1. Introduction
Large Language Models (LLMs) are increasingly powering sophisticated applications, including conversational agents capable of remarkable fluency and comprehension [
1]. While these models excel when trained on vast datasets typical of high-resource languages like English, their performance often diminishes significantly for low-resource languages such as Greek [
2]. This disparity presents a major obstacle for deploying LLM-based solutions in contexts requiring high linguistic precision and domain-specific knowledge, particularly where under-represented languages are crucial. For instance, supporting migrants navigating complex administrative systems in Greece demands accurate and contextually appropriate communication in Greek, a capability many general-purpose LLMs currently lack due to data scarcity and limited optimization for the language’s unique grammatical and syntactical structures.
The challenge of effectively leveraging LLMs for specialized, low-resource language applications is central to efforts like the SALLY project, which aims to develop an intelligent chatbot providing essential information to migrants in Greece [
3]. In Greece, as in many other countries, public services, including those related to healthcare and residency, are predominantly provided in Greek and require some level of communication in the local language [
4]. This monolingual approach creates a significant structural barrier for migrants who often lack proficiency in the language. Therefore, migrants often face significant language and bureaucratic barriers, necessitating AI tools that can deliver precise, reliable, and empathetic support in Greek. However, the tendency for LLMs trained predominantly on English corpora to produce inaccurate or irrelevant responses in this specific context, highlights a critical gap. Existing benchmarks often focused on English or general tasks and providing insufficient guidance on LLM suitability for Greek-language migrant support, which underscores the need for targeted evaluations.
This paper undertakes a focused examination of LLM performance in the context of Greek, crucial for migrant integration in Greece. Moving beyond general-purpose benchmarks, the work centers on realistic, domain-relevant tasks reflecting the informational needs of migrants, such as understanding administrative procedures or interpreting official texts. The goal is to identify the most capable LLM for integration into the SALLY project’s framework, ensuring optimal performance before deployment. The evaluation involves both human assessments from experts dedicated to social impact and technological advancements, and structured LLM-based self-evaluation, offering a robust comparison of six State-of-the-Art models. Notably, the alignment between human and machine evaluations suggests that LLMs, when appropriately guided, can serve as effective preliminary evaluators in similar settings. By identifying Claude 3.7 Sonnet as the most suitable model for integration into the SALLY chatbot, the study provides practical insights for deploying LLMs in sensitive, linguistically complex applications, while also contributing to emerging methodologies for model selection in low-resource and socially impactful domains.
More specifically, the contributions of our work can be summarised as follows:
We present a comprehensive evaluation of State-of-the-Art LLMs on Greek-language tasks situated within real-world migrant integration scenarios. To the best of our knowledge, this is the first study to systematically assess the performance of LLMs in addressing the unique linguistic and contextual challenges faced by migrants in Greek-speaking environments, offering novel insights into their applicability for supporting migrant integration.
We introduce a dual-layered evaluation framework that combines human expert judgment with structured LLM self-evaluation, allowing for both qualitative depth and scalability.
We offer practical insights into model performance variability across different dimensions in migrant assistance, using four key task types: reading comprehension, summarization, grammar and syntax correction, and emotion detection.
We introduce an evaluation dimension that accounts for the emotional and psychosocial aspects of migrant communication, reflecting the need for responses that are not only accurate but also empathetic and contextually appropriate, an often overlooked factor in LLM assessment for socially sensitive domains.
We explore the viability of LLMs as evaluators themselves, highlighting their potential as low-cost, preliminary screening tools that show strong alignment with human expert assessments.
The rest of the paper is structured as follows:
Section 2 presents related work relevant to our research.
Section 3 describes the specifics of the methodology followed to assess the performance of LLMs.
Section 4 presents the results we obtained, while
Section 5 discusses the findings. Finally,
Section 6 concludes our work.
2. Background
The growing demand for context-aware, domain-specific AI systems has highlighted the limitations of general-purpose LLMs in low-resource language settings and sensitive application areas [
5]. While many LLMs perform well in English and high-resource languages, their effectiveness often deteriorates when applied to linguistically complex or under-represented languages such as Greek. This performance gap becomes particularly problematic in high-stakes domains like migrant support, where communication must be not only accurate but also empathetic and culturally appropriate.
The SALLY research initiative addresses this gap by developing an intelligent chatbot designed to assist Third Country Nationals (TCNs) with accessing information and navigating bureaucratic procedures in Greece. To meet this goal, SALLY integrates generative AI with structured data, domain knowledge, and emotional sensitivity, all operating in Greek. However, the success of such a system hinges on the ability to rigorously evaluate LLM performance under real-world conditions and linguistic constraints. More specifically, deploying generative chatbots in sensitive domains entails several practical and societal risks. These systems can produce inaccurate, misleading, or overly general responses, which may be problematic in high-stakes domains, such as legal, healthcare support or minority groups, such as migrants [
6,
7]. Furthermore, the data used to train such models often contain embedded social biases, potentially leading to culturally insensitive or discriminatory outputs [
8]. To address these concerns, SALLY has been designed as a domain-driven model. At its core, SALLY combines traditional information retrieval with generative AI through Retrieval-Augmented Generation (RAG), pulling data from the Greek Ministry of Migration and Asylum’s official website (
migration.gov.gr, accessed on 21 May 2025) to craft informed replies grounded in reliable sources, while the involvement of professionals and experts working directly with migrants allows for more controlled and reliable information delivery.
A defining feature of SALLY is its focus on Greek-language support, a necessity driven by Greece’s role as a primary entry point for TCNs. While some migrants rely on widely spoken languages like English, many require assistance in Greek to navigate administrative processes, access services, and engage with local communities, key steps toward integration. In addition, sociolinguistic studies in migratory contexts have highlighted the complex, multilingual realities that migrants navigate, often relying on a mix of native, host-country, and intermediary languages depending on the setting and purpose of communication [
9]. In designing SALLY, these considerations informed the emphasis on clarity, tone, and contextually appropriate host language use, aiming to reduce communicative barriers. To address this, we evaluated six LLMs to assess their ability to process and generate Greek content effectively, providing insights into their suitability for SALLY’s goals.
In the following, we situate our work within recent efforts in multilingual LLM benchmarking, domain-specific chatbot development, and LLM-based evaluation frameworks. These studies inform our methodological choices and underscore the novelty of our contribution to the field.
2.1. Multilingual LLM Evaluation
Evaluating LLMs is a challenging task across the research community, with humans typically being used as evaluators. One example is the Chatbot Arena platform [
10] which provides a novel, State-of-the-Art approach through crowdsourced human preferences in a pairwise comparison system. With over 1 million votes, it has become a credible, open-access benchmark in the LLM community, using robust statistical methods to ensure accurate model ranking. Similarly, the BOSS benchmark [
11] offers a more comprehensive evaluation suite for NLP models, extending beyond typical tasks like classification to assess models on diverse challenges, including those faced by models like LLaMA and GPT-3.5-turbo. Another study [
12] assesses four LLMs across five tasks relevant to undergraduate computer science students, providing qualitative and quantitative evaluations to measure their effectiveness. In [
13], the authors evaluate a GPT-powered chatbot trained on COVID-19 data, using TF-IDF, BERT, BioBERT, and USE to filter responses.
While existing evaluation frameworks, such as the Chatbot Arena and the BOSS benchmark, have advanced the assessment of LLMs, they remain mainly focused on high-resource languages and general-purpose scenarios. Similarly, task-specific studies, such as those evaluating LLMs for education or domain-restricted dialogue systems like COVID-19 chatbots, offer useful insights but often rely on predefined metrics or filtered content that may not reflect the linguistic and sociocultural complexity of real-world users. In contrast, the present study situates LLM evaluation within a socially impactful, low-resource context, emphasizing the Greek language and migrant integration needs. By designing tasks rooted in trusted governmental content and combining expert human ratings with LLM self-assessment, the study provides a more nuanced, application-driven perspective on model suitability. This dual evaluation strategy not only complements but also extends prior work by offering a methodology for assessing LLMs in under-represented languages and mission-critical domains, like migration.
2.2. LLMs as Evaluators
Studies have also explored the use of LLMs as evaluators. One study [
14] assesses LLM-generated reading comprehension materials by comparing them to human-written counterparts through both automated and human evaluations. The results show that LLM-generated materials are rated higher than human written ones, with similar findings irrespective of the type of the evaluation. Another study [
15] examines whether detailed prompting or simpler methods like model perplexity align better with human judgments in natural language generation tasks. This study introduces a taxonomy that encompasses four evaluation categories: content, relevance, integrity, and engagement—tested in multiple benchmark datasets. BIG-bench benchmark [
16] evaluates large language models across 204 diverse and challenging tasks, with human expert raters providing a baseline for performance comparison. Additionally, study [
17] compares the topic detection and naming capabilities of LLMs to human participants, revealing significant differences and emphasizing the need for more nuanced evaluation metrics. Study [
18] tests the sensitivity of LLMs as evaluators and shows that LLM-based evaluators exhibit confusion between evaluation aspects, and in [
19], researchers shed even more light on the limitations of LLMs as evaluators, demonstrating their bias towards their own generations. Finally, EvaluLLM [
20] is an application that allows users to set up, run, and review evaluations using LLMs, while [
21] introduces EvalGen, which is a tool that aids in evaluating LLM outputs by using LLMs to generate and suggest evaluation criteria and assertions.
Recent efforts have also examined the use of LLMs as evaluators of other LLMs. Truong et al. argue for human alignment in LLM evaluation pipelines, showing that model-generated evaluations can diverge from human judgment without careful design [
22]. In follow-up studies, Fazzinga et al. and Lee et al. emphasize how structured, context-aware evaluation frameworks, such as those used in ACME, a chatbot supporting migrant counseling in Europe, can improve both system transparency and user satisfaction [
23,
24]. These insights validate our methodological choice to compare human expert assessments with LLM self-evaluations under a shared rubric, a hybrid approach that enables scalable pre-screening while preserving human oversight. The present study introduces a human–machine evaluation framework tailored to Greek, a low-resource language, and rooted in migrant integration tasks. By applying a shared, expert-informed rubric to both human and LLM evaluators, the study not only confirms strong alignment between the two but also demonstrates how LLMs can reliably support preliminary evaluations in socially critical domains. This dual approach, grounded in realistic content, offers a model for ethically conscious LLM selection in under-represented language contexts.
