


LLM4Rec: A Comprehensive Survey on the Integration of Large Language Models in Recommender Systems—Approaches, Applications and Challenges



Abstract
1. Introduction
- Enhanced Tailoring and Context Comprehension: Interpreting subtle user signals and preferences through rich language inputs, improving the contextual relevance of recommendations [4].
- Exploitation of Heterogeneous Unstructured Data: Leveraging sources such as reviews, social media content, and user comments to improve recommendation quality [5].
- Generative Abilities for Novel Suggestions: Generating fresh and exploratory recommendations, particularly in media and entertainment, by suggesting items beyond the categories requested by the users.
- Mitigation of Cold-Start and Data Scarcity Problems: Employing descriptive text data and contextual information to recommend unfamiliar users or items with little historical data [6].
- Real-Time Adaptation to User Preferences: In fast-paced domains like news, fashion, and social media, user preferences can shift rapidly. MixRec addresses this by using a dynamic mixture-of-experts framework that continuously adjusts to users’ evolving behaviors, enabling the system to deliver timely and contextually relevant recommendations [7].
- To explore how LLM architectures have been adapted for recommender systems;
- To compare their application across domains such as e-commerce, healthcare, and education;
- To identify challenges and gaps in current LLM4Rec research;
- To provide a structured taxonomy and benchmarking framework for future studies.
Paper Organization
2. Materials and Methods
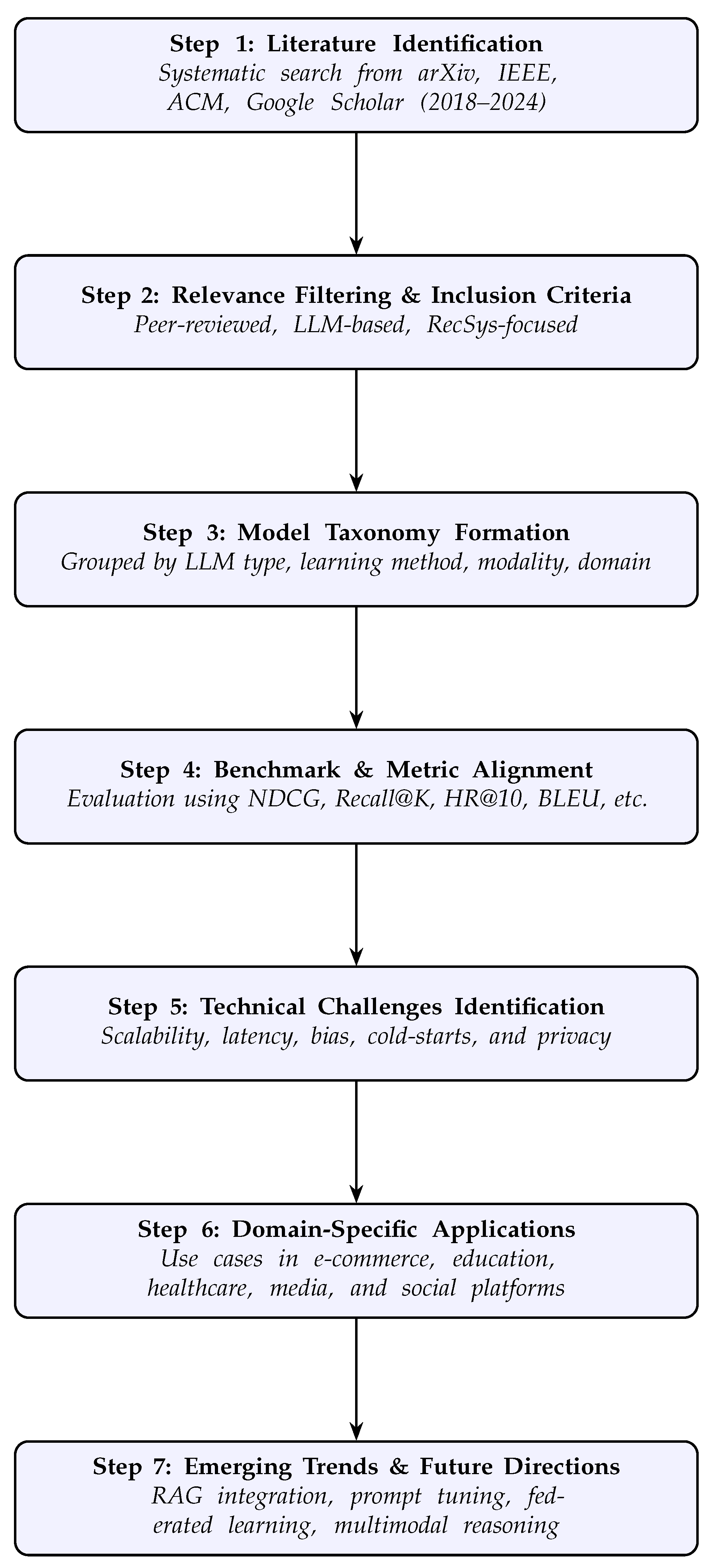
Research Strategy
- Paper Identification: Keyword-based searches (e.g., “LLM4Rec”, “BERT recommender”, “multimodal recommendation”) were conducted to retrieve the relevant literature from scholarly databases.
- Relevance Filtering and Inclusion: Only papers focusing on LLM-based recommendation tasks, benchmark evaluations, novel architectures, or technical challenges were retained. Duplicates and irrelevant works were excluded.
- Taxonomical Classification: Selected works were categorized by architecture type (generative/discriminative), Transformer backbone (e.g., BERT, GPT, T5), modality (text, multimodal), and domain (e.g., healthcare, e-commerce).
- Comparative Analysis: Each model was evaluated using standard metrics such as NDCG, Recall@K, AUC, BLEU, and latency/accuracy trade-offs. Fine-tuning strategies like prompt tuning, LoRA, and multitask learning were also compared.
- Trend and Gap Identification: We analyzed recurring limitations (e.g., cold-start problems, bias, latency) and emerging solutions (e.g., retrieval-augmented generation, federated learning, multimodal fusion) to inform future directions.
3. Contributions and Scope of the Survey
Guiding Research Questions
To support this goal, the following sub-questions are explored:How can large language models (LLMs) be effectively integrated into recommender systems to enhance personalization, ensure scalability, and support context-sensitive decision making across diverse domains and input types?
- Sub Q1: In what ways are LLM architectures—such as BERT, GPT, and T5—adapted, fine-tuned, or prompt-engineered to handle core recommendation tasks including sequential prediction, relevance ranking, and content generation?
- Sub Q2: What are the major deployment scenarios and use cases for LLM4Rec systems in sectors like e-commerce, healthcare, education, and social media? What domain-specific constraints (e.g., multilingual input, ethical considerations, regulatory frameworks) influence their design and performance?
- Sub Q3: Which technical limitations persist in current LLM4Rec pipelines—particularly regarding computational efficiency, fairness, data sparsity, cold-start issues, and user privacy—and how are these being addressed in state-of-the-art research?
- Sub Q4: How do LLM-based recommender models compare to traditional or hybrid systems in terms of key performance indicators such as NDCG, Recall@K, diversity, latency, and real-time responsiveness?
