
Transforming Data Annotation with AI Agents: A Review of Architectures, Reasoning, Applications, and Impact

 ,
,  , ,
, , 
Abstract

1. Introduction
1.1. Motivation and Contributions
- Comprehensive Taxonomy and Technical Analysis: We establish the first comprehensive framework that systematically classifies AI agents in data annotation. This contribution integrates a novel taxonomy based on agent capabilities with a deep analysis of architectural patterns ranging from single-agent systems to multi-agent collaborations to provide unified design principles and implementation guidelines for researchers and practitioners.
- Architectural Design and Evaluation Framework: We systematically examine various architectural approaches for agent-driven annotation systems, including single-agent pipelines, multi-agent collaborations, and human-in-the-loop (HITL) integration, providing practical design guidelines and trade-off considerations. Complementing this, we introduce a holistic evaluation framework with novel metrics and standardized benchmarks to rigorously assess agent performance, economic impact, and quality assurance.
- Real-world Applications and Tools: We present a thorough analysis of the practical ecosystem by examining transformative, real-world applications across diverse industries (e.g., healthcare, finance, and technology). This is paired with a critical assessment of the current landscape of tools, platforms, and frameworks, offering actionable guidance for technology selection and strategic implementation.
- Research Challenges and Future Directions: We systematically identify critical open challenges, including quality assurance, bias mitigation, transparency, privacy, and scalability in AI-agent-driven annotation. Based on this analysis, we outline a forward-looking research roadmap to guide the future development of robust, reliable, and responsible AI annotation agents.
1.2. Organization
2. Related Work
2.1. Human-Led and Classic-ML Annotation
2.2. Generative-AI and LLM-Centric Annotation
2.3. Limitations of the Existing Surveys
3. Revisiting Data Annotation
3.1. Traditional Approaches
3.2. Generic ML-Based Approaches
3.3. GenAI and LLM-Based Approaches
4. AI Agents: A Primer for Data Annotation
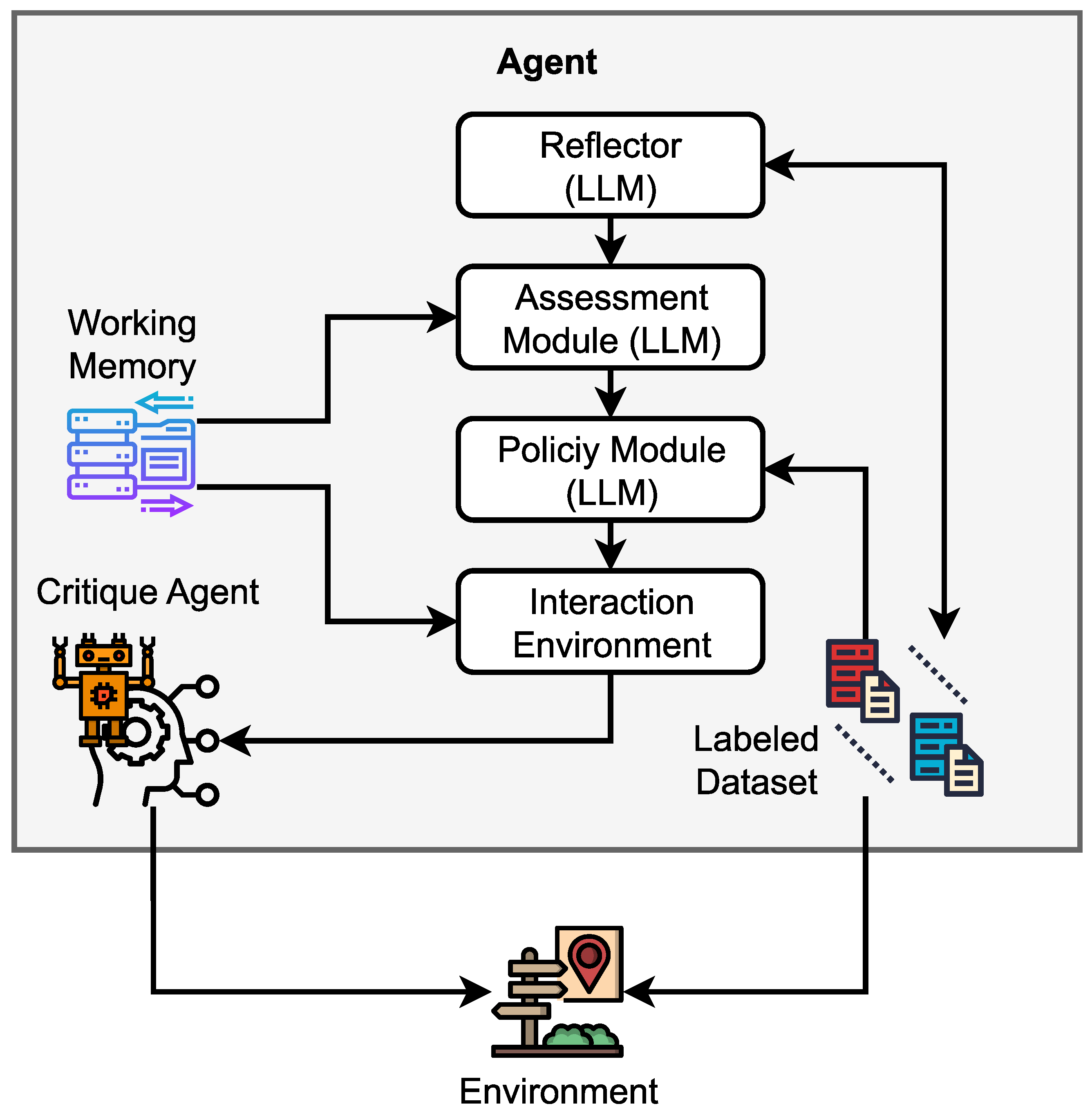
4.1. Overview of AI Agents
4.2. Classification of AI Agents
- Rule-Based Agents: Operate on predefined conditional logic and excel at structured annotation tasks with clear decision boundaries. These agents are commonly used for format validation, basic text classification, and quality control checks in annotation workflows. For example, rule-based agents automatically classify customer support tickets based on keyword patterns or validate the completeness of bounding box annotations [57,58].
- Model-Based Reflex Agents: Maintain internal representations of annotation environments to handle contextually dependent labeling tasks. These agents excel at sequential annotation tasks such as named entity recognition in text or object tracking across video frames, where current decisions depend on understanding previous annotation states [59,60].
- Goal-Based Agents: Plan and execute multi-step annotation strategies to achieve specific data quality and coverage objectives. These agents decompose complex annotation projects into manageable workflows, prioritize annotation tasks based on model training needs, and adapt strategies to meet quality targets. Examples include agents that orchestrate active learning pipelines to maximize model improvement per annotation effort [61].
- Utility-Based Agents: Evaluate annotation decisions by optimizing multiple factors including confidence scores, cost effectiveness, and expected model performance gains. These agents are particularly valuable in active learning scenarios, where they select the most informative samples for annotation while balancing annotation costs against anticipated improvements in model accuracy [61,62].
- Learning Agents: Continuously adapt annotation strategies based on feedback from human annotators, annotation quality metrics, and model performance indicators. These agents improve over time by refining their understanding of annotation guidelines, reducing error rates, and becoming more efficient at identifying cases requiring human intervention [46,47].
4.3. Role of AI Agents in Data Annotation
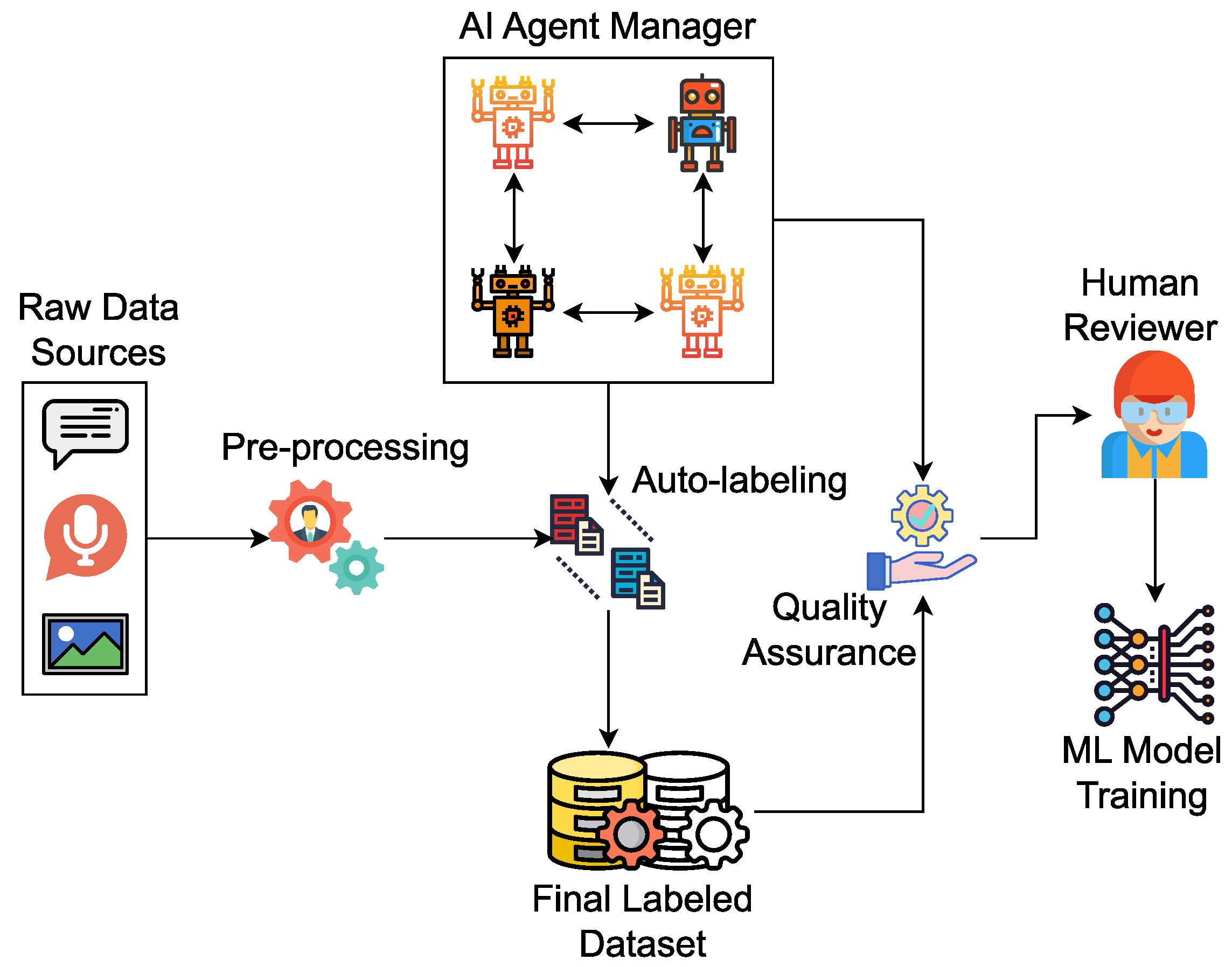
- Collaborative Workflows: Specialized agents coordinate tasks through role assignment, where retriever agents collect relevant examples, labeling agents apply consistent annotation schemas, and validator agents perform quality checks. This structure enables scalable annotation pipelines that maintain consistency across large datasets.
