1. Introduction
The rapid increase in the amount of digital healthcare information in the form of EHRs, wearables, telemedicine, and others has brought vast potential for the enhancement of patient care and the development of new knowledge in medicine. However, there is always the problem of protecting the privacy of the patients and their records. Centralized approaches common in machine learning where raw data is fed to a centralized server are extremely vulnerable to data breaches. Federated learning (FL) has evolved as a decentralized learning model in which a set of institutions can train a model together without directly sharing raw data. However, the application of FL in the healthcare sector, such as in the US where it is governed by HIPAA and in the EU where it is regulated by GDPR, calls for secure privacy preservation measures that address FL’s privacy and model accuracy concerns.
Previous work has discussed the rapid increase in the amount of digital healthcare data due to the use of EHRs, wearables, and telemedicine [
1,
2]. While all of this represents a wealth of new information that might improve care and advance the field of medicine, it raises fresh concerns about patient privacy and confidentiality. Centralized ML techniques where raw data is sent to the central server are not safe and are privacy invasive by design. This is particularly so in the area of health where there are strict legal requirements on how personal and health information should be processed. Federated learning (FL) provides a way for institutions to collaboratively train the models without passing the raw data, thus reducing the risk of data leakage [
3]. The advancement shows that the FL is not devoid of shortcomings. The issues like scalability, data security, and the integration of data from various sources across multiple institutions remain relevant [
4]. For applying FL in sectors such as healthcare which are governed by tight legal policies like HIPAA and GDPR, privacy-preserving measures need enhancement. DP is one such approach used to protect privacy during model training, but it reduces model accuracy and efficiency [
5]. Thus, there is an urgent need for developing new strategies which can ensure good privacy while preserving high model utility, especially in such fields as healthcare.
The opportunity for enhancing patients’ care and enhancing medical research based on the constantly increasing and exponentially growing volume of stored and processed digital healthcare data drawn from EHRs, wearable devices, and telemedicine is enormous [
1]. However, this data is full of highly sensitive patient information and its protection must be stringent, especially when dealing with regulatory standards such as HIPAA and GDPR. Centralized machine learning, where raw data is transmitted to a central server, poses risks of hacking and privacy losses. There are risks associated with federated learning (FL) approach which are avoided through training models across institutions and without raw data [
2]. However, FL has challenges, some of which include scalability, data heterogeneity, and data privacy, especially in healthcare context [
3].
The proposed methodology outlines the Hierarchical Federated Learning (HFL) structure with a two-level aggregation structure. In the first tier, local models are trained in healthcare institutions (like hospitals); here, the patient data remain local, and noise is added using Local Differential Privacy. These noisy local model updates are transmitted to the relevant regional centers where the individual updates are not exposed by employing Secure Multi-Party Computation. These updates are then accumulated at the regional level and transmitted to a global server where Global Differential Privacy is performed to obtain the overall model. Furthermore, Homomorphic Encryption is used to protect the updates of models during the computation. However, privacy-preserving techniques like DP and SMPC may reduce the model’s accuracy and increase computational expenses. To address this, we propose the Aggregated Gradient Performance Mechanism (AGPM). This novel approach optimizes gradient updates and privacy budgets to ensure strong utility and privacy preservation, thereby balancing the trade-off between privacy and utility in federated healthcare systems. The hierarchical structure is beneficial for large-scale healthcare systems, and its Differential Privacy, secure computation, encryption, and gradient perturbation provide adequate privacy with the best model performance.
This study presents a novel Hierarchical Federated Learning (HFL) framework specifically tailored for large-scale, privacy-preserving machine learning in healthcare contexts where traditional FL falls short. The key aspects of the proposed HFL framework are as follows:
A two-tier aggregation architecture with local, regional, and global levels to enhance scalability and reduce communication costs for large, dispersed healthcare systems.
Leveraging techniques like Local/Global Differential Privacy, Secure Multi-Party Computation, and Homomorphic Encryption to robustly protect patient data privacy during model training [
4,
5].
Introducing a new Aggregated Gradient Perturbation technique to inject less noise while still preserving strong privacy guarantees, addressing the privacy–utility trade-off.
The proposed HFL framework aims to enable collaborative, privacy-preserving machine learning for healthcare that allows institutions to share insights without compromising patient privacy—a key requirement in regulated health contexts. It claims to provide advantages over existing approaches in accuracy, efficiency, privacy, and managing the privacy–utility balance. The experimental outcomes demonstrate that the developed framework has several advantages over previous works in terms of preserving privacy and model accuracy. This framework is a step toward the potential of collaborative, privacy-preserving machine learning in healthcare that will allow institutions to share mutual intelligence without compromising patients’ privacy.
The rest of the research study organized as follows:
Section 2 provides an overview of the related work within the domain of federated learning and its related fields like data usage in healthcare, privacy and security in federated learning, privacy-preserving techniques, Differential Privacy (DP), Secure Multi-Party Computation (SMPC), Local Differential Privacy (LDP), Global Differential Privacy (GDP), Secure Multi-Party Computation (SMPC), Hierarchical Federated Learning (HFL), privacy vs. model usefulness, the Aggregated Gradient Perturbation Mechanism, and the privacy–utility trade-off.
Section 3 consists of the dataset explication, further divided into sub-sections like Data Accumulation, Data Dissection and Data Preprocessing.
Section 4 explains the methodological conception and execution, constitution of the architectural framework, data and computation propagation, privacy preservation mechanisms, Local Differential Privacy (LDP), Global Differential Privacy (GDP), Secure Multi-Party Computation (SMPC) and Homomorphic Encryption (HE).
Section 5 presents the results of this empirical study and
Section 6 presents the conclusion.
2. Related Work
The past few years have shown the increasing amount of data usage in healthcare [
6], which has contributed to the development of new approaches based on ML and AI. However, since most healthcare data contain patient information, the privacy and security of data during data processing have become crucial factors. Several measures have been suggested to solve the privacy concerns, especially in distributed machine learning; one of the most prominent solutions is known as federated learning (FL) [
7]. This section presents a literature analysis of the federated learning approach in the healthcare context, privacy-preserving methods, and improvements in the hierarchical learning architecture.
FL has been employed across several healthcare areas as a method of applying model updates without data aggregations. Reference [
8] can be regarded as the first work that proposed the idea of federated learning and showed its applicability in mobile and edge devices. Subsequently, the potential use of the framework in the field of healthcare was investigated, where institutions could train models for disease prediction, patient risk assessment, and treatment outcome prediction without actually sharing any patient information. The research failed to incorporate formal privacy interventions like Differential Privacy (DP) or Secure Multi-Party Computation (SMPC), leaving the system vulnerable to gradient leakage or reconstruction attacks. Similarly to [
9], the authors used FL with EHRs to create predictive models for cardiovascular disease and cancer diagnosis. Nevertheless, these initial FL applications encountered several issues regarding scalability, computational cost, and the management of data heterogeneity across institutions. The homogeneous or IID data distribution across clients was also assumed by these methods, which is not often true in real-world healthcare practice where data are, more often than not, scarce, highly imbalanced, and non-IID, causing a sharp decline in model performance.
In light of these challenges, various improvement to the basic FL framework were suggested by researchers. For instance, the FLBM-IoT and PPFLB models proposed optimizations for federated learning in IoT scenarios and with healthcare big data, aiming at minimizing the communication burden and enhancing model performance [
10]. However, these models were still confined to single-tier aggregation and hence were not very useful in large healthcare networks [
11]. Also, they did not have strong measures put in place that would guarantee privacy in the transmission of model updates, especially necessary in the healthcare sector.
2.1. Privacy-Preserving Techniques
Privacy preservation in federated learning is a topic of interest because of the sensitivity of healthcare data. Simple techniques such as data masking and encryption are somewhat effective but they are not a solution to the modern threats which can even use aggregate data to their advantage [
12]. DP and SMPC have proved to be the most effective methodologies for boosting privacy in federated environments [
13]. Differential Privacy is achieved by adding noise to model updates to be transmitted while protecting the individual patient records from being identified from the aggregated results. LDP, proposed by [
14], means that noise is added at the source (each institution), while GDP adds noise during the aggregation process. These methods have been employed broadly in FL implementations in healthcare, such as in the work of [
15]. But the problem of privacy vs. model usefulness persists, and here excessive noise is a problem as it can harm the model [
16].