4. Foundations of Recommendation Systems and LLM Integration
4.1. Traditional Recommender Systems
4.2. Large Language Models: Capabilities and Evolution
4.2.1. Bidirectional Encoder Representations from Transformers (BERT)
4.2.2. Generative Pre-Trained Transformer (GPT)

{kind=link}
{kind=link}
{kind=link}
| Aspect | BERT | GPT | T5 | RoBERTa | XLNet | ALBERT |
|---|---|---|---|---|---|---|
| Training Objective | MLM + NSP | Causal Language Modelling | Text-to-Text Generation | MLM (no NSP) | Permutation Language Modelling | MLM + Sentence Order Prediction |
| Pre-training Method | Autoencoding | Autoregressive decoding | Seq2Seq Text Generation | Longer MLM with dynamic masking | Permuted language modeling (Autoregressive + Autoencoding) | Factorized embeddings + shared weights |
| Bidirectional Context | Yes | No | Encoder–decoder (Partial) | Yes | Yes (via permutations) | Yes |
| Multilingual Support | mBERT available | GPT-3+ multilingual | mT5 variant | XLM-R variant available | Not standard | Requires adaptation |
| Fine-tuning Requirement | Required | Often not required | Required but efficient | Required for most tasks | Required | Required |
| Key Applications | QA, NER, classification | Generation, Q&A, dialogue | All NLP tasks unified | Sentiment, news classification | Classification, recsys, long-text analysis | Classification, low-resource NLP |
| Strengths | Transfer learning, context-rich embeddings | Few-shot capable, coherent generation | Unified architecture, efficient finetuning | Improved pretraining, better generalization | Bidirectional + long-range modeling | Lightweight, faster training, memory-efficient |
| Limitations | Computation-heavy, privacy bias | Bias + hallucinations | Large pretraining cost, model size | Still computation-heavy, no generation | Complex training, high computation | Slightly less performance on multilingual tasks |
| Evaluation Metrics | GLUE (80.5%), SQuAD v1.1 (F1: 93.2), SQuAD v2.0 (F1: 83.1) | GLUE (72.8), RACE (Accuracy: 59.0), Story Cloze Test (Accuracy: 86.5) | GLUE (89.3), SQuAD v1.1 (F1: 92.8), CNN/DailyMail (ROUGE-L: 36.6) | GLUE (88.5), SQuAD v1.1 (F1: 94.6), RACE (Accuracy: 89.8) | GLUE (89.8), SQuAD v1.1 (F1: 94.5), RACE (Accuracy: 89.8) | GLUE (89.4), SQuAD v2.0 (F1: 89.1), RACE (Accuracy: 89.4) |
4.2.3. Text-to-Text Transfer Transformer (T5)
4.2.4. XLNet
4.2.5. RoBERTa (A Robustly Optimized BERT Pretraining Approach)
4.2.6. ALBERT
4.2.7. Electra (Efficiently Learning an Encoder That Classifies Token Replacements Accurately)
| Aspect | Electra | BART | DistilBERT | Megatron-LM |
|---|---|---|---|---|
| Training Objective | Replaced Token Detection (RTD) | Denoising Autoencoding | Distilled Masked Language Modelling | Causal Language Modelling (Autoregressive) |
| Pre-training Method | Generator-discriminator with full token prediction | Noise-corruption and reconstruction | Knowledge distillation from BERT | Parallel training: tensor, pipeline, and data parallelism |
| Bidirectional Context | Yes (via discriminator) | Yes (encoder), No (decoder) | Yes (via distilled BERT) | No (unidirectional) |
| Multilingual Support | Not standard | Available via mBART | Available (e.g., distil-mBERT) | Varies by implementation |
| Fine-tuning Requirement | Yes | Yes | Yes (lightweight) | Often used for pretraining large LLMs |
| Key Applications | Text classification, QA, zero-shot NLU | Summarization, translation, recommender systems | Edge deployment, real-time NLP, cybersecurity | Scalable LLMs (e.g., GPT-3-like), RecSysLLM, few-shot learning |
| Strengths | Sample-efficient; outperforms BERT/RoBERTa on GLUE | Combines strengths of BERT + GPT; robust for sequence generation | 60% smaller than BERT-base, retains 90% of BERT’s performance; fast | Enables trillion-parameter models; advanced parallelism for training efficiency |
| Limitations | Not ideal for generation; training method complexity | High computation needs; domain-specific challenges in real-time systems | Slightly less accurate than BERT in some tasks | Massive GPU and memory requirements; sensitive to prompts |
| Evaluation Metrics | GLUE (Acc, MCC, Corr), SQuAD (F1: 90.1) | GLUE, SQuAD, ROUGE (CNN: ROUGE-L: 44.16) | GLUE (97% of BERT), SQuAD (F1: 89.2, EM: 86.9) | Perplexity (WikiText103: 8.63), Accuracy (LAMBADA: 68.5%) |
4.2.8. BART (Bidirectional and Auto-Regressive Transformers)
4.2.9. DistilBERT
4.2.10. Megatron-LM
4.2.11. ERNIE (Enhanced Representation Through Knowledge Integration)
4.2.12. FLAN (Fine-Tuned LAnguage Net)
| Aspect | ERNIE | FLAN | DeBERTa | UniLM |
|---|---|---|---|---|
| Training Objective | Knowledge-Enhanced MLM (entity and phrase masking) | Instruction-tuned language modelling | Decoding-enhanced MLM with disentangled attention | Unified language modelling (multi-mask mode) |
| Pre-training Method | Entity- and phrase-level masking with external knowledge | Task-specific instruction fine-tuning | Content and position disentangled representations + enhanced decoding | Bidirectional, unidirectional, and seq2seq masking patterns |
| Bidirectional Context | Yes (BERT-based) | Yes (fine-tuned on prompts) | Yes (with disentangled attention) | Supports multiple attention modes |
| Multilingual Support | Chinese (ERNIE 1.0); extended in ERNIE 2.0+ | Yes (FLAN-T5, multilingual-tuned) | Yes (via XLM-DeBERTa) | Not standard, but adaptable |
| Fine-tuning Requirement | Yes (for knowledge-specific tasks) | Often not needed (zero/few-shot capable) | Required but sample-efficient | Required per task type |
| Key Applications | QA, semantic similarity, NER, cloze prediction | Generalization across unseen instructions/tasks | Classification, QA, NLI, SQuAD | Translation, summarization, QA, generation |
| Strengths | Integrates structured knowledge for enhanced reasoning | Strong zero/few-shot learning, instruction-following | State-of-the-art contextual representation; improves over BERT/RoBERTa | Unified architecture for NLU and NLG |
| Limitations | Domain-specific models; limited multilinguality in base version | Instruction design impacts performance; lacks generative flexibility | More computation than BERT; not widely adopted in all toolchains | Complexity in managing multiple mask types; not plug-and-play |
| Evaluation Metrics | Outperforms BERT and XLNet on GLUE benchmark and 16 English tasks | Surpasses zero-shot GPT-3 on 20 of 25 tasks evaluated | Achieves state-of-the-art results on SuperGLUE benchmark | Improves CNN/DailyMail ROUGE-L to 40.51 and Gigaword ROUGE-L to 35.75 |
4.2.13. DeBERTa (Decoding-Enhanced BERT with Disentangled Attention)
4.2.14. UniLM (Unified Language Model)
4.2.15. CTRL (Conditional Transformer Language Model)
| Aspect | CTRL | LaMDA | GLaM | CLIP | DALL·E |
|---|---|---|---|---|---|
| Training Objective | Conditional generation using control codes | Dialogue-focused language modeling | Sparse mixture of expert language modeling | Contrastive language-image pretraining | Text-to-image generation |
| Pre-training Method | Supervised with control code annotations | Pretraining on dialogue-style corpora with safety filters | Autoregressive with sparse expert activation | Contrastive loss on image–text pairs | Autoregressive generation with discrete VQ-VAE image tokens |
| Bidirectional Context | Yes (encoder-style) | Yes, via optimized attention | No (autoregressive) | No (separate image and text encoders) | No (autoregressive image decoder) |
| Multimodal Support | No | No | No | Yes (image + text) | Yes (generates images from text) |
| Fine-tuning Requirement | Required for new control codes/domains | Fine-tuned for conversational quality | Not typical (few-shot capable) | Rarely fine-tuned (zero-shot) | Prompt-based; fine-tuning uncommon |
| Key Applications | Domain-specific text control (e.g., news, reviews) | Human-like multi-turn dialogue | Efficient large-scale language modeling | Zero-shot image classification, content understanding | Creative image synthesis from text prompts |
| Strengths | Control over generation content and domain | Sensible, specific, and engaging dialogue responses | Trillion-scale sparse model with high efficiency | Connects vision and language, zero-shot capable | High-quality, text-driven image generation |
| Limitations | Restricted to known control codes; limited flexibility | Still prone to hallucination; needs strong moderation | Sparse activation introduces architectural complexity | Limited generative capabilities; sensitivity to text encoding | Requires extensive compute; less robust for abstract prompts |
| Evaluation Metrics | Perplexity on WikiText-103: 62.3 | Human Eval (SSI): Sensibleness: 92.3%, Specificity: 91.7%, Interestingness: 86.5% | SuperGLUE Accuracy: 80.4%, BERTScore: 0.89 | ImageNet Zero-shot Accuracy: 76.2%, CLIPScore: 0.78 | FID: 8.6, SSIM: 0.92, PSNR: 24.1, CLIPScore: 0.83 |
4.2.16. LaMDA (Language Model for Dialogue Applications)
4.2.17. GLaM (Gated Language Model)
4.2.18. Multimodal Models: CLIP and DALL-E
4.3. LLMs in NLP vs. Recommendation
- Data Modalities and Pretraining Objectives:Most LLMs are pretrained on large unstructured corpora such as Wikipedia, where they learn from the structure and semantics of free-form text [26]. In contrast, recommendation systems rely on semi-structured and structured inputs, including user–item interaction logs, ratings, metadata, and reviews [70]. These data types require different pretraining objectives. For example, BERT4Rec [6] employs masked language modeling tailored to sequential behavior, while CoLLM [71] leverages rich textual metadata for generative recommendation.