- Adaptive Quality Control: Systems use confidence scoring to identify uncertain annotations requiring human review, anomaly detection to flag inconsistent labeling patterns, and cross-validation mechanisms in which multiple agents annotate the same samples independently to resolve disagreements and improve reliability.
- Context-Aware Adaptation: Agents adjust annotation strategies based on data characteristics, learn from feedback to refine guidelines, adapt to evolving annotation schemas, and handle domain shifts without requiring complete model retraining.
- Consensus Management: Multi-agent systems detect annotation conflicts, orchestrate consensus-building among human annotators, and maintain annotation histories to track changes in interpretation of ambiguous cases.
- Multimodal Integration: Advanced systems coordinate annotation across text, image, and audio modalities through specialized agents that preserve semantic consistency, resolve cross-modal dependencies, and ensure coherent labeling in unified annotation projects.
5. Research Methodology
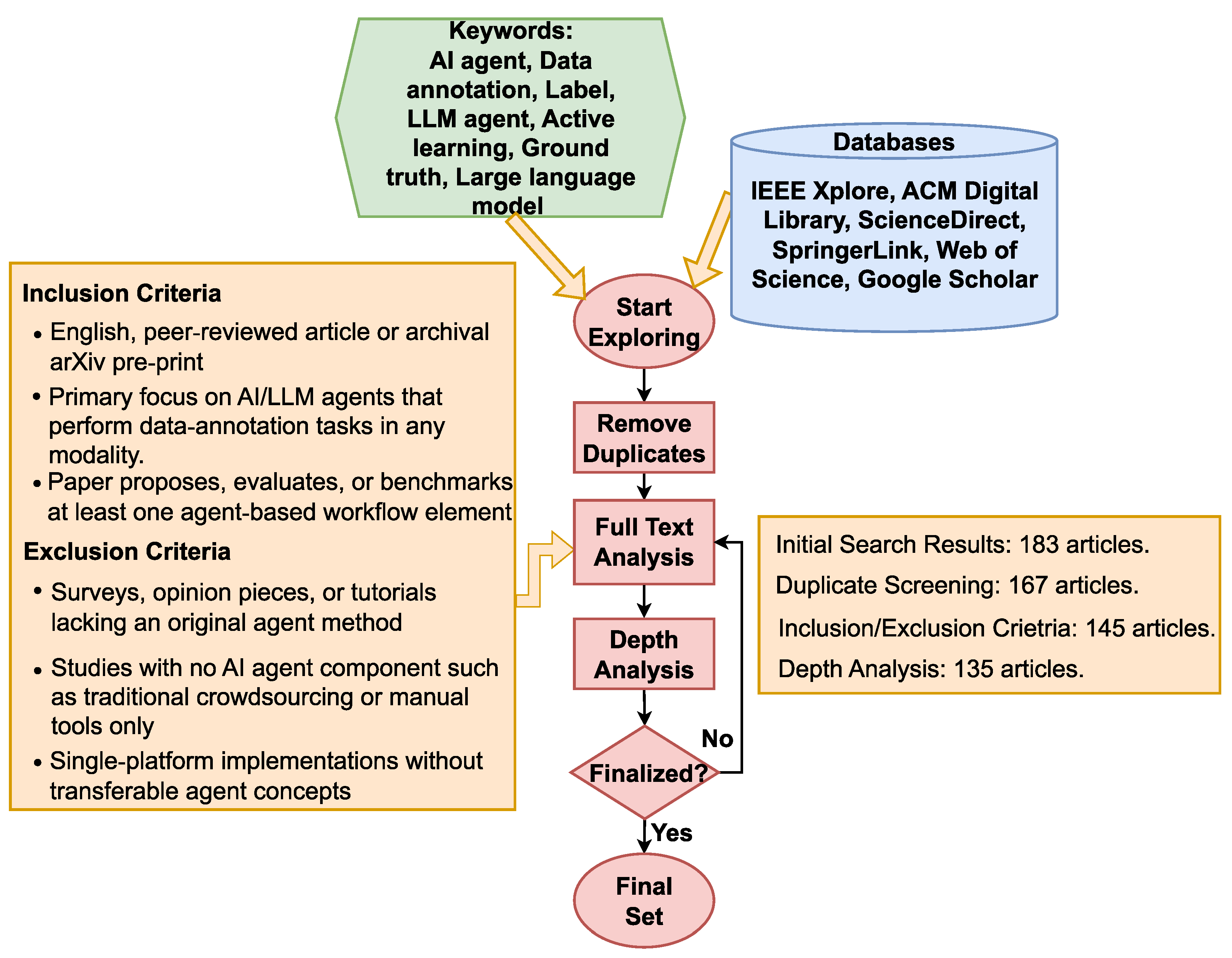
5.1. Keywords
(“AI agent” OR “autonomous agent” OR “LLM agent” OR “intelligent agent” AND “data annotation” OR label* OR “ground truth”),
(“AI agent” OR “LLM agent” AND “generative AI” OR “large language model” AND “active learning” OR “self-refine” OR “prompt engineering”),
(“AI agent” OR “autonomous agent” OR “LLM agent” AND “quality assurance” OR “inter-annotator agreement” OR “bias detection” AND “data annotation”)
5.2. Inclusion and Exclusion Criteria
5.3. Research Databases and Selection Process
- RQ-1: Which peer-reviewed studies introduce AI or LLM agents that automate data-annotation workflows across any modality?
- RQ-2: What multi-agent or single-agent architectures are reported for planning, labeling, and quality checking in annotation pipelines?
- RQ-3: Which real-world application domains, especially those with sensitive data such as healthcare, finance, or content moderation, deploy LLM annotators?
6. AI Agents for Annotation Workflow and Quality
6.1. Active Data Selection and Adaptive Annotation
- Active Sampling Strategies: Active sampling strategies aim to maximize the information gained per annotation while minimizing labeling effort [67,69]. AI agents enhance this process by intelligently prioritizing data using LLM-driven insights. For example, ActiveLLM [66] addresses the “cold start” problem in few-shot learning by leveraging GPT-4 and similar models to select informative instances even with minimal initial data. The LLM-guided sampling significantly boosts downstream classifier performance, outperforming both standard active learning and other few-shot methods. In parallel, efficiency-oriented approaches like ActivePrune [65] use LLMs to prune large unlabeled pools before selection by employing a two-stage filtering, which not only outperforms prior pruning methods but also cuts total annotation time by up to 74%.
- LLM-driven Active Learning: LLM-driven active learning allows the AI agents to actively select and annotate data in each iteration [68]. One notable framework, LLMaAA [70], treats an LLM as an “active annotator” within the loop to decide what to label next in order to provide high-quality pseudo-labels. Modern approaches [70,71] generate new unlabeled instances that are predicted to be informative, rather than drawing only from a fixed pool. In these approaches, AI agents pose hypothetical or synthesized examples on the fly, expanding the training set with “high-value” queries that a human or the LLM itself can then label [71].
- On-the-fly Guideline Adaptation: In terms of annotation guidelines, AI agents assist in adapting on the fly to improve consistency [72,73,74]. Complex information extraction (IE) tasks come with detailed guidelines that vanilla LLMs struggle to follow. To address this issue, Sainz et al. [75] fine-tune an LLM (e.g., GoLLIE model [75]) by following annotation guidelines, which leads to substantial improvements in zero-shot extraction accuracy on unseen IE tasks. Bibal et al. [76] introduce an iterative workflow in which LLM agents help update labeling instructions in response to annotator disagreements. The justifications are analyzed to identify ambiguities or shortcomings in the guidelines.
- Continuous Learning and Model Updates: AI-assisted annotation systems benefit greatly from continuous learning and frequent model updates. In the continuous learning setting, each batch of newly annotated data is immediately used to retrain or fine-tune the model before the next query selection [77]. These incremental updates allow the AI agent to progressively improve its predictions and selection strategy as more data becomes available. Recent research on lifelong learning for LLM-based agents underscores the importance of this adaptivity. For example, an LLM agent with memory and update mechanisms helps it integrate new knowledge without forgetting old knowledge, enabling continuous adaptation to changing data [78]. In effect, the AI annotator becomes smarter and more specialized with each iteration [79].
6.2. Annotation Quality and Consistency
- Knowledge Distillation and Augmentation: AI agents dramatically amplify annotation efforts by distilling knowledge from powerful models and augmenting datasets with synthetic examples [83,84]. The core idea of knowledge distillation in this context is to use LLM to generate labeled data or guidance that trains a small language model (SLM). Liu et al. [85] propose a knowledge distillation scheme where the system first analyzes the SLM weaknesses, then an LLM synthesizes new training examples specifically targeting those weak spots. Alongside distillation, LLM-based agents contribute to data augmentation for annotation. Instead of relying solely on human-curated examples, these LLM agents generate large quantities of plausible data points with labels [85,86].
- Bias and Fairness Checking: Maintaining high annotation quality and consistency is paramount, and AI agents play diverse roles in quality control. One contribution is through detecting and mitigating bias in labels, where LLM agents act as a second pair of eyes to review annotations for potential mistakes or biases. A recent study [64] used GPT-4 to re-evaluate crowdsourced annotations in an event extraction task, and the LLM flagged roughly 24% of the human-provided labels as debatable or likely errors. Another study [87] on political Twitter data found that zero-shot GPT-4 labeling not only achieved higher accuracy but also exhibited equal or lower bias compared to human annotators.
- Inter-annotator Agreement Conflict Resolution: When multiple annotators provide labels for the same item, disagreements often arise, resulting in ambiguity or differing interpretations. AI agents assist in resolving these conflicts to achieve higher inter-annotator agreement (IAA). For example, an LLM agent organizes the rationale and highlights where guidelines might be unclear. After iterative debate and guideline refinement, the annotations converge, and the guidelines are updated to codify the resolved distinctions [76]. Choi et al. [88] explore chain-of-thought prompting and majority voting among LLM agents to imitate a panel of annotators, producing more consistent labels at scale. This results in higher consistency than individual annotators by aggregating multiple perspectives.
- Automated Quality Control: AI agents excel at the tedious yet critical task of quality control in annotation projects. They perform automated checks on the annotated data to catch errors, inconsistencies, or low-quality labels much faster than manual review. One common technique is to employ an LLM as a quality reviewer: after initial annotation (by humans or another model), the LLM is prompted to verify the label given the input and the guidelines [89]. Another strategy is the “LLM-as-a-judge” approach, where an ensemble of LLMs reviews existing labels and flags those likely to be incorrect. Gat et al. [90] implement this by prompting multiple diverse LLMs to label the same data and measuring their agreement against the original label.
