


Signal Preprocessing for Enhanced IoT Device Identification Using Support Vector Machine
 ,
,  , , and
, , and 
Abstract

1. Introduction
2. Materials and Methods
2.1. Dataset Description
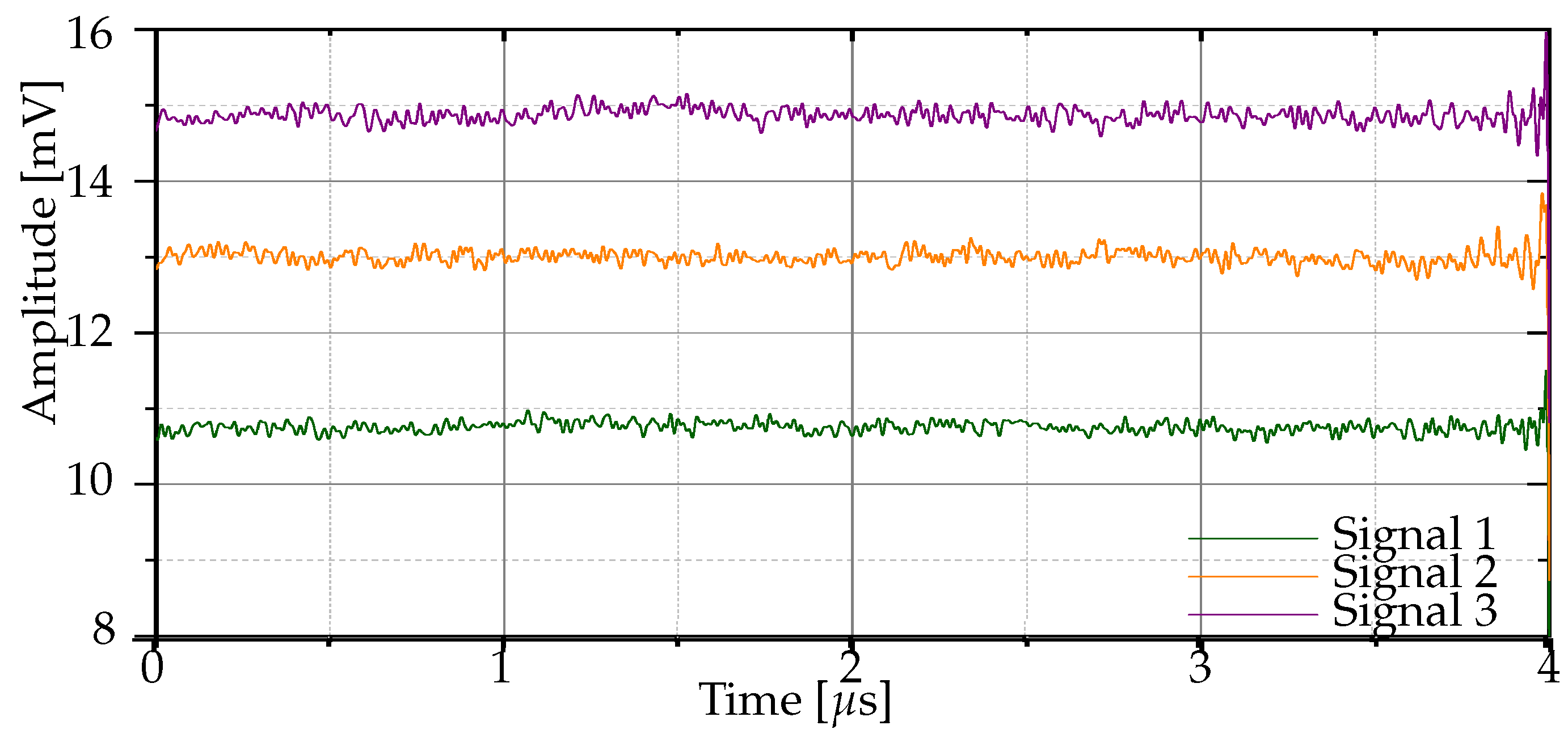
2.2. Definition and Characteristics of Raw Bluetooth Signals
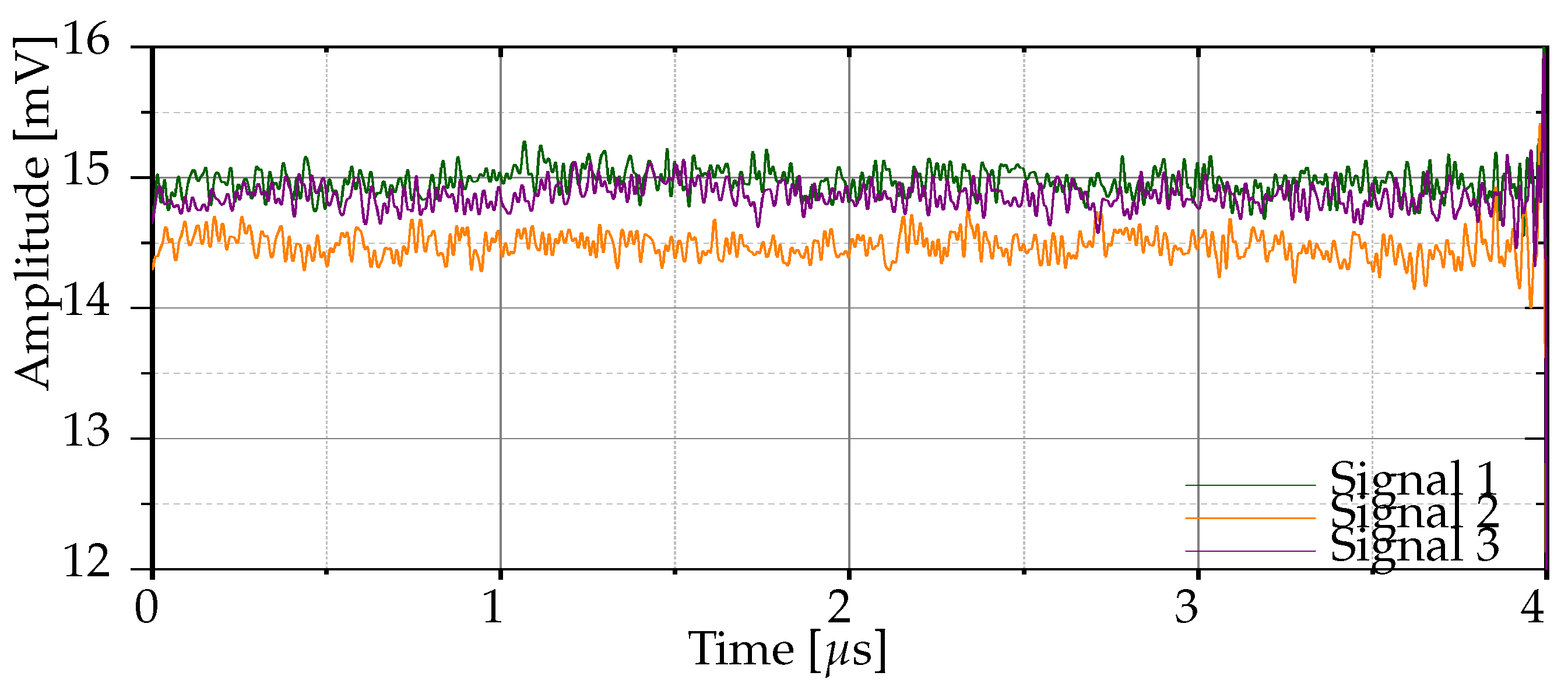
2.3. RF Signal Preprocessing Technique
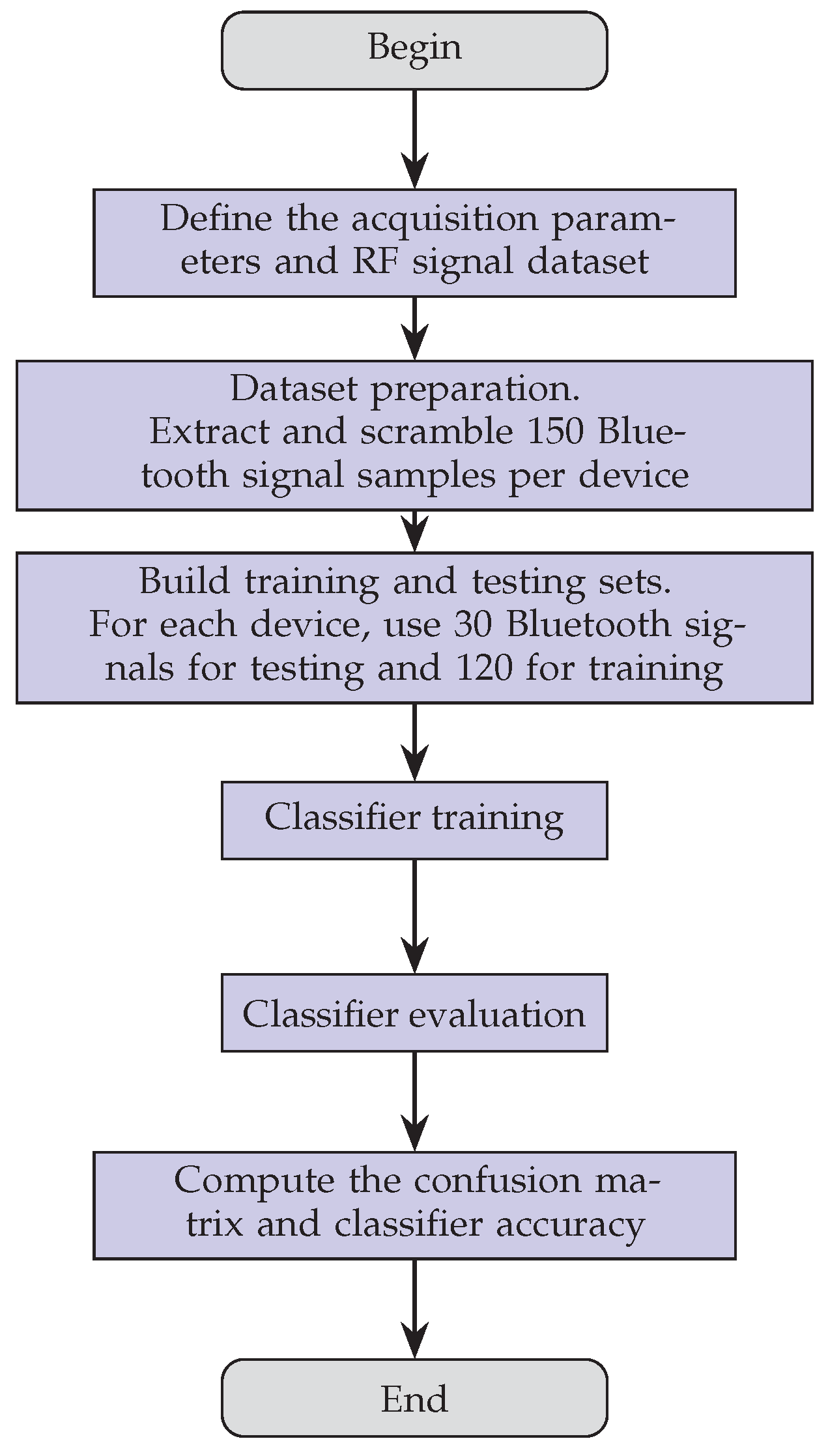
2.4. Classifier Description and Experimental Setup
| Algorithm 1 SVM-based classifier |
| function [accuracy] ← SVM_Classification() 1: Define the acquisition parameters and RF signal dataset 2: root←Dataset path 3: 4: 5: 6: 7: Devices← GetDir(root) 8: database← GetDataBase(root, ) {Load RF signal data} 9: 10: Dataset preparation 11: Initialize empty arrays dataframeTrain and dataframeTest 12: for to D do 13: subdata ← extract N samples from database for device i 14: r ← randperm(N) 15: for do 16: if then 17: dataframeTest ←dataframeTest∪ subdata(j) 18: else 19: dataframeTrain ←dataframeTrain∪ subdata(j) 20: end if 21: count ← count + 1 22: end for 23: Update indices: dima ←dima + N, dim←dim + N 24: end for 25: dataframe←dataframeTrain∪dataframeTest {Concatenate and shuffle} 26: 27: Build training and testing sets 28: xtrain, ytrain← features and labels for training set (120 Bluetooth signals/device) 29: xtest, ytest← features and labels for test set (30 Bluetooth signals/device) 30: 31: Classifier training 32: t← templateSVM(Standardize=True, Kernel=‘polynomial’, Order=4) 33: SVMModel← fitcecoc(xtrain, ytrain, Learners=t) 34: 35: Classifier evaluation 36: testpredict← predict(SVMModel, xtest) 37: 38: Compute the confusion matrix and classifier accuracy 39: ConfMat← confusionmat(testpredict, ytest)/K 40: accuracy← sum(diag(ConfMat))/D 41: 42: return accuracy end |
3. Results
3.1. SVM-Based Classifier with Raw Signals
3.2. SVM-Based Classifier with Normalized Raw Signals
3.3. SVM-Based Classifier with Mean-Normalized Raw Signals
3.4. SVM-Based Classifier with Max-Normalized Raw Signals
3.5. SVM-Based Classifier with Min-Normalized Raw Signals
4. Discussion
5. Conclusion and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Borges do Nascimento, I.J.; Marcolino, M.S.; Abdulazeem, H.M.; Weerasekara, I.; Azzopardi-Muscat, N.; Gonçalves, M.A.; Novillo-Ortiz, D. Impact of Big Data Analytics on People’s Health: Overview of Systematic Reviews and Recommendations for Future Studies. J. Med. Internet Res. 2021, 23, e27275. [Google Scholar] [CrossRef] [PubMed]
- Razzak, M.I.; Imran, M.; Xu, G. Big data analytics for preventive medicine. Neural Comput. Appl. 2019, 32, 4417–4451. [Google Scholar] [CrossRef] [PubMed]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A comprehensive evaluation of ensemble learning for stock-market prediction. J. Big Data 2020, 7, 20. [Google Scholar] [CrossRef]
- Thakkar, S.; Kazdaghli, S.; Mathur, N.; Kerenidis, I.; Ferreira–Martins, A.J.; Brito, S. Improved financial forecasting via quantum machine learning. Quantum Mach. Intell. 2024, 6, 27. [Google Scholar] [CrossRef]
