Exploiting Multimedia in Creating and Analysing Multimedia Web Archives


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Current Trends in Multimedia Analysis
3. The ARCOMEM Approach
3.1. Intelligently Harvesting and Sampling the Web
- Standard crawling. A standard web crawl starts with a seed list of URLs, and crawls outwards from the seed pages by following the outlinks. Constraints might be added to limit the number of hops the crawler is allowed to make from a seed page or to limit the crawler to specific Internet domains or IP addresses.
- API-directed crawling. In an API-directed crawl, the user provides keywords that describe the domain of the dataset they want to create. These keywords are then fed to the search APIs of common social media sources (e.g., Twitter, Facebook, YouTube, etc.), and the returned posts are examined for outlinks that are then used as seeds for a web crawl.
- Intelligent crawling. In an intelligent crawl, the user provides a detailed intelligent crawl specification (ICS) consisting of keywords, topics, events and entities that describe the target domain. A standard crawl and/or API-directed crawl is then started, and as new resources are harvested, they are scored against the ICS (using pattern matching and machine learning techniques). Scores for the outlinks of each resource are then created (combining the resource score with specific scores computed based on the link), and these scores are fed back to the large scale crawler, which prioritises the next URL to crawl based on the score. URLs with low scores will not be crawled.
3.2. Advanced, Scalable Multimodal Multimedia Content Analysis
3.3. Interoperability, Reusability and Provenance
4. Use Cases for Multimedia Analysis in Archiving Community Memories
- Guiding the crawl by identifying relevant documents.
- Reducing the size of the archive by removing irrelevant or duplicated content.
- Generating metadata for facilitating searching strategies within the archive.
- Summarising various aspects of the content of the archive (i.e., finding the events, people and places represented by the content of the archive).
4.1. Aggregating Social Commentary

