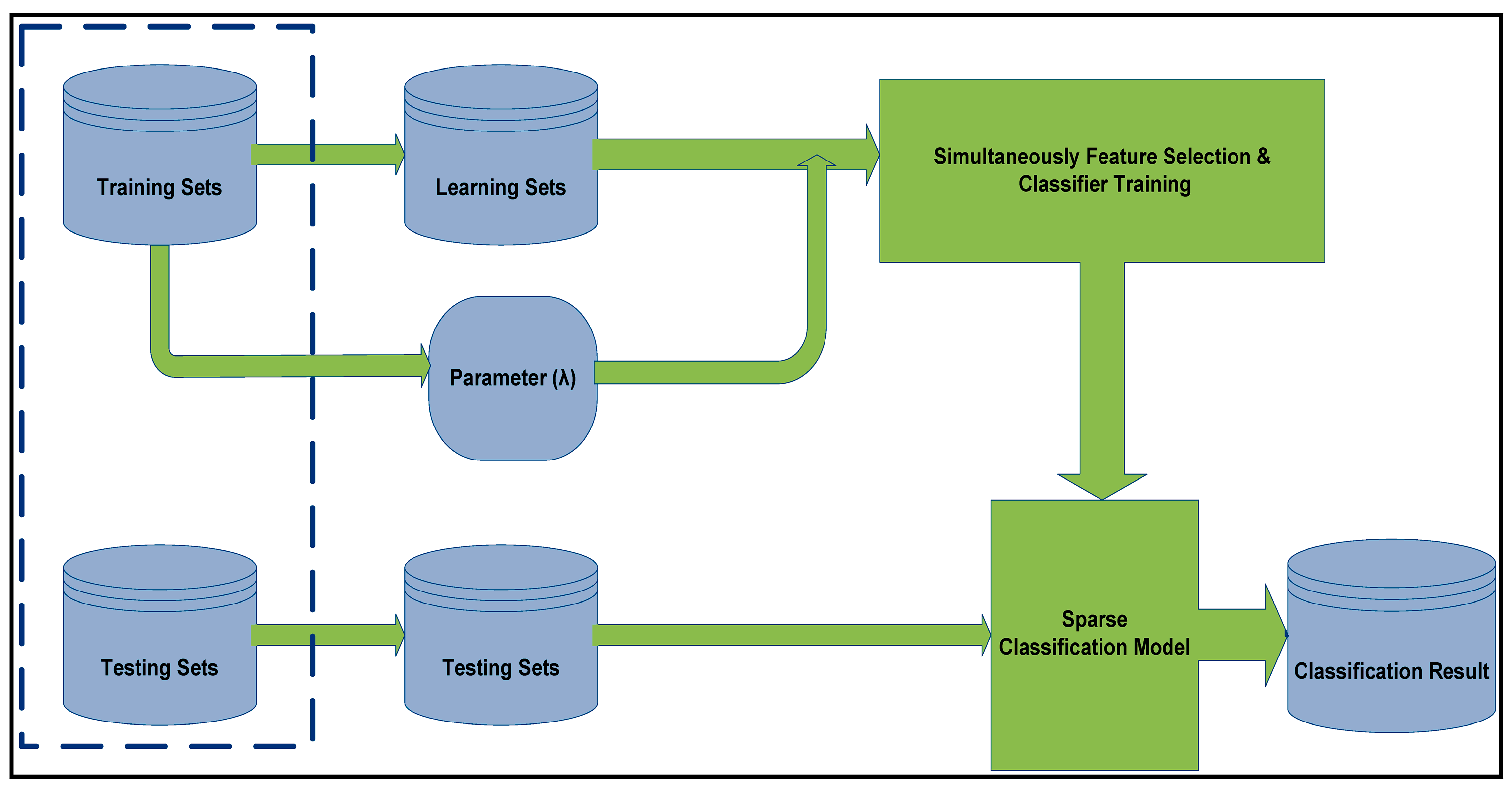
4.2. Experiment Design
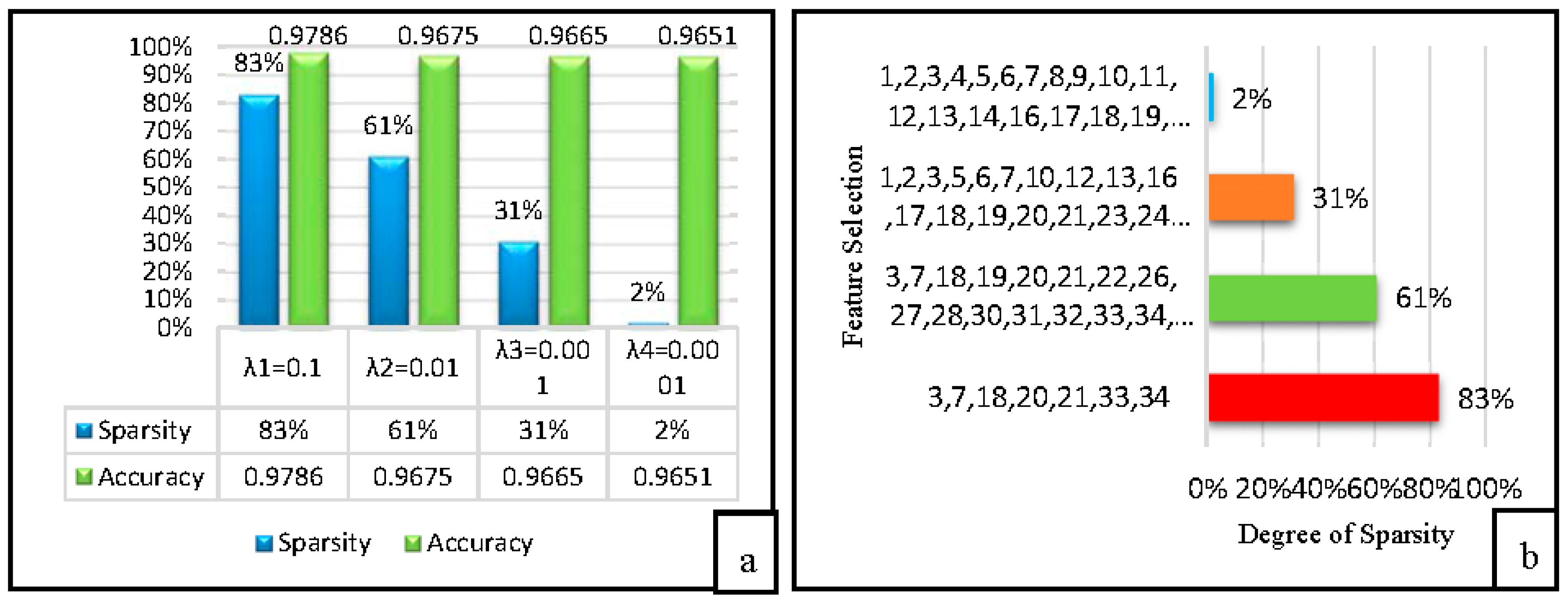
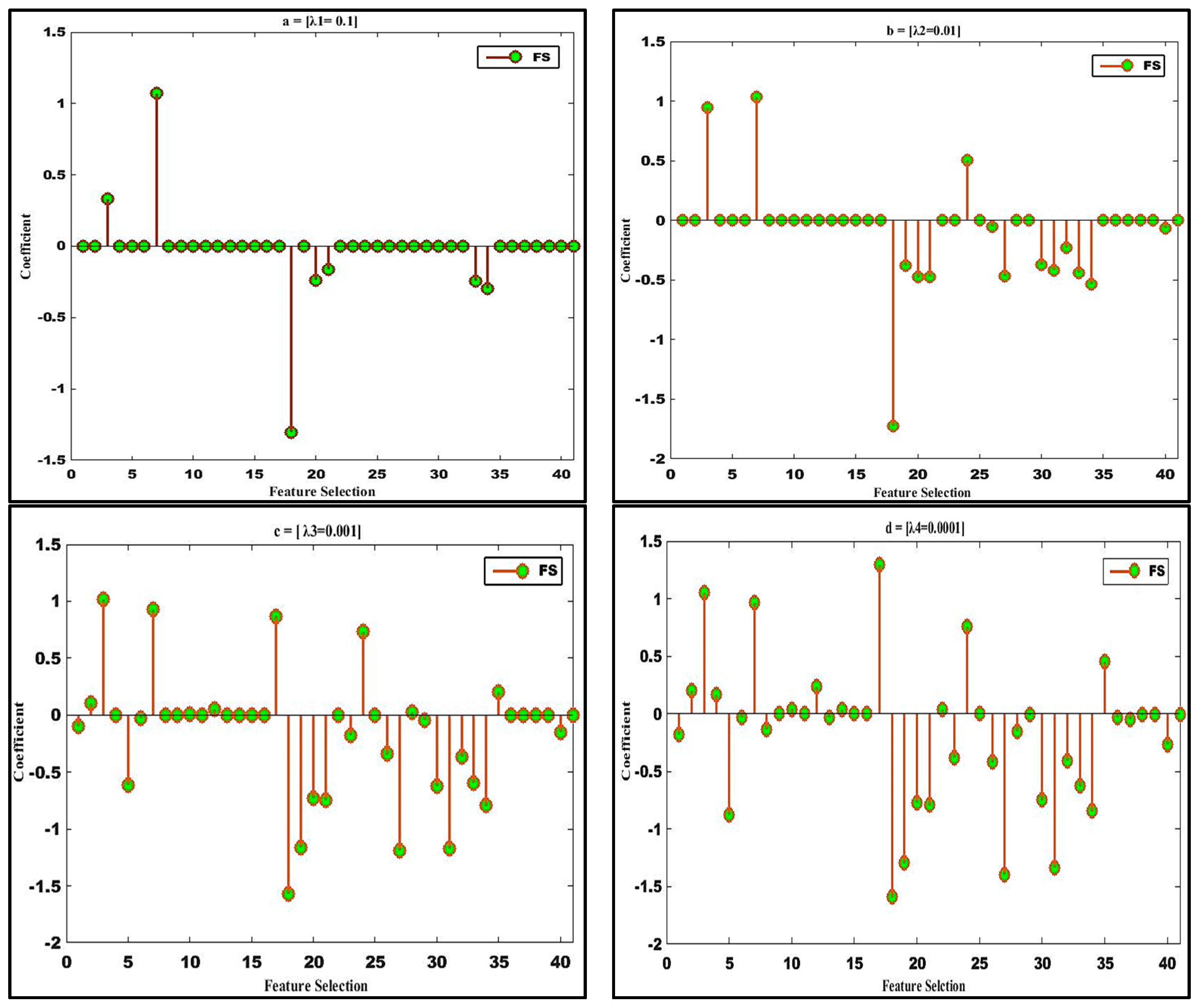
4.3. Experimental Results
4.4. Classification Detection Rate
5. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Kevric, J.; Jukic, S.; Subasi, A. An effective combining classifier approach using tree algorithms for network intrusion detection. Neural Comput. Appl. 2016, 1–8. [Google Scholar] [CrossRef]
- Louvieris, P.; Clewley, N.; Liu, X. Effects-based feature identification for network intrusion detection. Neurocomputing 2013, 121, 265–273. [Google Scholar] [CrossRef]
- European Cybercrime Centre (EC3). 2017. Available online: https://www.europol.europa.eu/activities-services/main-reports/internet-organised-crime-threat-assessment-iocta-2017 (accessed on 10 October 2017).