- Architectural Adaptations: Transformers remain the backbone of NLP due to their capacity to model long-range dependencies [22]. T5 reformulates diverse tasks into a unified text-to-text schema [26]. In recommendation systems, architecture design shifts toward hybrid or specialized models. XLNet4Rec [32,34] focuses on autoregressive learning over behavior sequences, while GraphRipple [72] integrates graph-based user–item relationships for deeper contextual modeling.
- Evaluation Criteria: Evaluation frameworks differ notably. NLP tasks employ BLEU for translation [73], ROUGE for summarization [74], and perplexity for generative fluency. In contrast, recommender systems use metrics such as NDCG, Recall, Precision, and CTR to assess ranking and personalization quality [14]. BERT4Rec demonstrates improved NDCG over collaborative filtering baselines [6], and ChatGPT has shown promising gains in CTR when adapted for dialogue-based recommendation [69].
- Context Representation: NLP systems derive context from linguistic dependencies across tokens and sentences [3]. Advances like DeBERTa enhance contextual encoding through disentangled attention [61]. Recommendation systems, on the other hand, use behavioral context such as clickstreams, timestamps, and user intent history. CoLLM [71] integrates such multimodal context to adapt recommendations to evolving user needs.
- Challenges within Domains: NLP faces issues including ambiguity, polysemy, and generalization across domains [75,76]. Recommendation systems contend with data sparsity, cold-start problems, and real-time responsiveness [77]. UPRec [78] introduces user-aware pretraining to combat sparsity, while GPT4Rec [4] employs prompt-based tuning to efficiently personalize recommendations in real time with low overhead.
5. Architecture, Optimization, and Technical Challenges in LLM4Rec
5.1. Paradigms of LLM4Rec
5.1.1. Discriminative Paradigm
- Task Orientation: Designed for tasks like next-item prediction, click-through rate (CTR) estimation, and personalized ranking.
- Fine-tuning: Most discriminative systems require supervised fine-tuning on domain-specific datasets to optimize performance.
- Precision: These models are highly accurate for structured and feature-rich recommendation tasks.
5.1.2. Generative Paradigm
- Flexibility: It can handle diverse tasks, including multi-modal recommendations, conversational agents, and open-ended suggestions.
- Pre-Trained Knowledge: Generative systems often perform well in no-tuning scenarios, leveraging their pre-trained knowledge for zero-shot or few-shot learning.
- Creativity: These models can go beyond traditional recommendations, suggesting novel items or categories.
5.2. Architecture and Design of LLM4Rec
- Latent Representations:User embeddings are derived from interaction histories, while item embeddings incorporate features like product metadata and textual reviews [81].
- Attention-Based Integration: Models like XLNet4Rec capture sequential user behaviors and align them with item attributes for enhanced personalization [34].
- User and Item IDs: By incorporating IDs into the token vocabulary, models can directly associate embeddings with specific users and items [6];
- Dynamic Tokenization: Frequent updates to embeddings enable real-time adaptation to new users or products [82].
5.3. Methodologies in LLM4Rec
- Cross-Modality Regularization: Aligns text and metadata embeddings to improve multimodal recommendations [89].
- Adaptive Aggregation: Dynamically combines the characteristics of the user and the item according to the interaction context.
5.4. Performance Evaluation and Benchmarking of LLM4Rec
5.4.1. Commonly Used Datasets and Benchmarks
- E-commerce and Retail: - Amazon Review Data [81]: This dataset includes user reviews, ratings, and metadata for millions of products, supporting text-based and hybrid recommendation tasks. - Taobao Dataset [92]: This is a large-scale dataset capturing user behaviors, including clicks, purchases, and reviews, often used for sequential and session-based recommendations. - AliExpress Dataset [93]: This dataset focuses on cross-border e-commerce, combining multilingual reviews with user interaction logs to evaluate cross-language recommendations.
- News and Media: - Microsoft News Dataset (MIND) [94]: This set contains news articles, click behaviors, and user session data, making it a benchmark for contextualized and personalized news recommendations. - Adressa Dataset [95]: This includes user clicks and reading behaviors on Norwegian news websites, testing the multilingual capabilities of LLMs. - MIND Your Language Dataset [96]: This dataset provides multilingual news articles with user interaction data, offering content-based and cross-lingual recommendations benchmarks.
- Social Media and Streaming: - MovieLens [97] features user–item movie ratings, serving as a baseline for collaborative filtering and hybrid models. - Spotify Dataset [98] captures user interactions with playlists, songs, and artists, ideal for music recommendations. - YouTube Dataset [99] offers insights into video watch behaviors, enabling sequential and content-based recommendation evaluations.
- Educational Platforms: - EdNet [100] contains hierarchical data from online education platforms, enabling personalized learning pathway recommendations. - ASSISTments [101] focuses on student performance in quizzes, allowing for adaptive learning recommendations. - KDD Cup 2010 Educational Data Challenge [102] tests knowledge tracing models by evaluating student responses to educational content.
- Healthcare and Lifestyle: - Synthea [103] simulates electronic health records (EHRs) with clinical notes, supporting health-related recommendations. - HealthTweets [104] consists of health-related tweets, enabling sentiment-aware lifestyle recommendations. - HeartSteps Dataset [105] tracks physical activity and contextual factors, which are useful for fitness app recommendations.
5.4.2. Evaluation Metrics and Performance Indicators
- Ranking Metrics: - Precision@K and Recall@K evaluate the accuracy of the top-K recommendations. - NDCG@K (Normalized Discounted Cumulative Gain) assesses ranking quality by accounting for the positions of relevant items in the recommendation list [106].
- Engagement Metrics: - Click-Through Rate (CTR) measures the likelihood of a user clicking on recommended items. - Dwell Time indicates user satisfaction by tracking how long users interact with recommended content [97].
- Contextual Metrics: - Temporal Adaptability evaluates how well recommendations evolve with changing user preferences. - Sentiment Sensitivity measures the model’s ability to align recommendations with user sentiments, especially in domains like health and wellness [104].
5.5. Technical Challenges in LLM4Rec
5.6. Emerging Techniques
6. Applications of LLM4Rec Across Domains
6.1. E-Commerce and Retail
6.2. News and Media Recommendations
6.3. Social Media and Content Personalization
6.4. Educational Resources and Learning Recommendations
6.5. Health and Lifestyle Recommendations
7. Discussion
7.1. Comparative Analysis of Surveyed Works
7.1.1. Model Type Distribution
7.1.2. Domain-Specific Applications
7.1.3. Paradigm Adoption Trends
- Some 57% of papers use discriminative models (e.g., BERT4Rec, PALR), primarily designed for structured prediction tasks such as next-item recommendation, click-through rate (CTR) estimation, and user–item ranking. These models typically rely on supervised learning with large labeled interaction datasets. Most employ fine-tuning on domain-specific corpora (e.g., Amazon, MIND) and achieve high performance on metrics like NDCG, Recall@K, and AUC. However, their reliance on labeled training data and limited capacity for dynamic reasoning restricts adaptability across domains.
- Some 35% leverage generative systems (e.g., GPT4Rec, RecMind) to handle open-ended, narrative, and conversational recommendation tasks. These models support zero-shot and few-shot learning scenarios, making them particularly useful in domains with sparse supervision or cold-start users/items. Generative models are commonly evaluated using BLEU, ROUGE, and diversity scores in addition to traditional metrics. Their strengths lie in producing personalized explanations, summarizing user history, and engaging in real-time dialogue, which are particularly valuable in media, entertainment, and education use cases.
- Some 8% adopt hybrid frameworks that combine discriminative and generative reasoning (e.g., CoLLM, FLAN-Tuned Recs). These models often encode user–item interaction sequences using Transformers (e.g., BERT or XLNet), and then apply generative heads or prompt-based decoding layers to produce natural-language recommendations or justifications. Hybrid systems are also more likely to integrate multimodal data (e.g., visual content, reviews, metadata) and are evaluated with a combination of CTR, diversity, and human evaluation scores. They offer the best of both paradigms but introduce challenges in training pipeline complexity and latency.
7.1.4. Analysis and Emerging Themes
8. Conclusions and Future Research Directions
Funding
Acknowledgments
Conflicts of Interest
References
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar] [CrossRef]
- Karypis, G. Evaluation of item-based top-N recommendation algorithms. In Proceedings of the 10th ACM International Conference on Information and Knowledge Management (CIKM), Atlanta, GA, USA, 5–10 November 2001; pp. 247–254. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. Available online: https://aclanthology.org/N19-1423 (accessed on 15 November 2024).