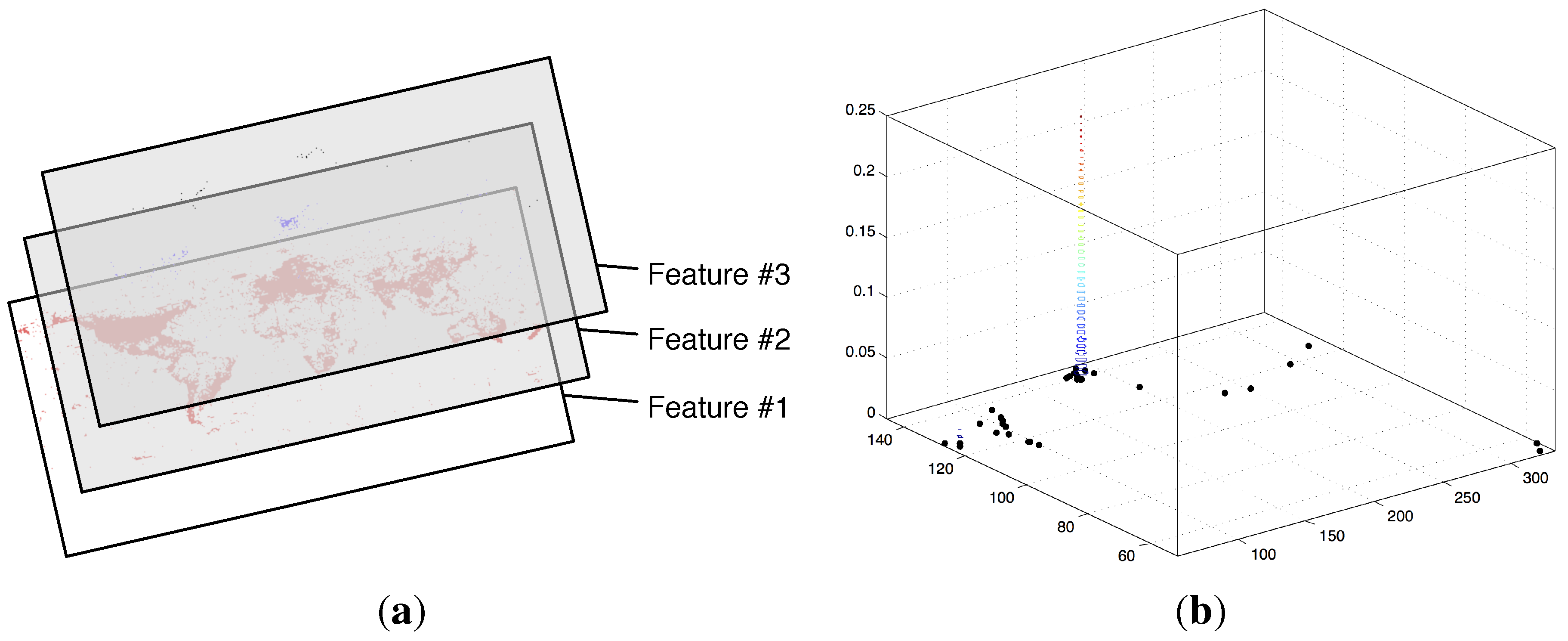
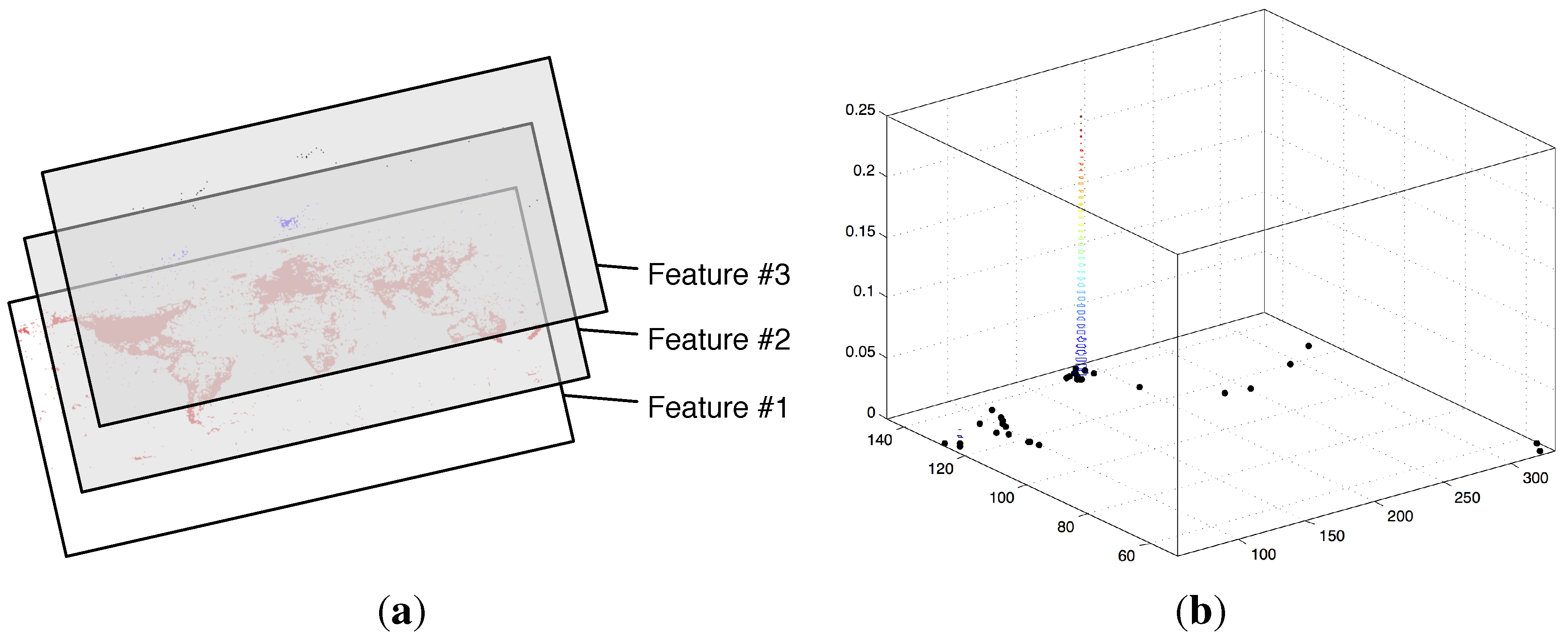
4.2. Measuring the Temporal Pulse of Social Multimedia

4.3. Recognising Social Events in Social Media Streams
4.4. Detecting Media about Individuals, Organisations and Places
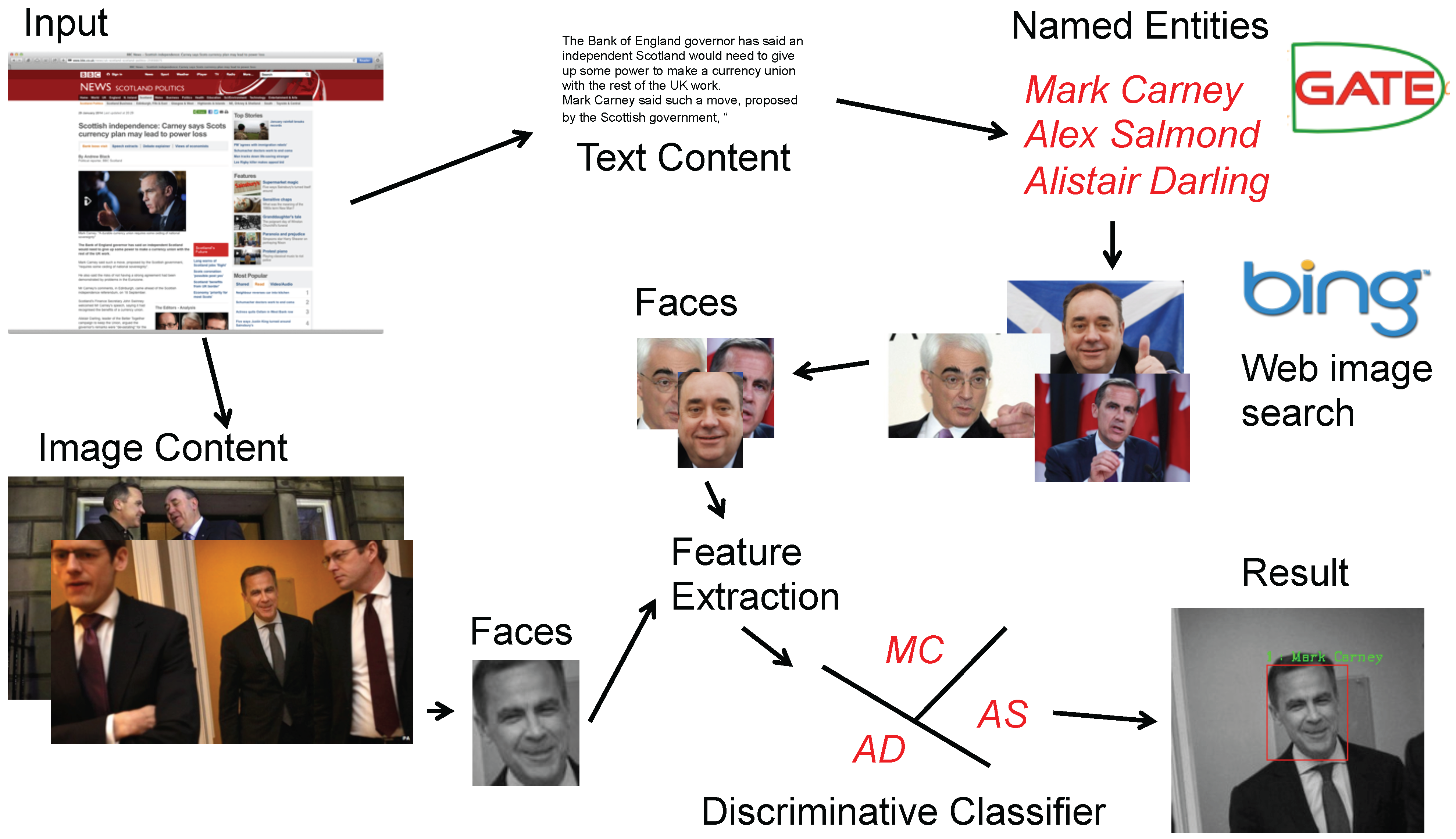
4.4.1. Recognising People

4.4.2. Recognising Organisations
4.4.3. Recognising Places
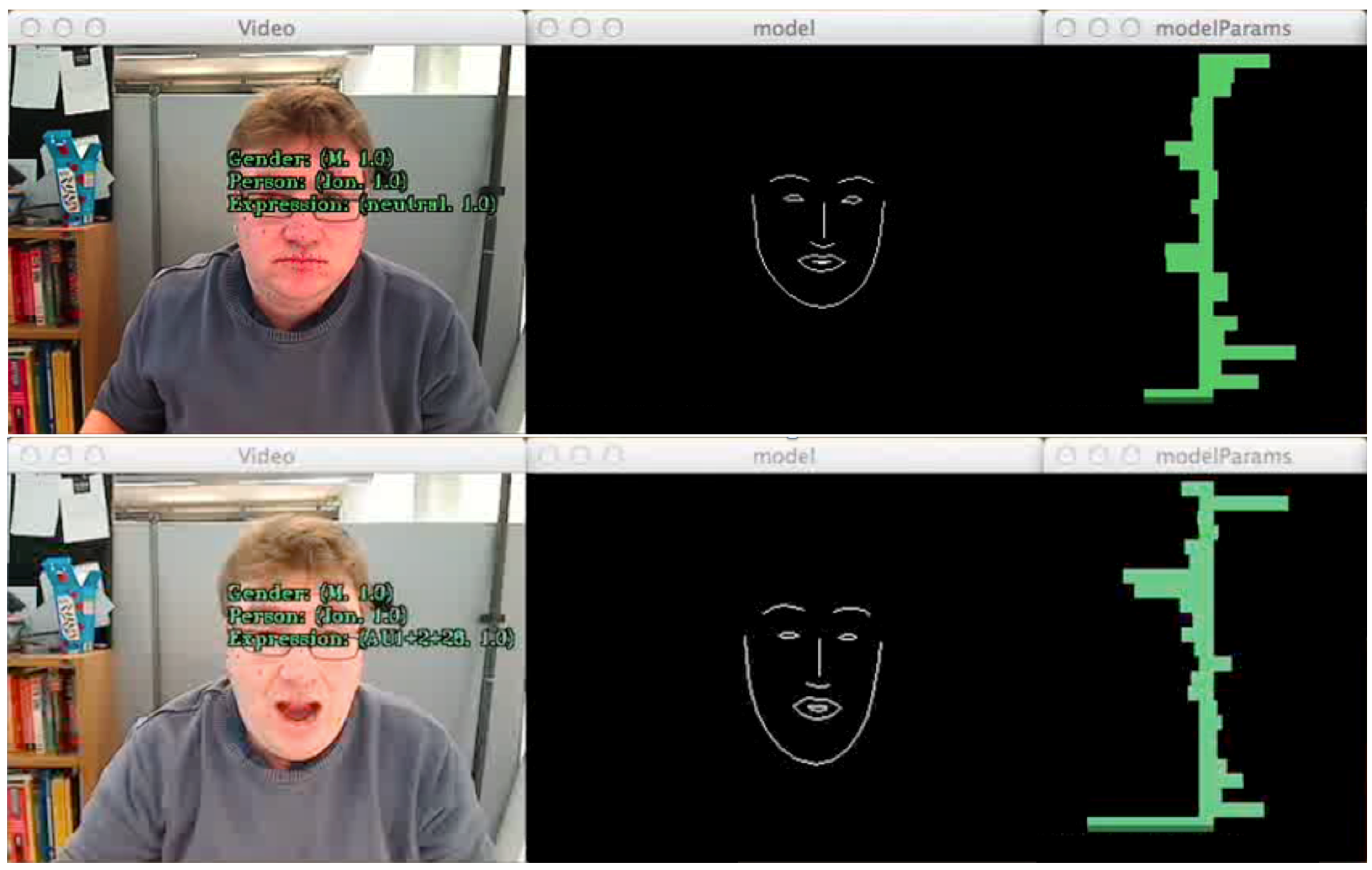
4.5. Measuring Opinion and Sentiment
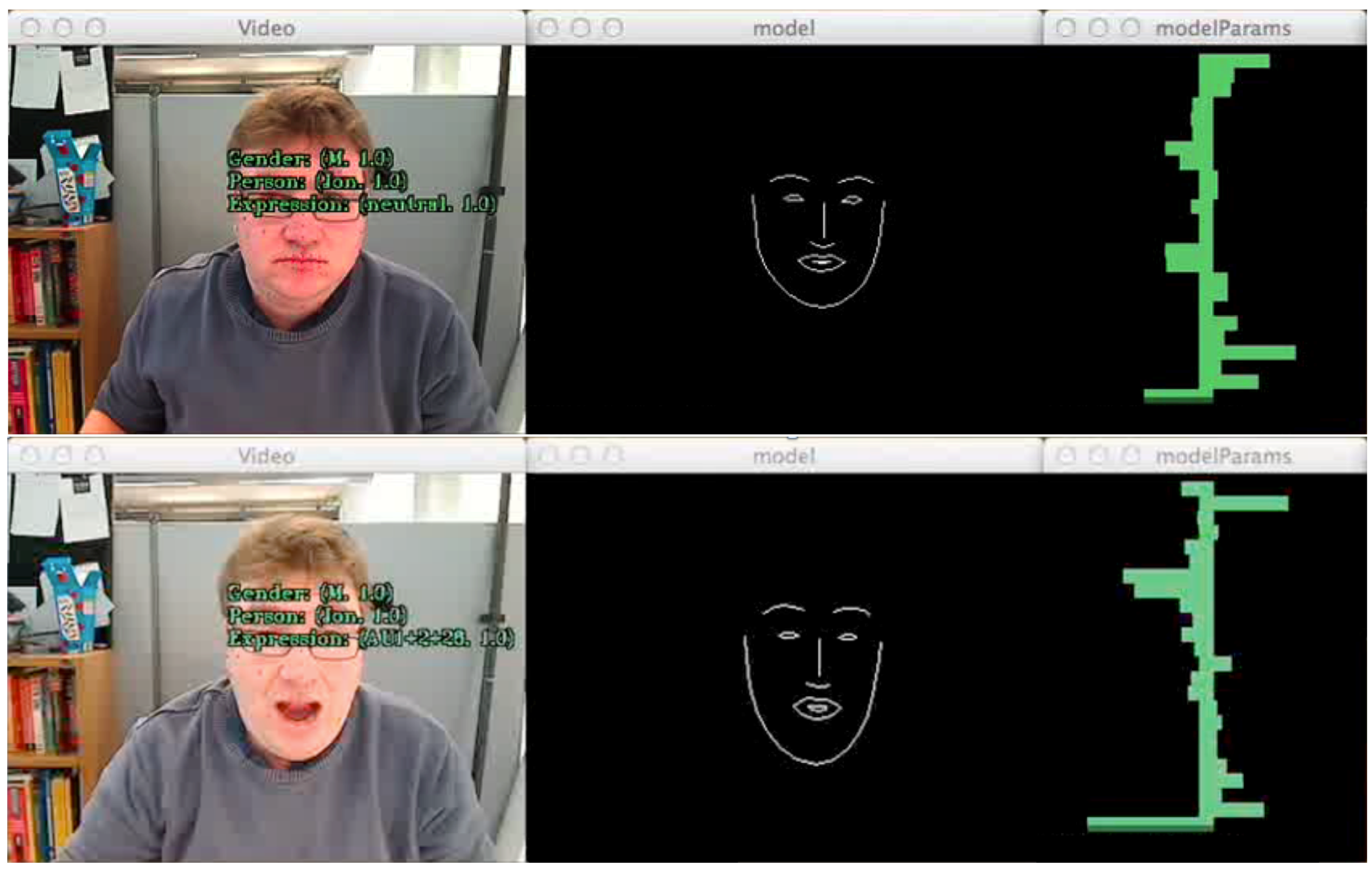
5. Conclusions and Outlook
- Image-entity-guided crawling. At the moment, within the ARCOMEM tools, the visual entity tools are applied to the archive after it has been created. However, visual entities could potentially