

Detecting Emerging DGA Malware in Federated Environments via Variational Autoencoder-Based Clustering and Resource-Aware Client Selection


Abstract
1. Introduction
- We introduce lightweight novelty detection where we leverage VAE latent space representations for accurate, privacy-preserving client unsupervised clustering for anomaly detection.
- We propose FedSAGE, a federated clustering and client selection framework that jointly addresses data heterogeneity and system heterogeneity.
- We evaluate our proposed method on a realistic testbed with multi-zone DGA for non-IID datasets and demonstrate the accuracy improvements in detection, clustering quality without sharing local data, and energy efficiency.
2. Related Work and Motivation
2.1. Federated Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Needs Labels? | Needs Auxiliary or Shared Data? | Clustered/Similarity Signal | Extra Communication vs. FedAvg | Computational Overhead |
|---|---|---|---|---|---|
| WSCC [8] | ✗ | ✗ | Full model weights; cosine/ distance | High—entire weight tensors transferred for pairwise comparison | Low (simple distance calc.) |
| K-FL [15] | ✗ | ✗ | Kalman-filtered weight trajectories | Moderate | Low |
| FedPVD [9] | ✗ | ✗ | Direction of weight change (ΔW) across rounds | Moderate | Low |
| IHC-FL [10] | ✗ | ✗ | Weight similarity + intra-cluster model exchange | Moderate to high | Medium |
| FLIS [11] | ✓ (labels on aux-set) | ✓ (server keeps small labeled dataset) | Output logits on shared aux-data | Low (only logits) | High (server runs inference K times per round) |
| FedSAGE (this work) | ✗ | ✗ | Latent -vector from pre-trained VAE | Low (only vector size ) | Low |
2.2. Federated Learning for Intrusion Detection
2.3. Limitations of Existing DGA Detection Methods
2.4. Research Gap and Motivation
- (Q1) How can DGA attacks be effectively detected in a distributed environment while preserving data privacy?
- (Q2) How can we mitigate non-IID data effects and ensure that even rare or novel DGA domains are learned by the global model?
- (Q3) How can client selection be optimized to balance computational efficiency and data importance, especially under system heterogeneity?
- (Q4) Is it feasible to perform novelty detection of DGA attacks in a label-free, unsupervised fashion?
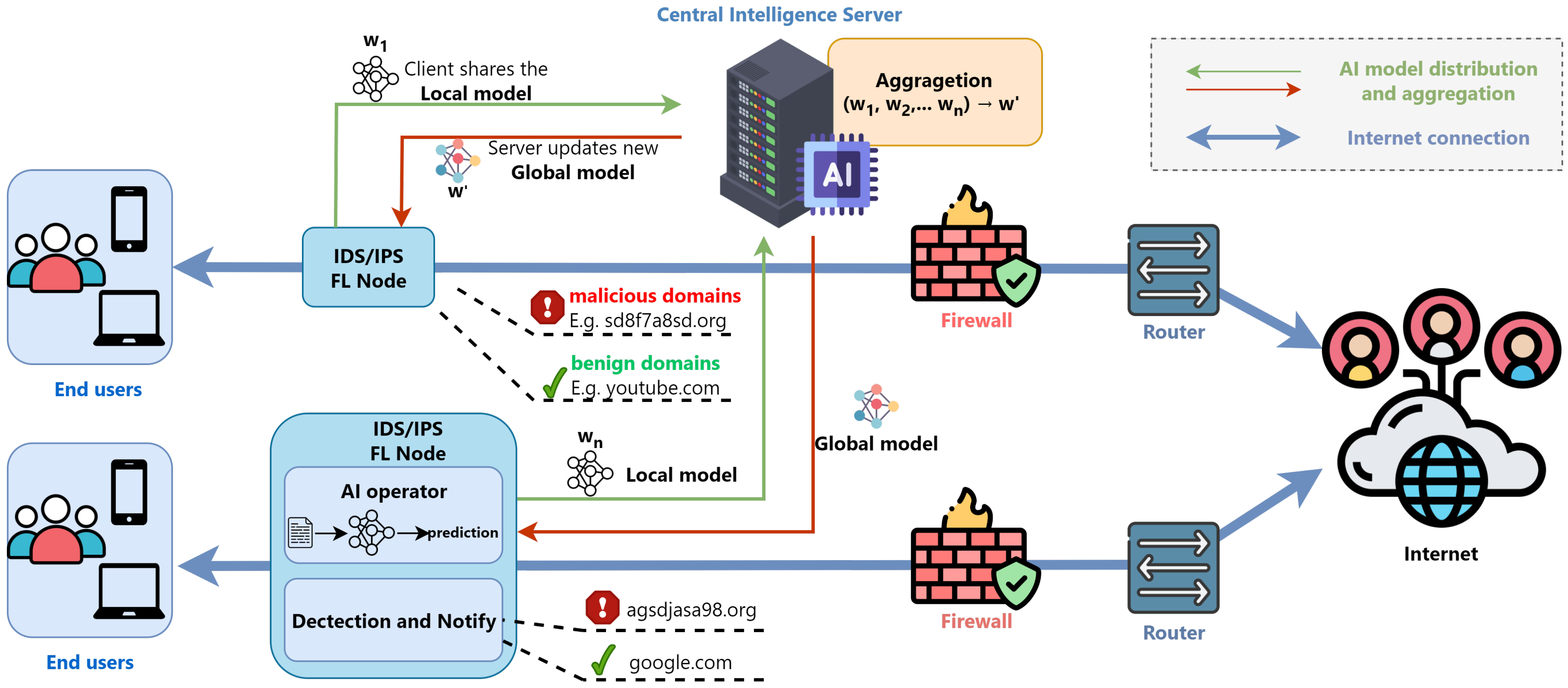
3. The Proposed FedSAGE Framework for Federated DGA Detection
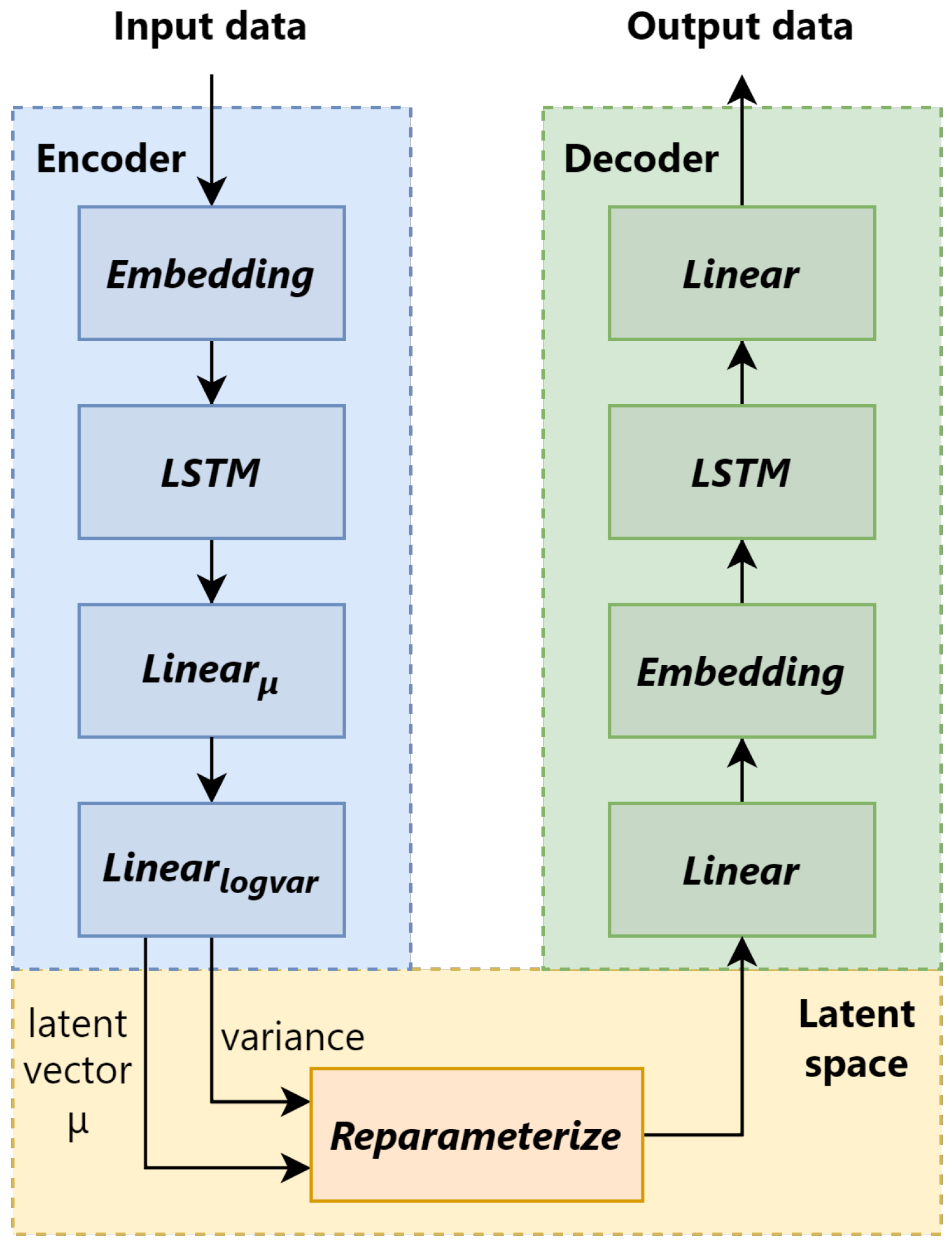
3.1. Variational Autoencoder Architecture
- The first term encourages accurate reconstruction of the input x from the latent variable z in Equation (1).