- Singh, R.; Kumar, H.; Singla, R. An intrusion detection system using network traffic profiling and online sequential extreme learning machine. Expert Syst. Appl. 2015, 42, 8609–8624. [Google Scholar] [CrossRef]
- Natesan, P.; Rajesh, P. Cascaded classifier approach based on Adaboost to increase detection rate of rare network attack categories. In Proceedings of the IEEE International Conference on Recent Trends In Information Technology (ICRTIT), Chennai, India, 19–21 April 2012. [Google Scholar]
- Mohammadi, M.; Raahemi, B.; Akbari, A.; Nassersharif, B. Class dependent feature transformation for intrusion detection systems. In Proceedings of the 19th IEEE Iranian Conference on Electrical Engineering, Tehran, Iran, 17–19 May 2011. [Google Scholar]
- Snort Intrusion Detection System. 2006. Available online: http://www.snort.org (accessed on 10 October 2017).
- Li, Y.; Wang, J.-L.; Tian, Z.-H.; Lu, T.-B.; Chen, Y. Building lightweight intrusion detection system using wrapper-based feature selection mechanisms. Comput. Secur. 2009, 28, 466–475. [Google Scholar] [CrossRef]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.S.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Dubouilh, P.; Iorkyase, E.; Tachtatzis, C.; Atkinson, R. Threat analysis of iot networks using artificial neural network intrusion detection system. In Proceedings of the IEEE International Symposium on Networks, Computers and Communications (ISNCC), Yasmine Hammamet, Tunisia, 11–13 May 2016. [Google Scholar]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Tachtatzis, C.; Atkinson, R. Shallow and Deep Networks Intrusion Detection System: A Taxonomy and Survey; Cornell University Library: Ithaca, NY, USA, 2017; arXiv preprint. [Google Scholar]
- Brifcani, A.; Issa, A. Intrusion detection and attack classifier based on three techniques: A comparative study. Eng. Technol. J. 2011, 29, 368–412. [Google Scholar]
- Roopadevi, E.; Bhuvaneswari, B.; Sahaana, B. Intrusion Detection using Support Vector Machine with Feature Reduction Techniques. Indian J. Sci. 2016, 23, 148–156. [Google Scholar]
- Zhang, J.; Zulkernine, M. A hybrid network intrusion detection technique using random forests. In Proceedings of the IEEE First International Conference on Availability Reliability and Security (ARES'06), Vienna, Austria, 20–22 April 2006. [Google Scholar]