be used to directly influence the crawl process; for example, if a crawl was specified to look at topics surrounding the Olympic games, then the crawl specification could contain images of the Olympic rings logo, and the visual analytics tools could be used to detect the presence of this logo in images. Pages with embedded images with the logo and the outlinks of these pages could then be given higher priority by the crawler.
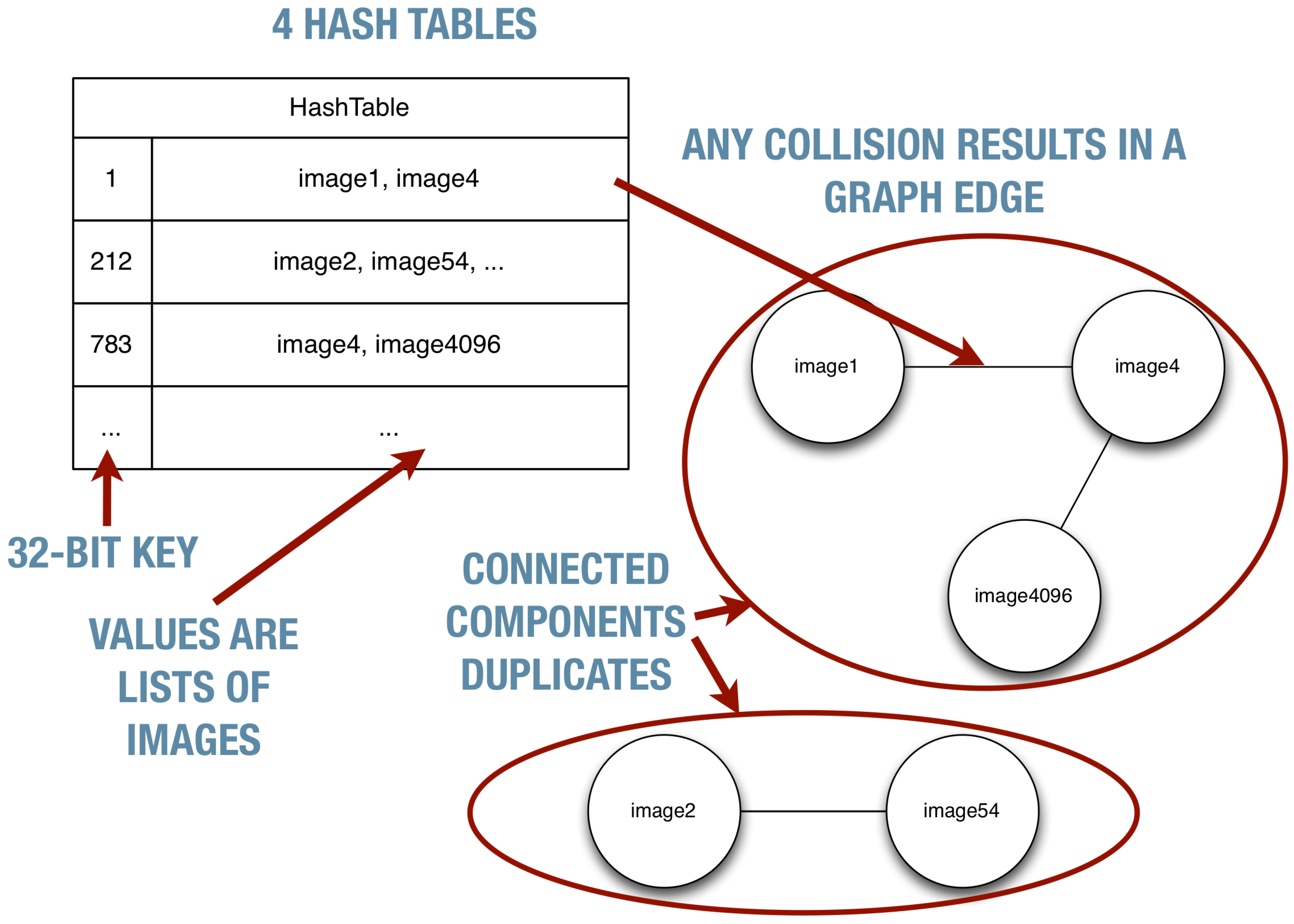
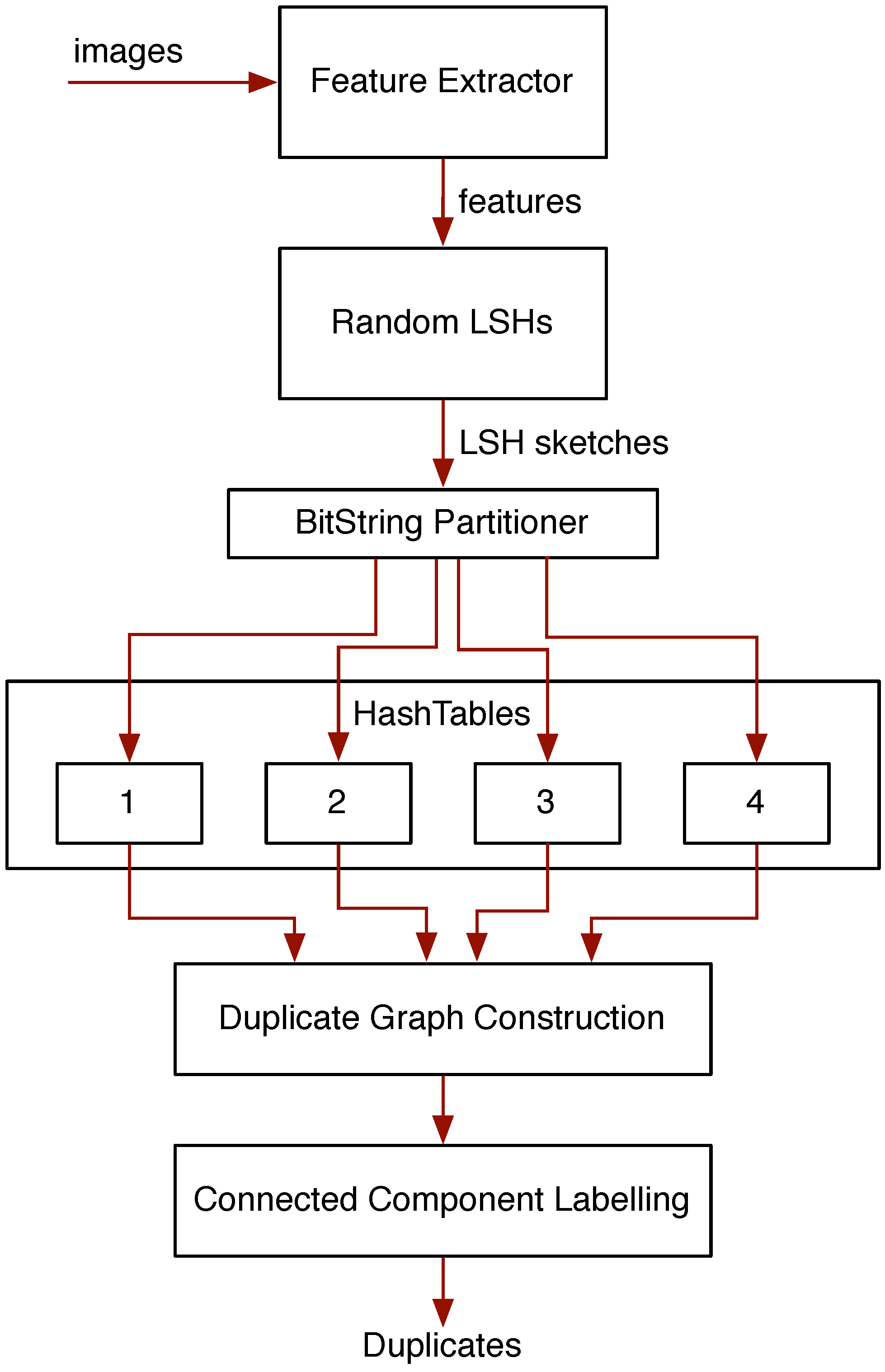
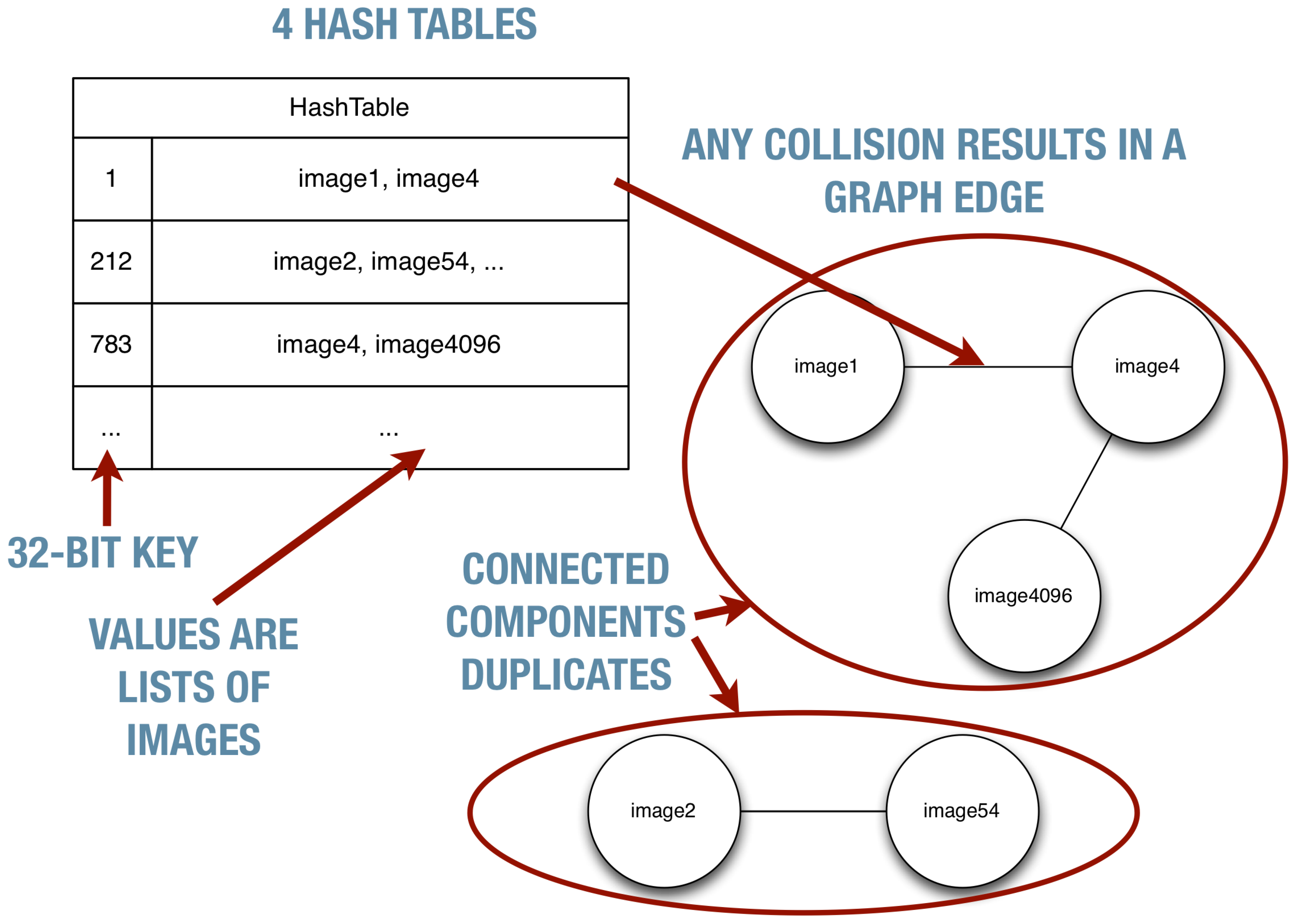
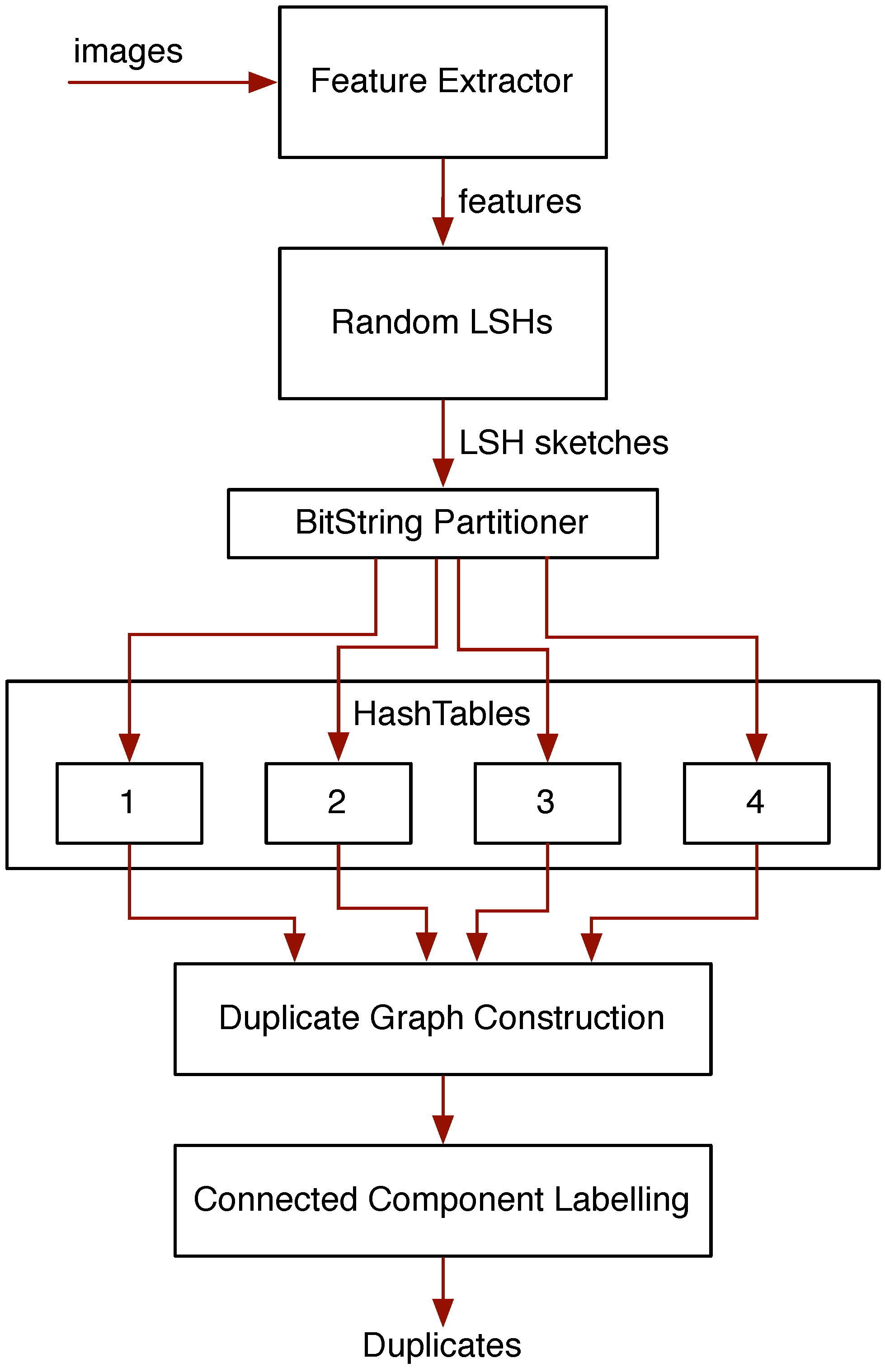
- Image-entity co-reference resolution in multilingual corpora. Image content is inevitably reused across different documents; often, the image will have been scaled or cropped as it is used in different documents. Our tools for detecting this kind of reuse are now quite robust and are capable of providing coreference resolution of the images and the entities they depict. This has many practical uses; for example, it could be used to link documents in different languages as being related, even though we may not have natural language processing tools for the languages in question. In turn, this coreference information could be used to help guide the crawler to new relevant content.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- ARCOMEM: Archiving Community Memories. Available online: http://www.arcomem.eu/ (accessed on 21 April 2014).