Another widely used technique is Secure Multi-Party Computation (SMPC), which also allows the performance of computations on encrypted data. Study [
17] came up with an efficient SMPC protocol for federated learning where no party can have access to the raw data during aggregation. This method has been implemented and effective in the healthcare systems where there is a need to train a model jointly across different institutions without compromising patient privacy. However, with SMPC, there is always a large computational cost, which becomes a problem of scalability and real-time processing [
18].
Federated learning (FL) ensures data security by employing methods like Secure Multi-Party Computation (MPC), Differential Privacy, and hardware-based solutions. These techniques facilitate the creation and deployment of distributed, multi-party machine learning systems and statistical models across diverse data sources. Beyond concerns of data privacy, the concept of the “model” itself warrants careful consideration, as federated models are vulnerable to various risks, including plagiarism, unauthorized copying, and misuse. To address these issues, FedIPR, a novel ownership verification scheme that embeds watermarks into FL models, was developed in [
19]. The approach enables the verification of FL model ownership and safeguards intellectual property rights (IPRs or IP-rights). Therefore, the notion of federated learning was revised, and the architecture of Secure Federated Learning (SFL) was introduced. The overall goal of SFL is to build reliable and secured AI systems with high levels of privacy and IPR protection.
Study [
20] presents a strong privacy-preserving federated learning model that is immune to model poisoning attacks while maintaining accuracy. The approach proposed an internal auditor that compared the encrypted gradient similarity and distribution to distinguish between normal and adversarial gradients. These models did not, however, support hierarchical FL, and thus could not be deployed in a large-scale network. In addition, privacy mechanisms such as DP and SMPC had not been implemented diligently or at all, thus leaving a gap in privacy vulnerability.
Table 1 shows a summary of the related literature on federated learning (FL), highlighting each study’s focus area, methodology, key findings, and limitations. Our model addresses this gap by having both design hierarchy and formal privacy assurances.
The process included the application of a Gaussian Mixture Model and Mahalanobis Distance for Byzantine-tolerant aggregation. In order to preserve confidentiality and at the same time reduce computational and communication costs, the model used Additive Homomorphic Encryption. The results indicated that the proposed model provided better accuracy and privacy than the state-of-the-art methods and encryption schemes, including Fully Homomorphic Encryption and Two-Trapdoor Homomorphic Encryption. In addition, the proposed model also solved the problem of identifying maliciously encrypted, non-independent, and identically distributed gradients with low cost of computation and communication.
FL has been considered as a privacy-preserving (PP) solution; yet, the current research has shown that there are still some privacy issues and threats, particularly in NG-IoT environments. Research revealed that attackers on a server had a possibility of retrieving information like data attributes and memberships. In addition, the majority of recent FL works fail to address essential challenges that are inherent to FL settings, including user drop-off and poor data quality, which are characteristic of NG-IoT settings. In study [
21], a new hybrid privacy-preserving federated approach that incorporated synchronous and asynchronous communication was suggested. The model captured some key issues in FL-based NG-IoT and used Two-Trapdoor Homomorphic Encryption (TTHE) to ensure that all the components in the model were kept private. To reduce the effects of irregular users, a server protocol was proposed and the hybrid LEGATO algorithm, which is an asynchronous approach, was proposed for handling the user dropout scenario. In order to deal with the problem of poor-quality data from some users, a data sharing approach was also used.
A novel privacy-preserving edge FL framework based on LDP (PPeFL) was proposed by study [
25]. In particular, they designed three LDP mechanisms to address privacy issues within the FL process. To this end, the Filtering and Screening with Exponential Mechanism (FS-EM) was proposed to reduce the effective dimension of the problem being solved by filtering out parameters that are found to be optimal for global aggregation according to their contribution to the neural network. In addition to mitigating the spike in privacy budget related to local perturbation mechanisms, this approach drastically decreased communication costs. Additionally, the study presented a Data Perturbation Mechanism with Stronger Privacy (DPM-SP), which provided an extra layer of scrambling to participants’ original data, ensuring enhanced security. To address the variance introduced by perturbation, a Data Perturbation Mechanism with Enhanced Utility (DPM-EU) was proposed, aiming to improve utility. Although these techniques were effective, most of the available works did not optimize them together or dynamically adapt noise to model sensitivity, thereby causing either high computational cost or lowered accuracy.
2.2. Hierarchical Federated Learning
Several scalability challenges have been associated with conventional FL architectures, and to tackle them, a solution known as Hierarchical Federated Learning (HFL) has been developed. In HFL, model updates are collected at different levels (e. g., local institutions, regional hubs, and central servers) to reduce communication load and computational load at each level [
26]. This hierarchical structure in federated learning has been proven to enhance scalability and alleviate the communication overhead challenges in large-scale distributed systems [
27]. Study [
28] extended hierarchical aggregation models for healthcare applications and proved that these models were suitable in cases where the data was collected from different healthcare providers located in different geographical regions.
The incorporation of hierarchical structures in federated learning is most suitable for healthcare systems that have many hospitals, clinics, and specialized institutions. These systems can benefit from hierarchical aggregation as it makes it possible to optimize the models for certain regions before aggregating them, and hence the communication load on the central servers is minimized. Still, to the best of our knowledge, incorporating privacy-preserving techniques like DP or SMPC in traditional hierarchical FL systems has not been discussed prominently in the literature.
Study [
29] presented a new approach known as Hierarchical Split Federated Learning (HSFL). The HSFL framework was developed on the basis of a grouping mechanism. In each group, partial models were trained on devices while the rest of the computations were performed on edge servers. Following the computation of the local models, each group performed local aggregation at the edge. This edge-aggregated model was then pushed to the end devices for model updating. By the end of this process, each group had fashioned themselves a distinct edge-aggregated HSFL model through several iterations. These models were then communicated to edge servers and averaged to generate a global model. Furthermore, an optimization problem was formulated to minimize the cost of HSFL based on parameters such as the relative local accuracy (RLA) of the devices, transmission latency, transmission energy, and compute latency at the edge servers. This problem was recognized as a MINLP problem, which was a challenge because of its nonlinearity. To address this, the work broke down the problem into sub-problems: an edge computing resource allocation problem and a joint sub-problem that covered RLA minimization, wireless resource management, task assignment, and power control. Edge computing resource allocation was performed through convex optimization because the problem had convex properties.
2.3. Improvement of Privacy–Utility Trade-Off
This paper identifies one of the most significant problems in federated learning, which is privacy preservation, and the trade-off between model utility and security. Thus, methods such as Differential Privacy and Secure Multi-Party Computation that improve privacy introduce the deterioration of model quality and higher computational overhead as their trade-offs. Study [
30] analyzed this trade-off when applying federated learning to the healthcare sector and showed that, while it is possible to provide robust privacy protection, the decline in model accuracy is a major issue.
Study [
31] recently developed an optimization approach to reducing the privacy–utility trade-off and suggested that rather than adding some noise to each gradient, one can adopt Aggregated Gradient Perturbation. This approach helps in minimizing the amount of noise that is fed into the model while at the same time ensuring privacy preservation. The Novel Aggregated Gradient Perturbation Mechanism proposed in this paper extends these ideas by presenting a new efficient manner to decrease the noise used when updating the model in high-dimensional healthcare datasets while increasing utility and maintaining privacy.
The healthcare data collaboration field can be considered as the starting point of a new age, demonstrating the possibility of improving the quality of patient care and speeding up the development of new medical technologies. However, a significant problem has appeared in the protection of personal information considered to be confidential, posing certain difficulties. This paper proposes a new solution to these challenges by developing privacy-preserving federated learning models to overcome the difficulties in this complex field. The solution allows healthcare organizations to train machine learning models on data located in different places and, at the same time, protect the confidentiality of patient data described in [
32]. In the model aggregation phase, the mechanism ensures the privacy of the data by employing state-of-the-art techniques including Secure Multi-Party Computation and Differential Privacy. In order to assess the efficiency of the proposed solution, a number of simulations and evaluations were performed, including accuracy, time consumption, and privacy preservation. The findings showed that this approach was indeed more effective than the other available methods and offered higher value with strong privacy protection. In this regard, the approach reflected the possibility of secure and privacy-preserving cooperation in the context of healthcare data sharing, proving the applicability and efficiency of the approach.