- Xu, Z.; Liu, X.; Liu, Z.; Huang, Z.; Xie, X. GPT4Rec: Graph Prompt Tuning for Streaming Recommendation. arXiv 2024, arXiv:2406.08229. [Google Scholar]
- Hou, Y.; Zhang, S.; Lin, T.; Yu, W. Large Language Models are Zero-Shot Rankers for Recommender Systems. arXiv 2023, arXiv:2305.08845. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar] [CrossRef]
- Liu, C.; Li, W.; Zhang, Y.; Li, H.; Ji, R. Beyond Inter-Item Relations: Dynamic Adaptive Mixture-of-Experts for LLM-Based Sequential Recommendation. arXiv 2024, arXiv:2408.07427. [Google Scholar]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Liang, D.; Krishnan, R.G.; Hoffman, M.D.; Jebara, T. Variational Autoencoders for Collaborative Filtering. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 689–698. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (UAI), Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. Available online: https://arxiv.org/abs/1205.2618 (accessed on 15 November 2024).
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef]
- Wu, L.; Zheng, Z.; Qiu, Z.; Wang, H.; Gu, H.; Shen, T.; Qin, C.; Zhu, C.; Zhu, H.; Liu, Q.; et al. A Survey on Large Language Models for Recommendation. arXiv 2023, arXiv:2305.19860. [Google Scholar] [CrossRef]
- Resnick, P.; Varian, H.R. Recommender Systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model. User Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Pouran Ben Veyseh, A.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent Advances in Natural Language Processing via Large Pre-trained Language Models: A Survey. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Alyafeai, Z.; AlShaibani, M.S.; Ahmad, I. A Survey on Transfer Learning in Natural Language Processing. arXiv 2020, arXiv:2007.04239. [Google Scholar]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Mehmood, T.; Serina, I. On the Behaviour of BERT’s Attention for the Classification of Medical Reports. In Proceedings of the 3rd Italian Workshop on Explainable Artificial Intelligence (XAI.it 2022), Udine, Italy, 28 November 2022; Volume 3277, pp. 16–30. Available online: http://ceur-ws.org/Vol-3277/paper2.pdf (accessed on 15 November 2024).
- Villatoro-Tello, E.; Parida, S.; Kumar, S.; Ghosh, S.; Solorio, T.; González, F.A.; Solano, L.R.; Molina, A.; López, A.; Villaseñor, L.; et al. Applying Attention-Based Models for Detecting Cognitive Processes and Mental Health Conditions. Cogn. Comput. 2021, 13, 1154–1171. [Google Scholar] [CrossRef] [PubMed]
- Eang, C.; Lee, S. Improving the Accuracy and Effectiveness of Text Classification Based on the Integration of the BERT Model and a Recurrent Neural Network (RNN_Bert_Based). Appl. Sci. 2024, 14, 8388. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. Available online: https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 15 November 2024).
- Rathje, S.; Mirea, D.M.; Sucholutsky, I.; Marjieh, R.; Robertson, C.E.; Van Bavel, J.J. GPT is an effective tool for multilingual psychological text analysis. Proc. Natl. Acad. Sci. USA 2024, 121, e2308950121. [Google Scholar] [CrossRef]
- Cai, Y.; Deng, Q.; Zhou, Y. Impact of GPT on the Academic Ecosystem. Sci. Educ. 2025, 34, 913–931. [Google Scholar] [CrossRef]
- Hua, S.; Jin, S.; Jiang, S. The Limitations and Ethical Considerations of ChatGPT. Data Intell. 2024, 6, 201–239. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J.; Bosma, M.; et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Fuadi, M.; Wibawa, A.D.; Sumpeno, S. Adaptation of Multilingual T5 Transformer for Indonesian Language. In Proceedings of the 2023 IEEE 9th Information Technology International Seminar (ITIS), Surabaya, Indonesia, 6–7 October 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Zayyanu, Z.M. Revolutionising Translation Technology: A Comparative Study of Variant Transformer Models—BERT, GPT, and T5. Comput. Sci. Eng. Int. J. 2024, 14, 15–27. [Google Scholar] [CrossRef]
- Tay, Y.; Dehghani, M.; Rao, J.; Fedus, W.; Abnar, S.; Chung, H.W.; Narang, S.; Yogatama, D.; Vaswani, A.; Metzler, D. Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers. arXiv 2021, arXiv:2109.10686. [Google Scholar]
- Fields, J.; Chovanec, K.; Madiraju, P. A Survey of Text Classification with Transformers: How Wide? How Large? How Long? How Accurate? How Expensive? How Safe? IEEE Access 2024, 12, 22860–22878. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Moreira, G.D.S.P.; Rabhi, S.; Lee, J.M.; Ak, R.; Oldridge, E. Transformers4Rec: Bridging the Gap between NLP and Sequential/Session-Based Recommendation. In Proceedings of the 15th ACM Conference on Recommender Systems (RecSys ’21), Amsterdam, The Netherlands, 27 September–1 October 2021; pp. 143–153. [Google Scholar] [CrossRef]
- Wang, Y.; Zheng, J.; Li, Q.; Wang, C.; Zhang, H.; Gong, J. XLNet-Caps: Personality Classification from Textual Posts. Electronics 2021, 10, 1360. [Google Scholar] [CrossRef]
- Vij, N.; Yacoub, A.; Kobti, Z. XLNet4Rec: Recommendations Based on Users’ Long-Term and Short-Term Interests Using Transformer. In Proceedings of the 2023 International Conference on Machine Learning and Applications (ICMLA), Jacksonville, FL, USA, 15–17 December 2023; pp. 647–652. [Google Scholar] [CrossRef]
- Zhang, H.; Shafiq, M.O. Survey of Transformers and Towards Ensemble Learning Using Transformers for Natural Language Processing. J. Big Data 2024, 11, 25. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Abhishek, K. News Article Classification using a Transfer Learning Approach. In Proceedings of the 2022 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 13–14 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Cai, F.; Ye, H. Chinese Medical Text Classification with RoBERTa. In Proceedings of the Biomedical and Computational Biology (BECB 2022), Kyoto, Japan, 15–17 December 2022; Volume 13637, pp. 223–236. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Choi, H.; Kim, J.; Joe, S.; Gwon, Y. Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks. arXiv 2021, arXiv:2101.10642. [Google Scholar]
- Abdal, M.N.; Oshie, M.H.K.; Haque, M.A.; Rahman, S. A Robust Model for Effective Spam Detection Based on ALBERT. In Proceedings of the 2023 6th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 22–24 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Y. An ALBERT-based TextCNN-Hatt hybrid model enhanced with topic knowledge for sentiment analysis of sudden-onset disasters. Eng. Appl. Artif. Intell. 2023, 123, 106136. [Google Scholar] [CrossRef]
- Petridis, C. Text Classification: Neural Networks VS Machine Learning Models VS Pre-trained Models. arXiv 2024, arXiv:2412.21022. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Ni, S.; Kao, H.Y. ELECTRA is a Zero-Shot Learner, Too. arXiv 2022, arXiv:2207.08141. [Google Scholar]
- Hao, Y.; Dong, L.; Bao, H.; Xu, K.; Wei, F. Learning to Sample Replacements for ELECTRA Pre-Training. arXiv 2021, arXiv:2106.13715. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020). Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Vinoda, D.; Yadav, P.K. SDBERT: SparseDistilBERT, a faster and smaller BERT model. arXiv 2022, arXiv:2208.10246. [Google Scholar]
- Kumar, S.; Deep, S.; Kalra, P. Enhancing Customer Service in Banking with AI: Intent Classification Using DistilBERT. Int. J. Curr. Sci. Res. Rev. 2024, 7, 2706–2713. [Google Scholar] [CrossRef]
- Benselloua, A.Y.M.; Messadi, S.A. Effective Malicious PowerShell Scripts Detection Using DistilBERT. In Proceedings of the 2023 IEEE Afro-Mediterranean Conference on Artificial Intelligence (AMCAI), Constantine, Algeria, 20–21 December 2023; pp. 166–171. [Google Scholar] [CrossRef]
- Kusal, S.; Patil, S.; Gupta, A.; Saple, H.; Jaiswal, D.; Deshpande, V.; Kotecha, K. Sentiment Analysis of Product Reviews Using Deep Learning and Transformer Models: A Comparative Study. In Proceedings of the Artificial Intelligence: Theory and Applications, Pune, India, 12–14 March 2024; Volume 843, pp. 195–208. [Google Scholar] [CrossRef]
- Salmony, M.Y.A.; Faridi, A.R. Bert Distillation to Enhance the Performance of Machine Learning Models for Sentiment Analysis on Movie Review Data. In Proceedings of the 2022 9th International Conference on Computing for Sustainable Global Development, New Delhi, India, 23–25 March 2022; pp. 400–405. [Google Scholar] [CrossRef]
- Narayanan, D.; Shoeybi, M.; Casper, J.; Patwary, M.; LeGresley, P.; Korthikanti, V.; Rasley, J.; Rajbhandari, S.; Ruwase, O.; Zadeh, A.Y.; et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. arXiv 2021, arXiv:2104.04473. [Google Scholar]
- Smith, S.P.; Patwary, M.; Norick, B.; LeGresley, P.; Rajbhandari, S.; Casper, J.; Liu, Z.; Prabhumoye, S.; Zoph, B.; Shoeybi, M.; et al. Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. arXiv 2022, arXiv:2201.11990. [Google Scholar]
- Xu, P.; Zhang, L.; Zhang, Y.; Wang, Y.; Gan, Z.; Henao, R.; Carin, L.; Wang, J.; Bansal, M.; Carin, L.; et al. MEGATRON-CNTRL: Controllable Story Generation with External Knowledge Using Large-Scale Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 16–20 November 2020; pp. 2831–2845. Available online: https://aclanthology.org/2020.emnlp-main.226/ (accessed on 15 January 2025).