2.3. Evaluation in Socially Sensitive and Low-Resource Contexts
Recent research has increasingly investigated the performance of LLMs in socially sensitive contexts, shedding light on their strengths and limitations in low-resource environments. Bubaš et al. and Lynch et al. conducted evaluations of conversational AIs and narrative generation using LLMs in under-resourced language contexts, including Croatian and sentiment analysis of ChatGPT (GPT 3.5/4) outputs, uncovering performance inconsistencies, translation artifacts, and reduced narrative fidelity [
25,
26]. These findings underline the importance of evaluating LLMs not just through general benchmarks but within the actual linguistic and cultural contexts they are intended to serve. Such concerns are especially acute in domains requiring high accuracy and sensitivity, such as migrant integration.
In parallel, domain-specific LLM evaluations have emerged as a critical area of study. Roumeliotis et al. reviewed performance characteristics of OpenAI models across different information domains, noting issues like hallucinations in medically oriented prompts [
27]. Similarly, Branda et al. demonstrated that chatbot designs tailored to public health emergencies improve trust and effectiveness, particularly when emotional support and factual accuracy are interdependent, a finding directly relevant to migrant support systems like ours, where regulatory clarity must be delivered with empathetic tone [
28].
All in all, the current landscape in assessing the performance of LLMs, emphasizes the necessity of tailored evaluation protocols for LLMs operating in low-resource, socially critical domains. Our work builds upon this foundation by introducing a Greek-language, domain-grounded benchmark for LLM evaluation in migrant support tasks and by validating an emotion-sensitive evaluation dimension that reflects real-world communication needs. In doing so, we address a documented gap in the literature and offer a replicable framework for assessing LLMs in linguistically and socially complex environments.
3. Method
This study evaluated six LLMs to determine their suitability for SALLY (see
Section 3.2 for more details). The evaluation utilized authentic content sourced from the Greek Ministry of Migration and Asylum website (
https://migration.gov.gr/), ensuring relevance to the real-world scenarios SALLY will encounter. Given Greek’s pivotal role in enabling migrants to access public services, employment, and social opportunities, coupled with its under-representation in LLM training datasets, the assessment prioritized Greek-language performance. To achieve a comprehensive analysis, we employed a dual methodology combining human evaluations with automated LLM self-evaluations, offering both practical and technical perspectives on model capabilities. The research protocol followed in this work has obtained an ethical approval from the Research Ethics Committee of the Aristotle University of Thessaloniki, Greece (101/23-10-2023, 272274/2023).
3.1. Evaluation Scope
The evaluation (
Figure 1) focused on four criteria, carefully selected to reflect SALLY’s core functionalities and the essential skills needed for effective migrant support. These criteria, along with their specific aims, are:
Reading Comprehension: Evaluates the LLM ability to interpret intricate official texts, such as asylum regulations, healthcare eligibility rules, or residency permit requirements, ensuring accurate responses to procedural queries [
29]. For instance, a prompt might ask, “What are the eligibility criteria for temporary residency?” based on a 300-word legal excerpt, testing precision in extracting key conditions.
Text Summarization: Assesses the capacity to distil verbose content into concise, actionable outputs, a critical skill for migrants overwhelmed by dense bureaucratic documents. An example task involved summarizing a 500-word asylum policy into a 50-word overview, preserving essentials like deadlines and contact points.
Grammar & Syntax: Measures linguistic accuracy and coherence in Greek, vital for credible and understandable responses. This included correcting errors in sentences like “She no have permit” to “She doesn’t have a permit”, focusing on verb conjugation, agreement, and preposition use.
Emotion Detection: Assesses the model’s ability to recognize and appropriately respond to emotional cues commonly found in migrant communications, such as anxiety, frustration or confusion [
24,
30]. For instance, a user message expressing distress over prolonged asylum procedures was used to test whether the system could generate a response that conveys understanding, reassurance, and emotional sensitivity. This task was assessed in collaboration with experts from the Center for Research and Technology Hellas (CERTH) and PRAXIS, an independent Civil Society Organisation in Greece, both with extensive experience in supporting vulnerable social groups and migration-related challenges.
The selection of these four evaluation criteria is grounded in empirical research and practical considerations for developing effective AI-powered support systems. The emphasis on reading comprehension and text summarization capabilities stems from the documented challenges in clinical decision support systems, where accurate interpretation and concise presentation of complex information have proven crucial for user trust and adoption [
29]. The inclusion of grammar and syntax as key criteria is particularly relevant for bilingual systems, as specialized LLMs have demonstrated superior performance in maintaining linguistic accuracy compared to general-purpose models. The focus on emotion detection is supported by recent research in the domain [
24], as well as in healthcare and crisis-response chatbots, where recognizing and responding to users’ emotional states, such as anxiety, stress, or frustration, has been shown to significantly enhance perceived helpfulness and trustworthiness [
31]. This highlights the importance of emotional intelligence and tone sensitivity in contexts requiring empathetic engagement. These criteria align with current best practices in LLM development, where specialized models designed with specific user needs in mind consistently outperform general-purpose LLMs across multiple evaluation metrics [
32].
In total, 42 tasks were curated by experts in the areas of social sciences and migration (PRAXIS), linguistics (ENL-AUTH) and technology (CSD-AUTH, CERTH) based on representative content from
migration.gov.gr. These tasks were designed to mirror potential real-world migrant inquiries and were distributed across the criteria: 12 for Reading Comprehension (e.g., interpreting legal texts), 18 for Grammar & Syntax (e.g., correcting flawed Greek sentences common in migrant communication), 6 for Summarization (e.g., condensing lengthy policy documents), and 6 for Emotion Detection (e.g., identifying emotional tones in user questions). For all evaluations, human and machine, responses generated for these tasks were scored on a standardized 1–5 Likert scale, where 1 indicated poor quality (inaccurate, unclear, irrelevant) and 5 denoted exceptional performance (accurate, clear, fully relevant, and well-formed). Example prompt templates are presented in
Table 1.
The evaluation took place outside the SALLY chatbot, using domain-relevant content and questions, rather than embedding them in the chatbot framework. This choice was primarily driven by the need to perform a clean, more controlled assessment of the core capabilities of LLMs without being influenced by chatbot-specific factors, such as user interface or system integration constraints. As the primary objective of the study is to assess and compare the LLMs’ capabilities for migrant-related contexts, rather than their performance within a specific end-to-end system, we emphasize the scientific question of model suitability over engineering considerations.
All prompts provided to the language models and the corresponding model-generated answers were in Greek, as the core objective of this study is to evaluate the performance of the LLMs specifically in the Greek language across the defined tasks. To enhance understanding for a broader audience, we provide an illustrative example of the texts and responses in English translation within the main body of the paper. Furthermore, all original Greek texts used in the evaluation, along with their English translations, are available for reference in Appendices
Appendix A and
Appendix B. For example, one of the instantiations of the Reading Comprehension template (
Table 1) was the following (the original questions were in Greek, but for clarity, we present equivalent text in English):
Given the following text, answer the question based only on the provided content.
Text: The accommodation structures provide temporary housing for third-country nationals or stateless persons who have applied for international protection in Greece. They also host family members of asylum seekers, unaccompanied or accompanied minors, and individuals belonging to vulnerable groups. These facilities ensure a stable living environment that meets basic living and social needs, as well as educational and learning requirements. Residents live under a regime of independent living while being required to follow internal regulations to maintain the smooth operation of the facility. Services provided include housing, food, legal and social information, psychological support, access to healthcare, personal hygiene supplies, clothing, Greek language lessons, and educational programs. Residents must leave the structures within 30 days of receiving a decision granting them international or subsidiary protection. For unaccompanied minors, this period starts upon reaching adulthood.
Question: How do people living in these accommodation structures experience their stay?
The prompt is then given to the six LLMs (
Section 3.2) in order to collect the responses and use them for human evaluation (
Section 3.3) and LLM self-evaluation (
Section 3.4). Example responses for this specific instantiation that are to be evaluated are given below (the evaluators are not aware of the sources of the responses).
Response 1: Under a regime of independent living.
Response 2: Those residing in the structures are in temporary accommodation and have the opportunity to become familiar with the host country, its rights and obligations. The accommodation structures provide a stable framework that meets not only the basic living and social needs of residents but also their educational and learning requirements. Residents live independently but must follow internal regulations to ensure the facility’s smooth operation. In the case of unaccompanied minors, their transition period starts upon reaching adulthood. Residents must leave the facility within 30 days of receiving a decision granting them protection.
Response 3: Residents in the structures live under a regime of independent living but are required to follow internal regulations for the smooth operation of the facility.
Response 4: Residents in the structures live under a regime of independent living and must adhere to internal regulations to ensure smooth operation of the facility.
Response 5: People residing in the structures live independently, covering their basic living and social needs as well as their educational and learning needs. They receive services such as housing, food, information on their rights and obligations, psychosocial support, access to healthcare, personal hygiene items, clothing, Greek language lessons, and access to education and skills development programs.
Response 6: According to the text, residents live under a regime of independent living but must follow internal regulations to ensure the smooth operation of the facility. The structures provide a stable framework that meets basic living and social needs, as well as educational and learning requirements. They receive services such as housing, food, information, psychosocial support, healthcare access, essential items, Greek language lessons, and educational programs.
3.2. Selected Large Language Models
Six LLMs were selected for evaluation based on their strong performance on the Chatbot Arena leaderboard [
10] at the time of the study and to represent diverse development approaches from leading organizations: (1) GPT-4o, (2) Claude 3.7 Sonnet, (3) Gemini 2.0 Flash, (4) DeepSeek V3, (5) Llama 3.3 70B, and (6) Grok 2. We focused on models that are either widely adopted, representative of different development philosophies, or accessible for academic and non-commercial use. Some, like GPT-4o and Claude 3.7, are already integrated into major platforms and widely tested in user-facing applications. Others, such as DeepSeek and Llama 3.3, offer open access, making them suitable for in-depth evaluation. We also considered variety in architecture and alignment strategies, from highly optimized proprietary systems to community-driven open-source models. The goal was to cover a spectrum of current LLM capabilities while keeping the evaluation grounded in realistic use cases.