- Farid, D.M.; Zhang, L.; Hossain, M.A.; Strachan, R. Hybrid decision tree and naïve Bayes classifiers for multi-class classification tasks. Expert Syst. Appl. 2014, 41, 1937–1946. [Google Scholar] [CrossRef]
- Koc, L.; Mazzuchi, T.A.; Sarkani, S. A network intrusion detection system based on a Hidden Naïve Bayes multiclass classifier. Expert Syst. Appl. 2012, 39, 13492–13500. [Google Scholar] [CrossRef]
- Farid, D.M.; Harbi, N.; Rahman, M.Z. Combining Naive Bayes and Decision Tree for Adaptive Intrusion Detection; Cornell University Library: Ithaca, NY, USA, 2010; arXiv preprint. [Google Scholar]
- Fahad, A.; Zahir, T.; Ibrahim, K.; Ibrahim, H.; Hussein, A. Toward an efficient and scalable feature selection approach for internet traffic classification. Comput. Netw. 2013, 57, 2040–2057. [Google Scholar] [CrossRef]
- Al-mamory, S.O.; Jassim, F.S. On the designing of two grains levels network intrusion detection system. Karbala Int. J. Mod. Sci. 2015, 1, 15–25. [Google Scholar] [CrossRef]
- Yang, J.; Olafsson, S. Optimization-based feature selection with adaptive instance sampling. Comput. Oper. Res. 2006, 33, 3088–3106. [Google Scholar] [CrossRef]
- Sánchez-Maroño, N.; Alonso-Betanzos, A.; Calvo-Estévez, R.M. A wrapper method for feature selection in multiple classes datasets. In International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Sani, R.A.; Ghasemi, A. Learning a new distance metric to improve an svm-clustering based intrusion detection system. In Proceedings of the IEEE International Symposium on Artificial Intelligence and Signal Processing (AISP), Mashhad, Iran, 3–5 March 2015. [Google Scholar]
- Sarikaya, R.; Hinton, G.E.; Deoras, A. Application of deep belief networks for natural language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 778–784. [Google Scholar] [CrossRef]
- Qian, Y.; Ye, M.; Zhou, J. Hyperspectral image classification based on structured sparse logistic regression and three-dimensional wavelet texture features. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2276–2291. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar]