7. Architectures and Frameworks for Agent-Driven Annotation
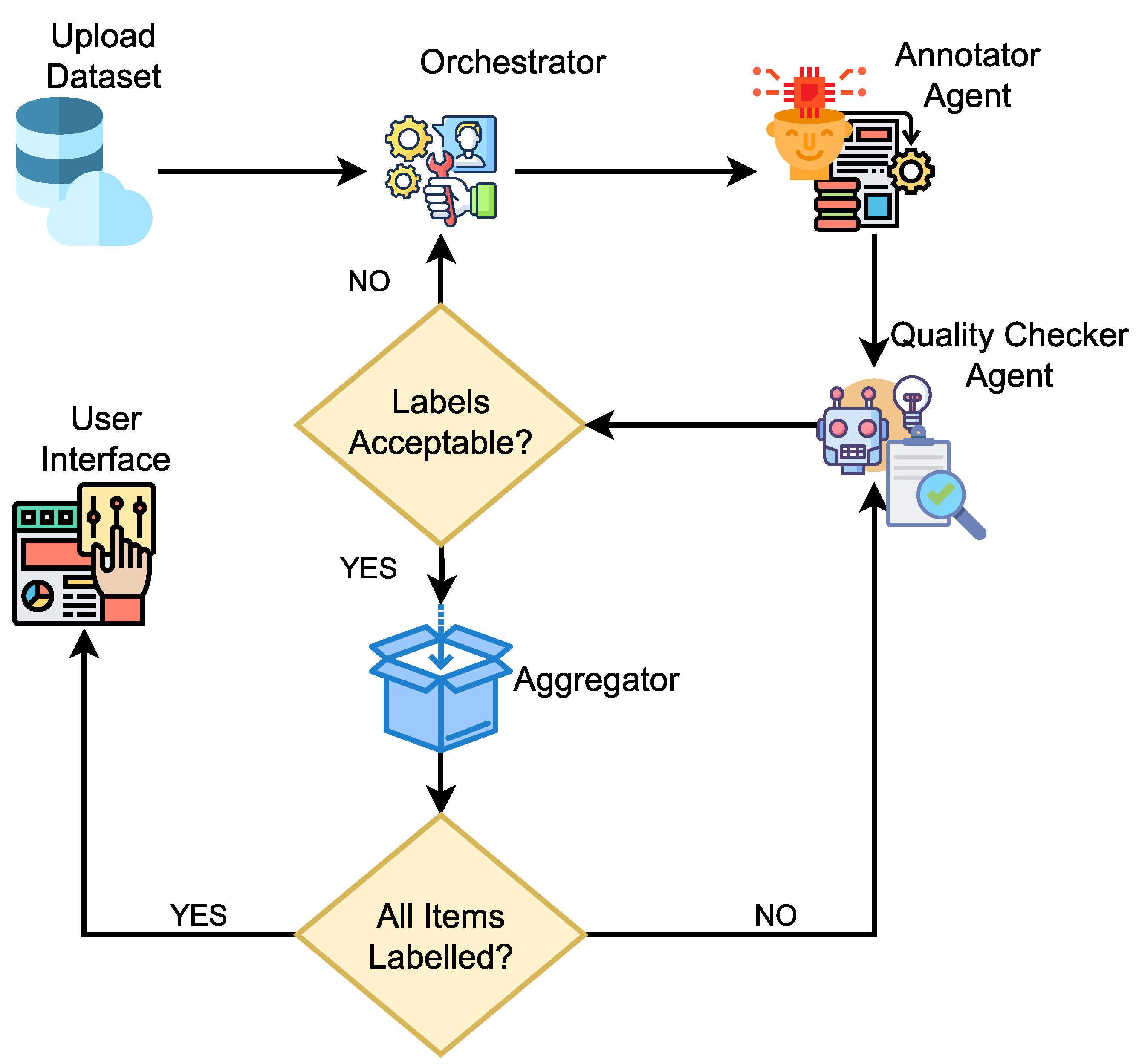
7.1. Single-Agent Sequential Pipeline
7.2. Dual-Agent Reviewer Models
7.3. Multi-Agent Collaboration
7.4. Human-in-the-Loop as Agent
8. Evaluating AI Agents in Data Annotation
8.1. Performance Metrics for AI Agents
8.2. Economic and User-Centric Metrics
8.3. Standardized Benchmarks and Evaluation Frameworks
8.4. Empirical and Quantitative Validation
9. Real-World Applications, Case Studies, and Tools
9.1. Content Moderation and Policy Compliance
9.2. Customer Feedback and Support Ticket Triage
9.3. Biomedical and Scientific Data Annotation
9.4. Multimodal Data Labeling
9.5. Case Studies
- Humanitarian and Low-Resource Settings: AI agents are transforming annotation capabilities in humanitarian response and low-resource linguistic contexts where labeled data scarcity presents significant challenges. In disaster response scenarios, agent-based systems can rapidly process and categorize social media posts by urgency, need type, and location [138] to enable faster humanitarian intervention. These annotation agents demonstrate remarkable cross-lingual transfer abilities, allowing organizations to leverage multilingual capabilities to annotate content in low-resource languages without extensive human translator networks. Kim et al. [139] developed an agent-based annotation framework that strategically directs limited bilingual human resources to only the most uncertain cases identified by the system, achieving annotation coverage that would be impossible through traditional methods. Recent implementations by humanitarian organizations have shown that AI annotation agents can reduce response time by up to 70% while maintaining annotation quality comparable to human experts, effectively democratizing data annotation capabilities beyond well-resourced domains and languages [140].
- Enterprise Adoption and Agent-Based Workflows: Organizations across sectors are implementing sophisticated AI annotation agents tailored to their domain-specific data needs. Financial institutions have deployed fraud detection annotation agents that pre-screen claims by analyzing textual descriptions and transaction patterns, categorizing risk levels before human investigator review. Technology companies have integrated annotation agents throughout their data pipelines, with foundation model developers like OpenAI, Anthropic, and Meta leveraging their own models to generate and annotate massive instruction-following datasets at unprecedented scale [24,141]. The traditional boundaries between data generation and annotation have blurred as agent-based approaches like Self-Instruct [24] enable the automatic creation of labeled examples from minimal seed data. Enterprise adoption has accelerated with the integration of LLM-based annotation agents into existing data workflows, creating hybrid systems where AI agents perform initial annotation at scale while human experts focus on quality assurance, edge case identification, and agent performance improvement through feedback loops. This paradigm shift has positioned AI annotation agents as standard components in enterprise data pipelines, with many organizations reporting 3–5x increases in annotation throughput and significant improvements in dataset quality.
9.6. Tools and Platforms for AI-Driven Annotation
- LangChain: LangChain, an open-source framework, has gained popularity for building LLM-powered applications. It provides abstractions for chaining prompts and actions, memory, and tool use [24]. It enables the creation of annotation agents through structured workflows where the system first processes annotation guidelines, then applies LLMs with chain-of-thought reasoning to each data item, optionally consults external APIs (such as knowledge bases), and finally produces the appropriate label. LangChain’s agents feature robust integration capabilities with the environment (files, databases, and APIs), making them particularly valuable for complex annotation tasks requiring external knowledge sources [142,143].
- Prodigy: Prodigy introduced model-assisted annotation features early in its development and has continuously expanded its capabilities over time. Recently, it integrated large language models (LLMs) into annotation workflows, supporting both few-shot and zero-shot paradigms by enabling LLMs to suggest labels or generate annotations directly, while retaining human oversight through an accept-or-reject verification mechanism [144]. Prodigy’s underlying philosophy centers on “AI as you annotate”, an approach designed to simultaneously accelerate the annotation process and deliver measurable quality improvements.
- Labelbox and Scale AI: Labelbox has pioneered AI agent-based annotation workflows, enabling trajectory training and evaluation for agent development where human labelers optimize agent prompts, fine-tune LLMs, and provide critical feedback on agent performance [145,146]. The platform’s 2025 enhancements include agent-specific capabilities in the Multimodal Chat Editor for trajectory labeling, allowing teams to create, edit, and annotate complete agent reasoning steps, tool calls, and observations [147]. Similarly, Scale AI has developed an advanced Data Engine featuring AI-based techniques with HITL systems, enabling annotators to identify high-value data for curating agent training sets and implementing automated quality controls that adapt to agent workflows. This human–AI collaborative approach represents a paradigm shift where professional annotator workforces are augmented by AI agents to deliver superior efficiency, quality, and cost effectiveness.
- Cleanlab Studio: Cleanlab has revolutionized data annotation through its Autolabeling Agent [124], which implements an advanced AI agent architecture designed to reduce annotation costs by up to 80%. The system employs active learning algorithms that intelligently identify the most informative data points for human review, while the agent autonomously handles confidently predicted examples. The HITL agent solution continuously learns from expert supervision, allowing teams to iterate through a workflow where the AI agent progressively improves its annotation capabilities based on expert corrections. Its trustworthy language model provides trustworthiness scores for agent-generated annotations, creating a reliability layer that enables organizations to confidently automate up to 99% of annotations while directing human attention only to uncertain cases requiring expert judgment.
- Snorkel: Snorkel features dedicated GenAI agent tools that support trajectory evaluation and annotation, allowing subject matter experts to review AI agent responses and rank them according to quality [148]. The platform’s programmatic labeling approach enables users to define labeling functions that can call LLMs under the hood, effectively merging the programmatic labeling paradigm with agent capabilities. Snorkel’s Multi-Schema Annotation capability further enhances this functionality by enabling organizations to customize label schemas to collect annotations for different agent evaluation metrics simultaneously. This platform revolutionizes how enterprises capture domain knowledge, build agent evaluation datasets, and fine-tune agent workflows through techniques such as instruction tuning and direct preference optimization.
- Open-source Initiatives: The open-source community continues to drive innovation in agent-based annotation through diverse projects and resources. The LLM4Annotation GitHub repository [24] serves as a comprehensive collection of research papers focused on leveraging agents for annotation workflows. Tools like autolabel [149] enable the creation of agent-based labeling pipelines that can be customized for specific domains, with built-in integration for HuggingFace datasets and models. Additionally, community projects demonstrate the practical implementations of agent-based annotation systems that leverage commercial APIs like OpenAI for common labeling tasks. These open initiatives provide valuable resources for organizations seeking to experiment with agent-based annotation before investing in enterprise solutions, fostering innovation and accessibility in the rapidly evolving field of AI-assisted data annotation.
- Additional Tools: Several platforms leverage AI agents to streamline and enhance annotation workflows. For instance, CVAT AI (https://www.cvat.ai/, accessed on 20 June 2025) Agents offer customization flexibility for integrating proprietary models into annotation pipelines [150], while Datasaur’s LLM Labs playground enables comparative performance testing across multiple language models to optimize annotation workflows [151]. For specialized use cases, GPTBoost (https://www.gptboost.io/, accessed on 20 June 2025) provides purpose-built Annotation Agents targeting sentiment analysis in communication data, and MEGAnno+ implements a balanced human–LLM collaborative system that preserves expert oversight while maximizing automation benefits [139]. Additionally, Agent Label (https://www.agentlabel.ai/, accessed on 20 June 2025) focuses on acceleration-oriented tools designed specifically for machine learning datasets, while established platforms such as V7 (https://www.v7labs.com/, accessed on 20 June 2025) have expanded their offerings to include AI Agents for document processing automation. Furthermore, Labellerr (https://www.labellerr.com/, accessed on 20 June 2025) distinguishes itself through transfer learning approaches that leverage pre-trained models to minimize coding requirements while maintaining annotation quality. These diverse platforms illustrate how agent-based annotation technologies are rapidly evolving to meet specific industry needs through specialized implementations.