- Yang, S.; Li, X.; Liu, C.; Song, K.; Zhang, Y.; Wu, J.; Wang, Z.; Zhang, M.; Chen, Q.; Xu, Y.; et al. Common Sense Enhanced Knowledge-Based Recommendation with Large Language Model. In Proceedings of the 29th International Conference on Database Systems for Advanced Applications (DASFAA 2024), Taipei, Taiwan, 21–24 May 2024; Volume 14854, pp. 406–421. [Google Scholar] [CrossRef]
- Zheng, Z.; Chao, W.; Qiu, Z.; Zhu, H.; Xiong, H. Harnessing Large Language Models for Text-Rich Sequential Recommendation. arXiv 2024, arXiv:2403.13325. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. ERNIE: Enhanced Representation through Knowledge Integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Hou, Y.; Fu, G.; Sachan, M. Understanding Knowledge Integration in Language Models with Graph Convolutions. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 1374–1386. Available online: https://aclanthology.org/2022.findings-emnlp.102.pdf (accessed on 15 January 2025).
- Wei, J. Finetuned Language Models Are Zero-Shot Learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- He, P. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. arXiv 2021, arXiv:2006.03654. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. A Unified Language Model Pre-training for Natural Language Understanding and Generation. arXiv 2019, arXiv:1905.03197. [Google Scholar]
- Keskar, N.S.; McCann, B.; Varshney, L.R.; Xiong, C.; Socher, R. CTRL: A Conditional Transformer Language Model for Controllable Generation. arXiv 2019, arXiv:1909.05858. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. LaMDA: Language Models for Dialog Applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Du, N.; Rao, A.; Kurian, J.; Catasta, M.; Hou, L.; Al-Rfou, R.; Xu, Y.; Chen, Z.; Narang, S.; Dai, Z.; et al. GLaM: Efficient Scaling of Language Models with Sparse Mixture-of-Experts. arXiv 2022, arXiv:2112.06905. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar] [CrossRef]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. arXiv 2021, arXiv:2102.12092. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. OpenAI Preprint. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 15 January 2025).
- Zhang, Y.; Jin, Y. Navigating User Experience of ChatGPT-based Conversational Recommender Systems: The Effects of Prompt Guidance and Recommendation Domain. arXiv 2024, arXiv:2405.13560. [Google Scholar]
- Fang, H.; Xu, G.; Long, Y.; Tang, W. An Effective ELECTRA-Based Pipeline for Sentiment Analysis of Tourist Attraction Reviews. Appl. Sci. 2022, 12, 10881. [Google Scholar] [CrossRef]
- Zhang, Y.; Feng, Y.; He, X.; Li, Y.; Lu, P.; Shi, C.; Liang, Y.; Zhang, H.; Hu, Y.; Liu, Y.; et al. CoLLM: Integrating Collaborative Embeddings into Large Language Models for Recommendation. arXiv 2023, arXiv:2310.19488. [Google Scholar] [CrossRef]
- Wang, M.; Hu, X.; Du, Y. Enhancing Recommender Systems Performance using Knowledge Graph Embedding with Graph Neural Networks. In Proceedings of the 2024 4th International Conference on Neural Networks, Information and Communication Engineering (NNICE), Tokyo, Japan, 18–20 March 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. Available online: https://aclanthology.org/P02-1040/ (accessed on 15 January 2025).
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out: Proceedings of the ACL-04 Workshop, Barcelona, Spain, 25 July 2004; pp. 74–81. Available online: https://aclanthology.org/W04-1013/ (accessed on 15 January 2025).
- Abeysiriwardana, M.; Sumanathilaka, D. A Survey on Lexical Ambiguity Detection and Word Sense Disambiguation. arXiv 2024, arXiv:2403.16129. [Google Scholar]
- Hu, J.; Xia, M.; Neubig, G.; Carbonell, J. Domain Adaptation of Neural Machine Translation by Lexicon Induction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 298–304. Available online: https://arxiv.org/abs/1906.00376 (accessed on 15 January 2025).
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. A Survey on Deep Learning-based Recommender Systems: From Collaborative Filtering to Content and Knowledge Aware Recommendation. IEEE Trans. Knowl. Data Eng. 2022, 34, 249–270. [Google Scholar] [CrossRef]
- Li, H.; Wang, Q.; Liu, Y.; Yu, P.S. UPRec: User-aware Pre-training for Sequential Recommendation. AI Open 2023, 4, 137–144. [Google Scholar] [CrossRef]
- Yang, F.; Chen, Z.; Jiang, Z.; Cho, E.; Huang, X.; Lu, Y. PALR: Personalization Aware LLMs for Recommendation. In Proceedings of the First Workshop on Generative Information Retrieval (Gen-IR) at SIGIR, Taipei, Taiwan, 23 July 2023; Available online: https://arxiv.org/abs/2305.07622 (accessed on 15 January 2025).
- Wang, Y.; Jiang, Z.; Chen, Z.; Yang, F.; Zhou, Y.; Cho, E.; Fan, X.; Huang, X.; Lu, Y.; Yang, Y. RecMind: Large Language Model Powered Agent For Recommendation. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, 16–21 June 2024; pp. 4351–4364. [Google Scholar]
- McAuley, J.; Pandey, R.; Leskovec, J. Inferring Networks of Substitutable and Complementary Products. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Sydney, Australia, 10–13 August 2015; pp. 785–794. [Google Scholar] [CrossRef]
- Guo, L.; Jin, J.; Zhang, H.; Zheng, Z.; Yang, Z.; Xing, Z.; Pan, F.; Niu, L.; Wu, F.; Xu, H.; et al. We Know What You Want: An Advertising Strategy Recommender System for Online Advertising. arXiv 2021, arXiv:2105.14188. [Google Scholar]
- Li, X.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation Tasks. In Proceedings of the ACL, Online, 1–6 August 2021; pp. 4583–4597. Available online: https://arxiv.org/abs/2101.00190 (accessed on 15 January 2025).
- Di Palma, D.; Biancofiore, G.M.; Anelli, V.W.; Narducci, F.; Di Noia, T.; Di Sciascio, E. Evaluating ChatGPT as a Recommender System: A Rigorous Approach. arXiv 2023, arXiv:2309.03613. [Google Scholar]
- Huang, K.; Altosaar, J.; Ranganath, R. ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission. arXiv 2019, arXiv:1904.05342. [Google Scholar]
- Hu, E.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, L.; Wang, H.; Rajan, A.; Chen, W.; Liu, W.; et al. LoRA: Low-rank adaptation of large language models. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 3–7 May 2021; Available online: https://arxiv.org/abs/2106.09685 (accessed on 15 January 2025).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059. [Google Scholar]
- Zhao, Y.; He, X.; Wang, X.; Li, M.; Chua, T.S. Multi-modal Recommendations: Aligning Text and Metadata Embeddings. In Proceedings of the ACM Recommender Systems Conference (RecSys), Copenhagen, Denmark, 16–20 September 2019; Available online: https://example.com/multi-modal-recommendations (accessed on 15 January 2025).
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- User Behavior Data from Taobao for Recommendation. Available online: https://tianchi.aliyun.com/dataset/649 (accessed on 15 January 2025).
- Alibaba E-Commerce User Behavior Dataset. 2020. Available online: https://yongfeng.me/dataset/ (accessed on 2 September 2024).
- Wu, F.; Qiao, Y.; Chen, J.-H.; Wu, C.; Qi, T.; Lian, J.; Liu, D.; Xie, X.; Gao, J.; Wu, W.; et al. MIND: A large-scale dataset for news recommendation. In Proceedings of the ACL, Online, 6–8 July 2020; pp. 3597–3606. Available online: https://aclanthology.org/2020.acl-main.331/ (accessed on 15 January 2025).