- The second term regularizes the encoder’s output to remain close to the prior .
- 1.
- The model can detect malicious domains that have not been previously encountered, without requiring explicit DGA labels.
- 2.
- The pre-trained encoder can be deployed on lightweight client devices, where it performs simple forward passes to generate domain embeddings, eliminating the need for on-device retraining.
- 3.
- It significantly reduces computational and communication overhead in FL environments, particularly at the edge or in IoT settings.
3.2. Unsupervised VAE Clustering for Novelty Detection
3.2.1. Client Clustering Based on Latent Encoding
- Responsibility : how well-suited point k is to be the exemplar for point i,
- Availability : how appropriate it would be for point i to choose point k as its exemplar.
3.2.2. Privacy-Preserving Latent Encoding
- 1.
- The encoder maps input domain strings to a low-dimensional latent mean vector , typically with . This process is non-invertible by design, as multiple inputs are projected to nearby or overlapping regions in latent space. The dimensionality reduction forces the model to compress only the most semantically relevant aspects of the input. This is aligned with the information bottleneck principle, which suggests that retains information that is useful for downstream tasks (e.g., clustering) while discarding instance-specific noise or details that might enable reconstruction.
- 2.
- During training, VAE introduces Gaussian noise into the encoding through the reparameterization trick in Equation (1). Even after training, the encoder learns to focus on capturing latent factors of variation, not full input recovery. Therefore, even if one were to recover a valid latent point , it is impossible to deterministically recover x, especially for non-deterministic inputs such as randomized domain names.
- 3.
- The decoder network used during training is not deployed or shared in the federated setup. The server only observes isolated latent vectors from independent clients. Even with white-box access, reconstructing a valid decoder without aligned -x pairs from each client is infeasible due to a lack of supervision and data pairing.
3.3. Client Selection with Data-Aware Scheduling
3.4. FedSAGE—Federated Selection and Clustering for Anomaly and Generative-Domain Evaluation
- Representation Learning: Using a shared pre-trained VAE to encode client data into a meaningful latent space.
- Client Clustering: Grouping clients via affinity propagation based on latent representations to capture data similarity.
- Efficient Selection: Selecting the fastest client(s) within each cluster to ensure training efficiency without sacrificing data diversity.
| Algorithm 1 FedSAGE: Federated Selection and Clustering for Anomaly and Generative-domain Evaluation |
|
4. Experiment Setup
4.1. DGA Datasets and Detection Models
- CNN Model: Built by a multiple-layer convolutional architecture to capture local n-gram patterns in domain names. It employs an embedding layer followed by four parallel 1D convolutional layers with kernel sizes of , each with 128 filters. Then, these outputs are pooled via adaptive max pooling and concatenated before passing through fully connected layers.
- BiLSTM Model: This uses a bidirectional LSTM encoder with a hidden dimension of 64 in each direction (128 total), followed by an attention mechanism that computes a weighted sum of hidden states. The attention-enhanced representation is then passed through batch-normalized dense layers for classification. This architecture is effective for modeling sequential correlations inherent in algorithmically generated domain names.
- Transformer Model: This model uses the global attention method for modeling input sequences, enabling parallel computation and strong generalization. It uses an embedding layer of size 64 with added positional encoding, followed by a stack of 4 Transformer encoder layers with 4 heads and a feedforward dimension of 256. Then, this final output is taken from the first token’s transformed representation, similar to BERT-style classification [39]. This model is the most computationally intensive among the three, but it demonstrates strong performance in capturing long-range semantic patterns.
4.2. Testbed Setup
- Idle energy—. Even when no training is underway, the device draws a baseline (static) power to keep fans, regulators, and memory alive. Multiplying this idle power by the time the device remains idle, , yields the unavoidable “background” energy budget.
- Computation energy—. During training, each compute resource c (CPU and GPU) operates at an average dynamic power ; multiplying by its active time gives the energy devoted purely to model computation.
- Communication energy—. Exchanging model parameters and gradients forces the network interface to transmit bytes at a data rate of . The term is the transmission time; when multiplied by the NIC’s transmit power , it captures the energy spent on networking.
4.3. Baseline
- FedAvg [5]: The standard FL algorithm in which all clients participate in each training round. Clients perform local training using their private data and send the updated model parameters to a central server, which aggregates them using weighted averaging. FedAvg does not account for system heterogeneity or data distribution skewness.
- FedRand (Random Selection): A strategy where a fixed number of clients is randomly selected in each round. This method reduces the training time by avoiding straggler clients but may overlook important data held by randomly excluded clients, especially under non-IID conditions.
- FedSpeed (Only Selection): This method selects only clients with high computational performance (e.g., faster devices) in each training round. While this improves system efficiency, it may exclude slower devices that possess critical or unique data, potentially hurting model generalization in non-IID settings.