10. Research Challenges and Future Directions
10.1. Quality and Reliability Concerns
10.2. Ethical and Legal Considerations
10.3. Transparency and Explainability
10.4. Human Displacement and Evolving Roles
10.5. Data Privacy and Security
10.6. Scalability and Cost Trade-Offs
10.7. Evaluation and Governance
11. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Lists of Abbreviation
| AI | Artificial Intelligence |
| AL | Active Learning |
| ANOVA | Analysis of Variance |
| API | Application Programming Interface |
| Auto-CoT | Automatic Chain-of-Thought |
| CLIP | Contrastive Language-Image Pre-training |
| CoT | Chain-of-Thought |
| CV | Computer Vision |
| EHR | Electronic Health Record |
| EM | Expectation-Maximization |
| EU | European Union |
| FedAvg | Federated Averaging |
| GDPR | General Data Protection Regulation |
| GenAI | Generative Artificial Intelligence |
| GPT | Generative Pre-trained Transformer |
| GPU | Graphics Processing Unit |
| HIPAA | Health Insurance Portability and Accountability Act |
| HITL | Human-in-the-Loop |
| IAA | Inter-Annotator Agreement |
| IE | Information Extraction |
| KG | Knowledge Graph |
| KL | Kullback-Leibler |
| LLM | Large Language Model |
| MES | Manufacturing Execution System |
| ML | Machine Learning |
| MTurk | Amazon Mechanical Turk |
| NLP | Natural Language Processing |
| OSS | Open-Source Software |
| QA | Question Answering |
| RAG | Retrieval Augmented Generation |
| ReAct | Reasoning and Acting |
| RL | Reinforcement Learning |
| SLM | Small Language Model |
| SR | Success Rate |
| ToT | Tree-of-Thought |
| XR | Extended Reality |
References
- Williams, K.L. The Role of Data in Artificial Intelligence: Informing, Training, and Enhancing AI Systems. In Proceedings of the International Conference on Information Technology-New Generations, Las Vegas, NV, USA, 27–29 April 2005; Springer: Berlin/Heidelberg, Germany, 2025; pp. 107–116. [Google Scholar]
- Ghaisas, S.; Singhal, A. Dealing with Data for RE: Mitigating Challenges while using NLP and Generative AI. In Handbook on Natural Language Processing for Requirements Engineering; Springer: Berlin/Heidelberg, Germany, 2025; pp. 457–486. [Google Scholar]
- Houenou, B. AI Labor Markets: Tradability, Wage Inequality and Talent Development. Available online: https://ssrn.com/abstract=5163063 (accessed on 31 July 2025).
- Haq, M.U.U.; Rigoni, D.; Sperduti, A. LLMs as Data Annotators: How Close Are We to Human Performance. arXiv 2025, arXiv:2504.15022. [Google Scholar] [CrossRef]
- Mirzakhmedova, N.; Gohsen, M.; Chang, C.H.; Stein, B. Are Large Language Models Reliable Argument Quality Annotators? In Proceedings of the Conference on Advances in Robust Argumentation Machines, Bielefeld, Germany, 5–7 June 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 129–146. [Google Scholar]
- Zhu, Y.; Yin, Z.; Tyson, G.; Haq, E.U.; Lee, L.H.; Hui, P. Apt-pipe: A prompt-tuning tool for social data annotation using chatgpt. In Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; pp. 245–255. [Google Scholar]
- Yao, B.; Xiao, H.; Zhuang, J.; Peng, C. Weakly supervised learning for point cloud semantic segmentation with dual teacher. IEEE Robot. Autom. Lett. 2023, 8, 6347–6354. [Google Scholar] [CrossRef]
- Sun, G.; Zhan, X.; Such, J. Building better ai agents: A provocation on the utilisation of persona in llm-based conversational agents. In Proceedings of the 6th ACM Conference on Conversational User Interfaces, Luxembourg, 8–10 July 2024; pp. 1–6. [Google Scholar]
- Zhang, L.; Zhang, Q.; Wang, H.; Xiao, E.; Jiang, Z.; Chen, H.; Xu, R. Trihelper: Zero-shot object navigation with dynamic assistance. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, UAE, 14–18 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 10035–10042. [Google Scholar]
- Gottipati, S.K.; Nguyen, L.H.; Mars, C.; Taylor, M.E. Hiking up that hill with cogment-verse: Train & operate multi-agent systems learning from humans. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, London, UK, 29 May–2 June 2023; pp. 3065–3067. [Google Scholar]
- Tsiakas, K.; Murray-Rust, D. Using human-in-the-loop and explainable AI to envisage new future work practices. In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 29 June–1 July 2022; pp. 588–594. [Google Scholar]
- Yuan, S.; Chen, Z.; Xi, Z.; Ye, J.; Du, Z.; Chen, J. Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training. arXiv 2025, arXiv:2501.11425. [Google Scholar]
- Renze, M.; Guven, E. Self-reflection in llm agents: Effects on problem-solving performance. arXiv 2024, arXiv:2405.06682. [Google Scholar]
- Grötschla, F.; Müller, L.; Tönshoff, J.; Galkin, M.; Perozzi, B. AgentsNet: Coordination and Collaborative Reasoning in Multi-Agent LLMs. arXiv 2025, arXiv:2507.08616. [Google Scholar]
- Wu, Q.; Bansal, G.; Zhang, J.; Wu, Y.; Li, B.; Zhu, E.; Jiang, L.; Zhang, X.; Zhang, S.; Liu, J.; et al. Autogen: Enabling next-gen LLM applications via multi-agent conversations. In Proceedings of the First Conference on Language Modeling, Philadelphia, PA, USA, 7–9 October 2024. [Google Scholar]
- Park, J.S.; O’Brien, J.; Cai, C.J.; Morris, M.R.; Liang, P.; Bernstein, M.S. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual Acm Symposium on User Interface Software and Technology, Francisco, CA, USA, 29 October–1 November 2023; pp. 1–22. [Google Scholar]
- Lewis, P.R.; Sarkadi, Ş. Reflective artificial intelligence. Minds Mach. 2024, 34, 14. [Google Scholar] [CrossRef]
- Chu, S.Y.; Kim, J.W.; Yi, M.Y. Think together and work better: Combining humans’ and LLMs’ think-aloud outcomes for effective text evaluation. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025; pp. 1–23. [Google Scholar]
- Nathani, D.; Madaan, L.; Roberts, N.; Bashlykov, N.; Menon, A.; Moens, V.; Budhiraja, A.; Magka, D.; Vorotilov, V.; Chaurasia, G.; et al. Mlgym: A new framework and benchmark for advancing ai research agents. arXiv 2025, arXiv:2502.14499. [Google Scholar]
- Yu, A.; Lebedev, E.; Everett, L.; Chen, X.; Chen, T. Autonomous Deep Agent. arXiv 2025, arXiv:2502.07056. [Google Scholar]
- Demrozi, F.; Turetta, C.; Machot, F.A.; Pravadelli, G.; Kindt, P.H. A comprehensive review of automated data annotation techniques in human activity recognition. arXiv 2023, arXiv:2307.05988. [Google Scholar] [CrossRef]
- Zhou, Y.; Guo, C.; Wang, X.; Chang, Y.; Wu, Y. A survey on data augmentation in large model era. arXiv 2024, arXiv:2401.15422. [Google Scholar] [CrossRef]
- Wang, K.; Zhu, J.; Ren, M.; Liu, Z.; Li, S.; Zhang, Z.; Zhang, C.; Wu, X.; Zhan, Q.; Liu, Q.; et al. A survey on data synthesis and augmentation for large language models. arXiv 2024, arXiv:2410.12896. [Google Scholar] [CrossRef]
- Tan, Z.; Beigi, A.; Wang, S.; Guo, R.; Bhattacharjee, A.; Jiang, B.; Karami, M.; Li, J.; Cheng, L.; Liu, H. Large language models for data annotation: A survey. arXiv 2024, arXiv:2402.13446. [Google Scholar] [CrossRef]
- Xi, Z.; Chen, W.; Guo, X.; He, W.; Ding, Y.; Hong, B.; Zhang, M.; Wang, J.; Jin, S.; Zhou, E.; et al. The rise and potential of large language model based agents: A survey. Sci. China Inf. Sci. 2025, 68, 121101. [Google Scholar] [CrossRef]
- Hiniduma, K.; Byna, S.; Bez, J.L. Data readiness for AI: A 360-degree survey. ACM Comput. Surv. 2025, 57, 1–39. [Google Scholar] [CrossRef]
- Zha, D.; Bhat, Z.P.; Lai, K.H.; Yang, F.; Jiang, Z.; Zhong, S.; Hu, X. Data-centric artificial intelligence: A survey. ACM Comput. Surv. 2025, 57, 1–42. [Google Scholar] [CrossRef]
- Liang, W.; Tadesse, G.A.; Ho, D.; Fei-Fei, L.; Zaharia, M.; Zhang, C.; Zou, J. Advances, challenges and opportunities in creating data for trustworthy AI. Nat. Mach. Intell. 2022, 4, 669–677. [Google Scholar] [CrossRef]
- Cao, Y.; Hong, S.; Li, X.; Ying, J.; Ma, Y.; Liang, H.; Liu, Y.; Yao, Z.; Wang, X.; Huang, D.; et al. Toward generalizable evaluation in the llm era: A survey beyond benchmarks. arXiv 2025, arXiv:2504.18838. [Google Scholar] [CrossRef]
- Xu, F.; Hao, Q.; Zong, Z.; Wang, J.; Zhang, Y.; Wang, J.; Lan, X.; Gong, J.; Ouyang, T.; Meng, F.; et al. Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models. arXiv 2025, arXiv:2501.09686. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N.A.; Khashabi, D.; Hajishirzi, H. Self-instruct: Aligning language models with self-generated instructions. arXiv 2022, arXiv:2212.10560. [Google Scholar]
- Zhu, K.; Wang, J.; Zhou, J.; Wang, Z.; Chen, H.; Wang, Y.; Yang, L.; Ye, W.; Zhang, Y.; Zhenqiang Gong, N.; et al. Promptbench: Towards evaluating the robustness of large language models on adversarial prompts. arXiv 2023, arXiv:2306.04528. [Google Scholar] [CrossRef]
- Estévez-Almenzar, M.; Baeza-Yates, R.; Castillo, C. A Comparison of Human and Machine Learning Errors in Face Recognition. arXiv 2025, arXiv:2502.11337. [Google Scholar]
- Wei, J.; Zhu, Z.; Luo, T.; Amid, E.; Kumar, A.; Liu, Y. To aggregate or not? learning with separate noisy labels. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 2523–2535. [Google Scholar]
- Nasution, A.H.; Onan, A. Chatgpt label: Comparing the quality of human-generated and llm-generated annotations in low-resource language nlp tasks. IEEE Access 2024, 12, 71876–71900. [Google Scholar] [CrossRef]
- Mamat, N.; Othman, M.F.; Abdoulghafor, R.; Belhaouari, S.B.; Mamat, N.; Mohd Hussein, S.F. Advanced technology in agriculture industry by implementing image annotation technique and deep learning approach: A review. Agriculture 2022, 12, 1033. [Google Scholar] [CrossRef]
- Nadisic, N.; Arhant, Y.; Vyncke, N.; Verplancke, S.; Lazendić, S.; Pižurica, A. A Deep Active Learning Framework for Crack Detection in Digital Images of Paintings. Procedia Struct. Integr. 2024, 64, 2173–2180. [Google Scholar] [CrossRef]
- Newman, J.; Cox, C. Corpus annotation. In A Practical Handbook of Corpus Linguistics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 25–48. [Google Scholar]
- Yang, C.; Sheng, L.; Wei, Z.; Wang, W. Chinese named entity recognition of epidemiological investigation of information on COVID-19 based on BERT. IEEE Access 2022, 10, 104156–104168. [Google Scholar] [CrossRef]