- Miranda-García, A.; Rego, A.Z.; Pastor-López, I.; Sanz, B.; Tellaeche, A.; Gaviria, J.; Bringas, P.G. Deep learning applications on cybersecurity: A practical approach. Neurocomputing 2024, 563, 126904. [Google Scholar] [CrossRef]
- Davis, J.J.; Clark, A.J. Data preprocessing for anomaly based network intrusion detection: A review. Comput. Secur. 2011, 30, 353–375. [Google Scholar] [CrossRef]
- Deshkar, P.A.; Laghate, K.; Ghorpade, A.; Padole, D.; Shende, H.; Kawale, P.; Sakhare, P. Data Pre-Processing Solution Using Statistical and Data Mining Techniques; Springer: Berlin/Heidelberg, Germany, 2024; pp. 84–112. [Google Scholar] [CrossRef]
- Research, G.V. Data Preparation Tools Market Size & Share Report, 2023–2030. 2023. Available online: https://www.grandviewresearch.com/industry-analysis/data-preparation-tools-market (accessed on 31 January 2025).
- Rehman, S.U.; Sowerby, K.W.; Alam, S.; Ardekani, I. Radio frequency fingerprinting and its challenges. In Proceedings of the 2014 IEEE Conference on Communications and Network Security, San Francisco, CA, USA, 29–31 October 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Soltanieh, N.; Norouzi, Y.; Yang, Y.; Karmakar, N.C. A Review of Radio Frequency Fingerprinting Techniques. IEEE J. Radio Freq. Identif. 2020, 4, 222–233. [Google Scholar] [CrossRef]
- Zhang, J.; Woods, R.; Sandell, M.; Valkama, M.; Marshall, A.; Cavallaro, J. Radio Frequency Fingerprint Identification for Narrowband Systems, Modelling and Classification. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3974–3987. [Google Scholar] [CrossRef]
- Jagannath, A.; Jagannath, J.; Kumar, P.S.P.V. A comprehensive survey on radio frequency (RF) fingerprinting: Traditional approaches, deep learning, and open challenges. Comput. Netw. 2022, 219, 109455. [Google Scholar] [CrossRef]
- Fan, C.; Chen, M.; Wang, X.; Wang, J.; Huang, B. A Review on Data Preprocessing Techniques Toward Efficient and Reliable Knowledge Discovery From Building Operational Data. Front. Energy Res. 2021, 9, 652801. [Google Scholar] [CrossRef]
- Qi, X.; Hu, A.; Zhang, Z. Data-and-Channel-Independent Radio Frequency Fingerprint Extraction for LTE-V2X. IEEE Trans. Cogn. Commun. Netw. 2024, 10, 905–919. [Google Scholar] [CrossRef]
- Peng, L.; Wu, Z.; Zhang, J.; Liu, M.; Fu, H.; Hu, A. Hybrid RFF Identification for LTE Using Wavelet Coefficient Graph and Differential Spectrum. IEEE Trans. Veh. Technol. 2024, 73, 11621–11636. [Google Scholar] [CrossRef]
- Al-Hazbi, S.; Hussain, A.; Sciancalepore, S.; Oligeri, G.; Papadimitratos, P. Radio Frequency Fingerprinting via Deep Learning: Challenges and Opportunities. In Proceedings of the International Wireless Communications and Mobile Computing (IWCMC), Ayia Napa, Cyprus, 27–31 May 2024; pp. 824–829. [Google Scholar] [CrossRef]
