2. Related Work
The extensive integration of the Internet of Things (IoT) across diverse applications has appeared as a transformative force, improving the general standard of living. However, due to its vast network of interconnected devices, inherent openness, and decentralized architecture, the IoT has progressively become a significant focus for unauthorized breaches. An extensive study was conducted in [
3] using feature selection, classification, and clustering on the UNSW-NB15 dataset to construct an efficient IDS. Due to improved cyber attacks, network security requires an effective IDS. This research tackled existing problems with multidimensional input data, unnecessary elements, and unimportant features when dealing with network datasets because these elements create performance problems in machine learning software. Researchers decreased the number of features through feature selection, improving model accuracy and efficiency. Clustering methods establish natural subgroup relations to extract anomalies from datasets. After that, decision tree and random forest classification methods are used to detect intrusions precisely. Experimental results have revealed better intrusion detection with fewer false alarms using the unified feature selection method, clustering, and classification. Through its integrated approach, this research shows that structured feature reduction and preprocessing strategies improve the effectiveness of machine learning IDSs. However, the exclusive use of data from the UNSW-NB15 dataset prevents generalization to current cyber attacks due to potential unseen threats. The exclusion process during feature selection might remove essential elements for recognizing new and advanced cyber attacks. Additional complexity from clustering and classification algorithms negatively impacts the system execution speed, particularly when running on systems with limited resources.
Due to increasing IoT device complexity and vulnerability, a sophisticated security solution must combine anomaly and signature-based detection. A hybrid solution was proposed that uses machine learning techniques to identify malicious acts, improving heterogeneous IoT security. The proposed IDS outperformed single-detection systems in DoS, probing, and Remote-to-Local (R2L) assaults in experimental testing. The hybrid IDS proposed in [
4] improves accuracy, false-positive rates, and real-time responsiveness. Since the IoT market is growing rapidly, the abovementioned report underlines how IDSs must handle device expansion and diversity. Extended research can solve significant IoT security issues with an extensible framework that defends against network-based assaults, improving cybersecurity. However, the model’s functioning strictly relies on preselected IoT network datasets, restricting its use for different network types and developing attack patterns. The hybrid IDS operating method could create an additional computational burden that might reduce real-time speed when running under resource-limited IoT conditions. Intrusion detection systems (IDSs) for the Internet of Things (IoT) are essential to meet the growing security challenges.
In [
5], signature-based, specification-based, hybrid IDS, and anomaly-based approaches were analyzed for IoT security capabilities and vulnerabilities. This study showed how IoT systems’ limited resources, heterogeneity, and widespread deployment make typical IDS solutions problematic. IDS classifications were categorized by installation type (hybrid, network-based, or host-based), and standard datasets and evaluation metrics were presented. IDS literature has several flaws, including low-weight real-time IDS frameworks and insufficient evaluation procedures.
However, such analyses and the prediction of upcoming directions in IoT intrusion detection systems might struggle to anticipate quick evolutions of attack methods, impacting their enduring success. Therefore, research in [
6] introduced NSF-HC SQLIAS, a new NLP-based model designed to predict SQL injection attacks (SQLIA) in Secure Cloud Process Management (SCPM) systems. It starts with the extraction of low-dimensional semantic features from SQL queries through the use of three techniques: N-Skip Gram (SKG), TF-IDF, and Continuous Bag of Words (CBOW). Random sampling and up-sampling techniques address class imbalance in the dataset. Subsequently, these features undergo refinement via feature selection methods that involve significant predictor tests and variance threshold feature selection (VTFS). This process aims to improve time efficiency and reduce redundant calculations. After that, min–max normalization is utilized to avert convergence and overfitting problems. Nine machine learning algorithms, such as naïve Bayes, neural networks, regression models, association rule mining, and ensemble techniques, are employed for binary classification (normal or SQLIA) of the processed features. These algorithms constitute a heterogeneous ensemble system, and final predictions are generated through a consensus model employing majority voting. The model’s experimental results demonstrate its superiority over existing methods, as it achieves an accuracy of 98.6%, an F measure of 0.993, and an AUC of 0.999 with CBOW features. However, scalability problems emerge when implementing this method in big cloud infrastructure because of the challenging nature of hidden Markov models. The system faces reduced effectiveness because it depends on transductive learning when dealing with previously unknown attack patterns and data types.
As mentioned in [
7], IoT security requires an IDS to monitor sensor data and prevent zero-day threats. The information security system relies on FDLNN to overcome signature-based detection. However, MKM-based clustering for cluster development using MQTT and AMQP communication with FDLNN intrusion detection and LFEHO-based data distribution enables sensor network configuration before head selection. Standard IDSs manage different IoT data types and detect threats through known and unknown intrusion detection and by distinguishing harmful activity from benign activity, making them unsuitable for this architecture. FDLNN surpassed all deep learning and neural network models for intrusion detection on the TON_IoT dataset, with 96.12% accuracy and outstanding precision and recall. LFEHO outperformed IANFIS and ANFIS regarding data distribution qualities like turnaround, responsiveness, and throughput. A previous study combined powerful clustering and communication protocols with deep learning detection methods to provide a precise, lightweight IoT IDS. However, the proposed deep learning-based intrusion detection system encounters performance limitations associated with high processing demands, causing problems on resource-limited IoT devices. The model exhibits reduced performance capability when faced with novel or unobserved attack patterns during operations not appearing in previous training data.
The study reported in [
8] presents a deep learning framework driven by SDN to improve security and efficiency in Healthcare IoT (H-CIoT) networks. Because of the dynamic nature and complexity of H-IoT devices, traditional network models are inadequate for ensuring security and QoS. Utilizing Software-Defined Networking (SDN), the proposed framework separates control and data planes, enabling flexible management of distributed network components. A Bidirectional LSTM (BiLSTM) module is utilized to identify different types of cyber attacks in the network. In addition, the DL model is trained using the patient’s medical history to make intelligent decisions about data transmission to the fog nodes. A CNN-based module is included to determine the fog node that offers the highest efficiency for data processing. The simulation outcomes demonstrate excellent performance, featuring a latency of 3 ms, an F1 score of 99.53%, an accuracy of 99.59%, and energy consumption of 55 W. The model demonstrates marked improvement over current methods in terms of accuracy, speed, and energy efficiency, establishing it as a robust solution for secure H-CIoT environments.
