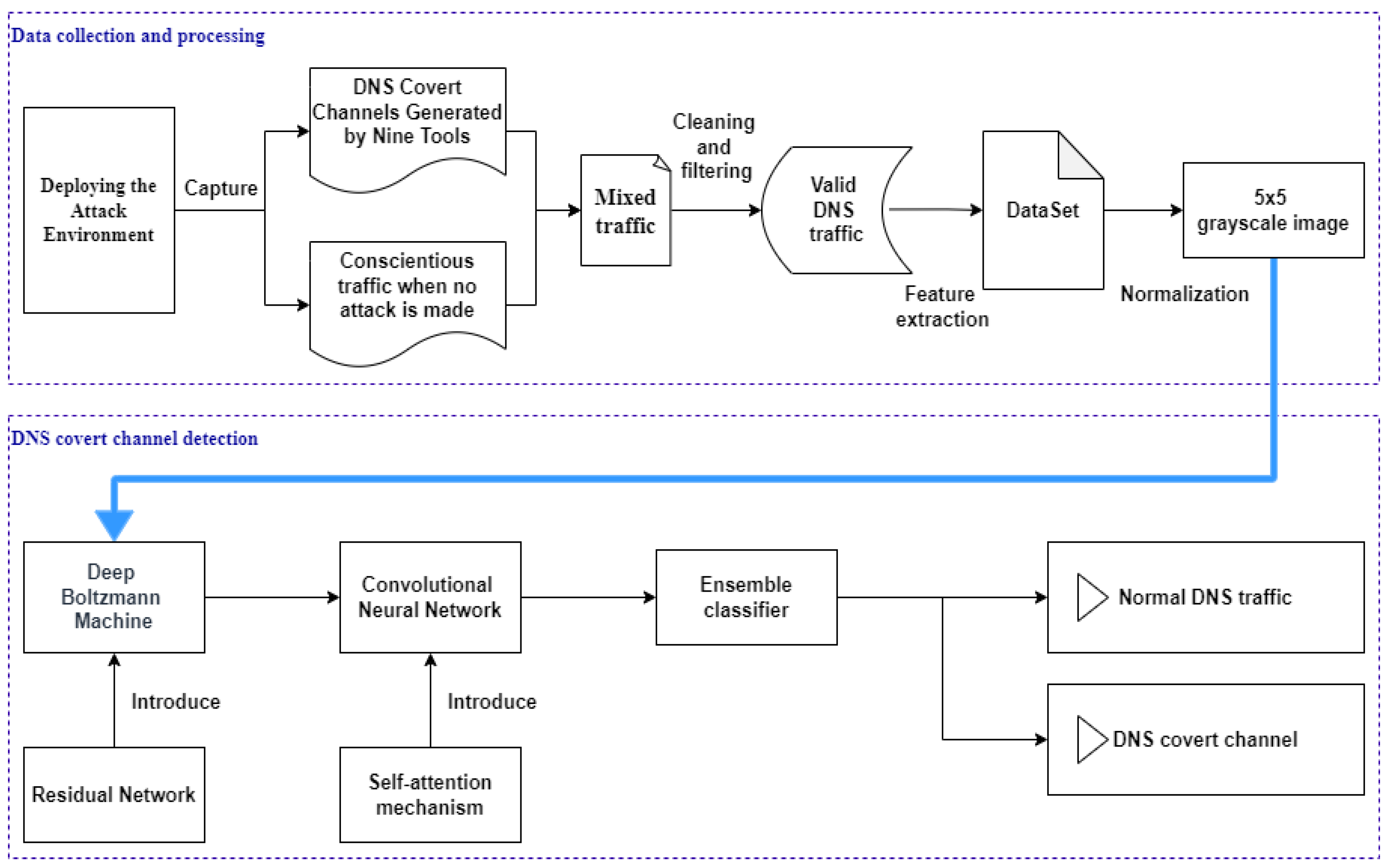
3.1. Data Processing Module
The data processing module consists of four components, with the primary objective of establishing a DNS attack environment. It collects both DCC traffic, generated during the attack, and standard DNS traffic. These data types are subsequently integrated and processed for use in the experiment. The following section presents a visual representation of this process, as illustrated in
Figure 2.
(1) Deploying the Attack Environment: The attack environment comprises the target client, a local DNS server, the “.top” root domain server, and a covert channel server. Nine DNS covert channel tools (iodine, dns2tcp, cobaltstrike, dnsexfiltrator, tcp-over-dns, dnsshell, dnscat, dnslivery, and ozymandns) [
19] are deployed and executed on the local DNS server to generate DCC traffic. These tools facilitate the establishment of covert channels with the target and enable the exfiltration of sensitive data. This configuration allows for the generation of diverse covert channel traffic, thereby simulating a variety of attack methods that an adversary might employ in a real-world context. Furthermore, Wireshark4.2.3 software is installed on the target device to capture the traffic generated during the attack.