- Li, J.; Qian, Y. Regularized multinomial regression method for hyperspectral data classification via pathwise coordinate optimization. In Proceedings of the IEEE Digital Image Computing: Techniques and Applications, DICTA’09, Melbourne, Australia, 1–3 December 2009. [Google Scholar]
- Li, J.; Qian, Y. Dimension reduction of hyperspectral images with sparse linear discriminant analysis. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Vancouver, BC, Canada, 24–29 July 2011. [Google Scholar]
- Liu, J.; Chen, J.; Ye, J. Large-scale sparse logistic regression. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the Second IEEE Symposium on Computational Intelligence for Security and Defence Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 53–58. [Google Scholar]
- Goel, R.; Sardana, A.; Joshi, R.C. Parallel Misuse and Anomaly Detection Model. Int. J. Netw. Secur. 2012, 14, 211–222. [Google Scholar]
- Shanmugavadivu, R.; Nagarajan, N. Network intrusion detection system using fuzzy logic. Indian J. Comput. Sci. Eng. 2011, 2, 101–111. [Google Scholar]
- Khan, L.; Awad, M.; Thuraisingham, B. A new intrusion detection system using support vector machines and hierarchical clustering. VLDB J. Int. J. Very Large Data Bases 2007, 16, 507–521. [Google Scholar] [CrossRef]
- Faraoun, K.M.; Boukelif, A. Securing network traffic using genetically evolved transformations. Malays. J. Comput. Sci. 2006, 19, 9. [Google Scholar]
- Mukkamala, S.; Sung, A.H.; Abraham, A. Intrusion detection systems using adaptive regression spines. In Enterprise Information Systems VI; Springer: Dordrecht, The Netherlands, 2006; pp. 211–218. [Google Scholar]
- Staniford, S.; Hoagland, J.A.; McAlerney, J.M. Practical automated detection of stealthy portscans. J. Comput. Secur. 2002, 10, 105–136. [Google Scholar] [CrossRef]
- Yu, W.-Y.; Lee, H.-M. An incremental-learning method for supervised anomaly detection by cascading service classifier and ITI decision tree methods. In Pacific-Asia Workshop on Intelligence and Security Informatics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Mazid, M.M.; Ali, A.S.; Tickle, K.S. A comparison between rule based and association rule mining algorithms. In Proceedings of the IEEE Third International Conference on Network and System Security, NSS’09, Gold Coast, Australia, 19–21 October 2009. [Google Scholar]