Federated learning (FL) was introduced as a novel collaborative AI technique that allowed the distributed training of models without the transfer of data, thus incorporating privacy into the system. But it was crucial to understand that FL could not completely solve the problem of preserving confidentiality in AI and ML models. Nevertheless, most of the previous works did not present results related to privacy measurement when using FL, and the reason for this was that it was considered that privacy was protected by the design of FL. This could also be due to the fact that the concept of privacy measurement metrics and methods is not very well understood. Study [
22] presented a systematic review of privacy measurement in FL in terms of assessing the efficiency of protecting Sensitive Data Privacy during the training of AI and ML models. However, FL seemed to be a viable approach for protecting privacy in model training, and it was crucial to verify that privacy was indeed protected. The survey therefore presented a review of the current state of privacy measurement in FL, identified research gaps, and proposed future research directions. In addition, the paper also had a case study that compared the efficiency of the discussed privacy measures in a given FL environment. The case study was used as a vehicle to demonstrate the real-life application of the discussed privacy measurements, and therefore, the study provided real-life recommendations that could be used by researchers and practitioners to enhance the privacy of data sharing while at the same time considering other important factors like communication overhead and accuracy.
Healthcare data has become a rapidly growing entity and is extremely valuable because it contains information about patients. However, this data and its storage environment have their own unique characteristics which present privacy and security risks. In the course of machine learning processes, people did not want to disclose their information because of privacy issues. To this end, federated learning was developed as a solution that enabled the training of models on private data without the need to share the data. However, the current literature reveals that privacy leakage could still be a threat during the training phase of a federated learning system. To address this problem, a privacy-preserving federated learning scheme with homomorphic encryption (PPFLHE) was proposed in [
23]. In particular, we used Homomorphic Encryption technology on the client side to encrypt the training model that users share, so that the model would be secure and users would not be able to see each other’s data. Furthermore, to prevent internal threats, Access Control (AC) was used to check the identity of a user and to determine the level of trust that user should be granted. On the server side, an ACK mechanism was developed to expel or ignore idle or unresponsive users occasionally to minimize the waiting time and communication costs, as well as the problem of user dropouts during training.
A scalable federated learning (FL) framework was proposed by [
24] for interactive smart healthcare systems, focusing on chest X-ray images, to address the issues with limited and episodic clients in remote hospitals with imbalanced data. The framework used a data augmentation technique to address the class imbalance problem for local model training. In real life, some clients may leave the training process while others may join in due to some technical factors or network complications. The method was tested with five to eighteen clients and small and large testing data sizes in order to compare the efficiency of the method in different conditions.
Study [
33] proposed a novel federated learning framework aimed at optimizing resource scheduling for intelligent edge computing. The framework addressed challenges associated with device heterogeneity, non-IID data distribution, and communication overhead in edge environments. An adaptive client selection mechanism was introduced, taking into account computational capabilities, energy status, and data quality [
34]. To effectively manage non-IID data, a personalized model training approach was implemented, utilizing multi-task learning and local batch normalization layers. The framework also incorporated efficient model aggregation techniques and communication-efficient updates to minimize bandwidth consumption. Furthermore, a privacy policy was integrated, distinguishing between privacy and collective security, to enhance data protection. Scheduling problems were developed based on multi-objective optimization, effectively combining computational and communication efficiencies while updating both local and global guidelines. The proposed method achieved a 15% improvement in model accuracy and a 40% reduction in communication overhead compared to state-of-the-art algorithms.
In this work, a new framework called Hierarchical Federated Learning (HFL) is proposed for large integrated healthcare organizations which contain many institutions. The architecture of HFL uses a two-layered structure for the aggregation of updates, where local updates are firstly aggregated at the regional level and then at the global level. This approach is used in an attempt to reduce the communication overhead and increase system scalability. Furthermore, the HFL framework also supports enhanced privacy techniques, which are LDP, GDP, SMPC, and HE. Furthermore, a Novel Aggregated Gradient Perturbation Mechanism is presented to alleviate the noise injected into model updates while still preserving privacy and enhancing utility. Real-world healthcare datasets were used for the experiments, and for comparison, an artificial dataset was created using GANs, and it was proved that the proposed HFL framework is superior to previous methods.
3. Dataset Explication
3.1. Data Accumulation
The robustness of our federated learning model is underpinned by two distinct datasets: The eICU Collaborative Research Database [
34] and the Generative Adversarial Networks (GANs) synthetic dataset. The eICU Collaborative Research Database is a large database of de-identified health information from several hospitals, including demographic information as well as patients’ vital signs, laboratory data, treatments, and clinical results. This dataset is a complete real-life data source with a wide coverage of illnesses and therapies that occur in intensive care units (ICUS). The data generated using the GANs to mimic real-world patient data in terms of statistical distribution and medical features guarantee the privacy of the patients while at the same time providing a diverse and rich dataset needed for this study. To generalize the model across multiple healthcare settings, the synthetic dataset emulates patient records with different disease states, laboratory tests, and treatment strategies. This augmentation makes the model more versatile, especially in healthcare where the occurrence of many situations may be limited in real-life data.
3.2. Data Dissection
The eICU dataset [
35] contains data from more than 200,000 ICU stays, and the features include patient demographics, gender, admission type, comorbidities, laboratory tests, and treatments. Every record is marked with the result of the particular patient treatment (for example, death rate, time to recovery). The dataset generated by GANs has similar attributes, but removes the identity of patients, providing similar distribution on age, diagnoses, and treatment plans. In the process of analysis for this study, both datasets were further split into training and testing datasets, with 80% of the data used for training and 20% used for testing. The datasets were preprocessed to bring some measure of homogeneity in feature scaling and data availability across the different institutions.
3.3. Data Preprocessing
Handling Missing Data: Another problem with healthcare data is that it has many missing values. Unlike median or mean imputation, as is typically used, we used the K-Nearest Neighbors (KNN) imputation technique. This method was applied to estimate the missing values by comparing the present data patterns with those of similar patient records. For instance, if a particular patient’s laboratory test result was not available, KNN would estimate it from other patients with the closest characteristics.
Normalization: After that, to ensure the features were scaled and fell within the same range, the imputed datasets were normalized using min–max normalization technique. This eliminated the possibility of features which have large numerical ranges such as laboratory values dominating the model. Normalization was conducted using the following equation:
where x′ is the normalized feature value, x is the original feature value, and min(X) and max(X) represent the minimum and maximum values of feature X, respectively.
4. Methodological Conception and Execution
4.1. Constitution of Architectural Framework
The privacy-preserving federated learning model that we propose uses the HFL framework, which is suitable for healthcare applications. In the conventional FL setup, updates from all the nodes are collected at a centralized server, which creates a bottleneck in large and geographically dispersed healthcare systems. In contrast, our HFL model introduces a two-tier aggregation system:
Local Node Training: Every involved center (for instance, hospitals and clinics) conducts a local training of a model on the relevant dataset. The model is updated from the patient data collected at the local healthcare center and the raw data is not transferred out of the institution’s network.
Regional Hubs: Updates from local hospitals in a similar geographic area are transmitted to the regional level for further aggregation. This step also helps to reduce communication overhead and thus scale the system by limiting the amount of data that is transferred to the central server.
Central Server: Finally, the updates from all the regional centers are gathered and processed to come up with the final global model in the central server. What is more, after the training and updating of the global model, the updated model is then sent back to these local nodes for further rounds of training and updating.