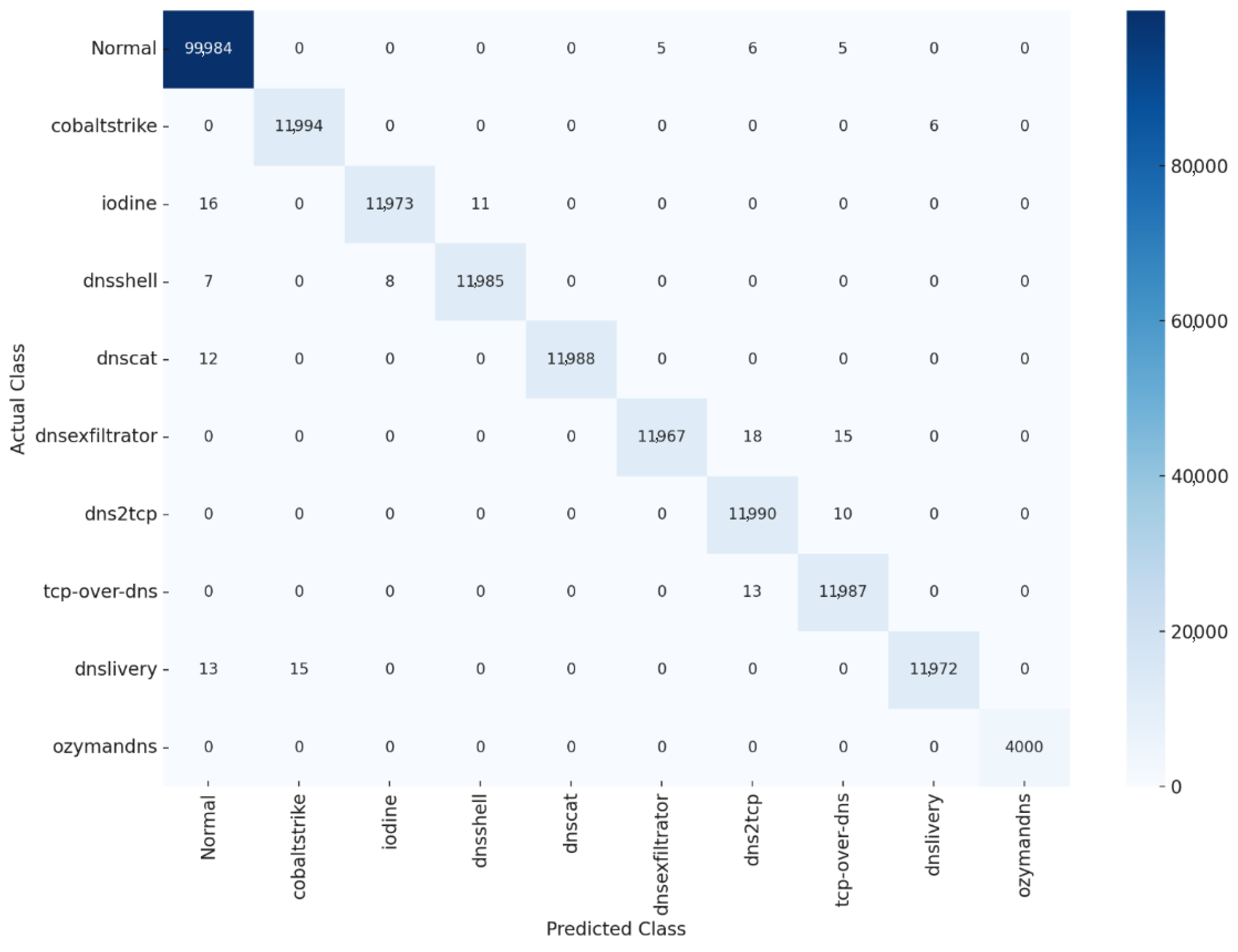
(2) Capturing Mixed Traffic: This study successfully captured a total of 100,000 samples of nine types of DCC attack traffic in the aforementioned attack environments and categorized them into DCC traffic sets. These samples represent a wide range of attack methods, ensuring diversity in the data. In addition, a further 100,000 benign DNS flows were captured from daily network activity over the last seven days and filtered as benign for training purposes. The resulting traffic was combined to create a comprehensive, balanced dataset, as shown in
Table 1.
(3) Data Processing: This module firstly cleans and filters the captured mixed traffic set to finally extract the valid DNS traffic and then performs feature extraction on the cleansed DNS traffic to finally form the dataset used for training.
In terms of feature extraction, the present study examined the characteristics of Domain Name System (DNS) traffic, thereby identifying eight main feature categories, namely string complexity, character structure, character combinations, vocabulary and labels, message length, resource record type, request-response pattern, and resource record content. The development of these features was undertaken to enhance the distinction between benign DNS traffic and DNS covert channel traffic.