- Gulla, J.A.; Zhang, L.; Liu, P.; Özgöbek, Ö.; Su, X. The Adressa dataset for news recommendation. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; pp. 1042–1048. [Google Scholar] [CrossRef]
- Iana, A.; Glavaš, G.; Paulheim, H. MIND Your Language: A Multilingual Dataset for Cross-Lingual News Recommendation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2024), Washington, DC, USA, 14–18 July 2024; pp. 553–563. [Google Scholar] [CrossRef]
- Harper, F.; Konstan, J. The MovieLens datasets: History and contexts. ACM Trans. Interact. Intell. Syst. 2016, 5, 19–29. [Google Scholar] [CrossRef]
- Brost, B.; Mehrotra, R.; Niedermayer, T.; Li, C.; McInerney, J.; Bouchard, H.; Lalmas, M.; Pike, M. The Music Streaming Sessions Dataset. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 328–332. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems (RecSys), Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar] [CrossRef]
- Choi, Y.; Lee, Y.; Shin, D.; Cho, J.; Park, S.; Lee, S.; Baek, J.; Bae, C.; Kim, B.; Heo, J. EdNet: A Large-Scale Hierarchical Dataset in Education. In Proceedings of the 21st Int. Conf. Artificial Intelligence in Education (AIED), Ifrane, Morocco, 6–10 July 2020; pp. 69–73. Available online: https://arxiv.org/abs/1912.03072 (accessed on 15 January 2025).
- Feng, M.; Heffernan, N.; Koedinger, K. Addressing the ASSISTments Dataset: Analyzing Student Performance for Adaptive Learning Recommendations. In Proceedings of the AIED, Brighton, UK, 6–10 July 2009. [Google Scholar]
- Barnes, T.; Stamper, J.; Feng, M. KDD Cup 2010: Educational Data Mining Challenge for Knowledge Tracing Models. In Proceedings of the KDD Cup, Washington, DC, USA, 25 July 2010; Available online: https://pslcdatashop.web.cmu.edu/KDDCup/ (accessed on 15 January 2025).
- Walonoski, T.; Walonoski, J.; Kramer, M.; Nichols, J.; Quina, A.; Moesel, C.; Hall, D.; Duffett, C.; Dube, K.; Gallagher, T.; et al. Synthea: Simulated Electronic Health Records Supporting Health-Related Recommendations. J. Am. Med. Inform. Assoc. 2018, 25, 230–237. [Google Scholar] [CrossRef]
- Karisani, N.; Agichtein, E. Did you mean lung cancer? Identifying health-related misinformation in social media. In Proceedings of the SIGIR, Ann Arbor, MI, USA, 8–12 July 2018. [Google Scholar] [CrossRef]
- Tewari, A.; Murphy, S.A.; Nahum-Shani, I. Personalized HeartSteps: A Reinforcement Learning Algorithm for Optimizing Physical Activity. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–24. [Google Scholar] [CrossRef]
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- Xie, X.; Sun, F.; Yang, X.; Yang, Z.; Gao, J.; Ou, W.; Cui, B. Explore User Neighborhood for Real-time E-commerce Recommendation. arXiv 2021, arXiv:2103.00442. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3645–3650. Available online: https://aclanthology.org/P19-1355/ (accessed on 15 January 2025).
- Ding, D.; Mallick, A.; Wang, C.; Sim, R.; Mukherjee, S.; Rühle, V.; Lakshmanan, L.V.S.; Awadallah, A.H. Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing. arXiv 2024, arXiv:2404.14618. [Google Scholar]
- Bolukbasi, T.; Chang, K.W.; Zou, J.; Saligrama, V.; Kalai, A. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. arXiv 2016, arXiv:1607.06520. [Google Scholar]
- Kusner, M.J.; Loftus, J.; Russell, C.; Silva, R. Counterfactual fairness. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4066–4076. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/hash/a486cd07e4ac3d270571622f4f316ec5-Abstract.html (accessed on 15 January 2025).
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A Survey on Bias and Fairness in Machine Learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Papernot, N.; et al. Extracting Training Data from Large Language Models. In Proceedings of the 30th USENIX Security Symposium, Virtual Event, 11–13 August 2021; pp. 2633–2650. Available online: https://www.usenix.org/conference/usenixsecurity21/presentation/carlini-extracting (accessed on 15 January 2025).
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html (accessed on 1 January 2025).
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Sahu, A.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Ie, E.; Hsu, C.W.; Mladenov, M.; Jain, V.; Narvekar, S.; Wang, J.; Wu, R.; Boutilier, C. RecSim: A Configurable Simulation Platform for Recommender Systems. arXiv 2019, arXiv:1909.04847. [Google Scholar]
- Zhao, X.; Xia, L.; Zhang, L.; Ding, Z.; Yin, D.; Tang, J. Deep Reinforcement Learning for Page-wise Recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems (RecSys), Vancouver, BC, Canada, 2–7 October 2018; pp. 95–103. [Google Scholar] [CrossRef]
- Ren, X.; Wei, W.; Xia, L.; Su, L.; Cheng, S.; Wang, J.; Yin, D.; Huang, C. Representation Learning with Large Language Models for Recommendation. arXiv 2023, arXiv:2310.15950. [Google Scholar]
- Zhou, Y.; Guo, J.; Sun, H.; Song, B.; Yu, F.R. Attention-guided Multi-step Fusion: A Hierarchical Fusion Network for Multimodal Recommendation. arXiv 2023, arXiv:2304.11979. [Google Scholar]
- Manzoor, M.A.; Albarri, S.; Xian, Z.; Meng, Z.; Nakov, P.; Liang, S. Multimodality Representation Learning: A Survey on Evolution, Pretraining and Its Applications. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 20, 74. [Google Scholar] [CrossRef]
- Faye, A.; Lebbah, M.; Bouchaffara, D. Lightweight Cross-Modal Representation Learning. arXiv 2024, arXiv:2403.04650. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the ICML, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. Available online: https://proceedings.mlr.press/v70/finn17a.html (accessed on 15 January 2025).
- Liu, X.; Wang, R.; Sun, D.; Hakkani-Tur, D.; Abdelzaher, T. Uncovering Cross-Domain Recommendation Ability of Large Language Models. In Proceedings of the Companion ACM Web Conference 2025 (WWW Companion ’25), Sydney, NSW, Australia, 6–10 April 2025. [Google Scholar]
- Kolb, T.E. Enhancing Cross-Domain Recommender Systems with LLMs: Evaluating Bias and Beyond-Accuracy Measures. In Proceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24), Bari, Italy, 14–18 October 2024. [Google Scholar]
- Lai, W.; Mesgar, M.; Fraser, A. Scaling the Multilingual Capability of LLMs with Cross-Lingual Feedback. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 12–17 August 2024. [Google Scholar]
- Jin, W.; Mao, H.; Li, Z.; Jiang, H.; Luo, C.; Wen, H.; Han, H.; Lu, H.; Wang, Z.; Li, R.; et al. Amazon-M2: A Multilingual Multi-locale Shopping Session Dataset for Recommendation and Text Generation. arXiv 2023, arXiv:2307.09688. [Google Scholar]
- Huang, Y.; Fan, C.; Li, Y.; Wu, S.; Zhou, T.; Zhang, X.; Sun, L. 1+1>2: Can Large Language Models Serve as Cross-Lingual Knowledge Aggregators? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), Miami, FL, USA, 6–10 November 2024. [Google Scholar]
- Yu, Z.; Wang, H.; Li, T. EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Layerwise Unified Compression and Adaptive Layer Tuning and Voting. arXiv 2024, arXiv:2406.15758. [Google Scholar]
- Expedera. Expedera NPUs Run Large Language Models Natively on Edge Devices. Expedera Blog 2024. Available online: https://www.expedera.com/blog/2024/01/08/expedera-npus-run-large-language-models-natively-on-edge-devices/ (accessed on 1 March 2025).