To generate the content for evaluation, we interacted with each LLM via its official online playground using default configurations, since no adjustments were made to parameters like temperature or top-p. For each of the 42 tasks, we provided the relevant source text from
migration.gov.gr along with a standardized prompt structured to mimic a migrant query (e.g., “Based on this text, how can a migrant apply for asylum in Greece?” or “What are the required documents according to this passage?”). This procedure ensured fairness, as all models responded to the identical inputs and context. The resulting set of 42 generated responses per model formed the corpus that was subsequently assessed in both the human and machine evaluation phases.
3.3. Human Evaluation
The human evaluation was conducted by seventeen native Greek-speaking individuals (11 men, 6 women). Their demographics spanned various age groups (23.5% 18–24, 29.4% 25–34, 41.2% 35–44, 5.9% 45+). Regarding educational background, 52.9% were at the PhD level, 35.3% had postgraduate (Master’s level) education, and 11.8% had an undergraduate degree. These individuals were selected for their extensive practical experience assisting TCNs with asylum processes, residency, and integration challenges, granting them deep domain expertise and familiarity with the specific linguistic needs and common issues faced by migrants. Choosing Greek speakers for this stage was essential, as their command of the language allowed for a detailed assessment of the LLMs’ handling of grammar, syntax, and reading comprehension. Their expertise secured an accurate evaluation of the models to produce well-structured and meaningful responses, which is critical for ensuring that the chatbot works as expected before being used by migrants.
This evaluation phase was conducted with domain experts rather than members of the target migrant population due to practical considerations. The chatbot is still undergoing iterative refinement, and expert users, such as professionals working in migrant support services, were better positioned to provide structured, actionable feedback. Their familiarity with typical user needs and interaction patterns enabled a more focused assessment of the system’s functionality, linguistic clarity, and coverage of relevant topics. Engaging experts allowed for a more efficient and technically informed evaluation process, helping to identify and address early design issues before involving end users in subsequent testing rounds.
Prior to the evaluation, participants attended a one-hour briefing session. This session outlined SALLY’s objectives (delivering accurate, empathetic support in Greek) and provided detailed guidelines on interpreting and consistently applying the 1–5 Likert scale across the four criteria. Sample responses illustrating different quality levels (e.g., a score of 2 for a Reading Comprehension answer missing key details vs. a score of 5 for a fully accurate one) were reviewed to calibrate judgment.
The evaluation itself spanned two weeks. Participants worked independently in a controlled setting, assessing the LLM-generated responses in a blind setup—they were unaware of which LLM produced each output they reviewed. For each response, they compared it against the original prompt and source text (where applicable) and assigned a score from 1 to 5 based on the predefined criteria: checking factual accuracy and completeness (Reading Comprehension), evaluating conciseness and preservation of key information (Summarization), verifying grammatical correctness and coherence (Grammar & Syntax), and judging the appropriateness and sensitivity of tone (Sentiment Analysis). This rigorous, expert-driven process ensured the ratings reflected not only technical accuracy but also practical utility and linguistic appropriateness within the migrant support context.
3.4. Machine Evaluation
Concurrently with the human assessment, we conducted a machine-powered evaluation where each of the six LLMs evaluated the full set of generated responses, including those produced by itself and its peers. The primary goals were to explore the potential of LLMs as evaluators in this specialized, low-resource language domain and to determine the degree of alignment between machine and expert human judgments.
Critically, for this phase, we did not use a simplified, abstract prompt for evaluation. Instead, we provided each LLM with the exact same detailed, structured questionnaire that was given to the human evaluators. This questionnaire contained the overall instructions, the 1–5 Likert scale definition, specific guidance and considerations for scoring within each of the four criteria (Reading Comprehension, Summarization, Grammar & Syntax, Sentiment Analysis), and illustrative examples.
The process involved inputting the full questionnaire text, followed by the specific LLM-generated response to be assessed, directly into the respective LLM’s online playground interface. The LLM was then prompted to follow the instructions in the questionnaire to assign a numerical score (1–5) and, where supported by the model’s interface or output style, provide brief justifications for its score. This was repeated for all responses generated across all 42 tasks for all six models, resulting in over 250 machine-generated scores per evaluating model. This evaluation used the identical set of generated responses provided to the human experts.
This approach rigorously tested the LLMs’ ability to understand and apply a complex, multi-faceted evaluation rubric designed for humans, directly within the target language and domain. By maintaining methodological consistency with the human evaluation, we aimed to obtain directly comparable results and assess the viability of using LLMs for nuanced, criteria-based quality assessment as a potentially scalable and cost-effective preliminary step in LLM selection for demanding applications like SALLY.
3.5. Example
To further illustrate the evaluation methodology, we present an additional example about responses for the Grammar & Syntax task (the original questions were in Greek, but for clarity, we present equivalent text in English). In this task, the evaluators receive a sentence with grammar or syntax errors and need to evaluate LLM responses that try to fix the errors. For the generation of the responses, the third prompt in
Table 1 was used. As such, given the incorrect input sentence:
“Migrants are goes Greece and not finding any helps for paper and doctors is missing”, the following six responses are generated (as mentioned, the evaluators are not aware of the sources of the responses):
Response 1: Migrants going to Greece cannot find help with their documents or access medical care.
Response 2: Migrants who go to Greece are not able to find help about papers and doctors.
Response 3: Migrants who go to Greece cannot find help with their documents or medical care.
Response 4: Migrants are going to Greece but cannot find any help with their papers, and medical care is unavailable.
Response 5: Migrants going to Greece are not able to find help with their papers or medical attention.
Response 6: Migrants goes to Greece but don’t finding help with their documents and no doctor can be found.
The correct LLM response, based on both human evaluation and the LLM’s self-evaluation, is the first one, generated by Claude 3.7 Sonnet, which properly adjusts verb tense, prepositions, and sentence structure. The other responses still contain errors, such as incorrect verb forms (“are goes” instead of “are going”), incorrect pluralization (“helps” instead of “help”), and unnatural phrasing (“doctors is missing” instead of “doctors are unavailable”).
It is worth mentioning that the human evaluators assessed not only the quality of responses but also their correctness across the four key criteria. For Reading Comprehension and Text Summarization, they evaluated the accuracy by comparing the LLM-generated responses against the original texts, which were extracted from the official website of the Ministry of Asylum in Greece. Specifically, for Reading Comprehension, evaluators read the original text, reviewed the given question, and assessed whether the LLM’s response reflected the content. Similarly, for Text Summarization, they compared the generated summary against the full text to verify its accuracy and completeness. For Grammar and Syntax, correctness was assessed based on the clarity and meaning of the sentences, ensuring grammatical and syntactical accuracy. Lastly, for Sentiment Analysis, evaluators examined the sentiment identified by the LLM in a given text to determine whether it correctly captured the intended emotions.
4. Results
This section presents the evaluation outcomes for the six LLMs, assessing their suitability in the SALLY chatbot. The evaluation encompasses both human assessments and machine-powered self-evaluations by the LLMs, focusing on the four criteria.
In the human evaluation (
Table 2), Claude 3.7 Sonnet led across all criteria with consistent, high-quality performance. It achieved the highest score in Grammar & Syntax (
Mean = 4.78,
Standard
Deviation = 0.28), reflecting its ability to produce grammatically accurate and well-structured Greek responses with minimal variability, a critical asset for a bilingual chatbot serving migrants. Its Reading Comprehension score (M = 4.32, SD = 0.46) further highlights its strength in accurately interpreting complex texts, such as official migration documents. In Sentiment Analysis (M = 4.41, SD = 0.61), it demonstrated a superior capacity to detect and respond to emotional nuances, essential for empathetic interactions, while its Summarization score (M = 4.11, SD = 0.78) indicates effective distillation of information.
GPT-4o followed as a strong contender, delivering robust performance across most criteria. It scored well in Grammar & Syntax (M = 4.21, SD = 0.60) and Reading Comprehension (M = 4.05, SD = 0.68), suggesting reliability in generating accurate and comprehensible responses. However, its slightly higher standard deviations compared to Claude 3.7 Sonnet indicate less consistency, and its Sentiment Analysis score (M = 2.94, SD = 0.55) was notably lower, pointing to a limitation in emotional responsiveness. Gemini 2.0 Flash also performed admirably, particularly in Sentiment Analysis (M = 4.23, SD = 0.90), nearly matching Claude 3.7 Sonnet, though its Summarization score (M = 3.58, SD = 0.87) and higher variability suggest it struggles with consistency in condensing complex content.
Grok 2 outperformed Llama 3.3 70B in several areas, notably in Sentiment Analysis (M = 3.88, SD = 0.78), where it surpassed GPT-4o, and tied with DeepSeek V3 in Summarization (M = 3.64, SD = 1.05). However, its variability, especially in Summarization, indicates instability that could undermine its reliability for SALLY needs. DeepSeek V3 showed a surprising edge in Summarization (M = 3.70, SD = 0.68), outperforming both Grok 2 and Llama 3.3 70B, but its lower scores in Grammar & Syntax (M = 2.90, SD = 0.83) and Sentiment Analysis (M = 2.76, SD = 0.97), coupled with higher variability (e.g., SD = 0.90 in Reading Comprehension), suggest it is less suited for comprehensive tasks. Llama 3.3 70B consistently underperformed, with the lowest Grammar & Syntax score (M = 1.47, SD = 0.50) and significant variability in Reading Comprehension (M = 2.23, SD = 1.04), highlighting substantial stability issues that render it the weakest candidate.
The machine-powered evaluation (
Table 3), where each LLM assessed all responses including its own, mirrored the human rankings, reinforcing the reliability of self-evaluation as a preliminary tool. Claude 3.7 Sonnet again led with outstanding scores in Summarization (M = 4.83, SD = 0.40), Sentiment Analysis (M = 4.66, SD = 0.51), Grammar & Syntax (M = 4.60, SD = 0.38), and Reading Comprehension (M = 4.50, SD = 0.31), showcasing its ability to self-assess accurately and consistently. GPT-4o maintained strong performance, particularly in Reading Comprehension (M = 4.41, SD = 0.49) and Summarization (M = 4.00, SD = 0.00), though its Sentiment Analysis score (M = 3.33, SD = 0.81) remained a weak point. Gemini 2.0 Flash excelled in Summarization (M = 4.33, SD = 0.51) and showed solid Sentiment Analysis (M = 4.16, SD = 0.40), aligning closely with its human evaluation results.