- FLIS (Federated Learning via Inference Similarity) [11]: A clustered FL approach that groups clients based on inference similarity (i.e., the similarity of model outputs on a shared auxiliary dataset). Although FLIS effectively addresses data heterogeneity, it introduces additional overhead by requiring an auxiliary dataset for server-side evaluation and similarity computation.
5. Results
5.1. Clustering Efficiency
5.2. Distributed Training Performance
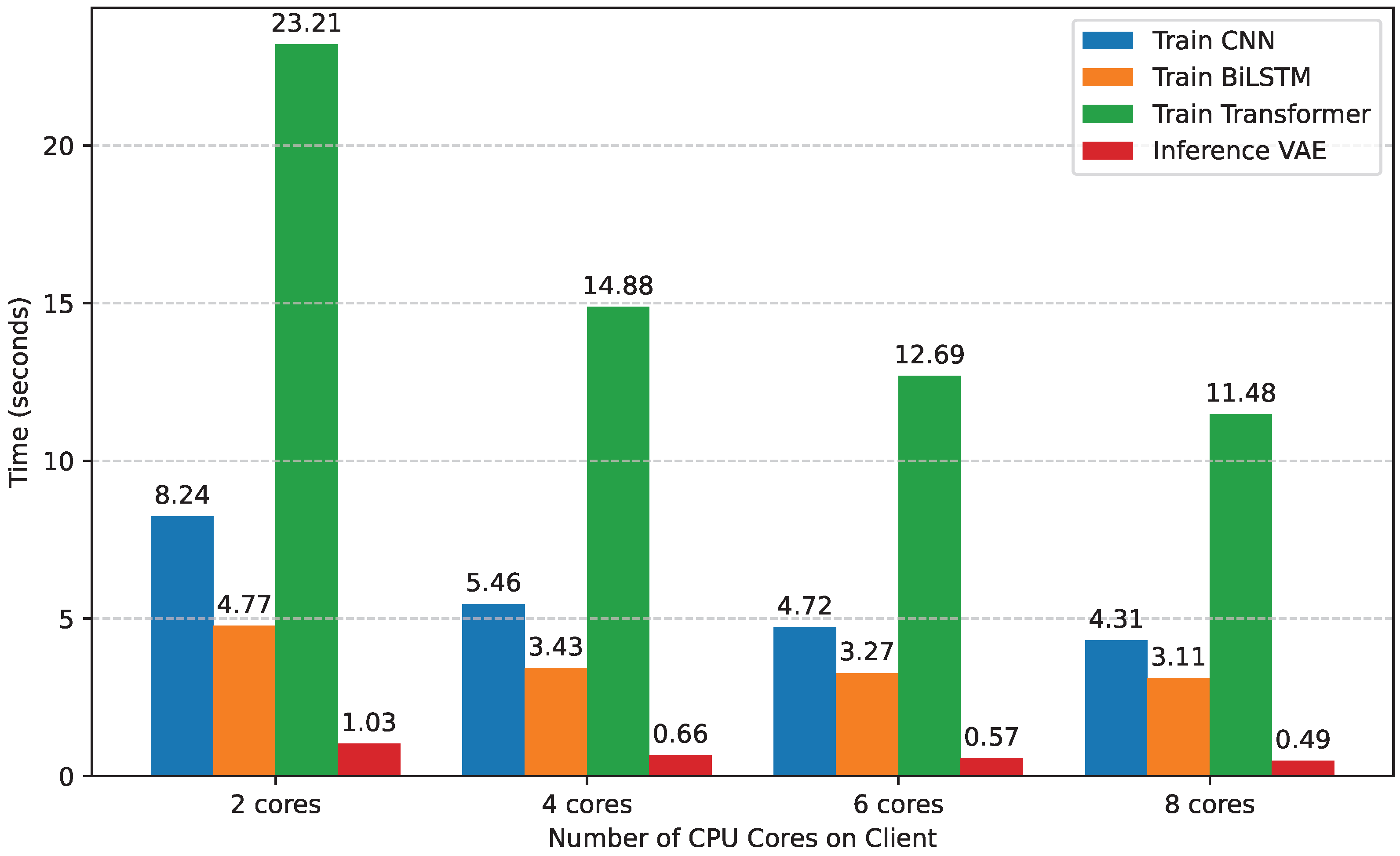
5.3. Client Performance Analysis
5.4. Energy Efficiency
5.5. Discussion and Analysis
- (Q1) Distributed DGA detection with privacy: We utilize a pre-trained VAE deployed for each client to map raw domain data into latent vectors without sharing raw data. These vectors are used for downstream clustering and anomaly detection, preserving privacy while enabling detection across decentralized IDS nodes (see Section 3.1, Section 3.2 and Section 4.1).