- Binns, R.; Veale, M.; Van Kleek, M.; Shadbolt, N. ‘It’s Reducing a Human Being to a Percentage’: Perceptions of Justice in Algorithmic Decisions. In Proceedings of the CHI, Montreal, QC, Canada, 21–26 April 2018. [Google Scholar] [CrossRef]
- Pariser, E. The Filter Bubble: What the Internet Is Hiding from You; Penguin Press: New York, NY, USA, 2011. [Google Scholar]
- Jobin, A.; Ienca, M.; Vayena, E. The global landscape of AI ethics guidelines. Nat. Mach. Intell. 2019, 1, 389–399. Available online: https://www.nature.com/articles/s42256-019-0088-2 (accessed on 15 January 2025). [CrossRef]
- Xu, W.; Xiao, J.; Chen, J. Leveraging Large Language Models to Enhance Personalized Recommendations in E-commerce. arXiv 2024, arXiv:2410.12829. [Google Scholar]
- Zhao, Q.; Qian, H.; Liu, Z.; Zhang, G.D.; Gu, L. Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph. arXiv 2024, arXiv:2402.13750. [Google Scholar]
- Wang, M.; Guo, Y.; Zhang, D.; Jin, J.; Li, M.; Schonfeld, D.; Zhou, S. Enabling Explainable Recommendation in E-commerce with LLM-powered Product Knowledge Graph. arXiv 2024, arXiv:2412.01837. [Google Scholar]
- Liu, Y.; Hu, M.; Sun, Y.; Ren, Y.; Tang, J. Conversational Recommender System and Large Language Model Are Made for Each Other in E-commerce Pre-sales Dialogue. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Available online: https://aclanthology.org/2023.findings-emnlp.643/ (accessed on 1 March 2025).
- Xiang, Y.; Yu, H.; Gong, Y.; Huo, S.; Zhu, M. Text Understanding and Generation Using Transformer Models for Intelligent E-commerce Recommendations. arXiv 2024, arXiv:2402.16035. [Google Scholar]
- Xu, X.; Zhou, Y.; Liu, Y.; Chen, H. Emerging Synergies Between Large Language Models and Machine Learning in E-commerce Recommendations. arXiv 2024, arXiv:2403.02760. [Google Scholar] [CrossRef]
- Liu, D.; Yang, B.; Du, H.; Greene, D.; Hurley, N.; Lawlor, A.; Dong, R.; Li, I. RecPrompt: A Self-tuning Prompting Framework for News Recommendation Using Large Language Models. arXiv 2023, arXiv:2312.10463. [Google Scholar]
- Wu, C.; Wu, F.; Qi, T.; Zhang, C.; Huang, Y.; Xu, T. MM-Rec: Visiolinguistic Model Empowered Multimodal News Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22), Madrid, Spain, 11–15 July 2022; pp. 2560–2564. [Google Scholar] [CrossRef]
- Gao, S.; Fang, J.; Tu, Q.; Yao, Z.; Chen, Z.; Ren, P.; Ren, Z. Generative News Recommendation. arXiv 2024, arXiv:2403.03424. [Google Scholar]
- Katz, G.; Sitton, H.; Gonen, G.; Kaplan, Y. Beyond the Surface: Uncovering Implicit Locations with LLMs for Personalized Local News. arXiv 2025, arXiv:2502.14660v. [Google Scholar]
- Friedman, L.; Ahuja, S.; Allen, D.; Tan, Z.; Sidahmed, H.; Long, C.; Xie, J.; Schubiner, G.; Patel, A.; Lara, H.; et al. Leveraging Large Language Models in Conversational Recommender Systems. arXiv 2023, arXiv:2305.07961. [Google Scholar]
- Irfan, R.; Khalid, O.; Khan, M.U.S.; Rehman, F.; Khan, A.U.R.; Nawaz, R. SocialRec: A Context-Aware Recommendation Framework With Explicit Sentiment Analysis. IEEE Access 2019, 7, 116295–116308. Available online: https://ieeexplore.ieee.org/abstract/document/8784145 (accessed on 17 December 2024). [CrossRef]
- Zhang, K.; Yu, R.; Shen, Y.; Wang, T.; Zheng, Z.; Yu, P.S.; Xiong, H. Prospect: Personalized Recommendation on Large Language Model-based Agent Platforms. arXiv 2024, arXiv:2403.14468. [Google Scholar]
- Jalan, R.; Prakash, T.; Pedanekar, N. LLM-BRec: Personalizing Session-based Social Recommendation with LLM-BERT Fusion Framework. In Proceedings of the 2nd Workshop on Generative Information Retrieval (Gen-IR) at the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; Available online: https://openreview.net/forum?id=gwHVlTNKsG (accessed on 12 December 2024).
- Li, Z.; Yazdanpanah, V.; Wang, J.; Gu, W.; Shi, L.; Cristea, A.I.; Kiden, S.; Stein, S. TutorLLM: Customizing Learning Recommendations with Knowledge Tracing and Retrieval-Augmented Generation. arXiv 2024, arXiv:2502.15709. [Google Scholar]
- Ma, B.; Khan, M.A.Z.; Yang, T.; Polyzou, A.; Konomi, S. How Good Are Large Language Models for Course Recommendation in MOOCs? arXiv 2024, arXiv:2504.08208. [Google Scholar]
- Li, X.; Zhang, C. E4SRec: An Elegant Effective Efficient Extensible Solution of Large Language Models for Sequential Recommendation. arXiv 2023, arXiv:2301.12345. [Google Scholar]
- Hua, W.; Xu, S.; Ge, Y.; Zhang, Y. OpenP5: Open-source Platform for Personalized Prompt Pretraining and Prediction. 2023. Available online: https://github.com/agiresearch/OpenP5 (accessed on 17 December 2024).
- Bao, K.; Wang, Q.; He, X. TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. arXiv 2023, arXiv:2305.00447. [Google Scholar]
- Chen, Z.; Li, X.; Fan, X. Real-Time Personalization for LLM-based Recommendation with Customized In-Context Learning. arXiv 2023, arXiv:2311.07985. [Google Scholar]
- Ma, Z.; Chen, H.; Ren, Y.; Natarajan, S.; Shah, C.; Agichtein, E.; Sun, J. Transforming Wearable Data into Health Insights using Large Language Model Agents. arXiv 2024, arXiv:2406.06464. [Google Scholar]
- Hegde, N.; Vardhan, M.; Nathani, D.; Rosenzweig, E.; Speed, C.; Karthikesalingam, A.; Seneviratne, M. Infusing behavior science into large language models for activity coaching. PLoS Digit. Health 2024, 3, e0000431. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Q.; Li, X. LoRec: Combating Poisons with Large Language Model for Robust Sequential Recommendation. arXiv 2024, arXiv:2403.11860. [Google Scholar] [CrossRef]


| Aspect | Discriminative Paradigm | Generative Paradigm |
|---|---|---|
| Task Focus | Classification, ranking, prediction | Open-ended recommendation, content generation |
| Adaptability | Requires domain-specific fine-tuning for best results | Supports zero-shot/few-shot scenarios using pre-trained knowledge |
| Key Strengths | High-precision and effective in structured, supervised environments | Flexible, can handle multimodal and conversational settings |
| Training Dependency | High; needs labeled interaction data for fine-tuning | Moderate; can be used out-of-the-box or lightly fine-tuned |
| Evaluation Metrics | NDCG, Recall@K, CTR, AUC | BLEU, ROUGE, Diversity, Human Evaluation, CTR |
| Use Cases | Sequential recommendation, CTR prediction, ranking | Conversational agents, narrative-driven recommenders, explanations |
| Examples | BERT4Rec [6], PALR [79] | GPT4Rec [4], RecMind [80] |
| Challenge Area | LLM4Rec-Specific Issues | Possible Solutions |
|---|---|---|
| Cross-Domain and Cross-Language Adaptation | Domain-specific tuning needed [26]; multilingual degradation in low-resource settings [95]; integration issues between structured and unstructured data [100] | Domain adaptation [26], multilingual tuning with mBERT, XLM-R [95], sparse attention, cross-modal integration [100] |
| Semantic Gap Between NLP and Recommendation Tasks | LLMs lack inductive bias for sequential patterns and structured metadata [6]; require extensive fine-tuning for user–item modeling [85] | BERT4Rec-style modeling [6], hybrid models with tabular input [85], metadata-aware tokenization |
| Scalability and Compute Constraints | High training/inference cost (GPT-3/4) [87], environmental impact [108], real-time infeasibility of large models [91] | Distillation (DistilBERT) [91], LoRA/adapters [86], sparse attention, carbon-aware optimization [108] |
| Cold Starts and Data Sparsity | Limited data for new users/items [81], masked pretraining [81] | Meta-learning, transfer learning, few-shot recommendation, collaborative filtering-enhanced prompts |
| Real-Time Recommendation | Large models unsuitable for ms-latency scenarios [99]; inference delay in LLM pipelines [98] | Lightweight models, caching, asynchronous reranking [98,99], TinyGPT variants |
| Bias and Fairness | Training corpora bias (gender, race) [110]; fairness metrics not native to LLMs [112] | Adversarial debiasing [111], demographic parity, counterfactual augmentation [131] |