String Complexity Features:
It is a well-established fact that standard DNS requests typically exhibit reasonable subdomain lengths. However, it has been observed that covert channels often utilize subdomains with excessively long or short lengths for the purpose of data encryption [
20]. Information entropy, which serves as a quantitative measure of randomness and uncertainty within data strings, is a valuable metric in this context. In the realm of DCC, encoding techniques are frequently employed to obfuscate the transmitted data, resulting in increased randomness of letter combinations and higher entropy values for subdomains. Consequently, entropy can effectively differentiate between covert channel traffic and standard DNS traffic. Generally, normal subdomains consist of meaningful words, whereas encoded domain names are less likely to form coherent words. Therefore, the presence of excessively long words in a domain name may indicate benign DNS traffic. The calculation of subdomain entropy is expressed as follows (Equation (1)):
where
H(
X) denotes the entropy of the random variable
X, denotes the characters in the subdomain string,
P(
x) denotes the probability of occurrence of
x, and n denotes the number of possible character types in the subdomain string.
Character-Building Features:
Covert channels may employ unconventional character combinations to embed data [
21]. For example, typical subdomains generally exhibit a low frequency of digits, while an increased frequency of digits may suggest data transmission. Furthermore, the structure of standard subdomains is characterized by a predominance of lowercase letters, whereas a higher occurrence of uppercase letters may indicate the presence of a covert channel. The presence of a significant percentage of consecutive consonants within a word is also indicative of a randomly generated character sequence. Moreover, frequent alternation between letters and numbers is a distinctive characteristic of covert channels, and such patterns can serve as reliable indicators of covert channel traffic.
Character Combination Features:
It is noteworthy that subdomains generated through covert channels may exhibit unusual character combinations that diverge from the patterns typically observed in standard traffic. The Jaccard index serves as a metric for quantifying the similarity between two sets. In normal subdomains, adjacent double characters generally adhere to specific linguistic patterns, whereas double-character combinations in covert channels tend to be more random. Additionally, the combination of three characters can also reflect the distribution pattern of characters, thereby aiding in the detection of anomalous behavior. This paper focuses exclusively on calculating the Jaccard index for a single domain name, and the simplified formula is presented as follows:
where |N| denotes the set of n-grams of the string and L represents the length of the string.
Lexical and tagging features:
The examination of covert channels has demonstrated the creation of subdomains that consist of a significant quantity of nonsensical words or tags. The primary objective of these channels is to detect anomalies that diverge from typical traffic patterns. In contrast, conventional subdomains typically include one or more semantically meaningful words, whereas covert channels may comprise arbitrary or meaningless sequences of characters, leading to a reduced word count. Additionally, standard DNS requests are characterized by a reasonable number of labels (subdomain components); an excessive number of labels may suggest that data is being partitioned and transmitted through a covert channel.
Message Length Features:
The utilization of covert channels often results in the creation of DNS messages that diverge from standard lengths, either by being excessively long or short, in an effort to obscure data or evade detection. For example, standard DNS messages are constrained by specific load length limitations, whereas covert channels may utilize larger UDP payloads to enable the transmission of covert data.
Resource Record Type Features:
The existence of covert channels can facilitate the embedding of data within a resource record, leading to anomalies in both the size and entropy of the record. For example, the size of resource records in standard DNS responses is typically small; however, unusually large sizes may indicate the occurrence of data injection. Additionally, a high level of entropy in the content of the resource record implies a random distribution of characters, which may serve as an indicator of data injection. Furthermore, irregularities in the types of resource records (e.g., A, AAAA, CNAME) may also suggest the transfer of data.
Request and Response Features:
The utilization of covert channels has been shown to produce responses characterized by multiple IP addresses or anomalous Time to Live (TTL) values, thereby augmenting the element of stealth. Response codes may exhibit atypical behavior, such as a high frequency of error codes, which could signify abnormal activity. Additionally, the employment of specific request types (e.g., TXT logging requests) by covert channels for data transmission can provide critical insights for detection purposes, as the distribution of request types can serve as a significant indicator of such activities.
Resource Record Content Features:
The utilization of covert channels has the potential to increase the entropy of resource record content, thereby enabling the injection of significant volumes of concealed data. These anomalies can be effectively employed to detect steganographic information. Moreover, the incorporation of additional data into UDP messages through covert channels aids in the identification of anomalous message structures.