- (Q2) Handling non-IID and rare DGA data: The use of affinity propagation clustering on VAE-derived latent vectors allows clients with similar data characteristics to be grouped together, ensuring semantic diversity is preserved in training (Section 3.2). Moreover, the experiments in Section 5.1 demonstrate that the clustering aligns with true DGA zones, even under non-uniform data.
- (Q3) Intelligent client selection under system heterogeneity: FedSAGE selects the top-ρ% fastest clients in each cluster (Section 3.3), combining data-aware and computation-aware strategies. This ensures participation from diverse data regions without incurring delays from stragglers. The result is a balance between efficiency and representativeness (see Algorithm 1, Table 4 and Table 5).
- (Q4) Unsupervised novelty detection of DGA: The VAE, trained only on benign domains, enables unsupervised anomaly detection in the latent space by identifying DGA domains that deviate from benign clusters (Section 3.1 and Section 3.2). This eliminates the need for labeled DGA data, as shown in the clustering and accuracy results (Figure 6, Table 4 and Table 5).
- Robust convergence with low communication cost (see Section 5.1 and Section 5.2),
- Strong and lightweight adaptability to real-world non-IID data (see Section 5.3),
- Superior energy efficiency under strict system constraints (see Section 5.4).
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liao, H.J.; Lin, C.H.R.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Sood, A.K.; Zeadally, S. A taxonomy of domain-generation algorithms. IEEE Secur. Priv. 2016, 14, 46–53. [Google Scholar] [CrossRef]
- Fu, Y.; Yu, L.; Hambolu, O.; Ozcelik, I.; Husain, B.; Sun, J.; Sapra, K.; Du, D.; Beasley, C.T.; Brooks, R.R. Stealthy domain generation algorithms. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1430–1443. [Google Scholar] [CrossRef]
- Minh, N.N.; Hieu, P.T.; Hai, V.; Thanh, N.H. DGA-based Intrusion Detection System using Federated Learning Method on Edge Devices. In Proceedings of the 2024 International Conference on Information Networking (ICOIN), Ho Chi Minh City, Vietnam, 17–19 January 2024; pp. 509–514. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Aouedi, O.; Piamrat, K.; Muller, G.; Singh, K. FLUIDS: Federated Learning with semi-supervised approach for Intrusion Detection System. In Proceedings of the 2022 IEEE 19th annual consumer communications & networking conference (CCNC), Las Vegas, NV, USA, 8–11 January 2022; pp. 523–524. [Google Scholar] [CrossRef]
- Duc, M.V.; Luan, N.T.; Tai, N.T.; Hieu, N.P.T.; Minh, N.N.; Hieu, P.T.; Hai, V.; Thanh, N.H. On the Impact of Heterogeneity on Federated Learning at the Edge with DGA Malware Detection. In Proceedings of the Asian Internet Engineering Conference 2024, Sydney, Australia, 9 August 2024; pp. 10–17. [Google Scholar]
- Tian, P.; Liao, W.; Yu, W.; Blasch, E. WSCC: A weight-similarity-based client clustering approach for non-IID federated learning. IEEE Internet Things J. 2022, 9, 20243–20256. [Google Scholar] [CrossRef]
- Bo, L.; Ping, Z.Y.; Cai, L.Q. FedPVD: Clustered Federated Learning with NoN-IID Data. In Proceedings of the 2023 IEEE 6th International Conference on Electronic Information and Communication Technology (ICEICT), Qingdao, China, 21–24 July 2023; pp. 551–556. [Google Scholar] [CrossRef]