- Fan, X.; Zhao, C.; Xiao, L.; Huang, X. Random Railings Enhancement For RFF Imbalanced Data Augmentation. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Glasgow, UK, 26–29 March 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Peng, Y.; Hou, C.; Zhang, Y.; Lin, Y.; Gui, G.; Gacanin, H.; Mao, S.; Adachi, F. Supervised Contrastive Learning for RFF Identification With Limited Samples. IEEE Internet Things J. 2023, 10, 17293–17306. [Google Scholar] [CrossRef]
- Xie, R.; Xu, W.; Chen, Y.; Yu, J.; Hu, A.; Ng, D.W.K.; Swindlehurst, A.L. A Generalizable Model-and-Data Driven Approach for Open-Set RFF Authentication. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4435–4450. [Google Scholar] [CrossRef]
- Qi, X.; Hu, A. Toward Novel Time Representations for RFF Identification Using Imperfect Data Sets. IEEE Internet Things J. 2023, 10, 2743–2753. [Google Scholar] [CrossRef]
- Chillet, A.; Gerzaguet, R.; Desnos, K.; Gautier, M.; Lohan, E.S.; Nogues, E.; Valkama, M. Understanding Radio Frequency Fingerprint Identification With RiFyFi Virtual Databases. IEEE Open J. Commun. Soc. 2024, 5, 3735–3752. [Google Scholar] [CrossRef]
- Santana-Cruz, R.F.; Moreno-Guzman, M.; Rojas-López, C.E.; Vázquez-Morán, R.; Vázquez-Medina, R. Bluetooth Device Identification Using RF Fingerprinting and Jensen-Shannon Divergence. Sensors 2024, 24, 1482. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, T.; Ma, Y.; Xi, Z.; He, C.; Wang, Y.; Lv, Z. A Low-Latency Approach for RFF Identification in Open-Set Scenarios. Electronics 2024, 13, 384. [Google Scholar] [CrossRef]
- Fan, Z.Y.; Cheng, W. Construction and Sharing of Radio Frequency Fingerprinting Dataset Based on Federated Learning. In Proceedings of the 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021; pp. 980–984. [Google Scholar] [CrossRef]
- Uzundurukan, E.; Ali, A.M.; Dalveren, Y.; Kara, A. Performance analysis of modular RF front end for RF fingerprinting of Bluetooth devices. Wirel. Pers. Commun. 2020, 112, 2519–2531. [Google Scholar] [CrossRef]
- Rusins, A.; Tiscenko, D.; Dobelis, E.; Blumbergs, E.; Nesenbergs, K.; Paikens, P. Wearable Device Bluetooth/BLE Physical Layer Dataset. Data 2024, 9, 53. [Google Scholar] [CrossRef]
- Uzundurukan, E.; Dalveren, Y.; Kara, A. A database for the radio frequency fingerprinting of Bluetooth devices. Data 2020, 5, 55. [Google Scholar] [CrossRef]
- Zhang, T.; Ren, P.; Ren, Z.; Xu, D. FWSResNet: An Edge Device Fingerprinting Framework Based on Scattering and Convolutional Networks. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Shen, G.; Zhang, J.; Marshall, A.; Cavallaro, J.R. Towards Scalable and Channel-Robust Radio Frequency Fingerprint Identification for LoRa. IEEE Trans. Inf. Forensics Secur. 2022, 17, 774–787. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Device Name |
|---|---|
| 1 | Amazfit Band 5 |
| 2 | Apple Watch SE |
| 3 | Fitbit Charge 5 |
| 4 | Fitbit Versa 4 |
| 5 | Garmin Instinct Crossover |
| 6 | Garmin Instinct SQ |
| 7 | Apple Watch Series 8 |
| 8 | iPhone 5 - 1 |
| 9 | iPhone 5 - 2 |