- Tahmasebi, N.; Demartini, G.; Dupplaw, D.; Hare, J.; Ioannou, E.; Jaimes, A.; Lewis, P.; Maynard, D.; Peters, W.; Risse, T.; et al. Models and Architecture Definition/Contribution to Models and Architecture Definition. ARCOMEM Deliverable D3.1/D4.1. Available online: http://www.arcomem.eu/wp-content/uploads/2012/05/D3_1.pdf (accessed on 21 April 2014).
- Hare, J.S.; Dupplaw, D.; Hall, W.; Lewis, P.; Martinez, K. The Role of Multimedia in Archiving Community Memories. In Proceedings of the 1st International Workshop on Archiving Community Memories, Lisbon, PT, USA, 6 September 2013.
- Enser, P.G.B.; Sandom, C.J.; Hare, J.S.; Lewis, P.H. Facing the reality of semantic image retrieval. J. Doc. 2007, 63, 465–481. [Google Scholar] [CrossRef]
- Hare, J.S.; Sinclair, P.A.S.; Lewis, P.H.; Martinez, K.; Enser, P.G.; Sandom, C.J. Bridging the Semantic Gap in Multimedia Information Retrieval: Top-down and Bottom-up Approaches. In Proceedings of the 3rd European Semantic Web Conference, Budva, Montenegro, 12 June 2006.
- Smeulders, A.W.M.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-Based Image Retrieval at the End of the Early Years. IEEE Trans. Pattern Anal. Mach. Intel. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Van de Sande, K.E.A.; Gevers, T.; Snoek, C.G.M. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intel. 2010, 32, 1582–1596. [Google Scholar] [CrossRef] [PubMed]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178.
- Flickr Photo Sharing. Available online: http://www.flickr.com/ (accessed on 21 April 2014).
- Hare, J.; Samangooei, S.; Lewis, P. Efficient Clustering and Quantisation of SIFT Features: Exploiting Characteristics of the SIFT Descriptor and Interest Region Detectors under Image Inversion. In Proceedings of the 1st ACM International Conference on Multimedia Retrieval, Trento, Italy, 17–20 April 2011.
- Zerr, S.; Siersdorfer, S.; Hare, J.; Demidova, E. Privacy-Aware Image Classification and Search. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 35–44.
- Huiskes, M.J.; Lew, M.S. The MIR Flickr Retrieval Evaluation. In Proceedings of the 2008 ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 26–31 October 2008.
- Hare, J.; Lewis, P.H. Explicit diversification of image search. In Proceedings of the 3rd ACM Conference on International Conference on Multimedia Retrieval, Dallas, TX, USA, 16–19 April 2013; pp. 295–296.
- Zontone, P.; Boato, G.; Natale, F.G.B.D.; Rosa, A.D.; Barni, M.; Piva, A.; Hare, J.; Dupplaw, D.; Lewis, P. Image Diversity Analysis: Context, Opinion and Bias. In Proceedings of the First International Workshop on Living Web: Making Web Diversity a True Asset, Collocated with the 8th International Semantic Web Conference, Washington, DC, USA, 25–29 October 2009.
- Agrawal, R.; Gollapudi, S.; Halverson, A.; Ieong, S. Diversifying Search Results. In Proceedings of the Second ACM International Conference on Web Search and Data Mining, Barcelona, Spain, 9–12 February 2009; pp. 5–14.
- Ionescu, B.; Menéndez, M.; Müller, H.; Popescu, A. Retrieving Diverse Social Images at MediaEval 2013: Objectives, Dataset and Evaluation. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013.
- Jain, N.; Hare, J.; Samangooei, S.; Preston, J.; Davies, J.; Dupplaw, D.; Lewis, P.H. Experiments in Diversifying Flickr Result Sets. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013.
- Fasel, B.; Luettin, J. Automatic facial expression analysis: A survey. Pattern Recognit. 2003, 36, 259–275. [Google Scholar] [CrossRef]
- Tian, Y.l.; Kanade, T.; Cohn, J.F. Facial Expression Analysis. In Handbook of Face Recognition; Springer: New York, NY, USA, 2005; pp. 247–275. [Google Scholar]
- Pantic, M.; Sebe, N.; Cohn, J.F.; Huang, T. Affective Multimodal Human-Computer Interaction. In Proceedings of the 13th annual ACM international conference on Multimedia, Singapore, 6–11 November 2005; pp. 669–676.
- Wang, W.; He, Q. A Survey on Emotional Semantic Image Retrieval. In Proceedings of the International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 117–120.
- Zontone, P.; Boato, G.; Hare, J.; Lewis, P.; Siersdorfer, S.; Minack, E. Image and Collateral Text in Support of Auto-annotation and Sentiment Analysis. In Proceedings of the 2010 Workshop on Graph-based Methods for Natural Language Processing, Uppsala, Sweden, 16 July 2010; pp. 88–92.
- Wang, W.; Yu, Y.; Jiang, S. Image Retrieval by Emotional Semantics: A Study of Emotional Space and Feature Extraction. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; Volume 4, pp. 3534–3539.
- Yanulevskaya, V.; van Gemert, J.C.; Roth, K.; Herbold, A.K.; Sebe, N.; Geusebroek, J.M. Emotional Valence Categorization Using Holistic Image Features. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 101–104.
- Siersdorfer, S.; Hare, J.; Minack, E.; Deng, F. Analyzing and Predicting Sentiment of Images on the Social Web. In Proceedings of the International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 715–718.
- Apache HBase Home. Available online: http://hbase.apache.org (accessed on 21 April 2014).
- Apache Hadoop Home. Available online: http://hadoop.apache.org (accessed on 21 April 2014).
- Kohlschütter, C.; Fankhauser, P.; Nejdl, W. Boilerplate Detection Using Shallow Text Features. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 3–6 February 2010; pp. 441–450.
- Hare, J.; Matthews, M.; Dupplaw, D.; Samangooei, S. Readability4J—Automated Webpage Information Extraction Engine. http://www.openimaj.org/openimaj-web/readability4j/ (accessed on 21 April 2014).