Grok 2 performed well in Summarization (M = 4.16, SD = 0.75) and Sentiment Analysis (M = 3.83, SD = 0.40), but its Grammar & Syntax score (M = 3.49, SD = 0.34) trailed the top models. DeepSeek V3 scored moderately in Reading Comprehension (M = 3.58, SD = 0.49) and Summarization (M = 3.50, SD = 0.54), but its lower Grammar & Syntax (M = 2.82, SD = 0.40) and Sentiment Analysis (M = 3.00, SD = 0.63) scores indicate limitations. Llama 3.3 70B ranked lowest, with poor performance in Reading Comprehension (M = 1.91, SD = 0.80) and Grammar & Syntax (M = 1.72, SD = 0.39), despite a decent Sentiment Analysis score (M = 3.83, SD = 0.75), underscoring its challenges in producing reliable outputs.
A comparison of average performance across the four criteria, illustrated in
Figure 2, reveals identical rankings between human and machine evaluations, suggesting that LLM self-evaluation could serve as an effective preliminary assessment method. This alignment is supported by statistical analyses: Kendall’s W
confirmed significant agreement among the 17 human evaluators, while a Mantel–Haenszel test
indicated a linear association between human and machine scores, with higher LLM ratings corresponding to higher human ratings.
Both human and machine evaluations rated Claude 3.7 Sonnet response highest for its precise correction of verb tense, prepositions, and sentence structure, while Llama 3.3 70B response retained errors (e.g., “goes” and “don’t finding”), reflecting its lower performance. These results collectively position Claude 3.7 Sonnet as the standout model, with GPT-4o and Gemini 2.0 Flash as viable alternatives, while highlighting the limitations of Llama 3.3 70B, DeepSeek V3, and Grok 2 for SALLY requirements.
5. Discussion
The evaluation of the six LLMs offers critical insights into selecting the most effective model for the SALLY chatbot. Claude 3.7 Sonnet outperformed its peers across all four criteria, making it the standout candidate. Its exceptional proficiency in Grammar & Syntax is particularly vital for a bilingual chatbot, ensuring clear and credible communication in Greek, a language under-represented in many LLM training datasets. Additionally, its strong Reading Comprehension ensures accurate interpretation of complex official texts, while its adeptness in Sentiment Analysis supports empathetic responses tailored to migrants’ emotional needs. Gemini 2.0 Flash also demonstrated notable strengths, particularly in Sentiment Analysis and Grammar & Syntax, positioning it as a viable alternative with well-rounded capabilities suited to diverse tasks. GPT-4o, while robust in most areas, showed a comparative weakness in Sentiment Analysis, though its overall performance remains competitive.
In contrast, Grok 2, DeepSeek V3, and Llama 3.3 70B exhibited more limited suitability for SALLY requirements. Grok 2 showed promise in Sentiment Analysis but lacked consistency across other criteria, suggesting it may not reliably meet the chatbot’s multifaceted demands. DeepSeek V3 excelled in Summarization yet faltered in Grammar & Syntax and Sentiment Analysis, limiting its versatility. Llama 3.3 70B consistently underperformed, particularly in Grammar & Syntax, with significant variability that undermines its reliability for a migrant support application.
Based on these findings, Claude 3.7 Sonnet emerges as the leading choice for integration into SALLY, with Gemini 2.0 Flash and GPT-4o as potential alternatives. The final decision will hinge on balancing these performance outcomes with practical considerations such as computational resources, cost, and ease of integration. Further testing, specifically targeting Greek-language proficiency, may refine this selection to ensure optimal performance in SALLY unique context.
A key observation from this study is the striking alignment between human evaluations and the LLMs’ self-assessments. This consistency suggests that machine-powered evaluation could serve as a valuable preliminary tool, particularly for projects like SALLY that operate in low-resource languages and domain-specific settings. Such an approach could streamline initial model screening, reducing time and resource demands while providing a reliable proxy for human judgment. However, its broader applicability requires further exploration across diverse tasks and languages to confirm its robustness.
Finally, the reliance on evaluations made by experts familiar with asylum processes, residency, and integration challenges, as well as with the linguistic needs and common issues faced by migrants was a deliberate and effective choice for this phase, leveraging their deep familiarity with migrant inquiries and Greek language nuances to assess technical accuracy and practical relevance. This mirrors professional practices in language quality assessment, where native speakers with domain expertise provide authoritative baselines. Yet, this represents only an initial step. Future evaluations plan to involve migrants, the chatbot target users, to gauge usability, effectiveness, and cultural sensitivity from their perspective. This two-phase strategy ensures both linguistic precision and user-centered design, critical for SALLY success.
6. Conclusions
This paper presents an evaluation of several LLMs to explore their suitability for the SALLY chatbot, an AI agent intended to support migrant integration by providing information in Greek. Greek is considered an under-resourced language in this context, and the application domain is socially sensitive. The analysis, which combined human expert assessments with structured LLM self-evaluations, indicated that Claude 3.7 Sonnet performed strongly, with Gemini 2.0 Flash also showing notable capabilities for addressing the linguistic and informational needs relevant to this application.
This research sought to explore several aspects that may contribute to the field. The study attempted a systematic evaluation of LLM performance specifically for the Greek language within the domain of migrant integration support, aiming to address linguistic and contextual challenges faced by migrants. A dual-layered evaluation framework was employed, combining human expert judgment with structured LLM self-evaluation. The application of this hybrid methodology was explored for a low-resource language and a socially impactful field. An aspect examined in this work was an emotion detection dimension, designed with consideration for the psychosocial complexities of migrant communication. This dimension assessed an LLM’s capacity to recognize and respond to certain emotional cues, such as anxiety or frustration, which can be an important factor in developing AI for specific user groups. The research also aimed to complement generic benchmarks by grounding the LLM evaluation in domain-relevant tasks derived from official governmental sources, which may enhance the potential applicability of the findings to real-world scenarios.
This research offers several findings and methodological considerations. A benchmark of selected LLMs on Greek-language tasks, situated within migrant integration scenarios, is provided, offering insights into their applicability. The development and application of the hybrid evaluation framework are detailed, which integrated human expertise with the analytical capabilities of LLMs, guided by a shared, expert-informed rubric. The study also presents insights into the performance variability of these LLMs across four task types relevant to migrant assistance: reading comprehension of official texts, summarization of information, grammar and syntax correction in Greek, and emotion detection. A notable finding is the indication of LLM potential as preliminary evaluators in specialized contexts. The results showed a strong alignment between LLM self-assessments and human expert judgments when LLMs were provided with detailed, human-designed rubrics, suggesting their utility as a scalable screening tool. Empirical evidence is also presented indicating that carefully designed prompts, based on potential real-world migrant interactions and policy documents, may contribute to improving the faithfulness and contextual appropriateness of LLM-generated outputs in such applications.
The deployment of AI in sensitive areas such as migrant support calls for careful attention to ethical considerations, including data privacy, bias mitigation, and transparency concerning AI capabilities and limitations. Therefore, the pre-integration testing conducted in this study is an important step for assessing LLM accuracy and attempting to minimize risks before real-world application. The selected LLM, Claude 3.7 Sonnet, would require further fine-tuning and integration with moderation and fact-checking mechanisms to support the delivery of responses that are accurate, equitable, and trustworthy.
While this study focused on the Greek language due to its role in accessing services and integration processes in Greece, and acknowledging the multilingual capabilities of modern LLMs, practical constraints limited the inclusion of a broader range of languages in this phase. Future work could consider the integration of native language support, guided by user feedback and evaluation. It is also important to note that the LLM landscape evolves rapidly; these findings represent capabilities at the time of testing. Thus, adaptable evaluation frameworks and custom evaluations tailored to specific linguistic and contextual demands, such as those explored here, can be valuable for specialized projects. This work aimed to address a gap in the literature by offering a framework for assessing LLMs in linguistically and socially complex environments, potentially contributing to the development of effective and ethically considered AI solutions for migrant support and similar domains.
Author Contributions
Conceptualization, G.M.; methodology, G.M. and S.T.; software, A.T., S.T., C.B. and K.M.; validation, K.M., M.P., M.K., E.D. and T.M.; formal analysis, A.T., S.T. and C.B.; investigation, A.T., S.T. and C.B.; visualization, A.T., S.T. and K.M.; writing—original draft preparation, A.T. and S.T.; writing—review and editing, A.T., S.T., C.B., K.M., M.P., M.K., E.D., T.M., S.V. and G.M.; supervision, T.M., S.V. and G.M.; project administration, G.M.; funding acquisition, G.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research project is carried out within the framework of the National Recovery and Resilience Plan Greece 2.0, funded by the European Union—NextGenerationEU (Implementation body: HFRI, Project Number: 15010).
Institutional Review Board Statement
This work has obtained an ethical approval from the Research Ethics Committee of the Aristotle University of Thessaloniki, Greece (101/23-10-2023, 272274/2023).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author(s).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LLM | Large Language Model |
| TCN | Third Country National |
| RAG | Retrieval-Augmented Generation |
| OWL | Web Ontology Language |
| RDF | Resource Description Framework |
| NLP | Natural Language Processing |
| QA | Question Answering |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| BERT | Bidirectional Encoder Representations from Transformers |
| BioBERT | Biomedical Bidirectional Encoder Representations from Transformers |
| USE | Universal Sentence Encoder |
| M | Mean |
| SD | Standard Deviation |
Appendix A
This appendix includes the original Greek texts.