| 10 | iPhone 6 - 1 |
| 11 | iPhone 6 - 2 |
| 12 | iPhone 5s - 1 |
| 13 | iPhone 5s - 2 |
| 14 | iPhone 6s - 1 |
| 15 | iPhone 6s - 2 |
| 16 | LG G4 - 1 |
| 17 | LG G4 - 2 |
| 18 | Samsung Note3 - 1 |
| 19 | Samsung Note3 - 2 |
| 20 | Samsung S5 - 1 |
| 21 | Samsung S5 - 2 |
| 22 | Samsung Galaxy S20 FE |
| 23 | Sony Xperia M5 - 1 |
| 24 | Sony Xperia M5 - 2 |
| Predicted Class | |||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | ||
| True class | 1 | 0.15 | 0.05 | 0.03 | 0.04 | 0.06 | 0.01 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 |
| 2 | 0.02 | 0.15 | 0.03 | 0.02 | 0.02 | 0.05 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | |
| 3 | 0.23 | 0.30 | 0.38 | 0.24 | 0.26 | 0.33 | 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.27 | 0.00 | 0.00 | |
| 4 | 0.08 | 0.09 | 0.08 | 0.18 | 0.12 | 0.11 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.11 | 0.00 | 0.00 | |
| 5 | 0.33 | 0.24 | 0.23 | 0.30 | 0.40 | 0.27 | 0.31 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.26 | 0.00 | 0.00 | |
| 6 | 0.02 | 0.02 | 0.03 | 0.02 | 0.01 | 0.04 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | |
| 7 | 0.13 | 0.12 | 0.20 | 0.16 | 0.10 | 0.16 | 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.12 | 0.00 | 0.00 | |
| 8 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.13 | 0.13 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.13 | 0.07 | 0.00 | 0.03 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.17 | 0.10 | 0.13 | 0.13 | 0.17 | 0.20 | 0.00 | 0.00 | 0.03 | 0.10 | 0.03 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.10 | 0.03 | 0.00 | 0.00 | 0.00 | |
| 11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.07 | 0.10 | 0.10 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.20 | 0.03 | 0.00 | 0.13 | 0.00 | 0.00 | 0.03 | 0.00 | |
| 12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.20 | 0.27 | 0.17 | 0.17 | 0.23 | 0.13 | 0.00 | 0.00 | 0.10 | 0.10 | 0.07 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.07 | 0.03 | 0.10 | 0.00 | 0.03 | 0.87 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 15 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.97 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.13 | 0.13 | 0.07 | 0.20 | 0.27 | 0.00 | 0.00 | 0.13 | 0.07 | 0.03 | 0.10 | 0.03 | 0.03 | 0.00 | 0.00 | 0.03 | |
| 17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.03 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.17 | 0.00 | 0.00 | 0.13 | 0.03 | 0.00 | 0.00 | 0.00 | |
| 18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.03 | 0.03 | 0.00 | 0.00 | 0.07 | 0.00 | 0.07 | 0.00 | 0.33 | 0.20 | 0.10 | 0.13 | 0.00 | 0.00 | 0.00 | |
| 19 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.10 | 0.17 | 0.23 | 0.13 | 0.17 | 0.03 | 0.00 | 0.27 | 0.07 | 0.50 | 0.33 | 0.10 | 0.37 | 0.00 | 0.00 | 0.00 | |
| 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 21 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.03 | 0.00 | 0.07 | 0.17 | 0.07 | 0.00 | 0.00 | 0.17 | 0.13 | 0.00 | 0.27 | 0.13 | 0.40 | 0.00 | 0.00 | 0.00 | |