- Kumar, M.P.; Tu, Z.X.; Chen, H.C.; Chen, K.C. Enhancing Learning in Fine-Tuned Transfer Learning for Rotating Machinery via Negative Transfer Mitigation. IEEE Trans. Instrum. Meas. 2024, 73, 2533613. [Google Scholar] [CrossRef]
- Tu, S.; Sun, J.; Zhang, Q.; Lan, X.; Zhao, D. Online Preference-based Reinforcement Learning with Self-augmented Feedback from Large Language Model. arXiv 2024, arXiv:2412.16878. [Google Scholar]
- Acharya, D.B.; Kuppan, K.; Divya, B. Agentic AI: Autonomous Intelligence for Complex Goals–A Comprehensive Survey. IEEE Access 2025, 13, 18912–18936. [Google Scholar] [CrossRef]
- Osakwe, I.; Chen, G.; Fan, Y.; Rakovic, M.; Singh, S.; Lim, L.; Van Der Graaf, J.; Moore, J.; Molenaar, I.; Bannert, M.; et al. Towards prescriptive analytics of self-regulated learning strategies: A reinforcement learning approach. Br. J. Educ. Technol. 2024, 55, 1747–1771. [Google Scholar] [CrossRef]
- Bianchini, F.; Calamo, M.; De Luzi, F.; Macrì, M.; Marinacci, M.; Mathew, J.G.; Monti, F.; Rossi, J.; Leotta, F.; Mecella, M. SAMBA: A reference framework for Human-in-the-Loop in adaptive Smart Manufacturing. Procedia Comput. Sci. 2025, 253, 2257–2267. [Google Scholar] [CrossRef]
- Karim, M.M.; Van, D.H.; Khan, S.; Qu, Q.; Kholodov, Y. AI Agents Meet Blockchain: A Survey on Secure and Scalable Collaboration for Multi-Agents. Future Internet 2025, 17, 57. [Google Scholar] [CrossRef]
- Dong, X.; Zhang, X.; Bu, W.; Zhang, D.; Cao, F. A Survey of LLM-based Agents: Theories, Technologies, Applications and Suggestions. In Proceedings of the 2024 3rd International Conference on Artificial Intelligence, Internet of Things and Cloud Computing Technology (AIoTC), Wuhan, China, 13–15 September 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 407–413. [Google Scholar]
- Huang, Y. Levels of AI agents: From rules to large language models. arXiv 2024, arXiv:2405.06643. [Google Scholar]
- Boyina, K.; Reddy, G.M.; Akshita, G.; Nair, P.C. Zero-Shot and Few-Shot Learning for Telugu News Classification: A Large Language Model Approach. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Faggioli, G.; Dietz, L.; Clarke, C.L.; Demartini, G.; Hagen, M.; Hauff, C.; Kando, N.; Kanoulas, E.; Potthast, M.; Stein, B.; et al. Perspectives on large language models for relevance judgment. In Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval, Taipei, Taiwan, 23 July 2023; pp. 39–50. [Google Scholar]
- Alizadeh, M.; Kubli, M.; Samei, Z.; Dehghani, S.; Zahedivafa, M.; Bermeo, J.D.; Korobeynikova, M.; Gilardi, F. Open-source LLMs for text annotation: A practical guide for model setting and fine-tuning. J. Comput. Soc. Sci. 2025, 8, 17. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Kim, H.; Rahman, S.; Mitra, K.; Miao, Z. Human-llm collaborative annotation through effective verification of llm labels. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–21. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Smola, A. Automatic chain of thought prompting in large language models. arXiv 2022, arXiv:2210.03493. [Google Scholar] [CrossRef]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. React: Synergizing reasoning and acting in language models. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Groeneveld, J.; Herrmann, J.; Mollenhauer, N.; Dreeßen, L.; Bessin, N.; Tast, J.S.; Kastius, A.; Huegle, J.; Schlosser, R. Self-learning agents for recommerce markets. Bus. Inf. Syst. Eng. 2024, 66, 441–463. [Google Scholar] [CrossRef]
- Ransiek, J.; Reis, P.; Sax, E. Adversarial and Reactive Traffic Agents for Realistic Driving Simulation. arXiv 2024, arXiv:2409.14196. [Google Scholar] [CrossRef]
- Monadjemi, S.; Guo, M.; Gotz, D.; Garnett, R.; Ottley, A. Human–Computer Collaboration for Visual Analytics: An Agent-based Framework. In Proceedings of the Computer Graphics Forum, Delft, The Netherlands, 28–30 June 2023; Wiley Online Library: Hoboken, NJ, USA, 2023; Volume 42, pp. 199–210. [Google Scholar]
- Joshi, R.; Pandey, K.; Kumari, S.; Badola, R. Artificial Intelligence: A Gateway to the Twenty-First Century. In The Intersection of 6G, AI/Machine Learning, and Embedded Systems; CRC Press: Boca Raton, FL, USA, 2025; pp. 146–172. [Google Scholar]
- Macedo, L. Artificial Intelligence Paradigms and Agent-Based Technologies. In Human-Centered AI: An Illustrated Scientific Quest; Springer: Berlin/Heidelberg, Germany, 2025; pp. 363–397. [Google Scholar]
- Roby, M. Learning and Reasoning Using Artificial Intelligence. In Machine Intelligence; Auerbach Publications: Abingdon-on-Thames, UK, 2023; pp. 237–256. [Google Scholar]
- Sapkota, R.; Roumeliotis, K.I.; Karkee, M. AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenge. arXiv 2025, arXiv:2505.10468. [Google Scholar] [CrossRef]
- Rodríguez-Barroso, N.; Cámara, E.M.; Collados, J.C.; Luzón, M.V.; Herrera, F. Federated Learning for Exploiting Annotators’ Disagreements in Natural Language Processing. Trans. Assoc. Comput. Linguist. 2024, 12, 630–648. [Google Scholar] [CrossRef]
- Azeemi, A.H.; Qazi, I.A.; Raza, A.A. Language Model-Driven Data Pruning Enables Efficient Active Learning. arXiv 2024, arXiv:2410.04275. [Google Scholar] [CrossRef]
- Bayer, M.; Reuter, C. Activellm: Large language model-based active learning for textual few-shot scenarios. arXiv 2024, arXiv:2405.10808. [Google Scholar]
- Zhu, Q.; Mao, Q.; Zhang, J.; Huang, X.; Zheng, W. Towards a robust group-level emotion recognition via uncertainty-aware learning. IEEE Trans. Affect. Comput. 2025. [Google Scholar] [CrossRef]
- Mishra, S.; Shinde, M.; Yadav, A.; Ayyub, B.; Rao, A. An AI-Driven Data Mesh Architecture Enhancing Decision-Making in Infrastructure Construction and Public Procurement. arXiv 2024, arXiv:2412.00224. [Google Scholar]
- Puerta-Beldarrain, M.; Gómez-Carmona, O.; Sánchez-Corcuera, R.; Casado-Mansilla, D.; López-de Ipiña, D.; Chen, L. A multifaceted vision of the Human-AI collaboration: A comprehensive review. IEEE Access 2025, 13, 29375–29405. [Google Scholar] [CrossRef]
- Zhang, R.; Li, Y.; Ma, Y.; Zhou, M.; Zou, L. Llmaaa: Making large language models as active annotators. arXiv 2023, arXiv:2310.19596. [Google Scholar] [CrossRef]
- Xia, Y.; Mukherjee, S.; Xie, Z.; Wu, J.; Li, X.; Aponte, R.; Lyu, H.; Barrow, J.; Chen, H.; Dernoncourt, F.; et al. From Selection to Generation: A Survey of LLM-based Active Learning. arXiv 2025, arXiv:2502.11767. [Google Scholar]
- Li, X.; Whan, A.; McNeil, M.; Starns, D.; Irons, J.; Andrew, S.C.; Suchecki, R. A Conceptual Framework for Human-AI Collaborative Genome Annotation. arXiv 2025, arXiv:2503.23691. [Google Scholar] [CrossRef] [PubMed]
- Croxford, E.; Gao, Y.; Pellegrino, N.; Wong, K.; Wills, G.; First, E.; Liao, F.; Goswami, C.; Patterson, B.; Afshar, M. Current and future state of evaluation of large language models for medical summarization tasks. NPJ Health Syst. 2025, 2, 6. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Sun, X.; Li, H.; Xu, R.; Wei, X. Difficulty aware programming knowledge tracing via large language models. Sci. Rep. 2025, 15, 11475. [Google Scholar] [CrossRef]
- Sainz, O.; García-Ferrero, I.; Agerri, R.; de Lacalle, O.L.; Rigau, G.; Agirre, E. Gollie: Annotation guidelines improve zero-shot information-extraction. arXiv 2023, arXiv:2310.03668. [Google Scholar]
- Bibal, A.; Gerlek, N.; Muric, G.; Boschee, E.; Fincke, S.C.; Ross, M.; Minton, S.N. Automating Annotation Guideline Improvements using LLMs: A Case Study. In Proceedings of the Context and Meaning: Navigating Disagreements in NLP Annotation, Abu Dhabi, UAE, 19 January 2025; pp. 129–144. [Google Scholar]
- Rodler, P.; Shchekotykhin, K.; Fleiss, P.; Friedrich, G. RIO: Minimizing user interaction in ontology debugging. arXiv 2012, arXiv:1209.3734. [Google Scholar] [CrossRef]
- Zheng, J.; Shi, C.; Cai, X.; Li, Q.; Zhang, D.; Li, C.; Yu, D.; Ma, Q. Lifelong Learning of Large Language Model based Agents: A Roadmap. arXiv 2025, arXiv:2501.07278. [Google Scholar] [CrossRef]
- Zhang, G.; Liang, W.; Hsu, O.; Olukotun, K. Adaptive Self-improvement LLM Agentic System for ML Library Development. arXiv 2025, arXiv:2502.02534. [Google Scholar]
- Ashktorab, Z.; Pan, Q.; Geyer, W.; Desmond, M.; Danilevsky, M.; Johnson, J.M.; Dugan, C.; Bachman, M. Emerging Reliance Behaviors in Human-AI Text Generation: Hallucinations, Data Quality Assessment, and Cognitive Forcing Functions. arXiv 2024, arXiv:2409.08937. [Google Scholar] [CrossRef]
- Wang, X.; Hu, J.; Ali, S. MAATS: A Multi-Agent Automated Translation System Based on MQM Evaluation. arXiv 2025, arXiv:2505.14848. [Google Scholar] [CrossRef]
- Ara, Z.; Salemi, H.; Hong, S.R.; Senarath, Y.; Peterson, S.; Hughes, A.L.; Purohit, H. Closing the Knowledge Gap in Designing Data Annotation Interfaces for AI-powered Disaster Management Analytic Systems. In Proceedings of the 29th International Conference on Intelligent User Interfaces, Greenville, SC, USA, 18–21 March 2024; pp. 405–418. [Google Scholar]
- Cronin, I. Autonomous AI agents: Decision-making, data, and algorithms. In Understanding Generative AI Business Applications: A Guide to Technical Principles and Real-World Applications; Springer: Berlin/Heidelberg, Germany, 2024; pp. 165–180. [Google Scholar]
- Upadhyay, R.; Phlypo, R.; Saini, R.; Liwicki, M. Sharing to learn and learning to share; fitting together meta, multi-task, and transfer learning: A meta review. IEEE Access 2024, 12, 148553–148576. [Google Scholar] [CrossRef]
- Liu, C.; Kang, Y.; Zhao, F.; Kuang, K.; Jiang, Z.; Sun, C.; Wu, F. Evolving knowledge distillation with large language models and active learning. arXiv 2024, arXiv:2403.06414. [Google Scholar] [CrossRef]
- Ding, B.; Qin, C.; Zhao, R.; Luo, T.; Li, X.; Chen, G.; Xia, W.; Hu, J.; Tuan, L.A.; Joty, S. Data augmentation using llms: Data perspectives, learning paradigms and challenges. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 1679–1705. [Google Scholar]