Appendix A.1. Reading Comprehension
Appendix A.1.1. Text
Oι δομές φιλοξενίας παρέχουν προσωρινή στέγαση σε υπηκόους τρίτων χωρών ή ανιθαγενείς που έχουν υποβάλει αίτηση διεθνούς προστασίας στην Ελλάδα. Φιλοξενούν επίσης μέλη οικογενειών αιτούντων άσυλο, ασυνόδευτους ή συνοδευόμενους ανηλίκους, και άτομα που ανήκουν σε ευάλωτες ομάδες. Aυτές οι εγκαταστάσεις διασφαλίζουν ένα σταθερό περιβάλλον διαβίωσης που καλύπτει βασικές ανάγκες διαβίωσης και κοινωνικές ανάγκες, καθώς και εκπαιδευτικές και μαθησιακές απαιτήσεις. Oι διαμένοντες ζουν υπό καθεστώς ανεξάρτητης διαβίωσης, ενώ απαιτείται να ακολουθούν εσωτερικούς κανονισμούς για τη διατήρηση της ομαλής λειτουργίας της δομής. Oι παρεχόμενες υπηρεσίες περιλαμβάνουν στέγαση, τροφή, νομικές και κοινωνικές πληροφορίες, ψυχολογική υποστήριξη, πρόσβαση στην υγειονομική περίθαλψη, είδη προσωπικής υγιεινής, ρουχισμό, μαθήματα ελληνικής γλώσσας και εκπαιδευτικά προγράμματα. Oι διαμένοντες πρέπει να εγκαταλείψουν τις δομές εντός 30 ημερών από την παραλαβή απόφασης που τους χορηγεί διεθνή ή επικουρική προστασία. Για τους ασυνόδευτους ανηλίκους, αυτή η περίοδος ξεκινά με την ενηλικίωσή τους.
Appendix A.1.2. Question
Πώς βιώνουν τη διαμονή τους οι άνθρωποι που ζουν σε αυτές τις δομές φιλοξενίας;
Appendix A.1.3. Responses
Response 1 Υπό καθεστώς ανεξάρτητης διαβίωσης.
Response 2 Όσοι διαμένουν στις δομές βρίσκονται σε προσωρινή φιλοξενία και έχουν την ευκαιρία να εξοικειωθούν με τη χώρα υποδοχής, τα δικαιώματα και τις υποχρεώσεις τους. Oι δομές φιλοξενίας παρέχουν ένα σταθερό πλαίσιο που καλύπτει όχι μόνο τις βασικές ανάγκες διαβίωσης και κοινωνικές ανάγκες των διαμενόντων αλλά και τις εκπαιδευτικές και μαθησιακές τους απαιτήσεις. Oι διαμένοντες ζουν ανεξάρτητα αλλά πρέπει να ακολουθούν εσωτερικούς κανονισμούς για να διασφαλίζεται η ομαλή λειτουργία της δομής. Στην περίπτωση των ασυνόδευτων ανηλίκων, η μεταβατική τους περίοδος ξεκινά με την ενηλικίωσή τους. Oι διαμένοντες πρέπει να εγκαταλείψουν τη δομή εντός 30 ημερών από την παραλαβή απόφασης που τους χορηγεί προστασία.
Response 3 Oι διαμένοντες στις δομές ζουν υπό καθεστώς ανεξάρτητης διαβίωσης αλλά απαιτείται να ακολουθούν εσωτερικούς κανονισμούς για την ομαλή λειτουργία της δομής.
Response 4 Oι διαμένοντες στις δομές ζουν υπό καθεστώς ανεξάρτητης διαβίωσης και πρέπει να τηρούν τους εσωτερικούς κανονισμούς για να διασφαλίζεται η ομαλή λειτουργία της δομής.
Response 5 Oι άνθρωποι που διαμένουν στις δομές ζουν ανεξάρτητα, καλύπτοντας τις βασικές τους ανάγκες διαβίωσης και κοινωνικές ανάγκες, καθώς και τις εκπαιδευτικές και μαθησιακές τους ανάγκες. Λαμβάνουν υπηρεσίες όπως στέγαση, τροφή, πληροφορίες για τα δικαιώματα και τις υποχρεώσεις τους, ψυχοκοινωνική υποστήριξη, πρόσβαση στην υγειονομική περίθαλψη, είδη προσωπικής υγιεινής, ρουχισμό, μαθήματα ελληνικής γλώσσας και πρόσβαση σε προγράμματα εκπαίδευσης και ανάπτυξης δεξιοτήτων.
Response 6 Σύμφωνα με το κείμενο, οι διαμένοντες ζουν υπό καθεστώς ανεξάρτητης διαβίωσης αλλά πρέπει να ακολουθούν εσωτερικούς κανονισμούς για να διασφαλίζεται η ομαλή λειτουργία της δομής. Oι δομές παρέχουν ένα σταθερό πλαίσιο που καλύπτει βασικές ανάγκες διαβίωσης και κοινωνικές ανάγκες, καθώς και εκπαιδευτικές και μαθησιακές απαιτήσεις. Λαμβάνουν υπηρεσίες όπως στέγαση, τροφή, πληροφορίες, ψυχοκοινωνική υποστήριξη, πρόσβαση στην υγειονομική περίθαλψη, είδη πρώτης ανάγκης, μαθήματα ελληνικής γλώσσας και εκπαιδευτικά προγράμματα.
Appendix A.2. Text Summarization
Appendix A.2.1. Text
H πρόσβαση στη διαδικασία διεθνούς προστασίας είναι δωρεάν και απεριόριστη. Κάθε υπήκοος τρίτης χώρας ή ανιθαγενής έχει το δικαίωμα να υποβάλει αίτηση διεθνούς προστασίας. H αρχική αίτηση στα σύνορα υποβάλλεται στα Κέντρα Υποδοχής και Ταυτοποίησης (ΚΥΤ) στα νησιά Λέσβος, Χίος, Σάμος, Κως και Λέρος, καθώς και στο σημείο ελέγχου του Έβρου. Εάν βρίσκεστε στην ενδοχώρα, μπορείτε να υποβάλετε αρχική αίτηση στα Κέντρα Υποδοχής και Ταυτοποίησης στη Μαλακάσα και τα Διαβατά. H αίτηση διεθνούς προστασίας υποβάλλεται αυτοπροσώπως. Εάν δεν έχετε καταγραφεί, μπορείτε να κλείσετε ραντεβού μέσω της ακόλουθης ηλεκτρονικής πλατφόρμας για να καταγραφείτε αυτοπροσώπως στα Κέντρα Υποδοχής και Ταυτοποίησης στη Μαλακάσα ή τα Διαβατά. Εάν έχετε εισέλθει στη χώρα χωρίς νόμιμες διατυπώσεις ή διαμένετε στην Ελλάδα χωρίς νόμιμες διατυπώσεις, θα μεταφερθείτε σε Κέντρο Υποδοχής και Ταυτοποίησης. Εάν δεν διαθέτετε έγγραφο δημόσιας αρχής που να αποδεικνύει την εθνικότητα και την ταυτότητά σας, θα υποβληθείτε σε διαδικασίες υποδοχής και ταυτοποίησης. Θα απαιτηθεί να παραμείνετε στο Κέντρο για όσο διάστημα χρειαστεί για την επεξεργασία της αίτησής σας, υπό την προϋπόθεση ότι αυτή η περίοδος δεν υπερβαίνει τις είκοσι πέντε (25) ημέρες. Σε ορισμένες περιπτώσεις (π.χ., εάν υποβάλετε αίτηση στα σύνορα σε ζώνες διέλευσης λιμένων ή αεροδρομίων, εάν εξαπατήσετε τις αρχές παρέχοντας ψευδείς πληροφορίες, εάν κρατείστε, και σε άλλες περιπτώσεις που ορίζονται από το νόμο), η αίτησή σας θα εξεταστεί κατά προτεραιότητα. Συνολικά, η εξέταση της αίτησής σας μπορεί να διαρκέσει από είκοσι (20) ημέρες έως έξι (6) μήνες, ανάλογα με την περίπτωσή σας. H πλήρης καταγραφή της αίτησής σας περιλαμβάνει στοιχεία ταυτοποίησης, τη χώρα καταγωγής σας, τα ονόματα του πατέρα, της μητέρας, του/της συζύγου και των παιδιών σας, τη διεύθυνση ηλεκτρονικού ταχυδρομείου σας εάν υπάρχει, βιομετρικά δεδομένα ταυτοποίησης, πλήρη περιγραφή των λόγων για τους οποίους ζητάτε διεθνή προστασία, τη διεύθυνση κατοικίας ή διαμονής σας, τη γλώσσα στην οποία επιθυμείτε να εξεταστεί η αίτησή σας και, εάν το επιθυμείτε, τον ορισμό εξουσιοδοτημένου αντιπροσώπου. Όταν υποβάλλετε την αίτηση, ένας διερμηνέας θα σας βοηθήσει σε μια γλώσσα που καταλαβαίνετε για να διευκολύνει την επικοινωνία με το προσωπικό της Υπηρεσίας Aσύλου. Όταν υποβάλλετε την αίτησή σας, πρέπει να απαντήσετε στις ερωτήσεις του προσωπικού με απόλυτη ειλικρίνεια. Εάν παρέχετε ψευδείς πληροφορίες ή ισχυρισμούς, αυτό θα επηρεάσει αρνητικά την αξιολόγηση της αίτησής σας.
Appendix A.2.2. Summaries
Summary 1 H πρόσβαση στη διαδικασία διεθνούς προστασίας στην Ελλάδα είναι δωρεάν. H αρχική αίτηση μπορεί να υποβληθεί στα Κέντρα Υποδοχής και Ταυτοποίησης ή μέσω ηλεκτρονικής πλατφόρμας. H διαδικασία ταυτοποίησης είναι υποχρεωτική, εκτός από λίγες εξαιρέσεις. H αίτηση περιλαμβάνει προσωπικά στοιχεία ταυτοποίησης, λόγους για την αναζήτηση διεθνούς προστασίας και την προτιμώμενη γλώσσα επικοινωνίας. Ένας διερμηνέας βοηθά στην επικοινωνία. H καταγραφή πρέπει να είναι αληθής, καθώς ψευδείς πληροφορίες ή ισχυρισμοί μπορούν να επηρεάσουν αρνητικά την απόφαση επί της αίτησης. O χρόνος επεξεργασίας της αίτησης κυμαίνεται από 20 ημέρες έως 6 μήνες.