| 22 | 0.04 | 0.03 | 0.03 | 0.06 | 0.03 | 0.04 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.12 | 0.00 | 0.00 | |
| 23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.93 | 0.00 | |
| 24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.97 | |
| Predicted Class | |||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | ||
| True class | 1 | 0.02 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 |
| 2 | 0.25 | 0.37 | 0.04 | 0.06 | 0.05 | 0.09 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.14 | 0.00 | 0.00 | |
| 3 | 0.14 | 0.17 | 0.56 | 0.25 | 0.21 | 0.34 | 0.35 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.18 | 0.00 | 0.00 | |
| 4 | 0.13 | 0.01 | 0.01 | 0.27 | 0.09 | 0.05 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | |
| 5 | 0.14 | 0.03 | 0.10 | 0.07 | 0.27 | 0.04 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | 0.00 | |
| 6 | 0.09 | 0.09 | 0.07 | 0.13 | 0.08 | 0.25 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.09 | 0.00 | 0.00 | |
| 7 | 0.06 | 0.03 | 0.02 | 0.03 | 0.05 | 0.02 | 0.24 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.00 | 0.00 | |
| 8 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.60 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | |
| 9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.90 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.33 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.73 | 0.30 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.17 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.03 | 0.20 | 0.03 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.77 | 0.00 | 0.03 | 0.00 | 0.00 | 0.13 | 0.03 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | |
| 14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.93 | 0.00 | 0.03 | 0.00 | 0.03 | 0.00 | 0.00 | 0.03 | 0.00 | 0.07 | 0.00 | |
| 15 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.97 | 0.07 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | |
| 16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.30 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | |
| 17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.03 | 0.23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.47 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.17 | 0.00 | 0.40 | 0.23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 19 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.63 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.33 | 0.30 | 0.00 | 0.33 | 0.00 | 0.00 | 0.00 | |
| 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.17 | 0.20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | 0.70 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 21 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.03 | 0.00 | 0.07 | 0.33 | 0.00 | 0.53 | 0.00 | 0.00 | 0.00 | |
| 22 | 0.17 | 0.30 | 0.20 | 0.19 | 0.23 | 0.22 | 0.21 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.47 | 0.00 | 0.00 | |