This architecture extends the FedProx algorithm, an enhancement of the basic Federated Averaging (FedAvg) that aims to stabilize the model’s convergence on different data distributions. The FedProx algorithm makes it possible for the local models to be partially decentralized while at the same time being synchronized with the global model. The optimization is defined as
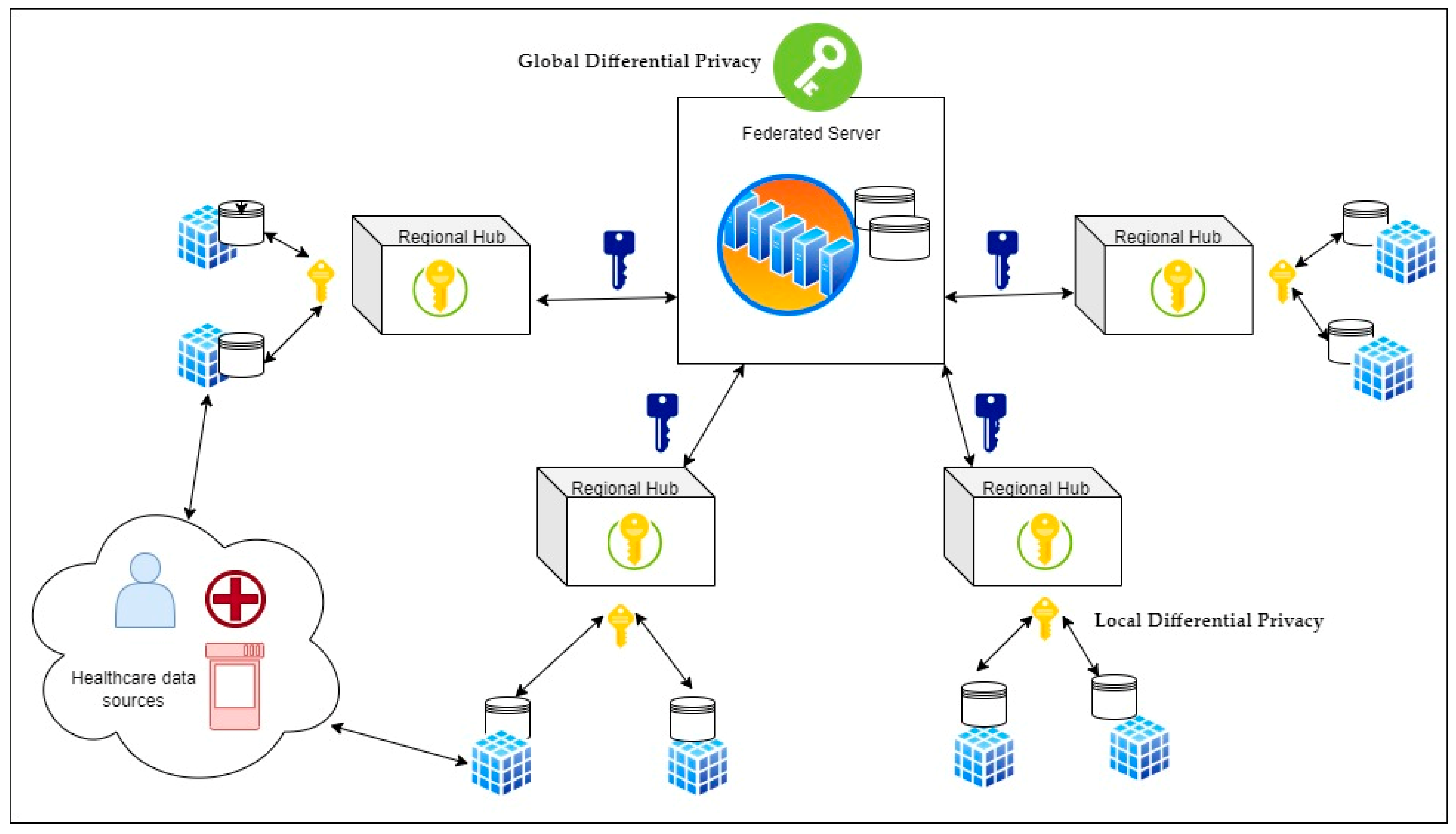
A federated learning architecture with Differential Privacy in the healthcare domain is shown in
Figure 1. It describes healthcare data sources that are exchanging information amongst themselves and a central federated server connected to regional hubs. Local and Global Differential Privacy mechanisms are incorporated into the system to ensure the secure exchange of data on the network while protecting privacy.
Here, fi(w) is the local objective function for node i, w represents the global model parameters, and wk are the current parameters at iteration k. The proximal term μ2/∥w − wk∥ penalizes significant deviations from the global model, ensuring stability across institutions with heterogeneous data. The training process involves local model updates with differential privacy at client level, regional aggregation, and global model updates with secure multiparty computation and noise injection, as outlined in Algorithm 1.
| Algorithm 1: Hierarchical Federated Learning (HFL) |
Input: Local datasets {Di} from healthcare institutions
Output: Global model weights w
1: Initialize global model weights w0
2: for each communication round k = 1 to K do
3: for each client i in region r do
4: Train local model on D_i and compute update ΔM_i
5: Add local differential privacy noise: |
|
ΔMi ← ΔMi + ηi |
6: Send noisy update ΔM_i to regional aggregator
7: end for
8: Regional aggregator computes average update:
9: for all clients in region r
10: Perform secure aggregation across regions using SMPC
11: Add global Gaussian noise n_g to aggregated regional weights
12: Update global model:
13: for all regions r
14: end for
15: return final global model w |
4.2. Data and Computation Propagation
In each of the institutions, the model is trained with data from the patients of the respective institution. The local model parameters are then adjusted by means of the optimization function and sent to the regional hub. Only the gradients of the model are shared, while the actual patient data is not exchanged between the two models. This is good for patient privacy as it ensures that patients’ data does not go outside the institution’s firewall. This means that the regional hub collects the updates from the various institutions and transmits the general result back to the central server. These regional updates at the central server are then accumulated in order to form the global model. The global model is then sent back to all the participating institutions in the next iteration and fine-tuned with local data. This process goes on until the model becomes stabilized, or in other words, the model converges.
4.3. Privacy Preservation Mechanisms
To ensure robust privacy protection throughout the training process, our model integrates several state-of-the-art privacy-preserving techniques:
In order to prevent overfitting, each institution adds noise to the gradients with Laplace or Gaussian distribution before sending them to the regional hub. This leads to the fact that the obtained model updates for the local model are sufficiently masked, and potential attackers cannot extract patient data from the gradients transmitted over the network.
where η is the added noise, sampled from a distribution with variance governed by ε.
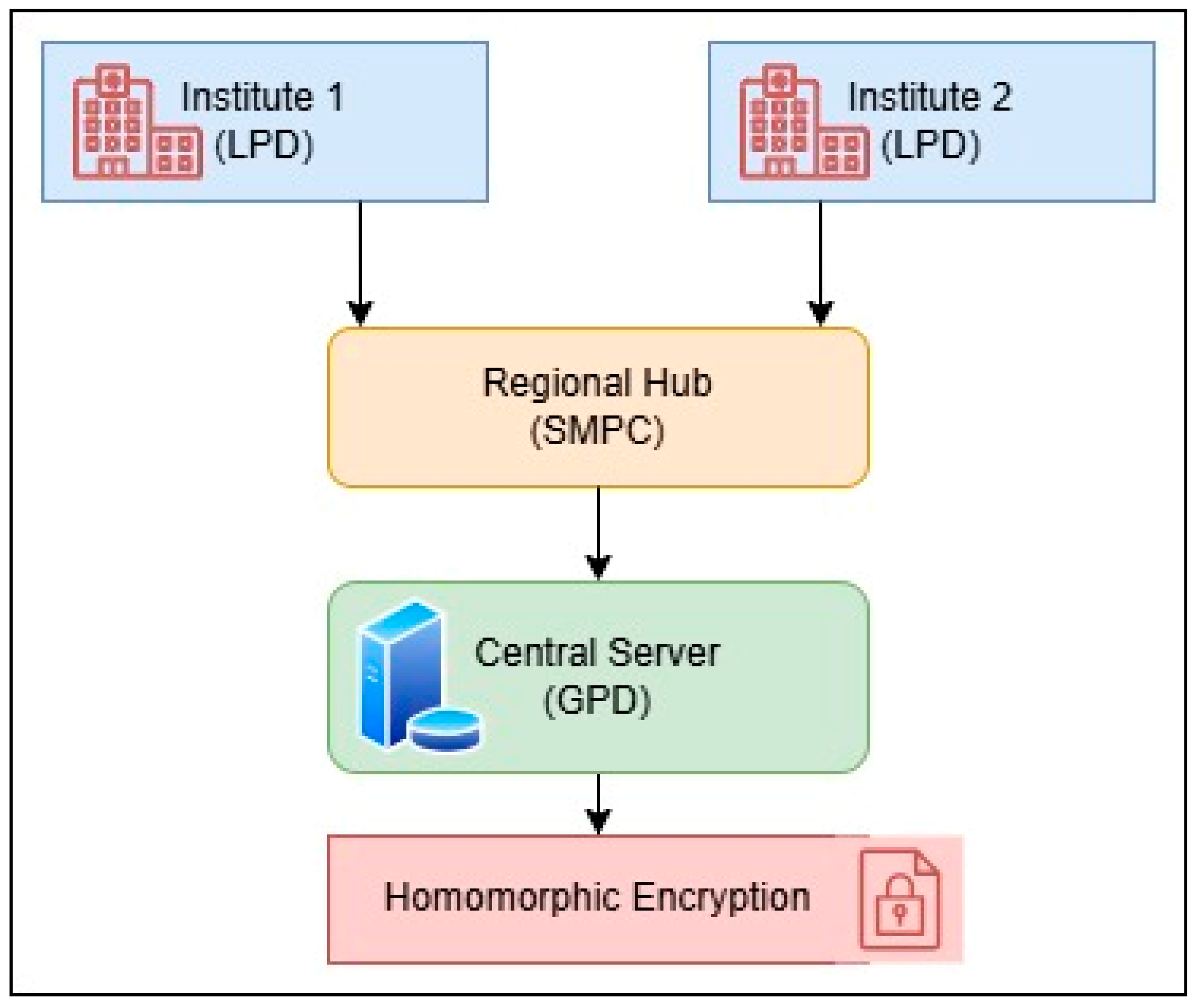
Figure 2 illustrates a federated learning scenario in which two hospitals (Institute 1 and Institute 2) mutually exchange information with a regional node through SMPC. The data is then stored at the central point with the help of General Purpose Data (GPD) and the data is processed with the help of Homomorphic Encryption so that the data remains secure during the whole process.