- Singh, S.P. Data Clustering Using K-Mean Algorithm for Network Intrusion Detection; Lovely Professional University: Jalandhar, India, 2010. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
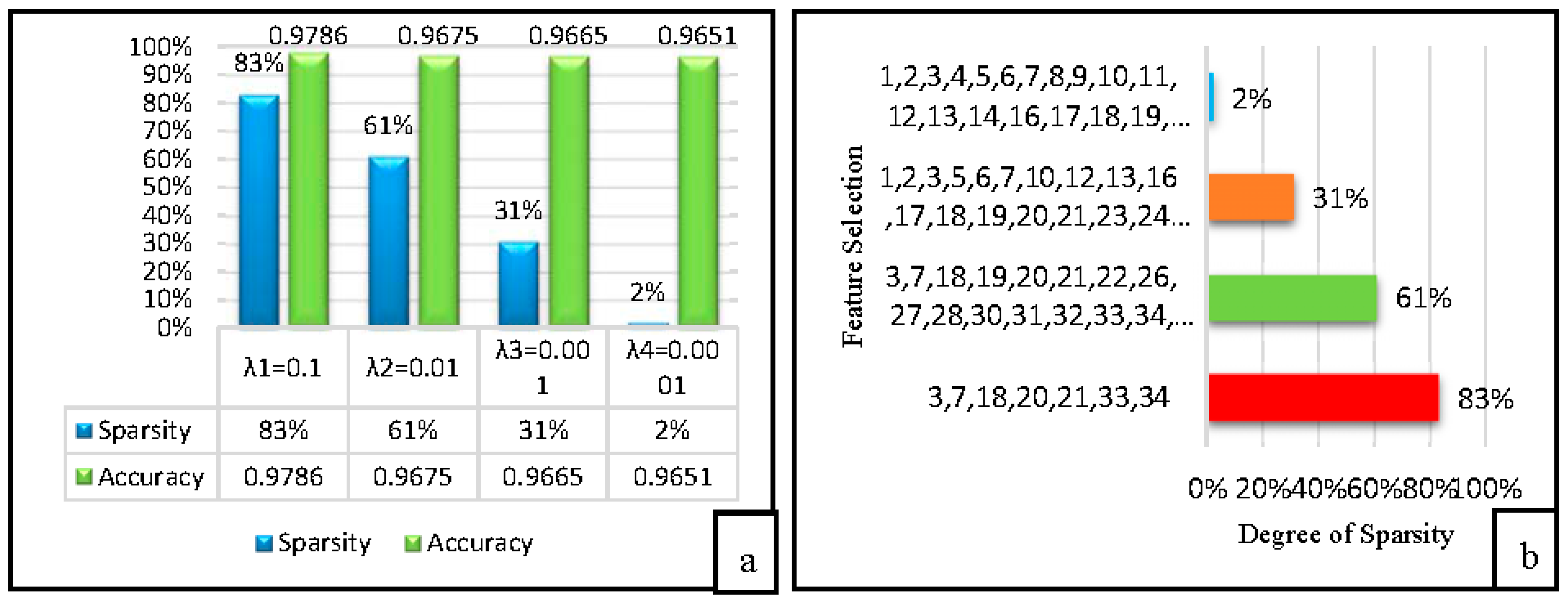{kind=link}
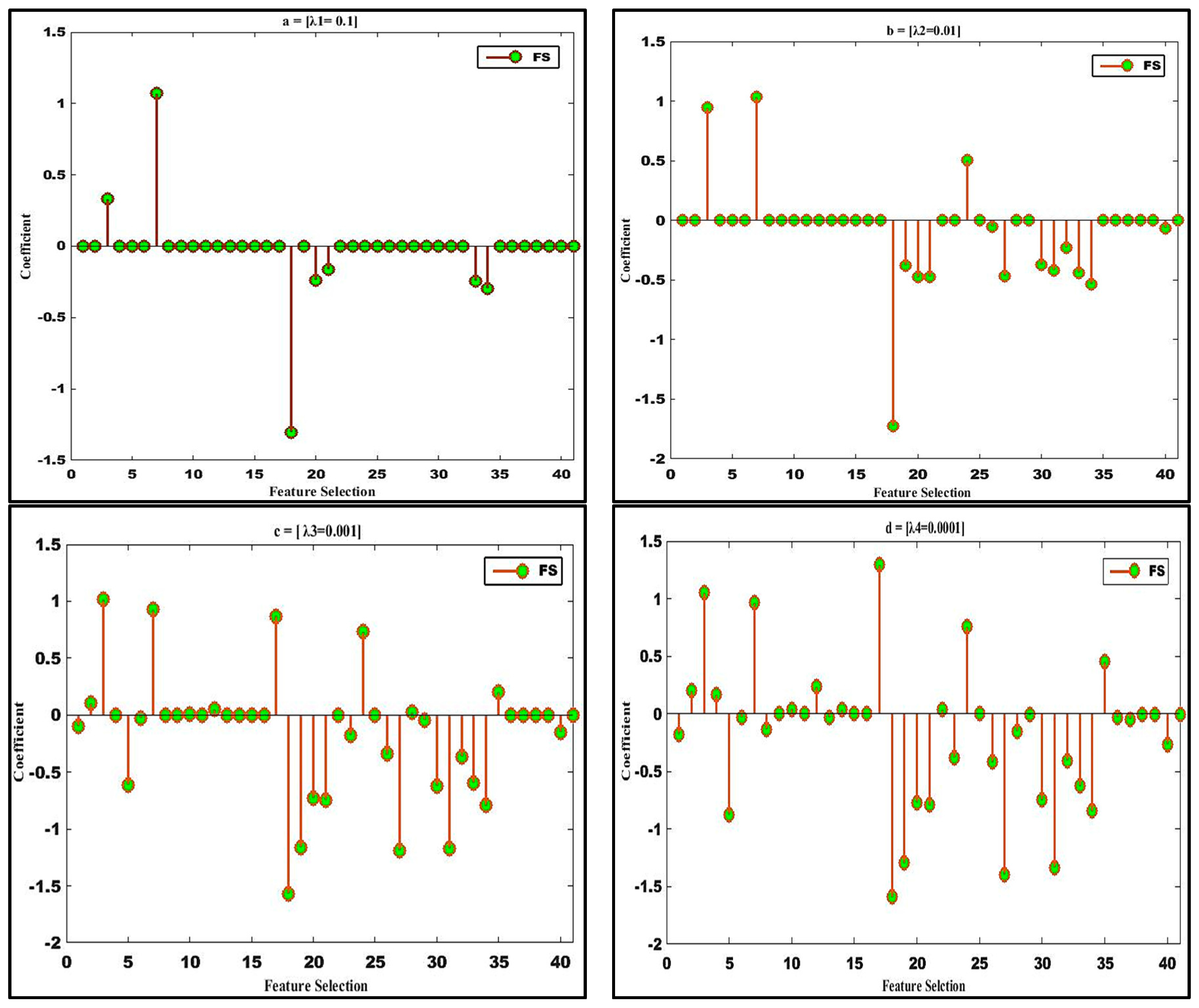{kind=link}
| Class | Training Samples | Testing Sample |
|---|---|---|
| Normal | 972,780 | 60,592 |
| Denial of Service (DoS) | 3,883,370 | 237,594 |
| Probe | 41,102 | 2377 |
| Remote-to-Local (R2L) | 16,347 | 8606 |
| User-to Root-(U2R) | 52 | 70 |
| Total Samples | 4,898,430 | 311,028 |
| S.No | Attributes | S.No | Attributes |
|---|---|---|---|
| 1 | Duration | 22 | is_guest_login |
| 2 | protocol_type | 23 | count |
| 3 | Service | 24 | srv_count |
| 4 | Flag | 25 | serror_rate |
| 5 | src_byte | 26 | srv_serror_rate |
| 6 | dst_bytes | 27 | rerror_rate |
| 7 | land | 28 | srv_error_rate |
| 8 | wrong_fragmnet | 29 | same_srv_rate |
| 9 | urgent | 30 | diff_srv_rate |
| 10 | Hot | 31 | srv_diff_host_rate |
| 11 | num_failed_logins | 32 | dst_host_count |
| 12 | logged_in | 33 | dst_host_srv_count |
| 13 | num_compromised | 34 | dst_host_srv_rate |
| 14 | root_shell | 35 | dst_host_diff_srv_rate |
| 15 | su_attempted | 36 | dst_host_same_src_port_rate |
| 16 | num_root | 37 | dst_host_srv_diff_host_rate |
| 17 | num_file_creations | 38 | dst_host_serror_rate |
| 18 | num_shells | 39 | dst_host_svr_serror_rate |
| 19 | num_access_files | 40 | dst_host_rerror_rate |
| 20 | num_outbound_cmds | 41 | dst_host_srv_rerror_rate |
| 21 | is_hot_login |
| Attack Classes | Training Dataset Attacks (22) |
|---|---|
| Denial of Service (DOS) | Back, Land, neptune, pod, smurf, teardrop |
| Remote to Local (R2L) | ftp_write, guess_passwd, imap, multihop, phf, spy, warezclient, warezmaster |
| User To Root (U2R) | buffer_overflow, perl, loadmodule, rootkit |
| Probing | ipsweep, nmap, portsweep, satan |
| Class | Training Samples | % of Occurrence |
|---|---|---|
| Normal | 812,814 | 75.6 |
| Denial of Service | 947,267 | 22.9 |
| Probe | 13,853 | 1.29 |
| R2L | 997 | 0.089 |
| U2R | 54 | 0.0047 |
| Total Samples | 1,774,985 | 100 |
| Algorithms | Size of Training Dataset | Size of Testing Dataset | DR (%) | Train Time (s) | Average Training Time per Sample (s) |