Summary 2 Aυτό το κείμενο εξηγεί τη διαδικασία υποβολής αίτησης για διεθνή προστασία στην Ελλάδα, η οποία είναι δωρεάν και ανοιχτή σε όλους τους υπηκόους τρίτων χωρών ή ανιθαγενείς. H αρχική αίτηση για διεθνή προστασία πρέπει να υποβληθεί στα Κέντρα Υποδοχής και Ταυτοποίησης στα νησιά Λέσβος, Χίος, Σάμος, Κως και Λέρος, καθώς και στη δομή του Έβρου. Εάν βρίσκεστε ήδη στην ενδοχώρα, μπορείτε να υποβάλετε την αρχική αίτηση στα Κέντρα Υποδοχής και Ταυτοποίησης στη Μαλακάσα και τα Διαβατά. H αίτηση για διεθνή προστασία πρέπει να υποβληθεί αυτοπροσώπως. Εάν δεν έχετε ακόμη καταγραφεί, μπορείτε να κλείσετε ραντεβού στην ακόλουθη ηλεκτρονική πλατφόρμα για να καταγραφείτε στα Κέντρα Υποδοχής και Ταυτοποίησης στη Μαλακάσα ή τα Διαβατά. Εάν εισέλθετε στη χώρα χωρίς νόμιμα έγγραφα ή παραμείνετε στην Ελλάδα χωρίς νόμιμα έγγραφα, θα μεταφερθείτε σε Κέντρο Υποδοχής και Ταυτοποίησης.
Summary 3 Το άρθρο περιγράφει τη διαδικασία υποβολής αίτησης για διεθνή προστασία στην Ελλάδα. Εξηγεί ότι οι υπήκοοι τρίτων χωρών ή οι ανιθαγενείς που επιθυμούν να ζητήσουν προστασία στην Ελλάδα μπορούν να υποβάλουν αίτηση διεθνούς προστασίας απευθείας στα σύνορα, στα αεροδρόμια, στο λιμάνι εισόδου ή στα γραφεία της Υπηρεσίας Aσύλου. H αίτηση υποβάλλεται δωρεάν και χωρίς την ανάγκη νομικής εκπροσώπησης. Το άρθρο αναφέρει επίσης ότι οι αιτούντες που υποβάλλουν την αίτησή τους στα σύνορα ή στο αεροδρόμιο θα μεταφερθούν σε Κέντρο Υποδοχής και Ταυτοποίησης, όπου θα καταγραφούν και η αίτησή τους θα εξεταστεί. Εάν οι αιτούντες δεν διαθέτουν έγκυρα ταξιδιωτικά έγγραφα ή έχουν εισέλθει παράτυπα στη χώρα, θα μεταφερθούν σε Κέντρο Υποδοχής και Ταυτοποίησης για περαιτέρω εξέταση. Το άρθρο τονίζει τη σημασία της παροχής αληθών πληροφοριών και ακριβών στοιχείων στην αίτηση, καθώς η παροχή ψευδών πληροφοριών ή η απόκρυψη γεγονότων μπορεί να επηρεάσει αρνητικά την έκβαση της αίτησης.
Summary 4 H πρόσβαση στις διαδικασίες διεθνούς προστασίας είναι δωρεάν και απεριόριστη, διαθέσιμη σε κάθε υπήκοο τρίτης χώρας ή ανιθαγενή. Oι αιτήσεις μπορούν να υποβληθούν σε διάφορα Κέντρα Υποδοχής και Ταυτοποίησης σε ορισμένα νησιά, εντός της χώρας ή μέσω ηλεκτρονικής πλατφόρμας. H εξέταση της αίτησης μπορεί να διαρκέσει από 20 ημέρες έως 6 μήνες, ανάλογα με την περίπτωση. Oι αιτούντες πρέπει να παρέχουν πλήρεις γενικές πληροφορίες, συμπεριλαμβανομένων στοιχείων ταυτότητας, διεύθυνσης ηλεκτρονικού ταχυδρομείου, βιομετρικών δεδομένων κ.λπ., καθώς και λόγους για την αναζήτηση προστασίας. Διατίθενται διερμηνείς για να βοηθήσουν στην επικοινωνία κατά τη διάρκεια της διαδικασίας. Ψευδείς πληροφορίες ή ισχυρισμοί μπορούν να επηρεάσουν αρνητικά την αίτηση.
Summary 5 H πρόσβαση στις διαδικασίες διεθνούς προστασίας είναι δωρεάν για όλους τους υπηκόους τρίτων χωρών ή ανιθαγενείς. Oι αρχικές αιτήσεις υποβάλλονται στα Κέντρα Υποδοχής και Ταυτοποίησης (ΚΥΤ) στα νησιά ή στον Έβρο. Στην ηπειρωτική Ελλάδα, οι αιτήσεις μπορούν να υποβληθούν στα ΚΥΤ Μαλακάσας και Διαβατών κατόπιν ηλεκτρονικού ραντεβού. Όσοι εισέρχονται ή διαμένουν παράνομα μεταφέρονται στα ΚΥΤ για διαδικασίες υποδοχής και ταυτοποίησης, όπου παραμένουν έως και 25 ημέρες. Oρισμένες αιτήσεις εξετάζονται κατά προτεραιότητα. H διαδικασία μπορεί να διαρκέσει από 20 ημέρες έως 6 μήνες. Κατά την καταγραφή, καταγράφονται πλήρη στοιχεία ταυτότητας, βιομετρικά δεδομένα και λόγοι ασύλου με τη βοήθεια διερμηνέα. H παροχή ψευδών πληροφοριών επηρεάζει αρνητικά την αξιολόγηση της αίτησης.
Summary 6 H πρόσβαση στη διεθνή προστασία είναι δωρεάν για υπηκόους τρίτων χωρών και ανιθαγενείς. Oι αιτήσεις μπορούν να υποβληθούν στα Κέντρα Υποδοχής και Ταυτοποίησης (ΚΥΤ) στα νησιά Λέσβος, Χίος, Σάμος, Κως, Λέρος ή στο Φυλάκιο Έβρου. Oι αιτούντες στην ηπειρωτική χώρα μπορούν να υποβάλουν αίτηση στα ΚΥΤ Μαλακάσας ή Διαβατών με ηλεκτρονικά ραντεβού. Όσοι εισέρχονται ή διαμένουν παράνομα μεταφέρονται στα ΚΥΤ για επεξεργασία και πρέπει να παραμείνουν έως και 25 ημέρες. Εξέταση κατά προτεραιότητα ισχύει για περιπτώσεις που αφορούν παράνομη είσοδο, ψευδείς πληροφορίες ή κρατούμενους αιτούντες. H επεξεργασία διαρκεί από 20 ημέρες έως 6 μήνες. Oι αιτούντες πρέπει να παρέχουν πλήρη στοιχεία ταυτότητας και λόγους προστασίας. Μπορούν να ορίσουν εξουσιοδοτημένο αντιπρόσωπο.
Appendix A.3. Grammar & Syntax
Appendix A.3.1. Sentence
Migrants are goes Greece and not finding any helps for paper and doctors is missing.
Appendix A.3.2. Responses
Response 1 Oι μετανάστες που πηγαίνουν στην Ελλάδα δεν μπορούν να βρουν βοήθεια με τα έγγραφά τους ή πρόσβαση σε ιατρική περίθαλψη.
Response 2 Oι μετανάστες που πηγαίνουν στην Ελλάδα δεν μπορούν να βρουν βοήθεια σχετικά με χαρτιά και γιατρούς.
Response 3 Oι μετανάστες που πηγαίνουν στην Ελλάδα δεν μπορούν να βρουν βοήθεια με τα έγγραφά τους ή ιατρική περίθαλψη.
Response 4 Oι μετανάστες πηγαίνουν στην Ελλάδα αλλά δεν μπορούν να βρουν καμία βοήθεια με τα χαρτιά τους, και η ιατρική περίθαλψη δεν είναι διαθέσιμη.
Response 5 Oι μετανάστες που πηγαίνουν στην Ελλάδα δεν είναι σε θέση να βρουν βοήθεια με τα χαρτιά τους ή ιατρική φροντίδα.
Response 6 Oι μετανάστες πηγαίνουν στην Ελλάδα αλλά δεν βρίσκουν βοήθεια με τα έγγραφά τους και δεν μπορεί να βρεθεί γιατρός.
Appendix A.4. Emotion Detection
Appendix A.4.1. Text
H κυβέρνηση εισήγαγε νέα μέτρα για την αποτελεσματικότερη διαχείριση των μεταναστευτικών ροών, γεγονός που δίνει ελπίδα σε πολλές οικογένειες που αγωνίζονται εδώ και χρόνια. Aυτά τα μέτρα περιλαμβάνουν τη μείωση των χρόνων αναμονής για τις αιτήσεις ασύλου και την προσφορά αυξημένης υποστήριξης στους μετανάστες για την ενσωμάτωσή τους στην κοινωνία. Είναι ένα βήμα προς την παροχή μιας καλύτερης ευκαιρίας για να χτίσουν ένα μέλλον και να συμβάλουν στις νέες τους κοινότητες.
Appendix A.4.2. Responses
Responses 1 Ελπιδοφόρο, Θετικό, Υποστηρικτικό, Aισιόδοξο.
Responses 2 Aισιόδοξο, Πραγματιστικό, Aνήσυχο, Υποστηρικτικό.
Responses 3 Ελπιδοφόρο, Ενθαρρυντικό, Θετικό, Προοδευτικό.
Responses 4 Θετικό, Υποστηρικτικό, Συμπονετικό, Επικεντρωμένο στην ευκαιρία.
Responses 5 Oρθολογικό, Προορατικό, Συμπεριληπτικό, Ενδυναμωτικό.
Responses 6 Πραγματιστικό, Ελπιδοφόρο, Aπογοητευμένο, Προσανατολισμένο στη λύση.
Appendix B
This appendix contains the English translations of the texts.
Appendix B.1. Reading Comprehension
Appendix B.1.1. Text
The accommodation structures provide temporary housing for third-country nationals or stateless persons who have applied for international protection in Greece. They also host family members of asylum seekers, unaccompanied or accompanied minors, and individuals belonging to vulnerable groups. These facilities ensure a stable living environment that meets basic living and social needs, as well as educational and learning requirements. Residents live under a regime of independent living while being required to follow internal regulations to maintain the smooth operation of the facility. Services provided include housing, food, legal and social information, psychological support, access to healthcare, personal hygiene supplies, clothing, Greek language lessons, and educational programs. Residents must leave the structures within 30 days of receiving a decision granting them international or subsidiary protection. For unaccompanied minors, this period starts upon reaching adulthood.