Another study [
9] introduced a hybrid intrusion detection system (IDS) that integrates Support Vector Machines (SVMs), Principal Component Analysis (PCA), Deep Belief Networks (DBNs) and adversarial learning to improve the detection of both known and zero-day cyber threats. Utilizing adversarial samples enhances the model’s capacity to identify developing attack patterns, and PCA diminishes feature dimensions by 40%, thereby boosting efficiency. With the help of SVM, threats can be classified accurately, and the system shows outstanding performance on the NSL-KDD and CICIDS2017 datasets, attaining an accuracy of as much as 99.73% and exhibiting a low false-positive rate. It is particularly effective at identifying sophisticated attacks such as botnets, R2L, and U2R. The model, which has an inference time of only 9 ms, is appropriate for real-time use in environments with heavy traffic and provides strong, scalable, and adaptable cybersecurity protection. However, the hybrid teacher learning optimization technique imposes excessive computation requirements, making it unfit for real-time intrusion detection in systems with limited computing capabilities. The system fails to accommodate dynamic attack patterns because of its cluster-based feature selection strategy. Because limited-resource environments necessitate cybersecurity, the development of small IDSs must be prioritized.
To meet this need, the IDS framework uses the OCSVM and PIO algorithms, as presented in [
10]. The system detects sophisticated anomalies with minimal resources, making it suitable for IoT networks and edge computing. OCSVM is the system’s principal anomaly detection utility because it detects dimensional deviations in multivariate data spaces well. Pigeon-inspired optimizer is used by the PIO technique to improve OCSVM parameter selection sensitivity. Multiple detection systems provide accurate findings without high system processing speeds. The proposed model passed f-measure, precision, false alarms, detection rate, and accuracy tests on the NSL-KDD and UNSW-NB15 datasets. Small systems can operate in real time, since this solution keeps the required execution time minimal. Intelligent IDSs can meet modern cybersecurity needs and operate efficiently with an effective adaptive strategy. However, a network intrusion detection system using lightweight technology achieves limited accuracy in detecting complex or new types of attacks because the OCSVM model operates at a basic level. The pigeon-inspired optimizer demonstrates difficulties when used to optimize security in extensive network environments.
Another scheme was proposed in [
11], incorporating a novel approach to intrusion detection that employs unsupervised learning to recognize various types of cyber attacks, such as DoS, DDoS, botnet, and infiltration attacks. The suggested system incorporates basic autoencoders (bAEs) for dimensionality reduction, along with a three-stage detection mechanism that includes a one-class SVM (OCSVM), deep autoencoders (dAEs), and DBSCAN clustering to map attack behaviors. It employs the MITRE ATT&CK framework for response prioritization and creates a cyber threat repository. It trains on normal, unlableled network traffic, allowing it to effectively recognize new attacks and reduce problems arising from imbalanced datasets. When evaluated using CSECIC-IDS2018 and CIC-IDS2017 datasets, the model demonstrated an accuracy exceeding 98%, surpassing current methods in terms of scalability and precision.
Modern industrial facilities need advanced intelligent cybersecurity solutions to safeguard operational areas from IoT expansion. A previous study in [
12] developed AI-operated intrusion detection systems for IIoT security to prevent complicated cyber attacks. Deep learning methods help AI systems analyze complex network patterns to find malicious computer irregularities. After processing real-time analytical data, neural networks can effectively identify zero-day assaults and new malware. The articlestates that IIoT devices need lightweight intelligent models for limited-resource contexts. Due to precise scalability and low false-positive error rates, the system passed benchmark testing and entered industrial use.
Another study in [
13] presented an evolutionary intelligence-based Unified Intrusion Detection System (UIDS) that identifies all IoT threats in IT systems. The UISD’s protective system combines signature- and anomaly-based methods to create full defensive capabilities. The system uses optimization methods to automatically change new attack vectors during operation. Because its detection methods work under multiple data arrangement patterns, the UIDS model has been deployed across IoT implementations. The framework enables straightforward installation by merging a standardized structural design with fast detection times and improved accuracy. The authors who proposed the model found that AI is essential for developing advanced intrusion detection solutions for IoT and IIoT networks. Developers can refer to the abovementioned study to create risk-averse intelligent cybersecurity tools that combat active threats. Nevertheless, the AI-based malware detection system faces challenges when processing multidimensional and unbalanced datasets. This may reduce its ability to identify uncommon or complex malware types used within Industrial IoT networks. The UIDS is a new intrusion detection system built specifically for IoT environments. This security system addresses IoT network difficulties like huge data streams, limited capacity, and multiple attack types using signature-based and anomaly-based detection methods. The UIDS uses optimization methods to improve detection accuracy and reduce false positives. The model outperforms conventional IDS models and handles IoT dataset complexity and scalability. System effectiveness depends on database data quality and variety. The system struggles to adapt to attack vectors in IoT systems that change regularly. However, a unified intrusion detection system used for IoT application struggles with scalability challenges as it operates across different IoT devices and networks with different capacities and target areas.
Intelligent and effective intrusion detection systems are needed to combat increasingly sophisticated cyber attacks. A hybrid anomaly detection system using k-means clustering and Sequential Minimal Optimization (SMO) has proposed by [
14]. The researchers devised an approach that addresses two significant performance constraints that limit real-time network security monitoring. According to the above mentioned study, traditional data mining algorithms are limited when processing high-traffic networks and fail when data are missing or noise occurs. The proposed model comprises two phases: First, k-means clustering groups network traffic behaviors in an unsupervised manor; then, SMO quickly classifies them using support vector machines. Genetic algorithms and subset selection minimize unnecessary characteristics, improving precision and processing speed and strengthening the model. When evaluated, the hybrid model using WEKA tools outperformed single algorithms, with a 94.48% detection rate, 1.2% false-positive rate, and ideal accuracy measures. The system excels in high-volume IoT and wireless sensor network applications. The research has shown that an effective IDS with great scalability was developed using feature optimization and hybrid machine learning to meet real-time performance and detection needs in dynamic networks. However, high-performance bottlenecks exist during processing in large-scale networks for both the k-mean array and sequential minimal optimization methods due to their complex algorithm structures, which also constrain their real-time usage.
The study in [
15] brought together CNNs and LSTMs to create a deep learning system that monitors IoT network anomalies. Standard signature-based detection methods and basic machine learning algorithms fail to handle modern sophisticated network activities. A CNN can be used to extract spatial features from traffic data, subsequently feeding temporal patterns to an LSTM model to detect anomalies more efficiently. The system implements a detection method designed to increase the performance of irregular activity identification in extensive and dynamic IoT networks. This concept enables automated detection systems to function automatically in real-time operations without extensive human supervision. Main issues associated with this approach include limitations regarding widespread application, resource utilization, and scalability issues. Similar to other approaches, this method relies on pre-labeled training data but proves inadequate in recognizing all complete IoT threats in actual deployment scenarios. Training and inference costs can make it challenging to run this process on limited-power edge devices. Such a system does not have built-in capabilities allowing it to promptly adjust its security responses to new and previously unseen attacks. Currently, no solution addresses energy consumption in real-time applications or latency requirements. Existing constraints drive the need for additional optimization, including the development of lightweight architectures and online learning features to achieve efficient, accurate, and scalable anomaly detection. Due to the growth of distributed cloud infrastructure systems, enterprises need better security procedures to detect sophisticated cyber attacks.