|---|---|---|---|---|---|
| VFDT [19] | 1,074,985 | 67,688 | 93.83 | 39.88 | 0.000003 |
| SPLR | 1,074,985 | 67,688 | 97.65 | 11.6 | 0.000001 |
| Bayes Net [29] | 49,596 | 15,437 | 90.62 | 6.28 | 0.00001 |
| J48 [29] | 49,596 | 15,437 | 92.06 | 15.85 | 0.00003 |
| LBK [29] | 49,596 | 15,437 | 92.22 | 10.63 | 0.00002 |
| C4.5 [30] | 49,596 | 15,437 | 92.06 | 15.85 | 0.0003 |
| Fuzzy Logic [31] | 49,596 | 15,437 | 91.65 | 192.16 | 0.0038 |
| SPLR | 49,596 | 15,437 | 98.26 | 7.5 | 0.000001 |
| Algorithm | Size of Training Datasets | Size of Testing Datasets | DR (%) | Train Time (s) | Average Training Time per Sample (s) |
|---|---|---|---|---|---|
| SVM [32] | 1,132,365 | 73,247 | 57.6 | 62,424 | 18.14 |
| GP [33] | 24,780 | 311,028 | 96.7 | 6480 | 0.2615 |
| ANN [12] | 4947 | 3117 | 92.27 | 780 | 0.1576 |
| MARS [34] | 11,982 | 11,982 | 96.46 | 30.66 | 0.0025 |
| Naïve Bayes [35] | 65,525 | 65,525 | 95 | 1.89 | 0.0013 |
| I T I [36] | 169,000 | 311,029 | 92.38 | 18 | 0.00002 |
| PD Tree [37] | 444,458 | 49,384 | 46.67 | 48.8 | 0.00002 |
| K-Means [38] | 55,000 | 25,000 | 86 | 13 | 0.00002 |
| Apriori [35] | 444,458 | 49,384 | 87.5 | 18.94 | 0.000005 |
| SPLR | 1,074,985 | 67,688 | 97.65 | 11.6 | 0.000001 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, R.A.; Qian, Y.; Kumar, D.; Ali, M.; Alvi, M.B. Network Intrusion Detection through Discriminative Feature Selection by Using Sparse Logistic Regression. Future Internet 2017, 9, 81. https://doi.org/10.3390/fi9040081
Shah RA, Qian Y, Kumar D, Ali M, Alvi MB. Network Intrusion Detection through Discriminative Feature Selection by Using Sparse Logistic Regression. Future Internet. 2017; 9(4):81. https://doi.org/10.3390/fi9040081
Chicago/Turabian StyleShah, Reehan Ali, Yuntao Qian, Dileep Kumar, Munwar Ali, and Muhammad Bux Alvi. 2017. "Network Intrusion Detection through Discriminative Feature Selection by Using Sparse Logistic Regression" Future Internet 9, no. 4: 81. https://doi.org/10.3390/fi9040081
APA StyleShah, R. A., Qian, Y., Kumar, D., Ali, M., & Alvi, M. B. (2017). Network Intrusion Detection through Discriminative Feature Selection by Using Sparse Logistic Regression. Future Internet, 9(4), 81. https://doi.org/10.3390/fi9040081