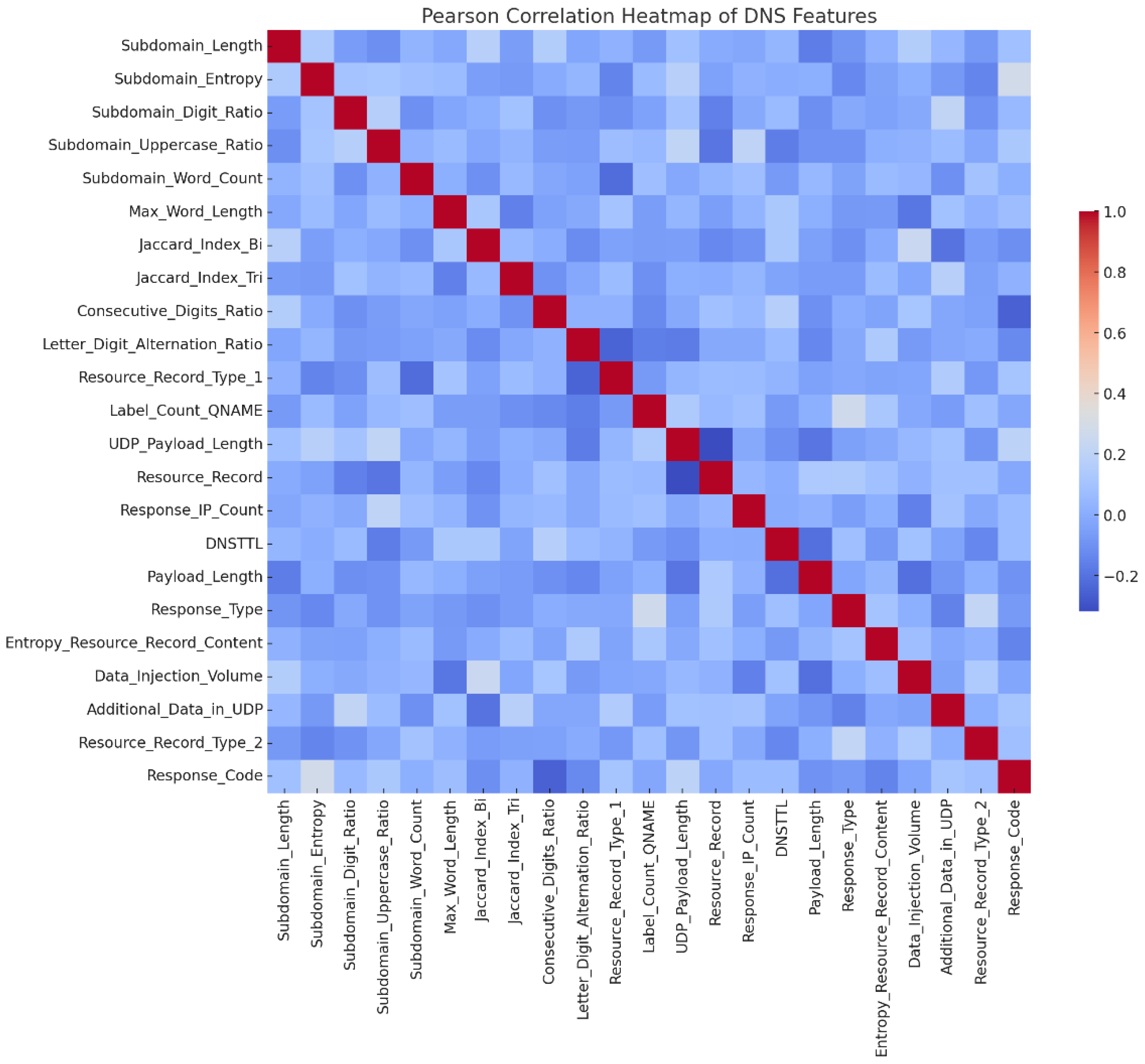
The selected features capture the fundamental characteristics of DNS traffic and enable effective discrimination between benign and malicious behaviors. In this study, a 23-dimensional feature set was systematically constructed through comparative analysis and iterative refinement, with a particular emphasis on the detection of DCC traffic. To ensure the uniqueness and relevance of each feature, Pearson correlation analysis was performed to identify potential redundancy, as illustrated in
Figure 3. Feature pairs exhibiting high correlation (|r| > 0.85) were examined, and only the most informative feature within each correlated group was retained. This process resulted in a compact, non-redundant, and informative feature set. The effectiveness of the selected features has been empirically validated, and the full list is presented in
Table 2.
(4) Generating Grayscale Image: To mitigate the model’s dependence on features with differing numerical scales, all selected feature values are first normalized and subsequently linearly scaled to integer values ranging from 0 to 255. Each DNS traffic instance is thereby represented as a 23-dimensional row vector, capturing key lexical, statistical, and protocol-level attributes of the DNS request.
To enhance both the interpretability and spatial learning capacity of the model, especially in architectures such as convolutional neural networks (CNNs) and Deep Boltzmann Machines (DBMs), this feature vector is transformed into a fixed-size grayscale image. The dimensions of the image are determined based on the total number of features; in this case, a 5 × 5 image is constructed to represent each instance. Since the number of features (23) is slightly less than the number of image pixels (25), two vacant positions are filled using zero-padding, maintaining shape compatibility while introducing minimal noise. The 23 features are placed into the 5 × 5 matrix following a row-major (left-to-right, top-to-bottom) order based on the predefined feature sequence listed in
Table 2. This fixed and reproducible layout ensures that every image maintains structural consistency, enabling the model to learn position-aware feature representations.