- Shih, C.H.; Kuo, J.J.; Sheu, J.P. Information-Exchangeable Hierarchical Clustering for Federated Learning with Non-IID Data. In Proceedings of the GLOBECOM 2023—2023 IEEE Global Communications Conference, Kuala Lumpur, Malaysia, 4–8 December 2023; pp. 231–236. [Google Scholar] [CrossRef]
- Morafah, M.; Vahidian, S.; Wang, W.; Lin, B. Flis: Clustered federated learning via inference similarity for non-iid data distribution. IEEE Open J. Comput. Soc. 2023, 4, 109–120. [Google Scholar] [CrossRef]
- Li, Q.; Shao, S.; Yang, C.; Chen, J.; Qi, F.; Guo, S. Communication-efficient Federated Learning Framework with Parameter-Ordered Dropout. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; pp. 1195–1200. [Google Scholar] [CrossRef]
- Alsamiri, J.; Alsubhi, K. Federated learning for intrusion detection systems in internet of vehicles: A general taxonomy, applications, and future directions. Future Internet 2023, 15, 403. [Google Scholar] [CrossRef]
- Bharati, S.; Mondal, M.R.H.; Podder, P.; Prasath, V.S. Federated learning: Applications, challenges and future directions. Int. J. Hybrid Intell. Syst. 2022, 18, 19–35. [Google Scholar] [CrossRef]
- Kim, H.; Kim, B.; Kim, Y.; You, C.; Park, H. K-fl: Kalman filter-based clustering federated learning method. IEEE Access 2023, 11, 36097–36105. [Google Scholar] [CrossRef]
- Xiao, P.; Cheng, S.; Stankovic, V.; Vukobratovic, D. Averaging is probably not the optimum way of aggregating parameters in federated learning. Entropy 2020, 22, 314. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Onietan, C.I.O.; Martins, I.; Owoseni, T.; Omonedo, E.C.; Eze, C.P. A preliminary study on the application of hybrid machine learning techniques in network intrusion detection systems. In Proceedings of the 2023 International Conference on Science, Engineering and Business for Sustainable Development Goals (SEB-SDG), Omu-Aran, Nigeria, 5–7 April 2023; Volume 1, pp. 1–7. [Google Scholar] [CrossRef]
- Haripriya, L.; Jabbar, M.A. Role of machine learning in intrusion detection system. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 925–929. [Google Scholar] [CrossRef]
- Lee, S.W.; Sidqi, H.M.; Mohammadi, M.; Rashidi, S.; Rahmani, A.M.; Masdari, M.; Hosseinzadeh, M. Towards secure intrusion detection systems using deep learning techniques: Comprehensive analysis and review. J. Netw. Comput. Appl. 2021, 187, 103111. [Google Scholar] [CrossRef]
- Agrawal, S.; Sarkar, S.; Aouedi, O.; Yenduri, G.; Piamrat, K.; Alazab, M.; Bhattacharya, S.; Maddikunta, P.K.R.; Gadekallu, T.R. Federated learning for intrusion detection system: Concepts, challenges and future directions. Comput. Commun. 2022, 195, 346–361. [Google Scholar] [CrossRef]
- Khraisat, A.; Alazab, A.; Singh, S.; Jan, T.; Gomez, A., Jr. Survey on federated learning for intrusion detection system: Concept, architectures, aggregation strategies, challenges, and future directions. ACM Comput. Surv. 2024, 57, 1–38. [Google Scholar] [CrossRef]
- Shahzad, H.; Sattar, A.R.; Skandaraniyam, J. DGA domain detection using deep learning. In Proceedings of the 2021 IEEE 5th International Conference on Cryptography, Security and Privacy (CSP), Zhuhai, China, 8–10 January 2021; pp. 139–143. [Google Scholar] [CrossRef]