Traditional intrusion detection systems struggle in dynamic cloud-based systems due to accuracy and scalability issues. Therefore, new IDSs should use classification and clustering techniques to detect known and unknown security vulnerabilities. A previous study in [
16] used two clustering methods and random forest classifiers. K-means is fast and easy to use, but GMM’s probabilistic features make it good at managing non-spherical clusters. The system initially divides traffic into groups through network analysis, using these features before RF classifiers identify attack types, including U2R, R2L, Probe, DoS, and normal attacks. The proposed model was evaluated using accuracy, DR, F1-score, FAR, recall, precision, and AUC metrics on the NSL-KDD and KDDCup99 datasets. The K-Means+RF hybrid model outperformed other models, with 99.85% accuracy and a 99.78% detection rate on the NSL-KDD dataset. Different threshold tests recognized attacks authentically, slightly increasing false-alert rates but maintaining outstanding detection results for DoS and regular attacks. The combination of unsupervised and supervised learning reduces false positives and improves categorization, major challenges encountered in developing IDSs. According to studies reported in the literature, time-sensitive feature choice and real-time flexibility have set a new standard for distributed cloud network intrusion detection reliability. The architecture lays the groundwork for intelligent cybersecurity systems on large cloud platforms. However, hybrid clustering and classification methods demonstrate limitations in terms of adaptability when operating with changing attack types or in environments not adequately included in training data.
Intrusion detection is needed to secure IoT networks as they grow in complexity and scale. Current intrusion detection systems (IDSs) struggle to handle high-dimensional data and identify new threats in real time. The authors of [
17] proposed a hybrid IDS framework with various machine learning classifiers and feature selection optimization to overcome restrictions. This approach maximizes accuracy and conserves processing power on limited IoT infrastructure. The researchers trained and evaluated logistic regression, decision tree, random forest, and K-nearest neighbor (KNN) classifiers on valid and malicious IoT traffic from 21 classes using IOT2023. Performance improvement began with label encoding and data cleansing. The random forest and decision tree classifiers achieved the highest accuracy of 99% for IoT traffic classification, notably for benign and common harmful behavior. The research shows that choosing the best features enhances model interpretability and performance quality. The ’uid, ’proto’, and ’duration’ features had the greatest impact among all other variables. Performance tests using metrics like ROC curve, the F1 score, precision, accuracy, and recall indicated good detection capabilities. The above mentioned study shows that ensemble learning and feature engineering are essential for IDS solutions in modern IoT contexts. The proposed methodology allows for deep learning and real-time deployment enhancements. Hybrid machine learning models improve IoT ecosystem safety in the face of rising security threats and provide operational direction for smart-domain IDS developments. Supplying IoT environments with hybrid machine learning systems is associated with challenges such as computational demands that can cause problems in terms of scalability and real-time response capabilities.
The Internet of Things (IoT) requires continuous intrusion detection, since network traffic generates large amounts of complex data. According to [
18], the PCM-RF hybrid technique selects characteristics using PCM and a random forest classifier to improve IoT intrusion detection system (IDS) performance. Traditional feature selection methods cannot manage high-dimensional, redundant, and irrelevant features that reduce IDS machine learning model performance. PCM removes unnecessary characteristics before entering the RF component to improve computational performance in the PCM-RF architecture. After feature ranking, RF evaluates the remaining inputs based on significance scores to select the best inputs for classification models. The system described above performed well compared to conventional methods on the CICIoT2023 dataset, which includes 34 network attacks. XGBoost detected 86% of targets and achieved 99.39% accuracy using selected features. This research shows how well the chosen features perform. The article referenced aboveshows PCM-RF can outperform standard detection methods for MitM, DDoS attacks, and overall attack identification. In restricted IoT networks, PCM filtering and RF ensembling yield high performance, system adaptability, and real-time intrusion detection. Previous research yielded a flexible hybrid feature selection strategy that improves IoT security categorization and the operational functionality of defense technology. Through effective adaptation, the proposed model advances intrusion detection. However, the PCM-RF hybrid feature selection mechanism shows limited adaptability to constantly shifting attack vectors, resulting in the deterioration of its effectiveness when deployed in the long term.
The system’s performance suffers from resource constraints in IoT devices, affecting its ability to detect intrusions in real time. Hackers use the expanding number of Internet of Things devices to increase their opportunities to launch large cyber assaults that endanger network protection and breach private information. A deep learning-based hybrid IDS was proposed in [
19] to detect and combat botnet intrusions in IoT networks. Due to the complexities in IoT traffic patterns, novel detection approaches are necessary, prompting the development of an IDS framework using CNN and LSTM components. The proposed model leverages the strengths of both CNN and LSTM architectures, using a CNN to extract spatial patterns in traffic data and LSTM to track temporal dependencies, allowing for detecting attack sequences across time periods. The system employs this combined structure to detect static network traffic patterns, along with dynamic behaviors, in IoT systems because accurate botnet recognition of stealthy and changing attacks is essential. The model obtains evaluation results via authentication with the Bot-IoT dataset, representing a benchmark resource for IoT botnet attack detection. Experimental findings show enhanced performance relative to standard machine learning approaches, with superior accuracy rates (greater than 99%) and improved precision, recall, and F1 scores. The system demonstrates a capacity for detecting false alarms effectively, which is an issue that IDSs normally struggle with. The proposed model adapts well to real-time IoT environments with restricted resource availability, in addition to exhibiting robust scalability features. The authors reported substantial progress in botnet detection methods, integrating deep learning architecture capabilities and solutions for single-model weaknesses. In addition, the abovementioned research provides an influential and intelligent IDS framework that uses hybrid deep learning to lead the way in securing future IoT networks against advanced botnet threats. However, the use of deep learning for botnet attack detection is associated with problems in terms of both scalability and real-time monitoring within IoT networks, which operate with constrained resources. Real-world deployment of deep learning models is difficult because they require large amounts of training data; however, the effective deployment of such data might prove difficult.