- Törnberg, P. Chatgpt-4 outperforms experts and crowd workers in annotating political twitter messages with zero-shot learning. arXiv 2023, arXiv:2304.06588. [Google Scholar]
- Choi, J.; Yun, J.; Jin, K.; Kim, Y. Multi-news+: Cost-efficient dataset cleansing via llm-based data annotation. arXiv 2024, arXiv:2404.09682. [Google Scholar]
- Nahum, O.; Calderon, N.; Keller, O.; Szpektor, I.; Reichart, R. Are LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Model Performance. arXiv 2024, arXiv:2410.18889. [Google Scholar] [CrossRef]
- Gat, Y.; Calderon, N.; Feder, A.; Chapanin, A.; Sharma, A.; Reichart, R. Faithful explanations of black-box nlp models using llm-generated counterfactuals. arXiv 2023, arXiv:2310.00603. [Google Scholar]
- Kumar, S.; Datta, S.; Singh, V.; Datta, D.; Singh, S.K.; Sharma, R. Applications, challenges, and future directions of human-in-the-loop learning. IEEE Access 2024, 12, 75735–75760. [Google Scholar] [CrossRef]
- Schleiger, E.; Mason, C.; Naughtin, C.; Reeson, A.; Paris, C. Collaborative Intelligence: A scoping review of current applications. Appl. Artif. Intell. 2024, 38, 2327890. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Li, P.; Liu, Y.; Yang, D. A dynamic LLM-powered agent network for task-oriented agent collaboration. In Proceedings of the First Conference on Language Modeling, Philadelphia, PA, USA, 7–9 October 2024. [Google Scholar]
- Yang, J.; Ding, R.; Brown, E.; Qi, X.; Xie, S. V-irl: Grounding virtual intelligence in real life. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 36–55. [Google Scholar]
- Madaan, A.; Tandon, N.; Gupta, P.; Hallinan, S.; Gao, L.; Wiegreffe, S.; Alon, U.; Dziri, N.; Prabhumoye, S.; Yang, Y.; et al. Self-refine: Iterative refinement with self-feedback. Adv. Neural Inf. Process. Syst. 2023, 36, 46534–46594. [Google Scholar]
- Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language agents with verbal reinforcement learning. Adv. Neural Inf. Process. Syst. 2023, 36, 8634–8652. [Google Scholar]
- Li, D.; Li, Y.; Mekala, D.; Li, S.; Wang, X.; Hogan, W.; Shang, J. DAIL: Data Augmentation for In-Context Learning via Self-Paraphrase. arXiv 2025, arXiv:2311.03319. [Google Scholar]
- Bubeck, S.; Chadrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of artificial general intelligence: Early experiments with GPT-4. arXiv 2023, arXiv:2303.12712. [Google Scholar] [CrossRef]
- Chen, Y.; Si, M. Reflections & Resonance: Two-Agent Partnership for Advancing LLM-based Story Annotation. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italia, 20–25 May 2024; pp. 13813–13818. [Google Scholar]
- Cohen, R.; Hamri, M.; Geva, M.; Globerson, A. Lm vs lm: Detecting factual errors via cross examination. arXiv 2023, arXiv:2305.13281. [Google Scholar] [CrossRef]
- Bandlamudi, J.; Mukherjee, K.; Agarwal, P.; Chaudhuri, R.; Pimplikar, R.; Dechu, S.; Straley, A.; Ponniah, A.; Sindhgatta, R. Framework to enable and test conversational assistant for APIs and RPAs. AI Mag. 2024, 45, 443–456. [Google Scholar] [CrossRef]
- Hong, S.; Zheng, X.; Chen, J.; Cheng, Y.; Wang, J.; Zhang, C.; Wang, Z.; Yau, S.K.S.; Lin, Z.; Zhou, L.; et al. Metagpt: Meta programming for multi-agent collaborative framework. arXiv 2025, arXiv:2308.00352 . [Google Scholar]
- Qian, C.; Liu, W.; Liu, H.; Chen, N.; Dang, Y.; Li, J.; Yang, C.; Chen, W.; Su, Y.; Cong, X.; et al. Chatdev: Communicative agents for software development. arXiv 2023, arXiv:2307.07924. [Google Scholar]
- Lin, M.; Chen, Z.; Liu, Y.; Zhao, X.; Wu, Z.; Wang, J.; Zhang, X.; Wang, S.; Chen, H. Decoding Time Series with LLMs: A Multi-Agent Framework for Cross-Domain Annotation. arXiv 2024, arXiv:2410.17462. [Google Scholar]
- Alam, F.; Biswas, M.R.; Shah, U.; Zaghouani, W.; Mikros, G. Propaganda to Hate: A Multimodal Analysis of Arabic Memes with Multi-agent LLMs. In Proceedings of the International Conference on Web Information Systems Engineering, Doha, Qatar, 2–5 December 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 380–390. [Google Scholar]
- Liu, W.; Chang, W.; Shi, C.; Wang, Y.; Hu, R.; Zhang, C.; Ouyang, H. Research on Intelligent Agent Technology and Applications Based on Large Models. In Proceedings of the 2024 IEEE 4th International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 6–8 December 2024; IEEE: Piscataway, NJ, USA, 2024; Volume 4, pp. 466–472. [Google Scholar]
- Li, M.; Shi, T.; Ziems, C.; Kan, M.Y.; Chen, N.F.; Liu, Z.; Yang, D. Coannotating: Uncertainty-guided work allocation between human and large language models for data annotation. arXiv 2023, arXiv:2310.15638. [Google Scholar]
- Colucci Cante, L.; D’Angelo, S.; Di Martino, B.; Graziano, M. Text Annotation Tools: A Comprehensive Review and Comparative Analysis. In Proceedings of the International Conference on Complex, Intelligent, and Software Intensive Systems, Taichung, Taiwan, 3–5 July 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 353–362. [Google Scholar]
- Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al. Agentbench: Evaluating llms as agents. arXiv 2023, arXiv:2308.03688. [Google Scholar] [CrossRef]
- Verma, G.; Kaur, R.; Srishankar, N.; Zeng, Z.; Balch, T.; Veloso, M. Adaptagent: Adapting multimodal web agents with few-shot learning from human demonstrations. arXiv 2024, arXiv:2411.13451. [Google Scholar]
- Schmidt, S.; Stappen, L.; Schwinn, L.; Günnemann, S. Generalized Synchronized Active Learning for Multi-Agent-Based Data Selection on Mobile Robotic Systems. IEEE Robot. Autom. Lett. 2024, 9, 8659–8666. [Google Scholar] [CrossRef]
- Wan, M.; Safavi, T.; Jauhar, S.K.; Kim, Y.; Counts, S.; Neville, J.; Suri, S.; Shah, C.; White, R.W.; Yang, L.; et al. Tnt-llm: Text mining at scale with large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 5836–5847. [Google Scholar]
- Tutul, A.A.; Nirjhar, E.H.; Chaspari, T. Investigating trust in human-AI collaboration for a speech-based data analytics task. Int. J. Hum. Comput. Interact. 2025, 41, 2936–2954. [Google Scholar] [CrossRef]
- Bolock, A.e.; Abouras, M.; Sabty, C.; Abdennadher, S.; Herbert, C. CARE: A Framework for Collecting and Annotating Emotions of Code-Switched Words. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Salamanca, Spain, 26–28 June 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 104–116. [Google Scholar]
- Qu, Q.; Liu, S.; Zhu, F.; Jensen, C.S. Efficient online summarization of large-scale dynamic networks. IEEE Trans. Knowl. Data Eng. 2016, 28, 3231–3245. [Google Scholar] [CrossRef]
- Hadian, A.; Nobari, S.; Minaei-Bidgoli, B.; Qu, Q. Roll: Fast in-memory generation of gigantic scale-free networks. In Proceedings of the 2016 International Conference on Management of Data, Francisco, CA, USA, 26 June–1 July 2016; pp. 1829–1842. [Google Scholar]
- Chang, C.M.; He, Y.; Du, X.; Yang, X.; Xie, H. Dynamic labeling: A control system for labeling styles in image annotation tasks. In Proceedings of the International Conference on Human-Computer Interaction, Washington, DC, USA, 29 June–4 July 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 99–118. [Google Scholar]
- Efrat, A.; Levy, O. The turking test: Can language models understand instructions? arXiv 2020, arXiv:2010.11982. [Google Scholar] [CrossRef]
- Zhao, Z.; Wallace, E.; Feng, S.; Klein, D.; Singh, S. Calibrate before use: Improving few-shot performance of language models. In Proceedings of the International Conference on Machine Learning. PMLR, Online, 18–24 July 2021; pp. 12697–12706. [Google Scholar]
- Smith, A.G.; Han, E.; Petersen, J.; Olsen, N.A.F.; Giese, C.; Athmann, M.; Dresbøll, D.B.; Thorup-Kristensen, K. RootPainter: Deep learning segmentation of biological images with corrective annotation. New Phytol. 2022, 236, 774–791. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Hessel, J.; Jiang, L.; West, P.; Lu, X.; Yu, Y.; Zhou, P.; Bras, R.L.; Alikhani, M.; Kim, G.; et al. Soda: Million-scale dialogue distillation with social commonsense contextualization. arXiv 2022, arXiv:2212.10465. [Google Scholar]
- Ho, N.; Schmid, L.; Yun, S.Y. Large language models are reasoning teachers. arXiv 2022, arXiv:2212.10071. [Google Scholar]
- Wu, T.; Yuan, W.; Golovneva, O.; Xu, J.; Tian, Y.; Jiao, J.; Weston, J.; Sukhbaatar, S. Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge. arXiv 2024, arXiv:2407.19594. [Google Scholar]
- Kang, H.J.; Harel-Canada, F.; Gulzar, M.A.; Peng, V.; Kim, M. Human-in-the-Loop Synthetic Text Data Inspection with Provenance Tracking. arXiv 2024, arXiv:2404.18881. [Google Scholar]
- Wu, J.; Deng, J.; Pang, S.; Chen, Y.; Xu, J.; Li, X.; Xu, W. Legilimens: Practical and unified content moderation for large language model services. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, Salt Lake City, UT, USA, 14–18 October 2024; pp. 1151–1165. [Google Scholar]
- Palla, K.; García, J.L.R.; Hauff, C.; Fabbri, F.; Lindström, H.; Taber, D.R.; Damianou, A.; Lalmas, M. Policy-as-Prompt: Rethinking Content Moderation in the Age of Large Language Models. arXiv 2025, arXiv:2502.18695. [Google Scholar]
- Wang, Y.; Zhong, W.; Li, L.; Mi, F.; Zeng, X.; Huang, W.; Shang, L.; Jiang, X.; Liu, Q. Aligning large language models with human: A survey. arXiv 2023, arXiv:2307.12966. [Google Scholar] [CrossRef]
- Wu, S.; Fung, M.; Qian, C.; Kim, J.; Hakkani-Tur, D.; Ji, H. Aligning LLMs with Individual Preferences via Interaction. arXiv 2024, arXiv:2410.03642. [Google Scholar] [CrossRef]
- Huang, M.; Jiang, Q.; Qu, Q.; Chen, L.; Chen, H. Information fusion oriented heterogeneous social network for friend recommendation via community detection. Appl. Soft Comput. 2022, 114, 108103. [Google Scholar] [CrossRef]
- Bojić, L.; Zagovora, O.; Zelenkauskaite, A.; Vuković, V.; Čabarkapa, M.; Veseljević Jerković, S.; Jovančević, A. Comparing large Language models and human annotators in latent content analysis of sentiment, political leaning, emotional intensity and sarcasm. Sci. Rep. 2025, 15, 11477. [Google Scholar] [CrossRef]