- Kumar, S.; Bhatia, A. Detecting domain generation algorithms to prevent ddos attacks using deep learning. In Proceedings of the 2019 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Goa, India, 16–19 December 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, W.W.; Gong, J.; Liu, Q. Detecting machine generated domain names based on morpheme features. In Proceedings of the 1st International Workshop on Cloud Computing and Information Security, Shanghai, China, 9–11 November 2013; Atlantis Press: Dordrecht, The Netherlands, 2013; pp. 408–411. [Google Scholar] [CrossRef]
- Yadav, S.; Reddy, A.K.K.; Reddy, A.N.; Ranjan, S. Detecting algorithmically generated malicious domain names. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement, Melbourne, Australia, 1–3 November 2010; pp. 48–61. [Google Scholar] [CrossRef]
- Drichel, A.; Meyer, U.; Schüppen, S.; Teubert, D. Analyzing the real-world applicability of DGA classifiers. In Proceedings of the 15th International Conference on Availability, Reliability and Security, Online, 25–28 August 2020; pp. 1–11. [Google Scholar] [CrossRef]
- Yu, B.; Pan, J.; Hu, J.; Nascimento, A.; De Cock, M. Character level based detection of DGA domain names. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Catania, C.; García, S.; Torres, P. Deep convolutional neural networks for DGA detection. In Proceedings of the Argentine Congress of Computer Science, Buenos Aires, Argentina, 1–5 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 327–340. [Google Scholar] [CrossRef]
- Tran, D.; Mac, H.; Tong, V.; Tran, H.A.; Nguyen, L.G. A LSTM based framework for handling multiclass imbalance in DGA botnet detection. Neurocomputing 2018, 275, 2401–2413. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Yang, L.; Fan, W.; Bouguila, N. Deep clustering analysis via dual variational autoencoder with spherical latent embeddings. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 6303–6312. [Google Scholar] [CrossRef] [PubMed]
- Ma, H. Achieving deep clustering through the use of variational autoencoders and similarity-based loss. Math. Biosci. Eng. 2022, 19, 10344–10360. [Google Scholar] [CrossRef] [PubMed]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Triastcyn, A.; Faltings, B. Federated learning with bayesian differential privacy. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2587–2596. [Google Scholar] [CrossRef]
- Ding, L.; Li, L.; Han, J.; Fan, Y.; Hu, D. Detecting Domain Generation Algorithms with Bi-LSTM. Comput. Mater. Contin. 2019, 61. [Google Scholar] [CrossRef]
- Gogoi, B.; Ahmed, T. DGA domain detection using pretrained character based transformer models. In Proceedings of the 2023 IEEE Guwahati Subsection Conference (GCON), Guwahati, India, 23–25 June 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, (Long and Short Papers). pp. 4171–4186. [Google Scholar] [CrossRef]



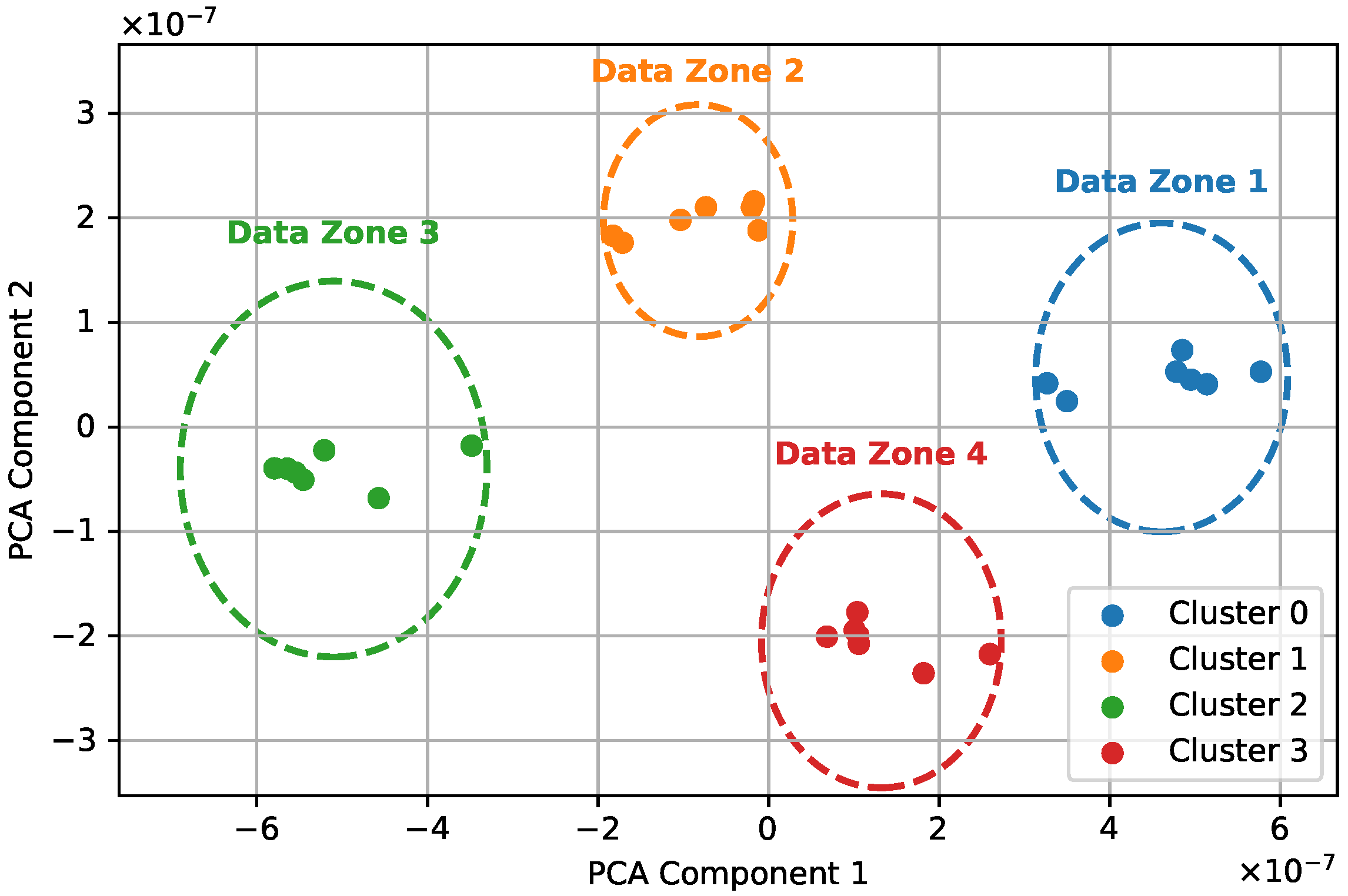
| Zone 1 | Zone 2 | Zone 3 | Zone 4 |
|---|---|---|---|
| banjori, corebot, necurs, ramnit, reconyc | bumblebee, orchard, qadars, gozi, vawtrak | bazarbackdoor, fobber, ramdo, padcrypt, zloader | locky, newgoz, ngioweb, dnschanger, pykspa |
| Component | Description |
|---|---|
| Client Devices | 30 Virtual Machines (VMs), Ubuntu 20.04, Intel Xeon Silver 4210 CPUs |
| System Heterogeneity | Random CPU cores per VM: 1 to 8 cores |
| Communication Layer | RabbitMQ over LAN (1 Gbps bandwidth) |
| Training Settings | SGD (lr = 1 × , momentum = 0.9), batch size = 32, up to 400 rounds |