- Cunningham, H.; Maynard, D.; Bontcheva, K.; Tablan, V.; Aswani, N.; Roberts, I.; Gorrell, G.; Funk, A.; Roberts, A.; Damljanovic, D.; et al. Text Processing with GATE, Version 6; Gateway Press: Louisville, KY, USA, 2011. [Google Scholar]
- GATE. General Architecture for Text Engineering. Available online: http://www.gate.ac.uk (accessed on 21 April 2014).
- Hare, J.S.; Samangooei, S.; Dupplaw, D.P. OpenIMAJ and ImageTerrier: Java Libraries and Tools for Scalable Multimedia Analysis and Indexing of Images. In Proceedings of the 19th ACM international conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 691–694.
- OpenIMAJ. Open Intelligent Multimedia Analysis in Java. Available online: http://www.openimaj.org (accessed on 21 April 2014).
- International Organization for Standardization. Information and Documentation—WARC File Format; ISO 28500:2009; ISO: Geneva, Switzerland, 2009. [Google Scholar]
- Hare, J.S.; Samangooei, S.; Dupplaw, D.P.; Lewis, P.H. Twitter’s Visual Pulse. In Proceedings of the 3rd ACM International Conference on Multimedia Retrieval, Dallas, TX, USA, 16–19 April 2013; pp. 297–298.
- Hare, J.; Samangooei, S.; Dupplaw, D.; Lewis, P. ImageTerrier: An Extensible Platform for Scalable High-Performance Image Retrieval. In Proceedings of the ACM International Conference on Multimedia Retrieval, Hong Kong, China, 5–8 June 2012.
- Gionis, A.; Indyk, P.; Motwani, R. Similarity Search in High Dimensions via Hashing. In Proceedings of the 25th International Conference on Very Large Data Bases, Edinburgh, Scotland, UK, 7–10 September 1999; pp. 518–529.
- Dong, W.; Charikar, M.; Li, K. Asymmetric Distance Estimation with Sketches for Similarity Search in High-Dimensional Spaces. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, Singapore, 20–24 July 2008; pp. 123–130.
- Dong, W.; Wang, Z.; Charikar, M.; Li, K. High-Confidence Near-Duplicate Image Detection. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieva, Hong Kong, China, 5–8 June 2012; pp. 1:1–1:8.
- Dupplaw, D.P.; Hare, J.S.; Samangooei, S. Twitter’s Visual Pulse Demo. Available online: https://www.youtube.com/watch?v=CBk5nDd6CLU (accessed on 21 April 2014).
- MediaEval. MediaEval Benchmarking Initiative for Multimedia Evaluation. Available online: http://www.multimediaeval.org (accessed on 21 April 2014).
- Reuter, T.; Papadopoulos, S.; Mezaris, V.; Cimiano, P.; de Vries, C.; Geva, S. Social Event Detection at MediaEval 2013: Challenges, Datasets, and Evaluation. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013.
- Samangooei, S.; Hare, J.; Dupplaw, D.; Niranjan, M.; Gibbins, N.; Lewis, P.; Davies, J.; Jai, N.; Preston, J. Social Event Detection Via Sparse Multi-Modal Feature Seating Contest and Incremental Density Based Clustering. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013.
- Parkhi, O.; Vedaldi, A.; Zisserman, A. On-the-Fly Specific Person Retrieval. In Proceedings of the 13th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), Dublin, Ireland, 23–25 May 2012; pp. 1–4.
- Psyllos, A.; Anagnostopoulos, C.N.; Kayafas, E. M-SIFT: A New Method for Vehicle Logo Recognition. In Proceedings of the IEEE International Conference on Vehicular Electronics and Safety, Istanbul, Turkey, 24–27 July 2012; pp. 261–266.
- Kalantidis, Y.; Pueyo, L.G.; Trevisiol, M.; van Zwol, R.; Avrithis, Y. Scalable Triangulation-Based Logo Recognition. In Proceedings of the 1st ACM International Conference on Multimedia Retrieval, Vancouver, CB, Canada, 26–31 October 2008; pp. 20:1–20:7.
- Davies, J.; Hare, J.; Samangooei, S.; Preston, J.; Jain, N.; Dupplaw, D.; Lewis, P.H. Identifying the Geographic Location of an Image with a Multimodal Probability Density Function. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013.
- Hauff, C.; Thomee, B.; Trevisiol, M. Working Notes for the Placing Task at MediaEval 2013. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013.
- Hare, J.S.; Davies, J.; Samangooei, S.; Lewis, P.H. Placing Photos with a Multimodal Probability Density Function. In Proceedings of the International Conference on Multimedia Retrieval, Glasgow, Scotland, UK, 1–4 April 2014.
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active shape models—Their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Cootes, T.; Edwards, G.; Taylor, C. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intel. 2001, 23, 681–685. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Schmidt, S.; Stock, W.G. Collective indexing of emotions in images. A study in emotional information retrieval. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 863–876. [Google Scholar] [CrossRef]
- San Pedro, J.; Siersdorfer, S. Ranking and Classifying Attractiveness of Photos in Folksonomies. In Proceedings of the 18th International World Wide Web Conference, Madrid, Spain, 20–24 April 2009; pp. 771–780.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Hare, J.S.; Dupplaw, D.P.; Lewis, P.H.; Hall, W.; Martinez, K. Exploiting Multimedia in Creating and Analysing Multimedia Web Archives. Future Internet 2014, 6, 242-260. https://doi.org/10.3390/fi6020242
Hare JS, Dupplaw DP, Lewis PH, Hall W, Martinez K. Exploiting Multimedia in Creating and Analysing Multimedia Web Archives. Future Internet. 2014; 6(2):242-260. https://doi.org/10.3390/fi6020242
Chicago/Turabian StyleHare, Jonathon S., David P. Dupplaw, Paul H. Lewis, Wendy Hall, and Kirk Martinez. 2014. "Exploiting Multimedia in Creating and Analysing Multimedia Web Archives" Future Internet 6, no. 2: 242-260. https://doi.org/10.3390/fi6020242
APA StyleHare, J. S., Dupplaw, D. P., Lewis, P. H., Hall, W., & Martinez, K. (2014). Exploiting Multimedia in Creating and Analysing Multimedia Web Archives. Future Internet, 6(2), 242-260. https://doi.org/10.3390/fi6020242