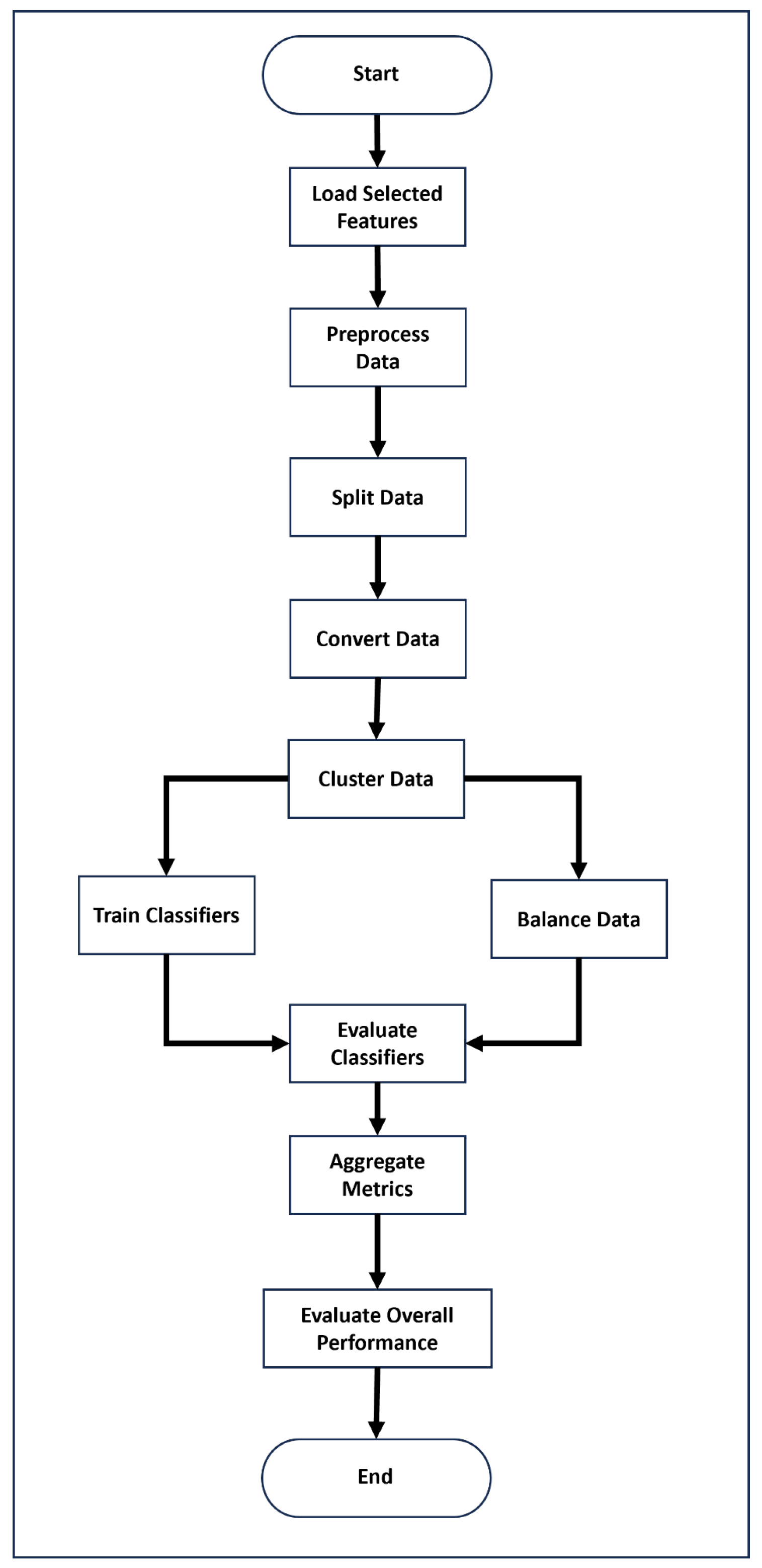
3. Design and Implementation of the Proposed CBC Method
The proposed CBC method is based on cluster classification of normal and abnormal traffic in the network. This technique aims to detect and classify unknown malicious traffic flow as an attack or benign traffic for a two-class classification. The enhanced CBC approach for intrusion detection involves oversampling unbalanced clusters, developing detection models, and selecting optimal models for intrusion detection and classification across eight clusters. To address the issue of unbalanced data, we employed the Synthetic Minority Over-sampling Technique (SMOTE). This method results in synthetic samples for the minority class to improve model performance and balance the dataset. The modelis also trained to detect eight types of classes, namely Mirai, Benign, Web, Brute force, DoS, Recon, DDoS, and Spoofing. The model is also trained to detect their subtypes. The clustering approach helps detect novel attacks because it calculates the similarity between new and malicious packets, then determines whether the new packet is virus-free or not. The features selected by SelectKBest are loaded from the dataset. They are further scaled and normalized. The dataset is divided into training and testing sets. Since the model is designed for both two-class and eight-class classification, eight distinct classes are mapped into these two classification categories. The distribution of data for the two-class and eight-class classifications is provided in the research about the benchmark dataset [
20]. K-mean clustering is applied using the NumClusters algorithm. For two-class classification, the data are mapped to eight clusters. For eight-class classification, the data are mapped to two clusters. After the dataset is mapped to clusters, the sampling method is applied for data balancing. Afterwards, the machine learning classifiers are applied to the balanced data. First, the performance of the individual classifier is evaluated. Then, the performance metrics are aggregated, and overall result evaluation is carried out using Equation (
1). Algorithm 1 shows the pseudo-code of the proposed CBC approach for a two-class classification problem. It starts with the loading of the dataset and the application of the oversampling method to balance the data to be used for the classification models. Similarly,
Figure 1 depicts a flow chart of the proposed cluster-based classification (CBC) method.
The Algorithm 1 also highlights the pseudo-code of the proposed CBC approach for eight-class classification. To visualize the clusters, PCA (principal component analysis) is applied to the dataset for dimensionality reduction.
Figure 2 shows the two-class cluster representation of attack and benign classifications using eight clusters.