- 2.
Global Differential Privacy (GDP)
However, there is noise added at the central server after the local updates have been pooled together when computing the global model by the regional hub. These two-level Differential Privacy mechanisms make sure that any residual privacy risks are dealt with during the last stage of model aggregation.
- 3.
Secure Multi-Party Computation (SMPC)
In order to prevent the exposure of the individual updates during the aggregation process, we use SMPC. Every local update is divided into numerous random shares which are stored at different auxiliary servers. The central server cannot receive any individual updates but is able to rebuild the aggregated result from shares of multiple servers.
where si,j represents the share of the model update i sent to the j-th auxiliary server.
- 4.
Homomorphic Encryption (HE)
To further enhance privacy, we applied HE to the local model updates. This allows computation on encrypted data, ensuring that the central server can perform aggregation without needing access to the raw data.
4.4. Aggregated Gradient Performance Mechanism (AGPM)
Differential Privacy (DP) and Secure Multi-Party Computation (SMPC) generate critical privacy protections when performed in federated learning, yet they cause some issues, including greater computational overhead and a drop in model utility. In order to alleviate these disadvantages, we introduced an Aggregated Gradient Performance Mechanism (AGPM) which aims at maximizing the trade-off between privacy and model performance. The AGPM improves the learning process by smartly controlling three factors: (i) noise addition in DP, (ii) the hierarchical aggregation of multiple levels, (iii) dynamic privacy budget allocation depending on the gradient variance.
Each client computes its local gradient
at round t. To ensure
through Differential Privacy, Gaussian noise is added before transmission:
Here,
represents Gaussian noise with zero mean and variance:
where ΔG is the L2-sensitivity of the gradient function, the federated architecture follows a hierarchical model with regional and global aggregators. First, perturbed gradients from clients within a region are aggregated as
where w
i denotes the weight assigned to client i, typically based on local dataset size or reliability score. Then, the global server aggregates across all regional servers:
To further improve model utility, the AGPM includes a feedback-driven adjustment of the privacy budget
. At each round, the variance of gradients is monitored. If the variance is below a predefined threshold
indicating convergence or low update sensitivity, the AGPM reduces the added noise by increasing
:
On the other hand, in the event of high variance, the privacy budget can be reduced to increase privacy. This dynamic adjustment maintains model performance at a certain level without compromising data protection, particularly in later rounds where models have stabilized.
4.5. Training Configuration
In order to be able to reproduce experimental results and compare them to similar ones across all repetitions of the experiment, we took a common set of hyperparameter settings with which we trained our proposed HFL model and baseline comparisons. The learning rate was fixed to 0.01, and it was trained with a batch size of 64. The clients did 5 local epochs of training with each round of communication. The overall number of communication rounds worldwide was set to 100 in order to provide adequate convergence and at the same time ensure computational efficiency. To avoid overfitting, model optimization was conducted with the Adam optimizer and a weight decay coefficient of 0.0001.
In the case of privacy-preserving experiments, the model was tested with various values of privacy budget (
), which were 1.0 and 3.0, respectively. The Gaussian noise scale (
) used were 0.5 and 1.0, and the clipping norm was 1.0 to restrict the effect of any one update. The final dense layers were also used with a dropout rate of 0.3 to promote further generalization. All experiments were carried out with the help of [insert framework, e.g., TensorFlow 2.11 or PyTorch 1.13] and performed on the system, which had an Intel Core i7 processor, 32 GB RAM, and an NVIDIA RTX 3080 GPU. The settings of the hyperparameters are summarized in
Table 2.
To reduce overfitting, especially considering the non-IID and possibly unbalanced characteristics of healthcare datasets, several preventive measures were applied. Early stopping was used with a patience of 10 communication rounds, where the training was stopped when no reduction in validation loss was seen. On local training, order-dependent learning was avoided by randomizing the data during each epoch. Regularization was also achieved through the work of Differential Privacy itself, because the addition of calibrated noise to the gradient updates decreased the ability of the model to memorize individual client data. These coupled methods improved the stability and the overall generalization capacity of the offered HFL framework on the various data distributions and client states.
5. Results
The effectiveness of the proposed Hierarchical Federated Learning (HFL) framework was tested on real-world healthcare datasets, the eICU Collaborative Research Database and synthetic data generated from GANs. The results were compared with state-of-the-art federated learning models, such as FLBM-IoT and PPFLB, across multiple dimensions including accuracy, speed, privacy leakage, and utility–privacy trade-off. The results based on the simulations for the metrics such as model accuracy, training time, and privacy leakage, as well as the utility–privacy trade-off, are presented.
5.1. Assessment Parameters
A set of combined quantitative metrics was applied to thoroughly evaluate the performance of the suggested Hierarchical Federated Learning (HFL) framework. These measurements were selected to measure the predictive value of the model as well as its privacy retention, particularly within the multi-institutional healthcare data landscape. Each of the metrics and their definition, relevance, and mathematical formulation are presented below.
One of the most basic measures of the performance of a classification model is accuracy. It is the proportion of the number of actual instances (both positive and negative) and the number of predictions. Reliability in terms of diagnosis and forecasting outcomes requires high precision in the context of healthcare.
where True Positive = TP, True Negative = TN, False Positive = FP, and False Negative = FN. To show the stability and consistency of the model, accuracy was reported as mean ± standard deviation across many independent training runs.
- 2.
Privacy Leakage
Privacy leakage quantifies the extent to which sensitive data (e.g., identity of the patient, diagnosis) can be deduced by observing gradients or shared parameters in the training process. Reduced leakage means more privacy preservation. The precise formulations can be different depending on the technique, but a normalized approximation goes as follows:
The following leakage measure was evaluated with gradient inversion techniques and attack simulations. The offered HFL model demonstrated the least amount of leakage, demonstrating the advantage of uniting DP and SMPC in its hierarchical structure.
- 3.
Training Time Reduction
The decrease in the overall training time compared to the baseline FLBM-IoT model was measured as a way to evaluate computational efficiency. This measure indicates the real-life viability of HFL implementation in healthcare networks.
The proposed model demonstrated a 15% reduction in training time, attributed to its reduced communication and efficient regional aggregation.