| FL Framework | Custom Python (3.8.10) + PyTorch (2.2.2) |
| Selection Ratio | (top fastest clients per cluster in FedSAGE and variants) |
| Data Partitioning | - Uniform: 5 K samples/label/client - Non-uniform: 2.5 K–7.5 K samples/label/client |
| DNN Model | Training Time (s) | Top-1 Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| FedAvg | FedSAGE | FedRand | FedSpeed | FLIS | ||
| 400 | 74.08 | 78.36 | 72.20 | 62.63 | 49.66 | |
| CNN | 600 | 74.08 | 84.65 | 72.66 | 63.58 | 72.14 |
| 800 | 76.69 | 87.53 | 77.19 | 65.26 | 72.82 | |
| 200 | 79.64 | 80.79 | 77.57 | 75.79 | 60.52 | |
| BiLSTM | 350 | 80.71 | 86.96 | 80.13 | 81.81 | 70.61 |
| 500 | 82.10 | 89.33 | 81.93 | 84.16 | 73.85 | |
| 500 | 63.02 | 65.98 | 61.52 | 64.30 | 53.37 | |
| Transformer | 1000 | 63.70 | 64.37 | 70.55 | 69.71 | 54.42 |
| 1500 | 64.86 | 76.09 | 74.80 | 65.64 | 55.76 | |
| DNN Model | Training Time (s) | Top-1 Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| FedAvg | FedSAGE | FedRand | FedSpeed | FLIS | ||
| 400 | 70.60 | 82.47 | 70.52 | 78.78 | 50.34 | |
| CNN | 600 | 75.28 | 84.11 | 70.52 | 81.38 | 59.22 |
| 800 | 77.85 | 87.85 | 78.48 | 85.66 | 66.24 | |
| 200 | 78.29 | 81.86 | 75.10 | 78.96 | 49.66 | |
| BiLSTM | 350 | 79.14 | 87.62 | 77.89 | 82.48 | 49.66 |
| 500 | 80.27 | 89.83 | 80.26 | 85.38 | 49.66 | |
| 500 | 65.12 | 66.96 | 62.64 | 63.65 | 53.44 | |
| Transformer | 1000 | 66.49 | 73.56 | 67.42 | 68.16 | 54.45 |
| 1500 | 67.63 | 80.32 | 69.05 | 72.64 | 54.96 | |
| Model Name | CNN | BiLSTM | Transformer | VAE |
| RAM Usages (GB) | 0.62 | 0.63 | 0.68 | 0.10 |
| DNN Model | Data Distribution | Energy Consumption on Each FL Algorithms (Joule) | ||||
|---|---|---|---|---|---|---|
| FedAvg | FedSAGE | FedRand | FedSpeed | FLIS | ||
| CNN | Uniform | 273,348.52 | 16,812.44 | 41,486.30 | - | 50,673.33 |
| Non-uniform | 175,649.49 | 9484.04 | 32,677.66 | 15,375.52 | 58,383.31 | |
| BiLSTM | Uniform | 33,878.16 | 6834.96 | 12,500.02 | 10,503.85 | 48,610.55 |
| Non-uniform | 54,085.36 | 6002.80 | 16,979.58 | 8923.32 | - | |
| Transformer | Uniform | - | 65,601.83 | 153,981.76 | - | - |
| Non-uniform | 884,910.56 | 53,835.56 | 185,082.63 | 92,980.70 | - | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duc, M.V.; Dang, P.M.; Phuong, T.T.; Truong, T.D.; Hai, V.; Thanh, N.H. Detecting Emerging DGA Malware in Federated Environments via Variational Autoencoder-Based Clustering and Resource-Aware Client Selection. Future Internet 2025, 17, 299. https://doi.org/10.3390/fi17070299
Duc MV, Dang PM, Phuong TT, Truong TD, Hai V, Thanh NH. Detecting Emerging DGA Malware in Federated Environments via Variational Autoencoder-Based Clustering and Resource-Aware Client Selection. Future Internet. 2025; 17(7):299. https://doi.org/10.3390/fi17070299
Chicago/Turabian StyleDuc, Ma Viet, Pham Minh Dang, Tran Thu Phuong, Truong Duc Truong, Vu Hai, and Nguyen Huu Thanh. 2025. "Detecting Emerging DGA Malware in Federated Environments via Variational Autoencoder-Based Clustering and Resource-Aware Client Selection" Future Internet 17, no. 7: 299. https://doi.org/10.3390/fi17070299
APA StyleDuc, M. V., Dang, P. M., Phuong, T. T., Truong, T. D., Hai, V., & Thanh, N. H. (2025). Detecting Emerging DGA Malware in Federated Environments via Variational Autoencoder-Based Clustering and Resource-Aware Client Selection. Future Internet, 17(7), 299. https://doi.org/10.3390/fi17070299