Figure 3 presents the eight considered classes, namely Mirai, Benign, Web, Brute force, DoS, Recon, DDoS, and Spoofing, using a two-class cluster representation. Here, we consider the IoTCIC2023 dataset [
20].
| Algorithm 1 Feature Selection, Data Preprocessing, Clustering, and Classification Algorithm |
Require: SelectedFeatures, Data, NumClusters, SamplingMethod, Classifiers
Ensure: OverallPerformance
1: Load the selected features from the dataset
2: Scale and normalize the data
3: Encode categorical data (if any)
4: Scale and normalize the data
5: Split the data into training and testing sets
6: This step varies depending on the algorithm variant
7: Variant A: Convert data from 34 classes to 2 classes (attack and normal)
8: Variant B: Convert data from 34 classes to 8 classes (types of attacks)
9: Apply K-Means clustering with NumClusters clusters
10: for each cluster C in clusters do
11: Extract data points belonging to cluster C
12: Apply SamplingMethod to balance the data
13: for each classifier in Classifiers do
14: Train on the balanced data
15: Evaluate the performance of using metric
16: end for
17: end for
18: Aggregate the performance metrics for each cluster
19: Evaluate the overall performance using:
Step 11: Calculate Accuracy
20: Calculate the accuracy of the model’s predictions:
Step 12: Report Performance Metrics
21: Report additional performance metrics:
22: Precision:
23: Detection Rate:
24: F1 Score:
25: return OverallPerformance
|
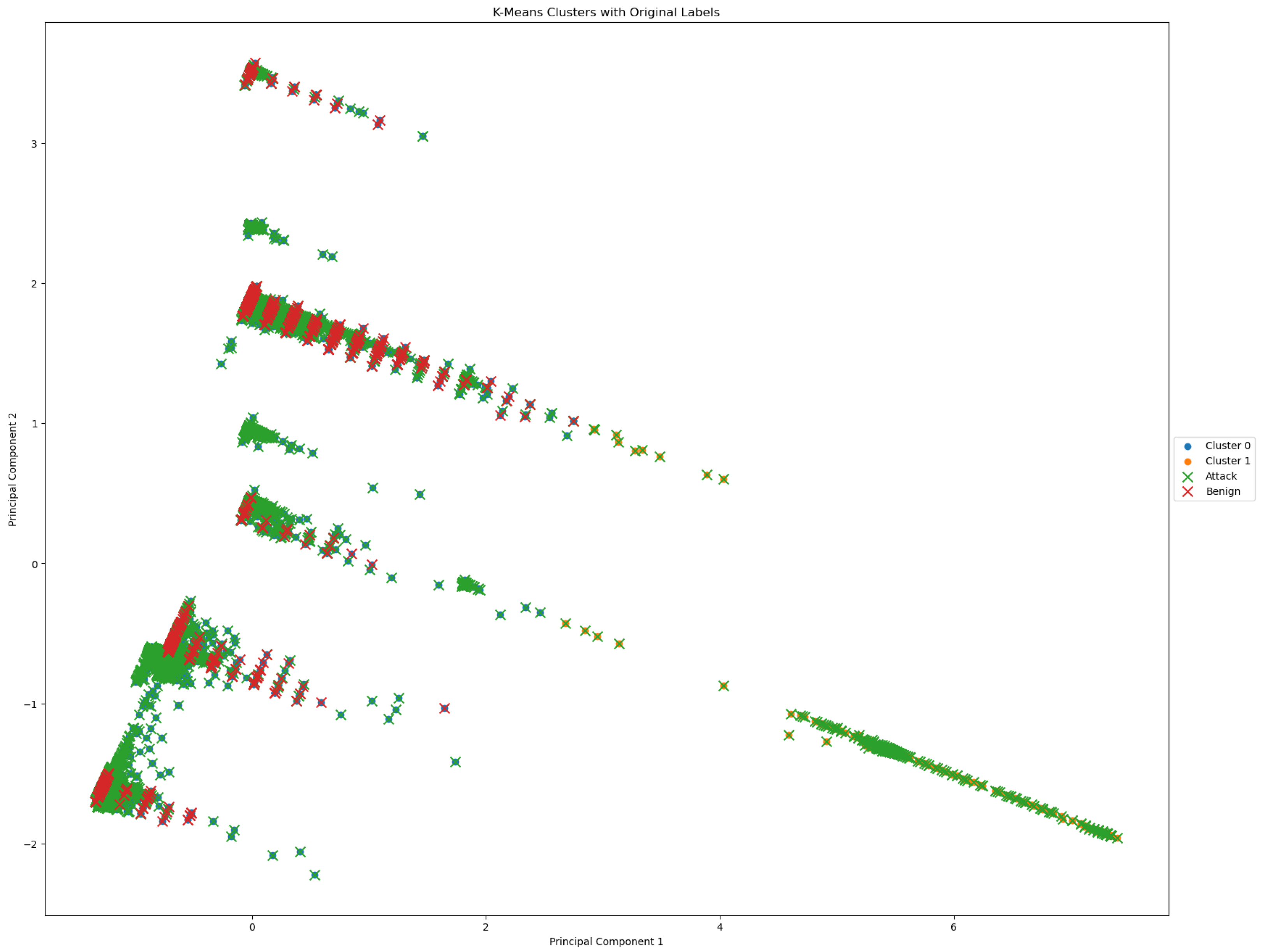
A scatter plot showing the cluster mapping for a binary classification problem with two clusters is shown in
Figure 4. Two primary components are used to visualize each data point. While the genuine classes vary slightly from the projected clusters in shape or color, the two clusters are represented by red and green colors. Areas of overlap or misclassifications in the feature space between the two classes are indicated by overlapping regions.