| 23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.87 | 0.00 | |
| 24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.97 | |
| Predicted Class | |||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | ||
| True class | 1 | 0.91 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 0.00 | 0.99 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 3 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | |
| 5 | 0.09 | 0.00 | 0.00 | 0.00 | 0.85 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.00 | 0.00 | |
| 6 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 7 | 0.01 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.90 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 8 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.90 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.77 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.47 | 0.00 | 0.00 | 0.03 | 0.00 | 0.03 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | |
| 14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.83 | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 15 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.00 | 0.00 | 0.87 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.83 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.03 | 0.07 | 0.00 | 0.00 | 0.00 | 0.60 | 0.37 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | |
| 19 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 | 0.10 | 0.00 | 0.03 | 0.03 | 0.07 | 0.60 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.93 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 21 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.67 | 0.37 | 0.00 | 0.00 | 0.00 | 0.00 | 0.27 | 0.00 | 0.00 | 0.77 | 0.00 | 0.00 | 0.00 | |
| 22 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.95 | 0.00 | 0.00 | |
| 23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | |
| 24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | |
| Predicted Class | |||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | ||
| True class | 1 | 0.93 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 |
| 2 | 0.01 | 0.99 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 3 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | |
| 5 | 0.02 | 0.00 | 0.00 | 0.00 | 0.87 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | |
| 6 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 7 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.90 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 8 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.87 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.97 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.83 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.17 | 0.90 | 0.03 | 0.03 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.23 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.53 | 0.07 | 0.03 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | |
| 13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.70 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | |
| 14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.87 | 0.00 | 0.00 | 0.00 | 0.07 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 15 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.93 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.87 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | 0.53 | 0.37 | 0.00 | 0.13 | 0.00 | 0.00 | 0.00 | |
| 19 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.53 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.77 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 21 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.27 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.27 | 0.00 | 0.00 | 0.73 | 0.00 | 0.00 | 0.00 | |
| 22 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.97 | 0.00 | 0.00 | |
| 23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | |
| 24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | |
| Predicted Class | |||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | ||
| True class | 1 | 0.91 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 0.00 | 0.99 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 3 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | |
| 5 | 0.09 | 0.00 | 0.00 | 0.00 | 0.85 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.00 | 0.00 | |
| 6 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 7 | 0.01 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.90 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 8 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.93 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.83 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.90 | 0.00 | 0.03 | 0.00 | 0.00 | 0.03 | 0.03 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.17 | 0.10 | 0.03 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | |
| 13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.57 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 | |
| 14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.80 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | |
| 15 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.73 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 17 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.17 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.80 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.03 | 0.17 | 0.00 | 0.00 | 0.00 | 0.70 | 0.30 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | |
| 19 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.20 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.70 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.83 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 21 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.50 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.20 | 0.00 | 0.00 | 0.80 | 0.00 | 0.00 | 0.00 | |