Appendix B.1.2. Question
How do people living in these accommodation structures experience their stay?
Appendix B.1.3. Responses
Response 1 Under a regime of independent living.
Response 2 Those residing in the structures are in temporary accommodation and have the opportunity to become familiar with the host country, its rights, and obligations. The accommodation structures provide a stable framework that meets not only the basic living and social needs of residents but also their educational and learning requirements. Residents live independently but must follow internal regulations to ensure the facility’s smooth operation. In the case of unaccompanied minors, their transition period starts upon reaching adulthood. Residents must leave the facility within 30 days of receiving a decision granting them protection.
Response 3 Residents in the structures live under a regime of independent living but are required to follow internal regulations for the smooth operation of the facility.
Response 4 Residents in the structures live under a regime of independent living and must adhere to internal regulations to ensure the smooth operation of the facility.
Response 5 People residing in the structures live independently, covering their basic living and social needs as well as their educational and learning needs. They receive services such as housing, food, information on their rights and obligations, psychosocial support, access to healthcare, personal hygiene items, clothing, Greek language lessons, and access to education and skills development programs.
Response 6 According to the text, residents live under a regime of independent living but must follow internal regulations to ensure the smooth operation of the facility. The structures provide a stable framework that meets basic living and social needs, as well as educational and learning requirements. They receive services such as housing, food, information, psychosocial support, healthcare access, essential items, Greek language lessons, and educational programs.
Appendix B.2. Text Summarization
Appendix B.2.1. Text
Access to the international protection process is free and unrestricted. Every third-country national or stateless person has the right to submit an application for international protection. The initial application at the borders is submitted at the Reception and Identification Centers on the islands of Lesvos, Chios, Samos, Kos, and Leros, as well as at the Evros checkpoint. If you are in the mainland, you can submit an initial application at the Reception and Identification Centers in Malakasa and Diavata. The international protection application is submitted in person. If you have not been registered, you can make an appointment through the following online platform to be registered in person at the Reception and Identification Centers in Malakasa or Diavata. If you have entered the country without legal formalities or are residing in Greece without legal formalities, you will be transferred to a Reception and Identification Center. If you do not have a public authority document proving your nationality and identity, you will undergo reception and identification procedures. You will be required to stay at the Center for as long as it takes to process your application, provided that this period does not exceed twenty-five (25) days. In some cases (e.g., if you submit an application at the border in crossing zones of ports or airports, if you deceive the authorities by providing false information, if you are detained, and in other cases specified by law), your application will be prioritized. In total, the examination of your application may take from twenty (20) days to six (6) months, depending on your case. The full registration of your application includes identification details, your country of origin, the names of your father, mother, spouse, and children, your email address if available, biometric identification data, a full account of the reasons you are seeking international protection, your residential or living address, the language in which you wish your application to be examined, and, if desired, the appointment of an authorized representative. When you submit the application, an interpreter will assist you in a language you understand to facilitate communication with the Asylum Service staff. When you submit your application, you must answer the staff’s questions with complete honesty. If you provide false information or claims, this will negatively affect the assessment of your application.
Appendix B.2.2. Summaries
Summary 1 Access to the international protection procedure in Greece is free of charge. The initial application can be submitted at Reception and Identification Centers or through an online platform. The identification process is mandatory, except for a few exceptions. The application includes personal identification details, reasons for seeking international protection, and the preferred language of communication. An interpreter assists with communication. The registration must be truthful, as false information or claims can negatively affect the decision on the application. The processing time for the application ranges from 20 days to 6 months.
Summary 2 This text explains the process of applying for international protection in Greece, which is free and open to all third-country nationals or stateless persons. The initial application for international protection must be submitted at the Reception and Identification Centers on the islands of Lesvos, Chios, Samos, Kos, and Leros, as well as at the Evros facility. If you are already on the mainland, you can submit the initial application at the Reception and Identification Centers in Malakasa and Diavata. The application for international protection must be submitted in person. If you have not yet registered, you can book an appointment on the following online platform to register at the Reception and Identification Centers in Malakasa or Diavata. If you enter the country without legal documents or remain in Greece without legal documents, you will be taken to a Reception and Identification Center.
Summary 3 The article describes the process of applying for international protection in Greece. It explains that third-country nationals or stateless persons who wish to seek protection in Greece can submit an application for international protection directly at the border, at airports, at the port of entry, or at the offices of the Asylum Service. The application is submitted free of charge and without the need for legal representation. The article also states that applicants who submit their application at the border or airport will be transferred to a Reception and Identification Center, where they will be registered and their application will be examined. If applicants do not have valid travel documents or have entered the country irregularly, they will be taken to a Reception and Identification Center for further examination. The article highlights the importance of providing truthful information and accurate details in the application, as providing false information or concealing facts may negatively affect the outcome of the application.
Summary 4 Access to international protection procedures is free and unrestricted, available to any third-country national or stateless person. Applications can be submitted at various Reception and Identification Centers on certain islands, within the country, or through an online platform. Application review can take 20 days to 6 months, depending on the case. Applicants must provide complete general information, including identity details, email address, biometric data, etc., as well as reasons for seeking protection. Interpreters are available to assist with communication during the process. False information or claims can negatively impact the application.
Summary 5 Access to international protection procedures is free for all third-country nationals or stateless persons. Initial applications are submitted at Reception and Identification Centers (RICs) on islands or in Evros. In mainland Greece, applications can be submitted at Malakasa and Diavata RICs after booking an online appointment. Those entering or staying illegally are transferred to RICs for reception and identification procedures, where they stay up to 25 days. Some applications are examined with priority. The process can take 20 days to 6 months. During registration, complete identity details, biometric data, and reasons for asylum are recorded with interpreter assistance. Providing false information negatively affects application evaluation.
Summary 6 Access to international protection is free for third-country nationals and stateless persons. Applications can be submitted at Reception and Identification Centers (RICs) on Lesvos, Chios, Samos, Kos, Leros islands, or Fylakio Evros. Mainland applicants can apply at Malakasa or Diavata RICs with online appointments. Those entering or staying illegally are transferred to RICs for processing and must stay up to 25 days. Priority review applies to cases involving illegal entry, false information, or detained applicants. Processing takes 20 days to 6 months. Applicants must provide complete identity details and reasons for protection. They may appoint an authorized representative.
Appendix B.3. Grammar & Syntax
Appendix B.3.1. Sentence
Migrants are goes Greece and not finding any helps for paper and doctors is missing.
Appendix B.3.2. Responses
Response 1 Migrants going to Greece cannot find help with their documents or access medical care.
Response 2 Migrants who go to Greece are not able to find help about papers and doctors.
Response 3 Migrants who go to Greece cannot find help with their documents or medical care.
Response 4 Migrants are going to Greece but cannot find any help with their papers, and medical care is unavailable.
Response 5 Migrants going to Greece are not able to find help with their papers or medical attention.
Response 6 Migrants goes to Greece but don’t finding help with their documents and no doctor can be found.
Appendix B.4. Emotion Detection
Appendix B.4.1. Text
The government has introduced new measures to manage migration flows more efficiently, which brings hope to many families who have struggled for years. These measures include reducing waiting times for asylum applications and offering increased support for migrants to integrate into society. It is a step toward giving them a better chance to build a future and contribute to their new communities.
Appendix B.4.2. Responses
Response 1 Hopeful, Positive, Supportive, Optimistic.
Response 2 Optimistic, Pragmatic, Concerned, Supportive.
Response 3 Hopeful, Encouraging, Positive, Progressive.
Response 4 Positive, Supportive, Compassionate, Focused on opportunity.
Response 5 Rational, Forward-thinking, Inclusive, Empowering.
Response 6 Pragmatic, Hopeful, Frustrated, Solution-oriented.