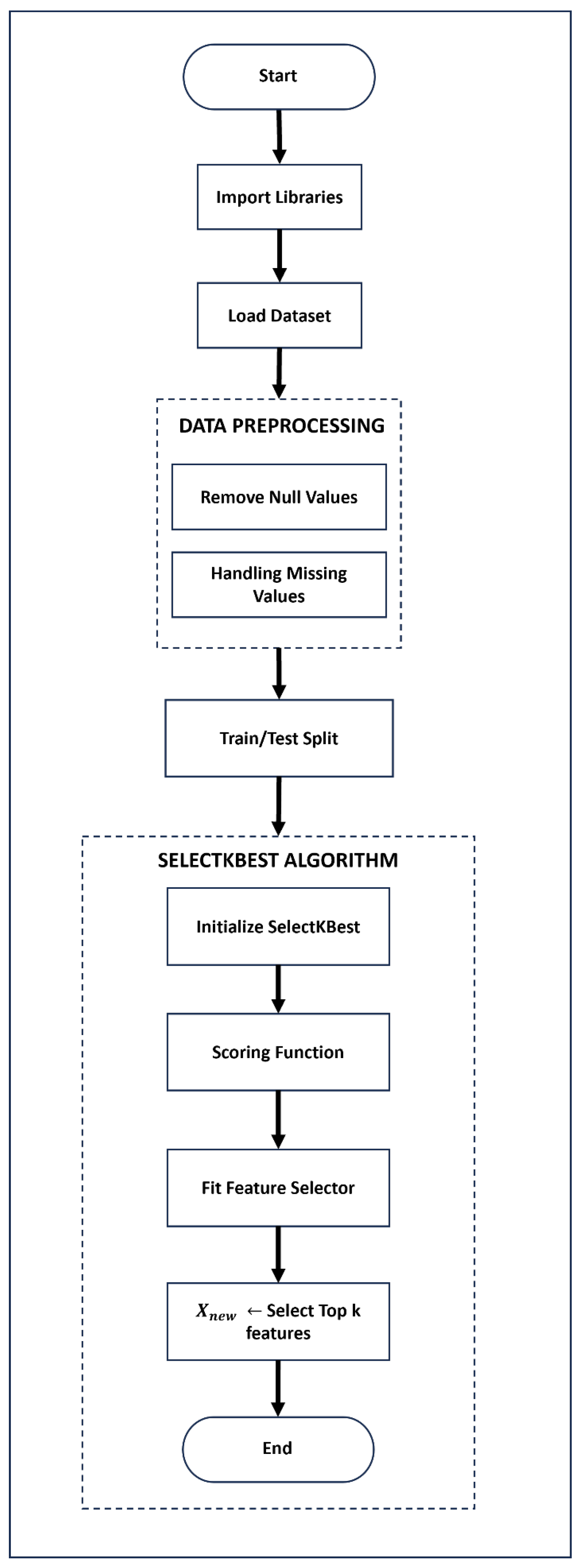
3.1. Feature Selection Using SelectKBest
Feature selection is a crucial step in improving the performance of a system. Researchers previously devised a method for feature selection using machine learning for intrusion detection systems in IoT networks, emphasizing effective feature selection to enhance detection accuracy. The authors utilized feature ranking and dimensionality reduction techniques to improve model performance and reduce computational overhead [
21]. For this purpose, the SelectKBest algorithm is employed, as it helps to select the optimal and robust features based on a scoring function. The top 10 selected features are UDP, psh_flag_number, rst_flag_number, TCP, Protocol Type, ack_flag_number, ack_count, ICMP, syn_flag_number, and fin_flag_number. After data loading, the necessary data pre-processing steps are performed, including the removal of null values and the handling of missing values. Afterwards, the SelectKBest algorithm is initialized with a scoring function, and it selects the top K features using Equation (
2). Algorithm 2 provides the pseudo code of the SelectBest algorithm used to select optimal features, and a flow diagram is presented in
Figure 5.
In this study, the SelectKBest feature selection method with Mutual Information (MI) is applied as the scoring function. The fact that MI captures both linear and non-linear dependencies between features and the target variable makes it appropriate for both two-class and eight-class classification tasks. It helps retain the most informative features, thereby improving model performance.
| Algorithm 2 SelectKBest Algorithm |
Require: X (Feature matrix), y (Target vector), k (Number of features to select)
Ensure: Xnew (Feature matrix with top k features)
1: Step 1: Data Preparation
2: Import necessary libraries
3: Load dataset X and target y
4: Remove rows with null values from X and corresponding entries from y
5: Fill missing values in X using an appropriate strategy (e.g., mean imputation)
6: Step 2: Feature Selection
7: Initialize the SelectKBest feature selector with a scoring function (e.g., for classification tasks) and k
8: Fit the feature selector to X and y
9: Transform X to select the top k features using the feature selector (Equation (2)):
10: return |
3.2. Data Organization and Preprocessing
Classification is performed using two-class and eight-class CBC; therefore, data organization differs for this approach [
2]. The types of attacks for two-class classification are listed in
Table 1. The labels and subtypes of for eight-class classification are shown in
Table 2.
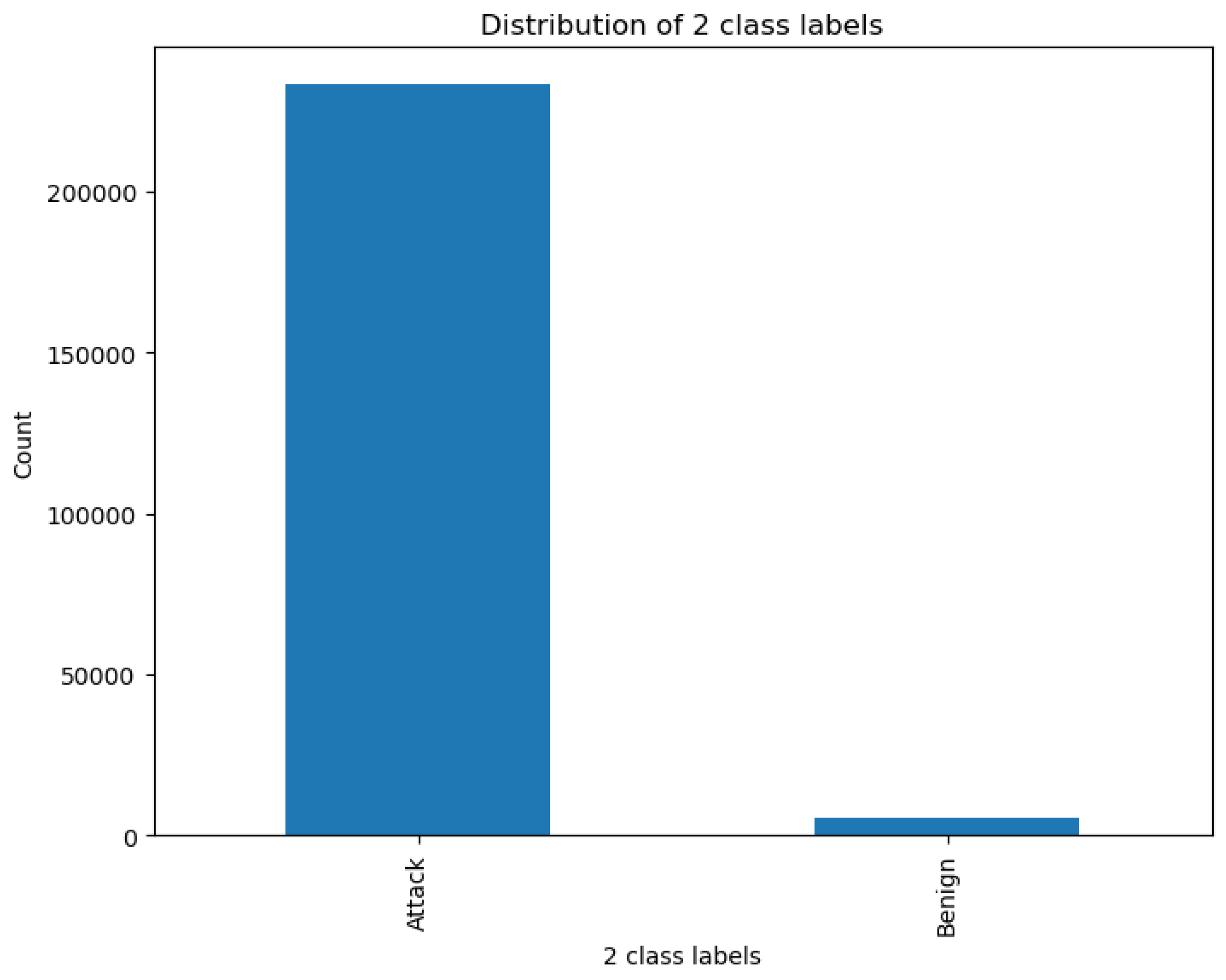
Figure 6 shows the two-class distribution of the attack and benign classes.