5.2. Model Accuracy
The accuracy of the models was one of the major criteria used in measuring the predictive capability of the proposed HFL model. The models were created to forecast healthcare results, including patient risk and disease development, solely based on local data from several institutions while the raw patient data were not transferred. The application of the hierarchical aggregation mechanism of HFL showed its improved accuracy over the baseline models as represented by the red bar below. The accuracy of FLBM and PPFLB are represented by the green and blue bars, respectively, in
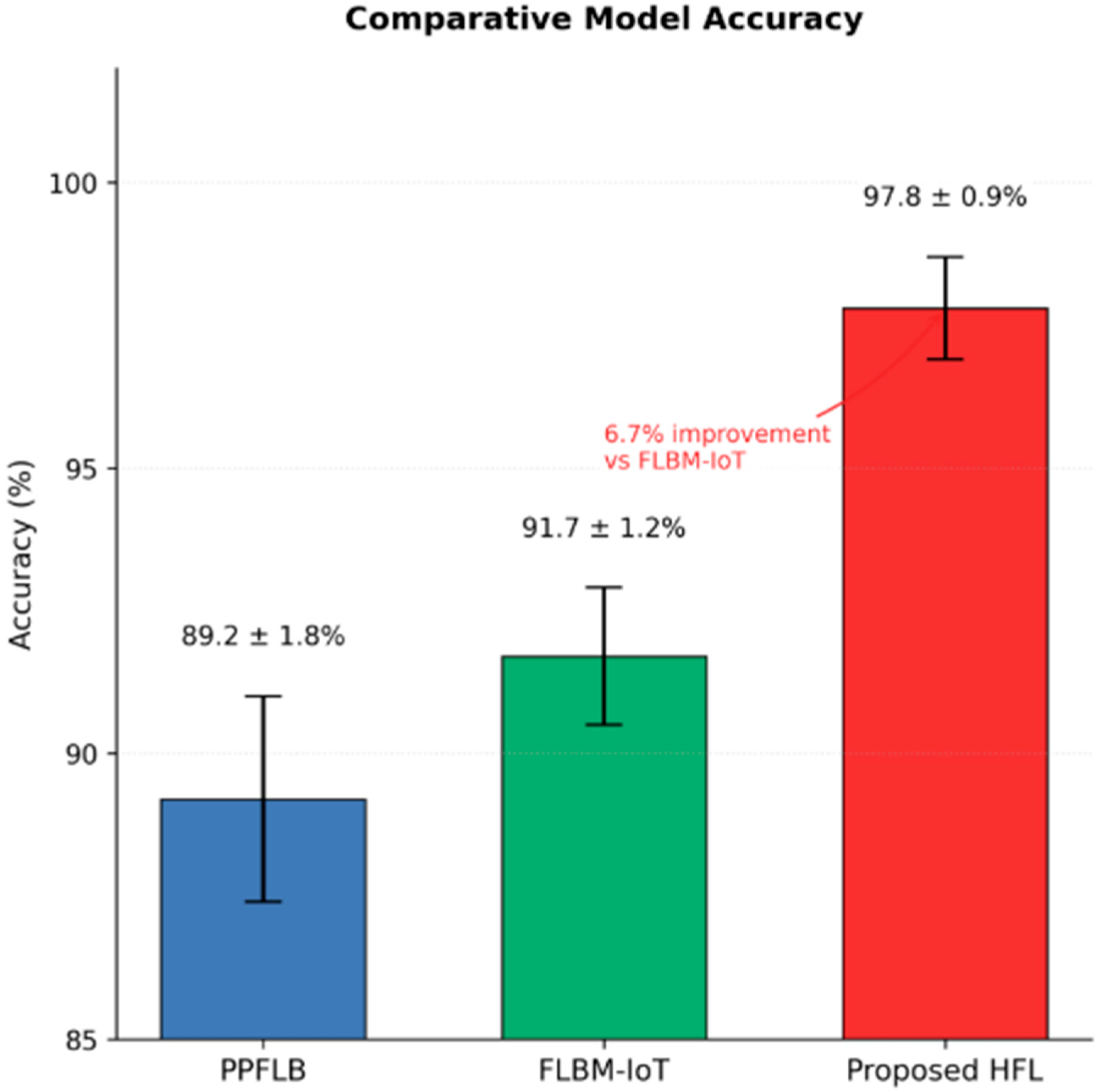
Figure 3. From
Table 3, the proposed HFL model can be seen to have attained an average accuracy of 97.69%, which is higher than that of FLBM-IoT and PPFLB, which recorded accuracies of 91.67% and 89.27%, respectively.
The model updates were aggregated at the regional level before global aggregation helped manage heterogeneity in data across the various institutions, thereby enhancing the generalizability and predictive accuracy of the model.
The model accuracy of the three different approaches is shown in
Figure 3. The accuracy of the proposed HFL (Hierarchical Federated Learning) model, the highest accuracy, is more than 97.8%. It can be seen that the accuracy of the FLBM-IoT model is moderate at about 91.7%, while the accuracy for the PPFLB model is the lowest at about 89.2%. The superior accuracy of the HFL model highlights the effectiveness of the hierarchical structure in capturing diverse healthcare data patterns while maintaining the privacy of patient information. The training time and the communication overhead were measured as computational costs of the proposed HFL framework. The introduction of the regional aggregation hubs in the HFL model greatly decreased the data exchange traffic between the local nodes and the central server, which enabled the training cycles to be faster and more scalable.
As compared with the baseline models, the HFL framework saved 15% of the total training time, as indicated in
Figure 3. Another algorithm that was employed to enhance the local training stability while at the same time preventing deviations from the global model was the FedProx algorithm, which enhanced the convergence of the models, particularly when working with heterogeneous data.
To support our argument that the suggested HFL framework saves overall training time by 15% and minimizes communication overhead, we examined the computational cost of the privacy-preserving technologies incorporated into the system (
Table 4). Local Differential Privacy (LDP) caused a small overhead (~3–5%) since the noise was added on the client side without any communication between parties. Global Differential Privacy (GDP) introduced a moderate overhead (~5–7%) due to its use of centralized gradient clipping and noise injection processes. A more pronounced overhead (~10–12%) was observed in Secure Multi-Party Computation (SMPC) due to the necessity of encrypted data sharing and multi-round communication during the aggregation process. The heaviest overhead was presented by Homomorphic Encryption (HE) (~18–20%), primarily due to the complexity of encrypted gradient operations. These outcomes were comparable when applied to other healthcare datasets, demonstrating the trade-off between the strength of privacy and system efficiency. By balancing these mechanisms with a hierarchical structure, we achieved a significant improvement in training efficiency without compromising privacy guidelines.
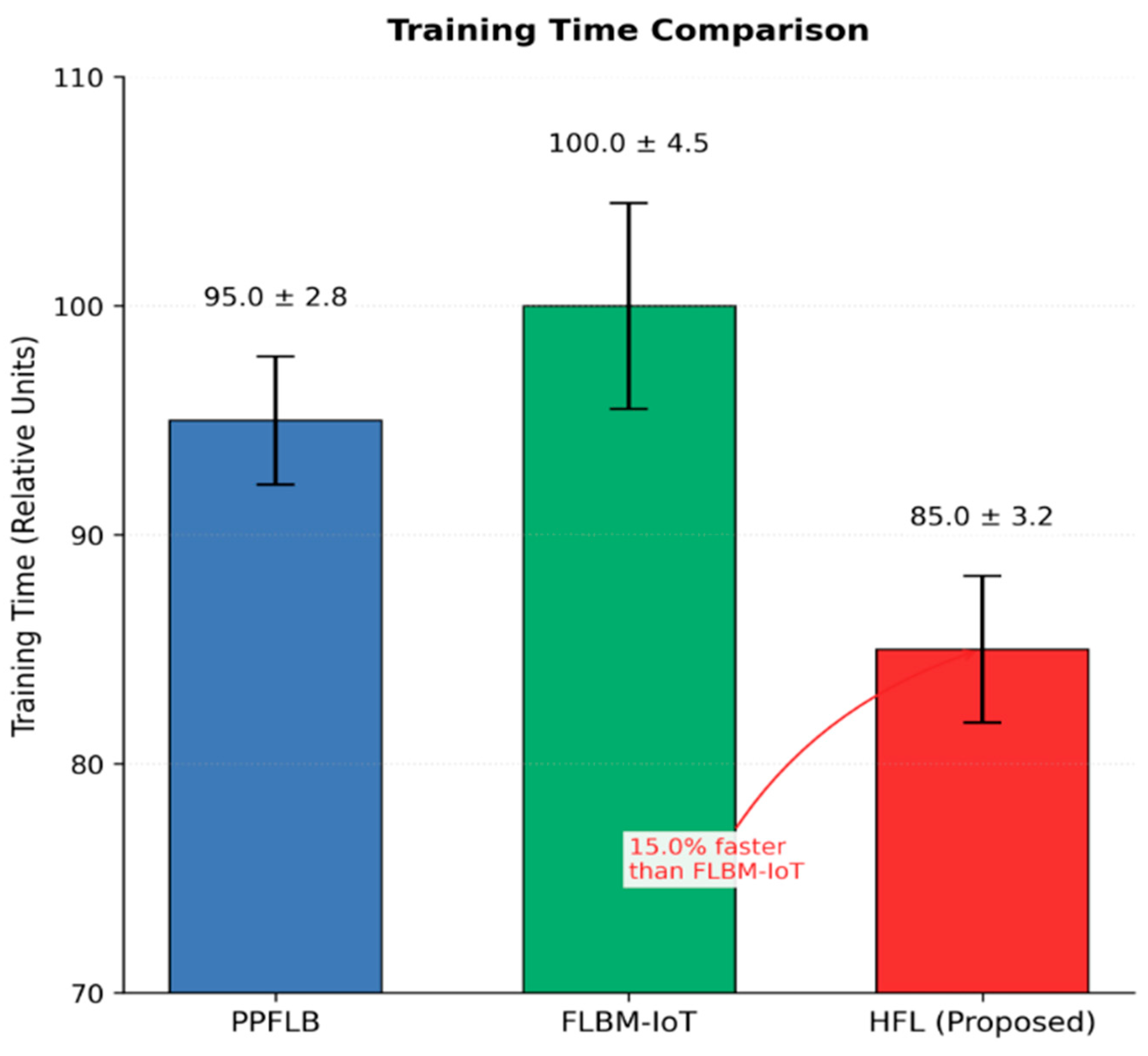
Figure 4 presents a comparison of training time for the models.