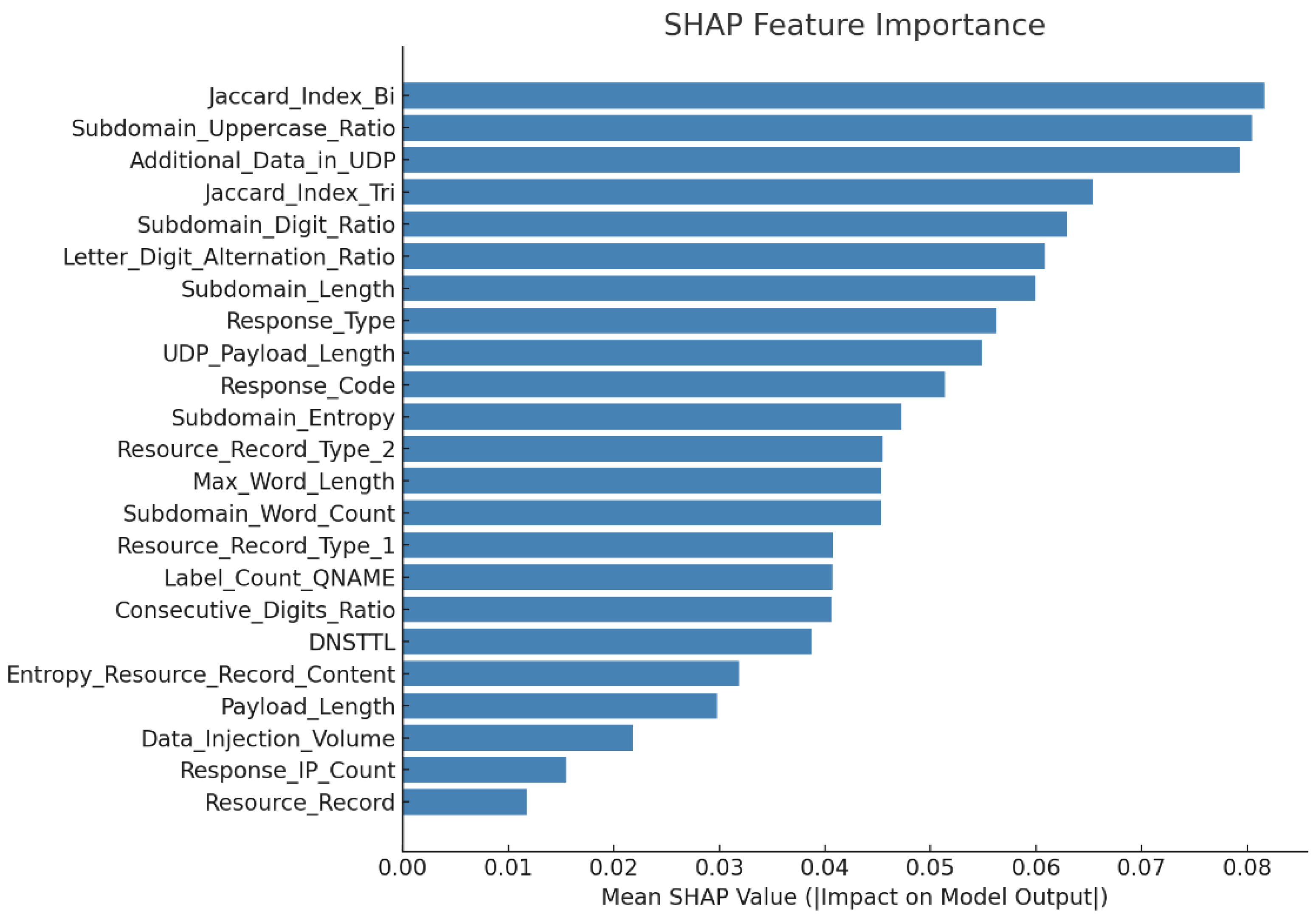
Additionally, to understand the contribution of each feature to the classification output, a SHAP (SHapley Additive exPlanations) analysis was conducted (
Figure 4). An example of the generated grayscale image, derived from a representative DNS traffic instance, is shown in
Figure 5.
As shown in
Figure 4, the top features influencing the prediction include Jaccard_Index_Bi, Subdomain_Uppercase_Ratio, and Additional_Data_in_UDP, each contributing a mean SHAP value greater than 0.07. These features are consistent with domain knowledge in DNS covert channel detection, as they reflect payload similarity, encoding behavior, and protocol anomalies. Importantly, the SHAP values provide an additive explanation model, meaning the final prediction can be decomposed as a sum of individual feature contributions. This ensures that highly weighted features directly push the model towards classifying the sample as DCC or not. For example, a high Jaccard_Index_Bi indicates frequent similarity between consecutive queries, which is typical in tunneling behavior and thus increases the DCC probability. Similarly, a high Subdomain_Uppercase_Ratio or Digit_Ratio often points to base32 or base64 encoding schemes used in covert channels.