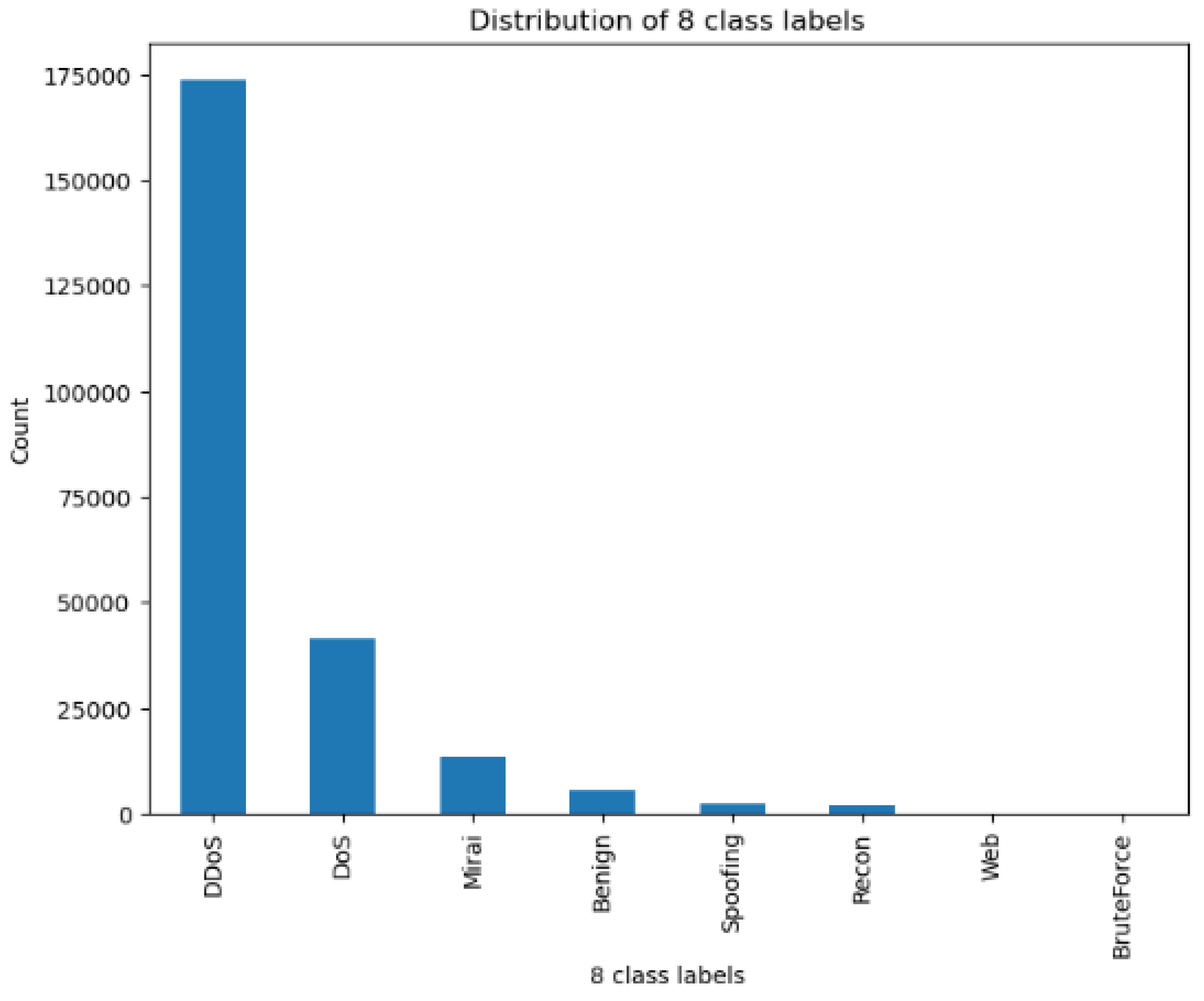
Figure 7 illustrates the eight-class distribution with the Mirai, Benign, Web, Brute force, DoS, Recon, DDoS, and Spoofing classes. The data are split with 70% designated for the training set and 30% designated for the test set for both classification problems.
3.3. Results and Analysis of the Proposed CBC Method
Accuracy, precision, detection rate, and F1 score are among the evaluation criteria used to assess the effectiveness of the suggested CBC technique. Machine learning algorithms are used to perform the comparison analysis: XGBoost, AdaBoost, KNN, and Random Forest. This section discusses the performance of the proposed CBC method. The evaluation of the proposed CBC approach is designed for two-class and eight-class classification using eight and two clusters, respectively.
Table 3 shows the results of eight-class classification represented in two clusters.
Table 4 shows the results of two-class classification mapped to eight clusters. Each cluster is trained on machine learning models, including XGBoost, AdaBoost, KNN, and Random Forest. The output of each model from each cluster is aggregated to observe the system’s overall performance.
Table 5 shows the unified results of eight-class classification with two clusters. KNN outperforms other methods, with an accuracy of 0.88.
Table 6 reports the collective performance of two-class classification with eight clusters. In the two-class classification, Random Forest performs better than other classifiers, yet it does not exhibit this advantage in the eight-class scenario. In the two-class classification scenario, the random forest classifier outperforms other models, highlighting its ability to handle binary classification problems effectively. The fact that its performance in the eight-class scenario was not as good does not undermine the effectiveness of the cluster-based classification (CBC) approach. The results show the capability of the CBC approach, which allows for the use of multiple classifiers tailored to the complexity of each cluster. The CBC method ensures that even when a single classifier, like Random Forest, does not dominate across all classes, the overall system maintains high accuracy and robustness by distributing the classification task across optimized clusters. This modularity enhances detection precision and better handles diverse and complex attack types. The eight-class classification scenario did not display any signs of unbalanced classes or any specific problems in this category. Random Forest achieved the highest accuracy of 0.9, higher than that achieved for eight-class classification.