| Privacy, Transparency, and User Control | Privacy leakage from memorized data [113]; explainability limitations [114] | Differential privacy [113], SHAP/LIME [114], opt-out tools, preference settings |
| Societal and Ethical Impact | Polarization/echo chambers [132], environmental and economic disparity [108] | Responsible AI frameworks [133], public audits, equitable compute access initiatives [108] |
| Model | Base Model | Limitations | Scalability | Latency Suitability | Multimodal | Training Cost/Eval |
|---|---|---|---|---|---|---|
| LLM-KERec [135] | GPT-style LLM + KG | Requires inferential KG construction; cold-start handling needs tuning | High | Moderate | No | Moderate/ HR@10 = 0.678 |
| LLM-PKG [136] | GPT-3 + product KG | Needs prompt engineering for graph reliability | Moderate | Moderate | Yes | Moderate/ NDCG@10 = 0.652 |
| CRS-LLM [137] | ChatGPT + CRS | Task split complexity in multi-agent flows | High | Moderate | No | Moderate/ F1@Turn = 0.711 |
| ChatGPT-Rank [134] | ChatGPT (API-based) | Latency limits real-time inference | High | Low | No | High/Recall@20 = 0.689 |
| HybridLLMRec [139] | LLM + GBDT/MLP fusion | Requires ensemble tuning across modalities | High | Moderate | Yes | High/Mixed-metric |
| Model | Base Model | Limitations | Scalability | Latency Suitability | Multimodal | Training Cost/Eval |
|---|---|---|---|---|---|---|
| T5 [26] | T5 | High pretraining cost | High | Moderate | No | High/ROUGE-L = 0.387 |
| RecPrompt [140] | LLM (GPT-style) | Prompt tuning requires extensive validation | Moderate | Moderate | No | Moderate/ NDCG@10 = 0.356 |
| MM-Rec [141] | ViLBERT + BERT | Requires rich image–text alignment | Moderate | Low | Yes | Moderate/F1 = 0.78 |
| GNR [142] | GPT-2 | Limited support for real-time updates | Low | Low | Yes | High/BLEU = 0.22 |
| Model | Base Model | Limitations | Scalability | Latency Suitability | Multimodal | Training Cost/Eval |
|---|---|---|---|---|---|---|
| CoLLM [71] | Frozen LLM + Collaborative Embeddings | Needs collaborative history; frozen LLM restricts adaptability | High | Moderate | No | High/HR@10 = 0.642 |
| RecLLM [144] | LLM + Retrieval-Augmented Dialogue | Requires high-quality user input for meaningful adaptation | Moderate | Moderate | No | High/ Precision@5 = 0.601 |
| SocialRec [145] | Context-Aware + Sentiment Classifier | Sentiment clustering may oversimplify user diversity | High | High | No | Moderate/F1 = 0.732 |
| Prospect [146] | Agent-Based LLM Coordination | Complex multi-agent embedding alignment | High | Moderate | Yes | High/BLEU = 0.31 |
| LLM-BRec [147] | BERT + LLM Fusion | Limited by session context length and user profile noise | Moderate | High | Yes | Moderate/ Recall@20 = 0.684 |
| Model | Base Model | Limitations | Scalability | Latency Suitability | Multimodal | Training Cost/Eval |
|---|---|---|---|---|---|---|
| E4SRec [150] | BERT4Rec | Limited to structured curricula | High | Moderate | No | Moderate/ HR@10 = 0.681 |
| OpenP5 [151] | GPT-2 | Weak in unstructured setups | Moderate | Low | No | Moderate/ Accuracy = 0.72 |
| TALLRec [152] | GPT | Struggles with goal shifts | Moderate | Moderate | No | Moderate/ Recall@10 = 0.645 |
| TutorLLM [148] | RAG + KT | High inference latency | Moderate | Low | No | Moderate/F1 = 0.683 |
| RecMind [80] | GPT + Agent | Inefficient at scale | Low | Low | No | Moderate/F1 = 0.684 |
| LLMs4MOOCs [149] | GPT + Prompt | Dataset domain bias | Moderate | Moderate | No | Moderate/ NDCG@10 = 0.688 |
| Model | Base Model | Limitations | Scalability | Latency Suitability | Multimodal | Training Cost/Eval |
|---|---|---|---|---|---|---|
| ClinicalBERT [85] | BERT | Limited to unstructured clinical notes | Moderate | Moderate | No | Moderate/AUC = 0.768 |
| CMS [154] | BERT + Sensor Fusion | Needs high-quality wearables | Low | Low | Yes | High/F1 = 0.792 |
| PALR [79] | Cross-Attention + BERT | Overfits on small datasets | Moderate | Moderate | No | Moderate/HR@10 = 0.658 |
| BeCoLLM [155] | GPT-style LLM + Behavior Science | Needs behavioral context history | High | High | Yes | High/AUC = 0.812 |
| ICL [153] | GPT-3 | Inconsistent for frequent changes | Moderate | High | No | Moderate/F1 = 0.749 |
| LoRec [156] | Transformer | Expensive adversarial training | Low | Low | No | High/AUC = 0.784 |
| XLNet4Rec [34] | XLNet | Requires long exercise history | Moderate | High | No | High/NDCG@10 = 0.662 |
| Model Type | Percentage | Examples/Characteristics |
|---|---|---|
| Transformer-Based Encoders | 38% | BERT4Rec, RoBERTa, UniSRec are optimized for sequential and ranking tasks. |
| Generative Models | 26% | GPT4Rec, RecMind support conversational, narrative, and open-ended recommendations. |
| Multimodal Models | 18% | CLIP, RLMRec integrate visual, behavioral, and textual signals for richer context modeling. |
| Scalable Models | 8% | Megatron-LM, Switch Transformer leverages tensor and pipeline parallelism for deployment. |
| Prompt/Instruction-Tuned | 10% | FLAN, DeBERTa, and CoLLM enable rapid adaptation with few-shot or zero-shot prompts. |
| Domain | Percentage | Datasets and Notable Models |
|---|---|---|
| E-commerce | 32% | Amazon, Taobao, AliExpress datasets’ use cases include cold-start prediction, multilingual personalization, and review-aware ranking (e.g., CoLLM, ChatGPT4Rec). |
| Healthcare | 18% | ClinicalBERT, Synthea, ad HealthTweets focus on sensitive data handling, trust, and privacy-preserving recommendations. |
| Media & Entertainment | 16% | Spotify, YouTube, MovieLens are applications in sequential and real-time personalization (e.g., RecMind, GPT4Rec). |
| Education | 12% | EdNet, KDD Cup, and ASSISTments; LLMs model student behavior, adaptive learning, and knowledge tracing. |
| Social Media | 11% | Twitter, Reddit, and Instagram use LLMs for personalized content feeds, engagement prediction, and toxicity filtering. |
| News & Lifestyle | 11% | MIND, Yahoo! News, HeartSteps; LLMs support context-aware, sentiment-driven, and multilingual recommendation tasks. |
| Theme | Key Models/Approaches | Observations and Challenges |
|---|---|---|
| Prompt Engineering | FLAN, CoLLM | Enables zero-shot/few-shot adaptation with minimal fine-tuning. Highly flexible but sensitive to prompt formulation. |
| Multimodal Fusion | RLMRec, RecVAE++ | Integrates text, visual, and behavioral data. Improves performance in cold-start scenarios. Requires alignment strategies. |
| Latency and Scalability | RecMind, GPT4Rec | Powerful but slow in real-time settings. Autoregressive decoding increases inference time. Distillation and sparse models emerging. |
| Underexplored Domains | Civic Tech, EdTech, Public Health | Limited research exists. LLMs could support low-resource, multilingual environments, especially with instruction-tuning. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shehmir, S.; Kashef, R. LLM4Rec: A Comprehensive Survey on the Integration of Large Language Models in Recommender Systems—Approaches, Applications and Challenges. Future Internet 2025, 17, 252. https://doi.org/10.3390/fi17060252
Shehmir S, Kashef R. LLM4Rec: A Comprehensive Survey on the Integration of Large Language Models in Recommender Systems—Approaches, Applications and Challenges. Future Internet. 2025; 17(6):252. https://doi.org/10.3390/fi17060252
Chicago/Turabian StyleShehmir, Sarama, and Rasha Kashef. 2025. "LLM4Rec: A Comprehensive Survey on the Integration of Large Language Models in Recommender Systems—Approaches, Applications and Challenges" Future Internet 17, no. 6: 252. https://doi.org/10.3390/fi17060252
APA StyleShehmir, S., & Kashef, R. (2025). LLM4Rec: A Comprehensive Survey on the Integration of Large Language Models in Recommender Systems—Approaches, Applications and Challenges. Future Internet, 17(6), 252. https://doi.org/10.3390/fi17060252