3.2. DNS Covert Channel Detection Module
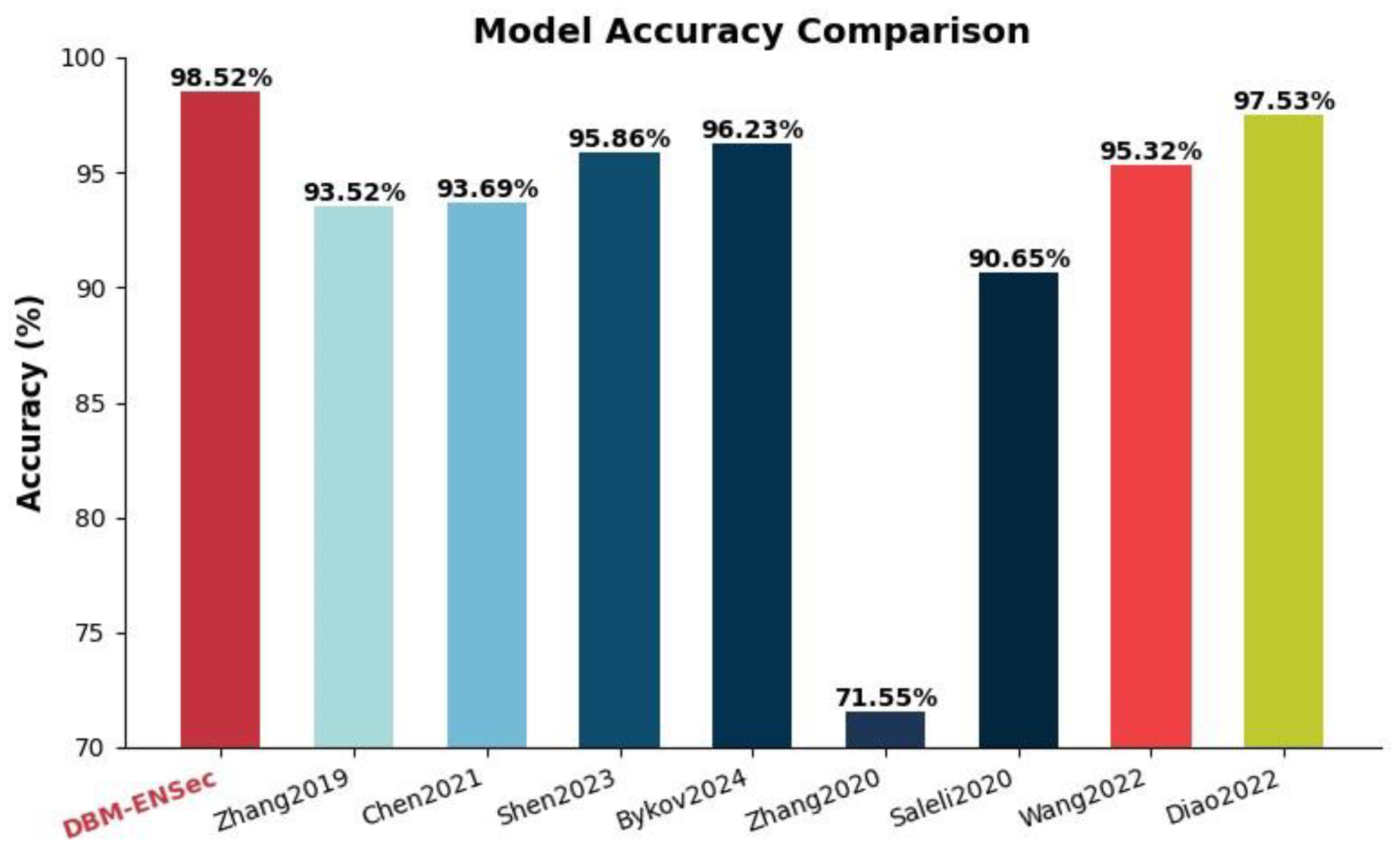
This paper presents a hybrid approach within the DCC detection module, which integrates an improved Deep Boltzmann Machine with a composite classifier to develop the DBM-ENSec model. The effectiveness of this model in identifying DCCs is demonstrated in
Figure 6.