Figure 8 and
Figure 9 illustrate present bar graphs for eight-class and two-class CBC, respectively.
3.4. Comparison with Existing State-of-the-Art Methods
The proposed approach implements the cluster-based classification methodology to detect novel and zero-day attacks. The feature vector is produced using the SelectKBest feature selection method with k = 10 because we selected means dynamically. Thus, 10 significant features are used to generate clusters, with an emphasis on the range and actions of IoT devices and the kinds of abnormalities frequently seen in these kinds of settings. The dataset proves why clustering methods such as k-means are ideal for identifying new or unidentified intrusions in Internet of Things networks. The capacity of the algorithm to distinguish between typical and unusual behaviors can be improved by applying k-means clustering to optimize feature sets that have been carefully chosen to include pertinent features like device type, communication frequency, and network traffic patterns. The clustering algorithm can more successfully group comparable data points and identify variations as possible risks thanks to this improvement, which reduces noise. Two classifications are presented: eight-class and two-class classification using two and eight clusters, respectively. For evaluation, four machine learning methods were employed: XGBoost, AdaBoost, KNN, and Random Forest. In the eight-class CBC scenario, KNN achieves the highest accuracy of 88.25%, whereas for the 2-class CBC scenario, Random Forest achieves the highest accuracy of 95.15%. All the methods achieve better results in the two-class CBC scenario, as it involves only two classes: Attack and Benign. However, an accuracy of less than 90% is achieved for all the models in the eight-class CBC scenario, as it involves eight different classes of attacks, with might have effects on performance.
Table 7 demonstrates the pivotal contributions of the CBC approach in overcoming the challenges associated with IoT attack detection and classification. Focusing on feature selection, clustering, and classification offers a comprehensive solution that surpasses using state-of-the-art techniques on various datasets. Its outstanding performance on the CICIoT2023 dataset highlights its potential as a reliable and scalable approach for protecting IoT networks from evolving threats. The results presented in the table also show that the cluster-based classification (CBC) approach performs slightly better on the UNSW-NB15 due to the dataset’s modern attack types, providing clearer separation. However, with its cleaner records, the NSL-KDD dataset still shows strong performance. These results are based on the diversity of datasets and attack types, since these datasets are based on normal network traffic and are not specific to IoT environments. The slightly lower scores are due to the complexity of separating overlapping attack patterns in UNSW-NB15, which includes diverse and modern threats not specific to IoT environments. NSL-KDD performs well because of its cleaner dataset but lacks the challenge of highly complex attacks, making it less reflective of real-world scenarios. Despite this, the CBC approach achieves strong results on both datasets, with accuracy exceeding 90%, proving its effectiveness in detecting different attacks. The results also show the model’s adaptability in distinguishing between subtle variations among multiple attack classes, showcasing the robustness of the CBC method, even in scenarios with varied data representations. Although few models have varying precision and recall values, the eight-class situation also shows their unique strengths in identifying specific attack types. The proposed CBC approach allows each model to perform optimally within its assigned cluster, contributing to balanced and effective overall detection across all classes, including eight-Class KNN and two-class RF.
4. Limitations
It is important to recognize and critically examine several shortcomings, even if our study on a hybrid intrusion model employing cluster-based classification for novel attack detection in the IoT is thorough and encouraging. The dataset used in this is the IoTCIC2023 dataset, and its characteristics and biases might have affected the study results. Due to differences in the network topology and attack strategy, the results may not apply to many IoT settings. However, for all datasets and for any attack situation, feature selection via SelectKBest with a fixed value of k = 10 may not be the best option. In some cases, model performance may vary due based on sensitivity to the considered features. One limitation of k-means and other clustering algorithms is that they work best within a limited set of situations involving data within a reasonable dimensionality and clusters with fairly uniform density. The types of assault in the dataset and their distribution have effects on clustering.
In the case of the classification of eight classes, this study considered eight predetermined types of assault. While this does not lead to new kinds of attacks in the IoT threat environment, new forms of attacks may appear in the future due to the ever-changing nature of this threat environment. The proposed technique performs well with eight classes mapped to two clusters. However, one potential disadvantage of the model is how well it adjusts to new and potential assault patterns. Frequently used assessment measures like F1 score, precision, recall, and accuracy may not sufficiently match the model’s performance in real-world circumstances. It should include other elements, like false positives/negatives and the resistance of the model to adversarial assaults. Due to differences in datasets, parameter setup, and algorithmic choice, the suggested CBC technique presents some difficulties when compared to current state-of-the-art techniques. Thus, generalizations regarding the superiority of the suggested method are impossible. Performance drops compared to the two-class scenario, since the eight-class classification job has more complexity and areas of possible compatibility in attack categories. It may be possible to improve the model’s performance if a better understanding of and support for multi-class categorization in an Internet of Things environment can be achieved. The consequences of the suggested model concerning security and deployment in the actual world should be thoroughly investigated. It is important to test the model regarding its response to malicious assaults and its ability to accurately detect attacks in changing IoT environments. The model’s scalability should be tested, especially for large-scale Internet of Things (IoT) installations. However, the applicability of such a model to Internet of Things devices with limited resources can be affected by various factors, including processing overhead and resource restrictions. Humans can find it challenging to understand model choices, especially when using complicated machine learning algorithms. Understanding how such results are achieved by the model is crucial to gain confidence and acceptance in real applications. However, if these constraints are tackled in future work, the suggested intrusion detection system might be more robust, flexible, and practical in real IoT contexts.
The cluster-based classification (CBC) approach effectively detects known and novel attacks by combining feature selection, clustering, and classification. However, some limitations must be considered. Scalability remains challenging, especially when deploying the model across large-scale IoT networks with dynamic and heterogeneous data sources. While the model shows good accuracy in IoT environments with the used dataset, its real-time detection capabilities in live traffic scenarios require further validation. The ability to identify previously unseen attacks is supported by clustering and anomaly detection mechanisms, but the model’s reliability depends on the diversity of training data. Moreover, the computational cost of clustering and classification processes, particularly during inference, raises concerns about practicality on resource-constrained IoT devices. Future work should explore lightweight versions of the CBC model, the optimization of real-time response, and thorough evaluation in real-world IoT settings to address these limitations effectively.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}