- Harrer, S.; Rane, R.V.; Speight, R.E. Generative AI agents are transforming biology research: High resolution functional genome annotation for multiscale understanding of life. EBioMedicine 2024, 109, 105446. [Google Scholar] [CrossRef] [PubMed]
- Toubal, I.E.; Avinash, A.; Alldrin, N.G.; Dlabal, J.; Zhou, W.; Luo, E.; Stretcu, O.; Xiong, H.; Lu, C.T.; Zhou, H.; et al. Modeling collaborator: Enabling subjective vision classification with minimal human effort via llm tool-use. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17553–17563. [Google Scholar]
- Beck, J.; Kemeter, L.M.; Dürrbeck, K.; Abdalla, M.H.I.; Kreuter, F. Towards Integrating ChatGPT into Satellite Image Annotation Workflows. A Comparison of Label Quality and Costs of Human and Automated Annotators. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 4366–4381. [Google Scholar] [CrossRef]
- Qu, Q.; Liu, S.; Yang, B.; Jensen, C.S. Efficient top-k spatial locality search for co-located spatial web objects. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management, Brisbane, Australia, 14–18 July 2014; IEEE: Piscataway, NJ, USA, 2014; Volume 1, pp. 269–278. [Google Scholar]
- Cao, X.; Chen, L.; Cong, G.; Jensen, C.S.; Qu, Q.; Skovsgaard, A.; Wu, D.; Yiu, M.L. Spatial keyword querying. In Proceedings of the Conceptual Modeling: 31st International Conference ER 2012, Florence, Italy, 15–18 October 2012; Proceedings 31. Springer: Berlin/Heidelberg, Germany, 2012; pp. 16–29. [Google Scholar]
- Tsiakas, K.; Murray-Rust, D. Unpacking Human-AI interactions: From interaction primitives to a design space. ACM Trans. Interact. Intell. Syst. 2024, 14, 1–51. [Google Scholar] [CrossRef]
- Yuan, H. Agentic Large Language Models for Healthcare: Current Progress and Future Opportunities. Med. Adv. 2025, 3, 37–41. [Google Scholar] [CrossRef]
- Qu, Q.; Chen, C.; Jensen, C.S.; Skovsgaard, A. Space-Time Aware Behavioral Topic Modeling for Microblog Posts. IEEE Data Eng. Bull. 2015, 38, 58–67. [Google Scholar]
- Kim, H.; Mitra, K.; Chen, R.L.; Rahman, S.; Zhang, D. Meganno+: A human-llm collaborative annotation system. arXiv 2024, arXiv:2402.18050. [Google Scholar]
- El Khoury, K.; Godelaine, T.; Delvaux, S.; Lugan, S.; Macq, B. Streamlined hybrid annotation framework using scalable codestream for bandwidth-restricted uav object detection. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, UAE, 27–30 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1581–1587. [Google Scholar]
- Chen, Z.Z.; Ma, J.; Zhang, X.; Hao, N.; Yan, A.; Nourbakhsh, A.; Yang, X.; McAuley, J.; Petzold, L.; Wang, W.Y. A survey on large language models for critical societal domains: Finance, healthcare, and law. arXiv 2024, arXiv:2405.01769. [Google Scholar] [CrossRef]
- Lazo, G.R.; Ayyappan, D.; Sharma, P.K.; Tiwari, V.K. Contextual Science and Genome Analysis for Air-Gapped AI Research. bioRxiv 2025. [Google Scholar] [CrossRef]
- Olawore, K.; McTear, M.; Bi, Y. Development and Evaluation of a University Chatbot Using Deep Learning: A RAG-Based Approach. In Proceedings of the International Symposium on Chatbots and Human-Centered AI, Thessaloniki, Greece, 4–5 December 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 96–111. [Google Scholar]
- Li, J. A comparative study on annotation quality of crowdsourcing and LLM via label aggregation. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 6525–6529. [Google Scholar]
- Zhou, Y.; Cheng, X.; Zhang, Q.; Wang, L.; Ding, W.; Xue, X.; Luo, C.; Pu, J. ALGPT: Multi-Agent Cooperative Framework for Open-Vocabulary Multi-Modal Auto-Annotating in Autonomous Driving. IEEE Trans. Intell. Veh. 2024, 1–15. [Google Scholar] [CrossRef]
- Mots’ oehli, M. Assistive Image Annotation Systems with Deep Learning and Natural Language Capabilities: A Review. In Proceedings of the 2024 International Conference on Emerging Trends in Networks and Computer Communications (ETNCC), Windhoek, Namibia, 23–25 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–9. [Google Scholar]
- Mazhar, A.; Shaik, Z.H.; Srivastava, A.; Ruhnke, P.; Vaddavalli, L.; Katragadda, S.K.; Yadav, S.; Akhtar, M.S. Figurative-cum-Commonsense Knowledge Infusion for Multimodal Mental Health Meme Classification. In Proceedings of the ACM on Web Conference 2025, Sydney, Australia, 28 April–2 May 2025; pp. 637–648. [Google Scholar]
- Sandhu, R.; Channi, H.K.; Ghai, D.; Cheema, G.S.; Kaur, M. An introduction to generative AI tools for education 2030. Integr. Gener. Educ. Achieve Sustain. Dev. Goals 2024, 1–28. [Google Scholar] [CrossRef]
- Ming, X.; Li, S.; Li, M.; He, L.; Wang, Q. AutoLabel: Automated Textual Data Annotation Method Based on Active Learning and Large Language Model. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Birmingham, UK, 16–18 August 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 400–411. [Google Scholar]
- Krishnan, N. Advancing Multi-Agent Systems Through Model Context Protocol: Architecture, Implementation, and Applications. arXiv 2025, arXiv:2504.21030. [Google Scholar] [CrossRef]
- Aejas, B.; Belhi, A.; Bouras, A. Toward an nlp approach for transforming paper contracts into smart contracts. In Intelligent Sustainable Systems: Selected Papers of WorldS4 2022, Volume 2; Springer: Berlin/Heidelberg, Germany, 2023; pp. 751–759. [Google Scholar]
- Kastrati, M.; Imran, A.S.; Hashmi, E.; Kastrati, Z.; Daudpota, S.M.; Biba, M. Unlocking language barriers: Assessing pre-trained large language models across multilingual tasks and unveiling the black box with Explainable Artificial Intelligence. Eng. Appl. Artif. Intell. 2025, 149, 110136. [Google Scholar] [CrossRef]
- Raza, S.; Chatrath, V. HarmonyNet: Navigating hate speech detection. Nat. Lang. Process. J. 2024, 8, 100098. [Google Scholar] [CrossRef]
- Khanduja, N.; Kumar, N.; Chauhan, A. Telugu language hate speech detection using deep learning transformer models: Corpus generation and evaluation. Syst. Soft Comput. 2024, 6, 200112. [Google Scholar] [CrossRef]
- Kao, J.P.; Kao, H.T. Large Language Models in radiology: A technical and clinical perspective. Eur. J. Radiol. Artif. Intell. 2025, 2, 100021. [Google Scholar] [CrossRef]
- Ostrovsky, A.M. Evaluating a large language model’s accuracy in chest X-ray interpretation for acute thoracic conditions. Am. J. Emerg. Med. 2025, 93, 99–102. [Google Scholar] [CrossRef]
- Almalky, A.M.A.; Zhou, R.; Angizi, S.; Rakin, A.S. How Vulnerable are Large Language Models (LLMs) against Adversarial Bit-Flip Attacks? In Proceedings of the Great Lakes Symposium on VLSI 2025, New Orleans, LA, USA, 30 June–2 July 2025; pp. 534–539. [Google Scholar]
- Zhang, L.; Zou, Q.; Singhal, A.; Sun, X.; Liu, P. Evaluating large language models for real-world vulnerability repair in c/c++ code. In Proceedings of the 10th ACM International Workshop on Security and Privacy Analytics, Porto, Portugal, 21 June 2024; pp. 49–58. [Google Scholar]
- Heo, S.; Son, S.; Park, H. HaluCheck: Explainable and verifiable automation for detecting hallucinations in LLM responses. Expert Syst. Appl. 2025, 272, 126712. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Alwahedi, F.; Battah, A.; Cherif, B.; Mechri, A.; Tihanyi, N.; Bisztray, T.; Debbah, M. Generative ai in cybersecurity: A comprehensive review of llm applications and vulnerabilities. Internet Things-Cyber-Phys. Syst. 2025, 5, 1–46. [Google Scholar] [CrossRef]
- Kaushik, D.; Lipton, Z.C.; London, A.J. Resolving the Human-Subjects Status of ML’s Crowdworkers. Commun. ACM 2024, 67, 52–59. [Google Scholar] [CrossRef]
- Reif, Y.; Schwartz, R. Beyond performance: Quantifying and mitigating label bias in llms. arXiv 2024, arXiv:2405.02743. [Google Scholar] [CrossRef]
- Feretzakis, G.; Papaspyridis, K.; Gkoulalas-Divanis, A.; Verykios, V.S. Privacy-preserving techniques in generative ai and large language models: A narrative review. Information 2024, 15, 697. [Google Scholar] [CrossRef]
- Ullah, I.; Hassan, N.; Gill, S.S.; Suleiman, B.; Ahanger, T.A.; Shah, Z.; Qadir, J.; Kanhere, S.S. Privacy preserving large language models: Chatgpt case study based vision and framework. IET Blockchain 2024, 4, 706–724. [Google Scholar] [CrossRef]
- Templin, T.; Fort, S.; Padmanabham, P.; Seshadri, P.; Rimal, R.; Oliva, J.; Hassmiller Lich, K.; Sylvia, S.; Sinnott-Armstrong, N. Framework for bias evaluation in large language models in healthcare settings. NPJ Digit. Med. 2025, 8, 414. [Google Scholar] [CrossRef]
- Sun, L.; Liu, D.; Wang, M.; Han, Y.; Zhang, Y.; Zhou, B.; Ren, Y.; Zhu, P. Taming unleashed large language models with blockchain for massive personalized reliable healthcare. IEEE J. Biomed. Health Inform. 2025, 29, 4498–4511. [Google Scholar] [CrossRef] [PubMed]
- Moreno-Sánchez, P.A.; Del Ser, J.; van Gils, M.; Hernesniemi, J. A Design Framework for operationalizing Trustworthy Artificial Intelligence in Healthcare: Requirements, Tradeoffs and Challenges for its Clinical Adoption. arXiv 2025, arXiv:2504.19179. [Google Scholar] [CrossRef]
- Mienye, I.D.; Obaido, G.; Jere, N.; Mienye, E.; Aruleba, K.; Emmanuel, I.D.; Ogbuokiri, B. A survey of explainable artificial intelligence in healthcare: Concepts, applications, and challenges. Inform. Med. Unlocked 2024, 51, 101587. [Google Scholar] [CrossRef]
- Törnberg, P. Best practices for text annotation with large language models. arXiv 2024, arXiv:2402.05129. [Google Scholar] [CrossRef]
- Khan, S.; Qiming, H. GPU-accelerated homomorphic encryption computing: Empowering federated learning in IoV. Neural Comput. Appl. 2025, 37, 10351–10380. [Google Scholar] [CrossRef]
- Xie, T.; Harel, D.; Ran, D.; Li, Z.; Li, M.; Yang, Z.; Wang, L.; Chen, X.; Zhang, Y.; Zhang, W.; et al. Data and System Perspectives of Sustainable Artificial Intelligence. arXiv 2025, arXiv:2501.07487. [Google Scholar] [CrossRef]
- Dai, X.; Li, J.; Liu, X.; Yu, A.; Lui, J. Cost-effective online multi-llm selection with versatile reward models. arXiv 2024, arXiv:2405.16587. [Google Scholar]
- Jiang, Y.; Wang, H.; Xie, L.; Zhao, H.; Qian, H.; Lui, J. D-llm: A token adaptive computing resource allocation strategy for large language models. Adv. Neural Inf. Process. Syst. 2024, 37, 1725–1749. [Google Scholar]