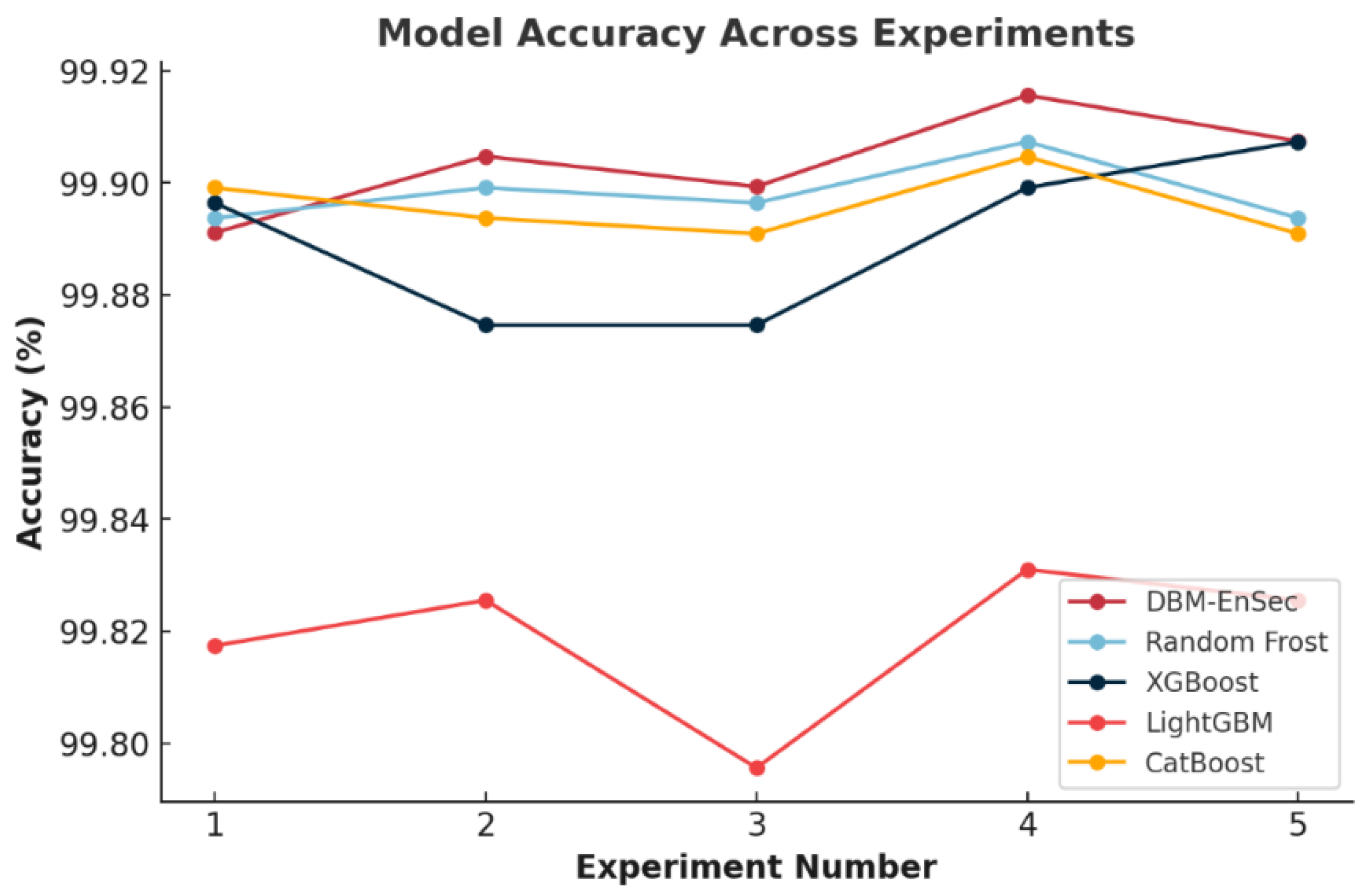
As illustrated in the figure above, the proposed model adopts a multi-stage architecture that combines unsupervised pre-training, spatial feature modeling, and ensemble-based decision making. First, the normalized DNS feature vector is mapped into a 5 × 5 grayscale image. This image is processed by a Deep Boltzmann Machine (DBM), which serves as an unsupervised feature abstraction module. The DBM captures high-level latent structures inherent in DNS traffic by learning the joint probability distribution of feature pixels, thus initializing the network in a way that reflects intrinsic data characteristics. The high-level representations from the DBM are fed into a convolutional neural network (CNN) that refines spatial-local patterns through a convolutional layer. The resulting feature maps are then passed through a self-attention mechanism, which identifies critical long-range dependencies across spatial dimensions, enhancing the model’s ability to detect sophisticated encoding behaviors. The resulting one-dimensional feature vector is then passed to an ensemble decision module, composed of four independent classifiers: XGBoost, Random Forest, LightGBM, and CatBoost. Each model is trained separately using the extracted vector representations. Their individual outputs are combined using a customized weighted ensemble strategy, in which prediction scores are aggregated based on each model’s F1-score performance on the validation set. This ensemble approach improves robustness and reduces model variance without relying on any single algorithm. This end-to-end architecture ensures that both low-level traffic patterns and high-order semantic features are captured. The combined use of unsupervised representation learning (DBM), spatial modeling (CNN + attention), and ensemble decision strategies offers a strong defense against overfitting while also improving generalization in detecting DNS covert channels (DCC). A comprehensive overview of the techniques employed in this model is provided below.
(1) Deep Boltzmann Machine (DBM):
In 2009, Salakhutdinov and Hinton introduced the concept of the Deep Boltzmann Machine and proposed a learning algorithm that utilizes variational approximation and Markov chains to estimate the expected value of a model [
22].
In this paper, we utilize the layer-by-layer pre-training capabilities of the Deep Boltzmann Machine to identify underlying patterns within the input data. These patterns include statistical distributions of characters, domain name lengths, and hierarchical structures, as well as critical information such as request types, response codes, and complex nonlinear relationships between domain names and query behaviors. The application of high-level feature modeling allows DBMs to optimize the input data by eliminating irrelevant or redundant information, including meaningless request fields and repetitive content. Simultaneously, this approach enhances the expressiveness of statistical attributes related to domain names (e.g., length and character distribution) and message characteristics (e.g., packet size and Time to Live (TTL) values). The result of this process is an initial feature representation that effectively highlights anomalous query behavior patterns, such as frequent requests for specific record types, anomalies in TTL values, and irregular distributions of error codes. Moreover, DBMs are capable of detecting potential deviations or traces of artifacts within the content of requests and responses. During the deeper mining process, DBMs extract covert communication patterns, including domain names with atypical lengths or malicious query features in specific formats, which facilitate the transmission of additional data through DNS fields. These deep features provide accurate and reliable inputs for subsequent detection models. The structural configuration of the DBM model is illustrated in
Figure 7.