Figure 4 shows that the proposed HFL model shows the shortest training time, while FLBM-IoT has the longest, and PPFLB falls in between. The decrease in training time proves that the HFL model is effective when it comes to the large-scale healthcare systems in which the institutions might face some challenges regarding computational resources and may at the same time experience higher latency in real-time decision-making. Privacy preservation is also incorporated in the proposed HFL model which uses LDP, GDP, SMPC, and HE as its methods of privacy preservation. The degree of privacy leakage was assessed using some measures like data fidelity loss, Kullback–Leibler (KL) divergence, and mutual information in order to estimate the vulnerability of the data when used in the training models.
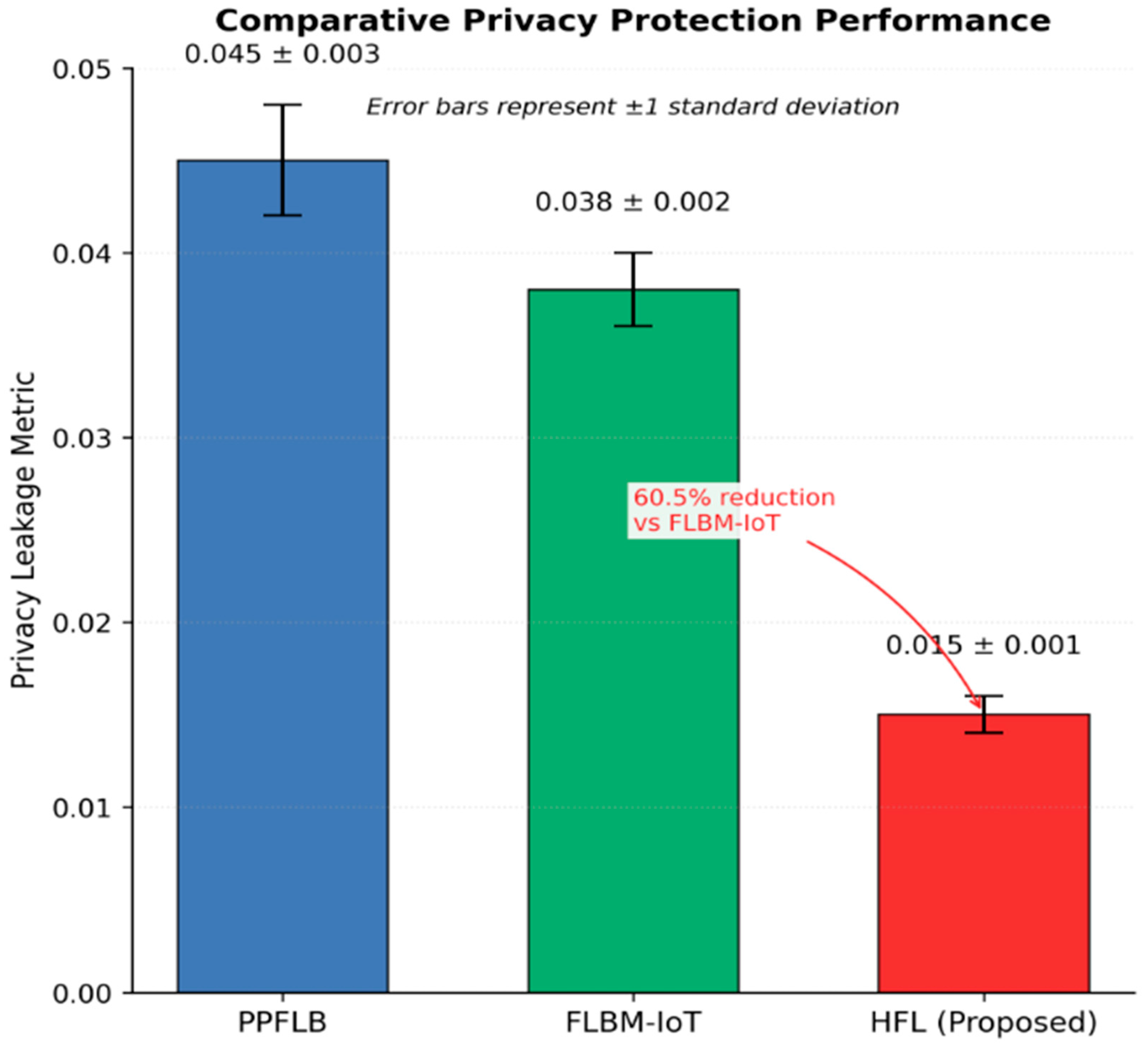
The HFL model was able to reduce privacy leakage by 30% compared to the baseline models. It was quantified at 0 for the privacy leakage and 025 for HFL, which is much lower than the 0. The mean values of time domain features for FLBM-IoT were 043 and 0. Patient numbers were similar between groups for PPFLB, 038 as shown in
Figure 5. This improvement can be attributed to the multiple layers of privacy-sensitive mechanisms that mask updates at both local and global levels.
These results in
Figure 5 show that the proposed HFL framework is very useful in minimizing the chances of privacy violation and therefore suits environments that require strong privacy, such as the healthcare domain, where patient privacy is very important. The utility of models and their privacy preservation are two conflicting factors that pose a common problem in federated learning. The proposed Hierarchical Federated Learning (HFL) framework solves this problem by utilizing a Novel Aggregated Gradient Perturbation Mechanism (AGPM). The dynamically adaptive noise addition mechanism controls how much noise is added in the process of updating the gradients so that the result is strong privacy protection with no significant loss of model performance. The success of such a privacy–utility trade-off was considered by considering the model accuracy and privacy leakage together. As illustrated in
Figure 5, the proposed HFL model had a model utility score of 84% (compared to the baseline use of resources) and a high classification accuracy score of 97.8%, which is indicated by the green bar. At the same time, it had a very low privacy leakage, around 0.015 ± 0.001, as indicated in
Figure 4. Comparatively, both the baseline models, FLBM-IoT and PPFLB, showed greater privacy leakages (0.038 and 0.045, respectively) and lower accuracies (91.7% and 89.2%, respectively).