- Li, J.; Han, B.; Li, S.; Wang, X.; Li, J. Collm: A collaborative llm inference framework for resource-constrained devices. In Proceedings of the 2024 IEEE/CIC International Conference on Communications in China (ICCC), Hangzhou, China, 7–9 August 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 185–190. [Google Scholar]
- Lang, J.; Guo, Z.; Huang, S. A comprehensive study on quantization techniques for large language models. In Proceedings of the 2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC), Xiamen, China, 27–29 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 224–231. [Google Scholar]
- An, Y.; Zhao, X.; Yu, T.; Tang, M.; Wang, J. Fluctuation-based adaptive structured pruning for large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, 26–27 February 2024; Volume 38, pp. 10865–10873. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Annotation | Multi-agent | LLM | Augmentation | Multimodal |
|---|---|---|---|---|---|
| Demrozi et al. [21] | ✓ | ✗ | ✗ | ✗ | ✓ |
| Zhou et al. [22] | ✗ | ✗ | ✗ | ✓ | ✓ |
| Wang et al. [23] | ✗ | ✗ | ✗ | ✓ | ✓ |
| Tan et al. [24] | ✓ | ✗ | ✓ | ✓ | ✗ |
| Xi et al. [25] | ✓ | ✗ | ✓ | ✗ | ✗ |
| Hiniduma et al. [26] | ✗ | ✗ | ✗ | ✗ | ✗ |
| Zha et al. [27] | ✗ | ✗ | ✗ | ✗ | ✓ |
| Liang et al. [28] | ✗ | ✗ | ✗ | ✗ | ✓ |
| Cao et al. [29] | ✗ | ✗ | ✗ | ✗ | ✗ |
| Xu et al. [30] | ✗ | ✗ | ✗ | ✓ | ✗ |
| Ours | ✓ | ✓ | ✓ | ✓ | ✓ |
| Ref. | Annotation Task | Techniques | Evidence/Results | Key Insight |
|---|---|---|---|---|
| Estévez-Almenzar et al. [36] | Face match labels | User study score check | Humans fix model errors | Hybrid oversight needed |
| Wei et al. [37] | Multi-annotator classification | EM vs vote approaches | Separation wins with noise | Keep annotator traces |
| Nasution and Onan [38] | Low-resource NLP labels | Zero/few-shot LLM | LLM near human accuracy | Experts still needed |
| Mamat et al. [39] | Crop vision tasks | CNN, YOLO, Mask-RCNN | Accuracy up 10–30 pp | Curated datasets essential |
| Ref. | Agent Blueprint | Annotation Modality | Core Concept | Remarks |
|---|---|---|---|---|
| Acharya et al. [45] | Hierarchical, goal-seeking stack (perception, reasoning, planning, action) | Conceptual blueprint for multi-stage, multimodal annotation pipelines | Autonomy, adaptability, long-horizon planning | Conceptual survey;Establish vocabulary for later task-specific agents |
| Osakwe et al. [46] | Single RL agent (A2C, PPO, DQN) optimizing SRL strategy | On-the-fly behavioral-sequence annotation from text-log traces | LSTM reward model + PPO/AC/DQN; episode-based training | Reward surpass random baseline;Demonstrate adaptive labeling with explicit rewards |
| Bianchini et al. [47] | HITL: LLM extractor, XR assistant, adaptive MES orchestrator | Procedural-instruction annotation in smart manufacturing (text + XR) | LLM parses docs to structured steps; XR guidance; MES sensor feedback | Qualitative error-rate reduction; Hybrid pipeline feed live industrial instructions |
| Xu et al. [30] | Multi-role LLM agent (Plan, Tool, Reflect) with self-correction loop | Automated outcome annotation (QA extraction, slot tagging, reasoning traces) | In-context learning, chain-of-thought, feedback refinement | Human-level label quality; Decomposition-based auditable labels |
| Xi et al. [25] | Generic LLM-agent stack (Brain/Perception/Action) | Taxonomy covering text, vision, and audio annotation scenarios | Memory modules, tool use, multimodal perception; few/zero-shot transfer | Synthesize benchmarks and risks; Provide classification schema for evaluating annotation agents |
| Ref. | Workflow | Mechanisms | Impact | Domain | Remarks |
|---|---|---|---|---|---|
| Rodriguez-Barroso et al. [64] | Post-label aggregation via federated clients | FedAvg on raw, disagreeing labels; preserves annotator privacy | Higher Macro-F1 than majority vote across 8 NLP tasks | Subjective text (sentiment, hate, toxicity) | Disagreement becomes a signal—federated agents upgrade label robustness without extra human passes |
| Azeemi et al. [65] | Pre-label pool pruning before active learning | KenLM perplexity filter + quantized-LLM scoring | Cuts AL wall-clock time ↓74% while matching quality | Translation, summarization, sentiment corpora | LLM “gatekeeper” trims pools so expensive AL heuristics stay fast yet effective |
| Bayer et al. [66] | Cold-start and few-shot selection | Zero-shot GPT-4 picks first-batch items, fully auditable | +17–24 pp accuracy, seconds-level runtime | GLUE-style text classification | General-purpose LLM agent eliminates AL cold-start pain at minimal cost |
| Zhu et al. [67] | In-model label refinement | Uncertainty-weighted fusion; KL regularizer | More robust group-emotion accuracy on 3 benchmarks | Vision (crowd images) | Probabilistic “self-grader” agent down-weights noisy features mid-pipeline |
| Mishra et al. [68] | End-to-end orchestration across data products | Human checkpoints, KG-edge uncertainty, federated governance | Scales to 1.5 M projects and 27 M tenders while ensuring auditability | Multimodal procurement data | Multi-agent mesh shows how systemic quality gates span every annotation stage |
| Ref. | Paradigm | Workflow | Coordination | Strengths | Limitations | Use Cases |
|---|---|---|---|---|---|---|
| Tan et al. [24] | Single-agent sequential pipeline (LLM as Generator, Assessor, Utilizer) | Taxonomy of generation, quality assessment, utilization across many data types | Prompt engineering, self-consistency scoring, filtering, downstream fine-tuning loops | Comprehensive blueprint over diverse modalities and stages | Conceptual survey; no concrete infrastructure specs | Designing new LLM-centric annotation pipelines in NLP or multimodal domains |
| Kumar et al. [91] | HITL active-learning loop | Data pre-processing, AL query, oracle labeling, model retrain | Uncertainty sampling, diversity sampling, iterative human feedback | Cuts labeling cost, preserves human oversight, domain-agnostic | Manpower-intensive; potential annotator bias | Biomedical imaging, NLP or CV tasks where AL reduces costly expert labels |
| Schleiger et al. [92] | Multi-agent human–AI collaboration | Shared-objective tasks with sustained two-way interaction; complementarity + shared goal + dialogue | Human intuition + AI computation; performance benefits catalogued | Gains in quality, creativity, safety and enjoyment when criteria met | Only 16 empirical systems; guidelines still emergent | High-stakes decision support where human judgment and AI scale must blend (e.g., clinical triage and manufacturing) |
| Liu et al. [93] | Single large-model agent with modular subsystems (Task Setting / Planning / Capability / Memory + Reflection) | Signal-analysis annotation: pre-processing, reasoning and planning, tool invocation, memory and reflection | Internal memory, self-questioning reflection, external tool calls (Matlab, RAG), multi-agent interaction bus | Autonomy, tool-use, continuous self-improvement, multimodal reasoning | Domain-specific (ETAR); relies on external tools and prompt engineering | Industrial / defense analytics needing rigorous, auditable annotation of complex sensor data |
| Ref. | Type | Agent Role | Metrics | Properties | Remarks |
|---|---|---|---|---|---|
| Liu et al. [109] | Benchmark, Performance | Benchmark harness testing LLMs as autonomous agents (8 environments) | Success Rate, F1, reward, avg. turns | CoT prompting; temp=0 | GPT-4 leads 27 models; exposes gaps in long-horizon reasoning for OSS LLMs. |
| Verma et al. [110] | Performance, Economic | Few-shot web agent adaptor (meta-learned planner) | Element Acc., Op. F1, Step SR, Overall SR (+4–7 pp) | Prompt-token cost; seconds-level latency | 1–2 multimodal demos boost success 21–45% while keeping compute low. |
| Schmidt et al. [111] | Performance, Economic | Multi-robot active-learning coordinator | mIoU 2.5 pp, Top-1 Acc. | Data-upload volume 90 % | Synchronized selection matches pool-based AL with a fraction of bandwidth. |
| Wan et al. [112] | Performance, Economic | LLM generator, assessor, and utilizer pipeline for taxonomy + labeling | Coverage > 99.5 %; pairwise-label Acc./Rel. | Cost $0.00006 vs $0.082 per call; human-vs-LLM agreement | Lightweight classifiers match GPT-4 quality at a fraction of runtime cost. |
| Tutul et al. [113] | Performance, User-centric | Explainable-AI assistant for anxiety annotation | Spearman = 0.261 on anxiety bins | 8-item Likert trust scale; behavior–trust correlation | Trust rises over time but dips after errors; validates user-centric metrics. |
| Bolock et al. [114] | Performance, User-centric | Web agent for real-time stimulus display | Reaction-time stats; ANOVA () | Scalable in-browser logging; bilingual participant pool | Low-cost agent captures valence shifts from code-switching at scale. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karim, M.M.; Khan, S.; Van, D.H.; Liu, X.; Wang, C.; Qu, Q. Transforming Data Annotation with AI Agents: A Review of Architectures, Reasoning, Applications, and Impact. Future Internet 2025, 17, 353. https://doi.org/10.3390/fi17080353
Karim MM, Khan S, Van DH, Liu X, Wang C, Qu Q. Transforming Data Annotation with AI Agents: A Review of Architectures, Reasoning, Applications, and Impact. Future Internet. 2025; 17(8):353. https://doi.org/10.3390/fi17080353
Chicago/Turabian StyleKarim, Md Monjurul, Sangeen Khan, Dong Hoang Van, Xinyue Liu, Chunhui Wang, and Qiang Qu. 2025. "Transforming Data Annotation with AI Agents: A Review of Architectures, Reasoning, Applications, and Impact" Future Internet 17, no. 8: 353. https://doi.org/10.3390/fi17080353
APA StyleKarim, M. M., Khan, S., Van, D. H., Liu, X., Wang, C., & Qu, Q. (2025). Transforming Data Annotation with AI Agents: A Review of Architectures, Reasoning, Applications, and Impact. Future Internet, 17(8), 353. https://doi.org/10.3390/fi17080353