(2) Residual networks:
To solve the problem of layer disappearance and layer explosion, this paper proposes the integration of a residual network (ResNet) within the framework of the Deep Boltzmann Machine (DBM) to improve the stability of feature transfer. In a conventional feedforward network, the stacked layers transform the input x into F(x), resulting in an overall network output defined as F(x) = H(x). When employing a constant mapping function f(x) = x where inputs and outputs are equal, it becomes challenging to directly fit such a constant mapping function within a layer. An alternative approach strategy involves a training network that enables us to fit an approximate f(x) = 0. The output is expressed as H(x) = F(x) + x, allowing the network to focus on learning the residual F(x) scenarios, which are required to perform constant mapping. The stacked layers are configured to learn F(x) = 0. The residual network is depicted in
Figure 8.
(3) One-dimensional convolutional neural network:
The present study introduces a two-layer one-dimensional convolutional neural network (1D-CNN) designed to extract finer-grained features, which will be implemented following the Deep Boltzmann Machine. This network utilizes mechanisms similar to those of the human brain in processing image data, effectively capturing local dependencies and significant patterns through convolutional operations. Convolutional neural networks (CNNs) have become fundamental in the field of computer vision due to their demonstrated effectiveness in feature extraction and pattern recognition. In this research, a CNN is employed to conduct a comprehensive analysis of DNS traffic features, thereby enhancing the accuracy and richness of feature representations and providing robust support for subsequent classification tasks. The formulation of the two-layer one-dimensional convolutional neural network is presented in Equation (3).
(4) Self-attention mechanism:
To address the limitations of traditional convolutional networks in modeling long-distance dependencies and to enhance the detection accuracy and adaptability of the model, this paper introduces the self-attention mechanism. Also referred to as the internal attention mechanism, the self-attention mechanism was proposed by Vaswani et al. [
23]. in 2017. This technique enables the model to dynamically allocate attention to various elements across the sequence while processing a specific element. In this study, the self-attention mechanism is integrated into a one-dimensional convolutional neural network (1D-CNN), allowing the model to capture relevant information from other positions in the sequence during the processing of a particular element. This approach not only investigates the shortcomings of traditional convolutional networks in managing long-range dependencies but also significantly enhances the model’s capacity to focus on critical information. As a result, the overall feature extraction process is improved, leading to a more precise and comprehensive feature representation for subsequent classification and detection tasks.
The self-attention mechanism operates by assessing the correlation between each element in the input sequence and all other elements within that sequence. The process comprises the following key steps:
1. Input Vector Transformation: Each element of the input sequence is transformed through a linear transformation into three distinct vector spaces: Query, Key, and Value.
2. Calculate Attention Score: The dot product between the query vectors and the key vectors is computed, subsequently scaled, and normalized, typically employing the softmax function, to derive the attention score. The precise formula is presented in Equation (4).
where
dk represents the dimension of the key vector, which is used to scale the result of the dot product.
3. Weighted Summing: The attention scores are employed to weight and aggregate the value vectors, resulting in the creation of a new representation.
The computational process of the self-attention mechanism is illustrated in
Figure 9.
(5) Flatten Layer:
The Flatten layer is specifically designed to transform a multi-dimensional feature map into a one-dimensional vector, which is commonly employed in the final stage of a convolutional neural network. The feature maps generated by convolutional or other feature extraction layers are often multidimensional; however, classifiers require one-dimensional vectors as input. The Flatten layer facilitates this transformation, thereby enabling subsequent classifiers to effectively process the extracted features.
(6) ENSec:
The classifier utilized in this study is an ensemble learning model developed by integrating four distinct machine learning algorithms through a combinatorial strategy. The algorithms employed include Random Forest [
24], XGBoost (eXtreme Gradient Boosting) [
25], LightGBM (Light Gradient Boosting Machine) [
26], and CatBoost (Categorical Boosting). The operation of each sub-model can be summarized as follows: It initially predicts DNS traffic, yielding four prediction values (0 or 1). These values are subsequently utilized to compute a decision score, with the corresponding F1 scores of the models serving as weights. The decision score is then compared against a predetermined threshold to ascertain whether the traffic is classified as a DCC. This approach amalgamates the prediction outcomes of the models along with their performance weights to enhance the accuracy and reliability of the final decision. The formula for calculating the decision score is presented in Equation (5).
where
Fi represents the F1 score of each model and
di denotes the prediction made by each model for the given DNS data, with a prediction of 1 indicating the presence of a DCC and 0 otherwise.
The specific DCC detection algorithm is outlined in Algorithm 1:
| Algorithm 1: DCC Detection Algorithm |
|


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}