References
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large Language Models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Dong, G.; Wang, H.; Sun, J.; Wang, X. Evaluating and Mitigating Linguistic Discrimination in Large Language Models. arXiv 2024, arXiv:2404.18534. [Google Scholar]
- Meditskos, G.; Tegos, S.; Bouas, C.; Tassios, A.; Manousaridis, K.; Papoutsoglou, M.; Mavropoulos, T.; Vrochidis, S. Towards Semantically Conscious, Conversation-Based Chatbot Services for Migrants. In Artificial Intelligence Applications and Innovations, Proceedings of the 20th IFIP WG 12.5 International Conference, AIAI 2024, Corfu, Greece, 27–30 June 2024; Springer: Cham, Switzerland, 2024; pp. 139–148. [Google Scholar]
- Anagnostou, O.; Kalpourtzi, N.; Karakosta, A.; Terzidis, A.; Yfantis, A.; Margalias, A.; Tzanetea, R.; Pallis, E.; Gavana, M.; Vantarakis, A.; et al. Health Needs and Access to Healthcare Services in Migrant Populations in Greece: Data From the Hprolipsis Study. Cureus 2025, 17, e78196. [Google Scholar] [CrossRef]
- Nazi, Z.A.; Hossain, M.R.; Mamun, F.A. Evaluation of open and closed-source LLMs for low-resource language with zero-shot, few-shot, and chain-of-thought prompting. Nat. Lang. Process. J. 2025, 10, 100124. [Google Scholar] [CrossRef]
- Hagendorff, T. Mapping the ethics of generative ai: A comprehensive scoping review. Minds Mach. 2024, 34, 39. [Google Scholar] [CrossRef]
- Klenk, M. Ethics of generative AI and manipulation: A design-oriented research agenda. Ethics Inf. Technol. 2024, 26, 9. [Google Scholar] [CrossRef]
- Wei, X.; Kumar, N.; Zhang, H. Addressing bias in generative AI: Challenges and research opportunities in information management. Inf. Manag. 2025, 62, 104103. [Google Scholar] [CrossRef]
- Mattheoudakis, M.; Fotiadou, G.; Papadopoulou, D. CLIL on the spot: Migrant education in Greece. Front. Educ. 2025, 9, 1504257. [Google Scholar] [CrossRef]
- Chiang, W.L.; Zheng, L.; Sheng, Y.; Angelopoulos, A.N.; Li, T.; Li, D.; Zhang, H.; Zhu, B.; Jordan, M.; Gonzalez, J.E.; et al. Chatbot arena: An open platform for evaluating llms by human preference. arXiv 2024, arXiv:2403.04132. [Google Scholar]
- Yuan, L.; Chen, Y.; Cui, G.; Gao, H.; Zou, F.; Cheng, X.; Ji, H.; Liu, Z.; Sun, M. Revisiting out-of-distribution robustness in nlp: Benchmarks, analysis, and LLMs evaluations. Adv. Neural Inf. Process. Syst. 2023, 36, 58478–58507. [Google Scholar]
- Agarwal, V.; Garg, M.K.; Dharmavaram, S.; Kumar, D. “Which LLM should I use?”: Evaluating LLMs for tasks performed by Undergraduate Computer Science Students in India. arXiv 2024, arXiv:2402.01687. [Google Scholar]
- Oniani, D.; Wang, Y. A qualitative evaluation of language models on automatic question-answering for COVID-19. In Proceedings of the 11th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Virtual, 21–24 September 2020; pp. 1–9. [Google Scholar]
- Xiao, C.; Xu, S.X.; Zhang, K.; Wang, Y.; Xia, L. Evaluating reading comprehension exercises generated by LLMs: A showcase of ChatGPT in education applications. In Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), Toronto, ON, Canada, 13–14 July 2023; pp. 610–625. [Google Scholar]
- Murugadoss, B.; Poelitz, C.; Drosos, I.; Le, V.; McKenna, N.; Negreanu, C.S.; Parnin, C.; Sarkar, A. Evaluating the Evaluator: Measuring LLMs’ Adherence to Task Evaluation Instructions. arXiv 2024, arXiv:2408.08781. [Google Scholar] [CrossRef]
- Srivastava, A.; Rastogi, A.; Rao, A.; Shoeb, A.A.M.; Abid, A.; Fisch, A.; Brown, A.R.; Santoro, A.; Gupta, A.; Garriga-Alonso, A.; et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv 2022, arXiv:2206.04615. [Google Scholar]
- Kosar, A.; De Pauw, G.; Daelemans, W. Comparative Evaluation of Topic Detection: Humans vs. LLMs. Comput. Linguist. Neth. J. 2024, 13, 91–120. [Google Scholar]
- Hu, X.; Gao, M.; Hu, S.; Zhang, Y.; Chen, Y.; Xu, T.; Wan, X. Are LLM-based Evaluators Confusing NLG Quality Criteria? arXiv 2024, arXiv:2402.12055. [Google Scholar]
- Panickssery, A.; Bowman, S.R.; Feng, S. Llm evaluators recognize and favor their own generations. arXiv 2024, arXiv:2404.13076. [Google Scholar]
- Desmond, M.; Ashktorab, Z.; Pan, Q.; Dugan, C.; Johnson, J.M. EvaluLLM: LLM assisted evaluation of generative outputs. In Proceedings of the Companion Proceedings of the 29th International Conference on Intelligent User Interfaces, Greenville, SC, USA, 18–21 March 2024; pp. 30–32. [Google Scholar]
- Shankar, S.; Zamfirescu-Pereira, J.; Hartmann, B.; Parameswaran, A.G.; Arawjo, I. Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences. arXiv 2024, arXiv:2404.12272. [Google Scholar]
- Truong, L.; Lee, S.; Sawhney, N. Enhancing Conversations in Migrant Counseling Services: Designing for Trustworthy Human-AI Collaboration. Proc. ACM Hum.-Comput. Interact. 2024, 8, 495. [Google Scholar] [CrossRef]
- Fazzinga, B.; Palmieri, E.; Vestoso, M.; Bolognini, L.; Galassi, A.; Furfaro, F.; Torroni, P. A Chatbot for Asylum-Seeking Migrants in Europe. In Proceedings of the 2024 IEEE 36th International Conference on Tools with Artificial Intelligence (ICTAI), Herndon, VA, USA, 28–30 October 2024; pp. 702–707. [Google Scholar]
- Lee, S.; Choi, D.; Truong, L.; Sawhney, N.; Paakki, H. Into the Unknown: Leveraging Conversational AI in Supporting Young Migrants’ Journeys Towards Cultural Adaptation. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025; pp. 1–19. [Google Scholar]
- Bubaš, G.; Čižmešija, A.; Kovačić, A. Development of an assessment scale for measurement of usability and user experience characteristics of Bing chat conversational AI. Future Internet 2023, 16, 4. [Google Scholar] [CrossRef]
- Lynch, C.J.; Jensen, E.J.; Zamponi, V.; O’Brien, K.; Frydenlund, E.; Gore, R. A structured narrative prompt for prompting narratives from large language models: Sentiment assessment of ChatGPT-generated narratives and real tweets. Future Internet 2023, 15, 375. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D. Chatgpt and open-ai models: A preliminary review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Branda, F.; Stella, M.; Ceccarelli, C.; Cabitza, F.; Ceccarelli, G.; Maruotti, A.; Ciccozzi, M.; Scarpa, F. The Role of AI-Based Chatbots in Public Health Emergencies: A Narrative Review. Future Internet 2025, 17, 145. [Google Scholar] [CrossRef]
- Jung, D.; Butler, A.; Park, J.; Saperstein, Y. Evaluating the Impact of a Specialized LLM on Physician Experience in Clinical Decision Support: A Comparison of Ask Avo and ChatGPT-4. arXiv 2024, arXiv:2409.15326. [Google Scholar]
- Nallur, V. Anxiety among migrants-questions for agent simulation. In Autonomous Agents and Multiagent Systems. Best and Visionary Papers, Proceedings of the AAMAS 2023 Workshops, London, UK, 29 May–2 June 2023; Springer: Cham, Switzerland, 2023; pp. 141–150. [Google Scholar]
- Coen, E.; Del Fiol, G.; Kaphingst, K.A.; Borsato, E.; Shannon, J.; Smith, H.S.; Masino, A.; Allen, C.G. Chatbot for the Return of Positive Genetic Screening Results for Hereditary Cancer Syndromes: A Prompt Engineering Study. Res. Sq. 2024. [Google Scholar] [CrossRef]
- Kamalloo, E.; Jafari, A.; Zhang, X.; Thakur, N.; Lin, J. Hagrid: A human-llm collaborative dataset for generative information-seeking with attribution. arXiv 2023, arXiv:2307.16883. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 
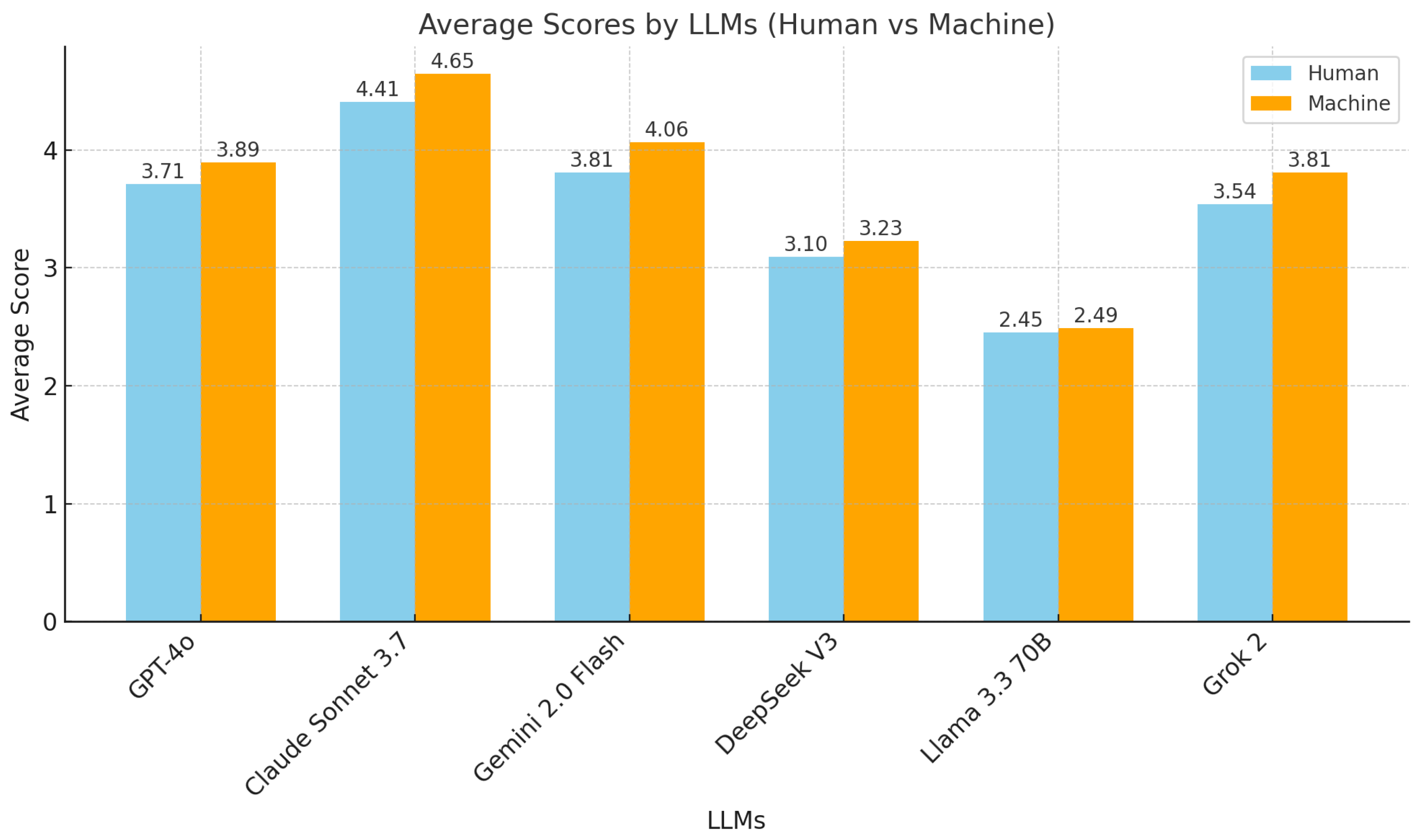

{kind=link}
{kind=link}