| 22 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.95 | 0.00 | 0.00 | |
| 23 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.97 | 0.00 | |
| 24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | |
| Preprocessing | Diagnostical | Effective | Recall | Specificity | F1 Score |
|---|---|---|---|---|---|
| Accuracy[%] | Accuracy[%] | [%] | [%] | [%] | |
| Raw signal | 30.59 | 33.33 | 35.96 | 96.98 | 29.09 |
| Normalized raw signal | 51.06 | 75.00 | 53.25 | 97.89 | 49.76 |
| Mean-normalized raw signal | 84.29 | 95.83 | 87.39 | 99.32 | 83.65 |
| Max-normalized raw signal | 86.21 | 100.00 | 87.34 | 99.39 | 86.19 |
| Min-normalized raw signal | 84.70 | 95.83 | 85.06 | 99.33 | 84.15 |
| Classifier | Raw Signal | Normalized | Mean-Normalized | Max-Normalized | Min-Normalized |
|---|---|---|---|---|---|
| SVM | 30.59 | 51.06 | 84.29 | 86.21 | 84.70 |
| Random Forest | 39.57 | 61.18 | 73.77 | 78.09 | 73.77 |
| Ref. | Preprocessing | Classifier | RF | Accuracy | Time |
|---|---|---|---|---|---|
| Variant | Technology | [%] | [s] | ||
| [22] | MNRS | JSD | BT | 99.20 | 0.21 |
| [21] | NR | DL-Based | Simulated Signals | 98.00 | NR |
| [15] | CFO | Hybrid | 4/5G devices | 98.84 | NR |
| [14] | CFO | CNN | LTE data | 97.30 | 40.16 |
| [14] | Homomorphic | SHAe | V2X devices | 97.30 | NR |
| [23] | CFO | KNN | LoRa | 93.23 | NR |
| [16] | Normalization | DL-Based | NR | NR | NR |
| [16] | NR | DL Models | RF devices | NR | NR |
| [18] | Data Augmentation | DL-Based | ZigBee devices | 92.68 | NR |
| [17] | NR | RRE | UAV | 95.60 | NR |
| [20] | CFO | CNN | ZigBee devices | 94.81 | NR |
| [28] | Large Scale | FWSResNet | LTE data | 99.50 | NR |
| [29] | CFO | DL-Based | LoRa devices | 96.40 | NR |
| [24] | Large Scale | FL | RF devices | NR | NR |
| [19] | NR | CNN | NR | 99.00 | NR |
| Prop. | MNRS | SVM | BT | 86.21 | 15.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santana-Cruz, R.F.; Moreno, M.; Aguilar-Torres, D.; Valverde-Domínguez, R.A.; Vázquez-Medina, R. Signal Preprocessing for Enhanced IoT Device Identification Using Support Vector Machine. Future Internet 2025, 17, 250. https://doi.org/10.3390/fi17060250
Santana-Cruz RF, Moreno M, Aguilar-Torres D, Valverde-Domínguez RA, Vázquez-Medina R. Signal Preprocessing for Enhanced IoT Device Identification Using Support Vector Machine. Future Internet. 2025; 17(6):250. https://doi.org/10.3390/fi17060250
Chicago/Turabian StyleSantana-Cruz, Rene Francisco, Martin Moreno, Daniel Aguilar-Torres, Román Arturo Valverde-Domínguez, and Rubén Vázquez-Medina. 2025. "Signal Preprocessing for Enhanced IoT Device Identification Using Support Vector Machine" Future Internet 17, no. 6: 250. https://doi.org/10.3390/fi17060250
APA StyleSantana-Cruz, R. F., Moreno, M., Aguilar-Torres, D., Valverde-Domínguez, R. A., & Vázquez-Medina, R. (2025). Signal Preprocessing for Enhanced IoT Device Identification Using Support Vector Machine. Future Internet, 17(6), 250. https://doi.org/10.3390/fi17060250