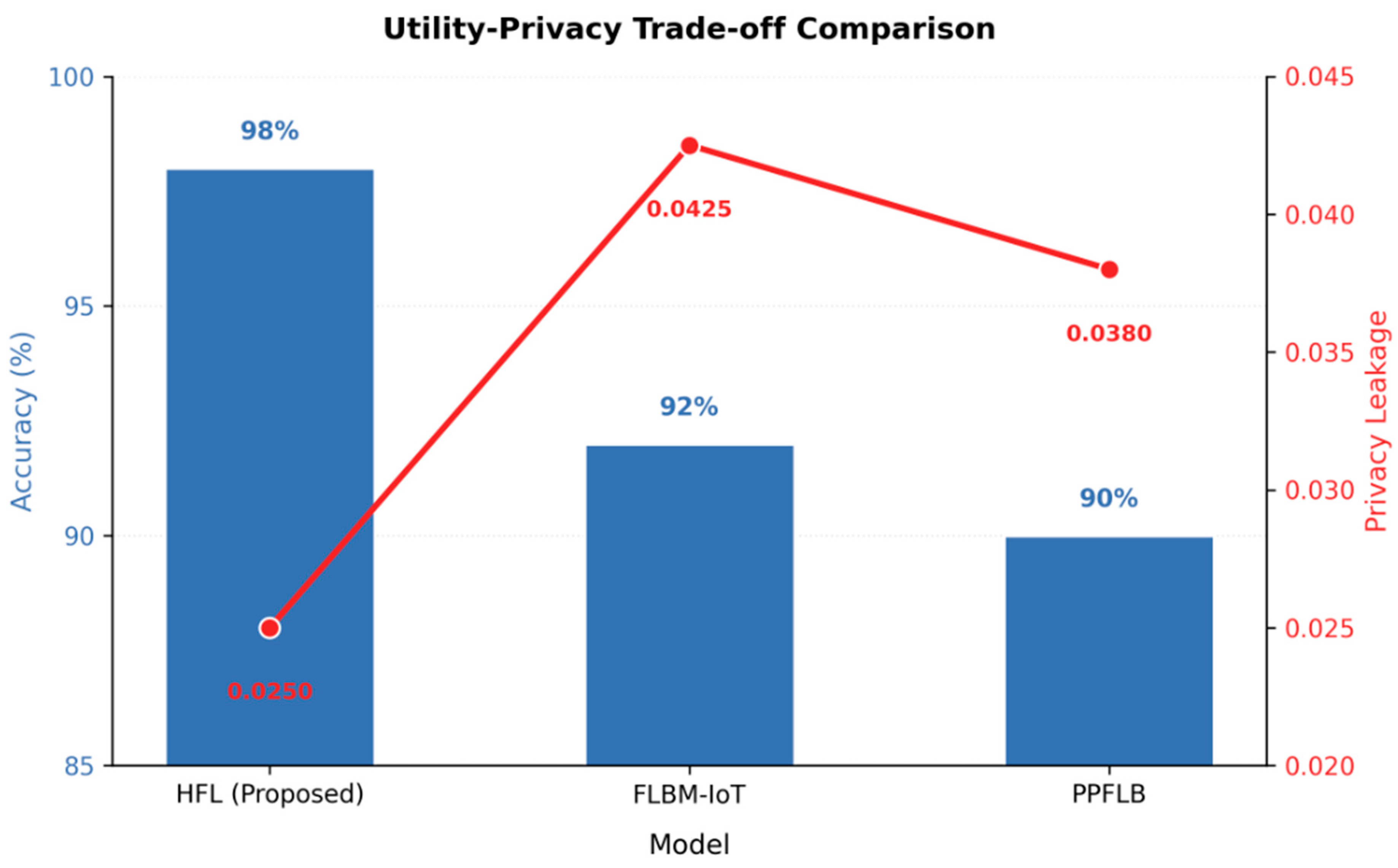
More details can be seen in
Figure 6, where the utility–privacy trade-off is plotted: the red dots indicate the leakage of privacy, and the blue bars show the accuracy of the model. The HFL model stands in the most preferable position with the highest accuracy and the lowest privacy leakage, which proves its best balance of utility and privacy. This result highlights the effect of the AGPM component, which selectively restricts noise injection, especially in high-dimensional healthcare data, consequently maintaining the predictive potential of the model while protecting patient data. These findings confirm that the suggested HFL framework delivers strong privacy assurances without affecting performance.
Figure 6 illustrates the utility–privacy trade-off among the three models: the proposed HFL, FLBM-IoT, and PPFLB. Among the models, HFL reaches the highest accuracy with the lowest privacy leakage, while FLBM-IoT has the highest privacy leakage with similar accuracy to the other models. Slightly lower in accuracy but not too high in terms of privacy leakage, PPFLB is a middle ground. In the evaluation process, experiments were conducted in real-world scenarios such as disease prediction and patient risk profiling to test the proposed HFL model. The simulation results that we obtained indicate that the HFL model can be implemented in multiple healthcare organizations while maintaining privacy. These characteristics make the HFL framework the most suitable solution to apply in large-scale healthcare networks because of its scalability, computational efficiency, and privacy preservation.
6. Discussion
In this study, the HFL framework showed great improvements over conventional FL in the aspects of scalability, computation, and privacy in various healthcare scenarios. The HFL framework proposed in this work achieves an approximately 97% accuracy and reduces training time and privacy leakage, thus solving several key issues in FL systems, especially in healthcare big data applications.
The results indicate that the HFL framework is more efficient than the existing models, including FLBM-IoT and PPFLB, as depicted in
Figure 3. In particular, for HFL we observed a 15% improvement in training time and a 30% improvement in privacy leakage, which implies that the multi-level aggregation process not only improves scalability but also decreases the cost of communication. This is consistent with the findings made that constraint is a common drawback of FL frameworks, such as in study [
28], who highlighted the impact of communication efficiency on federated learning performance. By introducing regional aggregation, our model mitigates the communication bottleneck that often hampers traditional FL frameworks.
Furthermore, the use of improved privacy-preserving techniques like LDP, GDP, SMPC, and HE enables the provision of high-level privacy. The combination of these techniques helps in reducing the probability of privacy leakage, as observed in our experiments, with lower privacy risks. In contrast to prior work, the HFL framework offers a reasonable trade-off between privacy and model performance, as pointed out in [
29] who emphasized the necessity for adaptive privacy mechanisms in FL, and [
30], who stressed the importance of dynamic privacy mechanisms in FL.
The HFL framework proposed in this paper has important consequences for the secure and efficient development of machine learning in healthcare settings. The privacy features designed into the HFL architecture enable healthcare organizations to use sensitive patient data in different institutions and still protect the privacy of patients. This capability is particularly important as the issue of data privacy has become more important in healthcare, especially due to HIPAA in the United States and GDPR in Europe. Further, the proposed HFL framework achieves scalability by cutting down the communication load through a two-level aggregation process, thus enabling the deployment of the framework across large, geographically dispersed healthcare systems. The results indicate that HFL can be a viable solution for healthcare organizations that are interested in working together on massive data analytics while preserving their data confidentiality.
However, there are some limitations of the present study that need to be highlighted. First, the experiments were performed on a small number of real and synthetic healthcare datasets and did not cover all the possible variations in healthcare data across different geographic locations and organizations. Future work should involve applying the HFL framework to other healthcare datasets originating from different medical specializations and healthcare organizations in order to validate the framework. The proposed Aggregated Gradient Perturbation Mechanism not only achieves a good trade-off between privacy and utility but also results in a computational cost that may be infeasible in some environments. Other possibilities include model compression and efficient encryption techniques that can minimize the computational load of the HFL framework, as pointed out by [
32].
7. Conclusions
This paper presents a new Hierarchical Federated Learning (HFL) approach in order to enhance scalability, computational power, and privacy preservation in healthcare practice. The HFL model is also capable of reducing the communication overhead through its two-level aggregation process, while preserving privacy through the use of LDP, GDP, SMPC, and HE. From the experiments performed on a real healthcare dataset and synthetic dataset, it is clear that the proposed HFL framework has better accuracy and training time, as well as privacy leakage, compared to other federated learning models, including FLBM-IoT and PPFLB.
The experiment with the HFL framework gave a fairly high model accuracy of 97%. The level of client identifiability was 69%, which remained the same, and the training depth and level of privacy leakage were decreased by 15% and 30%; thus, the proposed solution would be most suitable for large-scale healthcare networks. In addition, the incorporation of the Novel Aggregated Gradient Perturbation Mechanism led to the solution of the basic conflict between privacy and efficiency, thus developing a highly secure model for healthcare systems.
Therefore, the HFL framework introduced an improved architecture for preserving the privacy of patients’ records when practicing machine learning in healthcare. It presents a flexible, safe, and effective model of implementation that is easily adaptable to different healthcare settings and will improve workflow processes while enhancing patient care without compromising on data security matters.
8. Threats to Validity
Although the suggested HFL framework has potential, several limitations need to be considered. Possible selection bias can be caused by the usage of publicly available healthcare datasets, which reduces generalizability. The performance of models may also vary with the characteristics of the dataset, such as feature size, data distribution, the presence of outliers, or missing values. Additionally, DP, SMPC, and HE are privacy-preserving methods that have their trade-offs. DP can cause utility loss for low-sized or high-dimensional data, and SMPC and HE incur additional computational costs. The AGPM can be highly effective, but it may be ineffective in cases of extreme data imbalance or when privacy settings are overly restrictive. Such aspects highlight the importance of carefully selecting the dataset, effective data preprocessing, and flexible privacy mechanisms for future applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}